1. Introduction
Optimization concerns best decision-making, which is present in almost aspects of society. Formally speaking, it aims to optimize some criterion, called the
objective function, over some parameters of variables of interest. In many cases, the variable to optimize possesses certain constraints that should be incorporated or respected in the optimization process. There are studies on constrained optimization incorporating linear and nonlinear constraints, including Lagrange-based algorithms and interior points methods. Our work focuses on an important class of optimization problems with
geometric constraints in which the parameters or variables to be optimized are assumed to lie on some manifolds, a well-characterized object in differential geometry. In other words, we deal with
optimization problems on manifolds. Optimization on manifolds has abundant applications in modern data science. This is motivated by the systematic collection of modern complex data that take the manifold form. For example, one may encounter data in the forms of
positive definite matrices [
1], shape objects [
2], subspaces [
3,
4], networks and orthonormal frames [
5]. Statistical inference and learning of such data sets often involve optimization problems over manifolds. One of the notable examples is the estimation of the Fréchet mean for statistical inference, which can be cast as an optimization of the Fréchet function over manifolds [
6,
7,
8]. In addition to various examples with data and parameters lying on manifolds, many learning problems in big data analysis with the primary goal of extracting some lower-dimensions structure, and this lower-dimensional structure is often assumed to be a manifold. Learning this lower-dimensional structure often requires solving optimization problems over manifolds such as the Grassmannian.
The critical challenge for solving
optimization problems over manifolds lies in how to appropriately incorporate the underlying geometry of manifolds for optimization. Although there has been a fast development in optimization (over Euclidean spaces in general), and it is an extremely active ongoing research area, there is a tremendous challenge for extending theories and algorithms developed in optimization over Euclidean spaces to manifolds. The optimization approach on manifolds is superior to performing free Euclidean optimization and projecting the parameters back onto the search space after each iteration, such as in the projected gradient descent method. It has been shown to outperform standard algorithms for many problems [
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21]. Some of those algorithms, such as the Newton method [
22,
23], conjugate gradient descent algorithm [
3], steepest descent [
24], and trusted region method [
25,
26,
27,
28], have recently been extended to the Riemannian manifold from the Euclidean space, and most of the methods require the knowledge of the gradients [
29,
30,
31,
32,
33]. However, in many cases, analytical or simple forms of gradient information are unavailable. In other cases, the evaluations and calculations of the gradient or the Hessian (second form for the case of the manifold) can be expensive. There is a lack of gradient-free methods for optimization problems when the gradient information is not available or expensive to obtain or the objective function is expensive to evaluate. In these scenarios, gradient-free methods can be appealing alternatives. Many gradient-free methods are proposed for optimization problems in the Euclidean space, especially the state-of-the-art Bayesian optimization method, which has emerged as a very powerful tool in machine learning for tuning both learning parameters and hyperparameters [
34]. Such algorithms outperform many other global optimization algorithms [
35]. Bayesian optimization originated with the work of Kushner and Mockus [
36,
37]. It received considerably more attention after Jones’ work on the Efficient Global Optimization (EGO) algorithm [
38]. Following that work, innovations developed in the same literature include multi-fidelity optimization [
39], multi-objective optimization [
40], and a study of convergence rates [
41]. The observation by Snoek [
34] that Bayesian optimization is useful for training deep neural networks sparked significant interest in machine learning. Within this trend, Bayesian optimization has also been used to choose laboratory experiments in materials and drug design [
42], in the calibration of environmental models [
43], and in reinforcement learning [
44].
However, most studies mainly focus on the input domain in a Euclidean space. In recent years, with the surging collection of complex data, it is not common for the input domain to have such a simple form. For instance, the inputs might be restricted to a non-Euclidean manifold. Ref. [
45] proposed a general extrinsic framework for GP modeling on manifolds, which depends on the embedding of the manifold in the Euclidean space and the construction of extrinsic kernels for GPs on their images. Ref. [
46] learned a nested-manifold embedding and a representation of the objective function in the latent space using Bayesian optimization in low-dimensional latent spaces. Ref. [
47] exploited the geometry of non-Euclidean parameter spaces arising in robotics by using Bayesian optimization to properly measure similarities in the parameter space through the Gaussian process. Recently, Ref. [
48] implemented Riemannian Matern kernels on manifolds to place the Gaussian process prior and applied these kernels on the geometry-aware Bayesian optimization for a variety of robotic applications, including orientation control, manipulability optimization, and motion planning.
Motivated by the success of Bayesian optimization algorithms, in this work, we propose to develop the eBO framework on manifolds. In particular, we employ an extrinsic class of Gaussian processes on manifolds as the surrogate model for the objective function and utilize the uncertainty for calculating the acquisition function. An acquisition function can also be defined from this surrogate to decide where to sample [
49]. The algorithms are demonstrated and applied to both simulated and real data sets to various optimization problems over different manifolds, including spheres, positive definite matrices, and the Grassmannian.
We organize our work as follows. In
Section 2, we provide a streamlined introduction to Bayesian optimization on manifolds employing the extrinsic Gaussian process (eGP) on manifolds. In
Section 3, we present a concrete illustration of our eBO algorithm in the extrinsic setting in terms of optimizing the acquisition function from eGP. In
Section 4, we demonstrate numerical experiments on optimization problems over different manifolds, including spheres, positive definite matrices, and the Grassmann manifold, and showcase the performance of our approach.
2. Bayesian Optimization (BO) on Manifolds
Let
be an objective function defined over some manifold
M. We are interested in solving
Typically, the function
f lacks a known special structure such as concavity or linearity that would make it easy to optimize using techniques that leverage such structure to improve efficiency. Furthermore, we assume one only needs to be able to evaluate
without having to know first or second-order information, such as gradient, when evaluating
f. We refer to problems having this property as “derivative-free”. Lastly, we seek to know if the global optimizer exists. The principal ideas behind Bayesian optimization are to build a probabilistic model for the objective function by imposing a
Gaussian process prior, and this probabilistic model will be used to guide to where in
M the function is next evaluated. The posterior predictive distribution will then be computed. Instead of optimizing the usually expensive objective function, a cheap proxy function is often optimized, which will determine the next point to evaluate. One of the inherent difficulties lies in constructing
valid Gaussian processes on manifolds that will be utilized for Bayesian optimization on manifolds.
To be more specific, as above, let
be the objective function on
M for which we omit the potential dependence on some data; for now, the goal is to find the minimum:
. Let
,
, be a Gaussian process (GP) on the manifold
M with mean function
and covariance kernel
. Then we evaluate
at a finite number of points on the manifold following a multivariate Gaussian distribution, that is,
Here
is a covariance kernel defined on the manifold, which is a
positive semi-definite kernel on
M. It states that, for any sequence
,
After some evaluations, the GP gives us closed-form marginal means and variances. We denote the predictive means and variance as
and
, where
. The acquisition function, which we denote by
, determines which point in
M should be evaluated next via a proxy optimization
There are several popular choices of acquisition functions that are proposed for Bayesian optimization in Euclidean space [
49]. The analogous version can be generalized to manifolds. Under the Gaussian process prior, these functions depend on the model solely through its predictive mean function
and variance
. In the preceding, we denote the best current value as
We denote the cumulative distribution function of the standard normal as
. We adopt one of the acquisition functions as
which represents the
probability of improvement. Other acquisition functions, such as knowledge gradient and entropy search on manifolds, could also be developed, but here we focus on probability improvement. As seen above, a key component of Bayesian optimization methods on manifolds is utilizing Gaussian processes on a manifold
M, which are non-trivial to construct. The critical challenge for constructing the Gaussian process is constructing
valid covariance kernel on manifolds. In the following sections, we will utilize extrinsic Gaussian processes on manifolds by employing extrinsic covariance kernels via embeddings [
45] on the specific manifold.
3. Extrinsic Bayesian Optimization (eBO) on Manifolds
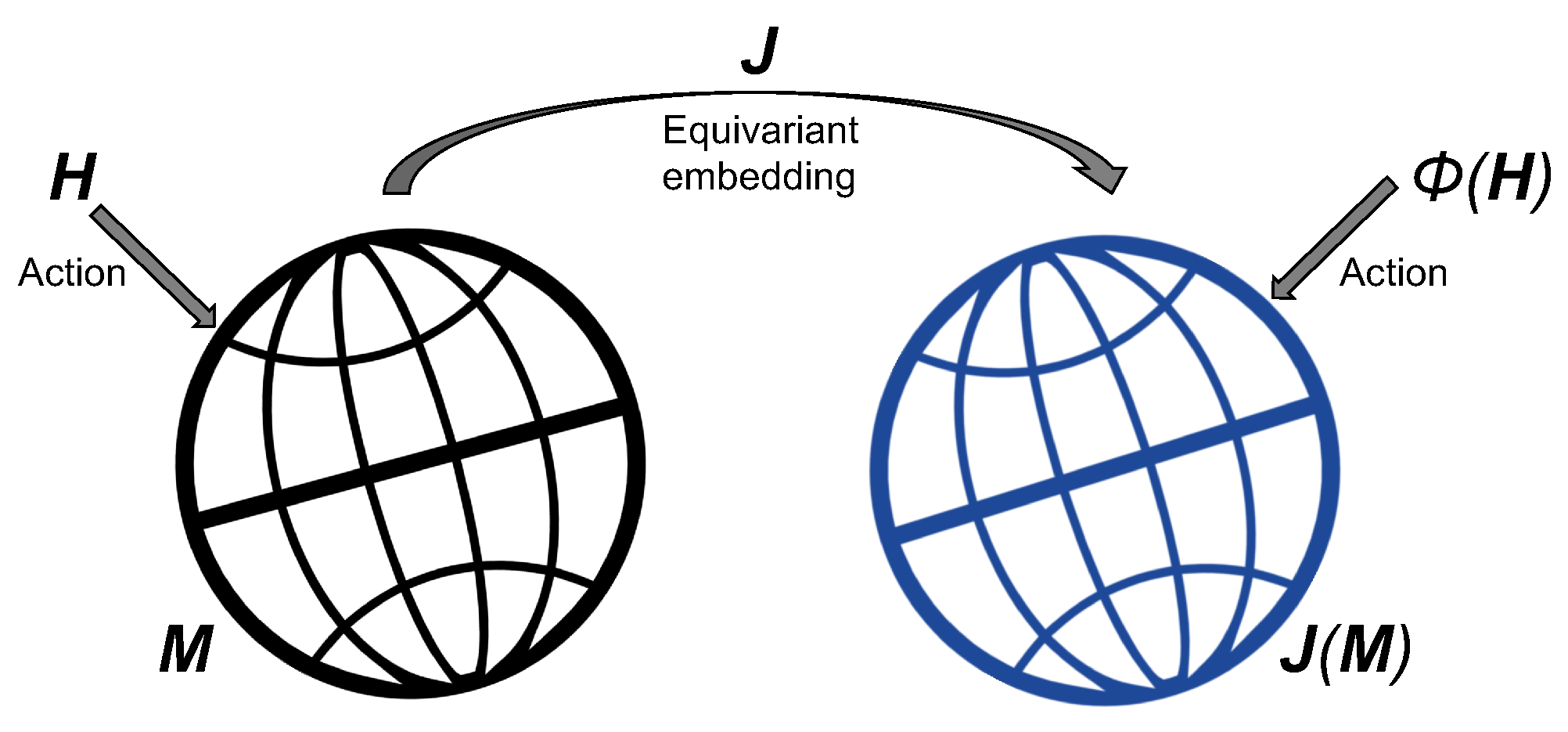
In this section, we will present the extrinsic Bayesian optimization algorithm on manifolds with the help of the illustrated eGP on manifolds. The key component of the extrinsic framework is the embedding map. Let
be an embedding of
M into some higher dimensional Euclidean space
(
) and denote the image of the embedding as
. By definition of an embedding,
J is a smooth map such that its differential
at each point
is an injective map from its tangent space
to
, and
J is a homeomorphism between
M and its image
.
Figure 1 provides a visual illustration of equivariant embedding. See
Section 4 in [
6] for some concrete examples of equivariant embeddings for well-known manifolds, such as the space of the sphere, symmetric positive definite matrices, and planar shapes. As mentioned above, we use eGP as the prior distribution of the objective function, and the main algorithm is described in Algorithm 1. Let
with prior mean
.
is an covariance kernel on
M induced by the embedding
J as:
where
is a valid covariance kernel on
.
| Algorithm 1 Extrinsic Bayesian optimization on manifolds. |
![Algorithms 16 00117 i001]() |
As above, let the predictive means and variance be
and
, where
denotes the data. The acquisition function defined by Equation (
4) represents the probability of improvement. To find out the next point to evaluate, we need to maximize the acquisition question. Since we use the zero mean eGP where
equals 0, the expression of
and
are given as follows:
Note that
depends on
x through
, let
where
. Therefore, the optimization of
over
x is
equivalent to the optimization of over . Let
be the optimizer of
over
, i.e.,
Then, one has
where
The key is to solve (
8). We consider the gradient descent or Newton’s method over the submanifolds
since the gradient is easy to obtain on
. Let
be the gradient of
in the Euclidean space, then the gradient of
over the submanifold
is given by
where
is the projection map
P from
onto the tangent space
. We propose the following gradient descent Algorithm 2 for finding
of
over
.
| Algorithm 2 Gradient algorithms for optimization along the submanifold . |
![Algorithms 16 00117 i002]() |
4. Examples and Applications
To illustrate the broad applications of our eBO framework, we utilize a large class of examples with data domains on different manifolds, including spheres, positive definite matrices, and the Grassmann manifold. We construct the extrinsic kernels for eGPs based on the corresponding embedding map on the specific manifold from [
45]. In this section, we show the simulation studies in
Section 4.1 and
Section 4.2 and the main application on real data in
Section 4.3. In
Section 4.1, the Fréchet mean estimation is carried out with data distributed on the sphere. In
Section 4.2, the eBO method is applied to the matrix approximation problem on Grassmannians. Lastly,
Section 4.3 considers a kernel regression problem on the manifold of positive definite matrices, which has essential applications in neuroimaging. We use the eBO method to solve the regression problem and show the difference between healthy samples and HIV+ samples. For all examples in this section, we consider the squared exponential kernel from [
45] as follows:
where
. The explicit form of embedding
J depends on the specific manifolds, which would be illustrated in the simulation cases. We initially set kernel coefficients as
, and the regularization coefficient
. After adding a new point to the data in Algorithm 2, we also update those coefficients by maximizing the likelihood of all data.
4.1. Estimation of Fréchet Means
We will first apply the eBO method to the estimation of sample Fréchet means on the sphere. Let
be
n points on the manifold, such as the sphere. The sample Fréchet function is defined as
and the minimization of
leads to the estimation of sample Fréchet mean
, where
The evaluation of
at the data point
will be our data points for guiding the optimization to find the Fréchet mean. The choice of distance
leads to different notions of means on manifolds. In the extrinsic setting, we can define an extrinsic mean via some embedding of the manifold onto some Euclidean space. Specifically, let
be some embedding of the manifold onto some higher-dimensional Euclidean space
. Then one can define the extrinsic distance as
where
is the Euclidean distance on
. This leads to the extrinsic Fréchet mean. Fortunately, the extrinsic mean has a close form expression, namely
, where
stands for the projection map onto the image
.
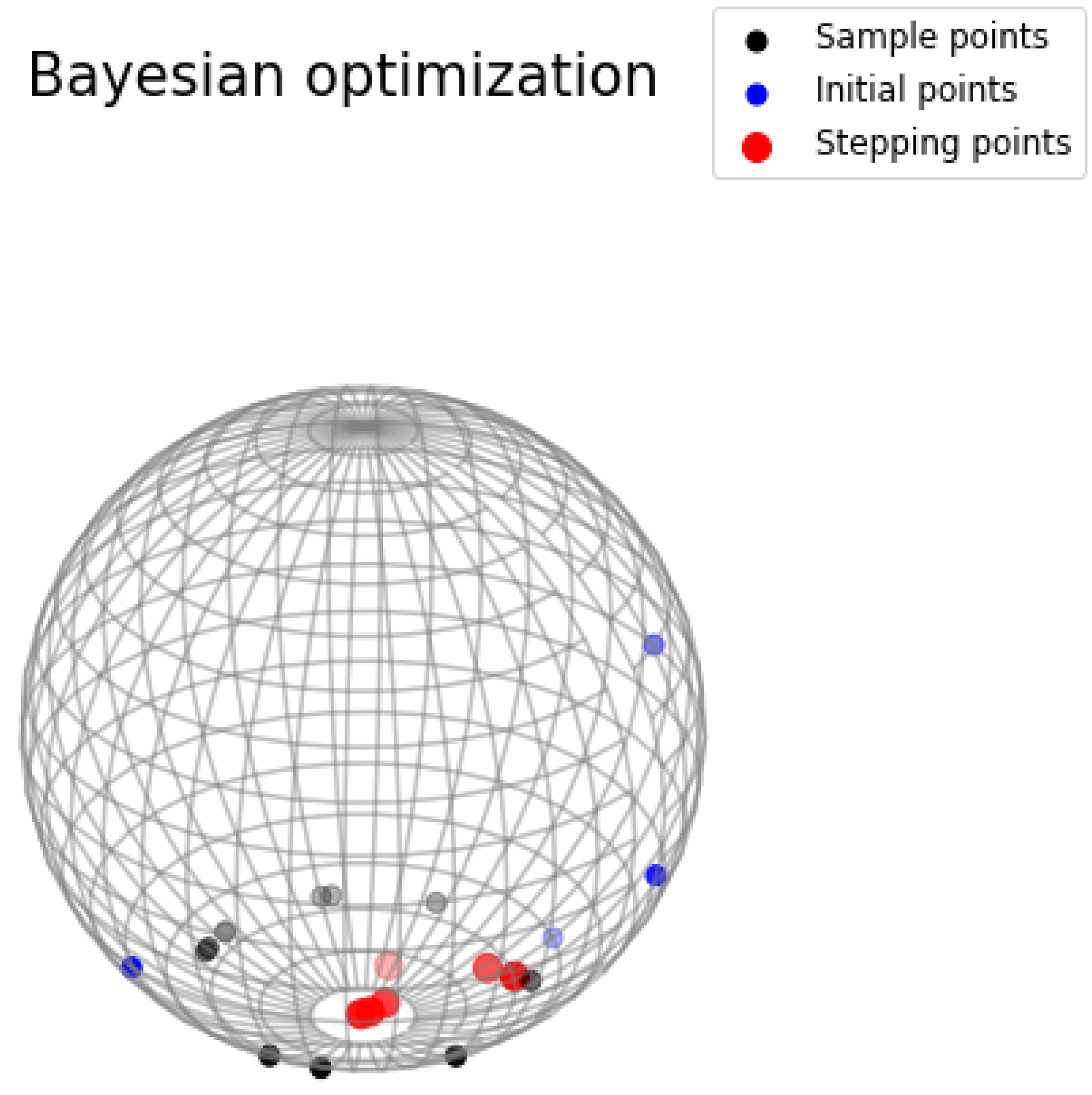
In our simulation study, we estimate the extrinsic mean on the sphere
and evaluate the performance of our eBO method by comparing it to the gradient descent (GD) algorithm in terms of convergence to the ground truth (the true minimizer given above). The embedding map
J is the identity map
. As shown in
Figure 2, we simulate some data on the sphere, and the goal is to find the extrinsic mean by solving Equation (
14). Specifically, those
points in black are sampled on the circle of latitude, which leads to the south pole
as the true extrinsic Fréchet mean. In terms of our BO Algorithm 1, we first sample those blue points randomly on the sphere as initial points and initialize the covariance matrix by evaluating the covariance kernel at these points. Then, we randomly select the direction on the sphere to maximize the acquisition function based on the eGP. In each iteration, we mark the minimizer as the stepping point in
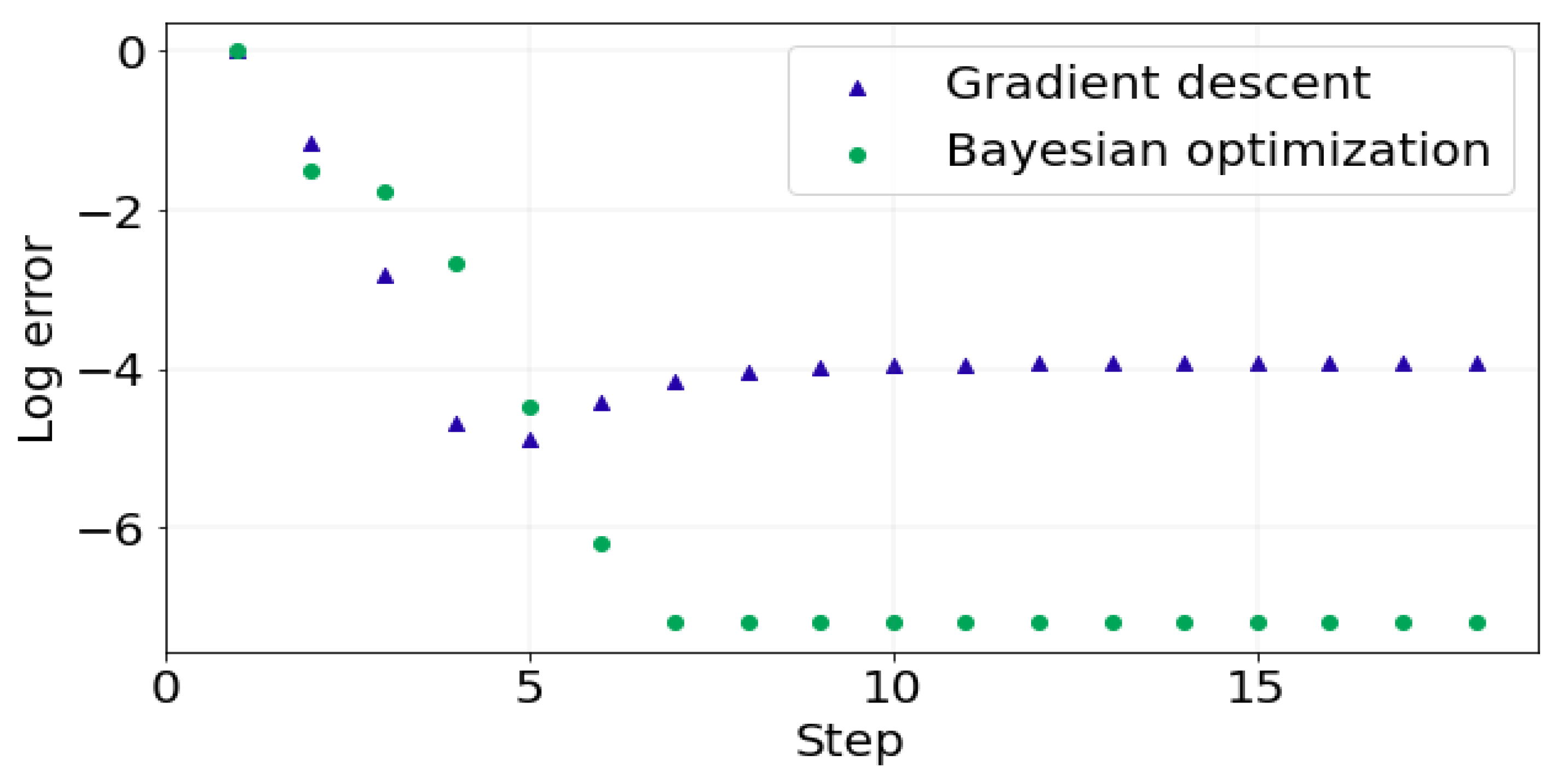
Figure 2 and add it to the data for the next iteration. Not surprisingly, those stepping points in red converge to the ground truth (south pole) after a few steps. We also compare our eBO method with the gradient descent (GD) method on the sphere under the same initialization. As illustrated in
Figure 3, although our BO method converges slightly slower than GD at the first four steps, the BO method achieves better accuracy with a few more steps. It confirms the quick convergence and high accuracy as the advantages of the eBO method.
4.2. Invariant Subspace Approximation on Grassmann Manifolds
We investigate two important manifolds, the Stiefel manifolds and the Grassmann manifolds (Grassmannians). The Stiefel manifold is the collection of p orthonormal frames in , that is, . Moreover, the Grassmann manifold is the space of all the subspaces of a fixed dimension p whose basis elements are p orthonormal unit vectors in , which is . Those two manifolds are closely related. The key difference between a point on the Grassmannian and a point on the Stiefel manifold is that the ordering of the p orthonormal vectors in does not matter for the former. In other words, the Grassmannian could be viewed as the quotient space of the Stiefel manifold modulo , the orthogonal group. That is, .
We consider the matrix approximation problem on the Grassmannian subspace manifold and apply the eBO method to solve it. Given a full rank matrix
, without loss of generality, we assume
and
, the goal is to approximate this matrix
F in the subspace
with
. From any matrix
, we approximate the original matrix
F from Algorithm 3.
| Algorithm 3 Matrix approximation on the Grassmann manifold. |
![Algorithms 16 00117 i003]() |
Here we consider the approximation error in Frobenius norm where
W depends on
X:
where the objective function
. In our simulation, we consider the matrix
with
and
. As we know, this matrix approximation problem achieves its minimal when
where
U is the left matrix in the Singular Value Decomposition (SVD) and
denotes its
jth column. Let
contain the first two columns of the SVD part
U. To apply the eBO method, we first sample some matrix following
,
as initial points. Similar to the sphere case, we have to map the minimizer of the acquisition function back to the manifold via the inverse embedding
. In
, for a given matrix
,
indicates us to apply the SVD decomposition to
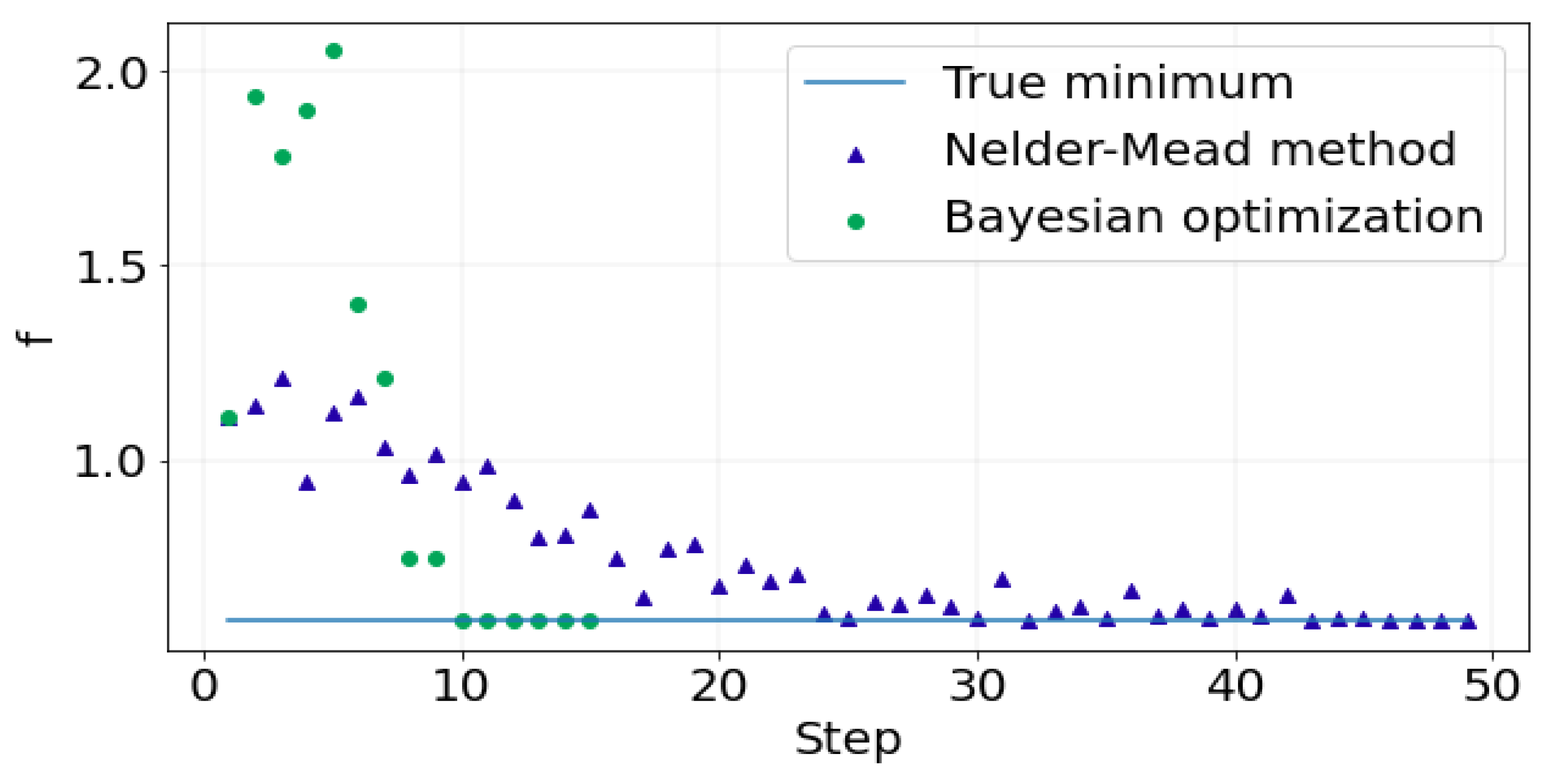
, then keep the first two columns. Since the closed form of the loss gradient is untouchable, we compare the BO method with the Nelder–Mead method. As shown in
Figure 4, our eBO method converges to the ground truth in a few steps faster than the Nelder–Mead method.
4.3. Positive Definite Matrices
Lastly, we apply the eBO method to a regression problem with the response on positive definite matrices. Let be n points from a regression model in which and , where stands for p by p positive semi-definite matrices. We are interested in modeling the regression map between z and y.
Let
be a kernel function defined on covariate space
. For example, one can take the standard Gaussian kernel. Let
be the regression map evaluated at a covariate level
z. We propose to estimate
g as
where
h is the bandwidth parameter of the kernel function
K. We take
to be the extrinsic distance on the
manifold. For the given input or covariate
z, we denote
as the objective function and look for the minimizer
as the weighed Fréchet mean on the
manifold. In order to calculate the extrinsic distance on the
manifold, we choose the embedding
J as the log-map on the matrix, which can map the
into
p by
p real symmetric matrices
:
For example, let
with a spectral decomposition
; we have the log-map of
A as
where
denotes the diagonal matrix whose diagonal entries are the logarithms of the diagonal entries of
. Moreover, embedding
J is a diffeomorphism, equivariant with respect to the actions of
, the
p by
p general linear group. That is, for
, we have
. On the other hand, the inverse of embedding
is the exp-map on the matrix, which takes the exponential function on the diagonal entries under the spectral decomposition. Then we obtain the extrinsic distance of two matrices
:
where
denotes the Frobenius norm of the matrix (i.e.
).
In our analysis, we focus on the case of
and
, which have important applications in diffusion tensor imaging (DTI), designed to measure the diffusion of water molecules in the brain. In more detail, diffusion represents the direction along the white matter tracks or fibers, corresponding to structural connections between brain regions along where brain activity and communications happen. DTI data are collected routinely in human brain studies. People are interested in using DTI to build predictive models of cognitive traits and neuropsychiatric disorders [
45]. The diffusions are characterized in terms of diffusion matrices, represented by 3 by 3 positive definite matrices. The data set consists of 46 subjects with 28
subjects and 18 healthy controls. Those 3 by 3 diffusion matrices were extracted along one atlas fiber tract of the splenium of the corpus callosum. All the DTI data were registered in the same atlas space based on arc lengths, with 75 tensors obtained along the fiber tract of each subject, which has been studied in [
45] in a regression and kernel regression setting. We aim to show the difference between the positive (HIV+) and control samples based on kernel regression results.
We consider the arc length tensor as the covariant
and the diffusion matrix as
in our framework at each arc length
z. In more detail, the arc length variable
z ranges from 0 to 48 with 75 different locations. We consider
as the standard Gaussian kernel with bandwidth
following the rule of thumb of the univariate variable. Overall, the dimension of the whole dataset is
, including 28
samples and 18 healthy samples. For each sample, the dimension is
consisting of the matrix from
over all 75 locations. Moreover, we separately apply the kernel regression model (
17) to the
group and the healthy group, yielding the corresponding estimators
and
for those two groups. That is, for each location
, we consider the objective function
with data
from those two groups separately. With the help of our eBO method, we obtain
,
from the
group and the healthy group, respectively. As shown in
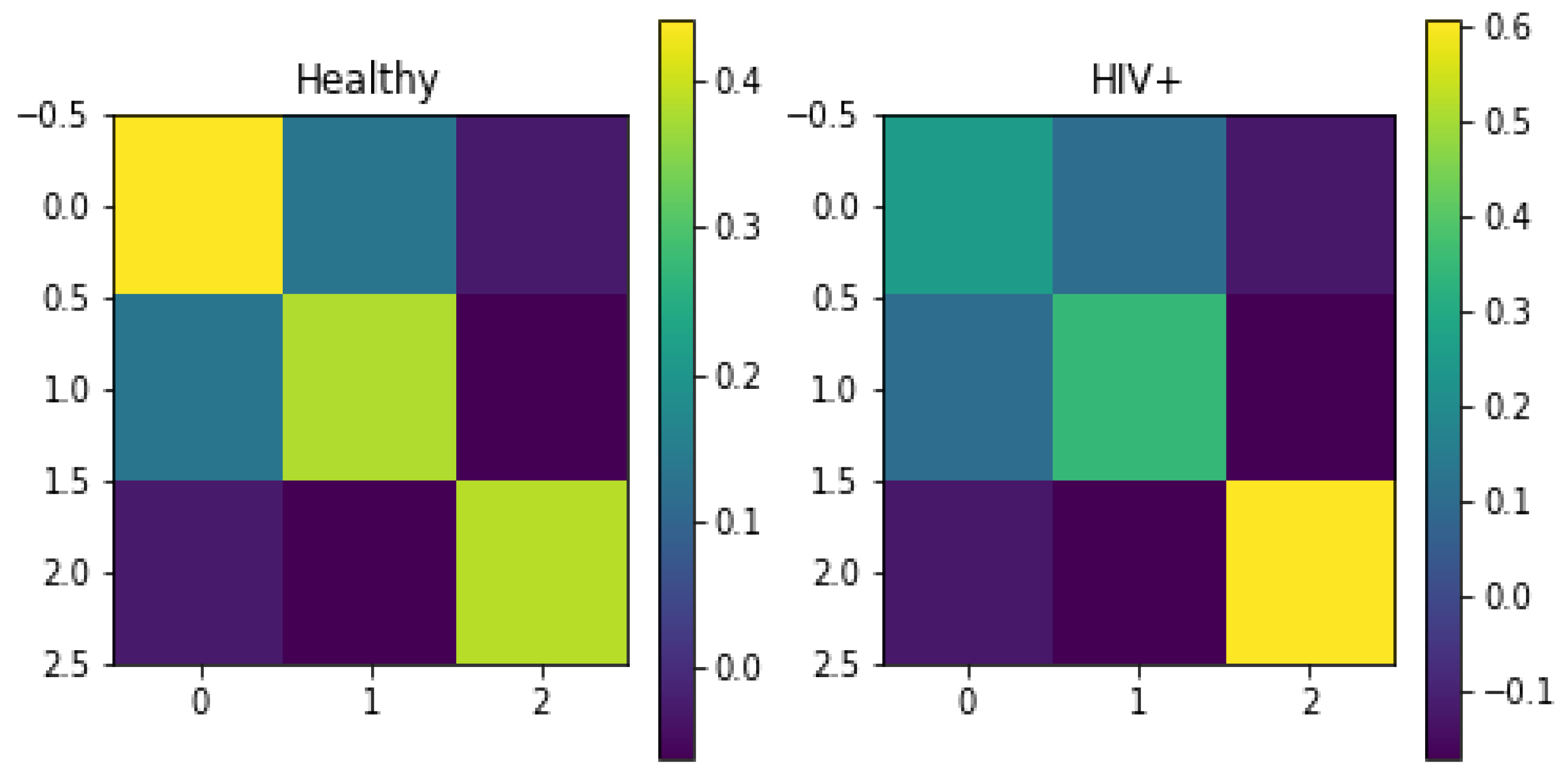
Figure 5, we observe the difference between
and
, the estimated diffusion tensors at the first arc length
from the
group and the healthy group, in particular for those diagonal entries. Furthermore, we carry out the two-sample test [
7] between
from the
group and
from the healthy group and yield an extremely small
p-value equal to
. This result indicates the difference between those two groups.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







