
STPM_SAHI: A Small-Target Forest Fire Detection Model Based on Swin Transformer and Slicing Aided Hyper Inference


Abstract
:1. Introduction
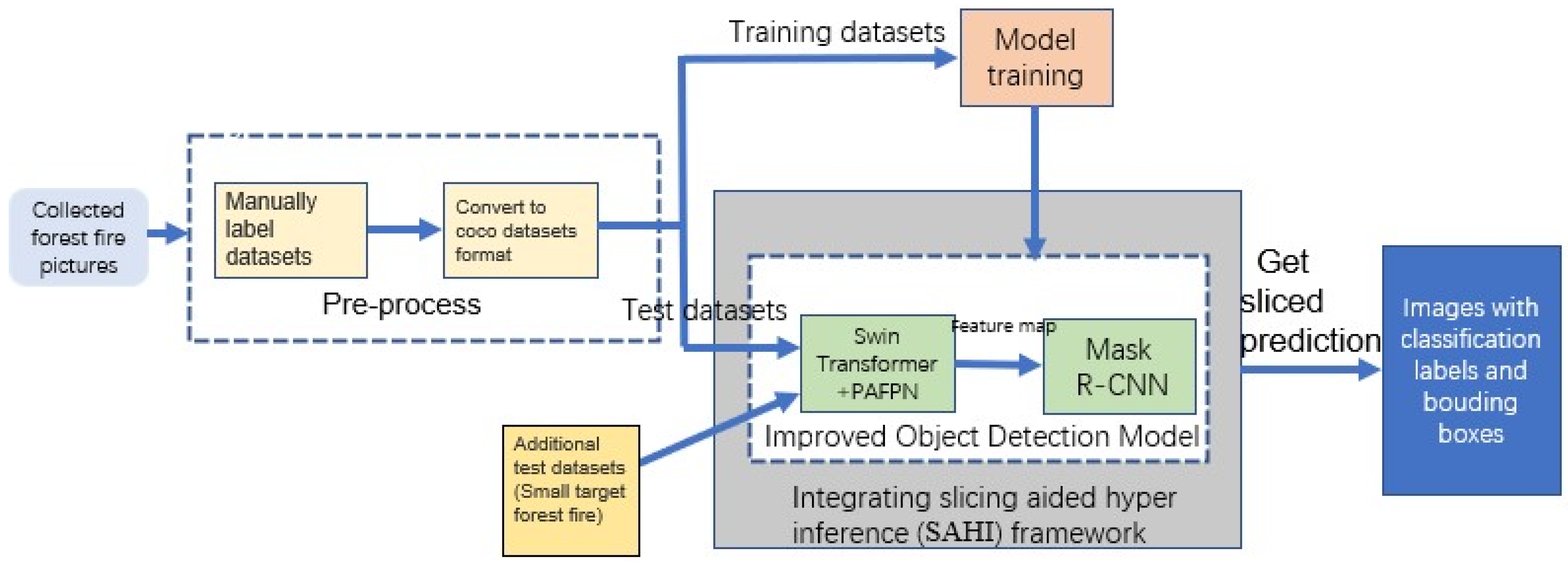
2. Materials and Methods
- (1)
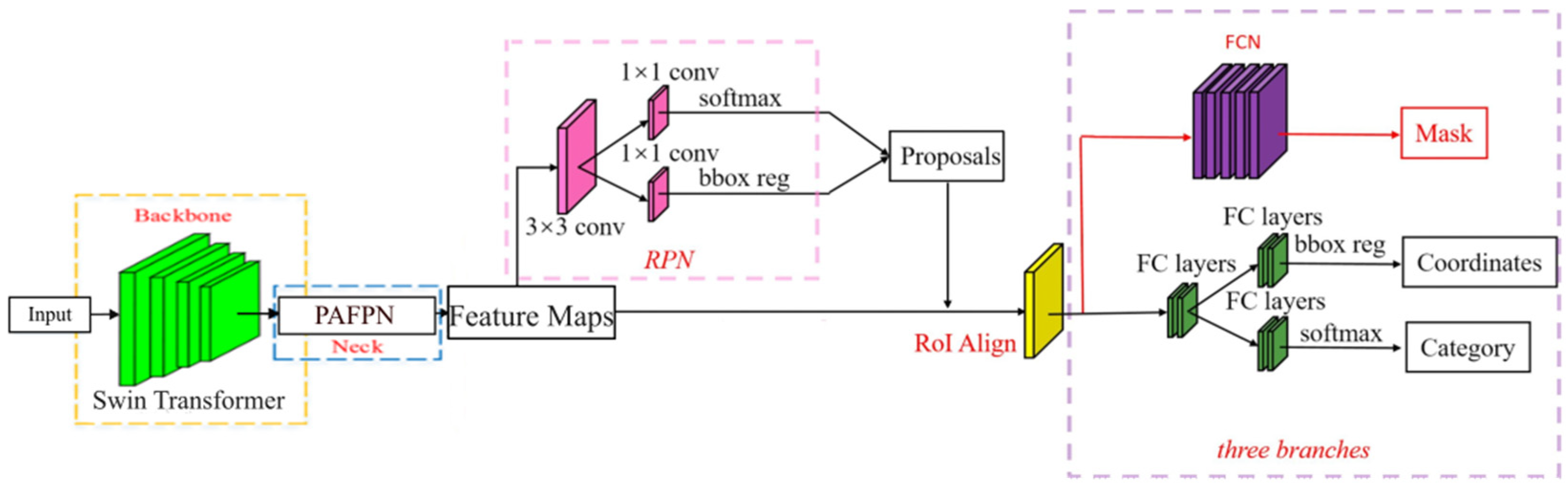
- We use Swin Transformer to replace the original backbone (ResNet-50) of the Mask R-CNN to make full use of its self-attention mechanism, thereby obtaining a larger receptive field and context information by capturing global information and strengthening the ability of local information acquisition. The model pays more attention to and fully learns the characteristics of forest fires, which improves the detection performance of small-target forest fire images captured by cameras and has better performance in detecting intensive forest fires.
- (2)
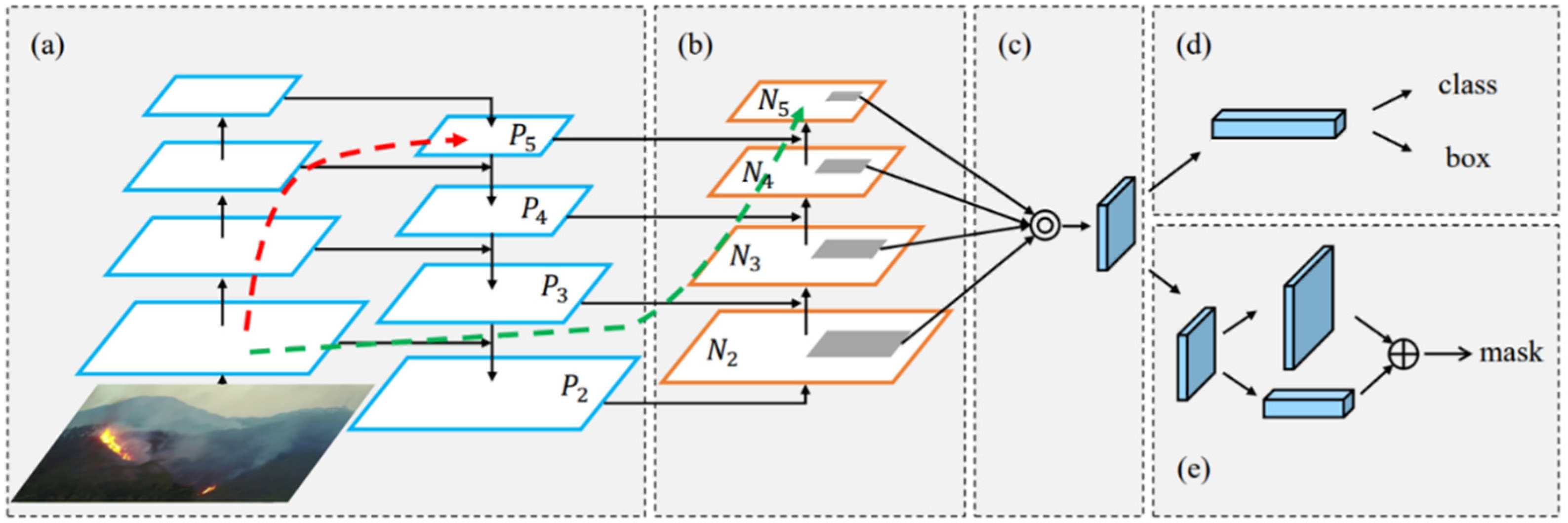
- We use PAFPN [31] to replace the Mask R-CNN detection framework’s original feature-fusion network, FPN [32]. Based on FPN, PAFPN adds a down-sampling module and an additional 3 × 3 convolution to build a bottom–up feature-fusion network to reduce the propagation path of the main feature layer and eliminate the impact of down-sampling fusion. The positioning capability of the whole feature hierarchy is enhanced.
- (3)
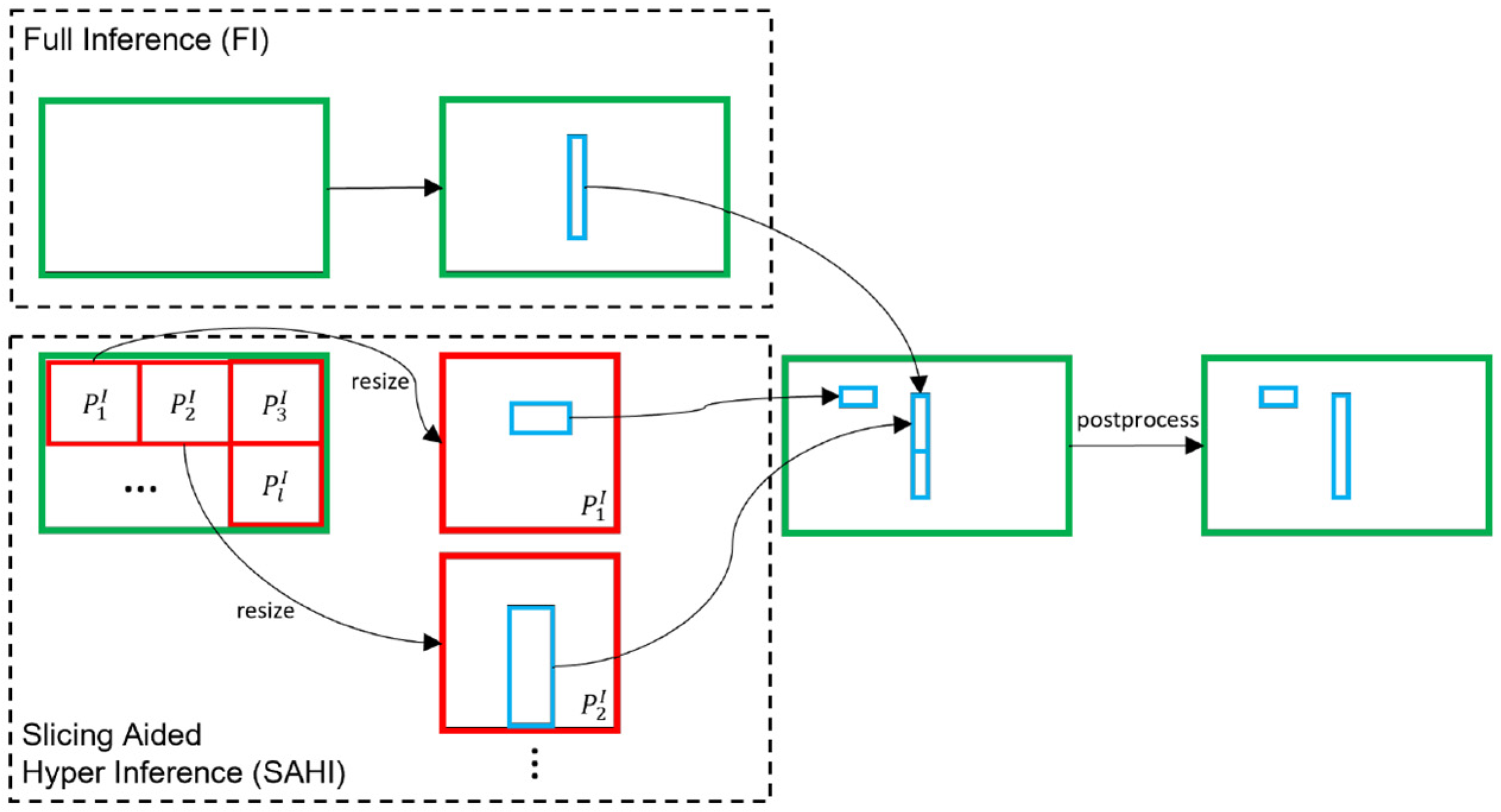
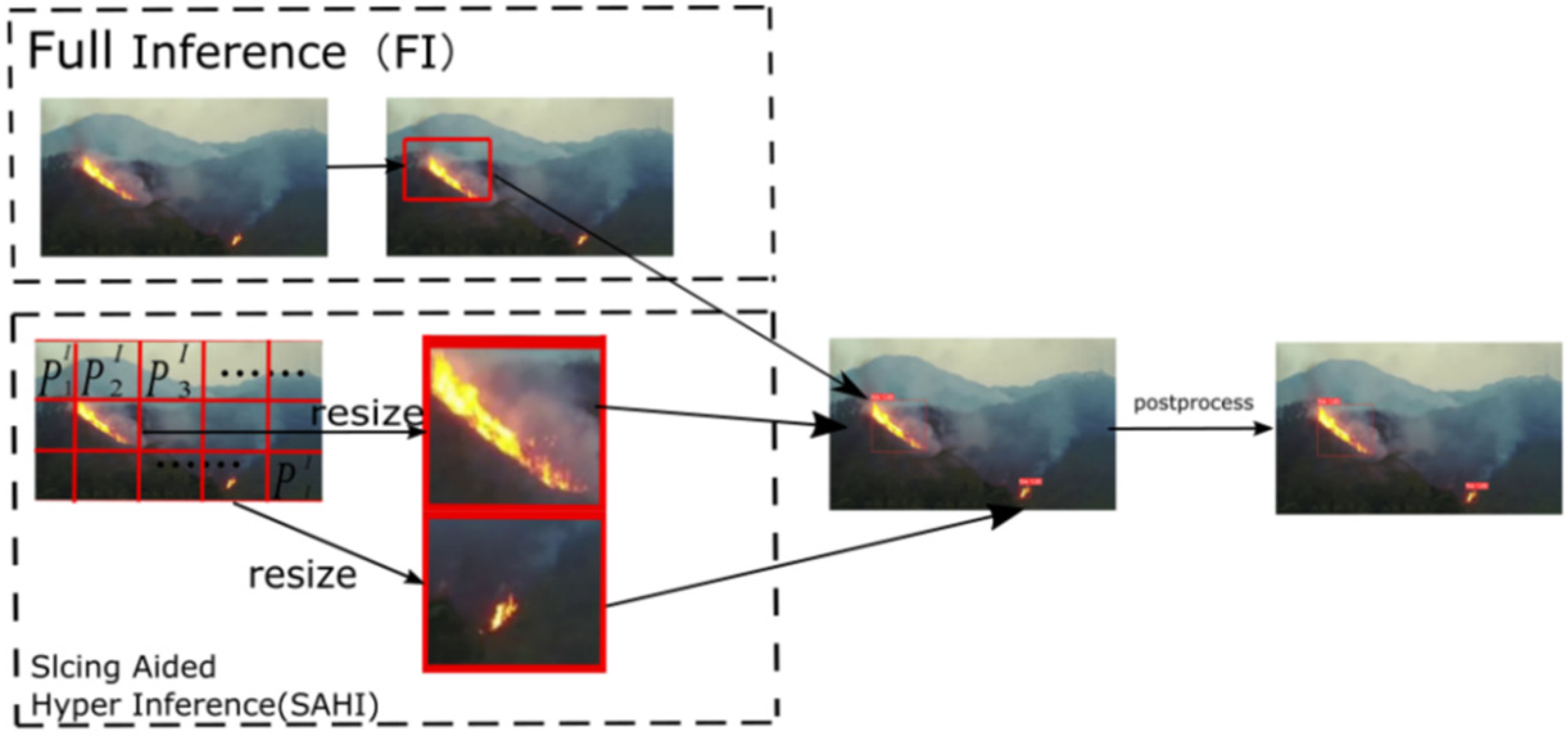
- After the model training, we integrated Slicing Aided Hyper Inference technology with our improved forest fire detection model, which solved the problem that the target pixels in small-target forest fires are small in proportion and lack sufficient details to be detected, while maintaining low computational resource requirements.
2.1. Dataset and Annotations
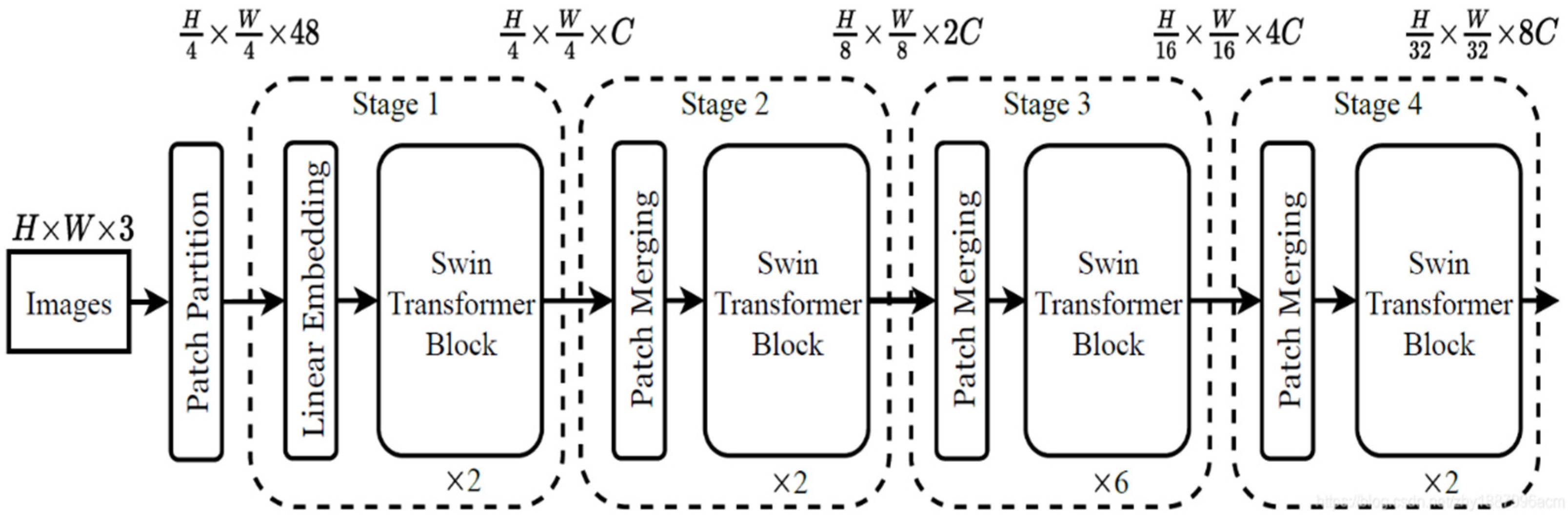
2.2. Swin Transformer
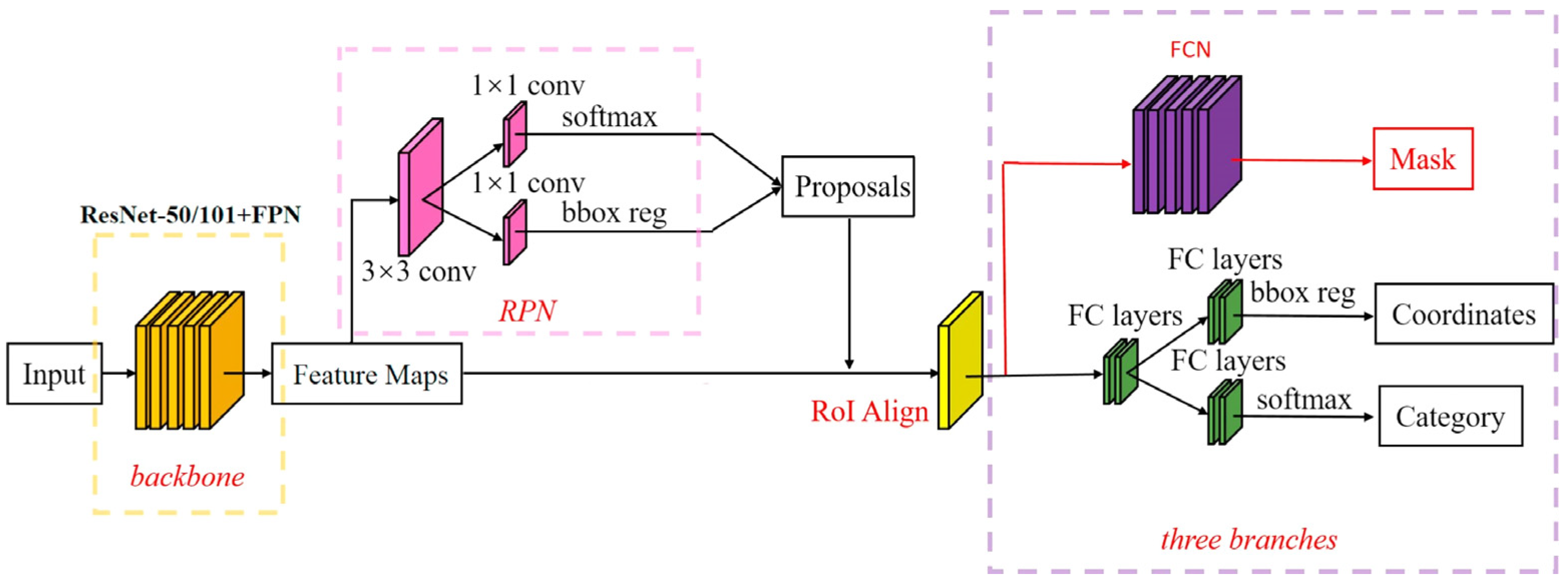
2.3. Mask R-CNN
2.4. PAFPN
2.5. Slicing Aided Hyper Inference
2.6. Improved Forest Fire Detection Model STPM
2.7. Small-Target Forest Fire Detection Model, STPM_SAHI
3. Results
3.1. Training
3.2. Model Evaluation
3.3. Detection Performance and Analysis
4. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sahoo, G.; Wani, A.; Rout, S.; Sharama, A. Impact and contribution of forest in mitigating global climate change. Des. Eng. 2021, 4, 667–682. [Google Scholar]
- Zhang, S.; Gao, D.; Lin, H.; Sun, Q. Wildfire Detection Using Sound Spectrum Analysis Based on the Internet of Things. Sensors 2019, 19, 5093. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.J.; Hovde, D.C.; Peterson, K.A.; Marshall, A.W. Fire detection using smoke and gas sensors. Fire Saf. J. 2007, 42, 507–515. [Google Scholar] [CrossRef]
- Yu, L.; Wang, N.; Meng, X. Real-time Forest fire detection with wireless sensor networks. In Proceedings of the International Conference on Wireless Communications, Networking and Mobile Computing, Wuhan, China, 26 September 2005; pp. 1214–1217. [Google Scholar]
- Zhang, J.; Li, W.; Yin, Z. Forest fire detection system based on wireless sensor network. In Proceedings of the 4th IEEE Conference on Industrial Electronics and Applications, Xi’an, China, 25–27 May 2009; pp. 520–523. [Google Scholar]
- Guo, C.H.; Qi, X.Y.; Gong, Y.L. Study on the Technology and Method of Forest Fire Monitoring by Using HJ Satellite Images. Remote Sens. Inf. 2010, 4, 85–99. [Google Scholar]
- Zhang, F.; Zhao, P.; Xu, S. Integrating multiple factors to optimize watchtower deployment for wildfire detection. Sci. Total Environ. 2020, 737, 139561. [Google Scholar] [CrossRef] [PubMed]
- Muid, A.; Kane, H.; Sarasawita, I. Potential of UAV Application for Forest Fire Detection. J. Phys. Conf. Ser. 2022, 2243, 012041. [Google Scholar] [CrossRef]
- Guan, Z.; Miao, X.; Mu, Y.; Sun, Q.; Ye, Q.; Gao, D. Forest Fire Segmentation from Aerial Imagery Data Using an Improved Instance Segmentation Model. Remote Sens. 2022, 14, 3159. [Google Scholar] [CrossRef]
- Chen, T.H.; Wu, P.H.; Chiou, Y.C. An early fire-detection method based on image processing. In Proceedings of the International Conference on Image Processing, Singapore, 24–27 October 2004; pp. 1707–1710. [Google Scholar]
- Çelik, T.; Özkaramanlı, H.; Demirel, H. Fire and smoke detection without sensors: Image processing-based approach. In Proceedings of the IEEE 15th European Signal Processing Conference, Poznan, Poland, 3–7 September 2007; pp. 1794–1798. [Google Scholar]
- Sakib, S.; Ahmed, N.; Kabir, A.J.; Ahmed, H. An Overview of Convolutional Neural Network: Its Architecture and Applications. Artif. Intell. Robot. 2018, 2018110546. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2012; Volume 25. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. arXiv 2019, arXiv:1911.09070. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Computer Society, Natal, Brazil, 5–7 August 2013. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshop (ICCVW), Venice, Italy, 29 October 2017. [Google Scholar]
- Ren, J.; Wang, Y. Overview of object detection algorithms using convolutional neural networks. J. Comput. Commun. 2022, 10, 115–132. [Google Scholar]
- Wu, S.; Zhang, L. Using popular object detection methods for real time forest fire detection. In Proceedings of the 11th International Symposium on Computational Intelligence and Design, Hangzhou, China, 8–9 December 2018; pp. 280–284. [Google Scholar]
- Kim, B.; Lee, J. A video-based fire detection using deep learning models. Appl. Sci. 2019, 9, 2862. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Akyon, F.C.; Altinuc, S.O.; Temizel, A. Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection. arXiv 2022, arXiv:2202.06934. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. arXiv 2018, arXiv:1803.01534. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Shamsoshoara, A.; Afghah, F.; Razi, A.; Zheng, L.; Fulé, P.Z.; Blasch, E. Aerial imagery pile burn detection using deep learning: The FLAME dataset. Comput. Netw. 2021, 193, 108001. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train (Multi-Scale) | Test (Multi-Scale) | Test (Small-Target Forest Fires) |
|---|---|---|---|
| Number of forest fire data set pictures | 2537 | 298 | 332 |
| Experimental Environment | Details |
|---|---|
| Programming language | Python 3.8 |
| Operating system | Windows 10 |
| Deep-learning framework | Pytorch 1.8.2 |
| GPU | NVIDIA RTX 3050ti |
| Deep-learning framework | Pytorch 1.8.2 |
| GPU acceleration tool | CUDA:11.1 |
| Training Parameters | Details |
|---|---|
| Epochs | 300 |
| Batch-size | 16 |
| Img-size | 512 |
| Initial learning rate | 0.00125 |
| Optimization algorithm | SGD |
| Average Precision (AP) | |
| at IoU = 0.5 | |
| AP Across Scales: | |
| for small target (Size < 322) | |
| for medium target (322 < Size < 962) | |
| for large target (Size > 962) | |
| Average Recall (AR) | |
| at IoU = 0.5 | |
| AR Across Scales: | |
| for small target (Size < 322) | |
| ARM | for medium target (322 < Size < 962) |
| for large target (Size > 962) |
| Model | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5 | 82.5 | 36.0 | 48.7 | 66.0 | 69.2 | 48.0 | 59.0 | 76.0 |
| EfficientDet | 84.5 | 36.3 | 50.2 | 64.1 | 68.6 | 49.8 | 64.2 | 73.0 |
| ResNet-50 + Mask R-CNN | 84.5 | 30.3 | 45.9 | 64.2 | 66.1 | 41.6 | 59.3 | 72.3 |
| ResNet-50 + PAFPN + Mask R-CNN | 85.7 | 34.2 | 47.0 | 65.6 | 67.1 | 44.1 | 60.6 | 73.0 |
| Swin Transformer + Mask R-CNN | 87.3 | 40.2 | 48.0 | 67.1 | 69.2 | 52.7 | 60.9 | 74.7 |
| Swin Transformer + PAFPN + Mask R-CNN(STPM, ours) | 89.4 | 42.4 | 53.7 | 67.9 | 71.2 | 56.1 | 67.0 | 75.0 |
| Model | Small-Target Forest Fires (%) |
|---|---|
| YOLOv5 | 22.7 |
| EfficientDet | 27.4 |
| ResNet-50 + Mask R-CNN | 33.9 |
| ResNet-50 + PAFPN + Mask R-CNN | 36.7 |
| Swin Transformer + Mask R-CNN | 46.2 |
| Swin Transformer + PAFPN + Mask R-CNN(STPM, ours) | 50.9 |
| STPM + SAHI(STPM_SAHI, ours) | 59.0 |
| Video Resolution (Pixel) | Time |
|---|---|
| 426 × 240 | 52.01 ms |
| 640 × 360 | 181.04 ms |
| 720 × 416 | 196.04 ms |
| 845 × 480 | 208.01 ms |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, J.; Lin, H.; Wang, F. STPM_SAHI: A Small-Target Forest Fire Detection Model Based on Swin Transformer and Slicing Aided Hyper Inference. Forests 2022, 13, 1603. https://doi.org/10.3390/f13101603
Lin J, Lin H, Wang F. STPM_SAHI: A Small-Target Forest Fire Detection Model Based on Swin Transformer and Slicing Aided Hyper Inference. Forests. 2022; 13(10):1603. https://doi.org/10.3390/f13101603
Chicago/Turabian StyleLin, Ji, Haifeng Lin, and Fang Wang. 2022. "STPM_SAHI: A Small-Target Forest Fire Detection Model Based on Swin Transformer and Slicing Aided Hyper Inference" Forests 13, no. 10: 1603. https://doi.org/10.3390/f13101603
APA StyleLin, J., Lin, H., & Wang, F. (2022). STPM_SAHI: A Small-Target Forest Fire Detection Model Based on Swin Transformer and Slicing Aided Hyper Inference. Forests, 13(10), 1603. https://doi.org/10.3390/f13101603