

A Novel Deep Reinforcement Learning (DRL) Algorithm to Apply Artificial Intelligence-Based Maintenance in Electrolysers


Abstract
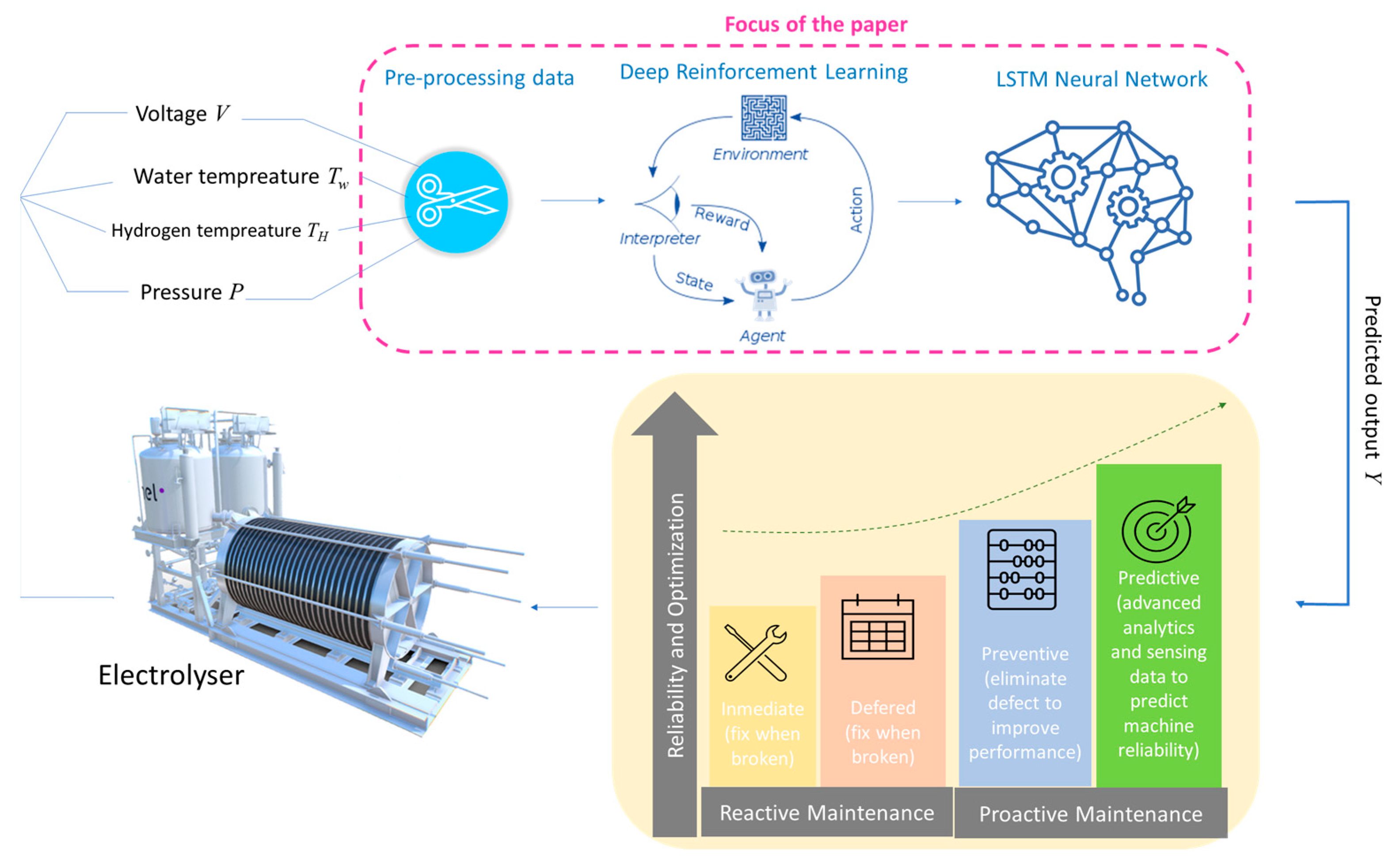
:1. Introduction
Background and Previous Works
- (1)
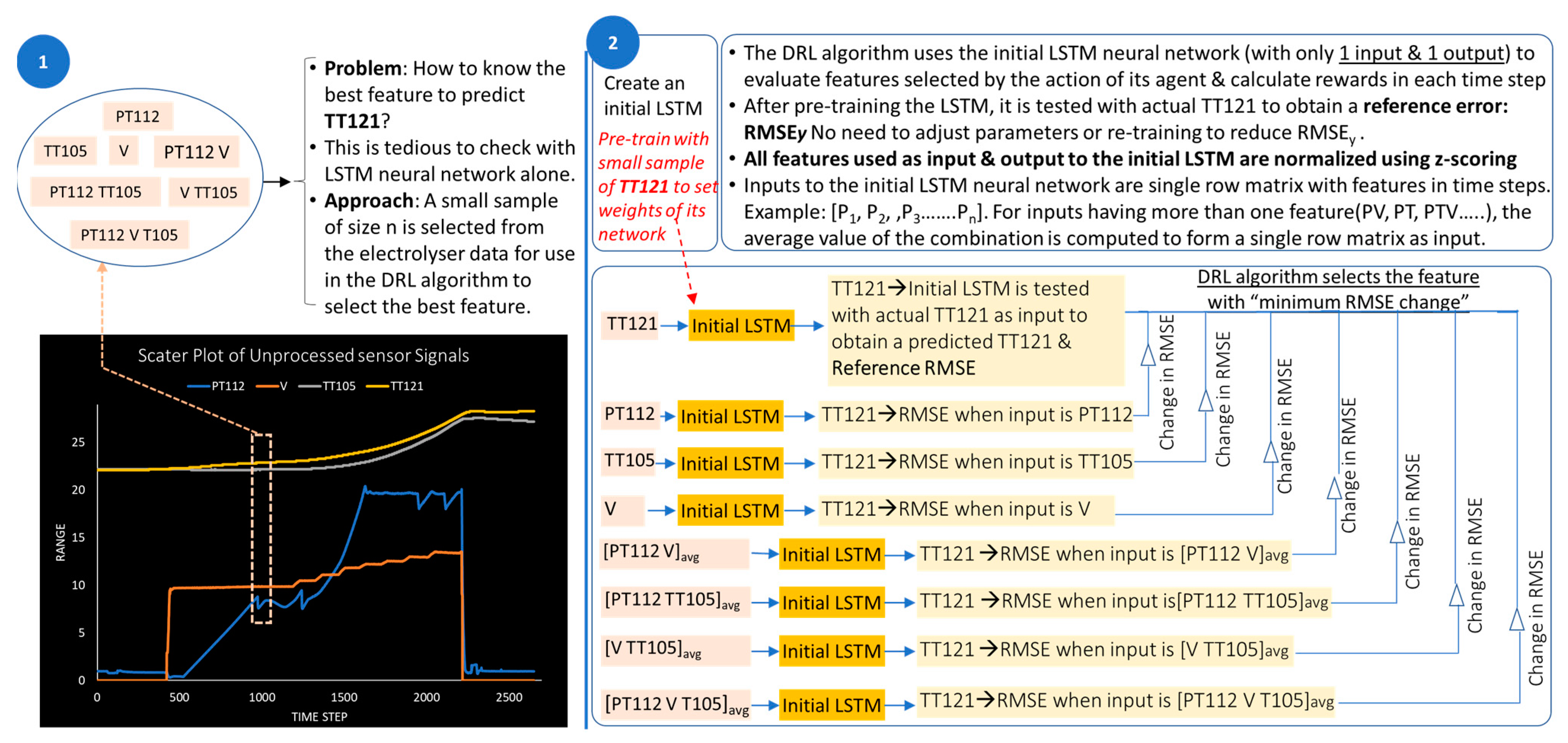
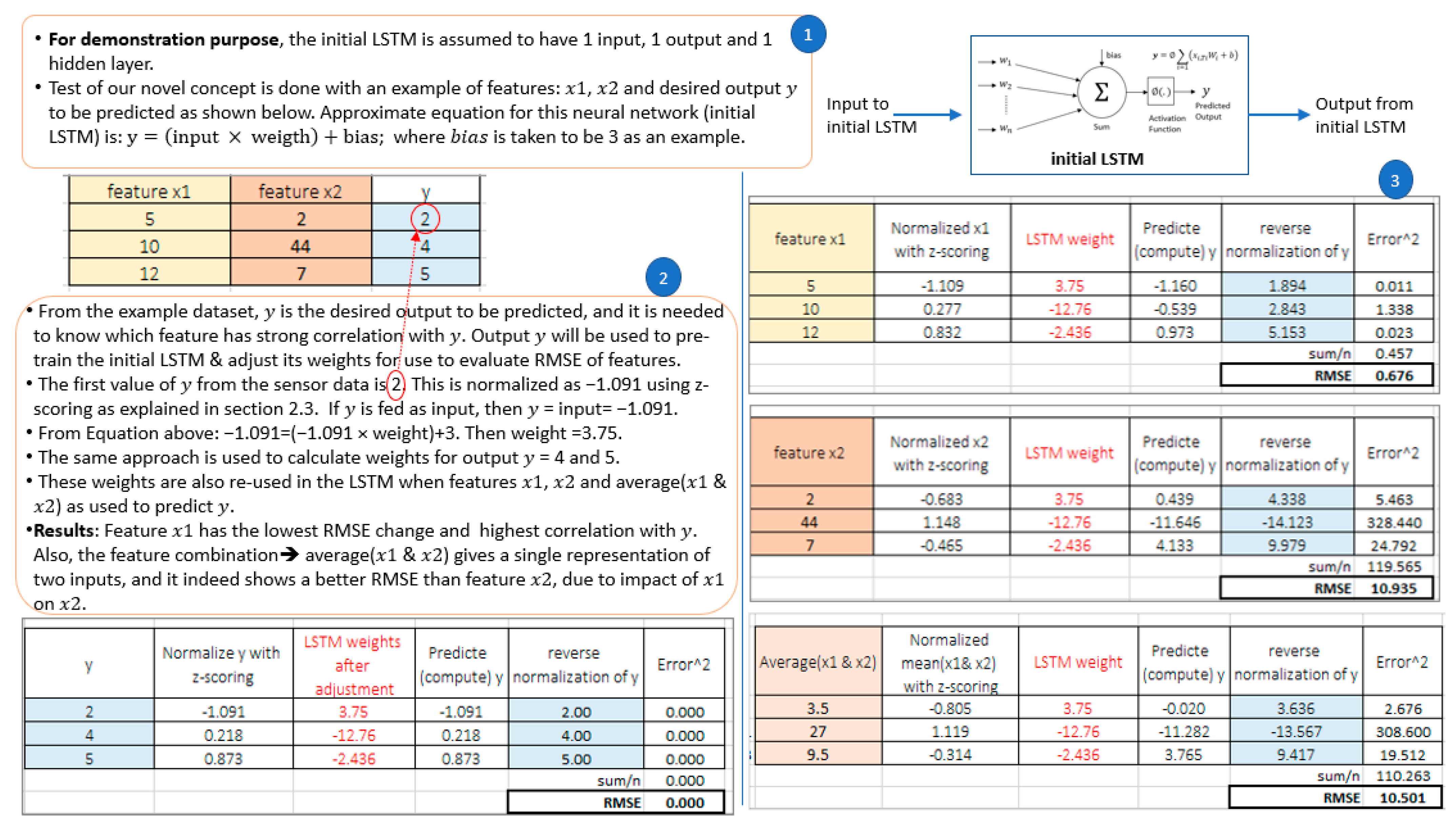
- A novel algorithm developed using DRL hybridised with LSTM. For predictive maintenance of an electrolyser, not all measured features can accurately predict the target sensor data, as the correlations between different features may be different. Any feature that is not well correlated with the data of interest will give an unassumable error during prediction. Hence, it is important to select appropriate feature(s) that, when used as input to the LSTM predictive model, will provide accurate prediction. In the case of multiple features obtained from the electrolyser, a manual process to select each feature(s) as input for the LSTM model followed by training with several parameter settings to reduce the prediction error is tedious. The developed DRL algorithm solves this problem by quickly searching through the feature set to select the one with the highest correlation to the sensor data (feature) of interest.A very important novelty of the DRL algorithm proposed in this paper lies in the unique method for evaluating each feature during iteration. The evaluation method is based on the comparison between a reference root-mean-square error (RMSE) and another one obtained from selected features. RMSE is an evaluation criterion used for LSTM models [18]. In the DRL algorithm, a simplified initial LSTM with one input and one output layer is used for evaluation.The best feature selected by the DRL algorithm is the one with the lowest RMSE difference, which is then used as input to a main LSTM neural network to predict the sensor data of interest for predictive maintenance.
- (2)
- Reduction of computational time when multiple features have to be evaluated. Another important novelty presented by the developed DRL algorithm is that when it has to select a feature set consisting of data from several sensors, it selects the average value, which gives a single representation of the combination. In addition, only a small sample of the feature set is needed. This approach saves computation time.
- (3)
- Experimental and real-time operation. The algorithm takes information from experimental data and selects the best dataset (also called feature) that accurately predicts the sensor data of interest. This reinforces the advantages of the hybrid DRL-LSTM model for the maintenance of actual electrolysers.
- (4)
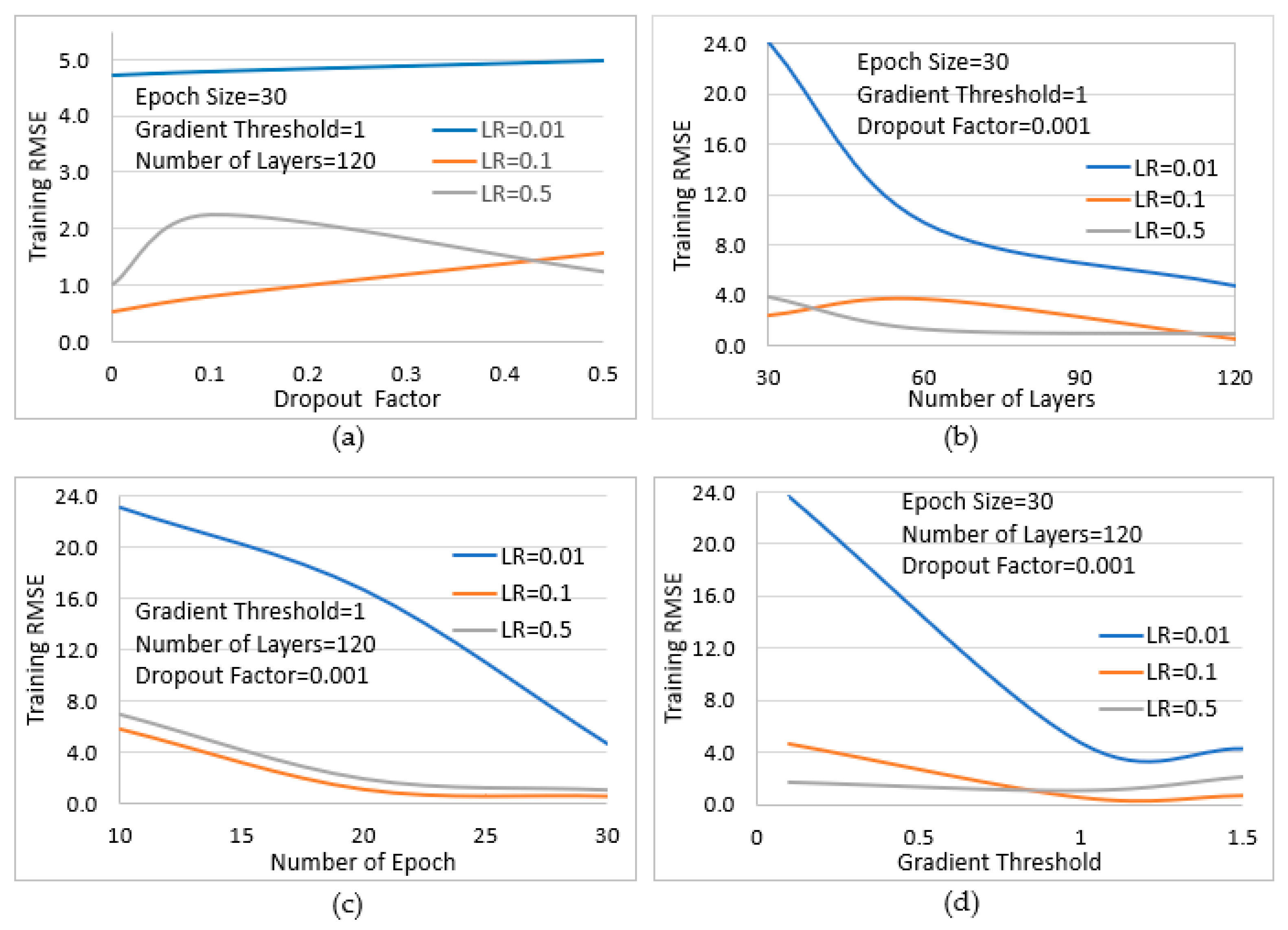
- Optimisation of the parameters of the main LSTM prediction model. The parameters of the main LSTM neural network used to predict the target variable are optimised by keeping some constant and varying others to observe the effect on the RMSE. This study provides a graphical guide to selecting the optimal combination for accurate prediction with minimal adjustment and retraining.
- (5)
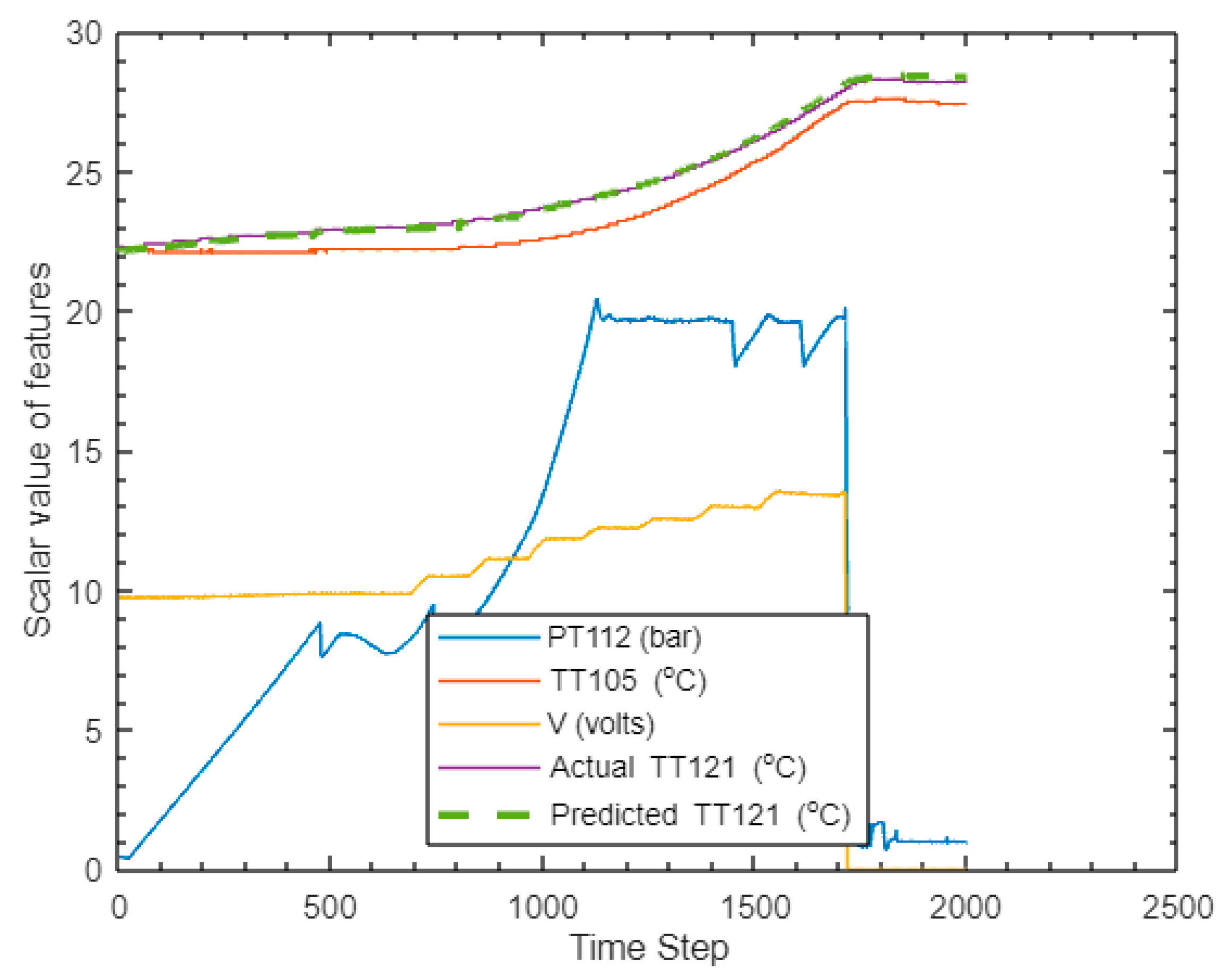
- Digital twin approach. This study also demonstrates the digital twins approach to visualise electrolyser performance by comparing the actual sensor reading with the predicted output to identify electrolyser failures, allowing maintenance to be planned well in advance.
2. Materials and Method
2.1. Initial Hypothesis
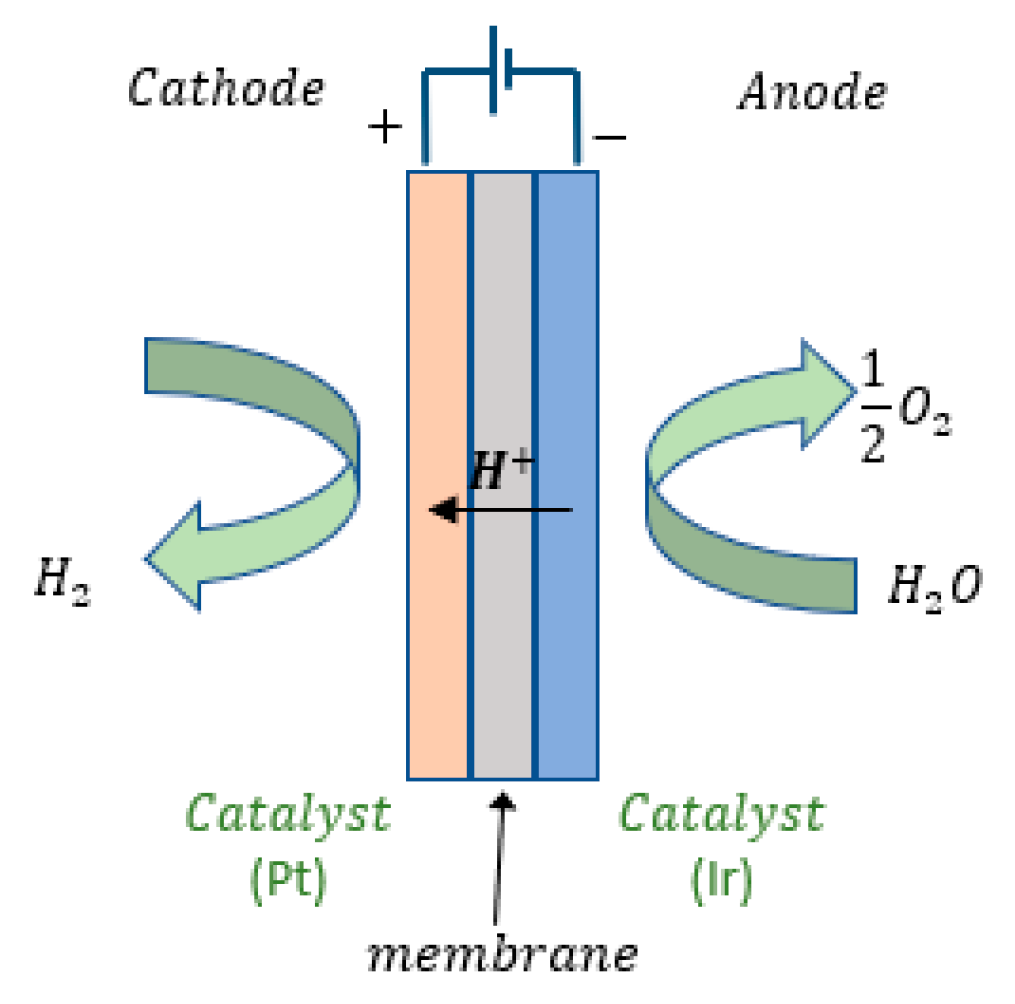
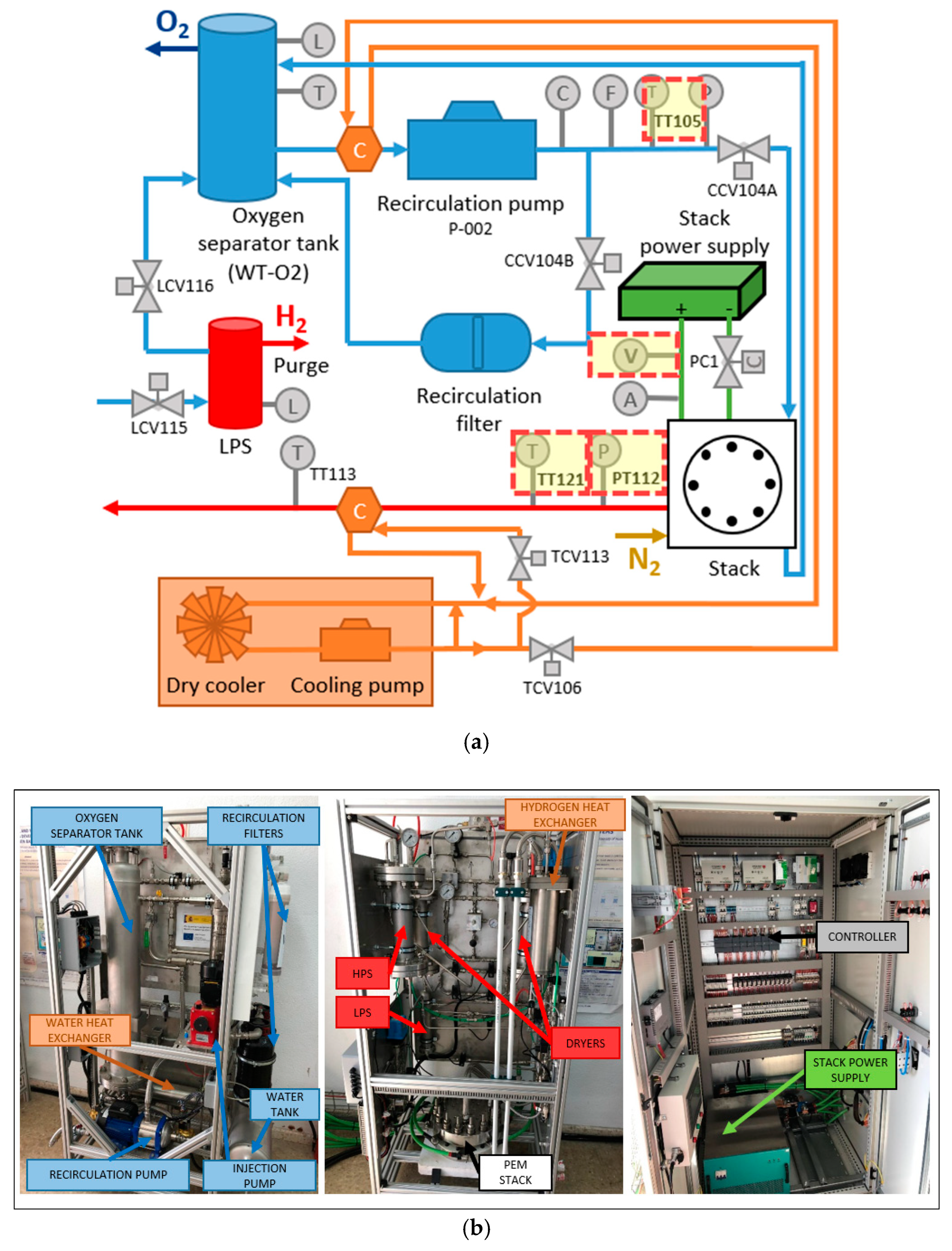
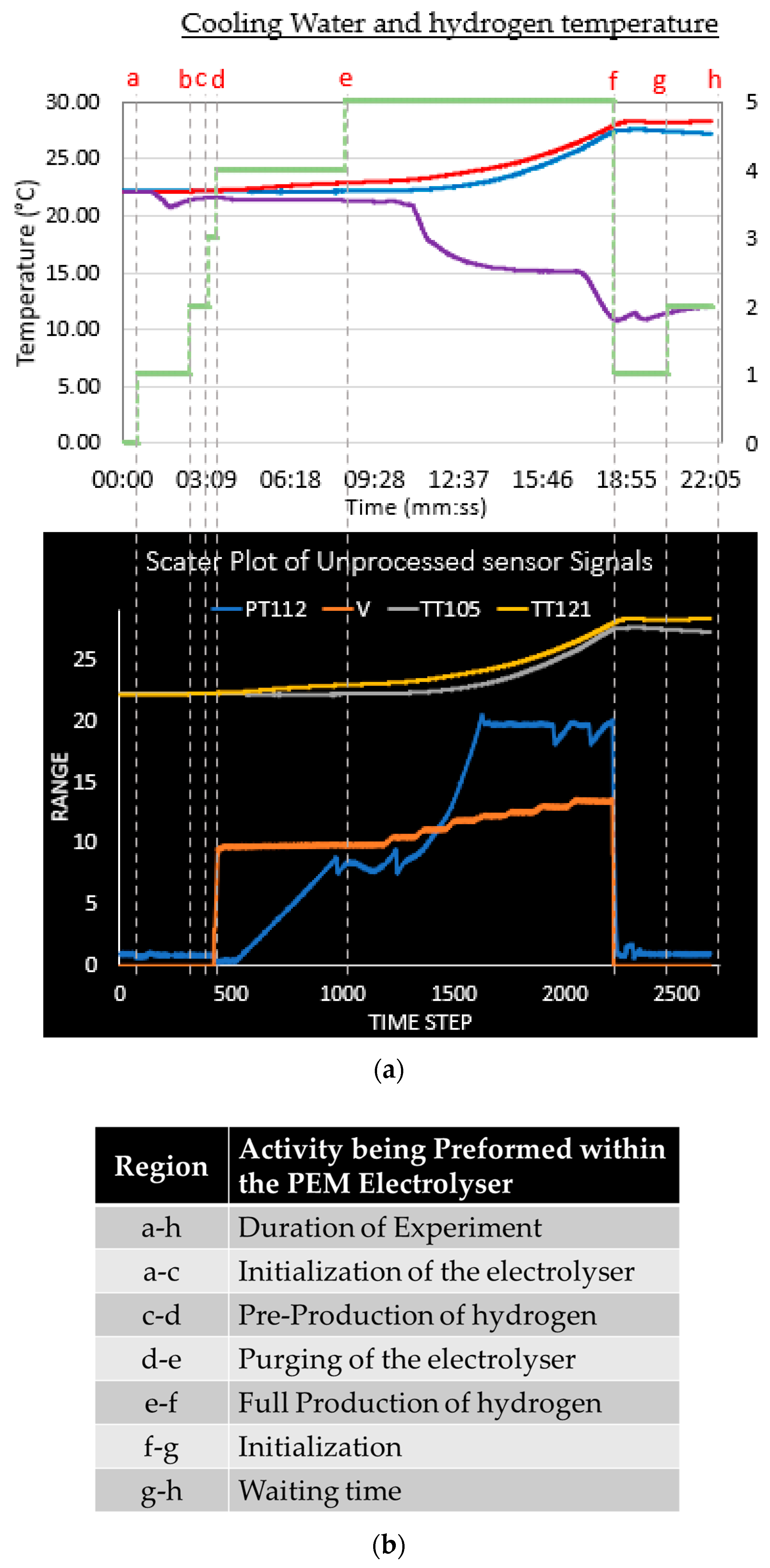
2.2. Materials for the Study
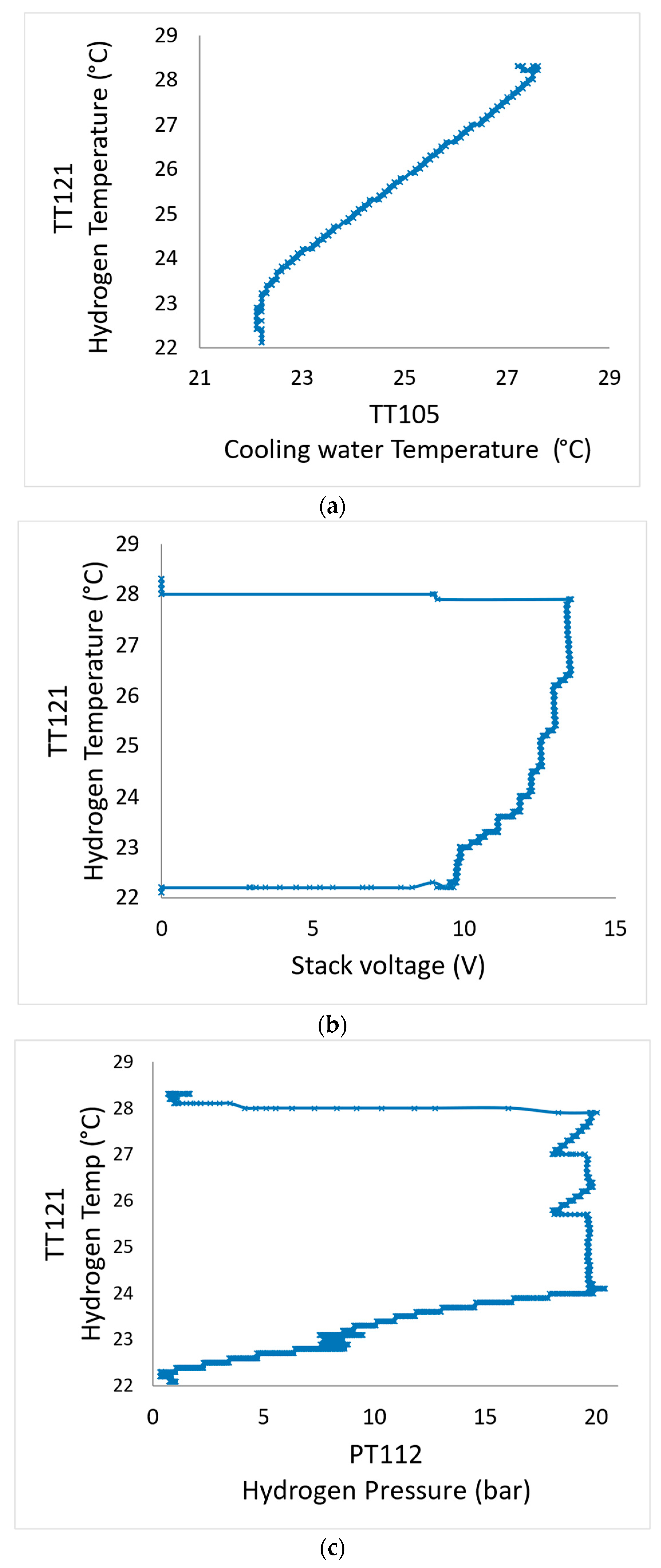
2.3. Method Phase 1—Pre-Processing of Input Data
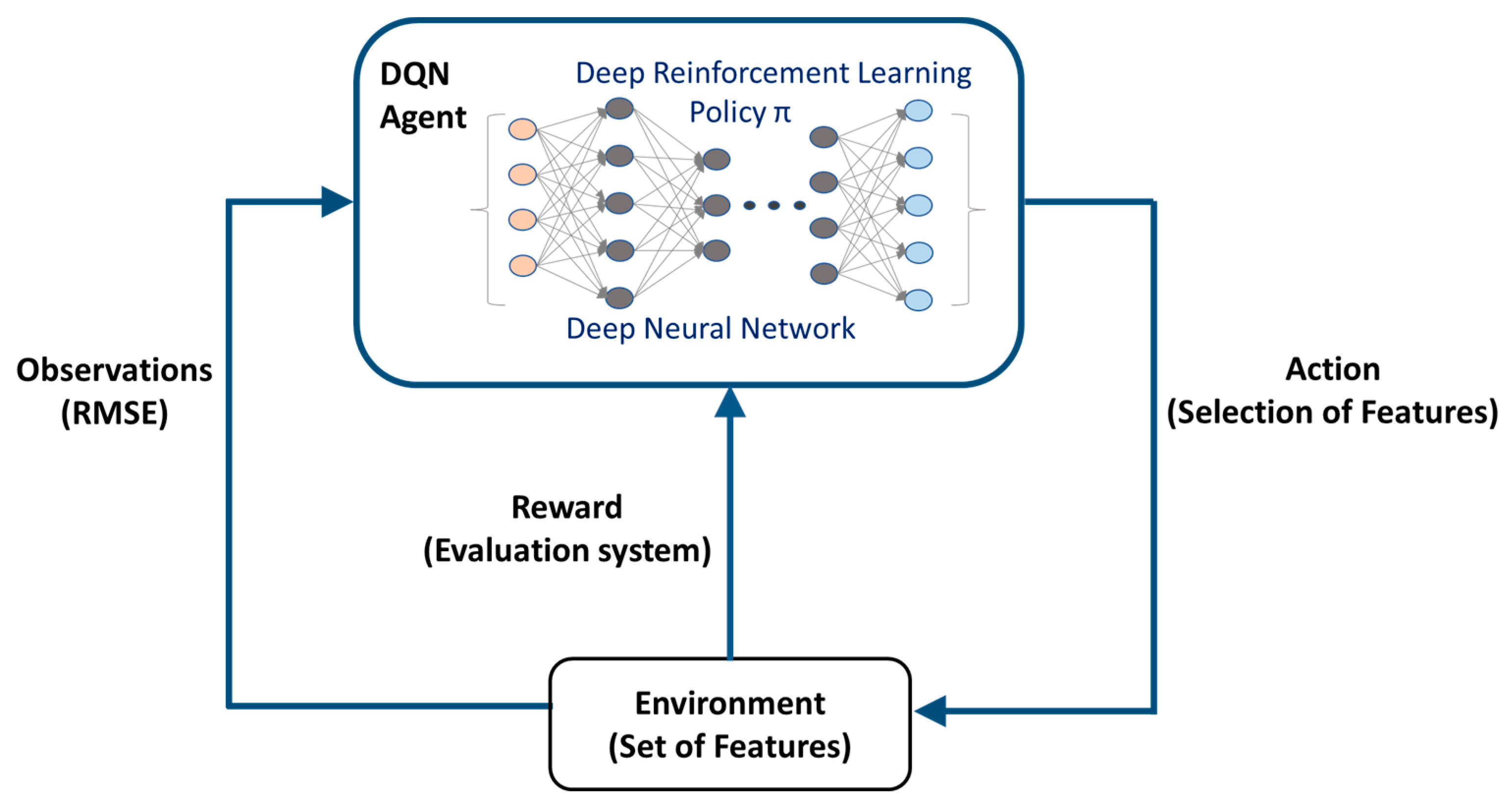
2.4. Method Phase 2—Conventional DRL for Selecting Features
- Explores the action space of the set of features;
- During each iteration interval, the agent selects a random action for which the value function is the greatest;
- The agent updates a critic based on a mini-batch of experiences.
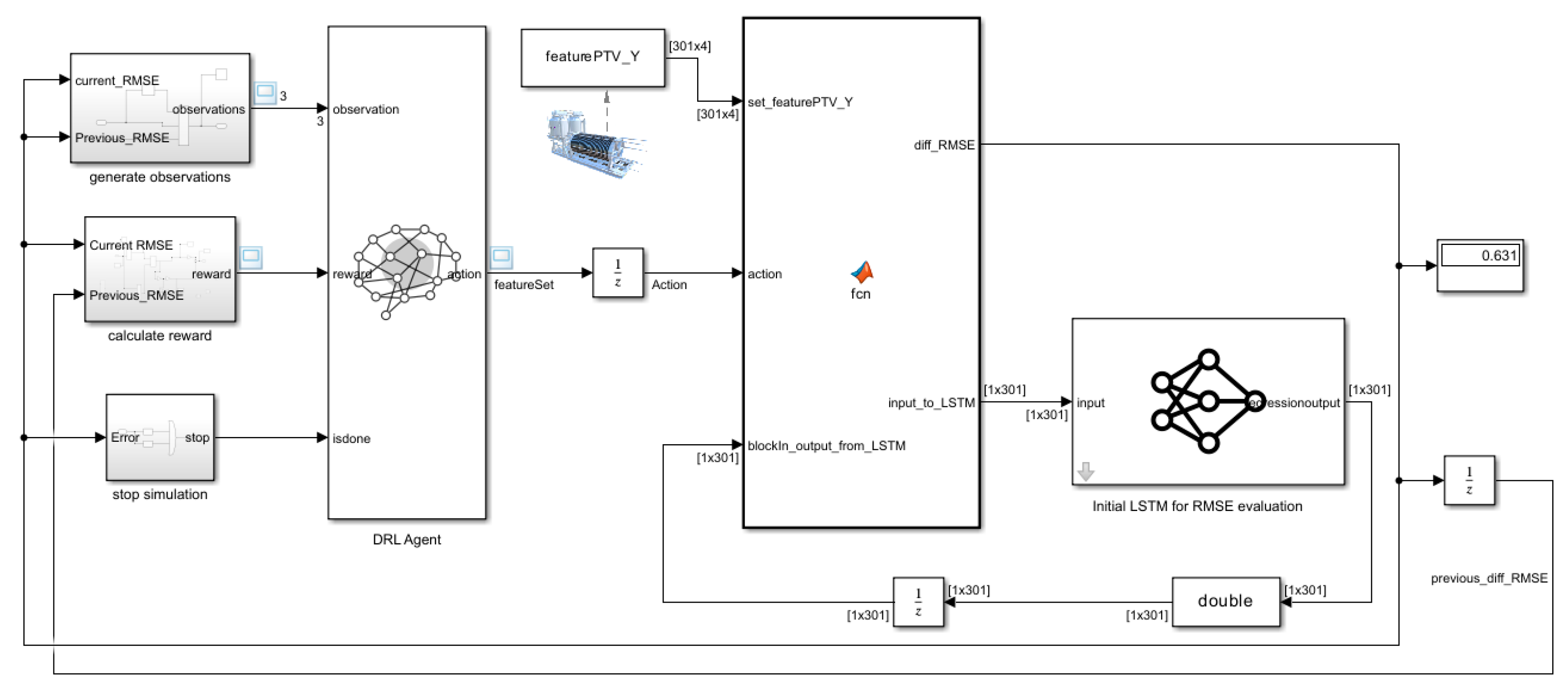
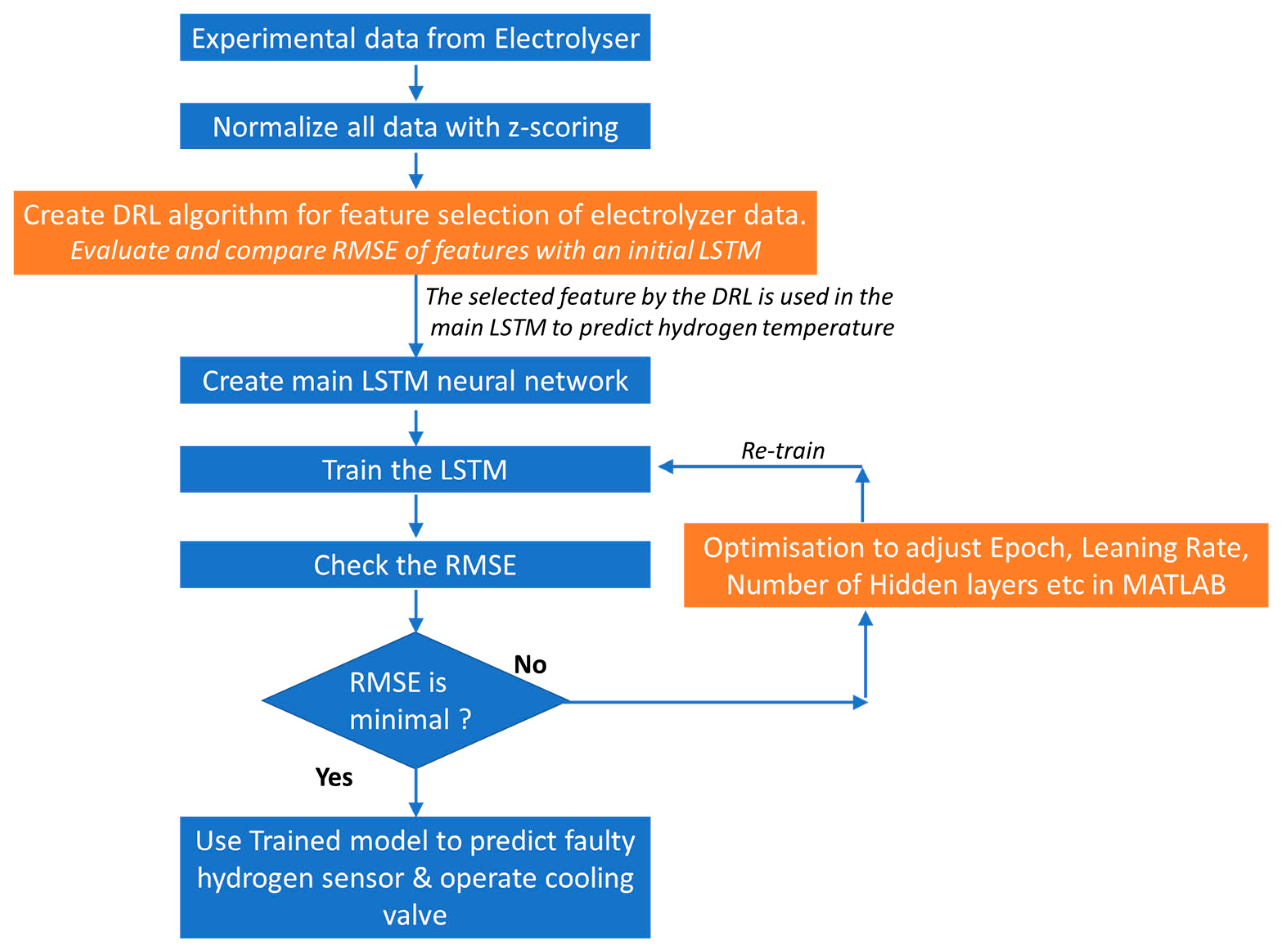
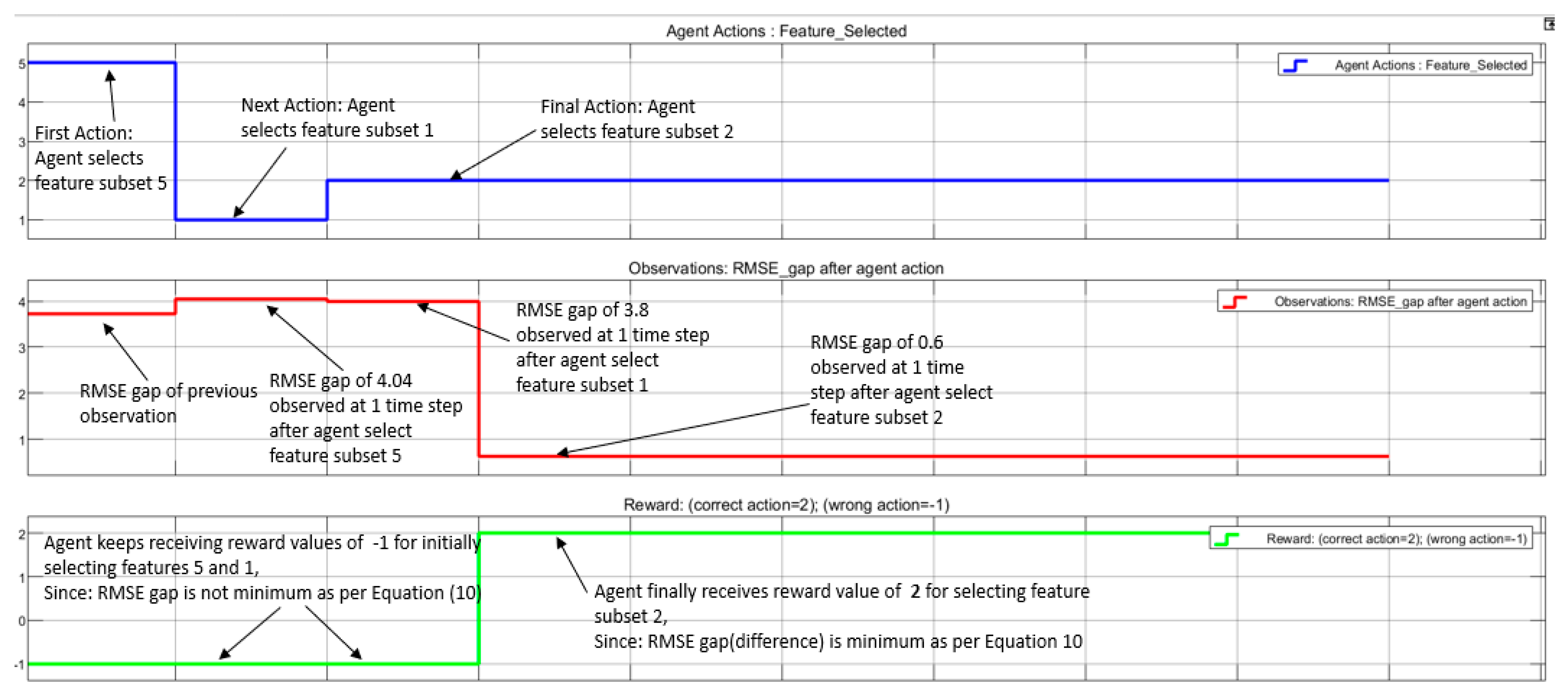
2.5. Method Phase 3—Authors’ Approach—DRL-Based Algorithm for Feature Selection Using Novel Evaluation Criteria
| Algorithm 1 Novel DRL algorithm proposed by authors | |
| Step 1: | Input data consisting of features: pressure [PT112], cooling water temperature [TT105], stack voltage [V], and hydrogen temperature [TT121]. |
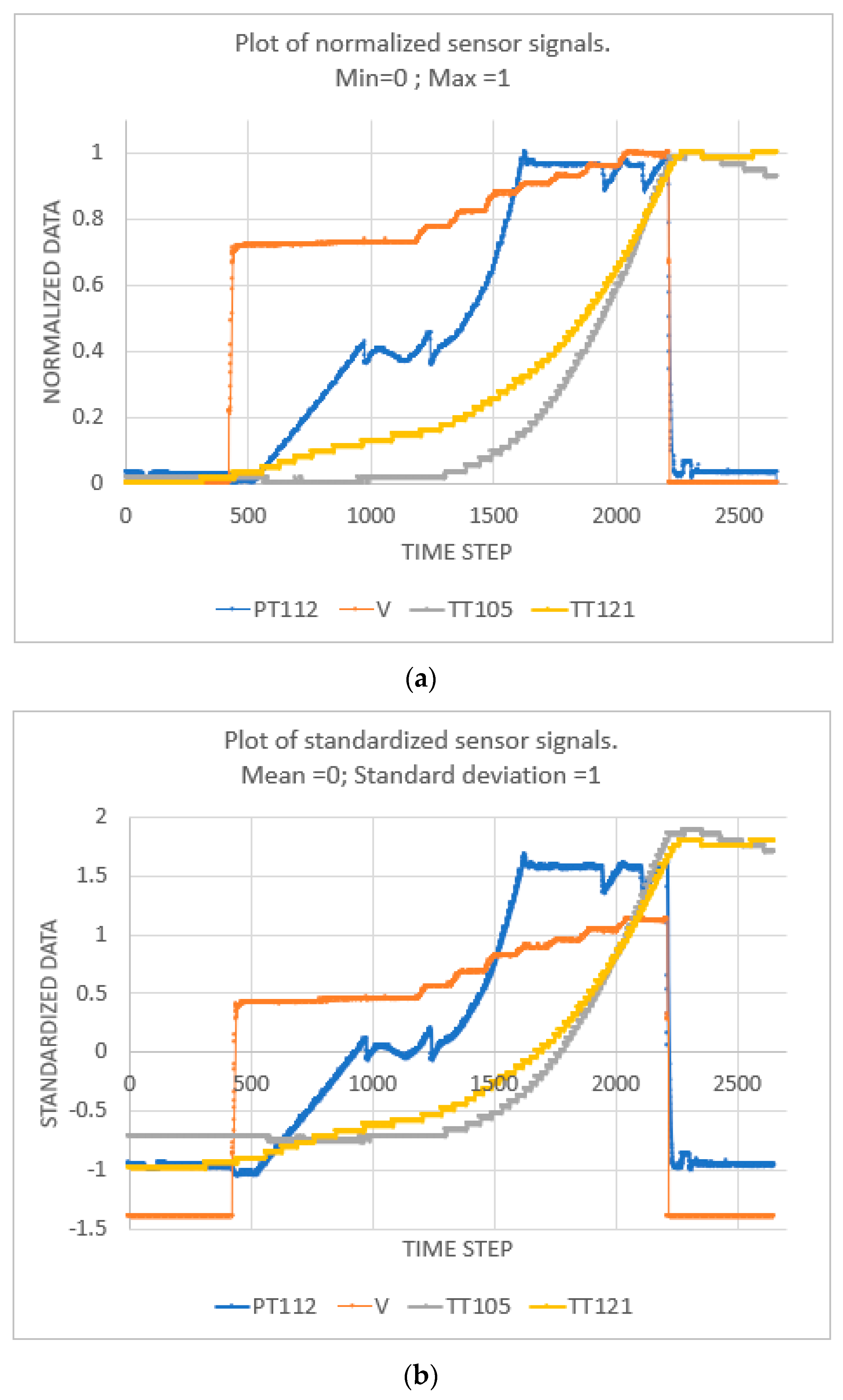
| Step 2: | Normalise each feature using: z-scoring → (data-mean)/(standard_deviation). |
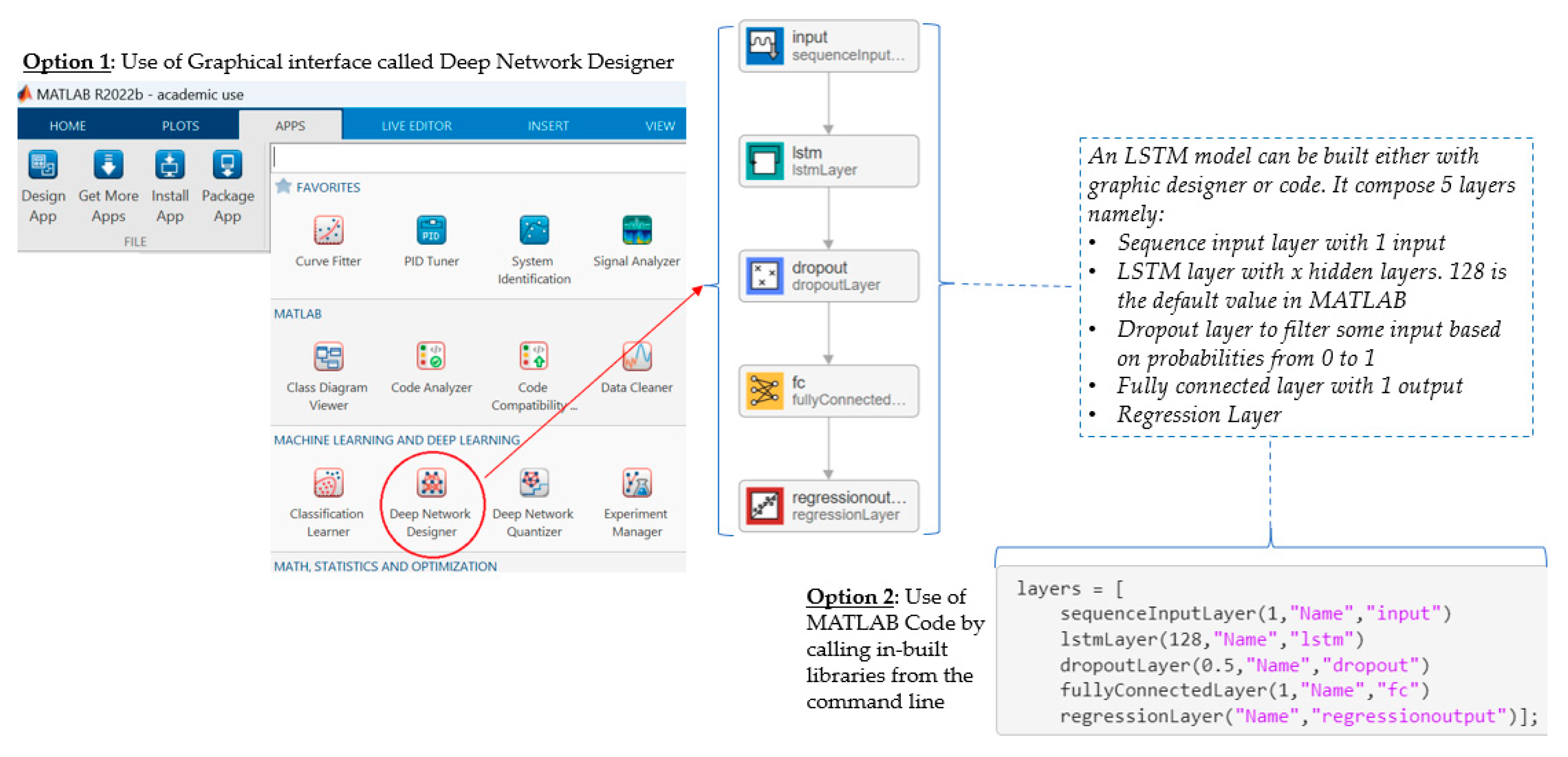
| Step 3: | Create and train an initial deep neural network (LTSM) with [TT121], as both input and output. |
| Step 4: | Obtain the matrix consisting of the subset of features. Subset 1 = [PT112]; Subset 2 = [TT105], Subset 3 = [V]; Subset 4 = [PT112, TT105], Subset 5 = [PT112, V]; Subset 6 = [TT105, V]; Subset 7 = [PT112, V, TT105]. |
| Step 5: | For feature subsets having two or more sensor data, obtain a single representation by computing the average. |
| Step 6: | Create DRL environment model with observations and action settings based on Table 3. |
| Step 7: | Create a DRL agent based on DQN policy. |
| Step 8: | Define discrete actions for the DRL agent as scalar vector: Action = selection of features from the set in Step 4 |
| Step 9: | Define the reward for the agent based on expression Equation (10): If action results in minimum RMSE difference Then reward = 2 Else Reward = −1 End if |
| Step 10: | Train the RL agent |
| Step 11: | For: each stochastic action taken by the agent Receive observations from the environment model: error (RMSE) Calculate the reward of the selected action. If reward > 0, then Store feature selected by the agent Else Take another action to select another feature from the subset |
|
Endif End | |
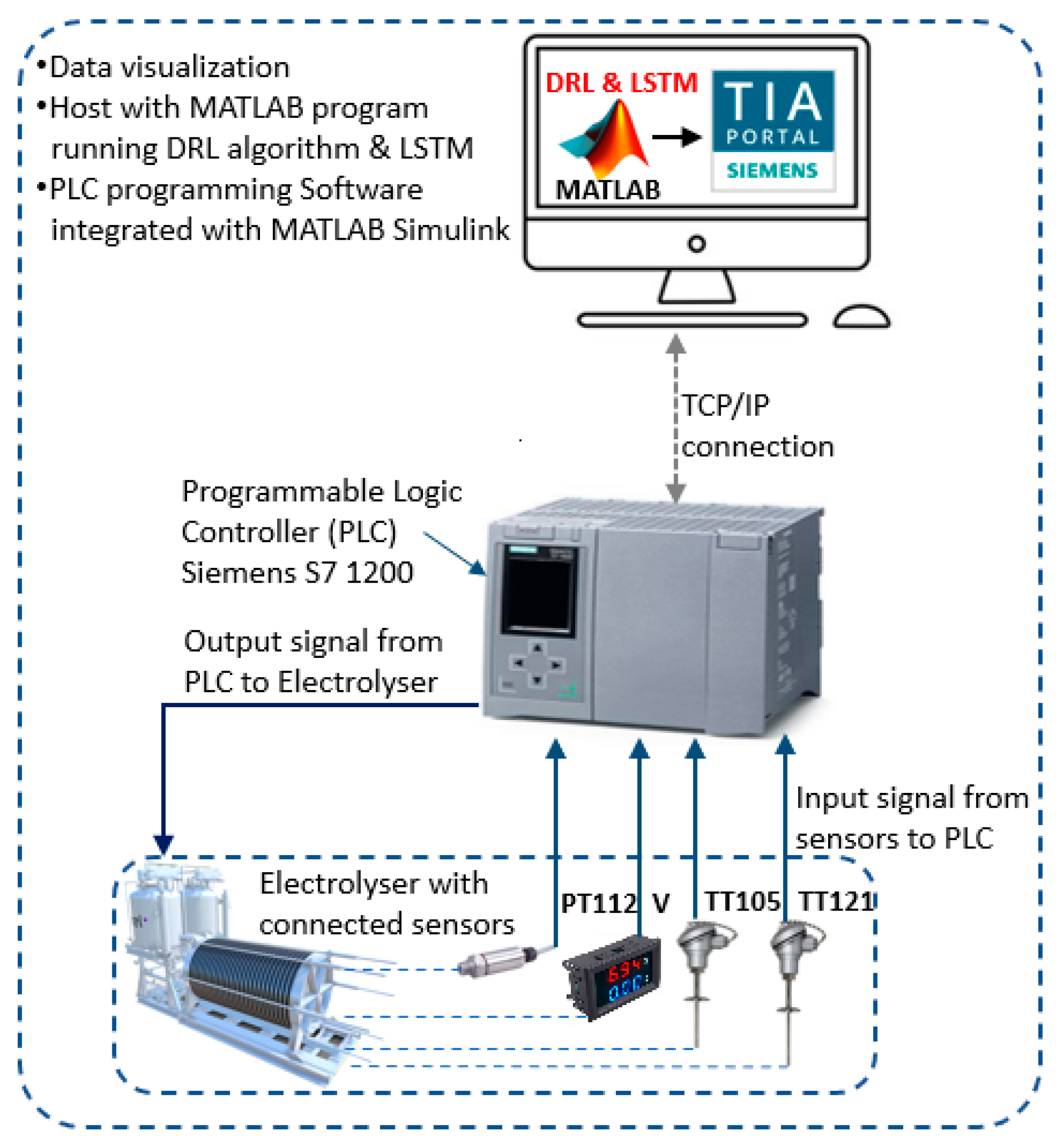
2.6. Method Phase 4—Artificial Intelligence-Based Predictive Maintenance for PEM Electrolyser
3. Results
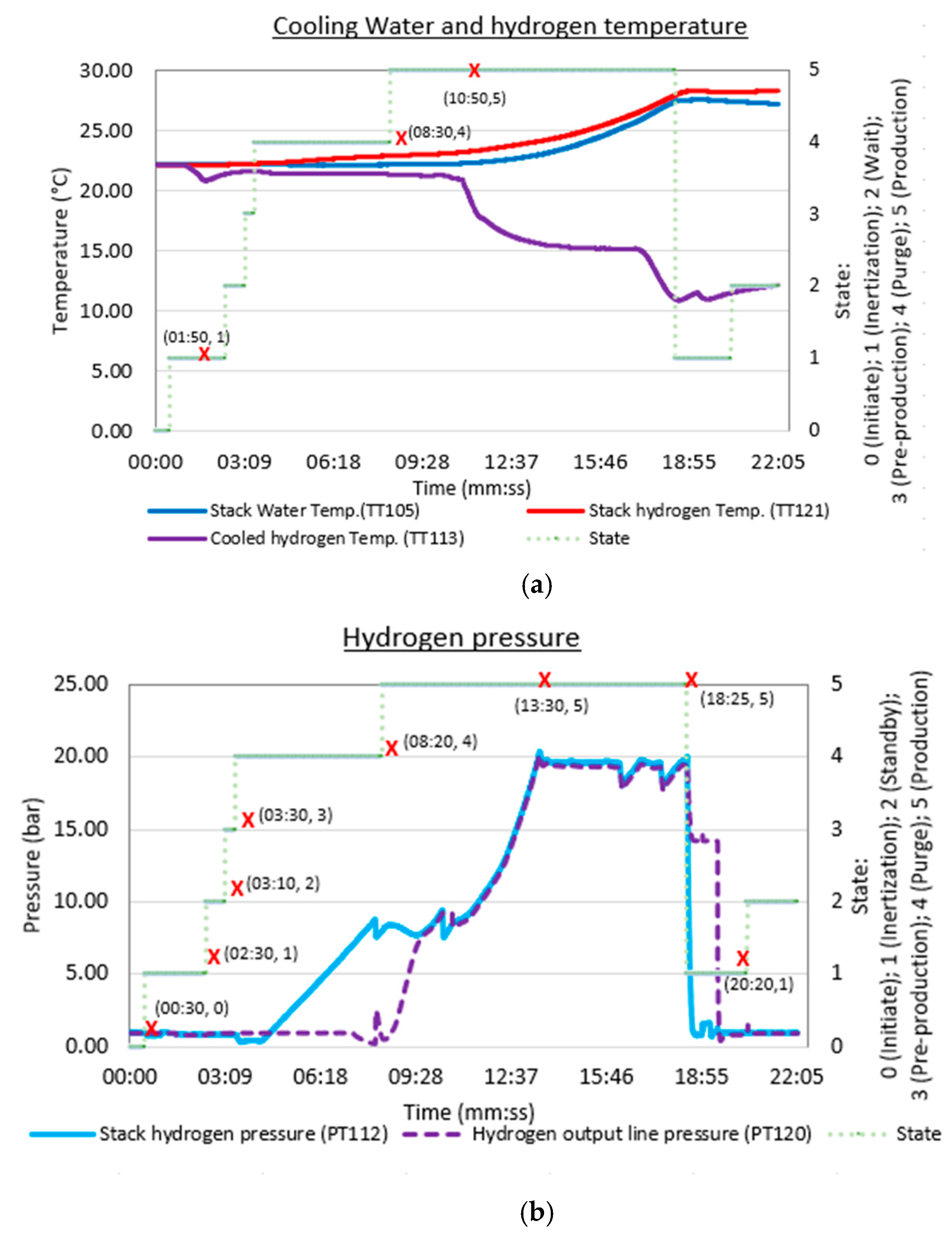
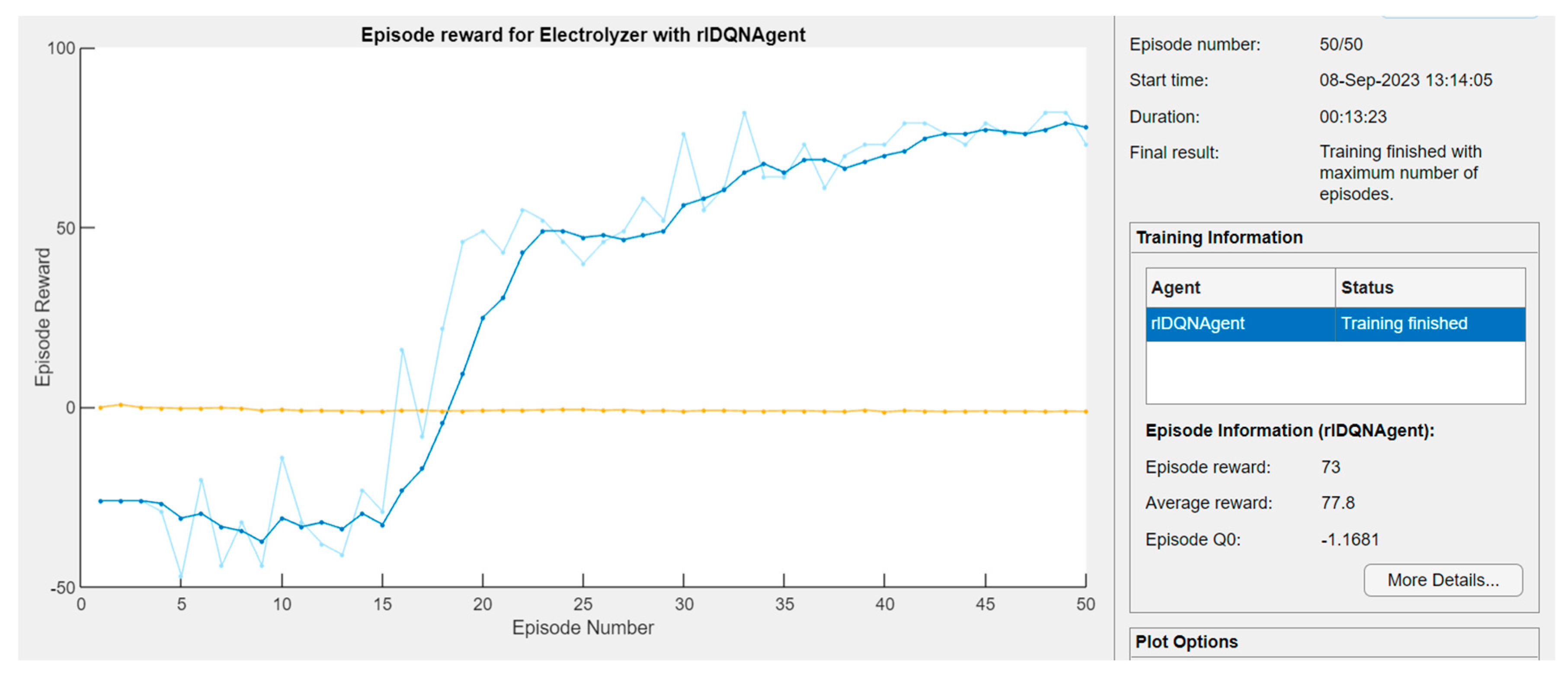
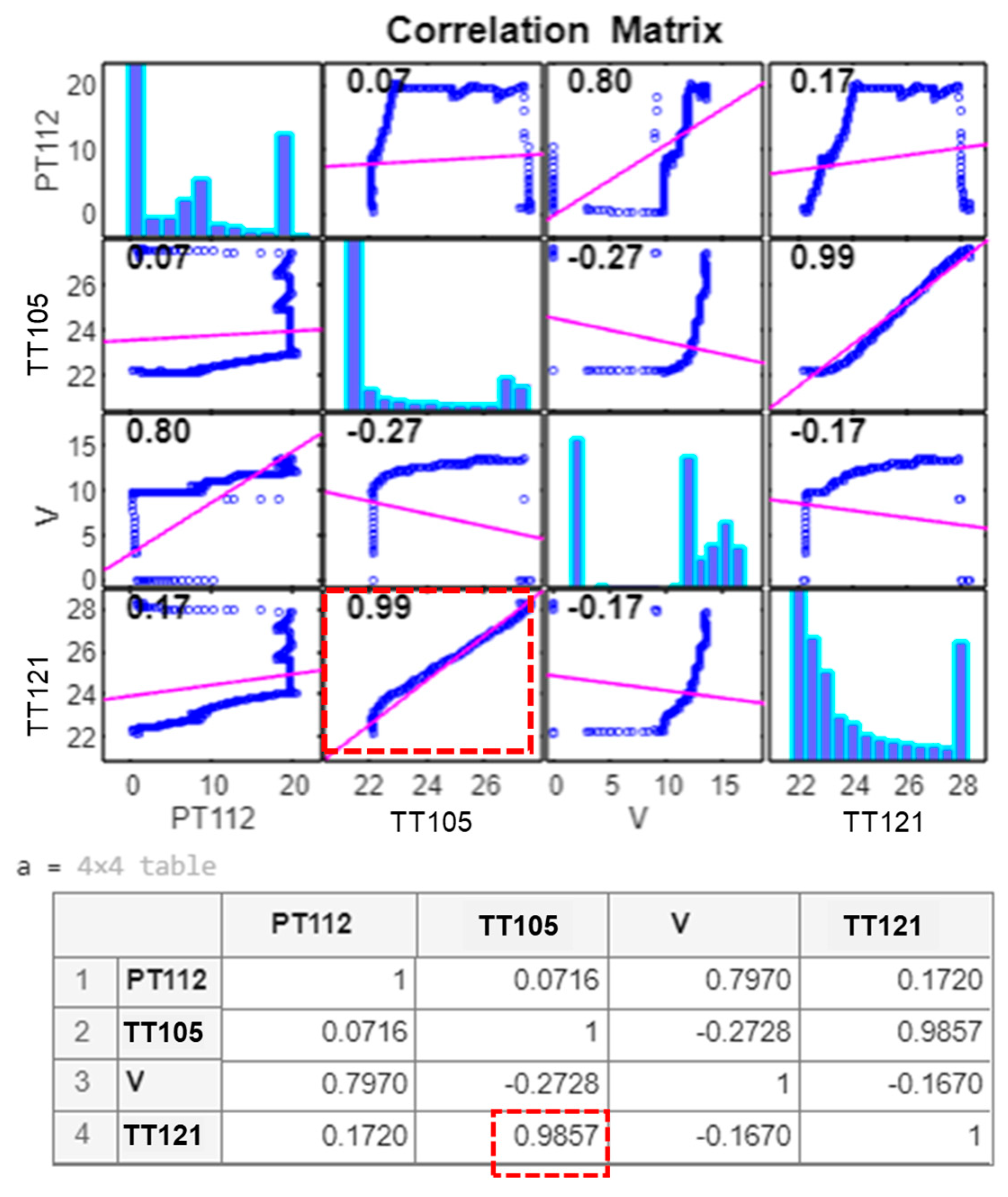
3.1. Results of Feature Selection Obtained from the Novel DRL Algorithm
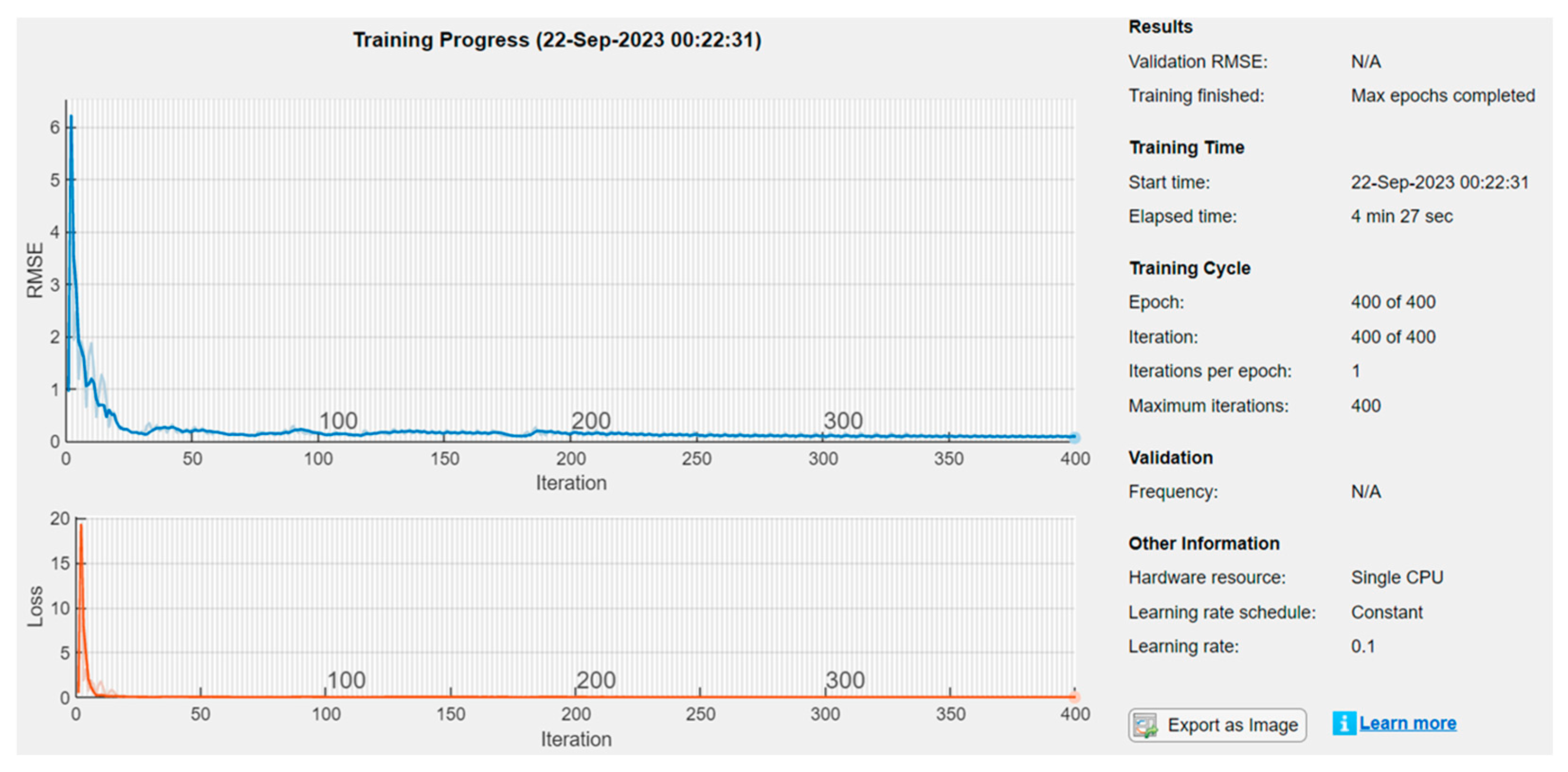
3.2. Results of Training and Prediction (Testing) with the LSTM Neural Network
- Training data size: time step 500:2300 (1800 data points = 90% of data);
- Test data size: time step 2301:2500 (200 data points = 10% of data).
3.3. Accuracy Validation—Comparison with Related Previous Works
4. Discussion
5. Conclusions
- Novel DRL algorithm: This selects the feature with the highest correlation with the hydrogen temperature transmitter (TT121), whose data is to be predicted in a PEM electrolyser. One of the novelties of the DRL algorithm lies in the method of evaluating each selected feature by the action of its internal agent, as discussed in Section 2.5 and shown in Figure 8, Figure 9 and Figure 10. The evaluation method is based on the comparison of a reference RMSE with the one obtained from the selected features. The DRL algorithm is also unique such that when the agent needs to select a feature subset consisting of more than one sensor data, the average value which gives a single representation of the combination is used for evaluation in the algorithm. This saves computation time.
- LSTM predictive model: The feature selected by the DRL algorithm is used by the LSTM model to predict the hydrogen temperature for use in predictive (smart) maintenance of the electrolyser. Parameters of the main LSTM were also studied using illustrative plots, as shown in Figure 19, to obtain an optimised combination to reduce the prediction error.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| ANN | Artificial Neural Networks |
| AORf | Average of Reward |
| BoP | Balance of Plant |
| DQN | Deep Q-network |
| DRL | Deep Reinforcement Learning |
| F | Condition of the feedwater |
| GPR | Gaussian Process Regression |
| HMI | Human Machine Interface |
| LSTM | Long Short-term Memory neural network |
| PEM | Proton Exchange Membrane |
| PHM | Prognostics and Health Management |
| RMSE | Root-mean-square error |
| MSE | Mean Squared Error |
| RMSEy | RMSE when the output y of a feature set is used to predict itself |
| RMSEf | RMSE when a selected feature f is used to predict the output |
| SCADA | Supervisory Control and Data Acquisition |
| SVM | Support Vector Machine |
| SGD | Stochastic Gradient Descent |
| LR | Learning Rate |
Symbols
| b | Bias added for each LSTM gate |
| Ct | Cell state of the LSTM at time t |
| C’t | Candidate value of cell state in the LSTM |
| ΔG | Gibbs free energy exchange (J) |
| ΔH | Enthalpy change (J) |
| ΔS | Entropy change (JK−1) |
| F | Faraday constant (26.81 Ah/mol) |
| ft | Forget gate of the LSTM |
| ht | Output for the hidden layer in LSTM at previous time t |
| ht−1 | Output for the hidden layer in LSTM at previous time t − 1 |
| iely | Current through the cell |
| it | Input gate of the LSTM |
| j | Current density |
| ncell | Number of cells |
| nf | Faraday efficiency which is affected by temperature |
| Molar flow rate of hydrogen (mol/h) | |
| Ot | Output gate of the LSTM |
| PT112 | Hydrogen pressure (bar) |
| R | Resistance of PEM membrane (Ω) |
| σ | Activation function (sigmoid function) in the LSTM |
| T | Operating temperature of the electrolyser (°C) |
| TT105 | Cooling water temperature (°C) |
| TT121 | Hydrogen water temperature exiting electrolyser (°C) |
| V | Electrolyser voltage (V) |
| v(featuret) | Assessment value function of the current state |
| v(featuret+1) | Assessment value function of successor states |
| Weight of forgot gate in LSTM | |
| Weight of input gate in LSTM | |
| Weight of output gate in LSTM | |
| xt | Input to the LSTM at time t |
References
- Rey, J.; Segura, F.; Andújar, J.M.; Ferrario, A.M. The Economic Impact and Carbon Footprint Dependence of Energy Management Strategies in Hydrogen-Based Microgrids. Electronics 2023, 12, 3703. [Google Scholar] [CrossRef]
- BS EN 13306:2010; British Standard, Maintenance Terminology. European Standard: London, UK, 2010.
- Ben-Daya, M.; Kumar, U.; Murthy, D.P. Introduction to Maintenance Engineering; Wiley: Hoboken, NJ, USA, 2016. [Google Scholar]
- Namuduri, S.; Narayanan, B.N.; Davuluru, V.S.P.; Burton, L.; Bhansali, S. Review—Deep Learning Methods for Sensor Based Predictive Maintenance and Future Perspectives for Electrochemical Sensors. J. Electrochem. Soc. 2020, 167, 037552. [Google Scholar] [CrossRef]
- Siracusano, S.; Van Dijk, N.; Backhouse, R.; Merlo, L.; Baglio, V.; Aricò, A. Degradation issues of PEM electrolysis MEAs. Renew. Energy 2018, 123, 52–57. [Google Scholar] [CrossRef]
- Li, N.; Araya, S.S.; Kær, S.K. The effect of Fe3+ contamination in feed water on proton exchange membrane electrolyzer performance. Int. J. Hydrogen Energy 2019, 44, 12952–12957. [Google Scholar] [CrossRef]
- Frensch, S.H.; Serre, G.; Fouda-Onana, F.; Jensen, H.C.; Christensen, M.L.; Araya, S.S.; Kær, S.K. Impact of iron and hydrogen peroxide on membrane degradation for polymer electrolyte membrane water electrolysis: Computational and experimental investigation on fluoride emission. J. Power Sources 2019, 420, 54–62. [Google Scholar] [CrossRef]
- Chandesris, M.; Médeau, V.; Guillet, N.; Chelghoum, S.; Thoby, D.; Fouda-Onana, F. Membrane degradation in PEM water electrolyzer: Numerical modeling and experimental evidence of the influence of temperature and current density. Int. J. Hydrogen Energy 2015, 40, 1353–1366. [Google Scholar] [CrossRef]
- Norazahar, N.; Khan, F.; Rahmani, N.; Ahmad, A. Degradation modelling and reliability analysis of PEM electrolyzer. Int. J. Hydrogen Energy, 2023; in press. [Google Scholar] [CrossRef]
- Fard, S.M.H.; Hamzeh, A.; Hashemi, S. Using reinforcement learning to find an optimal set of features. Comput. Math. Appl. 2013, 66, 1892–1904. [Google Scholar] [CrossRef]
- Pandit, A.A.; Pimpale, B.; Dubey, S. A Comprehensive Review on Unsupervised Feature Selection Algorithms; Springer: Berlin/Heidelberg, Germany, 2020; pp. 255–266. [Google Scholar] [CrossRef]
- Kim, M.; Bae, J.; Wang, B.; Ko, H.; Lim, J.S. Feature Selection Method Using Multi-Agent Reinforcement Learning Based on Guide Agents. Sensors 2022, 23, 98. [Google Scholar] [CrossRef]
- Kumar, R.; Kumar, S.; Cirrincione, G.; Cirrincione, M.; Guilbert, D.; Ram, K.; Mohammadi, A. Power Switch Open-Circuit Fault-Diagnosis Based on a Shallow Long-Short Term Memory Neural Network: Investigation of an Interleaved Buck Converter for Electrolyzer applications. In Proceedings of the 2021 IEEE Energy Conversion Congress and Exposition, ECCE 2021, Virtual, 10–14 October 2021; pp. 483–488. [Google Scholar] [CrossRef]
- Mohamed, A.; Ibrahem, H.; Yang, R.; Kim, K. Optimization of Proton Exchange Membrane Electrolyzer Cell Design Using Machine Learning. Energies 2022, 15, 6657. [Google Scholar] [CrossRef]
- Lee, H.; Gu, J.; Lee, B.; Cho, H.-S.; Lim, H. Prognostics and health management of alkaline water electrolyzer: Techno-economic analysis considering replacement moment. Energy AI 2023, 13, 100251. [Google Scholar] [CrossRef]
- Bahr, M.; Gusak, A.; Stypka, S.; Oberschachtsiek, B. Artificial Neural Networks for Aging Simulation of Electrolysis Stacks. Chem. Ing. Tech. 2020, 92, 1610–1617. [Google Scholar] [CrossRef]
- Zhao, D.; He, Q.; Yu, J.; Guo, M.; Fu, J.; Li, X.; Ni, M. A data-driven digital-twin model and control of high temperature proton exchange membrane electrolyzer cells. Int. J. Hydrogen Energy 2022, 47, 8687–8699. [Google Scholar] [CrossRef]
- Hudson, M.; Martin, B.; Hagan, T.; Demuth, H.B. Deep Learning ToolboxTM User’s Guide. 2023. Available online: www.mathworks.com (accessed on 26 July 2023).
- Kheirrouz, M.; Melino, F.; Ancona, M.A. Fault detection and diagnosis methods for green hydrogen production: A review. Int. J. Hydrogen Energy 2022, 47, 27747–27774. [Google Scholar] [CrossRef]
- Keddar, M.; Zhang, Z.; Periasamy, C.; Doumbia, M.L. Power quality improvement for 20 MW PEM water electrolysis system. Int. J. Hydrogen Energy 2022, 47, 40184–40195. [Google Scholar] [CrossRef]
- Mancera, J.J.C.; Manzano, F.S.; Andújar, J.M.; Vivas, F.J.; Calderón, A.J. An Optimized Balance of Plant for a Medium-Size PEM Electrolyzer: Design, Control and Physical Implementation. Electronics 2020, 9, 871. [Google Scholar] [CrossRef]
- Liu, C. Data Transformation: Standardization vs Normalization. Available online: https://www.kdnuggets.com/2020/04/data-transformation-standardization-normalization.html (accessed on 26 July 2023).
- de Arruda, H.F.; Benatti, A.; Comin, C.H.; Costa, L.d.F. Learning Deep Learning. Rev. Bras. Ensino Física 2022, 44. [Google Scholar] [CrossRef]
- Matlab. Reinforcement Learning ToolboxTM User’s Guide R2023a. 2019. Available online: www.mathworks.com (accessed on 26 July 2023).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Mikami, A. Long Short-Term Memory Recurrent Neural Network Architectures for Generating Music and Japanese Lyrics; Computer Science Department, Boston College: Boston, MA, USA, 2016. [Google Scholar]
- Guyon, I.; Elisseeff, A. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Siraskar, R.; Kumar, S.; Patil, S.; Bongale, A.; Kotecha, K. Reinforcement learning for predictive maintenance: A systematic technical review. Artif. Intell. Rev. 2023, 56, 1–63. [Google Scholar] [CrossRef]
- Duhirwe, P.N.; Ngarambe, J.; Yun, G.Y. Energy-efficient virtual sensor-based deep reinforcement learning control of indoor CO2 in a kindergarten. Front. Arch. Res. 2023, 12, 394–409. [Google Scholar] [CrossRef]
- Pannakkong, W.; Vinh, V.T.; Tuyen, N.N.M.; Buddhakulsomsiri, J. A Reinforcement Learning Approach for Ensemble Machine Learning Models in Peak Electricity Forecasting. Energies 2023, 16, 5099. [Google Scholar] [CrossRef]
- Liu, H.; Yu, C.; Wu, H.; Duan, Z.; Yan, G. A new hybrid ensemble deep reinforcement learning model for wind speed short term forecasting. Energy 2020, 202, 117794. [Google Scholar] [CrossRef]
- Chen, C.; Liu, H. Dynamic ensemble wind speed prediction model based on hybrid deep reinforcement learning. Adv. Eng. Informa. 2021, 48, 101290. [Google Scholar] [CrossRef]
- Almughram, O.; Abdullah ben Slama, S.; Zafar, B.A. A Reinforcement Learning Approach for Integrating an Intelligent Home Energy Management System with a Vehicle-to-Home Unit. Appl. Sci. 2023, 13, 5539. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scientific Studies | Key Contributions | Data Selection and Evaluation Method | Artificial Intelligence Concept Used for Predictive Maintenance of Electrolyser |
|---|---|---|---|
| Authors’ Proposal | Input data pre-processing. Predictive maintenance based on predicted data using artificial intelligence. | Novel algorithm based on hybridising DRL and LSTM neural network. | LSTM with optimised training strategy to reduce the root-mean-square error (RMSE). |
| Kumar et al. [13] | Open circuit fault prediction in the power converter of electrolyser. | n/a | LSTM |
| Mohamed et al. [14] | Prediction of different parameters of the electrolytic cell design using input parameters: hydrogen production rate, cathode area, anode area, and the type of cell design. | n/a | Machine learning models using polynomial and logistic regression. |
| Lee et al. [15] | Prognostics and health management model (PHM) to predict the load voltage of the electrolyser for the state of health information. The voltage is used as a state of health indicator which increases according to the time passed, and it is caused by the degradation of the electrolyser. | n/a | Machine learning models consisting of support vector machine (SVM) and Gaussian process regression (GPR) trained by using time, current, and power density as features and voltage as the output label to determine the potential fault. |
| Bahr et al. [16] | Application of artificial neural networks (ANN) in terms of modelling and simulating the aging process. | n/a | ANN with Stochastic gradient descent (SGD) is used to find the optimal weight parameters for the desired relationship between input and outputs. Inputs to the neural network are stack current, temperature, and time while the output is the voltage. |
| Zhao et al. [17] | Data-driven digital-twin model to develop a dynamic model for predicting power consumption, hydrogen production, and temperature. | n/a | Fuzzy logic and neural network are implemented to improve the durability of the electrolyser. |
| Component | Stack Model | Technical Characteristics |
|---|---|---|
| PEM Electrolyser | GINER® Merrimack stack | H2 production (Max): 2.22 Nm3/h Current density range: 300–3000 mA/cm2 Maximum H2 operating pressure: 40 bar Maximum operating temperature: 70 °C Cell voltage: 1.94 V Cell dimensions: Ø 352.44 mm Number of cells: 6 |
| DRL Model Component | Type | Training Parameter | Value |
|---|---|---|---|
| DRL agent policy | DQN | Learning rate Number of hidden layers Gradient threshold Discount factor Batch size Initial epsilon Epsilon decay Epsilon min Number of training episodes | 0.01 128 1 0.99 64 1 0.005 0.01 50 |
| Environment | Observation type Observation dimension Action type Actions Observation lower limit Observation upper lower limit | Continuous [3, 1] Discrete [1, 2, 3, 4, 5, 6, 7] [−inf, −inf, 0] [inf, inf, inf] |
| Training Parameter | Value | Training RMSE (LSTM) | Testing RMSE (Predicted Variable TT121) |
|---|---|---|---|
| Learning rate | 0.1 | 0.09 | 0.1351 |
| Number of layers | 40 | ||
| Epoch | 400 | ||
| Gradient threshold | 1 | ||
| Dropout | none (0) |
| Study | Method Used | Testing RMSE |
|---|---|---|
| Authors’ proposal | Hybrid of deep reinforcement learning (DRL) and long short-term memory (LSTM) | 0.1351 |
| Siraskar et al. [28] | Auto-setup reinforcement learning algorithm | 0.2082 |
| Duhirwe et al. [29] | Hybrid of DRL with extreme gradient boosting | 4.008 |
| Pannakkong et al. [30] | Reinforcement learning based on double DQN | 0.3956 * |
| Liu et al. [31] | Hybrid ensemble DRL | 0.9327 |
| Chen et al. [32] | Dynamic ensemble model based on deep reinforcement learning | 1.7416 |
| Almughram et al. [33] | Reinforcement learning hybridised with LSTM | 0.5196 * |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abiola, A.; Manzano, F.S.; Andújar, J.M. A Novel Deep Reinforcement Learning (DRL) Algorithm to Apply Artificial Intelligence-Based Maintenance in Electrolysers. Algorithms 2023, 16, 541. https://doi.org/10.3390/a16120541
Abiola A, Manzano FS, Andújar JM. A Novel Deep Reinforcement Learning (DRL) Algorithm to Apply Artificial Intelligence-Based Maintenance in Electrolysers. Algorithms. 2023; 16(12):541. https://doi.org/10.3390/a16120541
Chicago/Turabian StyleAbiola, Abiodun, Francisca Segura Manzano, and José Manuel Andújar. 2023. "A Novel Deep Reinforcement Learning (DRL) Algorithm to Apply Artificial Intelligence-Based Maintenance in Electrolysers" Algorithms 16, no. 12: 541. https://doi.org/10.3390/a16120541
APA StyleAbiola, A., Manzano, F. S., & Andújar, J. M. (2023). A Novel Deep Reinforcement Learning (DRL) Algorithm to Apply Artificial Intelligence-Based Maintenance in Electrolysers. Algorithms, 16(12), 541. https://doi.org/10.3390/a16120541