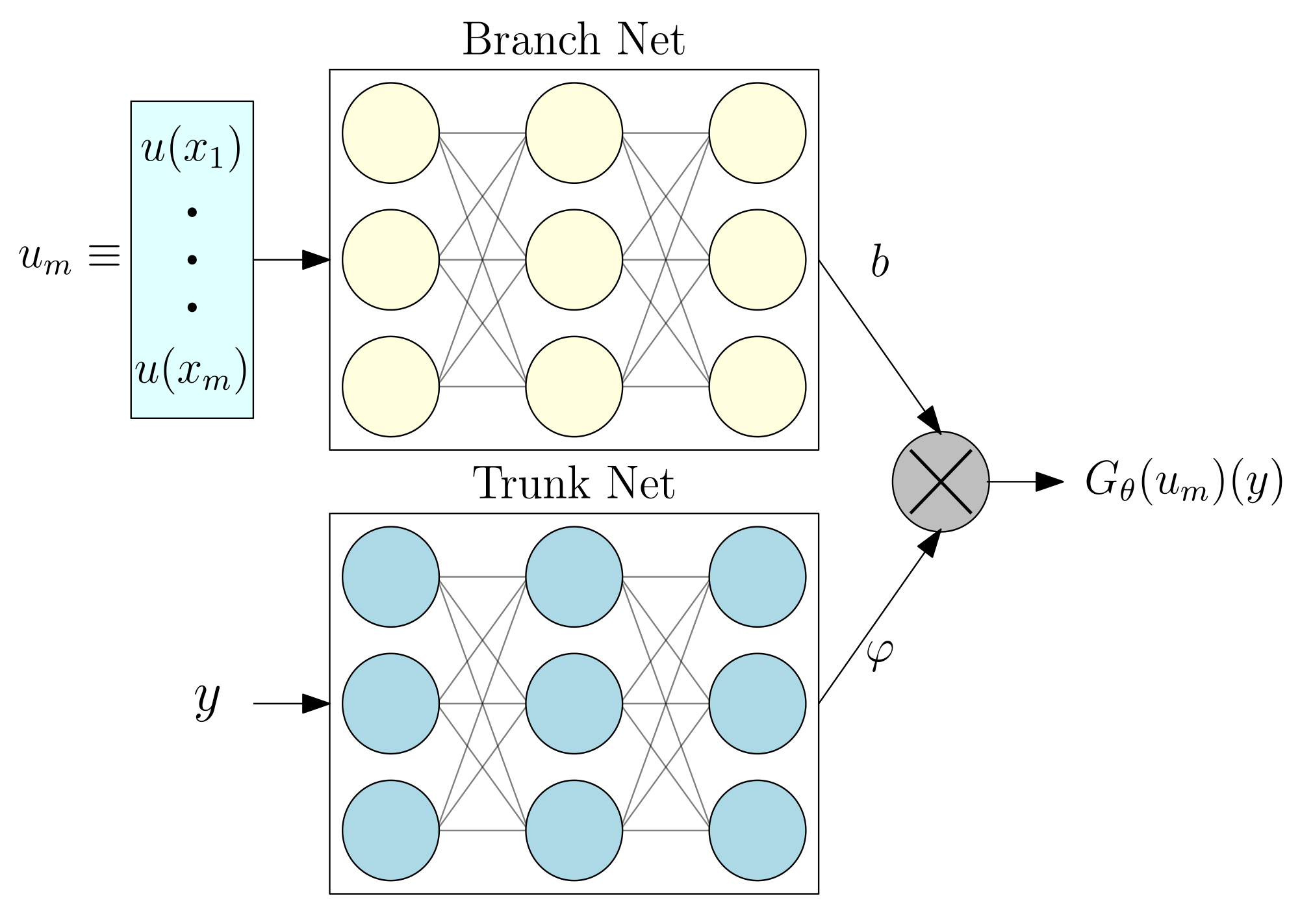
3. Federated Deep Operator Networks (Fed-DeepONet)
Let us start this section by describing some mathematical notations from federated learning [
17]. We let
denote the floor function, and we use
to denote the standard Euclidean norm. For any given positive integer
n, we let
denote the set
. We let
C denote the number of clients participating in the federated training of DeepONet and use variable
c to describe the clients within the set of clients
. For each client
, we use
and
to denote the
c-th client’s corresponding DeepONet loss and gradient of the loss
. We let
denote the stochastic gradient of
computed using the
c-th client’s dataset. This stochastic gradient
is an unbiased estimator of the exact gradient
[
25]. We also denote
as the weight of the
c-th client such that
, where
is the number of data triplets in the
c-th client. Let
K denote the number of local stochastic gradient updates taken by each client
and let
R denote the number of global synchronization events (also known as the number of communication rounds).
To train the proposed Fed-DeepONet, we follow a distributed optimization strategy. For traditional neural networks, this distributed strategy was introduced in [
16,
18], and it is known as federated averaging (FedAvg). Formally, we aim to solve the following optimization problem:
In the above,
, where
and
is the
c-th client’s DeepONet loss function based on
and the data triplet
collected by the
c-th client, i.e.,
Here, we have used the notations and to emphasize that and are, respectively, a discretized input, query location, and solution operator value collected by the c-th client.
The proposed Fed-DeepONet framework can work with independent and identically distributed and non-independent and identically distributed (heterogeneous) data. However, most of the applications we seek for Fed-DeepONet (e.g., learning digital twins, scientific computing, or material discovery) will present some level of data heterogeneity. For example, when the clients’ data presents slightly different properties while sharing some others. To provide a more detailed explanation for the causes of heterogeneous data, let us use the joint probability density function of the i-th client input–output data samples. Observe that we can factorize this joint as . Using this factorization, we can establish three causes of heterogeneous data for Fed-DeepONet.
- 1.
Different input distributions. In this situation, we have
and
for some
. This situation may occur when learning digital twins for synchronous generators. Suppose all the participating clients have generators with the same parameters and assume the datasets collected by each client are different. For instance, assume most clients have stable trajectories in their datasets, while the rest may have many unstable and disturbance trajectories. Such a situation makes the functional input space of the different clients skewed. However, notice that the output functional space remains the same for all clients. In
Section 4.3, we will design a simple experiment that evaluates the performance of Algorithms 1 and 2 to different levels of input distribution heterogeneity.
- 2.
Different conditional distributions. In this situation, we have the conditional probabilities satisfy
and
. For an example within the proposed framework, consider the generator digital twin learning task again. Then an example of this situation is when the clients use the same excitation signals for system identification but have generators with different parameters and responses. This paper will not approach such a situation from a federated learning perspective. Instead, we show, in our experiments (see
Section 4.4), that Fed-DeepONet can tackle this heterogeneous data situation by learning all parameter realizations (i.e., a library of digital twins) provided each client has access to the generators’ parameters. If the client does not know the parameters, then one could, for example, keep some of the Branch network parameters private. Such a strategy will control the bias introduced during each synchronization round. We left the details of this strategy for our future work.
- 3.
Different joint probabilities. In this situation, each client’s input and output functional spaces may have slightly different characteristics. In
Section 4.3, we present a simple experiment that aims at testing such a situation.
To train the proposed Fed-DeepONet, we first propose a federated averaging implementation of the stochastic gradient descent algorithm. Such an implementation requires us to loop over the following three steps:
- 1.
Broadcast to clients: The centralized server broadcasts to all the clients the most up-to-date DeepONet parameters, which we denote as . Here k is an integer variable used to denote the local update number for the c-th client.
- 2.
Client local updates: For any
, the
c-th client receives the most up-to-date DeepONet parameters
, sets
, and then executes
local stochastic gradient DeepONet updates over the client’s dataset
, i.e.,
where
is the learning rate, and
is the immediate result of the one-step stochastic gradient update from
, which implies that
if
mod
K is not equal to zero.
- 3.
Global synchronization: The centralized server aggregates the local DeepONet parameters into a unique global Fed-DeepONet parameter as follows, .
We provide a summary of the aforementioned training strategy for Fed-DeepONet in Algorithm 1.
| Algorithm 1 Federated Deep Operator Network (Fed-DeepONet) learning. Denote by (i) the DeepONet parameters of the c-th client, (ii) the immediate result from via a local stochastic gradient update, and (iii) the learning rate. A global synchronization round of the DeepONet parameters is executed by the centralized server every K steps. Run the algorithm for R DeepONet synchronization rounds. Formally, for each client , the client locally runs: |
|
Theoretically, under some assumptions, one can show (see [
21] for details) the convergence of Algorithm 1. In practice, however, not all the clients may be available for federated DeepONet training. To handle this intermittent training scenario, we introduce the set
, denoting the clients available at global synchronization round
k (note that
is assumed to be fixed for the next
K local updates). Furthermore, we observed that Algorithm 1 might present slow convergence when training Fed-DeepONets (see
Section 4.1). One can improve the Fed-DeepONet training convergence by using adaptive (also known as momentum-enhanced) stochastic gradient-based strategies, e.g., Adam [
12]. We summarize in Algorithm 2 a federated strategy for handling a variable number of available clients, which collectively trains Fed-DeepONet using a local adaptive stochastic optimization scheme. We call this strategy the Adaptive Fed-DeepONet.
| Algorithm 2 Adaptive Federated Deep Operator Network (Adaptive Fed-DeepONet) learning. Denote by (i) the DeepONet parameters of the c-th client, (ii) the immediate result from via an adaptive local stochastic gradient with momentum update, (iii) the step-size, (iv) the exponential decay rates for the moment estimates, (v) the first-moment vector, (vi) the second-moment vector, and (vii) a small positive number introduced to avoid division by zero during Adaptive Fed-DeepONet. A global synchronization round of the DeepONet parameters is executed by the centralized server every K steps. Run the algorithm for R DeepONet synchronization rounds. Formally, for each client , the client locally runs: |
|
4. Numerical Experiments
This section tests the efficacy of the proposed Fed-DeepONet framework. To this end, we use four experiments. In the first experiment (see
Section 4.1), we compare the federated training performance of the two proposed algorithms: Algorithm 1 (Fed-DeepONet) and Algorithm 2 (Adaptive Fed-DeepONet). In the second experiment (see
Section 4.2), we employ the Adaptive Fed-DeepONet to learn the solution operator of a pendulum. In the third experiment, we verify how the performance of Fed-DeepONet changes when we vary the data heterogeneity. In the final experiment (see
Section 4.4), we approximate the dynamic response of a library of pendulums using an Adaptive Fed-DeepONet. Let us start this section by describing the neural networks used for DeepONet, the distributed training dataset, and the metrics used to evaluate Fed-DeepONet.
Neural networks. To build the Branch and Trunk networks, we used feed-forward neural networks. For the Branch, we used 1 hidden layer with a width of 50 neurons. Further, the Branch’s input and output layers have, respectively, m (defined later) and 50 neurons. For the Trunk, we also used 1 hidden layer with 50 neurons. The Trunk’s input and output layers have, respectively, 1 and 50 neurons. We obtained these values for the design of the Branch and Trunk networks after employing a simple routine of hyper-parameter optimization. For the activation function, we employed the classical ReLU function. We coded these neural networks in PyTorch and published the code on GitHub.
Training dataset. For each experiment, we collected, using the true operator G, 10,000 training data triplets, i.e., . Then, we distributed these training data triplets among the C clients without repetition. Note that in these experiments, we used the number of clients C as a parameter to test the performance of Fed-DeepONet.
Metrics. To test the performance of Fed-DeepONet, we computed the
-relative error between solution trajectories. That is, for a given discretized input
, we use the trained Fed-DeepONet (denoted as
, where
is the vector of trained/optimized parameters) to predict the solution trajectory
at a collection of selected points
. Let
denote the solution generated by the true solution operator
G, then we compute the
-relative error as follows:
Pendulum system. In this section, we study the performance of Fed-DeepONet (Algorithm 1) and Adaptive Fed-DeepONet (Algorithm 2) using the following pendulum system with dynamics:
The parameters used to describe the above pendulum dynamics are the simulation time-horizon
T, the pendulum’s constant
k, and the initial condition
. In our first and second experiments (
Section 4.1 and
Section 4.2), we selected
s,
, and
. These are the same parameter values used in the original centralized DeepONet paper [
10] and our proposed centralized Bayesian DeepONet paper [
26]. For our fourth experiment, we allowed
k to take values within the interval
. We selected this arbitrary interval to showcase the ability of the Adaptive Fed-DeepONet to approximate libraries of parametrically complex dynamical systems (e.g., pendulums). Finally, we want to remark that, in practice, the values for these parameters depend on the dynamical system under study.
To generate the training and testing datasets, we follow [
10,
26] and sample the control input
u that drives the pendulum (
9) from the mean-zero Gaussian Random Field (GRF):
where the covariance kernel is
, i.e., the radial basis function (RBF) kernel with length-scale parameter
. We will also test the efficacy of the proposed Fed-DeepONet using the following collection of out-of-distribution input functions [
10]:
.
4.1. Experiment 1: Comparing Fed-DeepONet (Algorithm 1) and Adaptive Fed-DeepONet (Algorithm 2)
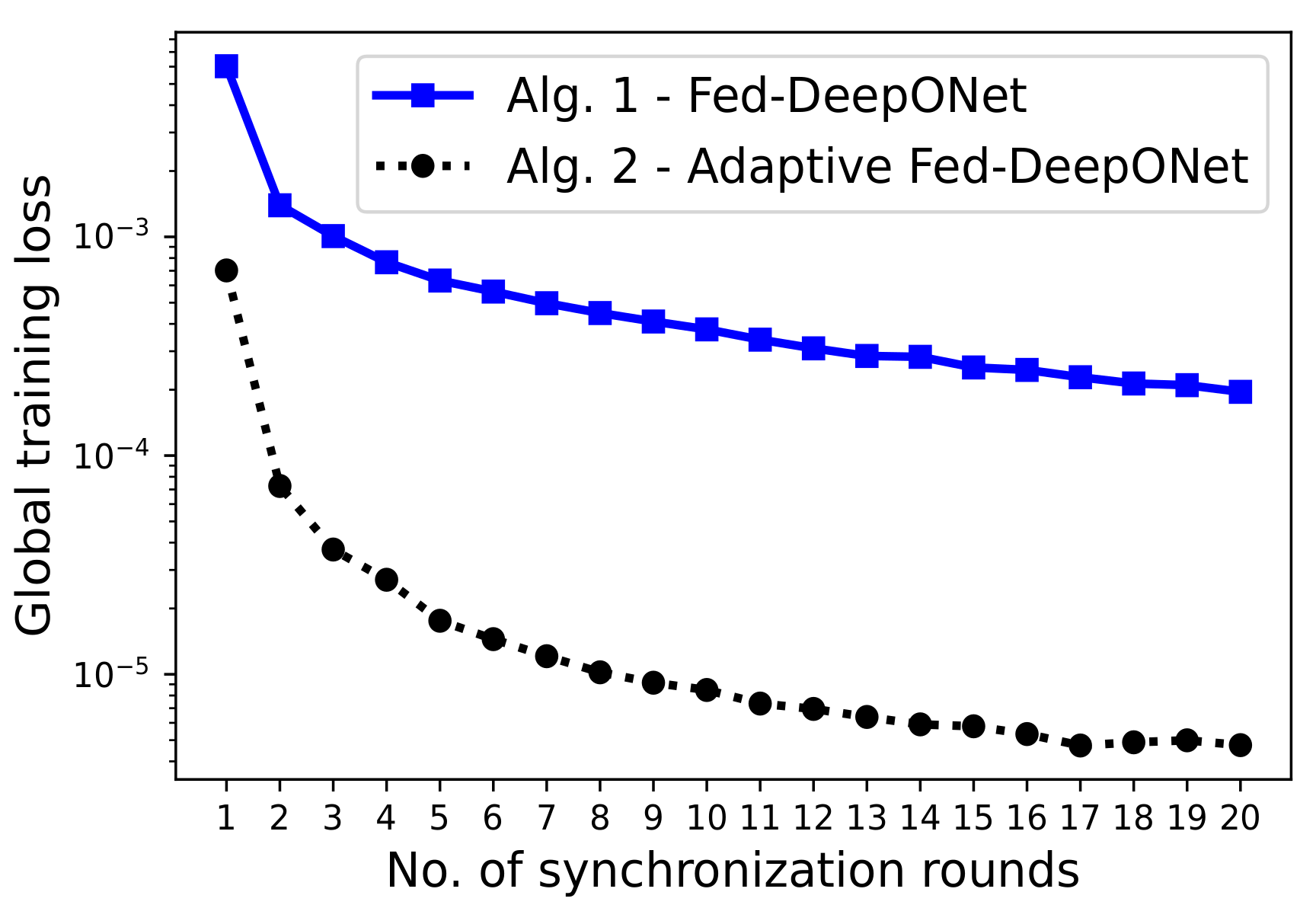
In our first experiment, we quickly verify our previous statement that Algorithm 1 presents slow convergence when training Fed-DeepONets. To this end, we construct an idealized federated training scenario and compare the global training convergences of Fed-DeepONet (Algorithm 1) and Adaptive Fed-DeepONet (Algorithm 2). The proposed idealized scenario assumes we have clients and a fraction of the C clients, selected uniformly at random at each global synchronization round, perform federated training. The federated dynamics are controlled by the number of synchronization rounds and the number of local updates, which we set, respectively, to the values and .
Figure 2 depicts the results of applying federated training using Algorithm 1 and Algorithm 2. Notice that, as expected, the training convergence of Fed-DeepONet is poor compared to the training convergence of the Adaptive Fed-DeepONet. We remark that this result is not new. In centralized deep learning [
27], even though most of the theoretical results are developed for stochastic gradient descent (SGD), one often uses adaptive versions of SGD in practice. These adaptive methods generally deal better with the non-convex nature of the loss function and training dynamics. These results motivate us to only employ the Adaptive Fed-DeepONet to demonstrate the proposed framework’s performance.
4.2. Experiment 2: Learning the Pendulum’s Solution Operator G
In this experiment, we used the adaptive Fed-DeepONet to approximate the solution operator G of the gravity pendulum with control input u described above.
Verifying the performance of Fed-DeepONet. In this experiment, we tested the proposed Fed-DeepONet using
as the available clients. Notice that the number of clients
C is a problem-dependent parameter. However, since we are interested in learning solution operators of complex dynamical systems, the potential applications for Fed-DeepONet may have a small number of clients. This motivates us to consider cases where the number of clients satisfies
. Further, we set the number of global synchronization DeepONet rounds to
and the number of local updates to
using a simple routine of hyper-parameter optimization [
27]. We remark, however, that, in practice, one may need to select the parameter values for
K and
R considering problem-dependent constraints, such as computational resources, communication resources, near real-time performance, or cyber-security.
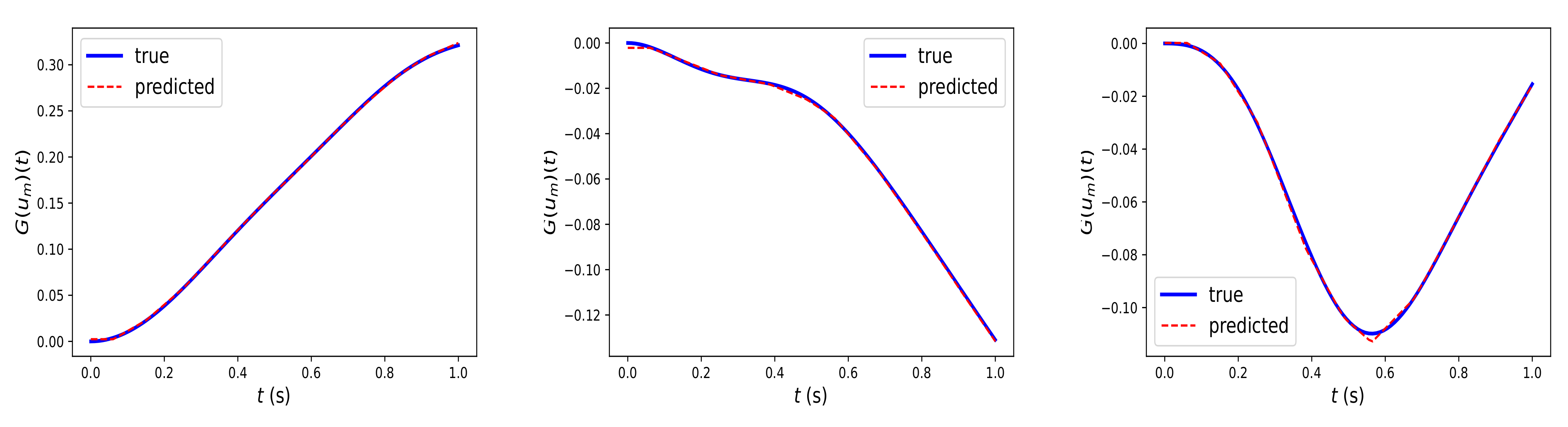
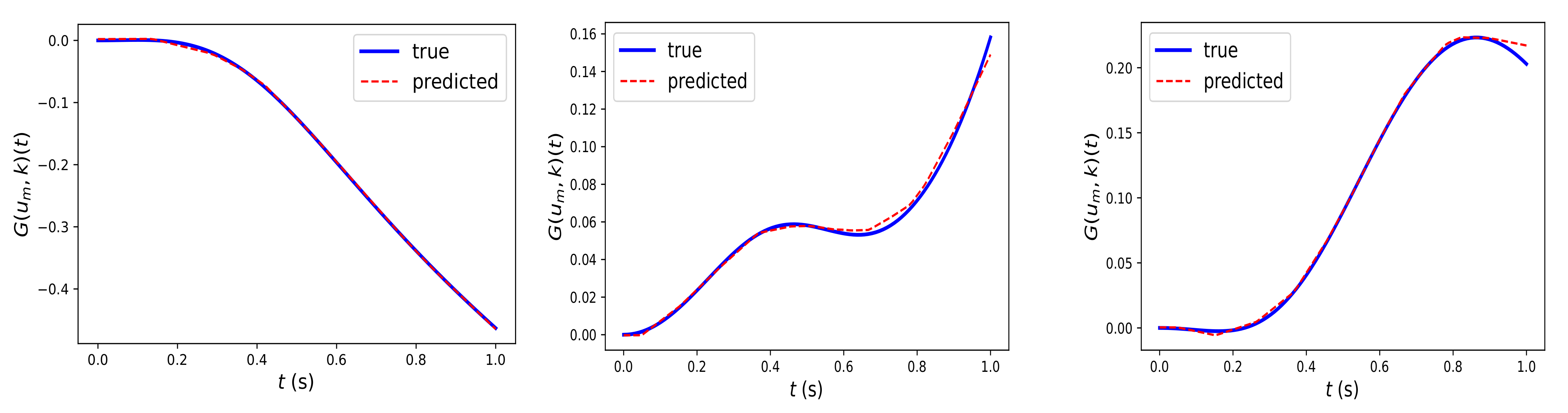
Figure 3 illustrates the prediction of the trained Fed-DeepONet
via Algorithm 2 for three solution trajectories driven by test input trajectories generated using the GRF and not included in the training dataset. Furthermore, we computed the mean
-relative error using the 100 test trajectories. We obtained a mean
-relative error of
%. Such a result illustrates the potential of DeepONet for protecting clients’ data privacy or employing high-performance distributed computing frameworks while preserving the extraordinary prediction capability of the centralized DeepONet.
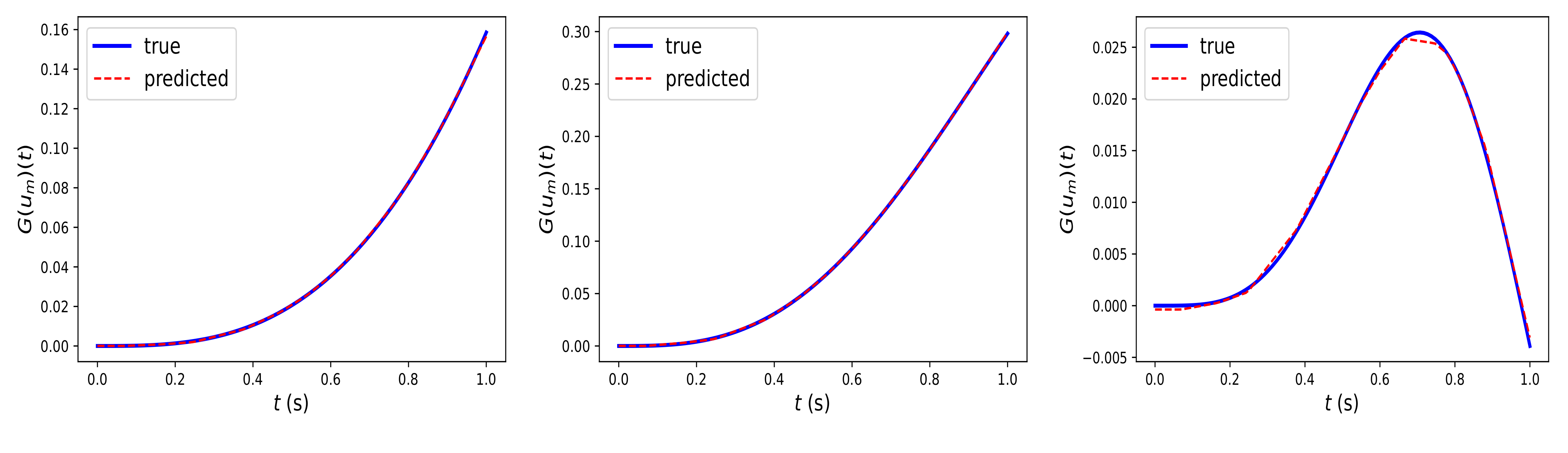
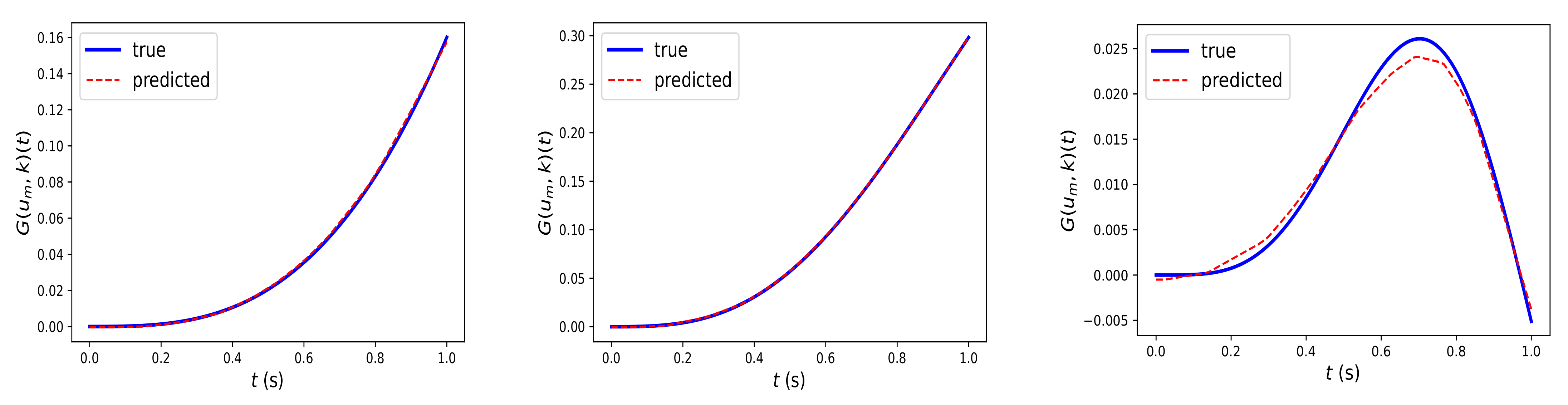
Similarly,
Figure 4 depicts the prediction of Fed-DeepONet
, trained using Algorithm 2, for the solution trajectories driven by the out-of-distribution inputs
. The results illustrate that Fed-DeepONet preserves the generalization capability of the centralized DeepONet.
Testing the sensitivity of Fed-DeepONet with respect to design parameters. This experiment tests the sensitivity of FeedDeepONet against the number of clients C and the fraction of available clients, which we denote as . First, we fixed the fraction of available clients to and varied the number of clients within set . Then, we fixed the number of clients to and varied the fraction of available clients within the set .
Table 1 and
Table 2 depict the mean and standard deviation of the
-relative errors
for the solution trajectories obtained using the 100 test input trajectories for different numbers of clients
C or fractions of available clients
. The results illustrate that Fed-DeepONet is robust to the different possible configurations of federated training.
Enabling different fractions of available clients during federated training. In this experiment, we tested the performance of the Adaptive Fed-DeepONet using a more realistic scenario, where fraction of available clients is time-dependent, i.e., it can vary during federated training. To this end, we fix the number of clients to and allow the fraction of available clients to vary at each global synchronization round. In particular, we let take any value within the interval . In other words, we always have at least 10% of clients available for federated training. After employing Fed-DeepONet, the mean and standard deviation of the -relative errors for the solution trajectories obtained using the 100 test input trajectories are, respectively, % and %. Clearly, these results illustrate that even in this more realistic scenario, the adaptive Fed-DeepONet framework can effectively learn such a complex infinite dimensional operator.
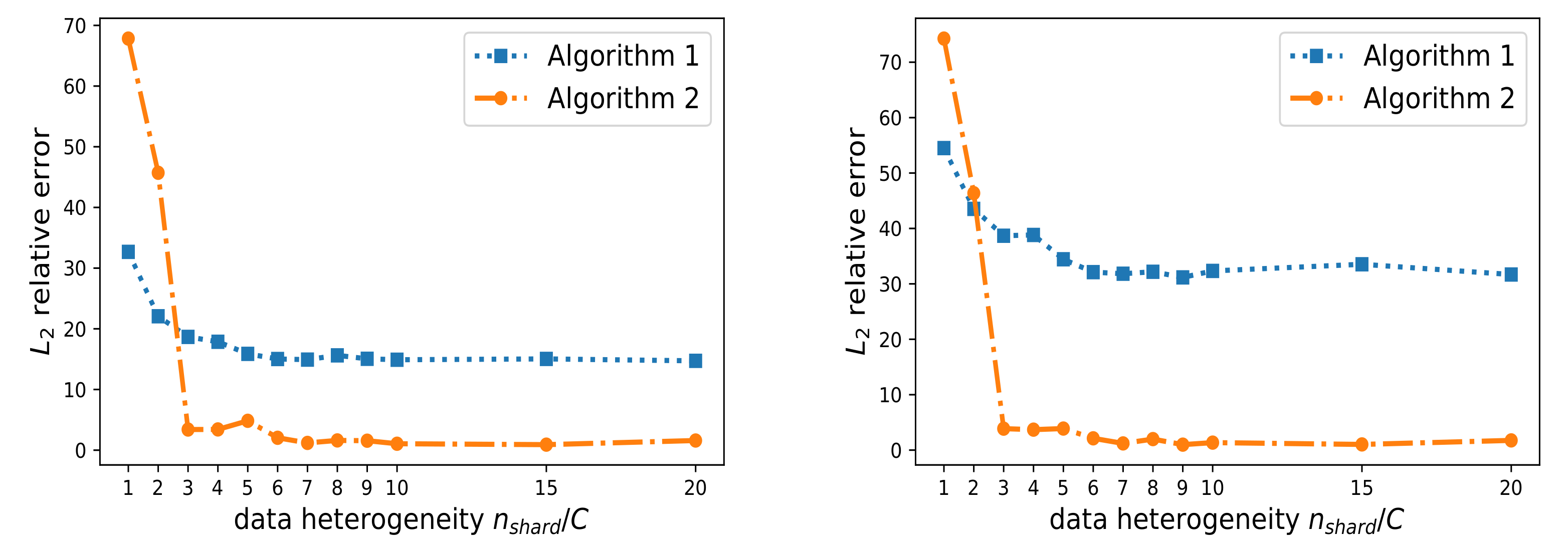
4.3. Experiment 3: Fed-DeepONet and Data Heterogeneity
To test the effect of data heterogeneity on the performance of Fed-DeepONet Algorithms 1 and 2, we designed the following two experiments.
In the first experiment, we modify the amount of data heterogeneity as follows. Consider the centralized dataset with N data triplets . We sort this dataset according to the target operator values (i.e., from smallest to largest). Then, we divide the sorted dataset into blocks/shards (for simplicity, we let ). We then assign to each of the clients blocks for sampling data. Notice that as the value of increases, the federated dataset becomes more independent and identically distributed. This is because the clients can get data from multiple blocks, making the data samples more diversified. As a result, the densities and become more statistically alike. On the other hand, as the value of decreases, the data heterogeneity increases. In particular, for this simple experiment, the data heterogeneity reaches its maximum when .
To verify the effect of data heterogeneity, we consider a federated training scenario with
clients and allow the fraction of available clients to vary at each global round. Moreover, we use
global synchronization rounds and
local updates.
Figure 5 (left) (resp.
Figure 5 (right)) depicts the mean
relative error for 100 in-distribution (resp. out-of-distribution) trajectories when we vary the data heterogeneity (i.e.,
). The results show that for the most extreme data heterogeneous setting, i.e., when
, Algorithm 1 outperforms Algorithm 2. However, in the less extreme data heterogeneity scenarios, Algorithm 2 has an excellent performance, similar to the case when the data collected by each client is independent and identically distributed.
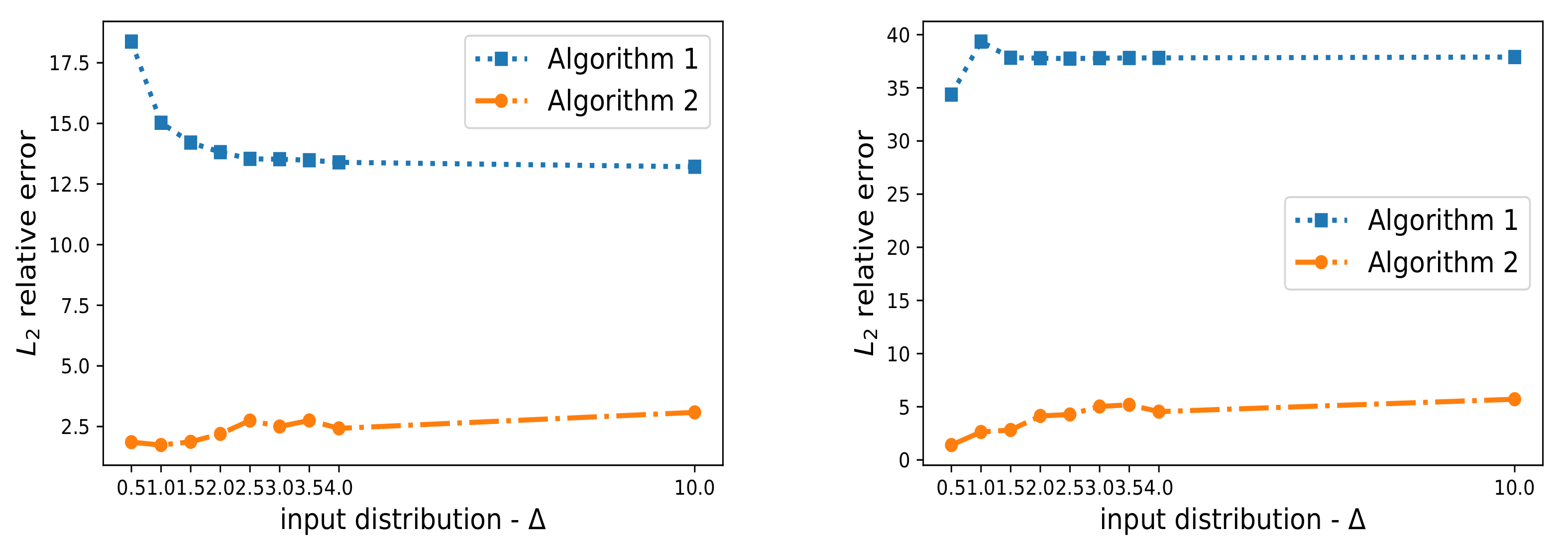
In our second experiment, we modify the input functional distribution (that is, the input data heterogeneity) for some of the C clients. In particular, we use two distinct Gaussian Random Fields (GRF). The first GRF uses the length-scale and the second GRF uses . We use the control parameter to increase the heterogeneity between the two input distributions. We follow a federated training scenario similar to the one described in the previous example and randomly assign one of the input distributions to each of the C clients.
Figure 6 (left) (resp.
Figure 6 (right)) depicts the mean
relative error for 100 in-distribution (resp. the out-of-distribution) trajectories when we vary the functional input data heterogeneity (i.e., we increase
). The results illustrate that as we increase the input data heterogeneity (i.e., as we increase
), the performance of the proposed adaptive Fed-DeepONet (Algorithm 2) does not deteriorate. Such a result shows that Algorithm 2 is robust against changes in the input distribution. Note also that Algorithm 1 is also not affected by the increase in data heterogeneity. The performance of Algorithm 1, however, is not acceptable.
4.4. Experiment 4: Learning a Library of Pendulums
In this experiment, we verified the capability of Fed-DeepONet trained using Algorithm 2 for approximating the dynamic response of a library of pendulums. That is, we trained the Fed-DeepONet to approximate the dynamic response of all the pendulums whose parameter k satisfies . Note that the true solution operator for the library of pendulums is for . Thus, the desired DeepONet will have two inputs to the Branch network; that is, and k. For testing purposes, we sampled k uniformly within the interval .
For the experiment, we set
,
,
, and
.
Figure 7 (resp.
Figure 8) depicts the Fed-DeepONet’s prediction of three solution trajectories driven by three test in-distribution (resp. out-of-distribution) inputs and the parameter
k sampled uniformly from the interval
. Furthermore, the corresponding mean
-relative error for the 100 (resp. three) solution trajectories driven by the test inputs (resp. the out-of-distribution inputs) is
% (resp.
%). The results clearly show that Fed-DeepONet effectively predicts and generalizes the dynamic response of a parametric library of pendulums.
5. Discussion
Our results: In this paper, we have presented a series of illustrative numerical experiments that aim to provide a glimpse of the potential of Fed-DeepONets for learning the solution operator of complex dynamical systems in a distributed manner. We have shown that the Adaptive Fed-DeepONet is robust to several scenarios, including time-dependent available clients or a different number of clients. We remark, however, that depending on the application, one must carefully select the hyper-parameters used for describing federated learning (e.g., K or R) or the dynamical system under study. For instance, one may obtain the parameter values for Fed-DeepONets using a hyper-parameter optimization routine that respects the underlying constraints of the problem.
The limitations of Fed-DeepONet: The proposed Fed-DeepONet framework has the following limitations. (i) Fed-DeepONet cannot assimilate data in real time. In other words, the federated training of DeepONets must be performed offline. This limitation is a direct consequence of using batch stochastic gradient descent and its variants for neural network training. One may use a distributed version of Kalman Filters to alleviate this limitation. However, training neural network parameters with Kalman Filters is a challenging task. (ii) While Fed-DeepONet protects data privacy, it may not protect the client’s information. A skillful adversary may infer information about the client’s process from observing the parameters transmitted to the central server. A simple solution to alleviate this limitation may be to keep some of the parameters private. (iii) Fed-DeepONet may fail to optimize multi-objective loss functions or constrained problems. This is another limitation inherited from using stochastic gradient descent for unconstrained optimization. Two possible solutions are as follows. One may use a penalty method to transform the problem into an unconstrained one. On the other hand, one may design a federated evolutionary strategy that can handle the underlying multi-objective problem.
Our future work: First, we aim to employ Fed-DeepONet to build digital twins for (i) distributed renewable energy resources and (ii) city-wide predictive models for the transmission of contagious diseases (e.g., COVID-19). Then, we will apply Fed-DeepONet to accelerate material science by enabling training with high-performance distributed and parallel computing platforms. Finally, we aim to extend our federated optimization strategy to a federated sampling strategy that enables quantifying uncertainty for DeepONets.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}