1. Introduction
Credit risk is the main financial risk concerned by banks. Credit scoring relates to a group of methods that are adopted to support the decision-making process of decision-makers, have been widely exploited by banks and financial institutions to prevent the loss caused by non-performing loans [
1,
2]. Credit scoring is a process of identifying whether a credit applicant is a legitimate or suspicious one. With the business expansion of banks and lending institutions and the accumulation of financial data, the evaluation of customer credit has gradually developed from manual audit mechanisms to automatic credit scoring using computer technology and big data. For credit risk managers, it is very important to accurately identify borrowers with high credit quality and potential loan defaulters. Consequently, more researchers are followed by focusing on seeking an algorithm to improve the performance of credit scoring. These studies include statistical-based methods such as linear discriminant analysis (LDA) [
3,
4], and logistic regression (LR) [
5,
6], artificial intelligence (AI)-based approaches such as artificial neural network (ANN) [
7,
8], decision tree (DT) [
9,
10], support vector machine (SVM), [
11], k-nearest neighbors (KNN) [
12,
13], Naïve Bayesian [
14,
15].
Though AI-based theories [
16,
17] provide the probability to realize accurate credit scoring, LR and LDA are still the most popular approaches as standard credit scoring algorithms due to their simplicity and easy implementation. However, limited by the complexity of LDA [
18] and LR [
19], these statistical-based credit scoring models are criticized for their failure of providing correct discrimination of good and bad applicants. To overcome such issues, researchers have contributed their efforts to developing machine learning algorithms to mine valuable information for accurate credit scoring [
20,
21]. Li [
22] improved the credit scoring performance by modeling the process of a reject inference issue based on an SVM algorithm. Tsai and Wu [
23] established a neural network for bankruptcy prediction and credit scoring. In their work, the performance of individual NN and the ensemble of NNs are investigated on three credit scoring and bankruptcy-related datasets. Lee [
24] combined classification and regression decision tree and multivariate adaptive regression splines (MARS) to predict the credit of customers. Their results show that CART regression DT and MARS outperform other traditional statistical-based credit scoring algorithms such as LR and LDA. Based on the consideration that different credit datasets are distinguished ranging from their unique scale to the number of predictive variables, according to the “no free lunch” theory [
25], an individual ML-based classifier is not the optimal solution to deal with all the complex credit scoring problems. Therefore, it has become increasingly important to integrate multiple ML-based credit scoring models into a robust one to improve the performance of credit scoring.
Pławiak [
26] cascaded multiple SVMs for Australian credit approval. In addition, a genetic algorithm is combined to optimize the hyper-parameter of the ensemble framework. Abellán and Castellano [
27] studied the impact of difference base classifier selection on the performance of ensemble algorithms. His study demonstrates that ensemble algorithms can be good choices compared with individual ML-based classifiers for gaining better credit scoring performance. Moreover, Credal DT is proved in their study as the optimal base learner for the ensemble framework. Ala’raj and Abbod [
28] considered the processing of combining data filtering and features selection, integration of different classifiers, and the combination strategy of integrating the output of multiple base learners of ensemble approaches. Their results showed the hybrid ensemble credit scoring algorithm gets better predictive performance on seven credit scoring datasets. Zhang [
29] addressed the outlier issue in credit datasets by establishing a multi-staged ensemble model. Furthermore, their study proposed a new feature reduction approach to enhance feature interpretability. Feng [
30] introduced a soft probability weighting mechanism for the dynamical ensemble of the base learners, thus reducing the risk of misclassification on risky loans and non-risky loans. To address the imbalance of credit scoring, Zhang [
31] introduced an under-sampling strategy and incorporated a voting-based outlier detection method to stack a hybrid ensemble algorithm. To encourage the diversity of base learners of ensemble learning algorithms, Xia [
32] proposed a novel heterogeneous ensemble method, which considered SVM, RF, XGBoost as base learners to reduce the credit scoring error. Nalić [
33] introduced multiple feature selection methods, and combined ensemble learning approaches to support the decision-making process of issuing a loan. Moreover, a new voting mechanism named if-any is proposed to combine the final results of base learners.
According to the ensemble strategy, ensemble algorithms can be divided into Bagging-type ensemble models [
34] and boosting-type ensemble approaches [
35]. According to the training strategy of Bagging and boosting, Bagging is an ensemble strategy that integrates multiple base learners by diversifying the training subset (object) while boosting is an optimization pattern that iteratively modifying the training target. RF and GDBT are representative Bagging-type ensemble approach and boosting ensemble approach. RF [
36], in which each base learner is optimized based on the same training target while keeping the input of DTs diversified from each other. However, such an optimization strategy that each base learner gets the same training target may increase the statistical correlation of the prediction results among base learners, which drives DTs in RF to make homogenized prediction results. By contrast, GBDT reduces the credit scoring error iteratively changing the optimization target while keeping the training features unchanged [
37]. However, the DTs [
38,
39] in the GBDT always work on the same training feature may harm the diversity of base learners while diversity is an important character for ensemble strategy.
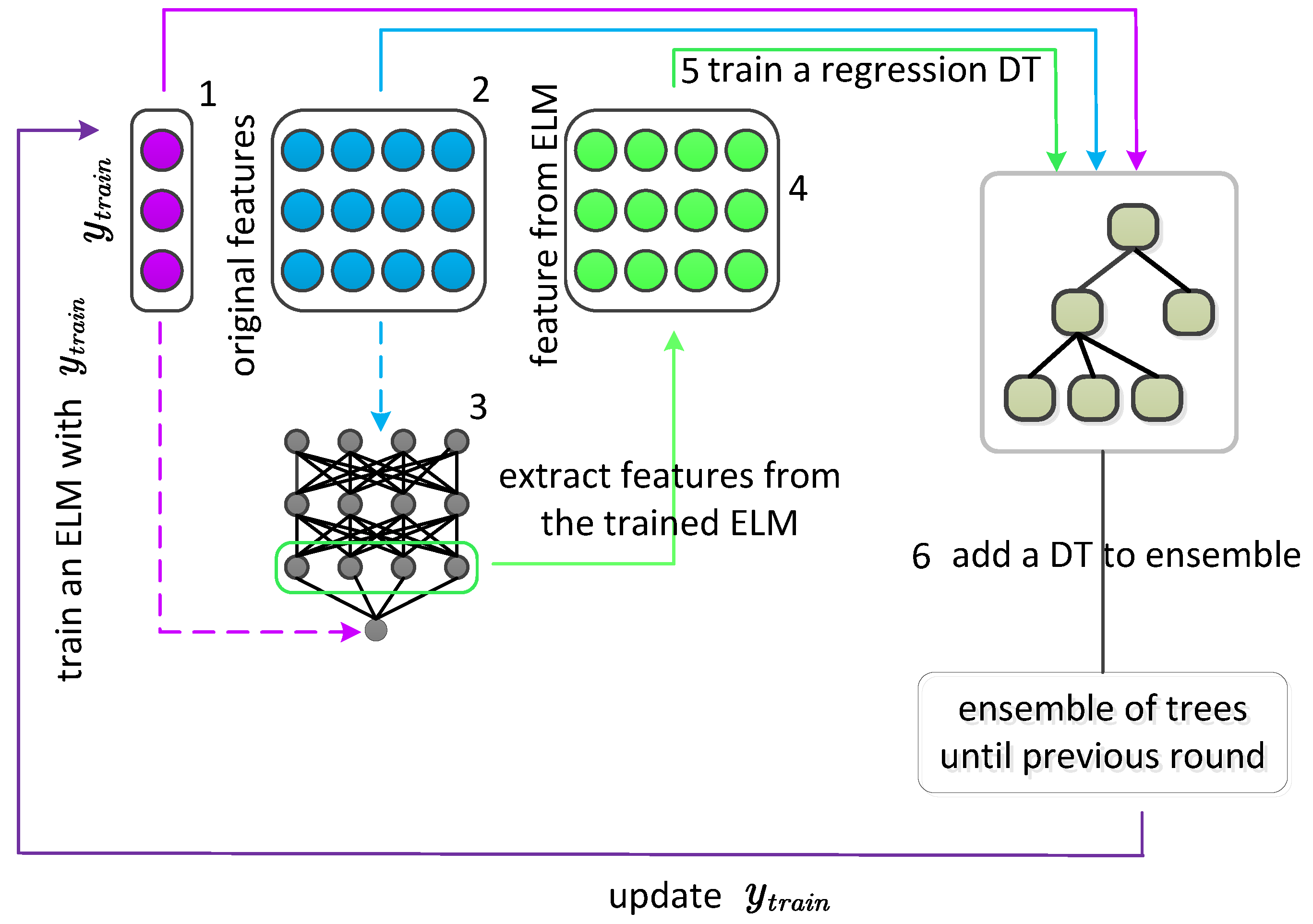
Based on the above considerations and inspired by the research of Tonnor [
40], in this study, we propose a supervised efficient NN-based augmented GBDT, named AugBoost-ELM, for credit scoring. AugBoost-ELM inherits the boosting training pattern from the GBDT framework, making it a robust ensemble method to achieve accurate credit scoring. Moreover, the extreme learning machine (ELM) [
41] is considered as an efficient supervised feature augmentation skill to step-wise enhance the diversity of based learners in GBDT, motivating AugBoost-ELM an efficient augmented GBDT compared with AugBoost-NN. In addition, the training strategy based on ELM avoids the problem that the training strategy on backpropagation NN-based is easy to fall into the local minimum, and it can generate robust augmented features for the boosting framework while accelerating the augmentation process.
3. Experimental Settings
3.1. Credit Datasets
Australian credit approval dataset is a collection that classifies potential borrowers who may get qualified in getting loans or not by analyzing multiple descriptive attributes range from loan characters, the information of borrowers.
German credit dataset records 1000 credit information from a German bank, each of which contains 20 features. These features include account balance information, duration of credit in a month to repayment history, etc.
Japanese credit dataset contains samples of credit individuals that provide positive or negative credit for banks and lending companies to determine whether granting a loan or not by introducing the knowledge of experts from a Japanese lending institution.
Taiwan dataset is designed to evaluate the predictive performance of the probability of default (PD). This dataset records the credit repayment status of credit card customers in Taiwan since 2005. Through the analysis of this data set, the analysis of credit card customers’ default in mainland China can be used for reference.
All the above dataset can be collected from UCI repository [
45]. The detail information of the above credit datasets is shown in
Table 1.
3.2. Credit Scoring Benchmark Models
In this study, various credit scoring models are selected as baselines to evaluate the effectiveness of AugBoost-ELM, which includes standard statistical credit scoring methods, ML-based individual classifiers, ensemble approaches. LR and LDA are two representative statistical-based credit scoring models, which have been popularized by researchers, banks, and lending companies due to their simplicity and low implementation advantages.
DT is a tree-structure learning algorithm that realizes credit scoring based on node splitting and tree growth, which have been widely used due to its good training efficiency and interpretability. SVM is a nonlinear learning method that maps a lower-dimensional feature space into a higher-dimensional feature space. KNN implement PD modeling by searching k nearest neighbors as prediction results. NN is a popular approach that is stacked by multiple neural layers to realized hierarchical end-to-end credit scoring. Random forest is an ensemble method that is ensemble by multiple DTs and implements parallel training to enhance the training efficiency of the ensemble framework. GBDT is a boosting-type ensemble solution that improves the predictive performance by iterative optimize the credit scoring error with multiple addictive regression DTs. XGBoost is a more efficient GBDT that grows each DT in a level-wise way. Based on the advantage of gradient descent, LightGBM further improves the training efficiency by leaf-wise growing DTs and introducing exclusive feature bunding (EFB) strategy and gradient-based one-side sampling (GOSS) skill.
3.3. Implementation Details of AugBoost-ELM
The parameters used in AugBoost-ELM can be seen in
Table 2. In the implementation of AugBoost-ELM, we use grid search optimization to fine-tune the hyper-parameters in AugBoost-ELM. Since AugBoost-ELM is a variant of GBDT, instead of jointly optimize the number of DTs in AugBoost-ELM and the learning rate, we fix the number of iterations and focus on fine-tuning an appropriate learning rate by a bisection method, the optimal learning rate is further determined by a grid search. Next, we focus on the optimization of hyper-parameters in each DT of AugBoost-ELM. Maximum depth is a parameter that controls the complexity of each DT in AugBoost-ELM, well control of the maximum depth of each DT can avoid the overfitting of AugBoost-ELM. Therefore, we grid search the maximum depth of DTs in AugBoost-ELM from the initialized searching space
. Further, we jointly optimize the parameter of minimal samples to split at each splitting node and the parameter of minimal samples at each leaf node from the searching space
. The subsample is a hyper-parameter that performs an under-sample operation on the original training set, we search this parameter from the initialized space
with fine-tuning stride
. In AugBoost-ELM, ELM is performed as a feature augmentation function for GBDT framework, therefore, we further fine-tune the hyper-parameters in ELM to generate robust augmented features. In ELM, the most important parameter that needs to be fine-tuned is the number of hidden nodes
L, we search the optimal
L from the value set
. Since each ELM completes the feature augmentation process in an NN-based framework, a standard feature normalization is first performed on credit data to accelerate the training of the ELM.
3.4. Finetuning Process of Credit Scoring Benchmarks
LR is a simple and linear algorithm that has been widely pursued in practical credit scoring for banks and lending institutions. To get a good predictive performance of LR, we adopt Newton’s method to iteratively minimize the empirical credit scoring error, and penalty is further introduced to alleviate the overfitting problem, which is optimized from the value set of .
KNN is a classical machine learning method that achieves credit scoring by finding the K nearest samples. Its final predictions are averaged from the states of the searched k nearest samples. Therefore, we focus on finetuning this parameter from the interval of with a search stride of 1.
To accelerate the finetuning process of SVM, in this study, radial basis function (RBF) kernel-based SVM is employed in this work for credit scoring. The major hyper-parameters that need to be finetuned in a RBF kernel-based SVM are and C, where regulates the form of mapping space and C represents penalty coefficient, which quantifies the penalty degree of misclassified samples.
We pre-fix the entire structure with two hidden layers to implement NN. We begin by constructing a stable NN structure from the architectural set with 64, 128, and 256 hidden nodes for hidden layers. Following that, we optimize the learning rate based on an initialized searching space of . To finetune the learning rate, we first select an acceptable learning rate interval using dichotomy and then identify the ideal learning rate using grid search with 5-fold cross-validation from the preset learning rate interval. Each hidden layer is activated by a ReLU function, and a sigmoid activation function is followed to get the probabilistic predictions. Because the credit scoring process is modeled as a binary classification process, the weight parameters of the NN are optimized using a binary cross-entropy loss function. Additionally, dropout is employed to minimize overfitting, and the optimal dropout rate is searched from the range of with an optimization step of 0.1.
RF is an efficient approach that realizes credit scoring in a Bagging-ensemble way. In the finetuning of a RF, we first searched the parameter that denotes the number of DTs to ensemble a RF from the interval of with a search step 100. After determining the overall ensemble framework of RF, we further finetune the parameters in each DT. To encourage the diversity of the ensemble, RF allows each tree within it to grow a deep structure to accommodate high bias low variance predictions. we first finetune the maximum depth of each DT in RF from the interval of with a finetune step of 1, where denotes a DT can grow its structure with an arbitrary depth. Next, the parameters of the minimum samples to split at each splitting node and minimum samples at each leaf node are determined by searching from the initial interval with an optimization step of 10.
Different from RF, GBDT ensemble DTs in a boosting ensemble style. Therefore, we first jointly optimize the number of DTs in a GBDT from the initial interval [50, 150] and the learning rate optimized from the initial set . Next, we determine the maximum depth of each DT by searching from the interval of with a search step of 1. Further, the parameters of minimum samples to split at each splitting node and the minimum samples at each leaf node are both determined from with a search step of 10. To further enhance the predictive performance of credit scoring, subsample skill is further incorporated, which is optimized from the set with an optimization step 0.05.
Based on finetuning pattern of GBDT, in the implementation of GBDT, we introduce and regularization into XGBoost framework to alleviate the overfitting issue, both of which are optimized from the initial set . Moreover, to further get a better credit scoring result, data-level subsample and feature-level subsample operations are further introduced, which are finetuned from .
Since AugBoost-ELM is an efficient supervised AugBoost variant, the optimization process of AugBoost-based models can be referred to the implementation details of AugBoost-ELM.
4. Experimental Results
To test the effectiveness of AugBoost-ELM, we first visualize the ROC curves of credit scoring models for comparison. ROC curve, also known as receiver operating characteristic curve, is a graphical measurement that reflects the sensitivity and specificity of credit scoring models under the different thresholds of predictive probability. The
x-axis represents the value of false positive rate (
FPR) and the
y-axis is the value of true positive rate (
TPR), where
TPR can be calculated as:
In Equations (
13) and (
14), the prediction results can be classified into four groups: TP, FP, TN, FN, which can be viewed from
Table 3.
Where TP is the number of accurate classified samples whose label is “bad”; FP counts the number of samples that are labeled as “good” while the prediction results are “bad”; FN calculates the number of samples whose label is “bad” and predicted as “good”; TN represents the number of “good” applicants that are correctly classified. The larger the area under the ROC curve implies the better performance a credit scoring algorithm is.
To testify the effectiveness of the feature enhancement mechanism for boosting framework, some baseline models are first selected for preliminary study. These models include statistical-based algorithms such as LR and LDA, ML-based individual classifiers such as DT, KNN, SVM, and NN, bagging-type ensemble method RF and boosting-class ensemble approach GBDT.
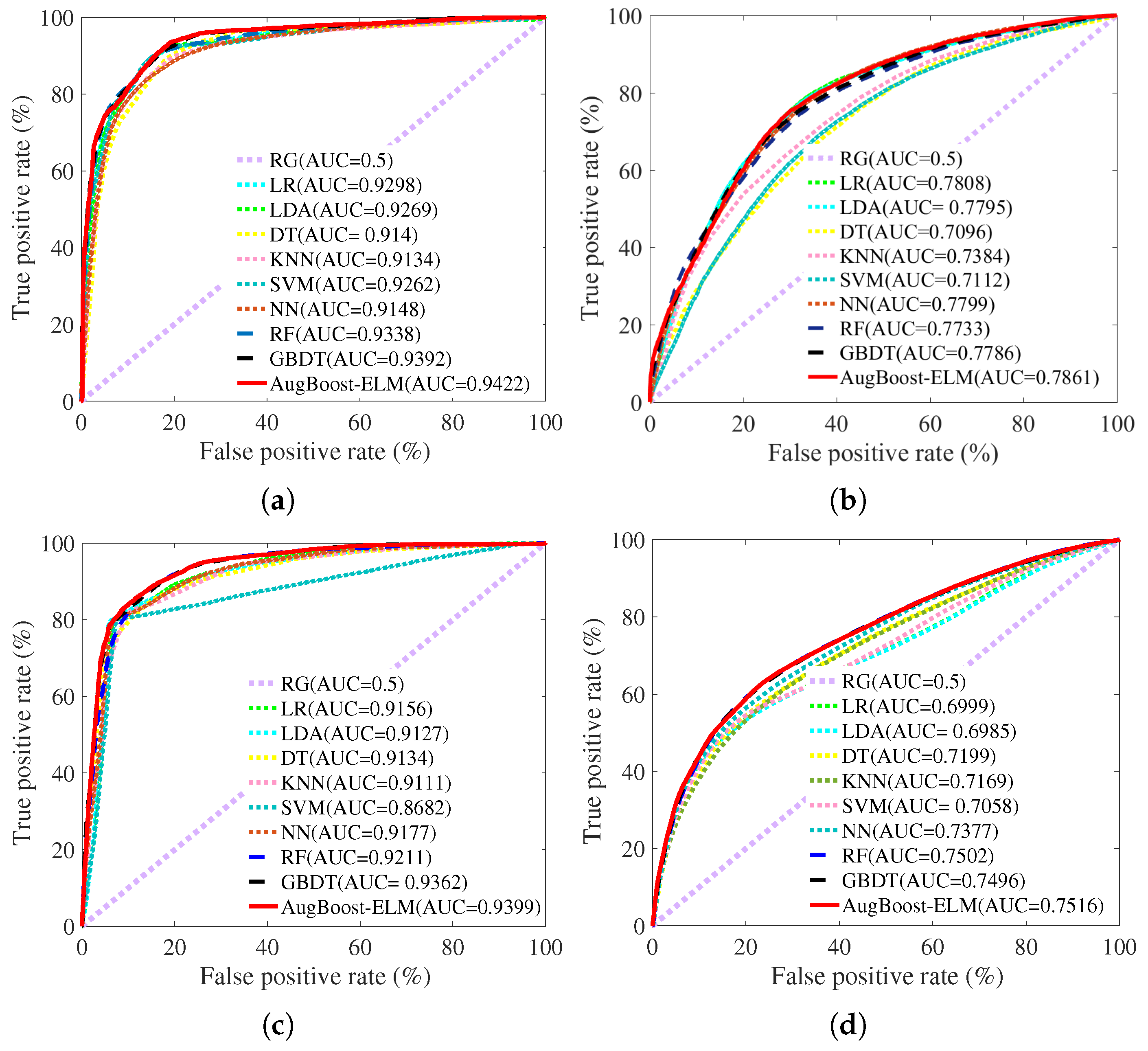
Figure 2 shows the ROC curves of various credit scoring models on the credit datasets.
Figure 2a represents the ROC curves of credit scoring models for the Australian dataset;
Figure 2b is the ROC curves of credit scoring models for the German dataset;
Figure 2c denotes the ROC curves of credit scoring models for the Japanese dataset;
Figure 2d illustrates the ROC curves of credit scoring models for the Taiwan dataset. All the ROC curves are an average based on 50 times repeated 10-fold cross-validation.
As is shown in
Figure 2a, on the Australian dataset, LR and LDA, KNN gets the smallest area under the ROC curve while AugBoost-ELM gets the largest area under the ROC curve, which demonstrates that AugBoost-ELM is the best algorithm to predict the PD for Australian compared with other baseline models. Compared with KNN, though DT improves the predictive performance, its ROC curve is worse than those of other credit scoring models, indicating that the single DT is not a good solution for accurate credit scoring. Compared with ML-based credit scoring models, statistical-based algorithms LR and LDA get the larger areas under ROC curves, providing evidence that why LR and LDA are popularized by industrial application. Compared with ML-based individual classifiers, the areas under ROC curves of RF and GBDT are significantly larger, which suggests that ensemble multiple weak learners into a stronger one is a good strategy to improve the performance of credit scoring.
As can be viewed from
Figure 2c, on the Japanese dataset, the largest area under the ROC curve of AugBoost-ELM implies AugBoost-ELM is the best algorithm for the credit scoring of the Japanese dataset. In addition, SVM gets the smallest area under the ROC curve. Though the ROC curves of other ML-based credit scoring algorithms such as DT, KNN, NN show better predictive ability than SVM, their performance on predicting the PD is worse than that of ensemble learning approaches.
The same as the results on the previous credit datasets, ensemble credit scoring algorithms get a larger ROC curve area compared with other credit scoring models further proves ensemble learning approaches are the good choice to improve the performance of credit scoring. On the Taiwan dataset, as can be observed from
Figure 2d, the ROC curve of AugBoost-ELM is close to that of GBDT. To reveal the concrete performance of credit scoring models, we further investigate the quantitative evaluation results of various credit scoring models on the credit datasets. In this study, we selected six metrics to comprehensively compare the performance of the credit scoring model, which include accuracy score, AUC score, precision score, recall score, F1 score, Brier loss.
Accuracy score computes the ratio of samples that are correctly classified, which is defined as:
AUC score calculates the area under the ROC curve and measures the overall predictive performance of credit scoring models.
The precision score represents the ratio of samples whose predicted result is “bad” while its label is “bad”, which can be calculated as:
Recall score measures how many “bad” applicants are correctly predicted, which can be defined as:
F1 is a comprehensive metric of precision score and recall score, which can be calculated as:
Brier loss score describes the average error between the predicted result and the label, which can be calculated as:
where
represents the predicted probability of the
i-th sample,
is the label of the
i-th sample, and
N is the number of samples.
Table 4 presents the performance comparison of credit scoring models for the Australian dataset. As can be seen from
Table 4, AugBoost-ELM gets the best AUC, which is consistent with the ROC curves in
Figure 2a, demonstrating AugBoost-ELM is a good choice to recognize good and bad applicants. On the Australian dataset, LR performs well, it achieves the best accuracy score. Therefore, if we are aiming at finding an efficient and effective credit scoring model for the Australian dataset, LR is the best choice. KNN gets the best precision score and worst recall score, leading to the comprehensive performance on the AUC score, F1 score, and BS poor. Moreover, compared with ML-based individual classifiers, RF and GBDT get better AUC score, F1 score, and BS, indicating the effectiveness of ensemble strategy. Compared with GBDT, though AugBoost-ELM gets better AUC score and precision score, its poor recall score results in a small F1 and large BS. In other words, if we focus on the discrimination of good/bad applicants, LR is the best choice; if we are concerned more about the prediction of the PD, AugBoost-ELM is a better choice.
Table 5 shows the performance comparison of credit scoring models for the German dataset. As can be seen from
Table 5, AugBoost-ELM gets the optimal AUC score, F1 score, and BS score, revealing that ELM-based supervised feature augmentation is able to enhance the discrimination ability of good/bad applicants. Furthermore,
Table 5 further demonstrates statistical-based credit scoring models are the alternative solution to achieve accurate credit scoring compared with ML-based individual classifiers. Furthermore, as is shown in
Table 5, in the comparison among ML-based individual classifiers, NN outperforms other ML-based credit scoring algorithms such as DT, KNN, and SVM. This is because NN is a robust algorithm that can learn nonlinear relationships from complex credit datasets. Compared with the bagging-based ensemble method RF, the superior performance of GBDT shows that boosting ensemble strategy is more suitable for the modeling of PD. Based on the good advantage of boosting framework, AugBoost-ELM, which is stage-wisely enhanced by the ELM-based supervised feature augmentation mechanism for the boosting framework, gets better predictive performance.
Table 6 is the performance comparison of credit scoring models for the Japanese dataset. As is shown in
Table 6, AugBoost-ELM achieves optimal accuracy score, AUC score, F1 score, and BS while LDA gets the best precision score and GBDT gets the optimal recall score. LDA gets a high precision score and low recall score, suggesting that LDA is a good method to discriminate the good applicant despite the ability to predict the bad applicants is poor. Moreover, compared with statistical-based algorithms and ML-based individual classifiers, the leading performance of RF, GBDT, and AugBoost-ELM further shows that ensemble strategy is practicable for the performance improvement for credit scoring.
Table 7 provides the performance comparison of credit scoring models for the Taiwan dataset. As can be seen from
Table 7, AugBoost-ELM realizes optimal scores on the metrics of accuracy, AUC, recall, F1, and BS, the effectiveness of AugBoost-ELM is fully illustrated. The improvement of recall score of AugBoost-ELM specifies the results that AugBoost-ELM improves the performance of credit scoring by reducing the misclassification of “bad” applicants. Moreover, as can be seen from
Table 7, ML-based individual classifiers outperform statistical-based algorithms on the Taiwan dataset. Though RF gets a high precision score, its recall score poor ability on discriminating “bad” applicants results in the poor performance of credit scoring for the Taiwan dataset. Besides, the leading performance of AugBoost-ELM compared with GBDT further demonstrates ELM-based supervised features augmentation can be a candidate for the improvement of boosting framework.
To further verify the effectiveness of AugBoost-ELM, we further select five advanced ensemble credit scoring models for comparison, which includes XGBoost, LightGBM, AugBoost-RP, AugBoost-PCA, AugBoost-NN while AugBoost-RP is step-wisely augmented by random projection method, AugBoost-PCA is step-wisely enhanced by principal component analysis (PCA), and AugBoost-NN is enhanced by NN algorithm.
Figure 3 shows the testing AUC curves of advanced ensemble credit scoring algorithms.
Figure 3a is the testing curves of advanced ensemble methods for the Australian dataset;
Figure 3b represents the testing curves of advanced ensemble algorithms for the German dataset;
Figure 3c illustrates the testing curves of advanced ensemble approaches for the Japanese dataset;
Figure 3d provides the testing curves of advanced ensemble methods for the Taiwan dataset.
As can be seen from
Figure 3a, the converged testing AUC curve of AugBoost-ELM is close to that of AugBoost-NN, both of which are higher than the converged testing AUC of unsupervised AugBoost-based models such as AugBoost-RP and AugBoost-PCA. Moreover, as can be seen from
Figure 3a, AugBoost-based models are superior to advanced ensemble approaches such as XGBoost and LightGBM. As can be observed from
Figure 3b, AugBoost-ELM gets the highest converged testing AUC than other advanced ensemble approaches. Compared with unsupervised AugBoost-based models, XGBoost and LightGBM achieve better testing AUC while their converged testing AUC is worse than that of supervised AugBoost-based models; Compared with AugBoost-NN, AugBoost-ELM gets a slightly higher testing AUC than AugBoost-NN, demonstrating that AugBoost-ELM can be a good alternative to AugBoost-NN. As can be viewed from
Figure 3c, similar to the results in
Figure 3b, the testing AUC curve of AugBoost-ELM is slightly higher than that of another supervised enhanced GBDT model AugBoost-NN; AugBoost-based models get higher converged testing curves of advanced ensemble approaches. The same conclusion can be drawn from
Figure 3d for the Taiwan dataset.
Table 8 shows the performance comparison of advanced ensemble models for credit datasets. As can be seen from
Table 8, on the Australian dataset, AugBoost-NN gets the best values of the metrics of AUC, recall, and F1 while AugBoost-PCA gets the optimal accuracy score and precision score. Compared with advanced ensemble approaches such as XGBoost, LightGBM, AugBoost-RP, and AugBoost-PCA, AugBoost-ELM achieves comparable performance on the AUC score, F1 score, demonstrating that AugBoost-ELM can be an alternative supervised AugBoost model to AugBoost-NN. On the German dataset, Japanese dataset, and Taiwan dataset, AugBoost-ELM get the best values of accuracy score, AUC score, recall score, F1 score, and BS, demonstrating that AugBoost-ELM is a comparable approach to other advanced ensemble approaches such as XGBoost, LightGBM, AugBoost-RP, AugBoost-PCA, and AugBoost-NN.
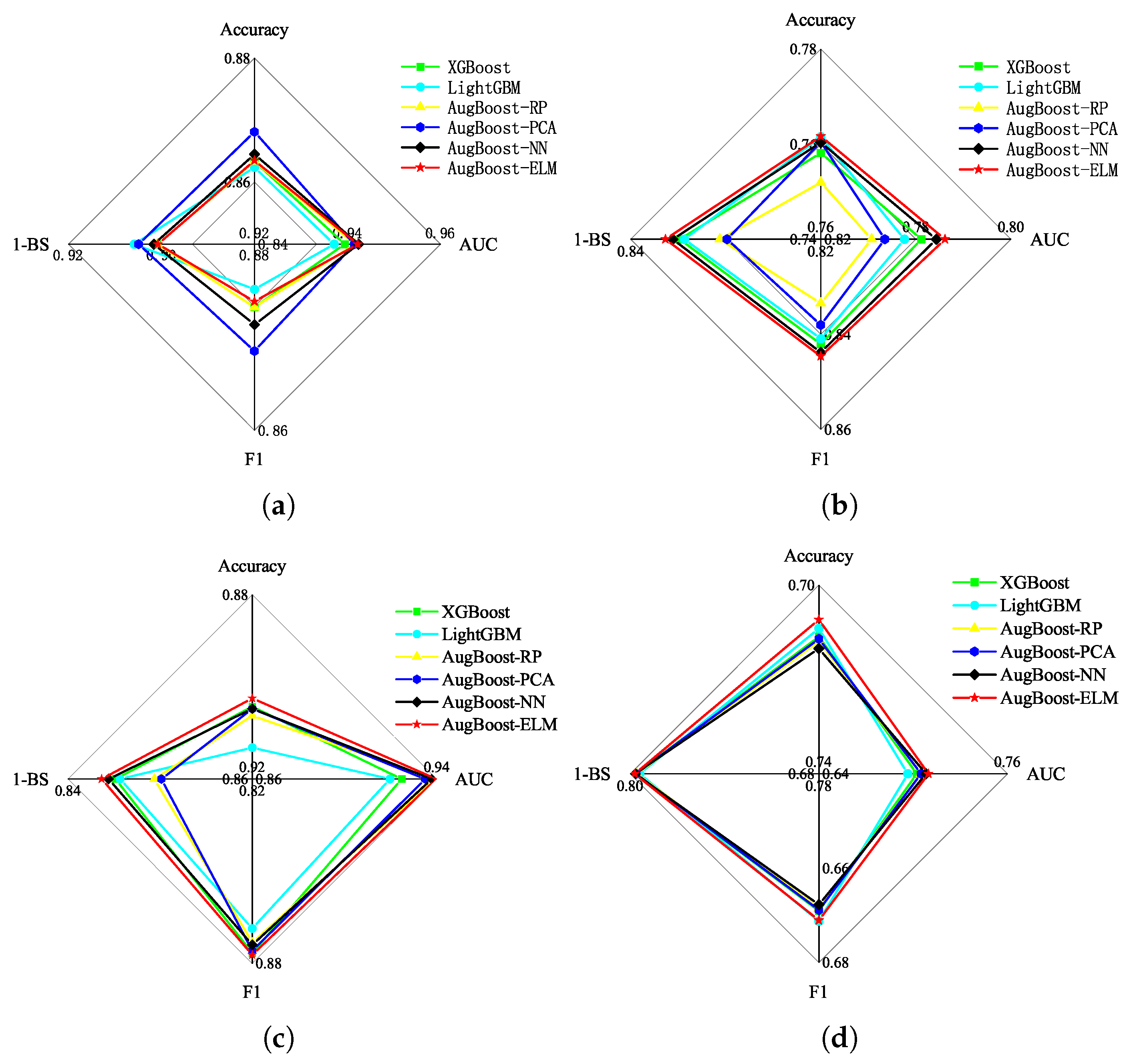
To analyze the overall performance of credit scoring, we select four comprehensive evaluation metrics, which include accuracy score, AUC score, F1 score, and BS for the further comparison.
Figure 4 shows the radar maps of advanced ensemble models for the credit datasets.
Figure 4a is the comparison result of ensemble approaches for the Australian dataset;
Figure 4b represents the performance radar map of advanced ensemble approaches for the German dataset;
Figure 4c illustrates the performance radar map of advanced ensemble methods for the Japanese dataset;
Figure 4a provides the performance radar map of advanced ensemble algorithms for the Taiwan dataset. The larger area that one radar map covers, the better overall performance a credit scoring model implies.
As can be seen from
Figure 4a, on the Australian dataset, AugBoost-ELM outperforms XGBoost and LightGBM while its radar map area is smaller than that of the other three AugBoost-based models including AugBoost-RP, AugBoost-PCA, and AugBoost-NN. As is shown in
Figure 4b–d, on the German dataset, Japanese dataset, and Taiwan dataset, AugBoost-ELM gets the largest radar maps area than other advanced boosting-based ensemble algorithms, not only providing the evidence that the supervised ELM-based feature augmentation can be an alternative to NN-based feature augmentation for boosting framework but also giving the illustration that supervised feature augmentation skill is superior to unsupervised feature augmentation for GBDT.
Since each credit scoring metric has its advantages and limitations, to give a view of the statistical ranks for credit scoring models, we perform a significance test procedure. Because parametric significance test method computers statistic value based on the assumption that credit scoring datasets follow a normal distribution, we adopt a simple and powerful non-parametric way for significance test. In this study, Friedman test, a rank-based non-parametric significance test, is introduced to investigate the statistical performance of credit scoring algorithms. The Friedman statistic value is calculated as:
where
K denotes the number of classifiers,
D represents the number of datasets.
is the average rank of
k-th classifier, and
,
,
,
,
are the ranks of
k-th classifier on
d-th dataset that are computed based on accuracy score, AUC, F1, and BS, respectively. By calculating the Friedman statistic value, the issue of whether there is a significant difference among credit scoring models is detected. Specifically, when
is larger than a critical value at a significance level, the null hypothesis (there is no significant difference between credit scoring models) is rejected, and a post hoc test, Nemenyi test, is further performed for pair-wise comparison. The critical difference (
) can be defined as:
where
is the critical difference at significance level
,
is the critical value at significance level
, which is computed from a studentized range.
To investigate the statistical difference among credit scoring models, we first compute
according to Equation (
20), rejecting the null hypothesis at significance level
. Next, we perform Nemenyi test for pair-wise comparison.
,
,
are first calculated to further computed CDs for different significance levels. According to Equation (
21), we can get
,
,
.
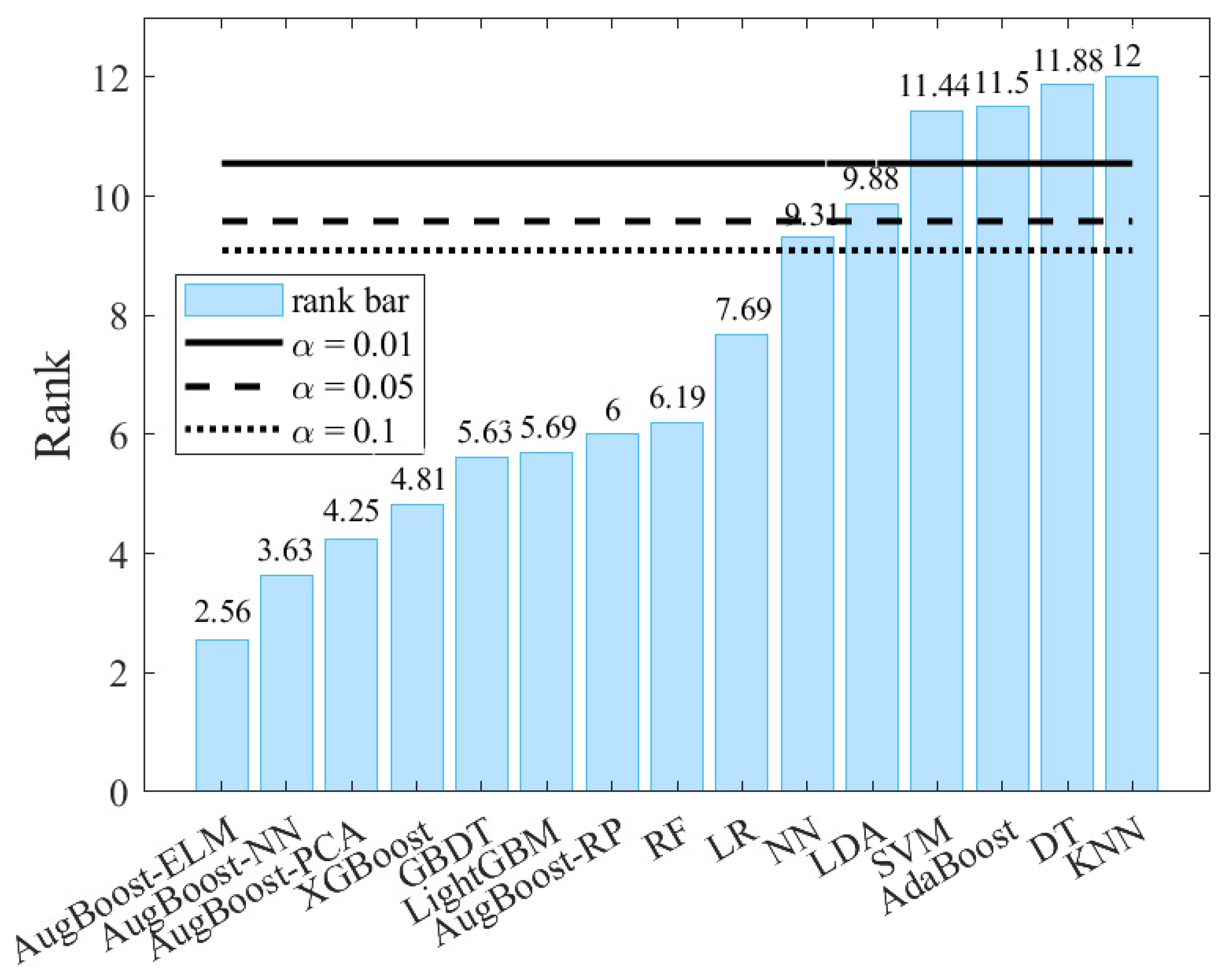
Figure 5 shows the average ranks of credit scoring models for the Nemenyi test. As can be seen from
Figure 5, if we consider AugBoost-ELM as the comparison baseline, SVM, AdaBoost, DT, and KNN are statistically inferior to AugBoost at significance level
; moreover, AugBoost-ELM outperforms LDA at the significance level
as well as it is superior to NN at the significance level
. Besides, as illustrated in
Figure 5, AugBoost-ELM, AugBoost-NN, and AugBoost-PCA rank in top 3, demonstrating the effectiveness of the augmentation mechanism for GBDT framework. The lower ranks of AugBoost-ELM and AugBoost-NN compared with AugBoost-PCA and AugBoost-RP further verify supervised augmentation is a better augmentation compared with unsupervised feature augmentation for GBDT.
In this study, ELM accomplishes the supervised step-wise feature augmentation process for GBDT, which avoids the iterative error back-propagation process of NN. Compared with NN-based feature augmentation for GBDT, ELM-based supervised feature augmentation accelerates the training process of the GBDT-based framework and avoids falling into local minima, leading to the robust generation of augmented features. Based on the above analysis, we further investigate the training efficiency by comparing the training cost of AugBoost-based models on the four credit datasets.
Table 9 shows the training cost comparison of AugBoost-based models on the four credit datasets. As can be seen from
Table 9, unsupervised AugBoost-based models such as AugBoost-RP and AugBoost-PCA get faster training speed. However, combined with the performance comparison analyzed above, supervised AugBoost models are the better solution for accurate credit scoring. Besides, as can be seen from the efficiency comparison among AugBoost-NN and AugBoost-ELM, the training efficiency of AugBoost-ELM has been greatly improved. Compared with AugBoost-NN, AugBoost-ELM reduces the training time by 86.90%, 85.24%, 88.14%, and 98.58% for the Australian dataset, German dataset, Japan dataset, and Taiwan dataset, respectively. Even in the incorporation with 1080Ti GPU, compared with AugBoost-NN, the efficiency improvement of AugBoost-ELM on large-scale datasets such as Taiwan is more significant than that on the small-scale datasets such as Australian, German, and Japan.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}