
Machine Learning Modeling of Forest Road Construction Costs




Abstract
:1. Introduction
2. Case Study
3. Modeling Methodology
3.1. Data Collection
3.1.1. Cost Elements
3.1.2. Explanatory Variables
3.2. Model Development
3.2.1. Linear Regression (LR)
3.2.2. K-Star
3.2.3. Multilayer Perceptron Neural Network (MLP)
3.2.4. Support Vector Machine (SVM)
3.2.5. Instance-Based Learning (IBL)
3.3. Model Training and Testing
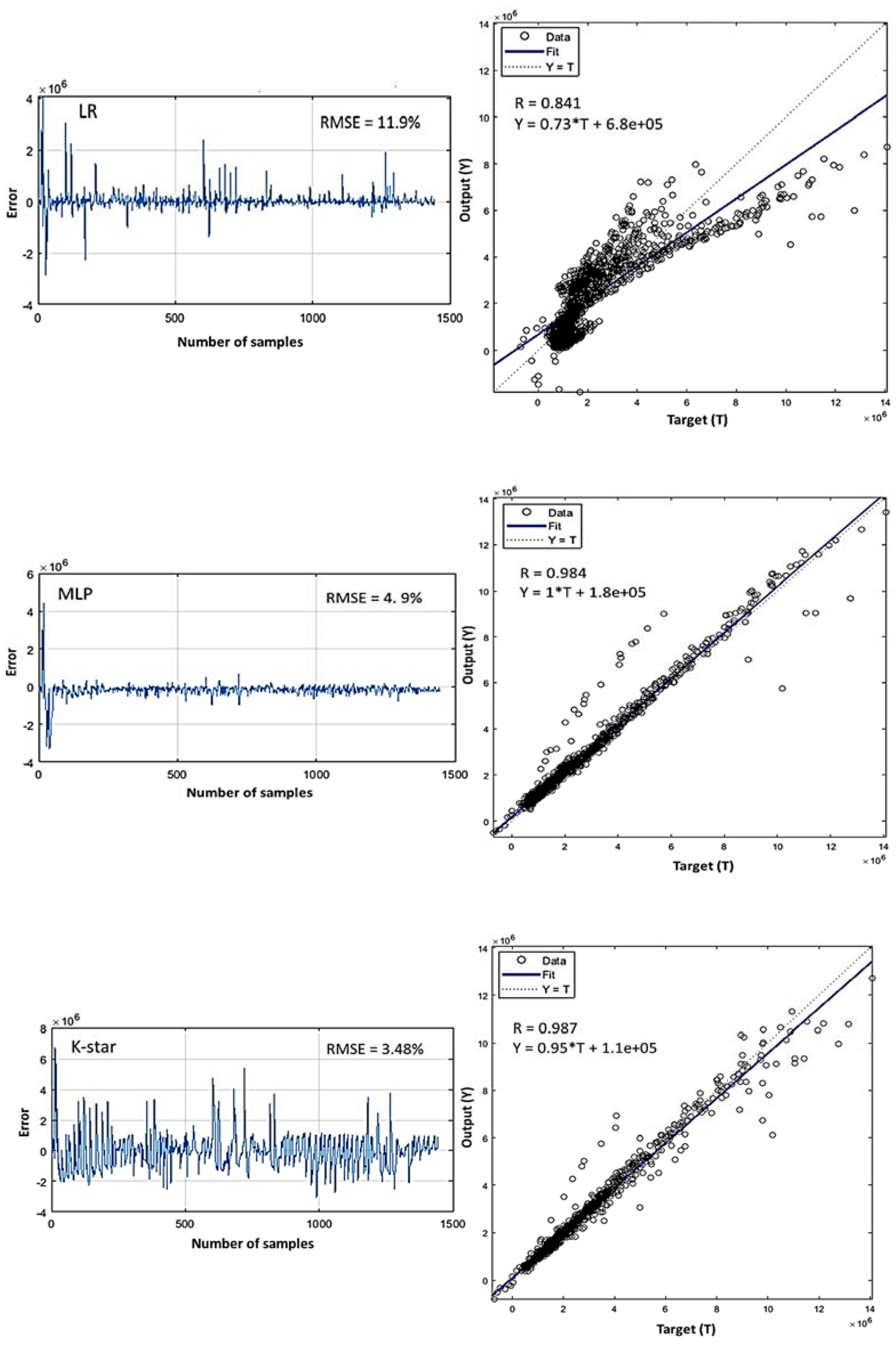
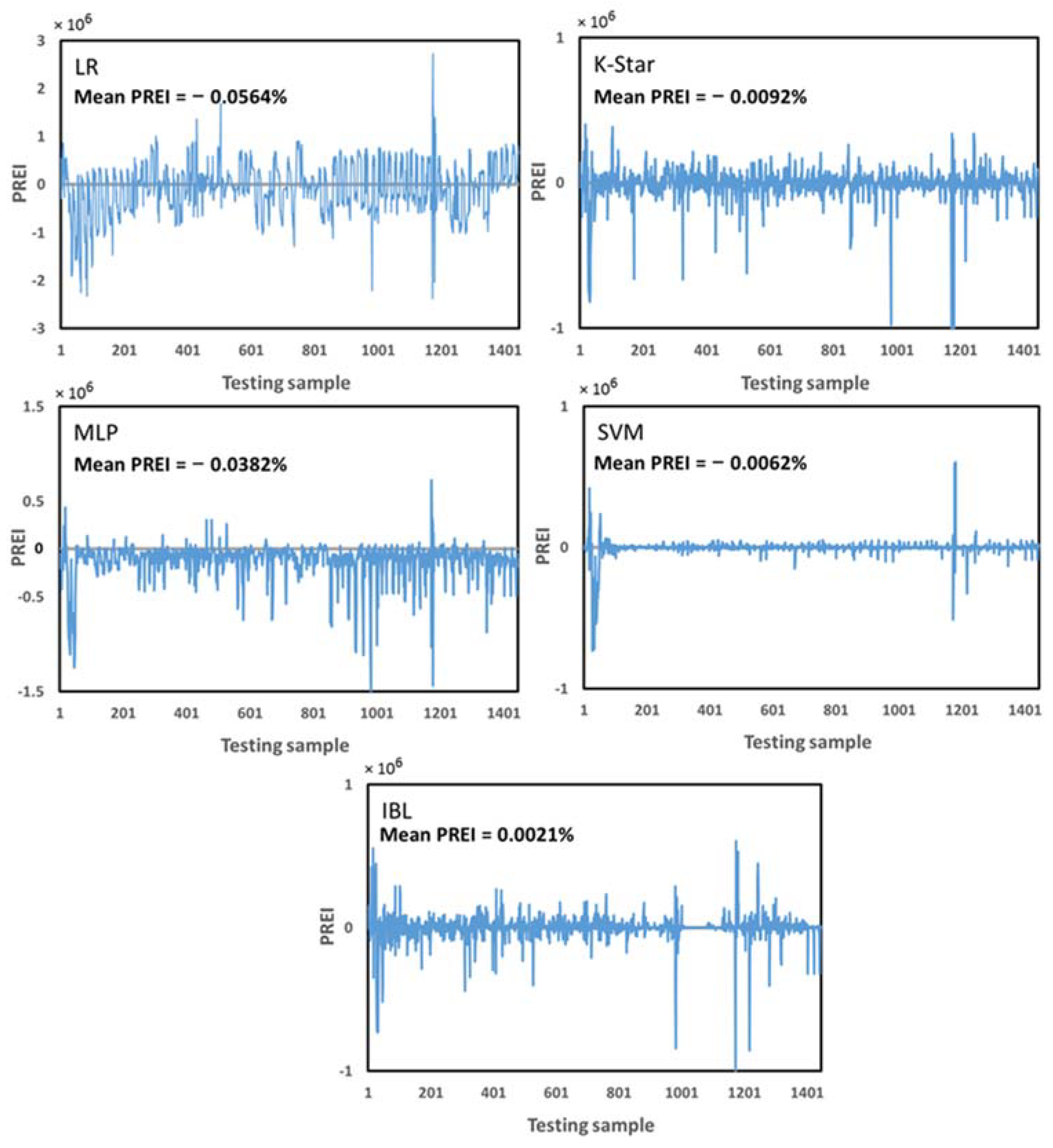
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ghajar, I.; Najafi, A.; Karimimajd, A.M.; Boston, K.; Ali Torabi, S. A program for cost estimation of forest road construction using engineer’s method. For. Sci. Technol. 2013, 9, 111–117. [Google Scholar] [CrossRef]
- Boston, K.; Leshchinsky, B.; Kemp, E.; Wortman, R. The use of a rotary asphalt broom to groom aggregate forest roads. Croat. J. For. Eng. 2017, 38, 119–126. [Google Scholar]
- De Witt, A.; Boston, K.; Leshchinsky, B. Predicting aggregate degradation in forest roads in Northwest Oregon. Forests 2020, 11, 729. [Google Scholar] [CrossRef]
- Sessions, J. Forest Road Operations in the Tropics; Springer: Berlin/Heidelberg, Germany; New York, NY, USA, 2007; 117p. [Google Scholar]
- Bruce, J.C.; Han, H.-S.; Akay, A.E.; Chung, W. ACCEL: Spreadsheet-based cost estimation for forest road construction. West. J. Appl. For. 2011, 26, 189–197. [Google Scholar] [CrossRef] [Green Version]
- Twito, R.H.; Reutebuch, S.E.; McGaughey, R.J.; Mann, C.N. Preliminary Logging Analysis Systems (PLANS), Overview; General Techincal Report PNW-199; USDA Forest Service: Portland, OR, USA, 1987; 24p.
- Epstein, R.; Weintraub, A.; Sessions, J.; Sessions, B.; Sapunar, P.; Nieto, E.; Bustamante, F.; Musante, H. PLANEX: A system to identify landing locations and access. In Proceedings of the International Mountain Logging and 11th Pacific Northwest Skyline Symposium, Seattle, WA, USA, 10–12 December 2001; pp. 10–12. [Google Scholar]
- Chung, W.; Sessions, J. NETWORK 2001—Transportation planning under multiple objectives. In Proceedings of the International Mountain Logging and 11th Pacific Northwest Skyline Symposium, Seattle, WA, USA, 10–12 December 2001; pp. 10–12. [Google Scholar]
- Dykstra, D.P. Timber Harvest Layout by Mathematical and Heuristic Programming. Ph.D. Thesis, Department of Forest Engineering, Oregon State University, Corvallis, OR, USA, 1976. [Google Scholar]
- Akay, A.E.; Boston, K.; Sessions, J. The evolution of computer-aided road design systems. Int. J. For. Eng. 2005, 16, 73–79. [Google Scholar] [CrossRef]
- Akay, A.E. Minimizing total costs of forest roads with computer-aided design model. Sadhana 2006, 31, 621–633. [Google Scholar] [CrossRef] [Green Version]
- Stückelberger, J.; Heinimann, H.R.; Chung, W. Improved road network design models with the consideration of various link patterns and road design elements. Can. J. For. Res. 2007, 37, 2281–2298. [Google Scholar] [CrossRef]
- Meignan, D.; Frayret, J.-M.; Pesant, G.; Blouin, M. A heuristic approach to automated forest road location. Can. J. For. Res. 2012, 42, 2130–2141. [Google Scholar] [CrossRef]
- Stückelberger, J.A.; Heinimann, H.R.; Burlet, E.C. Modeling spatial variability in the life-cycle costs of low-volume forest roads. Eur. J. For. Res. 2006, 125, 377–390. [Google Scholar] [CrossRef] [Green Version]
- Markow, M.J.; Aw, W.B. Estimating road construction costs for sector planning in developing countries. Transp. Res. Rec. 1974, 898, 52. [Google Scholar]
- Anderson, A.E.; Nelson, J. Projecting vector-based road networks with a shortest path algorithm. Can. J. For. Res. 2004, 34, 1444–1457. [Google Scholar] [CrossRef]
- Heinimann, H.R. A computer model to differentiate skidder and cable-yarder based road network concepts on steep slopes. J. For. Res. 1998, 3, 1–9. [Google Scholar] [CrossRef]
- Lucas, T.C. A translucent box: Interpretable machine learning in ecology. Ecol. Monogr. 2020, 90, e01422. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, Y.; Meng, Q.; Cheng, Q. A tailored machine learning approach for urban transport network flow estimation. Transp. Res. Part C Emerg. Technol. 2019, 108, 130–150. [Google Scholar] [CrossRef]
- Samuel, A.L. Some studies in machine learning using the game of checkers. IBM J. Res. Dev. 1959, 3, 210–229. [Google Scholar] [CrossRef]
- Clarviate. Web of Science Core Collection. 2020. Available online: https://clarivate.com/webofsciencegroup/solutions/web-of-science-core-collection/ (accessed on 15 November 2020).
- Ghajar, I.; Najafi, A.; Torabi, S.A.; Khamehchiyan, M.; Boston, K. An adaptive network-based fuzzy inference system for rock share estimation in forest road construction. Croat. J. For. Eng. 2012, 33, 313–328. [Google Scholar]
- Cleary, J.G.; Trigg, L.E. K*: An instance-based learner using an entropic distance measure. In Machine Learning Proceedings; Elsevier: Amsterdam, The Netherlands, 1995; pp. 108–114. [Google Scholar]
- Hush, D.R.; Horne, B.G. Progress in supervised neural networks. IEEE Signal Process. Mag. 1993, 10, 8–39. [Google Scholar] [CrossRef]
- Xu, Z.; Huang, X.; Lin, L.; Wang, Q.; Liu, J.; Yu, K.; Chen, C. BP neural networks and random forest models to detect damage by Dendrolimus punctatus Walker. J. For. Res. 2020, 31, 107–121. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support vector machine. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Carrasco, M.; López, J.; Maldonado, S. A second-order cone programming formulation for nonparallel hyperplane support vector machine. Expert Syst. Appl. 2016, 54, 95–104. [Google Scholar] [CrossRef]
- Aha, D.W.; Kibler, D.; Albert, M.K. Instance-based learning algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef] [Green Version]
- Bui, D.T.; Khosravi, K.; Tiefenbacher, J.; Nguyen, H.; Kazakis, N. Improving prediction of water quality indices using novel hybrid machine-learning algorithms. Sci. Total Environ. 2020, 721, 137612. [Google Scholar] [CrossRef]
- Jaafari, A.; Rezaeian, J.; Omrani, M.S. Spatial prediction of slope failures in support of forestry operations safety. Croat. J. For. Eng. 2017, 38, 107–118. [Google Scholar]
- He, Y.; Dai, L.; Zhang, H. Multi-branch deep residual learning for clustering and beamforming in user-centric network. IEEE Commun. Lett. 2020, 24, 2221–2225. [Google Scholar] [CrossRef]
- Jiang, L.; Zhang, B.; Han, S.; Chen, H.; Wei, Z. Upscaling evapotranspiration from the instantaneous to the daily time scale: Assessing six methods including an optimized coefficient based on worldwide eddy covariance flux network. J. Hydrol. 2021, 596, 126135. [Google Scholar] [CrossRef]
- Bennett, N.D.; Croke, B.F.W.; Guariso, G.; Guillaume, J.H.A.; Hamilton, S.H.; Jakeman, A.J.; Marsili-Libelli, S.; Newham, L.T.H.; Norton, J.P.; Perrin, C.; et al. Characterising performance of environmental models. Environ. Model. Softw. 2013, 40, 1–20. [Google Scholar] [CrossRef]
- Zhao, C.; Zhong, S.; Zhong, Q.; Shi, K. Synchronization of Markovian complex networks with input mode delay and Markovian directed communication via distributed dynamic event-triggered control. Nonlinear Anal. Hybrid Syst. 2020, 36, 100883. [Google Scholar] [CrossRef]
- Mousavi, A.A.; Zhang, C.; Masri, S.F.; Gholipour, G. Structural damage detection method based on the complete ensemble empirical mode decomposition with adaptive noise: A model steel truss bridge case study. Struct. Health Monit. 2021, 14759217211013535. [Google Scholar]
- Hu, B.; Wu, Y.; Wang, H.; Tang, Y.; Wang, C. Risk mitigation for rockfall hazards in steeply dipping coal seam: A case study in Xinjiang, northwestern China. Geomat. Nat. Hazards Risk 2021, 12, 988–1014. [Google Scholar] [CrossRef]
- Adnan, R.M.; Jaafari, A.; Mohanavelu, A.; Kisi, O.; Elbeltagi, A. Novel ensemble forecasting of streamflow using locally weighted learning algorithm. Sustainability 2021, 13, 5877. [Google Scholar] [CrossRef]
- Bie, Y.; Ji, J.; Wang, X.; Qu, X. Optimization of electric bus scheduling considering stochastic volatilities in trip travel time and energy consumption. Comput. Civ. Infrastruct. Eng. 2021, 1–19. [Google Scholar]
- Ros, F.; Guillaume, S. From supervised instance and feature selection algorithms to dual selection: A review. Sampl. Tech. Superv. Unsuperv. Tasks 2020, 83–128. [Google Scholar]
- Weis, C.V.; Jutzeler, C.R.; Borgwardt, K. Machine learning for microbial identification and antimicrobial susceptibility testing on MALDI-TOF mass spectra: A systematic review. Clin. Microbiol. Infect. 2020, 26, 1310–1317. [Google Scholar] [CrossRef] [PubMed]
- Rahmati, O.; Jaafari, A. Spatial Modeling of Soil Erosion Susceptibility with Support Vector Machine. In Intelligent Data Analytics for Decision-Support Systems in Hazard Mitigation; Springer: Berlin/Heidelberg, Germany, 2021; pp. 267–280. [Google Scholar]
- Üstün, B.; Melssen, W.J.; Buydens, L.M.C. Facilitating the application of Support Vector Regression by using a universal Pearson VII function based kernel. Chemom. Intell. Lab. Syst. 2006, 81, 29–40. [Google Scholar] [CrossRef]
- Göçken, M.; Özçalıcı, M.; Boru, A.; Dosdoğru, A.T. Integrating metaheuristics and artificial neural networks for improved stock price prediction. Expert Syst. Appl. 2016, 44, 320–331. [Google Scholar] [CrossRef]
- Mittas, N.; Angelis, L. Overestimation and underestimation of software cost models: Evaluation by visualization. In Proceedings of the 2013 39th Euromicro Conference on Software Engineering and Advanced Applications, Santander, Spain, 4–6 September 2013; pp. 317–324. [Google Scholar]
- Briand, L.C.; Langley, T.; Wieczorek, I. A replicated assessment and comparison of common software cost modeling techniques. In Proceedings of the 22nd International Conference on Software Engineering, Limerick, Ireland, 4–11 June 2000; pp. 377–386. [Google Scholar]
- Lederer, A.L.; Prasad, J. Causes of inaccurate software development cost estimates. J. Syst. Softw. 1995, 31, 125–134. [Google Scholar] [CrossRef]
- Boehm, B.W. Software engineering economics. IEEE Trans. Softw. Eng. 1984, SE-10, 4–21. [Google Scholar] [CrossRef]
- Bertisen, J.; Davis, G.A. Bias and error in mine project capital cost estimation. Eng. Econ. 2008, 53, 118–139. [Google Scholar] [CrossRef]
- Callegari, C.; Szklo, A.; Schaeffer, R. Cost overruns and delays in energy megaprojects: How big is big enough? Energy Policy 2018, 114, 211–220. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Model | ||||
|---|---|---|---|---|---|
| LR | K-Star | MLP | SVM | IBL | |
| Debug | True | True | True | True | True |
| Error on probabilities | False | - | - | - | - |
| Heuristic stop | 50 | - | - | - | - |
| Maximum boosting iteration | 500 | - | - | - | - |
| Number of boosting iteration | 30 | - | - | - | |
| Use cross validation | True | True | True | True | True |
| Learning rate | - | - | 0.3 | - | - |
| Number of hidden layer | - | - | 1–50 | - | - |
| Number of iteration | - | - | 400 | - | - |
| Validation threshold | - | - | 20 | - | - |
| Seed | - | - | 0 | 1 | - |
| Kernel | - | - | - | 4 types | - |
| Fold | - | - | - | 1 | - |
| Tolerance parameter | - | - | - | 0.001 | - |
| Entropic blend | - | False | - | - | - |
| Global blend | - | 20 | - | - | - |
| Missing mode | - | Average | - | - | |
| KNN | - | - | - | - | 1 |
| Distance weighting | - | - | - | - | No |
| Mean squared | - | - | - | - | True |
| Nearest neighbor search algorithm | - | - | - | - | Linear |
| Window size | - | - | - | - | 0 |
| Phase | Metric | Kernel | |||
|---|---|---|---|---|---|
| PK | NPK | RBFK | PUK | ||
| Training | R | 0.825 | 0.974 | 0.846 | 0.991 |
| RMSE (%) | 13.64 | 5.05 | 13.56 | 2.9 | |
| Time (s) | 13.14 | 26.12 | 17.32 | 50.37 | |
| Testing | R | 0.834 | 0.982 | 0.854 | 0.993 |
| RMSE (%) | 12.48 | 3.99 | 12.39 | 2.4 | |
| Time (s) | 13.17 | 26.37 | 17.92 | 49.07 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jaafari, A.; Pazhouhan, I.; Bettinger, P. Machine Learning Modeling of Forest Road Construction Costs. Forests 2021, 12, 1169. https://doi.org/10.3390/f12091169
Jaafari A, Pazhouhan I, Bettinger P. Machine Learning Modeling of Forest Road Construction Costs. Forests. 2021; 12(9):1169. https://doi.org/10.3390/f12091169
Chicago/Turabian StyleJaafari, Abolfazl, Iman Pazhouhan, and Pete Bettinger. 2021. "Machine Learning Modeling of Forest Road Construction Costs" Forests 12, no. 9: 1169. https://doi.org/10.3390/f12091169
APA StyleJaafari, A., Pazhouhan, I., & Bettinger, P. (2021). Machine Learning Modeling of Forest Road Construction Costs. Forests, 12(9), 1169. https://doi.org/10.3390/f12091169