
Research on Network Attack Traffic Detection HybridAlgorithm Based on UMAP-RF


Abstract
:1. Introduction
2. Related Works
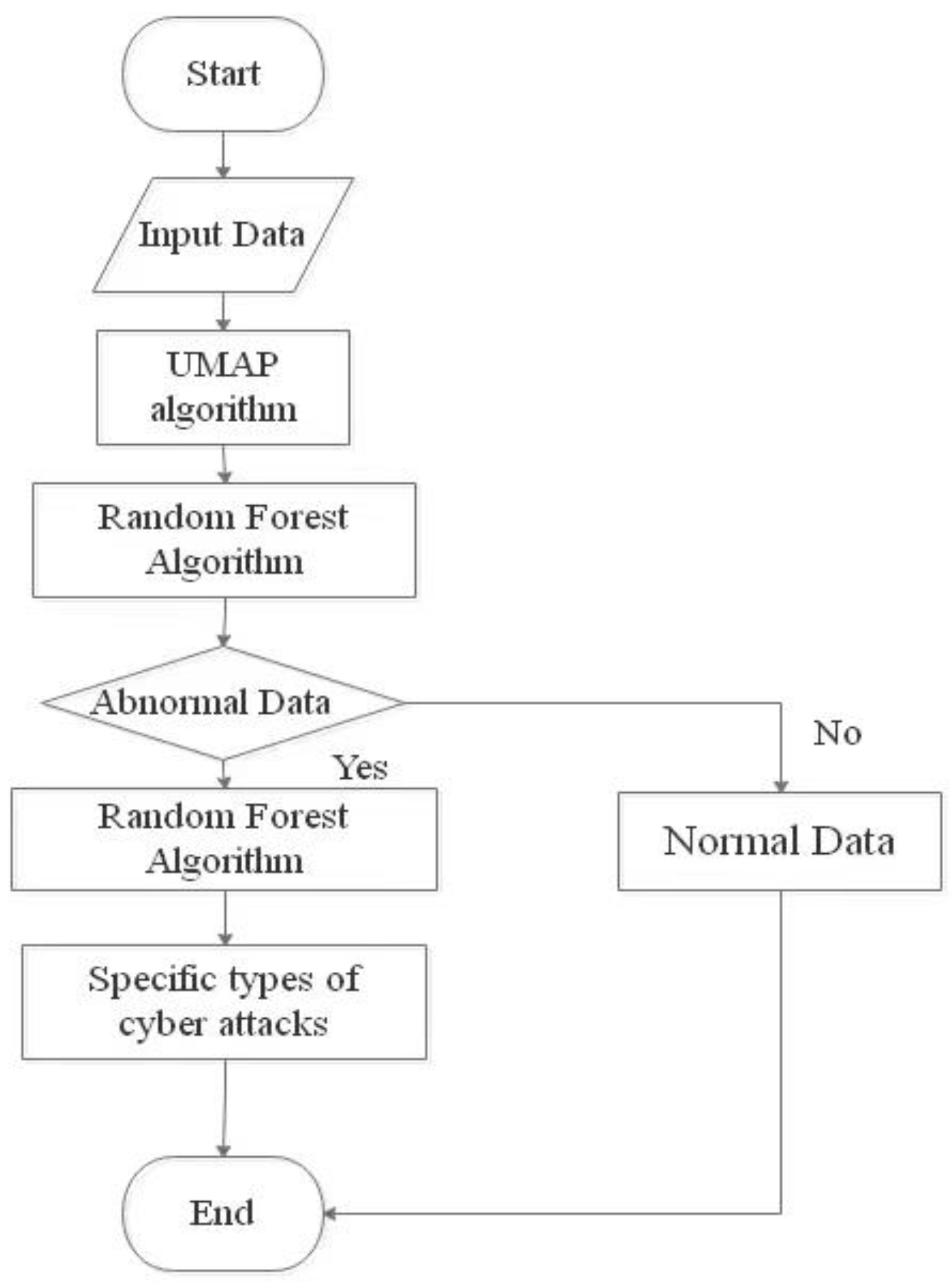
3. Hybrid Algorithm UMAP-RF
3.1. UMAP Dimensionality Reduction Algorithm
| Algorithm 1 UMAP algorithm |
| function UMAP (,,, min-dist,n-epochs) for all do fs-set []LocalFuzzySimplicialSet (,,) top-rep fs-set [] SpectralEmbedding(top-rep,) OptimizeEmbedding(top-rep, ,min-dist,n-epochs) return |
3.2. Random Forest Algorithm Based on Parameter Optimization
- Construct multiple sub-datasets. Form an intermediate dataset by selecting k samples through sampling with put-back from a dataset, including k samples, and then randomly select a few features among all features of this intermediate dataset as the final dataset;
- Build a sub-decision tree based on the sub-dataset. Assume that a sub-dataset has M features. When each node of the decision tree needs to split, randomly select m features from these features (m < M), then select one of the m features as the splitting attribute of the node. Keep repeating this step until it can no longer be classified. The principle of judgement is that the attribute selected by a node next time is the attribute used in the last split;
- Follow the above steps to construct a large number of sub-decision trees, which form a random forest;
- Input the dataset into different sub-decision trees. Different judgments will be obtained. The most judgmental result is the classification result obtained by the random forest.
| Algorithm 2 Random Forest algorithm |
For to :
To make a prediction at a new point : Classification: Let be the class prediction of the th random-forest tree. Then, . |
3.3. UMAP-RF Hybrid Algorithm
- Divide the UNSW-NB15 dataset into 70% training set, 10% validation set (Set hyperparameters) and 20% test set;
- Convert the non-numerical features to numerical values and remove non-numerical features, such as proto, service and state, from the dataset to obtain dataset δ;
- The processed dataset δ is dimensionally reduced by the UMAP algorithm to obtain dataset θ;
- Optimize the parameters of the random forest algorithm with the number of base evaluators and the maximum number of leaf nodes. n_estimators is set to 1000, and max_leaf_nodes is set to 10 by manual parameter tuning;
- Import the dataset θ obtained after UMAP dimensionality reduction into the improved random forest algorithm for training. Classify normal data α and abnormal data β, and complete malicious traffic detection;
- Import the detected abnormal data β into the improved random forest algorithm to classify the abnormal data β, and obtain each specific type of network attack traffic.
4. Experiment and Analysis
4.1. UNSW-NB15 Dataset and Experimental Environment
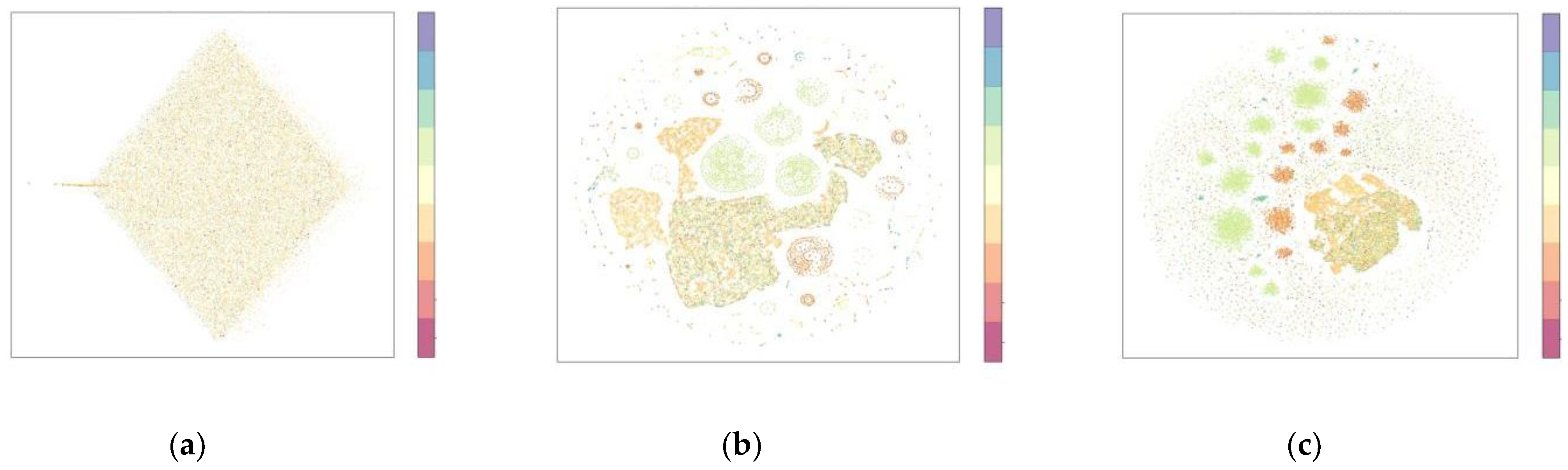
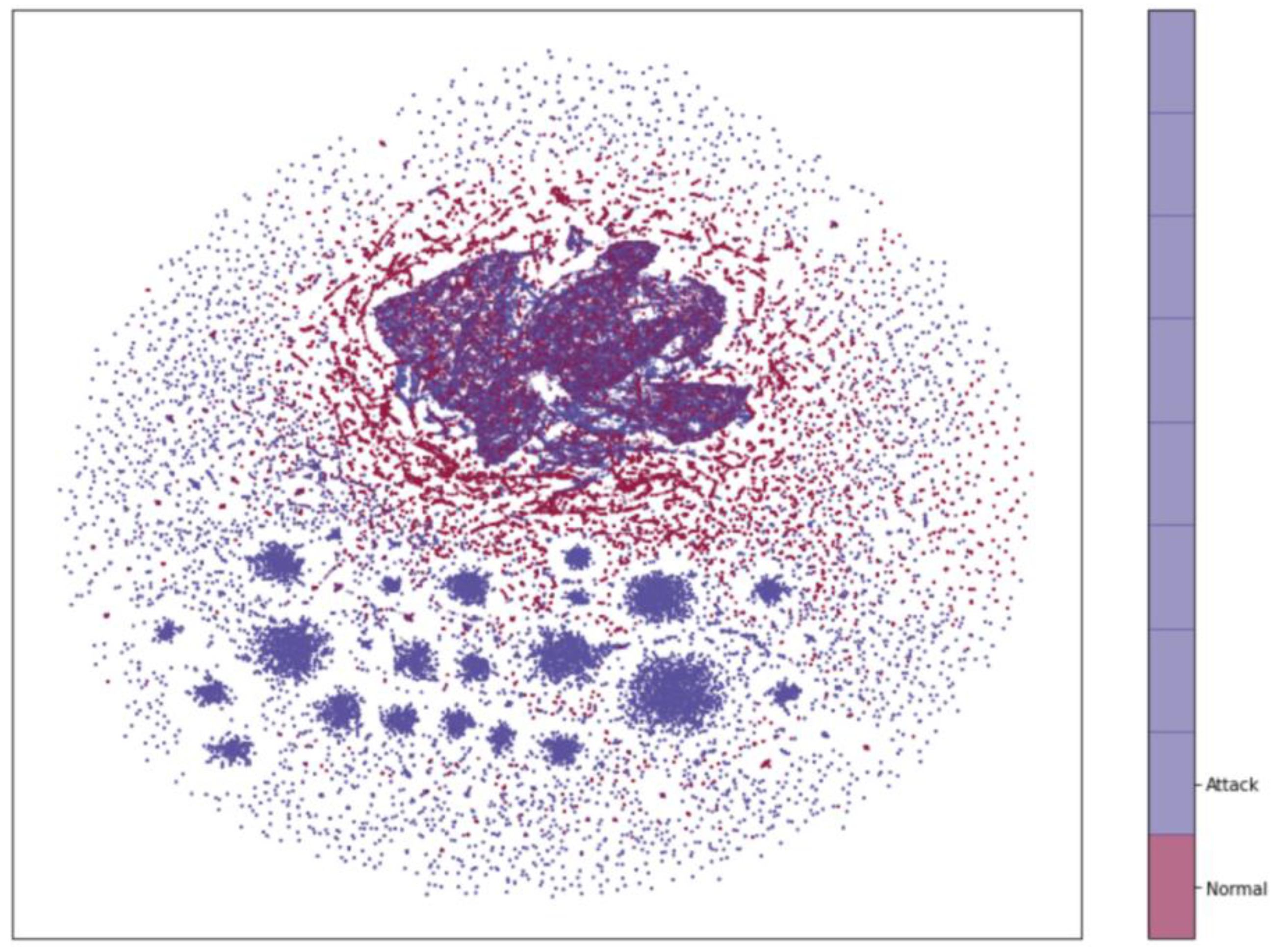
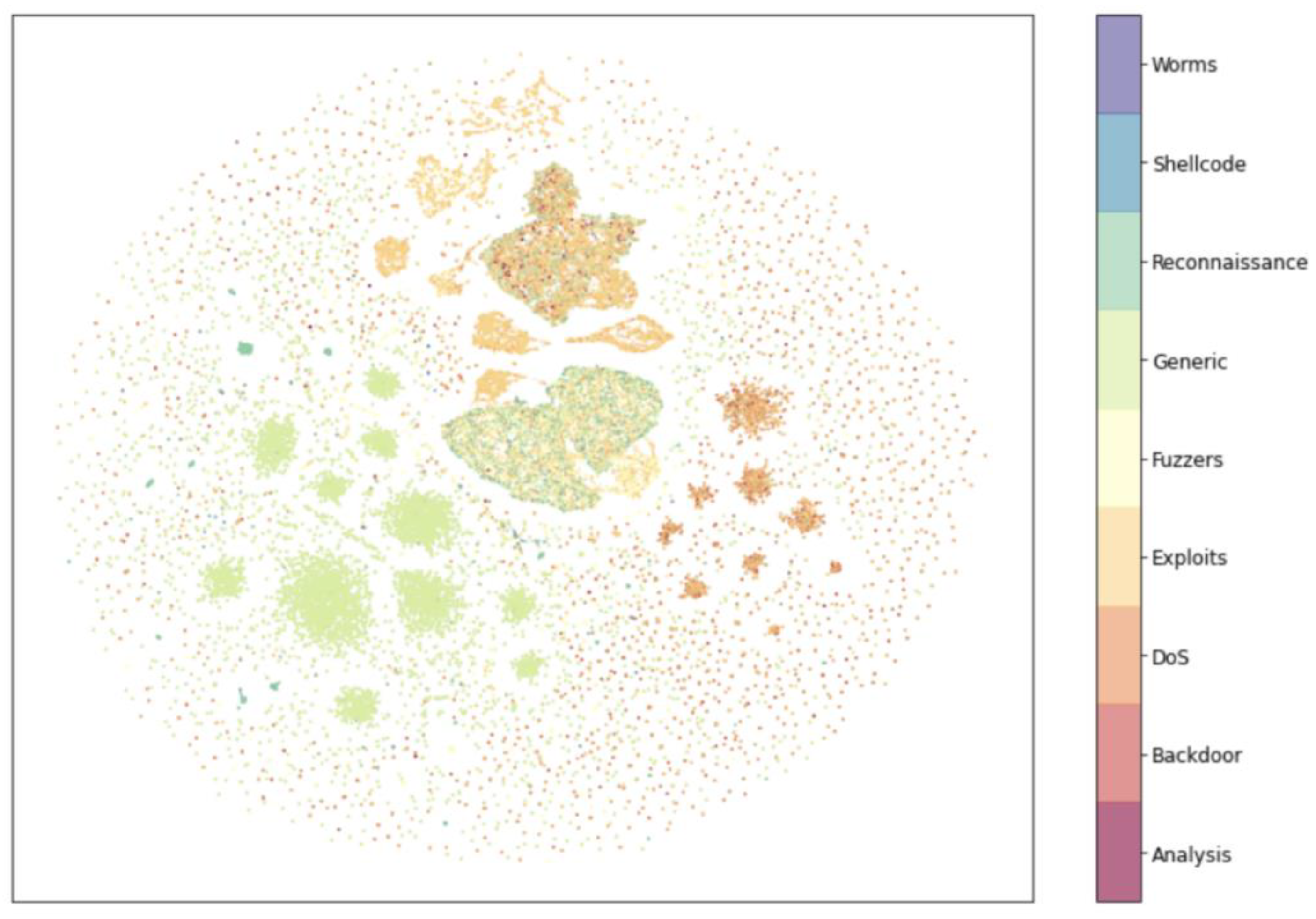
4.2. Experimental Results of Dimensionality Reduction Algorithm
4.3. Experimental Evaluation Metrics
4.4. Random Forest Classifier Parameter Settings
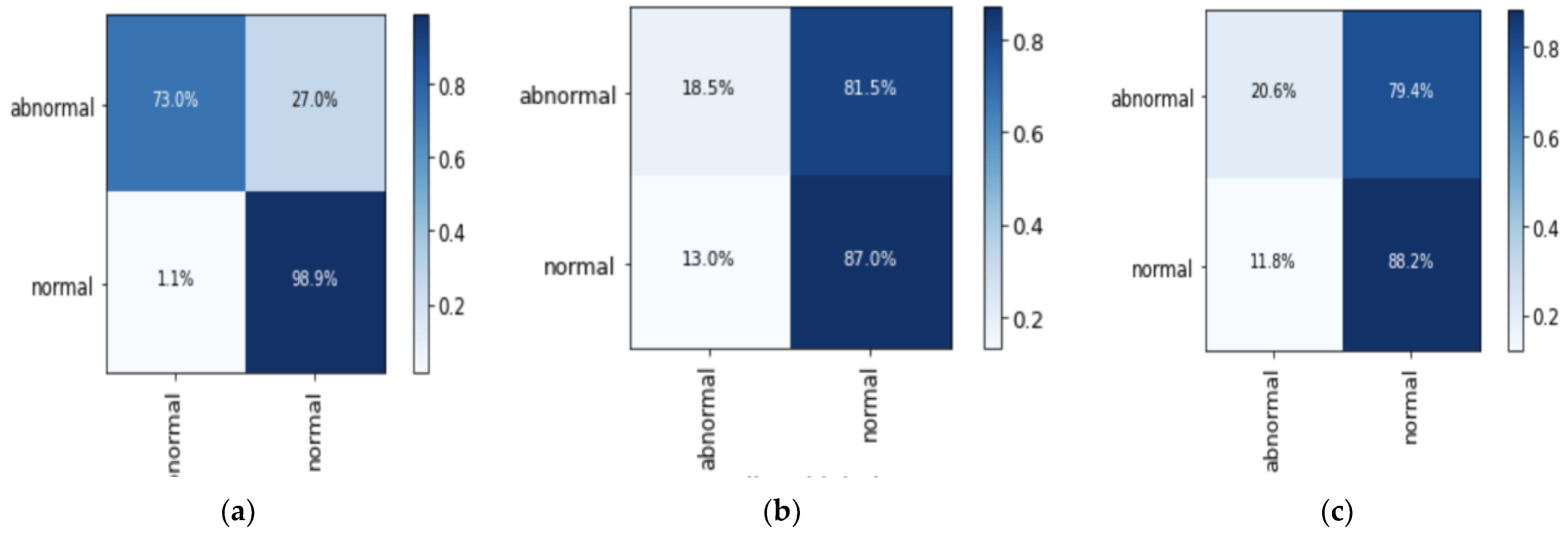
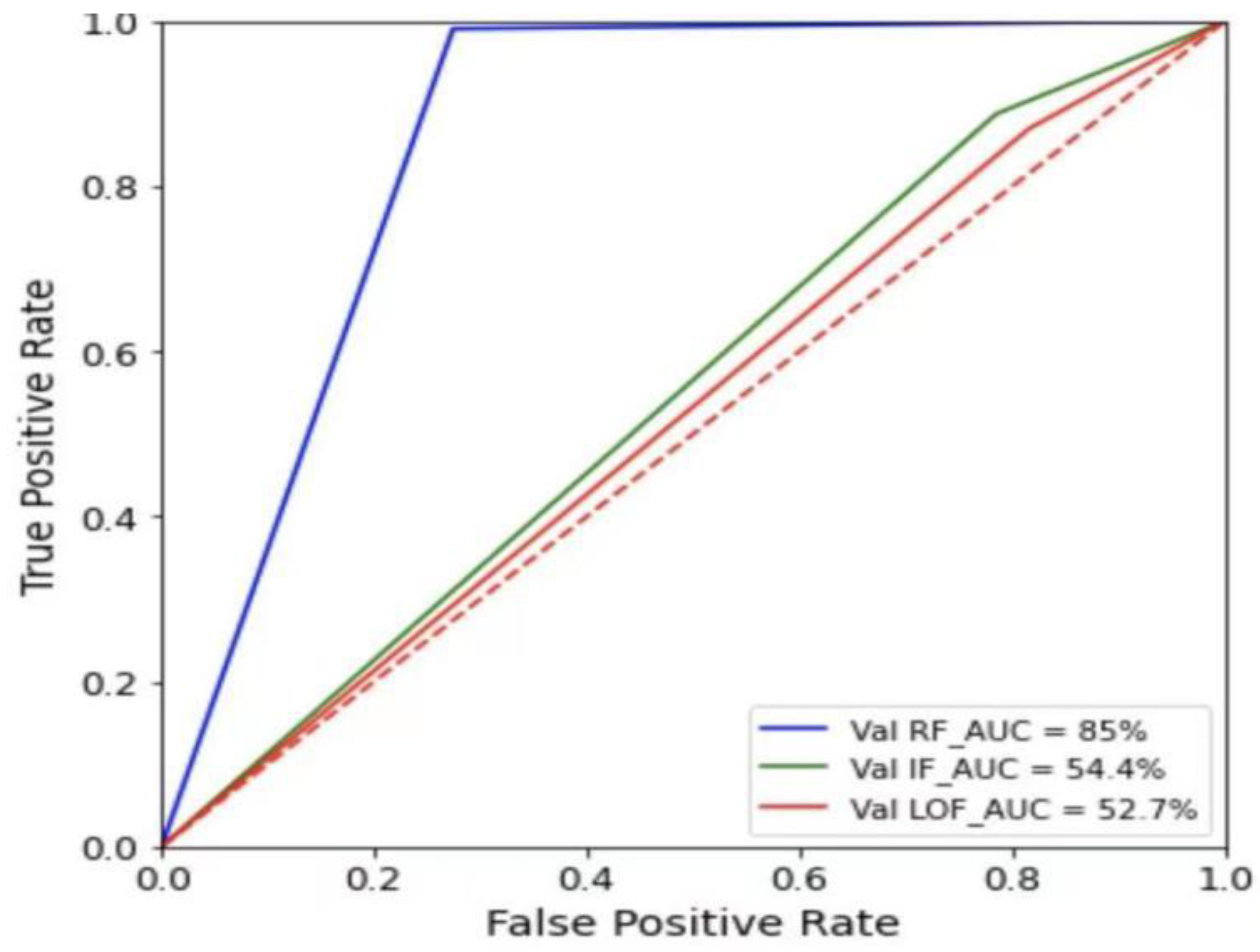
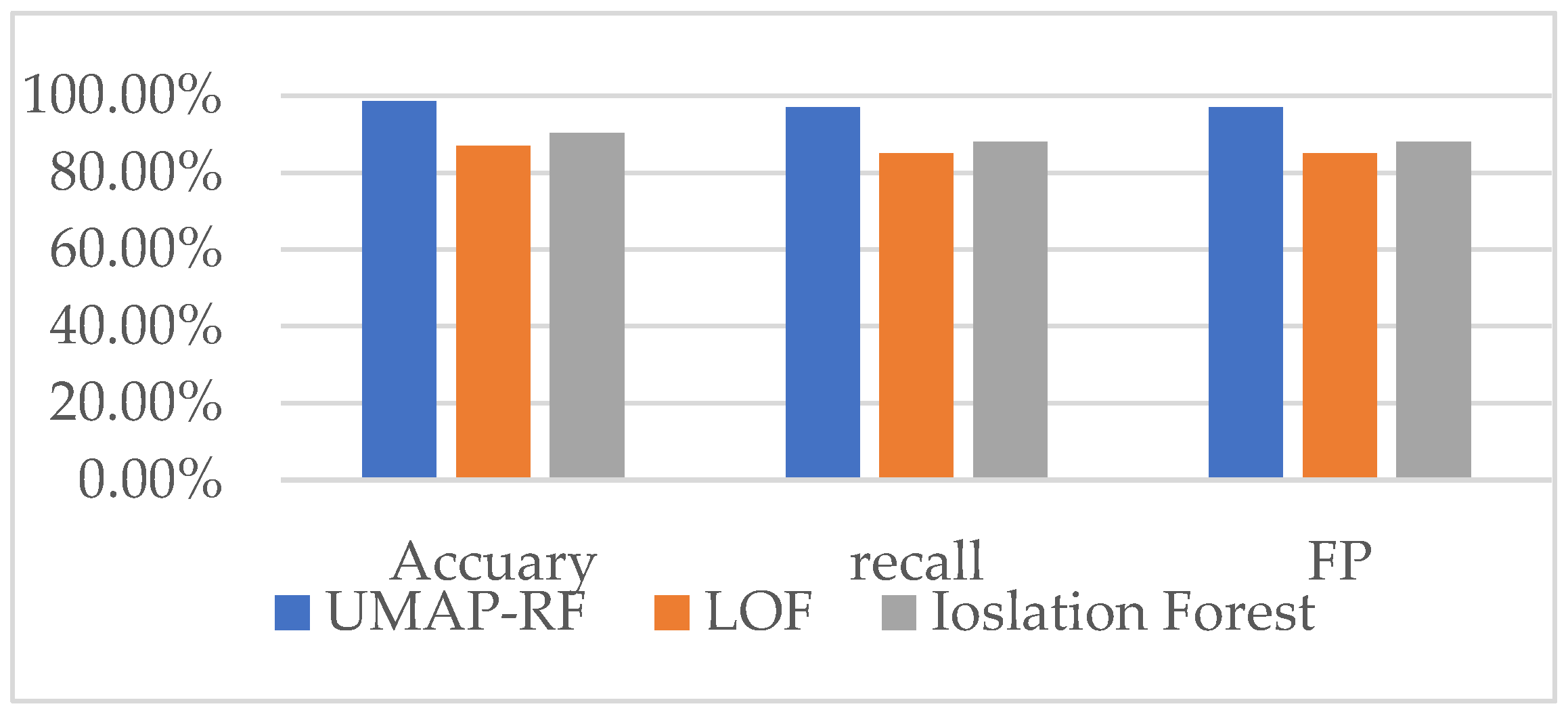
4.5. Analysis of Binary Classification Experimental Results
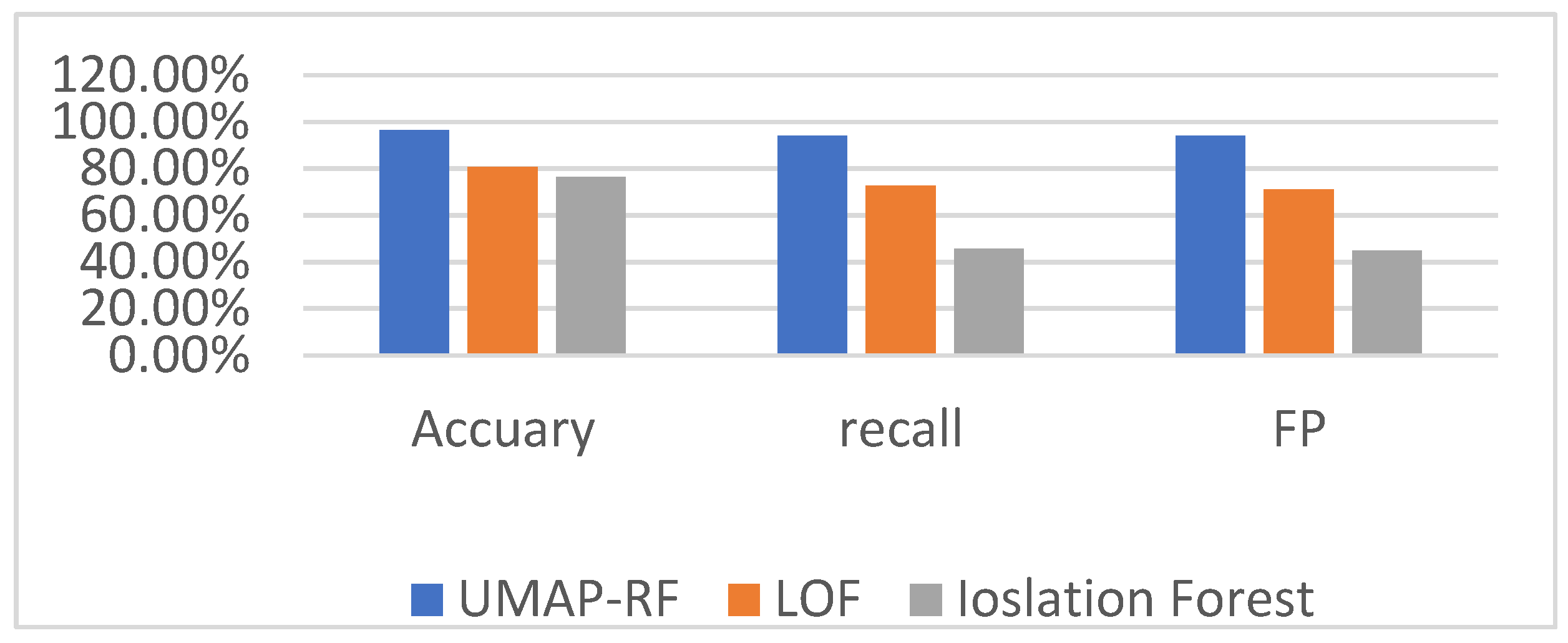
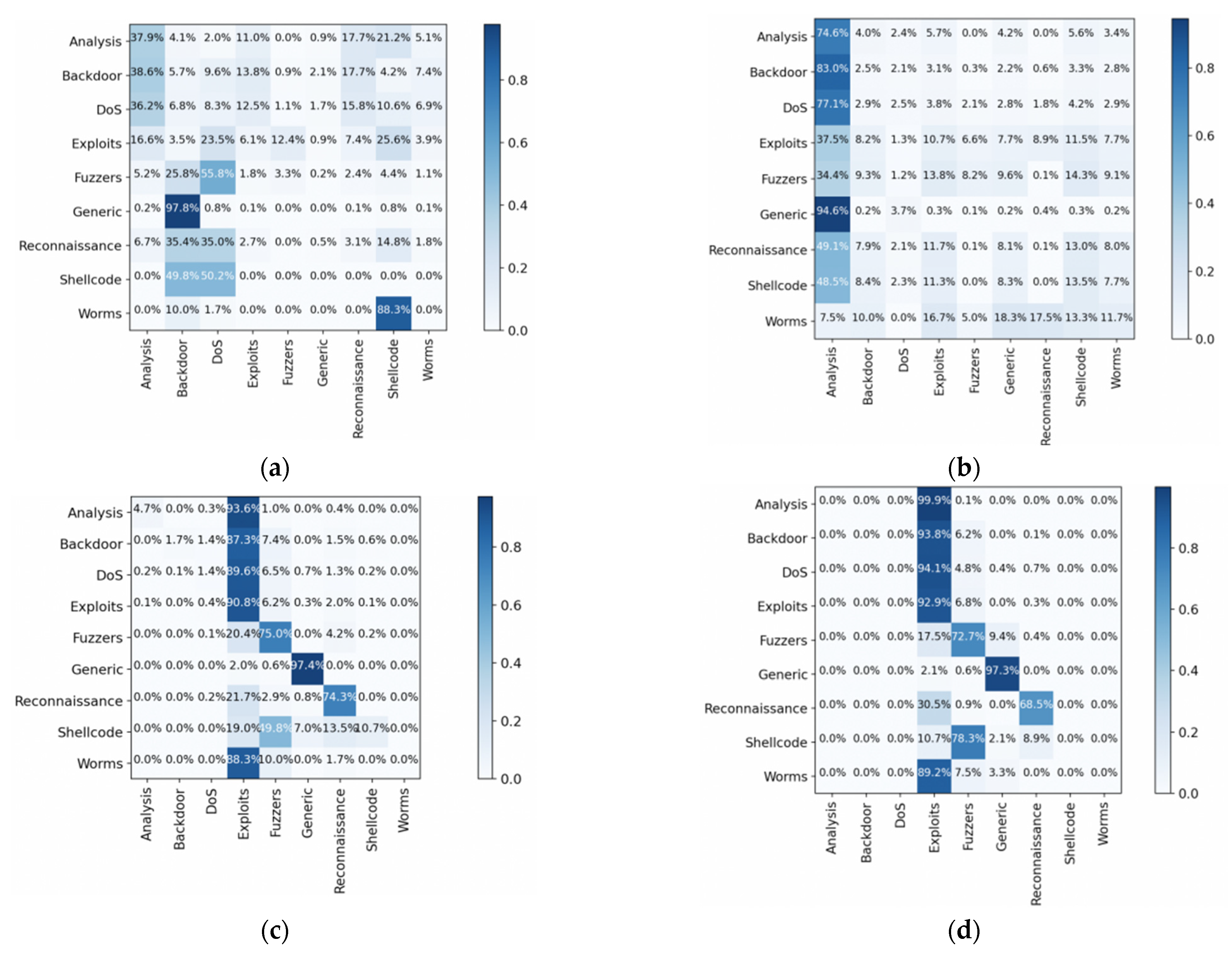
4.6. Analysis of Multi-Classification Experimental Results
4.7. Comparison of the Running Time of UMAP-RF Hybrid Algorithm and Other Algorithms
4.8. Time Complexity of the Hybrid Algorithm UMAP-RF
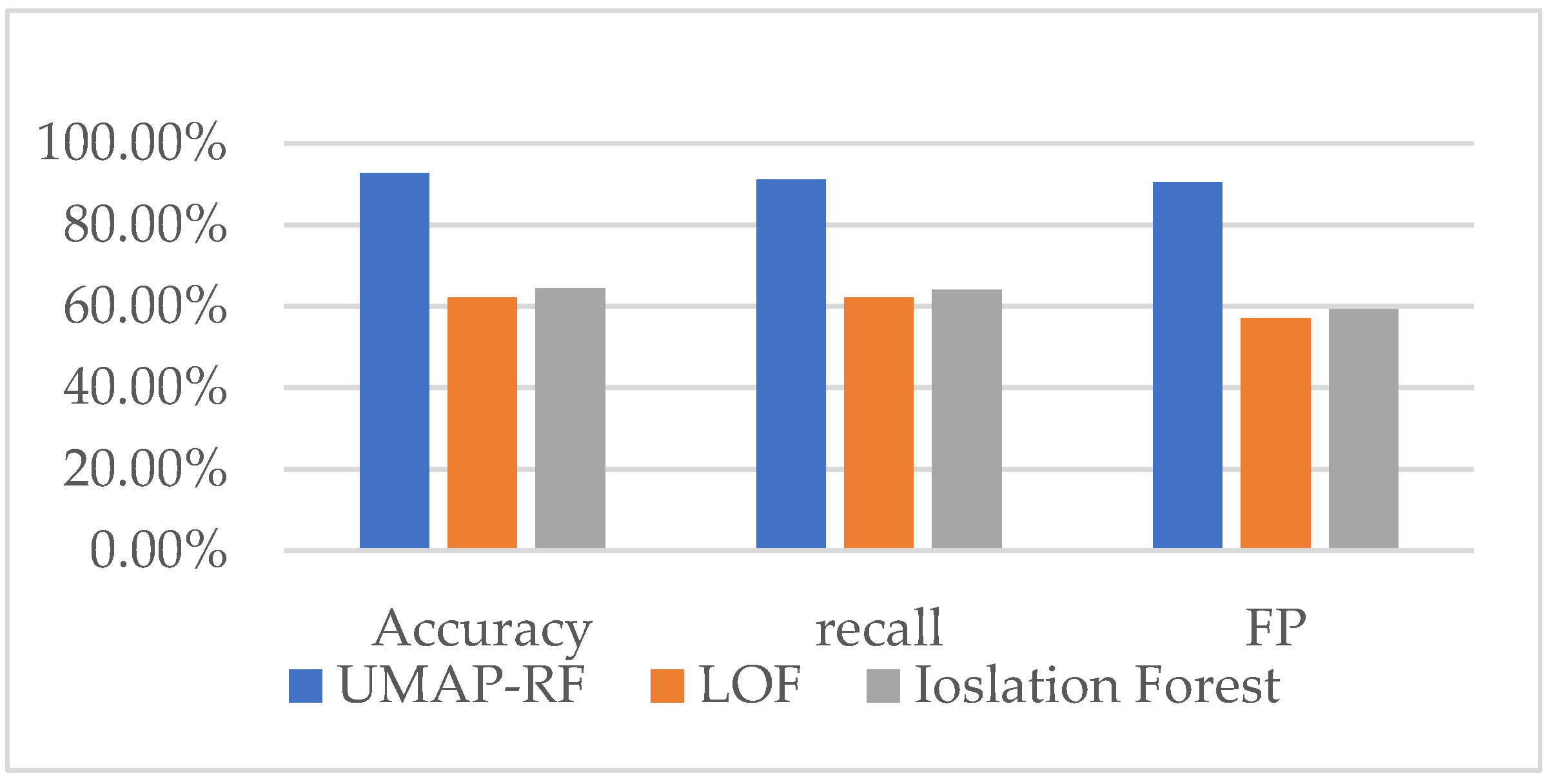
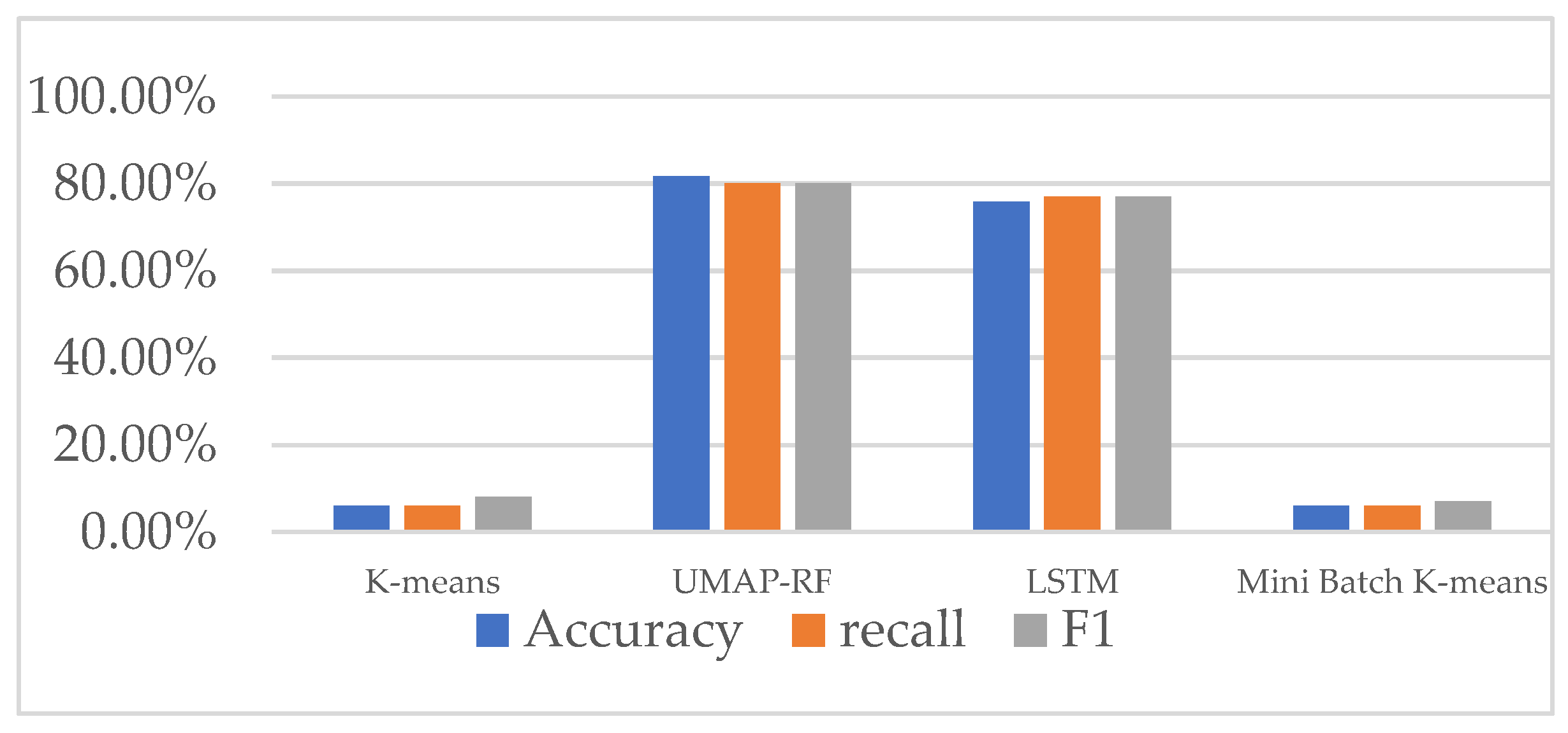
4.9. Comparison of the Detection Effect of UMAP-RF Hybrid Algorithm and other Algorithms
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- WEF. The Global Risks Report 2019. 2019. Available online: https://www.weforum.org/reports/the-global-risks-report-2019 (accessed on 15 January 2019).
- Patil, S.; Varadarajan, V.; Walimbe, D.; Gulechha, S.; Shenoy, S.; Raina, A.; Kotecha, K. Improving the Robustness of AI-Based Malware Detection Using Adversarial Machine Learning. Algorithms 2021, 14, 297. [Google Scholar] [CrossRef]
- Kim, M.S.; Kong, H.J.; Chung, S.; Hong, S.C. A flow-based method for abnormal network traffic detection. In Proceedings of the 2004 IEEE/IFIP Network Operations and Management Symposium (IEEE Cat. No. 04CH37507), Seoul, South Korea, 23 April 2004; pp. 599–612. [Google Scholar]
- Livieris, I.E. Forecasting Economy-Related Data Utilizing Weight-Constrained Recurrent Neural Networks. Algorithms 2019, 12, 85. [Google Scholar] [CrossRef] [Green Version]
- McInnes, L.; Healy, J.; Melville, J. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar]
- Bagui, S.; Walauskis, M.; DeRush, R.; Praviset, H.; Boucugnani, S. Spark Configurations to Optimize Decision Tree Classification on UNSW-NB15. Big Data Cogn. Comput. 2022, 6, 38. [Google Scholar] [CrossRef]
- Singh, N.; Virmani, D. Computational method to prove efficacy of datasets. J. Inf. Optim. Sci. 2021, 42, 211–233. [Google Scholar] [CrossRef]
- Bourou, S.; El Saer, A.; Velivassaki, T.-H.; Voulkidis, A.; Zahariadis, T. A Review of Tabular Data Synthesis Using GANs on an IDS Dataset. Information 2021, 12, 375. [Google Scholar] [CrossRef]
- Selva, D.; Nagaraj, B.; Pelusi, D.; Arunkumar, R.; Nair, A. Intelligent Network Intrusion Prevention Feature Collection and Classification Algorithms. Algorithms 2021, 14, 224. [Google Scholar] [CrossRef]
- Lippmann, R.; Cunningham, R.K.; Fried, D.J.; Graf, I.; Kendall, K.; Webster, S.; Zissman, M. Results of the DARPA 1998 Offline Intrusion Detection Evaluation. Recent Adv. Intrusion Detect. 1999, 99, 829–835. [Google Scholar]
- Lee, W.; Stolfo, S. Data Mining Approaches for Intrusion Detection. In Proceedings of the 7th USENIX Security Symposium, San Antonio, TS, USA, 26–29 January 1998. [Google Scholar]
- Wu, D.; Zhang, W.; Jia, H.; Leng, X. Simultaneous Feature Selection and Support Vector Machine Optimization Using an Enhanced Chimp Optimization Algorithm. Algorithms 2021, 14, 282. [Google Scholar] [CrossRef]
- Safavian, S.R.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef] [Green Version]
- Ruggieri, A.; Stranieri, F.; Stella, F.; Scutari, M. Hard and Soft EM in Bayesian Network Learning from Incomplete Data. Algorithms 2020, 13, 329. [Google Scholar] [CrossRef]
- Liu, Q.-F.; Iqbal, M.F.; Yang, J.; Lu, X.-Y.; Zhang, P.; Rauf, M. Prediction of chloride diffusivity in concrete using artificial neural network: Modelling and performance evaluation. Constr. Build. Mater. 2021, 268, 121082. [Google Scholar] [CrossRef]
- Hongyan, H.; Guoyan, H.; Bing, Z.; Yu, C. Research on intrusion detection model based on multiple feature selection strategies. Inf. Secur. Res. 2021, 7, 225–232. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Renjie, Z.; Wei, C.; Mengxin, H.; Lifa, W. Unbalanced sample flow detection based on variational autoencoder. Comput. Sci. 2021, 48, 62–69. [Google Scholar]
- Fengjie, H. Research on LightGBM based network intrusion detection system; Xidian University: Xian, China, 2020. [Google Scholar] [CrossRef]
- Meftah, S.; Rachidi, T.; Assem, N. Network based intrusion detection using the UNSW-NB15 dataset. Int. J. Comput. Digit. Syst. 2019, 8, 478–487. [Google Scholar]
- Kasongo, S.M.; Sun, Y. Performance analysis of intrusion detection systems using a feature selection method on the UNSW-NB15 dataset. J. Big Data 2020, 7, 1–20. [Google Scholar] [CrossRef]
- Cao, B.; Li, C.; Song, Y.; Qin, Y.; Chen, C. Network Intrusion Detection Model Based on CNN and GRU. Appl. Sci. 2022, 12, 4184. [Google Scholar] [CrossRef]
- Alzaqebah, A.; Aljarah, I.; Al-Kadi, O.; Damaševičius, R. A Modified Grey Wolf Optimization Algorithm for an Intrusion Detection System. Mathematics 2022, 10, 999. [Google Scholar] [CrossRef]
- Böhm, C.; Berchtold, S.; Keim, D.A. Searching in high-dimensional spaces: Index structures for improving the performance of multimedia databases. ACM Comput. Surv. CSUR 2001, 33, 322–373. [Google Scholar] [CrossRef]
- Uddin, M.P.; Mamun, M.A.; Afjal, M.I.; Hossain, M. Information-theoretic feature selection with segmentation-based folded principal component analysis (PCA) for hyperspectral image classification. Int. J. Remote Sens. 2021, 42, 286–321. [Google Scholar] [CrossRef]
- Wattenberg, M.; Viégas, F.; Johnson, I. How to use t-SNE effectively. Distill 2016, 1, e2. [Google Scholar] [CrossRef]
- Mengxiao, J. Research on network traffic anomaly detection algorithm based on SDN; Nanjing University of Posts and Telecommunications: Nanjing, China, 2020. [Google Scholar] [CrossRef]
- Alghushairy, O.; Alsini, R.; Soule, T.; Ma, X. A review of local outlier factor algorithms for outlier detection in big data streams. Big Data Cogn. Comput. 2021, 5, 1. [Google Scholar] [CrossRef]
- Aldino, A.A.; Darwis, D.; Prastowo, A.T.; Sujana, C. Implementation of K-means algorithm for clustering corn planting feasibility area in south lampung regency. J. Phys. Conf. Ser. 2021, 1751, 012038. [Google Scholar] [CrossRef]
- Ahmadov, E.Y. Comparative Aanalysis of K-Means, K-Means++ and Mini Batch K-Means Algorhitms in Phyton Environment. Probl. Inf. Technol. 2021, 119–128. [Google Scholar]
- Fan, D.; Sun, H.; Yao, J.; Zhang, K.; Yan, X.; Sun, Z. Well production forecasting based on ARIMA-LSTM model considering manual operations. Energy 2021, 220, 119708. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Feature | No. | Feature | No. | Feature | No. | Feature | No. | Feature |
|---|---|---|---|---|---|---|---|---|---|
| 1 | srcip | 11 | dttl | 21 | stcpb | 31 | sintpkt | 41 | ct_srv_src |
| 2 | sport | 12 | sloss | 22 | dtcpb | 32 | dintpkt | 42 | ct_srv_dst |
| 3 | dstip | 13 | dloss | 23 | smeansz | 33 | tcprtt | 43 | ct_dst_ltm |
| 4 | dsport | 14 | service | 24 | dmeansz | 34 | synack | 44 | ct_src_ ltm |
| 5 | proto | 15 | sload | 25 | trans_depth | 35 | ackdat | 45 | ct_src_dport_ltm |
| 6 | state | 16 | dload | 26 | res_bdy_len | 36 | is_sm_ips_ports | 46 | ct_dst_sport_ltm |
| 7 | dur | 17 | spkts | 27 | sjit | 37 | ct_state_ttl | 47 | ct_dst_src_ltm |
| 8 | sbytes | 18 | dpkts | 28 | djit | 38 | ct_flw_http_mthd | 48 | attack_cat |
| 9 | dbytes | 19 | swin | 29 | stime | 39 | is_ftp_login | 49 | label |
| 10 | sttl | 20 | dwin | 30 | ltime | 40 | ct_ftp_cmd |
| Algorithm | Running Time |
|---|---|
| PCA | 3.59 s |
| T-SNE | 695.31 s |
| UMAP | 93.82 s |
| Projections | |||
| Attack | Normal | ||
| Actual | Attack | TP | FN |
| Normal | FP | TN | |
| No. | Score | (n_estimators, max_leaf_nodes) |
|---|---|---|
| 1 | 83.7 | (800, 30) |
| 2 | 86.2 | (1600, 40) |
| 3 | 91.6 | (1000, 10) |
| 4 | 77.5 | (500, 70) |
| 5 | 81.1 | (2000, 20) |
| 6 | 85.4 | (200, 10) |
| Algorithm | Running Time |
|---|---|
| RF | 379.23 s |
| LOF | 1457.09 s |
| Isolation Forest | 1027.12 s |
| UMAP-RF | 243.39 s |
| Literature | Algorithm | ACC/% |
|---|---|---|
| Guoyan Huang [23] | (LR-RFE) + DT | 88.27% |
| Fengjie Hu [26] | light GBM | 85.78% |
| Meftah [27] | SVM | 82.00% |
| Kasongo [28] | XGBOOST+DT | 90.85% |
| Cao Bo [29] | CNN-GRU | 86.25% |
| Alzaqebah [30] | GWO-ELM | 81.00% |
| Proposed in this paper | UMAP-RF | 92.60% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, X.; Cheng, C.; Wang, Y.; Han, Z. Research on Network Attack Traffic Detection HybridAlgorithm Based on UMAP-RF. Algorithms 2022, 15, 238. https://doi.org/10.3390/a15070238
Du X, Cheng C, Wang Y, Han Z. Research on Network Attack Traffic Detection HybridAlgorithm Based on UMAP-RF. Algorithms. 2022; 15(7):238. https://doi.org/10.3390/a15070238
Chicago/Turabian StyleDu, Xiaoyu, Cheng Cheng, Yujing Wang, and Zhijie Han. 2022. "Research on Network Attack Traffic Detection HybridAlgorithm Based on UMAP-RF" Algorithms 15, no. 7: 238. https://doi.org/10.3390/a15070238
APA StyleDu, X., Cheng, C., Wang, Y., & Han, Z. (2022). Research on Network Attack Traffic Detection HybridAlgorithm Based on UMAP-RF. Algorithms, 15(7), 238. https://doi.org/10.3390/a15070238