
Measuring the Non-Transitivity in Chess

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
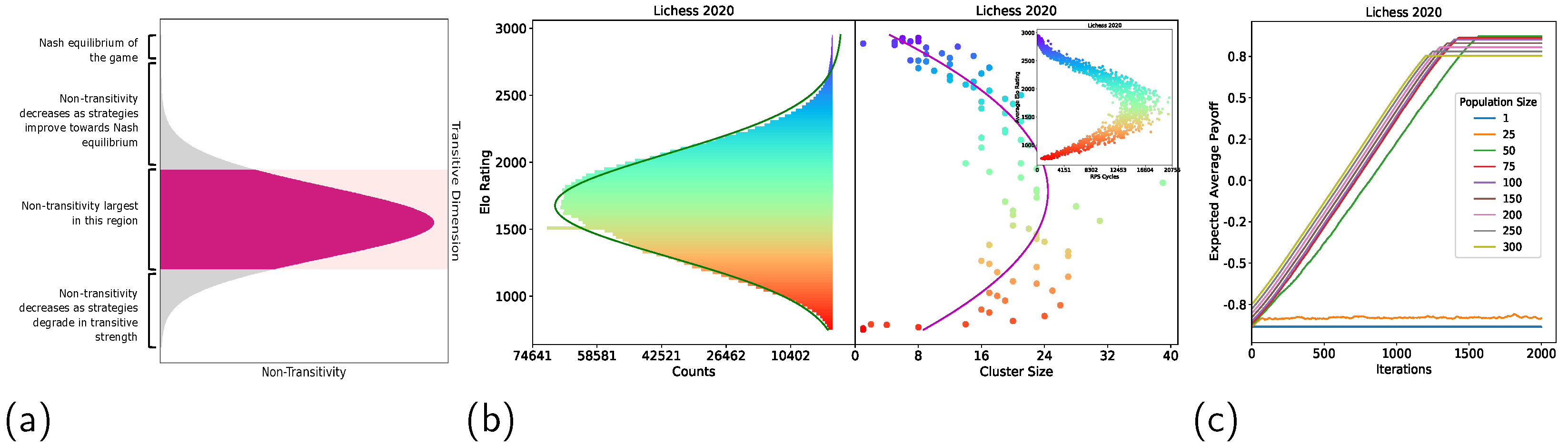
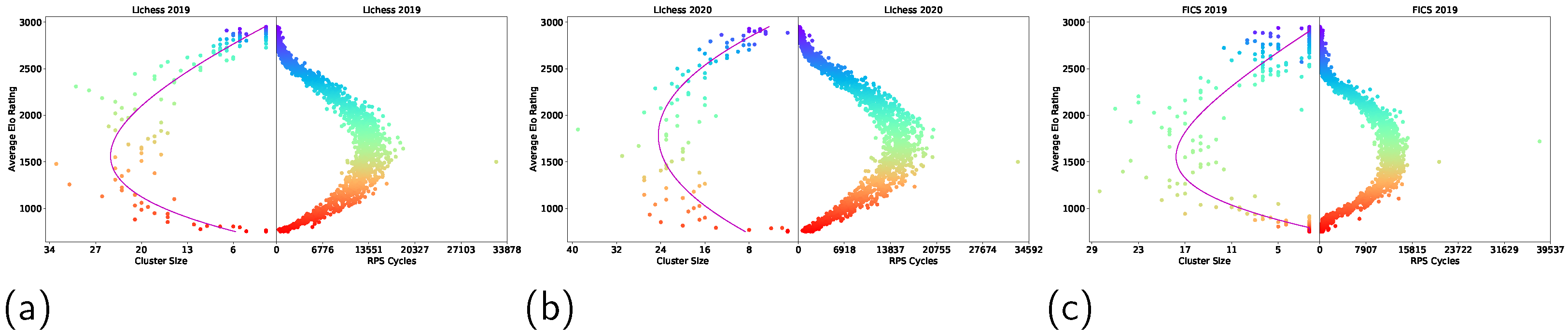
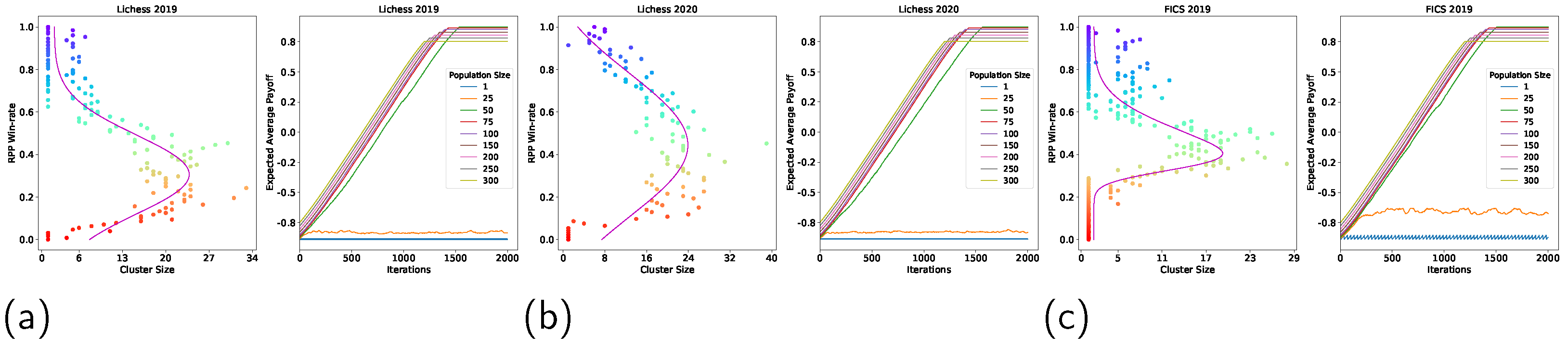
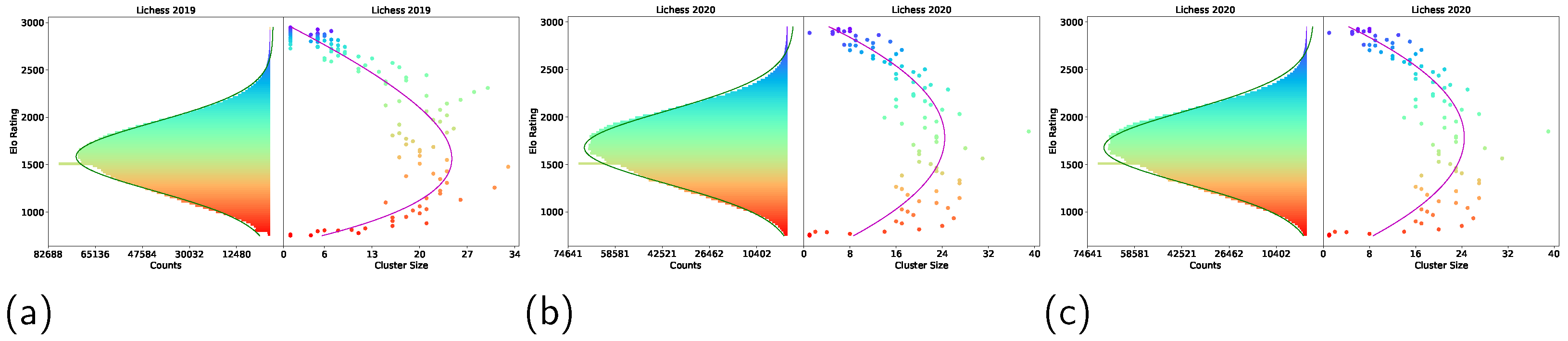
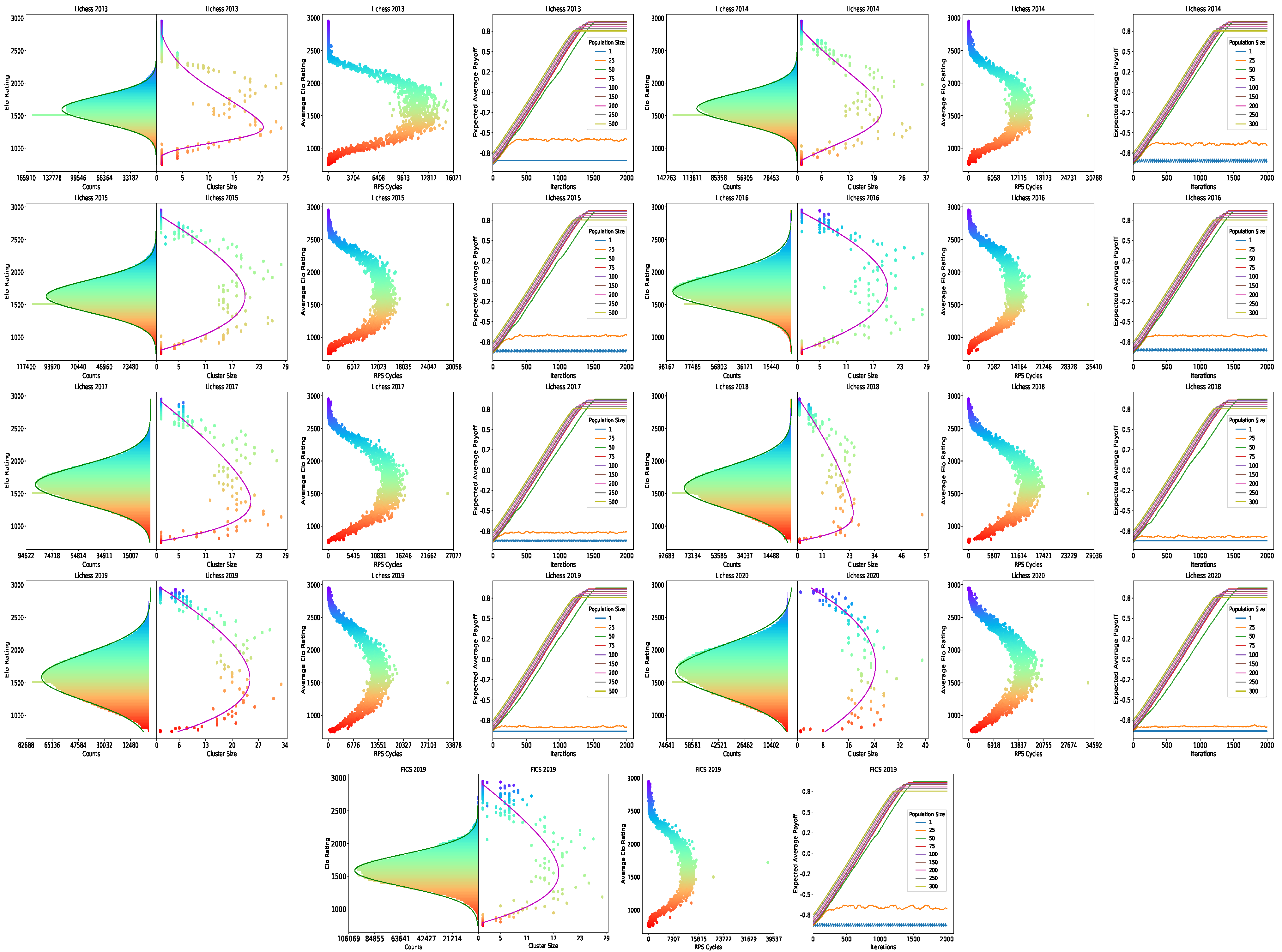
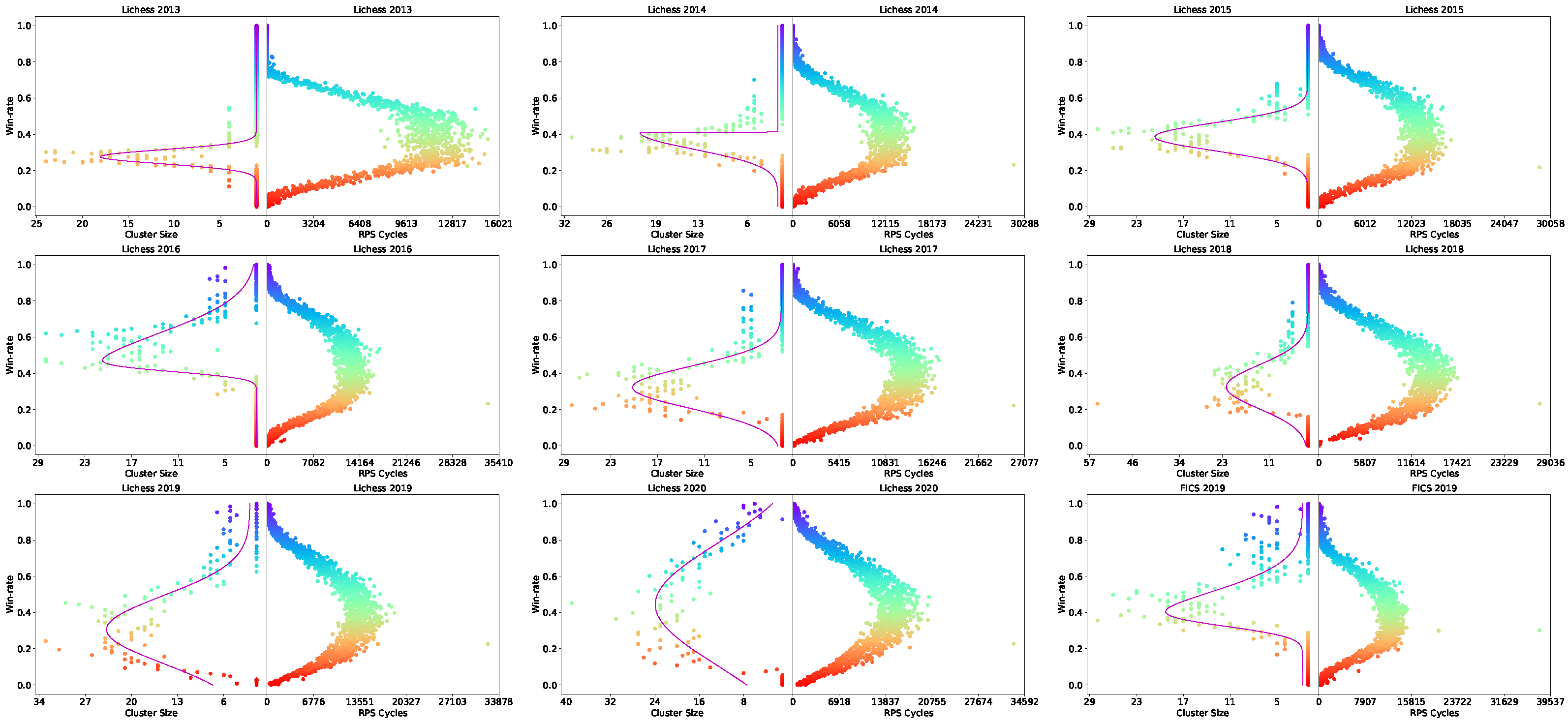
- We perform non-transitivity quantification in two ways (i.e., Nash Clustering and counting rock–paper–scissor cycles) on over one billion human games collected from Lichess and FICS. We found that the strategy space occupied by real-world chess strategies exhibited a spinning top geometry.
- We propose several algorithms to tackle the challenges of working with real-world data. These include a two-staged sampling algorithm to sample from a large amount of data, and an algorithm to convert real-world chess games into a Normal Form game payoff matrix.
- We propose mappings between different chess player rating systems, in order to allow our results to be translated between these rating systems.
- We investigate the implications of non-transitivity on population-based training methods, and propose a fixed-memory Fictitious Play algorithm to illustrate these implications. We find that it is not only crucial to maintain a relatively large population of agents/strategies for training to converge, but that the minimum population size is related to the degree of non-transitivity of the strategy space.
- We investigate potential links between the degree of non-transitivity and the progression of a human chess player’s skill. We found that, at ratings where the degree of non-transitivity is high, progression is harder, and vice versa.
2. Related Works
3. Theoretical Formulations and Methods
3.1. Game Theory Preliminaries
- denotes the number of players;
- denotes the joint strategy space of the game, where is the strategy space of the , . A strategy space is the set of strategies a player can adopt;
- , where is the payoff function for the player. A payoff function maps the outcome of a game resulting from a joint strategy to a real value, representing the payoff received by that player.
3.1.1. Normal Form (NF) Games
3.1.2. Extensive Form (EF) Games
3.2. Elo Rating
3.3. Non-Transitivity Quantification
3.3.1. Payoff Matrix Construction
| Algorithm 1: Two-Stage Uniform Sampling. |
 |
| Algorithm 2: Chess Payoff Matrix Construction. |
 |
3.3.2. Nash Clustering
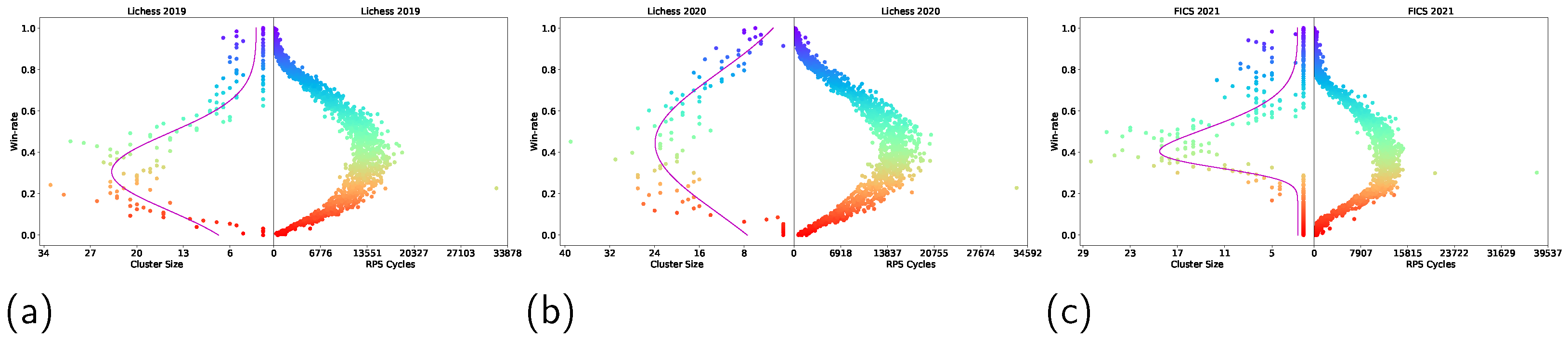
3.3.3. Rock–Paper–Scissor Cycles
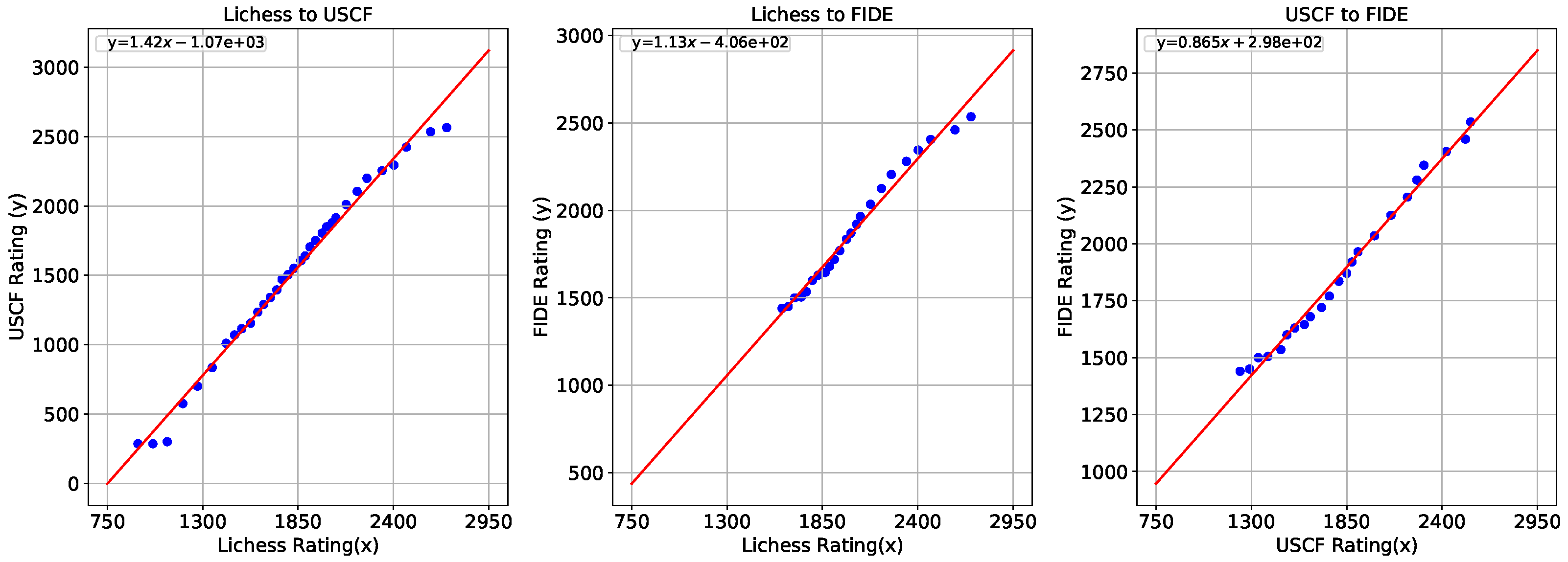
3.4. Relationships between Existing Rating Systems
3.5. Implications of Non-Transitivity on Learning
| Algorithm 3: Fixed-Memory Fictitious Play. |
 |
| Algorithm 4: Compute Win Rate. |
 |
3.6. Link to Human Skill Progression
3.7. Algorithm Hyperparameter Considerations
4. Results and Discussions
4.1. Non-Transitivity Quantification
4.2. Relationships between Existing Rating Systems
4.3. Implications of Non-Transitivity on Learning
4.4. Link to Human Skill Progression
5. Conclusions and Future Work
- In Section 3.3.1, missing data between match-ups of bins are filled using Elo formulas; that is, Equations (2) and (3). However, the Lichess ratings use the Glicko-2 system [20], which has a slightly different win probability formula that also considers the rating deviation and volatility of the rating. Therefore, a possible improvement would be to additionally collect the rating deviation and volatility of the players in every game, and apply the Glicko-2 predictive formula to compute the win probability, instead of Equation (2).
- Non-transitivity analysis could also be carried out using other online chess platforms, such as Chess.com [30], in order to provide more comprehensive evidence on the spinning top geometry of the real-world strategy space. Furthermore, the non-transitivity analysis could also be carried out using real-world data on other, more complex, zero-sum games, such as Go, DOTA and StarCraft.
- Other links between non-transitivity and human progression can be investigated. One possible method would be to monitor player rating progression from the start of their progress to when they achieve a sufficiently high rating in a chess platform, such as Lichess. Their rating progression can then be compared to the non-transitivity at that rating and in that year. However, player rating progression is typically not available on online chess platforms and, thus, would require monitoring player progress over an extended period of time.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Additional Results

Appendix B. Additional Results with Alternative Measure of Transitive Strength

Appendix C. Theorem Proofs
References
- Ensmenger, N. Is chess the drosophila of artificial intelligence? A social history of an algorithm. Soc. Stud. Sci. 2012, 42, 5–30. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shannon, C.E. XXII. Programming a computer for playing chess. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1950, 41, 256–275. [Google Scholar] [CrossRef]
- Campbell, M.; Hoane, A.J., Jr.; Hsu, F.h. Deep blue. Artif. Intell. 2002, 134, 57–83. [Google Scholar] [CrossRef] [Green Version]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. Mastering chess and shogi by self-play with a general reinforcement learning algorithm. arXiv 2017, arXiv:1712.01815. [Google Scholar]
- Czarnecki, W.M.; Gidel, G.; Tracey, B.; Tuyls, K.; Omidshafiei, S.; Balduzzi, D.; Jaderberg, M. Real World Games Look Like Spinning Tops. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Nash, J. Non-cooperative games. Ann. Math. 1951, 54, 286–295. [Google Scholar] [CrossRef]
- McIlroy-Young, R.; Sen, S.; Kleinberg, J.; Anderson, A. Aligning Superhuman AI with Human Behavior: Chess as a Model System. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event. CA, USA, 6–10 July 2020; pp. 1677–1687. [Google Scholar]
- Romstad, T.; Costalba, M.; Kiiski, J.; Linscott, G. Stockfish: A strong open source chess engine. 2017. Open Source. Available online: https://stockfishchess.org (accessed on 18 August 2021).
- Lichess. About lichess.org. Available online: https://lichess.org/about (accessed on 16 August 2021).
- FICS. FICS Free Internet Chess Server. Available online: https://www.freechess.org/ (accessed on 16 August 2021).
- Yang, Y.; Luo, J.; Wen, Y.; Slumbers, O.; Graves, D.; Bou Ammar, H.; Wang, J.; Taylor, M.E. Diverse Auto-Curriculum is Critical for Successful Real-World Multiagent Learning Systems. In Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, London, UK, 3–7 May 2021; pp. 51–56. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach; Prentice Hall: Englewood Cliffs, NJ, USA, 2002. [Google Scholar]
- Chaslot, G.; Bakkes, S.; Szita, I.; Spronck, P. Monte-Carlo Tree Search: A New Framework for Game AI. AIIDE 2008, 8, 216–217. [Google Scholar]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef] [PubMed]
- International Chess Federation. FIDE Charter, Art. 1 FIDE—Name, Legal Status and Seat. Available online: https://handbook.fide.com/files/handbook/FIDECharter2020.pdf (accessed on 16 August 2021).
- United States Chess Federation. About US Chess Federation. Available online: https://new.uschess.org/about (accessed on 16 August 2021).
- Glickman, M.E.; Doan, T. The US Chess Rating System. 2020. Available online: https://new.uschess.org/sites/default/files/media/documents/the-us-chess-rating-system-revised-september-2020.pdf (accessed on 18 August 2021).
- International Chess Federation. FIDE Handbook, B. Permanent Commissions/02. FIDE Rating Regulations (Qualification Commission)/FIDE Rating Regulations Effective from 1 July 2017 (with Amendments Effective from 1 February 2021). Available online: https://handbook.fide.com/chapter/B022017 (accessed on 20 August 2021).
- Glickman, M.E. The Glicko System; Boston University: Boston, MA, USA, 1995; Volume 16, pp. 16–17. [Google Scholar]
- Glickman, M.E. Example of the Glicko-2 System; Boston University: Boston, MA, USA, 2012; pp. 1–6. [Google Scholar]
- Deng, X.; Li, Y.; Mguni, D.H.; Wang, J.; Yang, Y. On the Complexity of Computing Markov Perfect Equilibrium in General-Sum Stochastic Games. arXiv 2021, arXiv:2109.01795. [Google Scholar]
- Balduzzi, D.; Tuyls, K.; Pérolat, J.; Graepel, T. Re-evaluating evaluation. In Proceedings of the NeurIPS; Neural Information Processing Systems Foundation, Inc.: Montréal, QC, Canada, 2018; pp. 3272–3283. [Google Scholar]
- Hart, S. Games in extensive and strategic forms. In Handbook of Game Theory with Economic Applications; Elsevier: Amsterdam, The Netherlands, 1992; Volume 1, pp. 19–40. [Google Scholar]
- Kuhn, H.W. Extensive games. In Lectures on the Theory of Games (AM-37); Princeton University Press: Princeton, NJ, USA, 2009; pp. 59–80. [Google Scholar]
- Elo, A.E. The Rating of Chessplayers, Past and Present; Arco Pub.: Nagoya, Japan, 1978. [Google Scholar]
- Edwards, S.J. Standard Portable Game Notation Specification and Implementation Guide. 1994. Available online: http://www.saremba.de/chessgml/standards/pgn/pgncomplete.htm (accessed on 10 August 2021).
- Balduzzi, D.; Garnelo, M.; Bachrach, Y.; Czarnecki, W.; Perolat, J.; Jaderberg, M.; Graepel, T. Open-ended learning in symmetric zero-sum games. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 434–443. [Google Scholar]
- Björklund, A.; Husfeldt, T.; Khanna, S. Approximating longest directed paths and cycles. In Proceedings of the International Colloquium on Automata, Languages, and Programming, Turku, Finland, 12–16 July 2004; pp. 222–233. [Google Scholar]
- ChessGoals. Rating Comparison Database. 2021. Available online: https://chessgoals.com/rating-comparison/.
- Chess.com. About Chess.com. Available online: https://www.chess.com/about (accessed on 16 August 2021).
- Yang, Y.; Wang, J. An Overview of Multi-Agent Reinforcement Learning from Game Theoretical Perspective. arXiv 2020, arXiv:2011.00583. [Google Scholar]
- Lanctot, M.; Zambaldi, V.; Gruslys, A.; Lazaridou, A.; Tuyls, K.; Pérolat, J.; Silver, D.; Graepel, T. A unified game-theoretic approach to multiagent reinforcement learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4193–4206. [Google Scholar]
- Perez-Nieves, N.; Yang, Y.; Slumbers, O.; Mguni, D.H.; Wen, Y.; Wang, J. Modelling Behavioural Diversity for Learning in Open-Ended Games. In Proceedings of the International Conference on Machine Learning, PMLR. Virtual, 18–24 July 2021; pp. 8514–8524. [Google Scholar]
- Liu, X.; Jia, H.; Wen, Y.; Yang, Y.; Hu, Y.; Chen, Y.; Fan, C.; Hu, Z. Unifying Behavioral and Response Diversity for Open-ended Learning in Zero-sum Games. arXiv 2021, arXiv:2106.04958. [Google Scholar]
- Dinh, L.C.; Yang, Y.; Tian, Z.; Nieves, N.P.; Slumbers, O.; Mguni, D.H.; Ammar, H.B.; Wang, J. Online Double Oracle. arXiv 2021, arXiv:2103.07780. [Google Scholar]
- Zhou, M.; Wan, Z.; Wang, H.; Wen, M.; Wu, R.; Wen, Y.; Yang, Y.; Zhang, W.; Wang, J. MALib: A Parallel Framework for Population-based Multi-agent Reinforcement Learning. arXiv 2021, arXiv:2106.07551. [Google Scholar]
- Lanctot, M.; Lockhart, E.; Lespiau, J.B.; Zambaldi, V.; Upadhyay, S.; Pérolat, J.; Srinivasan, S.; Timbers, F.; Tuyls, K.; Omidshafiei, S.; et al. OpenSpiel: A framework for reinforcement learning in games. arXiv 2019, arXiv:1908.09453. [Google Scholar]
- Chess.com. Stuck at the Same Rating for a Long Time. 2019; Available online: https://www.chess.com/forum/view/general/stuck-at-the-same-rating-for-a-long-time-1 (accessed on 16 August 2021).
- Lichess. My Friends Are Stuck at 1500–1600 How Long Will it Take Them to Get Up to 1700. 2021. Available online: https://lichess.org/forum/general-chess-discussion/my-friends-are-stuck-at-1500-1600-how-long-will-it-take-them-to-get-up-to-1700 (accessed on 13 March 2022).
- Lichess. Stuck at 1600 Rating. 2021. Available online: https://lichess.org/forum/general-chess-discussion/stuck-at-1600-rating (accessed on 13 March 2022).
- Hayward, R.B.; Toft, B. Hex, Inside and Out: The Full Story; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Daskalakis, C. Two-Player Zero-Sum Games and Linear Programming. 2011. Available online: http://people.csail.mit.edu/costis/6896sp10/lec2.pdf (accessed on 21 August 2021).







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sanjaya, R.; Wang, J.; Yang, Y. Measuring the Non-Transitivity in Chess. Algorithms 2022, 15, 152. https://doi.org/10.3390/a15050152
Sanjaya R, Wang J, Yang Y. Measuring the Non-Transitivity in Chess. Algorithms. 2022; 15(5):152. https://doi.org/10.3390/a15050152
Chicago/Turabian StyleSanjaya, Ricky, Jun Wang, and Yaodong Yang. 2022. "Measuring the Non-Transitivity in Chess" Algorithms 15, no. 5: 152. https://doi.org/10.3390/a15050152
APA StyleSanjaya, R., Wang, J., & Yang, Y. (2022). Measuring the Non-Transitivity in Chess. Algorithms, 15(5), 152. https://doi.org/10.3390/a15050152