1. Introduction
For processing visual data, convolutional neural networks (CNNs) are proving to be the best solutions nowadays. The most popular applications of convolutional neural networks in the field of image processing are image classification [
1,
2], object detection [
3,
4], semantic segmentation [
5,
6] and instance segmentation [
7,
8]. However, the biggest challenge of convolutional neural networks is their inability to recognize pose, texture and deformations of an object, caused by the pooling layers. Pooling layers are used in the feature maps. Where we can find several types of this layer: max pooling, min pooling, average pooling and sum pooling are the most common types of pooling layers [
9]. Due to this layer, the efficiency of the convolutional neural network to recognize the same object in different input images under different conditions is high. At the same time, the size of the tensors is reduced due to the pooling layer, thus reducing the computational complexity of the network. In most cases, pooling layers are one of the best tools for feature extraction; however, they introduce spatial invariance in convolutional neural networks. Due to the nature of the pooling layer, a great amount of information is lost, which in some cases may even be important features in the image. To compensate for this, the convolutional neural network needs a substantial amount of training data where data augmentation is necessary.
Geoffrey Hinton and his research team introduced capsule network theory as an alternative to convolutional neural networks. Hinton et al. published the first paper in the field of capsule networks in 2011 [
10], where the potential of the new theory is explained, but the solution for effective training it is not yet available. The next important milestone came in 2017, when Sabour et al. introduced the dynamic routing algorithm between capsule layers [
11]. Thanks to this dynamic routing algorithm, the training and optimization of capsule-based networks can be performed efficiently. Finally, Hinton et al. published a matrix capsule-based approach in 2018 [
12]. These are the three most important results that the inventors of the theory have published in the field of capsule networks. The basic building block of convolutional neural networks is the neuron, while capsule networks are made up of so-called capsules. A capsule is a group of related neurons, where each neuron’s output represents a different property of the same feature. Hence, the input and output of the capsule networks are both vectors (n-dimensional capsules), while the neural network works with scalar values (neurons). Instead of pooling layers, a dynamic routing algorithm was introduced in capsule networks. In this approach, the lower-level features (lower-level capsules) will only be sent to higher-level capsules that match its contents. This property makes capsule networks a more effective solution than convolutional neural networks in some use cases.
However, the training process for capsule networks can be much longer than for convolutional neural networks, where due to the high number of parameters, the memory requirements of the network can be much higher. Therefore, for complex datasets (e.g., large input images, high number of output classes), presently, capsule networks do not perform well yet. This is due to the complexity of the dynamic routing algorithm. For this reason, we have attempted to make modifications to the dynamic routing algorithm. Our primary aim was to reduce the time of the training process, and secondly to achieve a higher efficiency. In our method, we reduced the weight of the input capsule vector during the optimization in the routing process. We also proposed a parameterizable activation function interpreted in terms of vectors, based on the squash function. In this paper, we demonstrate the effectiveness of our proposed modified routing algorithm and compare it with other capsule network-based methods and convolutional neural network-based approaches.
This paper is structured as follows. In
Section 2, we provide the theoretical background of the capsule network theory proposed by Hinton et al. [
10] and Sabour et al. [
11].
Section 3 clarifies our improved routing mechanism for capsule network and our parameterizable activation squash function.
Section 4 describes the capsule network architecture used in this research. In
Section 5, we present the datasets used to compare the dynamic routing algorithm and our proposed solution. Our results are summarized in
Section 6, where we compare our improved routing solution with Sabour et al.’s method, and with some recently published neural network-based solutions. Finally, our conclusions based on our results are summarized in
Section 7.
2. Theory of Capsule Network
The capsule network [
10,
11,
12] (or CapsNet) is very similar to the classical neural network. The main difference is the basic building block. In the neural network, we use neurons, but in the capsule network, we can find capsules.
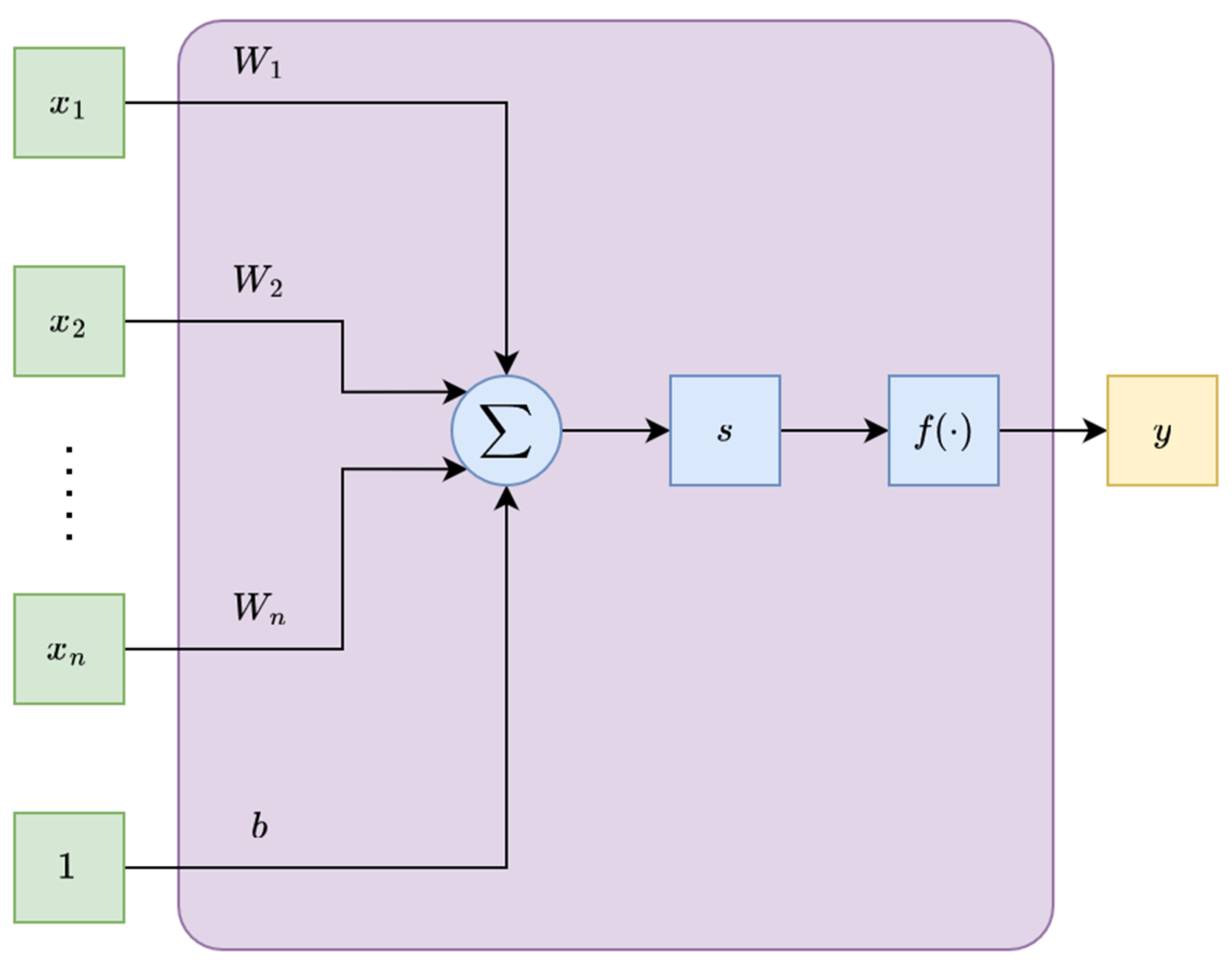
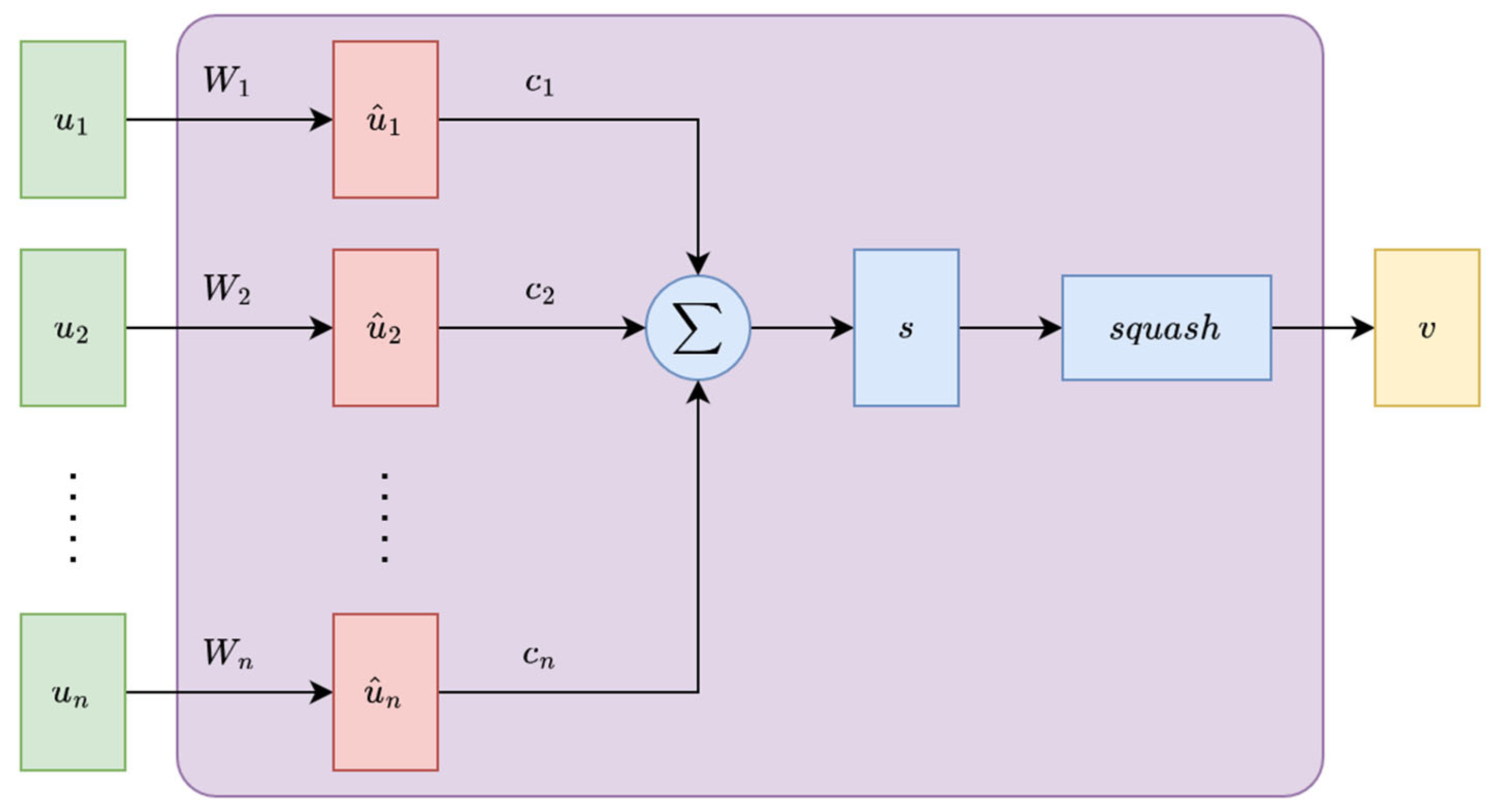
Figure 1 and
Figure 2 show the main differences between the classical artificial neurons and the capsules.
A capsule is a group of neurons that perform a multitude of internal computation and encapsulate the results of the computations into an n-dimensional vector. This vector is the output of the capsule. The length of this output vector is the probability and the direction of the vector, indicating certain properties about the entity.
In a capsule-based network, we use routing-by-agreement, where the output vector of any capsule is sent to all higher-level capsules. Each capsule output is compared with the actual output of the higher-level capsules. Where the outputs match, the coupling coefficient between the two capsules are increased.
Let
be a lower-level capsule and
be a higher-level capsule. The prediction vector is calculated as follows:
where
is a trainable weighting matrix and
is an output pose vector from the
-th capsule to the
-th capsule. The coupling coefficients are calculated with a simple SoftMax function, as follows:
where
is the log probability of capsule
coupled with capsule
, and it is initialized with zero values. The total input to capsule
is a weighted sum over the prediction vectors, calculated as follows:
In capsule networks, we use the length of the output vector to represent the probability for the capsule. Therefore, we use a non-linear activation function, which is called the squashing function. The squashing function is the next:
We can use the dynamic routing algorithm (by Sabour et al. [
11]) to update the
values in every iteration. In this case, the goal is to optimize the
vector. In the dynamic routing algorithm, the
vector is updated in every iteration, as follows:
3. Improved Routing Algorithm
Our experiments on capsule network theory have shown that the
input tensor in the dynamic routing algorithm has too large an impact on the output tensor and greatly increaes the processing time. When calculating the output vector
, the formula includes the input
twice:
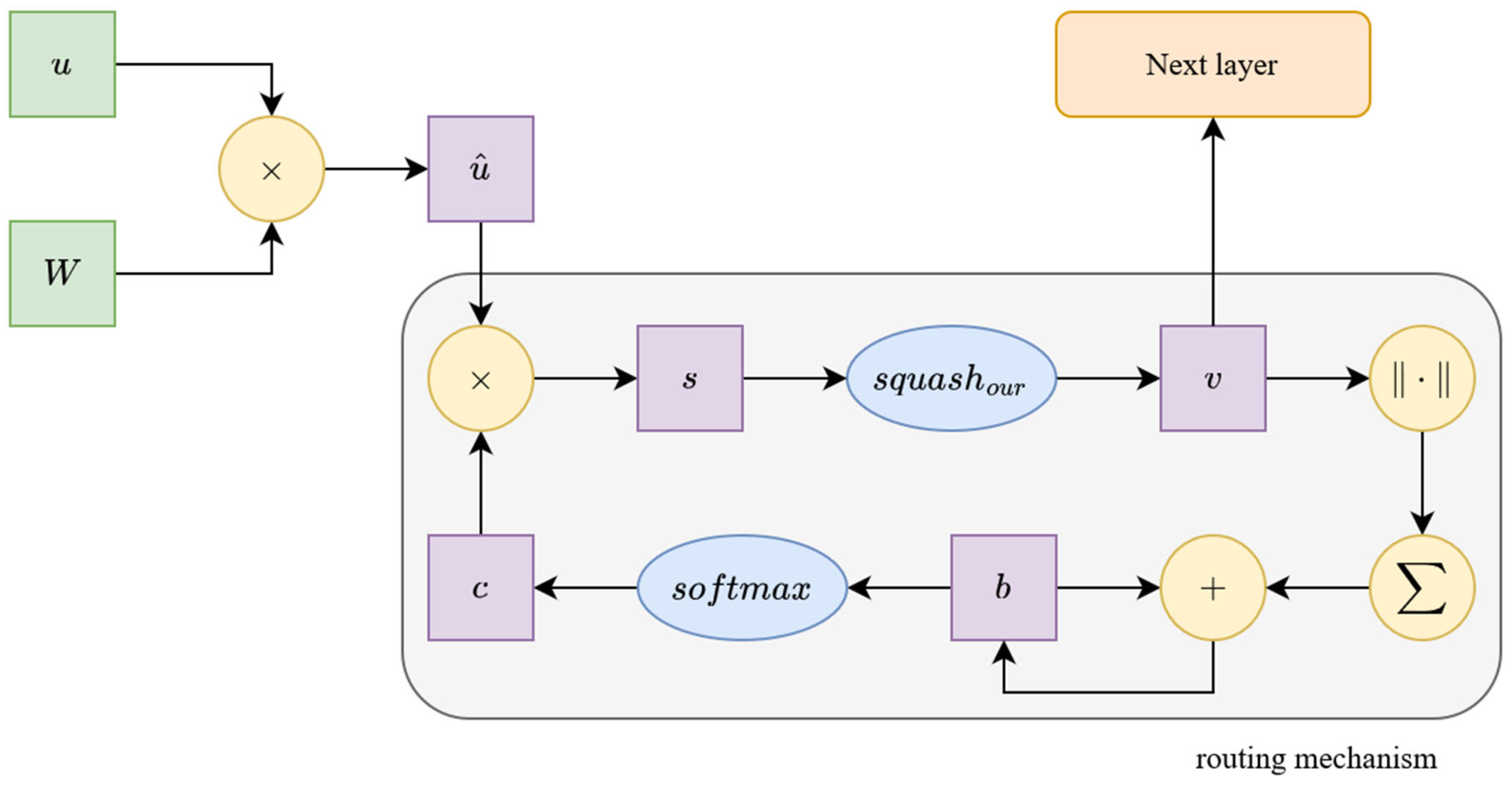
To improve the routing mechanism between lower-level and higher-level capsules, the following modifications to the routing algorithm are proposed:
Let
where
is the value of the
-th neuron of the
-th capsule. If
is an intermediate capsule layer, then
is the number of output capsules. If
is an output capsule layer, then
is the number of possible object categories.
Let
where
, let
This minimal modification makes the routing algorithm simpler and faster to compute. Our other proposed change concerns the squashing function. In the last capsule layer, we use a modified squashing function, as follows:
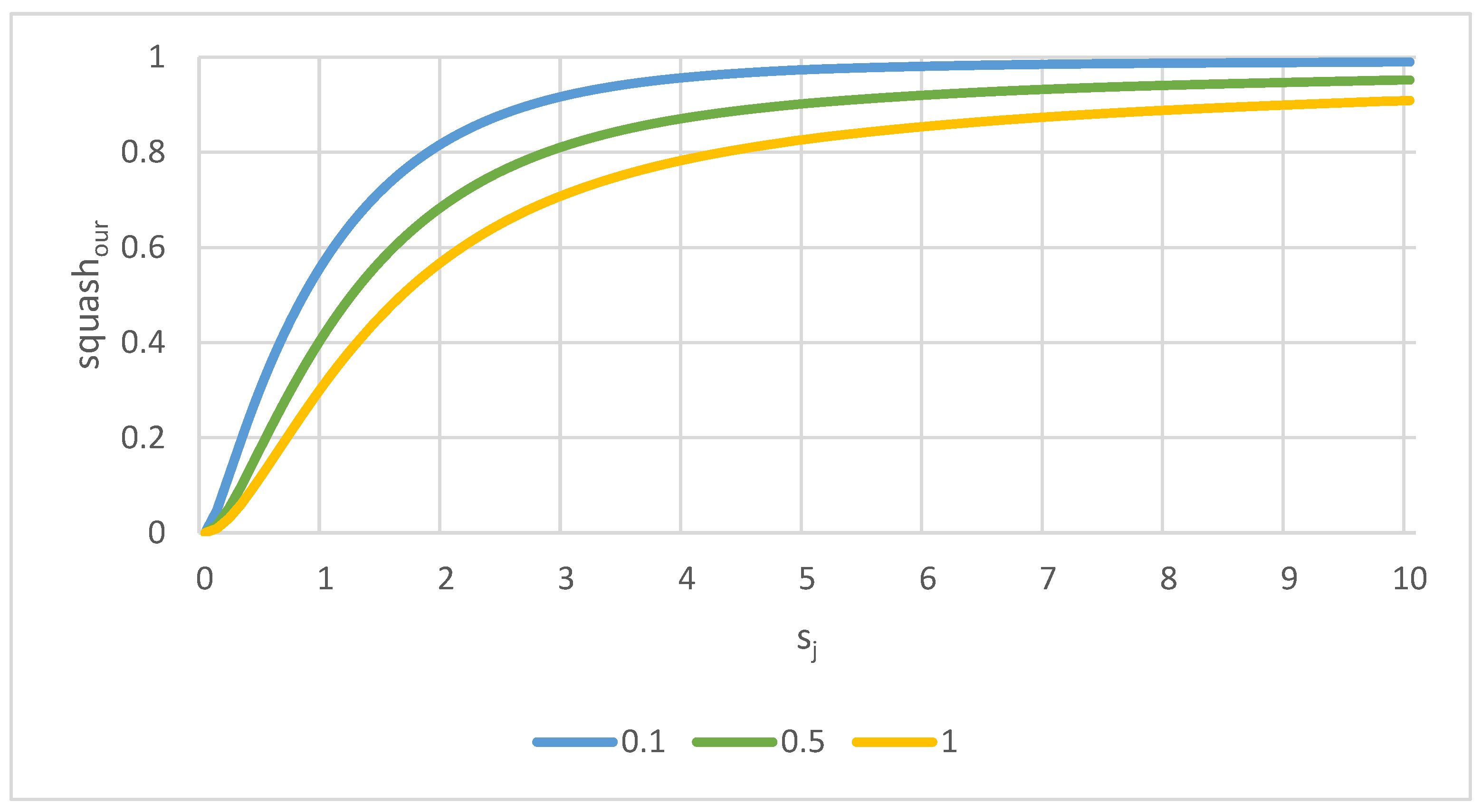
where
is a fine-tuning parameter. Based on our experience, we used
in this work.
Figure 3 shows a simple example of our squash function in a one-dimensional case for different values of
.
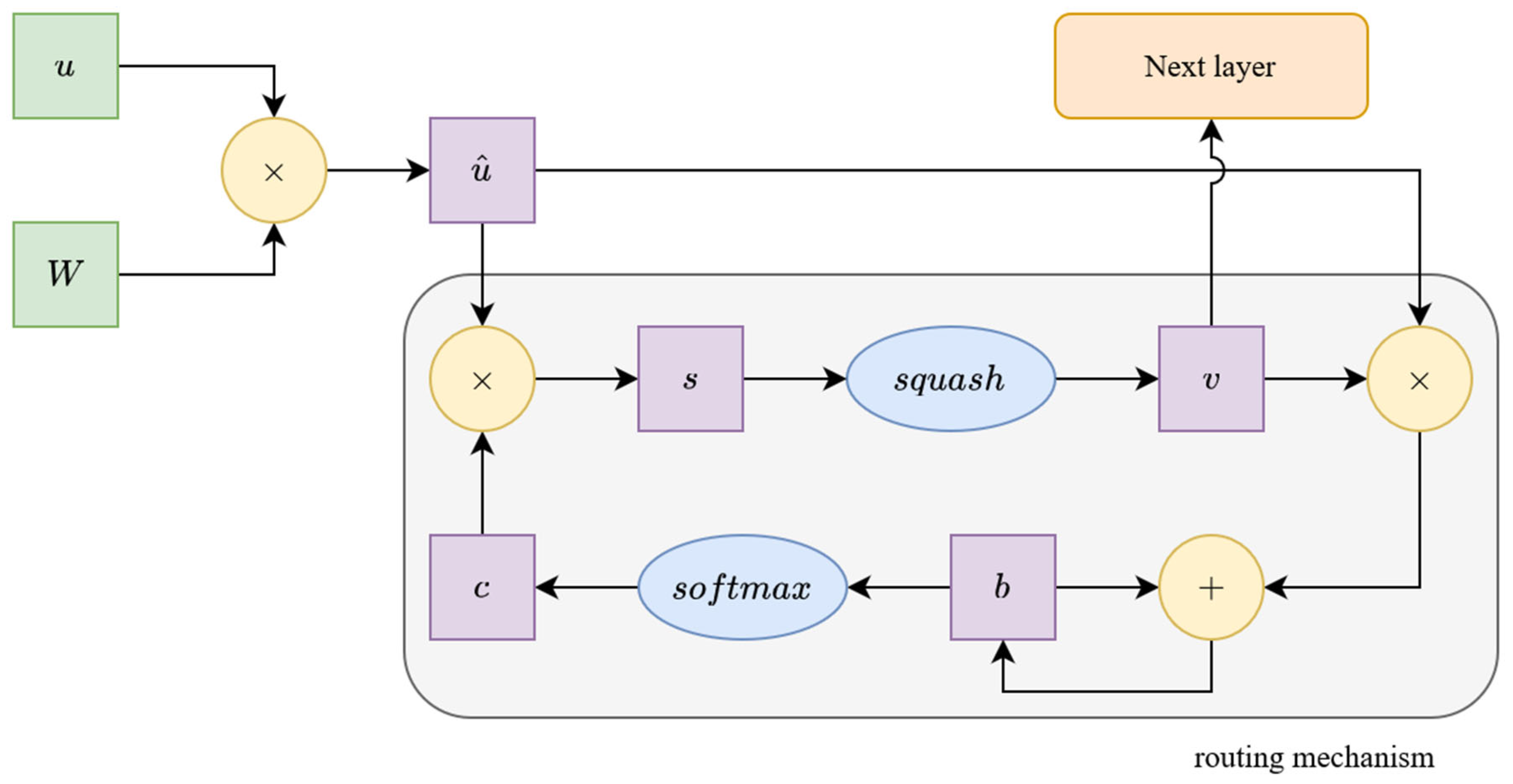
Figure 4 and
Figure 5 show a block diagram of the dynamic routing algorithm and our improved routing solution, where the main differences between the two methods are clearly visible.
4. Network Architecture
In this work, we have used the network architecture proposed by Sabour et al. [
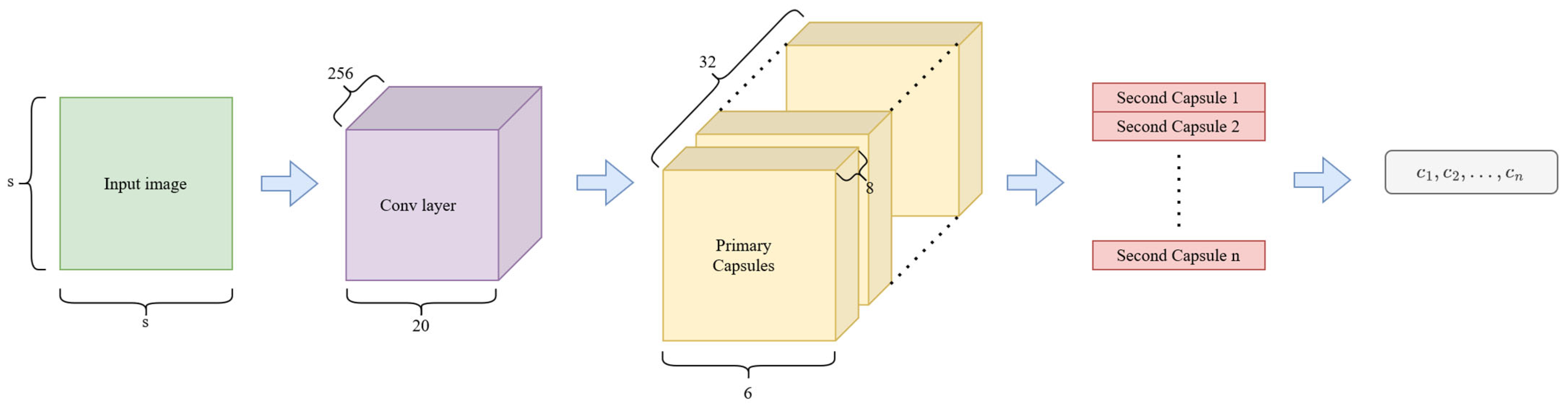
11] to compare our proposed routing mechanism with other optimization solutions in the field of capsule networks. This capsule network architecture is shown in
Figure 6. The original paper used a fixed
-sized input tensor, because they only tested the network efficiency for the MNIST [
13] dataset. In contrast, we trained and tested the capsule networks for six fundamentally different datasets in the field of image classification. In our work, the shape of the input layer varies depending on the dataset. We used the following input shapes:
,
and
. After the input layer, the capsule network architecture consisted of three main components: the first is a convolutional layer, the next is the primary capsule layer, and the last one is the secondary capsule layer.
The convolution layer contains
convolution kernels of size
with a stride of
, and a ReLU (rectified linear unit) [
14] activation layer. This convolutional layer generates the main visual features based on intensities for the primary capsule layer.
The primary capsule block contains a convolutional layer, where both the input and the output are of the size . This capsule block also contains a squash layer. In this case, the original squash function (Equation (4)) is used for both implementations. The output of this block contains capsules, where each capsule has dimensions. This capsule block contains advanced features, which are passed onto the secondary capsule block.
The secondary capsule block has one capsule per class. As mentioned earlier, we worked with several different datasets, so the number of capsules in this capsule block varied, always according to the class number of the dataset:
,
or
. This capsule block contains the routing mechanism, which is responsible for determining the connection weights between the lower and higher capsules. Therefore, this capsule block represents the main difference between the solution of Sabour et al. and our presented method. In this block, we applied our proposed squash function (Equation (11)). The secondary capsule block contains a trainable matrix, called
(Equation (14)). The shape of the
matrix, for both solutions, is
, where
is the number of output classes and
depends on the input image shape as follows:
where
is the size of the input image. The routing algorithm was run through
iterations in both cases. The output of this capsule block is a
-dimensional vector per each class. This means that the block produces
-dimensional capsules, where
is the number of output classes. The length of the output capsules represents the probability values belonging to the given class.
6. Results
In this work, the network architecture presented in
Section 4 has been designed in three different ways and trained separately on the datasets presented in
Section 5. The difference between the three networks is the routing algorithm used: the first is the original capsule network by Sabour et al., the second is our modified capsule network with some improvements, and the third is the efficient vector routing by Heinsen [
20]. Capsule networks are trained separately on the
presented dataset. For the implementation, we used Python 3.9.16 [
21] programming language with PyTorch 1.12.1 [
22] machine learning framework and CUDA toolkit 11.6 platform. The capsule networks are trained on the Paperspace [
23] online artificial intelligence platform with an Nvidia Quadro RTX4000 series graphical processing unit.
We trained all networks for
epochs with the Adam [
24] optimizer algorithm where the train and test batch size are both
. We also attempted to train the networks over many more epochs, but found that the difference between the three solutions does not change significantly after
epochs. In this study, we used
initial learning rate. In each epoch, we reduced the learning rate as follows:
where
is the initial learning rate and
is the learning rate in the
-th epoch. We used
and
hyperparameter values to control the exponential decay, and
to prevent any division by zero in the implementation. In the training process, we used the same loss function as proposed by Sabour et al.
where
, and are hyperparameters. In the present work, we used the same values for these hyperparameters as proposed by Sabour et al., in this case, , and . The original study also used reconstruction in the training process; however, we did not apply this in our work. During training without reconstruction, the efficiency of the capsule network is reduced. In the long term, we want to translate our results in the field of capsule networks into real-world applications. In this respect, reconstruction of the input image is a rarely necessary step. Therefore, we explicitly investigated the ability of capsule networks without reconstruction.
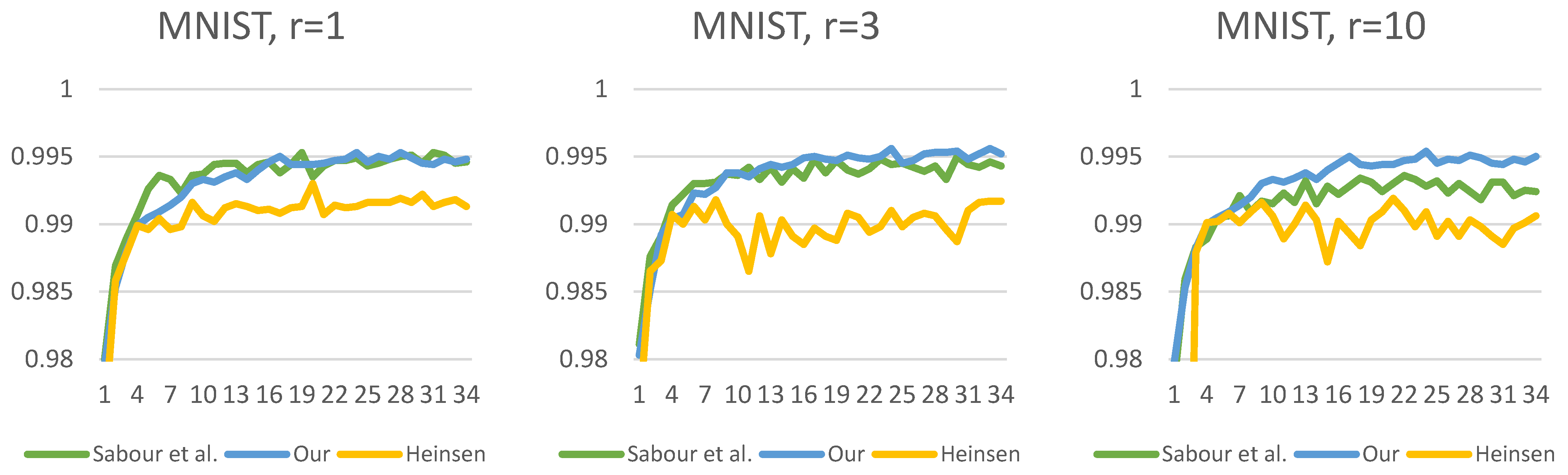
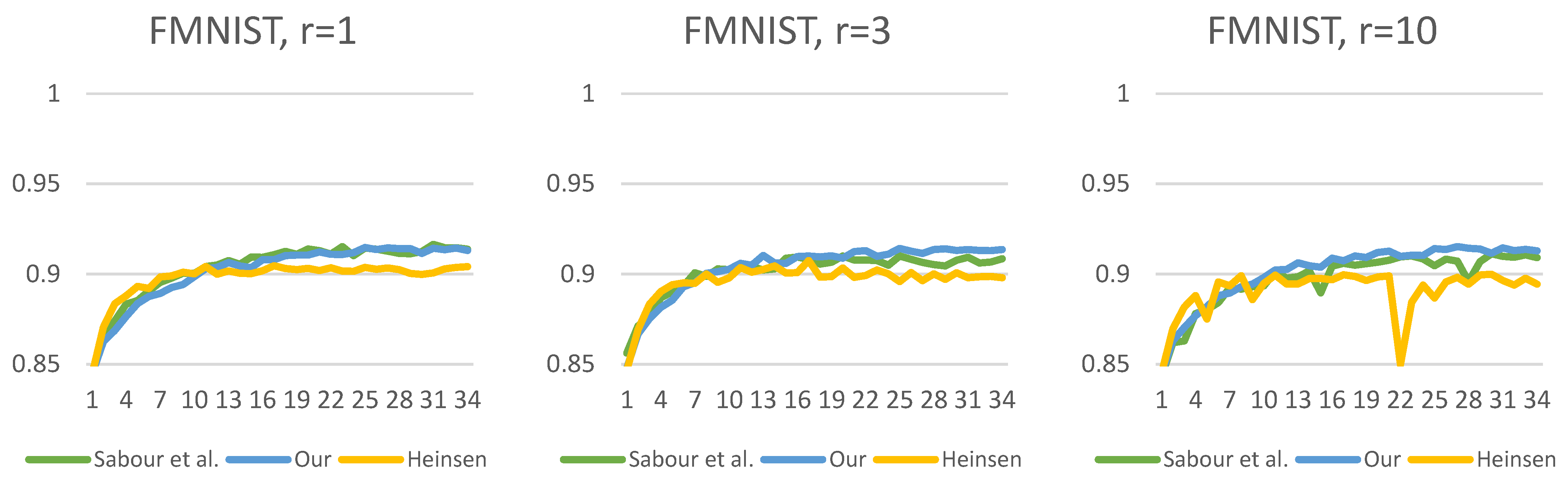
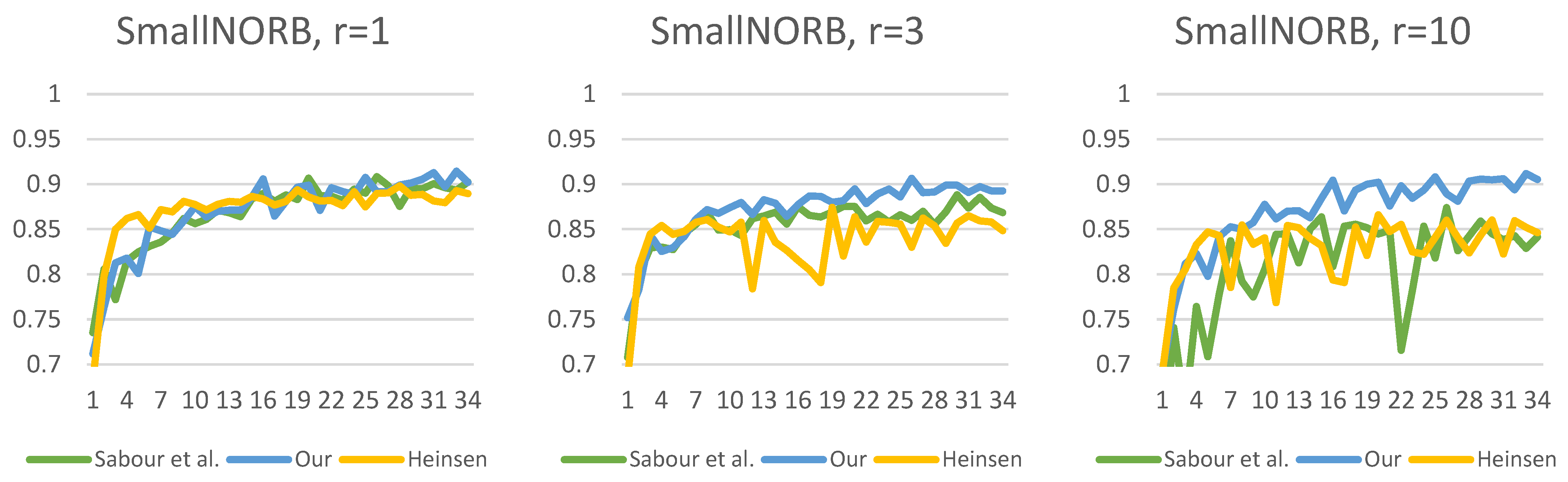
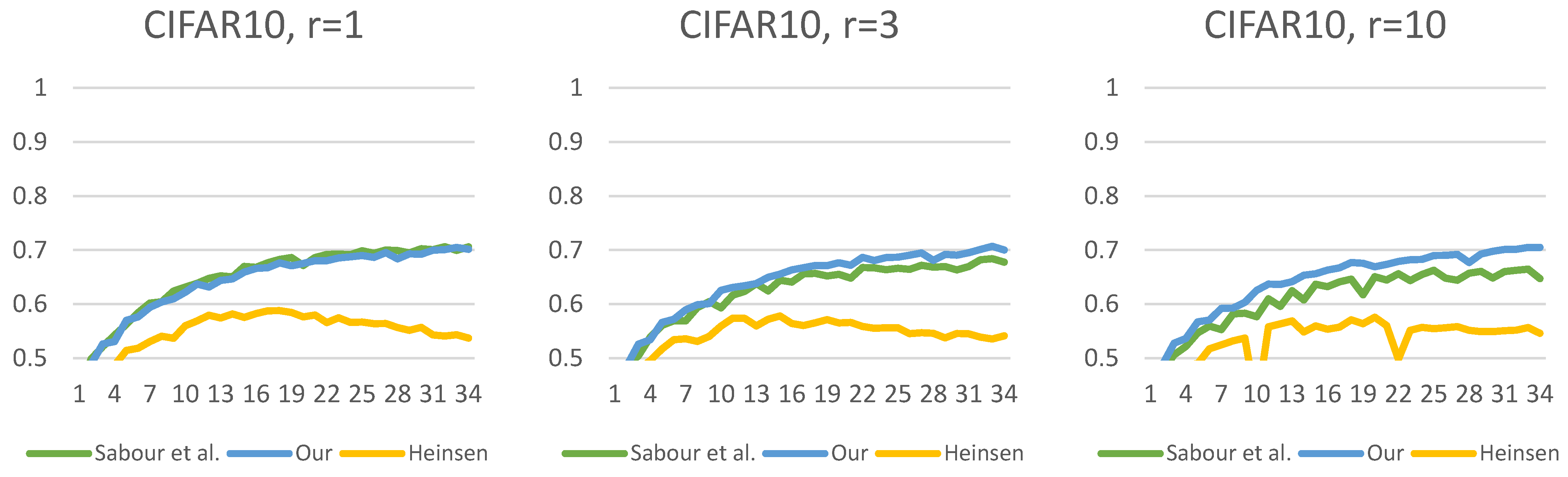
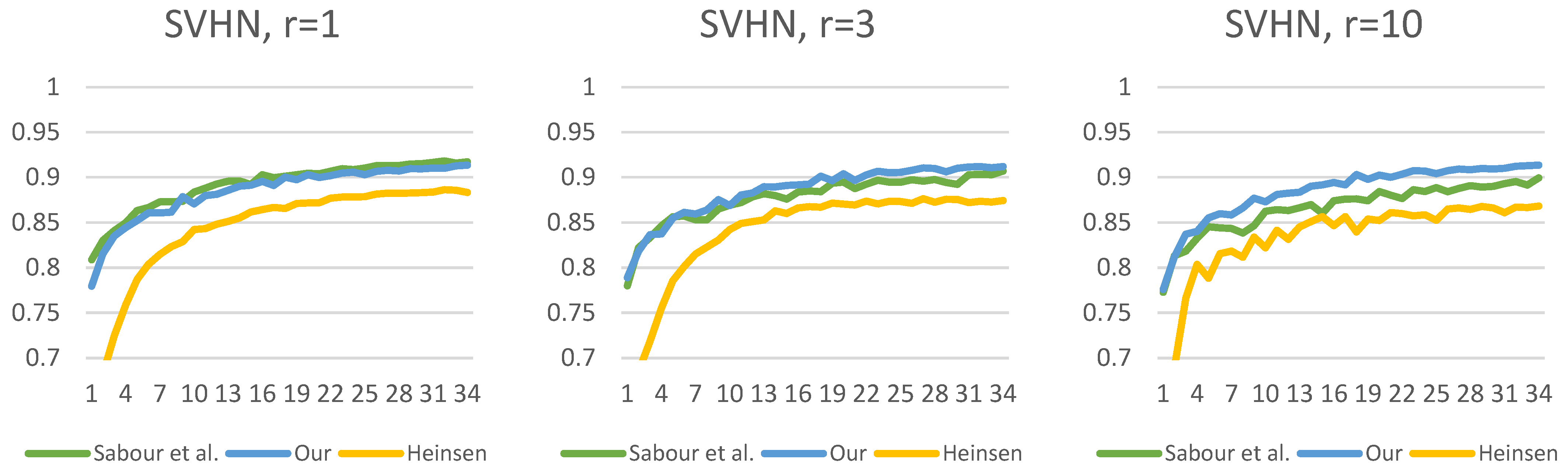
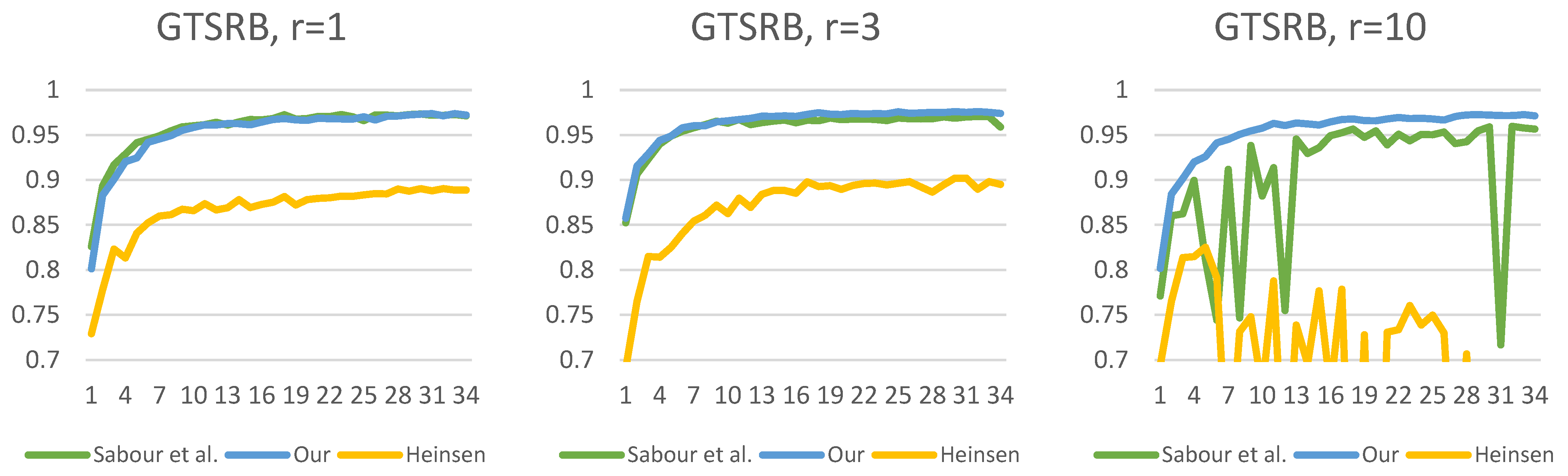
Figure 13,
Figure 14,
Figure 15,
Figure 16,
Figure 17 and
Figure 18 show the accuracy of the training processes for the test sets of the
presented datasets with different numbers of routings. The value of
indicates the number of iterations which the routing algorithm has optimized the coefficients. Based on Sabour et al.’s experiment, the
is a good choice; however, we showed the efficiency with
and
. This makes the difference more visible between the routing methods. As can be seen, for all
datasets, we have achieved efficiency gains compared to the two other capsule network solutions. The difference in efficiency between our and Sabour et al.’s solutions is minimal for about the first
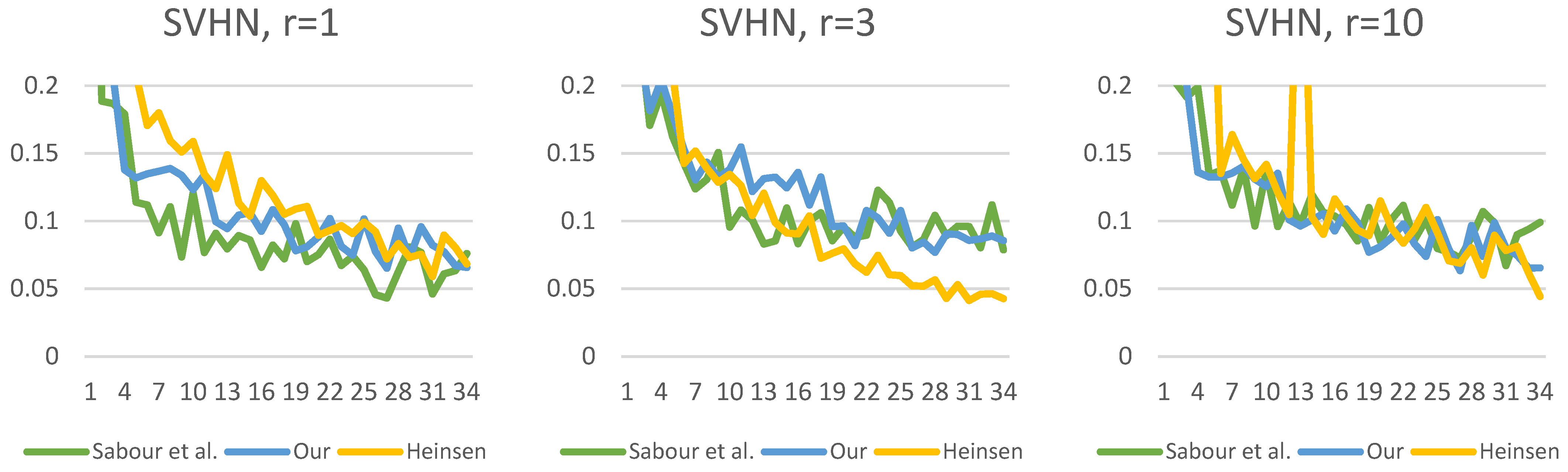
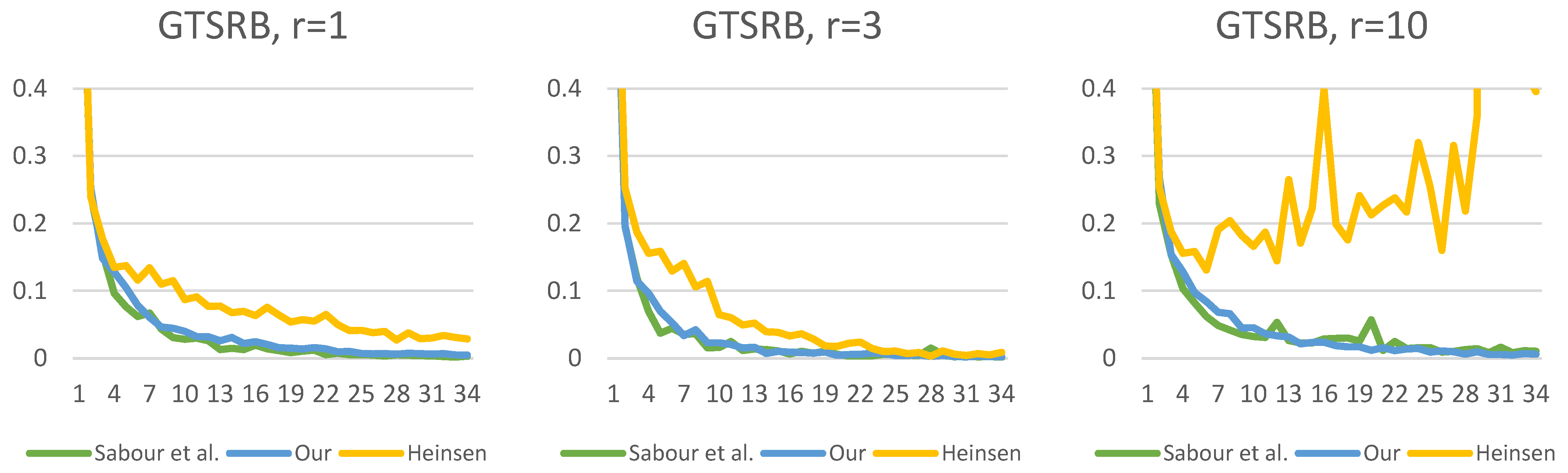
epochs; however, after that, there is a noticeable difference in the learning curve. Although Heinsen’s solution also proves to be effective in most cases; its performance is slightly lower than the other two solutions. It is also noticeable that changing the number of iterations has a much larger impact on Sabour et al.’s solution and that of Heinsen. Our proposed solution is less sensitive to the iteration value chosen during the optimization.
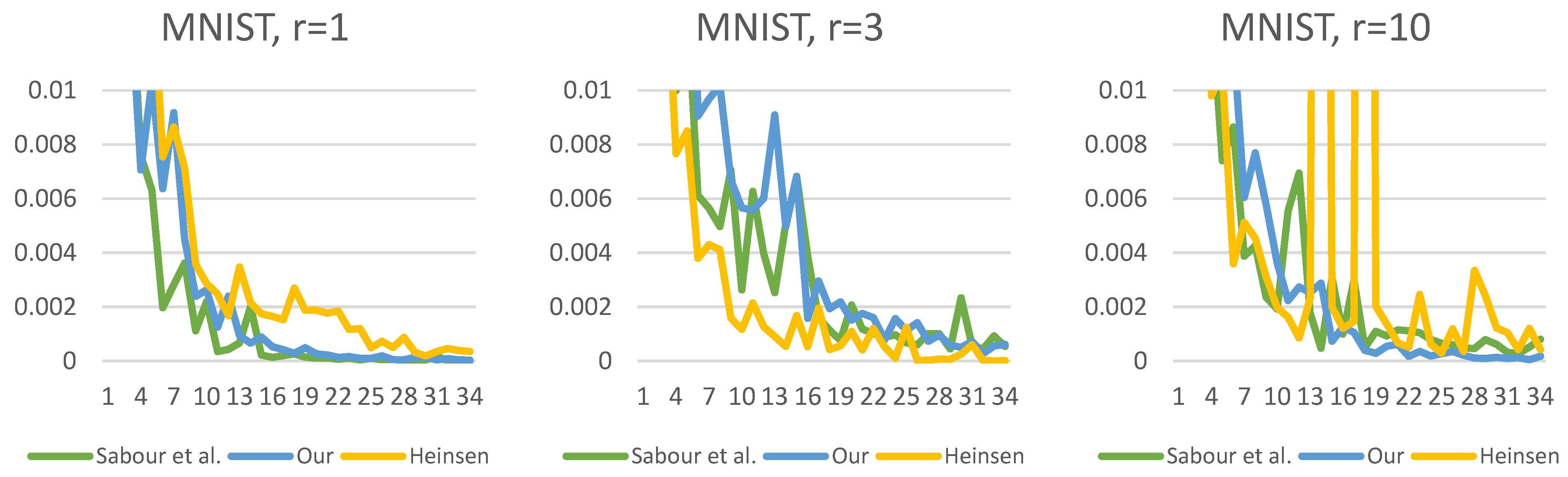
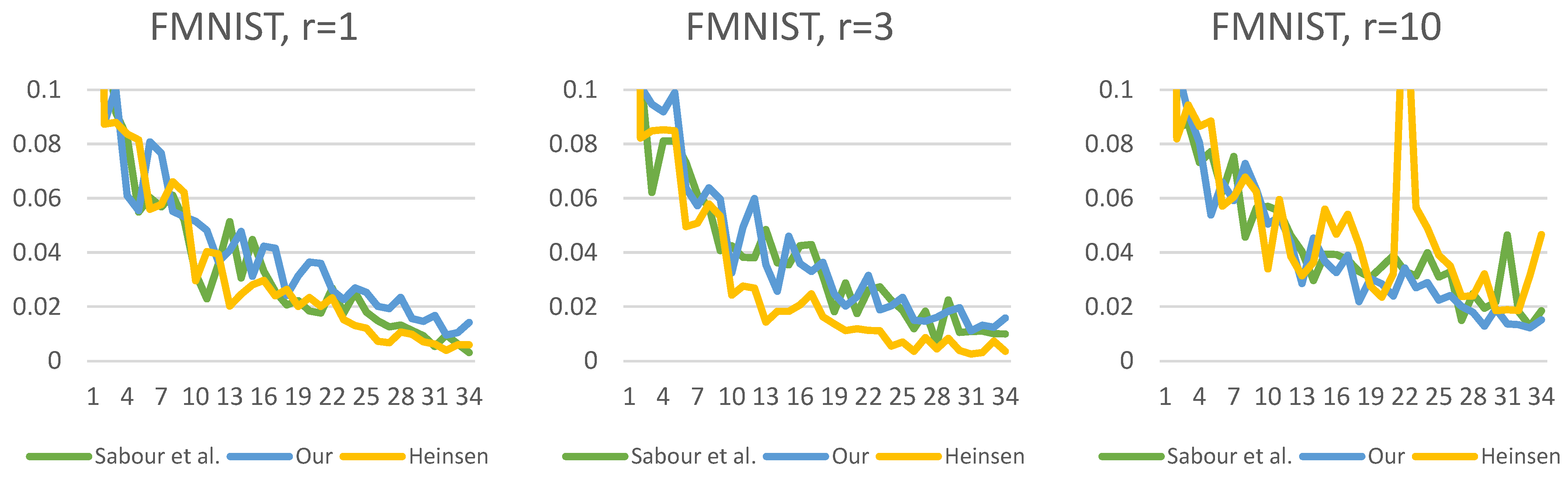
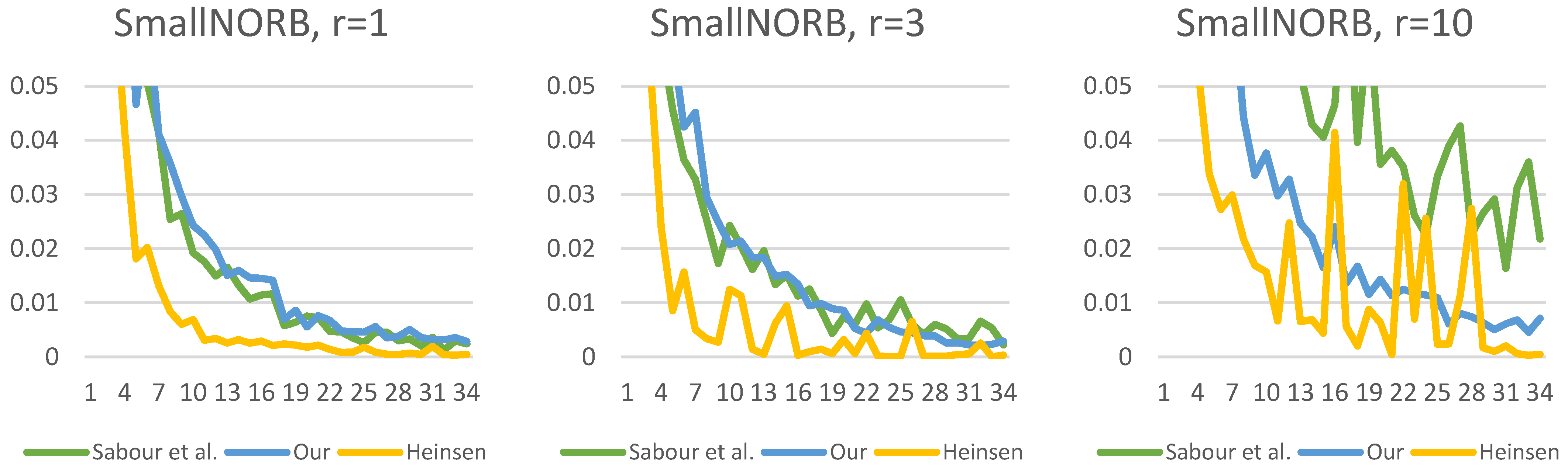
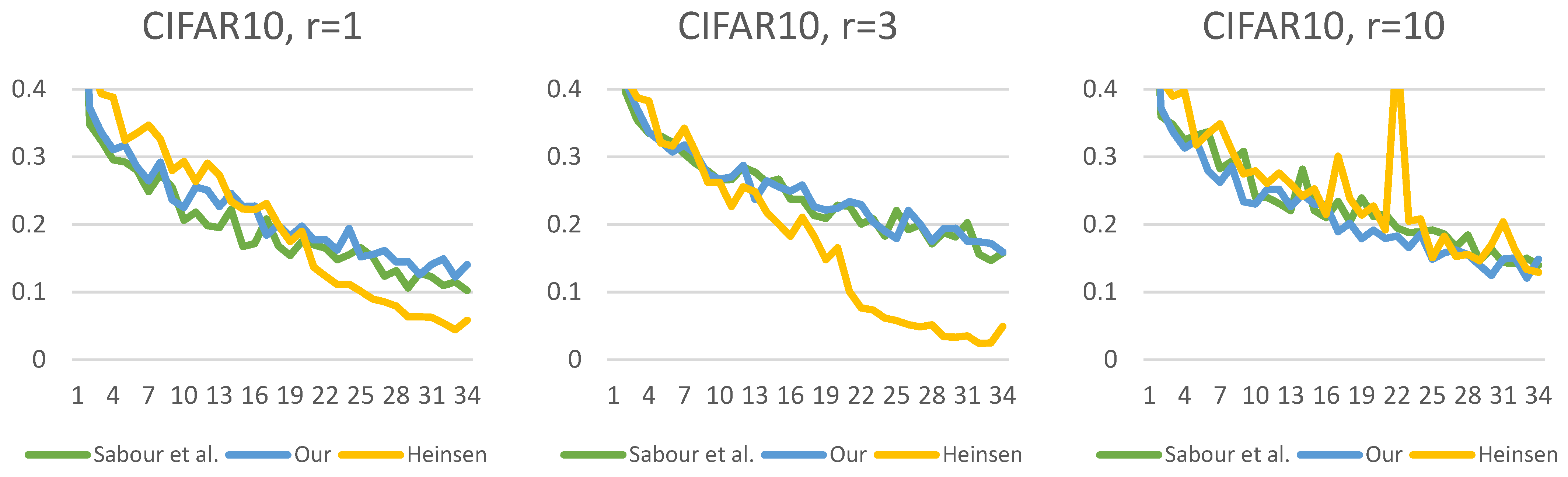
Figure 19,
Figure 20,
Figure 21,
Figure 22,
Figure 23 and
Figure 24 show the test losses (Equation (14)) during the training processes with different numbers of routings. There is not much difference in the loss function, but it is noticeable that our solution is less noisy and converges more smoothly.
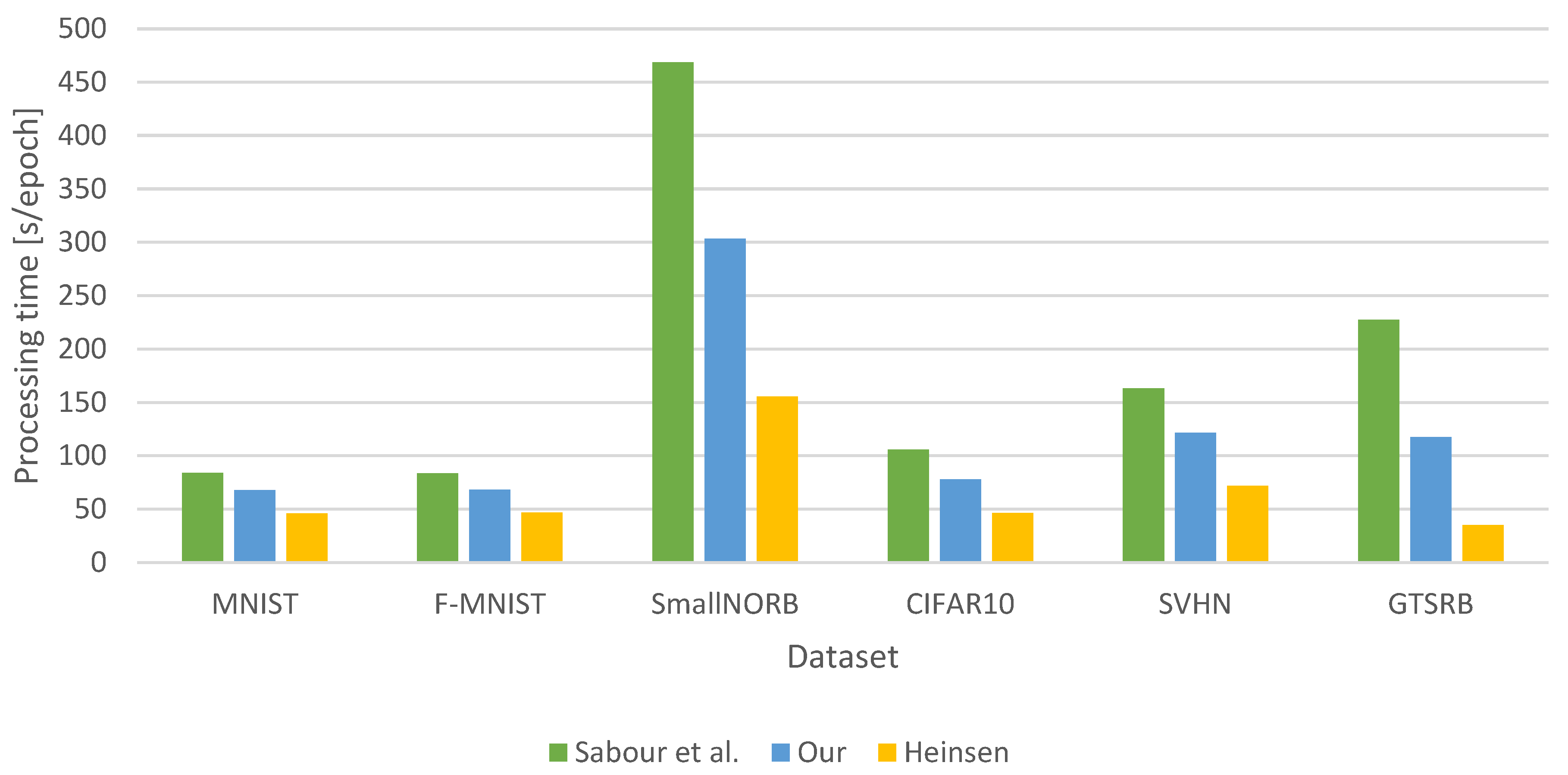
Figure 25 shows the processing times for the three capsule-based networks. It can be seen that for all
datasets, the capsule network was faster with our proposed routing algorithm than with the dynamic routing algorithm introduced by Sabour et al. The smallest increase was achieved for the Fashion-MNIST and MNIST datasets, but this still represents an
and a
speedup. For more complex datasets, much higher speed increases were achieved. A running time reduction of 25.55% was achieved for SVHN and 26.54% for CIFAR10. The best results were observed for the SmallNORB and GTSRB datasets. For SmallNORB it was 35.28%, while for GTSRB, it was 48.30%. Compared to Heinsen’s solution, our proposed algorithm performed worse, but the difference in efficiency between the two solutions is significant.
The test errors during the training process are shown in
Table 2, where the capsule-based solutions were compared with the recently released neural network-based approaches. It can be clearly seen that our proposed modifications to the routing algorithm have led to efficiency gains. It is important to note that our capsule-based solution does not always approach the effectiveness of the state-of-the-art solutions, however, the capsule network used consists of only three layers with a very minimal number of parameters (
). Its architecture is quite simple, but with further improvements, a higher efficiency can be achieved. Prior to this, we felt it necessary to improve the efficiency of the routing algorithm. Experience has shown that designing deep network architecture in the area of capsule networks is too resource-intensive. For this reason, it is necessary to increase the processing speed of the routing algorithm.
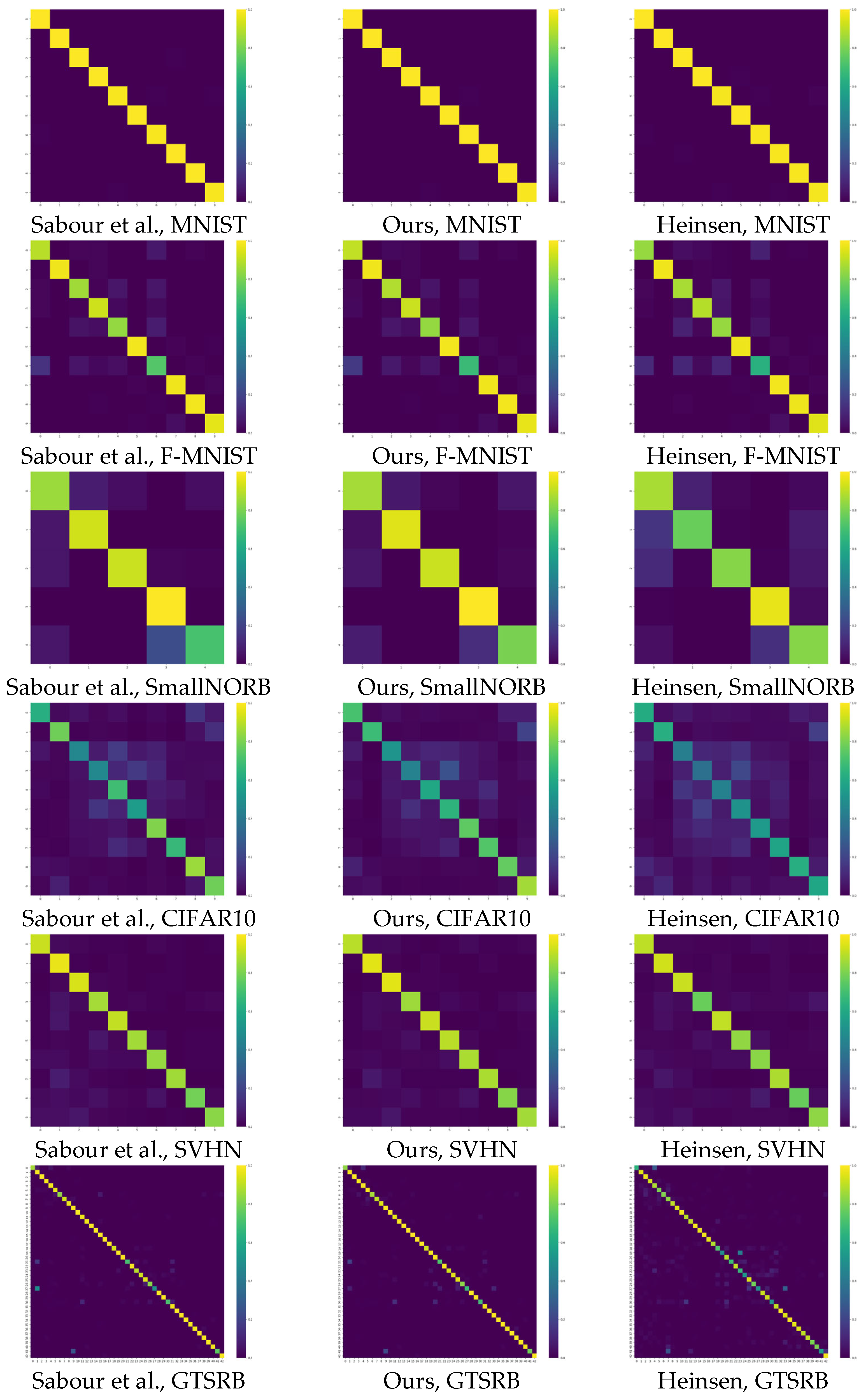
Figure 26 shows the confusion matrices for the capsule network-based approaches in the case of the
datasets used. It can be seen that for simpler datasets, such as MNIST, the difference between the three optimization algorithms is minimal. For more complex datasets, the differences are more pronounced.
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8 show the efficiencies achieved by capsule networks for each class, separately. This table also shows that our proposed method is in most cases able to provide a more effective solution than the other solutions tested. However, there are cases where our solution falls short compared with solutions by Sabour et al. and Heinsen.
Table 9 summarizes the percentage of classes per dataset that were able to provide the best result for a given solution. From this approach as well, our solution performed the best. Only in the case of the GTSRB dataset was the method proposed by Sabour et al. more efficient. For the other
datasets, our proposed method was able to achieve the best accuracy for most classes.
Table 10,
Table 11 and
Table 12 summarize the recall score, dice score and F1-score for the capsule-based implementations under study. It can be observed that, according to all three metrics, our proposed method performs the best. The solution by Sabour et al. performs better only for the Fashion-MNIST dataset, but there was no difference in accuracy of this dataset. The solution by Heinsen underperforms the other two solutions in the cases studied. It can also be seen that, where the method of Sabour et al. and our approach perform worse, the score of Heinsen’s solution also decreases in a similar way.
7. Conclusions
Our work involved research in the field of capsule networks. We showed the main differences between classical convolutional neural networks and capsule networks, highlighting the new potential of capsule networks. We have shown that the dynamic routing algorithm for capsule networks is too complex and that the training time makes it difficult to build more deep and complex networks. At the same time, capsule networks can achieve very good efficiency, but their practical application is difficult due to the complexity of routing. Therefore, it is important to improve the optimization algorithm and introduce novel solutions.
We proposed a modified routing algorithm for capsule networks and a parameterizable activation function for capsules, based on the dynamic routing algorithm introduced by Sabour et al. In this approach, we aimed to reduce the computational complexity of the current dynamic routing algorithm. Thanks to our proposed routing algorithm and activation function, the training time can be reduced. In our work, we have shown its effectiveness on different datasets, compared with neural network-based solutions and capsule-based solutions. As can be seen, the training time was reduced in all cases, by almost on average. Even in the worst case, a speed increase of almost was achieved. And in some cases, an increase in speed of almost can be seen. Despite the increase in speed, the efficiency of the network has not decreased. For several different metrics, our proposed solution was compared with other capsule-based methods. As we have shown, our proposed approach can increase the efficiency of the routing mechanism. For all six datasets tested in this research, our solution provided the highest results in almost all cases.
In the future, we would like to perform further research on routing algorithms and capsule networks to be able to achieve even greater improvements. We would like to carry out more complex studies on larger datasets, compared with other solutions. We would like to further optimize our solution based on the test results. Our goal is to be able to provide an efficient and fast solution for more complex tasks, such as instance segmentation or reconstruction, in the field of capsule networks. This is necessary to create much deeper and more complex capsule networks, so it is important to address the issue of optimization. This will allow us to apply the theory of capsule networks to real practical applications with great efficiency.





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}