1. Introduction
The alternating direction method of multipliers [
1] (ADMM) has been recognized as a simple but powerful algorithm to solve optimization problems of the form
where
and
are closed, proper, and convex functions,
,
,
. ADMM splits the problem into smaller pieces, each of which is then easier to handle, blending the benefits of dual decomposition and augmented Lagrangian methods [
1]. Starting from an initialization
and
, at each iteration, ADMM updates the primal and dual variables as
ADMM is guaranteed to converge under mild assumptions for any fixed value of the penalty parameter
, even if the subproblems are solved inexactly [
2]. Despite this, it is well-known that the choice of the parameter
is problem-dependent and can affect the practical performance of the algorithm, yielding a highly inefficient method when it is not properly selected. Some work has been done to develop suitable techniques for tuning the values of
at each iteration, with the aim of speeding up the convergence in practical applications [
3,
4,
5,
6]. In [
3], the authors proposed an adaptive strategy based on primal and dual residuals, with the idea that
forces both to have a similar magnitude. Such a scheme is not guaranteed to converge; nevertheless, the standard convergence theory (fixed values of
) still applies if one assumes that
becomes fixed after a finite number of iterations. A more general and reliable approach has been introduced in [
7], where the authors proposed a strategy for automatic selection of the penalty parameter in ADMM, borrowing ideas from spectral stepsize selection strategies in gradient-based methods for unconstrained optimization [
8,
9,
10,
11]. In particular, starting from the analysis of the dual unconstrained formulation of problem (
1), in [
7] an optimal penalty parameter at each iteration is defined as the reciprocal of the geometric mean of Barzilai–Borwein-like spectral stepsizes [
8,
10], corresponding to a gradient step of the Fenchel conjugates of the functions
H and
G, respectively.
Relying on the procedure suggested in [
7], this paper aims at investigating the practical efficiency of ADMM, employing adaptive selections of the penalty parameter based on different spectral stepsize rules. Indeed, spectral analysis of Barzilai–Borwein (BB) rules (and their variants) has shown how different choices can influence the practical acceleration of gradient-based methods for both constrained and unconstrained smooth optimization, due to the intrinsic different abilities of such stepsizes of capturing the spectral properties of the problem. Indeed, for strictly convex quadratic problems, the Barzilai–Borwein updating rules correspond to the inverses of the Rayleigh quotients of the Hessian, thus providing suitable approximations of the inverses of its eigenvalues. Such an ability has been exploited within ad hoc steplength selection strategies to obtain practical accelerations of gradient-based methods; moreover, this property is preserved in the case of general non-quadratic minimization problems [
9,
11,
12,
13]. In this view, we combine the adaptive ADMM scheme with state-of-the-art stepsizes to compute reliable approximations of the penalty parameter
at each iteration. The resulting variants of the ADMM scheme thus obtained are compared on two real-life applications in the frameworks of binary classification on distributed architectures and portfolio selection.
The paper is organized as follows. The adaptive ADMM algorithm is described in
Section 2. Numerical experiments are reported in
Section 3. Finally, some conclusions are drawn in
Section 4.
2. Adaptive Penalty Parameter Selection in ADMM Method
In this section, we describe the strategy for automatic selection of the penalty parameter in ADMM according to the procedure proposed in [
7], in which the authors introduced an adaptive selection of
based on the spectral properties of the Douglas–Rachford (DR) splitting method applied to the dual problem of (
1).
Given a closed convex (proper) function
f defined on
, the Fenchel conjugate of
f is the closed convex (proper) function
defined by
(see [
14]). The dual problem of (
1) is given by
where
and
denote, respectively, the Fenchel conjugate of
H and
G. Problem (
5) can be equivalently rewritten as
It can be proved that solving (
1) by ADMM is equivalent to solving the dual problem (
6) by means of the DR method [
15], which, in turn, is equivalent to applying the DR scheme to
In this way, two sequences
and
are generated such that
Then, Proposition 1 in [
7] proves that the choice of the parameter
that guarantees the minimal residual of
in DR steps is given by
where
are BB stepsizes arising by imposing the following quasi-Newton conditions:
where
,
,
, and
). Note that
and
can be interpreted as spectral gradient stepsizes of type BB1 for
and
, respectively.
Based on the equivalence between DR and ADMM, the optimal DR stepsize
defined in (
9) corresponds to the optimal penalty parameter for the ADMM scheme. Moreover, to compute practical estimates of these optimal parameters for ADMM, the dual problem is not required to be supplied, thanks to the theoretical link between primal and dual variables. Indeed, the optimality condition for Problem (
2) prescribes
which is equivalent to
Recalling that for a closed proper convex function
f,
if and only if
(see [
14], Corollary 23.5.1), from the previous relation, we obtain
and, hence, it follows
where
. Similarly, from the optimality condition for the subproblem (3), one can obtain
From (
12) and (
13), we have
Finally, one can define
and
, where
, and the set subtraction is given by the Minkowski–Pontryagin difference [
16,
17]. In particular, a practical computation of an element of
can be provided through quantities available at the current ADMM iteration by exploiting (
12); thus, with a slight abuse of notation, we may write
Then, the two BB-based rules can be recovered as
With a similar argument, the curvature estimates of
are provided by the following stepsizes:
where
and
. The previous quasi-Newton conditions express a local property of linearity of the dual subgradients with respect to the dual variables. The validity of this assumption can be checked during the iterative procedure to test the reliability of the spectral BB-based parameters. In particular, the stepsizes (
16)–(19) can be considered reliable when, respectively, the ratios
are bounded away from zero.
Then, as safeguarding condition, the update of the penalty parameter is realized in accordance with (
9) when both the ratios in (
20) are greater than a prefixed threshold
expressing the required level of reliability provided by the estimates (
10) and (11). If only one of the ratios satisfies the safeguarding condition, the corresponding stepsize is used to estimate
, which eventually is set equal to the last updated value when both stepsizes are considered inaccurate, i.e., when
and
.
A general ADMM scheme with adaptive selection of the penalty parameter based on the described procedure is outlined in Algorithm 1. We remark that different versions of Algorithm 1 arise depending on the different rules selected for computing the spectral stepsizes
and
in STEP 4. In particular, in the scheme originally proposed in [
7],
and
are provided by a generalization of the
adaptive steepest descent (ASD) strategy introduced in [
10], which performs a proper alternation of larger and smaller stepsizes. In the next section, we will compare this procedure with other updating rules based on both single and alternating BB-based strategies.
As final remark, we recall that a proof of the convergence of ADMM with variable penalty parameter was provided in [
3] under suitable assumptions on the increase and decrease in the sequence
(see
Section 4—Theorem 4.1 in [
3]). Although this convergence analysis cannot straightforwardly be applied to our case, as observed in [
7], this issue may be bypassed in practice by turning off the adaptivity after a finite number of steps.
| Algorithm 1 A general scheme for ADMM with adaptive penalty parameter selection |
| Initialize , , , , , |
| For |
| STEP 1 Compute by solving (2). |
| STEP 2 Compute by solving (3). |
| STEP 3 Update by means of (4). |
| STEP 4 If then |
| |
| Compute spectral stepsizes , according to (10) and (11) |
| Compute correlations , |
| if and then |
| |
| elseif and |
| |
| elseif and |
| |
| else |
| |
| endif |
| else |
| |
| endif |
| STEP 5 end for |
3. Numerical Experiments
In this section we present the results of the numerical experiments performed to assess the performances of Algorithm 1 equipped with different choices for the update of
in STEP 4. We compare the alternating strategy used in [
7] with BB1-like rules
(
16)–(
18), BB2-like rules
(17)–(19), and a different alternating strategy, based on a modified version of the ABB
rule [
18], introduced in [
19]. The five algorithms compared in this section are the following:
“Vanilla ADMM”, in which is fixed to throughout all iterations;
“Adaptive ADMM” [
7], in which
and
are set to
“Adaptive ADMM-BB1”, in which and are set to and , respectively;
“Adaptive ADMM-BB2”, in which and are set to and , respectively;
“Adaptive ADMM-ABB
”, in which
and
are set to
where
,
, and
is updated as follows:
For all the algorithms, following [
7], we set
and
. The methods stop when the relative residual is below a prefixed tolerance
within a maximum number of iterations, where the relative residual is defined by
with
and
. All experiments were performed using MATLAB. Recently, the PADPD algorithm [
20] has been proposed as an algorithm analogous to ADMM, but it has fixed stepsize and is out of the scope of this paper to compare.
3.1. Consensus -Regularized Logistic Regression
As a first experiment, we test the proposed algorithms on the solution of consensus
-regularized logistic regression (see Section 4.2 in [
1,
7]). Let us consider a dataset consisting of
M training pairs
. The aim is to build a linear classifier by minimizing a regularized logistic regression functional, exploiting a distributed computing architecture. One can do so by partitioning the original dataset into
S subsets of size
, such that
, and solving the optimization problem
where
is the local variable on the
s-th computational node, which acts as a linear classifier of the
s-th subset,
represents the
j-th training pair of the
s-th subset, and
z is the global variable.
We can reformulate problem (
22) as
where we set
,
,
,
, and
(i.e., the stacking of
S identity matrices of order
n). Scaling the dual variable, the augmented Lagrangian function associated with problem (
23) is
where
,
. Starting from given estimates
,
,
, and
, and observing that the minimization problem in
u can be split into
S independent optimization problems in
, at each iteration
k the adaptive ADMM updates the estimates as
The
S problems in (
24), which are smooth unconstrained optimization problems, are solved approximately via BFGS with a stopping criterion on the gradient and the objective function with a tolerance set to 10 times the tolerance given to the ADMM scheme. The minimization in (25) can be performed via a soft thresholding operator.
We considered 4 datasets from the LIBSVM (
https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/, accessed on 1 February 2023) dataset collection; to simulate real-life conditions, we created the instances by randomly extracted a training set consisting of 70% of the available data.
1 reports the final number of training pairs (
M) and the problem dimension (
n) for each of the datasets.
We considered
for all problems to enforce sparsity in the solutions and ran all the algorithms with
, stopping when the relative residual was below
and/or the number of iterations reached 500. The results of the tests are reported in
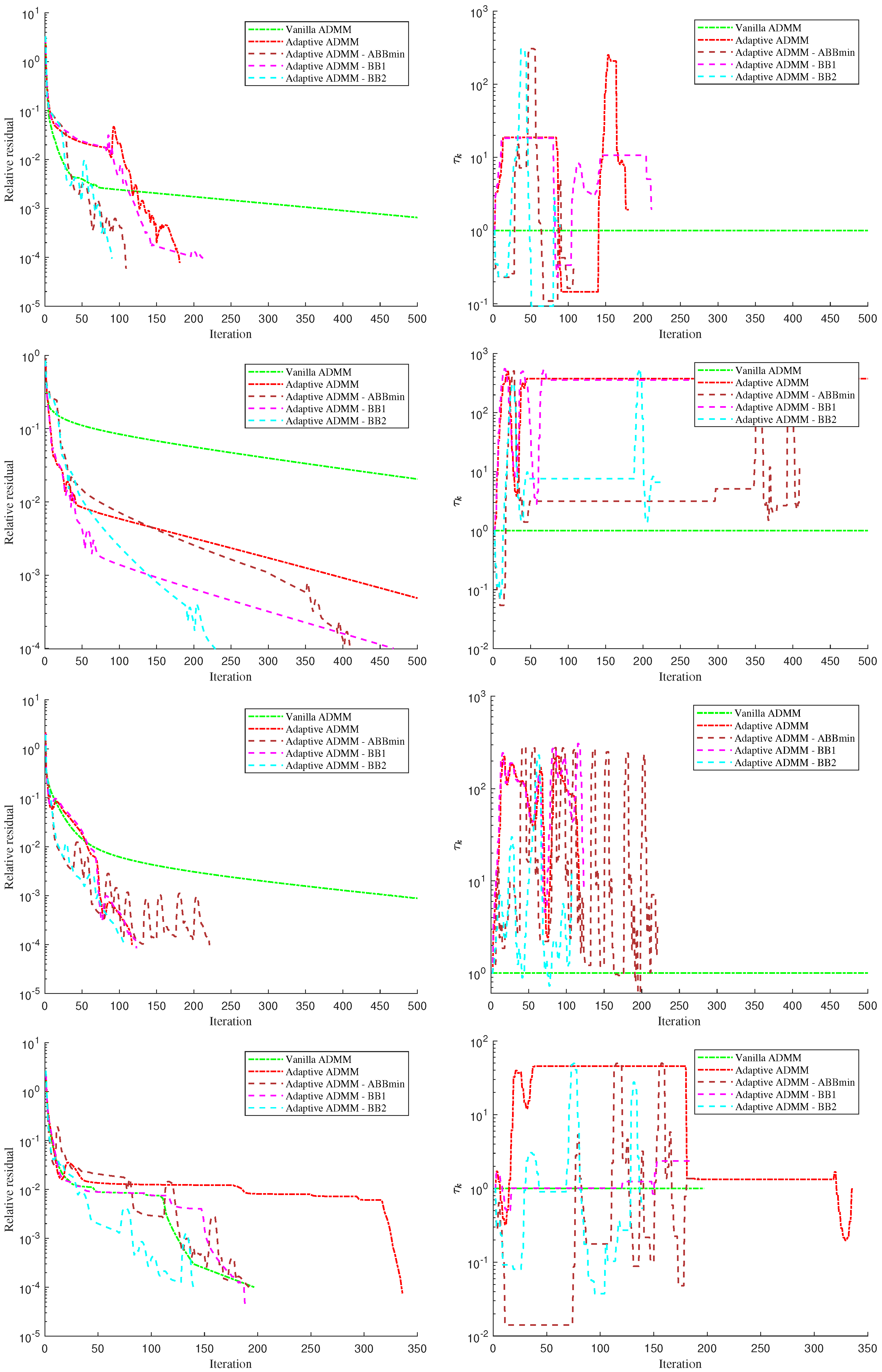
Figure 1 (left column) in terms of relative residual vs. number of iterations. We also report in the same figure (right columns) the history of
for each of the five algorithms.
From the pictures, it is clear that the four adaptive strategies are effective in reducing the number of iterations needed for convergence with respect to the “Vanilla ADMM”. Furthermore, the BB2 version is able to outperform the others in all the considered instances. By looking at the second and fourth row (problems “cod-rna” and “phishing”), it is interesting to observe that the performances of the adaptive strategies appear to decay as soon as is kept fixed for a large number of iterations. This is particularly true for algorithms “Adaptive ADMM” and “Adaptive ADMM-BB1”.
3.2. Portfolio Optimization
In the modern portfolio theory, an optimal portfolio selection strategy has to realize a trade-off between risk and return. Recently, l1-regularized Markowitz models have been considered; the l1 penalty term is used to stabilize the solution process and to obtain sparse solutions, which allow one to reduce holding costs [
21,
22,
23,
24]. We focus on a multi-period investment strategy [
23] that is either medium- or long-term; thus, it allows the periodic reallocation of wealth among the assets based on available information. The investment period is partitioned into
m sub-periods, delimited by the rebalancing dates
, at which points decisions are taken. Let
n be the number of assets and
the portfolio held at the rebalancing date
. The optimal portfolio is defined by the vector
, where
. A separable form of the risk measure obtained by summing single period terms is considered
where
is the covariance matrix, assumed to be positive definite, estimated at
. With this choice, the model satisfies the time consistency property.
-regularization has been used to promote sparsity in the solution. Moreover, the
penalty term either avoids or limits negative solutions; thus, it is equivalent to a penalty on short positions.
Let
and
be the initial wealth and the target expected wealth resulting from the overall investment, respectively, and let
be the expected return vector estimated at time
j. The l1-regularized selection can be formulated as the following compact constrained optimization problem [
23,
24]:
where
is a
diagonal block matrix,
A is an
lower bidiagonal block matrix, with blocks of dimension
, defined as
and
. Methods based on Bregman iteration have proved to be efficient for the solution of Problem (
27) as well [
23,
24,
25,
26]. Now we reformulate Problem (
27) as
where
restricted to the set
and
. Scaling the dual variable, the augmented Lagrangian function associated with Problem (
28) is
where
. Starting from given estimates
,
,
, and
, at each iteration
k, adaptive ADMM updates the estimates as
Given
, the u update (
29) is an equality-constrained problem that involves the solution of the related Karush–Kuhn–Tucker (KKT) system (see [
1], Section 4.2.5), which results in a linear system with positive definite coefficient matrix. The minimization with respect to
v can be carried out efficiently using the soft thresholding operator.
We test the effectiveness on the real market data. We show results obtained using the following datasets [
26]:
FF48 (Fama & French 48 Industry portfolios): Contain monthly returns of 48 from July 1926 to December 2015. We simulate investment strategies of length 10, 20, and 30 years, with annual rebalancing.
NASDAQ100 (NASDAQ 100 stock Price Data): Contains monthly returns from November 2004 to April 2016. We simulate investment strategy of length 10, with annual rebalancing.
Dow Jones (Dow Jones Industrial): Contains monthly returns from February 1990 to April 2016. We simulate investment strategy of length 10, with annual rebalancing.
We set for all the tests to enforce a sparse portfolio. We compared the 5 considered algorithms in terms of number of iterations needed to reach a tolerance on the relative residual, letting them run for a maximum of 3000 iterations. Moreover, we considered some financial performance measures expressing the goodness of the optimal portfolios, i.e.,
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6 report the results of the experiments performed on the 5 datasets with different choices for the value of
(namely,
,
, 1) for a total of 15 instances.
The five algorithms are overall able to obtain equivalent portfolios when converging to the desired tolerance. However, they behave quite differently in terms of iterations needed to converge. In general, the adaptive strategies allow a reduction in the computational complexity with respect to the Vanilla ADMM, which is unable to reach the desired tolerance in 9 out of 15 instances. Among the 4 adaptive strategies, “Adaptive ADMM-BB1” seems to be the most effective, being able to outperform all the others in 9 out of 15 instances, and being the second best in 4 out of 15, performing on average of iterations more than the best in this case. Unlike what happened in the case of consensus logistic regression problems, here “Adaptive ADMM-BB2” and “Adaptive ADMM-ABB” appear to perform poorly, suggesting that the use of too small of values for may slow down the convergence.
4. Conclusions
In this paper, we analyzed different strategies for the adaptive selection of the penalty parameter in ADMM. Exploiting the equivalence between ADMM and the Douglas–Rachford splitting method applied to the dual problem, as suggested in [
7], optimal penalty parameters can be estimated at each iteration from spectral stepsizes of a gradient step applied to the Fenchel conjugates of the objective functions. To this end, we selected different spectral steplength strategies based on the Barzilai–Borwein rules, which have been proved to be very efficient in the context of smooth unconstrained optimization.
We compared the different adaptive strategies on the solution of problems coming from distributed machine learning and multiperiod portfolio optimization. The results show that, while adaptive versions of ADMM are usually more effective than the “vanilla” one (using a prefixed penalty parameter), different strategies might perform better on different problems. Moreover, in some cases, the proposed alternation rule might get stuck with a fixed penalty parameter, leading to a slower convergence. Future work will deal with the analysis of an improved version of the adaptation strategies, aimed at solving the aforementioned issue and their analysis on wider problem classes.





{kind=link}