
Federated Optimization of ℓ0-norm Regularized Sparse Learning



Abstract
:1. Introduction
Related Work
2. Preliminaries
- 1.
- is restricted -strongly convex (RSC [43]) at the sparsity level s for a given , i.e., there exists a constant such that with , , we have
- 2.
- is restricted -strongly smooth (RSS [43]) at the sparsity level s for a given , i.e., there exists a constant such that with , , we have
- 3.
- has -bounded stochastic gradient variance, i.e.,
3. The Fed-HT Algorithm
| Algorithm 1. Federated Hard Thresholding (Fed-HT) |
|
4. The FedIter-HT Algorithm
| Algorithm 2. Federated Iterative Hard Thresholding (FedIter-HT) |
|
Statistical Analysis for M-Estimators
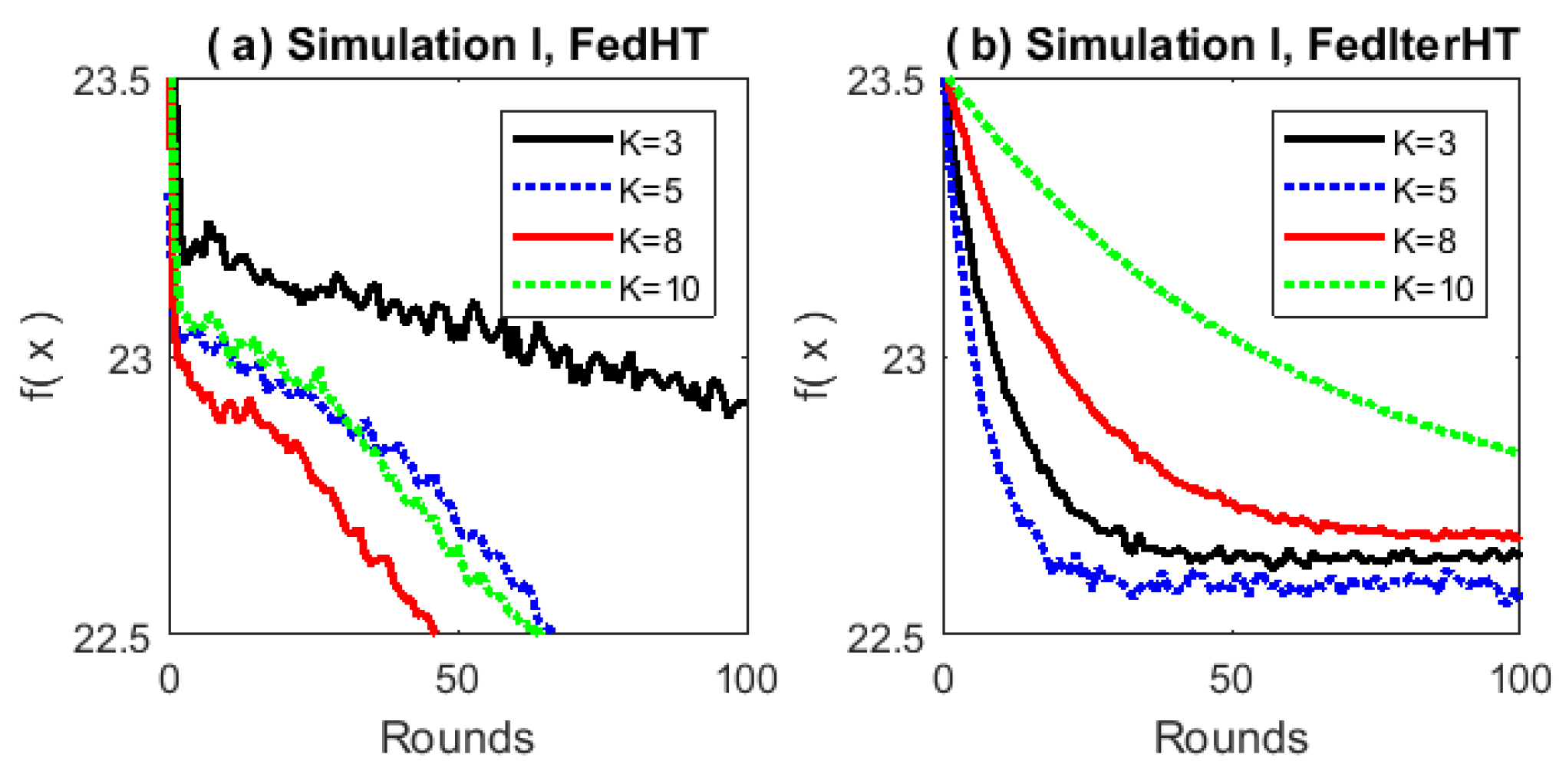
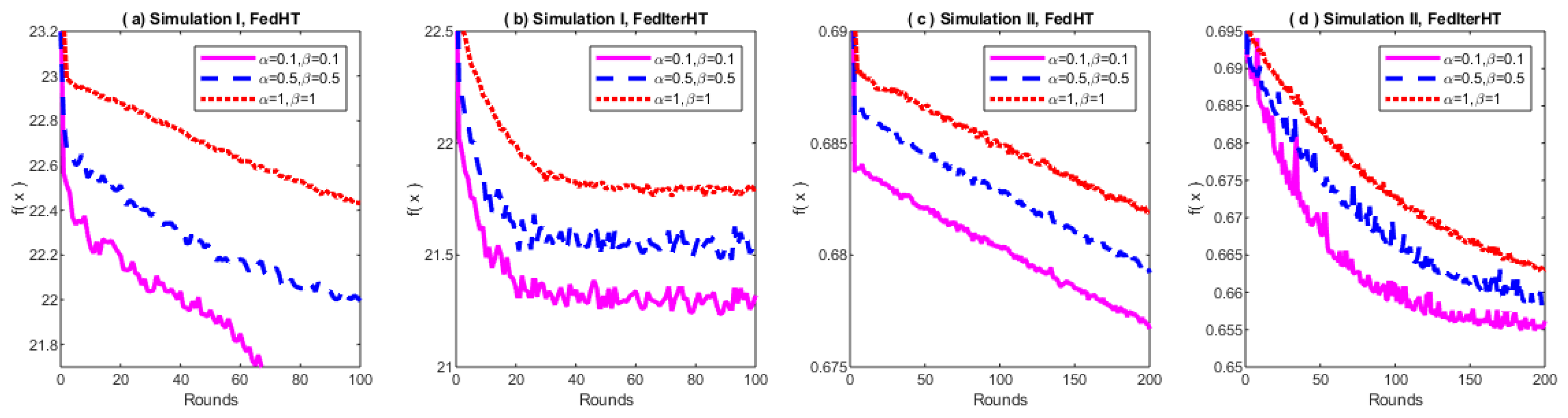
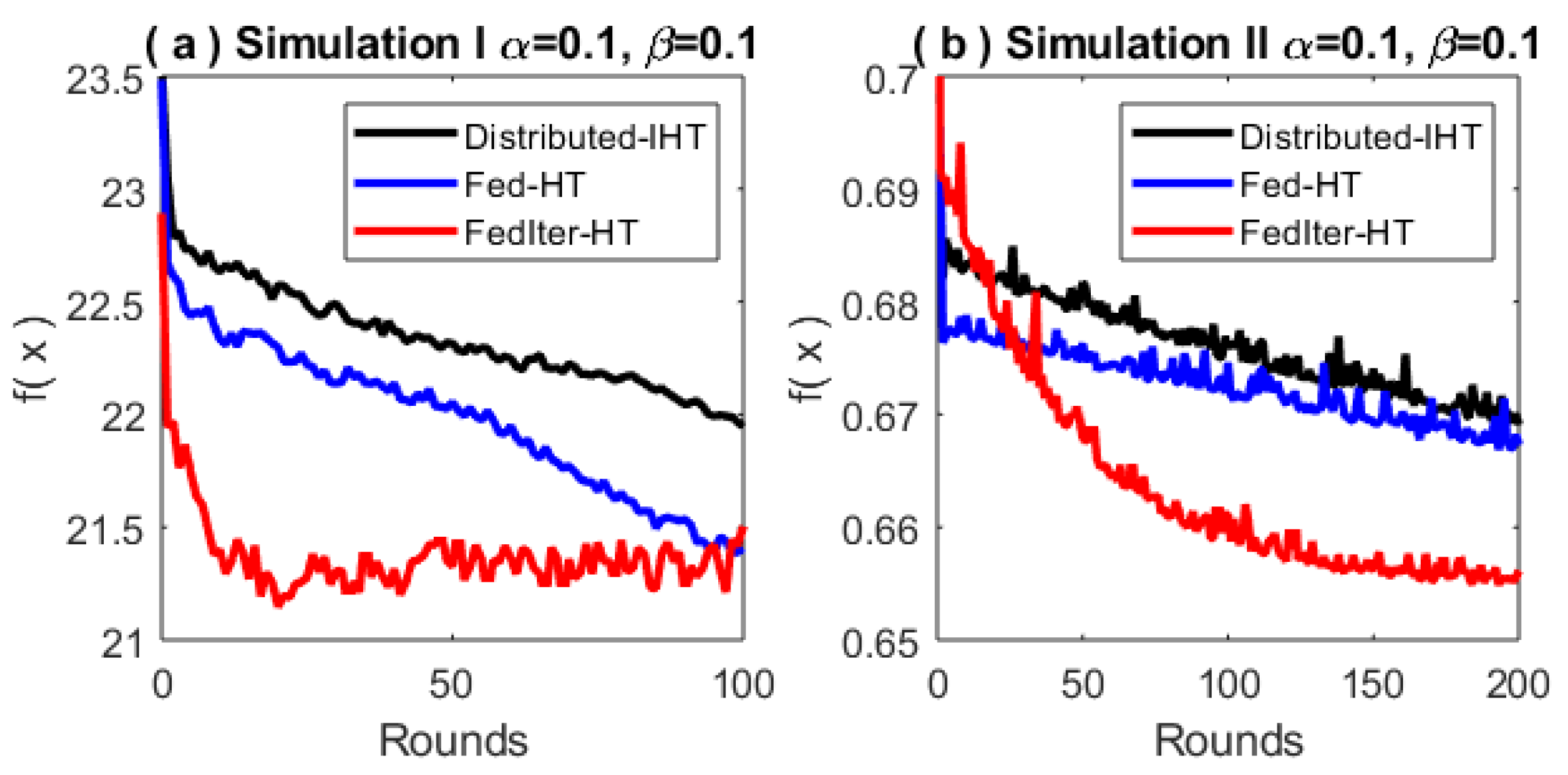
5. Experiments
5.1. Simulations
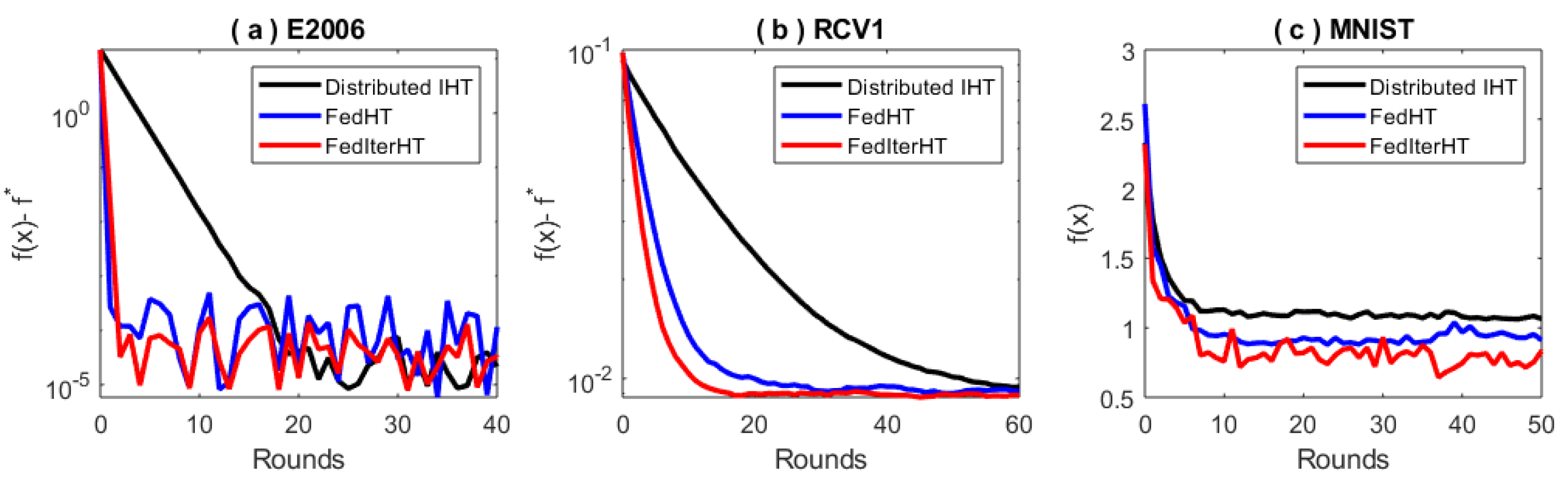
5.2. Benchmark Datasets
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| IHT | iterative hard thresholding |
| SGD | stochastic gradient descent |
| HT | hard thresholding |
| FL | federated learning |
| IID | independent and identically distributed |
Appendix A
Appendix A.1. Distributed IHT Algorithm
| Algorithm A1. Distributed-IHT |
|
Appendix A.2. More Experimental Details
Appendix A.3. Proof of Lemma 2
Appendix A.4. Proof of Theorem 1
Appendix A.5. Proof of Corollary 2
Appendix A.6. Proof of Theorem 2
Appendix A.7. Proof of Corollary 4
References
- Mohamed, S.; Heller, K.; Ghahramani, Z. Bayesian and l1 approaches to sparse unsupervised learning. arXiv 2011, arXiv:1106.1157. [Google Scholar]
- Quattoni, A.; Collins, M.; Darrell, T. Transfer learning for image classification with sparse prototype representations. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Lu, X.; Huang, Z.; Yuan, Y. MR image super-resolution via manifold regularized sparse learning. Neurocomputing 2015, 162, 96–104. [Google Scholar] [CrossRef]
- Chen, K.; Che, H.; Li, X.; Leung, M.F. Graph non-negative matrix factorization with alternative smoothed L0 regularizations. Neural Comput. Appl. 2022, 1–15. [Google Scholar] [CrossRef]
- Ravishankar, S.; Bresler, Y. Learning sparsifying transforms. IEEE Trans. Signal Process. 2012, 61, 1072–1086. [Google Scholar] [CrossRef]
- Tropp, J.A.; Gilbert, A.C. Signal recovery from random measurements via orthogonal matching pursuit. IEEE Trans. Inf. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef]
- Boufounos, S.; Raj, P.; Bahmani, S.; Boufounos, P.; Raj, B. Greedy Sparsity-Constrained Optimization. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.365.3874&rep=rep1&type=pdf (accessed on 1 July 2022).
- Jalali, A.; Johnson, C.; Ravikumar, P. On learning discrete graphical models using greedy methods. Adv. Neural Inf. Process. Syst. 2011, 24, 1935–1943. [Google Scholar]
- Mallat, S.G.; Zhang, Z. Matching pursuits with time-frequency dictionaries. IEEE Trans. Signal Process. 1993, 41, 3397–3415. [Google Scholar] [CrossRef]
- Pati, Y.C.; Rezaiifar, R.; Krishnaprasad, P.S. Orthogonal matching pursuit: Recursive function approximation with applications to wavelet decomposition. In Proceedings of the 27th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 1–3 November 1993; pp. 40–44. [Google Scholar]
- Needell, D.; Tropp, J.A. CoSaMP: Iterative signal recovery from incomplete and inaccurate samples. Appl. Comput. Harmon. Anal. 2009, 26, 301–321. [Google Scholar] [CrossRef]
- Foucart, S. Hard thresholding pursuit: An algorithm for compressive sensing. SIAM J. Numer. Anal. 2011, 49, 2543–2563. [Google Scholar] [CrossRef]
- Blumensath, T.; Davies, M.E. Iterative hard thresholding for compressed sensing. Appl. Comput. Harmon. Anal. 2009, 27, 265–274. [Google Scholar] [CrossRef]
- Jain, P.; Tewari, A.; Kar, P. On iterative hard thresholding methods for high-dimensional m-estimation. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 685–693. [Google Scholar]
- Nguyen, N.; Needell, D.; Woolf, T. Linear convergence of stochastic iterative greedy algorithms with sparse constraints. IEEE Trans. Inf. Theory 2017, 63, 6869–6895. [Google Scholar] [CrossRef]
- Bahmani, S.; Raj, B.; Boufounos, P.T. Greedy sparsity-constrained optimization. J. Mach. Learn. Res. 2013, 14, 807–841. [Google Scholar]
- Zhou, P.; Yuan, X.; Feng, J. Efficient stochastic gradient hard thresholding. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 1988–1997. [Google Scholar]
- Li, X.; Zhao, T.; Arora, R.; Liu, H.; Haupt, J. Stochastic variance reduced optimization for nonconvex sparse learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 917–925. [Google Scholar]
- Shen, J.; Li, P. A tight bound of hard thresholding. J. Mach. Learn. Res. 2017, 18, 7650–7691. [Google Scholar]
- Natarajan, B.K. Sparse approximate solutions to linear systems. SIAM J. Comput. 1995, 24, 227–234. [Google Scholar] [CrossRef] [Green Version]
- Wahlsten, D.; Metten, P.; Phillips, T.J.; Boehm, S.L.; Burkhart-Kasch, S.; Dorow, J.; Doerksen, S.; Downing, C.; Fogarty, J.; Rodd-Henricks, K.; et al. Different data from different labs: Lessons from studies of gene–environment interaction. J. Neurobiol. 2003, 54, 283–311. [Google Scholar]
- Kavvoura, F.K.; Ioannidis, J.P. Methods for meta-analysis in genetic association studies: A review of their potential and pitfalls. Hum. Genet. 2008, 123, 1–14. [Google Scholar]
- Lee, Y.G.; Jeong, W.S.; Yoon, G. Smartphone-based mobile health monitoring. Telemed. E-Health 2012, 18, 585–590. [Google Scholar] [CrossRef]
- Qin, Z.; Fan, J.; Liu, Y.; Gao, Y.; Li, G.Y. Sparse representation for wireless communications: A compressive sensing approach. IEEE Signal Process. Mag. 2018, 35, 40–58. [Google Scholar] [CrossRef]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends® Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Patterson, S.; Eldar, Y.C.; Keidar, I. Distributed compressed sensing for static and time-varying networks. IEEE Trans. Signal Process. 2014, 62, 4931–4946. [Google Scholar] [CrossRef]
- Lafond, J.; Wai, H.T.; Moulines, E. D-FW: Communication efficient distributed algorithms for high-dimensional sparse optimization. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4144–4148. [Google Scholar]
- Wang, J.; Kolar, M.; Srebro, N.; Zhang, T. Efficient distributed learning with sparsity. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3636–3645. [Google Scholar]
- Lin, Y.; Han, S.; Mao, H.; Wang, Y.; Dally, W.J. Deep gradient compression: Reducing the communication bandwidth for distributed training. arXiv 2017, arXiv:1712.01887. [Google Scholar]
- Shi, S.; Wang, Q.; Zhao, K.; Tang, Z.; Wang, Y.; Huang, X.; Chu, X. A distributed synchronous SGD algorithm with global top-k sparsification for low bandwidth networks. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 2238–2247. [Google Scholar]
- Hsu, T.M.H.; Qi, H.; Brown, M. Measuring the effects of non-identical data distribution for federated visual classification. arXiv 2019, arXiv:1909.06335. [Google Scholar]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.J.; Stich, S.U.; Suresh, A.T. SCAFFOLD: Stochastic controlled averaging for on-device federated learning. arXiv 2019, arXiv:1910.06378. [Google Scholar]
- Reddi, S.; Charles, Z.; Zaheer, M.; Garrett, Z.; Rush, K.; Konečnỳ, J.; Kumar, S.; McMahan, H.B. Adaptive Federated Optimization. arXiv 2020, arXiv:2003.00295. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. arXiv 2018, arXiv:1812.06127. [Google Scholar]
- Bernstein, J.; Zhao, J.; Azizzadenesheli, K.; Anandkumar, A. signSGD with majority vote is communication efficient and fault tolerant. arXiv 2018, arXiv:1810.05291. [Google Scholar]
- Sattler, F.; Wiedemann, S.; Müller, K.R.; Samek, W. Robust and communication-efficient federated learning from non-iid data. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 3400–3413. [Google Scholar] [CrossRef]
- Li, C.; Li, G.; Varshney, P.K. Communication-efficient federated learning based on compressed sensing. IEEE Internet Things J. 2021, 8, 15531–15541. [Google Scholar] [CrossRef]
- Han, P.; Wang, S.; Leung, K.K. Adaptive gradient sparsification for efficient federated learning: An online learning approach. In Proceedings of the 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS), Singapore, 29 November–1 December 2020; pp. 300–310. [Google Scholar]
- Yuan, H.; Zaheer, M.; Reddi, S. Federated composite optimization. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 18–24 July2021; pp. 12253–12266. [Google Scholar]
- Agarwal, A.; Negahban, S.; Wainwright, M.J. Fast Global Convergence Rates of Gradient Methods for High-Dimensional Statistical Recovery. Available online: https://proceedings.neurips.cc/paper/2010/file/7cce53cf90577442771720a370c3c723-Paper.pdf (accessed on 1 July 2022).
- Li, X.; Arora, R.; Liu, H.; Haupt, J.; Zhao, T. Nonconvex sparse learning via stochastic optimization with progressive variance reduction. arXiv 2016, arXiv:1605.02711. [Google Scholar]
- Wang, L.; Gu, Q. Differentially Private Iterative Gradient Hard Thresholding for Sparse Learning. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar]
- Loh, P.L.; Wainwright, M.J. Regularized M-estimators with nonconvexity: Statistical and algorithmic theory for local optima. J. Mach. Learn. Res. 2015, 16, 559–616. [Google Scholar]
- Kogan, S.; Levin, D.; Routledge, B.R.; Sagi, J.S.; Smith, N.A. Predicting risk from financial reports with regression. In Proceedings of the Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Boulder, CO, USA, 31 May–5 June 2009; Association for Computational Linguistics: Boulder, CO, USA, 2009; pp. 272–280. [Google Scholar]
- Lewis, D.D.; Yang, Y.; Rose, T.G.; Li, F. Rcv1: A new benchmark collection for text categorization research. J. Mach. Learn. Res. 2004, 5, 361–397. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| the HT operator that maintains the top items of x and sets the remaining elements to 0 | |
| the total number, the index of clients/devices | |
| the weight of each loss function on client i | |
| the total number, the index of communication rounds | |
| the total number, the index of local iterations | |
| the full gradient | |
| the stochastic gradient over the minibatch | |
| the stochastic gradient over a training example indexed by z on the i-th device | |
| the stepsize/learning rate of local update | |
| an indicator function | |
| the support of x or the index set of nonzero elements in x | |
| the optimal solution of Problem (2) | |
| the local parameter vector on device i at the k-th iteration of the t-th round | |
| the required sparsity level | |
| the optimal sparsity level of Problem (2), | |
| the projector takes only the elements of x indexed in | |
| , | the expectation over stochasticity across all clients and of client i, respectively |
| Dataset | Samples | Dimension | Samples Per Device | |
|---|---|---|---|---|
| Mean | Stdev | |||
| E2006-tfidf | 3308 | 150,360 | 33.8 | 9.1 |
| RCV1 | 20,242 | 47,236 | 202.4 | 114.5 |
| MNIST | 60,000 | 784 | 600 | – |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tong, Q.; Liang, G.; Ding, J.; Zhu, T.; Pan, M.; Bi, J. Federated Optimization of ℓ0-norm Regularized Sparse Learning. Algorithms 2022, 15, 319. https://doi.org/10.3390/a15090319
Tong Q, Liang G, Ding J, Zhu T, Pan M, Bi J. Federated Optimization of ℓ0-norm Regularized Sparse Learning. Algorithms. 2022; 15(9):319. https://doi.org/10.3390/a15090319
Chicago/Turabian StyleTong, Qianqian, Guannan Liang, Jiahao Ding, Tan Zhu, Miao Pan, and Jinbo Bi. 2022. "Federated Optimization of ℓ0-norm Regularized Sparse Learning" Algorithms 15, no. 9: 319. https://doi.org/10.3390/a15090319
APA StyleTong, Q., Liang, G., Ding, J., Zhu, T., Pan, M., & Bi, J. (2022). Federated Optimization of ℓ0-norm Regularized Sparse Learning. Algorithms, 15(9), 319. https://doi.org/10.3390/a15090319