1. Introduction
Machine learning (ML) is a subfield of artificial intelligence (AI) that involves the development of algorithms capable of learning patterns and making predictions based on data. It is a broad field that encompasses different approaches and techniques, including deep learning (DL). Deep learning is a subset of ML that involves the use of artificial neural networks (ANNs) with multiple layers to learn patterns from data [
1]. The neural networks in deep learning can have many layers, making it possible to extract complex features from data.
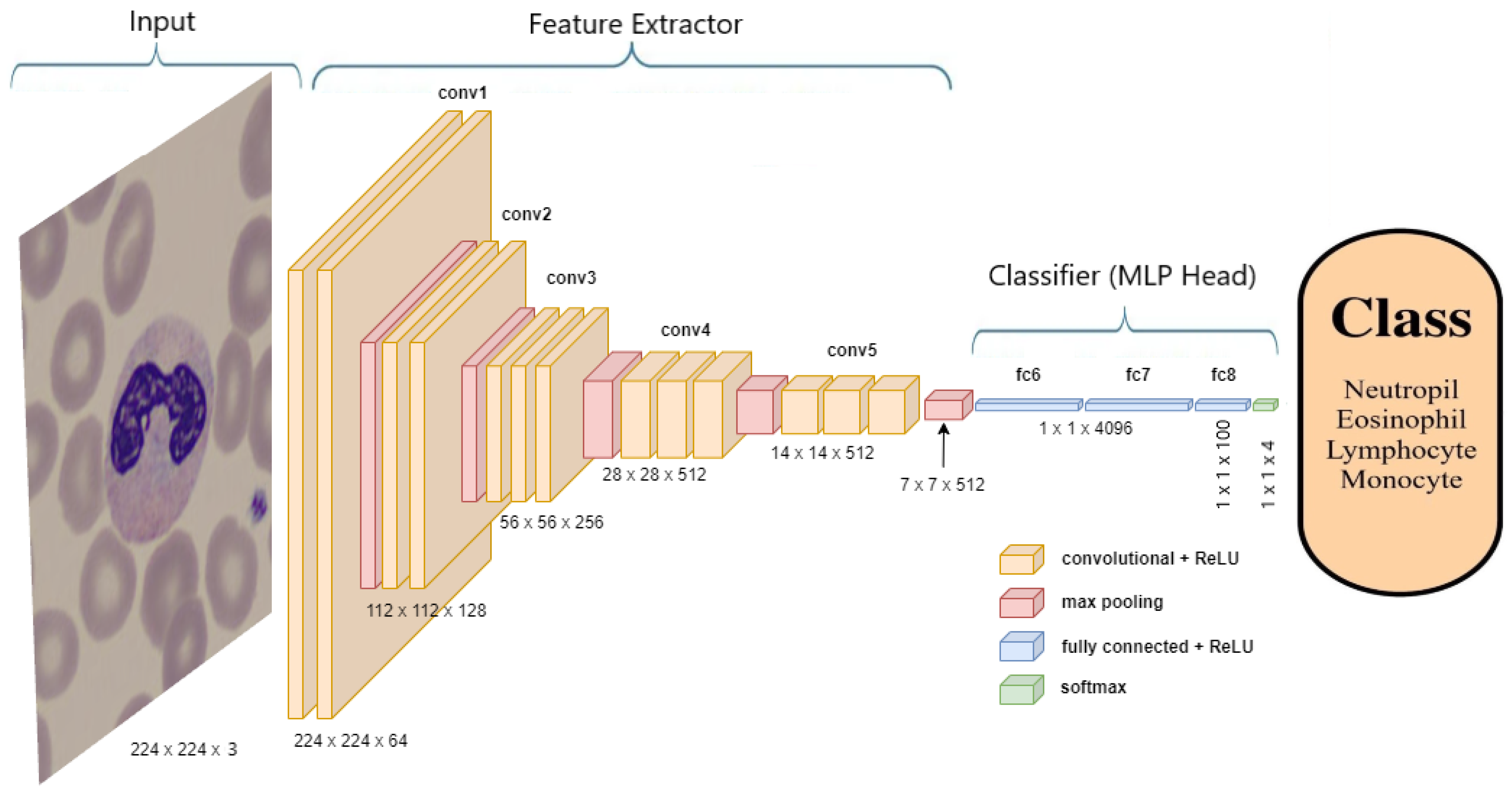
One popular application of DL is computer vision, where convolutional neural networks (CNNs) have proven to be very effective in image recognition tasks. CNNs use convolutional layers to extract features from images and pool those features to reduce the dimensionality of the data, allowing them to identify patterns and classify images into different categories [
2].
Pre-trained CNN models are models that have already been trained on large datasets, such as the ImageNet dataset, making them useful for transfer learning on other datasets. Examples of such models are the winners of the ImageNet Large-Scale Visual Recognition Challenge (ILSVRC), including DenseNets, ResNets, and VGGs [
3].
However, there has recently been growing interest in a new type of DL architecture called vision transformers (ViTs) [
4], which are based on the transformer architecture commonly used in natural language processing (NLP) tasks. The ViT encoder uses a self-attention mechanism to extract features from the input image, allowing the model to consider the entire image at one time and identify important regions. This makes ViTs more efficient in identifying global features in images, such as overall shape and color, and permits them to learn more complex relationships between different parts of the image. Also, ViTs use residual links to forward extracted features to an MLP head unaffected by its depth.
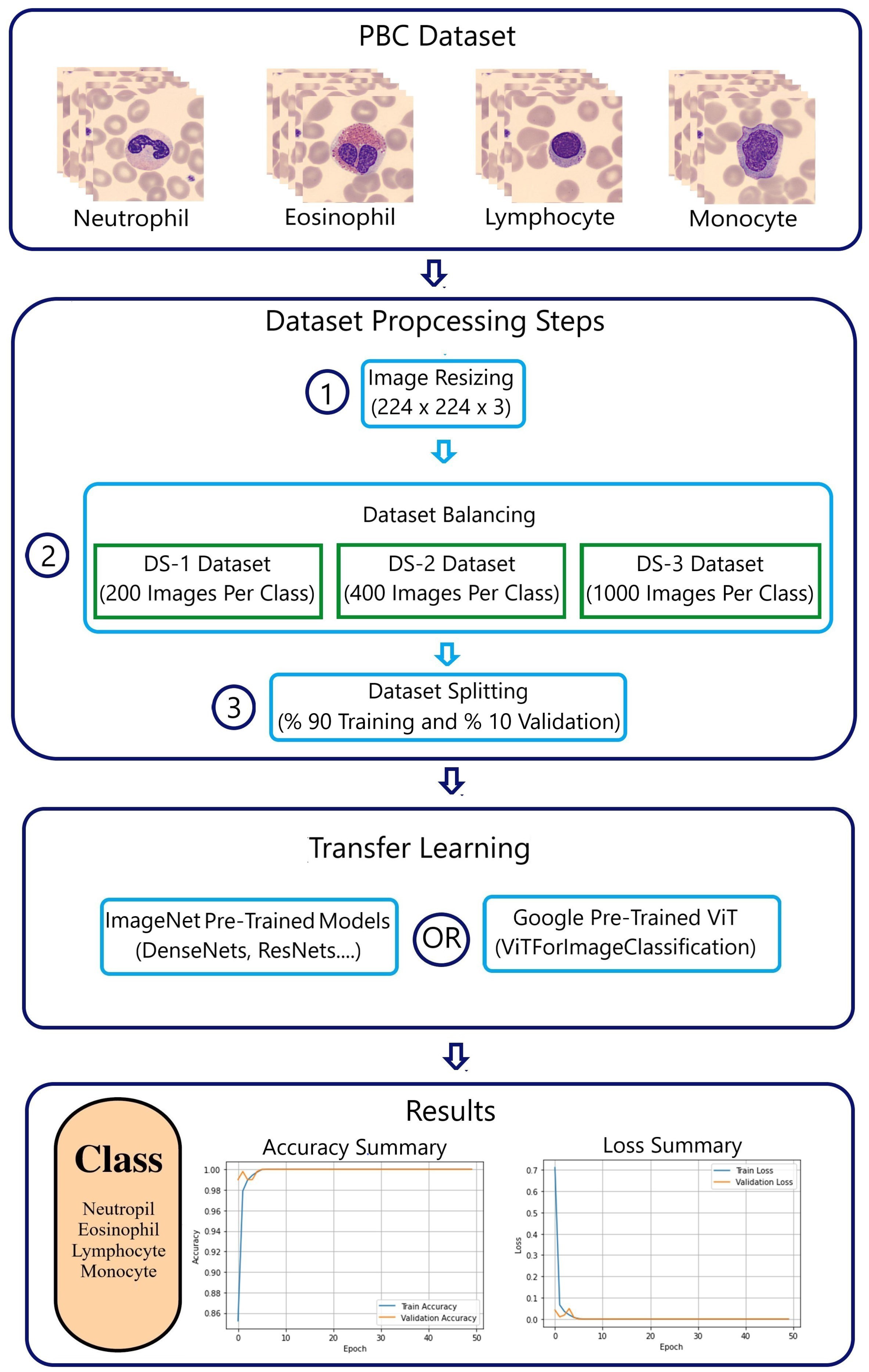
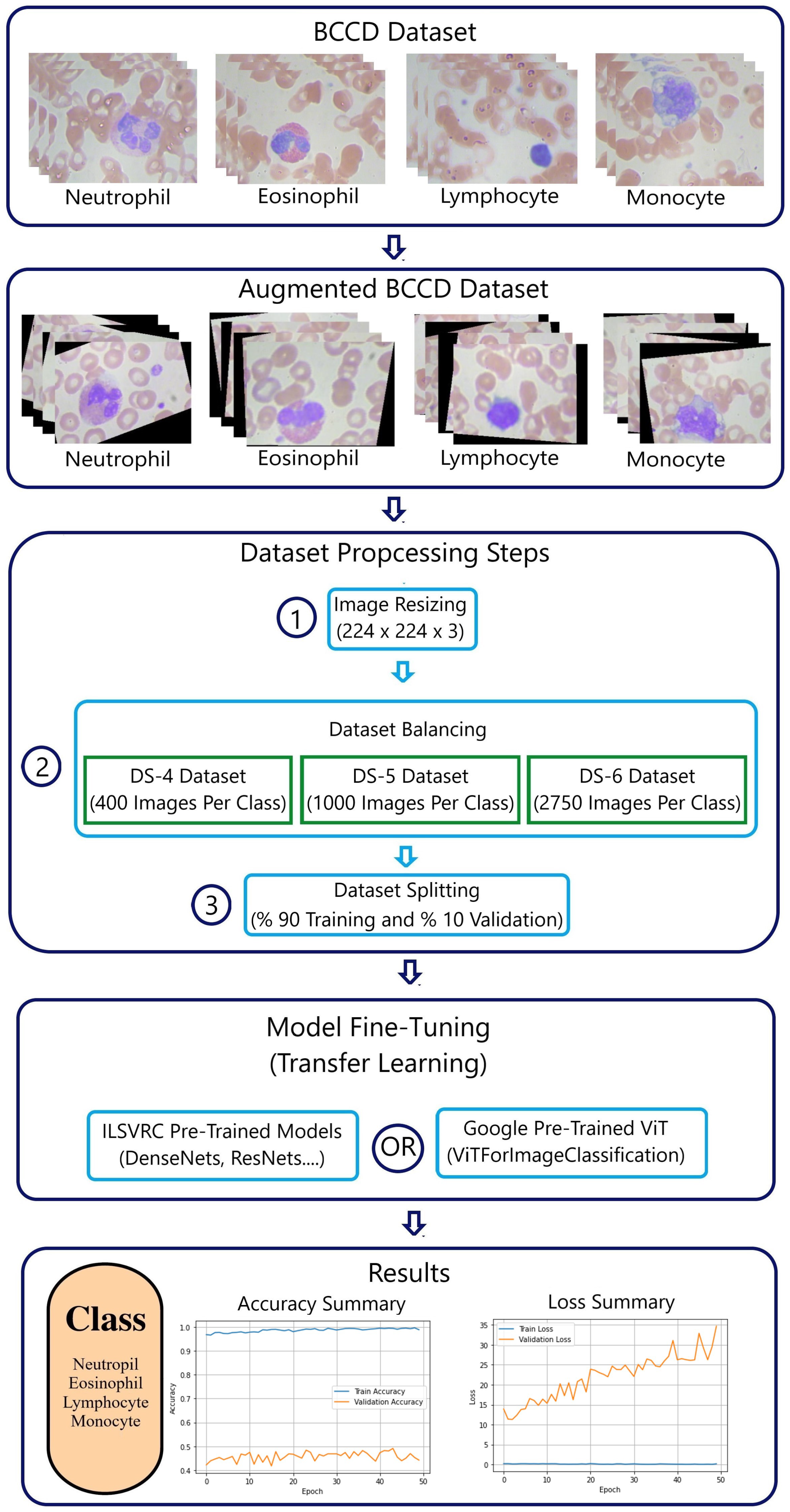
This work aimed to investigate the performance and optimization learning of two deep neural networks, ImageNet CNNs and the Google ViT, in classifying four white blood cell (WBC) types (neutrophil, eosinophil, lymphocyte, and monocyte) by means of transfer learning. This study used the PBC [
5] and BCCD [
6] datasets. PBC is a large imbalanced dataset with high-quality images, while BCCD is a small imbalanced dataset with poor-quality images. Data augmentation techniques were employed to increase the size of the BCCD dataset.
The paper will proceed with a literature review of the relevant research related to the detection and classification of WBCs using pre-trained CNNs and ViTs in
Section 2.
Section 3 will describe the methodology used in this study, while
Section 4 will present the experimental results obtained using pre-trained ILSVRC models and the Google ViT for blood cell classification. An in-depth analysis of the results will be provided in
Section 5, and the paper will be concluded in
Section 6.
Overall, the paper explores the effectiveness of pre-trained deep learning models in classifying WBC types from peripheral blood smear images. Transfer learning and data augmentation techniques were employed to address the imbalanced and poor-quality nature of the datasets. The results of the study can help improve the accuracy and efficiency of WBC classification, which could lead to the better diagnosis and treatment of blood disorders.
2. Related Works
Numerous research studies and publications have focused on the autonomous image analysis of white blood cells in microscopic peripheral blood smears. These studies leveraged transfer-based learning from pre-trained ImageNet models across various dataset sizes [
7,
8,
9,
10,
11,
12,
13,
14].
In their study [
7], Sharma et al. employed convolutional neural networks, including a custom five-layer CNN (“LeNet-5”), and pre-trained models such as “VGGs”, “Inception V3”, and “Xception” for white blood cell classification. They tackled the challenging BCCD dataset, initially containing only 349 low-quality images distributed among four white blood cell categories: monocyte, lymphocyte, neutrophil, and eosinophil. Through extensive data augmentation techniques, they substantially expanded the dataset to over 3000 images per category. This augmented dataset was then divided into training and testing subsets, ultimately achieving an average classification accuracy of 87% for all four white blood cell types.
In a similar vein, Alam and Islam [
8] also used the BCCD dataset for object identification considering red blood cells (RBCs), white blood cells (WBCs), and platelets. They divided the BCCD dataset into 300 images for training, reserving the remaining images for testing. The authors employed the Tiny YOLO model for object identification and incorporated pre-trained CNNs like VGG-16, ResNet-50, Inception V3, and MobileNet. Notably, all types of white blood cells were identified as WBC cells without further classification. However, no single model excelled in the identification of all RBCs, WBCs, and platelets simultaneously.
In another work [
9], an automated system was introduced for classifying eight types of blood cells using convolutional neural networks (CNNs), specifically VGG-16 and Inceptionv3, with the PBC dataset. An impressive accuracy of 96.2% was achieved.
Jung et al. [
10] introduced “W-Net”, a CNN-based architecture for classifying five different types of white blood cells. They utilized a dataset from the Catholic University of Korea (CUK), comprising 6562 images of these five WBC types. Additionally, the LISC dataset was used, and the pre-trained ResNet model was included for comparison. The results demonstrated that W-Net achieved an average accuracy of 97%.
In a different approach, a deep learning model using DenseNet121 was presented in [
11] for classifying different white blood cell (WBC) types. The augmented BCCD dataset was employed, consisting of 12,444 images, including 3120 eosinophils, 3103 lymphocytes, 3098 monocytes, and 3123 neutrophils. Image pre-processing included the cropping of the WBC images. Then, augmentation techniques, such as flipping, rotation, brightness adjustment, and zooming, were applied to the isolated WBCs. The DenseNet121 model achieved an average accuracy of 98.84%.
Abou El-Seoud and colleagues [
12] introduced a CNN-based architecture comprising five layers for classifying five types of white blood cells. They employed the BCCD dataset and applied augmentation techniques, including rotation, flipping, and shearing, to create a balanced training dataset with approximately 2500 images per class. The testing dataset contained fewer than 50 images, and the achieved average accuracy stood at an impressive 96.78%.
In their study [
13], Sahlol and colleagues introduced a CNN-based architecture that utilized VGG-19 as a feature extractor and incorporated the Statistically Enhanced Salp Swarm Algorithm (SESSA) as an optimized classifier for categorizing five types of white blood cells (WBCs). Two datasets, the ALL-IDB and C-NMC datasets, were employed, resulting in an impressive average accuracy of 96.11%.
Almezhghwi and Serte [
14] employed transfer learning with pre-trained CNNs like “ResNet”, “DenseNet”, and “VGG” to classify five types of white blood cells (WBCs) using a small dataset called LISC, which contained 242 images. They applied image segmentation to isolate WBCs and used data augmentation techniques, including data transformations and generative adversarial networks (GANs). The DenseNet-169 model achieved the highest average accuracy at 98.8%.
In this literature review, we examined a series of studies (
Table 1) focusing on automating the classification of white blood cells in microscopic blood smears. These studies utilized diverse deep learning techniques, pre-trained models, and datasets, collectively showcasing the potential for precise white blood cell classification. The common thread across these works was the application of deep learning to enhance performance in this crucial medical domain.
4. Results
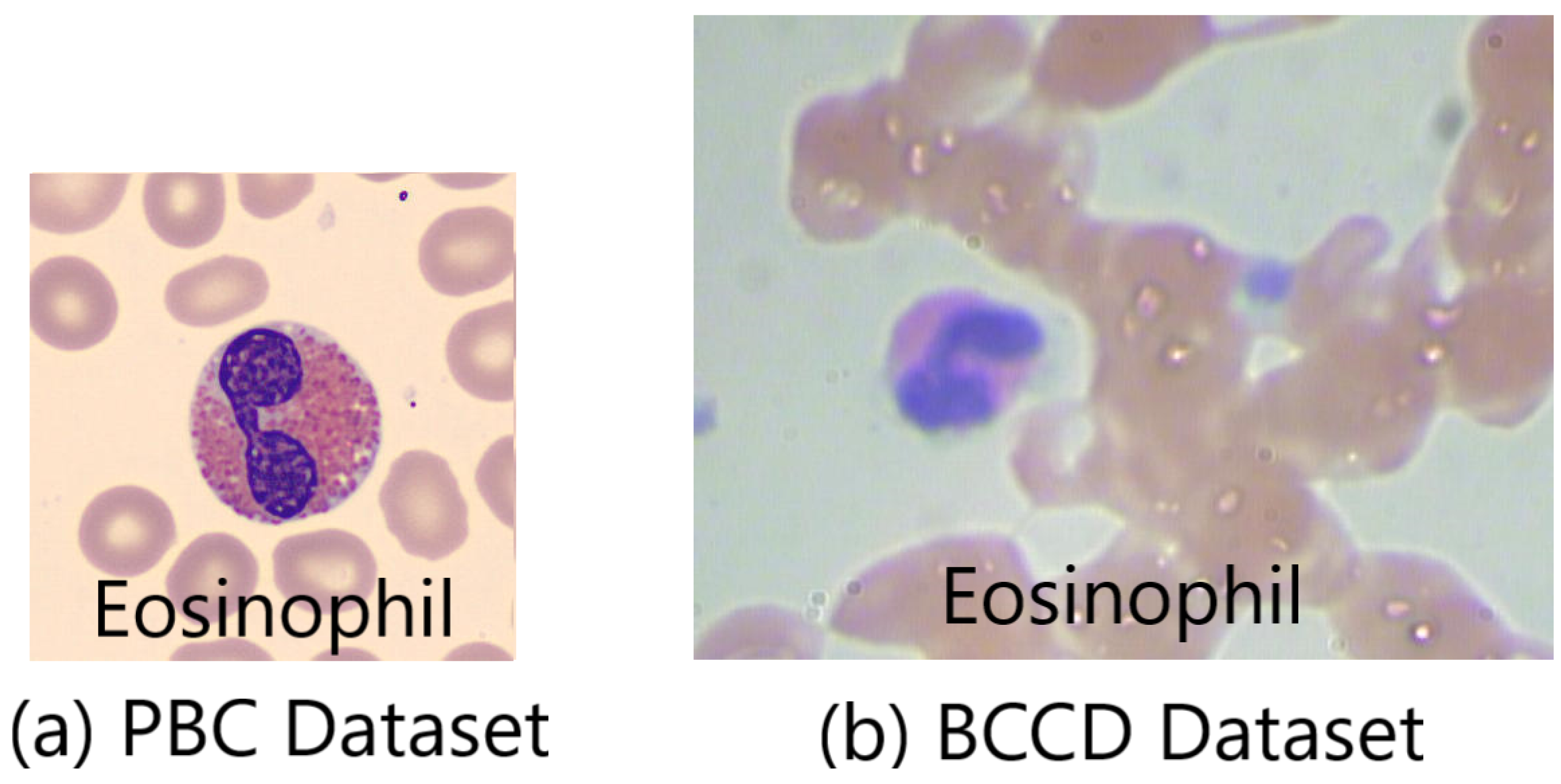
This section explains the experimental results for classifying WBC cells using the seven pre-trained ImageNet ILSVRC models and the Google ViTForImageClassification. The experiments were conducted on both the online peripheral blood smear PBC and BCCD datasets. The PBC dataset is characterized by being a large imbalanced dataset with standardized consistent high-quality images that are full of details, whereas the BCCD dataset is a small imbalanced dataset with blurred and noisy images due to the fact that the samples were manually prepared, stained, and captured.
In these experiments, the imbalanced PBC dataset was represented by three balanced datasets: DS-1 (200 images per class), DS-2 (400 images per class), and DS-3 (1000 images per class). Due to the small size of the BCCD dataset, data augmentation techniques were applied to increase the amount of data. Thus, the imbalanced BCCD dataset was embodied by three balanced datasets: DS-4 (400 images per class), DS-5 (1000 images per class), and DS-6 (2750 images per class). The dataset balancing was aimed at evaluating the ImageNet CNNs and Google ViT based on minimal metrics, namely accuracy and loss.
4.1. PBC Dataset Results
Table 6 shows the tenth-epoch validation accuracy and loss (VA and VL) values of the seven pre-trained ImageNet ILSVRC models versus the Google ViT. The Google ViT exhibited exceptionally stable performance compared to all ImageNet ILSVRC models. The Google ViT had a validation accuracy of 100 percent and a validation loss close to zero when fitted with the three PBC datasets (DS-1, DS-2, and DS-3).
As shown in
Table 7, the Google ViT again outperformed all ILSVRC models, with an accuracy difference (AD) value of zero, representing the difference between the training and validating accuracies (TA and VA).
Table 8 clearly shows the development of an overfitting problem in all ILSVRC models due to the high variances caused by the high LD values when fitted using the DS-1 and DS-1 datasets. However, the size of the small and medium datasets DS-1 and DS-2 had no impact on the behavior of the Google ViT, which showed great results in such cases.
Finally, the larger number of trainable parameters for Google ViT compared to all ILSVRC models during the transfer learning process explained its need for additional computational resources and a longer training and validating time.
4.2. BCCD Dataset Results
Table 9 shows the tenth-epoch validation accuracy and loss (VA and VL) values of the seven pre-trained ImageNet ILSVRC models versus the Google ViT. The models were fitted with the three BCCD datasets (DS-4, DS-5, and DS-6). The Google ViT demonstrated better performance than all ImageNet ILSVRC models.
The Google ViT reached an 88.6% validation accuracy and a validation loss close to one when fitted with the BCCD DS-6 dataset. By comparison, when fitted with the DS-6 dataset, all ImageNet ILSVRC models displayed poor optimization learning and performance. This was due to the great amount of noise caused by the overuse of data augmentation and the poor quality of the original BCCD dataset images.
As shown in
Table 10, the Google ViT fitted with the DS-6 dataset again outperformed the other models, reaching a +11.64% accuracy difference (AD) value, which was far better than any AD achieved by the ILSVRC models.
Table 11 clearly demonstrates that the Google ViT fitted with the DS-6 dataset again outperformed the other models, achieving a loss difference (LD) of around 1%, which was lower than any LD attained by the ILSVRC models.
5. Discussion
The experimental results presented in this study provide valuable insights into the performance of the pre-trained ImageNet ILSVRC models and the Google ViT (vision transformer) when applied to the classification of white blood cells (WBCs). In this section, we discuss the key findings, implications, and limitations and provide a summary based on the results obtained from the PBC and BCCD datasets.
5.1. PBC Dataset Results
The results obtained from the PBC datasets demonstrated a stark contrast in the performance of the pre-trained ImageNet ILSVRC models and the Google ViT. The Google ViT consistently outperformed all ImageNet models across all three PBC datasets (DS-1, DS-2, and DS-3) in terms of both validation accuracy (VA) and validation loss (VL). It achieved a remarkable 100% validation accuracy and a validation loss close to zero. This exceptional performance suggests that the Google ViT is well-suited for handling imbalanced datasets with high-quality, detailed images.
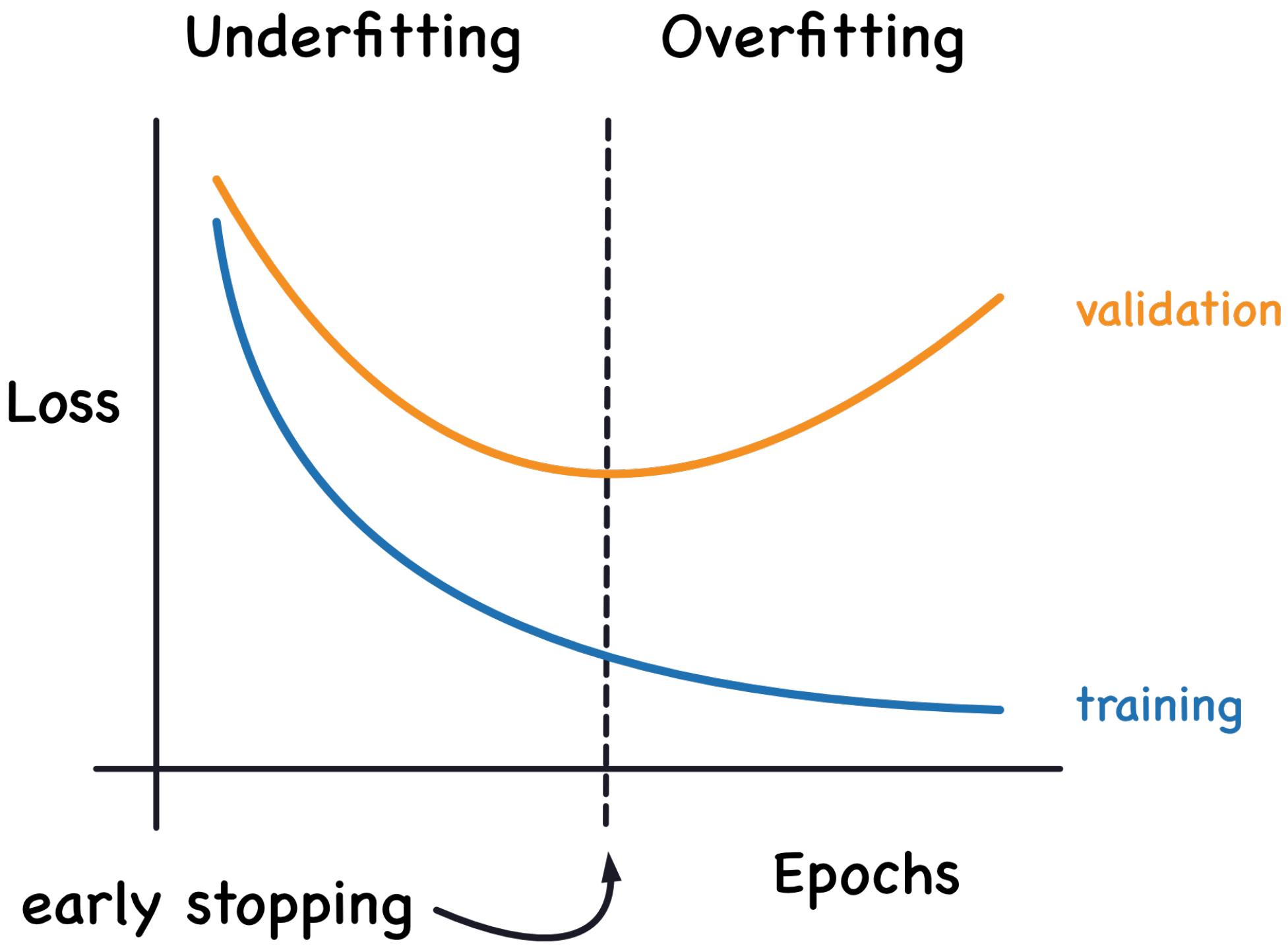
Furthermore, when we analyzed the accuracy difference (AD) values, it was evident that the Google ViT maintained a constant 0% AD across all three PBC datasets. In contrast, the ImageNet models exhibited positive AD values, indicating overfitting issues, especially when working with the DS-1 dataset. This overfitting was likely due to the high variances caused by the presence of limited data in DS-1. The Google ViT’s consistent performance regardless of dataset size suggested its robustness in dealing with small and medium-sized datasets.
The LD (loss difference) values further emphasized the Google ViT’s superiority. While the ImageNet models displayed varying degrees of loss difference as the dataset size increased, the Google ViT consistently maintained minimal loss differences, once again highlighting its stability.
Overall, the performance of the Google ViT on the PBC datasets indicated its effectiveness in handling large, imbalanced, and high-quality image datasets while mitigating overfitting issues.
5.2. BCCD Dataset Results
In contrast to the PBC datasets, the BCCD datasets presented a more challenging scenario due to their small size, noise, and poor image quality. The Google ViT continued to demonstrate its superior performance, achieving an 88.36% validation accuracy and a validation loss close to one when fitted with the BCCD DS-6 dataset. This exceptional performance, especially when handling the most challenging dataset, DS-6, is a testament to the robustness of the Google ViT.
When compared to the ImageNet models, the Google ViT was consistently superior across all three BCCD datasets (DS-4, DS-5, and DS-6) in terms of the accuracy difference (AD) and loss difference (LD) values. The AD values for the Google ViT were consistently lower, indicating its ability to maintain a higher accuracy. In addition, the LD values for the Google ViT remained minimal, underscoring its stability even when dealing with small, noisy, and low-quality image datasets.
The superior performance of the Google ViT on the BCCD datasets, especially the DS-6 dataset, highlights its resilience in the face of challenging data conditions and noise. This makes it a promising choice for applications where image quality is a concern or where the dataset size is limited.
5.3. Score-CAM
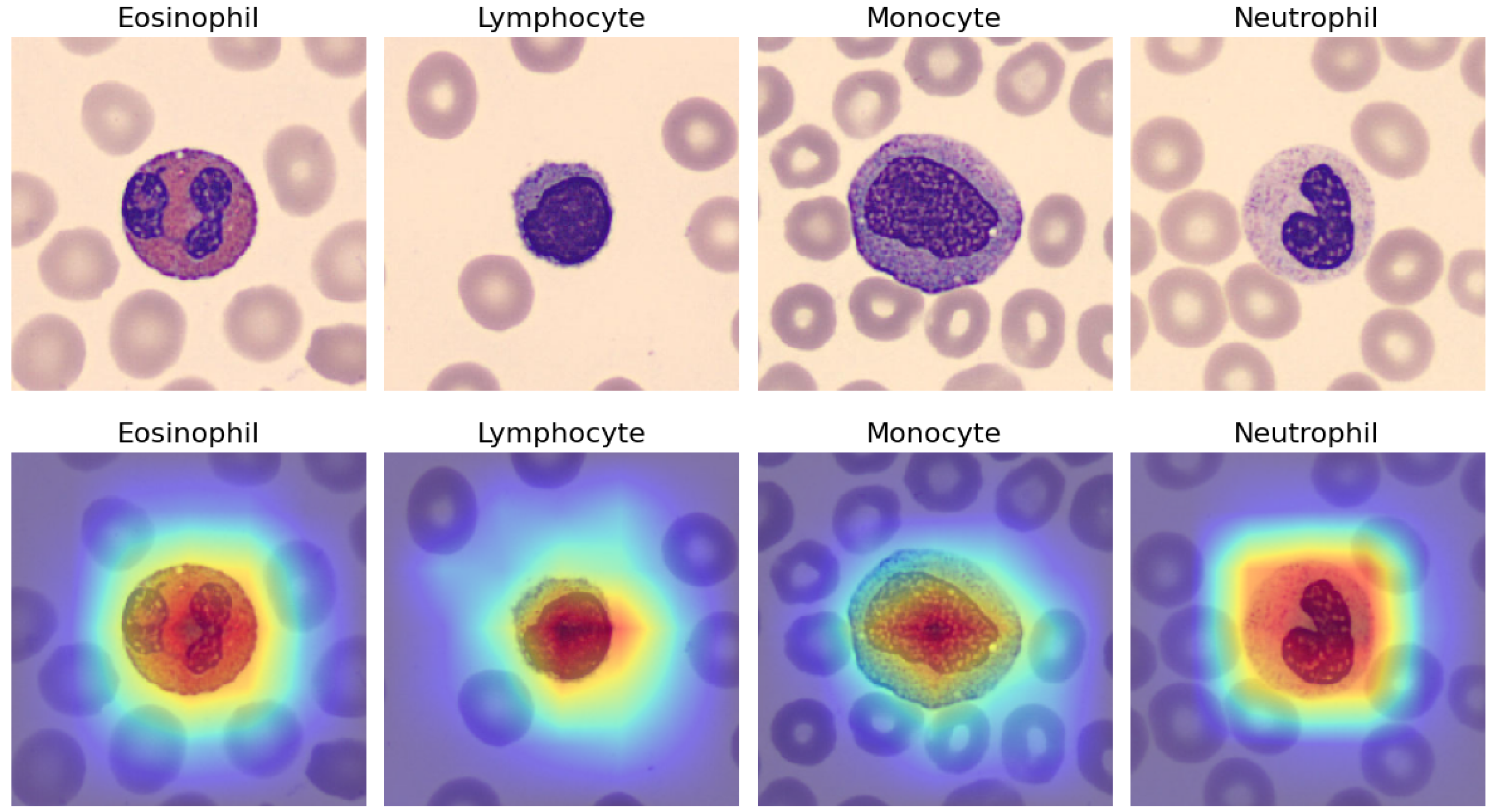
These findings received additional support from the utilization of Score-CAM, as depicted in
Figure 8, which offers a visual representation of the fitted pre-trained DenseNet-169 model’s performance using the DS-3 PBC dataset. In
Figure 8, four selected WBCs, namely an eosinophil, lymphocyte, monocyte, and neutrophil, randomly taken from the DS-3 PBC dataset, are presented in the upper section. Meanwhile, the lower section of
Figure 8 displays their corresponding Score-CAM images, highlighting the specific areas of focus detected by the DenseNet-169 model.
5.4. Implications and Limitations
The findings in this study have significant implications for the field of deep learning and computer vision. The Google ViT’s consistent and exceptional performance, even on challenging datasets, suggests its potential for a wide range of medical image analysis and diagnostic applications. Its robustness to dataset size and quality could lead to more accurate and reliable results in various healthcare settings, providing valuable support for medical professionals.
One of the strengths of this study was its focus on key metrics such as accuracy, loss, accuracy difference (AD), and loss difference (LD), which provided a comprehensive evaluation of the models’ performance. The results were clear and consistent across all datasets, supporting the conclusion that the Google ViT is a powerful choice for medical image classification tasks.
This work featured many novel aspects and perspectives when compared to the previously cited works [
7,
8,
9,
10,
11,
12,
13,
14].
Firstly, it utilized the Google ViT for the first time and proved its superiority in performance and stability compared to the ImageNet CNNs under the same circumstances and conditions. The Google ViT achieved superior performance, with an average 100% accuracy. Secondly, this work shed light on and stressed the significance of data processing techniques, such as data balancing, in order to achieve better performance and a higher accuracy. Additionally, it demonstrated the negative impacts of poor data processing habits, such as the overuse of data augmentation methods without considering the preservation of an acceptable ratio between the original data and their augmented versions. Finally, it clearly showed how such a case could be exaggerated in the event of unclean noisy image data.
One limitation of our study lay in its exclusive focus on the classification of four mature WBC types. This raises the question of whether our findings would hold true if additional blood cell classes, such as basophils; segmented/banded neutrophils; immature granulocytes (pro-myelocytes, myelocytes, meta-myelocytes); and erythroblasts, were included. The inclusion of these additional cell classes could significantly increase the complexity of the classification task due to their numerous similarities, presenting a challenging avenue for future research.
5.5. Summary
In summary, the experimental results from this study demonstrated that the Google ViT consistently outperformed the pre-trained ImageNet ILSVRC models when classifying white blood cells (WBCs), even when dealing with challenging datasets. Its exceptional stability, regardless of dataset size or image quality, highlights its potential for various medical image analysis tasks. Researchers and practitioners in the field of medical imaging should consider the Google ViT as a reliable and robust tool for image classification tasks, particularly in healthcare applications. This study emphasizes the importance of selecting the right deep learning model to achieve high performance in medical image analysis and paves the way for further advancements in the field.
6. Conclusions
In conclusion, this study thoroughly assessed the performance of the Google ViT when classifying four types of WBCs using peripheral blood smear images from two online datasets, the PBC and BCCD datasets. To address data scarcity, the study employed three balanced datasets (DS-1, DS-2, and DS-3) from the PBC dataset, which contained high-quality images of various blood cell groups. The Google ViT exhibited superior performance compared to the ImageNet CNNs when dealing with data shortages. Furthermore, the study applied data augmentation techniques to create three balanced datasets (DS-4, DS-5, and DS-6) from the low-quality BCCD dataset, introducing noise to the data. In this scenario, the Google ViT demonstrated its robustness and resilience to noisy data, in contrast to the ImageNet CNNs. In summary, this work underscored the effectiveness of ViTs in scenarios of data insufficiency and the presence of unclean data.
In future research, we will expand the scope of this study to encompass additional blood cell classes, including basophils; segmented/banded neutrophils; immature granulocytes (pro-myelocytes, myelocytes, meta-myelocytes); erythroblasts; and other related cell types. These additional classes exhibit notable similarities among themselves. Additionally, our study will aim to augment the number of images within each class to provide a more challenging task for both ViTs and pre-trained CNNs.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}