
Bayesian Opportunities for Brain–Computer Interfaces: Enhancement of the Existing Classification Algorithms and Out-of-Domain Detection


Abstract
:1. Introduction
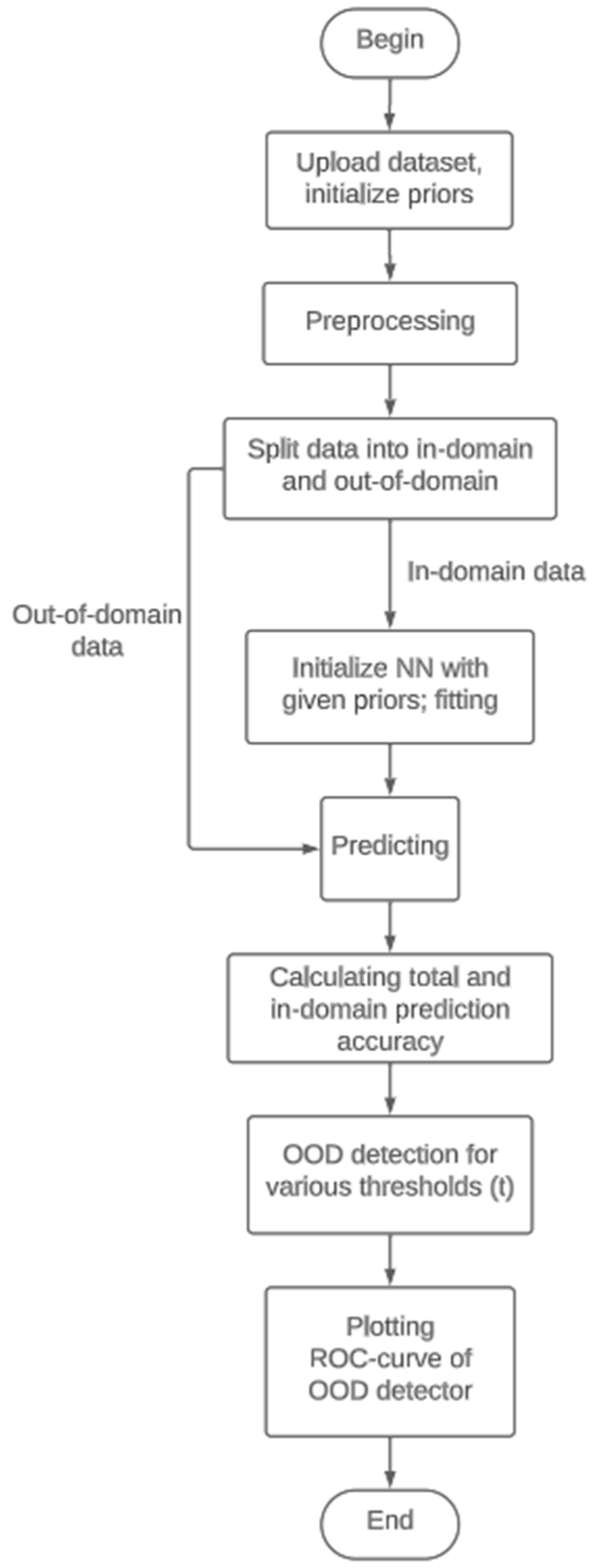
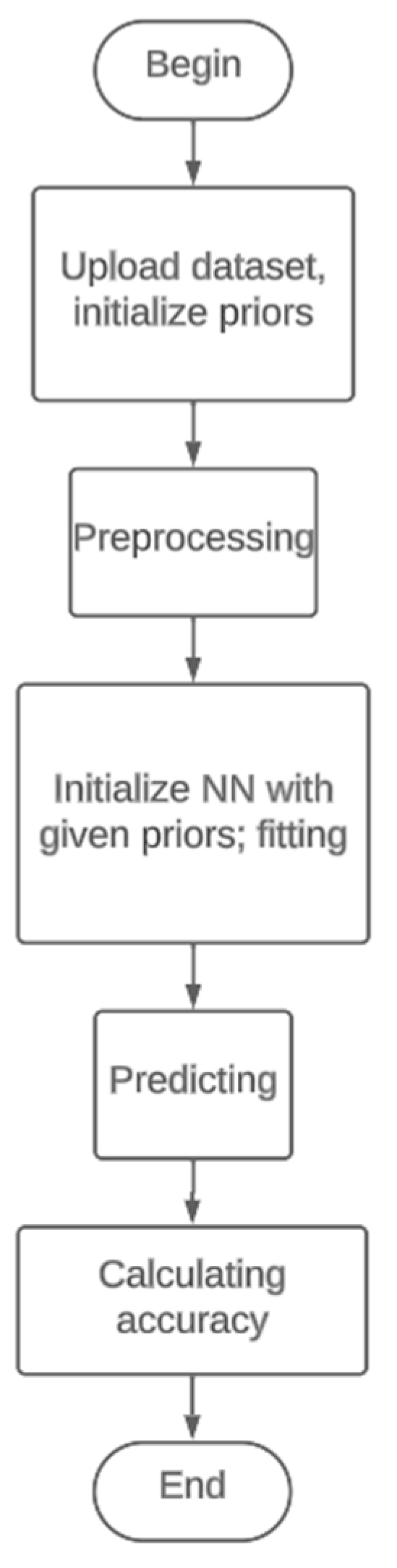
2. Materials and Methods
2.1. Dataset
2.2. Architectures and Related Methods
2.3. Experiments
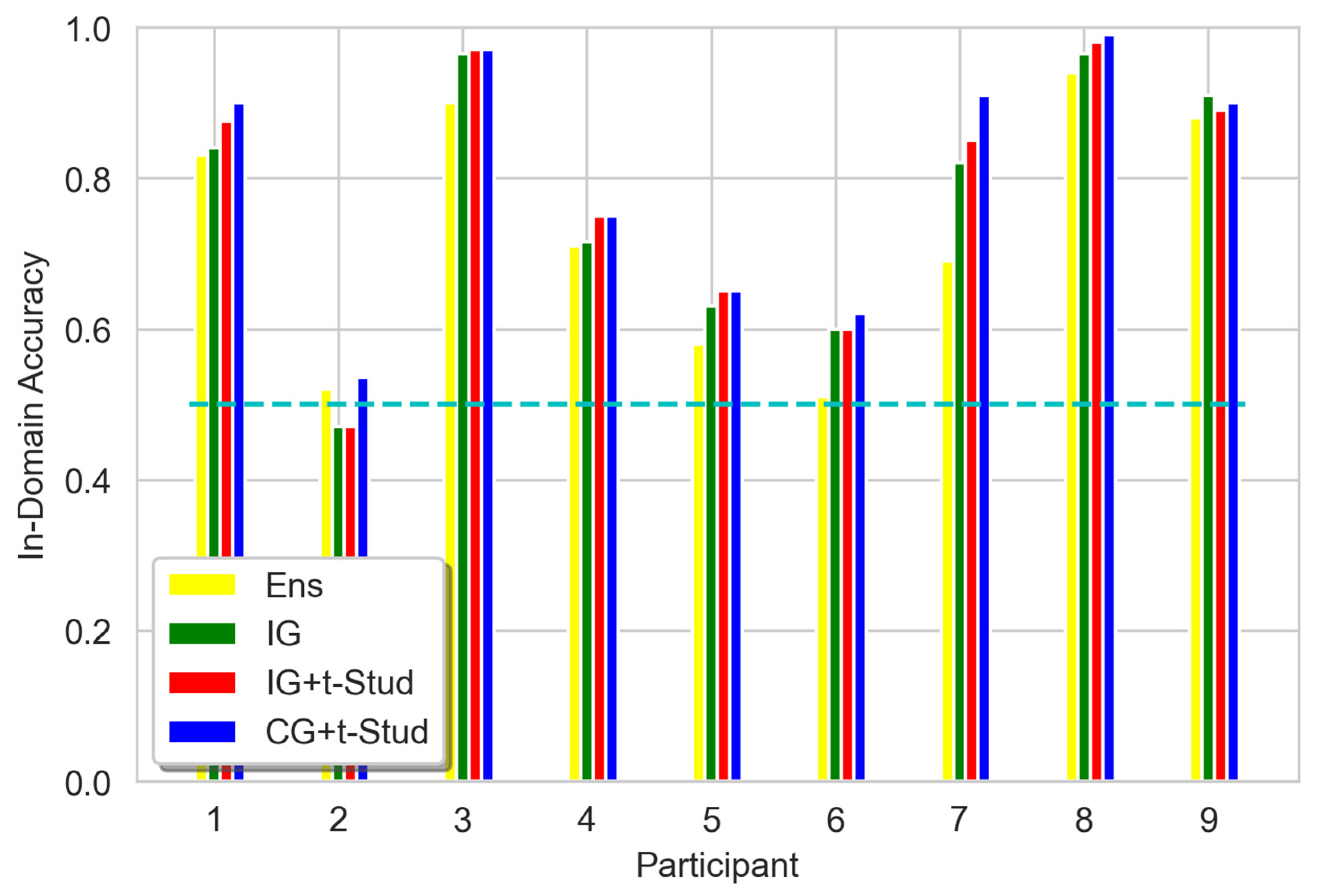
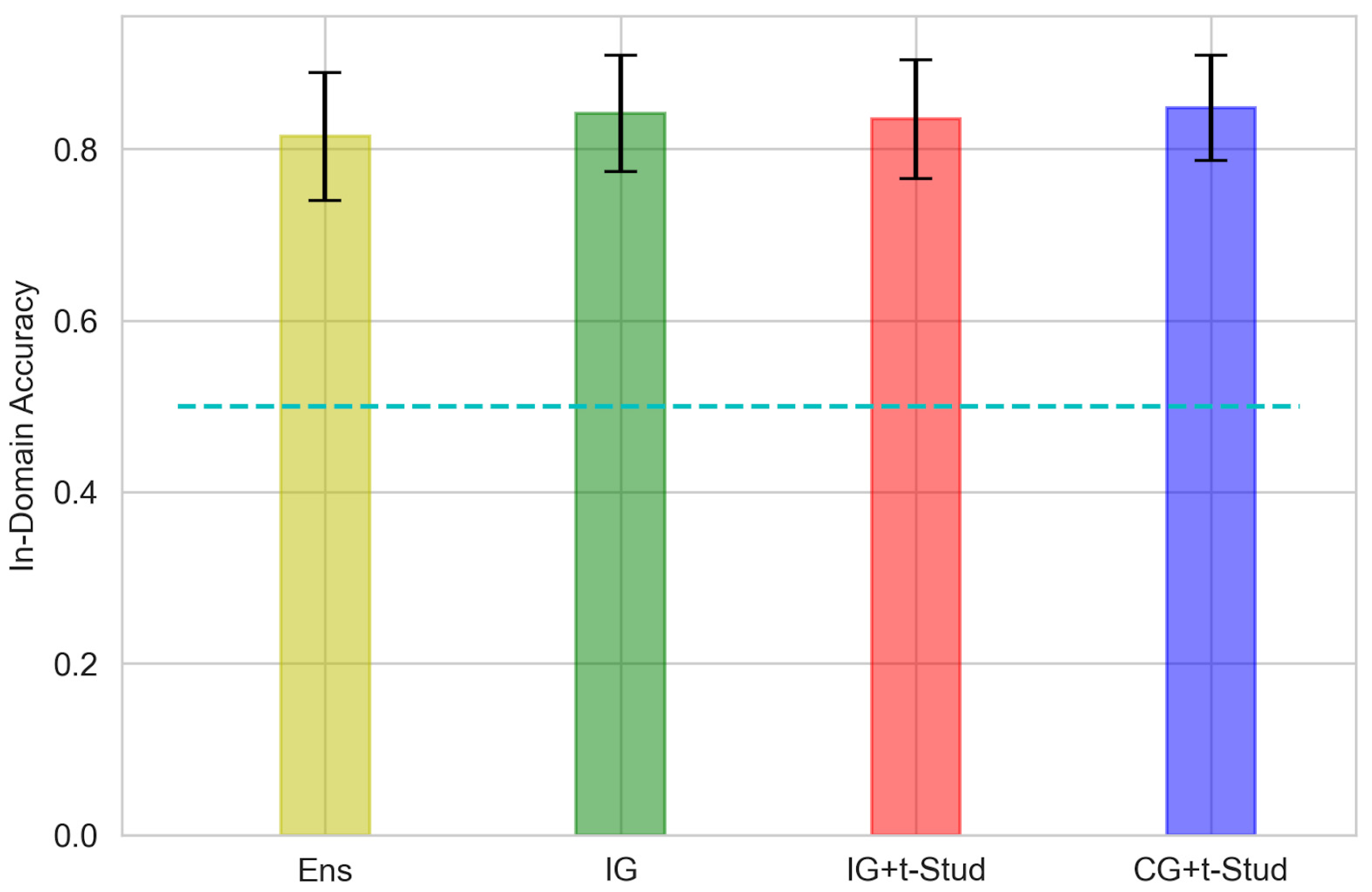
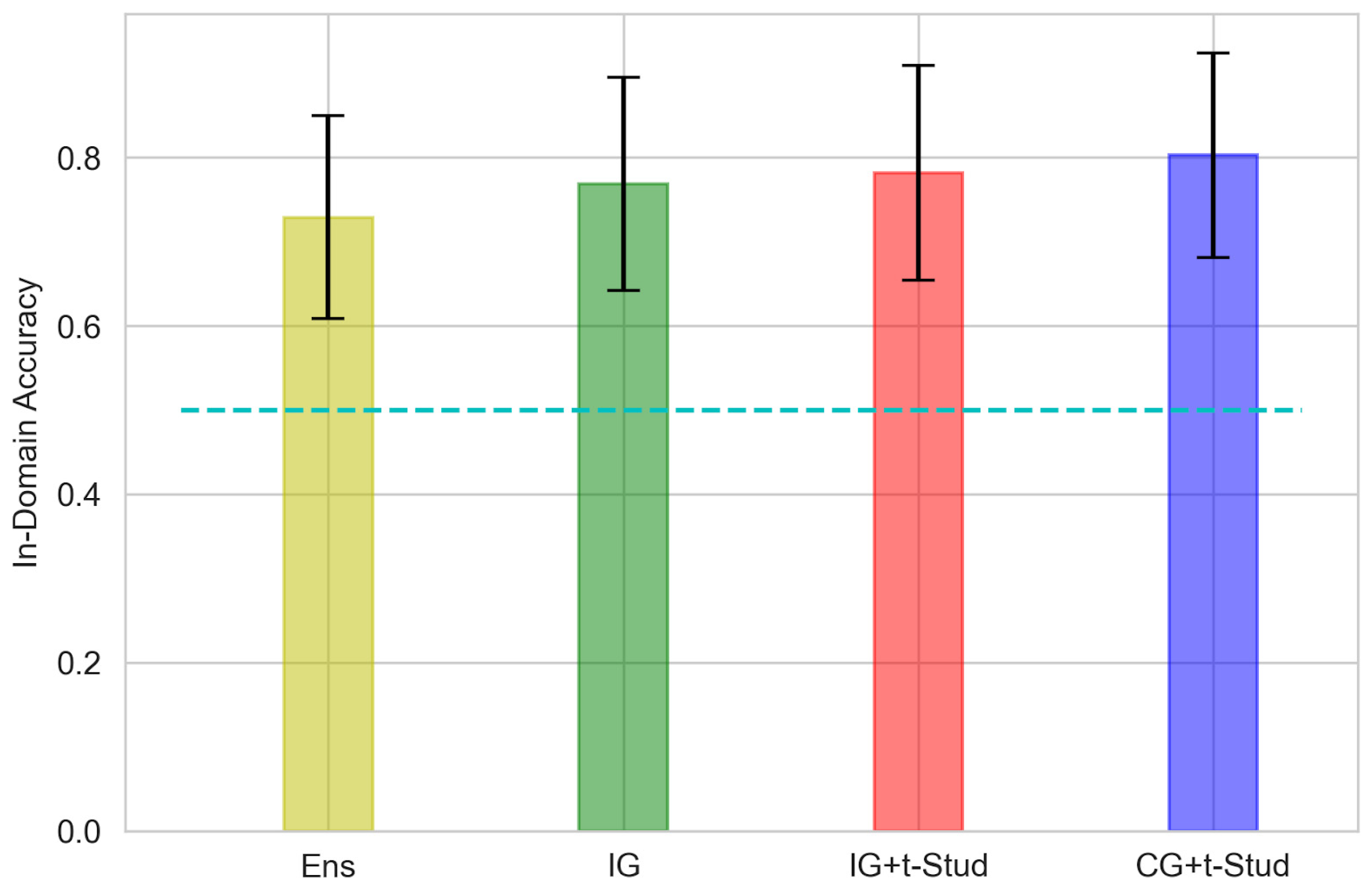
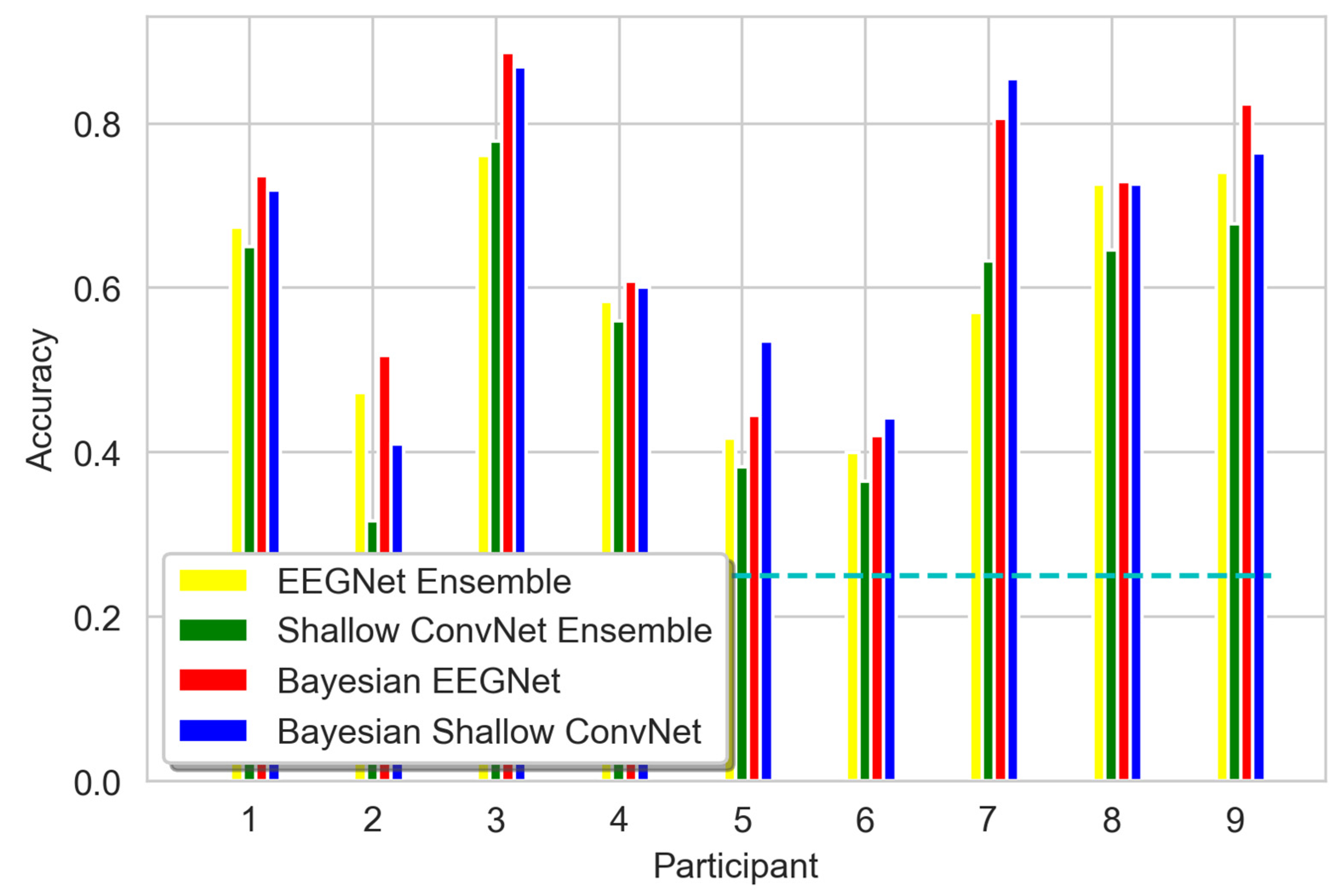
3. Results
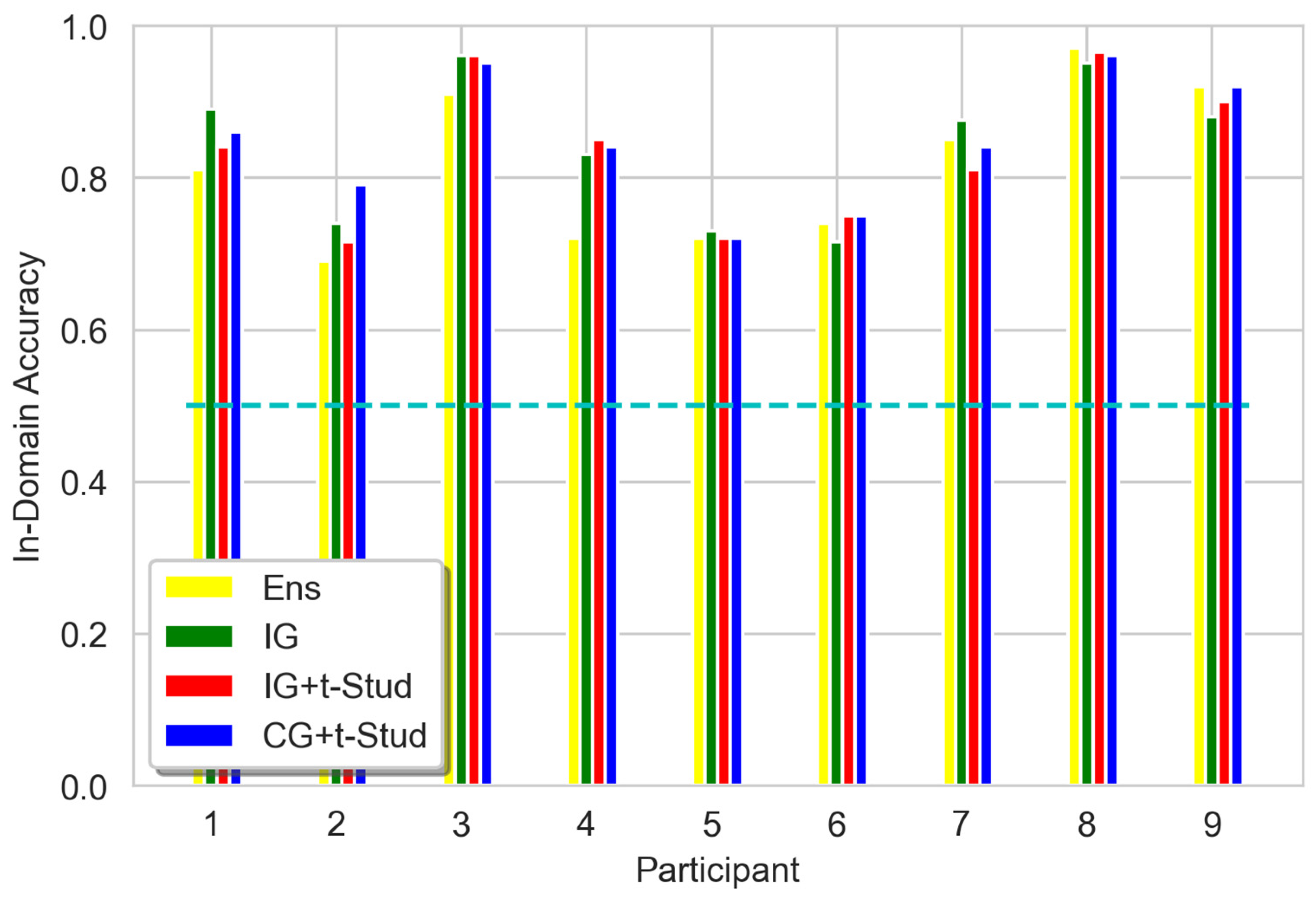
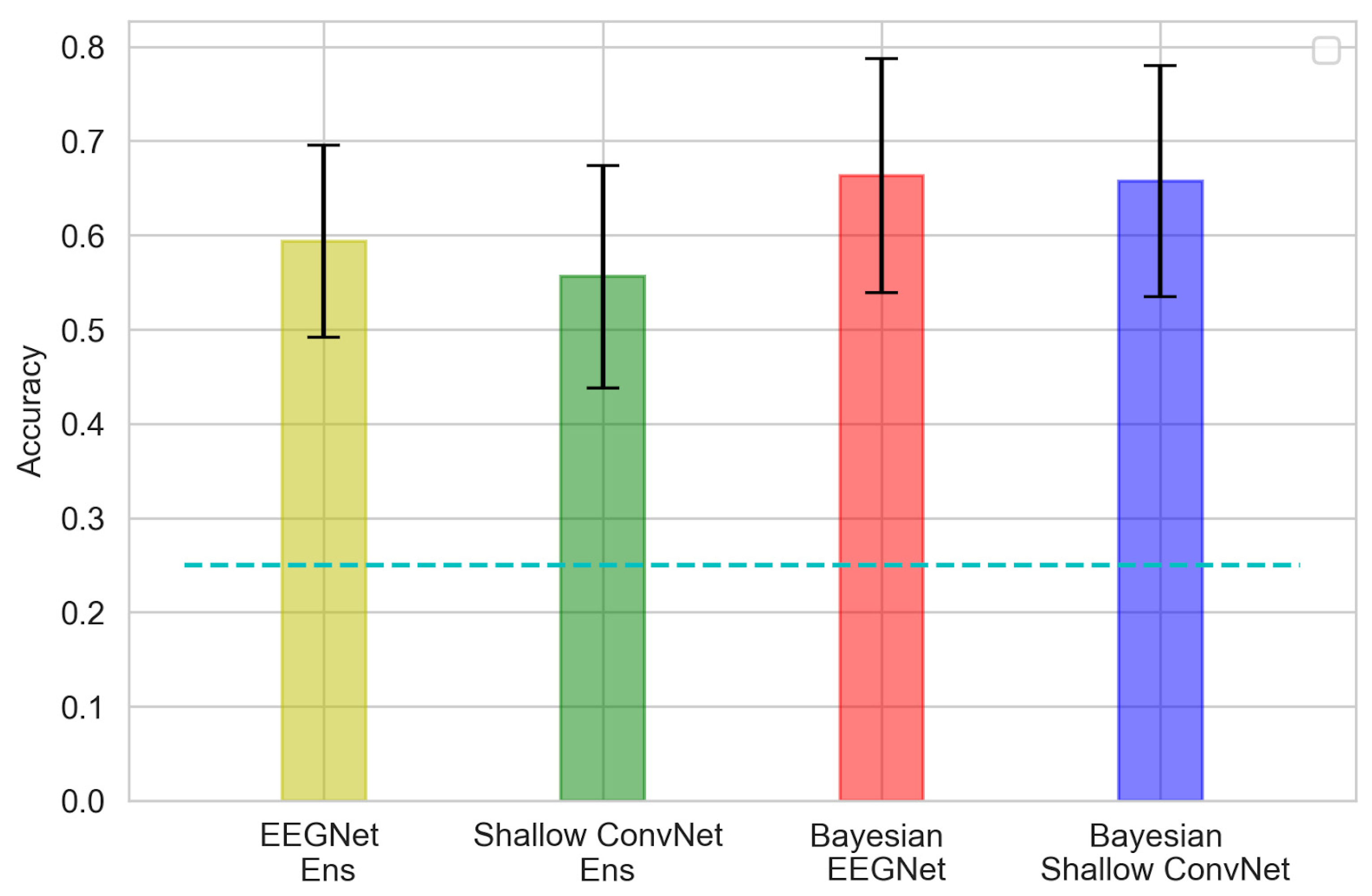
3.1. Accuracy of in-Domain Data Classification
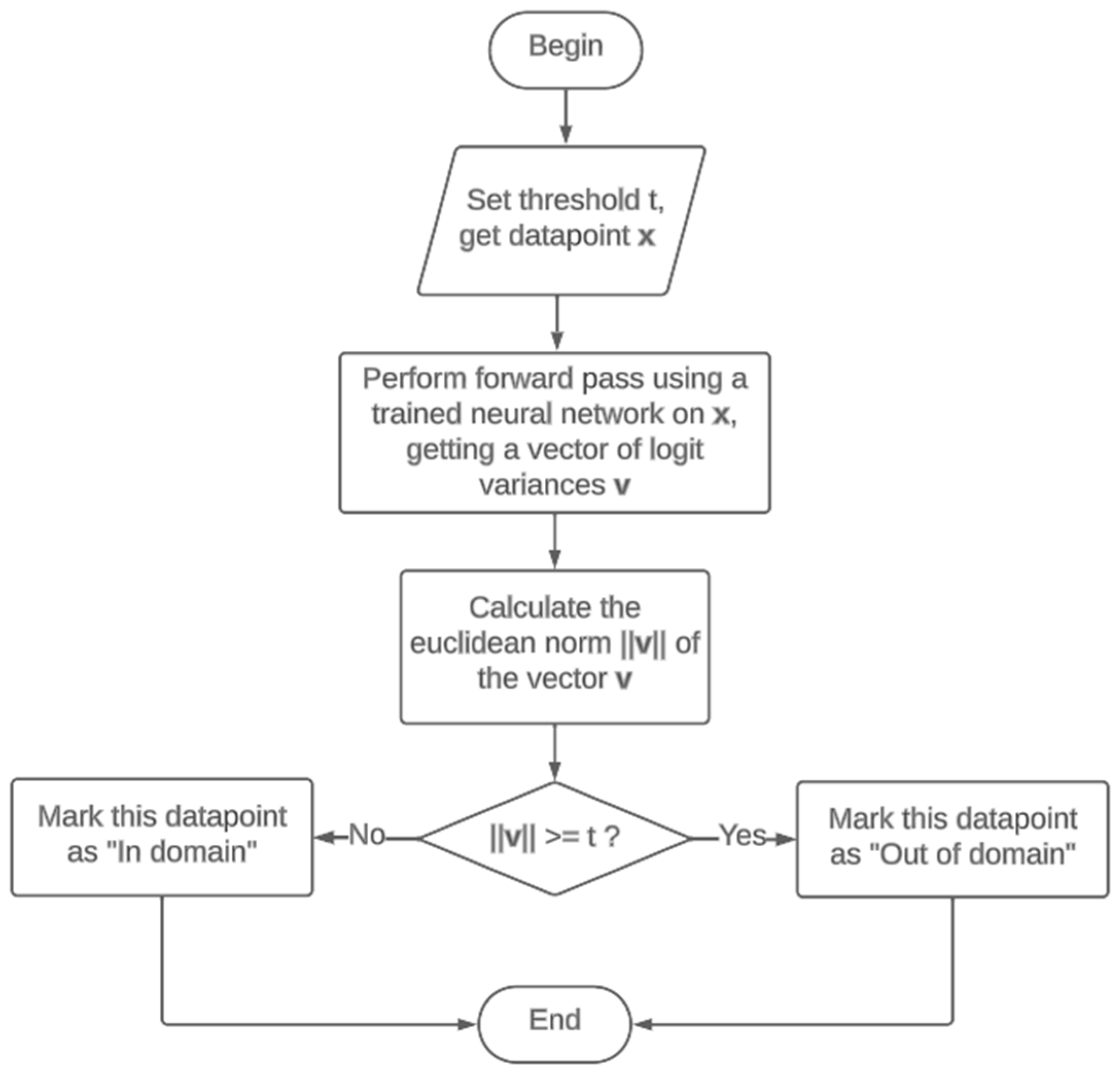
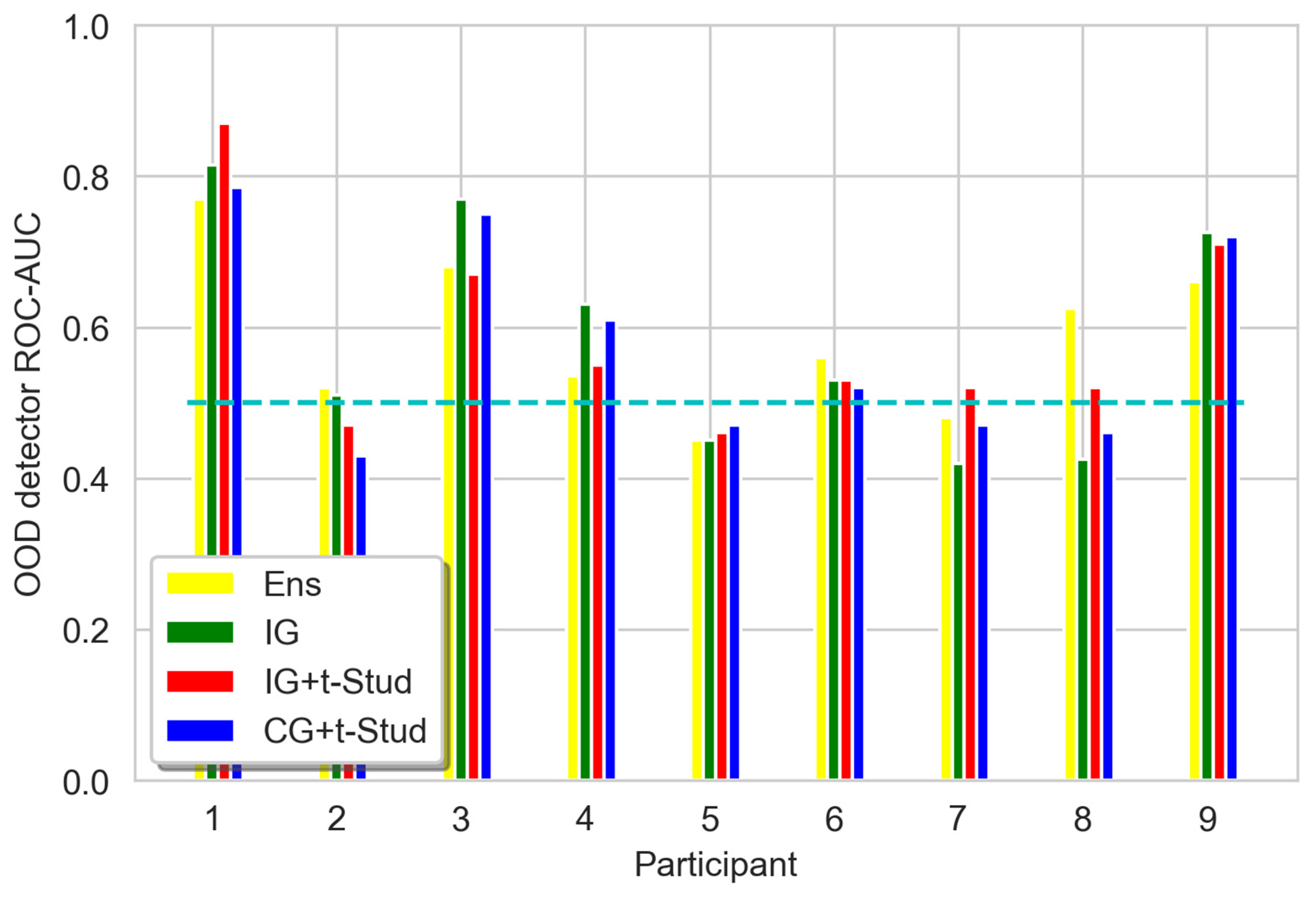
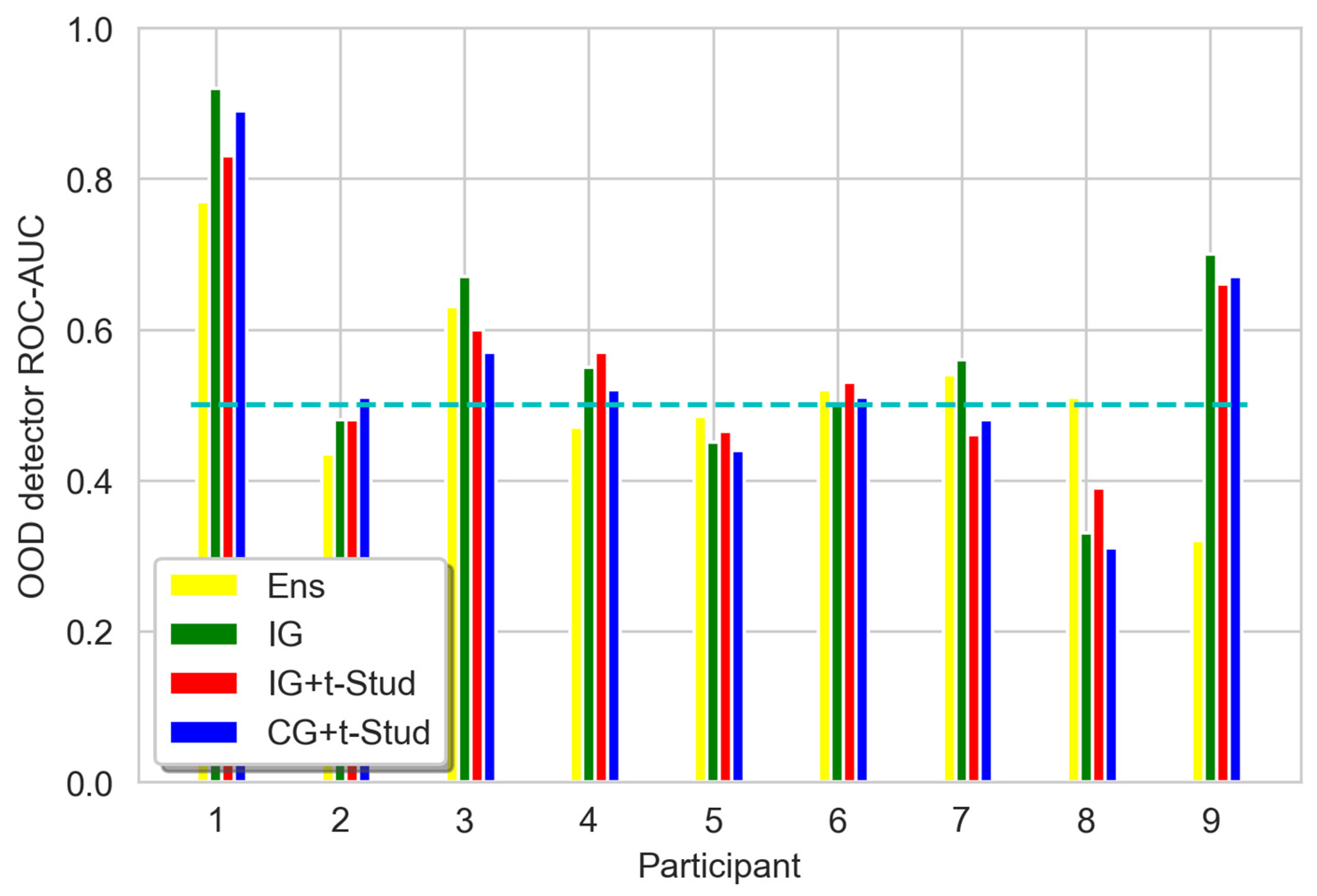
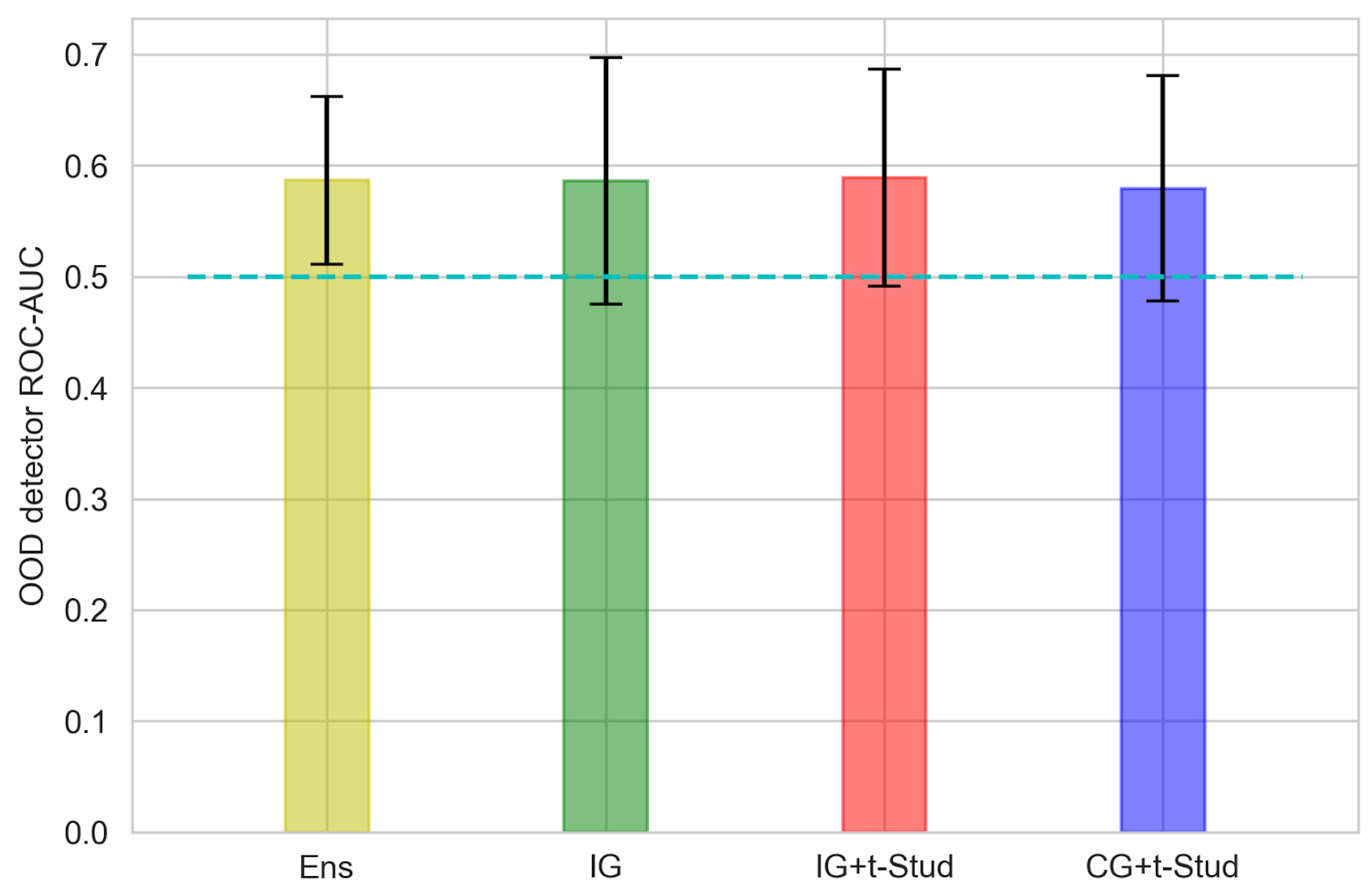
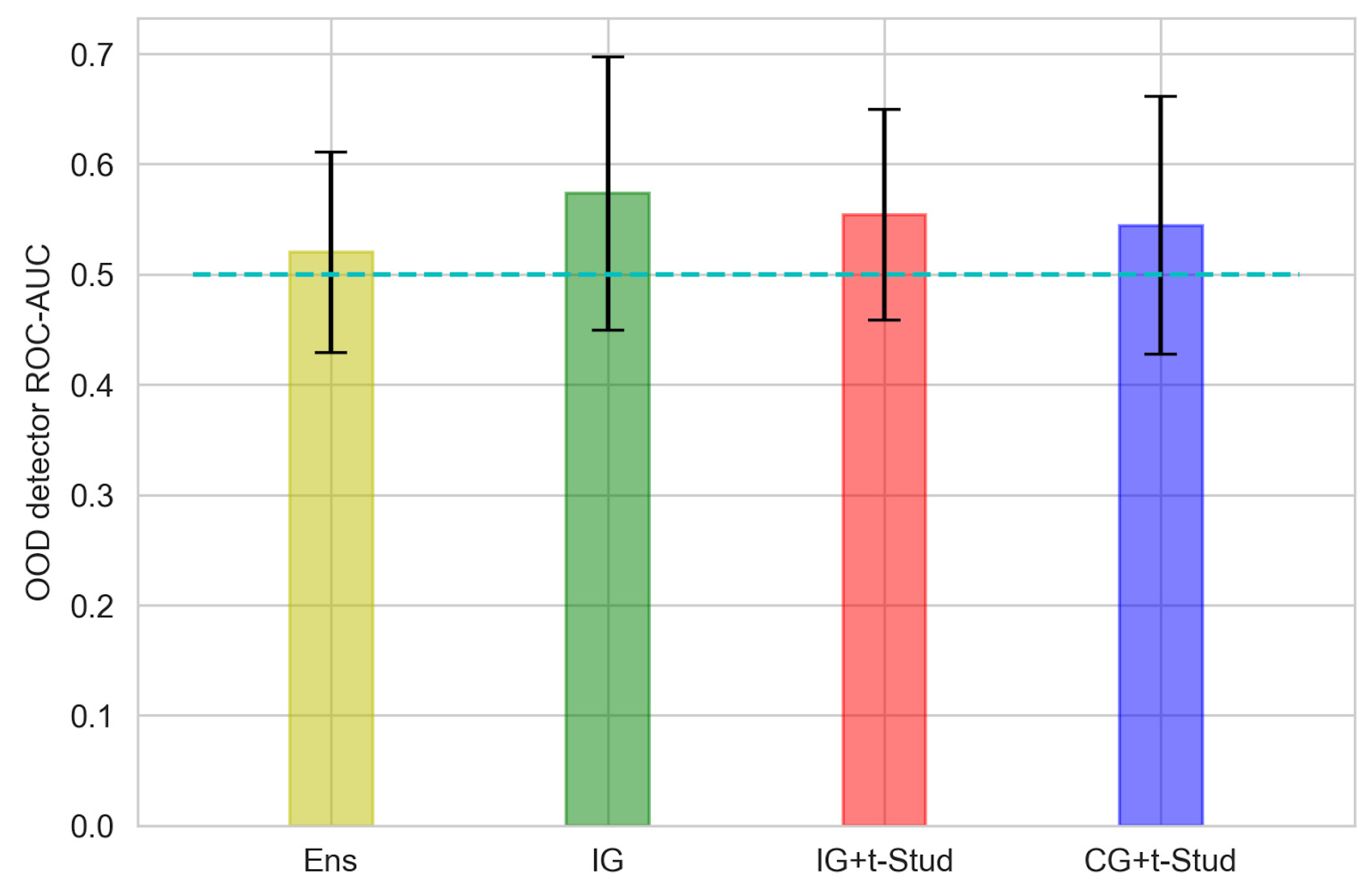
3.2. Out-Of-Domain Data Detection
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lotte, F.; Bougrain, L.; Cichocki, A.; Clerc, M.; Congedo, M.; Rakotomamonjy, A.; Yger, F. A review of classification algorithms for EEG-based brain–computer interfaces: A 10 year update. J. Neural Eng. 2018, 15, 031005. [Google Scholar] [CrossRef] [PubMed]
- Wojcikiewicz, W.; Vidaurre, C.; Kawanabe, M. Stationary Common Spatial Patterns: Towards robust classification of non-stationary EEG signals. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; IEEE: Prague, Czech Republic, 2011; pp. 577–580. [Google Scholar]
- Zheng, Y.; Chen, G.; Huang, M. Out-of-Domain Detection for Natural Language Understanding in Dialog Systems. IEEE/ACM Trans. Audio Speech Lang. Process 2020, 28, 1198–1209. [Google Scholar] [CrossRef]
- Zeng, Z.; He, K.; Yan, Y.; Liu, Z.; Wu, Y.; Xu, H.; Jiang, H.; Xu, W. Modeling Discriminative Representations for Out-of-Domain Detection with Supervised Contrastive Learning 2021. Available online: http://arxiv.org/abs/2105.14289 (accessed on 3 August 2023).
- Ryu, S.; Koo, S.; Yu, H.; Lee, G.G. Out-of-domain Detection based on Generative Adversarial Network. In Proceedings of the Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 714–718. [Google Scholar]
- Major, D.; Lenis, D.; Wimmer, M.; Berg, A.; Neubauer, T.; Bühler, K. On the Importance of Domain Awareness in Classifier Interpretations in Medical Imaging. IEEE Trans. Med. Imaging 2023, 42, 2286–2298. [Google Scholar] [CrossRef]
- Wellhausen, L.; Ranftl, R.; Hutter, M. Safe Robot Navigation Via Multi-Modal Anomaly Detection. IEEE Robot. Autom. Lett. 2020, 5, 1326–1333. [Google Scholar] [CrossRef]
- Caron, S.; Hendriks, L.; Verheyen, R. Rare and Different: Anomaly Scores from a combination of likelihood and out-of-distribution models to detect new physics at the LHC. SciPost Phys. 2022, 12, 77. [Google Scholar] [CrossRef]
- Maddox, W.J.; Izmailov, P.; Garipov, T.; Vetrov, D.P.; Wilson, A.G. A.G. A Simple Baseline for Bayesian Uncertainty in Deep Learning. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., Alché-Buc, F.d., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32, Available online: https://proceedings.neurips.cc/paper_files/paper/2019/file/118921efba23fc329e6560b27861f0c2-Paper.pdf (accessed on 15 August 2023).
- Hendrycks, D.; Gimpel, K. A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks 2018. Available online: http://arxiv.org/abs/1610.02136 (accessed on 3 August 2023).
- Duan, T.; Wang, Z.; Liu, S.; Srihari, S.N.; Yang, H. Uncertainty Detection and Reduction in Neural Decoding of EEG Signals 2022. Available online: http://arxiv.org/abs/2201.00627 (accessed on 9 February 2023).
- Milanés-Hermosilla, D.; Trujillo-Codorniú, R.; Lamar-Carbonell, S.; Sagaró-Zamora, R.; Tamayo-Pacheco, J.J.; Villarejo-Mayor, J.J.; Delisle-Rodriguez, D. Robust Motor Imagery Tasks Classification Approach Using Bayesian Neural Network. Sensors 2023, 23, 703. [Google Scholar] [CrossRef]
- Jospin, L.V.; Laga, H.; Boussaid, F.; Buntine, W.; Bennamoun, M. Hands-On Bayesian Neural Networks—A Tutorial for Deep Learning Users. IEEE Comput. Intell. Mag. 2022, 17, 29–48. [Google Scholar] [CrossRef]
- Joyce, J. Bayes’ Theorem. In The Stanford Encyclopedia of Philosophy; Zalta, E.N., Ed.; Metaphysics Research Lab, Stanford University: Stanford, CA, USA, 2021; Available online: https://plato.stanford.edu/archives/fall2021/entries/bayes-theorem/ (accessed on 18 July 2023).
- Wang, H.; Yeung, D.-Y. A Survey on Bayesian Deep Learning. ACM Comput. Surv. 2021, 53, 1–37. [Google Scholar] [CrossRef]
- Li, M.; Li, F.; Pan, J.; Zhang, D.; Zhao, S.; Li, J.; Wang, F. The MindGomoku: An Online P300 BCI Game Based on Bayesian Deep Learning. Sensors 2021, 21, 1613. [Google Scholar] [CrossRef]
- Siddique, T.; Mahmud, M.S. Classification of fNIRS Data Under Uncertainty: A Bayesian Neural Network Approach 2021. Available online: http://arxiv.org/abs/2101.07128 (accessed on 28 June 2023).
- Blundell, C.; Cornebise, J.; Kavukcuoglu, K.; Wierstra, D. Weight Uncertainty in Neural Networks 2015. Available online: http://arxiv.org/abs/1505.05424 (accessed on 9 February 2023).
- Schupbach, J.; Sheppard, J.W.; Forrester, T. Quantifying Uncertainty in Neural Network Ensembles using U-Statistics. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: Glasgow, UK, 2020; pp. 1–8. [Google Scholar]
- Zeng, X.; Wu, J.; Wang, D.; Zhu, X.; Long, Y. Assessing Bayesian model averaging uncertainty of groundwater modeling based on information entropy method. J. Hydrol. 2016, 538, 689–704. [Google Scholar] [CrossRef]
- Henning, C.; D’Angelo, F.; Grewe, B.F. Are Bayesian Neural Networks Intrinsically Good at Out-of-Distribution Detection? 2021. Available online: http://arxiv.org/abs/2107.12248 (accessed on 21 June 2023).
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A Compact Convolutional Network for EEG-based Brain-Computer Interfaces. J. Neural Eng. 2018, 15, 056013. [Google Scholar] [CrossRef] [PubMed]
- Schirrmeister, R.T.; Springenberg, J.T.; Fiederer, L.D.J.; Glasstetter, M.; Eggensperger, K.; Tangermann, M.; Hutter, F.; Burgard, W.; Ball, T. Deep learning with convolutional neural networks for EEG decoding and visualization: Convolutional Neural Networks in EEG Analysis. Hum. Brain Mapp. 2017, 38, 5391–5420. [Google Scholar] [CrossRef] [PubMed]
- Brunner, C.; Leeb, R.; Müller-Putz, G.; Schlögl, A.; Pfurtscheller, G. BCI Competition 2008–Graz Data Set A; Institute for Knowledge Discovery (Laboratory of Brain-Computer Interfaces), Graz University of Technology: Styria, Austria, 2008; Volume 16, pp. 1–6. [Google Scholar]
- Fortuin, V.; Garriga-Alonso, A.; Ober, S.W.; Wenzel, F.; Rätsch, G.; Turner, R.E.; van der Wilk, M.; Aitchison, L. Bayesian Neural Network Priors Revisited 2022. Available online: http://arxiv.org/abs/2102.06571 (accessed on 9 February 2023).
- Springenberg, J.T.; Klein, A.; Falkner, S.; Hutter, F. Bayesian Optimization with Robust Bayesian Neural Networks. In Advances in Neural Information Processing Systems; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29, Available online: https://proceedings.neurips.cc/paper_files/paper/2016/file/a96d3afec184766bfeca7a9f989fc7e7-Paper.pdf (accessed on 18 July 2023).
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization 2019. Available online: http://arxiv.org/abs/1711.05101 (accessed on 11 July 2023).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8024–8035. [Google Scholar]
- Gramfort, A. MEG and EEG data analysis with MNE-Python. Front. Neurosci. 2013, 7, 267. [Google Scholar] [CrossRef] [PubMed]
- Hunter, J.D. Matplotlib: A 2D Graphics Environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Waskom, M. seaborn: Statistical data visualization. JOSS 2021, 6, 3021. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat Methods 2020, 17, 261–272. [Google Scholar] [CrossRef]
- Tran, B.-H.; Rossi, S.; Milios, D.; Filippone, M. All You Need is a Good Functional Prior for Bayesian Deep Learning. J. Mach. Learn. Res. 2022, 23, 1–56. [Google Scholar]
- Zhang, Y.; Zhou, G.; Jin, J.; Zhao, Q.; Wang, X.; Cichocki, A. Sparse Bayesian Classification of EEG for Brain–Computer Interface. IEEE Trans. Neural Netw. Learning Syst. 2016, 27, 2256–2267. [Google Scholar] [CrossRef]
- Wang, W.; Qi, F.; Wipf, D.; Cai, C.; Yu, T.; Li, Y.; Yu, Z.; Wu, W. Sparse Bayesian Learning for End-to-End EEG Decoding. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 1–18. [Google Scholar] [CrossRef]
- Higger, M.; Quivira, F.; Akcakaya, M.; Moghadamfalahi, M.; Nezamfar, H.; Cetin, M.; Erdogmus, D. Recursive Bayesian Coding for BCIs. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 25, 704–714. [Google Scholar] [CrossRef] [PubMed]
- Sun, S.; Lu, Y.; Chen, Y. The stochastic approximation method for adaptive Bayesian classifiers: Towards online brain–computer interfaces. Neural Comput. Applic 2011, 20, 31–40. [Google Scholar] [CrossRef]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational Inference: A Review for Statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef]
- Chen, X.; Lan, X.; Sun, F.; Zheng, N. A Boundary Based Out-of-Distribution Classifier for Generalized Zero-Shot Learning 2022. Available online: http://arxiv.org/abs/2008.04872 (accessed on 7 July 2023).
- Tonin, F.; Pandey, A.; Patrinos, P.; Suykens, J.A.K. Unsupervised Energy-based Out-of-distribution Detection using Stiefel-Restricted Kernel Machine. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; IEEE: Shenzhen, China, 2021; pp. 1–8. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | BNN | Deterministic Ensembles |
|---|---|---|
| entry 1 | data | data |
| Number of chains | 4 | n/a |
| Weight samples in chain | 40 | n/a |
| Number of steps for burn-in phase | 200 | n/a |
| Step size | 0.01 | n/a |
| Sampling frequency | 200 | n/a |
| Number of first samples to be discarded | 10 | n/a |
| Number of epochs | n/a | 350 (EEGNetV4), 100 (Shallow ConvNet) |
| Batch size | 288 | 64 |
| Learning rate | n/a | 0.000625 |
| Momentum decay | 0.01 | 0.0 |
| Number of samples/networks | 120 | 120 |
| Temporal convolution size | 1 × 64 (EEGNetV4), 25 × 1 (Shallow ConvNet) | 1 × 64 (EEGNetV4), 25 × 1 (Shallow ConvNet) |
| Spatial convolution size | 22 × 1 (EEGNetV4), 1 × 22 (Shallow ConvNet) | 22 × 1 (EEGNetV4), 1 × 22 (Shallow ConvNet) |
| Experiment | Time (HH:MM:SS) |
|---|---|
| Training for OOD detection (Bayesian EEGNet) | 01:19:52 |
| Training for OOD detection (Bayesian Shallow ConvNet) | 00:30:02 |
| Training for OOD detection (Ensemble of EEGNets) | 01:57:54 |
| Training for OOD detection (Ensemble of Shallow ConvNets) | 00:19:22 |
| Training on 4 classes (Bayesian EEGNet) | 02:31:02 |
| Training on 4 classes (Bayesian Shallow ConvNet) | 00:54:19 |
| Training on 4 classes (Ensemble of EEGNets) | 03:46:32 |
| Training on 4 classes (Ensemble of Shallow ConvNets) | 00:35:00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chetkin, E.I.; Shishkin, S.L.; Kozyrskiy, B.L. Bayesian Opportunities for Brain–Computer Interfaces: Enhancement of the Existing Classification Algorithms and Out-of-Domain Detection. Algorithms 2023, 16, 429. https://doi.org/10.3390/a16090429
Chetkin EI, Shishkin SL, Kozyrskiy BL. Bayesian Opportunities for Brain–Computer Interfaces: Enhancement of the Existing Classification Algorithms and Out-of-Domain Detection. Algorithms. 2023; 16(9):429. https://doi.org/10.3390/a16090429
Chicago/Turabian StyleChetkin, Egor I., Sergei L. Shishkin, and Bogdan L. Kozyrskiy. 2023. "Bayesian Opportunities for Brain–Computer Interfaces: Enhancement of the Existing Classification Algorithms and Out-of-Domain Detection" Algorithms 16, no. 9: 429. https://doi.org/10.3390/a16090429
APA StyleChetkin, E. I., Shishkin, S. L., & Kozyrskiy, B. L. (2023). Bayesian Opportunities for Brain–Computer Interfaces: Enhancement of the Existing Classification Algorithms and Out-of-Domain Detection. Algorithms, 16(9), 429. https://doi.org/10.3390/a16090429