


An Intelligent Control Method for Servo Motor Based on Reinforcement Learning

 ,
, 
Abstract
:1. Introduction
2. Basic Knowledge
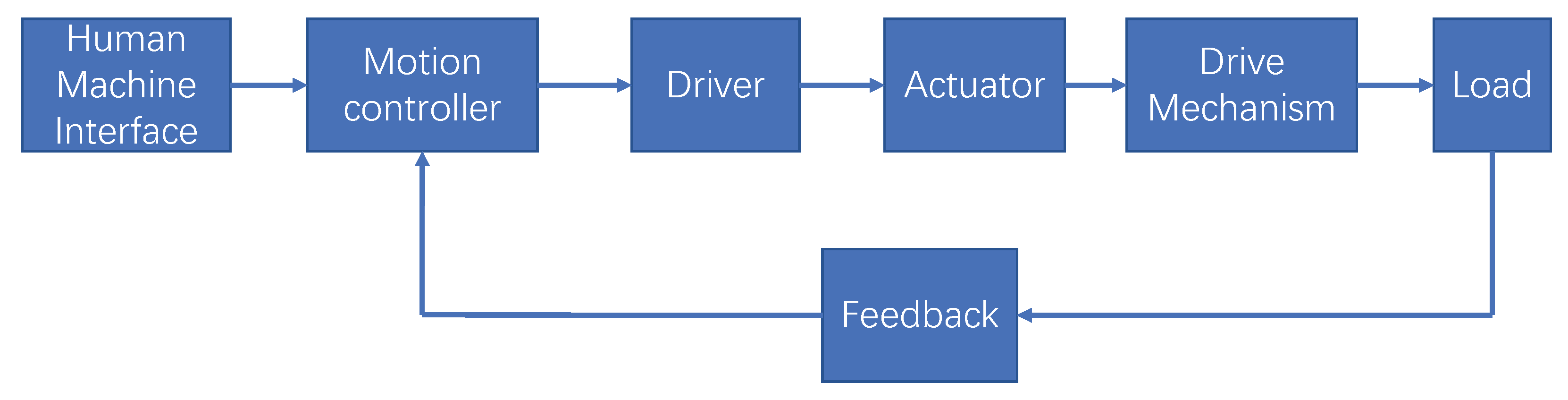
2.1. Motion Control System
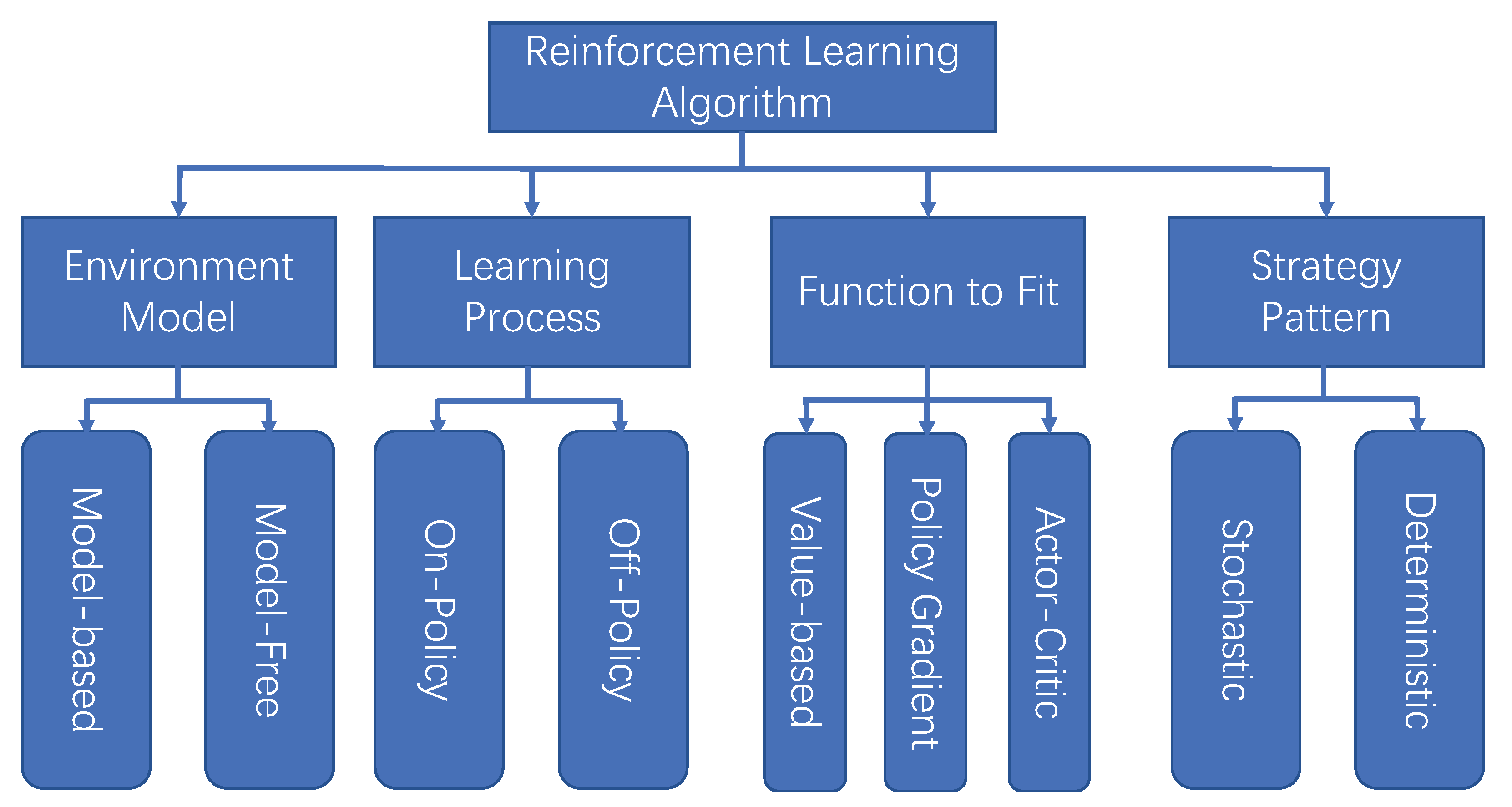
2.2. Reinforcement Learning
2.2.1. On-Policy Algorithm and Off-Policy Algorithm
2.2.2. Model-Free Algorithm and Model-Based Algorithm
2.2.3. Value Function Algorithm and Policy Gradient Algorithm
2.2.4. Stochastic Strategy and Deterministic Strategy
3. Problem Description
3.1. Control Mode of Servo Motor
3.2. State Information of Servo Motor
3.3. Task of Agent
The Interaction between Agent and Environment
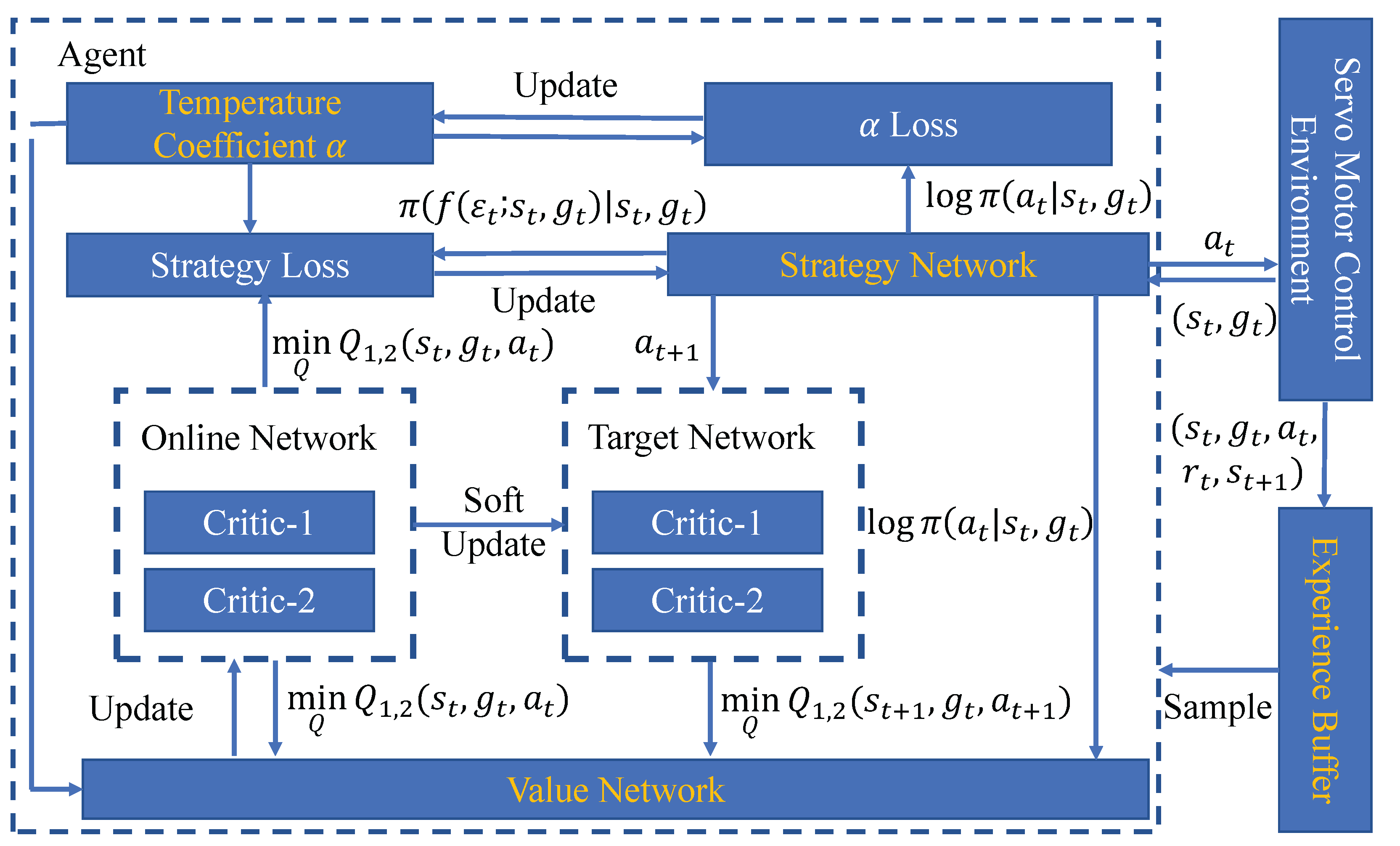
4. The Proposed Intelligent Control Method
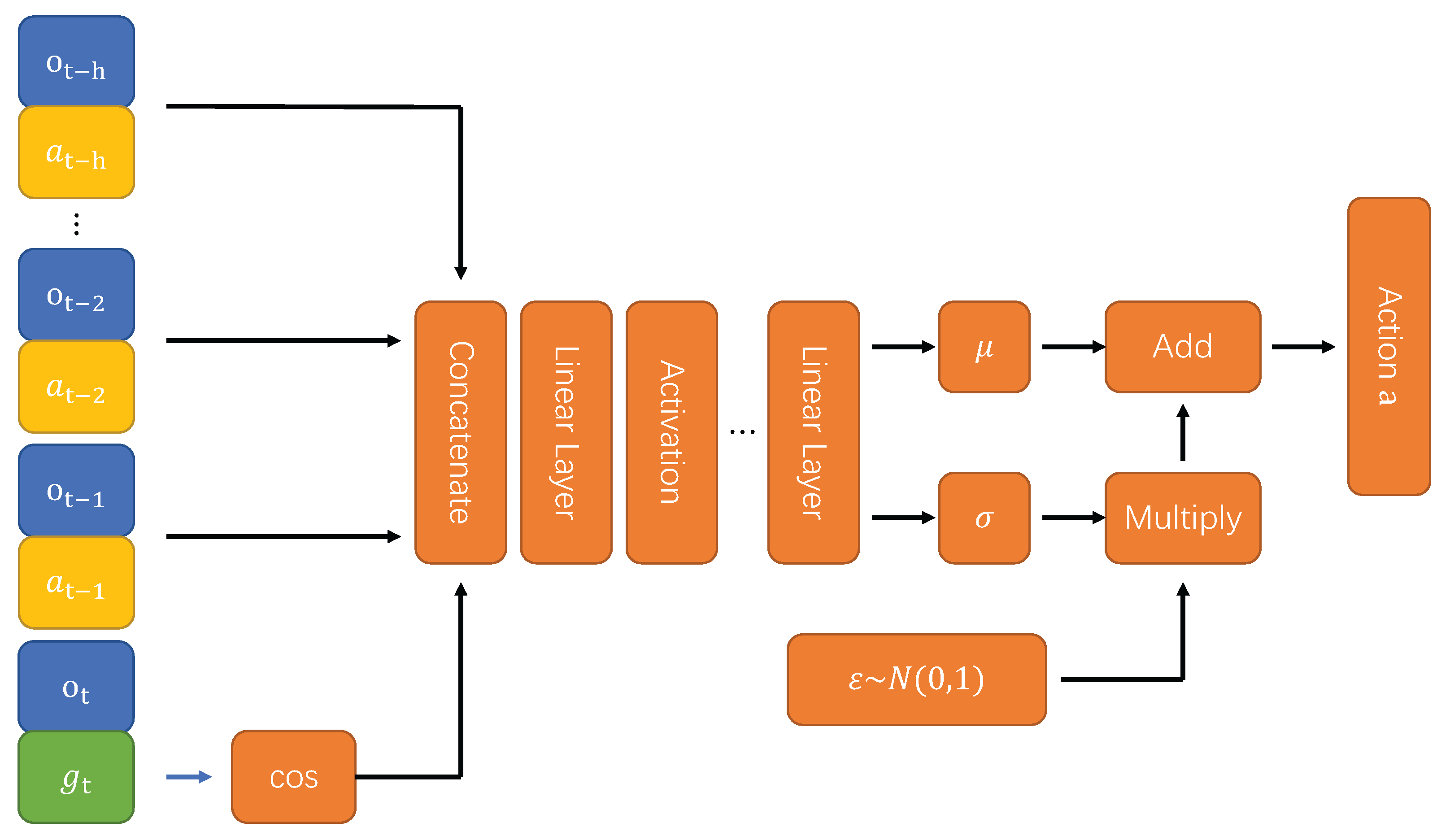
4.1. The Structure of the Control Method
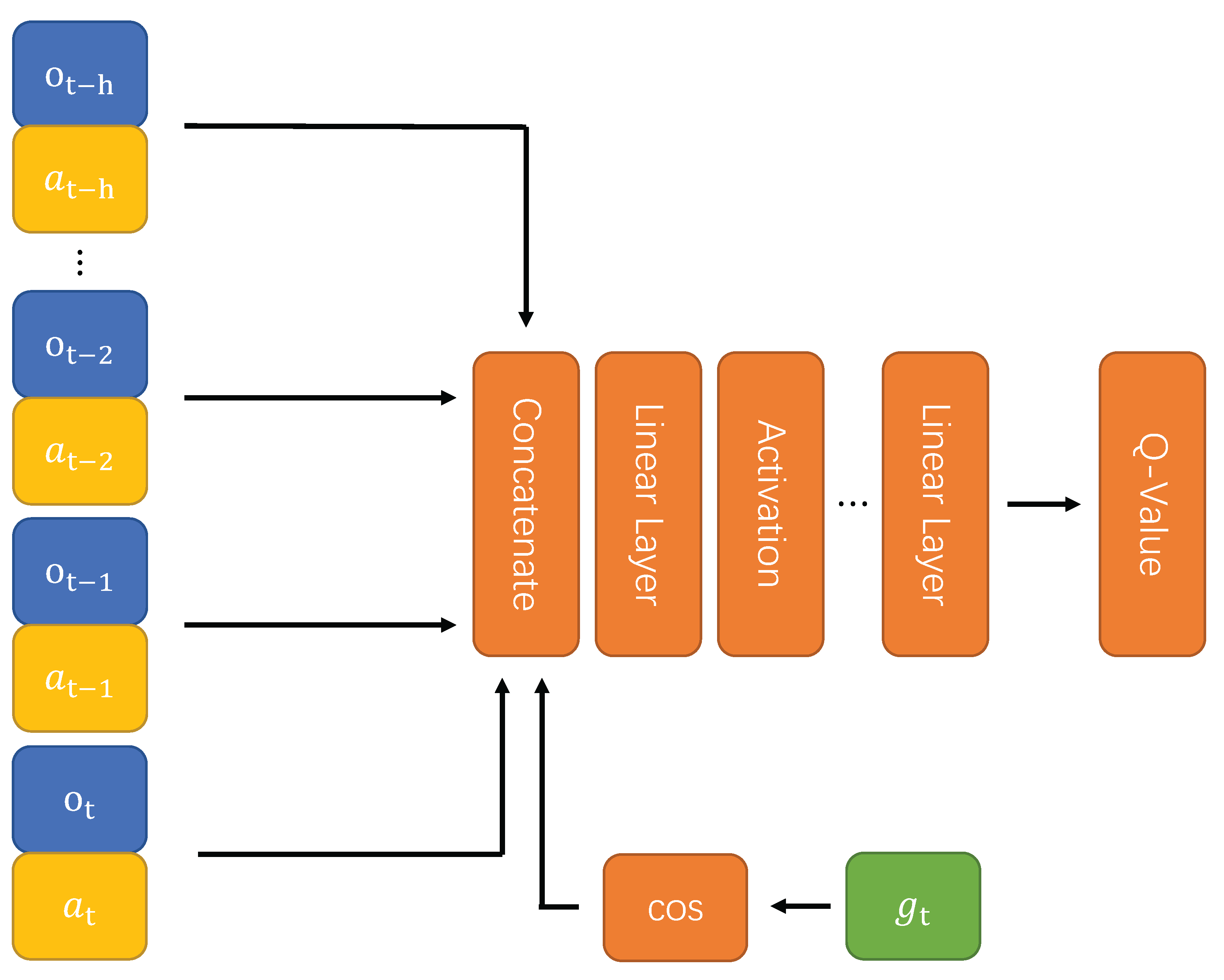
4.1.1. Structure and Loss Function of Value Network
4.1.2. Structure and Loss Function of Strategy Network
4.1.3. Temperature Coefficient and Its Loss Function
| Algorithm 1 The proposed intelligent control method |
|
5. Experiment and Analysis
5.1. Experimental Environment and Setting
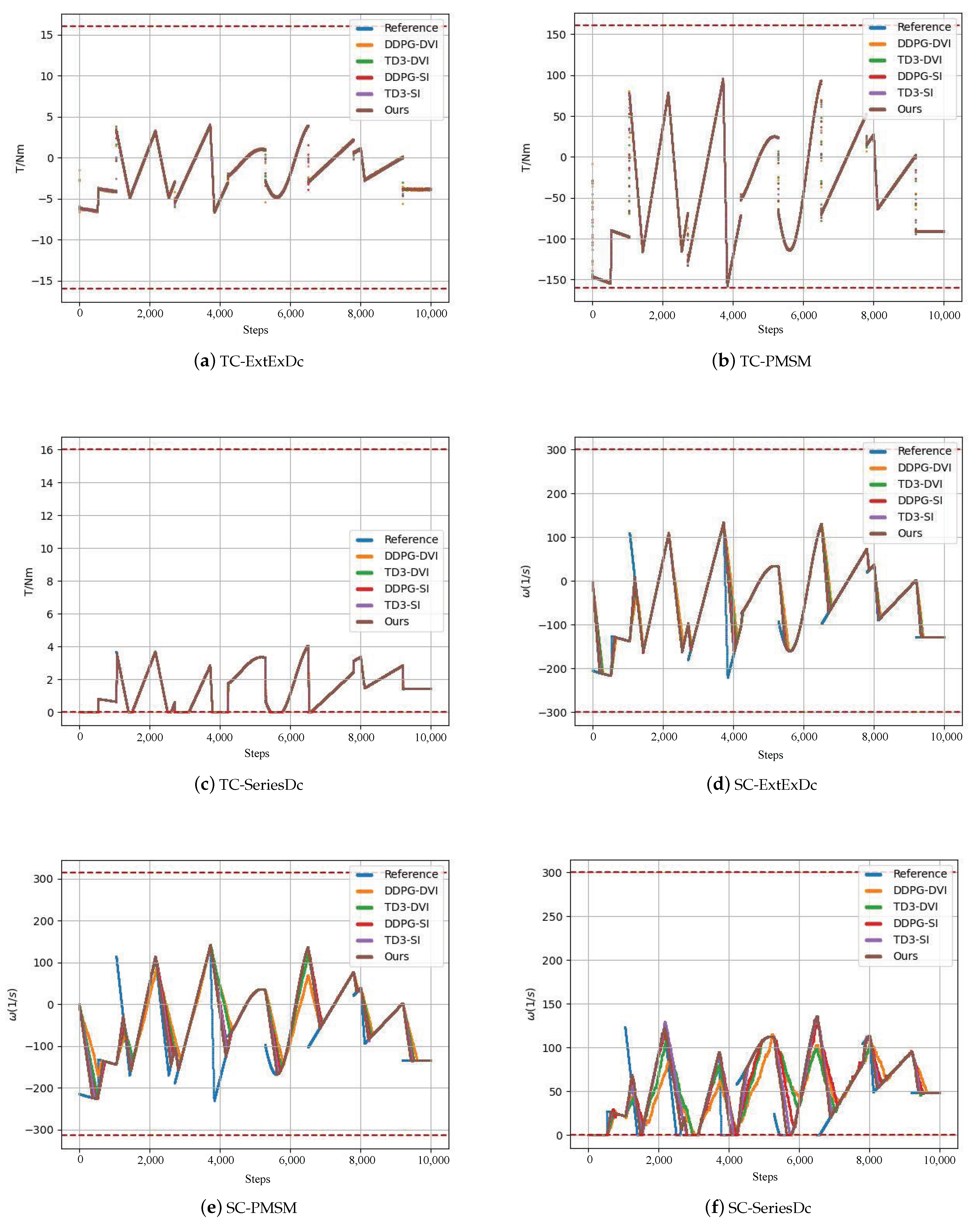
5.2. Comparison Experiment for Control Performance
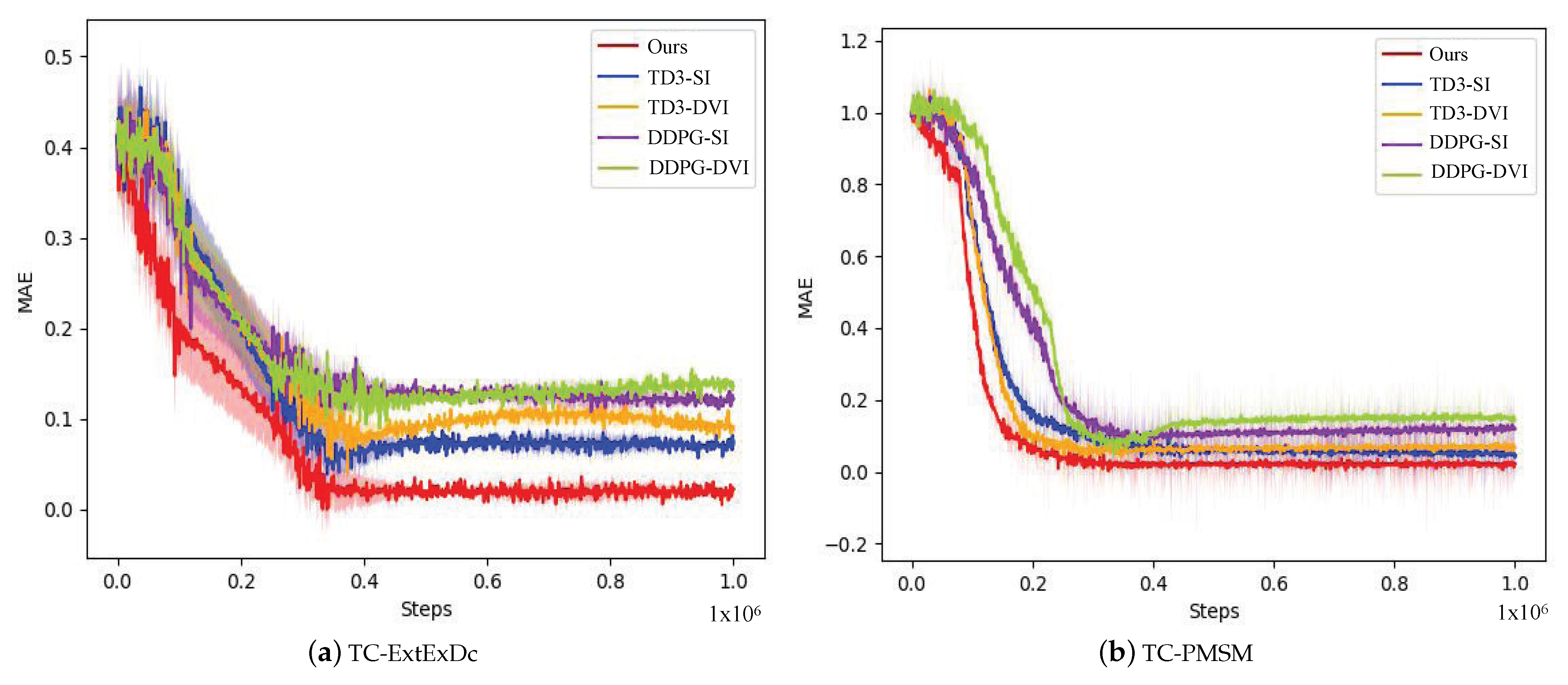
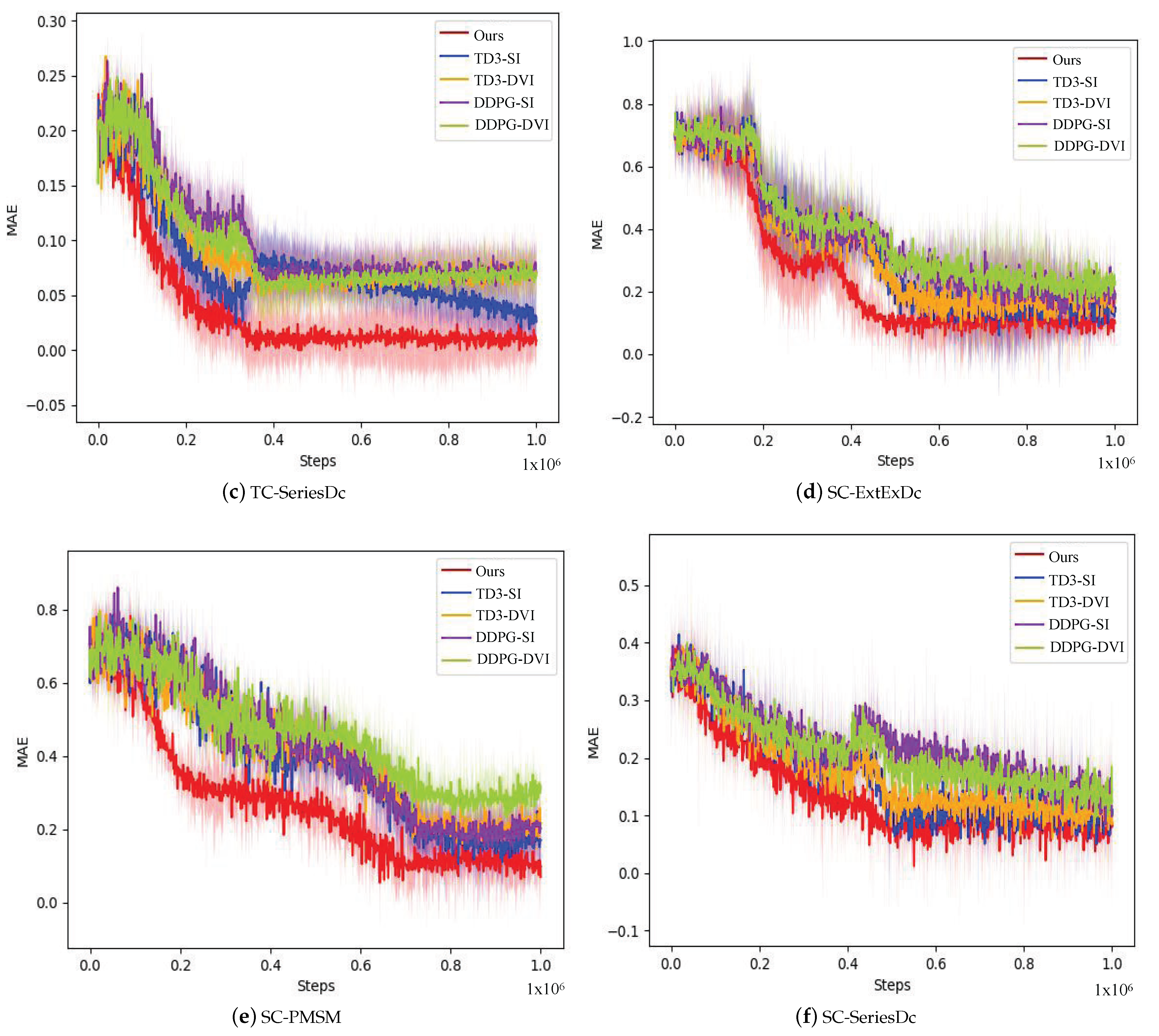
5.3. Comparison Experiment for Training Speed
5.4. Inference Speed Test
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jinkun, L. MATLAB Simulation of Advanced PID Control, 2nd ed.; Electronic Industry Press: Beijing, China, 2004. [Google Scholar]
- Baojun, G.; Yanping, L.; Dajun, T. Electromechanics; Higher Education Press: Beijing, China, 2020. [Google Scholar]
- Coskun, M.Y.; İtik, M. Intelligent PID control of an industrial electro-hydraulic system. ISA Trans. 2023, 139, 484–498. [Google Scholar] [CrossRef]
- Chen, P.; He, Z.; Chen, C.; Xu, J. Control Strategy of Speed Servo Systems Based on Deep Reinforcement Learning. Algorithms 2018, 11, 65. [Google Scholar] [CrossRef]
- Maosheng, Z.; Jie, D.; Xi, X. Control strategy of electro-mechanical actuator based on deep reinforcement learning-PI control. Appl. Sci. Technol. 2022, 49, 18–22. [Google Scholar]
- Wang, C.-H.; Guo, C.-W.C.; Tsay, D.-M.; Perng, J.-W. PMSM Speed Control Based on Particle Swarm Optimization and Deep Deterministic Policy Gradient under Load Disturbance. Machines 2021, 9, 343. [Google Scholar] [CrossRef]
- Schenke, M.; Kirchgässner, W.; Wallscheid, O. Controller Design for Electrical Drives by Deep Reinforcement Learning: A Proof of Concept. IEEE Trans. Ind. Inform. 2020, 16, 4650–4658. [Google Scholar] [CrossRef]
- Hoel, C.J.; Wolff, K.; Laine, L. Ensemble quantile networks: Uncertainty-aware reinforcement learning with applications in autonomous driving. IEEE Trans. Intell. Transp. Syst. 2023, 24, 6030–6041. [Google Scholar] [CrossRef]
- Zhou, W.; Cao, Z.; Deng, N.; Jiang, K.; Yang, D. Identify, Estimate and Bound the Uncertainty of Reinforcement Learning for Autonomous Driving. IEEE Trans. Intell. Transp. Syst. 2023, 24, 7932–7942. [Google Scholar] [CrossRef]
- Chen, L.; Wang, Y.; Miao, Z.; Mo, Y.; Feng, M.; Zhou, Z.; Wang, H. Transformer-Based Imitative Reinforcement Learning for Multirobot Path Planning. IEEE Trans. Ind. Inform. 2023, 19, 10233–10243. [Google Scholar] [CrossRef]
- Yu, X.; Luo, W. Reinforcement learning-based multi-strategy cuckoo search algorithm for 3D UAV path planning. Expert Syst. Appl. 2023, 223, 119910. [Google Scholar] [CrossRef]
- Orr, J.; Dutta, A. Multi-agent deep reinforcement learning for multi-robot applications: A survey. Sensors 2023, 23, 3625. [Google Scholar] [CrossRef]
- Walke, H.R.; Yang, J.H.; Yu, A.; Kumar, A.; Orbik, J.; Singh, A.; Levine, S. Don’t start from scratch: Leveraging prior data to automate robotic reinforcement learning. Proc. Mach. Learn. Res. 2023, 205, 1652–1662. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Tian, M.; Wang, K.; Lv, H.; Shi, W. Reinforcement learning control method of torque stability of three-phase permanent magnet synchronous motor. J. Phys. Conf. Ser. 2022, 2183, 12–24. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2016, arXiv:1509.02971. [Google Scholar]
- Song, Z.; Yang, J.; Mei, X.; Tao, T.; Xu, M. Deep reinforcement learning for permanent magnet synchronous motor speed control systems. Neural Comput. Appl. 2021, 33, 5409–5418. [Google Scholar] [CrossRef]
- Hamed, R.N.; Abolfazl, Z.; Holger, V. Actor–critic learning based PID control for robotic manipulators. Appl. Soft Comput. 2023, 151, 111153. [Google Scholar]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy Gradient Methods for Reinforcement Learning with Function Approximation; Advances in Neural Information Processing Systems; Morgan Kaufmann Publisher: Burlington, NJ, USA, 2000; pp. 1057–1063. [Google Scholar]
- Ståhlberg, S.; Bonet, B.; Geffner, H. Learning General Policies with Policy Gradient Methods. Proc. Int. Conf. Princ. Knowl. Represent. Reason. 2023, 19, 647–657. [Google Scholar]
- Scott, F.; Herke, V.H.; David, M. Addressing Function Approximation Error in Actor-Critic Methods. International Conference on Machine Learning. arXiv 2018, arXiv:1802.09477. [Google Scholar]
- Kumar, H.; Koppel, A.; Ribeiro, A. On the sample complexity of actor-critic method for reinforcement learning with function approximation. Mach. Learn. 2023, 112, 2433–2467. [Google Scholar] [CrossRef]
- Van, H.H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; AAAI: Menlo Park, CA, USA, 2016; pp. 2094–2100. [Google Scholar]
- Jianwei, L.; Feng, G.; Xionglin, L. A Review of Deep Reinforcement Learning Based on Value Function and Strategy Gradient. Chin. J. Comput. 2019, 42, 1406–1438. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. arXiv 2018, arXiv:1801.01290. [Google Scholar]
- Schaul, T.; Horgan, D.; Gregor, K.; Silver, D. Universal Value Function Approximators. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37. [Google Scholar]
- Voigtlaender, F. The universal approximation theorem for complex-valued neural networks. Appl. Comput. Harmon. Anal. 2023, 64, 33–61. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P.; et al. Soft actor-critic algorithms and applications. arXiv 2018, arXiv:1812.05905. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Balakrishna, P.; Book, G.; Kirchgässner, W.; Schenke, M.; Traue, A.; Wallscheid, O. Gym-electric-motor (GEM): A python toolbox for the simulation of electric drive systems. J. Open Source Softw. 2021, 6, 2498. [Google Scholar] [CrossRef]
- Diederik, P.K.; Jimmy, B. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 13–19. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | State Dimension | Target | Duty Cycle Dimension | Motor |
|---|---|---|---|---|
| TC-ExtExDc | 7 | Torque control | 2 | Externally excited DC motor |
| SC-ExtExDc | 7 | Speed control | 2 | Externally excited DC motor |
| TC-PMSM | 14 | Torque control | 3 | Three-phase permanent magnet synchronous motor |
| SC-PMSM | 14 | Speed control | 3 | Three-phase permanent magnet synchronous motor |
| TC-SeriesDc | 5 | Torque control | 1 | Series DC motor |
| SC-SeriesDc | 5 | Speed control | 1 | Series DC motor |
| Control Task | TD3-SI | TD3-DVI | DDPG-SI | DDPG-DVI | Ours |
|---|---|---|---|---|---|
| TC-ExtExDc | 0.029 ± 0.002 | 0.021 ± 0.006 | 0.022 ± 0.004 | 0.035 ± 0.006 | 0.016 ± 0.002 |
| TC-PMSM | 0.320 ± 0.014 | 0.474 ± 0.016 | 0.312 ± 0.012 | 0.434 ± 0.019 | 0.308 ± 0.014 |
| TC-SeriesDc | 0.035 ± 0.004 | 0.048 ± 0.002 | 0.045 ± 0.003 | 0.029 ± 0.004 | 0.013 ± 0.002 |
| SC-ExtExDc | 13.509 ± 1.351 | 16.785 ± 1.262 | 14.827 ± 1.316 | 18.949 ± 1.401 | 12.60 ± 1.229 |
| SC-PMSM | 29.591 ± 4.053 | 38.271 ± 4.231 | 32.670 ± 4.122 | 43.365 ± 5.032 | 25.590 ± 3.653 |
| SC-SeriesDc | 12.478 ± 1.133 | 19.503 ± 1.231 | 18.549 ± 1.393 | 21.798 ± 1.538 | 11.251 ± 1.513 |
| Control Task | Time |
|---|---|
| TC-ExtExDc | 7.87805 |
| TC-PMSM | 8.16622 |
| TC-SeriesDc | 7.80392 |
| SC-ExtExDc | 7.80206 |
| SC-PMSM | 8.19868 |
| SC-SeriesDc | 7.85899 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, D.; Wang, S.; Yang, Y.; Zhang, H.; Chen, H.; Mei, X.; Chen, S.; Qiu, J. An Intelligent Control Method for Servo Motor Based on Reinforcement Learning. Algorithms 2024, 17, 14. https://doi.org/10.3390/a17010014
Gao D, Wang S, Yang Y, Zhang H, Chen H, Mei X, Chen S, Qiu J. An Intelligent Control Method for Servo Motor Based on Reinforcement Learning. Algorithms. 2024; 17(1):14. https://doi.org/10.3390/a17010014
Chicago/Turabian StyleGao, Depeng, Shuai Wang, Yuwei Yang, Haifei Zhang, Hao Chen, Xiangxiang Mei, Shuxi Chen, and Jianlin Qiu. 2024. "An Intelligent Control Method for Servo Motor Based on Reinforcement Learning" Algorithms 17, no. 1: 14. https://doi.org/10.3390/a17010014
APA StyleGao, D., Wang, S., Yang, Y., Zhang, H., Chen, H., Mei, X., Chen, S., & Qiu, J. (2024). An Intelligent Control Method for Servo Motor Based on Reinforcement Learning. Algorithms, 17(1), 14. https://doi.org/10.3390/a17010014