

Novel MIA-LSTM Deep Learning Hybrid Model with Data Preprocessing for Forecasting of PM2.5


Abstract
:1. Introduction
- The use of an effective imputation method for handling missing information in the data by using an iterative method with an extra tree regressor as an estimator for finding replacements for missing fields in multivariate data.
- Anomalies in the data are detected using an autoencoder that uses LSTM for encoding and decoding purposes where the threshold was set on the value of MAE for identifying the anomaly in the dataset
- The proposed MIA-LSTM model that integrates a multivariate iterative imputation method and an autoencoder LSTM predicts PM2.5 concentration with increased prediction accuracy by adding an extra LSTM layer in the last stage.
2. Related Work
2.1. Missing Values, Imputation, and Forecasting
2.2. Outliers, Anomalies, and Forecasting
2.3. Modern Methods Used for Forecasting
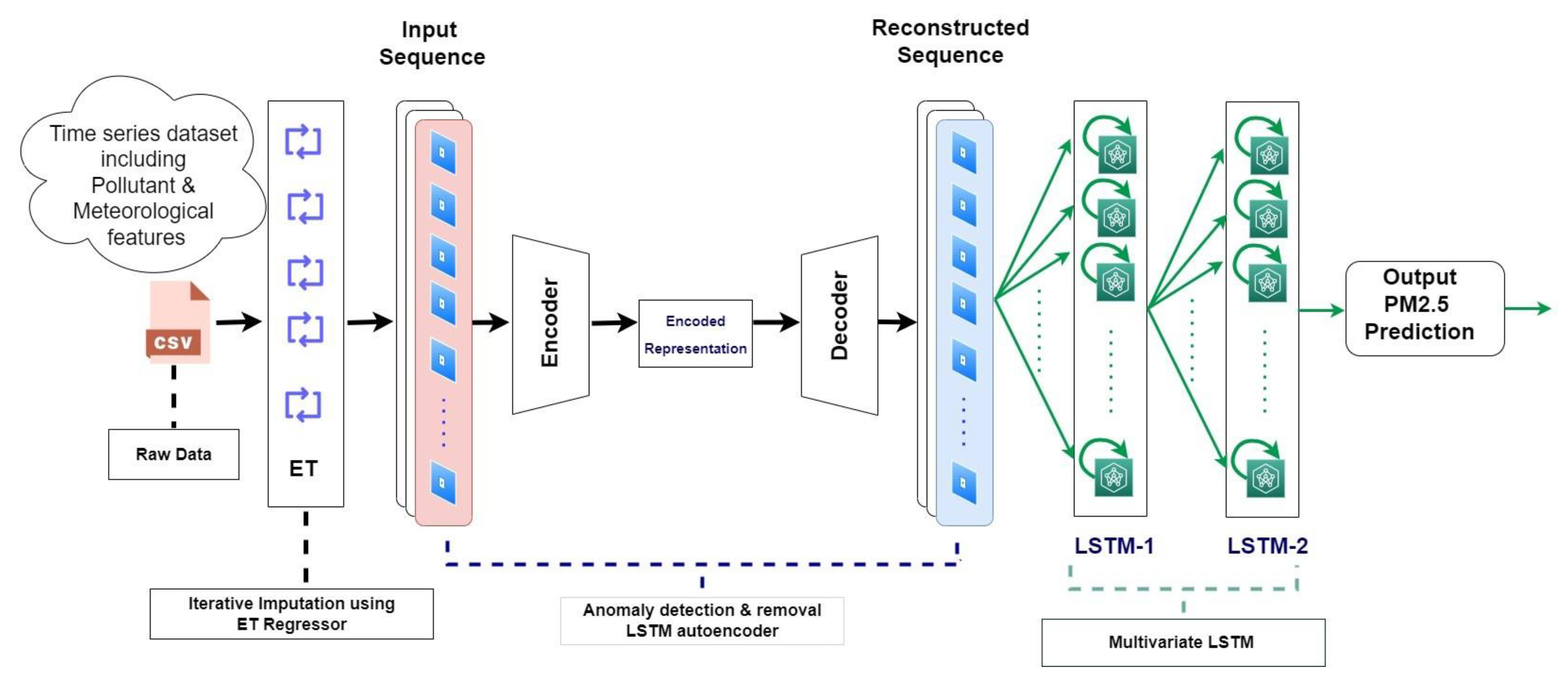
3. Proposed MIA-LSTM Model
| Algorithm 1. Algorithm for Proposed Method: |
| 1. Input feature1, feature2,→featurex. |
| 2. Output values prediction for PM2.5 based on minimum RMSE/MAE values |
| [v1 v2 v3] |
| 3. Perform iterative imputation on raw data 4. Input [ f1| f2| ....... fn] |
| 4. Remove the data with missing values |
| 5. Now, split data into two |
| [f11, f12, f13.....f1n]: without missing values |
| [f21, f22, f23.....f2n]: missing values |
| 6. for i = 0, where I = iteration |
| Apply ET regressor on [f11, f12, f13→f1n] by randomly choosing optimal point |
| 7. Impute the data in place of missing values by predicting the values |
| 8. Let |
| Pvj→predicted values at current level Pvi→predicted values at |
| α→minimum threshold at previous value for stopping criteria |
| If Pvj − Pvi <= α, |
| Then Stop |
| Else go to step 7 i++ |
| 9. Apply LSTM for Anomaly detection |
| Training set [m1, m2. mn] where m is n dimensional data |
| Testing set [m’1, m’2. m’n] |
| Timestamp T = 24 |
| 10. On training dataset (Train) calculate reconstructional error using MAE (Threshold |
| (MAE = max(RE))) |
| 11. On testing dataset (test) Threshold < MAE (test) |
| Set 1 -> Anomaly |
| Else |
| Set 2 -> Normal |
| 12. Now, apply LSTM on normal dataset after removing anomalies Input Train and test |
| dataset |
| 13. Normalize the normal Dataset into 0-1 |
| 14. Choose window size of training data and testing data |
| 15. Train the network N |
| 16. Predict the values of testing data |
| 17. Calculate the Loss using MSE, RMSE, and MAE |
| End |
3.1. Dataset
3.2. Iterative Imputation Using Extra Tree Regressor
3.3. Anomaly Detection and Removal
Multivariate LSTM for Forecasting of Particulate Matter
4. Evaluation Matrices
5. Results & Discussions
5.1. Extra Tress Regressor Usage as an Estimator for Iterative Imputation
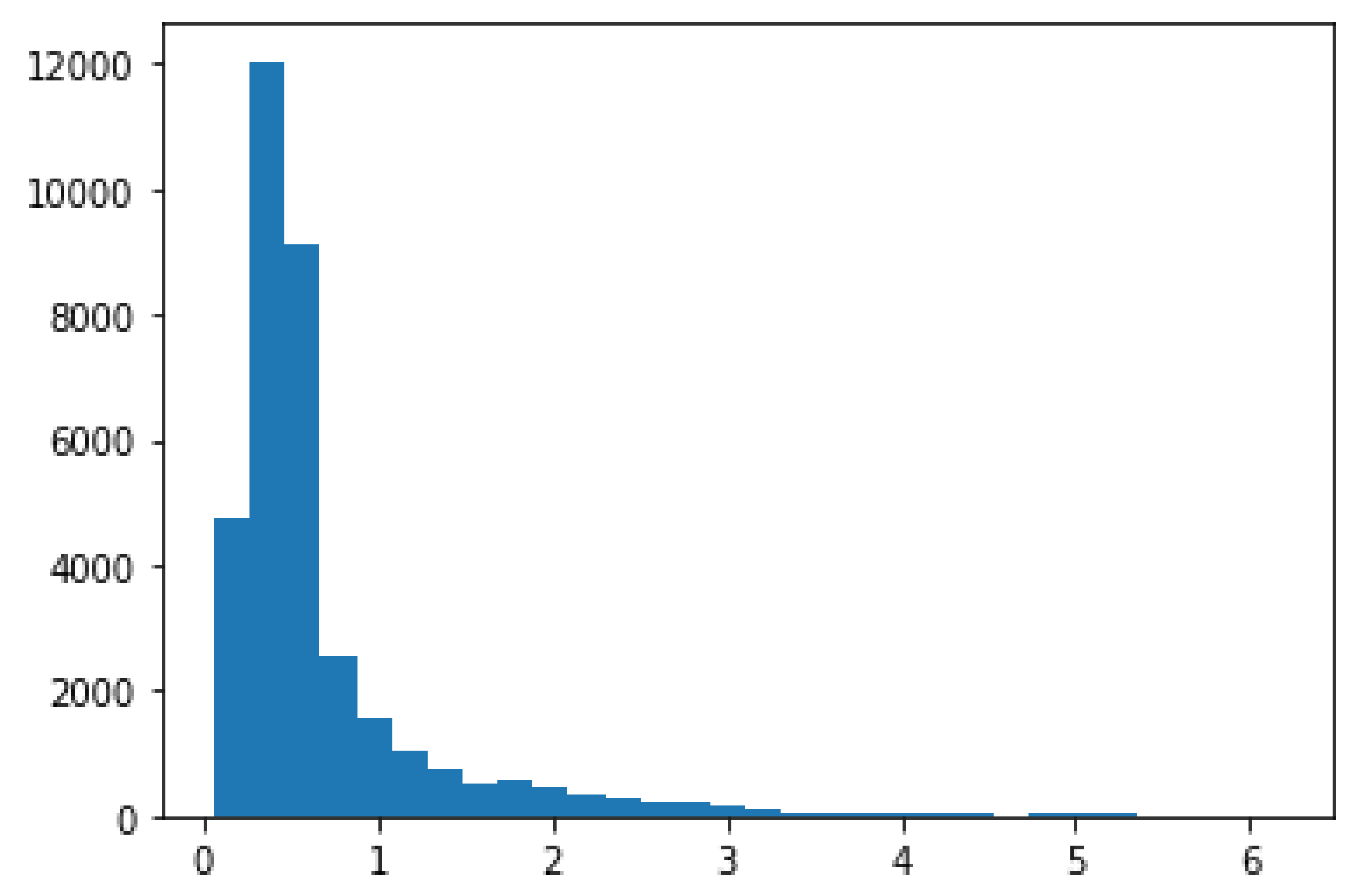
5.2. Removing Outliers Based on the Values of MAE
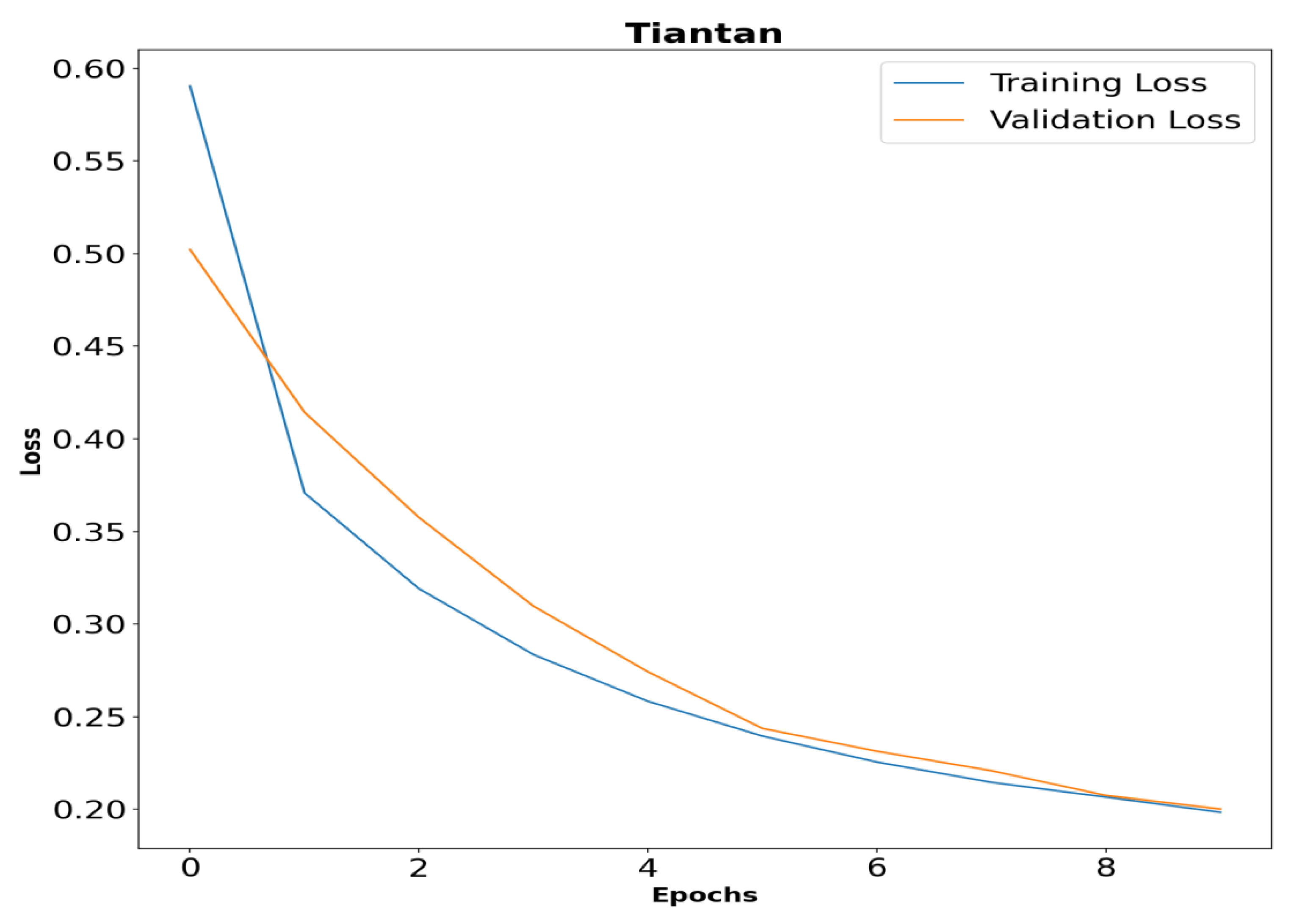
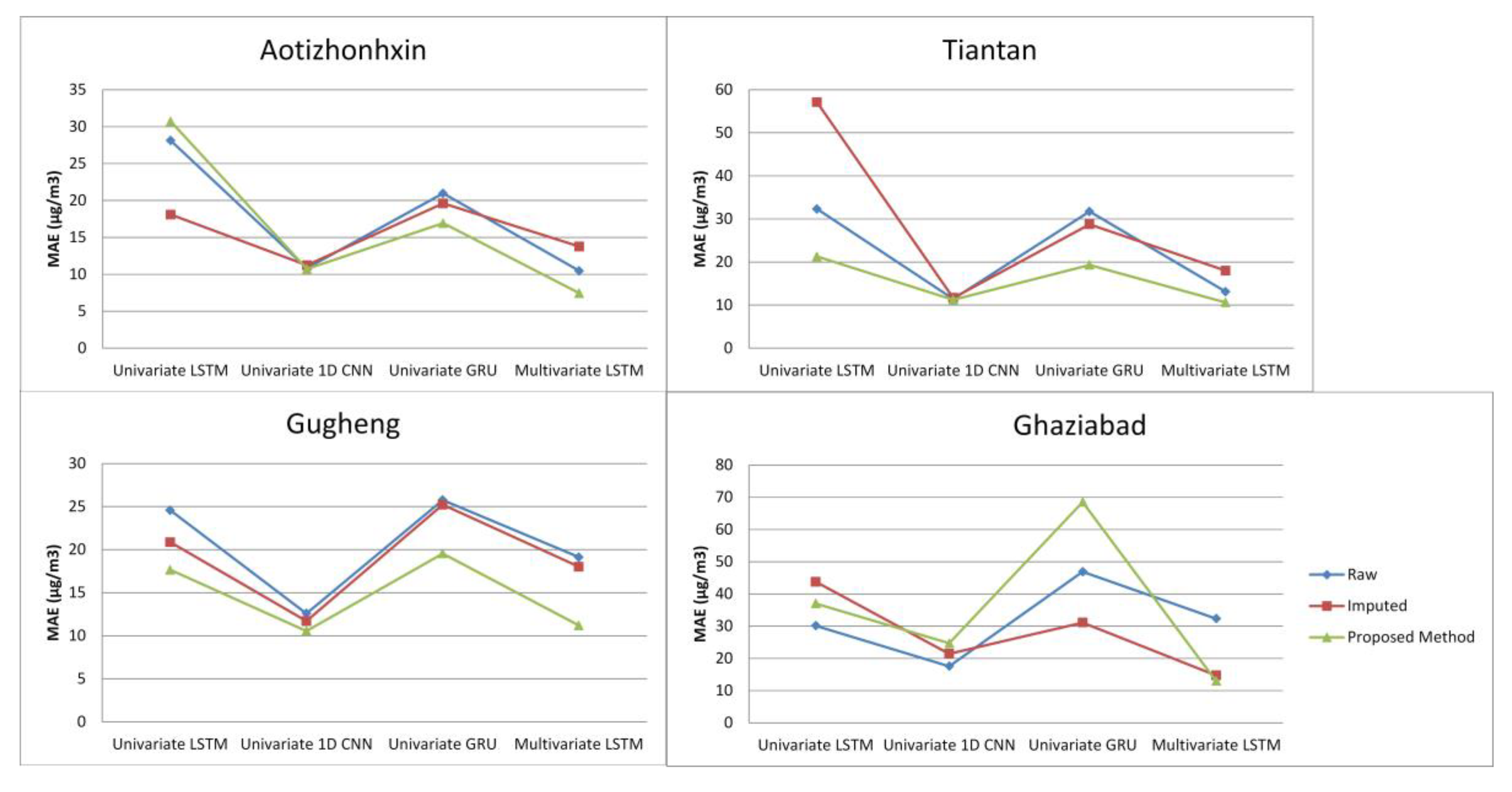
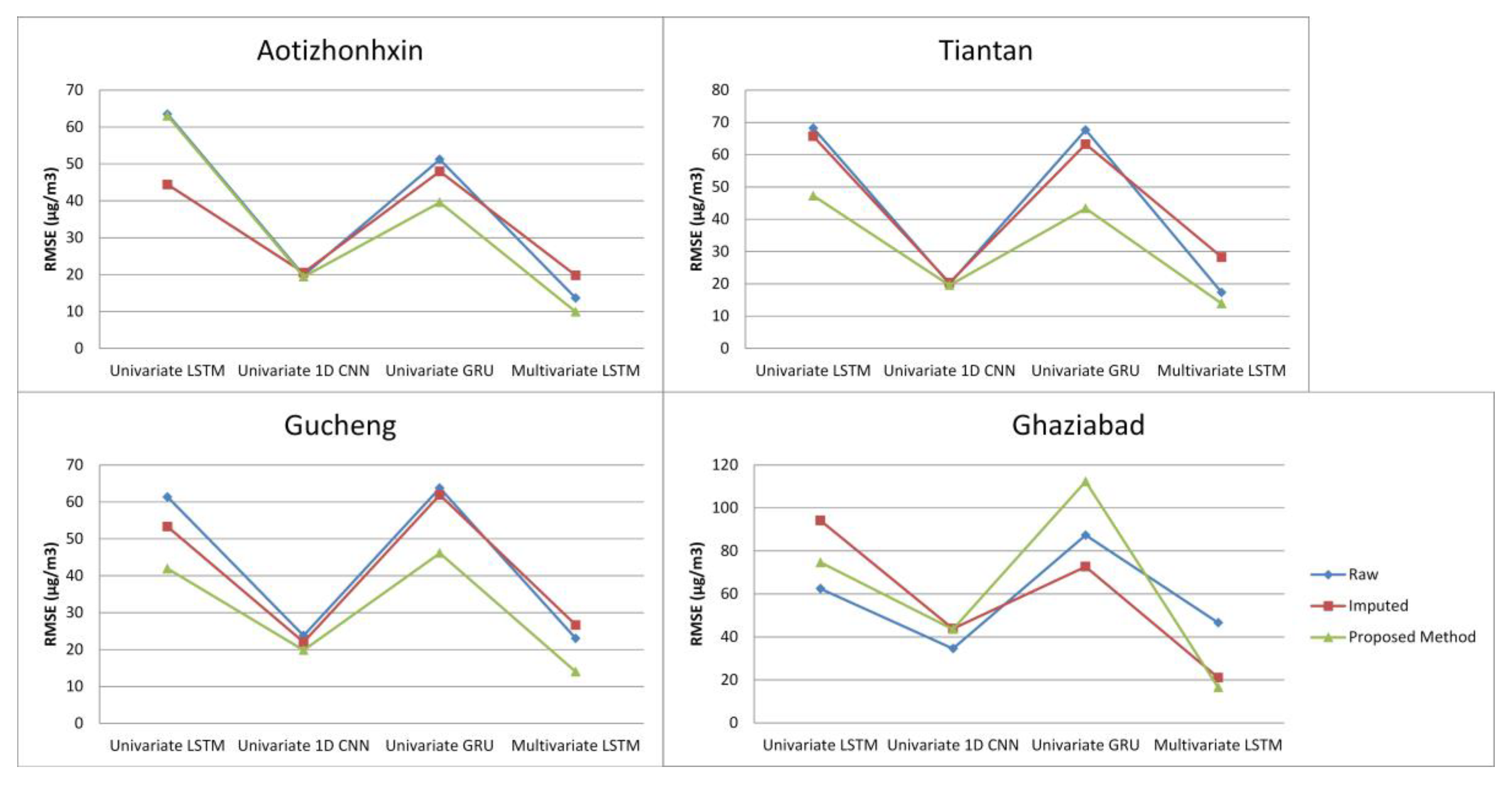
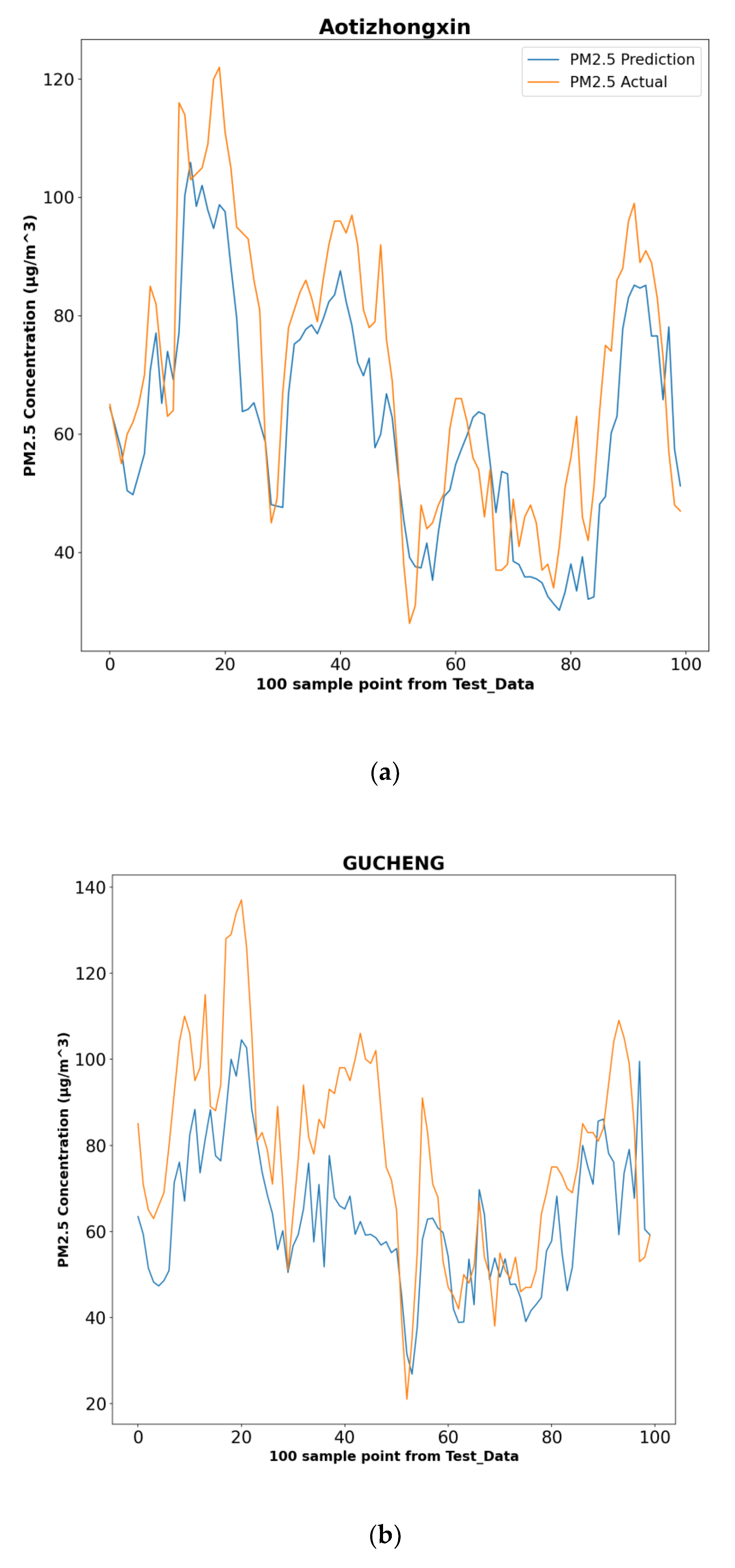
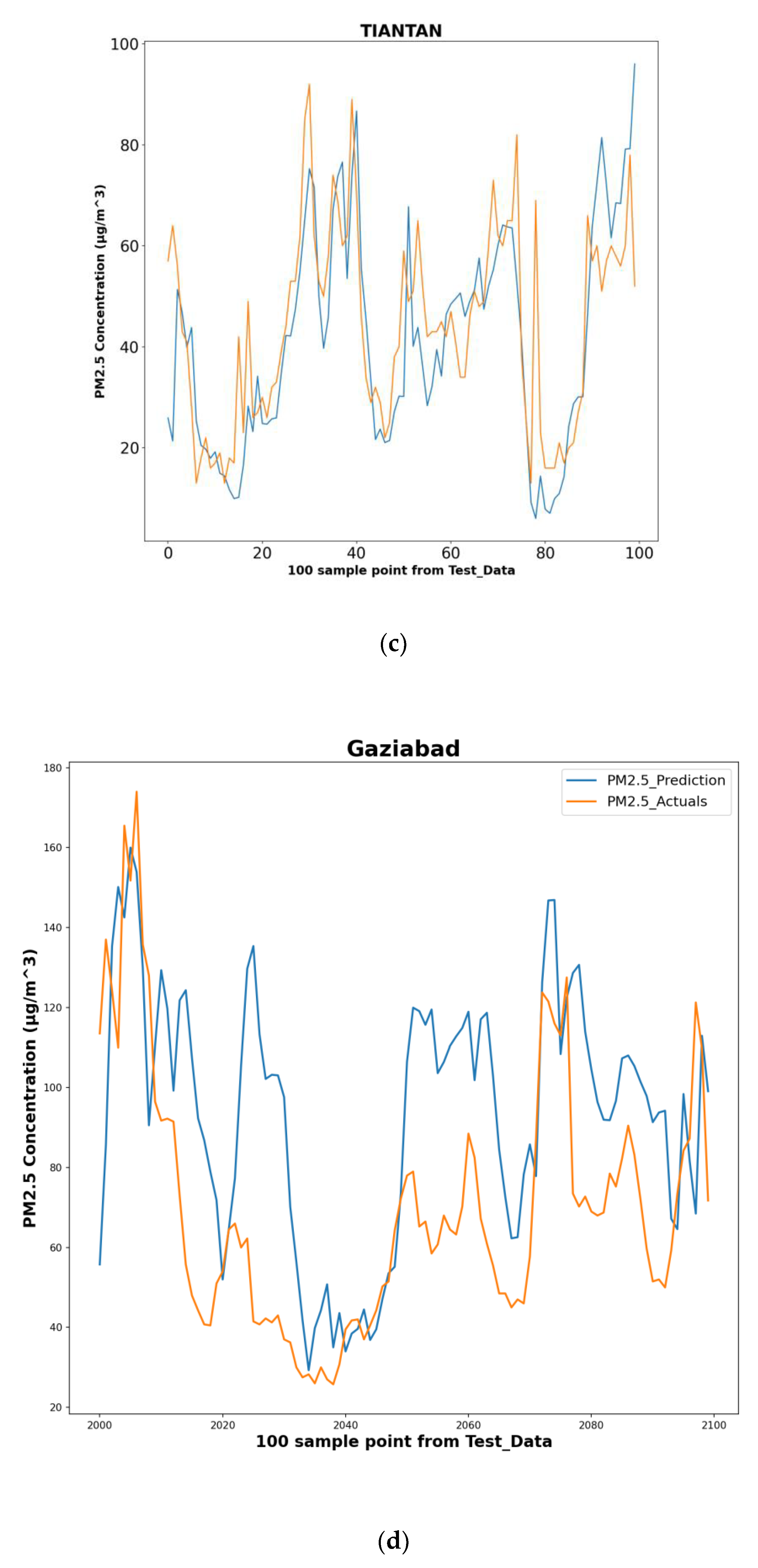
5.3. Performance of Proposed Method
6. Conclusions and Future Scope
- Datasets from different locations with different pollutant concentrations can be harnessed to understand the behavior of air pollution in those particular locations.
- The time complexity is one of the important parameters for forecasting models. Reducing the time complexity without affecting the accuracy of the forecasting can be one of the key aspects of the proposed work.
- More complex models and algorithms, such as an ensemble and CNN-LSTM, can be utilized to further improve the accuracy of air pollution forecasting.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yang, Y.; Bao, W.; Li, Y.; Wang, Y.; Chen, Z. Land Use Transition and Its Eco-Environmental Effects in the Beijing–Tianjin–Hebei Urban Agglomeration: A Production–Living–Ecological Perspective. Land 2020, 9, 285. [Google Scholar] [CrossRef]
- Bagcchi, S. Delhi has overtaken Beijing as the world’s most polluted city, report says. BMJ 2014, 348, g1597. [Google Scholar] [CrossRef] [PubMed]
- Hazlewood, W.R.; Coyle, L. On Ambient Information Systems: Challenges of Design and Evaluation. In Ubiquitous Developments in Ambient Computing and Intelligence: Human-Centered Applications; IGI Global: Hershey, PA, USA, 2011; pp. 94–104. [Google Scholar] [CrossRef]
- Jung, C.-R.; Hwang, B.-F.; Chen, W.-T. Incorporating long-term satellite-based aerosol optical depth, localized land use data, and meteorological variables to estimate ground-level PM2.5 concentrations in Taiwan from 2005 to 2015. Environ. Pollut. 2018, 237, 1000–1010. [Google Scholar] [CrossRef] [PubMed]
- Shaadan, N.; Jemain, A.A.; Latif, M.T.; Deni, S.M. Anomaly detection and assessment of PM10 functional data at several locations in the Klang Valley, Malaysia. Atmos. Pollut. Res. 2015, 6, 365–375. [Google Scholar] [CrossRef] [Green Version]
- Khadse, C.B.; Chaudhari, M.A.; Borghate, V.B. Conjugate gradient back-propagation based artificial neural network for real time power quality assessment. Int. J. Electr. Power Energy Syst. 2016, 82, 197–206. [Google Scholar] [CrossRef]
- Pandey, A.; Gadekar, P.S.; Khadse, C.B. Artificial Neural Network based Fault Detection System for 11 kV Transmission Line. IEEE Xplore 2021, 1, 7–136. [Google Scholar] [CrossRef]
- Allison, P.D. Missing Data. In Sage University Papers Series on Quantitative Applications in the Social Sciences; Sage: Thousand Oaks, CA, USA, 2001; pp. 7–136. [Google Scholar]
- Little, D.R. Rubin, Statistical Analysis with Missing Data; John Wiley and Sons: New York, NY, USA, 2002. [Google Scholar]
- Xia, Y.; Fabian, P.; Stohl, A.; Winterhalter, M. Forest climatology: Estimation of missing values for Bavaria, Germany. Agric. For. Meteorol. 1999, 96, 131–144. [Google Scholar] [CrossRef] [Green Version]
- Junninen, H.; Niska, H.; Tuppurainen, K.; Ruuskanen, J.; Kolehmainen, M. Methods for imputation of missing values in air quality data sets. Atmos. Environ. 2004, 38, 2895–2907. [Google Scholar] [CrossRef]
- Plaia, A.; Bondi, A. Single imputation method of missing values in environmental pollution data sets. Atmos. Environ. 2006, 40, 7316–7330. [Google Scholar] [CrossRef]
- Narkhede, G.G.; Hiwale, A.S.; Khadse, C.B. Artificial Neural Network for the Prediction of Particulate Matter (PM2.5). IEEE 2021, 1, 1–5. [Google Scholar] [CrossRef]
- Bashir, F.; Wei, H.-L. Handling missing data in multivariate time series using a vector autoregressive model based imputation (VAR-IM) algorithm: Part I: VAR-IM algorithm versus traditional methods. IEEE 2016, 1, 611–616. [Google Scholar] [CrossRef]
- Zainuri, N.A.; Jemain, A.A.; Muda, N. A Comparison of Various Imputation Methods for Missing Values in Air Quality Data. Sains Malays. 2015, 44, 449–456. [Google Scholar] [CrossRef]
- Wijesekara, W.M.L.K.N.; Wijesekara, L. Liyanage, Comparison of Imputation Methods for Missing Values in Air Pollution Data: Case Study on Sydney Air Quality Index. In Advances in Information and Communication. FICC 2020. Advances in Intelligent Systems and Computing; Arai, K., Kapoor, S., Bhatia, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1130. [Google Scholar]
- Samal, K.K.R.; Babu, K.S.; Das, S.K. A Neural Network Approach with Iterative Strategy for Long-term PM2.5 Forecasting. In Proceedings of the 2021 IEEE 18th India Council International Conference (INDICON), Guwahati, India, 19–21 December 2021; pp. 1–6. [Google Scholar]
- Buuren, S.V.; Groothuis-Oudshoorn, K. Mice: Multivariate Imputation by Chained Equations in R. J. Stat. Softw. 2011, 45, 1–67. [Google Scholar] [CrossRef] [Green Version]
- Alsaber, A.R.; Pan, J.A. Al-Hurban, Handling Complex Missing Data Using Random Forest Approach for an Air Quality Monitoring Dataset: A Case Study of Kuwait Environmental Data (2012 to 2018). Int. J. Environ. Res. Public Health 2021, 18, 7908071. [Google Scholar] [CrossRef]
- Kim, T.; Kim, J.; Yang, W.; Lee, H.; Choo, J. Missing Value Imputation of Time-Series Air-Quality Data via Deep Neural Networks. Int. J. Environ. Res. Public Health 2021, 18, 12213. [Google Scholar] [CrossRef]
- Gessert, G.H. Handling missing data by using stored truth values. ACM SIGMOD Rec. 1991, 20, 30–42. [Google Scholar] [CrossRef]
- Pesonen, E.; Eskelinen, M.; Juhola, M. Treatment of missing data values in a neural network based decision support system for acute abdominal pain. Artif. Intell. Med. 1998, 13, 139–146. [Google Scholar] [CrossRef]
- Caruana, R. An non-parametric EM-style algorithm for imputing missing values. In Proceedings of the Eighth International Workshop on Artificial Intelligence and Statistics, Key West, FL, USA, 4–7 January 2001; Morgan Kaufmann: Burlington, MA, USA, 2001; pp. R3:35–R3:40. Available online: https://proceedings.mlr.press/r3/caruana01a.html (accessed on 24 October 2022).
- Kahl, F. Minimal projective reconstruction including missing data. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 418–424. [Google Scholar] [CrossRef]
- Zhang, S.; Jin, Z.; Zhu, X. Missing data imputation by utilizing information within incomplete instances. J. Syst. Softw. 2011, 84, 452–459. [Google Scholar] [CrossRef]
- Fouad, K.M.; Ismail, M.M.; Azar, A.T.; Arafa, M.M. Advanced methods for missing values imputation based on similarity learning. PeerJ Comput. Sci. 2021, 7, 619. [Google Scholar] [CrossRef]
- Zhai, Y.; Ding, X.; Jin, X.; Zhao, L. Adaptive LSSVM based iterative prediction method for NOx concentration prediction in coal-fired power plant considering system delay. Appl. Soft Comput. 2020, 89, 106070. [Google Scholar] [CrossRef]
- Chang, Y.S.; Abimannan, S.; Chiao, H.T. An ensemble learning based hybrid model and framework for air pollution forecasting. Environ. Sci. Pollut. Res. 2020, 27, 38155–38168. [Google Scholar] [CrossRef] [PubMed]
- Samal, K.; Babu, K.; Das, S. Spatio-temporal Prediction of Air Quality using Distance Based Interpolation and Deep Learning Techniques. EAI Endorsed Trans. Smart Cities 2018. [Google Scholar] [CrossRef]
- Samal, K.K.R.; Babu, K.S.; Das, S.K. Time Series Forecasting of Air Pollution using Deep Neural Net-work with Multi-output Learning. In Proceedings of the 2021 IEEE 18th India Council International Conference (INDICON), Guwahati, India, 19–21 December 2021; pp. 1–5. [Google Scholar]
- Samal, K.K.; Babu, K.; Panda, A.K.; Das, S.K. Data Driven Multivariate Air Quality Forecasting using Dynamic Fine Tuning Autoencoder Layer. In Proceedings of the 2020 IEEE 17th India Council International Conference (INDICON), New Delhi, India, 10–13 December 2020; pp. 1–6. [Google Scholar]
- Mahajan, S.; Kumar, B.; Pant, U.K. Tiwari, Incremental Outlier Detection in Air Quality Data Using Statistical Methods. In Proceedings of the 2020 International Conference on Data Analytics for Business and Industry: Way Towards a Sustainable Economy (ICDABI), Sakheer, Bahrain, 26–27 October 2020; pp. 1–5. [Google Scholar]
- Chen, Z.; Peng, Z.; Zou, X.; Sun, H.; Lu, W.; Zhang, Y.; Wen, W.; Yan, H.; Li, C. Deep Learning Based Anomaly Detection for Muti-dimensional Time Series: A Survey. In Cyber Security; CNCERT 2021; Springer: Berlin/Heidelberg, Germany, 2022; Volume 1506. [Google Scholar]
- Zhang, C.; Li, S.; Zhang, H.; Chen, Y. VELC: A New Variational AutoEncoder Based Model for Time Series Anomaly Detection. arXiv 2019, arXiv:1907.01702. [Google Scholar] [CrossRef]
- Provotar, O.I.; Linder, Y.M.; Veres, M.M. Unsupervised Anomaly Detection in Time Series Using LSTM-Based Autoencoders. In Proceedings of the 2019 IEEE International Conference on Advanced Trends in Information Theory (ATIT), Kyiv, Ukraine, 18–20 December 2019; pp. 513–517. [Google Scholar]
- Shogrkhodaei, S.S.Z.; Razavi-Termeh, A.V. Fathnia, Spatio-temporal modeling of PM2.5 risk mapping using three machine learning algorithms. Environ. Pollut. 2021, 289, 117859. [Google Scholar] [CrossRef] [PubMed]
- Pun, T.B.; Shahi, T.B. Nepal Stock Exchange Prediction Using Support Vector Regression and Neural Networks. In Proceedings of the 2018 Second International Conference on Advances in Electronics, Computers and Communications (ICAECC), Bangalore, India, 9–10 February 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Elman, J.L.; Zipser, D. Learning the hidden structure of speech. J. Acoust. Soc. Am. 1988, 83, 1615–1626. [Google Scholar] [CrossRef] [Green Version]
- Omlin, C.; Thornber, K.; Giles, C. Fuzzy finite-state automata can be deterministically encoded into recurrent neural networks. IEEE Trans. Fuzzy Syst. 1998, 6, 76–89. [Google Scholar] [CrossRef]
- Chandra, R.; Jain, A.; Chauhan, D.S. Deep learning via LSTM models for COVID-19 infection forecasting in India. PLoS ONE 2022, 17, e0262708. [Google Scholar] [CrossRef]
- Shahi, T.B.; Shrestha, A.; Neupane, A.; Guo, W. Stock Price Forecasting with Deep Learning: A Comparative Study. Mathematics 2020, 8, 1441. [Google Scholar] [CrossRef]
- Ahmed, D.M.; Hassan, M.M.; Mstafa, R.J. A Review on Deep Sequential Models for Forecasting Time Series Data. Appl. Comput. Intell. Soft Comput. 2022, 2022, 6596397. [Google Scholar] [CrossRef]
- Branco, N.W.; Cavalca, M.S.M.; Stefenon, S.F.; Leithardt, V.R.Q. Wavelet LSTM for Fault Forecasting in Electrical Power Grids. Sensors 2022, 22, 8323. [Google Scholar] [CrossRef]
- Neto, N.F.S.; Stefenon, S.F.; Meyer, L.H.; Ovejero, R.G.; Leithardt, V.R.Q. Fault Prediction Based on Leakage Current in Contaminated Insulators Using Enhanced Time Series Forecasting Models. Sensors 2022, 22, 6121. [Google Scholar] [CrossRef]
- Cawood, P.; Van Zyl, T. Evaluating State-of-the-Art, Forecasting Ensembles and Meta-Learning Strategies for Model Fusion. Forecasting 2022, 4, 732–751. [Google Scholar] [CrossRef]
- Stefenon, S.F.; Ribeiro, M.H.D.M.; Nied, A.; Yow, K.-C.; Mariani, V.C.; Coelho, L.D.S.; Seman, L.O. Time series forecasting using ensemble learning methods for emergency prevention in hydroelectric power plants with dam. Electr. Power Syst. Res. 2021, 202, 107584. [Google Scholar] [CrossRef]
- Tiwari, A.; Gupta, R.; Chandra, R. Delhi air quality prediction using LSTM deep learning models with a focus on COVID-19 lockdown. arXiv 2021, arXiv:2102.10551. [Google Scholar] [CrossRef]
- Karroum, K.; Lin, Y.; Chiang, Y.-Y.; Ben Maissa, Y.; El Haziti, M.; Sokolov, A.; Delbarre, H. A Review of Air Quality Modeling. Mapan 2020, 35, 287–300. [Google Scholar] [CrossRef]
- Navares, R.; Aznarte, J.L. Predicting air quality with deep learning LSTM: Towards comprehensive models. Ecol. Inform. 2019, 55, 101019. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, H.; Duan, Z. A novel hybrid model for multi-step daily AQI forecasting driven by air pollution big data. Air Qual. Atmos. Health 2020, 13, 197–207. [Google Scholar] [CrossRef]
- Zheng, J.; Wang, Y.; Li, S.; Chen, H. The Stock Index Prediction Based on SVR Model with Bat Optimization Algorithm. Algorithms 2021, 14, 299. [Google Scholar] [CrossRef]
- Du, P.; Wang, J.; Hao, Y.; Niu, T.; Yang, W. A novel hybrid model based on multi-objective Harris hawks optimization algorithm for daily PM2.5 and PM10 forecasting. Appl. Soft Comput. 2020, 96, 106620. [Google Scholar] [CrossRef]
- Aggarwal, A.; Toshniwal, D. Detection of anomalous nitrogen dioxide (NO2) concentration in urban air of India using proximity and clustering methods. J. Air Waste Manag. Assoc. 2019, 69, 805–822. [Google Scholar] [CrossRef] [PubMed]
- Al-Janabi, S.; Mohammad, M.; Al-Sultan, A. A new method for prediction of air pollution based on intelligent computation. Soft Comput. 2019, 24, 661–680. [Google Scholar] [CrossRef]
- Xayasouk, T.; Lee, H.; Lee, G. Air Pollution Prediction Using Long Short-Term Memory (LSTM) and Deep Autoencoder (DAE) Models. Sustainability 2020, 12, 2570. [Google Scholar] [CrossRef] [Green Version]
- Kalajdjieski, J.; Zdravevski, E.; Corizzo, R.; Lameski, P.; Kalajdziski, S.; Pires, I.; Garcia, N.; Trajkovik, V. Air Pollution Prediction with Multi-Modal Data and Deep Neural Networks. Remote. Sens. 2020, 12, 4142. [Google Scholar] [CrossRef]
- Spyrou, E.D.; Tsoulos, I.; Stylios, C. Applying and Comparing LSTM and ARIMA to Predict CO Levels for a Time-Series Measurements in a Port Area. Signals 2022, 3, 235–248. [Google Scholar] [CrossRef]
- Dey, P.; Emam, H.; Md, H.; Mohammed, C.; Md, A.; Andersson, H.K.M. Comparative Analysis of Recurrent Neural Networks in Stock Price Prediction for Different Frequency Domains. Algorithms 2021, 14, 251. [Google Scholar] [CrossRef]
- Ding, W.; Zhu, Y. Prediction of PM2.5 Concentration in Ningxia Hui Autonomous Region Based on PCA-Attention-LSTM. Atmosphere 2022, 13, 1444. [Google Scholar] [CrossRef]
- Chen, S.X. Beijing Multi-Site Air-Quality Data Data Set. 2018. Available online: https://archive.ics.uci.edu/ml/datasets/Beijing+Multi-Site+Air-Quality+Data (accessed on 1 March 2022).
- CPCB. Air Pollution. 2022. Available online: https://cpcb.nic.in/air-pollution. (accessed on 10 March 2022).
- Nguyen, H.; Tran, K.; Thomassey, S.; Hamad, M. Forecasting and Anomaly Detection approaches using LSTM and LSTM Autoencoder techniques with the applications in supply chain management. Int. J. Inf. Manag. 2020, 57, 102282. [Google Scholar] [CrossRef]
- Mishra, B.; Shahi, T.B. Deep learning-based framework for spatiotemporal data fusion: An instance of Landsat 8 and Sentinel 2 NDVI. J. Appl. Remote. Sens. 2021, 15, 034520. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference No | Technique | Preprocessing Method | Strength | Limitations |
|---|---|---|---|---|
| [28] | CNN-BILSTM-IDW | Linear interpolation for missing values | Deep learning and geostatistical approach obtained better accuracy. | Time complexity is not discussed in the hybrid method. |
| [49] | LSTM | Missing values ignored | Different LSTM configurations were tested. | Missing values ignored. |
| [50] | VMD-LASSO-SAE-DESN | VMD and LASSO | Extracted information from high-resolution dataset. | Time complexity is not mentioned. |
| [53] | Proximity and clustering method | Linear interpolation for missing values | Anomalies detected from air pollution dataset. | Not mentioned. |
| [55] | LSTM and DAE | Only checked for missing values | LSTM proved slightly better than DAE. | Data preprocessing needs to be taken care of. |
| [56] | Four different architecture including CNN | Simple imputation of backward fill used for imputation | Data plus images used for pollution prediction. | Requires more computational power. |
| [57] | Univariate LSTM | Negative values present in dataset were removed | Model performance checked with different batch size. | Calibration part is missing for the deployed device. |
| [58] | Simple RNN, LSTM, and GRU | Null values are removed | For lower time intervals, LSTM and GRU obtained good accuracy. | Imputation not performed for missing values. |
| [59] | PCA-Attention-LSTM | Missing values filled with average of adjacent values | Analysis of variable importance was performed. | Time complexity is not mentioned. |
| Dataset | Beijing Multisite Air Quality Data Dataset | Ghaziabad |
|---|---|---|
| Dataset Type | Multivariate | Multivariate |
| Time Interval | Hourly | Hourly |
| Monitoring Sites | Aotizhongxin, Gucheng, and Tiantan | Vasundhara, Ghaziabad UPPCB |
| Monitoring Period | 1st March 2013 to 28th February 2017 | 11 January 2017 to 11 December 2021 |
| Numbers of attributes | 18 (row number, year, month, day, hour, PM2.5 concentration (µg/m3), PM10 concentration (µg/m3), SO2 concentration (µg/m3), NO2 concentration (µg/m3), CO concentration (µg/m3), O3 concentration (µg/m3), temperature (degree Celsius), pressure (hPa), dew point temperature (degree Celsius), precipitation (mm), wind direction, wind speed (m/s), name of the air quality monitoring site | 13 (datetime, PM2.5 concentration (µg/m3), PM10 concentration (µg/m3), SO2 concentration (µg/m3), NO, NO2 and NOx concentration (µg/m3), CO concentration (µg/m3), Ozone concentration (µg/m3), temperature (degree Celsius), relative humidity, wind speed (m/s), name of the air quality monitoring site |
| Missing values | Aotizhongxin (9.26%), Gucheng (7.3%), and Tiantan (6.3%) | Vasundhara (15%) |
| Aotizhonhxin | Gucheng | |||
| Model | RMSE | R2 | RMSE | R2 |
| Extra Trees Regressor | 16.8418 | 0.9560 | 18.9825 | 0.9470 |
| Random Forest Regressor | 18.7612 | 0.9455 | 20.8966 | 0.9357 |
| Light Gradient Boosting Machine | 18.1819 | 0.9488 | 20.0165 | 0.9410 |
| Gradient Boosting Regressor | 22.0409 | 0.9250 | 24.9048 | 0.9086 |
| Decision Tree Regressor | 27.2191 | 0.8853 | 30.3225 | 0.8646 |
| Tiantan | Ghaziabad | |||
| Model | RMSE | R2 | RMSE | R2 |
| Extra Trees Regressor | 16.4132 | 0.9579 | 37.8253 | 0.8812 |
| Random Forest Regressor | 17.9955 | 0.9493 | 40.8506 | 0.8615 |
| Light Gradient Boosting Machine | 17.0169 | 0.9546 | 39.0488 | 0.8734 |
| Gradient Boosting Regressor | 20.7811 | 0.9325 | 45.0922 | 0.8322 |
| Decision Tree Regressor | 25.7433 | 0.8961 | 58.983 | 0.7162 |
| RAW Data (Removed Missing Values) | Imputed Data | Proposed Method | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Aotizhonhxin | MAE | RMSE | R2 | MAE | RMSE | R2 | MAE | RMSE | R2 |
| Univariate LSTM | 28.1138 | 63.4783 | 0.45535 | 18.083 | 44.4132 | 0.7165 | 30.6951 | 63.0365 | 0.3073 |
| Univariate 1D | 10.8385 | 19.8228 | 0.9468 | 11.2217 | 20.54922 | 0.9393 | 10.7215 | 19.4150 | 0.9342 |
| Univariate GRU | 20.9584 | 51.2164 | 0.6454 | 19.6057 | 47.97042 | 0.6692 | 16.9252 | 39.5841 | 0.7268 |
| Multivariate LSTM | 10.4696 | 13.6125 | 0.7509 | 13.7667 | 19.78918 | 0.8095 | 7.44549 | 9.8883 | 0.8159 |
| Gucheng | MAE | RMSE | R2 | MAE | RMSE | R2 | MAE | RMSE | R2 |
| Univariate LSTM | 24.574 | 61.329 | 0.5888 | 20.867 | 53.297 | 0.619 | 17.653 | 41.912 | 0.6882 |
| Univariate 1D | 12.586 | 23.795 | 0.9381 | 11.699 | 22.004 | 0.9351 | 10.56 | 19.832 | 0.9302 |
| Univariate GRU | 25.761 | 63.746 | 0.5557 | 25.227 | 61.884 | 0.4863 | 19.555 | 46.121 | 0.6224 |
| Multivariate LSTM | 19.12256 | 23.00376 | 0.148226 | 18.0171 | 26.6355 | 0.8444 | 11.1987 | 13.9660 | 0.6480 |
| Tiantan | MAE | RMSE | R2 | MAE | RMSE | R2 | MAE | RMSE | R2 |
| Univariate LSTM | 32.311 | 68.194 | 0.3872 | 57.104 | 65.6630 | −0.382 | 21.272 | 47.265 | 0.6202 |
| Univariate 1D | 11.431 | 19.983 | 0.9474 | 11.674 | 20.352 | 0.9373 | 11.211 | 19.567 | 0.9349 |
| Univariate GRU | 31.733 | 67.657 | 0.3969 | 28.747 | 63.273 | 0.3939 | 19.312 | 43.369 | 0.6802 |
| Multivariate LSTM | 13.10567 | 17.301 | 0.8305 | 18.0027 | 28.239 | 0.8054 | 10.6244 | 13.884 | 0.5845 |
| Ghaziabad | MAE | RMSE | R2 | MAE | RMSE | R2 | MAE | RMSE | R2 |
| Univariate LSTM | 30.1511 | 62.4346 | 0.4963 | 43.7731 | 94.1758 | 0.4100 | 37.0318 | 74.6937 | 0.4000 |
| Univariate 1D | 17.5631 | 34.6024 | 0.8453 | 21.4284 | 43.8764 | 0.87194 | 24.7072 | 43.5987 | 0.7955 |
| Univariate GRU | 46.8667 | 87.3550 | 0.0140 | 31.1143 | 72.6943 | 0.6484 | 68.5177 | 112.294 | −0.3561 |
| Multivariate LSTM | 32.3471 | 46.6165 | 0.6351 | 14.7406 | 21.0891 | 0.2630 | 13.002 | 16.5374 | −0.0237 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Narkhede, G.; Hiwale, A.; Tidke, B.; Khadse, C. Novel MIA-LSTM Deep Learning Hybrid Model with Data Preprocessing for Forecasting of PM2.5. Algorithms 2023, 16, 52. https://doi.org/10.3390/a16010052
Narkhede G, Hiwale A, Tidke B, Khadse C. Novel MIA-LSTM Deep Learning Hybrid Model with Data Preprocessing for Forecasting of PM2.5. Algorithms. 2023; 16(1):52. https://doi.org/10.3390/a16010052
Chicago/Turabian StyleNarkhede, Gaurav, Anil Hiwale, Bharat Tidke, and Chetan Khadse. 2023. "Novel MIA-LSTM Deep Learning Hybrid Model with Data Preprocessing for Forecasting of PM2.5" Algorithms 16, no. 1: 52. https://doi.org/10.3390/a16010052
APA StyleNarkhede, G., Hiwale, A., Tidke, B., & Khadse, C. (2023). Novel MIA-LSTM Deep Learning Hybrid Model with Data Preprocessing for Forecasting of PM2.5. Algorithms, 16(1), 52. https://doi.org/10.3390/a16010052