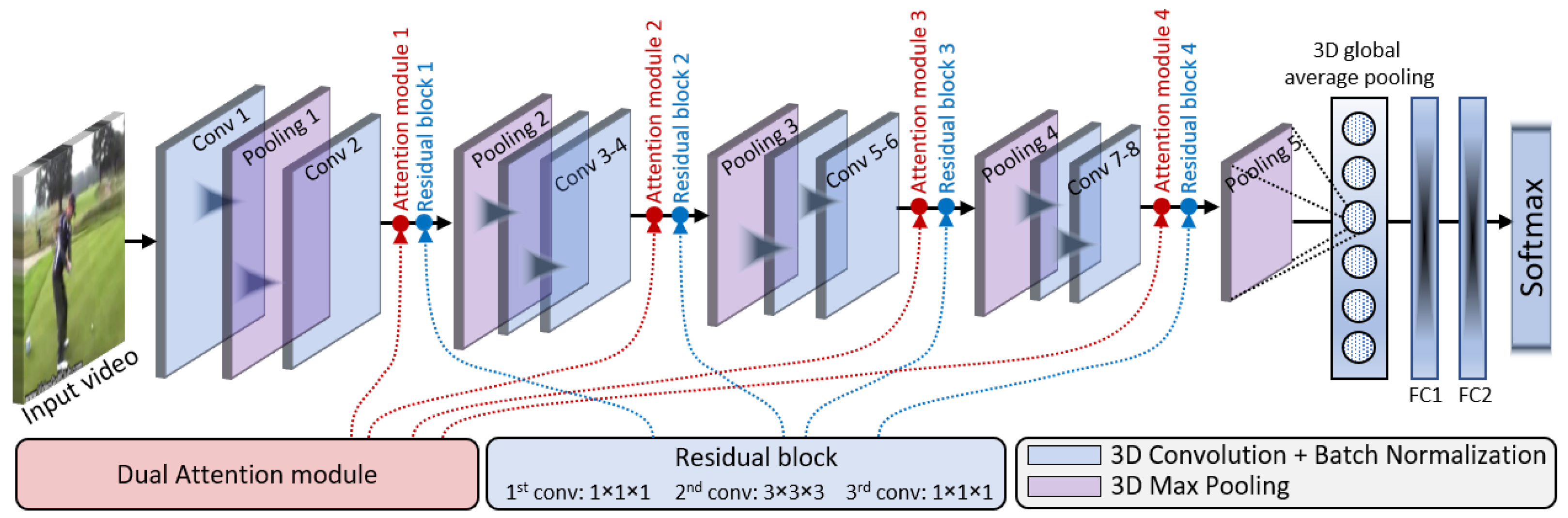
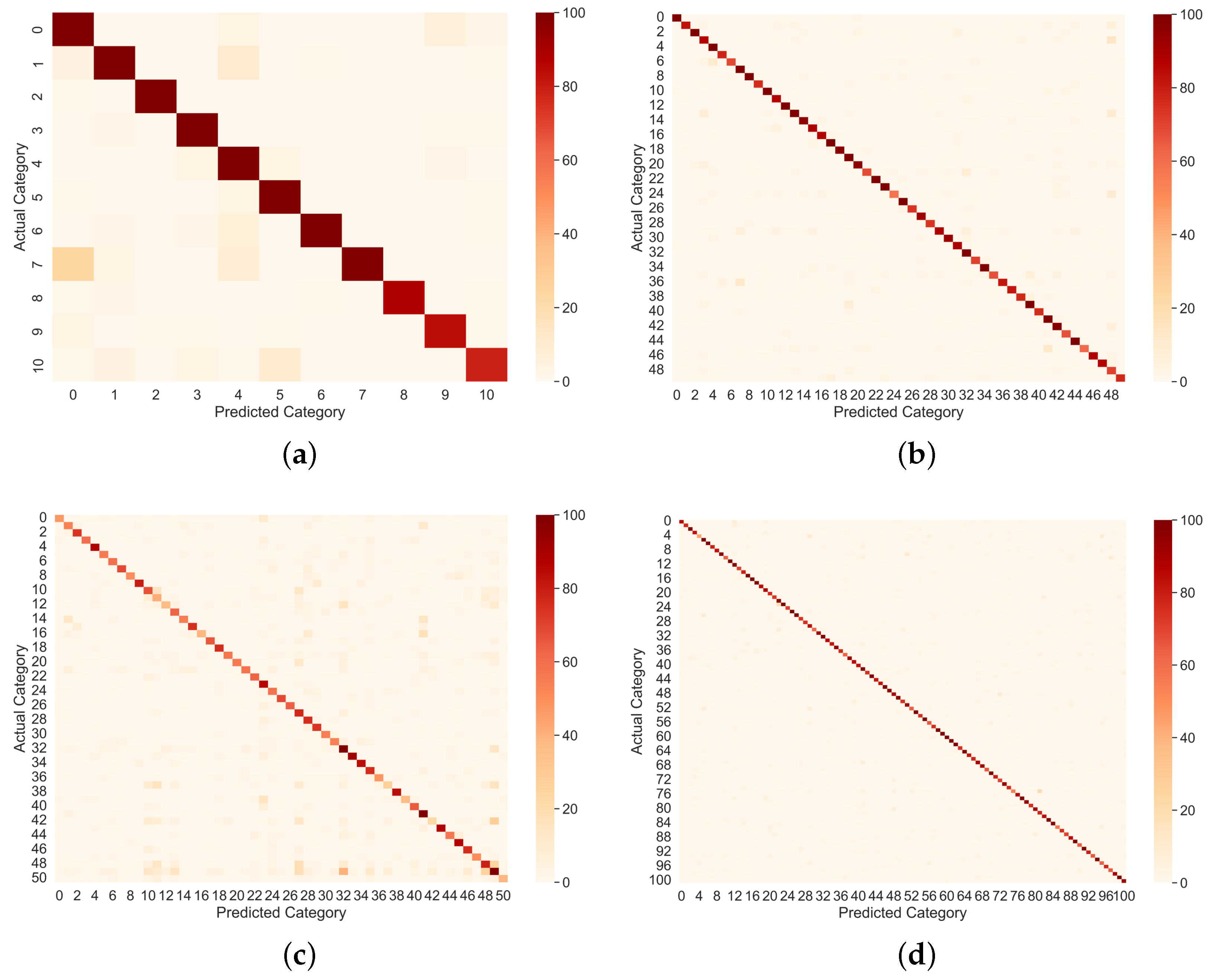
In this section, we provide a comprehensive experimental evaluation of our proposed framework on various human activity recognition datasets. This section begins by providing a brief overview of the datasets used, and the implementation details and tools utilized in this study. Afterwards, we present a detailed analysis of the experimental results obtained from the proposed framework, including a comparative analysis with the state-of-the-art human action recognition methods. Additionally, an ablation study is presented, where the proposed method was analyzed with different modifications to the network architecture. Lastly, we assess the runtime performance of our proposed framework using metrics such as seconds per frame (SPF) and frames per second (FPS). We compare the obtained runtime results with the runtime results of state-of-the-art methods.
4.1. Datasets and Implementation Details
In this paper, we evaluate the perofmance of our DA-R3DCNN method on four publicly available benchmark datasets for human activity recognition tasks: UCF11 [
27], HMDB51 [
28], UCF50 [
29], and UCF101 [
30]. These datasets are exclusively created for human activity recognition task, and contain videos collected from different sources and have different lengths, resolutions, and viewpoints of humans actions in the videos. The UCF11 [
27] dataset comprises 1640 videos collected from YouTube which are then categorized into 11 distinct action classes of human actions. All videos in the dataset are annotated by action appearance, where each video has a spatial resolution of
. The HMDB51 [
28] dataset is a relatively large dataset, containing 6849 videos, categorized into 51 categories. This dataset has a wide range of variation in camera motion, object scale, view point, and background clutter, which makes it challenging for human action recognition tasks. Videos in this dataset are collected from different sources, including movies, YouTube, Prelinger archive, and Google videos. The UCF50 [
29] dataset consists of 6676 realistic videos collected from YouTube, containing human actions performed by different subjects in different environments with varying viewpoints. Videos in this dataset are divided into 50 distinct actions by action appearance in the video. Finally, the UCF101 [
30] is the largest dataset amongst the above mentioned datasets, containing 13,320 videos of different human actions. This dataset is the extended version of the UCF50 [
29], having comparatively more videos and large variation in actions, categorized into 101 action classes. The number of videos per class in each dataset is approximately 100 to 200, and the duration of video clips is in between 2 and 3 s, with a frame rate of 25 FPS.
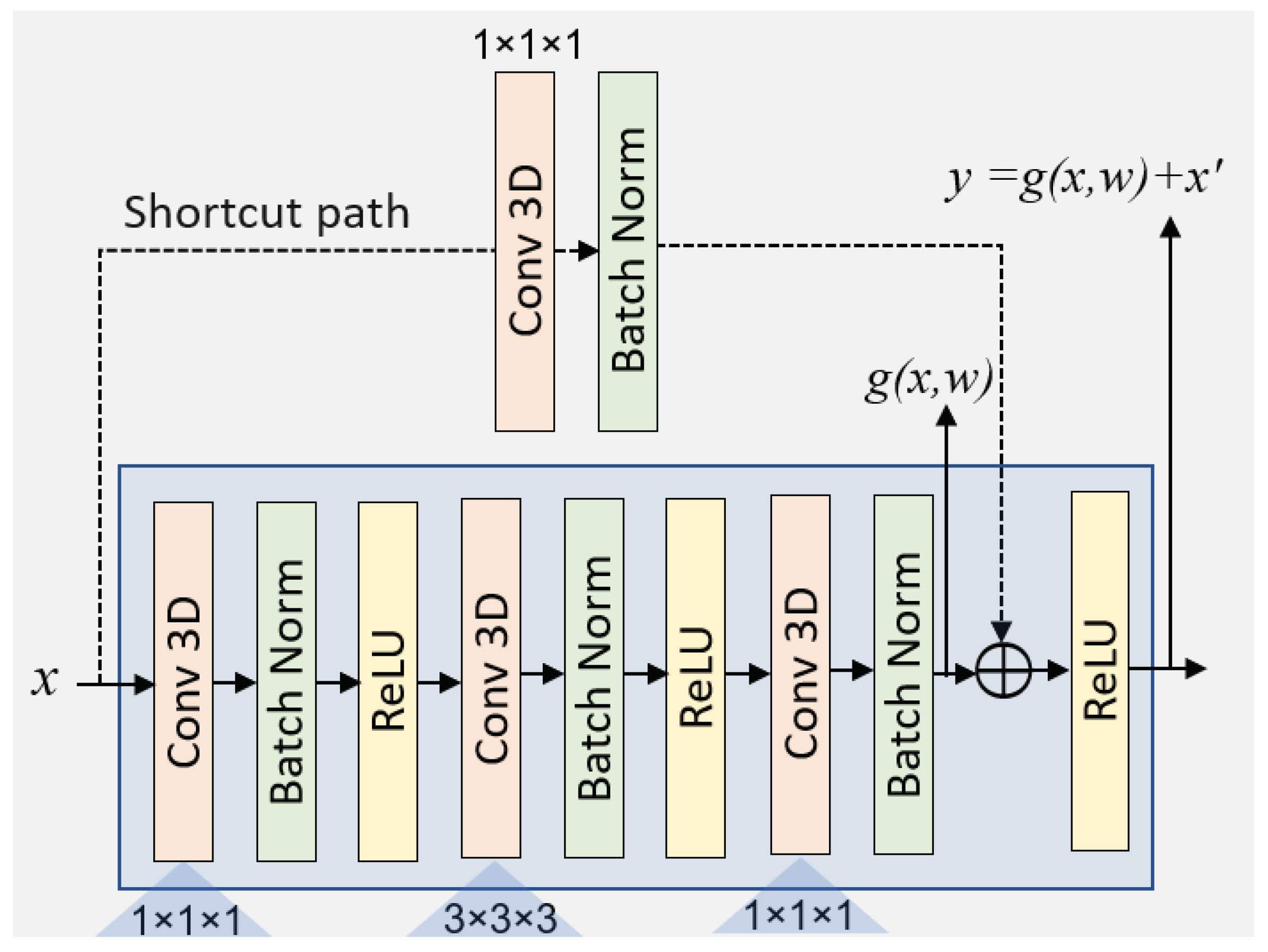
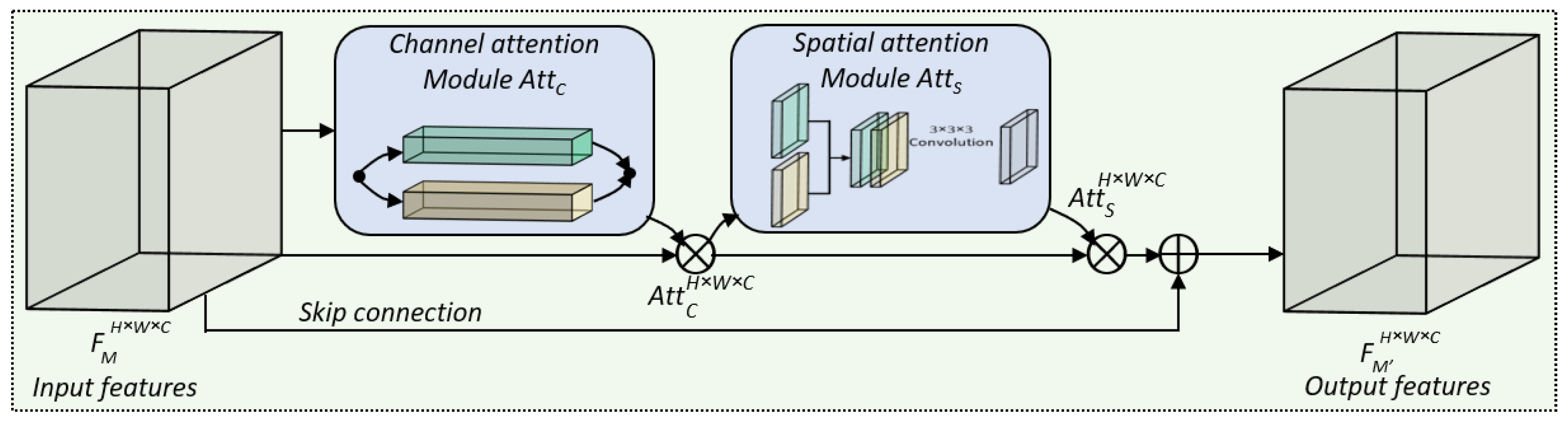
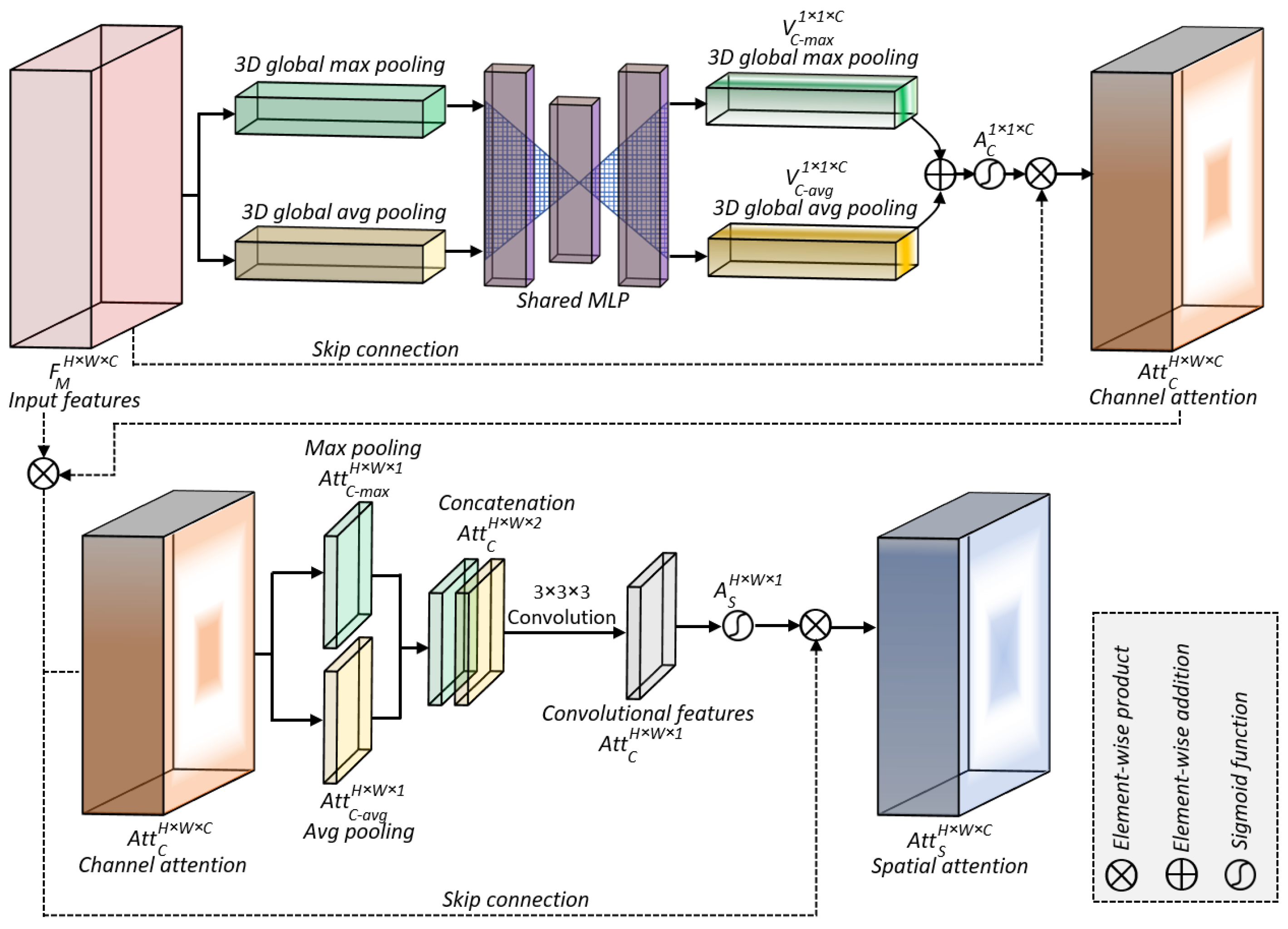
For implementation, we used Python version 3 utilizing Keras with a TensorFlow 2.0 backend. We performed the experiments on a computer system equipped with an Intel(R) Xeon(R) CPU E5-2640, operating at a frequency of 2.50 GHz, and 32 GB of dedicated main memory (RAM). Additionally, we employed two dedicated Tesla GPUs with compute capabilities of 7.5 as hardware resources along with the Nvidia CUDA 11.0 library. To train the proposed DA-R3DCNN model, we used 70% of data for training, 20% for validation, and 10% for testing the model performance after training. The same data splitting ratio was considered for each dataset used in the experiments of this paper. It is worth mentioning here that each set of data (including training, validation, and test sets) contained all classes, where each class consisted of videos as per their corresponding split ratios (training 70%, validation 20%, and test 10%). Further, for model’s weights adjustment and convergence, we employed the Adam optimizer with a fixed learning rate of 0.0001 and utilized categorical cross-entropy loss to adjust the network weights. We set the input sequence length to 16 frames, allowing the DA-R3DCNN model to extract spatiotemporal information by sliding multiple 3D kernels over the sequence of frames. To obtain and compare the performance of our DA-R3DCNN method with the state-of-the-art methods, we used two different evaluation metrics: model accuracy performance evaluation and runtime performance evaluation. For accuracy comparison, we compared the average accuracy of our model for each dataset with the state-of-the-art methods, whereas, for runtime performance comparison, we used two metrics: FPS and SPF.
4.3. Comparison with the State-of-the-Art Methods
This section presents a comprehensive quantitative comparison between our proposed DA-R3DCNN model and state-of-the-art methods for human action recognition. The comparisons were based on average accuracy and were conducted on the UCF11, UCF50, HMDB51, and UCF101 datasets, as shown in
Table 3,
Table 4,
Table 5, and
Table 6, respectively.
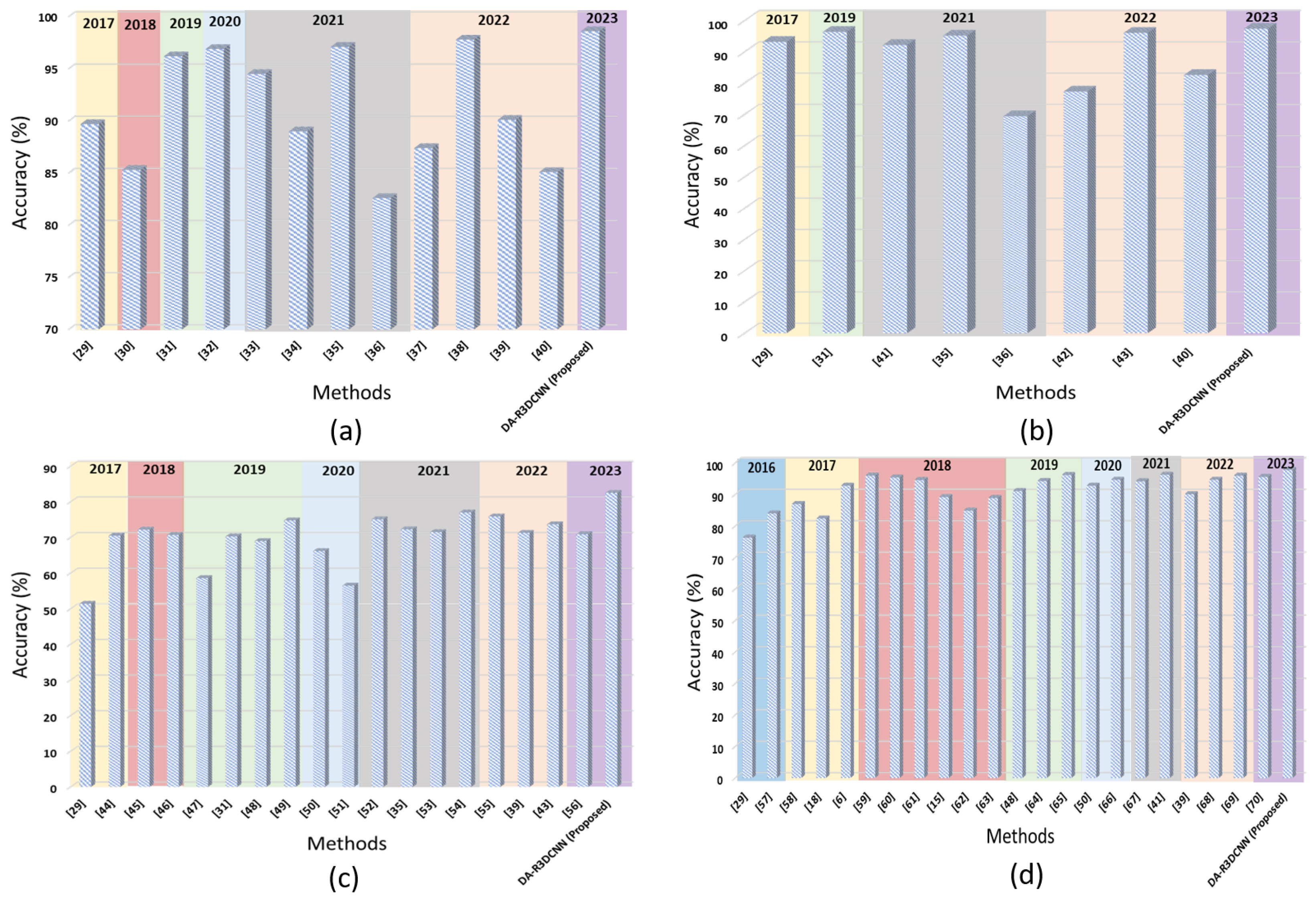
Table 3 showcases the results that indicate that our proposed DA-R3DCNN achieved the highest accuracy of 98.6%, surpassing all other methods. The Fusion-based discriminative features method [
31] came in second place, with an accuracy of 97.8%. Among the comparative methods, the lowest accuracy on the UCF11 dataset was obtained by the Local-global features + QSVM method [
32], which achieved an accuracy of 82.6%. The rest of the comparative methods included Multi-task hierarchical clustering [
33], BT-LSTM [
34], Deep autoencoder [
35], Two-stream attention LSTM [
36], Weighted entropy-variances-based feature selection [
37], Dilated CNN + BiLSTM + RB [
38], DS-GRU [
39], Squeezed CNN [
40], BS-2SCN [
41], and 3DCNN [
42]. These methods achieved accuracies of 89.7%, 85.3%, 96.2%, 96.9%, 94.5%, 89.0%, 97.1%, 87.4%, 90.1%, and 85.1%, respectively. Based on the comparative assessment, the proposed DA-R3DCNN achieved an average accuracy improvement of 8.47% as compared to the average results of state-of-the-art methods on the UCF11 dataset.
For the UCF50 dataset, the results presented in
Table 4 validate that the proposed DA-R3DCNN framework achieved the best results by attaining an accuracy of 97.4%, followed by the Deep autoencoder [
35] method, which obtained a runner-up accuracy of 96.4%. Among all the comparative methods on the UCF50 dataset, the Local-global features + QSVM method [
32] achieved the lowest accuracy of 69.4%. The other methods in the comparison included Multi-task hierarchical clustering [
33], Ensemble model with swarm-based optimization [
43], DS-GRU [
39], Hybrid Deep Evolving Neural Networks [
44], ViT + Multi Layer LSTM [
45], and 3DCNN [
42], which achieved accuracies of 93.2%, 92.2%, 95.2%, 77.3%, 96.1%, and 82.6%, respectively. Upon analyzing the comparative results presented in
Table 4, it is evident that the proposed DA-R3DCNN exhibited an average accuracy improvement of 10.93% over the average results of the state-of-the-art methods on the UCF50 dataset.
In the case of the challenging HMDB51 dataset, the proposed DA-R3DCNN achieved the highest accuracy of 82.5%, surpassing all other comparative methods considered in our assessments. The Evidential deep learning method [
56] emerged as the runner-up with an accuracy of 77.0%. Among the comparative methods, Multi-task hierarchical clustering [
33] achieved the lowest accuracy of 51.4% on the HMDB51 dataset. Other comparative methods included STPP + LSTM [
46], TSN [
48], Deep autoencoder [
35], TS-LSTM + temporal-inception [
50], HATNet [
51], Correlational CNN + LSTM [
52], STDAN [
53], DB-LSTM + SSPF [
54], DS-GRU [
39], TCLC [
55], Semi-supervised temporal gradient learning [
57], BS-2SCN [
41], ViT + Multi Layer LSTM [
45], and MAT-EffNet [
58]. These methods achieved accuracies of 70.5%, 72.2%, 70.7%, 58.6%, 70.3%, 69.0%, 74.8%, 66.2%, 56.5%, 75.1%, 72.3%, 71.5%, 75.9%, 71.3%, 73.7%, and 70.9%, respectively. From the list of comparative assessments in
Table 5, the proposed DA-R3DCNN achieved an average improvement of 19.01%, in terms of accuracy over the average results of the state-of-the-art methods on the HMDB51 dataset.
Finally, for the UCF101 dataset, the results listed in
Table 6 demonstrate that the proposed DA-R3DCNN surpassed all other comparative methods by achieving the highest accuracy of 97.8%. The Ensemble model with swarm-based optimization method [
43] secured the runner-up position with an accuracy of 96.3%. On the UCF101 dataset, the Multi-task hierarchical clustering [
33] obtained the lowest accuracy of 76.3% among all the comparative methods. Additional comparative methods included Saliency-aware 3DCNN with LSTM [
59], Spatio-temporal multilayer networks [
60], Long-term temporal convolutions [
20], CNN + Bi-LSTM [
8], OFF [
61], TVNet [
62], Attention cluster [
63], Videolstm [
17], Two stream convnets [
64], Mixed 3D-2D convolutional tube [
65], TS-LSTM + Temporal-inception [
50], TSN + TSM [
66], STM [
67], Correlational CNN + LSTM [
52], ResCNN-DBLSTM [
68], SC-BDLSTM [
69], BS-2SCN [
41], TDS-BiLSTM [
70], META-RGB + Flow [
71], and Spurious-3D Residual Network [
72]. These methods achieved accuracies of 84.0%, 87.0%, 82.4%, 92.8%, 96.0%, 95.4%, 94.6%, 89.2%, 84.9%, 88.9%, 91.1%, 94.3%, 96.2%, 92.8%, 94.7%, 94.2%, 90.1%, 94.7%, 96.0%, and 95.6%, respectively. Furthermore, it is evident from the results listed in
Table 6 that the proposed DA-R3DCNN exhibited an average accuracy improvement of 7.17% as compared to the average results of state-of-the-art methods on the UCF101 dataset. Additionally, for clear understanding of comparative assessment, we also present the visual overview of comparative analysis of our proposed DA-R3DCNN with the state-of-the-art human action recognition methods on UCF11, UCF50, HMDB51, and UCF101 datasets in
Figure 6. The quantitative comparisons depicted in
Figure 6 illustrate the performance of comparative methods published up to 2023.
Furthermore, to assess the performance generalization of our method, we conducted an analysis of confidence intervals, following the methodology outlined in [
73]. This analysis was performed on each dataset used in this study, and a comparison was made between the confidence intervals of our proposed method and those of the state-of-the-art approaches. It is worth noting that a confidence level of 95% was employed for estimating the confidence intervals of both our method and the state-of-the-art methods. The resulting confidence interval values for our proposed method and the state-of-the-art methods are given in
Table 7. Upon examining these values, we observe that our proposed method exhibited higher confidence levels with narrower intervals on all the dataset when compared to the state-of-the-art methods. For instance, for the UCF11 dataset, the confidence interval of our proposed method spanned from 97.31 to 99.10, with a range of only 1.79. In contrast, the average confidence interval of the state-of-the-art methods ranged from 87.74 to 94.20, showing a comparatively larger range of 6.46. Similarly, for the UCF50 dataset, our proposed method achieved a confidence interval between 96.78 and 98.42, with a small range of 1.64, while the state-of-the-art methods had an average confidence interval ranging from 79.86 to 95.74, indicating a larger range of 15.88. Analyzing the HMDB51 dataset, we observe that our proposed method had a confidence interval of 92.21 to 94.16, with a narrow range of 1.95. In contrast, the state-of-the-art methods exhibited an average confidence interval ranging from 65.97 to 72.67, demonstrating a comparatively larger range of 6.70. Lastly, for the UCF101 dataset, our proposed method demonstrated a confidence interval between 96.89 and 98.46, with a small range of 1.57, whereas the state-of-the-art methods have an average confidence interval ranging from 88.93 to 93.57, indicating a larger range of 4.64. It is worth mentioning here that our proposed method consistently achieved higher confidence levels across all datasets, with narrower intervals, in comparison to the state-of-the-art methods. This observation serves to verify the effectiveness of our proposed method in surpassing existing approaches in terms of performance generalization.
The conducted comparative assessments validate the effectiveness of the proposed DA-R3DCNN based on the obtained improvement in the results, across each dataset used in this work. These results verify the robustness of our proposed DA-R3DCNN framework over the state-of-the-art methods for human action recognition task.
4.4. Run Time Analysis
In this section, we examine the inference time of our proposed DA-R3DCNN framework and assess its suitability for real-time human activity recognition tasks, considering metrics such as SPF and FPS. To evaluate the overall run time performance, we conducted inference time measurements of the proposed DA-R3DCNN model on both GPU and CPU computing platforms. These measurements were then compared with the runtime results of the state-of-the-art human activity recognition methods, and the findings are presented in
Table 8. This analysis provides a comprehensive perspective on the run time efficiency of our proposed DA-R3DCNN model across different computing platforms. The results presented in
Table 8 highlight the superior inference efficiency of the proposed DA-R3DCNN model as compared to state-of-the-art methods, as demonstrated by SPF and FPS metrics on both GPU and CPU computing platforms. The findings indicate that, when utilizing GPU resources, our proposed DA-R3DCNN achieved the best SPF of 0.0045 and an FPS of 240. The runner-up method, OFF [
61], achieved an SPF of 0.0048 and an FPS of 215. Conversely, the Videolstm [
17] method exhibited the highest SPF of 0.0940 and the lowest FPS of 10.6, indicating the least favorable run time performance among all the comparative methods. These results underscore the exceptional inference efficiency of our proposed DA-R3DCNN model when compared to existing approaches. On the CPU computing platform, the proposed DA-R3DCNN framework demonstrated significant superiority over existing methods, achieving an SPF of 0.0058 and an FPS of 187. In comparison, the second-best performing method, Optical-flow + Multi-layer LSTM [
47], achieved an SPF of 0.18 and an FPS of 3.5. Conversely, the Deep autoencoder [
35] method exhibited the poorest runtime performance with an SPF of 0.43 and an FPS of 1.5. These results further validate the exceptional run time efficiency of our proposed DA-R3DCNN framework when compared to alternative approaches on the CPU computing platform.
Further, to ensure a fair comparison of the run time results obtained for both GPU and CPU platforms, we scaled the run time results (as in [
74]) of the state-of-the-art methods to match the hardware resources utilized in our study (i.e., a 2.5 GHz CPU and a 585 MHz GPU). The scaled run time results are provided in the second section of
Table 8, enabling an equitable assessment and comparison of the performance of the proposed DA-R3DCNN framework against existing methods. Analyzing the scaled results presented in
Table 8, it becomes evident that scaling amplifies the advantages of the proposed DA-R3DCNN model in terms of SPF and FPS metrics for both GPU and CPU computing platforms. When utilizing GPU resources, the proposed DA-R3DCNN outperformed other methods with the best SPF of 0.0045 and an FPS of 240. The STPP + LSTM [
46] method secured the second-best position, with SPF and FPS values of 0.0063 and 154.6, respectively. These findings highlight the enhanced performance of the proposed DA-R3DCNN model when considering the scaled runtime results, solidifying its superiority over alternative approaches. The Videolstm [
17] method had the highest SPF of 0.1606 and lowest FPS of 6.2, indicating the worst run time results amongst all the comparative methods. When running on CPU computing platform, the proposed DA-R3DCNN framework had the lowest SPF of 0.0058 and highest FPS of 187, indicating the best results obtained on CPU resources as compared to other comparative methods. Among the scaled results in
Table 8, the Optical-flow + Multi-layer LSTM [
47] emerged as the runner-up with an SPF of 0.23 and an FPS of 2.6 on the CPU computing platform. On the other hand, the Deep autoencoder [
35] method exhibited the least favorable performance on CPU resources, achieving an SPF of 0.56 and an FPS of 1.1. These findings further solidify the superior run time performance of the proposed DA-R3DCNN model when compared to alternative methods on the CPU computing platform.
It is evident from the listed scaled and non-scaled results in
Table 8 that the proposed DA-R3DCNN provides significant improvement for both GPU and CPU computing platforms. For instance, for non-scaled run time results, the proposed DA-R3DCNN provided an improvement of up to 7× for SPF and 3× for FPS metric when running on GPU resources. When running on CPU resources, the proposed DA-R3DCNN achieved an improvment of up to 52× for SPF and 74× for FPS for the non-scaled run time results. Similarly, for the scaled run time results, the proposed DA-R3DCNN provided an improvement of 13× for SPF and 5× for FPS when running on GPU resources. When running on CPU resources, the proposed DA-R3DCNN framework achieved an improvement of 68× for SPF and 100× for FPS. These results show the efficiency and applicability of the proposed DA-R3DCNN method for real-time human activity recognition in resource constraint environments.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}