
Enhanced Intrusion Detection Systems Performance with UNSW-NB15 Data Analysis



Abstract
:1. Introduction
2. Related Work
3. Proposed Research Methodology
3.1. Logistic Regression
- Logit function: The logistic regression model determines the likelihood that the dependent variable will take a particular value using the logit function.
- S-shaped curve: The logistic regression model generates an S-shaped curve that shows the likelihood that, for a given value of the independent variables, the dependent variable will take the value of 1.
- Maximum Likelihood Estimation: The logistic regression model estimates the model parameters using maximum likelihood estimation.
3.2. Decision Tree
- Simple to comprehend and interpret since they provide a visualizable, tree-like framework for the decision-making process.
- Their ability to handle both categorical and numerical data makes them useful for a wide range of applications.
- Non-parametric meaning they do not make any assumptions about the distribution of the data.
- Can handle missing values in the data by using different techniques such as surrogate splits or imputation.
3.3. Random Forest
- Random sampling of the training data: a random subset of the training data is used to train each tree in the forest.
- Random feature selection: a random collection of features is taken into consideration for splitting at each decision tree split.
- Prediction aggregation: the ultimate forecast is derived from the sum of the forecasts made by each tree within the forest.
3.4. Support Vector Machine
- Maximum margin: SVM seeks to identify the hyperplane with the greatest margin between classes. The gap between each class’s nearest data points and the hyperplane is known as the margin. Through margin maximization, SVM may minimize overfitting and improve generalization performance.
- Kernel trick: To separate data that is not linearly separable in the original space, SVM can apply various kernel functions to transform the input data into a higher-dimensional space. SVM can handle complex datasets thanks to a technique called the kernel trick.
- Robustness against outliers: Because SVM only takes into account data points that are closest to the decision border, it is less susceptible to outliers than other classification methods.
- Binary classification: SVM is limited to classifying data into two groups because it is a binary classification system. It can, however, be expanded to address multi-class classification issues by utilizing strategies like one-vs-all or one-vs-one.
4. Dataset Description and Properties
- Fuzzers: These cyberattacks overwhelm and crash servers and network systems by using a large amount of randomized data, or “fuzz”. This has 18,184 and 6062 instances for training and testing, respectively.
- Backdoors: These are exploits that employ reputable system gateways to obtain unauthorized access and install malicious software that gives attackers remote access to a system to facilitate an exploit. This has 1746 and 583 instances for training and testing, respectively.
- Analysis: This attack also known as Active Reconnaissance, uses various methods such as port scans, vulnerability scans, spam files and foot printing to gather information about a network without exploiting it. This has 2000 and 677 instances for training and testing, respectively.
- Exploits: The target of this attack is to know vulnerabilities in operating systems to gain unauthorized access and control. Exploit software can be used to automate these attacks once a potential vulnerability is detected. This has 33,393 and 11,132 instances for training and testing, respectively.
- Denial of service (DoS): When too many unauthorized connections are made to a network, resources are either momentarily or permanently blocked from being accessed by authorized users. Although it can be challenging to spot these attacks, several obvious indications can be offered. This has 12,264 and 4089 instances for training and testing, respectively.
- Generic: A generic attack is a type of cryptographic attack that targets the secret key used in encryption. This type of attack can be used against various types of ciphers such as block ciphers, stream ciphers, and message authentication code ciphers, and is frequently mentioned as a “birthday attack” due to the vulnerability of ciphers to collisions, which occur more frequently with random attack attempts. This has 40,000 and 18,871 instances for training and testing, respectively.
- Reconnaissance: This involves discovering as much as possible about a target host or public network. By utilizing the information acquired, exploit techniques are employed to gain access to the target host or network. This kind of reconnaissance includes social media searches in addition to using publicly accessible information like Whois, ARIN records, and Shodan. This has 10,491 and 3496 instances for training and testing, respectively.
- Shellcode: An exploit attack that makes uses a payload (small piece of code), to gain unauthorized access to a target’s computer. The payload is inserted into an active application, giving the attacker control over the compromised device through a command shell. This has 1133 and 378 instances for training and testing, respectively.
- Worms: A worm is a type of cyberattack that rapidly spreads through a network by infecting multiple systems. It infects the individual computers and leverages them as controlled devices, known as “zombies” or “bots”, which can then be used in coordinated attacks as part of a larger network of infected devices, called a “botnet”. This has 130 and 44 instances for training and testing, respectively.
4.1. Dataset Features
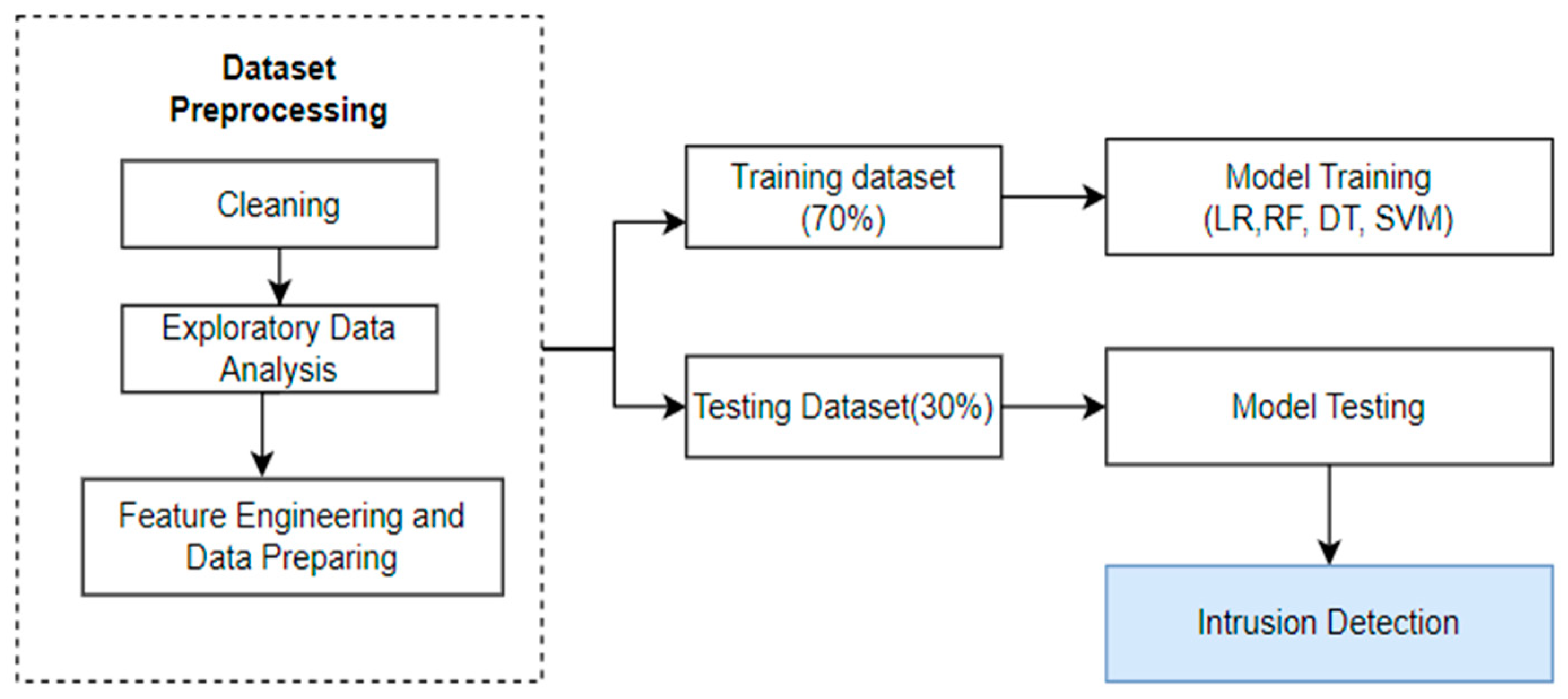
- Data collection and cleaning: The dataset was collected from the four files listed in Table 2. Target features were identified, null values were checked, and numerical and categorical features were identified.
- Exploratory Data Analysis: A heatmap was used to identify and remove highly correlated values.
- Feature Engineering and Data Preparation: New features were added, and the data was standardized using the standard scalar and Onehotencode functions.
- Train and Test Data Split: A training set (70%) and a testing set (30%) were generated from the dataset.
- Training and Testing of the Models: On the training set, methods for logistic regression, decision trees, random forests, and linear SVM were applied; on the testing set, their efficacy was assessed.
4.2. Data Pre-Processing
4.3. Exploratory Data Analysis
4.4. Feature Engineering and Data Preparing
5. Results and Discussion
5.1. Performance Matrix
5.2. AUC and ROC
5.3. Experiment Analysis
5.4. Hyper-Parameter Tuning
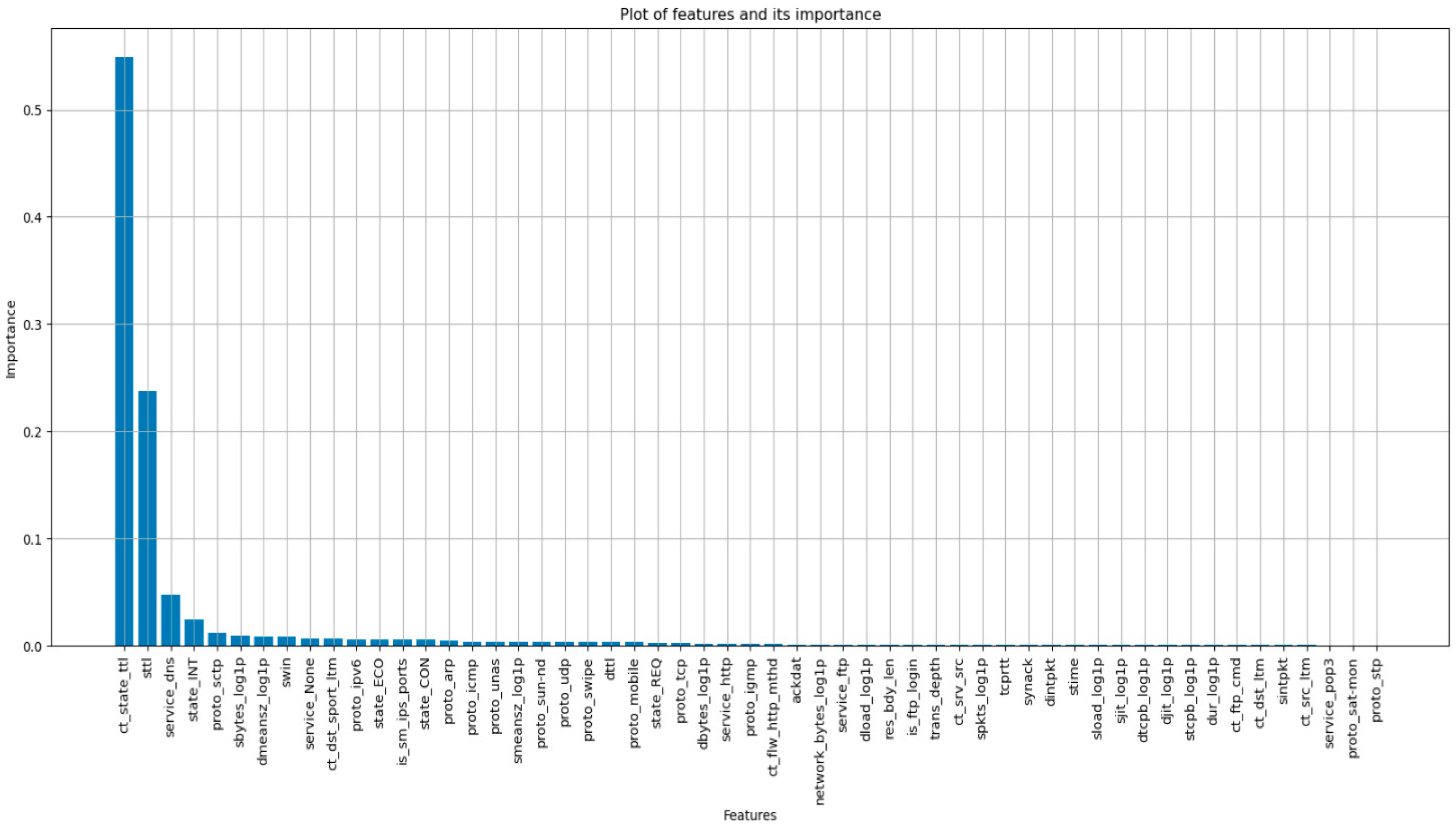
5.5. Models with Important Features
5.6. Comparative Analysis of the Models Implemented
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, H.; Lang, B. Machine learning and deep learning methods for intrusion detection systems: A survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Alazab, M.; Soman, K.P.; Poornachandran, P.; Al-Nemrat, A.; Venkatraman, S. Deep learning approach for intelligent intrusion detection system. IEEE Access 2019, 7, 41525–41550. [Google Scholar] [CrossRef]
- Almseidin, M.; Alzubi, M.; Kovacs, S.; Alkasassbeh, M. Evaluation of machine learning algorithms for intrusion detection systems. In Proceedings of the IEEE 15th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 14–16 September 2017; pp. 000277–000282. [Google Scholar]
- Aldweesh, A.; Derhab, A.; Emam, A.Z. Deep learning approaches for anomaly-based intrusion detection systems: A survey, taxonomy, and open issues. Knowl.-Based Syst. 2020, 189, 105124. [Google Scholar] [CrossRef]
- Kumar, V.; Sinha, D.; Das, A.K.; Pandey, S.C.; Goswami, R.T. An integrated rule-based intrusion detection system: Analysis on UNSW-NB15 data set and the real time online dataset. Clust. Comput. 2020, 23, 1397–1418. [Google Scholar] [CrossRef]
- Kasongo, S.M.; Sun, Y. Performance Analysis of Intrusion Detection Systems Using a Feature Selection Method on the UNSW-NB15 Dataset. J. Big Data 2020, 7, 105. [Google Scholar] [CrossRef]
- Saba, T.; Rehman, A.; Sadad, T.; Kolivand, H.; Bahaj, S.A. Anomaly-based intrusion detection system for IoT networks through deep learning model. Comput. Electr. Eng. 2022, 99, 107810. [Google Scholar] [CrossRef]
- Abdulhammed, R.; Faezipour, M.; Abuzneid, A.; AbuMallouh, A. Deep and machine learning approaches for anomaly-based intrusion detection of imbalanced network traffic. IEEE Sens. Lett. 2018, 3, 1–4. [Google Scholar] [CrossRef]
- Savas, O.; Deng, J. Big Data Analytics in Cybersecurity; CRC Press: Boca Raton, FL, USA, 2017; Available online: https://www.google.co.uk/books/edition/Big_Data_Analytics_in_Cybersecurity/KD0PEAAAQBAJ?hl=en&gbpv=1&printsec=frontcover (accessed on 11 January 2023).
- Mishra, S.; Tyagi, A.K. The Role of Machine Learning Techniques in Internet of Things-Based Cloud Applications. In Internet of Things; Springer: Berlin/Heidelberg, Germany, 2022; pp. 105–135. [Google Scholar] [CrossRef]
- Zhang, F.; Kodituwakku, H.A.D.E.; Hines, J.W.; Coble, J. Multilayer Data-Driven Cyber-Attack Detection System for Industrial Control Systems Based on Network, System, and Process Data. IEEE Trans. Ind. Inform. 2019, 15, 4362–4369. [Google Scholar] [CrossRef]
- Mahmood, T.; Afzal, U. Security Analytics: Big Data Analytics for cybersecurity: A review of trends, techniques and tools. In Proceedings of the 2013 2nd National Conference on Information Assurance (NCIA), Rawalpindi, Pakistan, 11–12 December 2013; pp. 129–134. [Google Scholar] [CrossRef]
- Rajawat, A.S.; Bedi, P.; Goyal, S.B.; Shaw, R.N.; Ghosh, A. Reliability Analysis in Cyber-Physical System Using Deep Learning for Smart Cities Industrial IoT Network Node. In AI and IoT for Smart City Applications; Piuri, V., Shaw, R.N., Ghosh, A., Islam, R., Eds.; Studies in Computational Intelligence; Springer: Singapore, 2022; Volume 1002. [Google Scholar] [CrossRef]
- Jing, D.; Chen, H.-B. SVM Based Network Intrusion Detection for the UNSW-NB15 Dataset. In Proceedings of the 2019 IEEE 13th International Conference on ASIC (ASICON), Chongqing, China, 29 October–1 November 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Zhiqiang, L.; Mohi-Ud-Din, G.; Bing, L.; Jianchao, L.; Ye, Z.; Zhijun, L. Modeling Network Intrusion Detection System Using Feed-Forward Neural Network Using UNSW-NB15 Dataset. In Proceedings of the 2019 IEEE 7th International Conference on Smart Energy Grid Engineering (SEGE), Oshawa, ON, Canada, 12–14 August 2019; pp. 299–303. [Google Scholar] [CrossRef]
- Moualla, S.; Khorzom, K.; Jafar, A. Improving the performance of machine learning-based network intrusion detection systems on the UNSW-NB15 dataset. Comput. Intell. Neurosci. 2021, 2021, 1–13. [Google Scholar] [CrossRef]
- Tahri, R.; Jarrar, A.; Lasbahani, A.; Balouki, Y. A comparative study of Machine learning Algorithms on the UNSW-NB 15 Dataset. In ITM Web of Conferences; EDP Sciences: Tangier, Morocco, 2022; Volume 48, p. 03002. [Google Scholar]
- Belouch, M.; El Hadaj, S.; Idhammad, M. Performance evaluation of intrusion detection based on machine learning using Apache Spark. Procedia Comput. Sci. 2018, 127, 1–6. [Google Scholar] [CrossRef]
- Kabir, M.H.; Rajib, M.S.; Rahman, A.S.M.T.; Rahman, M.M.; Dey, S.K. Network Intrusion Detection Using UNSW-NB15 Dataset: Stacking Machine Learning Based Approach. In Proceedings of the 2022 International Conference on Advancement in Electrical and Electronic Engineering (ICAEEE), Gazipur, Bangladesh, 24–26 February 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Chkirbene, Z.; Eltanbouly, S.; Bashendy, M.; AlNaimi, N.; Erbad, A. Hybrid machine learning for network anomaly intrusion detection. In Proceedings of the 2020 IEEE International Conference on Informatics, IoT, and Enabling Technologies (ICIoT), Doha, Qatar, 2–5 February 2020; pp. 163–170. [Google Scholar]
- Gu, J.; Lu, S. An effective intrusion detection approach using SVM with naïve Bayes feature embedding. Comput. Secur. 2021, 103, 102158. [Google Scholar] [CrossRef]
- Besharati, E.; Naderan, M.; Namjoo, E. LR-HIDS: Logistic regression host-based intrusion detection system for cloud environments. J. Ambient Intell. Hum. Comput. 2019, 10, 3669–3692. [Google Scholar] [CrossRef]
- Bhusal, N.; Gautam, M.; Benidris, M. Detection of Cyber Attacks on Voltage Regulation in Distribution Systems Using Machine Learning. IEEE Access 2021, 9, 40402–40416. [Google Scholar] [CrossRef]
- Kumar, M.N.; Koushik, K.V.S.; Deepak, K. Prediction of heart diseases using data mining and machine learning algorithms and tools. Int. J. Sci. Res. Comput. Sci. Eng. Inf. Technol. 2018, 3, 887–898. [Google Scholar]
- Lee, S.J.; Yoo, P.D.; Asyhari, A.T.; Jhi, Y.; Chermak, L.; Chan, Y.Y.; Taha, K. IMPACT: Impersonation attack detection via edge computing using deep autoencoder and feature abstraction. IEEE Access 2020, 8, 65520–65529. [Google Scholar] [CrossRef]
- Rahman, M.A.; Asyhari, A.T.; Leong, L.S.; Satrya, G.B.; Tao, M.H.; Zolkipli, M.F. Scalable machine learning-based intrusion detection system for IoT-enabled smart cities. Sustain. Cities Soc. 2020, 61, 102324. [Google Scholar] [CrossRef]
- Apruzzese, G.; Andreolini, M.; Colajanni, M.; Marchetti, M. Hardening Random Forest Cyber Detectors Against Adversarial Attacks. In IEEE Transactions on Emerging Topics in Computational Intelligence; IEEE: New York, NY, USA, 2020; Volume 4, pp. 427–439. [Google Scholar] [CrossRef]
- Najar, A.A.; Manohar Naik, S. DDoS attack detection using MLP and Random Forest Algorithms. Int. J. Inf. Technol. 2022, 14, 2317–2327. [Google Scholar] [CrossRef]
- Cervantes, J.; Garcia-Lamont, F.; Rodríguez-Mazahua, L.; Lopez, A. A comprehensive survey on support vector machine classification: Applications, challenges and trends. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Kolias, C.; Kambourakis, G.; Stavrou, A.; Gritzalis, S. Intrusion detection in 802.11 networks: Empirical evaluation of threats and a public dataset. IEEE Commun. Surv. Tutor. 2016, 18, 184–208. [Google Scholar] [CrossRef]
- Moustafa, N. The UNSW-NB15 Dataset, Research Data Australia. Available online: https://researchdata.edu.au/the-unsw-nb15-dataset/1957529 (accessed on 9 November 2023).
- The UNSW-NB15 Dataset (no Date) The UNSW-NB15 Dataset|UNSW Research. Available online: https://research.unsw.edu.au/projects/unsw-nb15-dataset (accessed on 9 November 2023).
- Huang, J.; Li, Y.F.; Xie, M. An empirical analysis of data preprocessing for machine learning-based software cost estimation. Inf. Softw. Technol. 2015, 67, 108–127. [Google Scholar] [CrossRef]
- Miranda-Calle, J.D.; Reddy, C.V.; Dhawan, P.; Churi, P. Exploratory data analysis for cybersecurity. World J. Eng. 2021, 18, 734–749. [Google Scholar] [CrossRef]
- Network Fields: Elastic Common Schema (ECS) Reference [Master] (no Date) Elastic. Available online: https://www.elastic.co/guide/en/ecs/master/ecs-network.html (accessed on 9 November 2023).
- Kocher, G.; Kumar, G. Analysis of machine learning algorithms with feature selection for intrusion detection using UNSW-NB15 dataset. Int. J. Netw. Secur. Its Appl. 2021, 13, 21–31. [Google Scholar]
- Dickson, A.; Thomas, C. Analysis of UNSW-NB15 Dataset Using Machine Learning Classifiers. In Proceedings of the Machine Learning and Metaheuristics Algorithms, and Applications: Second Symposium, SoMMA 2020, Chennai, India, 14–17 October 2020; Revised Selected Papers 2. Springer: Singapore, 2021; pp. 198–207. [Google Scholar]
- Choudhary, S.; Kesswani, N. Analysis of KDD-Cup’99, NSL-KDD and UNSW-NB15 datasets using deep learning in IoT. Procedia Comput. Sci. 2020, 167, 1561–1573. [Google Scholar] [CrossRef]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for multi-class classification: An overview. arXiv 2020, arXiv:2008.05756. [Google Scholar]
- Lipton, Z.C.; Elkan, C.; Narayanaswamy, B. Thresholding classifiers to maximize F1 score. arXiv 2014, arXiv:1402.1892. [Google Scholar]
- Tama, B.A.; Comuzzi, M.; Rhee, K.H. TSE-IDS: A two-stage classifier ensemble for intelligent anomaly-based intrusion detection system. IEEE Access 2019, 7, 94497–94507. [Google Scholar] [CrossRef]
- Primartha, R.; Tama, B.A. Anomaly detection using random forest: A performance revisited. In Proceedings of the 2017 International Conference on Data and Software Engineering (ICoDSE), Palembang, Indonesia, 1–2 November 2017; pp. 1–6. [Google Scholar]



{kind=link}
{kind=link}
| Feature Name | Data Type | Description |
|---|---|---|
| proto | nominal | Transaction protocol |
| state | nominal | Represents the state |
| service | nominal | Indicates the used services such as http, ftp, smtp, ssh, dns, ftp-data, irc and none (-) |
| sbytes | Integer | Number of bytes used from source to destination |
| dbytes | Integer | Number of bytes from destination to source |
| attack_cat | nominal | Attack types |
| label | binary | Indicates to normal (0) or attack (1) records |
| File Name | File Size | Record Count | Number of Features |
|---|---|---|---|
| UNSWNB15_1.csv | 161.2 MB | 700,000 | 49 |
| UNSWNB15_2.csv | 157.6 MB | 700,000 | 49 |
| UNSWNB15_3.csv | 147.4 MB | 700,000 | 49 |
| UNSWNB15_4.csv | 91.3 MB | 440,044 | 49 |
| Variable 1 | Variable 2 | Correlation Value |
|---|---|---|
| stime | Ltime | 1 |
| swin | Dwin | 0.997174708 |
| dloss | Dpkts | 0.992128631 |
| dbytes | Dloss | 0.991376462 |
| dbytes | Dpkts | 0.970803704 |
| ct_dst_ltm | ct_src_dport_ltm | 0.960191873 |
| ct_srv_src | ct_srv_dst | 0.956759024 |
| sbytes | Sloss | 0.954961115 |
| ct_srv_dst | ct_dst_src_ltm | 0.951066477 |
| ct_src_ltm | ct_src_dport_ltm | 0.945315205 |
| ct_srv_src | ct_dst_src_ltm | 0.942174265 |
| ct_dst_ltm | ct_src_ltm | 0.938506142 |
| tcprtt | Synack | 0.932940833 |
| ct_src_dport_ltm | ct_dst_sport_ltm | 0.921432623 |
| tcprtt | Ackdat | 0.921293044 |
| ct_src_dport_ltm | ct_dst_src_ltm | 0.910904101 |
| Sttl | ct_state_ttl | 0.905564623 |
| Sttl | Label | 0.904224554 |
| Logistic Regression |
|---|
| Step 1: Import the sklearn libraries |
| Step 2: Define the hyperparameter tuning function to select the best hyperparameters by implementing the grid search method |
| Step 3: Define a function to evaluate the performance of the model in terms of Accuracy, F1-Score, and False Alarm Rate |
| Step 4: Create an instance of SGDC classifier with logistic regression loss function and L2 regularization |
| Step 5: Define a dictionary of hyperparameters to be tuned during hyperparameter tuning |
| Step 6: Create a final LR model with the best hyperparameters. Step 7: Evaluate the performance of the best logistic model on training and testing data |
| Algorithm | Train | Test |
|---|---|---|
| LR | 0.983171129855572 | 0.982896428268793 |
| Linear SVM | 0.99171621060382 | 0.991621576012526 |
| DT | 0.987964953232175 | 0.987722200601008 |
| f | 0.992686447486772 | 0.985617231685103 |
| GBDT | 0.99545734190109 | 0.986483043307548 |
| DT with FS | 0.987717151251344 | 0.987328334371178 |
| RF with FS | 0.994109889715638 | 0.986345597491184 |
| Train | Test | |||||||
|---|---|---|---|---|---|---|---|---|
| Algorithm | TP | FP | FN | TN | TP | FP | FN | TN |
| LR | 1,539,416 | 13,446 | 5629 | 219,541 | 660,174 | 5728 | 2461 | 93,652 |
| Linear SVM | 1,532,183 | 20,679 | 732 | 224,438 | 657,023 | 8879 | 329 | 95,784 |
| DT | 1,539,546 | 13,316 | 3489 | 221,681 | 660,123 | 5779 | 1526 | 94,587 |
| RF | 1,241,042 | 1241 | 2455 | 177,687 | 663,950 | 1952 | 2483 | 93,630 |
| GBDT | 1,240,920 | 1363 | 1439 | 178,703 | 663,662 | 2240 | 2275 | 93,838 |
| DT with FS | 1,231,647 | 10,636 | 2883 | 1,777,259 | 660,125 | 5777 | 1602 | 94,511 |
| RF with FS | 1,241,434 | 849 | 1999 | 178,143 | 664,054 | 1848 | 2358 | 93,755 |
| Model | Accuracy | Precision | Recall | F1-Score | FAR |
|---|---|---|---|---|---|
| Logistic Regression | 0.9893 | 0.9914 | 0.9963 | 0.9938 | 0.0576 |
| SVM | 0.9879 | 0.9867 | 0.9995 | 0.9930 | 0.0848 |
| Decision Tree | 0.9904 | 0.9913 | 0.9977 | 0.9945 | 0.0575 |
| Random Forest | 0.9942 | 0.9971 | 0.9963 | 0.9967 | 0.0204 |
| Decision Tree—XGB Classifier | 0.9941 | 0.9966 | 0.9966 | 0.9966 | 0.0233 |
| Decision Tree—with Features | 0.9903 | 0.9913 | 0.9976 | 0.9944 | 0.0576 |
| Random Forest—with Feature | 0.9945 | 0.9972 | 0.9965 | 0.9965 | 0.0194 |
| Released Year | Reference | Model Implemented | Benchmark | Proposed Model |
|---|---|---|---|---|
| 2019 | [15] | Logistic Regression | 83.15 | 98.93 |
| 2018 | [18] | SVM | 92.28 | 98.79 |
| Decision Tree | 95.82 | 99.04 | ||
| Random Forest | 97.49 | 99.42 | ||
| 2022 | [19] | Stack Model − [XGBoost KNN + XGBoost NN KNN] | 96.24 | 99.41 |
| 2020 | [20] | Logistic Regression | 83 | 98.93 |
| 2021 | [21] | Support Vector Machine | 98.92 | 98.79 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
More, S.; Idrissi, M.; Mahmoud, H.; Asyhari, A.T. Enhanced Intrusion Detection Systems Performance with UNSW-NB15 Data Analysis. Algorithms 2024, 17, 64. https://doi.org/10.3390/a17020064
More S, Idrissi M, Mahmoud H, Asyhari AT. Enhanced Intrusion Detection Systems Performance with UNSW-NB15 Data Analysis. Algorithms. 2024; 17(2):64. https://doi.org/10.3390/a17020064
Chicago/Turabian StyleMore, Shweta, Moad Idrissi, Haitham Mahmoud, and A. Taufiq Asyhari. 2024. "Enhanced Intrusion Detection Systems Performance with UNSW-NB15 Data Analysis" Algorithms 17, no. 2: 64. https://doi.org/10.3390/a17020064
APA StyleMore, S., Idrissi, M., Mahmoud, H., & Asyhari, A. T. (2024). Enhanced Intrusion Detection Systems Performance with UNSW-NB15 Data Analysis. Algorithms, 17(2), 64. https://doi.org/10.3390/a17020064