
Grammatical Evolution-Driven Algorithm for Efficient and Automatic Hyperparameter Optimisation of Neural Networks



Abstract
:1. Introduction
2. Background
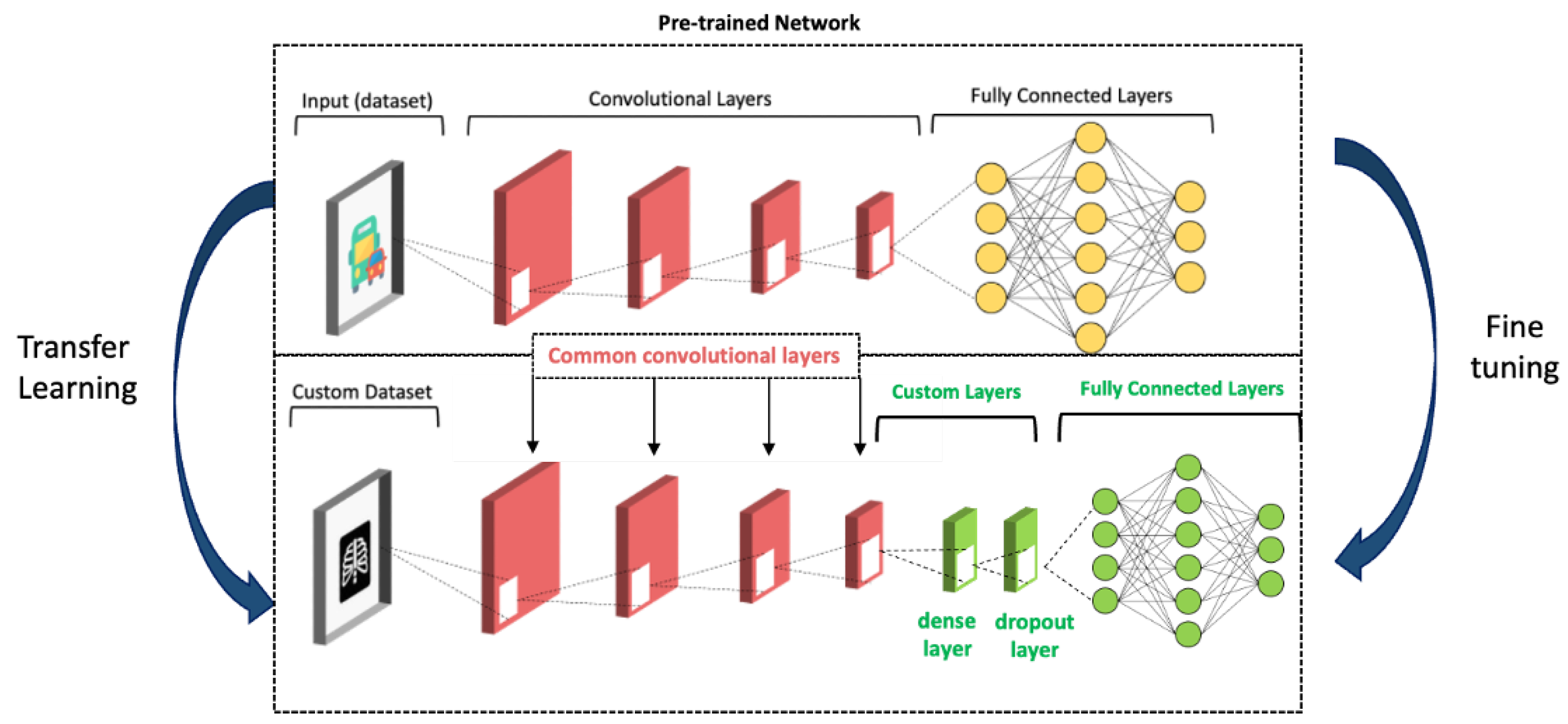
2.1. Convolutional Neural Networks
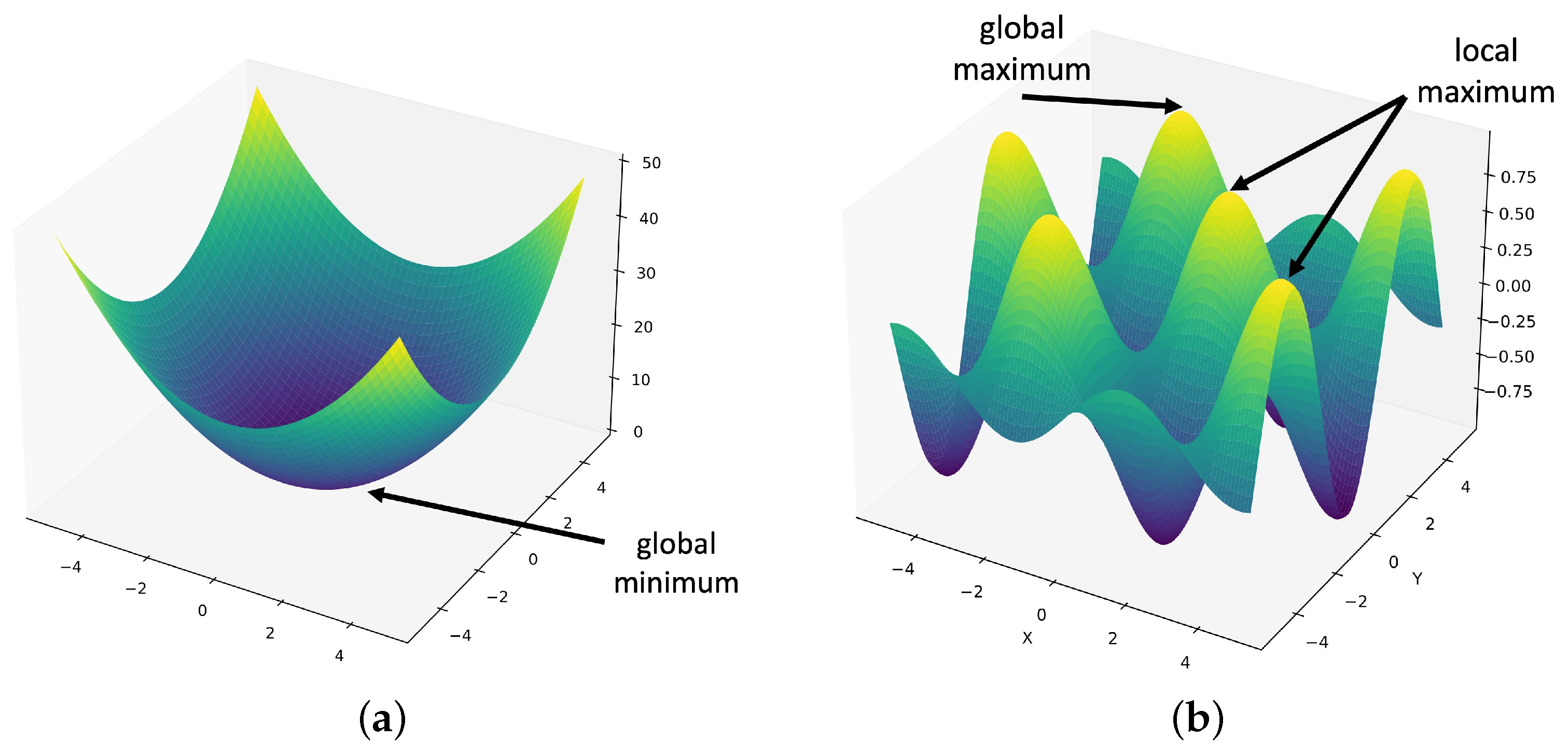
2.2. Mathematical Optimisation
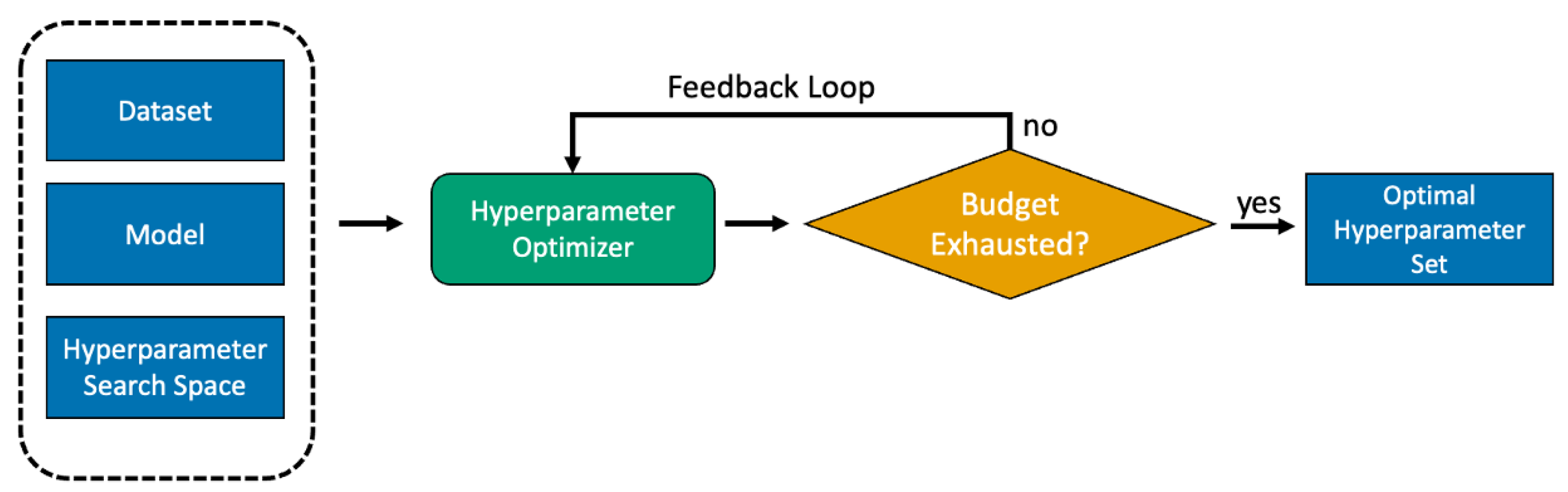
2.3. Hyperparameter Optimisation
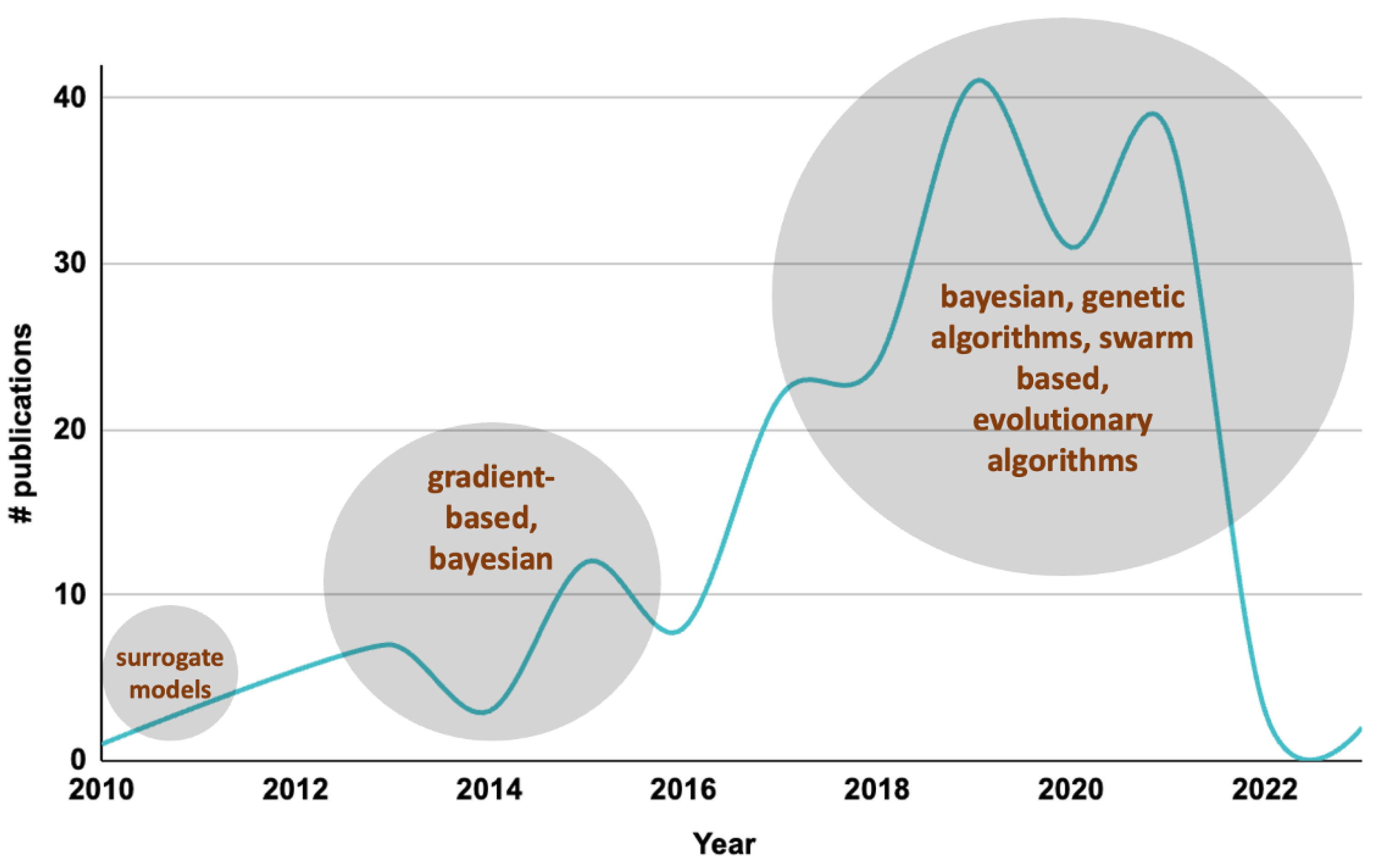
3. Related Works
4. Materials and Methods
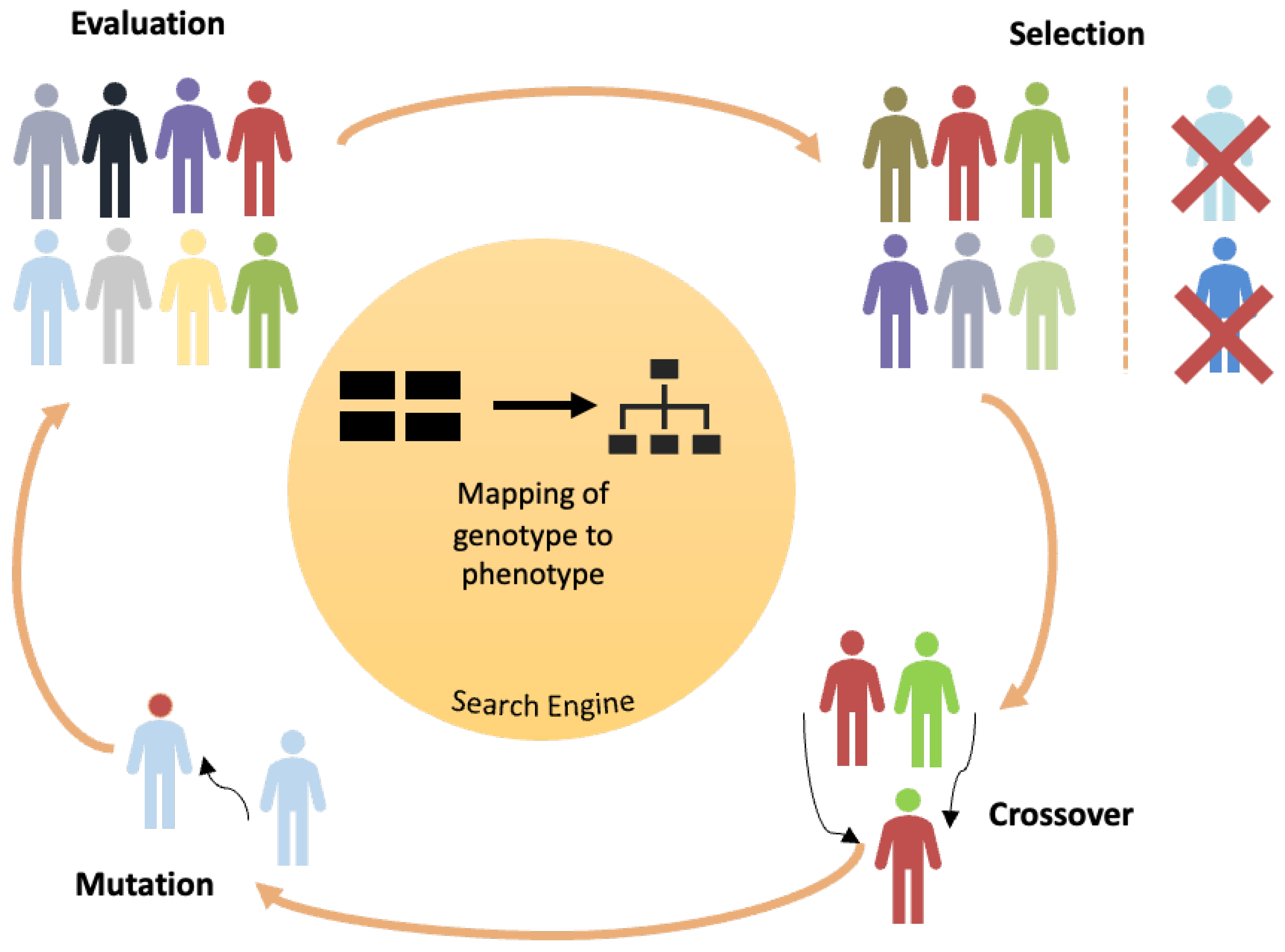
4.1. Grammatical Evolution
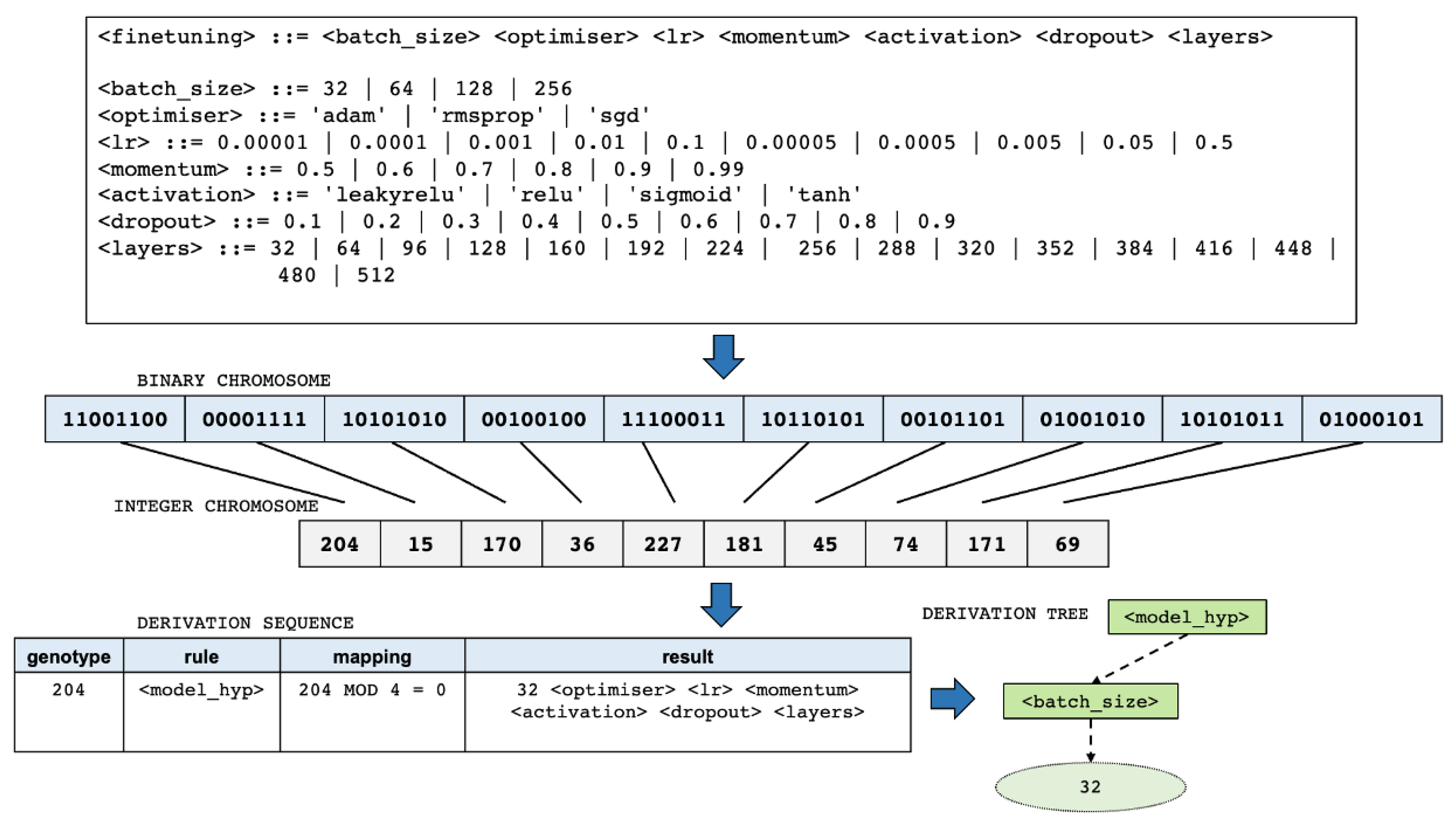
4.2. Mapping of Genotype to Phenotype
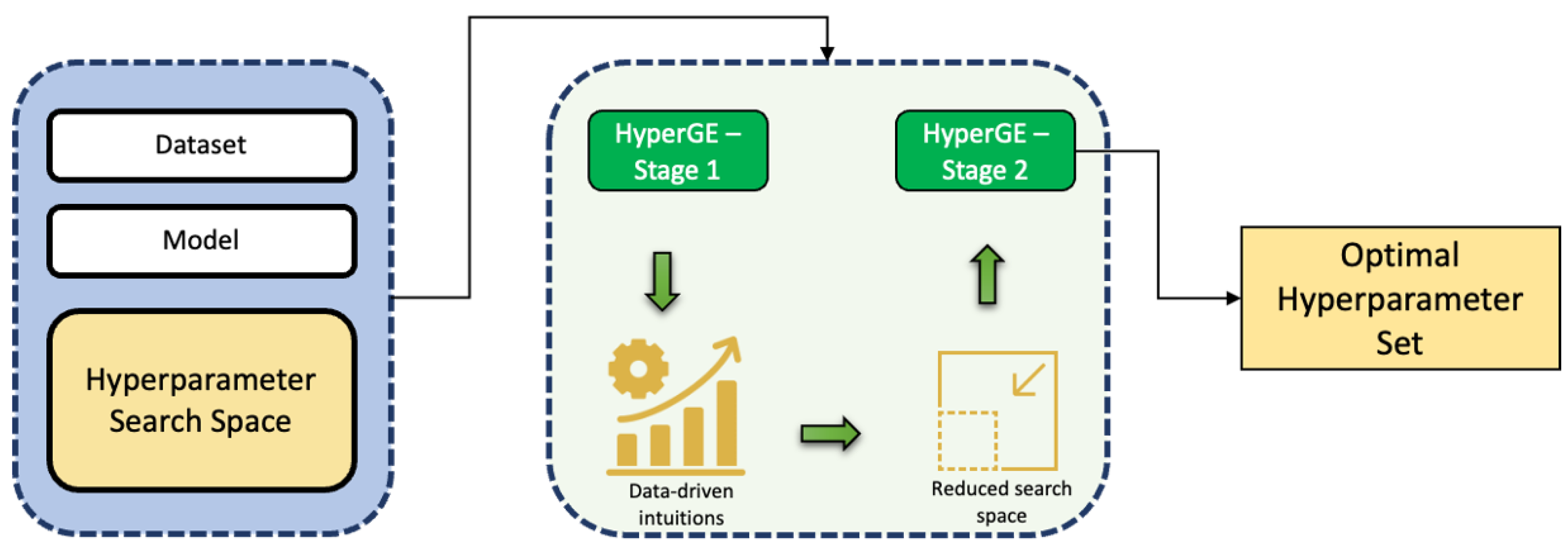
4.3. Overview of HyperGE
4.4. Hyperparameter Search Space
5. Experimental Setup
5.1. NN Architectures
5.2. Datasets
5.3. Evolutionary Hyperparameters
6. Results and Discussion
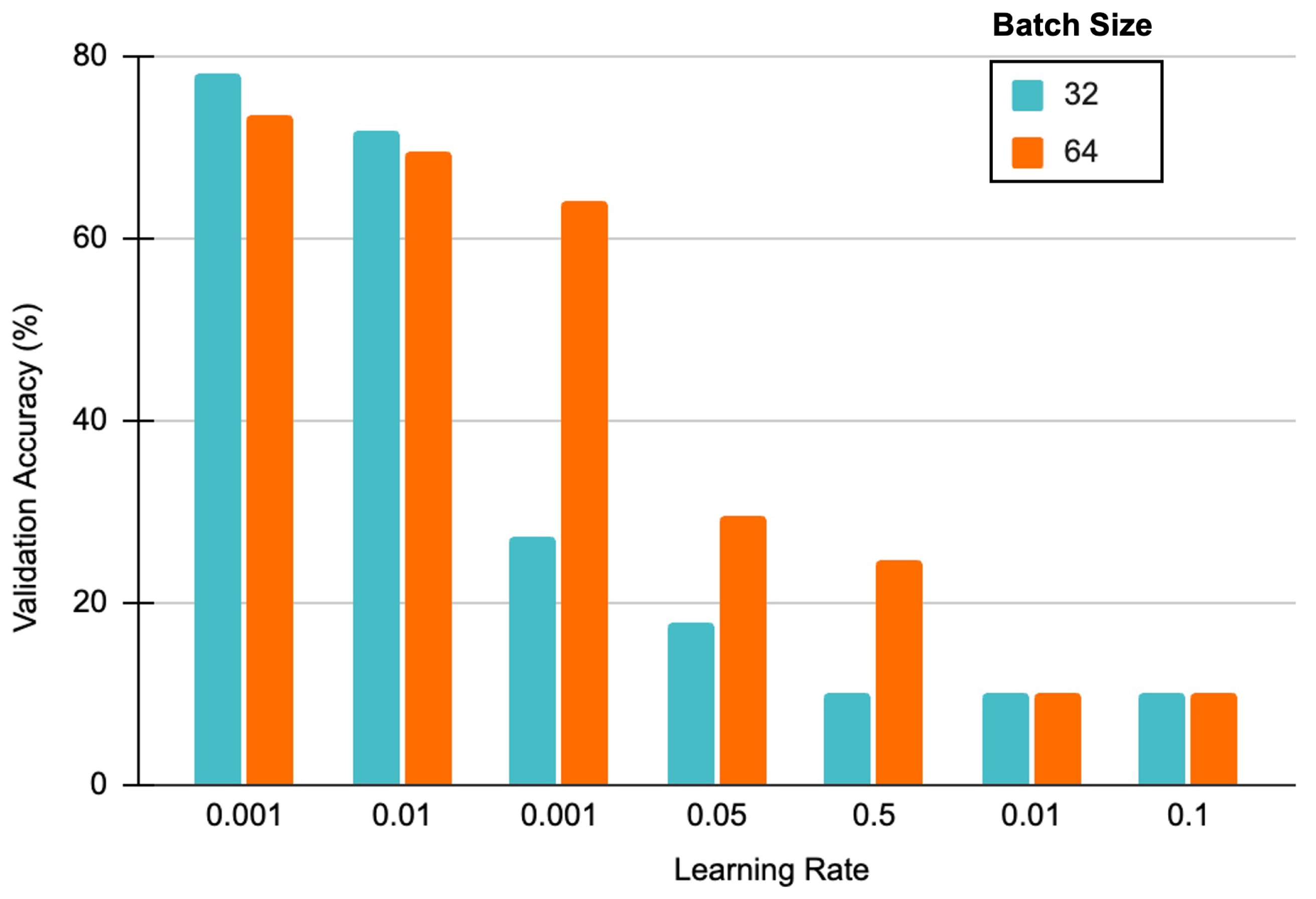
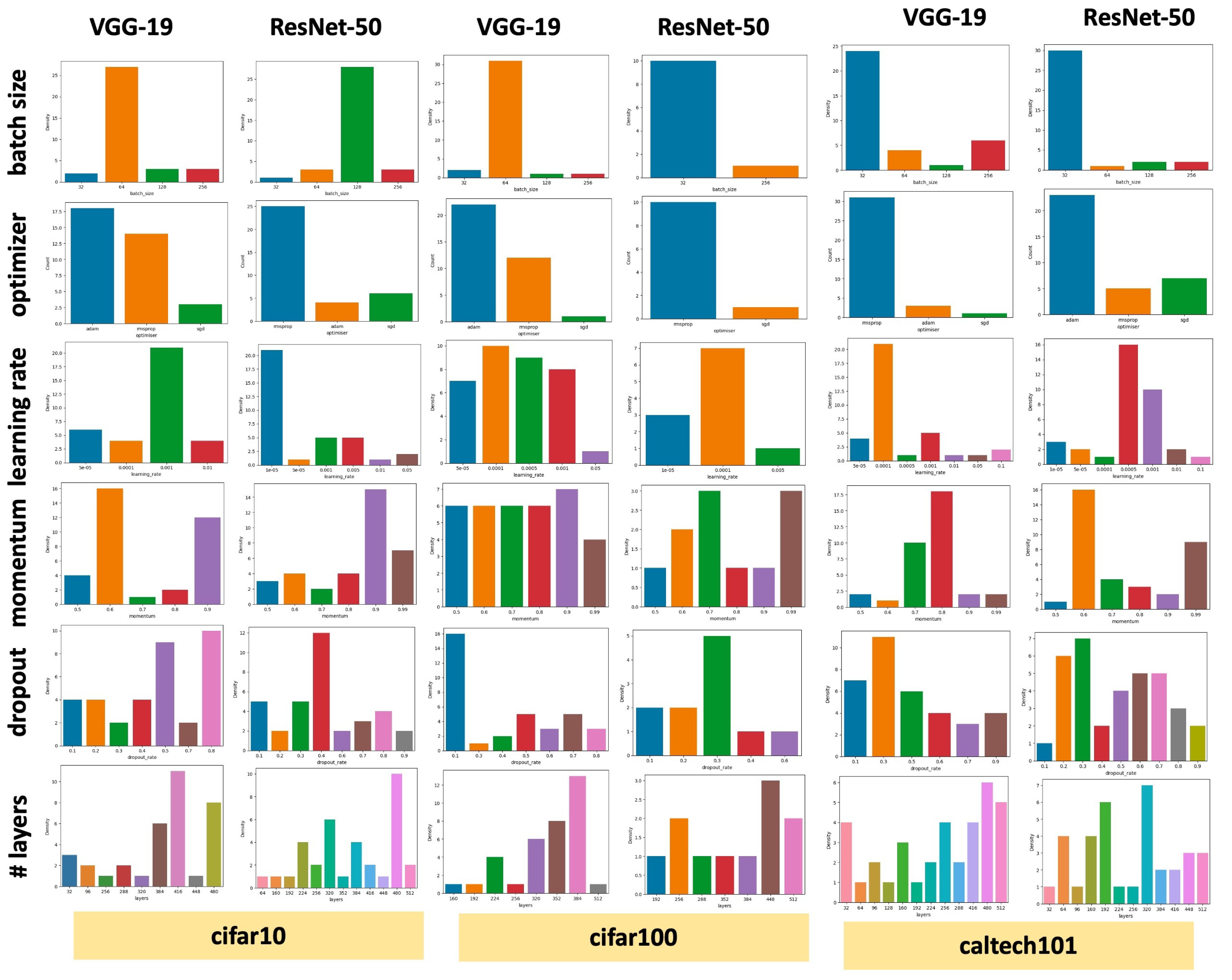
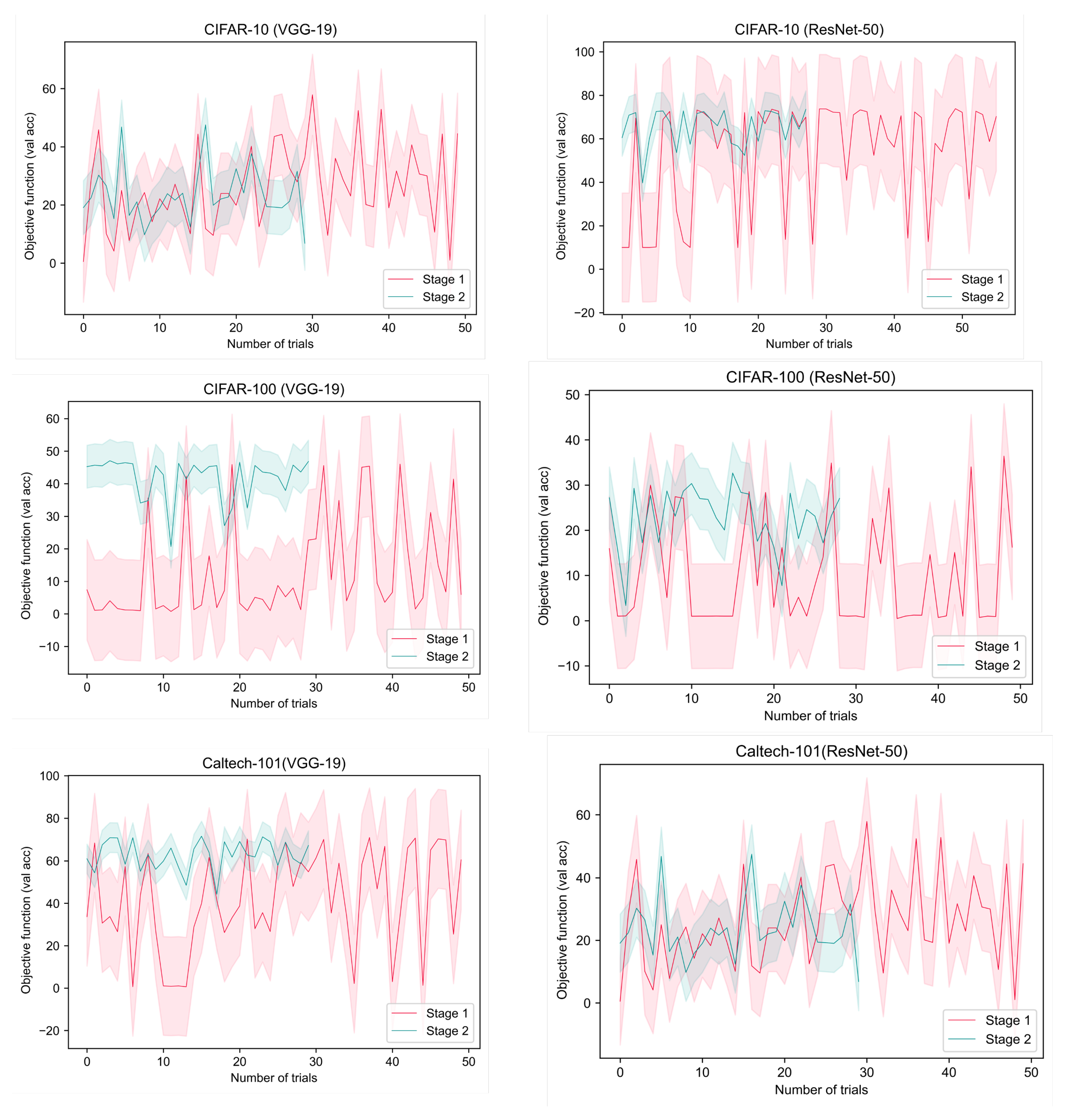
6.1. Refining the Search Space with HyperGE
6.2. Comparitive Analysis with SOTA
7. Conclusions and Future Scope
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kshirsagar, M.; More, T.; Lahoti, R.; Adgaonkar, S.; Jain, S.; Ryan, C. Rethinking Traffic Management with Congestion Pricing and Vehicular Routing for Sustainable and Clean Transport. In Proceedings of the 14th International Conference on Agents and Artificial Intelligence—Volume 3: ICAART, Online, 3–5 February 2022; pp. 420–427. [Google Scholar] [CrossRef]
- Bahja, M. Natural Language Processing Applications in Business. In E-Business-Higher Education and Intelligence Applications; BoD–Books on Demand: Norderstedt, Germany, 2020. [Google Scholar] [CrossRef]
- Hewamalage, H.; Bergmeir, C.; Bandara, K. Recurrent Neural Networks for Time Series Forecasting: Current status and future directions. Int. J. Forecast. 2021, 37, 388–427. [Google Scholar] [CrossRef]
- Xiao, Y.; Wu, L.; Guo, J.; Li, J.; Zhang, M.; Qin, T.; Liu, T.Y. A Survey on Non-Autoregressive Generation for Neural Machine Translation and Beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 1–20. [Google Scholar] [CrossRef]
- Diaz, G.I.; Fokoue-Nkoutche, A.; Nannicini, G.; Samulowitz, H. An effective algorithm for hyperparameter optimisation of neural networks. IBM J. Res. Dev. 2017, 61, 9:1–9:11. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Bochinski, E.; Senst, T.; Sikora, T. Hyper-parameter optimisation for convolutional neural network committees based on evolutionary algorithms. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3924–3928. [Google Scholar] [CrossRef] [Green Version]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimisation. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for Hyper-Parameter Optimisation. In Advances in Neural Information Processing Systems; Shawe-Taylor, J., Zemel, R., Bartlett, P., Pereira, F., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2011; Volume 24. [Google Scholar]
- DeCastro-García, N.; Castañeda, Á.L.M.; García, D.E.; Carriegos, M.V. Effect of the Sampling of a Dataset in the Hyperparameter Optimisation Phase over the Efficiency of a Machine Learning Algorithm. Complexity 2019, 2019, 6278908. [Google Scholar] [CrossRef] [Green Version]
- Hensman, J.; Fusi, N.; Lawrence, N.D. Gaussian Processes for Big Data. arXiv 2013, arXiv:1309.6835. [Google Scholar]
- Zhang, L.; Zhang, L.; Zhang, L. Application research of digital media image processing technology based on wavelet transform. EURASIP J. Image Video Process 2018, 2018, 138. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Han, X.; Zhang, Z.; Ding, N.; Gu, Y.; Liu, X.; Huo, Y.; Qiu, J.; Yao, Y.; Zhang, A.; Zhang, L.; et al. Pre-trained models: Past, present and future. AI Open 2021, 2, 225–250. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Bergstra, J.; Komer, B.; Eliasmith, C.; Yamins, D.; Cox, D.D. Hyperopt: A Python library for model selection and hyperparameter optimisation. Comput. Sci. Discov. 2015, 8, 014008. [Google Scholar] [CrossRef]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimisation Framework. arXiv 2019, arXiv:1907.10902. [Google Scholar]
- Liaw, R.; Liang, E.; Nishihara, R.; Moritz, P.; Gonzalez, J.E.; Stoica, I. Tune: A Research Platform for Distributed Model Selection and Training. arXiv 2018, arXiv:1807.05118. [Google Scholar]
- Hayes, P.; Anderson, D.; Cheng, B.; Spriggs, T.J.; Johnson, A.; McCourt, M. SigOpt Documentation; Technical Report SO-12/14 – Revision 1.07; SigOpt, Inc.: San Francisco, CA, USA, 2019. [Google Scholar]
- Li, L.; Jamieson, K.; DeSalvo, G.; Rostamizadeh, A.; Talwalkar, A. Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimisation. J. Mach. Learn. Res. 2017, 18, 6765–6816. [Google Scholar]
- Jaderberg, M.; Dalibard, V.; Osindero, S.; Czarnecki, W.M.; Donahue, J.; Razavi, A.; Vinyals, O.; Green, T.; Dunning, I.; Simonyan, K.; et al. Population Based Training of Neural Networks. arXiv 2017, arXiv:1711.09846. [Google Scholar]
- Yu, T.; Zhu, H. Hyper-Parameter Optimization: A Review of Algorithms and Applications. arXiv 2020, arXiv:2003.05689. [Google Scholar]
- Springenberg, J.T.; Klein, A.; Falkner, S.; Hutter, F. Bayesian Optimisation with Robust Bayesian Neural Networks. In Advances in Neural Information Processing Systems; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29. [Google Scholar]
- Levesque, J.; Gagné, C.; Sabourin, R. Bayesian Hyperparameter Optimization for Ensemble Learning. arXiv 2016, arXiv:1605.06394. [Google Scholar]
- Stang, M.; Meier, C.; Rau, V.; Sax, E. An Evolutionary Approach to Hyper-Parameter Optimisation of Neural Networks; Springer: Cham, Switzerland, 2020; pp. 713–718. [Google Scholar] [CrossRef]
- Han, J.H.; Choi, D.J.; Park, S.U.; Hong, S.K. Hyperparameter Optimisation Using a Genetic Algorithm Considering Verification Time in a Convolutional Neural Network. J. Electr. Eng. Technol. 2020, 15, 721–726. [Google Scholar] [CrossRef]
- Xiao, X.; Yan, M.; Basodi, S.; Ji, C.; Pan, Y. Efficient Hyperparameter Optimisation in Deep Learning Using a Variable Length Genetic Algorithm. arXiv 2020, arXiv:2006.12703. [Google Scholar]
- Yeh, W.C.; Lin, Y.P.; Liang, Y.C.; Lai, C.M.; Huang, C.L. Simplified swarm optimisation for hyperparameters of convolutional neural networks. Comput. Ind. Eng. 2023, 177, 109076. [Google Scholar] [CrossRef]
- Basha, S.; Vinakota, S.K.; Dubey, S.R.; Pulabaigari, V.; Mukherjee, S. Autofcl: Automatically tuning fully connected layers for transfer learning. arXiv 2020, arXiv:2001.11951. [Google Scholar]
- Basha, S.S.; Vinakota, S.K.; Pulabaigari, V.; Mukherjee, S.; Dubey, S.R. AutoTune: Automatically Tuning Convolutional Neural Networks for Improved Transfer Learning. Neural Netw. 2021, 133, 112–122. [Google Scholar] [CrossRef]
- Vaidya, G.; Ilg, L.; Kshirsagar, M.; Naredo, E.; Ryan, C. HyperEstimator: Evolving Computationally Efficient CNN Models with Grammatical Evolution. In Proceedings of the 19th International Conference on Smart Business Technologies, Lisbon, Portugal, 14–16 July 2022; pp. 57–68. [Google Scholar]
- Ryan, C.; Collins, J.; Neill, M.O. Grammatical evolution: Evolving programs for an arbitrary language. In Genetic Programming; Banzhaf, W., Poli, R., Schoenauer, M., Fogarty, T.C., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; pp. 83–96. [Google Scholar]
- O’Neill, M.; Ryan, C. Grammatical evolution. IEEE Trans. Evol. Comput. 2001, 5, 349–358. [Google Scholar] [CrossRef] [Green Version]
- Ryan, C.; Kshirsagar, M.; Chaudhari, P.; Jachak, R. GETS: Grammatical Evolution based Optimisation of Smoothing Parameters in Univariate Time Series Forecasting. In Proceedings of the 12th International Conference, ICAART, Valletta, Malta, 22–24 February 2020; pp. 595–602. [Google Scholar] [CrossRef]
- Ryan, C.; Kshirsagar, M.; Vaidya, G.; Cunningham, A.; Sivaraman, R. Design of a cryptographically secure pseudo random number generator with grammatical evolution. Sci. Rep. 2022, 12, 8602. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report 0; University of Toronto: Toronto, ON, USA, 2009. [Google Scholar]
- Li, F.F.; Andreeto, M.; Ranzato, M.; Perona, P. Caltech 101; CaltechDATA: Pasadena, CA, USA, 2022. [Google Scholar] [CrossRef]
- Fenton, M.; McDermott, J.; Fagan, D.; Forstenlechner, S.; O’Neill, M.; Hemberg, E. PonyGE2: Grammatical Evolution in Python. arXiv 2017, arXiv:1703.08535. [Google Scholar]
- Baldominos, A.; Saez, Y.; Isasi, P. Evolutionary Convolutional Neural Networks: An Application to Handwriting Recognition. Neurocomput. 2018, 283, 38–52. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Type | Scope | #Combinations |
|---|---|---|---|
| # dense layers | Integer | {32, 64, 96, 128, 160, 192, 224, 256, 288, 320, 352, 384, 416, 448, 480, 512} | 16 |
| dropout rate | Decimal | {0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9} | 9 |
| optimiser | Categorical | {adam, sgd, rmsprop} | 3 |
| learning rate | Decimal | {0.00001, 0.0001, 0.001, 0.01, 0.1, 0.00005, 0.0005, 0.005, 0.05, 0.5} | 10 |
| momentum | Decimal | {0.5, 0.6, 0.7, 0.8, 0.9, 0.99} | 6 |
| batch size | Choice | {32, 64, 128, 256} | 4 |
| Total combinations | 103,680 |
| Evolutionary Hyperparameters | Values | |
|---|---|---|
| HyperGE-Stage 1 | HyperGE-Stage 2 | |
| Population size | 10 | 10 |
| Number of generations | 5 | 3 |
| Search Engine | Genetic Algorithm | Genetic Algorithm |
| Crossover Type | Variable One-Point | Variable One-Point |
| Mutation Type | Integer Flip Per Codon | Integer Flip Per Codon |
| Crossover probability | 0.95 | 0.95 |
| Mutation probability | 0.01 | 0.01 |
| Selection Type | Tournament | Tournament |
| Initilialisation method | Position Independent grow | Position Independent grow |
| Dataset | VGG-19 | ResNet-50 | Reduction in Search Space | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Fitness (Stage 1) | Fitness (Stage 2) | Fitness (Stage 1) | Fitness (Stage 2) | ||||||
| Mean (VA %) | std | Mean (VA %) | std | Mean (VA %) | std | Mean (VA %) | std | ||
| cifar10 | 59.02 | 13.93 | 76.75 | 9.27 | 53.29 | 25.05 | 65.50 | 8.52 | ∼90% |
| cifar100 | 13.05 | 15.45 | 41.83 | 6.57 | 10.18 | 11.57 | 22.72 | 6.81 | ∼90% |
| caltech101 | 41.60 | 23.27 | 62.79 | 6.95 | 26.07 | 13.93 | 23.60 | 9.27 | ∼90% |
| Dataset | Approach | Model | # Trials | # Epochs/Time | Test Accuracy (%) |
|---|---|---|---|---|---|
| CIFAR-10 | Springenberg et al. [5] | ResNet-32 | 104 | 6 h | 93 |
| Lévesque et al. [24] | cuda-convnet | 250 | 88 | ||
| HyperGE | VGG-19 | 80 | 50/3 h | 84.98 | |
| HyperGE | ResNet-50 | 50 | 30/2 h | 82.80 | |
| Caltech-101 | Autotune(BO) [30] | ResNet-50 | - | 50 | 92.01 |
| Autotune(RS) [30] | ResNet-50 | - | 50 | 92.94 | |
| HyperGE | VGG-19 | 80 | 50 | 88.75 | |
| HyperGE | ResNet-50 | 80 | 30 | 91.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vaidya, G.; Kshirsagar, M.; Ryan, C. Grammatical Evolution-Driven Algorithm for Efficient and Automatic Hyperparameter Optimisation of Neural Networks. Algorithms 2023, 16, 319. https://doi.org/10.3390/a16070319
Vaidya G, Kshirsagar M, Ryan C. Grammatical Evolution-Driven Algorithm for Efficient and Automatic Hyperparameter Optimisation of Neural Networks. Algorithms. 2023; 16(7):319. https://doi.org/10.3390/a16070319
Chicago/Turabian StyleVaidya, Gauri, Meghana Kshirsagar, and Conor Ryan. 2023. "Grammatical Evolution-Driven Algorithm for Efficient and Automatic Hyperparameter Optimisation of Neural Networks" Algorithms 16, no. 7: 319. https://doi.org/10.3390/a16070319
APA StyleVaidya, G., Kshirsagar, M., & Ryan, C. (2023). Grammatical Evolution-Driven Algorithm for Efficient and Automatic Hyperparameter Optimisation of Neural Networks. Algorithms, 16(7), 319. https://doi.org/10.3390/a16070319