

A Data Analysis Smart System for the Optimal Deployment of Nanosensors in the Context of an eHealth Application



Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
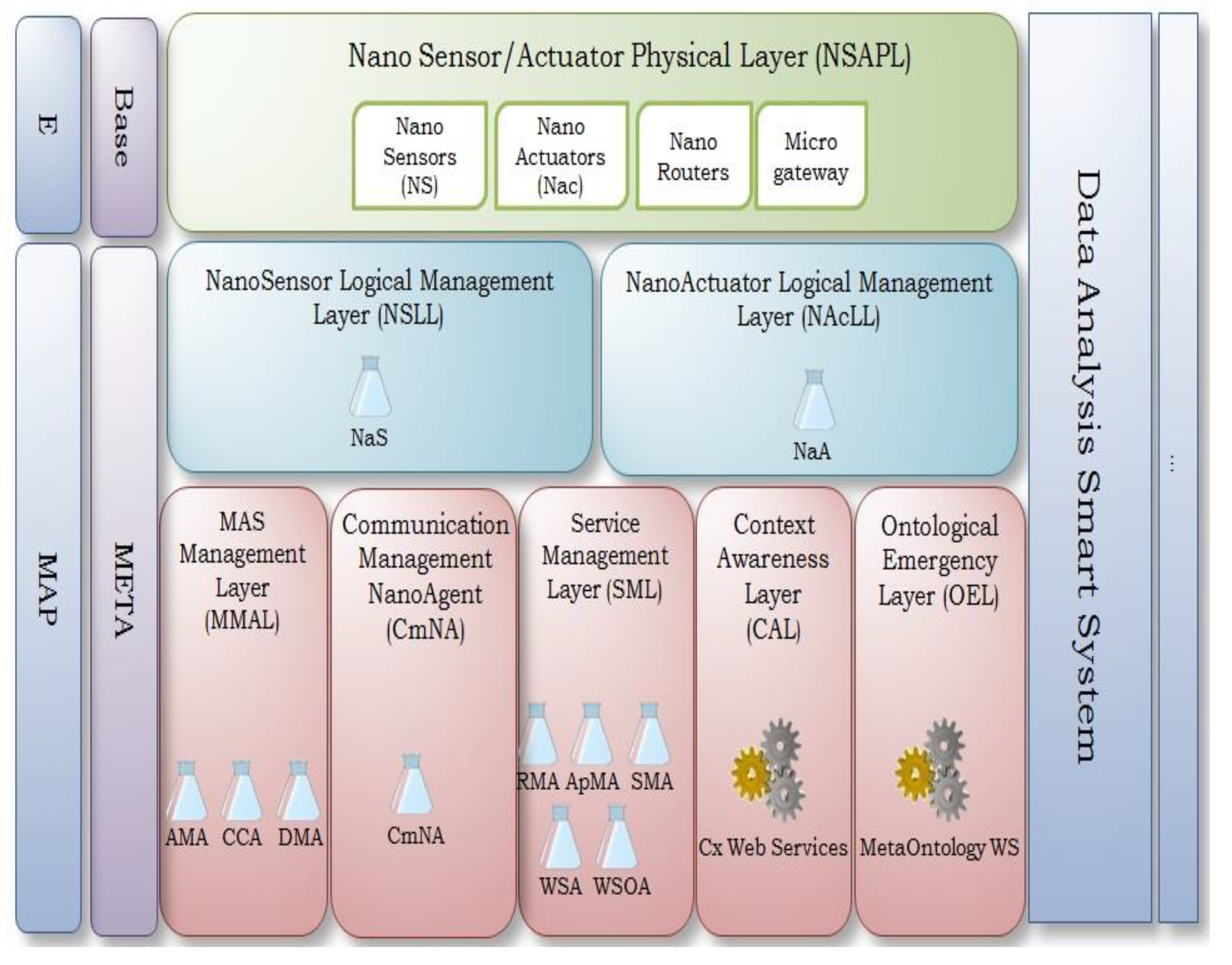
3.1. Autonomic Cycles in ARMNANO
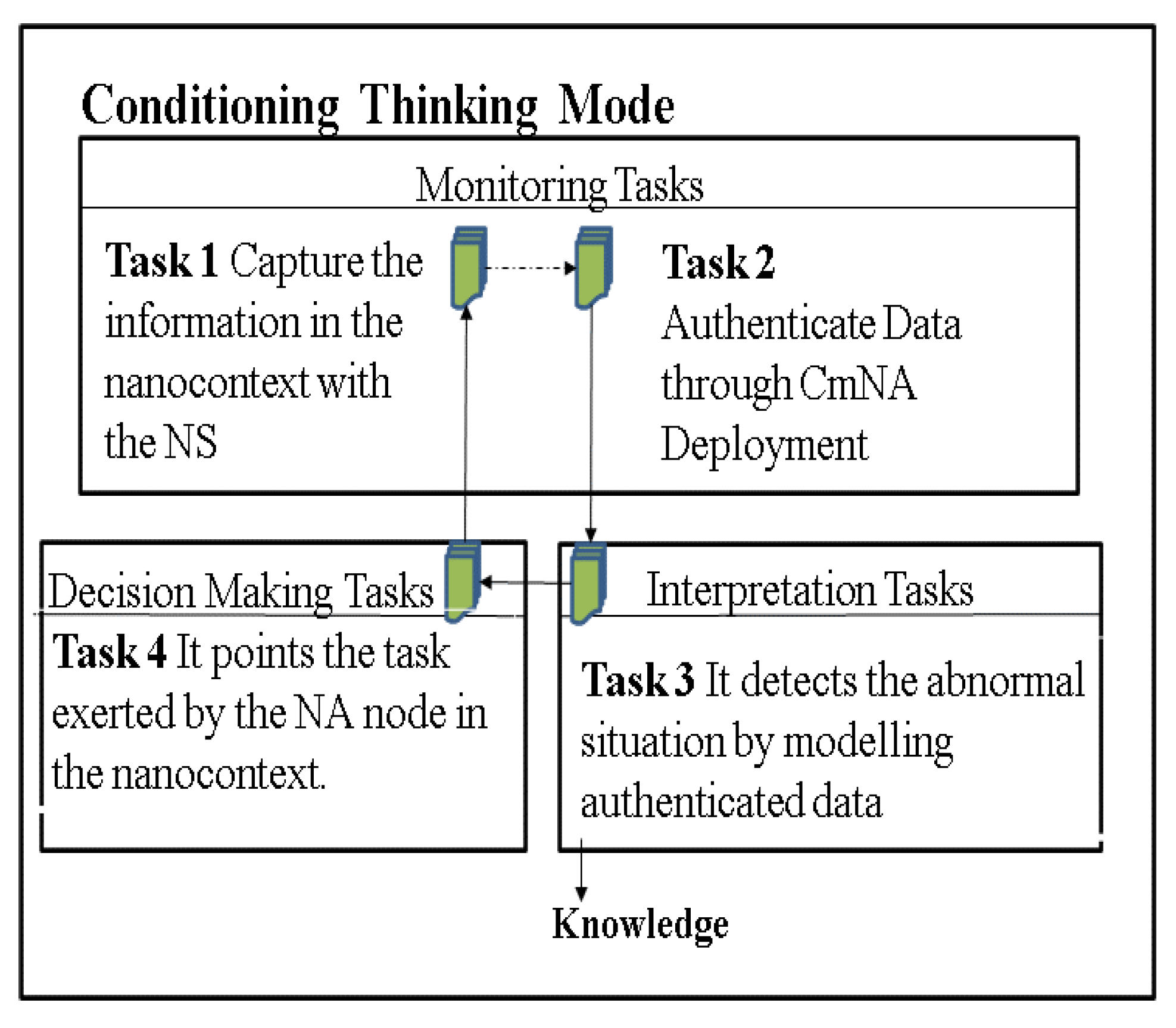
3.2. Description of the CTM AC
3.3. Definition of the Tasks
3.4. Genetic Algorithms (GA)
4. Results
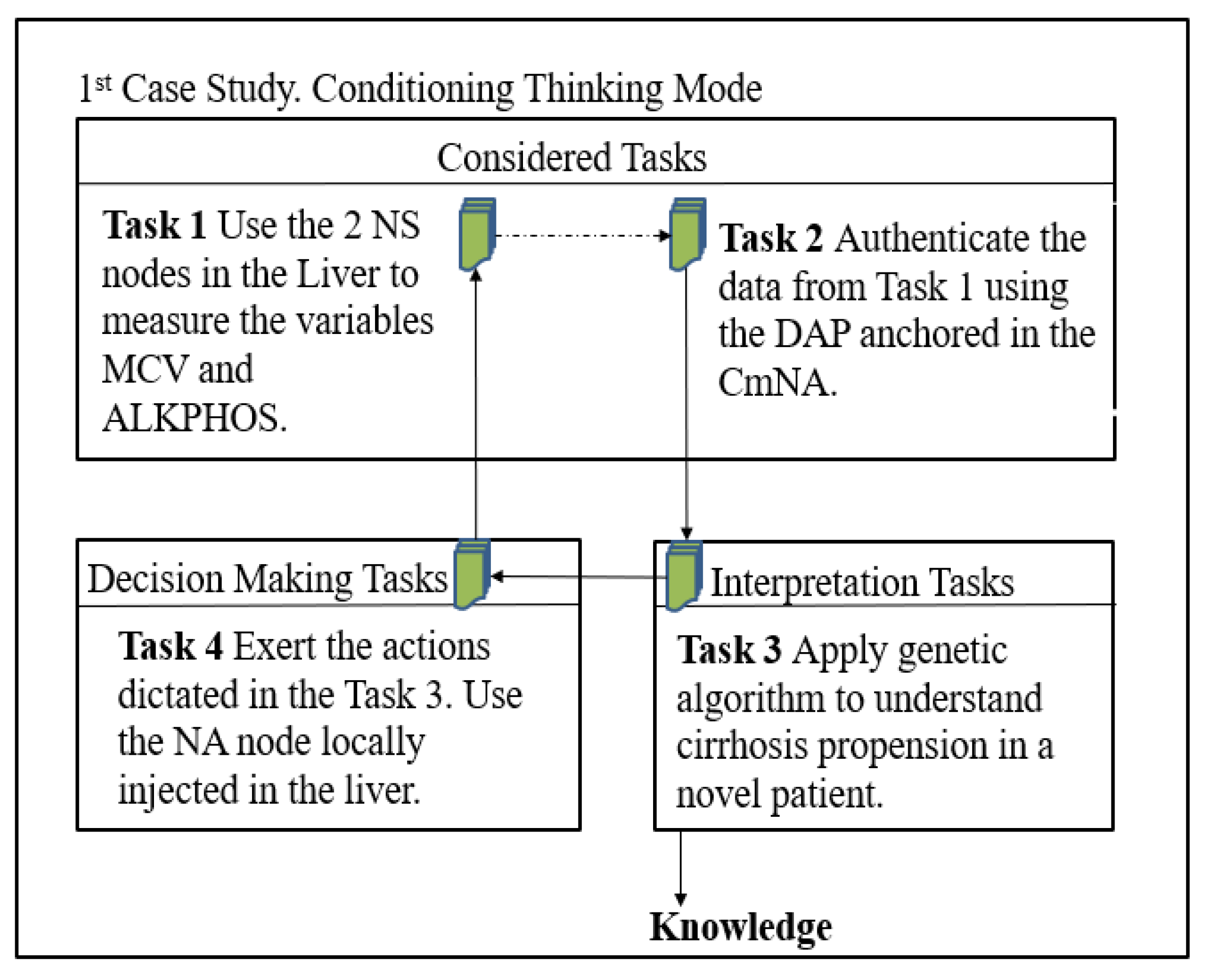
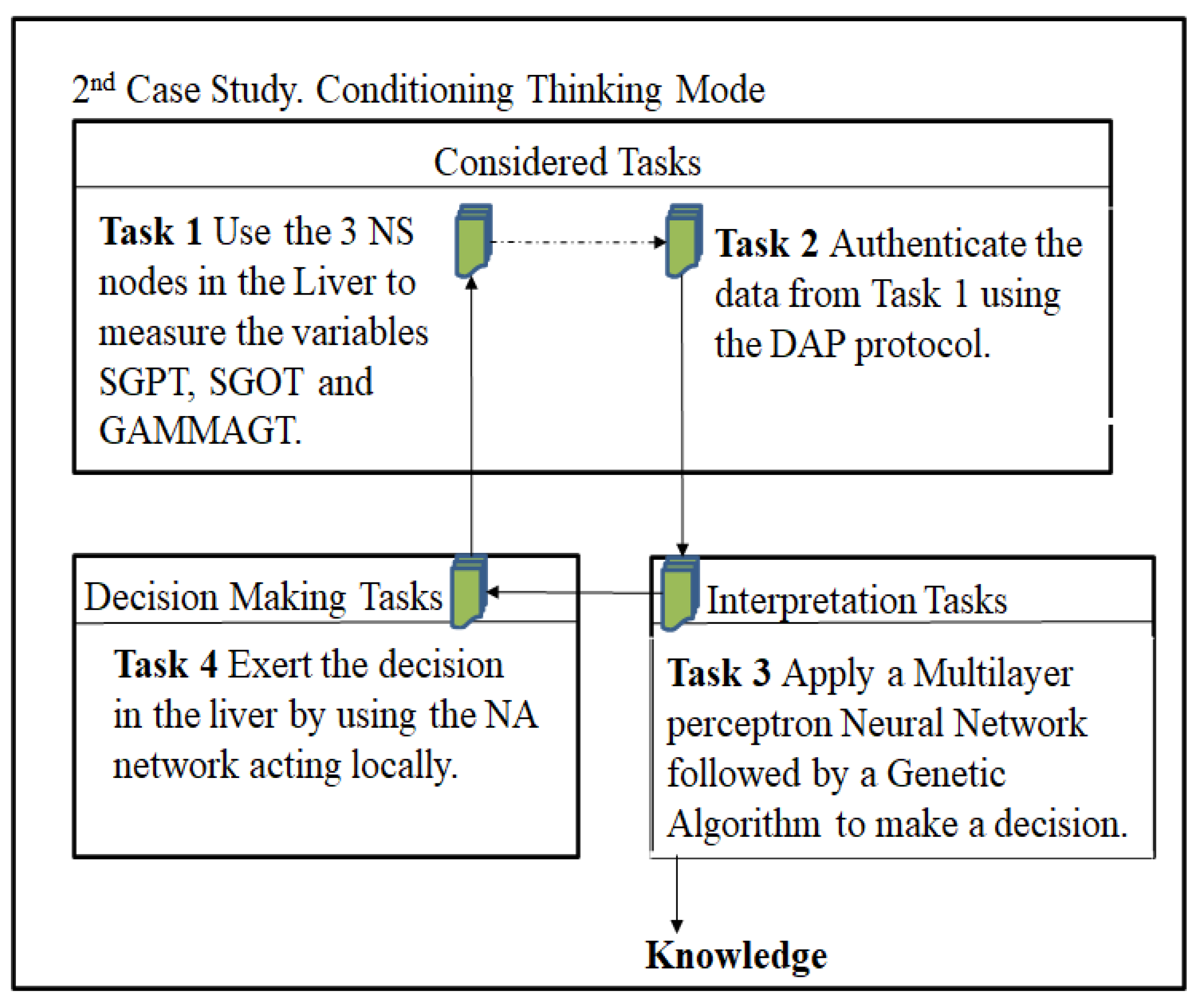
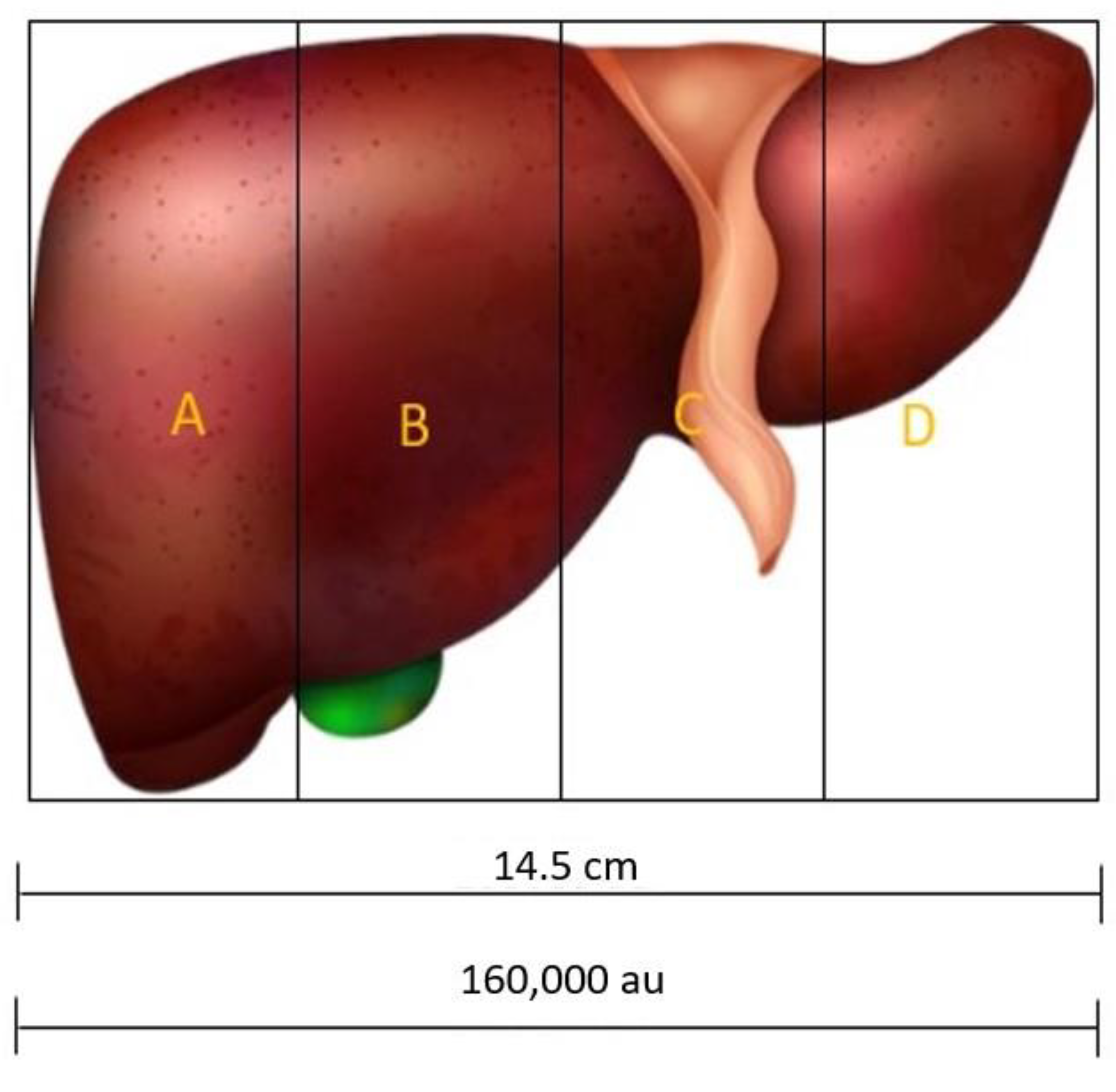
4.1. Description of the Case Study
4.2. Case Study 1: Liver Status in a Unisensor System
4.3. Case Study 2: Liver Status in Multisensor System
5. Numerical Results and Analysis
5.1. Specification of the Genetic Algorithm
- Number of generations: [10, 50, 100, 150, 200]
- Population size: [10, 30, 50, 70, 100]
5.2. Case Studies
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- García-Haro, J.; García-Sanchez, S.; Canovas-Carrasco, S. The IEEE 1906.1 Standard: Nanocommunications as a New Source of Data. In Proceedings of the ITU Kaleidoscope: Challenges for a Data-Driven Society, Nanjing, China, 27–29 November 2017. [Google Scholar]
- Lopez-Pacheco, A.; Aguilar, J. NANO-Communication Management System for Smart Environments. Rev. Venez. Comput. 2018, 5, 12–22. [Google Scholar]
- García-Haro, J.; García-Sanchez, S.; Canovas-Carrasco, S. The IEEE 1906.1 Standard: Some Guidelines for Strengthening Future Normalization in Electromagnetic Nanocommunications. IEEE Commun. Stand. Mag. 2018, 2, 26–32. [Google Scholar]
- Lopez-Pacheco AAguilar, J.; Puerto, E.; Garcia, R. An ontological model based on the ontology driven architecture paradigm for a middleware in the management of nano-devices in a smart environment. J. Phys. Conf. Ser. 2019, 1386, 012138. [Google Scholar] [CrossRef]
- Lopez-Pacheco, A.; Aguilar, J. Data Analysis Smart Systems in a Nanodevices Based Middleware. Contemp. Eng. Sci. 2018, 11, 4665–4679. [Google Scholar] [CrossRef]
- Lopez-Pacheco, A.; Aguilar, J. Autonomic Reflective Middleware for the Management of NANOdevices in a Smart Environment (ARMNANO). Curr. Anal. Commun. Eng. 2019, 2, 56–63. [Google Scholar]
- Millery, M.; Ramos, W.; Lien, C.; Aguirre AKukafka, R. Design of a Community-Engaged Health Informatics Platform with an Architecture of Participation. AMIA Annu. Symp. Proc. 2015, 2015, 905–914. [Google Scholar]
- Divya, V.; Kumar, S. A Comprehensive Review on Various Signal Conditioning Methods in Nano-Sensor Based Applications. J. Comput. Theor. Nanosci. 2020, 17, 2043–2050. [Google Scholar] [CrossRef]
- Zamuda, A.; Zarges, C.; Stiglic, G.; Hrovat, G. Stability selection using a genetic algorithm and logistic linear regression on healthcare records. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Berlin Germany, 15–19 July 2017. [Google Scholar]
- Wilmer, C. Genetic Algorithm Design of MOF-based Gas Sensor Arrays for CO2-in-Air Sensing. Sensors 2020, 20, 924–936. [Google Scholar]
- Ghaheri, A.; Shoar, S.; Naderan, M.; Shahabuddin, S. The Applications of Genetic Algorithms in Medicine. Oman Med. J. 2015, 30, 406–416. [Google Scholar] [CrossRef]
- Kumar, A.; Tyagi, P.; Bhatnagar, A. Genetic Algorithm and their applicability in Medical Diagnostic: A Survey. Int. J. Sci. Eng. Res. 2016, 7, 1143–1145. [Google Scholar]
- Alpers, S.; Skogen, J.; Maeland, S.; Pallesen, S.; Rabben, A.; Lunde, L.; Fadnes, L. Alcohol Consumption during a Pandemic Lockdown Period and Change in Alcohol Consumption Related to Worries and Pandemic Measures. Int. J. Environ. Res. Public Health 2021, 18, 1220. [Google Scholar] [CrossRef] [PubMed]
- Jongwook, J.; Byung-Gook, P.; Hyungcheol, S. Investigation of Thermal Noise Factor in Nanoscale MOSFETs. J. Semicond. Technol. Sci. 2010, 10, 225–231. [Google Scholar]
- Asrani, S.; Devarbhavi, H.; Eaton, J.; Kamath, P. Burden of liver diseases in the world. J. Hepatol. 2019, 70, 151–171. [Google Scholar] [CrossRef]
- Leong, Y.; Tan, E.; Leong, S.; Koh, C.; Nguyen, L.; Chen, J.; Xia, K.; Ling, X. Where nanosensors meet machine learning: Prospects and challenges in detecting Disease X. ACS Nano 2022, 16, 13279–13293. [Google Scholar] [CrossRef]
- Akyol, D.; Orgulu, B. Towards a Different Architecture in Cooperation with Nanotechnology and Genetic Science: New Approaches for the Present and the Future. Archit. Res. 2014, 4, 1–12. [Google Scholar]
- Dorj, U.; Lee, M.; Choi, J.; Lee, Y.; Jeong, G. The Intelligent Healthcare Data Management System Using Nanosensors. J. Sens. 2017, 2017, 7483075. [Google Scholar] [CrossRef]
- Bushko, R. Future of eHealth: Can Consumers Cure Themselves? Stud. Health Technol. Inform. 2009, 149, 178–184. [Google Scholar]
- Mehr, H.; Craven, M.; Leono, A.; Keenan, G.; Cronin, A. A universal system for digitization and automatic execution of the chemical synthesis literature. Science 2020, 370, 101–108. [Google Scholar] [CrossRef]
- Niroumand, H.; Zain, M.; Jamil, M. Statistical Methods for Comparison of Data Sets of Construction Methods and Building Evaluation. Procedia-Soc. Behav. Sci. 2013, 89, 218–221. [Google Scholar]
- Severson, T.; Besur, S.; Bonkovsky, H. Genetic factors that affect nonalcoholic fatty liver disease: A systematic clinical review. World J. Gastroenterol. 2016, 29, 6742–6756. [Google Scholar] [CrossRef]
- Mejía-Salazar, J.; Rodrigues Cruz, K.; Materón Vásques, E.; Novais de Oliveira, O., Jr. Microfluidic Point-of-Care Devices: New Trends and Future Prospects for eHealth Diagnostics. Sensors 2020, 20, 1951. [Google Scholar] [CrossRef]
- Chakravarthy, V.; Hakkim Devan Mydeen, P.; Seenivasan, M. Study on Internet of Nanotechnology (IoNT) in a Healthcare Monitoring System, In Handbook of Research on Nano-Drug Delivery and Tissue Engineering: Guide to Strengthening Healthcare Systems; Rajakumari, R., Hanna, J., Sabu, T., Nandakumar, K., Eds.; Apple Academic Press: New York, NY, USA, 2022. [Google Scholar]
- Mujawar, M.; Gohel, H.; Bhardwaj, S.; Srinivasan, S.; Hickman, N.; Kaushik, A. Nano-enabled biosensing systems for intelligent healthcare: Towards COVID-19 management. Mater. Today Chem. 2020, 17, 100306. [Google Scholar] [CrossRef] [PubMed]
- Kedar, N.; Ravindharan, E.; Paramananda, J. Applications of IoT in Health Care: Challenges and Benefits. In IoT Applications, Security Threats, and Countermeasures; Padmalaya, N., Niranjan, R., Ravichandran, P., Eds.; CRC Press: Boca Raton, FL, USA, 2021. [Google Scholar]
- Singh, K.; Nayak, V.; Singh, J.; Singh, R. Nano-enabled wearable sensors for the Internet of Things (IoT). Mater. Lett. 2021, 304, 130614. [Google Scholar] [CrossRef]
- Vizcarrondo, J.; Aguilar, J.; Exposito, E.; Subias, A. MAPE-K as a service-oriented architecture. IEEE Lat. Am. Trans. 2017, 15, 1163–1175. [Google Scholar]
- Sánchez, M.; Aguilar, J.; Cordero, J.; Valdiviezo-Díaz, P.; Barba-Guamán, L.; Chamba-Eras, L. Cloud Computing in Smart Educational Environments: Application in Learning Analytics as Service. In New Advances in Information Systems and Technologies; Rocha, Á., Correia, A., Adeli, H., Reis, L., Mendonça Teixeira, M., Eds.; Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2016; Volume 444, pp. 993–1002. [Google Scholar]
- Aguilar, J.; Garcès-Jimènez, A.; Gallego-Salvador, N.; Gutierrez De Mesa, J.; Gomez-Pulido, J.; Garcìa-Tejedor, A. Autonomic Management Architecture for Multi-HVAC Systems in Smart Buildings. IEEE Access 2019, 7, 123402–123415. [Google Scholar] [CrossRef]
- Morales, L.; Ouedraogo, C.; Aguilar, J. Experimental comparison of the diagnostic capabilities of classification and clustering algorithms for the QoS management in an autonomic IoT platform. Serv. Oriented Comput. Appl. 2019, 13, 199–219. [Google Scholar] [CrossRef]
- Aguilar, J. Definition of an energy function for the random neural to solve optimization problems. Neural Netw. 1998, 11, 731–737. [Google Scholar]
- I. S. 1906.1; IEEE Recommended Practice for Nanoscale and Molecular Communication Framework. IEEE Communications Society: New York, NY, USA, 2015.
- Russell, A. Rough Consensus and Running Code’ and the Internet-OSI Standards War. IEEE Ann. Hist. Comput. 2006, 28, 48–61. [Google Scholar] [CrossRef]
- Scorza, M.; Elce, A.; Zarrilli, F.; Liguori, R.; Amato, F.; Castaldo, G. Genetic Diseases That Predispose to Early Liver Cirrhosis. Int. J. Hepathol. 2014, 2014, 713754. [Google Scholar] [CrossRef]
- Moon, A.; Singal, A.; Tapper, E. Contemporary Epidemiology of Chronic Liver Disease and Cirrhosis. Clin. Gastroenterol. Hepatol. 2020, 18, 2650–2666. [Google Scholar] [CrossRef]
- Bellentani, S.; Tiribelli, C.; Saccoccio, G.; Sodde, M.; Fratti, N.; De Martin, C.; Cristianini, G. Prevalence of Chronic Liver Disease in the General Population of Northern Italy. The Dionysos Study. Hepatology 1994, 20, 1442–1450. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task Name | Data Collection Mode | Data Source |
|---|---|---|
| Task 1 | Observation of the nanocontext | NS node measurement |
| Task 2 | Data validation in the CmNA layer [2] | Mc unit data delivery to DASS [6] |
| Task 3 | Data analysis in DASS | Data previously prepared [6] |
| Task 4 | NA node-released action | Results generated by the ML techniques |
| Variable | Normal Level |
|---|---|
| 1. Mean Corpuscular Volume (MCV) | The normal range is between 80–100 fL |
| 2. Alkaline phosphotase (alkphos) | The normal range is between 44 and 147 IU/L |
| 3. Alanine aminotransferase (sgpt) | The normal range is between 7 to 56 units/L in serum. |
| 4. Aspartate aminotransferase (sgot) | Normal range is between 8 to 45 units/L in the serum. |
| 5. Gamma-glutamyl transpeptidase (gammagt) | The normal range in adults is between 0 and 30 IU/L |
| Cycles | Population Size |
|---|---|
| 10 | 100 |
| ALKPHOS | MCV | DCH (FF) |
|---|---|---|
| 76 | 85 | 24,225 |
| No. of NSs | DCH (FF) |
|---|---|
| 3 NSs | 162,500 |
| 4 NSs | 156,500 |
| 5 NSs | 132,000 |
| 10 NSs | 132,000 |
| Patient | No. of NSs | DCH (FF) |
|---|---|---|
| 1 | 4 NSs | 156,500 |
| 2 | 5 NSs | 152,500 |
| 3 | 3 NSs | 158,000 |
| 4 | 5 NSs | 148,000 |
| N | 5 NSs | 155,500 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lopez, A.; Aguilar, J. A Data Analysis Smart System for the Optimal Deployment of Nanosensors in the Context of an eHealth Application. Algorithms 2023, 16, 81. https://doi.org/10.3390/a16020081
Lopez A, Aguilar J. A Data Analysis Smart System for the Optimal Deployment of Nanosensors in the Context of an eHealth Application. Algorithms. 2023; 16(2):81. https://doi.org/10.3390/a16020081
Chicago/Turabian StyleLopez, Alberto, and Jose Aguilar. 2023. "A Data Analysis Smart System for the Optimal Deployment of Nanosensors in the Context of an eHealth Application" Algorithms 16, no. 2: 81. https://doi.org/10.3390/a16020081
APA StyleLopez, A., & Aguilar, J. (2023). A Data Analysis Smart System for the Optimal Deployment of Nanosensors in the Context of an eHealth Application. Algorithms, 16(2), 81. https://doi.org/10.3390/a16020081