
Informer-WGAN: High Missing Rate Time Series Imputation Based on Adversarial Training and a Self-Attention Mechanism

Abstract
:1. Introduction
- We propose a model for multidimensional time series imputation, which is based on the WGAN-GP framework and uses the informer part of the network structure to form the generator and the discriminator. The networks proposed outperform the original informer model and the GAN-based AST model in both real-world datasets.
- We propose a random missing rate training method for the time series imputation problem which improves the accuracy of the data imputation model for time series imputation with different missing rates.
2. Related Work
2.1. Time Series Imputation
2.2. Generative Adversarial Networks
2.3. Attention Mechanism
3. Materials and Methods
3.1. Materials
Dataset
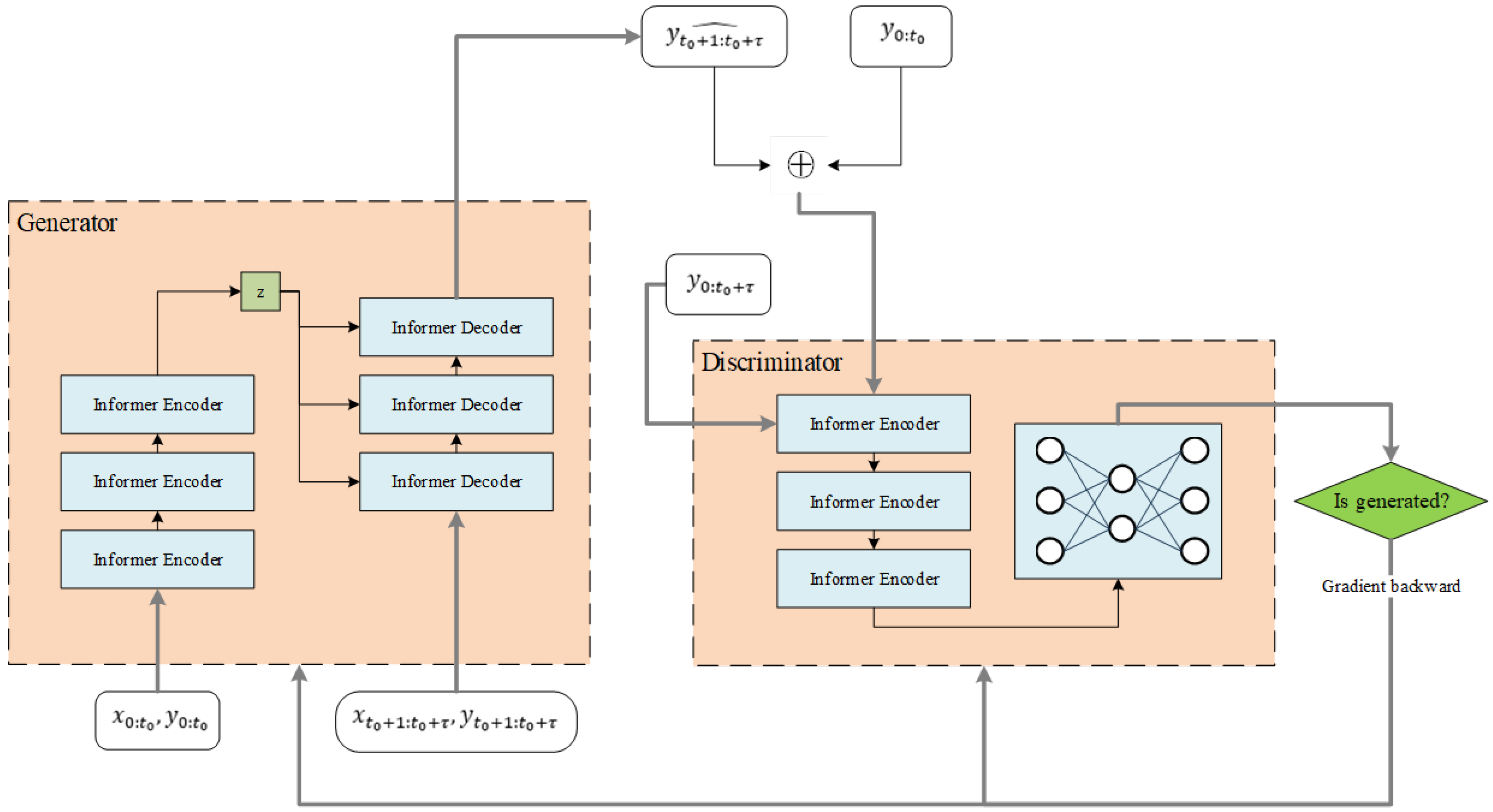
3.2. Informer-WGAN Model
3.2.1. Problem Definition
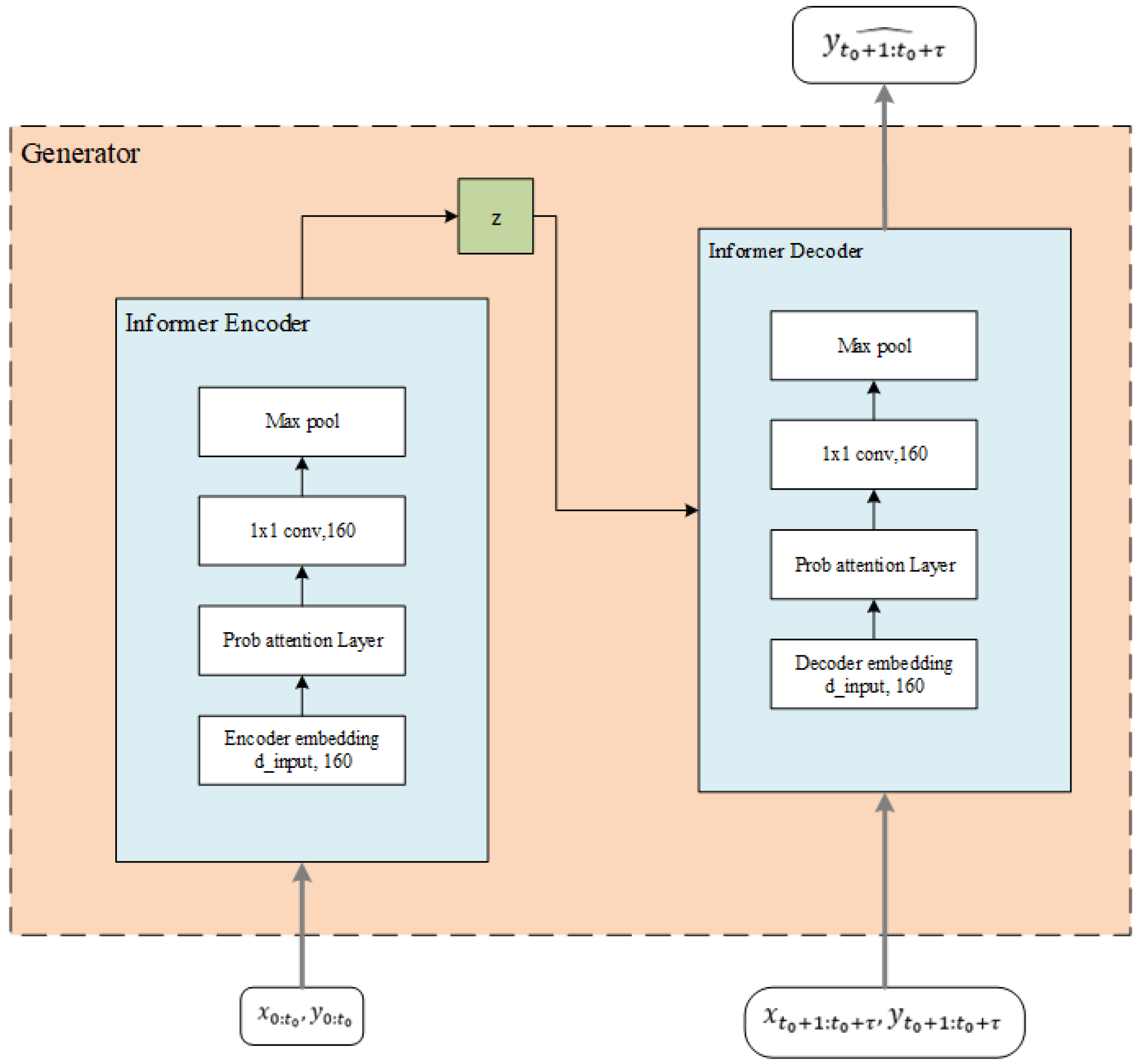
3.2.2. Generator
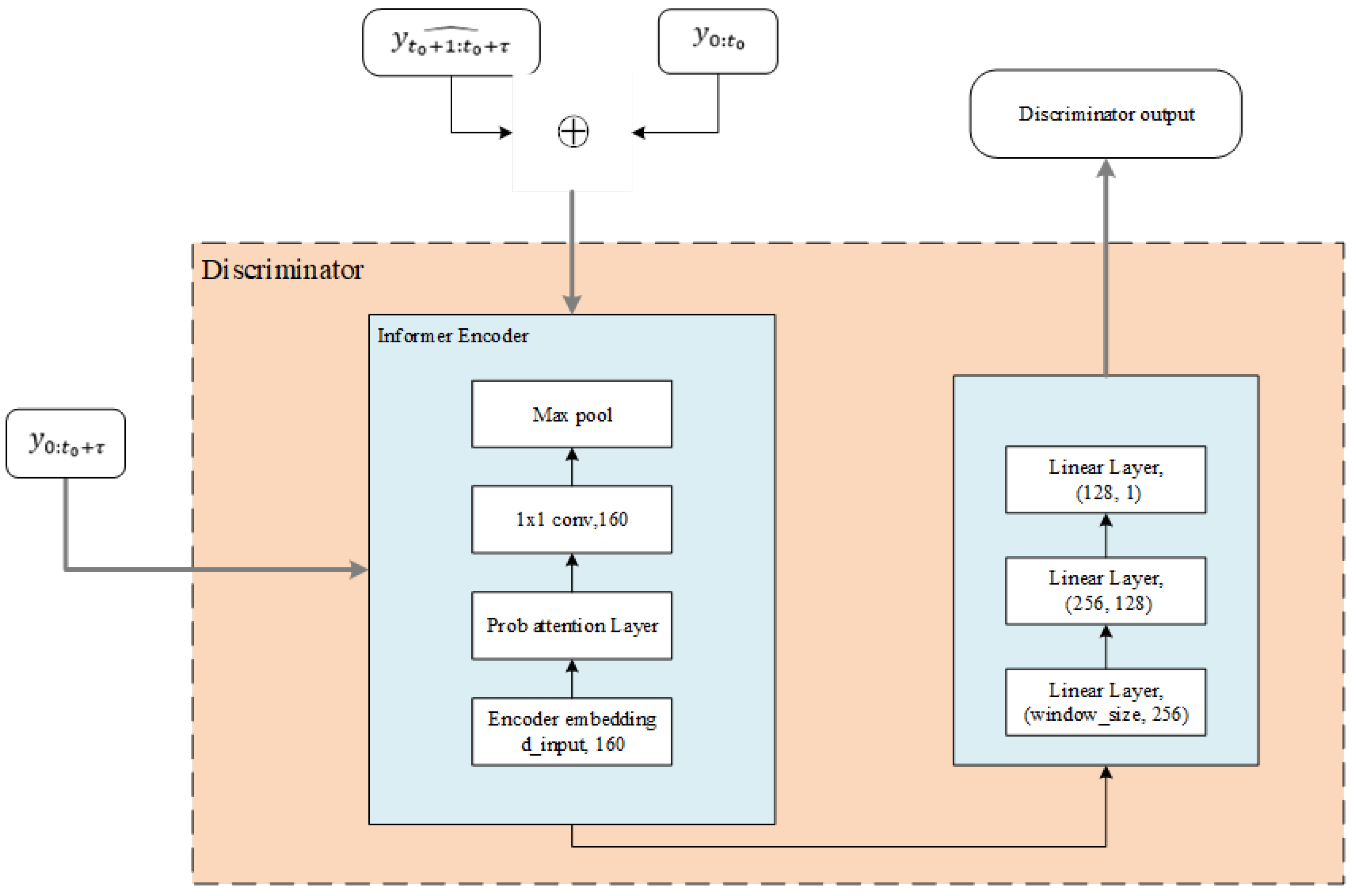
3.2.3. Discriminator
3.2.4. Random Training
| Algorithm 1 GAN training process based on random missing rate. |
|
4. Results
4.1. Evaluation Indicators
4.2. Implementation Details
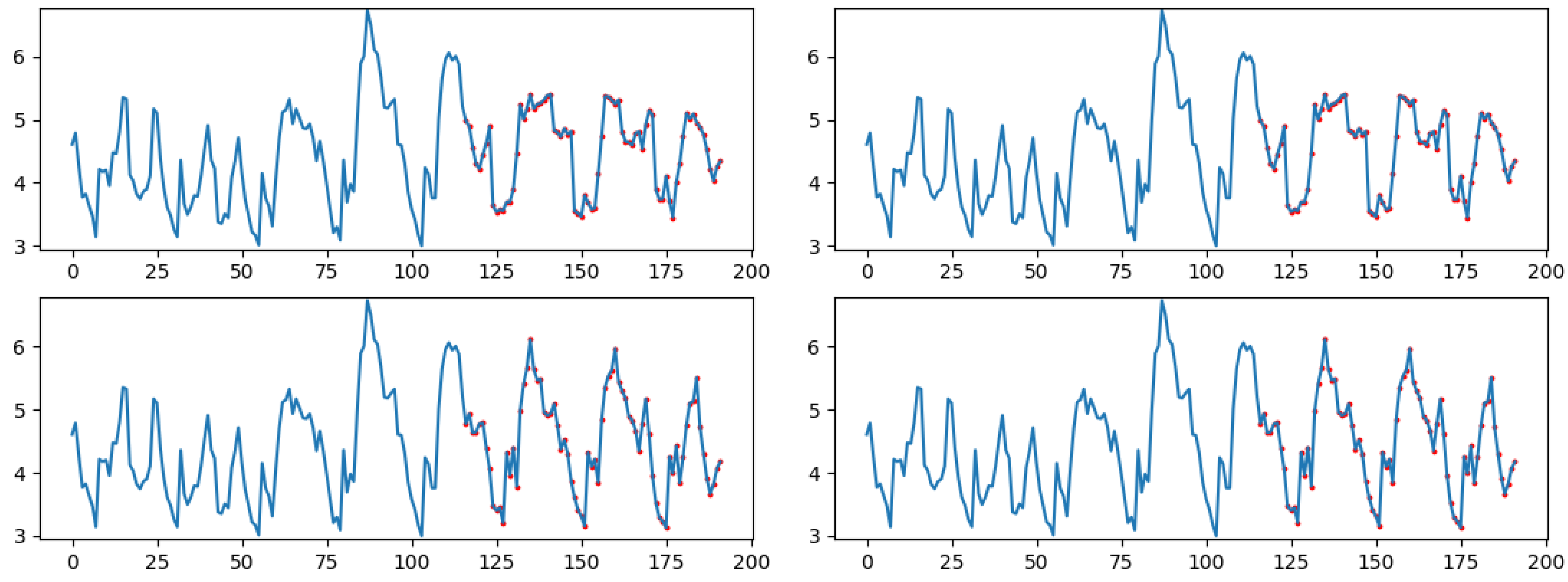
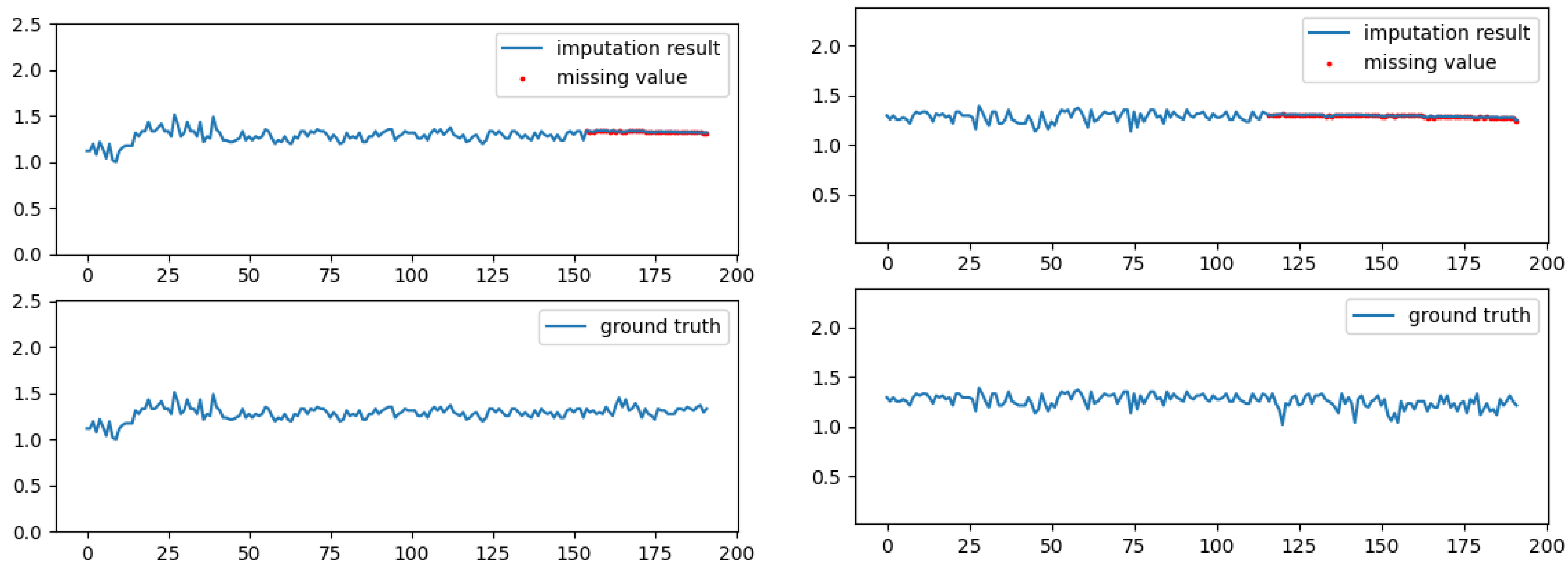
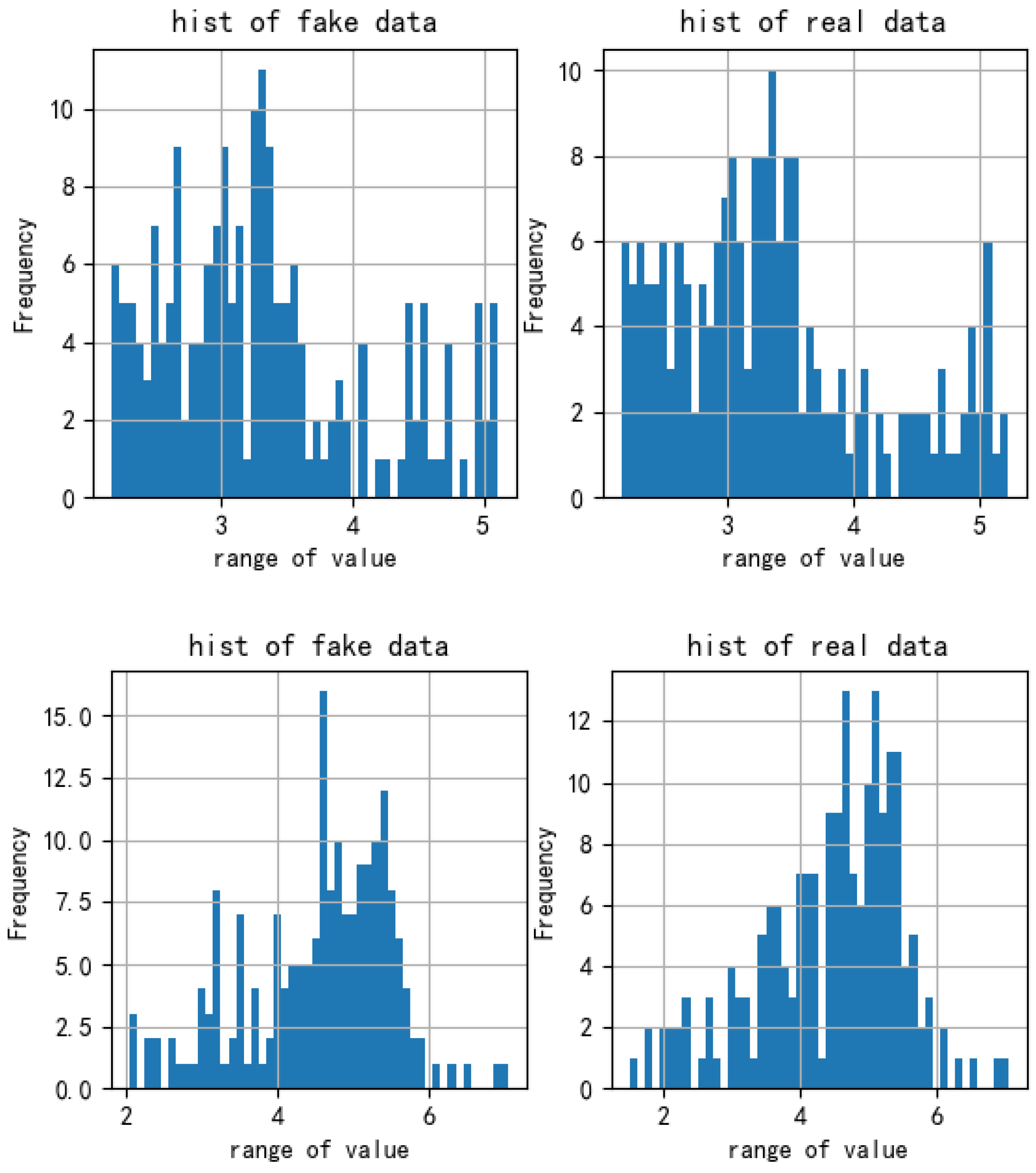
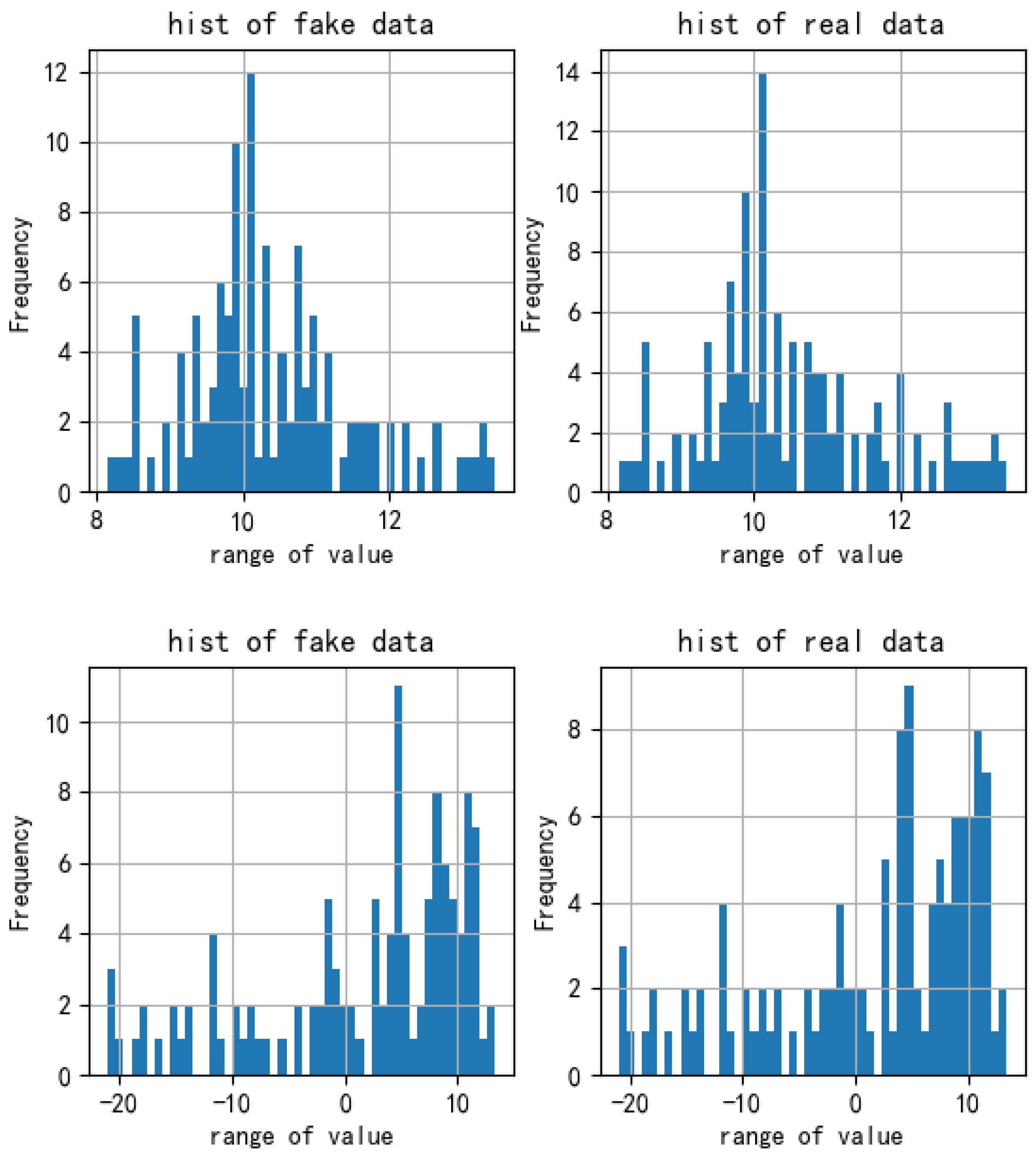
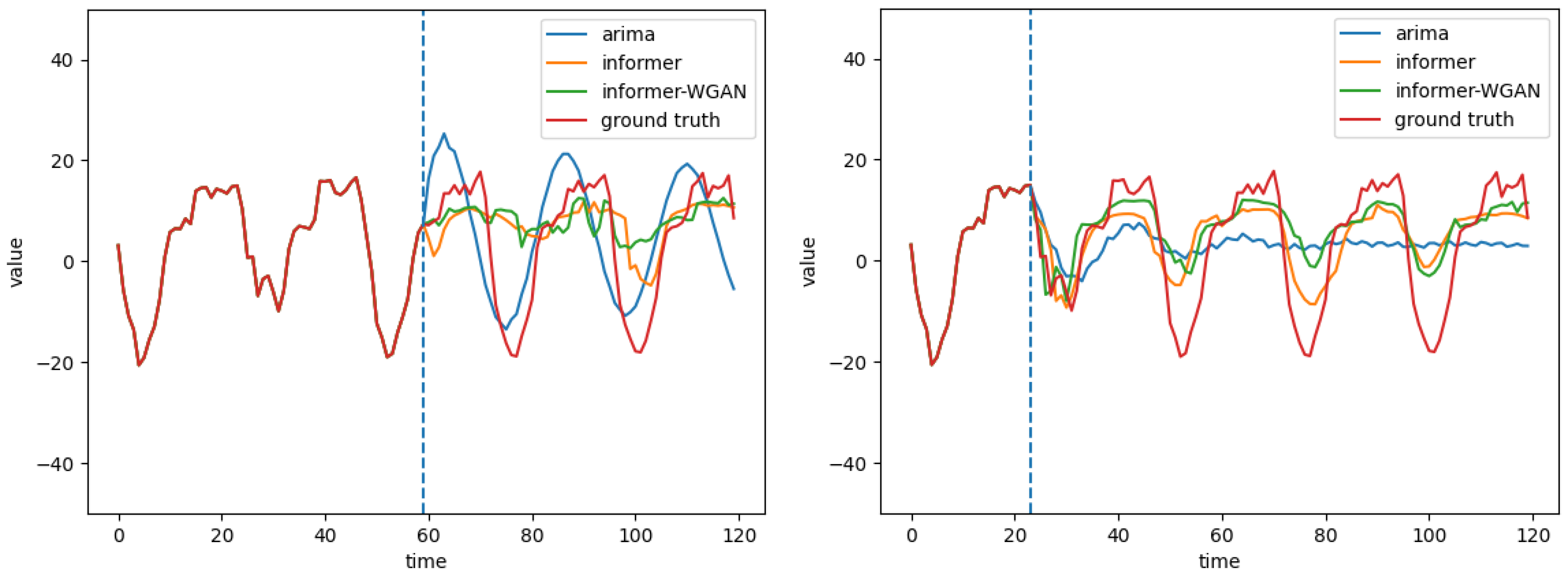
4.3. Performance Comparison
5. Discussion
5.1. Performance Comparison
5.1.1. Informer Discriminator vs. Linear Discriminator
5.1.2. Random Training Process
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chatfield, C. The Analysis of Time Series: An Introduction; Chapman and Hall: London, UK; CRC: Boca Raton, FL, USA, 2003. [Google Scholar]
- Luo, Y.; Zhang, Y.; Cai, X.; Yuan, X. E2gan: End-to-end generative adversarial network for multivariate time series imputation. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 3094–3100. [Google Scholar]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Schafer, J.L. Analysis of Incomplete Multivariate Data; CRC Press: Boca Raton, FL, USA, 1997. [Google Scholar]
- Contreras-Reyes, J.E.; Palma, W. Statistical analysis of autoregressive fractionally integrated moving average models in R. Comput. Stat. 2013, 28, 2309–2331. [Google Scholar] [CrossRef] [Green Version]
- Wu, S.; Xiao, X.; Ding, Q.; Zhao, P.; Wei, Y.; Huang, J. Adversarial sparse transformer for time series forecasting. Adv. Neural Inf. Process. Syst. 2020, 33, 17105–17115. [Google Scholar]
- Rahman, M.G.; Islam, M.Z. Missing value imputation using decision trees and decision forests by splitting and merging records: Two novel techniques. Knowl.-Based Syst. 2013, 53, 51–65. [Google Scholar] [CrossRef]
- Folguera, L.; Zupan, J.; Cicerone, D.; Magallanes, J.F. Self-organizing maps for imputation of missing data in incomplete data matrices. Chemom. Intell. Lab. Syst. 2015, 143, 146–151. [Google Scholar] [CrossRef]
- Längkvist, M.; Karlsson, L.; Loutfi, A. A review of unsupervised feature learning and deep learning for time-series modeling. Pattern Recognit. Lett. 2014, 42, 11–24. [Google Scholar] [CrossRef] [Green Version]
- Salinas, D.; Flunkert, V.; Gasthaus, J.; Januschowski, T. DeepAR: Probabilistic forecasting with autoregressive recurrent networks. Int. J. Forecast. 2020, 36, 1181–1191. [Google Scholar] [CrossRef]
- Pwasong, A.; Sathasivam, S. Forecasting comparisons using a hybrid ARFIMA and LRNN models. Commun. Stat.-Simul. Comput. 2018, 47, 2286–2303. [Google Scholar] [CrossRef]
- Liu, C.; Hoi, S.C.; Zhao, P.; Sun, J. Online arima algorithms for time series prediction. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Zhang, J.; Man, K.F. Time series prediction using RNN in multi-dimension embedding phase space. In Proceedings of the SMC’98 Conference Proceedings—1998 IEEE International Conference on Systems, Man, and Cybernetics (Cat. No. 98CH36218), San Diego, CA, USA, 14 October 1998; Volume 2, pp. 1868–1873. [Google Scholar]
- Lai, G.; Chang, W.C.; Yang, Y.; Liu, H. Modeling long-and short-term temporal patterns with deep neural networks. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 95–104. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Luo, Y.; Cai, X.; Zhang, Y.; Xu, J.; Yuan, X. Multivariate time series imputation with generative adversarial networks. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Yoon, J.; Jarrett, D.; Van der Schaar, M. Time-series generative adversarial networks. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Correia, G.M.; Niculae, V.; Martins, A.F. Adaptively sparse transformers. arXiv 2019, arXiv:1909.00015. [Google Scholar]
- Martins, A.; Astudillo, R. From softmax to sparsemax: A sparse model of attention and multi-label classification. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1614–1623. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21), Virtual, 2–9 February 2021. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | F | L | D |
|---|---|---|---|
| electricity | hourly | 32,304 | 370 |
| ETTh1 | hourly | 17,420 | 6 |
| Missing Rate | mae | mse | rmse | mape | mspe | p_corr |
|---|---|---|---|---|---|---|
| 20% | 0.82615 | 6.70904 | 2.39374 | 0.19931 | 0.44089 | 0.95462 |
| 40% | 0.86958 | 7.50290 | 2.61123 | 0.21357 | 0.51383 | 0.95277 |
| 60% | 0.89981 | 7.64285 | 2.63168 | 0.23651 | 0.70946 | 0.94944 |
| 80% | 0.97250 | 8.13361 | 2.72510 | 0.27141 | 0.79367 | 0.93473 |
| Missing Rate | mae | mse | rmse | mape | mspe | p_corr |
|---|---|---|---|---|---|---|
| 20% | 1.90835 | 10.73479 | 3.27281 | 0.53457 | 9.75783 | 0.77216 |
| 40% | 1.97126 | 12.07560 | 3.47173 | 0.54006 | 10.14137 | 0.75321 |
| 60% | 2.01376 | 12.42590 | 3.52390 | 0.58413 | 11.62296 | 0.74823 |
| 80% | 2.05503 | 12.64088 | 3.55464 | 0.57709 | 10.30420 | 0.74734 |
| Imputation Model | mae | mse | rmse | mape | mspe | p_corr |
|---|---|---|---|---|---|---|
| ARIMA | 2.47689 | 31.01061 | 4.43682 | 0.20056 | 0.06220 | 0.86310 |
| AST | 2.22961 | 181.73460 | 9.469879 | 1.15476 | 11.27290 | 0.48822 |
| Informer | 1.74750 | 19.67988 | 4.21687 | 0.61075 | 3.34536 | 0.84613 |
| ST-WGAN | 1.35948 | 60.82138 | 5.773326 | 0.86076 | 8.81188 | 0.84930 |
| Informer-WGAN | 0.89969 | 7.64734 | 2.61395 | 0.23624 | 0.70543 | 0.94789 |
| Imputation Model | mae | mse | rmse | mape | mspe | p_corr |
|---|---|---|---|---|---|---|
| ARIMA | 2.48034 | 19.27467 | 4.35074 | 0.52469 | 4.69485 | 0.65881 |
| AST | 7.87295 | 94.89117 | 9.70722 | 2.44605 | 14.57877 | 0.38196 |
| Informer | 2.11488 | 11.82524 | 3.43685 | 0.59489 | 9.80083 | 0.74467 |
| ST-WGAN | 2.23207 | 21.70739 | 4.60613 | 0.69644 | 24.20782 | 0.65263 |
| Informer-WGAN | 2.01439 | 12.37496 | 3.51492 | 0.56910 | 10.93439 | 0.74725 |
| Missing Rate | ARIMA | Infomer | Informer-WGAN |
|---|---|---|---|
| 20% | 2.711 | 1.791 | 1.119 |
| 40% | 4.247 | 1.830 | 1.157 |
| 60% | 4.612 | 2.019 | 1.188 |
| 80% | 12.609 | 2.062 | 1.283 |
| Missing Rate | ARIMA | AST | Infomer | Informer-WGAN |
|---|---|---|---|---|
| 20% | 2.709 | 2.477 | 2.311 | 2.309 |
| 40% | 3.036 | 7.487 | 2.339 | 2.338 |
| 60% | 3.156 | 9.963 | 2.438 | 2.437 |
| 80% | 3.736 | 19.567 | 2.574 | 2.569 |
| Missing Rate | ARIMA | Infomer | Informer-WGAN |
|---|---|---|---|
| 20% | 0.937/0.345 | 1.337/0.747 | 1.029/0.920 |
| 40% | 1.081/0.254 | 1.348/0.737 | 1.055/0.911 |
| 60% | 0.858/0.186 | 1.404/0.696 | 1.073/0.902 |
| 80% | 1.132/0.089 | 1.430/0.694 | 1.130/0.880 |
| Missing Rate | ARIMA | Infomer | Informer-WGAN |
|---|---|---|---|
| 20% | 2.066/0.762 | 1.795/0.773 | 1.796/0.774 |
| 40% | 2.240/0.737 | 1.804/0.767 | 1.847/0.756 |
| 60% | 2.311/0.732 | 1.832/0.750 | 1.867/0.751 |
| 80% | 2.439/0.652 | 1.903/0.739 | 1.883/0.748 |
| Missing Rate | Informer-WGAN (Linear Discriminator) | Informer-WGAN (Informer Discriminator) |
|---|---|---|
| 20% | 1.710 | 1.119 |
| 40% | 1.708 | 1.157 |
| 60% | 1.798 | 1.188 |
| 80% | 1.866 | 1.283 |
| Missing Rate | Informer-WGAN (20% Train) | Informer-WGAN (Random Train) |
|---|---|---|
| 20% | 1.560 | 1.119 |
| 40% | 2.326 | 1.157 |
| 60% | 2.582 | 1.188 |
| 80% | 2.689 | 1.283 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qian, Y.; Tian, L.; Zhai, B.; Zhang, S.; Wu, R. Informer-WGAN: High Missing Rate Time Series Imputation Based on Adversarial Training and a Self-Attention Mechanism. Algorithms 2022, 15, 252. https://doi.org/10.3390/a15070252
Qian Y, Tian L, Zhai B, Zhang S, Wu R. Informer-WGAN: High Missing Rate Time Series Imputation Based on Adversarial Training and a Self-Attention Mechanism. Algorithms. 2022; 15(7):252. https://doi.org/10.3390/a15070252
Chicago/Turabian StyleQian, Yufan, Limei Tian, Baichen Zhai, Shufan Zhang, and Rui Wu. 2022. "Informer-WGAN: High Missing Rate Time Series Imputation Based on Adversarial Training and a Self-Attention Mechanism" Algorithms 15, no. 7: 252. https://doi.org/10.3390/a15070252
APA StyleQian, Y., Tian, L., Zhai, B., Zhang, S., & Wu, R. (2022). Informer-WGAN: High Missing Rate Time Series Imputation Based on Adversarial Training and a Self-Attention Mechanism. Algorithms, 15(7), 252. https://doi.org/10.3390/a15070252