
CUDA and OpenMp Implementation of Boolean Matrix Product with Applications in Visual SLAM



Abstract
:1. Introduction
2. Prior Works
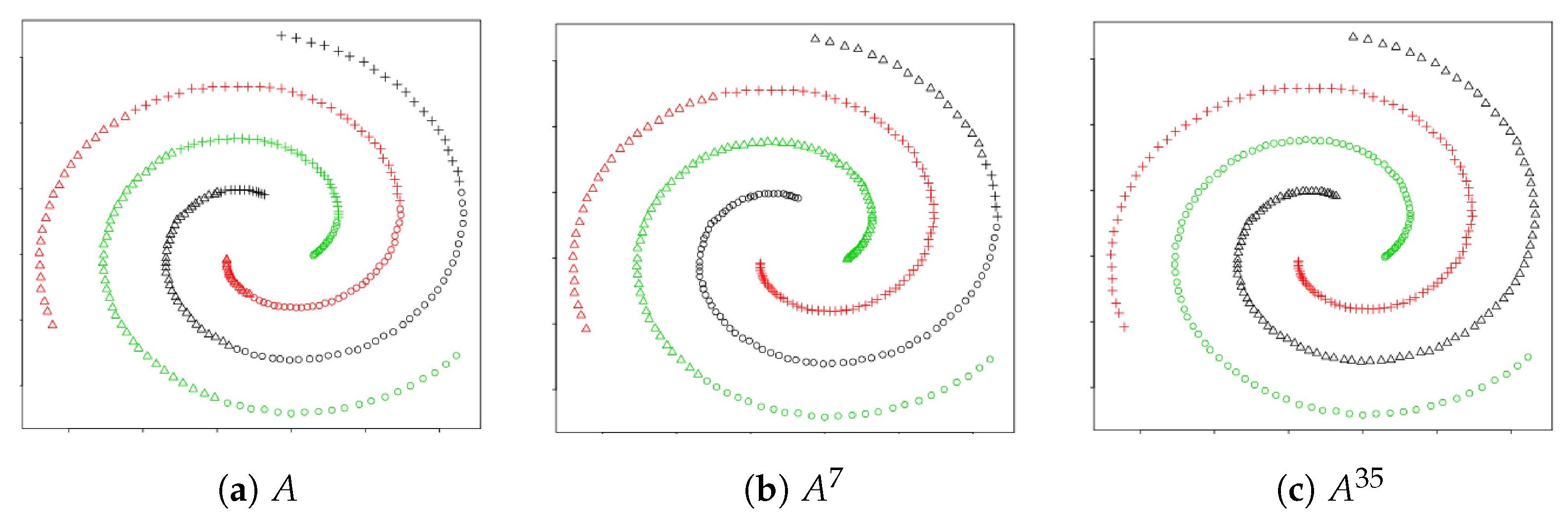
3. Review of the Transformation
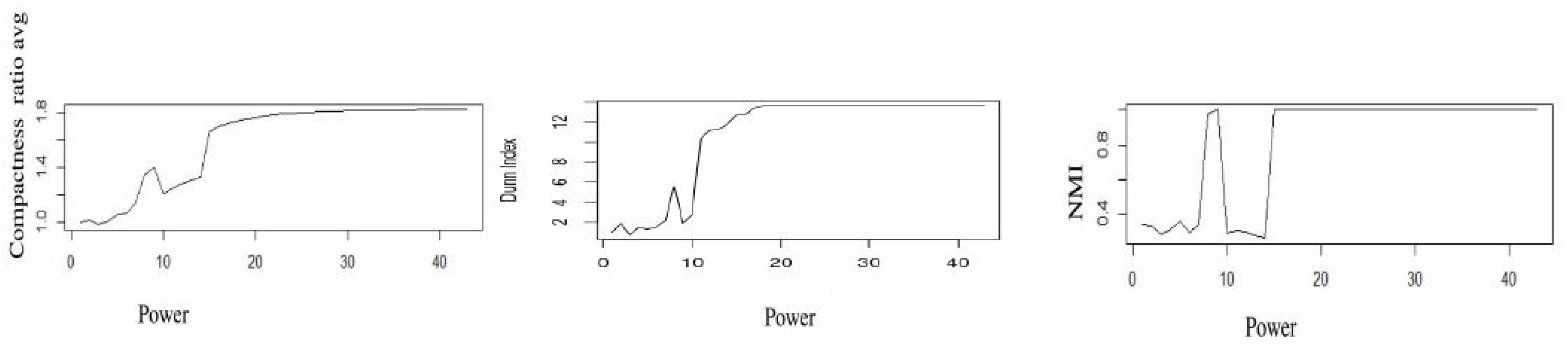
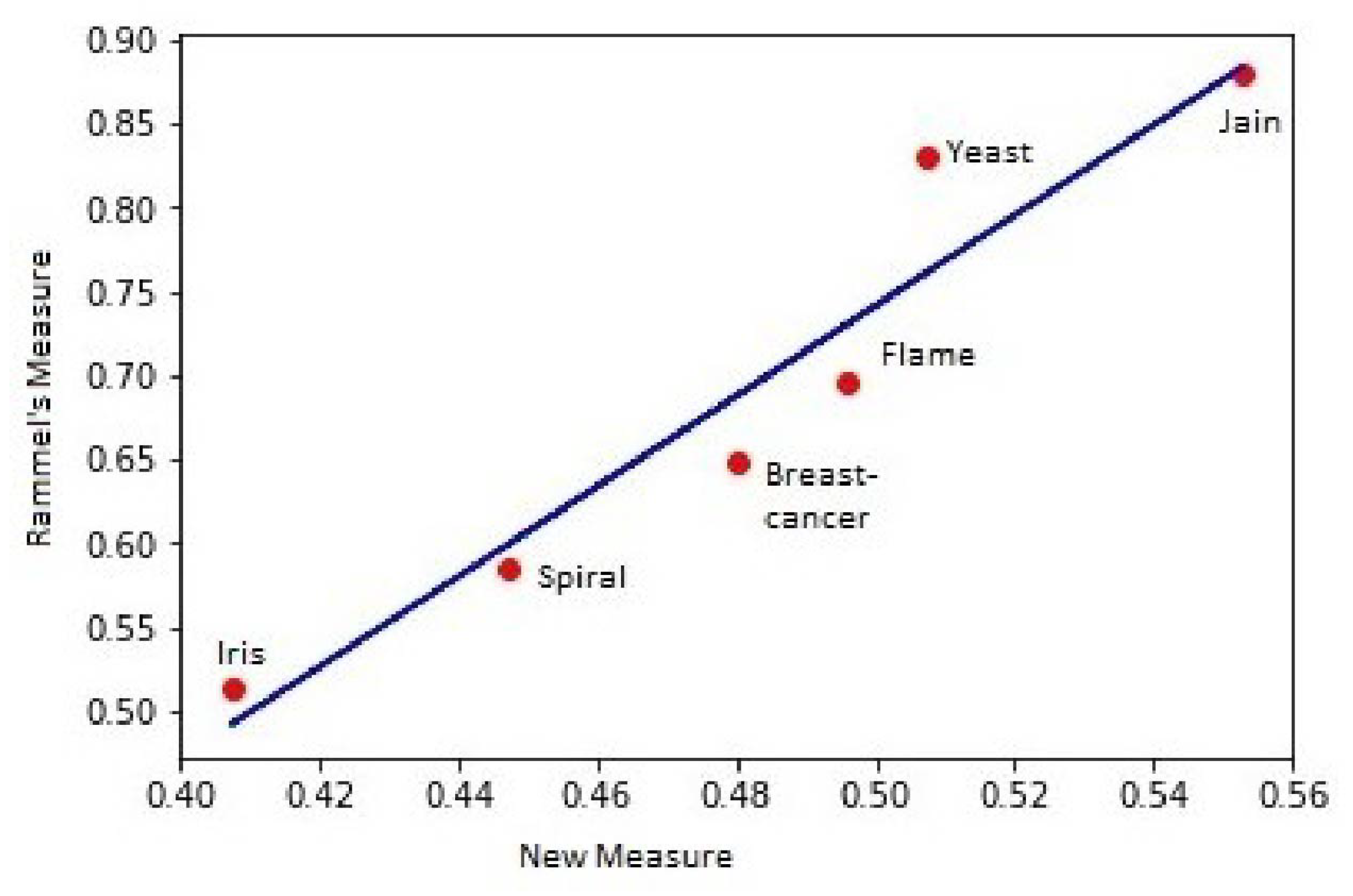
4. The New Ultrametricity Measure
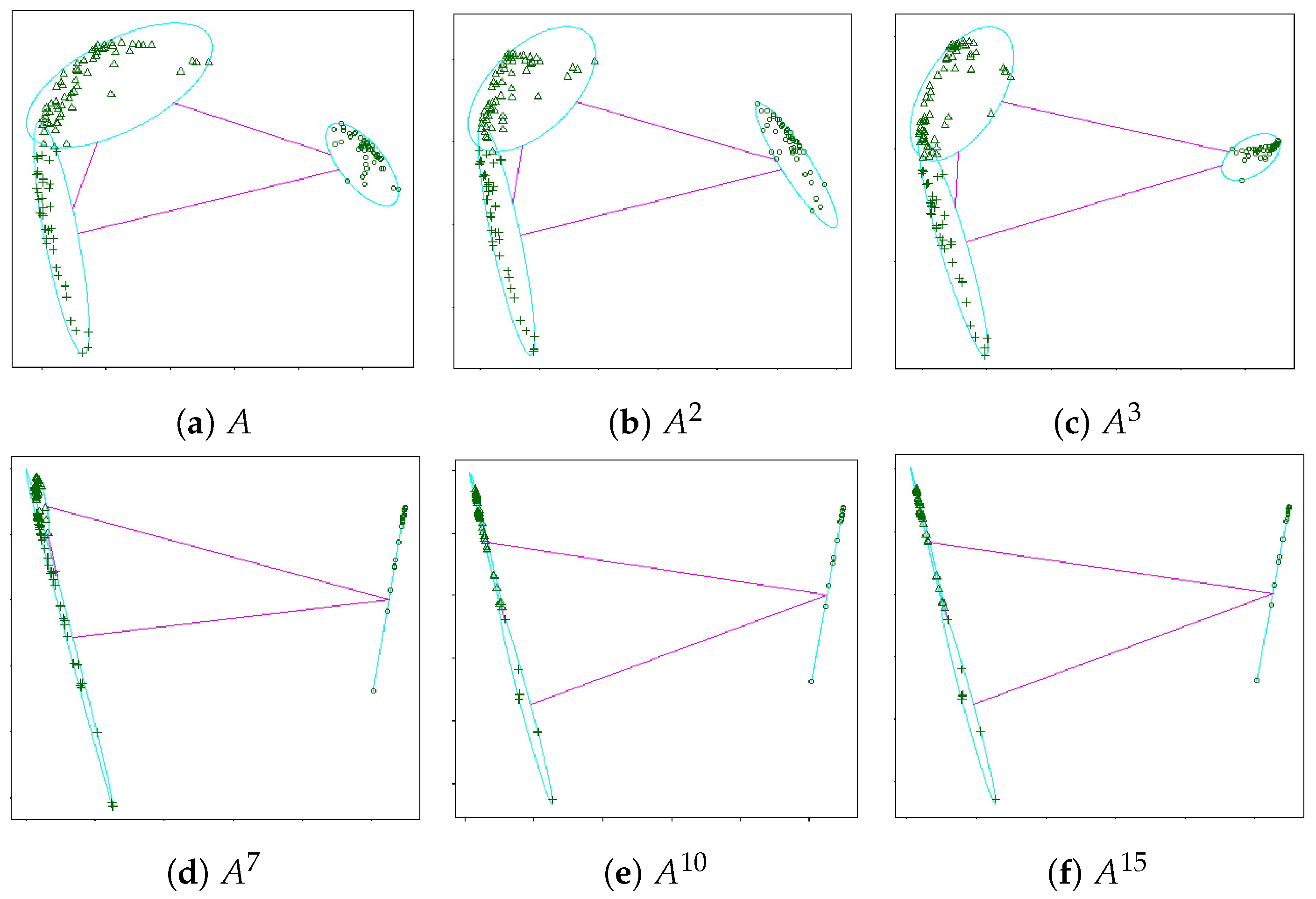
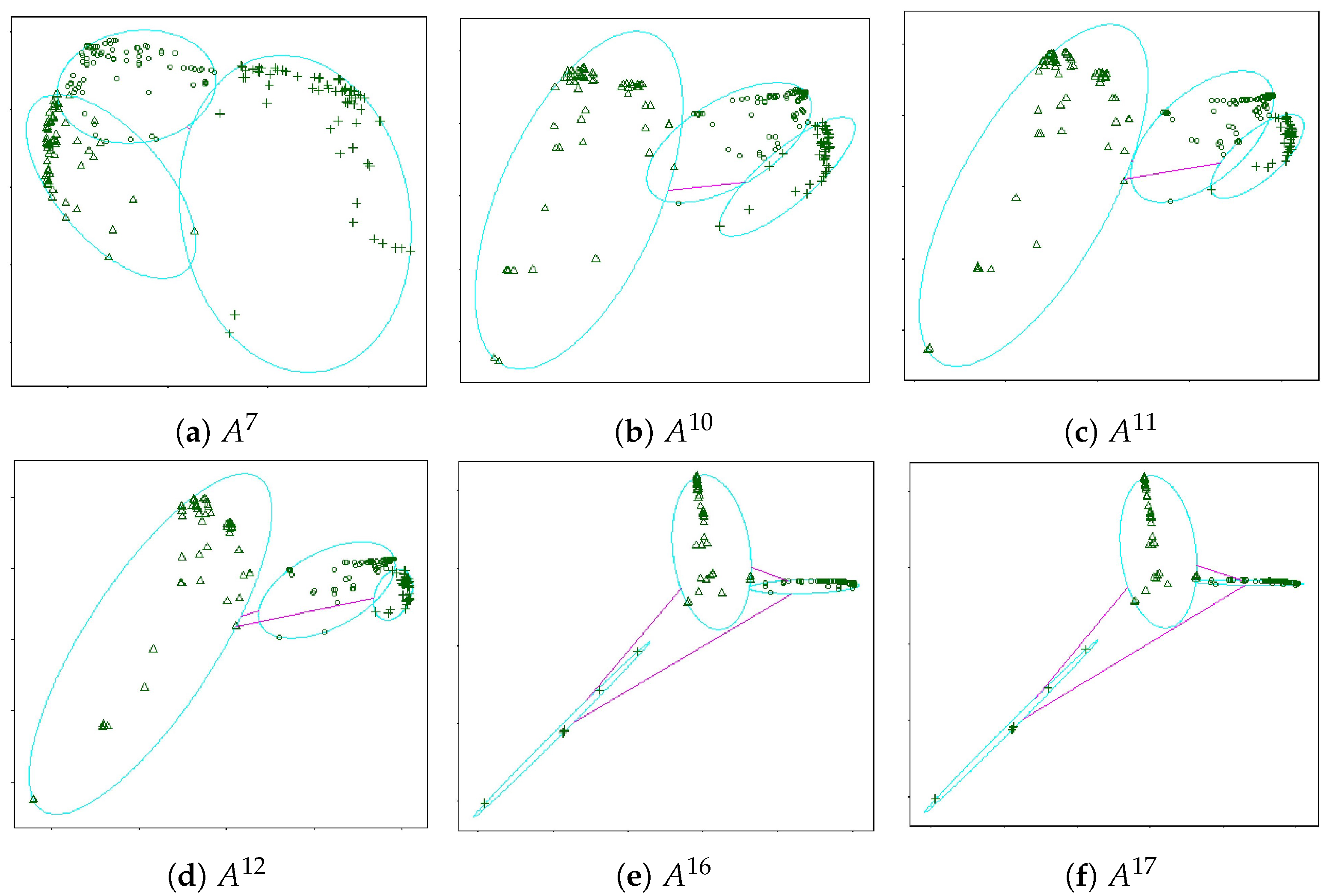
5. Ultrametric-PAM and Ultrametric-FABMAP
| Algorithm 1: Ultrametric-PAM) Runs PAM with the transformed distance matrices |
| Input: Euclidean distance matrix A Output: matrix of a dendrogram
|
| Algorithm 2 AVX-256 Transformation |
|
| Algorithm 3 CUDA-TRANSFORMATION |
|
| Algorithm 4 (Ultrametric-FABMAP). Runs FABMAP with the transformed distance matrices |
| Input: Euclidean distance matrix A, Training, Testing Dataset Output: confusion matrix
|
6. Experiments
6.1. Metrics
6.2. Definition and Examples:
6.3. Datasets
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Simovici, D.; Hua, K. Data Ultrametricity and Clusterability. J. Phys. Conf. Ser. 2020, 1334, 012002. [Google Scholar] [CrossRef] [Green Version]
- Tan, Y. On the powers of matrices over a distributive lattice. Linear Algebra Its Appl. 2001, 336, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Tan, Y.J. On the transitive matrices over distributive lattices. Linear Algebra Its Appl. 2005, 400, 169–191. [Google Scholar] [CrossRef] [Green Version]
- Murtagh, F. Sparse p-adic data coding for computationally efficient and effective big data analytics. P-Adic Numbers Ultrametric Anal. Appl. 2016, 8, 27–42. [Google Scholar] [CrossRef] [Green Version]
- Bradley, P.E.; Keller, S.; Weinmann, M. Unsupervised Feature Selection Based on Ultrametricity and Sparse Training Data: A Case Study for the Classification of High-Dimensional Hyperspectral Data. Remote Sens. 2018, 10, 1564. [Google Scholar] [CrossRef] [Green Version]
- Murtagh, F. Identifying and Exploiting Ultrametricity. In Proceedings of the Advances in Data Analysis, Proceedings of the 30th Annual Conference of the Gesellschaft für Klassifikation e.V., Freie Universität Berlin, 8–10 March 2006; Decker, R., Lenz, H., Eds.; Springer: New York, NY, USA, 2006; pp. 263–272. [Google Scholar] [CrossRef]
- Murtagh, F.; Contreras, P. The Future of Search and Discovery in Big Data Analytics: Ultrametric Information Spaces. arXiv 2012, arXiv:1202.3451. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley: New York, NY, USA, 2009. [Google Scholar]
- K-Medoids. Available online: https://en.wikipedia.org/wiki/K-medoids (accessed on 10 December 2022).
- K-Medoids Clustering with Solved Example. Available online: https://www.geeksforgeeks.org/ml-k-medoids-clustering-with-example/ (accessed on 10 December 2022).
- Cummins, M.J.; Newman, P. FAB-MAP: Probabilistic Localization and Mapping in the Space of Appearance. Int. J. Robot. Res. 2008, 27, 647–665. [Google Scholar] [CrossRef]
- Glover, A.; Maddern, W.; Warren, M.; Reid, S.; Milford, M.; Wyeth, G. OpenFABMAP: An Open Source Toolbox for Appearance-based Loop Closure Detection. In Proceedings of the International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; IEEE: St. Paul, MN, USA, 2012. [Google Scholar]
- Rammal, R.; Anglès D’Auriac, J.C.; Douçot, B. On the degree of ultrametricity. J. Phys. Lett. 1985, 46, 945–952. [Google Scholar] [CrossRef]
- Cattaneo, D.; Vaghi, M.; Valada, A. LCDNet: Deep Loop Closure Detection for LiDAR SLAM based on Unbalanced Optimal Transport. arXiv 2021, arXiv:2103.05056. [Google Scholar]
- Lu, S.; Xu, X.; Tang, L.; Xiong, R.; Wang, Y. DeepRING: Learning Roto-translation Invariant Representation for LiDAR based Place Recognition. arXiv 2022, arXiv:2210.11029. [Google Scholar]
- Zarringhalam, A.; Ghidary, S.S.; Khorasani, A.M. Self-supervised Vector-Quantization in Visual SLAM using Deep Convolutional Autoencoders. arXiv 2022, arXiv:2207.06732. [Google Scholar]
- Zarringhalam, A.; Ghidary, S.S.; Khorasani, A.M. Semi-supervised Vector-Quantization in Visual SLAM using HGCN. arXiv 2022, arXiv:2207.06738. [Google Scholar]
- Murtagh, F.; Downs, G.; Contreras, P. Hierarchical Clustering of Massive, High Dimensional Data Sets by Exploiting Ultrametric Embedding. SIAM J. Sci. Comput. 2008, 30, 707–730. [Google Scholar] [CrossRef]
- Gillet, V.J.; Wild, D.J.; Willett, P.; Bradshaw, J. Similarity and Dissimilarity Methods for Processing Chemical Structure Databases. Comput. J. 1998, 41, 547–558. [Google Scholar] [CrossRef]
- Brown, R.D.; Martin, Y.C. Use of Structure–Activity Data To Compare Structure-Based Clustering Methods and Descriptors for Use in Compound Selection. J. Chem. Inf. Comput. Sci. 1996, 36, 572–584. [Google Scholar] [CrossRef]
- Downs, G.M.; Willett, P.; Fisanick, W. Similarity Searching and Clustering of Chemical-Structure Databases Using Molecular Property Data. J. Chem. Inf. Comput. Sci. 1994, 34, 1094–1102. [Google Scholar] [CrossRef]
- Rammal, R.; Anglès D’Auriac, J.C.; Douçot, B. Several Remarks on Dissimilarities and Ultrametrics. Sci. Ann. Comput. Sci. 2015, 25, 155–170. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Compactness Avg. | Compactness Ratio Avg. | Dunn Index | Dunn Index Ratio | |
|---|---|---|---|---|
| 0.4826358111 | 1.0163461701 | 0.0246030 | 0.7697904 | |
| 0.4663649138 | 0.9820825208 | 0.04667035 | 1.460238898 | |
| 0.4799552411 | 1.0107013609 | 0.0418983 | 1.310931155 | |
| 0.5017430685 | 1.056582695 | 0.047757 | 1.494265365 | |
| 0.5400191638 | 1.1371854226 | 0.1781176 | 5.5730085 | |
| 0.8553148705 | 1.8164010431 | 043437224 | 13.5907955 |
| Compactness Avg. | Compactness Ratio Avg. | Dunn Index | Dunn Index Ratio | |
|---|---|---|---|---|
| 0.456225532 | 1 | 0.01110 | 1 | |
| 0.499903924 | 1.095738596 | 0.042091 | 3.7914944142 | |
| 0.60707534 | 1.330647448 | 0.169928 | 15.3067877 | |
| 0.286708931 | 0.628436839 | 1.7971900 | 161.88682261 |
| Compactness Avg. | Compactness Ratio Avg. | Dunn Index | Dunn Index Ratio | |
|---|---|---|---|---|
| 0.258152 | 1 | 0.09880 | 1 | |
| 0.287839 | 1.114996 | 0.14560 | 1.47364530 | |
| 0.317521 | 1.229975 | 0.138675 | 1.4034885859 | |
| 0.34202 | 1.324878 | 0.46684 | 4.7248466 |
| Compactness Avg. | Compactness Ratio Avg. | Dunn Index | Dunn Index Ratio | |
|---|---|---|---|---|
| 0.339115 | 1 | 0.049510 | 1 | |
| 0.570942 | 1.683624 | 0.312755 | 6.31701349 | |
| 0.67483 | 1.989974 | 0.37255 | 7.52478121 | |
| 0.70014 | 2.06461 | 0.429812 | 8.681313 | |
| 0.716623 | 2.113215 | 0.445516 | 8.9985077 |
| Dataset | No, Extracted Features | Method | BoW | |
|---|---|---|---|---|
| Train/Test | Train/Test | — | %Acc | %Rec |
| Newer College One Loop (Train) Newer College Three Loops (Test) | 11,208 | Ultrametric FABMAP | Ground Truth | Ground Truth |
| Ultrametric BoW | %89.6 | %97.4 | ||
| 6736 | FABMAP2 | %50.3 %54.83 | %100 %90.9 | |
| BoW | %59.55 %42 %96 | %81.5 %93 %86 | ||
| Dataset | Method | Acc | Recall |
|---|---|---|---|
| Lip6 Indoor | Ultrametric Bow | %68.11 %57 | %66 %87 |
| Dataset | No, Extracted Features | Method | Acc | Recall |
|---|---|---|---|---|
| Train/Test | Train/Test | ______ | ___ | _____ |
| Newer College One Loop (Train) Newer College Three loops (Test) | 11,208 | Ultrametric FABMAP | %57 %62 %66.1 | %93 %84 %81.66 |
| Ultrametric BoW | Ground Truth | Ground Truth | ||
| 6736 | FABMAP2 | %51 %61 | %92.9 %83 | |
| BoW | %63 | %100 |
| Dataset-Size | Method | Time | Speedup |
|---|---|---|---|
| 6736 × 6736 | AVX-256 | 1 min 6 s | 1.51 |
| 6736 × 6736 | GPU | 1 min 39 s | 1. |
| Dataset-Size | PAM | Ultrametric-PAM | Speedup |
|---|---|---|---|
| 6736 × 6736 | 3.5 days | 18 min | ×280 |
| 11,712 × 11,712 | 14 days | 2 h and 23 min | ×1254. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zarringhalam, A.; Shiry Ghidary, S.; Mohades, A.; Sadegh-Zadeh, S.-A. CUDA and OpenMp Implementation of Boolean Matrix Product with Applications in Visual SLAM. Algorithms 2023, 16, 74. https://doi.org/10.3390/a16020074
Zarringhalam A, Shiry Ghidary S, Mohades A, Sadegh-Zadeh S-A. CUDA and OpenMp Implementation of Boolean Matrix Product with Applications in Visual SLAM. Algorithms. 2023; 16(2):74. https://doi.org/10.3390/a16020074
Chicago/Turabian StyleZarringhalam, Amir, Saeed Shiry Ghidary, Ali Mohades, and Seyed-Ali Sadegh-Zadeh. 2023. "CUDA and OpenMp Implementation of Boolean Matrix Product with Applications in Visual SLAM" Algorithms 16, no. 2: 74. https://doi.org/10.3390/a16020074
APA StyleZarringhalam, A., Shiry Ghidary, S., Mohades, A., & Sadegh-Zadeh, S. -A. (2023). CUDA and OpenMp Implementation of Boolean Matrix Product with Applications in Visual SLAM. Algorithms, 16(2), 74. https://doi.org/10.3390/a16020074