5.1. Synthetic Datasets
The first synthetic dataset used for the numerical experiments was the Circle dataset. Its points were divided into two parts concentrated around small and large circles, as shown in
Figure 2, where the training and testing sets are depicted in the left and right pictures, respectively. In order to optimize the model parameters in the numerical experiments, we performed cross-validation. Gaussian noise with a standard deviation of
was added to the data for all experiments.
The second synthetic dataset (the Normal dataset) contained points generated from normal distributions with two expectations:
and
. Anomalies were generated from a uniform distribution in the interval
. The training and testing sets are depicted in
Figure 3.
First, we studied the Circle dataset. The F1-score measures obtained for ABIForest are shown in
Table 2, where the F1-score is presented as a function of the hyperparameters
and
with the number of trees in the isolation forest of
. It is interesting to note that ABIForest was sensitive to changes in
, whereas
did not significantly impact the results. For comparison purposes, the F1-score measures of the original iForest as a function of the number of trees
T and the hyperparameter
are shown in
Table 3. It can be seen from
Table 3 that the largest value of the F1-score was achieved with 150 trees in the forest and with
. One can also see from
Table 2 and
Table 3 that ABIForest provided results that outperformed the same results of the original iForest.
Similar numerical experiments with the Normal dataset are presented in
Table 4 and
Table 5. We can see again that ABIForest outperformed iForest, namely, the best value of the F1-score provided by iForest was
, whereas the best value of the F1-score for ABIForest was
, and this result was obtained with
.
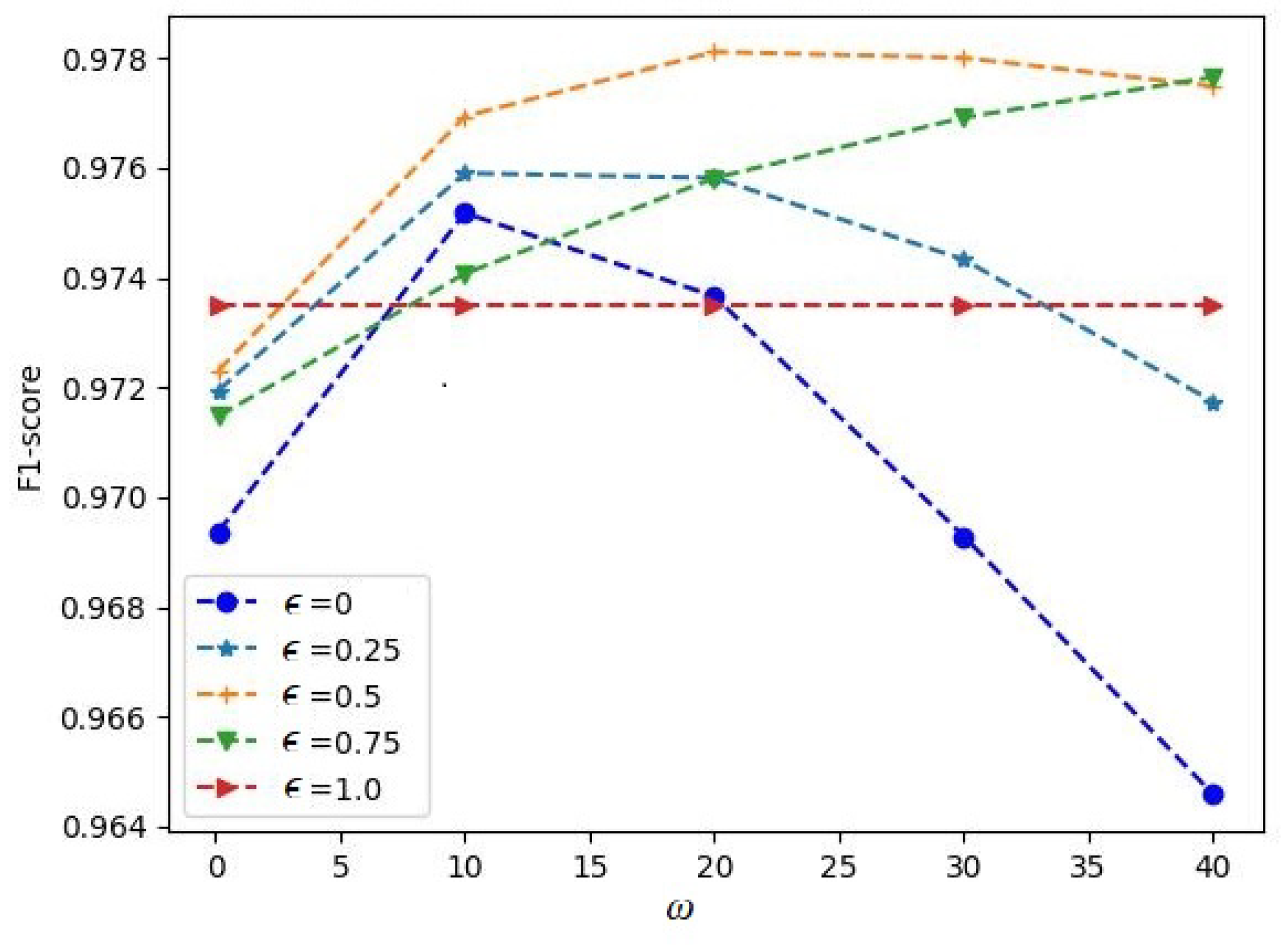
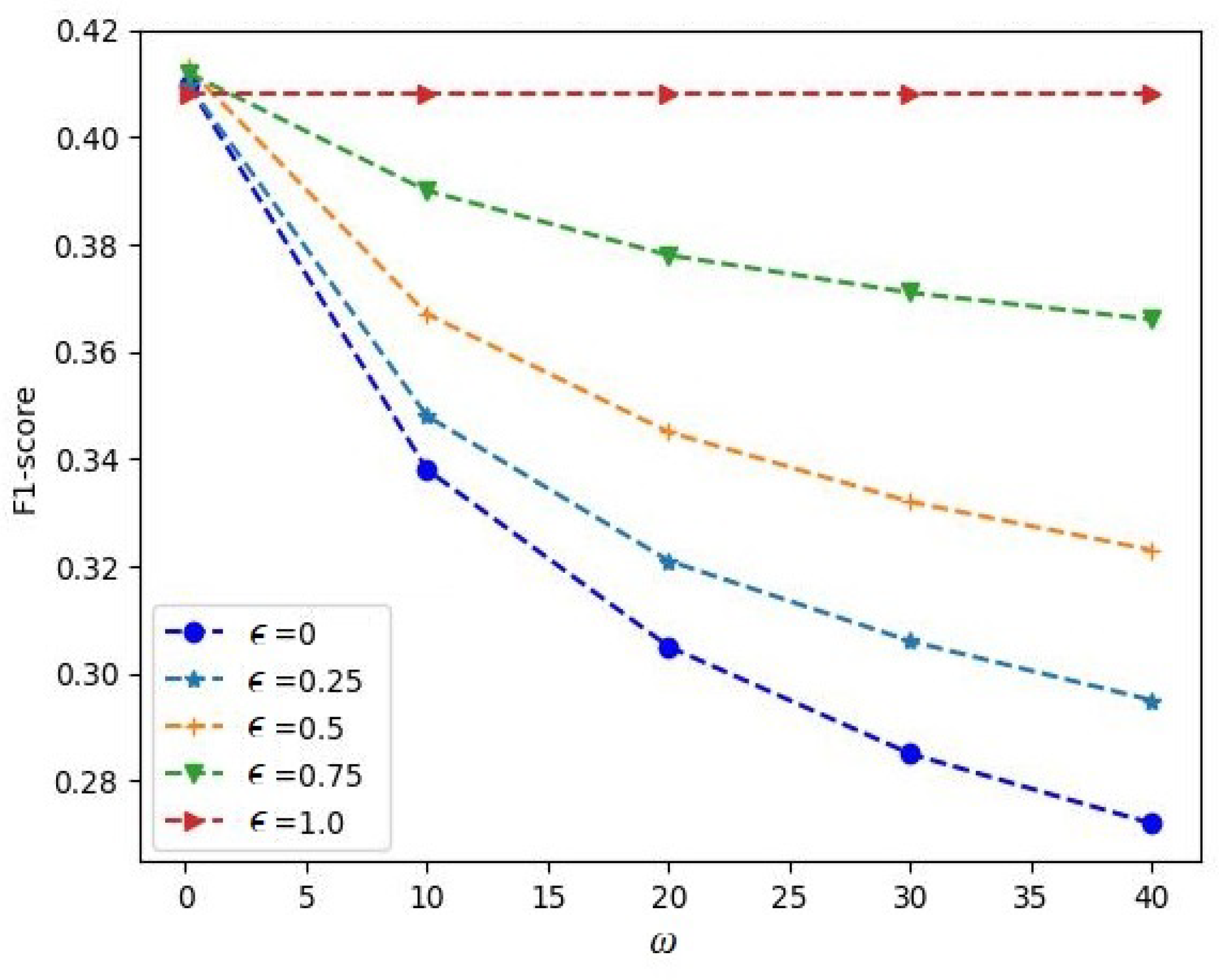
Figure 4 illustrates how the F1-score depended on the hyperparameter
for the Circle dataset. The corresponding functions are depicted for different contamination parameters
, and they were obtained for the case of
trees in iForest. It can be seen from
Figure 4 that the largest value of the F1-score was achieved with
and
. It can also be seen from the results in
Figure 4 that the F1-score significantly depended on the hyperparameter
, especially for small values of
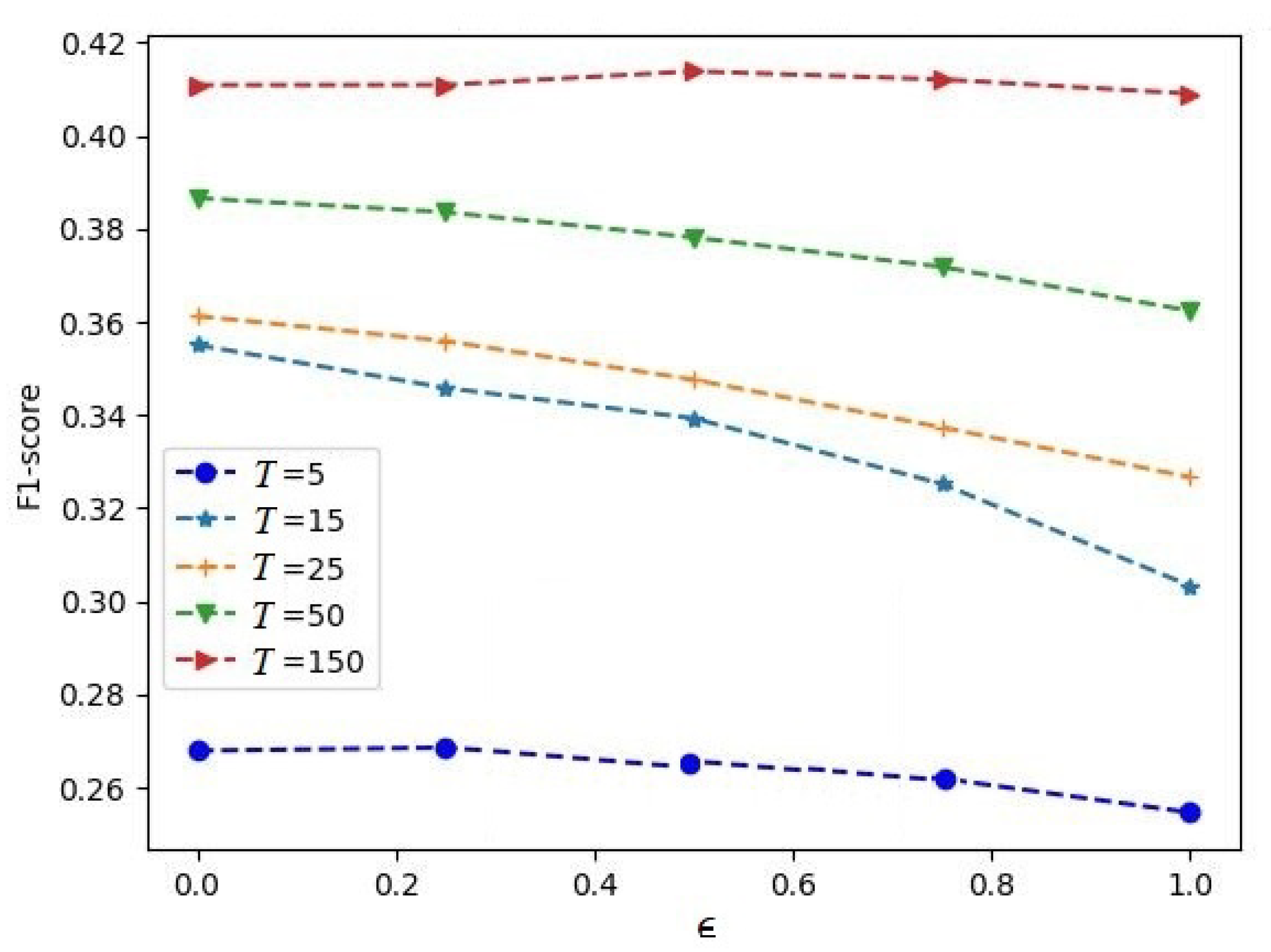
. The F1-score measures as functions of the contamination parameter
for different numbers of trees in iForest
T for the Circle dataset obtained with the hyperparameters
and
are depicted in
Figure 5.
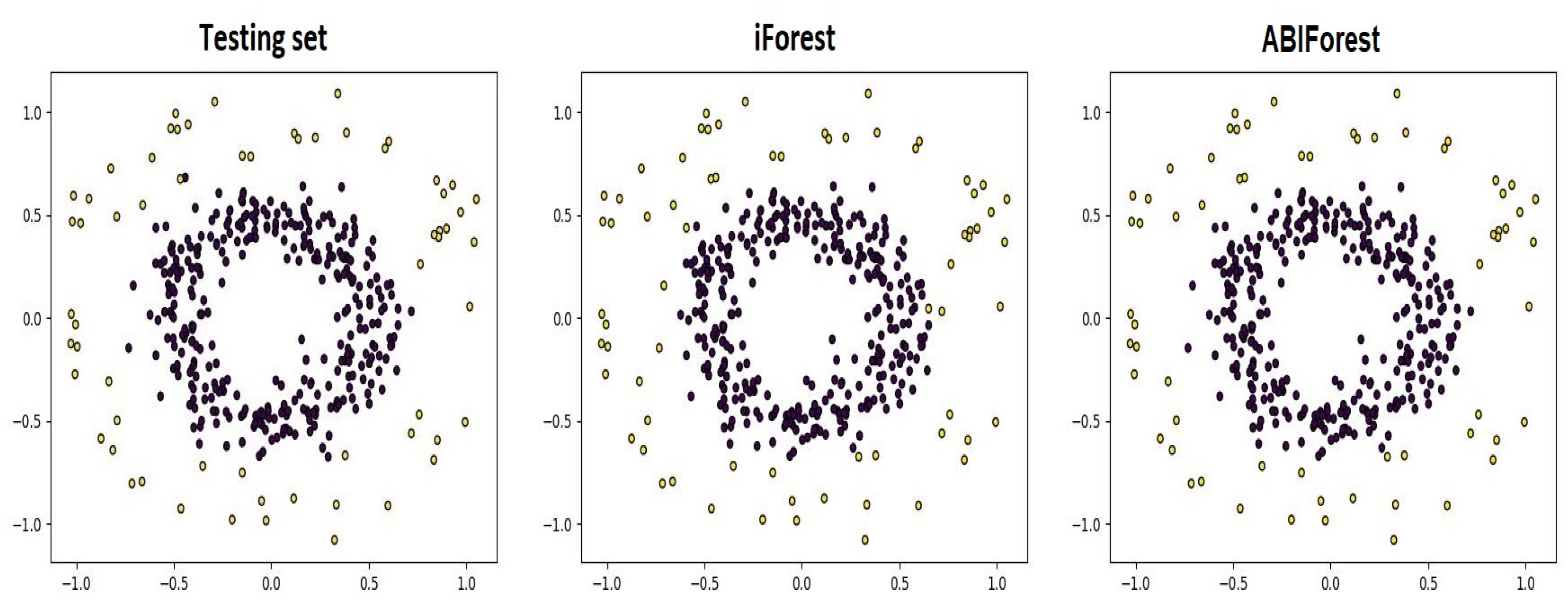
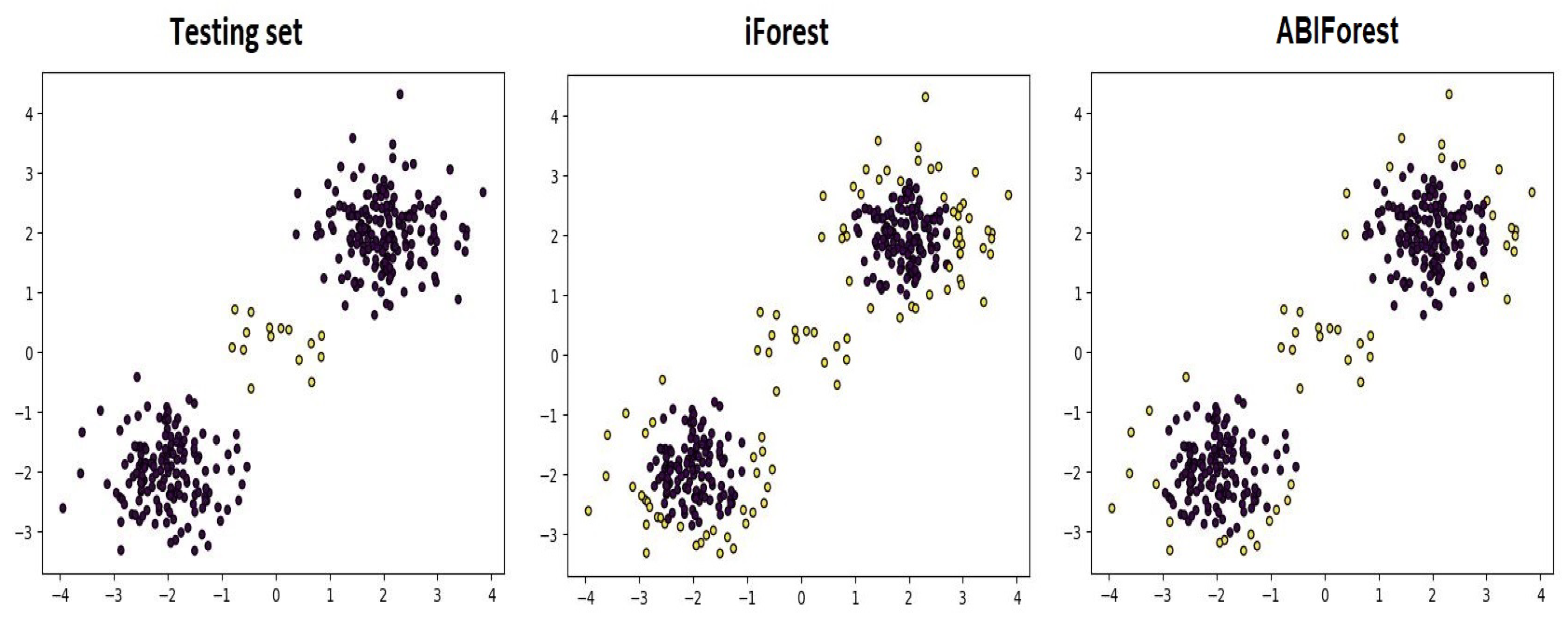
Figure 6 illustrates the results of a comparison between iForest and ABIForest on the basis of the test set, which is depicted in the left panel of
Figure 6. The predictions obtained by iForest consisting of 150 trees with
are depicted in the central panel. The predictions obtained by ABIForest with
,
, and
are shown in the right panel. One can see in
Figure 6 that some points in the central panel were incorrectly identified as anomalous ones, whereas ABIForest correctly classified them as normal instances.
Figure 6 should not be considered as a single realization that defines the F1-score. It is one of many cases corresponding to different generations of test sets; therefore, the numbers of normal and anomalous instances can be different in each realization.
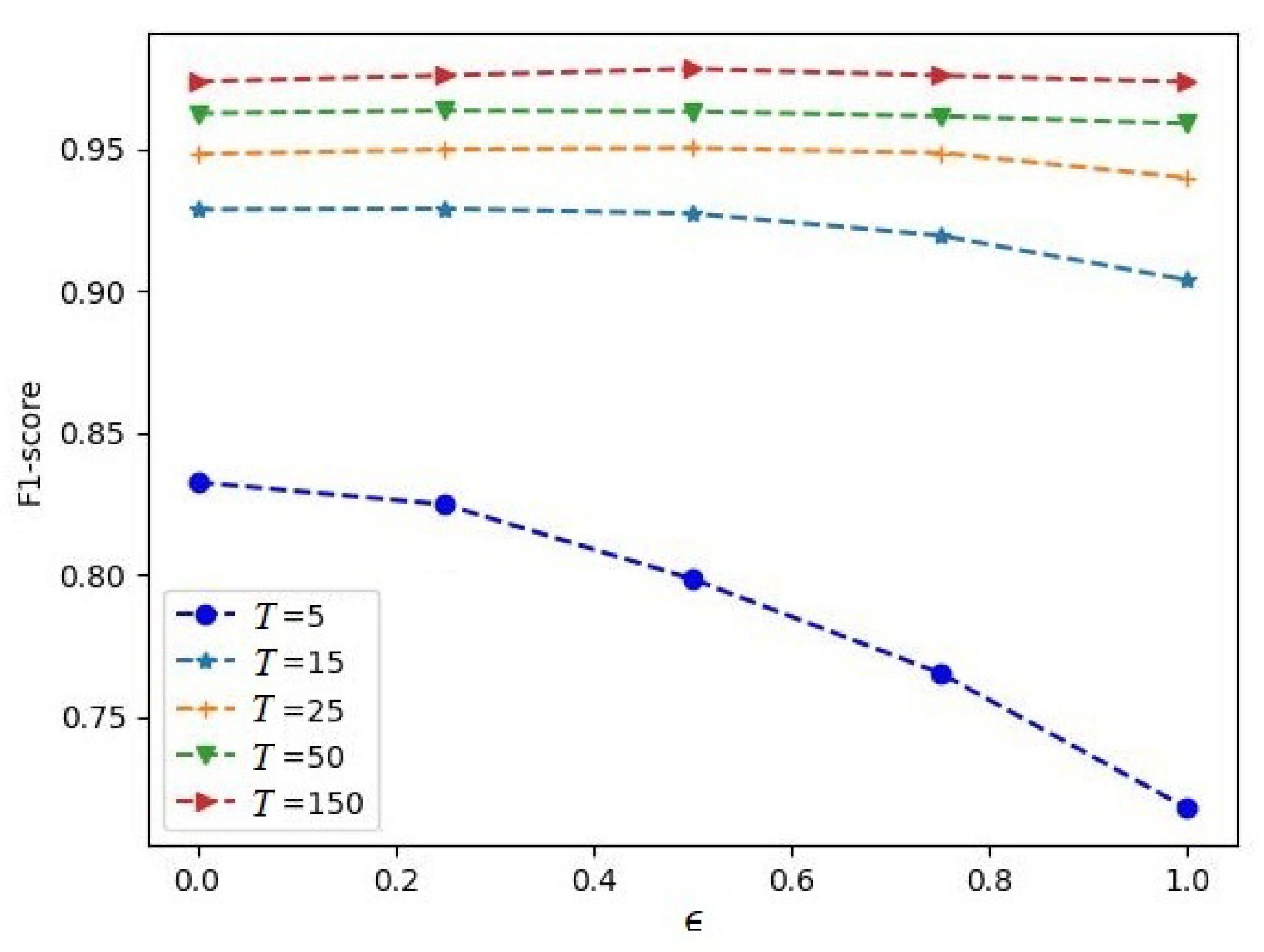
Similar dependencies for the Normal dataset are shown in
Figure 7 and
Figure 8. However, it follows from
Figure 7 that the largest values of the F1-score were achieved for
. This implies that the main contribution to the attention weights was caused by the softmax operation. The F1-score measures shown in
Figure 8 were obtained with the hyperparameters
and
.
The results of a comparison between iForest and ABIForest for the Normal dataset are shown in
Figure 9, where a realization of the test set and the predictions of iForest and ABIForest are shown in the left, central, and right panels, respectively. The predictions were obtained by means of iForest consisting of 150 trees with
and by ABIForest consisting of the same number of trees with
,
, and
.
Another interesting question is that of how the prediction accuracy of ABIForest depends on the size of the training data. The corresponding results for the synthetic datasets are shown in
Figure 10, where the solid and dashed lines correspond to the F1-scores of iForest and ABIForest, respectively. The numbers of trees in all experiments were taken as
. The same results are also given in numerical form in
Table 6. It can be seen in
Figure 10 for the Circle dataset that the F1-score of iForest decreased with the increase in the number of training data after
. This was because the number of trees (
) was fixed, and the trees could not be improved. This effect was discussed in [
17], where the problems of swamping and masking were studied. The authors of [
17] considered subsampling to overcome these problems. One can see in
Figure 10 that ABIForest coped with this difficulty. Another behavior of ABIForest could be observed for the Normal dataset, which was characterized by two clusters of normal points. In this case, the F1-score decreased as
n increased, and then increased with
n.
5.2. Real Datasets
The first real dataset that was used in the numerical experiments is called the Credit dataset (
https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud, (accessed on 1 November 2022). According to the dataset’s description, it contains transactions made by credit cards in September 2013 by European cardholders, with 492 fraud cases out of
transactions. We used only 1500 normal instances and 400 anomalous ones, which were randomly selected from the whole Credit dataset. The second dataset, called the Ionosphere dataset (
https://www.kaggle.com/datasets/prashant111/ionosphere, (accessed on 1 November 2022)) is a collection of radar returns from the ionosphere. The next dataset is called the Arrhythmia dataset (
https://www.kaggle.com/code/medahmedkrichen/arrhythmia-classification, (accessed on 1 November 2022)).The smallest classes with numbers of 3, 4, 5, 7, 8, 9, 14, and 15 were combined to form outliers in the Arrhythmia dataset. The Mulcross dataset (
https://github.com/dple/Datasets, (accessed on 1 November 2022)) was generated from a multivariate normal distribution with two dense anomaly clusters. We used 1800 normal and 400 anomalous instances. The Http dataset (
https://github.com/dple/Datasets, (accessed on 1 November 2022)) was used in [
17] to study iForest. The Pima dataset (
https://github.com/dple/Datasets, (accessed on 1 November 2022)) aims to predict whether or not a patient has diabetes. The Credit, Mulcross, and Http datasets were reduced to simplify the experiments.
The numerical results are shown in
Table 7. ABIForest is presented in
Table 7 with the hyperparameters
,
, and
, as well as the F1-score. iForest is presented with the hyperparameter
and the corresponding F1-score. The hyperparameters leading to the largest F1-score are presented in
Table 7. It can be seen from
Table 7 that ABIForest provided outstanding results for five of the six datasets. It is also interesting to point out that the optimal values of the hyperparameter
for the Ionosphere and Mullcross datasets were equal to 0. This implies that the attention weights were entirely determined by the softmax operation (see (
17)). A contrary case was when
. In this case, the softmax operations and their parameter
were not used, and the attention weights were entirely determined by the parameters
, which could be regarded as the weights of trees.
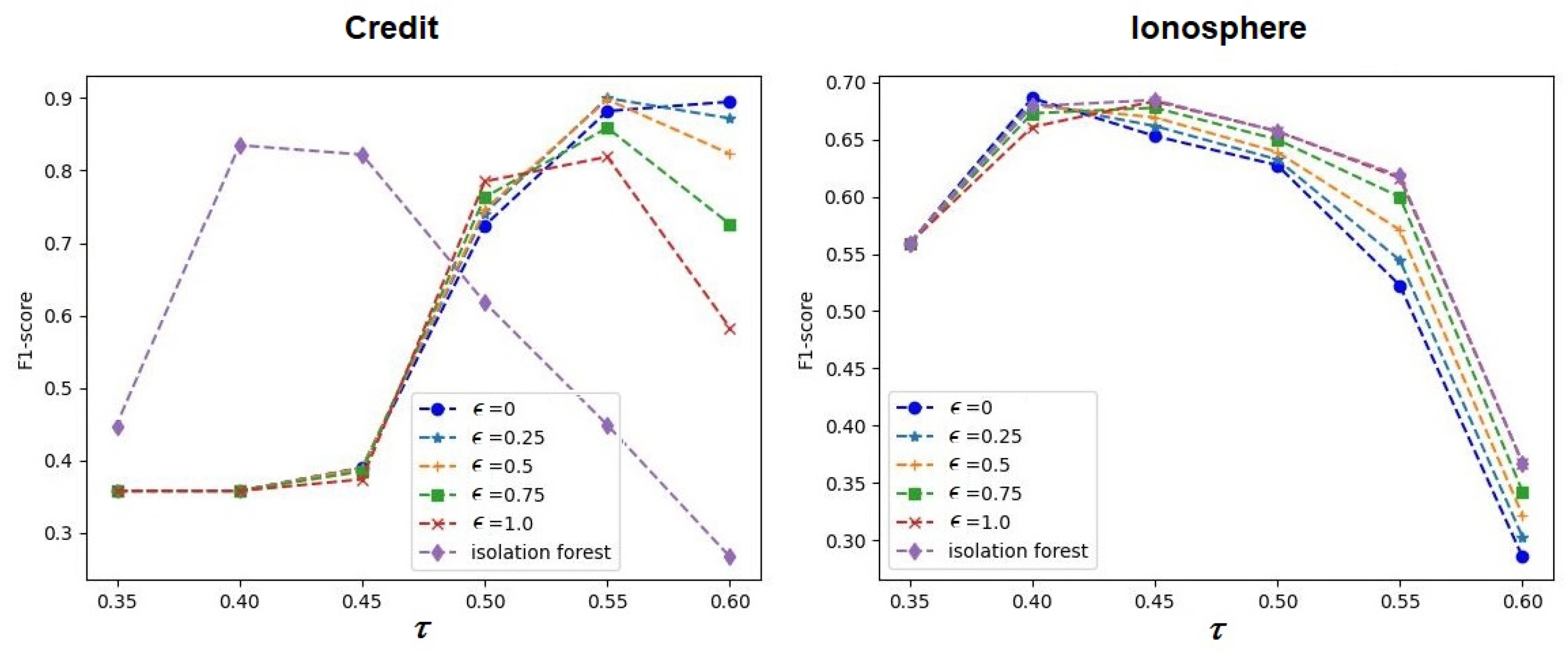
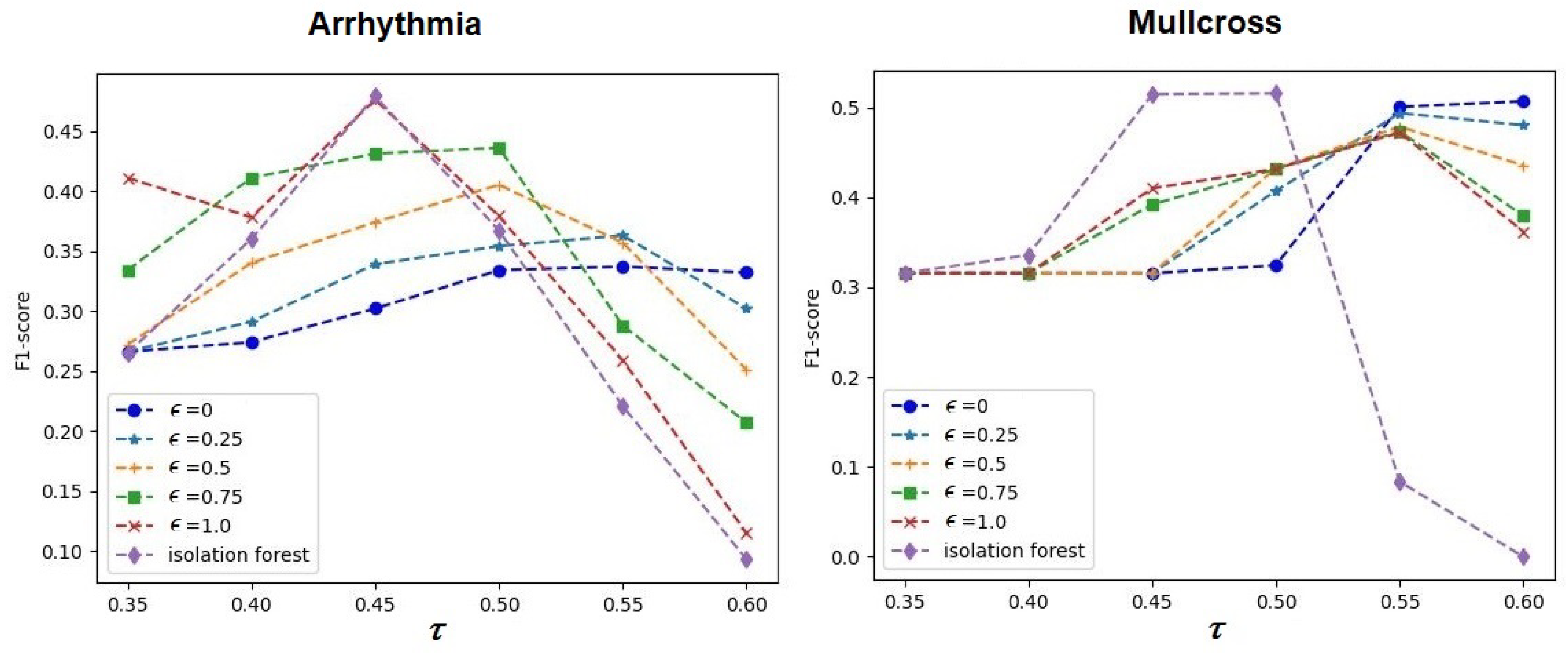
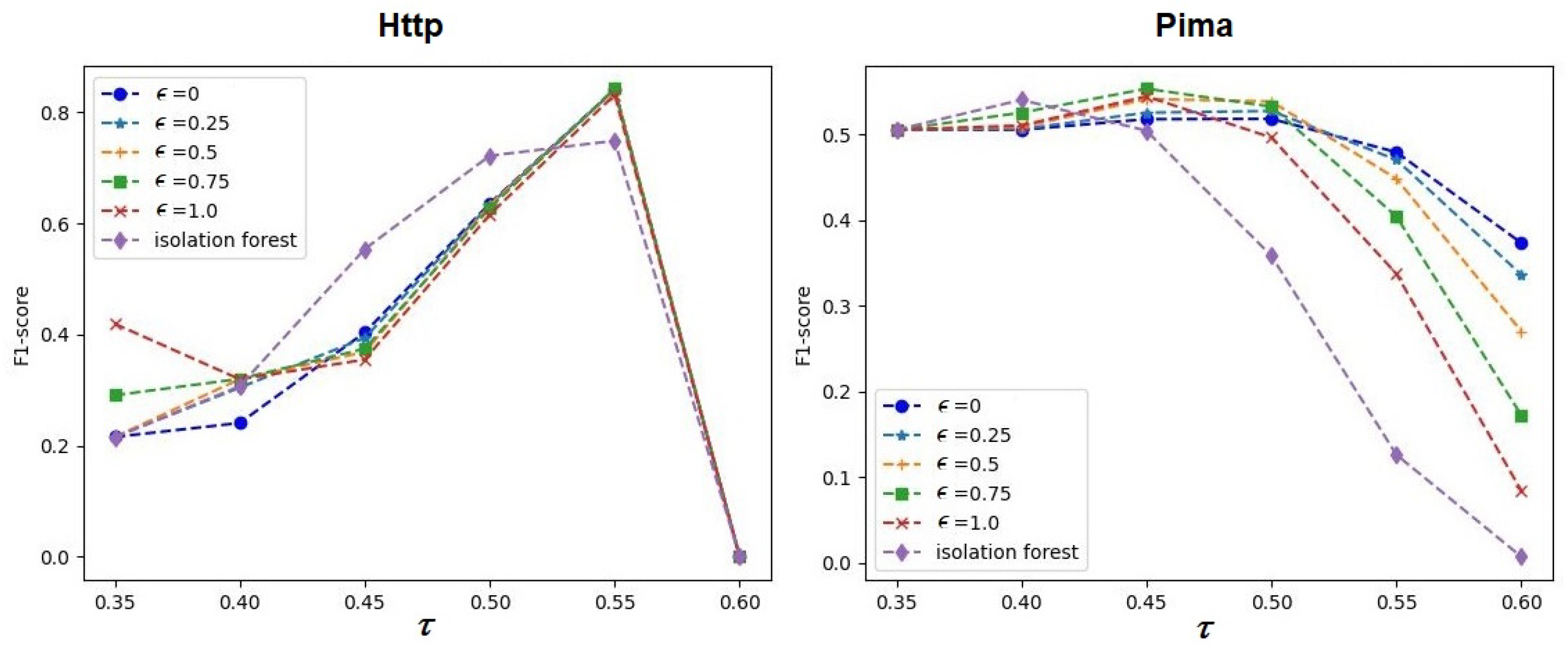
It is interesting to study how the hyperparameter
impacts the performance of ABIForest and iForest. The corresponding dependencies are depicted in
Figure 11,
Figure 12 and
Figure 13. The results of comparisons were obtained under the conditions of the optimal values of
and
given in
Table 7. One can see in
Figure 11 that
differently impacted the performance of ABIForest and iForest for the Credit dataset, whereas the corresponding dependencies scarcely differed for the Ionosphere dataset. This peculiarity was caused by the optimal values of the contamination parameter
. It can be seen from
Table 7 that
for the Ionosphere dataset. This implies that the attention weights were determined only by the softmax operations, which weakly impacted the model performance, and their values were close to
. Moreover, the Ionosphere dataset was one of the smallest datasets, with a large number of anomalous instances (see
Table 1). Therefore, additional learnable parameters may lead to overfitting. This is a reason for why the optimal hyperparameter
did not impact the model performance. It is also interesting to note that the optimal value of the contamination parameter for the Mullcross dataset was 0 (see
Table 7). However, one can see quite different dependencies in the right panel of
Figure 12. This was caused by the large impact of the softmax operations, whose values were far from
, and they provided results that were different from those of iForest.
Generally, one can see in
Figure 11,
Figure 12 and
Figure 13 that the models strongly depended on the hyperparameters
and
. Most of the dependencies illustrated that there was an optimal value of
for each case that was close to
for iForest and for ABIForest. The same can be said about the contamination parameter
.
In order to study how ABIForest performed in comparison with iForest by changing the number of instances, we considered the Ionosphere dataset.
Table 8 shows the F1-score measures obtained by iForest and ABIForest for different numbers of instances that were randomly selected from the dataset under the condition that the ratio of normal and anomalous instances was not changed. It can be seen from
Table 8 that ABIForest provided better results in comparison with those of iForest. Moreover, the difference between the F1-score measures increased as
n decreased. It is also interesting to note that iForest outperformed ABIForest by
. This can be explained by the overfitting of ABIForest due to the training parameters (vector
). Another question is that of how the number of anomalous instances impacts the performance of ABIForest under the condition that the number of normal instances is not changed. The corresponding numerical results are shown in
Table 9. It is important to point out that ABIForest outperformed iForest for all numbers of anomalous instances. Moreover, the difference between the F1-score measures for ABIForest and iForest increased as
decreased.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}