



Forestry Big Data: A Review and Bibliometric Analysis
 , , , ,
, , , , 
Abstract
:1. Introduction
2. The Definition and Applications of FBD
3. Research Methodology and Initial Data Statistics
3.1. Data Collection
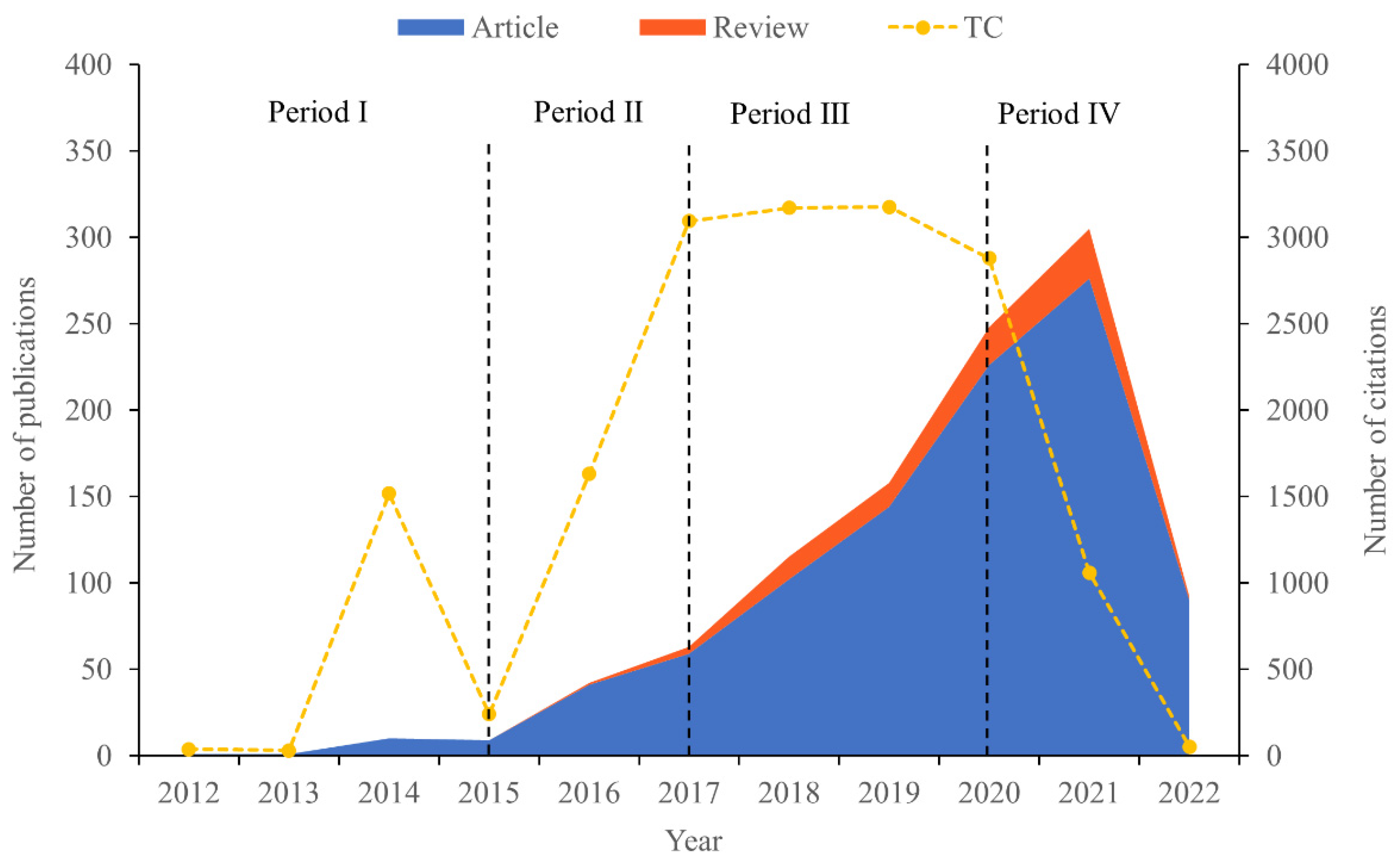
3.2. Initial Data Statistics
3.3. Statistic Analysis
4. Bibliometric Analysis
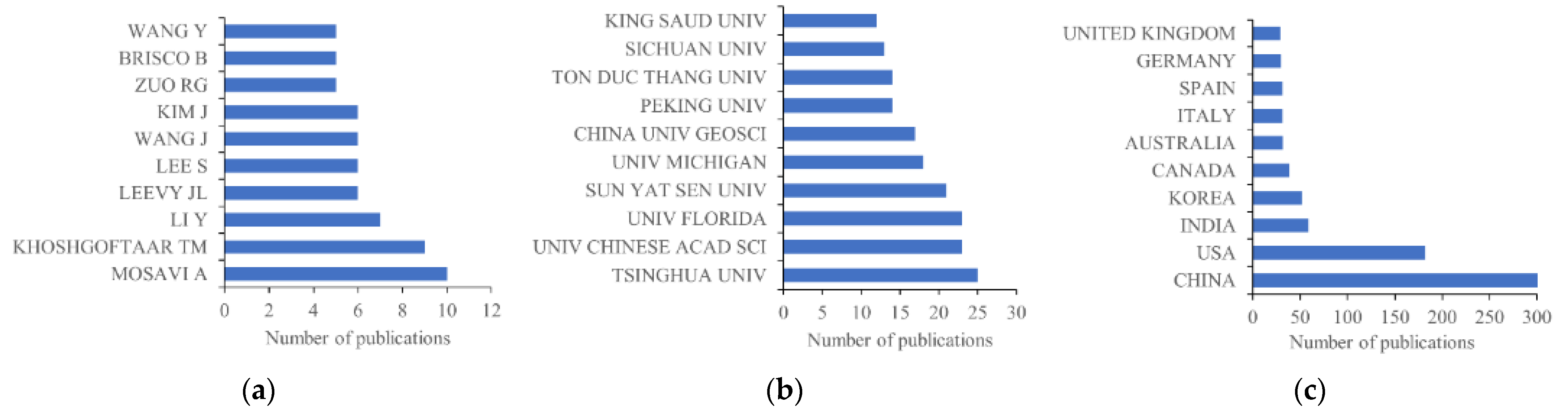
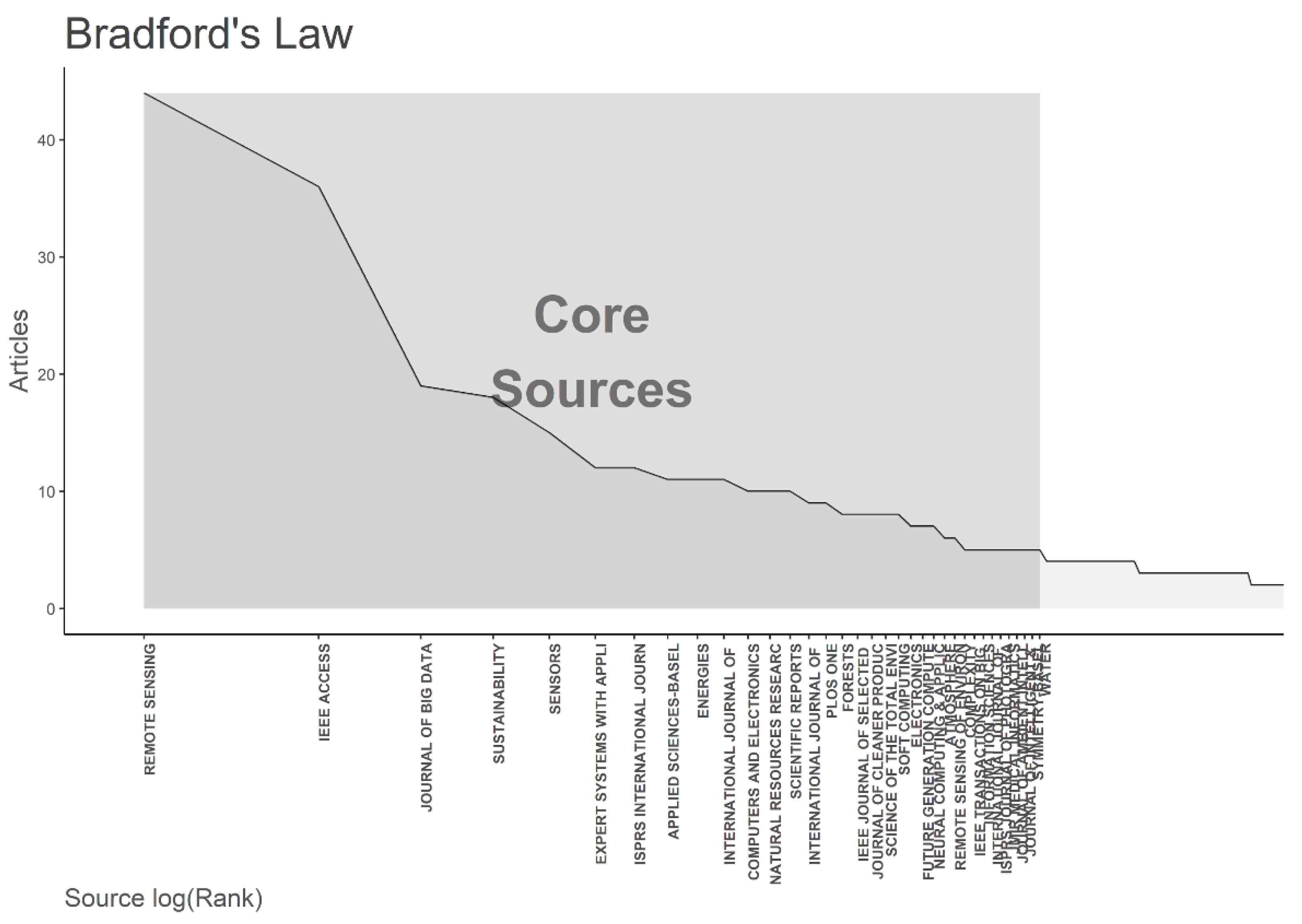
4.1. Active Authors, Institutes, Countries, and Journals
4.2. Citation Burst Detection of Keywords and References
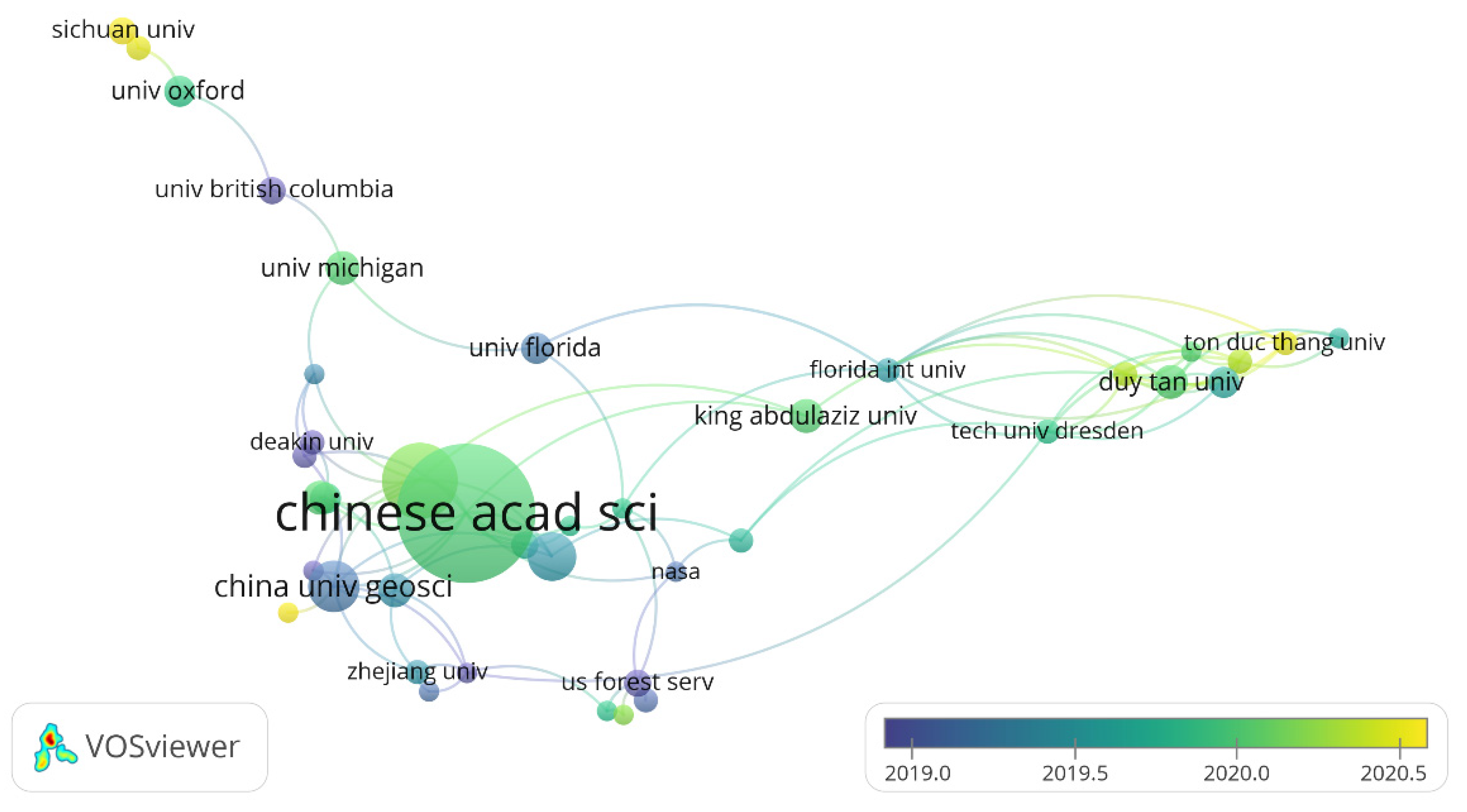
5. Network Analysis of Publications
6. Main Research Streams of FBD
6.1. Timeline Distribution of the Cluster Analysis of the Keywords
6.2. Timeline Distribution of the Cluster Analysis of the References
6.3. Emerging Research Areas of FBD
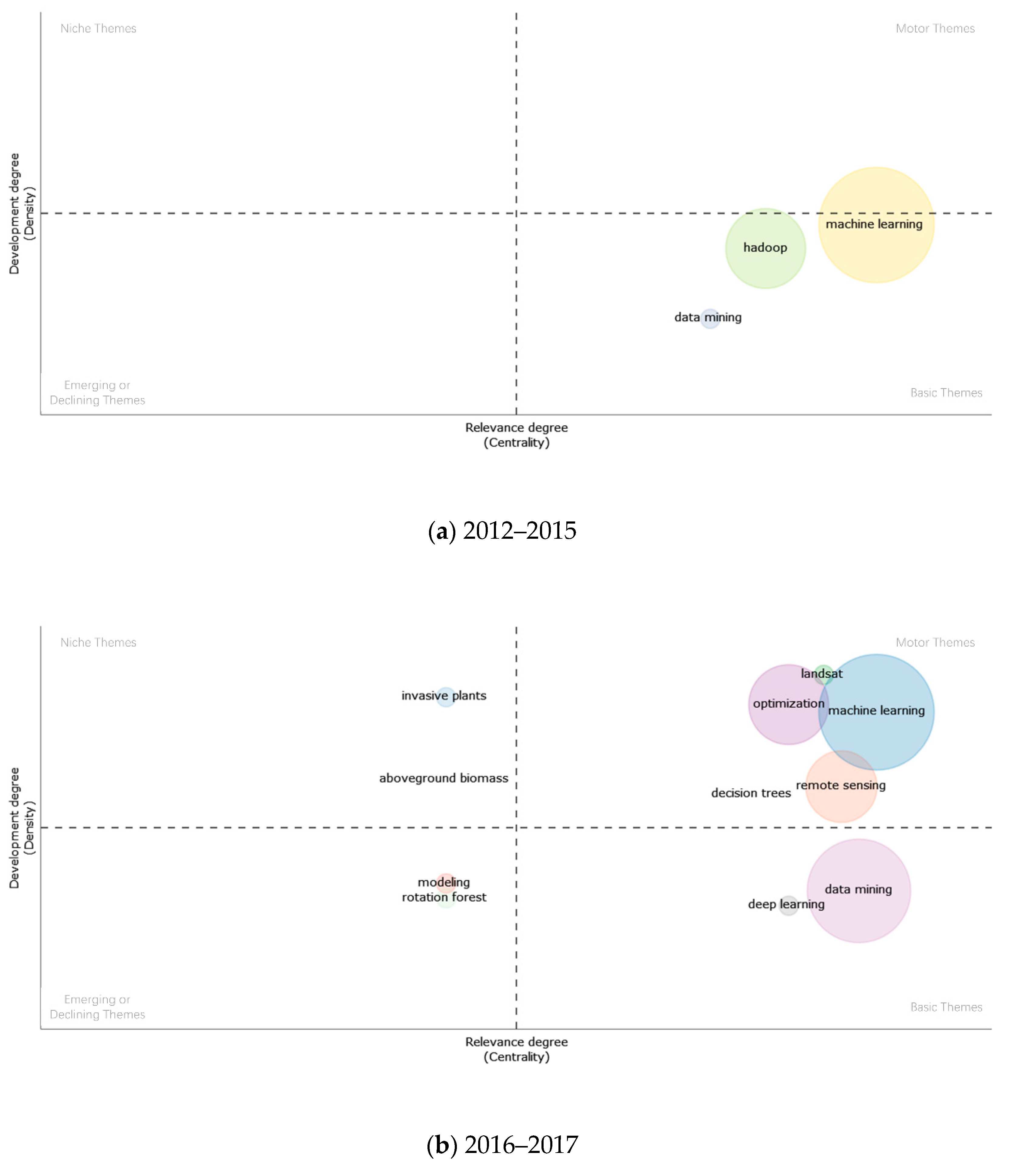
6.3.1. Strategic Diagram of FBD-Related Publications
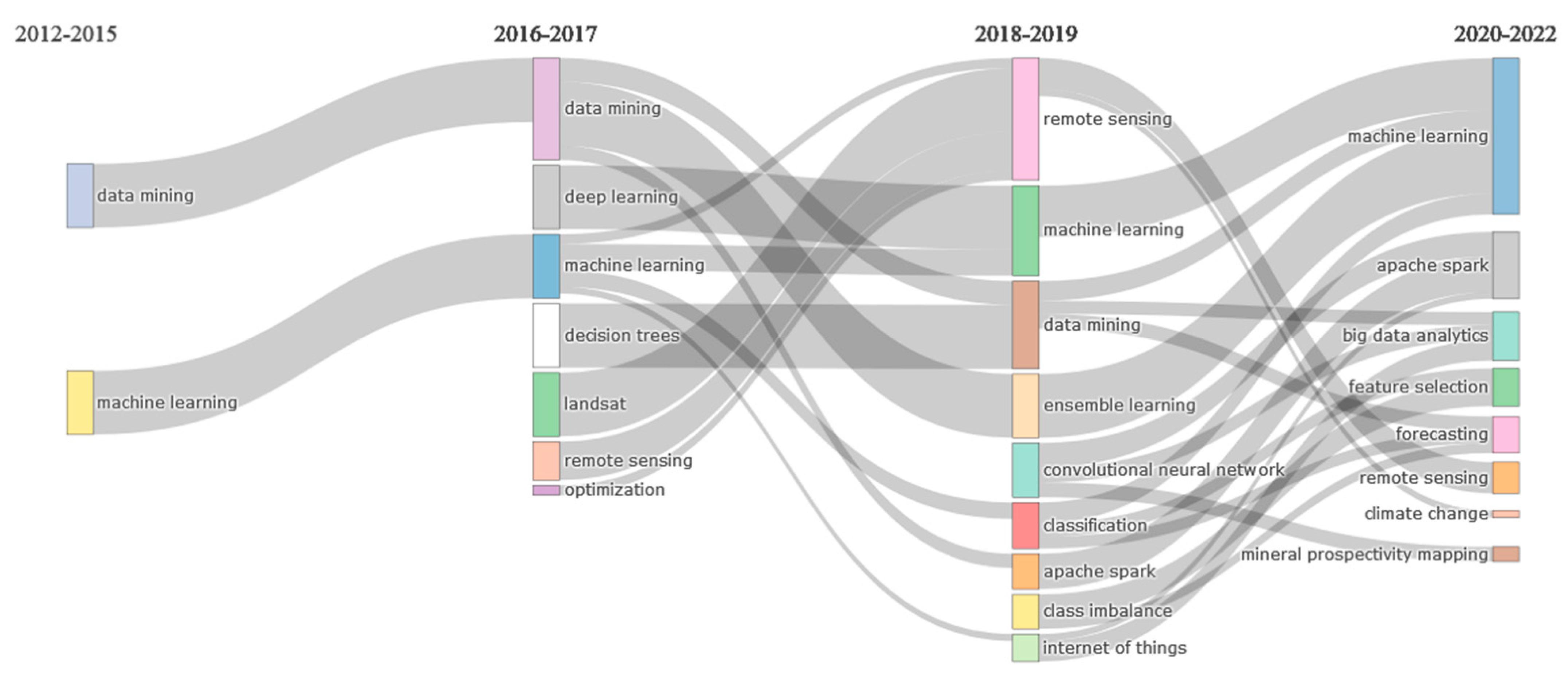
6.3.2. Thematic Evolution of FBD-Related Publications
7. Discussion
8. Conclusions and Limitation
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, M.; Mao, S.; Liu, Y.; Chen, M.; Mao, S.; Liu, Y. Big Data: A Survey. Mob. Netw. Appl. 2014, 19, 171–209. [Google Scholar] [CrossRef]
- Fan, J.; Han, F.; Liu, H. Challenges of Big Data Analysis. Natl. Sci. Rev. 2014, 1, 293–314. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Hao, T.; Chi, T. Evaluation on China’s Forestry Resources Efficiency Based on Big Data. J. Clean. Prod. 2017, 142, 513–523. [Google Scholar] [CrossRef]
- Sagiroglu, S.; Sinanc, D. Big Data: A Review. In Proceedings of the 2013 International Conference on Collaboration Technologies and Systems (CTS), San Diego, CA, USA, 20–24 May 2013; pp. 42–47. [Google Scholar]
- Lu, R.; Zhu, H.; Liu, X.; Liu, J.; Shao, J. Toward Efficient and Privacy-Preserving Computing in Big Data Era. IEEE Netw. 2014, 28, 46–50. [Google Scholar] [CrossRef]
- Liao, H.; Tang, M.; Luo, L.; Li, C.; Chiclana, F.; Zeng, X.J. A Bibliometric Analysis and Visualization of Medical Big Data Research. Sustainability 2018, 10, 166. [Google Scholar] [CrossRef]
- Kitchin, R.; McArdle, G. What Makes Big Data, Big Data? Exploring the Ontological Characteristics of 26 Datasets. Big Data Soc. 2016, 3. [Google Scholar] [CrossRef]
- Baru, C.; Bhandarkar, M.; Nambiar, R.; Poess, M.; Rabl, T. Benchmarking Big Data Systems and the BigData Top100 List. Big Data 2013, 1, 60–64. [Google Scholar] [CrossRef]
- FAO. Global Forest Resources Assessment 2020; FAO: Rome, Italy, 2020. [Google Scholar]
- Shen, X.; Cao, L.; Chen, D.; Sun, Y.; Wang, G.; Ruan, H. Prediction of Forest Structural Parameters Using Airborne Full-Waveform LiDAR and Hyperspectral Data in Subtropical Forests. Remote Sens. 2018, 10, 1729. [Google Scholar] [CrossRef]
- Shen, X.; Cao, L.; Coops, N.C.; Fan, H.; Wu, X.; Liu, H.; Wang, G.; Cao, F. Quantifying Vertical Profiles of Biochemical Traits for Forest Plantation Species Using Advanced Remote Sensing Approaches. Remote Sens. Environ. 2020, 250, 112041. [Google Scholar] [CrossRef]
- Busch, J.; Ferretti-Gallon, K. What Drives Deforestation and What Stops It? A Meta-Analysis. Rev. Environ. Econ. Policy 2017, 11, 3–23. [Google Scholar] [CrossRef] [Green Version]
- LaBau, V.J.; Bones, J.T.; Kingsley, N.P.; Lund, H.G.; Smith, W.B. A History of the Forest Survey in the United States: 1830–2004; US Department of Agriculture, Forest Service: Washington, DC, USA, 2007.
- Zou, W.; Jing, W.; Chen, G.; Lu, Y.; Song, H. A Survey of Big Data Analytics for Smart Forestry. IEEE Access 2019, 7, 46621–46636. [Google Scholar] [CrossRef]
- Foody, G.M. Remote Sensing of Tropical Forest Environments: Towards the Monitoring of Environmental Resources for Sustainable Development. Int. J. Remote Sens. 2003, 24, 4035–4046. [Google Scholar] [CrossRef]
- Wulder, M.A.; White, J.C.; Nelson, R.F.; Næsset, E.; Ørka, H.O.; Coops, N.C.; Hilker, T.; Bater, C.W.; Gobakken, T. Lidar Sampling for Large-Area Forest Characterization: A Review. Remote Sens. Environ. 2012, 121, 196–209. [Google Scholar] [CrossRef]
- Buddenbaum, H.; Seeling, S.; Hill, J. Fusion of Full-Waveform Lidar and Imaging Spectroscopy Remote Sensing Data for the Characterization of Forest Stands. Int. J. Remote Sens. 2013, 34, 4511–4524. [Google Scholar] [CrossRef]
- Schulte to Bühne, H.; Pettorelli, N. Better Together: Integrating and Fusing Multispectral and Radar Satellite Imagery to Inform Biodiversity Monitoring, Ecological Research and Conservation Science. Methods Ecol. Evol. 2018, 9, 849–865. [Google Scholar] [CrossRef]
- Borz, S.A.; Proto, A.R. Application and Accuracy of Smart Technologies for Measurements of Roundwood: Evaluation of Time Consumption and Efficiency. Comput. Electron. Agric. 2022, 197, 106990. [Google Scholar] [CrossRef]
- Weinstein, R. RFID: A Technical Overview and Its Application to the Enterprise. IT Prof. 2005, 7, 27–33. [Google Scholar] [CrossRef]
- Farve, R. Using Radio Frequency Identification (RFID) for Monitoring Trees in the Forest: State-of-the-Technology Investigation; United States Department of Agriculture (USDA): Washington, DC, USA, 2014.
- Merigó, J.M.; Cancino, C.A.; Coronado, F.; Urbano, D. Academic Research in Innovation: A Country Analysis. Scientometrics 2016, 108, 559–593. [Google Scholar] [CrossRef]
- Keathley-Herring, H.; Van Aken, E.; Gonzalez-Aleu, F.; Deschamps, F.; Letens, G.; Orlandini, P.C. Assessing the Maturity of a Research Area: Bibliometric Review and Proposed Framework. Scientometrics 2016, 109, 927–951. [Google Scholar] [CrossRef]
- Moed, H.F. Bibliometric Indicators Reflect Publication and Management Strategies. Scientometrics 2000, 47, 323–346. [Google Scholar] [CrossRef]
- Merigó, J.M.; Mas-Tur, A.; Roig-Tierno, N.; Ribeiro-Soriano, D. A Bibliometric Overview of the Journal of Business Research between 1973 and 2014. J. Bus. Res. 2015, 68, 2645–2653. [Google Scholar] [CrossRef]
- Železnik, D.; Blažun Vošner, H.; Kokol, P. A Bibliometric Analysis of the Journal of Advanced Nursing, 1976–2015. J. Adv. Nurs. 2017, 73, 2407–2419. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, Q.; Cui, F. Scientific Research on Ecosystem Services and Human Well-Being: A Bibliometric Analysis. Ecol. Indic. 2021, 125, 107449. [Google Scholar] [CrossRef]
- Huang, L.; Xia, Z.; Cao, Y. A Bibliometric Analysis of Global Fine Roots Research in Forest Ecosystems during 1992–2020. Forests 2022, 13, 93. [Google Scholar] [CrossRef]
- Huang, L.; Zhou, M.; Lv, J.; Chen, K. Trends in Global Research in Forest Carbon Sequestration: A Bibliometric Analysis. J. Clean. Prod. 2020, 252, 119908. [Google Scholar] [CrossRef]
- Bovenzi, M. Metrics of Whole-Body Vibration and Exposure-Response Relationship for Low Back Pain in Professional Drivers: A Prospective Cohort Study. Int. Arch. Occup. Environ. Health 2009, 82, 893–917. [Google Scholar] [CrossRef]
- Ruslandi; Roopsind, A.; Sist, P.; Peña-Claros, M.; Thomas, R.; Putz, F.E. Beyond Equitable Data Sharing to Improve Tropical Forest Management. Int. For. Rev. 2014, 16, 497–503. [Google Scholar] [CrossRef]
- Zhao, M.; Li, D.; Long, Y. Forestry Big Data Platform by Knowledge Graph. J. For. Res. 2021, 32, 1305–1314. [Google Scholar] [CrossRef]
- Lummitsch, S.; Findeisen, E.; Haas, M.; Carl Sascha Lummitsch, C.; Carl, C. The Perspective of Optical Measurement Methods in Forestry. Photonics Educ. Meas. Sci. 2019, 11144, 346–351. [Google Scholar] [CrossRef]
- Borz, S.A.; Păun, M. Integrating Offline Object Tracking, Signal Processing, and Artificial Intelligence to Classify Relevant Events in Sawmilling Operations. Forests 2020, 11, 1333. [Google Scholar] [CrossRef]
- Hartsch, F.; Kemmerer, J.; Labelle, E.R.; Jaeger, D.; Wagner, T. Integration of Harvester Production Data in German Wood Supply Chains: Legal, Social and Economic Requirements. Forests 2021, 12, 460. [Google Scholar] [CrossRef]
- Keefe, R.F.; Zimbelman, E.G.; Picchi, G. Use of Individual Tree and Product Level Data to Improve Operational Forestry. Curr. For. Rep. 2022, 8, 148–165. [Google Scholar] [CrossRef]
- Torresan, C.; Garzón, M.B.; O’grady, M.; Robson, T.M.; Picchi, G.; Panzacchi, P.; Tomelleri, E.; Smith, M.; Marshall, J.; Wingate, L.; et al. A New Generation of Sensors and Monitoring Tools to Support Climate-Smart Forestry Practices. Can. J. For. Res. 2021, 51, 1751–1765. [Google Scholar] [CrossRef]
- Li, J.; Zhang, C.; Liu, J.; Li, Z.; Yang, X. An Application of Mean Escape Time and Metapopulation on Forestry Catastrophe Insurance. Phys. A Stat. Mech. Its Appl. 2018, 495, 312–323. [Google Scholar] [CrossRef]
- van Eck, N.J.; Waltman, L. Software Survey: VOSviewer, a Computer Program for Bibliometric Mapping. Scientometrics 2010, 84, 523–538. [Google Scholar] [CrossRef]
- Mourao, P.R.; Martinho, V.D. Forest Entrepreneurship: A Bibliometric Analysis and a Discussion about the Co-Authorship Networks of an Emerging Scientific Field. J. Clean. Prod. 2020, 256, 120413. [Google Scholar] [CrossRef]
- Chen, C. A Glimpse of the First Eight Months of the COVID-19 Literature on Microsoft Academic Graph: Themes, Citation Contexts, and Uncertainties. Front. Res. Metr. Anal. 2020, 5, 607286. [Google Scholar] [CrossRef]
- Aria, M.; Cuccurullo, C. Bibliometrix: An R-Tool for Comprehensive Science Mapping Analysis. J. Informetr. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Wang, X.; Xu, Z.; Qin, Y. Structure, Trend and Prospect of Operational Research: A Scientific Analysis for Publications from 1952 to 2020 Included in Web of Science Database. Fuzzy Optim. Decis. Mak. 2022. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, L.; Zhao, Y.; Zheng, R.; Song, K. A Scientometric Review of Blockchain Research. Inf. Syst. E-Bus. Manag. 2021, 19, 757–787. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef] [PubMed]
- Lam-Gordillo, O.; Baring, R.; Dittmann, S. Ecosystem Functioning and Functional Approaches on Marine Macrobenthic Fauna: A Research Synthesis towards a Global Consensus. Ecol. Indic. 2020, 115, 106379. [Google Scholar] [CrossRef]
- Forliano, C.; De Bernardi, P.; Yahiaoui, D. Entrepreneurial Universities: A Bibliometric Analysis within the Business and Management Domains. Technol. Forecast. Soc. Change 2021, 165, 120522. [Google Scholar] [CrossRef]
- Muja, M.; Lowe, D.G. Scalable Nearest Neighbor Algorithms for High Dimensional Data. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2227–2240. [Google Scholar] [CrossRef] [PubMed]
- Hasan, S.S.; Zhang, Y.; Chu, X.; Teng, Y. The Role of Big Data in China’s Sustainable Forest Management. For. Econ. Rev. 2019, 1, 96–105. [Google Scholar] [CrossRef]
- Liu, T.; Yang, L.; Mao, H.; Ma, F.; Wang, Y.; Zhan, Y. Knowledge Domain and Emerging Trends in Podocyte Injury Research From 1994 to 2021: A Bibliometric and Visualized Analysis. Front. Pharmacol. 2021, 12, 3508. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Salehi, B.; Mohammadimanesh, F.; Brisco, B.; Homayouni, S.; Gill, E.; DeLancey, E.R.; Bourgeau-Chavez, L. Big Data for a Big Country: The First Generation of Canadian Wetland Inventory Map at a Spatial Resolution of 10-m Using Sentinel-1 and Sentinel-2 Data on the Google Earth Engine Cloud Computing Platform. Can. J. Remote Sens. 2020, 46, 15–33. [Google Scholar] [CrossRef]
- Amani, M.; Ghorbanian, A.; Ahmadi, S.A.; Kakooei, M.; Moghimi, A.; Mirmazloumi, S.M.; Moghaddam, S.H.A.; Mahdavi, S.; Ghahremanloo, M.; Parsian, S.; et al. Google Earth Engine Cloud Computing Platform for Remote Sensing Big Data Applications: A Comprehensive Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5326–5350. [Google Scholar] [CrossRef]
- Tamiminia, H.; Salehi, B.; Mahdianpari, M.; Quackenbush, L.; Adeli, S.; Brisco, B. Google Earth Engine for Geo-Big Data Applications: A Meta-Analysis and Systematic Review. ISPRS J. Photogramm. Remote Sens. 2020, 164, 152–170. [Google Scholar] [CrossRef]
- Kousis, A.; Tjortjis, C. Data Mining Algorithms for Smart Cities: A Bibliometric Analysis. Algorithms 2021, 14, 242. [Google Scholar] [CrossRef]
- Herrera-Franco, G.; Montalván-Burbano, N.; Carrión-Mero, P.; Jaya-Montalvo, M.; Gurumendi-Noriega, M. Worldwide Research on Geoparks through Bibliometric Analysis. Sustainability 2021, 13, 1175. [Google Scholar] [CrossRef]
- Colonna, L. A Taxonomy and Classification of Data Mining. SMU Sci. Technol. Law Rev. 2013, 16, 309. [Google Scholar]
- Mannila, H. Data Mining: Machine Learning, Statistics, and Databases. In Proceedings of the 8th International Conference on Scientific and Statistical Data Base Management, SSDBM 1996, Stockholm, Sweden, 18–20 June 1996; Institute of Electrical and Electronics Engineers Inc.: Interlaken, Switzerland; pp. 2–8. [Google Scholar]
- Liu, H.; Shen, X.; Cao, L.; Yun, T.; Zhang, Z.; Fu, X.; Chen, X.; Liu, F. Deep Learning in Forest Structural Parameter Estimation Using Airborne LiDAR Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1603–1618. [Google Scholar] [CrossRef]
- Krawczyk, B.; Woźniak, M.; Schaefer, G. Cost-Sensitive Decision Tree Ensembles for Effective Imbalanced Classification. Appl. Soft Comput. J. 2014, 14, 554–562. [Google Scholar] [CrossRef]
- Sun, S.; Huang, R. An Adaptive K-Nearest Neighbor Algorithm. In Proceedings of the 2010 7th International Conference on Fuzzy Systems and Knowledge Discovery, FSKD 2010, Yantai, China, 10–12 August 2010; pp. 91–94. [Google Scholar]
- Zhang, W.Q. Application Research of Data Mining Technology on Growth Management of Forestry. Adv. Mater. Res. 2014, 846–847, 995–998. [Google Scholar] [CrossRef]
- Diez, Y.; Kentsch, S.; Fukuda, M.; Caceres, M.L.L.; Moritake, K.; Cabezas, M. Deep Learning in Forestry Using Uav-Acquired Rgb Data: A Practical Review. Remote Sens. 2021, 13, 2837. [Google Scholar] [CrossRef]
- Keefe, R.F.; Wempe, A.M.; Becker, R.M.; Zimbelman, E.G.; Nagler, E.S.; Gilbert, S.L.; Caudill, C.C. Positioning Methods and the Use of Location and Activity Data in Forests. Forests 2019, 10, 458. [Google Scholar] [CrossRef]
- Salloum, S.; Dautov, R.; Chen, X.; Peng, P.X.; Huang, J.Z. Big Data Analytics on Apache Spark. Int. J. Data Sci. Anal. 2016, 1, 145–164. [Google Scholar] [CrossRef]
- Moradi, F.; Darvishsefat, A.A.; Pourrahmati, M.R.; Deljouei, A.; Borz, S.A. Estimating Aboveground Biomass in Dense Hyrcanian Forests by the Use of Sentinel-2 Data. Forests 2022, 13, 104. [Google Scholar] [CrossRef]
- Klimetzek, D.; Stăncioiu, P.T.; Paraschiv, M.; Niță, M.D. Ecological Monitoring with Spy Satellite Images— the Case of Red Wood Ants in Romania. Remote Sens. 2021, 13, 520. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | NP | TC | AC | H-Index | PY-Start |
|---|---|---|---|---|---|
| MOSAVI A | 10 | 206 | 20.60 | 7 | 2020 |
| KHOSHGOFTAAR TM | 9 | 81 | 9.00 | 7 | 2019 |
| LI Y | 7 | 51 | 7.29 | 5 | 2016 |
| LEEVY JL | 6 | 62 | 10.33 | 5 | 2019 |
| LEE S | 6 | 113 | 18.83 | 4 | 2018 |
| WANG J | 6 | 62 | 10.33 | 4 | 2019 |
| KIM J | 6 | 54 | 9.00 | 3 | 2018 |
| ZUO RG | 5 | 225 | 45.00 | 5 | 2017 |
| BRISCO B | 5 | 276 | 55.20 | 4 | 2020 |
| WANG Y | 5 | 44 | 8.80 | 4 | 2016 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, W.; Qiu, Q.; Yuan, C.; Shen, X.; Cao, F.; Wang, G.; Wang, G. Forestry Big Data: A Review and Bibliometric Analysis. Forests 2022, 13, 1549. https://doi.org/10.3390/f13101549
Gao W, Qiu Q, Yuan C, Shen X, Cao F, Wang G, Wang G. Forestry Big Data: A Review and Bibliometric Analysis. Forests. 2022; 13(10):1549. https://doi.org/10.3390/f13101549
Chicago/Turabian StyleGao, Wen, Quan Qiu, Changyan Yuan, Xin Shen, Fuliang Cao, Guibin Wang, and Guangyu Wang. 2022. "Forestry Big Data: A Review and Bibliometric Analysis" Forests 13, no. 10: 1549. https://doi.org/10.3390/f13101549
APA StyleGao, W., Qiu, Q., Yuan, C., Shen, X., Cao, F., Wang, G., & Wang, G. (2022). Forestry Big Data: A Review and Bibliometric Analysis. Forests, 13(10), 1549. https://doi.org/10.3390/f13101549