

Delving into Causal Discovery in Health-Related Quality of Life Questionnaires

 , and
, and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Directed Acyclic Graph
2.2. Methodology
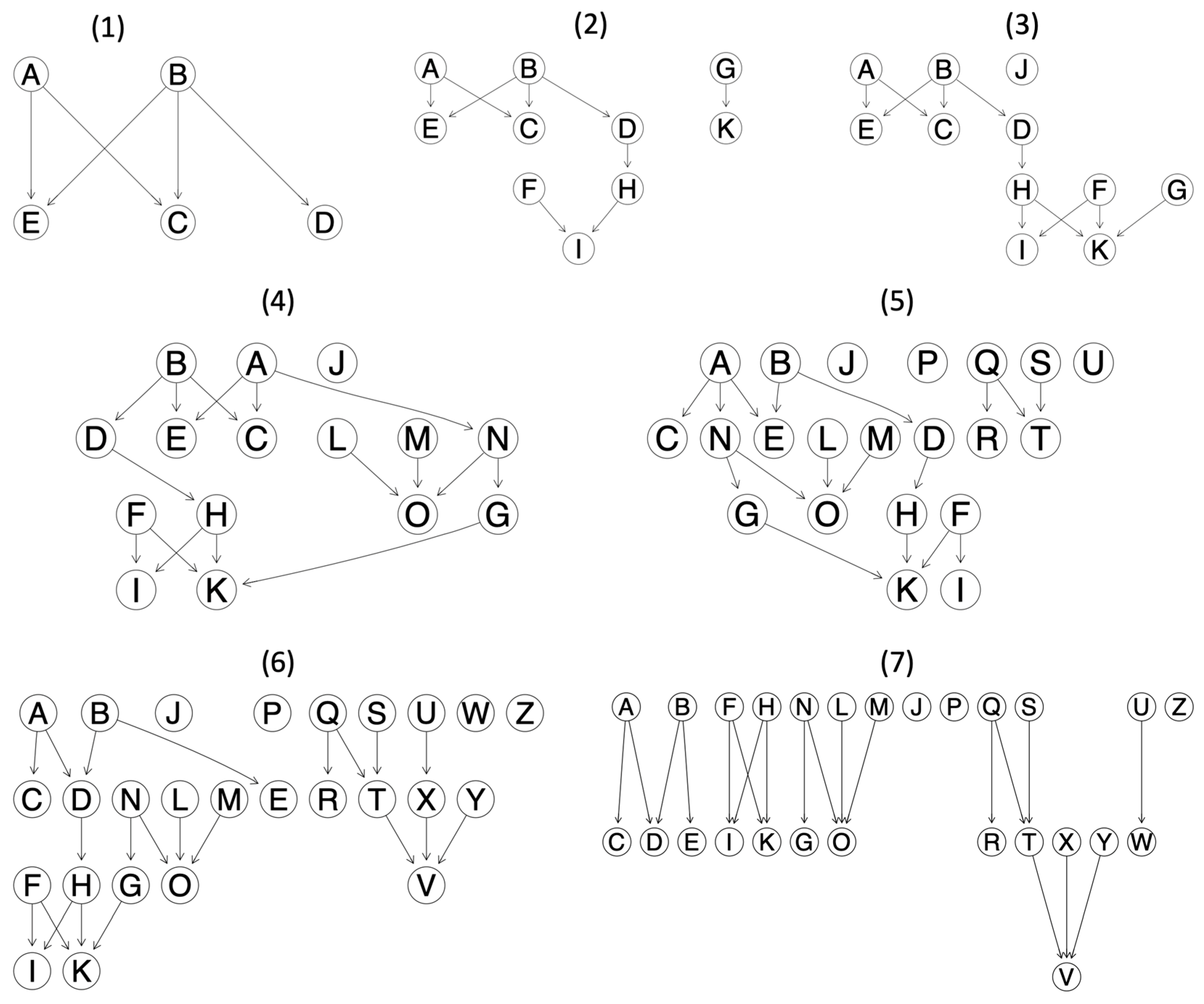
2.2.1. Synthetic Directed Acyclic Graphs
2.2.2. Simulations
- Grow–Shrink (GS) [60], employing the “gs” function: This is based on the Grow–Shrink Markov blanket, which is a Markov blanket detection algorithm.
- Incremental Association (IA) [61], employing the “iamb” function: This is based on the Markov blanket detection algorithm of the same name.
- Interleaved Incremental Association (Inter-IA) [62], employing the “inter.iamb” function: This is a variant of the IA algorithm, which differentiates in using gradual forward selection to avoid false positives in the Markov blanket detection phase.
- Fast Incremental Association (Fast-IA), employing the “fast.iamb” function: This is another variant of the IA algorithm that employs speculative stepwise forward selection to reduce the number of conditional independence tests.
- The mean HD between the estimated and the true DAG across the 1000 iterations.
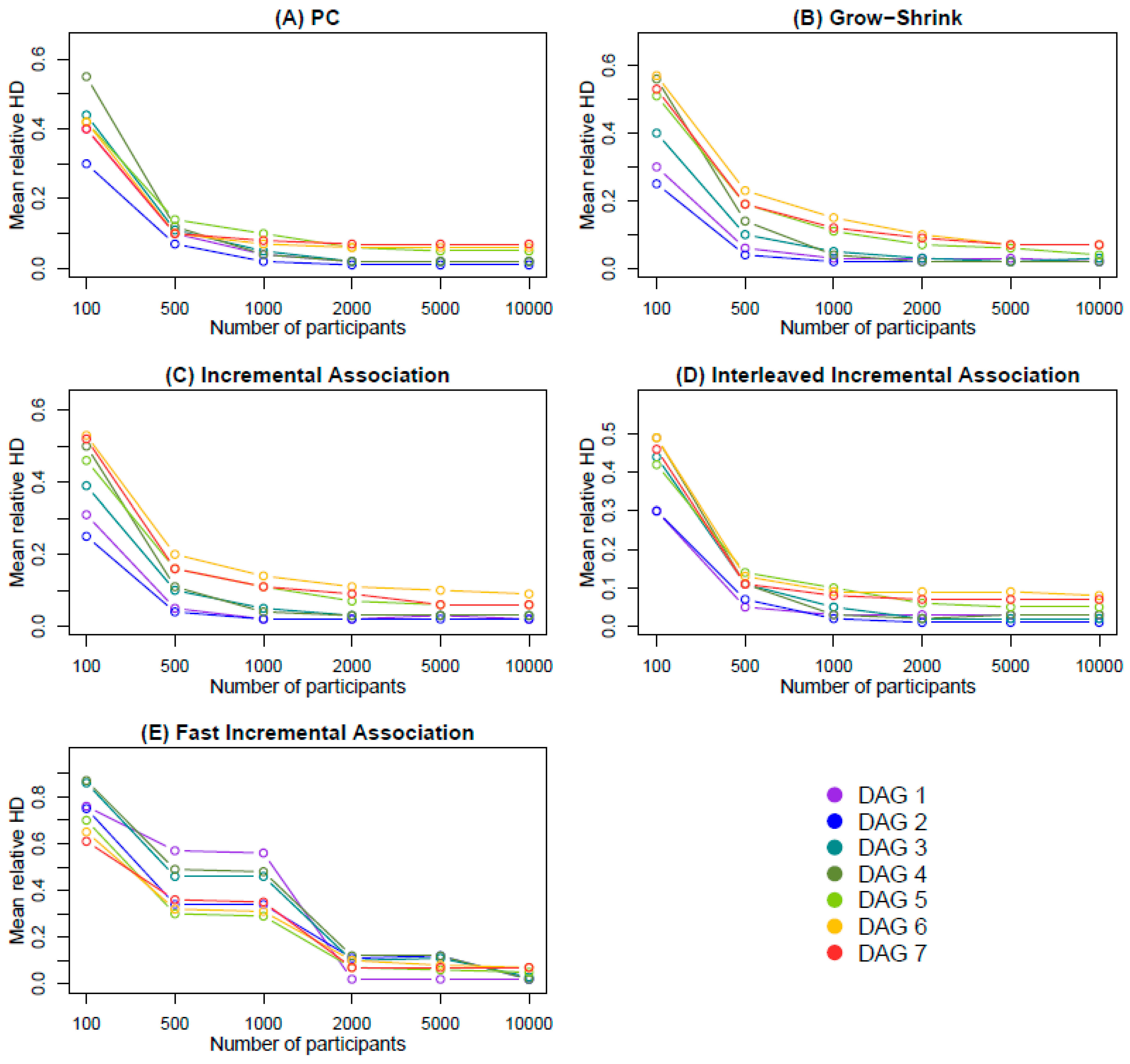
- The mean relative HD across the 1000 iterations, defined as the mean HD between the estimated and the true DAG, divided by the number of edges of the true DAG.
- The number of the cases where the HD between the estimated and the true DAG was zero across the 1000 iterations.
- The mean SHD between the estimated and the true DAG across the 1000 iterations.
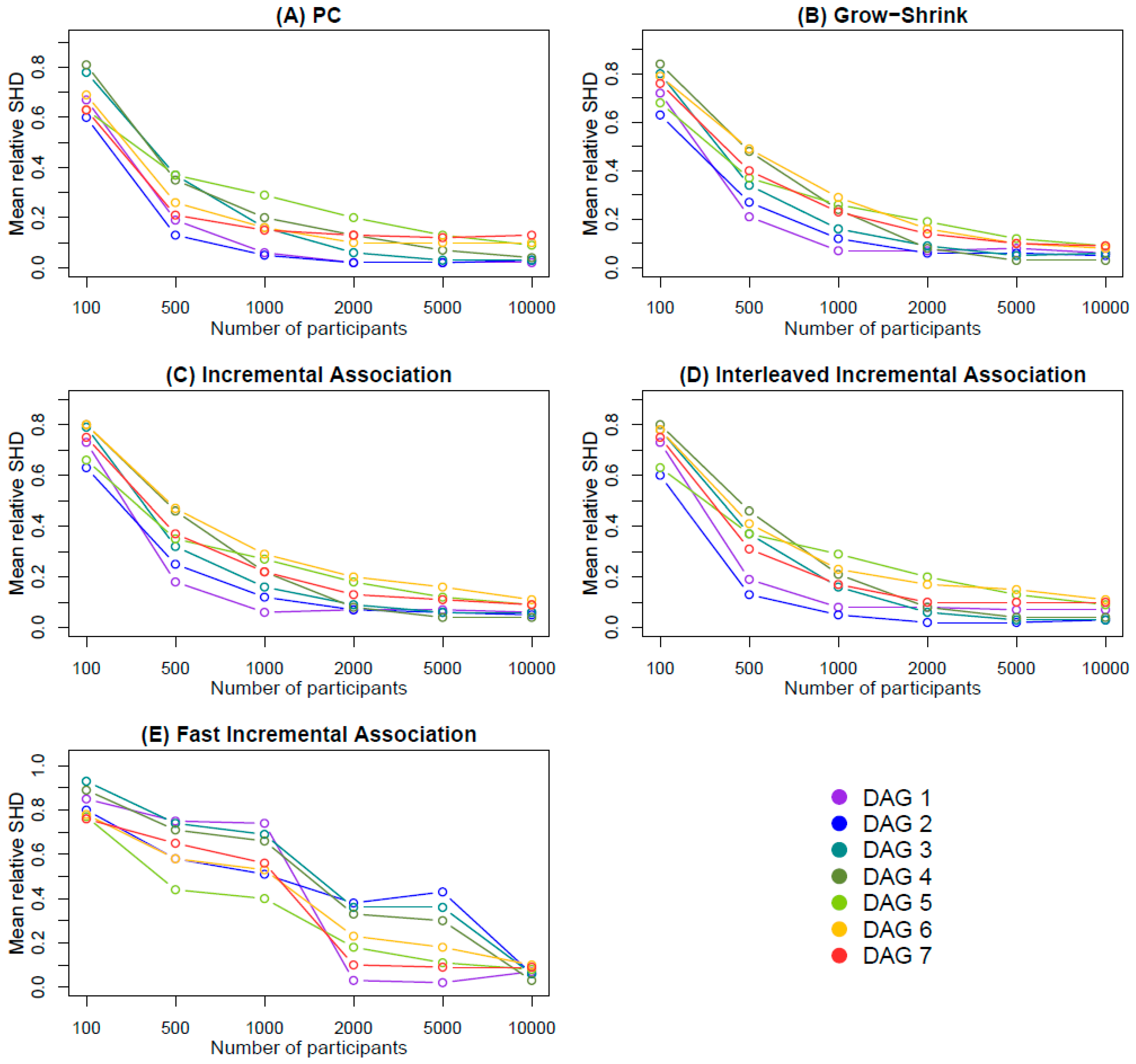
- The mean relative SHD across the 1000 iterations, defined as the mean SHD between the estimated and the true DAG, divided by the number of edges of the true DAG.
- The number of cases where the SHD between the estimated and the true DAG was zero across the 1000 iterations.
2.2.3. Shareability and Interoperability
2.2.4. Available Resources
3. Results
3.1. Simulation Findings
3.2. Resource Description Framework Knowledge Graph
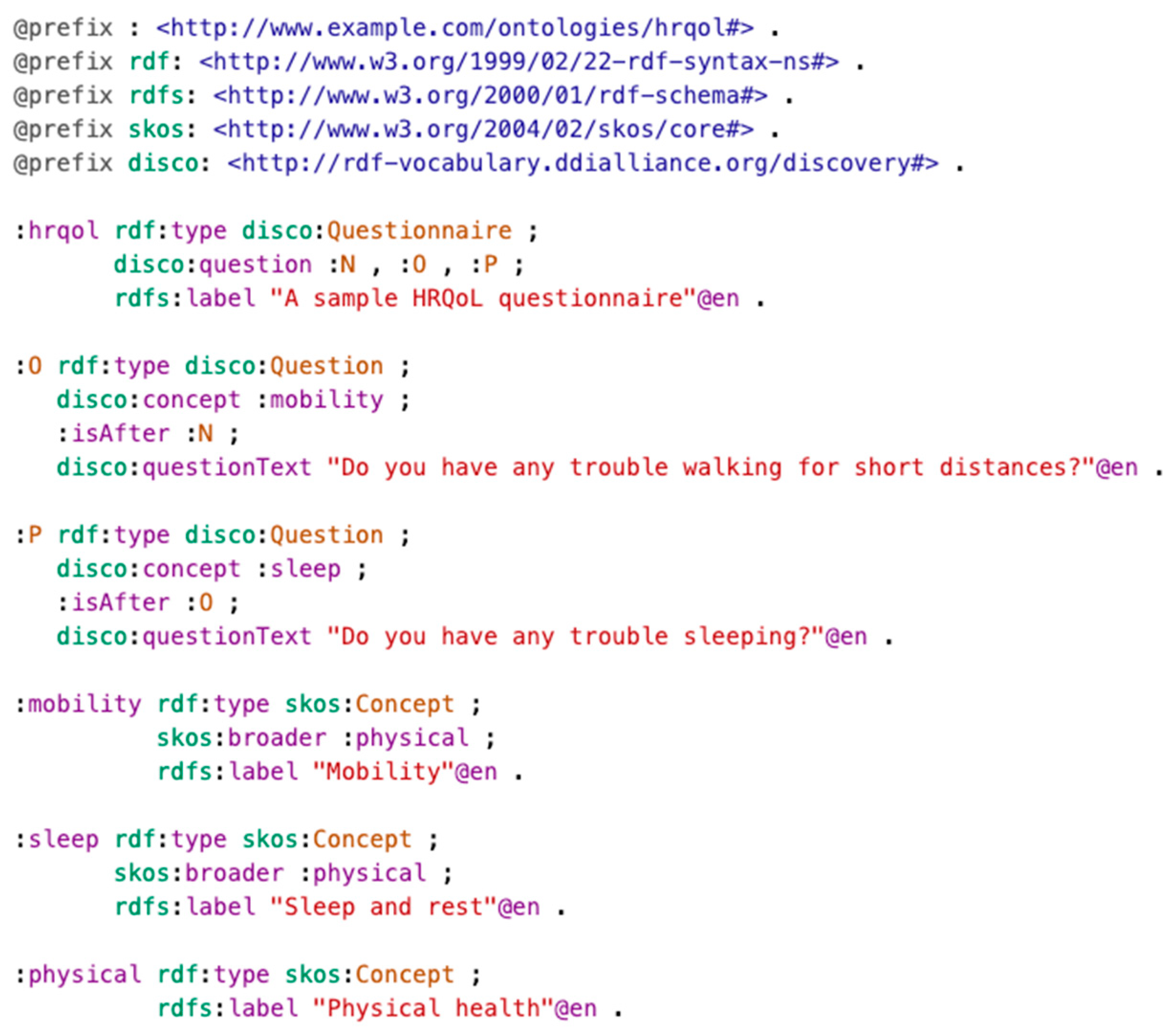
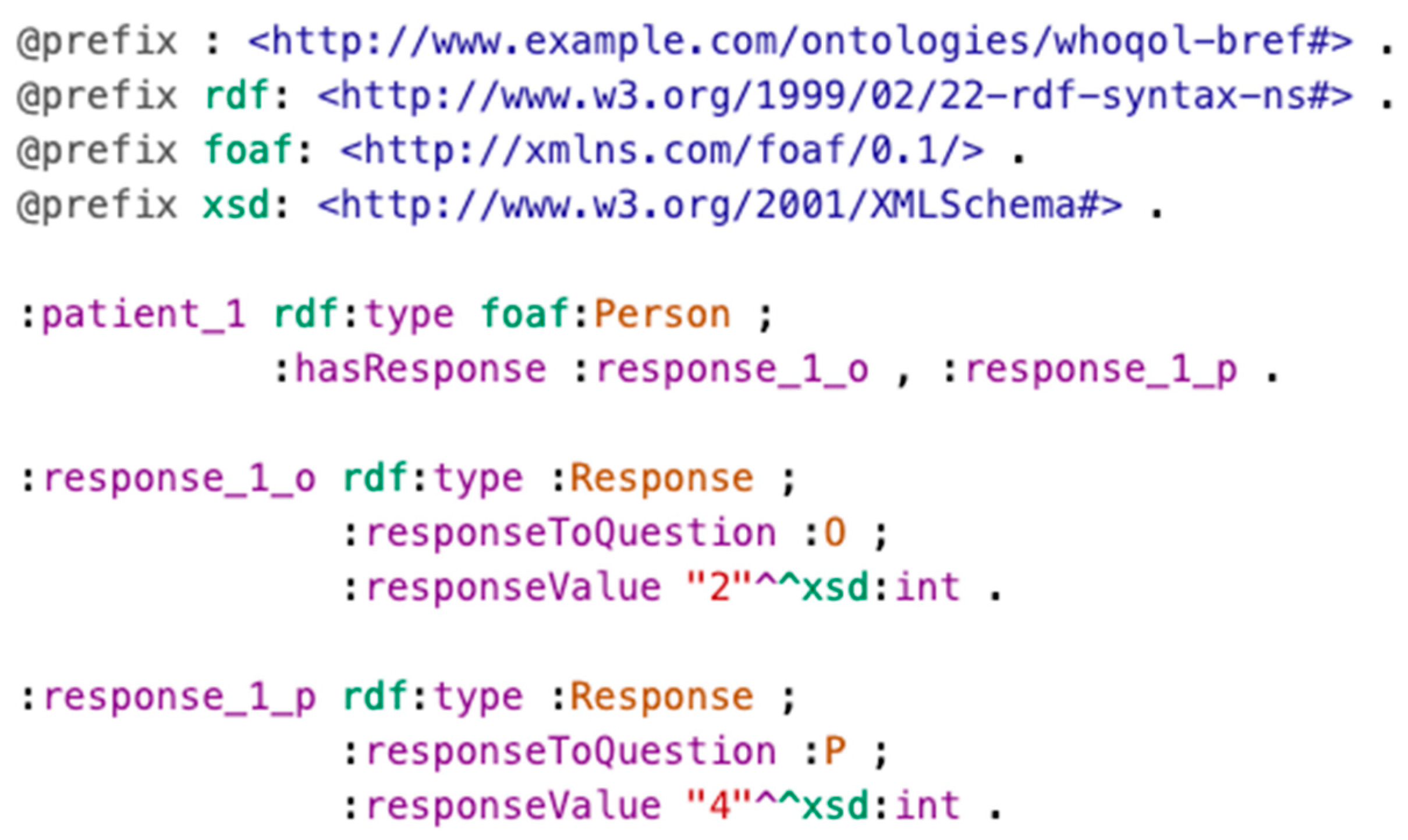
3.2.1. Representing Questionnaires and Responses
- ○
- The excerpt shown in the figure only includes three sample hypothetical questions for illustration purposes. The representation of an actual HRQoL questionnaire would include all the questions.
- ○
- In order to also represent the order of questions in the questionnaire, every question contains information about the previous one via predicate “:isAfter”.
- ○
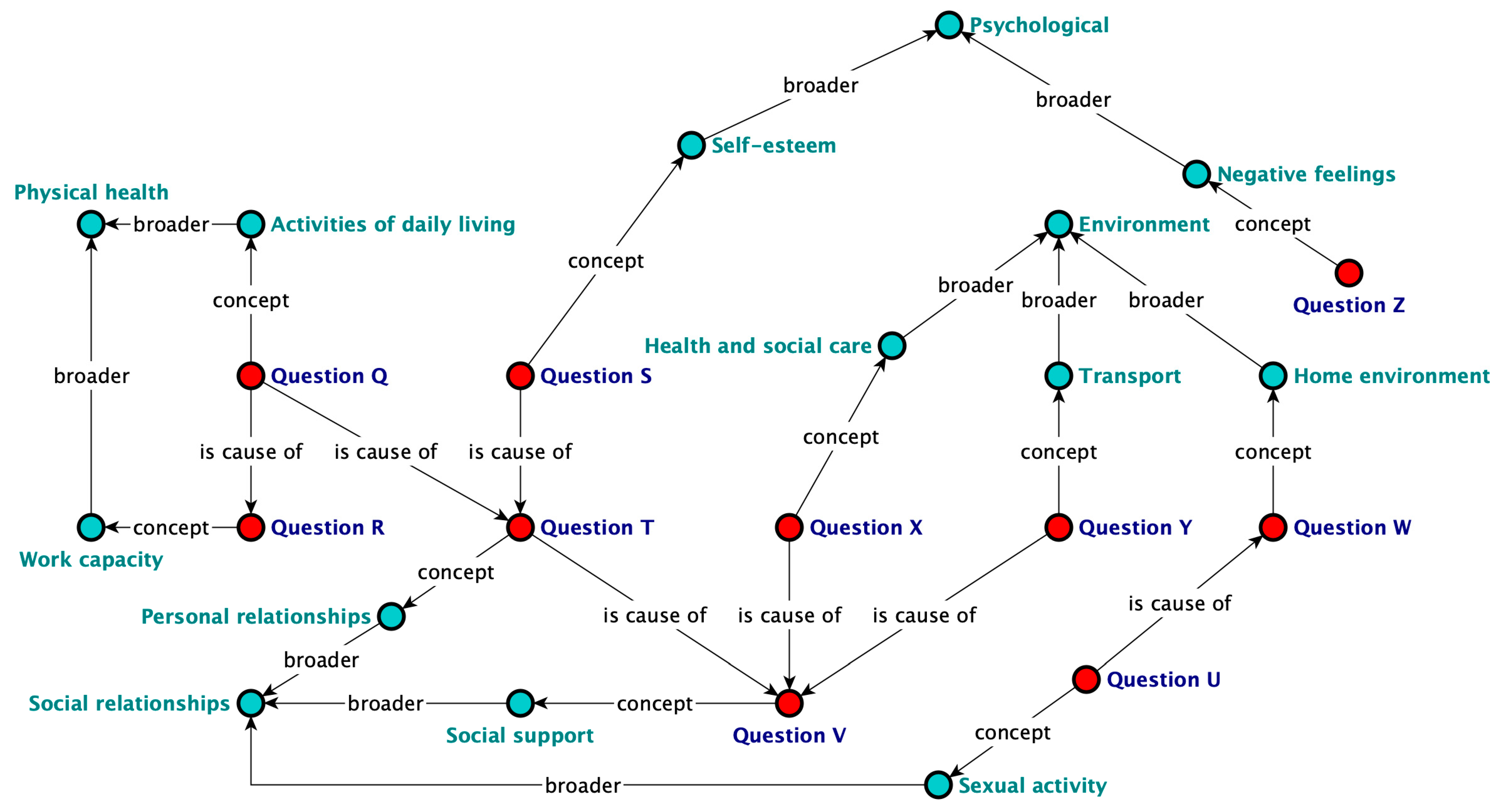
- The association of questions to facets (see Section 2.2.3) is materialized via DDI-RDF predicate “disco:concept”.
- ○
- The association of facets to domains is materialized via SKOS predicate “skos:broader”, which represents a narrower–broader interrelationship.
3.2.2. Representing Cause–Effect Relationships
4. Discussion
4.1. Causal Discovery
4.2. Knowledge Representation via Semantic KGs
4.3. Impact, Limitations, and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PC | DAG # | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| # of nodes | 5 | 10 | 11 | 15 | 21 | 26 | 26 | |
| Sample size n | # of edges | 5 | 9 | 11 | 16 | 17 | 21 | 19 |
| 100 | HD | 2.01 | 2.70 | 4.89 | 8.84 | 7.12 | 8.86 | 7.66 |
| rHD | 0.40 | 0.30 | 0.44 | 0.55 | 0.42 | 0.42 | 0.40 | |
| 0’s in HD | 13 | 11 | 0 | 0 | 0 | 0 | 0 | |
| SHD | 3.33 | 5.41 | 8.60 | 12.99 | 10.78 | 14.56 | 11.89 | |
| rSHD | 0.67 | 0.60 | 0.78 | 0.81 | 0.63 | 0.69 | 0.63 | |
| 0’s in SHD | 5 | 3 | 0 | 0 | 0 | 0 | 0 | |
| 500 | HD | 0.52 | 0.60 | 1.25 | 1.85 | 2.33 | 2.14 | 1.82 |
| rHD | 0.10 | 0.07 | 0.11 | 0.12 | 0.14 | 0.10 | 0.10 | |
| 0’s in HD | 532 | 491 | 226 | 107 | 45 | 84 | 142 | |
| SHD | 0.95 | 1.16 | 4.05 | 5.62 | 6.24 | 5.42 | 3.91 | |
| rSHD | 0.19 | 0.13 | 0.37 | 0.35 | 0.37 | 0.26 | 0.21 | |
| 0’s in SHD | 526 | 479 | 85 | 19 | 8 | 20 | 48 | |
| 1000 | HD | 0.18 | 0.21 | 0.50 | 0.56 | 1.63 | 1.50 | 1.48 |
| rHD | 0.04 | 0.02 | 0.05 | 0.04 | 0.10 | 0.07 | 0.08 | |
| 0’s in HD | 832 | 805 | 603 | 561 | 157 | 220 | 220 | |
| SHD | 0.30 | 0.42 | 1.72 | 3.14 | 4.85 | 3.28 | 2.92 | |
| rSHD | 0.06 | 0.05 | 0.16 | 0.20 | 0.29 | 0.16 | 0.15 | |
| 0’s in SHD | 828 | 797 | 378 | 171 | 46 | 141 | 149 | |
| 2000 | HD | 0.10 | 0.11 | 0.20 | 0.30 | 0.97 | 1.26 | 1.35 |
| rHD | 0.02 | 0.01 | 0.02 | 0.02 | 0.06 | 0.06 | 0.07 | |
| 0’s in HD | 909 | 896 | 820 | 747 | 373 | 270 | 231 | |
| SHD | 0.12 | 0.19 | 0.68 | 2.02 | 3.32 | 2.20 | 2.49 | |
| rSHD | 0.02 | 0.02 | 0.06 | 0.13 | 0.20 | 0.10 | 0.13 | |
| 0’s in SHD | 905 | 888 | 716 | 325 | 144 | 252 | 211 | |
| 5000 | HD | 0.10 | 0.12 | 0.22 | 0.28 | 0.77 | 1.26 | 1.40 |
| rHD | 0.02 | 0.01 | 0.02 | 0.02 | 0.05 | 0.06 | 0.07 | |
| 0’s in HD | 903 | 889 | 807 | 757 | 456 | 272 | 226 | |
| SHD | 0.11 | 0.18 | 0.37 | 1.07 | 2.29 | 2.12 | 2.37 | |
| rSHD | 0.02 | 0.02 | 0.03 | 0.07 | 0.13 | 0.10 | 0.12 | |
| 0’s in SHD | 903 | 889 | 803 | 573 | 299 | 271 | 226 | |
| 10,000 | HD | 0.10 | 0.12 | 0.22 | 0.33 | 0.78 | 1.27 | 1.36 |
| rHD | 0.02 | 0.01 | 0.02 | 0.02 | 0.05 | 0.06 | 0.07 | |
| 0’s in HD | 905 | 885 | 801 | 712 | 445 | 249 | 232 | |
| SHD | 0.12 | 0.23 | 0.33 | 0.59 | 1.60 | 2.06 | 2.39 | |
| rSHD | 0.02 | 0.03 | 0.03 | 0.04 | 0.09 | 0.10 | 0.13 | |
| 0’s in SHD | 905 | 885 | 801 | 692 | 390 | 249 | 232 |
| GS | DAG # | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| # of nodes | 5 | 10 | 11 | 15 | 21 | 26 | 26 | |
| Sample size n | # of edges | 5 | 9 | 11 | 16 | 17 | 21 | 19 |
| 100 | HD | 1.48 | 2.27 | 4.42 | 9.04 | 8.62 | 11.89 | 10.02 |
| rHD | 0.30 | 0.25 | 0.40 | 0.56 | 0.51 | 0.57 | 0.53 | |
| 0’s in HD | 49 | 17 | 0 | 0 | 0 | 0 | 0 | |
| SHD | 3.60 | 5.68 | 8.76 | 13.37 | 11.62 | 16.65 | 14.41 | |
| rSHD | 0.72 | 0.63 | 0.80 | 0.84 | 0.68 | 0.79 | 0.76 | |
| 0’s in SHD | 28 | 1 | 0 | 0 | 0 | 0 | 0 | |
| 500 | HD | 0.31 | 0.40 | 1.15 | 2.22 | 3.17 | 4.83 | 3.58 |
| rHD | 0.06 | 0.04 | 0.10 | 0.14 | 0.19 | 0.23 | 0.19 | |
| 0’s in HD | 714 | 645 | 241 | 65 | 11 | 2 | 18 | |
| SHD | 1.03 | 2.45 | 3.69 | 7.73 | 6.28 | 10.37 | 7.58 | |
| rSHD | 0.21 | 0.27 | 0.34 | 0.48 | 0.37 | 0.49 | 0.40 | |
| 0’s in SHD | 703 | 283 | 38 | 2 | 0 | 0 | 0 | |
| 1000 | HD | 0.14 | 0.18 | 0.50 | 0.70 | 1.92 | 3.07 | 2.26 |
| rHD | 0.03 | 0.02 | 0.05 | 0.04 | 0.11 | 0.15 | 0.12 | |
| 0’s in HD | 870 | 832 | 580 | 498 | 94 | 52 | 116 | |
| SHD | 0.37 | 1.05 | 1.71 | 3.76 | 4.44 | 6.16 | 4.32 | |
| rSHD | 0.07 | 0.12 | 0.16 | 0.24 | 0.26 | 0.29 | 0.23 | |
| 0’s in SHD | 866 | 602 | 228 | 101 | 3 | 20 | 62 | |
| 2000 | HD | 0.13 | 0.17 | 0.32 | 0.38 | 1.23 | 2.16 | 1.67 |
| rHD | 0.03 | 0.02 | 0.03 | 0.02 | 0.07 | 0.10 | 0.09 | |
| 0’s in HD | 877 | 841 | 731 | 679 | 264 | 145 | 195 | |
| SHD | 0.35 | 0.54 | 0.96 | 1.28 | 3.25 | 3.26 | 2.59 | |
| rSHD | 0.07 | 0.06 | 0.09 | 0.08 | 0.19 | 0.16 | 0.14 | |
| 0’s in SHD | 877 | 789 | 565 | 444 | 43 | 130 | 175 | |
| 5000 | HD | 0.15 | 0.18 | 0.26 | 0.35 | 0.94 | 1.55 | 1.39 |
| rHD | 0.03 | 0.02 | 0.02 | 0.02 | 0.06 | 0.07 | 0.07 | |
| 0’s in HD | 857 | 820 | 769 | 701 | 414 | 203 | 225 | |
| SHD | 0.41 | 0.52 | 0.54 | 0.55 | 2.02 | 2.13 | 1.97 | |
| rSHD | 0.08 | 0.06 | 0.05 | 0.03 | 0.12 | 0.10 | 0.10 | |
| 0’s in SHD | 857 | 816 | 760 | 674 | 268 | 201 | 220 | |
| 10,000 | HD | 0.11 | 0.18 | 0.31 | 0.36 | 0.75 | 1.37 | 1.26 |
| rHD | 0.02 | 0.02 | 0.03 | 0.02 | 0.04 | 0.07 | 0.07 | |
| 0’s in HD | 889 | 836 | 732 | 687 | 475 | 245 | 275 | |
| SHD | 0.29 | 0.48 | 0.63 | 0.50 | 1.50 | 1.76 | 1.67 | |
| rSHD | 0.06 | 0.05 | 0.06 | 0.03 | 0.09 | 0.08 | 0.09 | |
| 0’s in SHD | 889 | 831 | 727 | 680 | 375 | 326 | 345 |
| IA | DAG # | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| # of nodes | 5 | 10 | 11 | 15 | 21 | 26 | 26 | |
| Sample size n | # of edges | 5 | 9 | 11 | 16 | 17 | 21 | 19 |
| 100 | HD | 1.54 | 2.21 | 4.32 | 8.06 | 7.85 | 11.03 | 9.93 |
| rHD | 0.31 | 0.25 | 0.39 | 0.50 | 0.46 | 0.53 | 0.52 | |
| 0’s in HD | 44 | 25 | 0 | 0 | 0 | 0 | 0 | |
| SHD | 3.66 | 5.68 | 8.72 | 12.79 | 11.17 | 16.72 | 14.32 | |
| rSHD | 0.73 | 0.63 | 0.79 | 0.80 | 0.66 | 0.80 | 0.75 | |
| 0’s in SHD | 25 | 2 | 0 | 0 | 0 | 0 | 0 | |
| 500 | HD | 0.27 | 0.37 | 1.05 | 1.73 | 2.79 | 4.14 | 3.01 |
| rHD | 0.05 | 0.04 | 0.10 | 0.11 | 0.16 | 0.20 | 0.16 | |
| 0’s in HD | 747 | 665 | 280 | 124 | 23 | 15 | 37 | |
| SHD | 0.89 | 2.29 | 3.49 | 7.35 | 5.97 | 9.96 | 7.00 | |
| rSHD | 0.18 | 0.25 | 0.32 | 0.46 | 0.35 | 0.47 | 0.37 | |
| 0’s in SHD | 736 | 290 | 46 | 5 | 1 | 0 | 2 | |
| 1000 | HD | 0.10 | 0.20 | 0.50 | 0.60 | 1.95 | 2.85 | 2.11 |
| rHD | 0.02 | 0.02 | 0.05 | 0.04 | 0.11 | 0.14 | 0.11 | |
| 0’s in HD | 898 | 819 | 589 | 553 | 122 | 36 | 118 | |
| SHD | 0.30 | 1.10 | 1.80 | 3.50 | 4.56 | 6.06 | 4.14 | |
| rSHD | 0.06 | 0.12 | 0.16 | 0.22 | 0.27 | 0.29 | 0.22 | |
| 0’s in SHD | 898 | 581 | 255 | 111 | 10 | 12 | 50 | |
| 2000 | HD | 0.12 | 0.18 | 0.32 | 0.40 | 1.22 | 2.30 | 1.63 |
| rHD | 0.02 | 0.02 | 0.03 | 0.03 | 0.07 | 0.11 | 0.09 | |
| 0’s in HD | 887 | 837 | 713 | 655 | 271 | 69 | 202 | |
| SHD | 0.34 | 0.62 | 0.94 | 1.29 | 3.14 | 4.26 | 2.53 | |
| rSHD | 0.07 | 0.07 | 0.09 | 0.08 | 0.18 | 0.20 | 0.13 | |
| 0’s in SHD | 887 | 787 | 532 | 395 | 176 | 60 | 180 | |
| 5000 | HD | 0.14 | 0.21 | 0.34 | 0.41 | 1.04 | 2.00 | 1.18 |
| rHD | 0.03 | 0.02 | 0.03 | 0.03 | 0.06 | 0.10 | 0.06 | |
| 0’s in HD | 867 | 808 | 694 | 665 | 325 | 90 | 250 | |
| SHD | 0.36 | 0.57 | 0.69 | 0.58 | 2.06 | 3.38 | 2.17 | |
| rSHD | 0.07 | 0.06 | 0.06 | 0.04 | 0.12 | 0.16 | 0.11 | |
| 0’s in SHD | 867 | 799 | 687 | 643 | 200 | 86 | 194 | |
| 10,000 | HD | 0.12 | 0.18 | 0.33 | 0.43 | 1.05 | 1.90 | 1.13 |
| rHD | 0.02 | 0.02 | 0.03 | 0.03 | 0.06 | 0.09 | 0.06 | |
| 0’s in HD | 879 | 837 | 715 | 638 | 352 | 121 | 305 | |
| SHD | 0.30 | 0.48 | 0.63 | 0.60 | 1.60 | 2.30 | 1.63 | |
| rSHD | 0.06 | 0.05 | 0.06 | 0.04 | 0.09 | 0.11 | 0.09 | |
| 0’s in SHD | 879 | 834 | 713 | 633 | 308 | 113 | 310 |
| Inter-IA | DAG # | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| # of nodes | 5 | 10 | 11 | 15 | 21 | 26 | 26 | |
| Sample size n | # of edges | 5 | 9 | 11 | 16 | 17 | 21 | 19 |
| 100 | HD | 1.52 | 2.70 | 4.89 | 7.90 | 7.12 | 10.34 | 8.68 |
| rHD | 0.30 | 0.30 | 0.44 | 0.49 | 0.42 | 0.49 | 0.46 | |
| 0’s in HD | 63 | 11 | 0 | 0 | 0 | 0 | 0 | |
| SHD | 3.65 | 5.41 | 8.60 | 12.74 | 10.78 | 16.46 | 14.19 | |
| rSHD | 0.73 | 0.60 | 0.78 | 0.80 | 0.63 | 0.78 | 0.75 | |
| 0’s in SHD | 35 | 3 | 0 | 0 | 0 | 0 | 0 | |
| 500 | HD | 0.27 | 0.60 | 1.25 | 1.69 | 2.33 | 2.83 | 2.05 |
| rHD | 0.05 | 0.07 | 0.11 | 0.11 | 0.14 | 0.13 | 0.11 | |
| 0’s in HD | 742 | 491 | 226 | 176 | 45 | 37 | 99 | |
| SHD | 0.93 | 1.16 | 4.05 | 7.34 | 6.24 | 8.53 | 5.85 | |
| rSHD | 0.19 | 0.13 | 0.37 | 0.46 | 0.37 | 0.41 | 0.31 | |
| 0’s in SHD | 737 | 479 | 85 | 10 | 8 | 0 | 6 | |
| 1000 | HD | 0.14 | 0.21 | 0.50 | 0.55 | 1.63 | 1.94 | 1.50 |
| rHD | 0.03 | 0.02 | 0.05 | 0.03 | 0.10 | 0.09 | 0.08 | |
| 0’s in HD | 875 | 805 | 603 | 584 | 157 | 77 | 208 | |
| SHD | 0.38 | 0.42 | 1.72 | 3.40 | 4.85 | 4.76 | 3.31 | |
| rSHD | 0.08 | 0.05 | 0.16 | 0.21 | 0.29 | 0.23 | 0.17 | |
| 0’s in SHD | 871 | 797 | 378 | 103 | 46 | 22 | 85 | |
| 2000 | HD | 0.14 | 0.11 | 0.20 | 0.38 | 0.97 | 1.94 | 1.28 |
| rHD | 0.03 | 0.01 | 0.02 | 0.02 | 0.06 | 0.09 | 0.07 | |
| 0’s in HD | 865 | 896 | 820 | 684 | 373 | 83 | 249 | |
| SHD | 0.40 | 0.19 | 0.68 | 1.27 | 3.32 | 3.63 | 1.97 | |
| rSHD | 0.08 | 0.02 | 0.06 | 0.08 | 0.20 | 0.17 | 0.10 | |
| 0’s in SHD | 865 | 888 | 716 | 421 | 144 | 69 | 228 | |
| 5000 | HD | 0.13 | 0.12 | 0.22 | 0.42 | 0.77 | 1.83 | 1.32 |
| rHD | 0.03 | 0.01 | 0.02 | 0.03 | 0.05 | 0.09 | 0.07 | |
| 0’s in HD | 877 | 889 | 807 | 649 | 456 | 113 | 247 | |
| SHD | 0.35 | 0.18 | 0.37 | 0.67 | 2.29 | 3.10 | 1.88 | |
| rSHD | 0.07 | 0.02 | 0.03 | 0.04 | 0.13 | 0.15 | 0.10 | |
| 0’s in SHD | 877 | 889 | 803 | 611 | 299 | 110 | 241 | |
| 10,000 | HD | 0.14 | 0.12 | 0.22 | 0.40 | 0.78 | 1.58 | 1.33 |
| rHD | 0.03 | 0.01 | 0.02 | 0.03 | 0.05 | 0.08 | 0.07 | |
| 0’s in HD | 864 | 885 | 801 | 669 | 445 | 179 | 241 | |
| SHD | 0.35 | 0.23 | 0.33 | 0.59 | 1.60 | 2.38 | 1.81 | |
| rSHD | 0.07 | 0.03 | 0.03 | 0.04 | 0.09 | 0.11 | 0.10 | |
| 0’s in SHD | 864 | 885 | 801 | 656 | 390 | 177 | 238 |
| Fast-IA | DAG # | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| # of nodes | 5 | 10 | 11 | 15 | 21 | 26 | 26 | |
| Sample size n | # of edges | 5 | 9 | 11 | 16 | 17 | 21 | 19 |
| 100 | HD | 3.82 | 6.75 | 9.51 | 13.87 | 11.98 | 13.69 | 11.61 |
| rHD | 0.76 | 0.75 | 0.86 | 0.87 | 0.70 | 0.65 | 0.61 | |
| 0’s in HD | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| SHD | 4.23 | 7.21 | 10.23 | 14.26 | 13.10 | 16.28 | 14.36 | |
| rSHD | 0.85 | 0.80 | 0.93 | 0.89 | 0.77 | 0.78 | 0.76 | |
| 0’s in SHD | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 500 | HD | 2.85 | 3.09 | 5.04 | 7.81 | 5.04 | 6.78 | 6.81 |
| rHD | 0.57 | 0.34 | 0.46 | 0.49 | 0.30 | 0.32 | 0.36 | |
| 0’s in HD | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| SHD | 3.77 | 5.18 | 8.12 | 11.34 | 7.45 | 12.22 | 12.29 | |
| rSHD | 0.75 | 0.58 | 0.74 | 0.71 | 0.44 | 0.58 | 0.65 | |
| 0’s in SHD | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 1000 | HD | 2.82 | 3.09 | 5.06 | 7.64 | 4.89 | 6.56 | 6.58 |
| rHD | 0.56 | 0.34 | 0.46 | 0.48 | 0.29 | 0.31 | 0.35 | |
| 0’s in HD | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| SHD | 3.67 | 4.60 | 7.54 | 10.56 | 6.72 | 11.11 | 10.56 | |
| rSHD | 0.74 | 0.51 | 0.69 | 0.66 | 0.40 | 0.53 | 0.56 | |
| 0’s in SHD | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 2000 | HD | 0.09 | 0.96 | 1.14 | 1.90 | 1.23 | 2.17 | 1.26 |
| rHD | 0.02 | 0.11 | 0.10 | 0.12 | 0.07 | 0.10 | 0.07 | |
| 0’s in HD | 915 | 182 | 151 | 63 | 279 | 55 | 266 | |
| SHD | 0.14 | 3.43 | 3.94 | 5.29 | 2.98 | 4.93 | 1.84 | |
| rSHD | 0.03 | 0.38 | 0.36 | 0.33 | 0.18 | 0.23 | 0.10 | |
| 0’s in SHD | 915 | 176 | 117 | 32 | 86 | 50 | 238 | |
| 5000 | HD | 0.08 | 1.06 | 1.21 | 1.85 | 1.00 | 1.76 | 1.26 |
| rHD | 0.02 | 0.12 | 0.11 | 0.12 | 0.06 | 0.08 | 0.07 | |
| 0’s in HD | 918 | 75 | 90 | 49 | 368 | 122 | 260 | |
| SHD | 0.11 | 3.83 | 3.99 | 4.84 | 1.90 | 3.78 | 1.63 | |
| rSHD | 0.02 | 0.43 | 0.36 | 0.30 | 0.11 | 0.18 | 0.09 | |
| 0’s in SHD | 918 | 75 | 89 | 48 | 262 | 122 | 258 | |
| 10,000 | HD | 0.12 | 0.22 | 0.30 | 0.36 | 0.90 | 1.53 | 1.31 |
| rHD | 0.02 | 0.02 | 0.03 | 0.02 | 0.05 | 0.07 | 0.07 | |
| 0’s in HD | 882 | 804 | 740 | 688 | 388 | 211 | 249 | |
| SHD | 0.34 | 0.56 | 0.61 | 0.50 | 1.39 | 2.15 | 1.76 | |
| rSHD | 0.07 | 0.06 | 0.06 | 0.03 | 0.08 | 0.10 | 0.09 | |
| 0’s in SHD | 882 | 799 | 726 | 669 | 333 | 206 | 248 |
References
- Herdman, M.; Gudex, C.; Lloyd, A.; Janssen, M.F.; Kind, P.; Parkin, D.; Bonsel, G.; Badia, X. Development and Preliminary Testing of the New Five-Level Version of EQ-5D (EQ-5D-5L). Qual. Life Res. 2011, 20, 1727–1736. [Google Scholar] [CrossRef] [PubMed]
- Janssen, M.F.; Pickard, A.S.; Golicki, D.; Gudex, C.; Niewada, M.; Scalone, L.; Swinburn, P.; Busschbach, J. Measurement Properties of the EQ-5D-5L Compared to the EQ-5D-3L across Eight Patient Groups: A Multi-Country Study. Qual. Life Res. 2013, 22, 1717–1727. [Google Scholar] [CrossRef] [PubMed]
- van Hout, B.; Janssen, M.F.; Feng, Y.-S.; Kohlmann, T.; Busschbach, J.; Golicki, D.; Lloyd, A.; Scalone, L.; Kind, P.; Pickard, A.S. Interim Scoring for the EQ-5D-5L: Mapping the EQ-5D-5L to EQ-5D-3L Value Sets. Value Health 2012, 15, 708–715. [Google Scholar] [CrossRef] [PubMed]
- Ware, J.E.; Sherbourne, C.D. The MOS 36-Item Short-Form Health Survey (SF-36): I. Conceptual Framework and Item Selection. Med. Care 1992, 30, 473–483. [Google Scholar] [CrossRef]
- The Whoqol Group. Development of the World Health Organization WHOQOL-BREF Quality of Life Assessment. Psychol. Med. 1998, 28, 551–558. [Google Scholar] [CrossRef] [PubMed]
- Orley, J.; Kuyken, W. Quality of Life Assessment: International Perspectives; Springer: Berlin, Germany, 1994; ISBN 0387582053. [Google Scholar]
- Group, W. Development of the WHOQOL: Rationale and Current Status. Int. J. Ment. Health 1994, 23, 24–56. [Google Scholar] [CrossRef]
- Szabo, S.; On Behalf of the WHOQOL Group. The World Health Organization Quality of Life (WHOQOL) Assessment Instrument. In Quality of Life and Pharmaeconomics in Clinical Trials, 2nd ed.; Lippincott-Raven Publisher: New York, NY, USA, 1996; pp. 355–362. [Google Scholar]
- Aaronson, N.K.; Ahmedzai, S.; Bergman, B.; Bullinger, M.; Cull, A.; Duez, N.J.; Filiberti, A.; Flechtner, H.; Fleishman, S.B.; De Haes, J.C.J.M.; et al. The European Organization for Research and Treatment of Cancer QLQ-C30: A Quality-of-Life Instrument for Use in International Clinical Trials in Oncology. JNCI J. Natl. Cancer Inst. 1993, 85, 365–376. [Google Scholar] [CrossRef] [PubMed]
- Oerlemans, S.; Efficace, F.; Kieffer, J.M.; Kyriakou, C.; Xochelli, A.; Levedahl, K.; Petranovic, D.; Borges, F.C.; Bredart, A.; Shamieh, O.; et al. International Validation of the EORTC QLQ-CLL17 Questionnaire for Assessment of Health-related Quality of Life for Patients with Chronic Lymphocytic Leukaemia. Br. J. Haematol. 2022, 197, 431–441. [Google Scholar] [CrossRef] [PubMed]
- Cella, D.F.; Tulsky, D.S.; Gray, G.; Sarafian, B.; Linn, E.; Bonomi, A.; Silberman, M.; Yellen, S.B.; Winicour, P.; Brannon, J.; et al. The Functional Assessment of Cancer Therapy Scale: Development and Validation of the General Measure. J. Clin. Oncol. 1993, 11, 570–579. [Google Scholar] [CrossRef] [PubMed]
- Brady, M.J.; Cella, D.F.; Mo, F.; Bonomi, A.E.; Tulsky, D.S.; Lloyd, S.R.; Deasy, S.; Cobleigh, M.; Shiomoto, G. Reliability and Validity of the Functional Assessment of Cancer Therapy-Breast Quality-of-Life Instrument. J. Clin. Oncol. 1997, 15, 974–986. [Google Scholar] [CrossRef]
- Cella, D.F.; Bonomi, A.E.; Lloyd, S.R.; Tulsky, D.S.; Kaplan, E.; Bonomi, P. Reliability and Validity of the Functional Assessment of Cancer Therapy—Lung (FACT-L) Quality of Life Instrument. Lung Cancer 1995, 12, 199–220. [Google Scholar] [CrossRef] [PubMed]
- Ward, W.L.; Hahn, E.A.; Mo, F.; Hernandez, L.; Tulsky, D.S.; Cella, D. Reliability and Validity of the Functional Assessment of Cancer Therapy-Colorectal (FACT-C) Quality of Life Instrument. Qual. Life Res. 1999, 8, 181–195. [Google Scholar] [CrossRef] [PubMed]
- Cella, D.; Jensen, S.E.; Webster, K.; Hongyan, D.; Lai, J.-S.; Rosen, S.; Tallman, M.S.; Yount, S. Measuring Health-Related Quality of Life in Leukemia: The Functional Assessment of Cancer Therapy–Leukemia (FACT-Leu) Questionnaire. Value Health 2012, 15, 1051–1058. [Google Scholar] [CrossRef] [PubMed]
- Janda, M.; Obermair, A.; Cella, D.; Perrin, L.C.; Nicklin, J.L.; Ward, B.G.; Crandon, A.J.; Trimmel, M. The Functional Assessment of Cancer-Vulvar: Reliability and Validity. Gynecol. Oncol. 2005, 97, 568–575. [Google Scholar] [CrossRef] [PubMed]
- Jackson, I.L.; Isah, A.; Arikpo, A.O. Assessing Health-Related Quality of Life of People with Diabetes in Nigeria Using the EQ-5D-5L: A Cross-Sectional Study. Sci. Rep. 2023, 13, 22536. [Google Scholar] [CrossRef] [PubMed]
- Xiao, Y.; Zhang, L.; Wei, Q.; Ou, R.; Hou, Y.; Liu, K.; Lin, J.; Yang, T.; Shang, H. Health-related Quality of Life in Patients with Multiple System Atrophy Using the EQ-5D-5L. Brain Behav. 2022, 12, e2774. [Google Scholar] [CrossRef] [PubMed]
- Claflin, S.; Campbell, J.A.; Norman, R.; Mason, D.F.; Kalincik, T.; Simpson-Yap, S.; Butzkueven, H.; Carroll, W.M.; Palmer, A.J.; Blizzard, C.L.; et al. Using the EQ-5D-5L to Investigate Quality-of-Life Impacts of Disease-Modifying Therapy Policies for People with Multiple Sclerosis (MS) in New Zealand. Eur. J. Health Econ. 2023, 24, 939–950. [Google Scholar] [CrossRef] [PubMed]
- Zeng, X.; Sui, M.; Liu, R.; Qian, X.; Li, W.; Zheng, E.; Yang, J.; Li, J.; Huang, W.; Yang, H.; et al. Assessment of the Health Utility of Patients with Leukemia in China. Health Qual. Life Outcomes 2021, 19, 65. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Yang, L.; Chen, Z.; Chen, X.; Guo, Y.; Wang, X.; Dong, X.; Wang, T.; Zhang, L.; Qiu, Z.; et al. Health-related Quality of Life Measured by the Short Form 36 in Immune Thrombocytopenic Purpura: A Cross-sectional Survey in China. Eur. J. Haematol. 2007, 78, 518–523. [Google Scholar] [CrossRef] [PubMed]
- Yang, R.; Yao, H.; Lin, L.; Ji, J.; Shen, Q. Health-Related Quality of Life and Burden of Fatigue in Chinese Patients with Immune Thrombocytopenia: A Cross-Sectional Study. Indian J. Hematol. Blood Transfus. 2020, 36, 104–111. [Google Scholar] [CrossRef] [PubMed]
- Cherchir, F.; Oueslati, I.; Yazidi, M.; Chaker, F.; Chihaoui, M. Assessment of Quality of Life in Patients with Permanent Hypoparathyroidism Receiving Conventional Treatment. J. Diabetes Metab. Disord. 2023, 22, 1617–1623. [Google Scholar] [CrossRef] [PubMed]
- Hossain, M.J.; Islam, M.W.; Munni, U.R.; Gulshan, R.; Mukta, S.A.; Miah, M.S.; Sultana, S.; Karmakar, M.; Ferdous, J.; Islam, M.A. Health-Related Quality of Life among Thalassemia Patients in Bangladesh Using the SF-36 Questionnaire. Sci. Rep. 2023, 13, 7734. [Google Scholar] [CrossRef] [PubMed]
- Brzoska, P. Assessment of Quality of Life in Individuals with Chronic Headache. Psychometric Properties of the WHOQOL-BREF. BMC Neurol. 2020, 20, 267. [Google Scholar] [CrossRef]
- Bat-Erdene, E.; Hiramoto, T.; Tumurbaatar, E.; Tumur-Ochir, G.; Jamiyandorj, O.; Yamamoto, E.; Hamajima, N.; Oka, T.; Jadamba, T.; Lkhagvasuren, B. Quality of Life in the General Population of Mongolia: Normative Data on WHOQOL-BREF. PLoS ONE 2023, 18, e0291427. [Google Scholar] [CrossRef] [PubMed]
- Floris, F.; Comitini, F.; Leoni, G.; Moi, P.; Morittu, M.; Orecchia, V.; Perra, M.; Pilia, M.P.; Zappu, A.; Casini, M.R.; et al. Quality of Life in Sardinian Patients with Transfusion-Dependent Thalassemia: A Cross-Sectional Study. Qual. Life Res. 2018, 27, 2533–2539. [Google Scholar] [CrossRef] [PubMed]
- Nolte, S.; Liegl, G.; Petersen, M.A.; Aaronson, N.K.; Costantini, A.; Fayers, P.M.; Grønvold, M.; Holzner, B.; Johnson, C.D.; Kemmler, G.; et al. General Population Normative Data for the EORTC QLQ-C30 Health-Related Quality of Life Questionnaire Based on 15,386 Persons across 13 European Countries, Canada and the Unites States. Eur. J. Cancer 2019, 107, 153–163. [Google Scholar] [CrossRef]
- Pamuk, G.E.; Harmandar, F.; Ermantaş, N.; Harmandar, O.; Turgut, B.; Demir, M.; Vural, Ö. EORTC QLQ-C30 Assessment in Turkish Patients with Hematological Malignancies: Association with Anxiety and Depression. Ann. Hematol. 2008, 87, 305–310. [Google Scholar] [CrossRef] [PubMed]
- Efficace, F.; Platzbecker, U.; Breccia, M.; Cottone, F.; Carluccio, P.; Salutari, P.; Di Bona, E.; Borlenghi, E.; Autore, F.; Levato, L.; et al. Long-Term Quality of Life of Patients with Acute Promyelocytic Leukemia Treated with Arsenic Trioxide vs Chemotherapy. Blood Adv. 2021, 5, 4370–4379. [Google Scholar] [CrossRef] [PubMed]
- Youron, P.; Singh, C.; Jindal, N.; Malhotra, P.; Khadwal, A.; Jain, A.; Prakash, G.; Varma, N.; Varma, S.; Lad, D.P. Quality of Life in Patients of Chronic Lymphocytic Leukemia Using the EORTC QLQ-C30 and QLQ-CLL17 Questionnaire. Eur. J. Haematol. 2020, 105, 755–762. [Google Scholar] [CrossRef] [PubMed]
- Criscitiello, C.; Spurden, D.; Piercy, J.; Rider, A.; Williams, R.; Mitra, D.; Wild, R.; Corsaro, M.; Kurosky, S.K.; Law, E.H. Health-Related Quality of Life among Patients with HR+/HER2–Early Breast Cancer. Clin. Ther. 2021, 43, 1228–1244. [Google Scholar] [CrossRef] [PubMed]
- Ursini, L.A.; Nuzzo, M.; Rosa, C.; Di Guglielmo, F.C.; Di Tommaso, M.; Trignani, M.; Borgia, M.; Allajbej, A.; Patani, F.; Di Carlo, C.; et al. Quality of Life in Early Breast Cancer Patients: A Prospective Observational Study Using the FACT-B Questionnaire. In Vivo 2021, 35, 1821–1828. [Google Scholar] [CrossRef] [PubMed]
- Kandel, M.; Dalle, S.; Bardet, A.; Allayous, C.; Mortier, L.; Dutriaux, C.; Guillot, B.; Leccia, M.; Dalac, S.; Legoupil, D.; et al. Quality-of-life Assessment in French Patients with Metastatic Melanoma in Real Life. Cancer 2020, 126, 611–618. [Google Scholar] [CrossRef] [PubMed]
- Dean, G.E.; Redeker, N.S.; Wang, Y.-J.; Rogers, A.E.; Dickerson, S.S.; Steinbrenner, L.M.; Gooneratne, N.S. Sleep, Mood, and Quality of Life in Patients Receiving Treatment for Lung Cancer. Oncol. Nurs. Forum 2013, 40, 441–451. [Google Scholar] [CrossRef] [PubMed]
- Dean, G.E.; Sabbah, E.A.; Yingrengreung, S.; Ziegler, P.; Chen, H.; Steinbrenner, L.M.; Dickerson, S.S. Sleeping with the Enemy: Sleep and Quality of Life in Patients with Lung Cancer. Cancer Nurs. 2015, 38, 60–70. [Google Scholar] [CrossRef] [PubMed]
- Bakas, T.; McLennon, S.M.; Carpenter, J.S.; Buelow, J.M.; Otte, J.L.; Hanna, K.M.; Ellett, M.L.; Hadler, K.A.; Welch, J.L. Systematic Review of Health-Related Quality of Life Models. Health Qual. Life Outcomes 2012, 10, 134. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Liu, L.; Le, T.D. Practical Approaches to Causal Relationship Exploration; Springer: Berlin/Heidelberg, Germany, 2015; ISBN 3319144332. [Google Scholar]
- Boutsika, A.; Michailidis, M.; Ganopoulou, M.; Dalakouras, A.; Skodra, C.; Xanthopoulou, A.; Stamatakis, G.; Samiotaki, M.; Tanou, G.; Moysiadis, T.; et al. A Wide Foodomics Approach Coupled with Metagenomics Elucidates the Environmental Signature of Potatoes. iScience 2023, 26, 105917. [Google Scholar] [CrossRef] [PubMed]
- Skodra, C.; Michailidis, M.; Moysiadis, T.; Stamatakis, G.; Ganopoulou, M.; Adamakis, I.-D.S.; Angelis, L.; Ganopoulos, I.; Tanou, G.; Samiotaki, M.; et al. Disclosing the Molecular Basis of Salinity Priming in Olive Trees Using Proteogenomic Model Discovery. Plant Physiol. 2023, 191, 1913–1933. [Google Scholar] [CrossRef] [PubMed]
- Ganopoulou, M.; Michailidis, M.; Angelis, L.; Ganopoulos, I.; Molassiotis, A.; Xanthopoulou, A.; Moysiadis, T. Could Causal Discovery in Proteogenomics Assist in Understanding Gene–Protein Relations? A Perennial Fruit Tree Case Study Using Sweet Cherry as a Model. Cells 2021, 11, 92. [Google Scholar] [CrossRef] [PubMed]
- Ganopoulou, M.; Kangelidis, I.; Sianos, G.; Angelis, L. Causal Models for the Result of Percutaneous Coronary Intervention in Coronary Chronic Total Occlusions. Appl. Sci. 2021, 11, 9258. [Google Scholar] [CrossRef]
- Piccininni, M.; Konigorski, S.; Rohmann, J.L.; Kurth, T. Directed Acyclic Graphs and Causal Thinking in Clinical Risk Prediction Modeling. BMC Med. Res. Methodol. 2020, 20, 179. [Google Scholar] [CrossRef] [PubMed]
- Raghu, V.K.; Zhao, W.; Pu, J.; Leader, J.K.; Wang, R.; Herman, J.; Yuan, J.-M.; Benos, P.V.; Wilson, D.O. Feasibility of Lung Cancer Prediction from Low-Dose CT Scan and Smoking Factors Using Causal Models. Thorax 2019, 74, 643–649. [Google Scholar] [CrossRef] [PubMed]
- Sachs, K.; Perez, O.; Pe’er, D.; Lauffenburger, D.A.; Nolan, G.P. Causal Protein-Signaling Networks Derived from Multiparameter Single-Cell Data. Science 2005, 308, 523–529. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Niyogi, D. Identification of Linkages between Urban Heat Island Magnitude and Urban Rainfall Modification by Use of Causal Discovery Algorithms. Urban Clim. 2020, 33, 100659. [Google Scholar] [CrossRef]
- Farnia, L.; Alibegovic, M.; Cruickshank, E. On Causal Structural Learning Algorithms Oracles’ Simulations and Considerations. Knowl. Based Syst. 2023, 276, 110694. [Google Scholar] [CrossRef]
- Krethong, P.; Jirapaet, V.; Jitpanya, C.; Sloan, R. A Causal Model of Health-related Quality of Life in Thai Patients with Heart-failure. J. Nurs. Scholarsh. 2008, 40, 254–260. [Google Scholar] [CrossRef]
- Tangkawanich, T.; Yunibhand, J.; Thanasilp, S.; Magilvy, K. Causal Model of Health: Health-related Quality of Life in People Living with HIV/AIDS in the Northern Region of Thailand. Nurs. Health Sci. 2008, 10, 216–221. [Google Scholar] [CrossRef] [PubMed]
- Gąsior, J.S.; Młyńczak, M.; Williams, C.A.; Popłonyk, A.; Kowalska, D.; Giezek, P.; Werner, B. The Discovery of a Data-Driven Causal Diagram of Sport Participation in Children and Adolescents with Heart Disease: A Pilot Study. Front. Cardiovasc. Med. 2023, 10, 1247122. [Google Scholar] [CrossRef] [PubMed]
- Varni, J.W.; Seid, M.; Kurtin, P.S. PedsQLTM 4.0: Reliability and Validity of the Pediatric Quality of Life InventoryTM Version 4.0 Generic Core Scales in Healthy and Patient Populations. Med. Care 2001, 39, 800–812. [Google Scholar] [CrossRef] [PubMed]
- Varni, J.W.; Burwinkle, T.M.; Seid, M.; Skarr, D. The PedsQLTM* 4.0 as a Pediatric Population Health Measure: Feasibility, Reliability, and Validity. Ambul. Pediatr. 2003, 3, 329–341. [Google Scholar] [CrossRef] [PubMed]
- Scutari, M.; Graafland, C.E.; Gutiérrez, J.M. Who Learns Better Bayesian Network Structures: Accuracy and Speed of Structure Learning Algorithms. Int. J. Approx. Reason. 2019, 115, 235–253. [Google Scholar] [CrossRef]
- Greenland, S.; Pearl, J. Causal Diagrams. In Encyclopedia of Epidemiology; Boslaugh, S., Ed.; Technical Report; Sage Publications: Thousand Oaks, CA, USA; pp. 149–156.
- Nagarajan, R.; Scutari, M.; Lèbre, S.; Nagarajan, R.; Scutari, M.; Lèbre, S. Bayesian Networks in R with Applications in Systems Biology; Springer: Berlin/Heidelberg, Germany, 2013; ISBN 978-1-4614-6445-7. [Google Scholar]
- Scutari, M. Learning Bayesian Networks with the Bnlearn R Package. J. Stat. Softw. 2010, 35, 1–22. [Google Scholar] [CrossRef]
- Colombo, D.; Maathuis, M.H. Order-Independent Constraint-Based Causal Structure Learning. J. Mach. Learn. Res. 2014, 15, 3741–3782. [Google Scholar]
- Spirtes, P.; Glymour, C.; Scheines, R. Causation, Prediction, and Search; Springer: New York, NY, USA, 1993; ISBN 1461276500. [Google Scholar]
- Spirtes, P.; Glymour, C.N.; Scheines, R. Causation, Prediction, and Search; The MIT Press: Cambridge, MA, USA; London, UK, 2000; ISBN 0262194406. [Google Scholar]
- Margaritis, D. Learning Bayesian Network Model Structure from Data. Ph.D. Thesis, Carnegie-Mellon University, Pittsburgh, PA, USA, 2003. [Google Scholar]
- Tsamardinos, I.; Aliferis, C.F.; Statnikov, A.R. Algorithms for Large Scale Markov Blanket Discovery. In Proceedings of the FLAIRS Conference, St. Augustine, FL, USA, 12–14 May 2003; Volume 2. [Google Scholar]
- Yaramakala, S.; Margaritis, D. Speculative Markov Blanket Discovery for Optimal Feature Selection. In Proceedings of the Fifth IEEE International Conference on Data Mining (ICDM’05), Houston, TX, USA, 27–30 November 2005; p. 4. [Google Scholar]
- Tsamardinos, I.; Brown, L.E.; Aliferis, C.F. The Max-Min Hill-Climbing Bayesian Network Structure Learning Algorithm. Mach. Learn. 2006, 65, 31–78. [Google Scholar] [CrossRef]
- Cyganiak, R.; Wood, D.; Lanthaler, M.; Klyne, G.; Carroll, J.J.; McBride, B. RDF 1.1 Concepts and Abstract Syntax. W3C Recomm. 2014, 25, 1–22. [Google Scholar]
- Fensel, D.; Şimşek, U.; Angele, K.; Huaman, E.; Kärle, E.; Panasiuk, O.; Toma, I.; Umbrich, J.; Wahler, A. Knowledge Graphs; Springer Nature: Cham, Switzerland, 2020. [Google Scholar] [CrossRef]
- Bosch, T.; Cyganiak, R.; Gregory, A.; Wackerow, J. DDI-RDF Discovery Vocabulary: A Metadata Vocabulary for Documenting Research and Survey Data. In Proceedings of the LDOW, Rio de Janeiro, Brazil, 14 May 2013. [Google Scholar]
- Miles, A.; Bechhofer, S. SKOS Simple Knowledge Organization System Reference. W3C Recomm. 2009. Available online: https://www.w3.org/TR/skos-reference.
- Antoniazzi, F.; Viola, F. RDF Graph Visualization Tools: A Survey. In Proceedings of the 2018 23rd Conference of Open Innovations Association (FRUCT), Bologna, Italy, 13–16 November 2018; pp. 25–36. [Google Scholar]
- Musen, M.A. The Protégé Project: A Look Back and a Look Forward. AI Matters 2015, 1, 4–12. [Google Scholar] [CrossRef] [PubMed]
- Liebig, T.; Opitz, M.; Vialard, V.; Wenzel, M. Scalable No-Code Knowledge Graph Exploration and Querying with SemSpect. In Proceedings of the 19th International Conference on Semantic Systems, Leipzig, Germany, 20–22 September 2023. [Google Scholar]







| Cause Domain | Effect Domain | Count |
|---|---|---|
| Environment | Physical health | 3 |
| Environment | Psychological | 2 |
| Environment | Social relationships | 2 |
| Physical health | Environment | 1 |
| Physical health | Social relationships | 1 |
| Psychological | Environment | 1 |
| Psychological | Social relationships | 1 |
| Social relationships | Environment | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ganopoulou, M.; Kontopoulos, E.; Fokianos, K.; Koparanis, D.; Angelis, L.; Kotsianidis, I.; Moysiadis, T. Delving into Causal Discovery in Health-Related Quality of Life Questionnaires. Algorithms 2024, 17, 138. https://doi.org/10.3390/a17040138
Ganopoulou M, Kontopoulos E, Fokianos K, Koparanis D, Angelis L, Kotsianidis I, Moysiadis T. Delving into Causal Discovery in Health-Related Quality of Life Questionnaires. Algorithms. 2024; 17(4):138. https://doi.org/10.3390/a17040138
Chicago/Turabian StyleGanopoulou, Maria, Efstratios Kontopoulos, Konstantinos Fokianos, Dimitris Koparanis, Lefteris Angelis, Ioannis Kotsianidis, and Theodoros Moysiadis. 2024. "Delving into Causal Discovery in Health-Related Quality of Life Questionnaires" Algorithms 17, no. 4: 138. https://doi.org/10.3390/a17040138
APA StyleGanopoulou, M., Kontopoulos, E., Fokianos, K., Koparanis, D., Angelis, L., Kotsianidis, I., & Moysiadis, T. (2024). Delving into Causal Discovery in Health-Related Quality of Life Questionnaires. Algorithms, 17(4), 138. https://doi.org/10.3390/a17040138