Prediction of Aboveground Biomass from Low-Density LiDAR Data: Validation over P. radiata Data from a Region North of Spain

 ,
,  and
and
Abstract
:1. Introduction
2. Materials and Methods
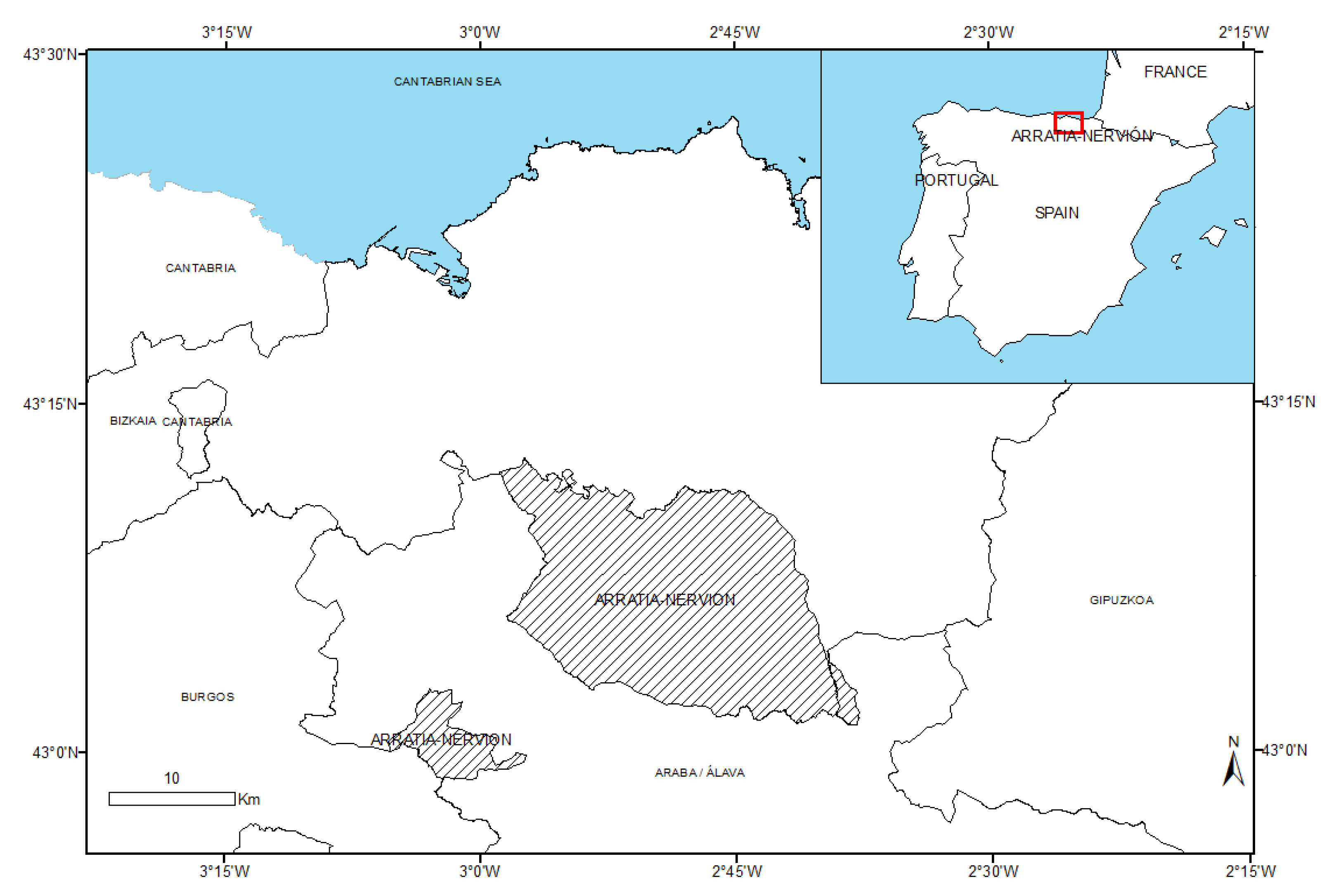
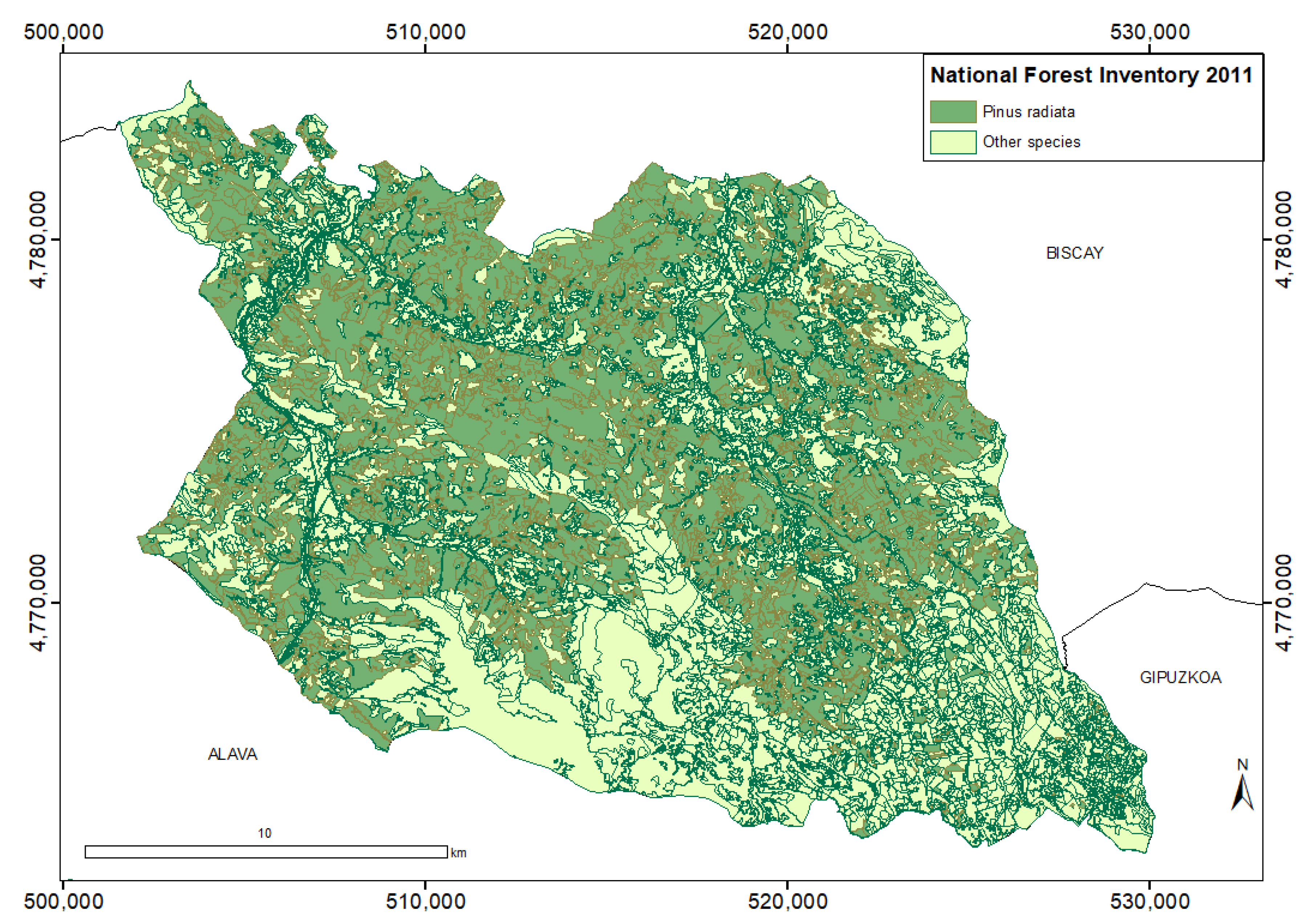
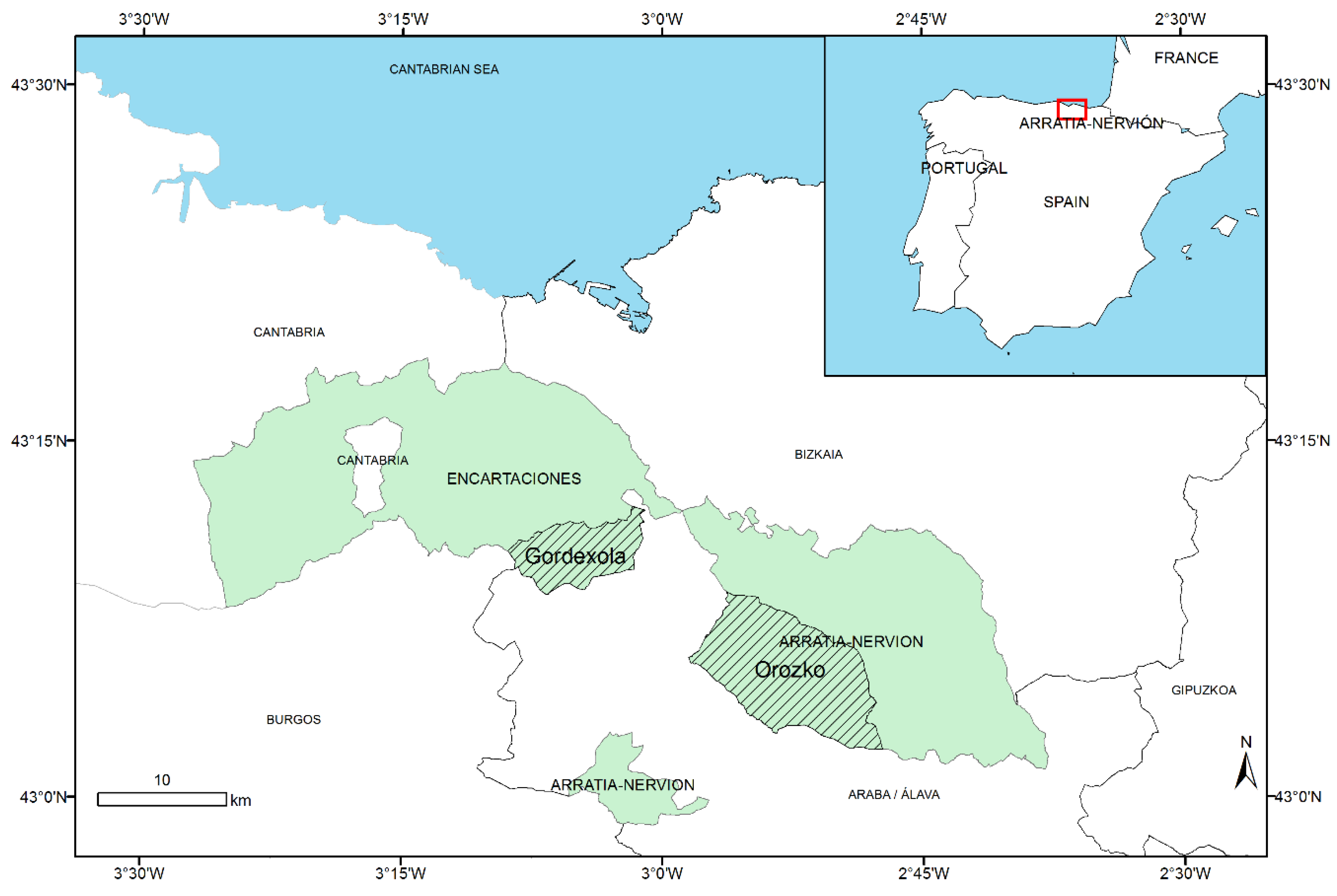
2.1. Study Area
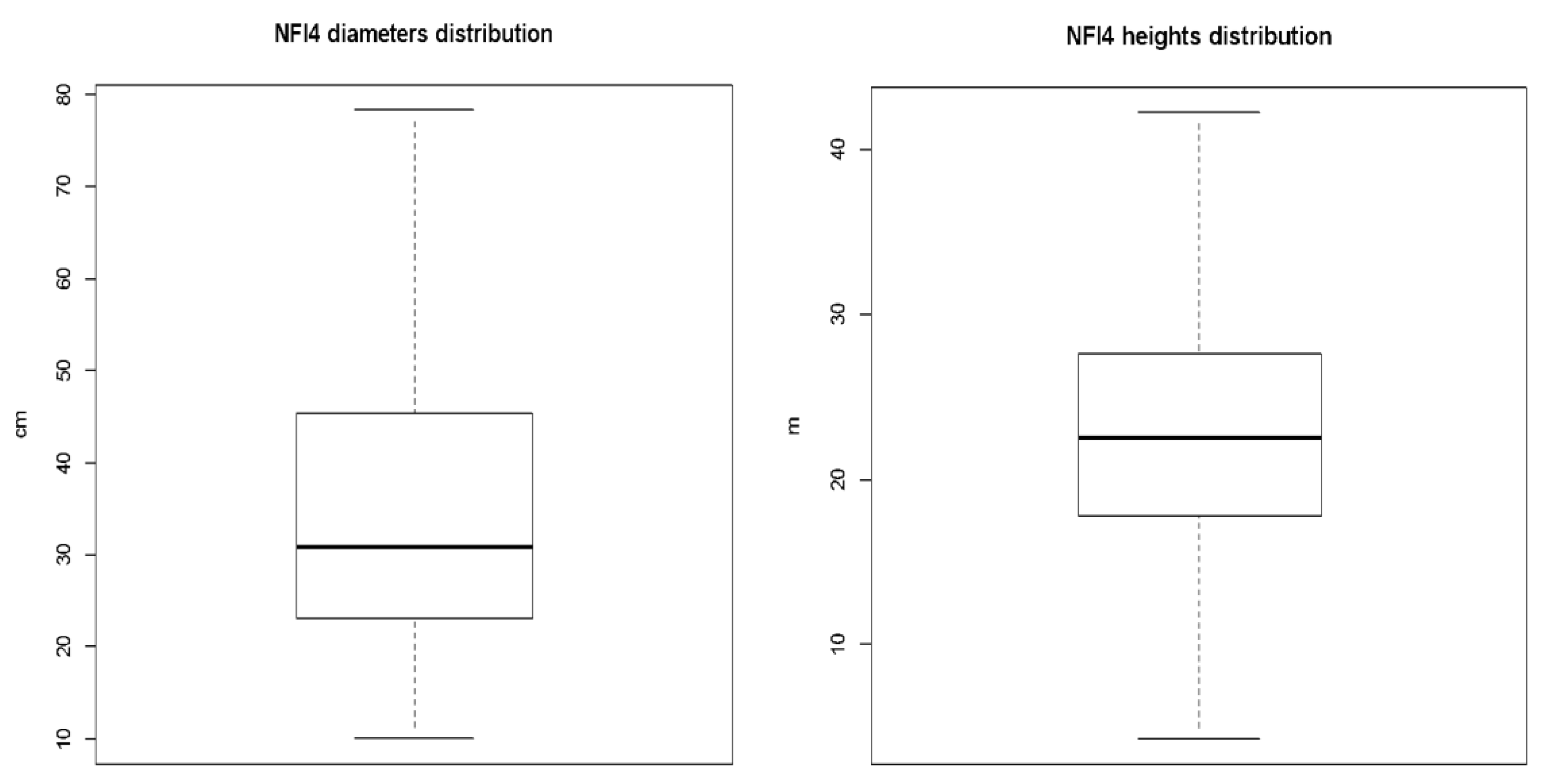
2.2. Field Data Collection
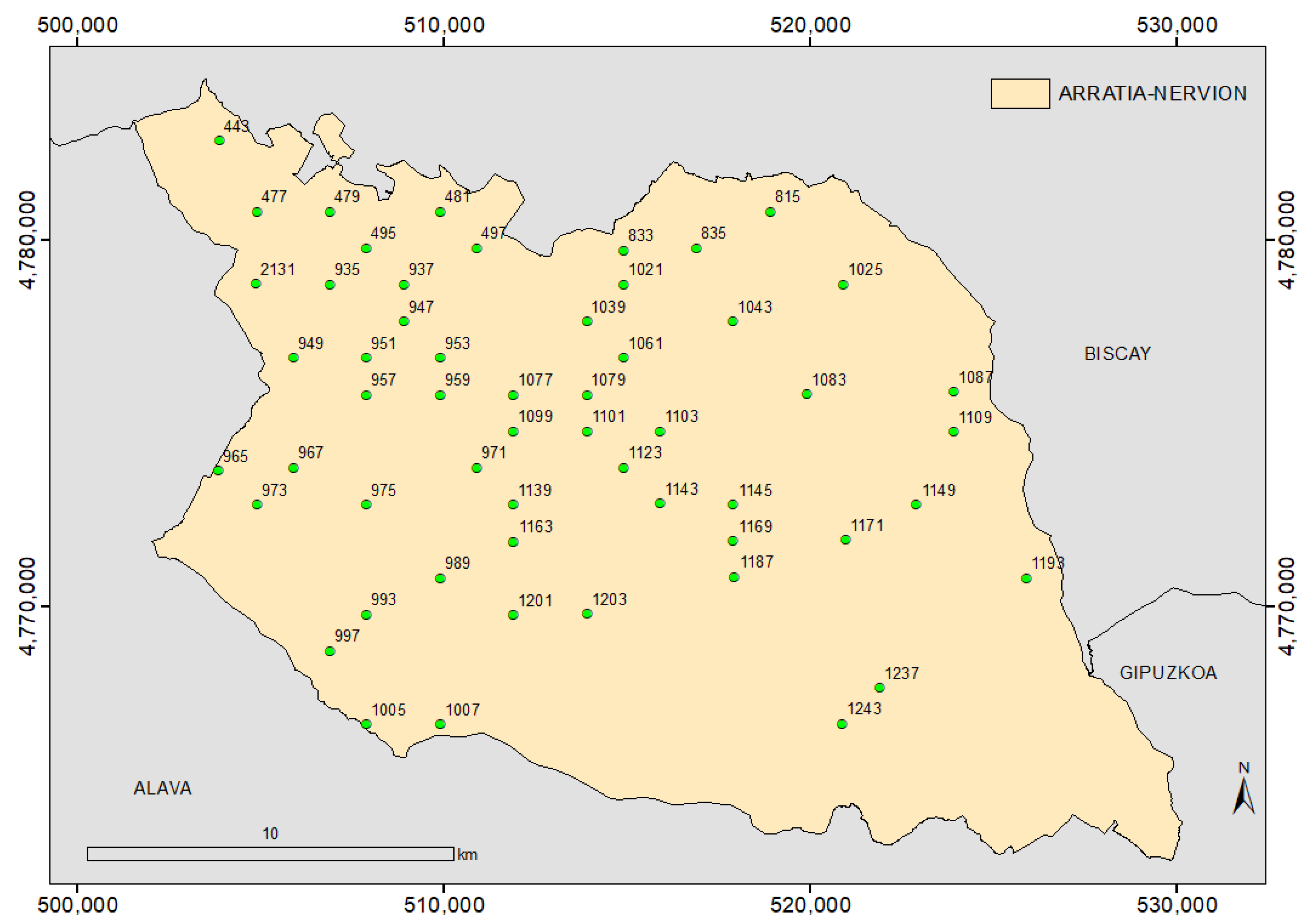
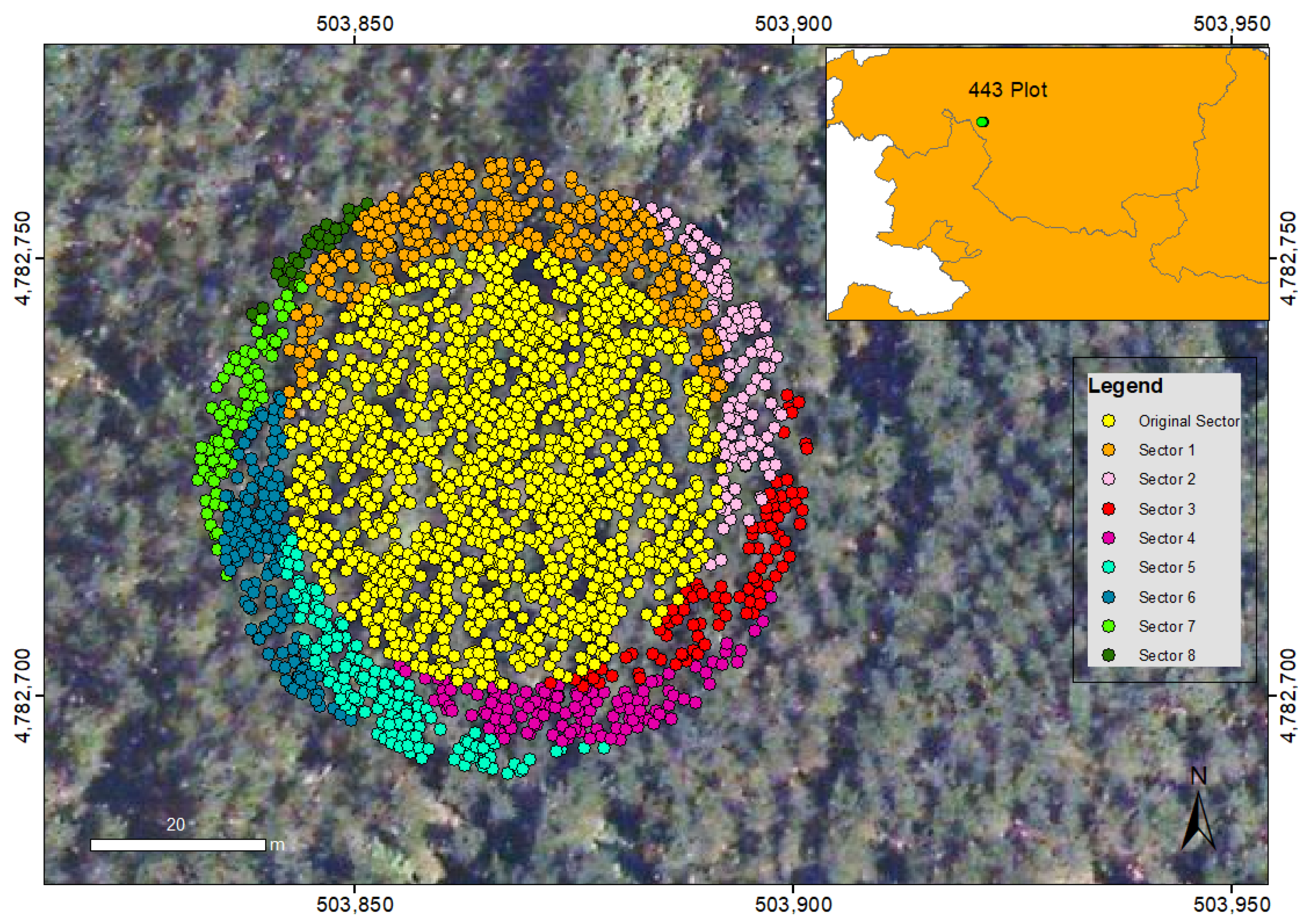
2.3. Field Plot Positioning
2.4. LiDAR Data
2.5. Orthophotos
2.6. Methods
2.6.1. Biomass Field Calculation
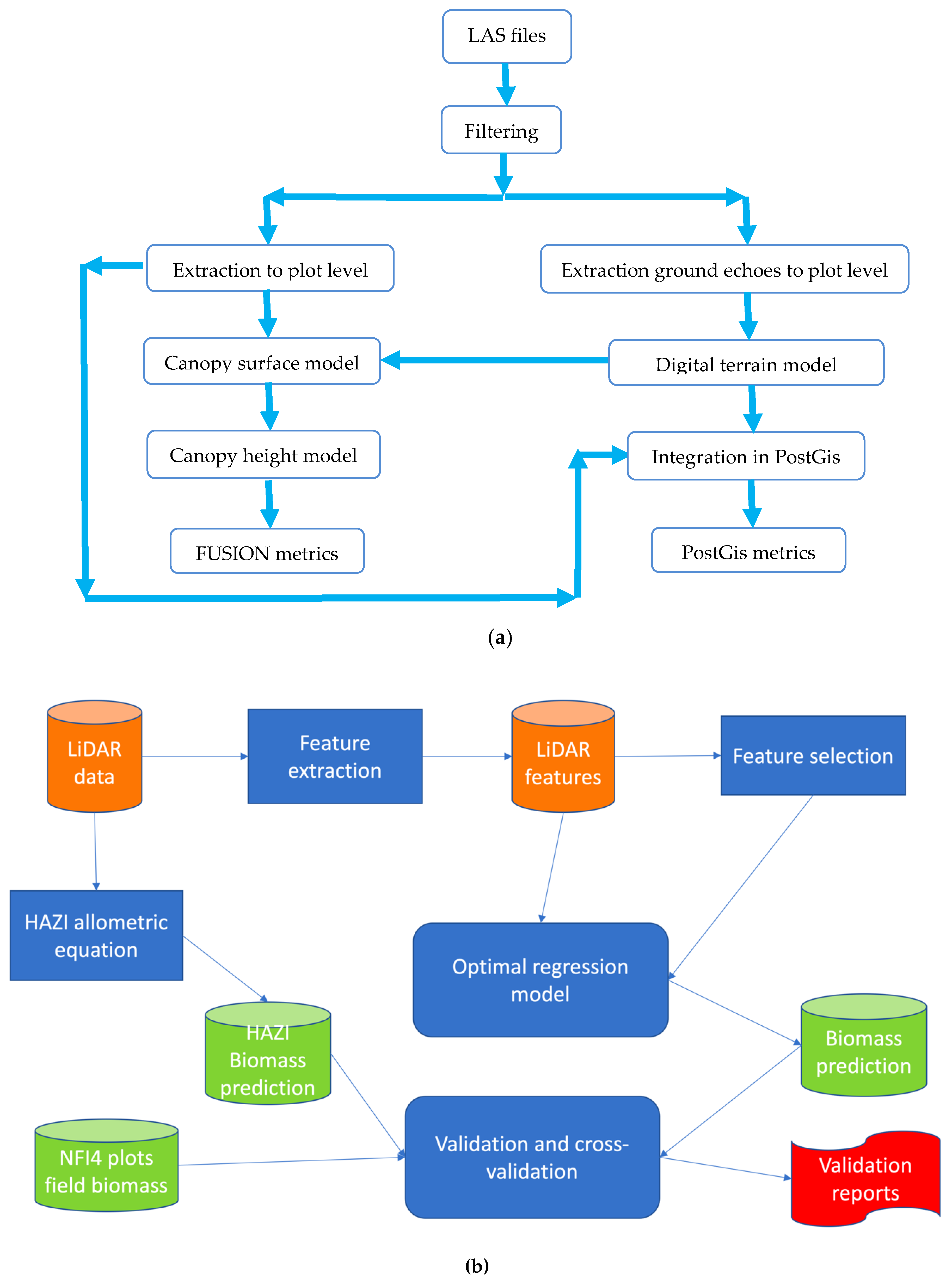
2.6.2. LiDAR Data Processing and Overall Process
2.6.3. Regression Analysis
2.6.4. Validation
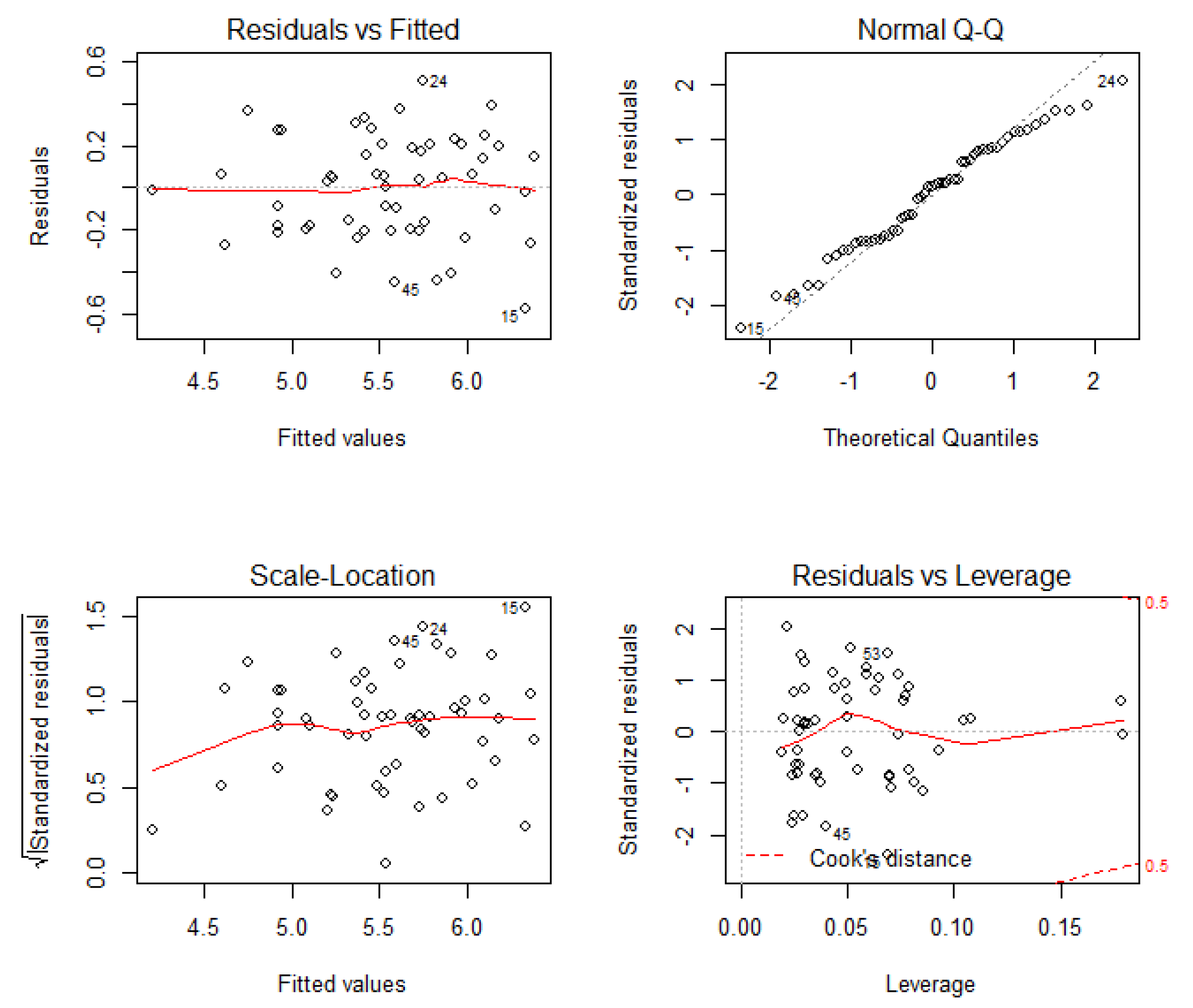
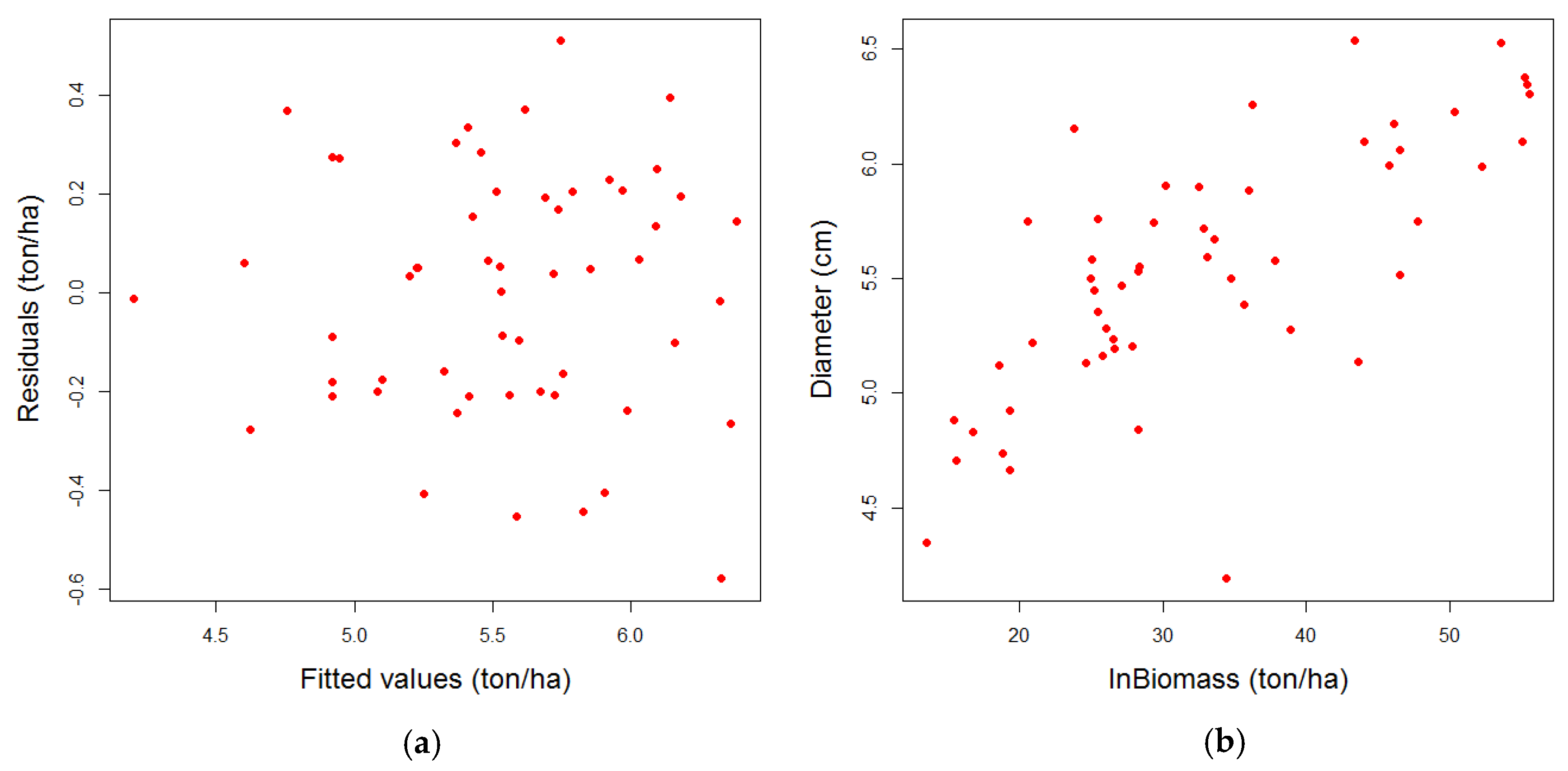
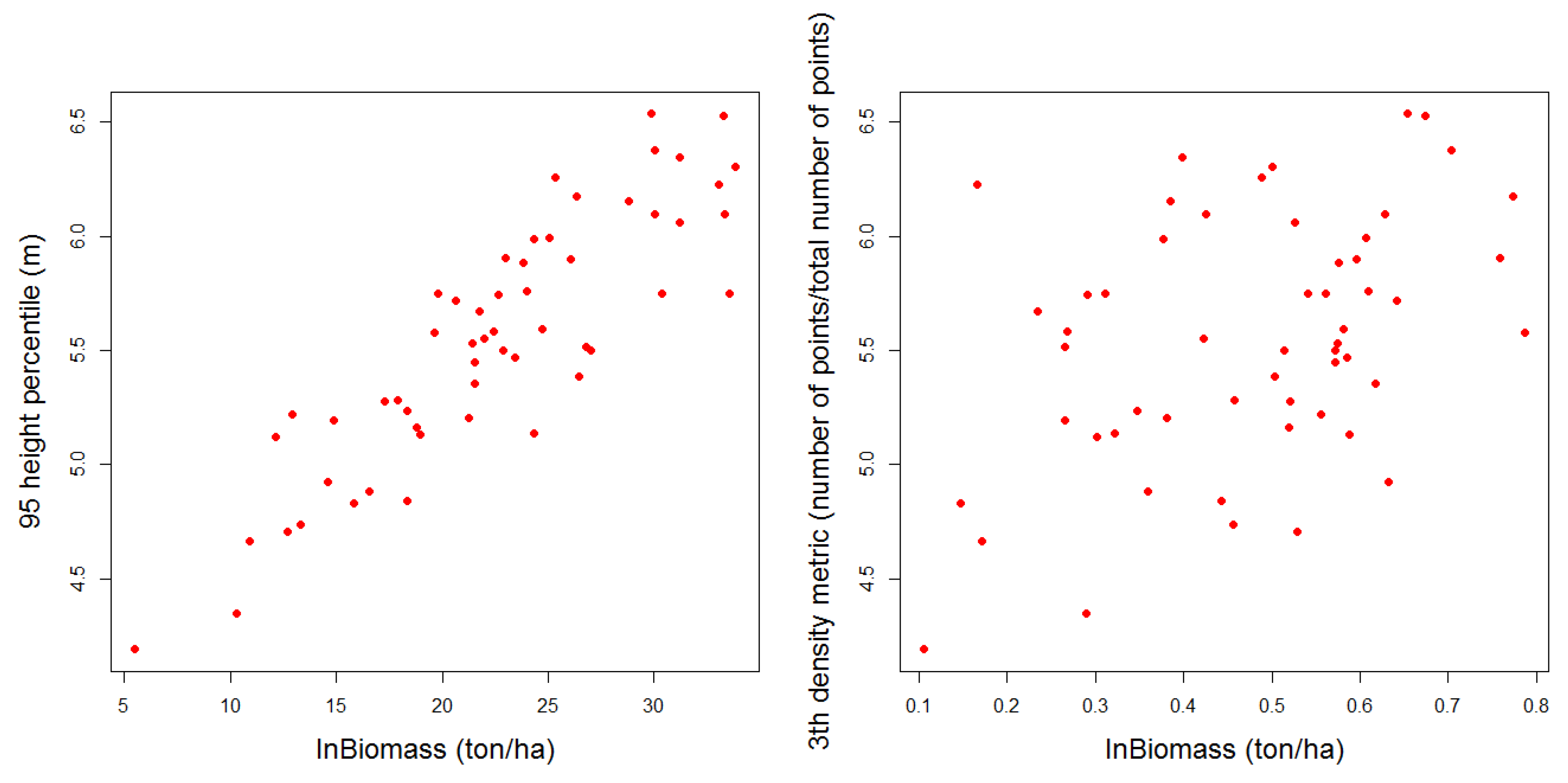
3. Results
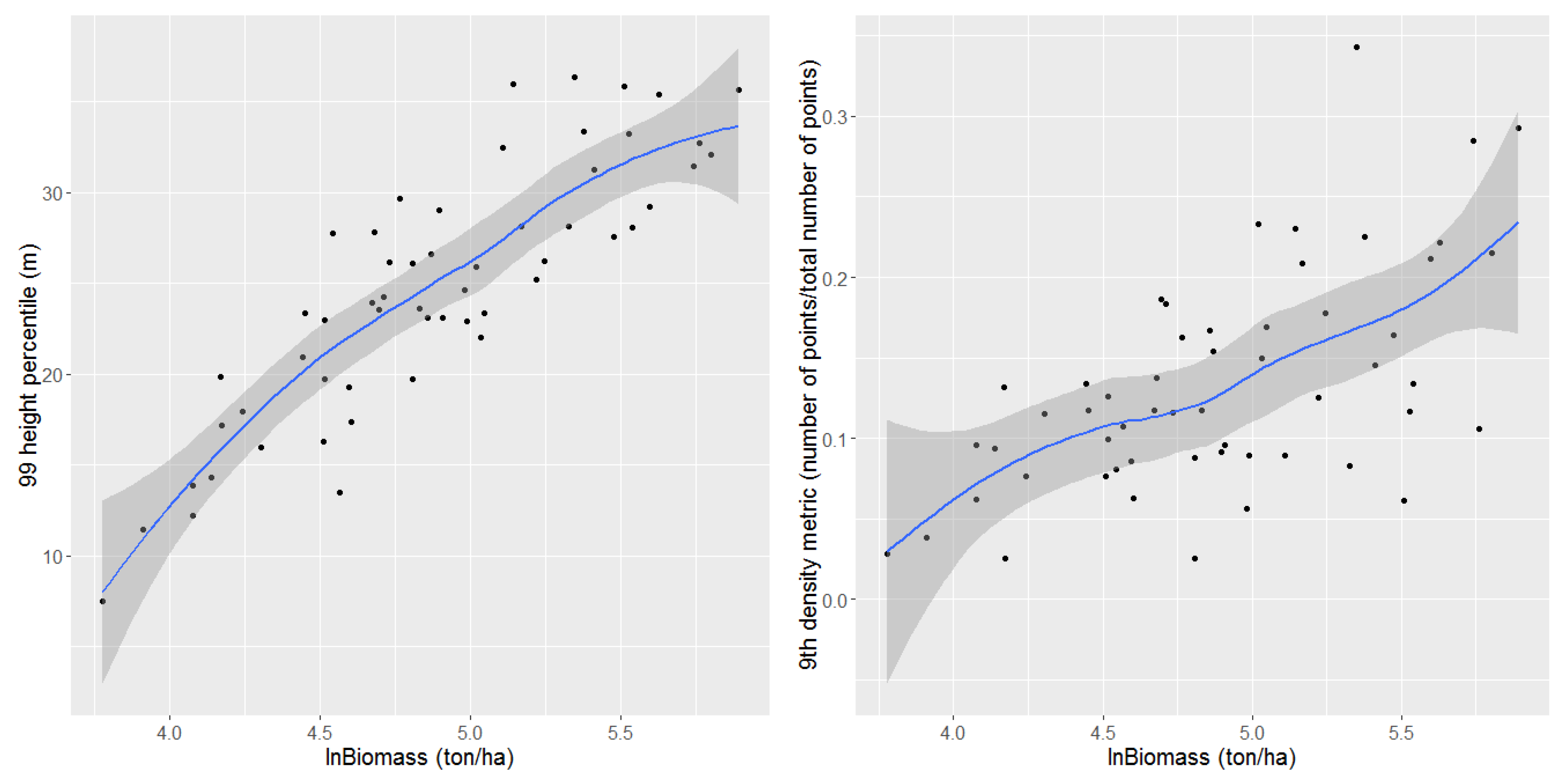
3.1. Results
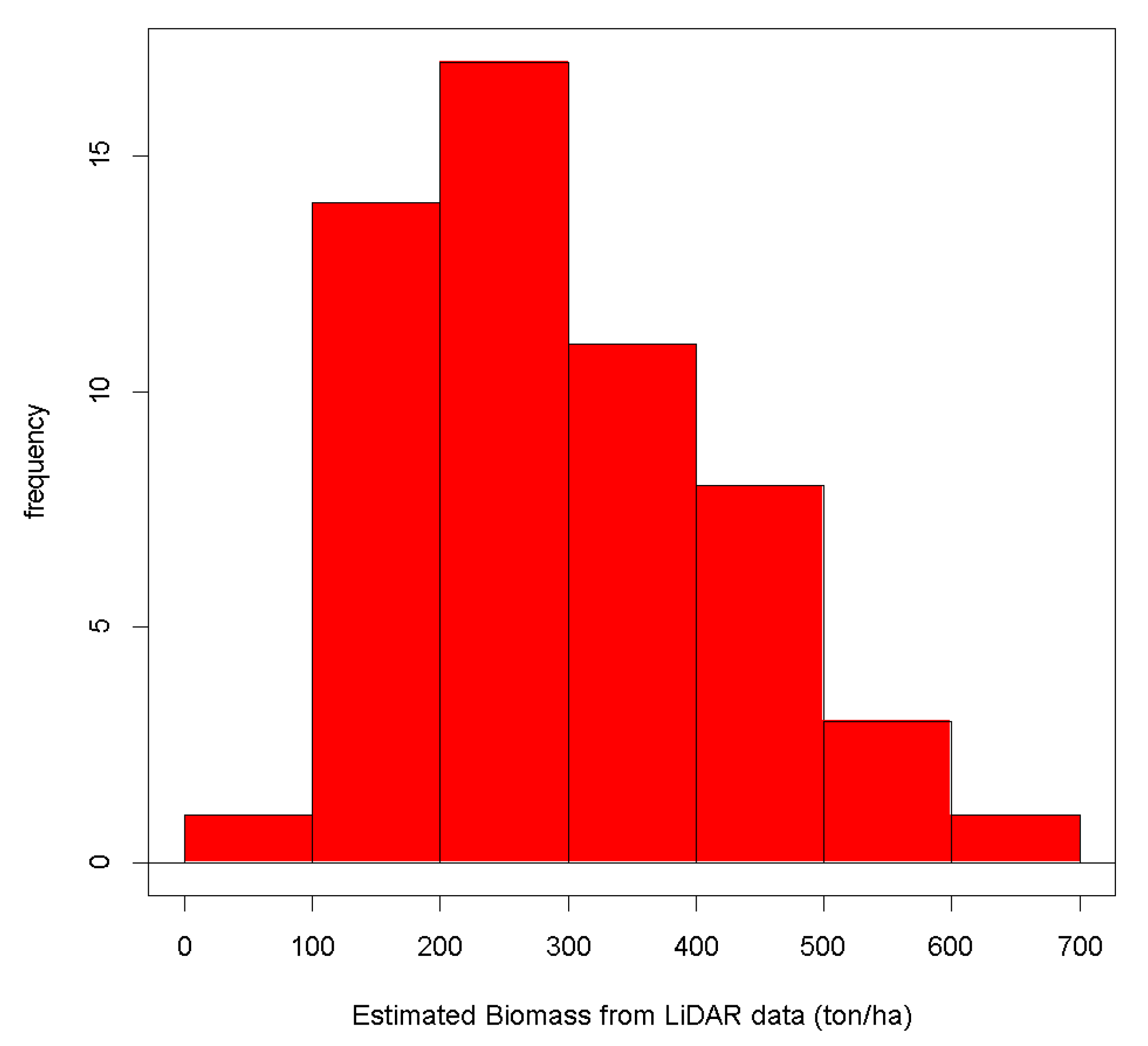
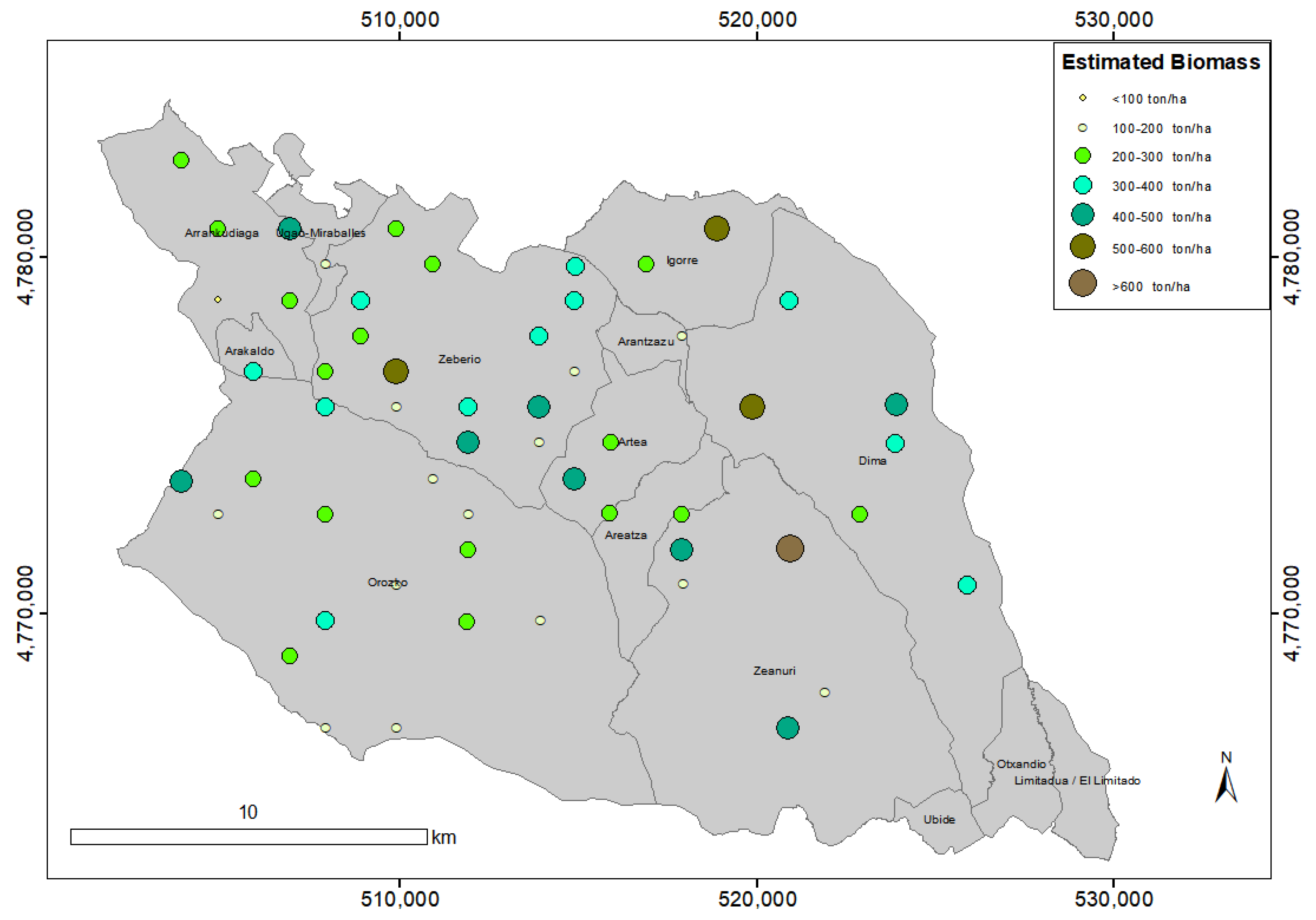
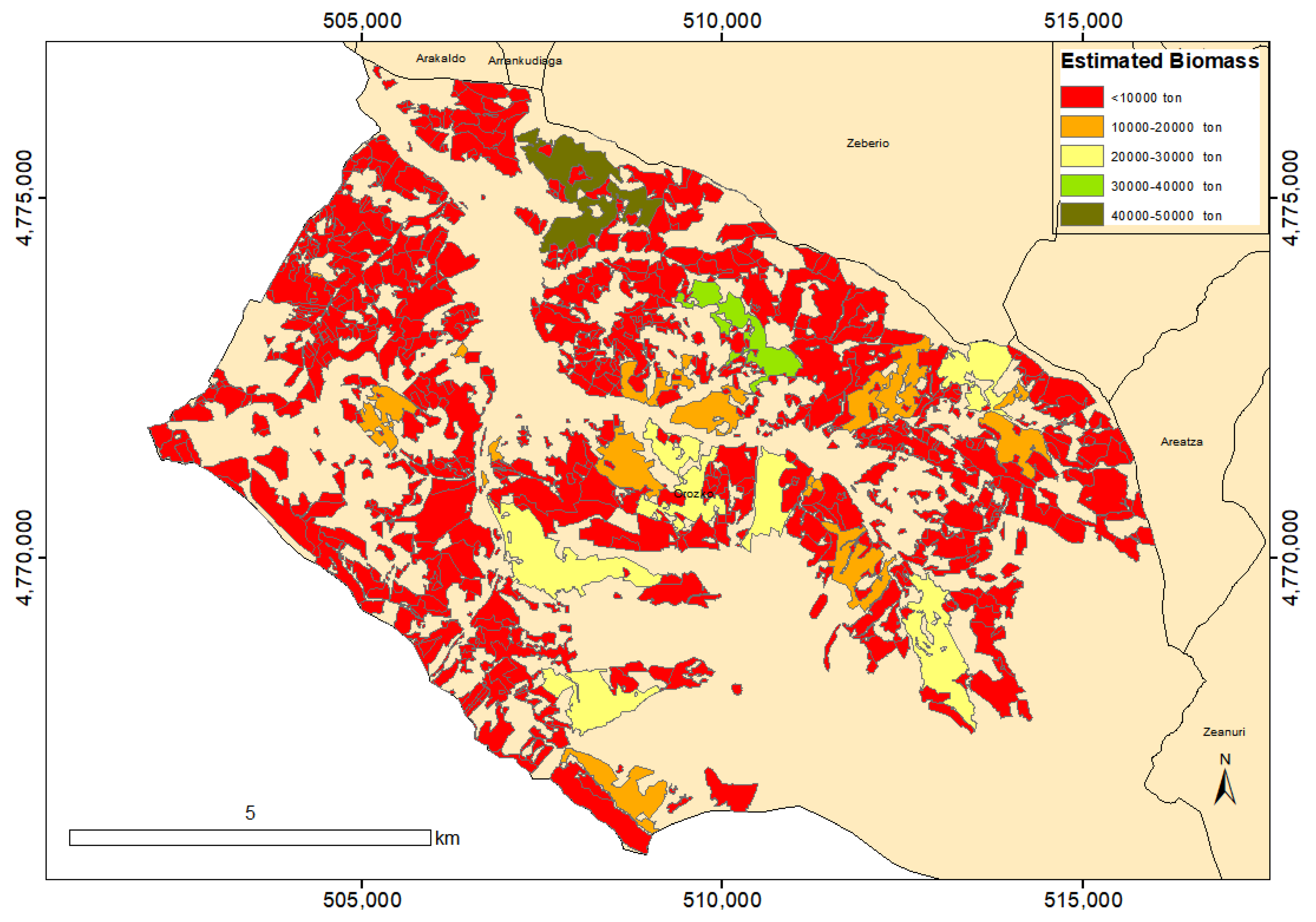
3.2. Application of the Selected Model
3.3. Validation of the Selected Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description | Variable | Description |
|---|---|---|---|
| count | number of returns above the minimum height | ccr | canopy relief ratio:((mean - min)/(max – min) |
| densitytotal | total returns used for calculating cover | eqm | elevation quadratic mean |
| densityabove | returns above height break | ecm | elevation cubic mean |
| densitycell | density of returns used for calculating cover | r1count,…,r9count | count of return 1,…,9 points above the minimum height |
| min | minimum value for cell | rothercount | count of other returns above the minimum height |
| max | maximum value for cell | allcover | (all returns above cover height (h))/(total returns) |
| mean | mean value for cell | afcover | (all returns above cover h)/(total first returns) |
| mode | modal value for cell | allcount | number of returns above cover h |
| stddev | standard deviation of cell values | allabovemean | (all returns above mean h)/(total returns) |
| variance | variance of cell values | allabovemode | (all returns above h mode)/(total returns) |
| cv | coefficient of variation for cell | afabovemean | (all returns above mean h)/(total first returns) |
| cover | cover estimate for cell | afabovemode | (all returns above h mode)/(total first returns) |
| abovemean | proportion of first (or all) returns above the mean | fcountmean | number of first returns above mean h |
| abovemode | proportion of first (or all) returns above the mode | fcountmode | number of first returns above h mode |
| skewness | skewness computed for cell | allcountmean | number of returns above mean h |
| kurtosis | kurtosis computed for cell | allcountmode | number of returns above h mode |
| AAD | average absolute deviation from mean for the cell | totalfirst | total number of first returns |
| p01,…,p99 | 1st,…,99th percentile value for cell | totalall | total number of returns |
| iq | 75th percentile minus 25th percentile for cell |
References
- IPCC. Climate Change 2014: Synthesis Report. Contribution of Working Groups I, II and III to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change; Core Writing Team, Pachauri, R.K., Meyer, L.A., Eds.; IPCC: Geneva, Switzerland, 2014; 151p. [Google Scholar]
- Poudel, K.P.; Temesgen, H. Methods for estimating aboveground biomass and its components for Douglas-fir and lodgepole pine trees. Can. J. For. Res. 2016, 46, 77–87. [Google Scholar] [CrossRef] [Green Version]
- Bi, H.; Long, Y.; Turner, J.; Lei, Y.; Snowdon, P.; Li, Y.; Harper, R.; Zerihun, A.; Ximenes, F. Additive prediction of aboveground biomass for Pinus radiata (D. Don) plantations. For. Ecol. Manag. 2010, 259, 2301–2314. [Google Scholar] [CrossRef]
- Espinosa, M.; Acuña, E.; Cancino, J.; Perry, D.A. Carbon Sink Potential of Radiata Pine Plantations in Chile. Forestry 2005, 78, 11–19. [Google Scholar] [CrossRef]
- Aragonés, A.; Espinel, S.; Ritter, E. Caracterización mediante el uso de RADP de la población de Pinus radiata del País Vasco. Invest. Agr. Sist. Rec. For. 1994, 3, 135–146. [Google Scholar]
- Cuarto Inventario Forestal Nacional COMUNIDAD AUTÓNOMA DEL PAÍS VASCO/EUSKADI.
- Corona, P. Consolidating new paradigms in large-scale monitoring and assessment of forest ecosystems. Environ. Res. 2016, 144, 8–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Corona, P. Integration of forest mapping and inventory to support forest management. iForest 2010, 3, 59–64. [Google Scholar] [CrossRef]
- Guo, Z.; Chi, H.; Sun, G. Estimating Forest Aboveground Biomass using HJ-1 Satellite CCD and ICESat GLAS Waveform Data. Sci. China-Earth Sci. 2010, 53, 16–25. [Google Scholar] [CrossRef]
- Næsset, E.; Gobakken, T.; Solberg, S.; Gregoire, T.G.; Nelson, R.; Ståhl, G.; Weydahl, D. Model-Assisted Regional Forest Biomass Estimation using LiDAR and InSAR as Auxiliary Data: A Case Study from a Boreal Forest Area. Remote Sens. Environ. 2011, 115, 3599–3614. [Google Scholar] [CrossRef]
- Nelson, R.; Margolis, H.; Montesano, P.; Sun, G.; Cook, B.; Corp, L.; Andersen, H.; deJong, B.; Pellat, F.P.; Fickel, T.; et al. Lidar-Based Estimates of Aboveground Biomass in the Continental US and Mexico using Ground, Airborne, and Satellite Observations. Remote Sens. Environ. 2017, 188, 127–140. [Google Scholar] [CrossRef]
- García, M.; Saatchi, S.; Ustin, S.; Balzter, H. Modelling Forest Canopy Height by Integrating Airborne LiDAR Samples with Satellite Radar and Multispectral Imagery. Int. J. Appl. Earth Observ. Geoinf. 2018, 66, 159–173. [Google Scholar] [CrossRef]
- Nelson, R.; Oderwald, R.; Gregoire, T.G. Separating the ground and airborne laser sampling phases to estimate tropical forest basal area, volume, and biomass. Remote Sens. Environ. 1997, 60, 311–326. [Google Scholar] [CrossRef]
- Nilsson, M. Estimation of tree heights and stand volume using an airborne lidar system. Remote Sens. Environ. 1996, 56, 1–7. [Google Scholar] [CrossRef]
- Næsset, E. Predicting forest stand characteristics with airborne scanning laser using a practical two-stage procedure and field data. Remote Sens. Environ. 2002, 80, 88–99. [Google Scholar] [CrossRef]
- Shi, Y.; Wang, T.; Skidmore, A.K.; Heurich, M. Important LiDAR Metrics for Discriminating Forest Tree Species in Central Europe. ISPRS J. Photogramm. Remote Sens. 2018, 137, 163–174. [Google Scholar] [CrossRef]
- Vaglio Laurin, G.; Puletti, N.; Chen, Q.; Corona, P.; Papale, D.; Valentini, R. Above Ground Biomass and Tree Species Richness Estimation with Airborne Lidar in Tropical Ghana Forests. Int. J. Appl. Earth Observ. Geoinf. 2016, 52, 371–379. [Google Scholar] [CrossRef]
- Magnussen, S.; Nord-Larsen, T.; Riis-Nielsen, T. Lidar Supported Estimators of Wood Volume and Aboveground Biomass from the Danish National Forest Inventory (2012–2016). Remote Sens. Environ. 2018, 211, 146–153. [Google Scholar] [CrossRef]
- Ene, L.T.; Gobakken, T.; Andersen, H.; Næsset, E.; Cook, B.D.; Morton, D.C.; Babcock, C.; Nelson, R. Large-Area Hybrid Estimation of Aboveground Biomass in Interior Alaska using Airborne Laser Scanning Data. Remote Sens. Environ. 2018, 204, 741–755. [Google Scholar] [CrossRef]
- Shao, G.; Shao, G.; Gallion, J.; Saunders, M.R.; Frankenberger, J.R.; Songlin, F. Improving Lidar-based aboveground biomass estimation of temperate hardwood forests with varying site productivity. Remote Sens. Environ. 2018, 204, 872–882. [Google Scholar] [CrossRef]
- Nelson, R.; Krabill, W.; MacLean, G. Determining Forest Canopy Characteristics using Airborne Laser Data. Remote Sens. Environ. 1984, 15, 201–212. [Google Scholar] [CrossRef]
- Popescu, S.C. Estimating Biomass of Individual Pine Trees using Airborne Lidar. Biomass Bioenergy 2007, 31, 646–655. [Google Scholar] [CrossRef]
- Goldbergs, G.; Levick, S.R.; Lawes, M.; Edwards, A. Hierarchical Integration of Individual Tree and Area-Based Approaches for Savanna Biomass Uncertainty Estimation from Airborne LiDAR. Remote Sens. Environ. 2018, 205, 141–150. [Google Scholar] [CrossRef]
- Yavaşlı, D.D. Estimation of Above Ground Forest Biomass at Muğla using ICESat/GLAS and Landsat Data. Remote Sens. Appl. Soc. Environ. 2016, 4, 211–218. [Google Scholar] [CrossRef]
- Nie, S.; Wang, C.; Zeng, H.; Xi, X.; Li, G. Above-Ground Biomass Estimation using Airborne Discrete-Return and Full-Waveform LiDAR Data in a Coniferous Forest. Ecol. Indic. 2017, 78, 221–228. [Google Scholar] [CrossRef]
- Montealegre, A.L.; Lamelas, M.T.; de la Riva, J.; García-Martín, A.; Escribano, F. Cartografía De La Biomasa Aérea Total En Masas De Pinus Halepensis Mill. En El Entorno De Zaragoza Mediante Datos LiDAR-PNOA y Trabajo De Campo. Análisis espacial y representación geográfica: Innovación y aplicación; Universidad de Zaragoza: Zaragoza, Spain, 2015; pp. 769–776. [Google Scholar]
- I.C.O.N.A. Segundo Inventario Forestal Nacional. Explicaciones y Métodos, Spain, 1986–1995, 1990.
- Pearson, T.R.H.; Walker, S.; Brown, S. Sourcebook for Land Use, Land-Use Change and Forestry Projects; World Bank: Washington, DC, USA, 2005. [Google Scholar]
- Cohen, J. A Coefficient of Agreement for Nominal scales. Educ. Psychol. Measur. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Ecuaciones de cubicación para el pino radiata en el País Vasco – IKT/HAZI – Arkaute, Spain. 2004.
- Gobakken, T.; Næsset, E.; Nelson, R.; Bollandsås, O.M.; Gregoire, T.G.; Ståhl, G.; Holm, S.; Ørka, H.O.; Astrup, R. Estimating biomass in Hedmark County, Norway using national forest inventory field plots and airborne laser scanning. Remote Sens. Environ. 2012, 123, 443–456. [Google Scholar] [CrossRef]
- Næsset, E.; Gobakken, T. Estimation of Above- and Below-Ground Biomass across Regions of the Boreal Forest Zone using Airborne Laser. Remote Sens. Environ. 2008, 112, 3079–3090. [Google Scholar] [CrossRef]
- Næsset, E. Effects of Different Flying Altitudes on Biophysical Stand Properties Estimated from Canopy Height and Density Measured with a Small-Footprint Airborne Scanning Laser. Remote Sens. Environ. 2004, 91, 243–255. [Google Scholar] [CrossRef]
- Næsset, E.; Gobakken, T. Estimating Forest Growth using Canopy Metrics Derived from Airborne Laser Scanner Data. Remote Sens. Environ. 2005, 96, 453–465. [Google Scholar] [CrossRef]
- Walpole, R.E.; Myers, R.H.; Myers, S.L.; Ye, K. Probabilidad y Estadística Para Ingeniería y Ciencias; Novena, Ed.; Pearson Educational: Mexico D.F., Mexico, 2012. [Google Scholar]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Automat. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Kleinbaum, D.; Kupper, L.; Nizam, A.; Rosenberg, E. Applied Regression Analysis and Other Multivariable Methods, 5th ed.; Cengage Learning: Boston, MA, USA, 2014. [Google Scholar]
- Baskerville, G. Use of Logarithmic Regression in the Estimation of Plant Biomass. Can. J. Forest. Res. 1972, 2, 49–53. [Google Scholar] [CrossRef]
- Saltelli, A.; Ratto, M.; Campolongo, F.; Cariboni, J.; Gatelli, D.; Saisana, M.; Tarantola, S. Global Sensitivity Analysis; The Primer: West Sussex, UK, 2008. [Google Scholar]
- Rykiel, E.J., Jr. Testing Ecological Models: The Meaning of Validation. Ecol. Model. 1996, 90, 229–244. [Google Scholar] [CrossRef]
- Steel, R.G.D.; Torrie, J.H. Principles and Procedures of Statistics, with Special Reference to Biological Sciences; McGraw-Hill: New York, NY, USA, 1960. [Google Scholar]
- Picard, N.; Saint-André, L.; Henry, M. Manual for Building Tree Volume and Biomass Allometric Equations:Fromfiled Measurement to Prediction; Food and Agricultural Organization of the United Nations; Rome and Centre Coopération Internationale en Food and Agricultural Organization of the United Nations: Montpellier, France, 2012; 215p. [Google Scholar]
- Saltelli, A.; Tarantola, S.; Chan, K. A Quantitative, Model Independent Method for Global Sensitivity Analysis of Model Output. Technometrics 1999, 41, 39–56. [Google Scholar] [CrossRef]
- Homma, T.; Saltelli, A. Importance Measures in Global Sensitivity Analysis of Nonlinear Models. Reliabil. Eng. Syst. Saf. 1996, 52, 1–17. [Google Scholar] [CrossRef]
- Næsset, E. Estimating Above-Ground Biomass in Young Forests with Airborne Laser Scanning. Int. J. Remote Sens. 2011, 32, 473. [Google Scholar] [CrossRef]
- González-Ferreiro, E.; Aranda, U.; Miranda, D. Estimation of Stand Variables in Pinus Radiata D. Don Plantations using Different LiDAR Pulse Densities. Forestry 2012, 85. [Google Scholar] [CrossRef]
- He, Q.; Chen, E.; An, R.; Li, Y. Above-Ground Biomass and Biomass Components Estimation using LiDAR Data in a Coniferous Forest. Forests 2013, 4, 984–1002. [Google Scholar] [CrossRef]
- Hall, S.A.; Burke, I.C.; Box, D.O.; Kaufmann, M.R.; Stoker, J.M. Estimating Stand Structure using Discrete-Return Lidar: An Example from Low Density, Fire Prone Ponderosa Pine Forests. For. Ecol. Manag. 2005, 208, 189–209. [Google Scholar] [CrossRef]
- Adhikari, H.; Heiskanen, J.; Siljander, M.; Maeda, E.; Heikinheimo, V.; Pellikka, P.K.E. Determinants of Aboveground Biomass Across an Afromontane Landscape Mosaic in Kenya. Remote Sens. 2017, 9, 1–19. [Google Scholar] [CrossRef]
- Jakubowski, M.K.; Guo, Q.; Kelly, M. Tradeoffs between lidar pulse density and forest measurement accuracy. Remote Sens. 2013, 130, 245–253. [Google Scholar] [CrossRef]
- Ruiz, L.A.; Hermosilla, T.; Mauro, F.; Godino, M. Analysis of the Influence of Plot Size and LiDAR Density on Forest Structure Attribute Estimates. Forests 2014, 5, 936–951. [Google Scholar] [CrossRef] [Green Version]
- Treitz, P.; Lim, K.; Woods, M.; Pitt, D.; Nesbitt, D.; Etheridge, D. LiDAR Sampling Density for Forest Resource Inventories in Ontario, Canada. Remote Sens. 2012, 4, 830–848. [Google Scholar] [CrossRef] [Green Version]
- Magnussen, S.; Næsset, E.; Gobakken, T. Reliability of LiDAR Derived Predictors of Forest Inventory Attributes: A Case Study with Norway Spruce. Remote Sens. Environ. 2010, 114, 700–712. [Google Scholar] [CrossRef]
- Corona, P.; Fattorini, L. Area-based lidar-assisted estimation of forest standing volume. Can. J. For. Res. 2008, 38, 2911–2916. [Google Scholar] [CrossRef] [Green Version]
- Næsset, E.; Gobakken, T.; Bollandsås, O.M.; Gregoire, T.G.; Nelson, R.; Ståhl, G. Comparison of Precision of Biomass Estimates in Regional Field Sample Surveys and Airborne LiDAR-Assisted Surveys in Hedmark County, Norway. Remote Sens. Environ. 2013, 130, 108–120. [Google Scholar] [CrossRef]
- D'Oliveira, M.V.N.; Reutebuch, S.E.; McGaughey, R.J.; Andersen, H. Estimating Forest Biomass and Identifying Low-Intensity Logging Areas using Airborne Scanning Lidar in Antimary State Forest, Acre State, Western Brazilian Amazon. Remote Sens. Environ. 2012, 124, 479–491. [Google Scholar] [CrossRef]
- Mascaro, J.; Detto, M.; Asner, G.P.; Muller-Landau, H.C. Evaluating Uncertainty in Mapping Forest Carbon with Airborne LiDAR. Remote Sens. Environ. 2011, 115, 3770–3774. [Google Scholar] [CrossRef]
- García-Gutiérrez, J.; Martínez-Álvarez, F.; Troncoso, A.; Riquelme, J.C. A Comparison of Machine Learning Regression Techniques for LiDAR-Derived Estimation of Forest Variables. Neurocomputing 2015, 167, 24–33. [Google Scholar] [CrossRef]
- Vaglio Laurin, G.; Chen, Q.; Lindsell, J.A.; Coomes, D.A.; Frate, F.D.; Guerriero, L.; Pirotti, F.; Valentini, R. Above Ground Biomass Estimation in an African Tropical Forest with Lidar and Hyperspectral Data. ISPRS J. Photogramm. 2014, 89, 49–58. [Google Scholar] [CrossRef]
- Treuhaft, R.N.; Anser, G.P.; Law, B.E. Structure-Based Forest Biomass from Fusion of Radar and Hyperspectral Observations. Geophys. Res. Lett. 2003, 30, 1472–1487. [Google Scholar] [CrossRef]















| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.00 | 0.99 | 0.99 | 0.97 | 0.96 | 0.98 | 0.98 | 0.98 | 0.98 |
| 1 | -- | 1.00 | 0.99 | 0.96 | 0.94 | 0.95 | 0.95 | 0.97 | 0.98 |
| 2 | -- | -- | 1.00 | 0.98 | 0.95 | 0.95 | 0.95 | 0.96 | 0.96 |
| 3 | -- | -- | -- | 1.00 | 0.98 | 0.98 | 0.94 | 0.93 | 0.91 |
| 4 | -- | -- | -- | -- | 1.00 | 0.98 | 0.94 | 0.93 | 0.91 |
| 5 | -- | -- | -- | -- | -- | 1.00 | 0.98 | 0.97 | 0.95 |
| 6 | -- | -- | -- | -- | -- | -- | 1.00 | 0.99 | 0.96 |
| 7 | -- | -- | -- | -- | -- | -- | -- | 1.00 | 0.98 |
| 8 | -- | -- | -- | -- | -- | -- | -- | -- | 1.00 |
| Regressors | R2adj | SE | AIC | SW | BP | DW | VIF | RESET | B |
|---|---|---|---|---|---|---|---|---|---|
| {p99,abovemean} | 0.79 | 0.25 | 7.70 | 0.76 | 0.09 | 0.40 | 1.28 | 0.75 | 0.02 |
| {p99,allabovemean} | 0.79 | 0.25 | 7.69 | 0.76 | 0.09 | 0.40 | 1.28 | 0.75 | 0.02 |
| {p99,tr_3} | 0.79 | 0.25 | 8.38 | 0.68 | 0.10 | 0.34 | 1.12 | 0.83 | 0.02 |
| {p99,tr_4} | 0.79 | 0.25 | 8.50 | 0.64 | 0.09 | 0.29 | 1.15 | 0.81 | 0.02 |
| {p95,allabovemean} | 0.79 | 0.25 | 8.59 | 0.40 | 0.16 | 0.41 | 1.26 | 0.64 | 0.02 |
| {p95,abovemean} | 0.79 | 0.25 | 8.61 | 0.40 | 0.16 | 0.40 | 1.27 | 0.64 | 0.02 |
| {p99,tr_2} | 0.79 | 0.25 | 8.97 | 0.76 | 0.10 | 0.39 | 1.12 | 0.84 | 0.02 |
| {p95,tr_3} | 0.79 | 0.25 | 9.18 | 0.48 | 0.19 | 0.35 | 1.11 | 0.74 | 0.02 |
| {p99,allcover} | 0.79 | 0.25 | 9.36 | 0.81 | 0.08 | 0.45 | 1.14 | 0.82 | 0.01 |
| {p95,tr_2} | 0.79 | 0.25 | 9.47 | 0.53 | 0.18 | 0.41 | 1.10 | 0.76 | 0.02 |
| Variables | Estimated Value | Lower Bound | Upper Bound |
|---|---|---|---|
| Constant | 3.774 | 3.500 | 4.048 |
| p_95 | 0.548 | 0.111 | 0.984 |
| tr_3 | 0.67 | 0.056 | 0.078 |
| Variables | Si | STi | Variance | D1 | Dt |
|---|---|---|---|---|---|
| p95 | 0.8128 | 0.9453 | 0.1314 | 0.1068 | 0.0072 |
| tr_3 | 0.8513 | 0.8404 | 0.1426 | 0.1214 | 0.0228 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tojal, L.-T.; Bastarrika, A.; Barrett, B.; Sanchez Espeso, J.M.; Lopez-Guede, J.M.; Graña, M. Prediction of Aboveground Biomass from Low-Density LiDAR Data: Validation over P. radiata Data from a Region North of Spain. Forests 2019, 10, 819. https://doi.org/10.3390/f10090819
Tojal L-T, Bastarrika A, Barrett B, Sanchez Espeso JM, Lopez-Guede JM, Graña M. Prediction of Aboveground Biomass from Low-Density LiDAR Data: Validation over P. radiata Data from a Region North of Spain. Forests. 2019; 10(9):819. https://doi.org/10.3390/f10090819
Chicago/Turabian StyleTojal, Leyre-Torre, Aitor Bastarrika, Brian Barrett, Javier Maria Sanchez Espeso, Jose Manuel Lopez-Guede, and Manuel Graña. 2019. "Prediction of Aboveground Biomass from Low-Density LiDAR Data: Validation over P. radiata Data from a Region North of Spain" Forests 10, no. 9: 819. https://doi.org/10.3390/f10090819
APA StyleTojal, L. -T., Bastarrika, A., Barrett, B., Sanchez Espeso, J. M., Lopez-Guede, J. M., & Graña, M. (2019). Prediction of Aboveground Biomass from Low-Density LiDAR Data: Validation over P. radiata Data from a Region North of Spain. Forests, 10(9), 819. https://doi.org/10.3390/f10090819