1. Introduction
It has been widely recognized that forests can provide ecosystem services (ESs). Much research has been produced on the quantitative evaluation of ESs, which is mainly divided into two methods: value quantity evaluation and quality evaluation. The most representative method of value quantity is the market value method proposed by Costanza [
1,
2]. On this basis, some researchers have put forward the equivalent factor method [
3]. The method of matter quality is closer to the process of material circulation and energy exchange within an ecosystem, and the evaluation results are more favorable for ecosystem-related research. This method primarily focuses on the energy method [
4] and the model method [
5,
6]. For the ESs of the Grain for Green Project (GGP), the model method is generally used to calculate the quality evaluation. The model method can be divided into two types: the first is a model established based on the land-use change, used to obtain the ES evaluation of GGP [
7,
8,
9]. The GGP is mainly applied to areas with serious soil erosion and the cultivated land with a slope above 25 degrees. Therefore, its spatial distribution is very scattered. It is challenging to accurately evaluate the GGP stand with this method. The second model utilizes the assessment of ESs based on the ecological data of the GGP monitored by forest ES observation stations [
10,
11]. This method takes the standard age of a dominant forest species as the smallest unit to evaluate. Further, it focuses on the direct monitoring of the stand’s impact on the environment before and after the implementation of the GGP. The ecological monitoring of the GGP started as early as 2012, but the real realization of the nationwide network monitoring of forest ecosystem services through observation stations began in 2015. The monitoring network includes 32 special monitoring stations for ecological benefits, 59 forest ecological stations under CFERN, over 200 auxiliary observation points, and over 7000 sample plots. The unified ecological monitoring standard of the GGP has contributed to the accurate assessment of ESs. However, with the continuous implementation of the GGP, it is necessary to assess its future ESs in order to help the government formulate an implementation plan.
At present, some scholars have studied the simulation and prediction of ESs. However, most mathematicians carry out predictions based on land use [
12,
13,
14]. This prediction method is not suitable for evaluating the GGP. Although the GGP causes changes in forests and farmland, not all changes are due to the GGP. The regional distribution of the GGP is very scattered, and changes within the GGP are not great compared to the changes in overall land use, making it difficult to predict the GGP’s ecological benefits. Only by using long-term positioning observation data collected in the field can accurate predictions regarding ESs be made.
The GGP has been formally implemented since 1999, and of all projects in China is the largest in scale, longest in duration, affecting the largest population, and attracting the largest amount of investment. However, since large-scale ecological monitoring for the GGP started in 2015, it has been difficult to accurately predict future ES data due to the lack of past ecological monitoring. It is important for researchers to find the most appropriate way to realize the prediction of ESs for the GGP [
15].
Ensemble learning is a kind of machine learning classification. “Ensemble” refers to systems created by combining various models or classifiers [
16]. Ensemble learning is generally used where there is a lack of sufficient data to correctly represent the data distribution, when various models apply to a given situation, and when the selected model cannot correctly represent the sought decision boundary [
17]. In the existing research, ensemble learning is widely used in the computing [
18,
19,
20] and medical fields [
21,
22]. There are few applications in the ecological field, mainly focusing on forest fire monitoring [
23]. Therefore, it is feasible to use the method of ensemble learning to predict the ESs of the GGP as an innovative attempt to predict the ES of a small sample of data.
This paper uses the GGP’s quantitative ES results published in 2015, 2017, and 2019, based on long-term field positioning observation network data, and uses an integrated learning algorithm to form predictions. On this basis, a neural network is used to predict the GGP’s future ESs. The results of this study can not only fill the gaps in available ES data, but also provide a scientific basis for the further implementation of the GGP in the study area.
3. Materials and Methods
3.1. Study Area
This paper focuses on the prediction of ESs of the GGP in 14 contiguous, poverty-stricken areas in China. They are mostly distributed across the Loess Plateau, the Qinghai Tibet Plateau, some areas of the Inner Mongolia Plateau, several large desert marginal areas, and some rocky desertification areas in the South [
26] (
Figure 1).
The GGP’s main goal is to protect the environment, stop the cultivation of farmland with serious soil erosion, desertification and salinization, and plant trees and grasses as per local conditions to restore vegetation. The State Council arranges the State Forestry Administration, together with the National Development and Reform Commission, the Ministry of Finance, the Western Development Office of the State Council, and the State Grain Administration, to plan the project. GGP tasks are distributed to each province by the State Forestry Administration every year. A new round of the GGP has been implemented since 2014, and all farmers participating in the GGP have been given a land subsidy of 1600 yuan per mu. By 2020, the central government had invested 535.3 billion yuan in the GGP. The Chinese Government stipulates that contiguous poverty-stricken areas are key for GGP implementation, both in the present and well into the future. On the one hand, the implementation of the GGP will contribute to poverty alleviation in these regions. On the other hand, the ecological environment of these areas is poor, and the implementation of the GGP can produce more ESs, such as soil consolidation (soil consolidation reduces nitrogen loss, phosphorus loss, potassium loss, and organic matter loss), forest nutrient retention (of nitrogen, phosphorus, and potassium), water conservation, carbon fixation and oxygen release, the purification of the atmosphere (providing air negative ions, the absorption of air pollutants, dust retention, TSP retention, PM10 retention, and PM2.5 retention), forest protection (farmland protection, windbreak and sand fixation), species conservation, and so on. It is also helpful in solving the problem of soil erosion in the study area.
Forest protection is only provided by shelterbelts, and shelterbelts are not planted in all areas. Additionally, there is no accounting for the quality of species conservation. Therefore, forest protection and species conservation are not discussed in this study.
3.2. Experimental Data
In this paper, the data is provided by the GGP management centre for state forest and grassland administration, including the quantitative results of ESs and resource areas of the GGP in 2015, 2017, and 2019. Since the GGP is a forestry project, the state will assign an implementation task every year; that is, the area in which the project will be implemented. Therefore, in order to eliminate the influence of area on the accuracy of the prediction results, the mass per unit area is used for the follow-up work. The ecosystem service data of GGP can be accessed from Annex I.
3.3. Experimental Environment
The experimental environment of this study is Ubuntu 20.04 64 bit, CPU: Intel i7-10875h, GPU: titanx, RAM: 16 GB, ROM: 500 GB.
The programming language used is Python. The languages used in the framework are NumPy, Matplotlib, pandas, sklearn, and Python.
3.4. Methods
3.4.1. Ensemble Learning
The most important concept of ensemble learning is that it does not aim to generate any specific algorithm. The key point of its application is to select and fuse weak classifiers to construct strong classifiers, thereby realizing real scene prediction with a more optimized ensemble system.
In this paper, fusion training was carried out under the sklearn machine learning library developed in the Python language. SVR, linear regression, extremely randomized trees (ET), eXtreme gradient boosting (XGBoost), and the decision treeregressor (DT) were selected to analyze the data. After initial training, the R2 scores of all models were 0.74, 0.61, 0.815, 0.803, and 0.792, respectively. XGBoost, ET, and DT have the highest and most similar scores. Therefore, using these three models in tandem will result in higher prediction accuracy. Therefore, this study selected the XGBoost, ET, and DT models for integrated learning and to establish an integrated system.
3.4.2. Extremely Randomized Trees
ET is an ensemble learning method [
27,
28]. It is composed of multiple individual learners, and the individual learner of the ET is a decision tree [
29]. A decision tree is a tree-like machine learning method which divides data samples through a series of problems or decisions until the best decision is found [
30].
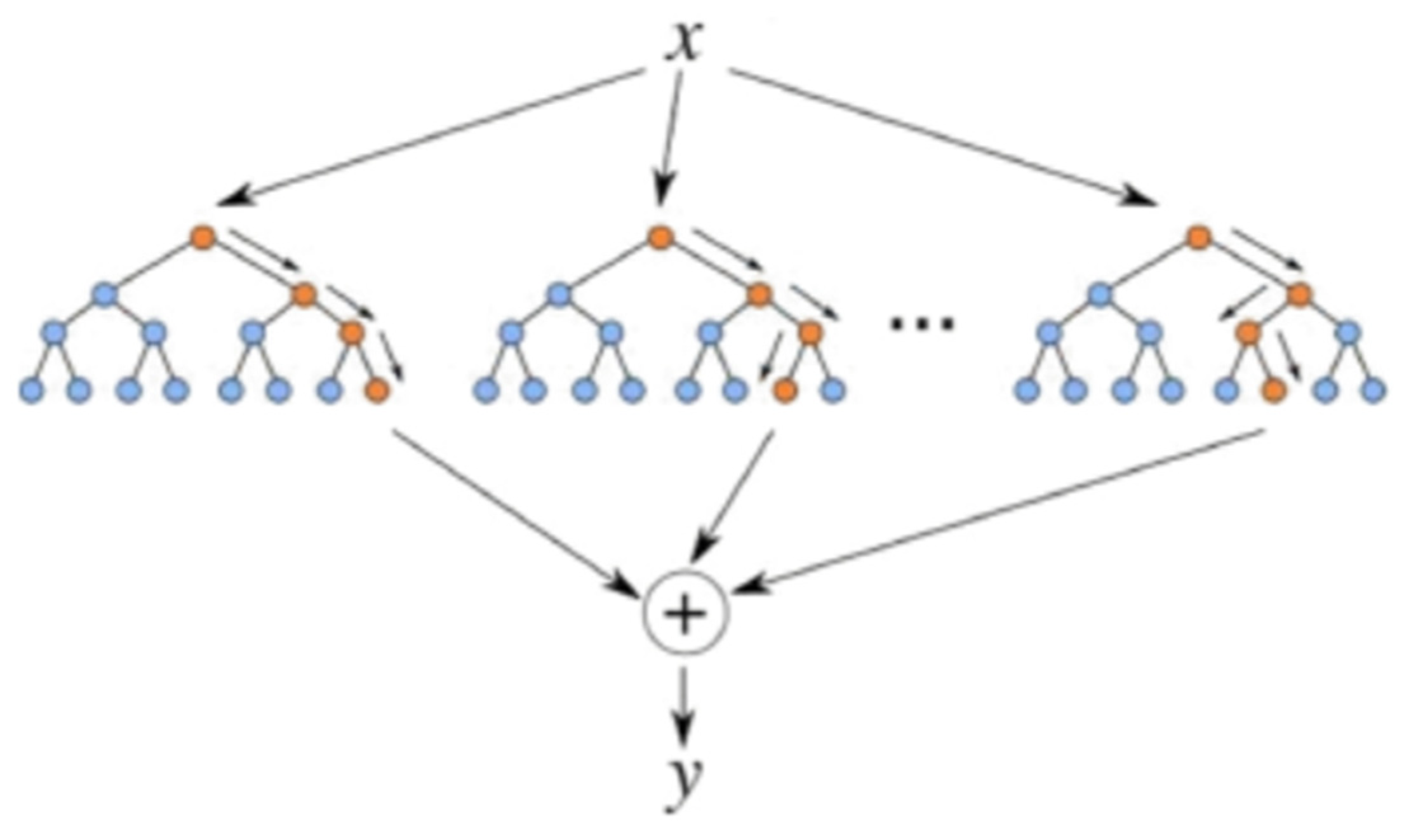
Figure 2 shows the schematic diagram of an ET algorithm. The ET algorithm uses the original training set x to sample each decision tree and uses multiple decision trees for training. As the split algorithms generated by ET are random, all the samples used are only randomly selected, and the output result is a certain average of the output of each decision tree. After the partition feature is selected, the algorithm will be more aggressive, and randomly select an eigenvalue to divide the decision tree. Therefore, the randomness of ET is reflected by the fact that the feature space of its bifurcation is randomly determined [
30,
31]. For this reason, an ET algorithm has better generalization than a random forest in some scenarios.
3.4.3. eXtreme Gradient Boosting
XGBoost (extreme gradient boosting) is a machine learning algorithm which originated from the GBDT model. It uses a variety of methods to accelerate its training process and improve accuracy. As a new scalable, end-to-end boosting tree algorithm, it makes accurate predictions based on tree classifiers (
Figure 3), and improves operation efficiency [
32,
33]. It uses a prediction model based on a decision tree to work through a gradient enhancement framework [
34]. It is an efficient model of reinforcement ensemble learning [
35,
36]. Specifically, XGBoost improves its algorithm based on a gradient lifting decision tree. The lifting tree includes a regression tree and a classification tree. The goal of the algorithm is to optimize the objective function value, which can efficiently build the lifting tree and run in parallel [
37].
In addition, XGBoost has the advantage of scalability in all scenarios, and its computing speed is fast [
38]. The running speed of the system on a single machine is more than ten times faster than other popular solutions, and it can be expanded to billions of examples in a distributed or memory-limited environment. It can be combined with other machine learning algorithms to obtain an algorithm with a more accurate prediction function. The scalability of XGBoost is due to several important system and algorithm optimizations. For example, a novel sparse data-sensing algorithm is used to process sparse data; a reasonable weighted quantile sketch can process data with weighted features in approximate tree learning. As parallel and distributed computing can make learning faster, the exploration of the model can be undertaken more quickly [
38]. For these reasons, XGBoost is currently the best tool on the market for small-scale data [
39].
3.4.4. Decision Treeregressor
Although decision treeregressor is a supervised machine learning algorithm, it is widely used in ensemble learning. An ensemble classifier is one that combines several basic classifiers together for its final classification. The classifier, for example, can be any kind of SVM or supervised DT. The DT classification model is represented by a tree structure: rather, the paths from roots to nodes represent rules. Each internal node represents a feature test, each branch represents a possible test result, each leaf node represents a classification [
40], and the bifurcation path from each node represents a possible attribute value [
41], mostly used for the classification of numerical and categorical data. The DT only has a single output: that is, from the root node, it can only reach one leaf node, and thus its rules are unique [
42]. As a result, it can be used for data classification and prediction.
Figure 4 shows a simple DT model. It includes a binary target variable
y (0 or 1) and two continuous variables
x1 and
x2, ranging from 0 to 1. The main components of a DT model are nodes and branches, and the most important steps of establishing the model are splitting, stopping, and pruning [
43].
3.4.5. Cluster Analysis
Clustering analysis performed by gathering highly similar data together, with discrete data being considered as noise in the process of experimentation. Therefore, clustering is an important part of data cleaning [
44].
In a clustering problem, silhouette analysis is used to study the distance between clusters. Silhouette analysis measures the compactness of points in the same class compared with points in different classes. This measure is visualized by the silhouette graph, which provides a method to evaluate the number of classes. The silhouette value is within the range of (−1, 1), where values close to 1 indicate that the sample is far away from the adjacent class, values of 0 mean that the sample is almost on the decision boundary of two adjacent classes, and negative values mean that the sample is divided into the wrong class. Based on the silhouette analysis method, the number of the two algorithms is divided as to whether K-means (divided into 10 classes) or Birch (divided into 11 classes) is the most appropriate. The dimension reduction visualization results of clustering are shown in
Figure 5 and
Figure 6.
From the above figures, it can be determined that both K-means and Birch algorithms show good clustering and discretization and can eliminate some discrete data. The accuracy of the results is improved.
3.4.6. Standardization Treatment
Due to the different nature of each ecosystem service function index, each has different dimensions and orders of magnitude. When the level of each index varies greatly, if the original index value is directly used for analysis it will highlight the role of any index with a higher value in the comprehensive analysis and weaken the role of any index with a lower value. Therefore, in order to ensure the reliability of the results, it is necessary to standardize the original index data.
In this study, min/max normalization is used to normalize the data, and the original data is transformed linearly, so that the results fall to (0, 1) intervals. The conversion function is as follows:
where
max is the maximum value of the sample data and
min is the minimum value of the sample data.
3.4.7. Auto-XGBoost-ET-DT Model
We built a new model framework of ensemble learning for reverse prediction, namely an auto-XGBoost-ET-DT model. The workflow of the model is shown in
Figure 7.
The basic design of the auto-XGBoost-ET-DT model is based on XGBoost, ET, and DT. First, the method in
Section 3.4.4 and
Section 3.4.5 was used to clean and standardize the training dataset. The processed dataset was randomly divided into three parts: 64% was used as the training set, 16% as the verification set, and 20% as the test set. The training set was used to train the above three models in the sklearn machine learning library developed by Python. Three groups of feature data were obtained. On this basis, a model fusion automaton was designed using the Python framework to determine the fusion weights for the three models. The verification set was mainly used to verify the parameters of the model in the model fusion automaton. Finally, the R2 test and mean squared error (MSE) loss function were performed using the prediction results of the test set and the auto-XGBoost-ET-DT model.
The neural network realizes the model fusion automaton. The neural network contains a fully connected layer, and only three neurons were used for weight regression. The loss function of the neural network is the mean square error (MSE). The network trains 300,000 epochs on the verification set and 1–100,000 epochs were optimized by the SGD optimization algorithm to determine the optimization direction. The Adam optimization algorithm was used to improve the optimization speed from 100,001 epochs to 200,000 epochs. The SGD optimization algorithm was used again to optimize the details from 200,001 epochs to 300,000 epochs. The basic learning rate for SGD was 1 × 10−2, for Adam was 1 × 10−4, and for L2 was 1 × 10−4. The specific code can be found in Annex II.
3.4.8. Coupling Coordination Model
The coupling coordination model is usually used to measure the synchronous relationship between the development of the phenomenon interaction between two or more systems [
45,
46,
47].
Considering the different dimensions between the original data of each evaluation index, the range of the standard formula was used to standardize the data. Since the indicators are all positive effects, the formula was selected as:
where
i is the evaluation sample,
j is the index, and
yijmax and
yijmin represent the maximum and minimum values of the index
j in all samples, respectively.
The entropy weight method was used to calculate the weight of each index by using the difference degree of each index value. The proportion of index
j in all samples
Pij was as follows:
After that, we found the entropy of the index:
Finally, we calculated the entropy weight of the evaluation index:
According to the comprehensive evaluation function , we calculated the comprehensive evaluation indexes U1 and U2 of ES and ED. When 0 ≤ |U1 − U2| ≤ 0.1, ES and ED are synchronous. When U1 − U2 > 0.1, ES lags. When U1 − U2 < −0.1, ED lags.
The coupling correlation function is .
In addition, the composite harmonic index needs to be calculated: .
Where α and β represent the weights of ES and ED, respectively. Because they are equally important, α and β are both taken as 0.5. Finally, coupling coordination scheduling was calculated.
According to the coupling and cooperative scheduling, the types of coordinated development were divided into different levels, as shown in
Table 1.
5. Discussion
5.1. Analysis of ESs of the GGP
The results show that the ecosystem service function will continue to increase with the continued implementation of the GGP. The increases of the ecosystem service functions in three years are 3.70–6.34% for soil consolidation, 2.72–3.71% for forest nutrient retention, 2.52–6.09% for water conservation, 3.00–4.64% for carbon fixation and oxygen release, and 3.82–5.75% for dust retention. The biggest annual increase is in the function of soil conservation, and the biggest difference in annual increases regards the function of water conservation, which is particularly important when considering that soil and water conservation are the GGP’s primary goals. When the project task is assigned each year, the GGP is mainly considered for areas with serious soil erosion. After the implementation of the project in a given area, the degree of soil erosion is reduced, and the functions of soil conservation and water conservation play a greater role.
5.2. Comparison with Other Predictions
Lin et al. evaluated the Qingjiang River Basin and predicted ESs in the next 20 years based on land-use changes and ecological disasters [
48]. Lin’s research is located in the Wuling mountain area, meaning that their research results have certain comparability. According to Lin’s research results, the annual increase of ESs in the Qingjiang River Basin from 2020 to 2035 is about 1.68–5.88%, similar to our research results (2.52–6.34%). Our research results are high because we only considered the implementation of the GGP, while Lin considered the negative impact of ecological disasters.
When Yirsaw used land-use to predict ES [
13], the relative errors of all LUCC classes were less than 5%. In our study, the R2 test of the data in the first 10 years based on the auto-xgboost-et-DT model reverse prediction showed that the score almost approached 0, proving that the accuracy was more than 99.9%.
Biomass carbon increased by 8% from 2001 to 2050 under the forest incentives policy scenario in Lawler’s research on the prediction of ESs in the United States based on land-use changes. The GGP is also a kind of forest-incentive policy. Our prediction of carbon growth is between 4.87% and 6.39% per year, larger than in Lawler’s study. This is mainly due to the fact that our carbon growth considers biomass carbon and soil carbon. Additionally, most GGP stands are in the stage of vigorous growth, providing much more carbon sequestration than mature or overly mature stands. The time scale predicted by Lawler is larger. On the one hand, the accuracy of the prediction results may be reduced. On the other hand, the carbon sequestration function will be reduced when the trees are almost mature in 50 years.
It is not a challenge to determine from the above comparison that our research has some limitations, since the time sequence of the training data used in the prediction was too short thus the prediction accuracy of the ESs was reduced. Simultaneously, compared with the prediction based on LUCC, we cannot simulate the changes of ESs under different scenarios. These problems need to be further explored in the future.
However, our method has some advantages in prediction accuracy. Further, the prediction based on the ensemble learning method is more suitable for the prediction of the GGP ESs. It can also realize the prediction of multiple ESs at the same time instead of only obtaining a total value of the ESs. This prediction has higher ecological significance.
5.3. Coordination Types of ES and Economic Development of the GGP
The types of coordinated development of ecological and economic benefits of the GGP in 2017, 2019 and 2020 are compared and analysed, as shown in
Figure 19. In the study area, the development degree of ecological and economic benefits has changed significantly. In 2017, 65% of the counties achieved the synchronous development of ecological economy, while 17% of the counties have fallen behind in ecology, especially in the central region, where the ecological environment particularly needs to be improved. At the same time, economic development is relatively low in the western and eastern regions, and their ecological footprints need to be further optimized. By 2019, most of the counties are lagging in ecological development, accounting for 92%. Only 3% of the counties have achieved the same level of development in both ecology and economy. The counties in the central region, which used to be ahead in terms of ecological development, have also switched into a development mode focused more on the economy. In 2020, most of the counties are in a state of prioritizing ecological development, while their economic development lags, accounting for 84%. Only 9% of the counties have coordinated their development of ecology and economy, and the remaining 7% are in a state of prioritizing economic development.
The main reason for the difference in ecological and economic development between 2017 and 2019 is that 2020 is an important point in time for China’s anti-poverty efforts. The state has made great efforts to help poorer areas grow economically, and the economy was strongly prioritized in 2019. By 2020, ecological development will be significantly ahead, as the GGP will develop more than the economy within this year.
5.4. Coupling Analysis of ESs and Economic Development of the GGP
The maps below show the distribution and degree of coupling coordination within the study area (
Figure 20a–c), demonstrating that the coupling coordination degree of ESs and economic benefits of the GGP have a high degree of coordination. Most regions have achieved extreme coordination and coupling, accounting for 90%. The coupling coordination degree of 97% of counties has been improved compared with that of 2019 (
Figure 20d), which is 10% higher than that of 2017. This not only shows that the ESs and economic development of the GGP in the concentrated contiguous destitute areas have proceeded at largely the same pace for two years, but also that the concentrated contiguous destitute areas are at a high level of ecosystem service improvement and economic development coordination, with high consistency and mutual influence. At the same time, at present, when the ecosystem service function of the GGP is improved, the concentrated contiguous destitute areas achieve a high level of economic benefits. This proves that “green water and green mountains” is a necessary developmental underpinning for “golden water and silver mountains”. In addition, the degree of coupling coordination is no longer distributed along the “Hu Huanyong line,” but instead is more dispersed. With the improvement of ecological benefits, the development of some regions will break the existing concept of dividing the two sides of China’s economic development along the “Hu Huanyong line”.
6. Conclusions
Using an ensemble learning algorithm to predict the quality of the GGP ESs, results were obtained which show that with the continued implementation of the GGP, ESs will also continue to increase. This plays an important role in the protection of China’s ecological environment and achieves the implementation goal of the project.
The coupling coordination analysis of ESs and the economic development of the GGP shows that 97% of the counties in the study area are in a state of extreme coupling, which is 10% higher than that of 2017 and 84% higher than that of 2019. The experimental results effectively confirm that at present, when the ESs of the GGP are improved, the economic benefits of contiguous destitute areas can achieve greater development space. The implementation of the GGP needs to be further promoted. At the same time, it is important for continuing economic development to manage and protect existing GGP resources to the maximum extent and continue to improve ecosystem service functions. Finally, the implementation of the project has made a certain contribution to the realization of the goal of poverty alleviation in China.
The time-series data of the ESs of the GGP effectively increased using the research method proposed in this paper. The ESs that the GGP can produce in the future are successfully predicted. This provides a reliable scientific basis for the further implementation of the GGP. It also provides a new method for ES prediction. As time goes on, the GGP will evaluate ESs over a longer time period, greatly improving the prediction accuracy of the ESs. Further, the GGP is greatly influenced by various policies published by the state. Future research should capture the focus, emotion, and value tendency of the Grain for Green Projects based on big data technology and integrate the prediction of emotional tendency and attitudes to better realize the ESs of the GGP.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}