1. Introduction
Life-testing and reliability experiments are typically terminated before all sample items fail. Under standard failure censoring, the test concludes when a specified number of units have failed; see, e.g., Bhattacharyya [
1], LaRiccia [
2], Schneider and Weissfeld [
3], Fernández [
4] and Jaheen and Okasha [
5] and references therein. Progressive censorship is an extension of failure censoring in which a certain number of live units can be excluded from the study (i.e., censored) at each failure time. This pattern of censorship offers substantial versatility to the researcher, and also permits the collection of degradation or deterioration data with the objective of analyzing the aging mechanism. The progressive censoring scheme has been widely analyzed in recent decades. Papers by Kemaloglu and Gebizlioglu [
6], Wang et al. [
7], Lee et al. [
8], Almongy et al. [
9], Chen and Gui [
10] and Abu-Moussa et al. [
11] are just a sample. Comprehensive analyses of the state of the art on progressive censorship are provided in the works of Balakrishnan and Aggarwala [
12] and Balakrishnan and Cramer [
13].
The Weibull distribution with scale parameter
and shape parameter
is a flexible log-location–scale model for the analysis of time-to-event data that is valuable in many disciplines, including economics, biometry, management, engineering and the actuarial, social and environmental sciences. The Weibull
distribution plays a relevant role in many survival and reliability analyses, and has been successfully applied to describe the reliability of both components and equipment in industrial engineering, as well as human and animal disease mortality. Various studies and applications of the Weibull model can be found in Thoman et al. [
14], Meeker and Escobar [
15], Nordman and Meeker [
16], Chen et al. [
17], Tsai et al. [
18], Fernández [
19], Roy [
20], Algarni [
21], Boult et al. [
22], Li et al. [
23] and Yu et al. [
24]. This model reduces to the exponential distribution when
see, e.g., Fernández et al. [
25], Lee et al. [
26], Fernández [
27], Yousef et al. [
28] and Tanackov et al. [
29].
The development of confidence sets for Weibull parameters and quantiles from test samples is of great interest and practical relevance in many experimental analyses. In particular, these regions are useful for model selection, parametric estimation and hypothesis testing. In practice, joint confidence sets for the Weibull scale and shape parameters,
and
are often based on the unconditional distribution of pivotal quantities related to the maximum likelihood estimator (MLE) of
denoted as
However,
does not contain all the sample information. In the Weibull case, the whole sample is minimally sufficient. Confidence regions for
can also be derived by using the conditional distribution of
, given the observed values of the ancillary statistics. From a strictly logical point of view, the conditional approach seems more appropriate because it obeys the Sufficient Principle. Uniformly most accurate confidence sets do not exist in the Weibull case. Region size minimization is an alternative optimality criterion that is commonly used to select the best confidence set; see, for example, Casella and Berger [
30], Lehmann and Romano [
31] and Fernández [
32]. At first glance, as smaller confidence sets contain fewer points, they are less likely to cover false values. Interval estimation from progressively censored data has been considered by many authors, including Viveros and Balakrishnan [
33], Wu [
34], Lawless [
35] and Fernández [
36].
This paper deals with the construction of minimum-area confidence regions for Weibull parameters and quantiles based on progressively censored data when the principle of conditioning on ancillary statistics is adopted. Our approach is based on the general results of Hora and Buehler [
37] for location–scale parameter problems, which are also valid for log-location–scale models, such as the Weibull distribution, because the logarithmic transformation is strictly monotonic. According to Hora and Buehler [
37], conditional frequentist confidence sets and Bayesian credibility sets for invariantly estimable functions are numerically equivalent when the analyst assumes independent Lebesgue measure priors on the location parameter and the logarithm of the scale parameter. In our setting, the Weibull parameters and quantiles correspond to invariantly estimable functions, and the proposed optimal confidence regions would include the points with the highest posterior density (HPD) assuming independent flat priors for
and
The above diffuse Bayesian approach satisfies the Conditionality, Likelihood and Sufficiency Principles, and often allows us to substantially reduce the areas of confidence regions.
The remainder of this paper is structured as follows. Given a progressively censored sample from the Weibull model, the next section presents the likelihood function, as well as a diffuse improper prior density for the Weibull parameters and the corresponding posterior density function. Minimum-area confidence regions for the Weibull parameters based on the Conditionality Principle, which coincide with the Bayesian HPD credibility sets in the diffuse case, are derived in
Section 3, whereas
Section 4 is concerned with the determination of the smallest-size joint confidence set for two arbitrary Weibull quantiles. Algorithms to find the optimal confidence regions via simulation, as well as applications to hypotheses testing, are also suggested. A numerical example regarding failure times for an insulating fluid between two electrodes is considered in
Section 5 for illustrative and comparative purposes. Finally,
Section 6 offers some concluding remarks.
2. Weibull Models and Progressive Censoring
Suppose that the lifetime
X of a certain device follows the Weibull distribution with scale parameter
and shape parameter
which is denoted as
The probability density function (pdf) and cumulative distribution function (cdf) of
X are then given by
respectively. Moreover, the reliability or survival function of
X is defined as
and the failure rate is given by
for
The k-th moment of is obtained to be where is the well-known gamma function. The parameter determines the scaling of the density, whereas the parameter controls its shape. In many practical cases, the survival of populations with increasing decreasing or constant hazard risks can be modeled by Weibull distributions.
Assume now that n randomly selected units from a population with unknown parameters and are put on life test under a progressive censoring scheme and also that is the the observed realization of the random sample of failure times That is, units are simultaneously placed on test at time zero in the life-testing experiment; for randomly selected living units are retired from the study at the i-th observed failure time, so, prior to the -th failure, there are units on inspection; finally, at the time of the s-th observed failure, the test is concluded, i.e., the remaining units are removed from the analysis. The constants s and are prefixed integers which must satisfy the assumptions: for and
The likelihood function for
given
is then defined by
In accordance with (
1) and (
2), the likelihood becomes
where
and
are the observed values of the random quantities
respectively, and
Given the censoring scheme
it is clear that the observed sample
is minimal sufficient for
Hereafter, it will be assumed that and Note that the probability that is zero when In such a case, the unique MLE of denoted by can be derived by solving the equations and via iterative procedures. In our situation, the MLE of is an insufficient statistic. Hence, the confidence regions for based on do not satisfy the Sufficiency Principle.
As mentioned earlier, the Weibull distribution is a log-location-scale parameter model. Specifically, the random variable
has a Gumbel
distribution with location and scale parameters
and
respectively. From Hora and Buehler [
37], it follows for any level
that the conditional
-confidence sets for Gumbel parameters and quantiles are numerically equivalent to the corresponding
-credibility sets obtained with the improper prior density
see also Lawless ([
35], p. 565, Property 2). Since the logarithmic transformation is strictly monotonic, the above results are also valid for Weibull parameters and quantiles when the prior pdf is defined by
for
Assuming this diffuse prior model, the posterior pdf of
given
can be expressed as
where
The posterior pdf of
given
is unimodal, which implies that the HPD estimate (or posterior mode) of
denoted by
is unique. The posterior pdf of
given
is given by
whereas the posterior pdf of
conditional on
given
is defined as
Therefore, the posterior distribution of
given
and
is chi-square with
degrees of freedom, i.e.,
The posterior cdf of
conditional to
is then given by
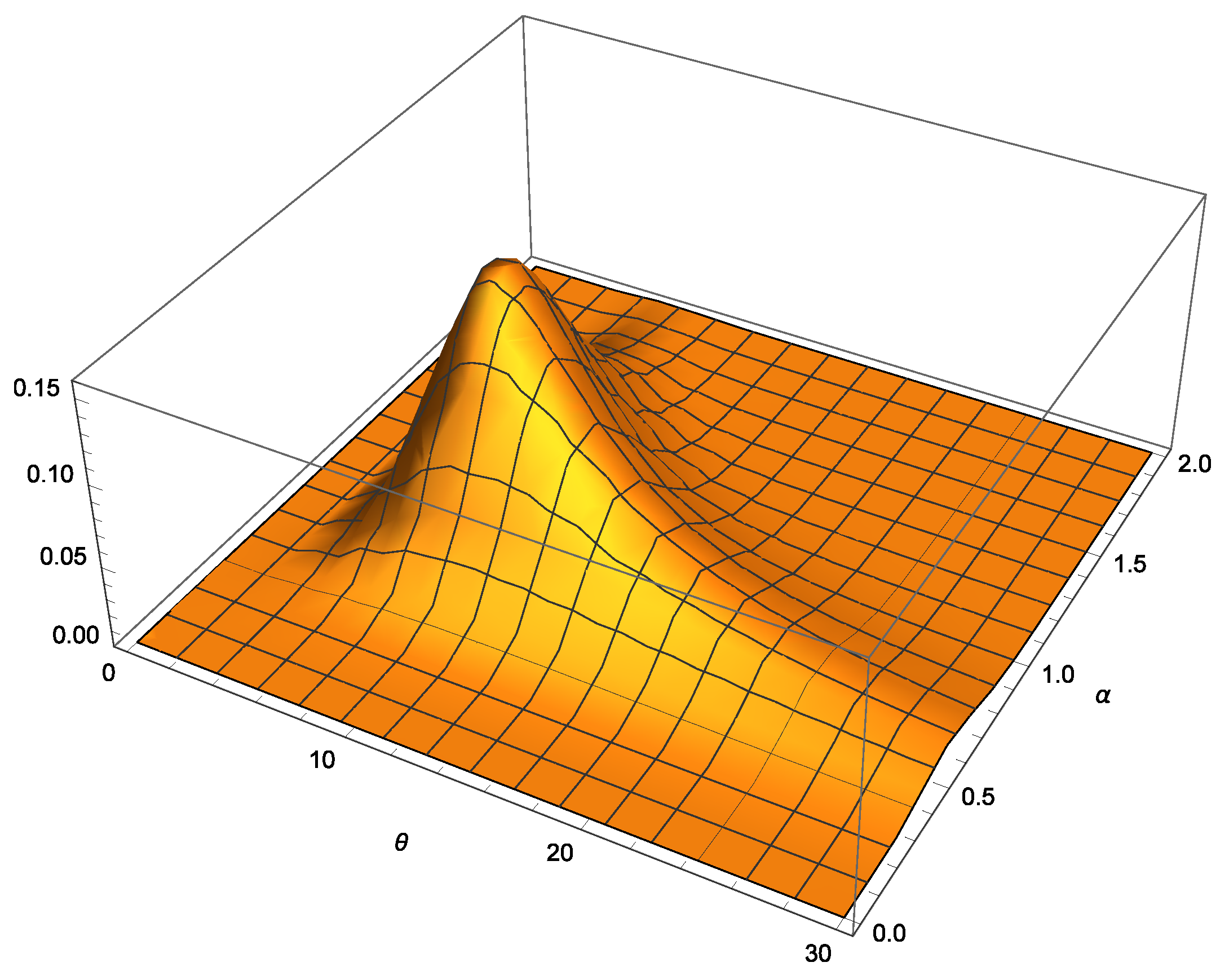
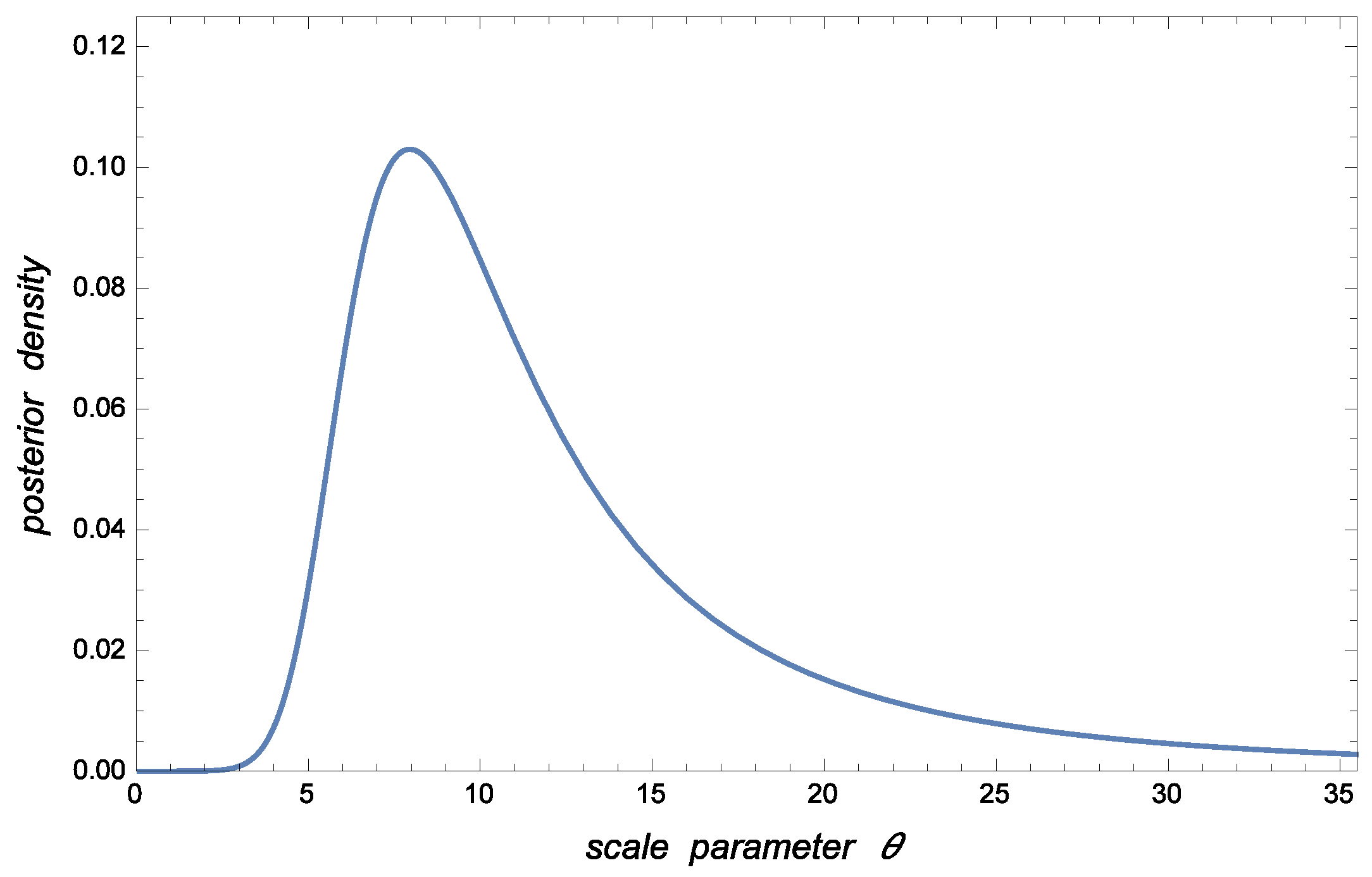
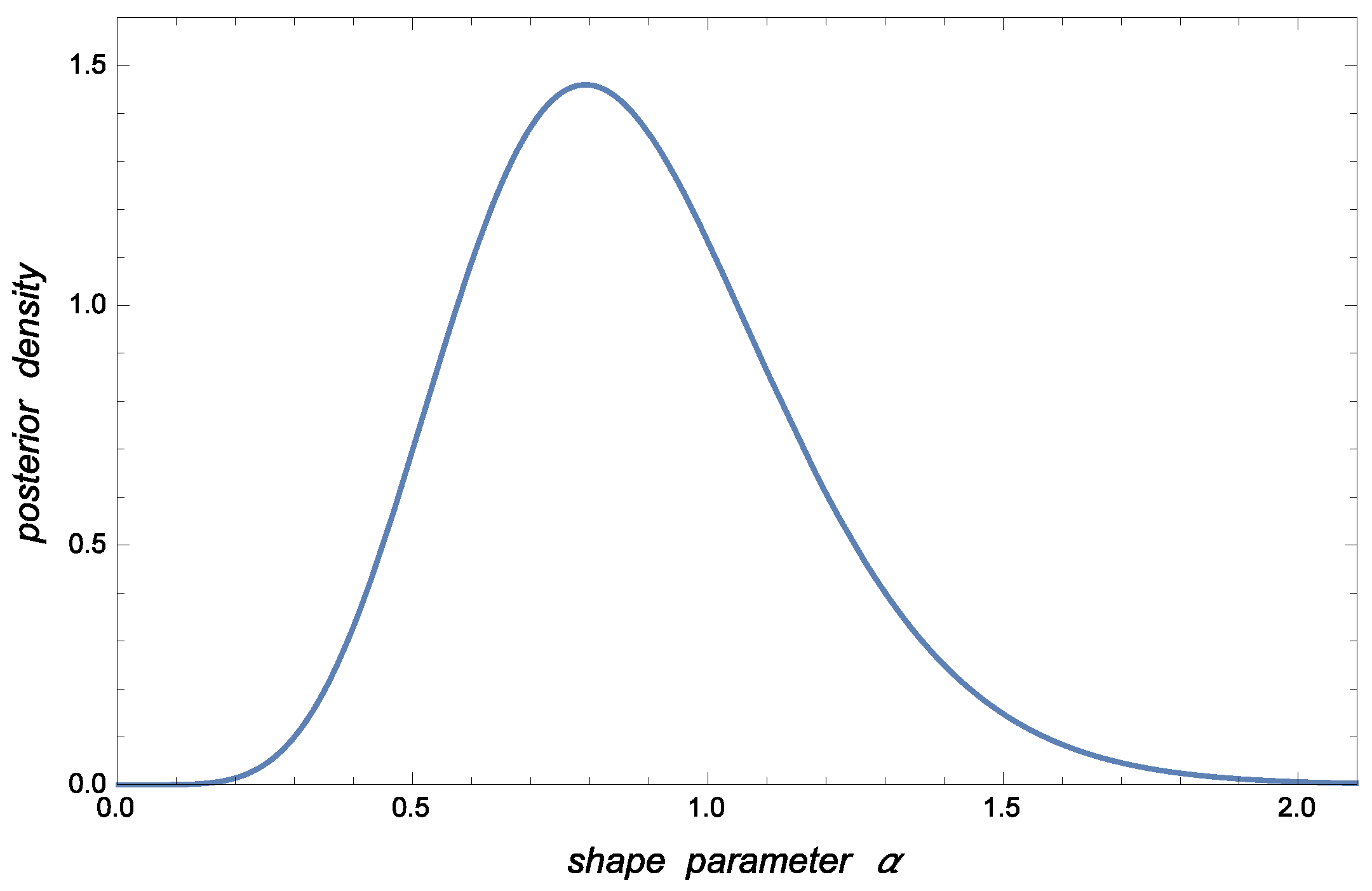
As graphical illustrations,
Figure 1 shows the posterior pdf for
conditional to
associated with the case to be analyzed in
Section 5. The corresponding posterior pdfs for
and
are displayed in
Figure 2 and
Figure 3.
3. Optimal Regions for the Weibull Parameters
Assume that
denotes the confidence or credibility level and also that
represents the
-quantile of the random posterior density of
given
The Bayesian HPD
-credibility region for
is then defined as
where
The region
is also the conditional (frequentist)
-confidence region for
with minimum area. The Bayesian credibility degree
coincides with the frequency-based confidence level of the random region
Therefore, the smallest-size
confidence set for
based on the Conditionality Principle given
may be defined as
Since the joint posterior pdf of
and
derived in (
3) is unimodal, it is clear that
is a simply connected region. Hence, the set
is bounded by a single curve
, which does not intersect itself, i.e., the region limited by the contour
results in the required
-confidence set.
An approximate value of can be obtained through simulation. A simple algorithm for determining a random sample of size m from the posterior distribution of conditional to can be sketched as follows: Given a large integer number for simulate an observation from the uniform distribution and another value from the distribution, and then determine and In such a case, constitute a random sample of size m from the posterior distribution of Since is the -quantile of the random variable an approximation of is given by the -quantile of the simulated sample
For interested readers, Thomopoulos [
38] focuses on the fundamentals of Monte Carlo methods using basic computer simulation techniques.
The smallest confidence regions presented in this paper can also be applied in hypotheses testing. For instance, if
is the observed value of
and
is the progressive censoring scheme, the
p-value associated to the test of the null hypothesis
versus the alternative hypothesis
based on the smallest confidence sets for
would be defined by
where
It is easy to show that
i.e., the constant
equals
An approximation of
is given by the proportion of the simulated sample data
that are at least
That is, the
p-value is approximately given by the proportion of simulated sample data
that are less than
More formally,
where I
denotes the indicator function.
4. Optimal Regions for Two Weibull Quantiles
Given the Weibull u-quantile is defined as Our goal in this section is to construct the smallest-size confidence region for the pair of Weibull quantiles where
The posterior pdf of
given
can be expressed as
where
denotes the Jacobian (determinant) for the change of variables from
to
The Jacobian is defined by
where
and
After some calculations, it is derived that
where
for
because
and
As a consequence of the above results, the posterior pdf of
given
is defined as
for
Obviously,
where
for
constitute a random sample of size
m from the posterior distribution of
conditional to
In this case, the minimum-area
-confidence region for
denoted by
is defined as
where
As discussed, the smallest-size confidence regions are relevant to practitioners because they are less likely to contain spurious parameter values.
An approximation of the constant
is given by the
-quantile of the simulated sample
because
is precisely the
-quantile of the random variable
In our situation, the
p-value associated to the test
:
against
:
based on the smallest confidence sets for
would be defined by
where
Hence,
where
Furthermore, if an analyst uses the above random sample, it is clear that the
p-value for testing
versus
is approximately given by
Note that testing and is equivalent to checking and which implies that the corresponding reliabilities of the device in study at times and are and For example, and is identical to the null hypothesis and
5. Illustrative Applications
A progressively censored sample studied by Balakrishnan and Cramer ([
13], p. 9) is considered in this section to illustrate the results developed above. This sample is based on the data reported by Nelson ([
39], p. 105) concerning times to breakdown (in minutes) of an insulating fluid between two electrodes subject to a voltage of 34 kV. According to engineering considerations, for a fixed voltage level, the time to breakdown,
follows a Weibull distribution.
In our case, the progressive censoring scheme is
and the sample of observed failure times is given by:
Therefore,
and
It can be shown that the maximum likelihood estimates of
and
are
and
respectively. Moreover, the value of
is obtained to be
The posterior pdfs for
and
given
are plotted in
Figure 1,
Figure 2 and
Figure 3, respectively. The HPD estimate (or posterior mode) of
is given by
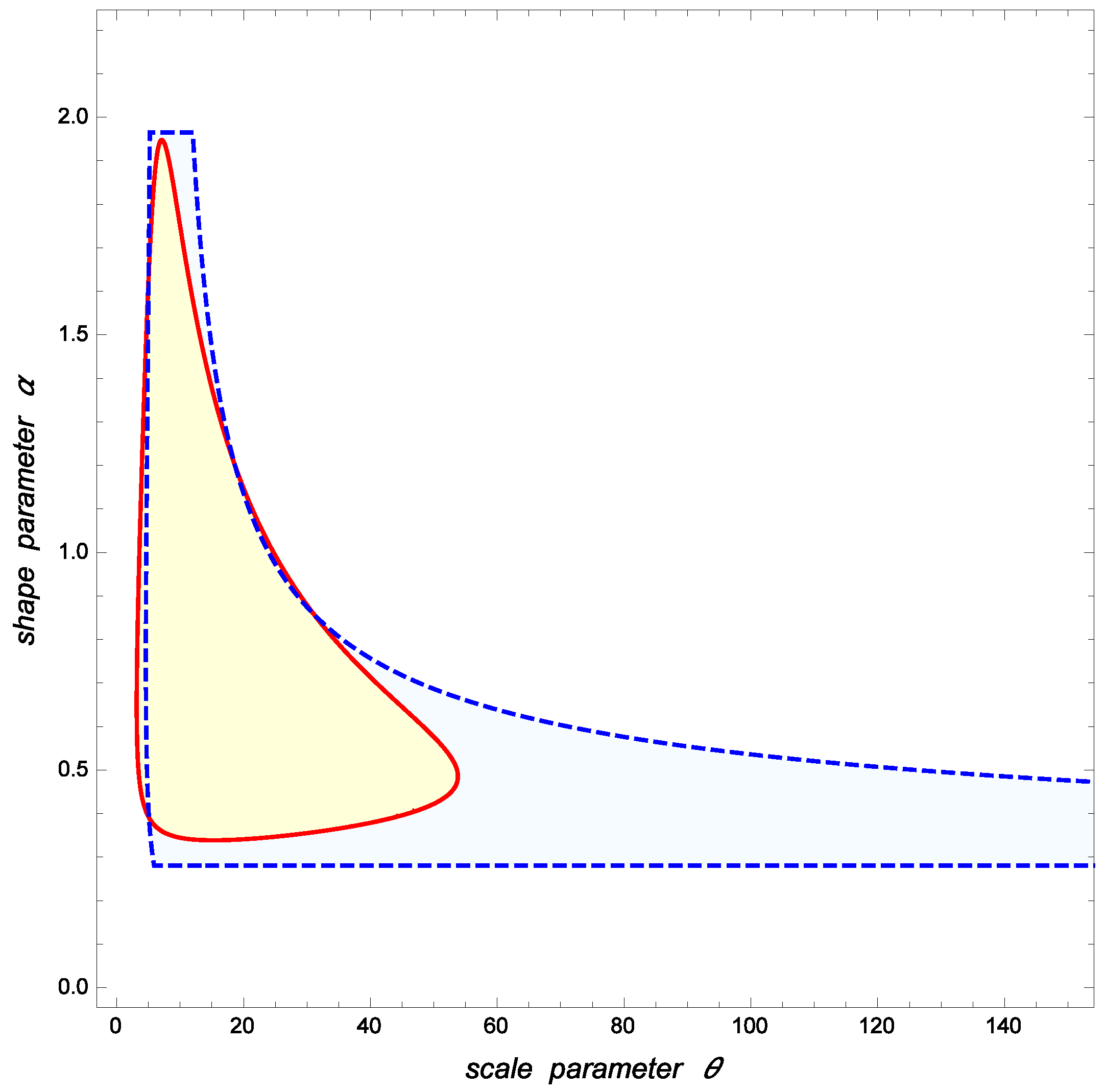
Balakrishnan and Cramer ([
13], p. 387) derived that the joint 95% confidence region for
and
suggested by Wu [
34], which is denoted by
is defined by
Assuming that the confidence level is
the optimal (minimum area) 95% confidence region for
proposed in this paper is given by
where the 0.05-quantile of the random posterior density of
given
is
This set is also the Bayesian HPD
-credibility region for
in the noninformative case. For illustrative and comparative purposes, the 95% confidence regions
and
are depicted in
Figure 4.
The area of the optimal region is whereas Note also that, if is small, the values of such that could be very large. For instance, the point is contained in which is clearly unrealistic because is too small compared to In general, our approach can greatly reduce the areas of the confidence regions for the Weibull parameters. In the above situation,
Consider that a reliability engineer aims to check whether is reasonable or not. Since the p-value for testing versus is calculated to be the values and are quite admissible. In contrast, and are not reasonable because the p-value for testing against is only
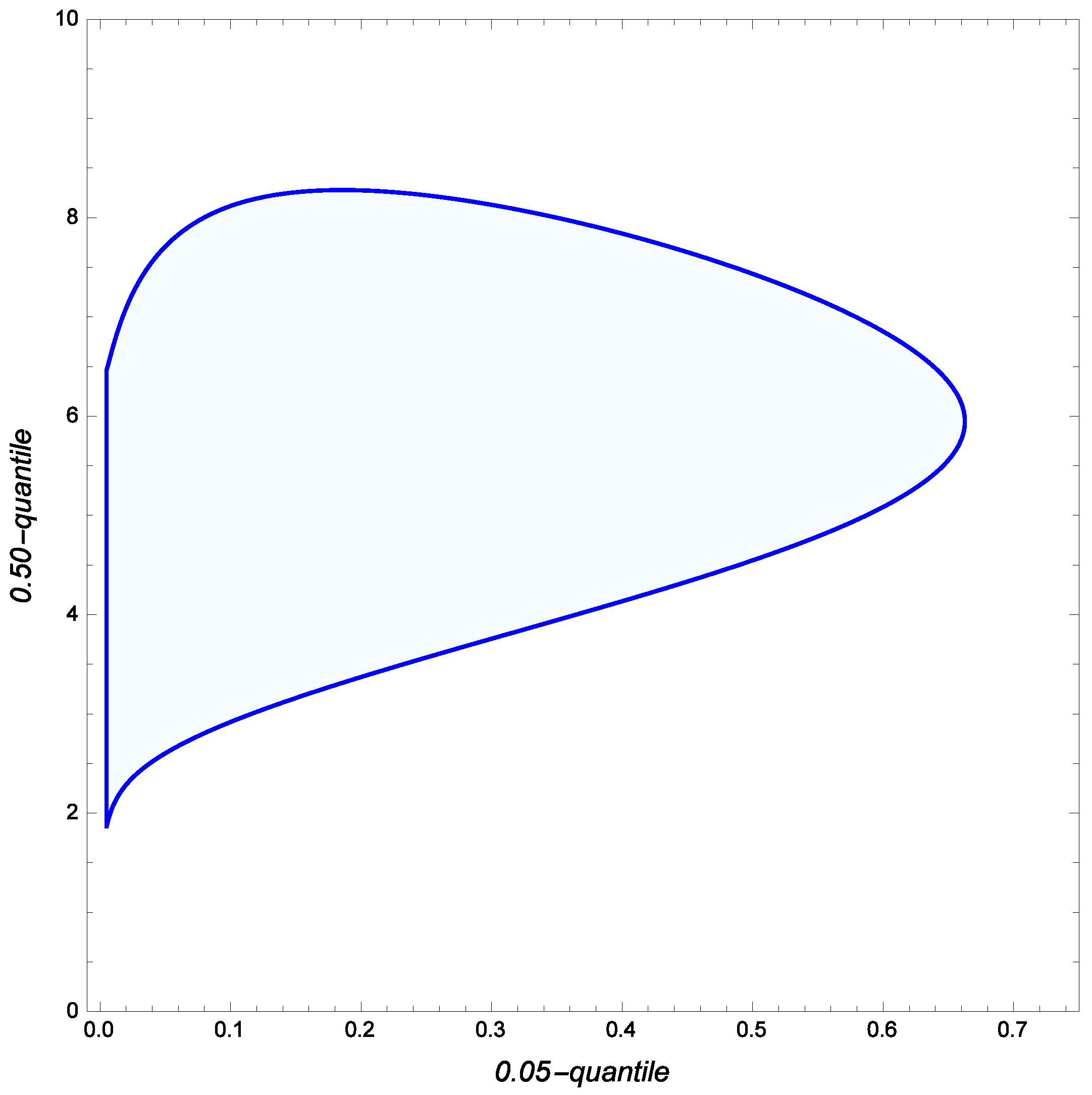
Suppose now that an analyst seeks to determine the smallest-size 90% confidence region for the pair of Weibull quantiles
where
and
In this case, the minimum-area 90% confidence region for
is defined as
where
This set, which is also the diffuse Bayesian HPD
-credibility region for
is depicted in
Figure 5.
Evidently, the proposed confidence region can be used to perform hypothesis tests about In particular, the null hypothesis : cannot be rejected when is the level of confidence. Specifically, the p-value is obtained to be In contrast, : is not acceptable because the p-value is now only
6. Concluding Remarks
Optimal joint confidence regions for the scale and shape parameters of the Weibull distribution and two Weibull quantiles are presented in this paper when available data are progressively censored. The proposed confidence sets have minimum area among all those which are based on the Conditionality Principle, and they numerically coincide with the Bayesian highest posterior density credibility sets in the noninformative case.
Smallest-area confidence regions are found by using simulation methods and numerical integration. The suggested approach is valid for both standard failure and progressive censoring, as well as for uncensored samples, and is also applicable to hypothesis testing.
Our methodology obeys the Conditionality, Sufficiency and Likelihood Principles. In contrast, the unconditional methods based on the MLEs and other insufficient statistics violate these principles. In our view, reducing available sample information to insufficient statistics is not appropriate. Moreover, in terms of area, the optimal confidence regions offer appreciable gains over the existing confidence sets. Furthermore, the reduction in area is overwhelming in some cases. In addition, our perspective allows us to construct minimum-size confidence sets for other invariantly estimable functions of the Weibull parameters.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




