1. Introduction
Over the past few decades, surrogate modelling or so-called meta-modelling has increasingly been employed for predicting results of physical computer simulations. Simulations can become prohibitively expensive when multiple realizations are required, as is the case with Uncertainty Quantification (UQ) or optimisation processes; the fast evaluation speed of surrogates makes them an attractive alternative, and have led to their wide acceptance and adoption in several engineering fields (see [
1] for an overview of UQ with surrogate strategies). In the case of aerospace engineering design problems, where the failure allowance is quite limited, uncertainties for the design space variables are propagated through the output and have to be estimated accurately without any loss of reliability and within a reasonable period of time. In uncertainty quantification processes, even using surrogates for approximating physical phenomena can be quite time consuming and costly due to the need for many high-fidelity simulations to achieve reliable and robust designs, especially in the case of high-dimensional design optimisation problems. Thus, in an effort to further alleviate the computational burden of UQ, single-fidelity surrogates are extended to multi-fidelity versions by using additive and multiplicative correction approaches to reach an acceptable accuracy in limited time. Multi-fidelity models use different fidelity levels, which may significantly reduce the computational load and accelerate the computation. These models have been widely used to overcome the computational burden in uncertainty modelling and optimisation processes for complex simulations. The key feature behind the multi-fidelity methodology is to increase the accuracy of the intensively sampled low-fidelity simulations by exploiting a limited number of high-fidelity simulations, thus maintaining an acceptable computational cost. A comprehensive review for multi-fidelity methods in uncertainty quantification can be found in [
2].
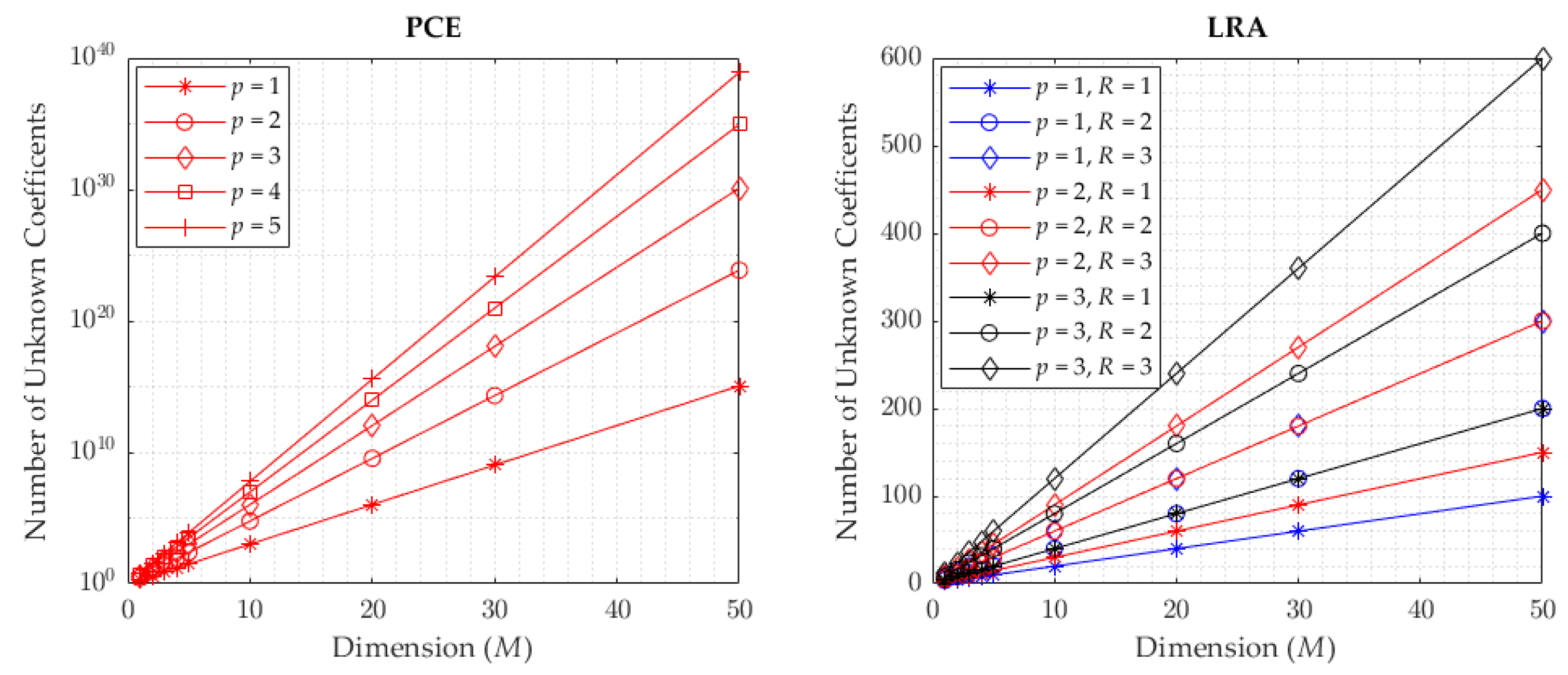
The main challenge in simulation-based realisations of engineering problems is the outgrowth in dimensionality, which increases the complexity and the computational time for calculating hyperparameters of the implemented surrogate. Particularly as dimensionality grows large, the Low-Rank Approximation (LRA) methodology is a prominent tool among surrogate modelling strategies model strategies, since the method models the response of the system as the sum of a smaller number of rank-one tensors, which are products of univariate functions. Since approximating the system of outputs is conducted using a smaller number of rank tensors, the number of unknown coefficients to be calculated grows only linearly with the input dimensions, which makes the method very advantageous, especially in high-dimensional cases. The LRA method has been applied to several engineering disciplines recently, with particular focus on scaling with dimensionality; these topics include reliability-based optimisation [
3,
4,
5], surrogate model strategies [
6,
7], uncertainty propagation [
8,
9,
10], sensitivity analysis [
11] and comparative studies with the Polynomial Chaos Expansion (PCE) method [
12]. LRA is proposed as an alternative surrogate technique to the widely applied PCE. The number of unknown coefficients grows exponentially with the input size in the PCE method, whereas LRA has the advantage of only linearly increasing the number of coefficients with input size. In this study, LRA is therefore selected as a promising surrogate modelling method to overcome the burden of dimensionality as an alternative to PCE.
A number of related studies have been carried out in the literature. For instance, Blatman and Sudret [
13] focused on uncertainty quantification and sensitivity analysis for high-dimensional problems; in particular, they calculated design variable sensitivities for different sizes of problems with the surrogate model using the Sparse Polynomial Chaos Expansion (SPCE) method. It was shown that SPCE was advantageous over PCE in terms of the number of analyses required to make an accurate prediction. In a following study, Blatmann and Sudret [
14] combined SPCE with an adaptive algorithm to automatically determine the important polynomial coefficients. Comparing the results of the adaptive SPCE method with full PCE and stepwise SPCE demonstrated that the adaptive SPCE method could represent high-dimensional problems with fewer data. Konakli and Sudret [
3] performed a reliability analysis for high-dimensional models using LRA, where the number of unknown coefficients increased linearly depending on the problem size. It was concluded that the LRA method outperformed the SPCE method while also using fewer analysis results. Papaioannou et al. [
15] integrated the PCE method with the PLS method to approximate unknown orthogonal polynomial coefficients for high-dimensional problems and found that the PCE-PLS method provides more accurate estimations compared to the LRA method when a small number of simulations results are used. Recently, Son and Du [
16] integrated the generalised dimension reduction algorithm with the PCE method for efficient uncertainty quantification of non-standard distribution types and Zuhal et al. [
17] performed reliability analysis using the Kriging method integrated with the PLS algorithm instead of orthogonal polynomial-based methods for high-dimensional problems. Among multi-fidelity applications, Peterstorfer et al. [
18] applied the multi-fidelity Monte Carlo (MFMC) method and Quaglino et al. [
19] performed high-dimensional uncertainty quantification studies using the multi-level Monte Carlo method.
High-fidelity engineering simulations are usually computationally expensive, and uncertainty quantification processes using high-fidelity engineering models struggle with extreme computational cost. Multi-fidelity methods leverage both high-fidelity and low-fidelity data to reduce the high computational or experimental costs by achieving high accuracy simultaneously. As multi-fidelity surrogate modelling methods reduce the computational cost of simulations with an acceptable accuracy, this approach can be a remedy for uncertainty quantification processes [
2]. In uncertainty quantification studies, orthogonal polynomial-based surrogate models such as multi-fidelity PCE [
20] and SPCE [
21] can be preferred since they successfully represent the general behaviour of computational models. In [
20,
21] studies, additive and multiplicative correction terms were used to extend the multi-fidelity versions of PCE and SPCE. In addition, there are studies in which multi-fidelity extensions of these methods are made with the Gaussian process such as [
22]. Other widely used multi-fidelity methods are kernel-based methods such as the multi-fidelity Gaussian process [
23], coKriging [
24], and Stochastic Radial Basis function [
25]. These methods are preferred in optimisation studies due to their success in capturing local properties and are also used in uncertainty analysis. In addition, there are methods such as Polynomial Chaos-coKriging [
26] and Sparse Polynomial Chaos-Kriging [
27], which combine the ability to capture global features of orthogonal-based methods with the ability to capture local features of kernel-based methods.
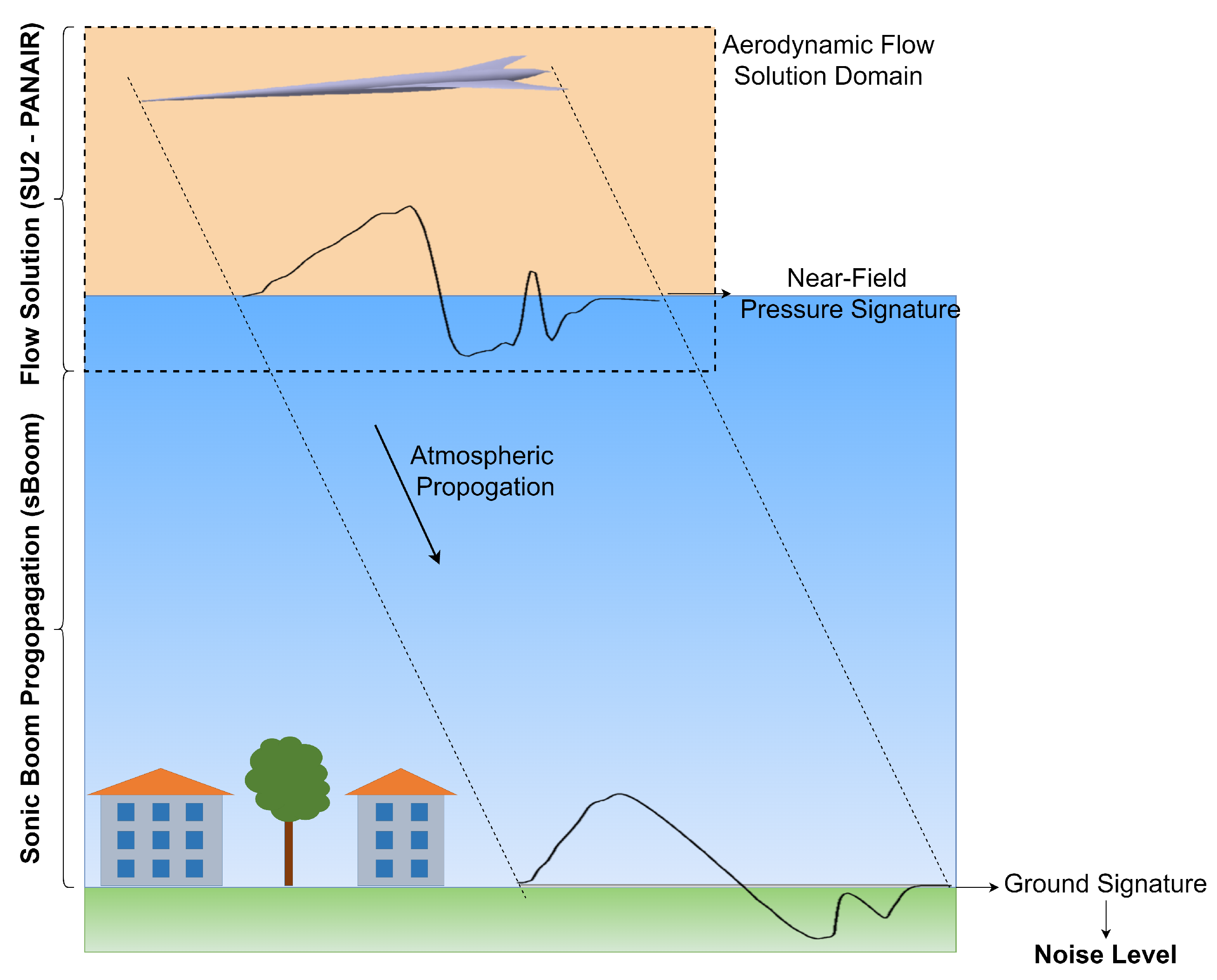
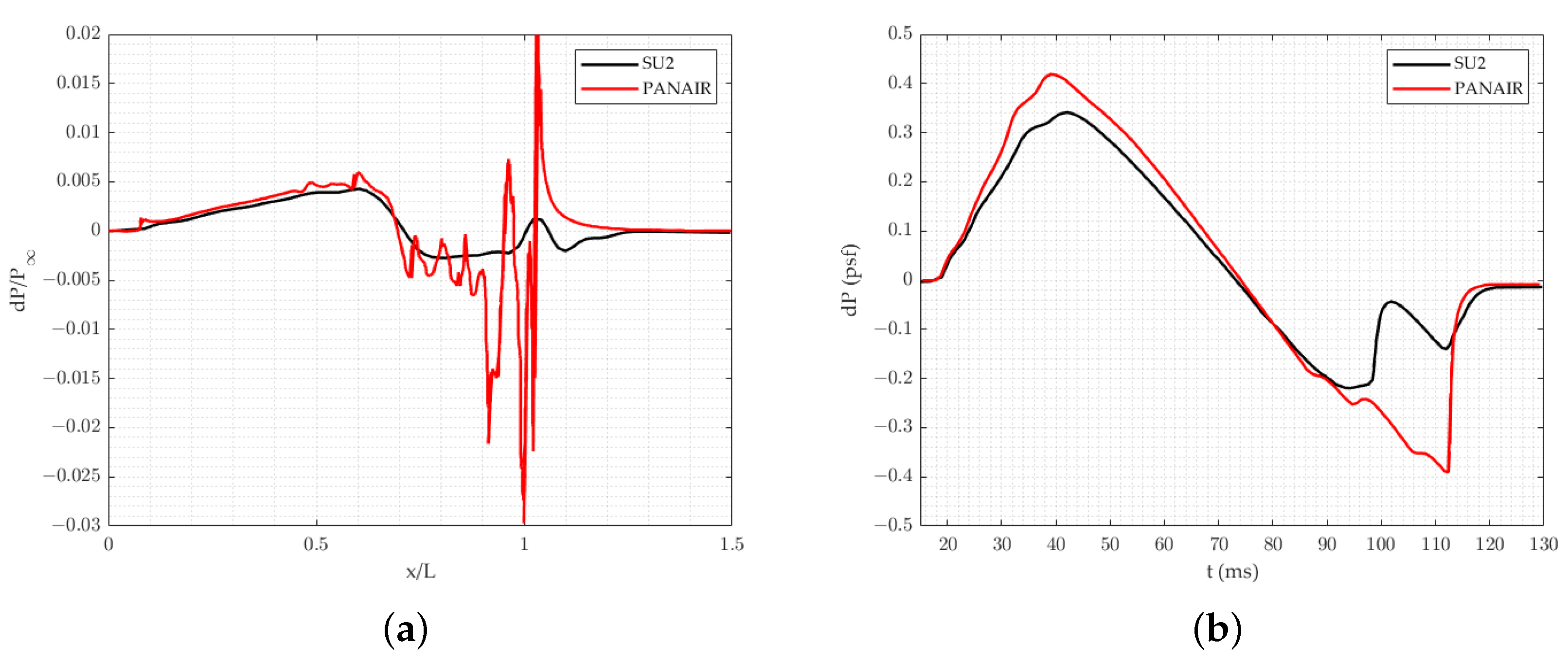
Regarding the uncertainty quantification for a low-boom aircraft design, the effects of uncertainties in flight conditions and atmospheric profile at the sonic boom level were studied by West et al. [
28] using a mixed uncertainty quantification and second-order probability method; they performed the uncertainty quantification for flow analysis through a PCE surrogate model, which significantly increased the computational demand. Philips and West [
29] and Nikbay et al. [
30] studied the effect of aeroelastic impacts on sonic boom using the non-intrusive PCE method. Nikbay et al. [
30] examined the effect of uncertainties due to the material properties on the sonic boom and reduced the number of uncertain parameters by performing sensitivity analysis. Rallabhandi et al. [
31] used the PCE method for uncertainty calculation and performed robust low boom design using atmospheric uncertainties. West and Philips [
32] measured the uncertainty in the sonic boom level using the results of a small number of expensive analyses and based on three different fidelity levels with the multi-fidelity PCE method. Tekaslan et al. [
20] performed low-dimensional sonic boom uncertainty analysis using MFMC and MF-PCE methods. To the best of the authors’ knowledge, the LRA method has not been applied to any engineering problems in the aviation field yet and the LRA method has not been implemented within a multi-fidelity modelling approach. The authors implemented the LRA method into an uncertainty quantification process for sonic boom prediction and further developed a novel multi-fidelity approach of the LRA method which is called the MF-LRA method in this paper. This new approach is comprehensively compared with the multi-fidelity PCE method. In addition, it is observed that the literature lacks high-dimensional numerical multi-fidelity benchmark problems; so as a contribution of the authors, a new multi-fidelity extension of the Sobol’-Levitan function is implemented and presented in this study.
Within this perspective, this paper first aims to present a comprehensive performance assessment by constructing a multi-fidelity extension to a Low-Rank Approximation and comparing the results with a competing approach of multi-fidelity Polynomial Chaos Expansion for multi-fidelity analytical test cases. Then, the present approach is used for the uncertainty quantification of high-dimensional supersonic aircraft design problems within an application-oriented framework.
The remainder of the paper is as follows: In
Section 2, some of the basic properties and concepts are introduced for the present methods and the details of the multi-fidelity extension of the surrogates are explained. In
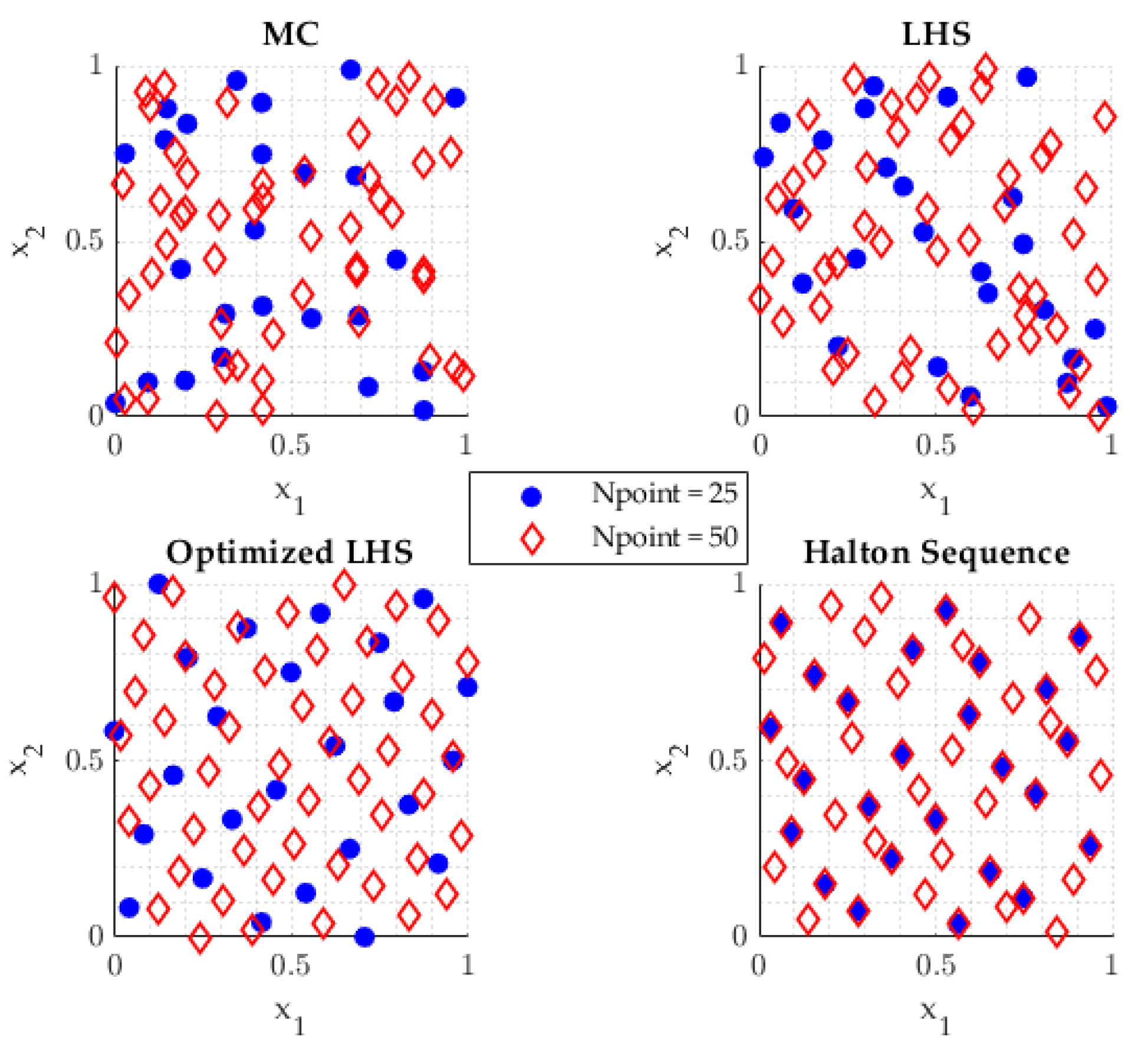
Section 3, the details of the computational experiment (e.g., the selected sampling strategy for the design of experiments (DoE)) are given; accuracy metrics and performance results for both analytical and high-dimensional engineering problem test cases are also demonstrated. In the final section, the results are discussed and current challenges along with the recommendations for further investigations are presented.
5. Discussion and Conclusions
In the uncertainty quantification studies, the required number of realisations become a computational burden due to the excessive number of unknown coefficients involved. Depending on the selected procedure for modelling the response, the curse-of-dimensionality may cause time-consuming computations and out-of-memory problems. Considering those drawbacks, the Low-Rank Approximation (LRA) method becomes a promising surrogate model, in which the unknown coefficients grow only linearly with respect to the input dimensions. In the present study, the LRA method is investigated and compared with widely used PCE methodology within an application-oriented framework. Their ability to capture the uncertainty propagation of sonic boom prediction with four uncertain variables is assessed for low-dimensional engineering problems. The LRA method is observed to generate more accurate results compared to the PCE method, even for higher dimensions and when very limited amount of data are available. Thus, the multi-fidelity extension of Low-Rank Approximation method is proposed by the authors and applied to uncertainty quantification of high-dimensional supersonic aircraft design.
The methodology already derived is demonstrated on several multi-fidelity uncertainty quantification benchmarks and applied to high-dimensional real-world engineering problems. Since the quantification of the uncertainty strictly depends on the success of the surrogate, the LRA and PCE methods are first compared in terms of surrogate modelling capabilities and through local and global accuracy metrics, with the purpose of displaying the surrogate performance of the LRA and PCE methods. Moreover, to demonstrate the efficiency of proposed multi-fidelity extensions for improving the convergence history, single-fidelity versions are taken into consideration for comparison.
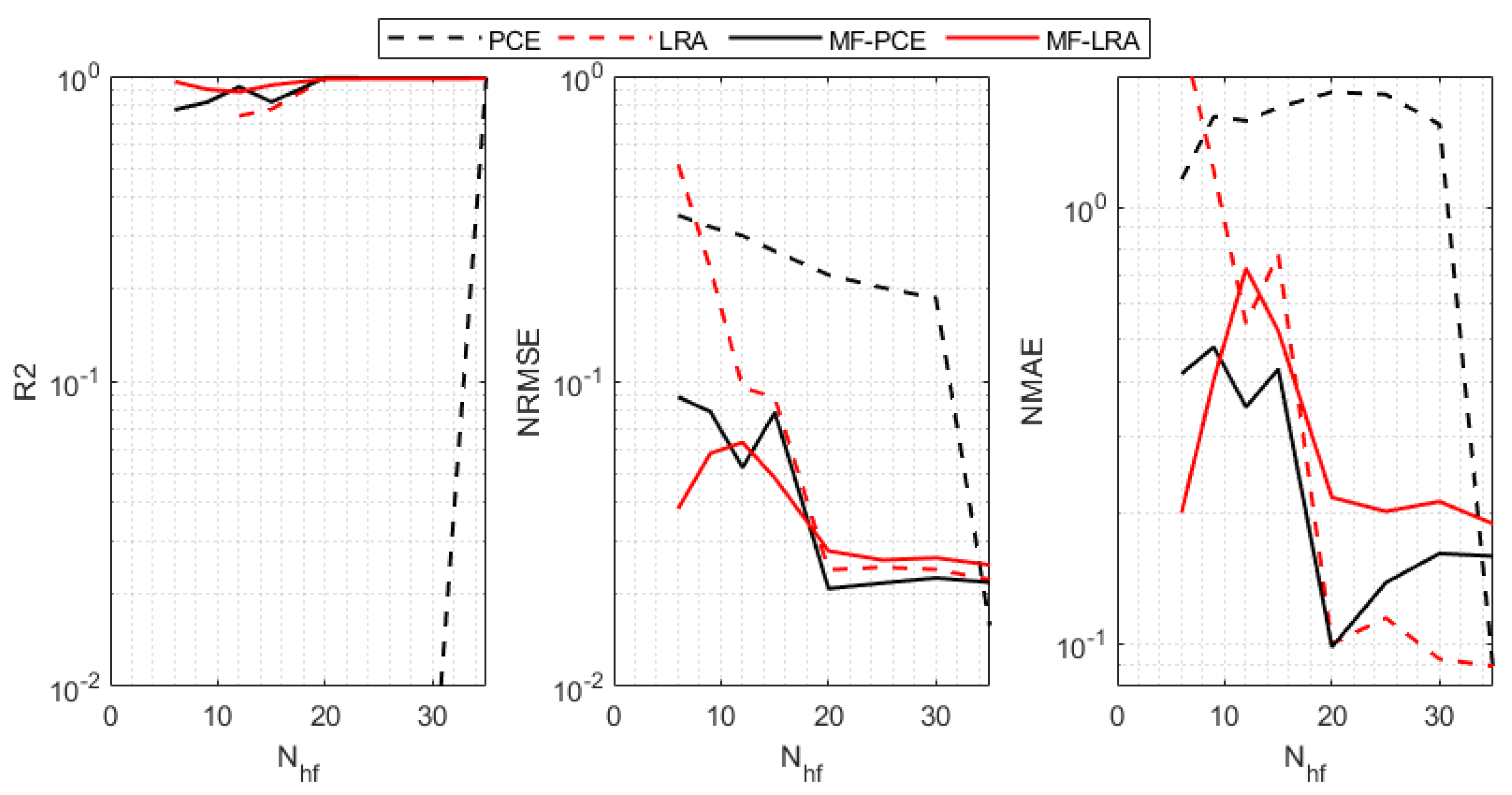
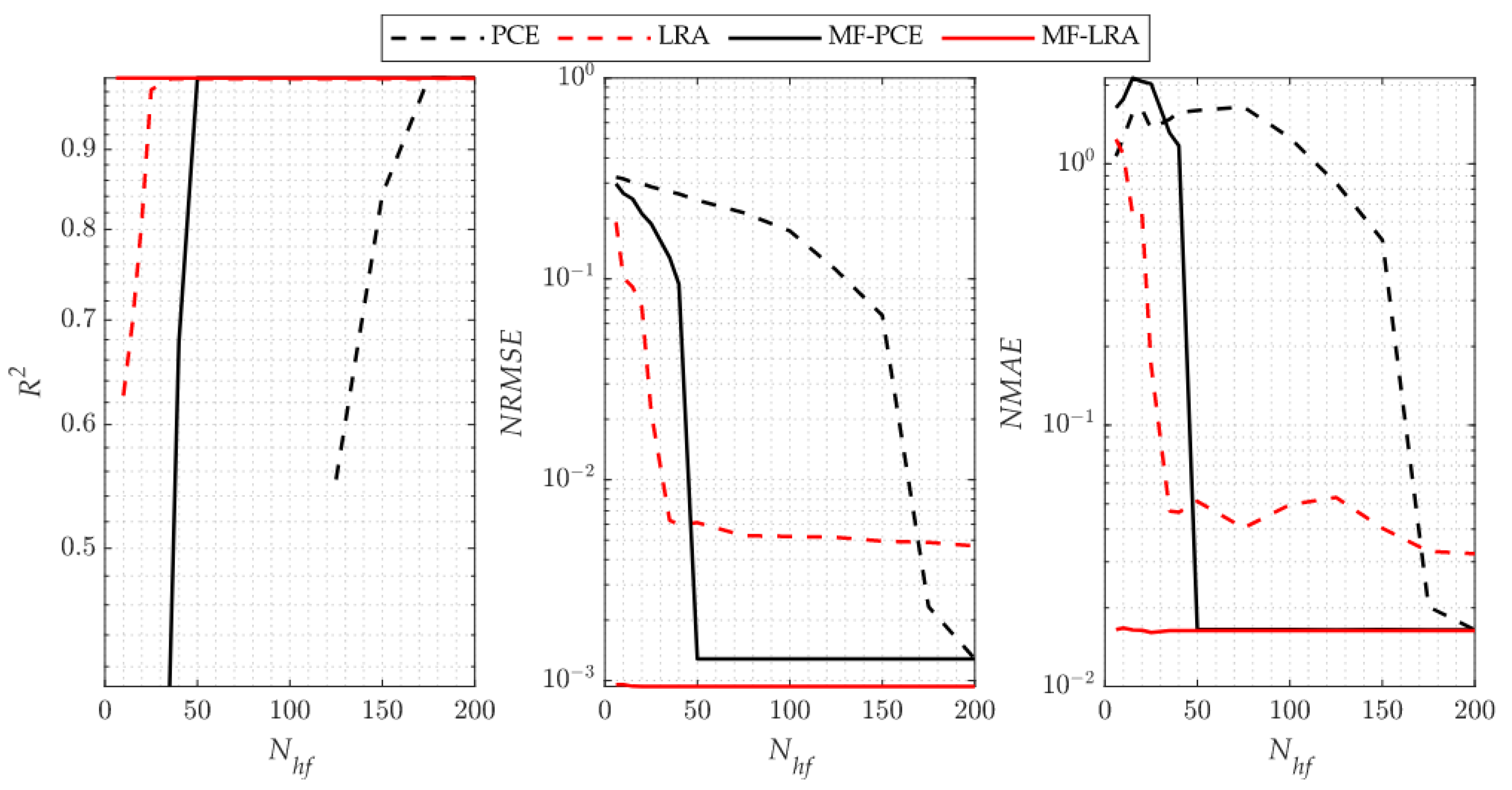
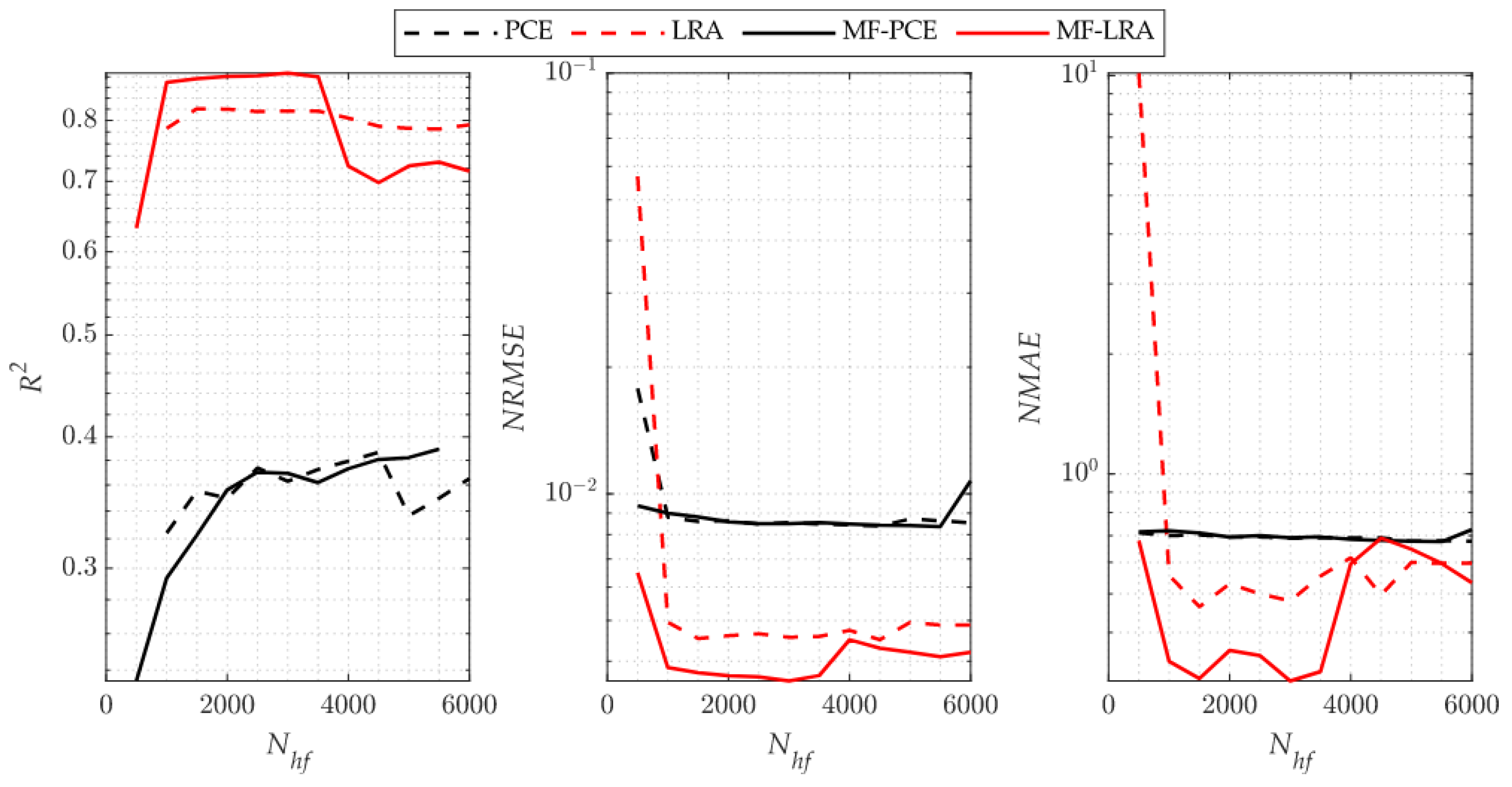
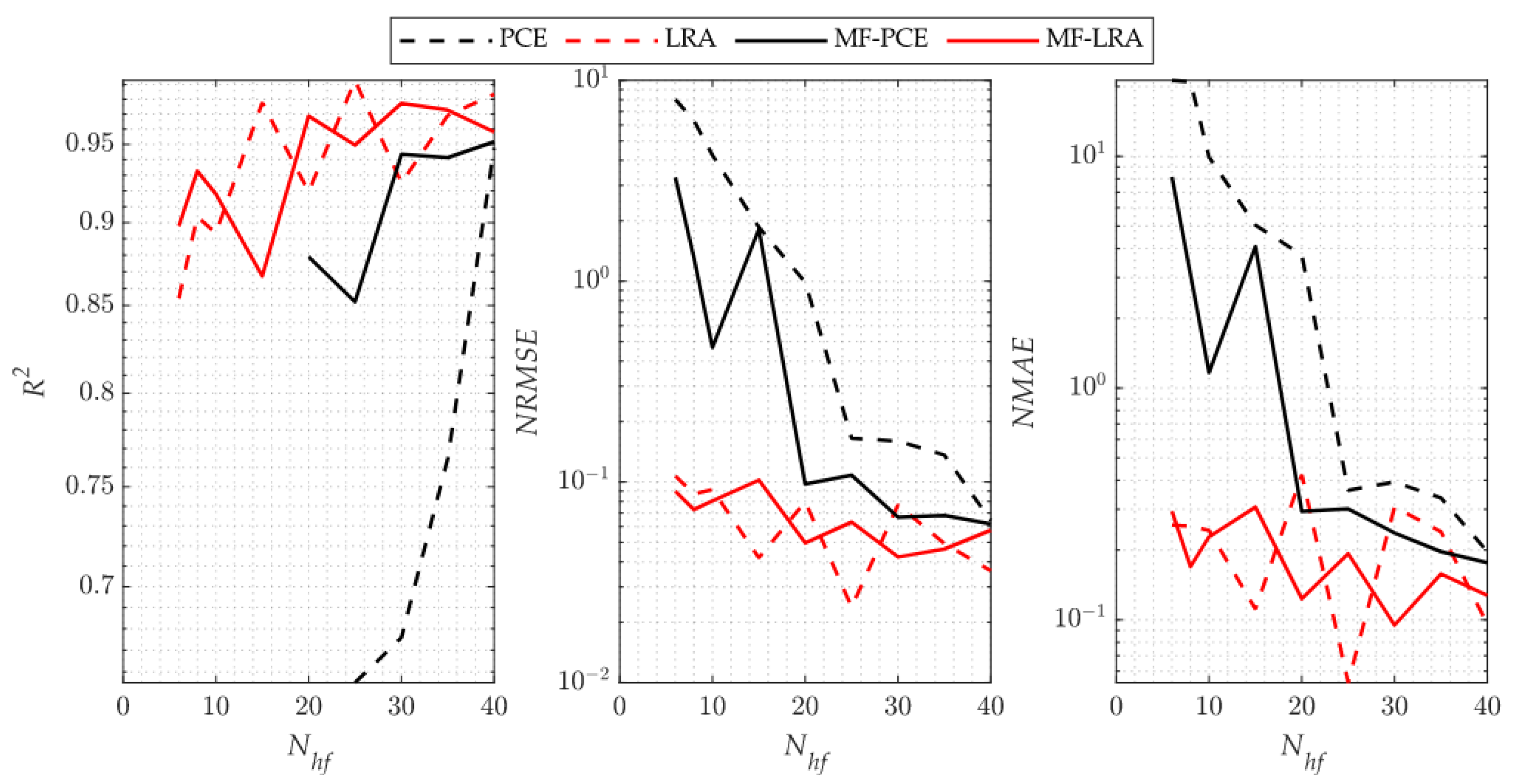
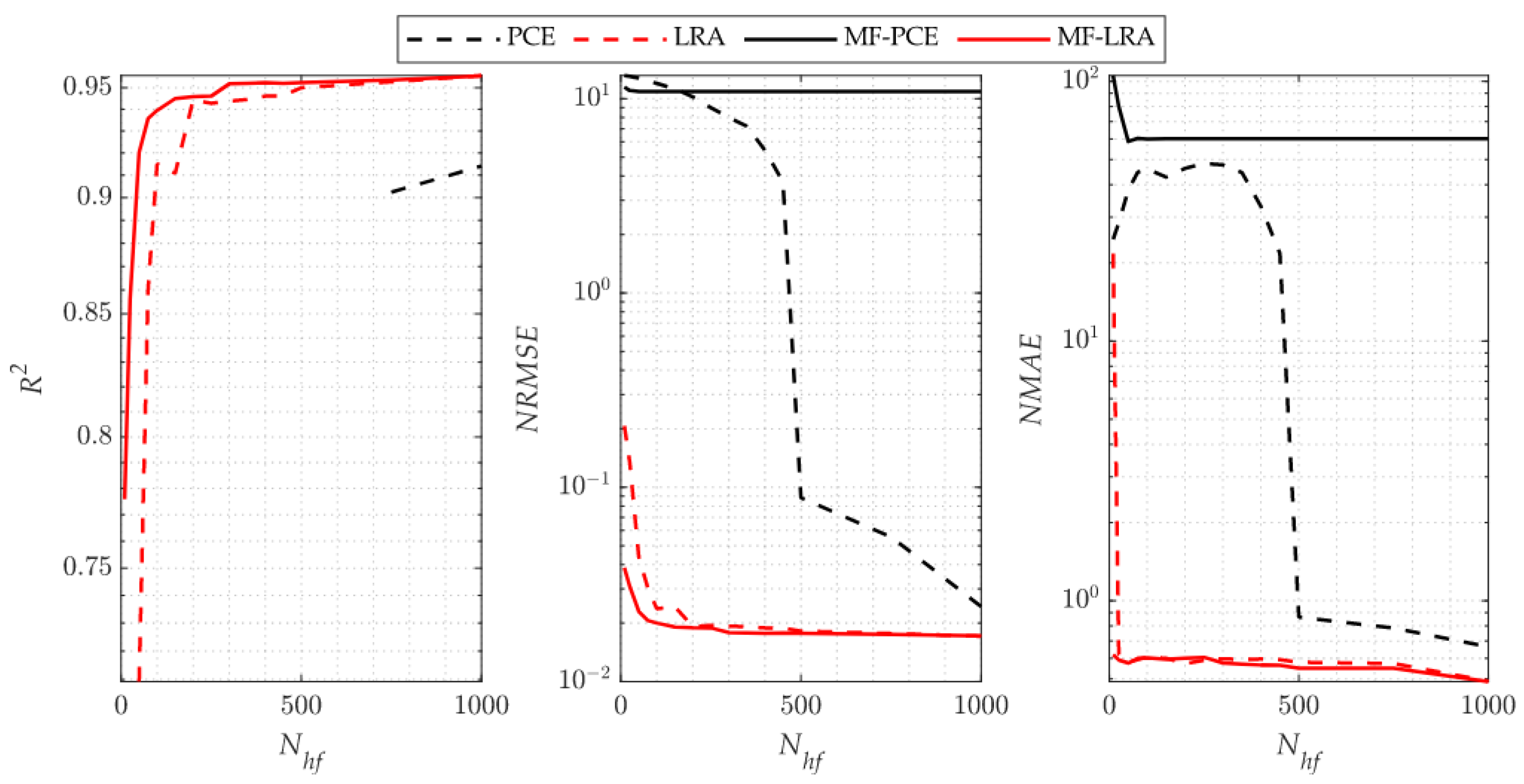
As it is indicated by the accuracy metrics of the single- and multi-fidelity surrogate models for the benchmark problems, an accurate surrogate model can be achieved with a small number of high-fidelity simulations by using the LRA method. When using the PCE method, however, many more high-fidelity simulations are required to set up a single- or multi-fidelity surrogate model with a similar accuracy. The number of high-fidelity simulations required in the single-fidelity PCE method is more than two to three times the number of high-fidelity simulations required in the LRA method for the 4-D Park and 4-D sonic boom uncertainty quantification implementations. However, as the problem dimension increases, it is observed that this ratio is five times in the 8-D Borehole function, and much higher than five times in the 30-D Sobol’-Levitan function and 32-D sonic boom uncertainty quantification problem. The performance difference is attributed to the fact that the LRA method contains fewer unknown coefficients than that of the PCE method due to the univariate polynomials that the LRA method employs. It is observed from the analytical test cases that the single- and multi-fidelity PCE and LRA methods are successful in capturing global features of the response. Since the surrogate modelling methods considered in the present study use orthogonal polynomials that show smooth behaviour in the design space, it can be observed from the metric that the success of capturing local features is low. These methods are generally preferred in uncertainty and sensitivity analysis due to their ability to deal with the general behaviour of the design space. However, because of their inefficient ability to capture local features, they are generally not preferred for optimisation.
Considering the comparison of the multi-fidelity versions of the methods with the single-fidelity methods, when using the same number of high-fidelity analyses, the multi-fidelity surrogate versions produce more accurate results by making use of low-fidelity model information. When the high-fidelity simulations required to construct a surrogate model with similar accuracy using the LRA and MF-LRA methods are compared, it is observed that the number of high-fidelity simulations required in the LRA method is two to three times the number of simulations needed in the MF-LRA method. Considering the single- and multi-fidelity applications of the PCE method, the number of high-fidelity simulations required in the PCE method for low-dimensional problems is two to three times the number of simulations required by the MF-PCE method. In high-dimensional problems, it is observed that an accurate model cannot be obtained with the multi-fidelity PCE method. In this respect, a more accurate surrogate model can be established with fewer simulations in low- and high-dimensional problems with the LRA method compared to the PCE method. Moreover, with the multi-fidelity version of the LRA method, accurate surrogate models are constructed with only few simulations results. The number of unknowns increases exponentially with the problem dimension in both single- and multi-fidelity PCE methods. Thus, an accurate surrogate model can be established for low-dimensional problems. However, in high-dimensional problems, an accurate surrogate model cannot be established with a low number of simulations. Moreover, the accuracy level of the low-fidelity surrogate model directly affects the ability to model the response of the multi-fidelity surrogate model. The importance of the accuracy level of the low-fidelity model is especially noticeable when the number of high-fidelity analyses are increased in the multi-fidelity surrogate, and it causes the multi-fidelity model to have lower accuracy values than the single-fidelity model, as observed in the Sobol’-Levitan benchmark function and 32-D sonic boom uncertainty quantification problem.
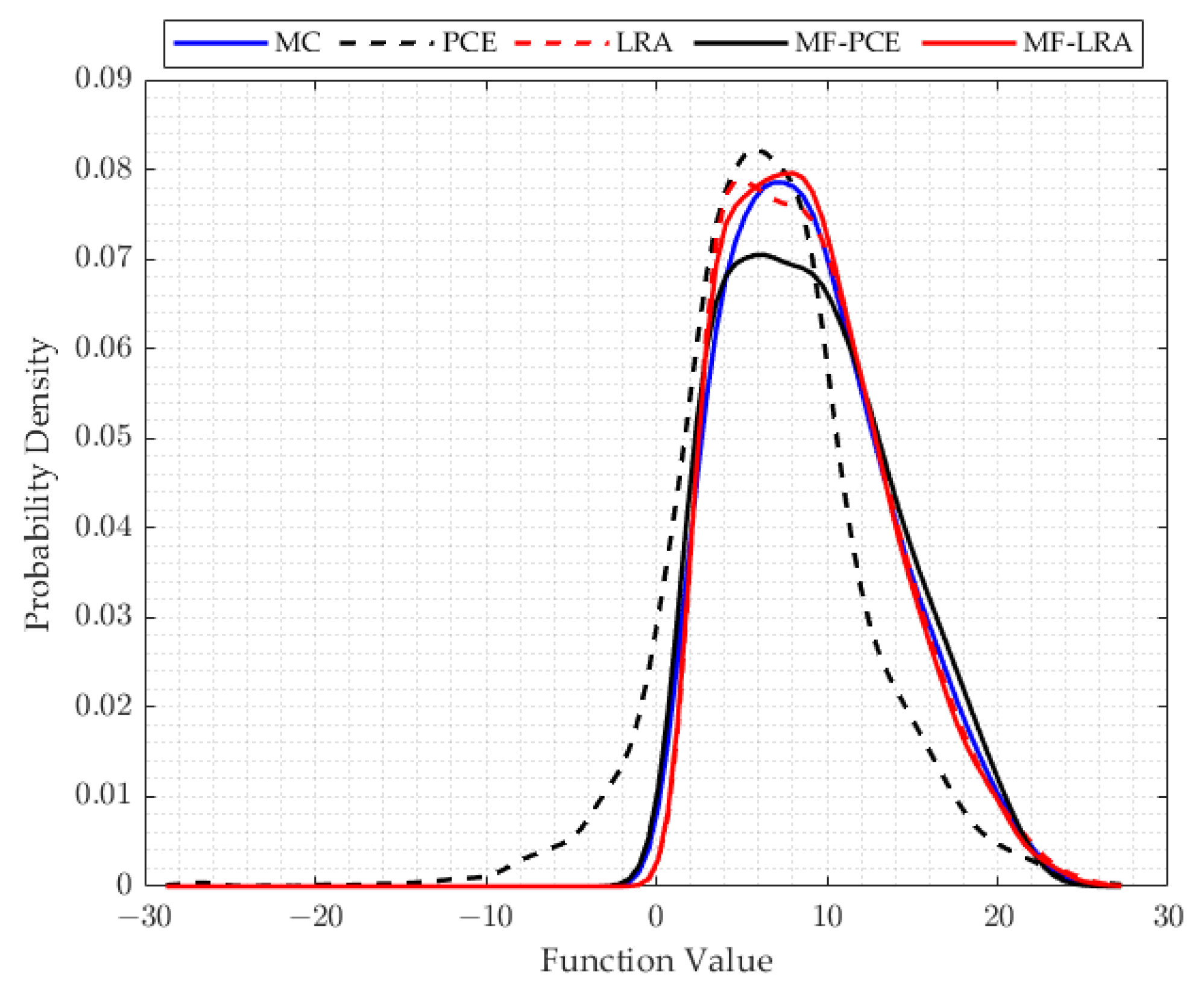
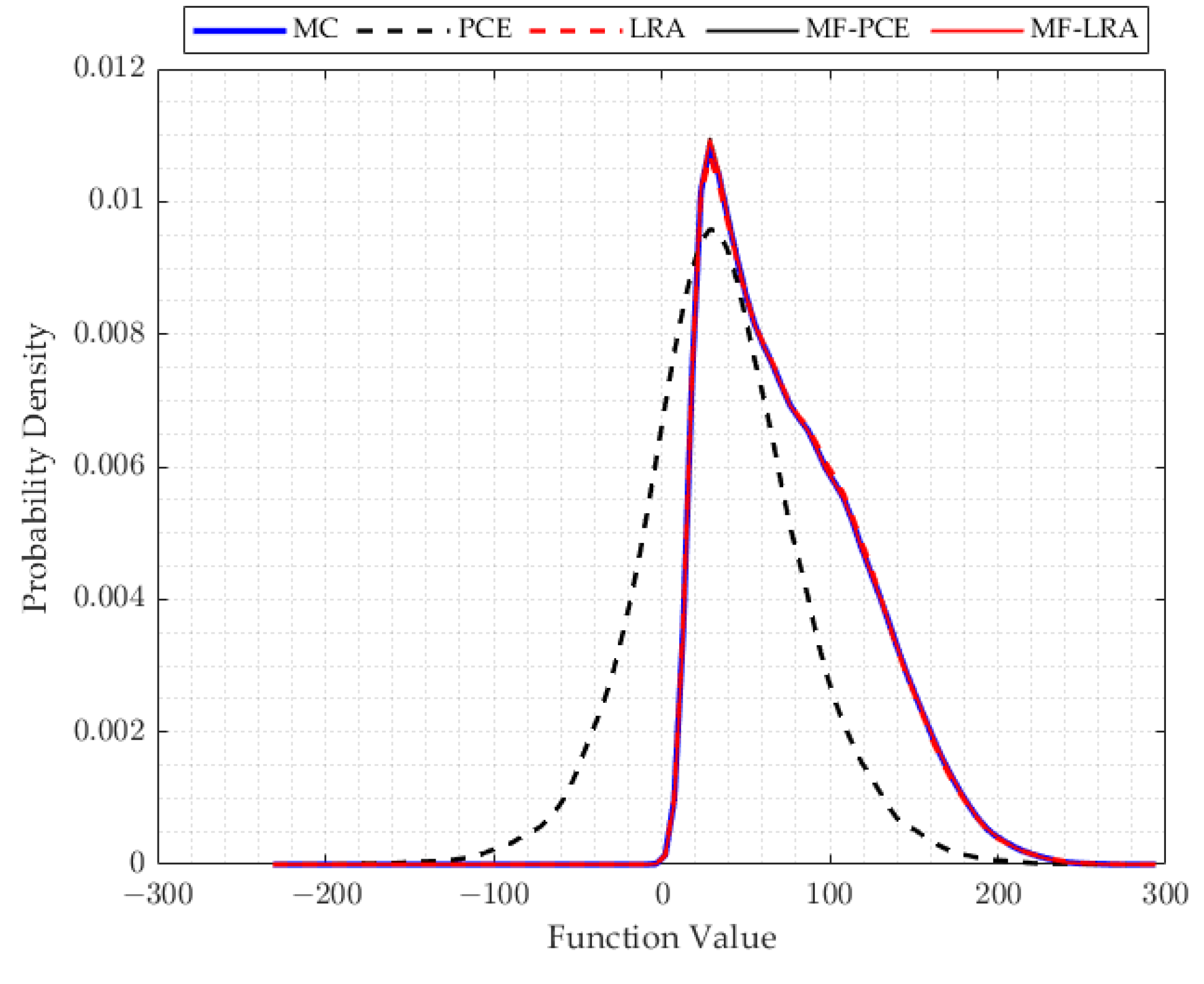
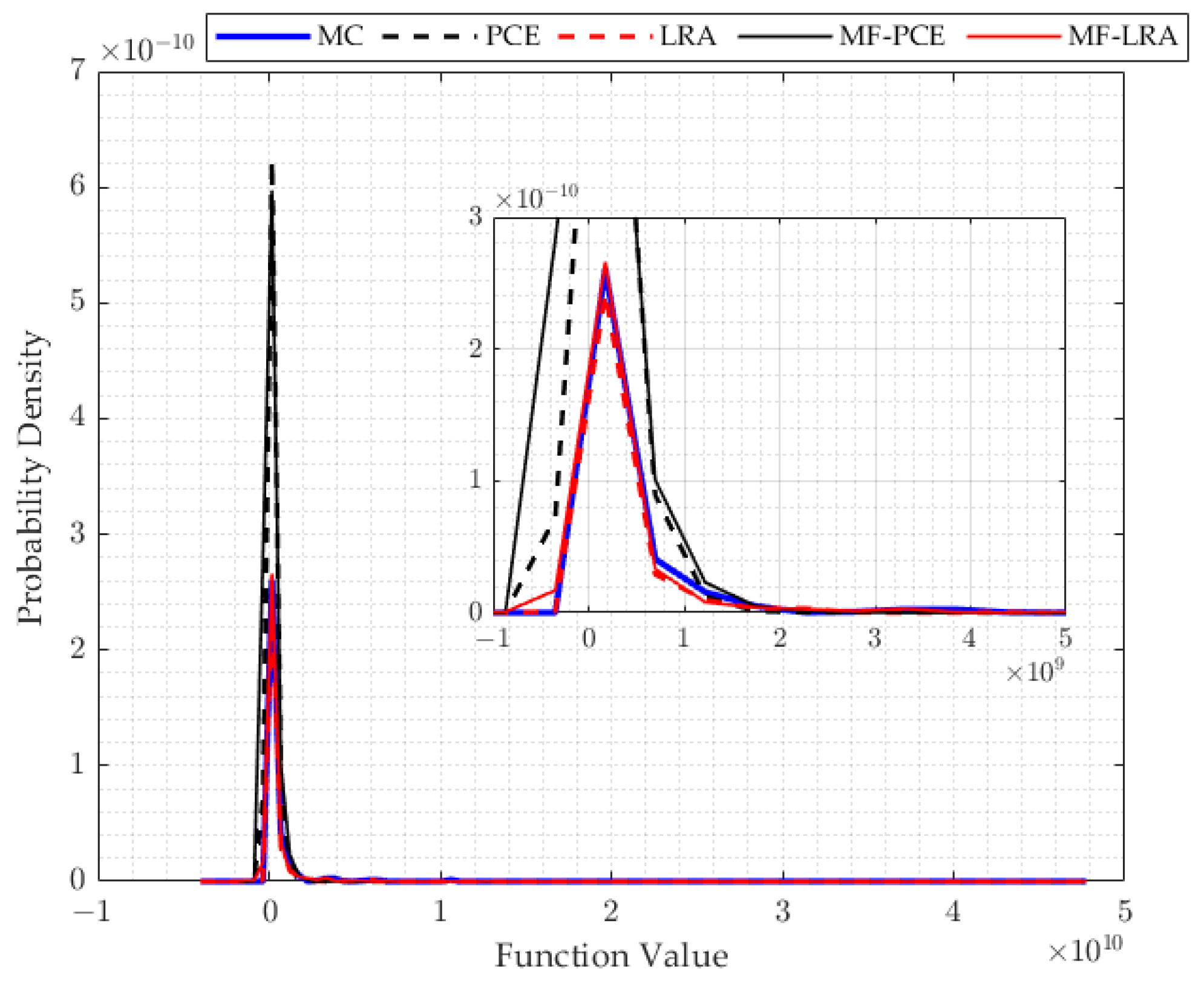
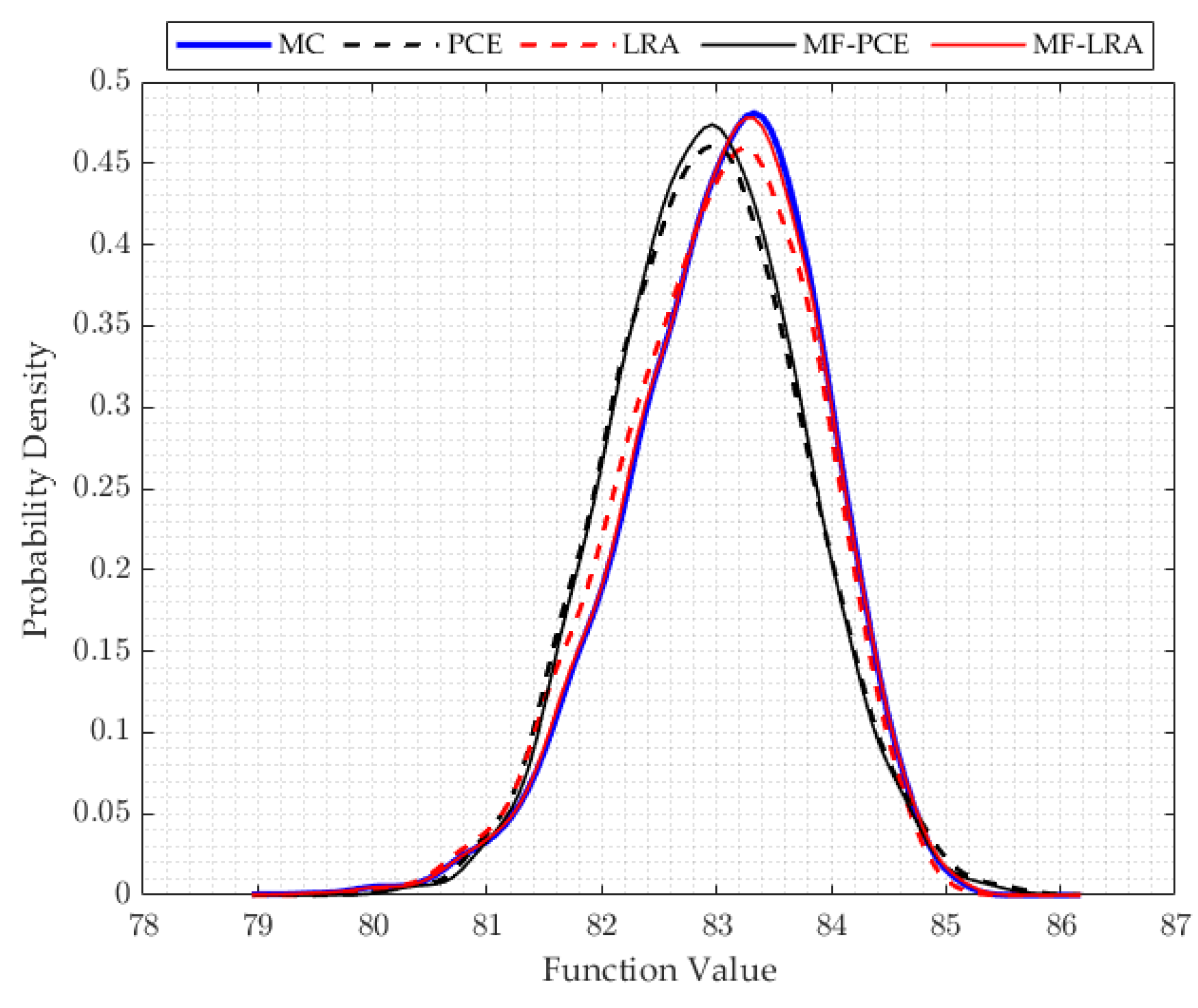
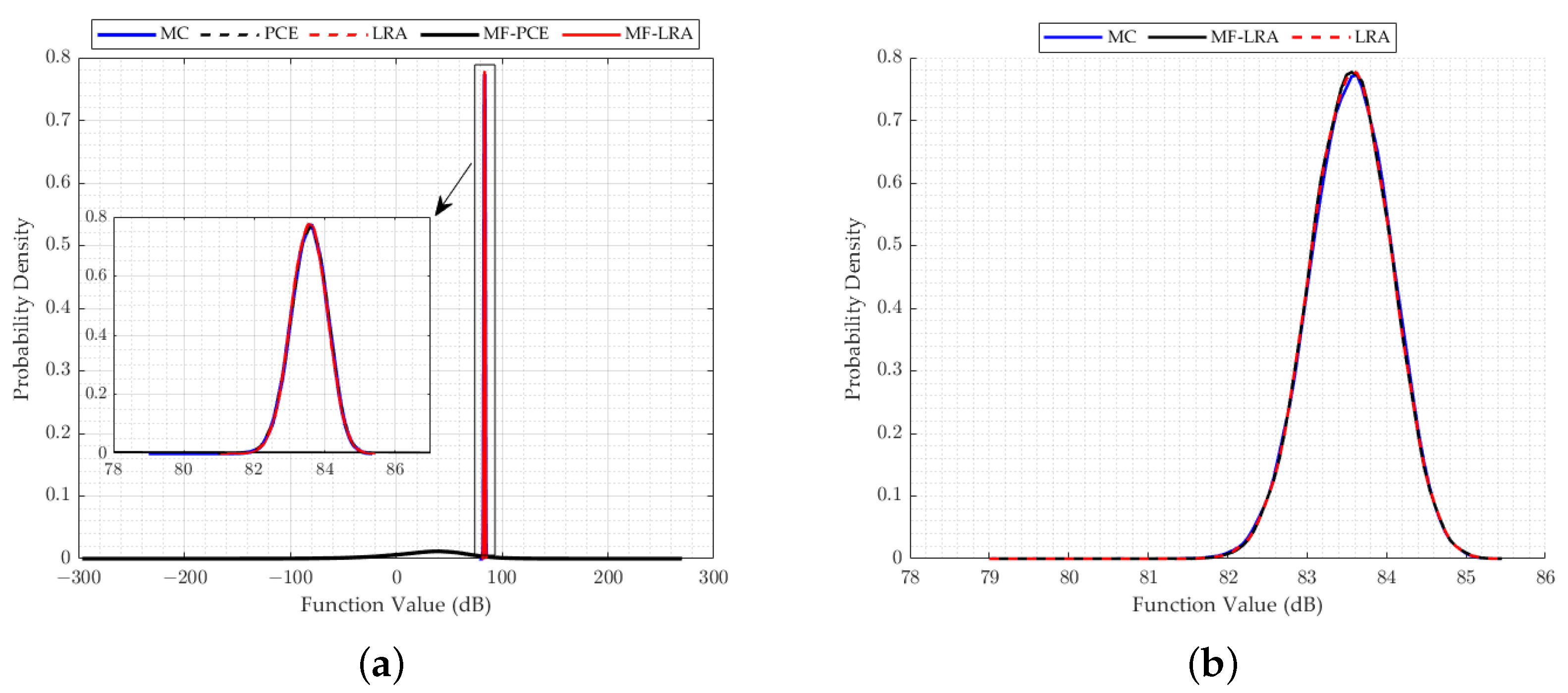
When examining the results of the uncertainty analysis tackled with different methods, it is observed that the PDF results of the LRA method are in good agreement with the MC results, although a small number of the analyses results are used in all applications of the single- and multi-fidelity LRA method. In many applications, when using the same number of results of the analyses, the PDF values obtained by the PCE method produce incompatible results with the MC method. A remarkable point in the results is that the single- and multi-fidelity LRA methods can model the tail region of the PDF very accurately, which has crucial importance in reliability studies. Small probabilities of exceedence used in the reliability analysis can be obtained more accurately by the LRA method which makes the LRA method more advantageous than the PCE method in reliability studies. In addition, the success of the LRA method in modelling the general behaviour of the computational model can be observed from the mean, standard deviation, skewness, and kurtosis values shared in the results of the engineering problem, which can also be observed in PDF functions. While the mean and standard deviation are obtained correctly with the single- and multi-fidelity PCE method, parameter estimates that explain the behaviour of the PDF function such as skewness and kurtosis contain high errors. However, the single- and multi-fidelity LRA method can estimate the mean and standard deviation values, as well as the skewness and kurtosis values, quite accurately.
Despite the outperforming results of the LRA method when compared to another popular polynomial basis approximation, PCE, further investigations are needed for challenging problems to observe the capturing capability for a wide range of benchmarks with diverse mathematical characteristics. Based on the present results, one particular challenge in some implementations may be the ability to capture local behaviours. Therefore, advanced investigations are required to enhance the ability to represent local characteristics. In addition, applications for higher dimensional industrial problems are currently underway.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}