

Automatic Detection and Counting of Stacked Eucalypt Timber Using the YOLOv8 Model

 ,
,  ,
, 
Abstract
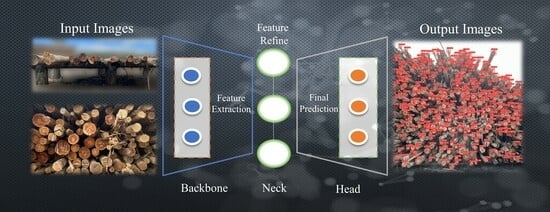
:
1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Annotation Format and Dataset Splitting
2.3. Architecture and Configuration Model
2.4. Accuracy Measurements
3. Results
3.1. Model Performance
3.2. Model Generalization
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pásztory, Z.; Heinzmann, B.; Barbu, M.C. Manual and Automatic Volume Measuring Methods for Industrial Timber. In Proceedings of the IOP Conference Series: Earth and Environmental Science; Institute of Physics Publishing: Bristol, UK, 2018; Volume 159. [Google Scholar]
- Cremer, T.; Berendt, F.; de Diez, F.M.; Wolfgramm, F.; Blasko, L. Accuracy of Photo-Optical Measurement of Wood Piles. In Proceedings of the 1st International Electronic Conference on Forests—Forests for a Better Future: Sustainability, Innovation, Interdisciplinarity, Online, 15–30 November 2020; MDPI: Basel, Switzerland, 2020; p. 90. [Google Scholar]
- Purfürst, T.; De Miguel-Díez, F.; Berendt, F.; Engler, B.; Cremer, T. Comparison of Wood Stack Volume Determination between Manual, Photo-Optical, IPad-LiDAR and Handheld-LiDAR Based Measurement Methods. iForest 2023, 16, 243–252. [Google Scholar] [CrossRef]
- Husch, B.; Beers, T.W.; Kershaw, J.A., Jr. Forest Mensuration, 4th ed.; Wiley: Hoboken, NJ, USA, 2002; ISBN 978-0471018506. [Google Scholar]
- Husch, B.; Miller, C.I.; Beers, T.W. Forest Mensuration, 3rd ed.; Krieger Publishing Company: Malabar, FL, USA, 1993. [Google Scholar]
- Antunes Santana, O.; Imaña Encinas, J.; Riesco Muñoz, G. Stacking Factor in Transporting Firewood Produced from a Mixture of Caatinga Biome Species in Brazil. Int. J. For. Eng. 2023, 34, 54–63. [Google Scholar] [CrossRef]
- Koman, S.; Feher, S. Basic Density of Hardwoods Depending on Age and Site. Wood Res. 2015, 60, 907–912. [Google Scholar]
- Glass, S.V.; Zelinka, S.L.; Johnson, J.A. Investigation of Historic Equilibrium Moisture Content Data from the Forest Products Laboratory; United States Department of Agriculture, Forest Service, Forest Products Laboratory: Madison, WI, USA, 2014.
- Watanabe, K.; Kobayashi, I.; Kuroda, N. Investigation of Wood Properties That Influence the Final Moisture Content of Air-Dried Sugi (Cryptomeria japonica) Using Principal Component Regression Analysis. J. Wood Sci. 2012, 58, 487–492. [Google Scholar] [CrossRef]
- Carvalho, A.M.; Camargo, F.R.A. Avaliacao Do Metodo de Recebimento de Madeira Por Estere [Evaluation of the Method of Receiving Wood by Stere]. Rev. O Papel 1996, 57, 65–68. [Google Scholar]
- Nylinder, M.; Kubénka, T.; Hultnäs, M. Roundwood Measurement of Truck Loads by Laser Scanning. In Field Study at Arauco Pulp Mill Nueva Aldea; 2008; pp. 1–9. Available online: https://docplayer.net/33097769-Roundwood-measurement-of-truck-loads-by-laser-scanning-a-field-study-at-arauco-pulp-mill-nueva-aldea.html (accessed on 15 May 2023).
- Kunickaya, O.; Pomiguev, A.; Kruchinin, I.; Storodubtseva, T.; Voronova, A.; Levushkin, D.; Borisov, V.; Ivanov, V. Analysis of Modern Wood Processing Techniques in Timber Terminals. Cent. Eur. For. J. 2022, 68, 51–59. [Google Scholar] [CrossRef]
- Campos, J.C.C.; Leite, H.G. Forest Measurement: Questions and Answers, 5th ed.; UFV: Viçosa, Brazil, 2017; ISBN 978-8572695794. [Google Scholar]
- Soares, C.B.S.; Paula Neto, F.; Souza, A.L. Dendrometria e Inventário Florestal, 2nd ed.; Universidade Federal de Viçosa: Viçosa, Brazil, 2011. [Google Scholar]
- Mederski, P.S.; Naskrent, B.; Tomczak, A.; Tomczak, K. Accuracy of Photo-Optical Timber Measurement Using a Stereo Camera Technology. Croat. J. For. Eng. 2023, 45, 10. [Google Scholar] [CrossRef]
- Leite, R.V.; do Amaral, C.H.; de Pires, R.P.; Silva, C.A.; Soares, C.P.B.; Macedo, R.P.; da Silva, A.A.L.; Broadbent, E.N.; Mohan, M.; Leite, H.G. Estimating Stem Volume in Eucalyptus Plantations Using Airborne LiDAR: A Comparison of Area- and Individual Tree-Based Approaches. Remote Sens. 2020, 12, 1513. [Google Scholar] [CrossRef]
- Pu, Y.; Xu, D.; Wang, H.; Li, X.; Xu, X. A New Strategy for Individual Tree Detection and Segmentation from Leaf-on and Leaf-off UAV-LiDAR Point Clouds Based on Automatic Detection of Seed Points. Remote Sens. 2023, 15, 1619. [Google Scholar] [CrossRef]
- Bertola, A.; Soares, C.P.B.; Ribeiro, J.C.; Leite, H.G.; de Souza, A.L. Determination of Piling Factors through Digitora Software. Rev. Árvore 2003, 27, 837–844. [Google Scholar] [CrossRef]
- Silveira, D.D.P. Estimation of the Volume Wooden Stacked Using Digital Images and Neural Networks. Master’s Thesis, Universidade Federal de Viçosa, Viçosa, Brazil, 2014. [Google Scholar]
- Kärhä, K.; Nurmela, S.; Karvonen, H.; Kivinen, V.-P.; Melkas, T.; Nieminen, M. Estimating the Accuracy and Time Consumption of a Mobile Machine Vision Application in Measuring Timber Stacks. Comput. Electron. Agric. 2019, 158, 167–182. [Google Scholar] [CrossRef]
- Moskalik, T.; Tymendorf, Ł.; van der Saar, J.; Trzciński, G. Methods of Wood Volume Determining and Its Implications for Forest Transport. Sensors 2022, 22, 6028. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics; Version 8.0.0; 2023; Available online: https://github.com/ultralytics/ultralytics (accessed on 15 May 2023).
- Fang, Y.; Guo, X.; Chen, K.; Zhou, Z.; Ye, Q. Accurate and Automated Detection of Surface Knots on Sawn Timbers Using YOLO-V5 Model. Bioresources 2021, 16, 5390–5406. [Google Scholar] [CrossRef]
- Ma, J.; Yan, W.; Liu, G.; Xing, S.; Niu, S.; Wei, T. Complex Texture Contour Feature Extraction of Cracks in Timber Structures of Ancient Architecture Based on YOLO Algorithm. Adv. Civ. Eng. 2022, 2022, 7879302. [Google Scholar] [CrossRef]
- Liu, Y.; Hou, M.; Li, A.; Dong, Y.; Xie, L.; Ji, Y. Automatic Detection of Timber-Cracks in Wooden Architectural Heritage Using YOLOv3 Algorithm. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 1471–1476. [Google Scholar] [CrossRef]
- Kurdthongmee, W. Improving Wood Defect Detection Accuracy with Yolo V3 by Incorporating Out-of-Defect Area Annotations. Available online: https://ssrn.com/abstract=4395580 (accessed on 21 July 2023).
- Cui, Y.; Lu, S.; Liu, S. Real-Time Detection of Wood Defects Based on SPP-Improved YOLO Algorithm. Multimed. Tools Appl. 2023, 82, 21031–21044. [Google Scholar] [CrossRef]
- Davies, E.R. The Dramatically Changing Face of Computer Vision. In Advanced Methods and Deep Learning in Computer Vision; Elsevier: Amsterdam, The Netherlands, 2022; pp. 1–91. [Google Scholar]
- Goodale, M.A.; Milner, A.D. Separate Visual Pathways for Perception and Action. Trends Neurosci. 1992, 15, 20–25. [Google Scholar] [CrossRef]
- Zhu, S.-C.; Wu, Y. Statistics of Natural Images. In Computer Vision; Springer International Publishing: Cham, Switzerland, 2023; pp. 19–35. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6–12, 2014, Proceedings, Part I 13; Springer International Publishing: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Gavali, P.; Banu, J.S. Deep Convolutional Neural Network for Image Classification on CUDA Platform. In Deep Learning and Parallel Computing Environment for Bioengineering Systems; Elsevier: Amsterdam, The Netherlands, 2019; pp. 99–122. [Google Scholar]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, S.; Tu, W.; Yu, H.; Li, C. Using Computer Vision and Compressed Sensing for Wood Plate Surface Detection. Opt. Eng. 2015, 54, 103102. [Google Scholar] [CrossRef]
- Cavalin, P.; Oliveira, L.S.; Koerich, A.L.; Britto, A.S. Wood Defect Detection Using Grayscale Images and an Optimized Feature Set. In Proceedings of the IECON 2006—32nd Annual Conference on IEEE Industrial Electronics, Paris, France, 6–10 November 2006; pp. 3408–3412. [Google Scholar]
- Tzutalin, D. LabelImg 2015. Available online: https://github.com/tzutalin/labelImg (accessed on 15 May 2023).
- Terven, J.; Cordova-Esparza, D. A Comprehensive Review of YOLO: From YOLOv1 to YOLOv8 and Beyond. arXiv 2023, arXiv:2304.00501. [Google Scholar] [CrossRef]
- Aharon, N.; Orfaig, R.; Bobrovsky, B.-Z. BoT-SORT: Robust Associations Multi-Pedestrian Tracking. arXiv 2022, arXiv:2206.14651. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Jocher, G. YOLOv5 by Ultralytics; Version 7.0; 2020; Available online: https://github.com/ultralytics/yolov5/releases/tag/v7.0 (accessed on 21 June 2023).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016. ECCV 2016; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Ahmed, D.; Sapkota, R.; Churuvija, M.; Karkee, M. Machine Vision-Based Crop-Load Estimation Using YOLOv8. arXiv 2023. [Google Scholar] [CrossRef]
- Hajjaji, Y.; Alzahem, A.; Boulila, W.; Farah, I.R.; Koubaa, A. Sustainable Palm Tree Farming: Leveraging IoT and Multi-Modal Data for Early Detection and Mapping of Red Palm Weevil. arXiv 2023, arXiv:2306.16862. [Google Scholar] [CrossRef]
- Bayrak, O.C.; Erdem, F.; Uzar, M. Deep Learning Based Aerial Imagery Classification for Tree Species Identification. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2023, 48, 471–476. [Google Scholar] [CrossRef]
- Sportelli, M.; Apolo-Apolo, O.E.; Fontanelli, M.; Frasconi, C.; Raffaelli, M.; Peruzzi, A.; Perez-Ruiz, M. Evaluation of YOLO Object Detectors for Weed Detection in Different Turfgrass Scenarios. Appl. Sci. 2023, 13, 8502. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, Q.; Jiang, P.; Zheng, Y.; Yuan, L.; Yuan, P. LDS-YOLO: A Lightweight Small Object Detection Method for Dead Trees from Shelter Forest. Comput. Electron. Agric. 2022, 198, 107035. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Splitting | Precision | Recall | mAP50 |
|---|---|---|---|
| Train | 0.814 | 0.812 | 0.844 |
| Validation | 0.778 | 0.798 | 0.839 |
| Test | 0.741 | 0.779 | 0.799 |
| File Name | Type | File | Observed Count | Estimated Count | E | RE% |
|---|---|---|---|---|---|---|
| A | Image | .jpg | 278 | 147 | 131 | −47.122 |
| B | Image | .jpg | 387 | 260 | 127 | −32.817 |
| C | Image | .jpg | 540 | 300 | 240 | −44.444 |
| D | Image | .jpg | 580 | 300 | 280 | −48.276 |
| E | Image | .jpg | 534 | 300 | 234 | −43.82 |
| F | Image | .jpg | 586 | 300 | 286 | −48.805 |
| G | Image | .jpg | 524 | 300 | 224 | −42.748 |
| H | Image | .jpg | 546 | 300 | 246 | −45.055 |
| I | Image | .jpg | 452 | 273 | 179 | −39.602 |
| J | Image | .jpg | 217 | 114 | 103 | −47.465 |
| Video S1 | video | .avi | 4742 | 4152 | 590 | −12.442 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Casas, G.G.; Ismail, Z.H.; Limeira, M.M.C.; da Silva, A.A.L.; Leite, H.G. Automatic Detection and Counting of Stacked Eucalypt Timber Using the YOLOv8 Model. Forests 2023, 14, 2369. https://doi.org/10.3390/f14122369
Casas GG, Ismail ZH, Limeira MMC, da Silva AAL, Leite HG. Automatic Detection and Counting of Stacked Eucalypt Timber Using the YOLOv8 Model. Forests. 2023; 14(12):2369. https://doi.org/10.3390/f14122369
Chicago/Turabian StyleCasas, Gianmarco Goycochea, Zool Hilmi Ismail, Mathaus Messias Coimbra Limeira, Antonilmar Araújo Lopes da Silva, and Helio Garcia Leite. 2023. "Automatic Detection and Counting of Stacked Eucalypt Timber Using the YOLOv8 Model" Forests 14, no. 12: 2369. https://doi.org/10.3390/f14122369
APA StyleCasas, G. G., Ismail, Z. H., Limeira, M. M. C., da Silva, A. A. L., & Leite, H. G. (2023). Automatic Detection and Counting of Stacked Eucalypt Timber Using the YOLOv8 Model. Forests, 14(12), 2369. https://doi.org/10.3390/f14122369