
Multi-Objective BiLevel Optimization by Bayesian Optimization



Abstract
:1. Introduction
2. Preliminaries
3. Methodology
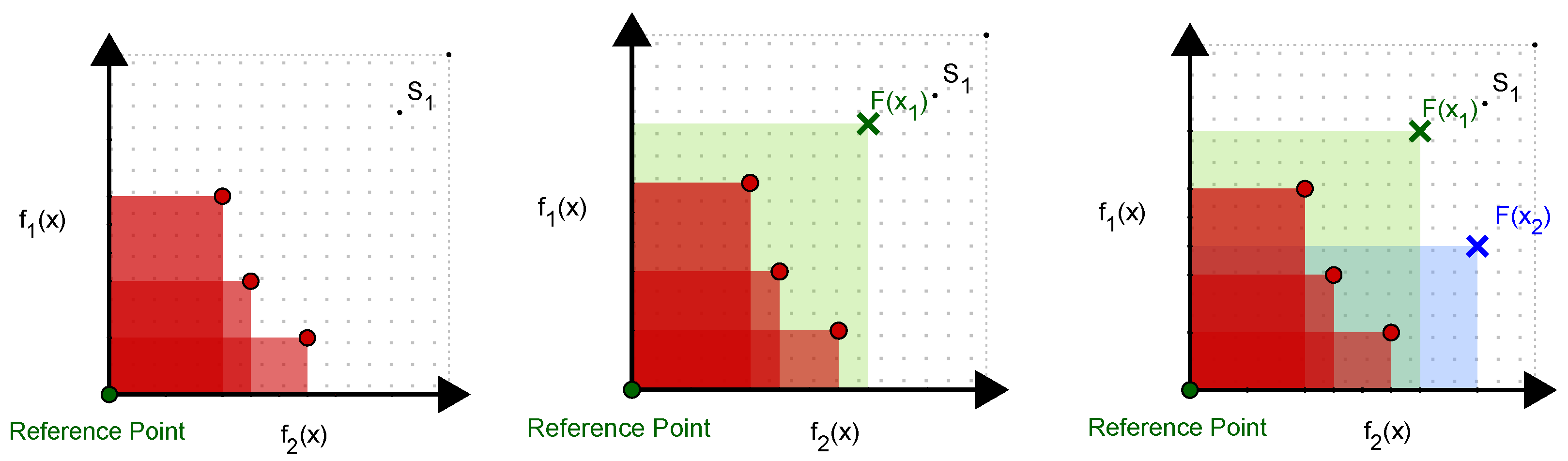
3.1. Noise-Free Setting
| Algorithm 1: Upper-level Optimization |
| Inputs: , Batch points per epoch q, Number of iteration n, Reference point
|
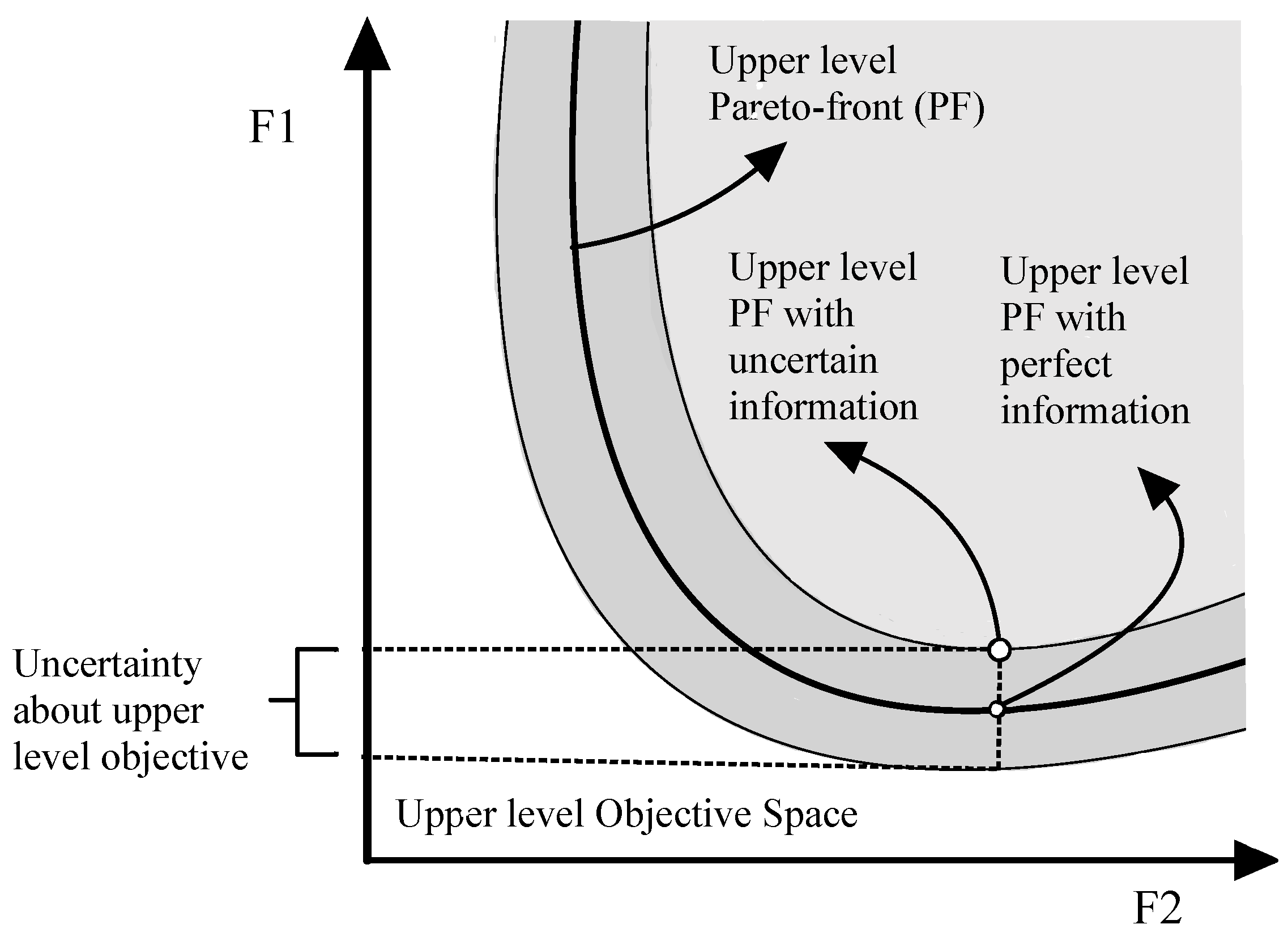
3.2. Noisy Setting
| Algorithm 2: Proposed Algorithm |
| Inputs: , Batch points in each iteration Q, The number of iterations for BO: N, Reference point
|
4. Experiments
4.1. Noise-Free Experiments
4.1.1. Parameters
4.1.2. Performance Measures
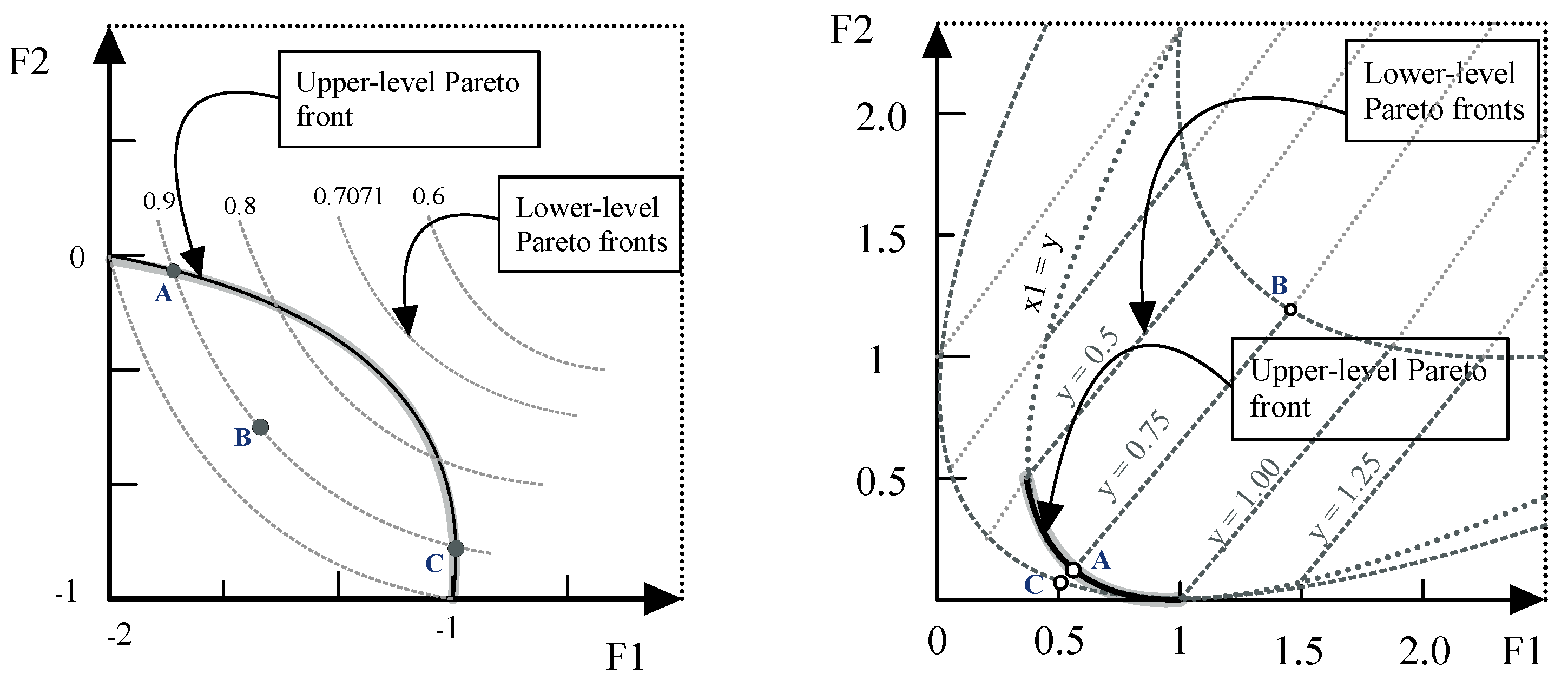
4.1.3. Test Problems
Problem 1
Problem 2
Problem 3
Practical Case: CEO Problem
4.1.4. Results and Observations
Problem 1
Problem 2
Problem 3
Practical Case: CEO Problem
4.2. Noisy Experiments
4.2.1. Performance Metrics
4.2.2. Parameters
4.2.3. Test Problems
Example 1
Example 2
Example 3
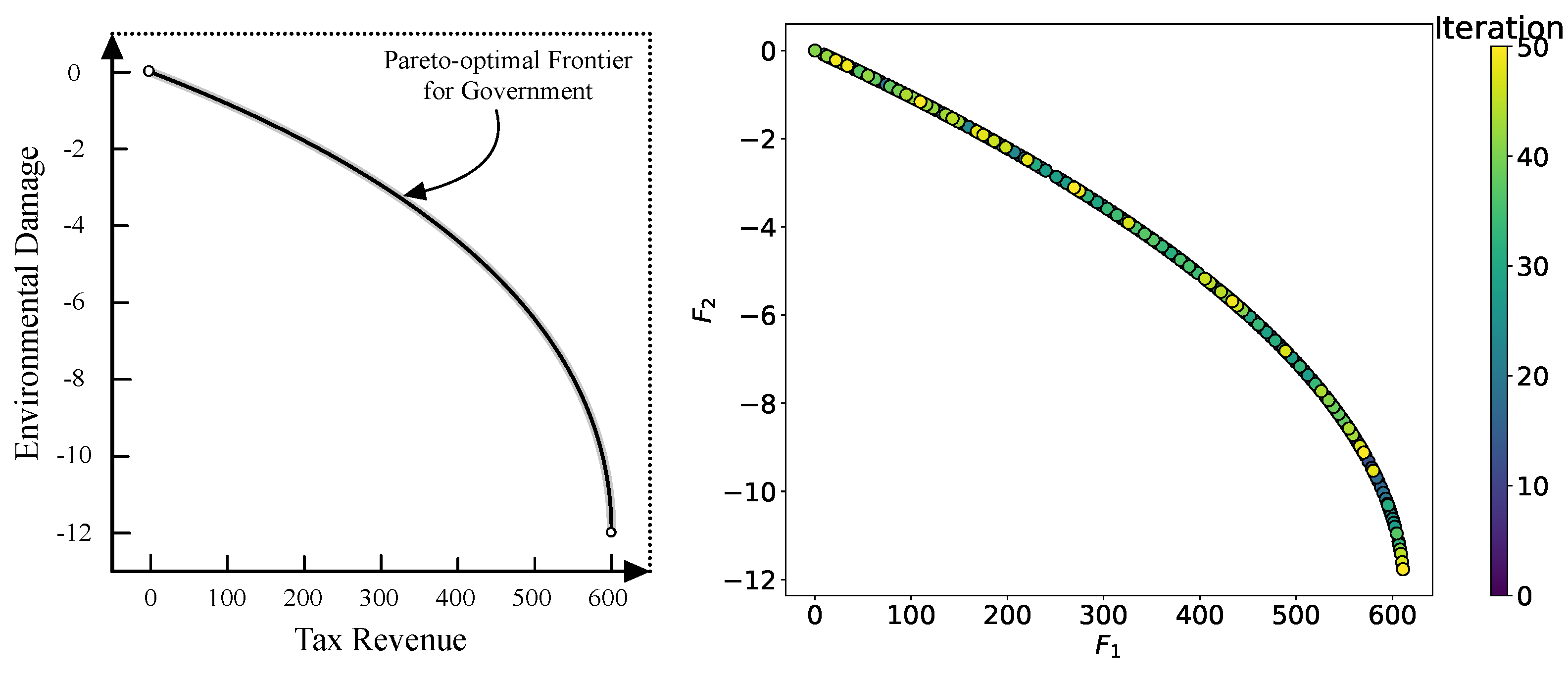
Practical Case: Gold Mining in Kuusamo
4.2.4. Results of Test Problems
Example 1
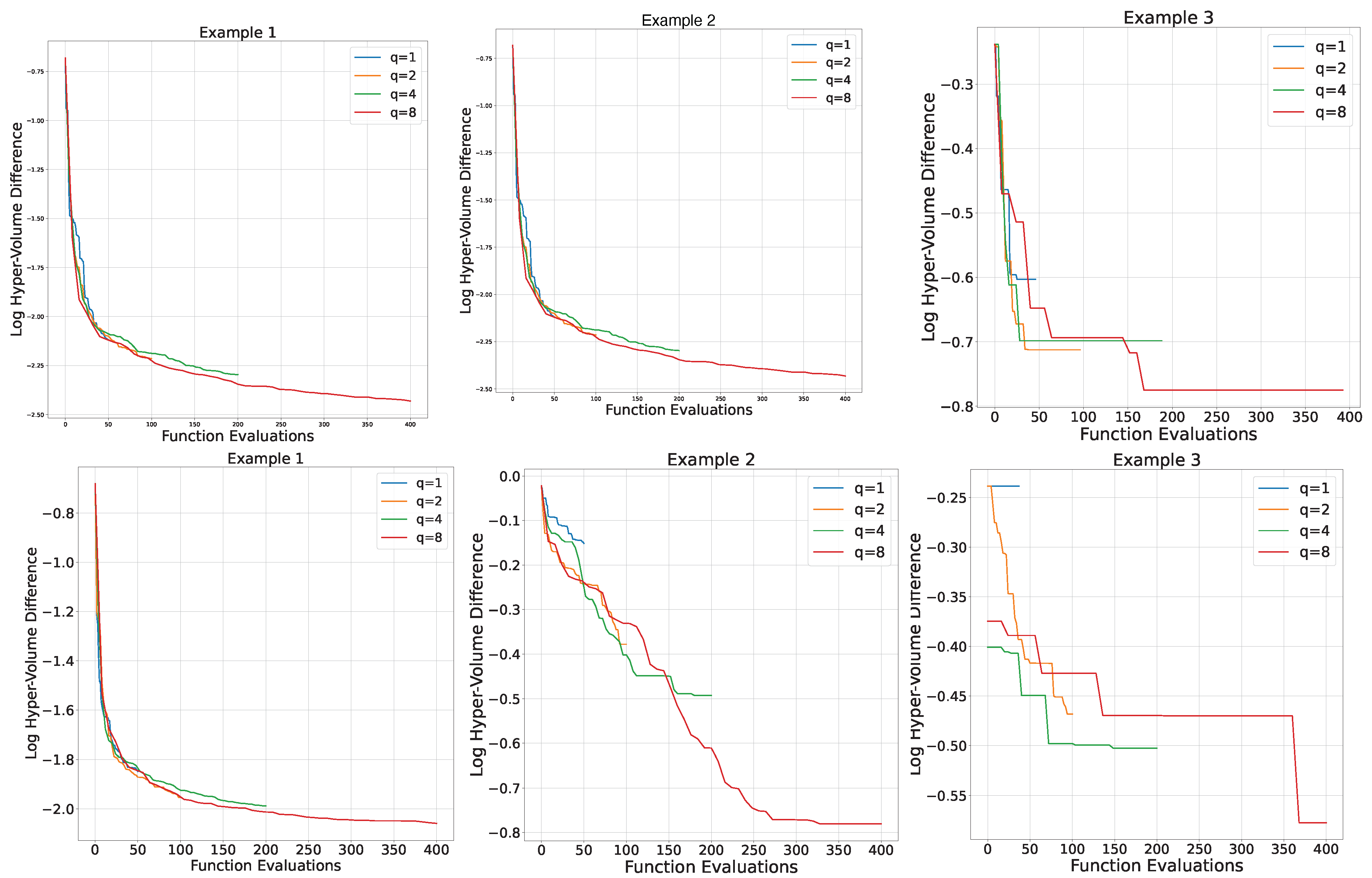
Example 2
Example 3
Practical Case: Gold Mining in Kuusamo
5. Discussion
5.1. Limitations
6. Conclusions
Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ParEGO | Parallel Efficient Global Optimization |
| MOEA | Multi-Objective Evolutionary Algorithm |
| DBMA | Decomposition-Based Memetic Algorithm |
| H-BLEMO | Hybrid EMO-Cum-Local-Search Bilevel Programming Algorithm |
| OMOPSO-BL | Multi-objective Optimization by Particle Swarm Optimization for Bilevel Problems |
| NSGA-II | Non-Dominated Sorting Genetic Algorithm |
| CMODE/D | Competitive Mechanism-Based Multi-Objective Differential Evolution Algorithm |
| m-BLEAQ | Multi-Objective Bilevel Evolutionary Algorithm Based on Quadratic Approximations |
| MOBO | Multi-objective Bilevel Optimization |
| EHVI | Expected Hypervolume Improvement |
| NEHVI | Noisy Expected Hypervolume Improvement |
| IGD | Inverted Generational Distance |
| HVI | Hypervolume Improvement |
| HV | Hypervolume Improvement |
| GP | Gaussian Process |
| EI | Expected Improvement |
| FE | Function Evaluation |
| BO | Bayesian Optimization |
| qEI | q-Expected Improvement |
| qKG | q-Knowledge Gradient |
References
- Stackelberg, H.v. The Theory of the Market Economy; William Hodge: London, UK, 1952. [Google Scholar]
- Gupta, A.; Kelly, P.; Ehrgott, M.; Bickerton, S. Applying Bi-level Multi-Objective Evolutionary Algorithms for Optimizing Composites Manufacturing Processes. In Evolutionary Multi-Criterion Optimization; Purshouse, R.C., Fleming, P.J., Fonseca, C.M., Greco, S., Shaw, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 615–627. [Google Scholar]
- Gupta, A.; Ong, Y.S.; Kelly, P.A.; Goh, C.K. Pareto rank learning for multi-objective bi-level optimization: A study in composites manufacturing. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 1940–1947. [Google Scholar] [CrossRef]
- Barnhart, B.; Lu, Z.; Bostian, M.; Sinha, A.; Deb, K.; Kurkalova, L.; Jha, M.; Whittaker, G. Handling practicalities in agricultural policy optimization for water quality improvements. In Proceedings of the Genetic and Evolutionary Computation Conference, GECCO ’17, Berlin, Germany, 15–19 July 2017; pp. 1065–1072. [Google Scholar] [CrossRef]
- del Valle, A.; Wogrin, S.; Reneses, J. Multi-objective bi-level optimization model for the investment in gas infrastructures. Energy Strategy Rev. 2020, 30, 100492. [Google Scholar] [CrossRef]
- Gao, D.Y. Canonical Duality Theory and Algorithm for Solving Bilevel Knapsack Problems with Applications. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 893–904. [Google Scholar] [CrossRef]
- Tostani, H.; Haleh, H.; Molana, S.; Sobhani, F. A Bi-Level Bi-Objective optimization model for the integrated storage classes and dual shuttle cranes scheduling in AS/RS with energy consumption, workload balance and time windows. J. Clean. Prod. 2020, 257, 120409. [Google Scholar] [CrossRef]
- Wein, L. Homeland Security: From Mathematical Models to Policy Implementation: The 2008 Philip McCord Morse Lecture. Oper. Res. 2009, 57, 801–811. [Google Scholar] [CrossRef]
- Al-Shedivat, M.; Bansal, T.; Burda, Y.; Sutskever, I.; Mordatch, I.; Abbeel, P. Continuous Adaptation via Meta-Learning in Nonstationary and Competitive Environments. arXiv 2017, arXiv:1710.03641. [Google Scholar]
- Franceschi, L.; Frasconi, P.; Salzo, S.; Grazzi, R.; Pontil, M. Bilevel Programming for Hyperparameter Optimization and Meta-Learning. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; Volume 80, pp. 1568–1577. [Google Scholar]
- Mannino, C.; Bernt, F.; Dahl, G. Computing Optimal Recovery Policies for Financial Markets. Oper. Res. 2012, 60, iii-1565. [Google Scholar] [CrossRef]
- Dogan, V.; Prestwich, S. Bilevel Optimization. In International Conference on Machine Learning, Optimization, and Data Science; Nicosia, G., Ojha, V., La Malfa, E., La Malfa, G., Pardalos, P.M., Umeton, R., Eds.; Springer: Cham, Switzerland, 2024; pp. 243–258. [Google Scholar]
- Dogan, V.; Prestwich, S. Bayesian Optimization with Multi-objective Acquisition Function for Bilevel Problems. In Irish Conference on Artificial Intelligence and Cognitive Science; Longo, L., O’Reilly, R., Eds.; Springer: Cham, Switzerland, 2023; pp. 409–422. [Google Scholar]
- Emmerich, M.; Giannakoglou, K.; Naujoks, B. Single- and multiobjective evolutionary optimization assisted by Gaussian random field metamodels. Evol. Comput. IEEE Trans. 2006, 10, 421–439. [Google Scholar] [CrossRef]
- Knowles, J. ParEGO: A hybrid algorithm with on-line landscape approximation for expensive multiobjective optimization problems. IEEE Trans. Evol. Comput. 2006, 10, 50–66. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, W.; Tsang, E.; Virginas, B. Expensive Multiobjective Optimization by MOEA/D With Gaussian Process Model. IEEE Trans. Evol. Comput. 2010, 14, 456–474. [Google Scholar] [CrossRef]
- Daulton, S.; Balandat, M.; Bakshy, E. Differentiable Expected Hypervolume Improvement for Parallel Multi-Objective Bayesian Optimization. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Christiansen, S.; Patriksson, M.; Wynter, L. Stochastic bilevel programming in structural optimization. Struct. Multidiscip. Optim. 2001, 21, 361–371. [Google Scholar] [CrossRef]
- Alves, M.J.; Antunes, C.H.; Carrasqueira, P. A PSO Approach to Semivectorial Bilevel Programming: Pessimistic, Optimistic and Deceiving Solutions. In Proceedings of the 2015 Annual Conference on Genetic and Evolutionary Computation, Madrid, Spain, 11–15 July 2015. [Google Scholar]
- Alves, M.J.; Antunes, C.H.; Costa, J.P. Multiobjective Bilevel Programming: Concepts and Perspectives of Development. In Multiple Criteria Decision Making; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Islam, M.M.; Singh, H.K.; Ray, T. A Nested Differential Evolution Based Algorithm for Solving Multi-objective Bilevel Optimization Problems. In Proceedings of the ACALCI, Canberra, Australia, 2–5 February 2016. [Google Scholar]
- Abo-Sinna, M.A.; Baky, I.A. Interactive balance space approach for solving multi-level multi-objective programming problems. Inf. Sci. 2007, 177, 3397–3410. [Google Scholar] [CrossRef]
- Deb, K.; Sinha, A. An Efficient and Accurate Solution Methodology for Bilevel Multi-Objective Programming Problems Using a Hybrid Evolutionary-Local-Search Algorithm. Evol. Comput. 2010, 18, 403–449. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Hu, T.; Guo, X.; Chen, Z.; Zheng, Y. Solving high dimensional bilevel multiobjective programming problem using a hybrid particle swarm optimization algorithm with crossover operator. Knowl.-Based Syst. 2013, 53, 13–19. [Google Scholar] [CrossRef]
- Carrasqueira, P.; Alves, M.; Antunes, C. A Bi-level Multiobjective PSO Algorithm. In Proceedings of the EMO 2015; Springer: Cham, Switzerland, 2015; Volume 9018, pp. 263–276. [Google Scholar] [CrossRef]
- Chevalier, C.; Ginsbourger, D. Fast Computation of the Multi-Points Expected Improvement with Applications in Batch Selection. In Proceedings of the Revised Selected Papers of the 7th International Conference on Learning and Intelligent Optimization—Volume 7997, LION 7; Springer: Berlin/Heidelberg, Germany, 2013; pp. 59–69. [Google Scholar] [CrossRef]
- Wu, J.; Frazier, P. The Parallel Knowledge Gradient Method for Batch Bayesian Optimization. In Proceedings of the NeurIPS, Barcelona, Spain, 5–6 December 2016. [Google Scholar]
- González, J.I.; Dai, Z.; Hennig, P.; Lawrence, N.D. Batch Bayesian Optimization via Local Penalization. In Proceedings of the AISTATS, Cadiz, Spain, 9–11 May 2016. [Google Scholar]
- Mejía-De-Dios, J.A.; Rodríguez-Molina, A.; Mezura-Montes, E. Multiobjective Bilevel Optimization: A Survey of the State-of-the-Art. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 5478–5490. [Google Scholar] [CrossRef]
- Kim, Y.; Pan, Z.; Hauser, K. MO-BBO: Multi-Objective Bilevel Bayesian Optimization for Robot and Behavior Co-Design. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 9877–9883. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Dogan, V.; Prestwich, S. Multi-objective Bilevel Decision Making with Noisy Objectives: A Batch Bayesian Approach. Available online: https://scholar.google.com.hk/scholar?hl=en&as_sdt=0%2C5&q=Multi-objective+Bilevel+Decision+Making+with+Noisy+Objectives%3A+A+Batch+Bayesian+Approach.&btnG= (accessed on 25 March 2024).
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning, The MIT Press: Cambridge, MA, USA, 2005.
- Wada, T.; Hino, H. Bayesian Optimization for Multi-objective Optimization and Multi-point Search. arXiv, 2019; arXiv:1905.02370. [Google Scholar]
- Yang, K.; Emmerich, M.; Deutz, A.; Bäck, T. Multi-Objective Bayesian Global Optimization using expected hypervolume improvement gradient. Swarm Evol. Comput. 2019, 44, 945–956. [Google Scholar] [CrossRef]
- Gardner, J.R.; Kusner, M.J.; Xu, Z.; Weinberger, K.Q.; Cunningham, J.P. Bayesian Optimization with Inequality Constraints. In Proceedings of the 31st International Conference on International Conference on Machine Learning—Volume 32, ICML’14, Beijing, China, 21–26 June 2014; pp. II-937–II-945. [Google Scholar]
- Lyu, W.; Yang, F.; Yan, C.; Zhou, D.; Zeng, X. Batch Bayesian Optimization via Multi-objective Acquisition Ensemble for Automated Analog Circuit Design. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Alves, M.; Antunes, C.; Costa, J. New concepts and an algorithm for multiobjective bilevel programming: Optimistic, pessimistic and moderate solutions. Oper. Res. 2021, 21. [Google Scholar] [CrossRef]
- Daulton, S.; Balandat, M.; Bakshy, E. Parallel Bayesian Optimization of Multiple Noisy Objectives with Expected Hypervolume Improvement. In Proceedings of the NeurIPS, Virtual, 6–14 December 2021. [Google Scholar]
- Balandat, M.; Karrer, B.; Jiang, D.R.; Daulton, S.; Letham, B.; Wilson, A.G.; Bakshy, E. BoTorch: A Framework for Efficient Monte-Carlo Bayesian Optimization. Adv. Neural Inf. Process. Syst. 2020, 33, 21524–21538. [Google Scholar]
- Blank, J.; Deb, K. pymoo: Multi-Objective Optimization in Python. IEEE Access 2020, 8, 89497–89509. [Google Scholar] [CrossRef]
- Coello Coello, C.A.; Reyes Sierra, M. A Study of the Parallelization of a Coevolutionary Multi-objective Evolutionary Algorithm. In Proceedings of the MICAI 2004: Advances in Artificial Intelligence; Monroy, R., Arroyo-Figueroa, G., Sucar, L.E., Sossa, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 688–697. [Google Scholar]
- Li, H.; Zhang, L. An efficient solution strategy for bilevel multiobjective optimization problems using multiobjective evolutionary algorithm. Soft Comput. 2021, 25, 8241–8261. [Google Scholar] [CrossRef]
- Deb, K.; Sinha, A. Solving Bilevel Multi-Objective Optimization Problems Using Evolutionary Algorithms. In Proceedings of the EMO, Nantes, France, 7–10 April 2009. [Google Scholar]
- Sinha, A.; Malo, P.; Deb, K.; Korhonen, P.; Wallenius, J. Solving Bilevel Multicriterion Optimization Problems With Lower Level Decision Uncertainty. IEEE Trans. Evol. Comput. 2016, 20, 199–217. [Google Scholar] [CrossRef]
- Sinha, A.; Malo, P.; Frantsev, A.; Deb, K. Multi-objective Stackelberg game between a regulating authority and a mining company: A case study in environmental economics. In Proceedings of the 2013 IEEE Congress on Evolutionary Computation, Cancun, Mexico, 20–23 June 2013; pp. 478–485. [Google Scholar] [CrossRef]
- Fonseca, C.; Paquete, L.; Lopez-Ibanez, M. An Improved Dimension-Sweep Algorithm for the Hypervolume Indicator. In Proceedings of the 2006 IEEE International Conference on Evolutionary Computation, Vancouver, BC, Canada, 16–21 July 2006; pp. 1157–1163. [Google Scholar] [CrossRef]
- Deb, K.; Sinha, A. Constructing test problems for bilevel evolutionary multi-objective optimization. In Proceedings of the 2009 IEEE Congress on Evolutionary Computation, Trondheim, Norway, 18–21 May 2009; pp. 1153–1160. [Google Scholar] [CrossRef]
- Cobalt, L. LATITUDE 66 COBALT OY REPORTS A NEW COBALT-GOLD DISCOVERY IN KUUSAMO, FINLAND. Available online: https://lat66.com/wp-content/uploads/2023/03/Lat66-News-Release-21-March-2023.pdf (accessed on 25 March 2024).
- Mounsaveng, S.; Laradji, I.H.; Ayed, I.B.; Vázquez, D.; Pedersoli, M. Learning Data Augmentation with Online Bilevel Optimization for Image Classification. arXiv 2020, arXiv:2006.14699. [Google Scholar]
- Han, Y.; Liu, J.; Xiao, B.; Wang, X.; Luo, X. Bilevel Online Deep Learning in Non-stationary Environment. arXiv 2022, arXiv:2201.10236. [Google Scholar]
- Li, H.; Zhang, L. A Bilevel Learning Model and Algorithm for Self-Organizing Feed-Forward Neural Networks for Pattern Classification. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4901–4915. [Google Scholar] [CrossRef]
- Liu, R.; Gao, J.; Zhang, J.; Meng, D.; Lin, Z. Investigating Bi-Level Optimization for Learning and Vision from a Unified Perspective: A Survey and Beyond. arXiv 2021, arXiv:2101.11517. [Google Scholar] [CrossRef]
- Binois, M.; Wycoff, N. A Survey on High-dimensional Gaussian Process Modeling with Application to Bayesian Optimization. ACM Trans. Evol. Learn. Optim. 2022, 2, 1–26. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Problem | Formulation | Pareto-Optimal Solutions |
|---|---|---|
| Problem 1 n = 1 m = 2 | ||
| Problem 2 n = 1 m = 2 | ||
| Problem 3 n = 1 m = K |
| Proposed Algorithm | DBMA | H-BLEMO | |||||
|---|---|---|---|---|---|---|---|
| (q) | UL | LL | UL | LL | UL | LL | |
| Problem 1 | 1 | 4500 | 27,000 | 22,229 | 312,500 | 14,163 | 629,590 |
| 2 | 6500 | 54,000 | |||||
| 4 | 11,500 | 108,000 | |||||
| 8 | 18,500 | 216,000 | |||||
| Problem 2 (K = 3) | 1 | 2700 | 14,580 | 12,028 | 312,500 | 16,146 | 700,634 |
| 2 | 4300 | 28,620 | |||||
| 4 | 7200 | 38,880 | |||||
| 8 | 9900 | 48,060 | |||||
| Problem 3 (K = 14) | 1 | 2675 | 57,780 | N/A | N/A | 18,733 | 319,499 |
| 2 | 1575 | 34,020 | |||||
| 4 | 6575 | 142,020 | |||||
| 8 | 3125 | 67,500 | |||||
| Proposed Algorithm | DBMA | OMOPSO-BL | H-BLEMO | ||||||
|---|---|---|---|---|---|---|---|---|---|
| (q) | HV | IGD | HV | IGD | HV | IGD | HV | IGD | |
| Problem 1 | 1 | 0.3524 ±0.0003 | 0.0143 ±0.0005 | 0.3075 | N/A | 0.3068 | 0.0156 | 0.3024 | 0.0113 |
| 2 | 0.3632 ±0.005 | 0.0138 ±0.002 | |||||||
| 4 | 0.3621 ±0.012 | 0.0126 ±0.005 | |||||||
| 8 | 0.3773 ±0.019 | 0.0119 ±0.009 | |||||||
| Problem 2 (K = 3) | 1 | 0.2067 ±0.005 | 0.0105 ± 0.006 | 0.2069 | N/A | 0.2074 | 0.0102 | 0.2067 | 0.0063 |
| 2 | 0.2097 ±0.0005 | 0.0068 ±0.002 | |||||||
| 4 | 0.2125 ±0.002 | 0.0045 ±0.0005 | |||||||
| 8 | 0.2144 ±0.0004 | 0.0032 ±0.0002 | |||||||
| Problem 3 (K = 14) | 1 | 0.2026 ±0.004 | 0.0105 ±0.006 | N/A | N/A | 0.2018 | 0.0312 | 0.2059 | 0.0105 |
| 2 | 0.1915 ± 0.023 | 0.0147 ± 0.002 | |||||||
| 4 | 0.2089 ±0.009 | 0.0141 ± 0.001 | |||||||
| 8 | 0.2241 ±0.042 | 0.0138 ± 0.0087 | |||||||
| Exteme Point | Leader’s Objective () | Follower’s Objective () | Leader’s Optimal Decision () | Follower’s Optimal Decision () |
|---|---|---|---|---|
| (529.86, 1480.09) | (3554.98, 5266.08) | |||
| (964.41, 264.74) | (533.02, 646.19) | |||
| (474.48, 1849.36) | (1030.12, 1468.39) | |||
| (1038.90, 307.90) | (830.79, 523.31) |
| Problem | Formulation |
|---|---|
| Example 1 n = 1 m = K | |
| Example 2 n = K m = K | |
| Example 3 n = K m = K |
| Category | Level | Formulation |
|---|---|---|
| Variables | Upper level | [per unit tax imposed on the mine] |
| Lower level | q [amount of metal extracted by the mine] | |
| Objectives | Upper level | [tax revenue] |
| [environmental damage] | ||
| Lower level | [profit] | |
| Constraints | Upper level | |
| Lower level | ||
| Uncertainty | Upper level | |
| Parameters | ||
| Number of Variables | Proposed Algorithm | m-BLEAQ | H-BLEMO | ||||
|---|---|---|---|---|---|---|---|
| IGD | FE | IGD | FE | IGD | FE | ||
| Example 1 | 15 | 0.0044 | 4032 | 0.0013 | 6464 | 0.0046 | 39,818 |
| Example 2 | 10 | 0.0051 | 4022 | 0.0069 | 22,223 | 0.0134 | 106,003 |
| Example 3 | 10 | 0.0076 | 4022 | 0.0079 | 25,364 | 0.0134 | 132,907 |
| Example 1 | 20 | 0.0105 | 4042 | - | - | - | - |
| Example 2 | 20 | 0.1032 | 4042 | 0.0435 | 34,110 | 0.1106 | 191,357 |
| Example 3 | 20 | 0.0924 | 4042 | 0.0623 | 36,439 | 0.1321 | 216,083 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dogan, V.; Prestwich, S. Multi-Objective BiLevel Optimization by Bayesian Optimization. Algorithms 2024, 17, 146. https://doi.org/10.3390/a17040146
Dogan V, Prestwich S. Multi-Objective BiLevel Optimization by Bayesian Optimization. Algorithms. 2024; 17(4):146. https://doi.org/10.3390/a17040146
Chicago/Turabian StyleDogan, Vedat, and Steven Prestwich. 2024. "Multi-Objective BiLevel Optimization by Bayesian Optimization" Algorithms 17, no. 4: 146. https://doi.org/10.3390/a17040146
APA StyleDogan, V., & Prestwich, S. (2024). Multi-Objective BiLevel Optimization by Bayesian Optimization. Algorithms, 17(4), 146. https://doi.org/10.3390/a17040146