
Multi-Scale Forest Fire Recognition Model Based on Improved YOLOv5s



Abstract
:1. Introduction
2. The Proposed Method
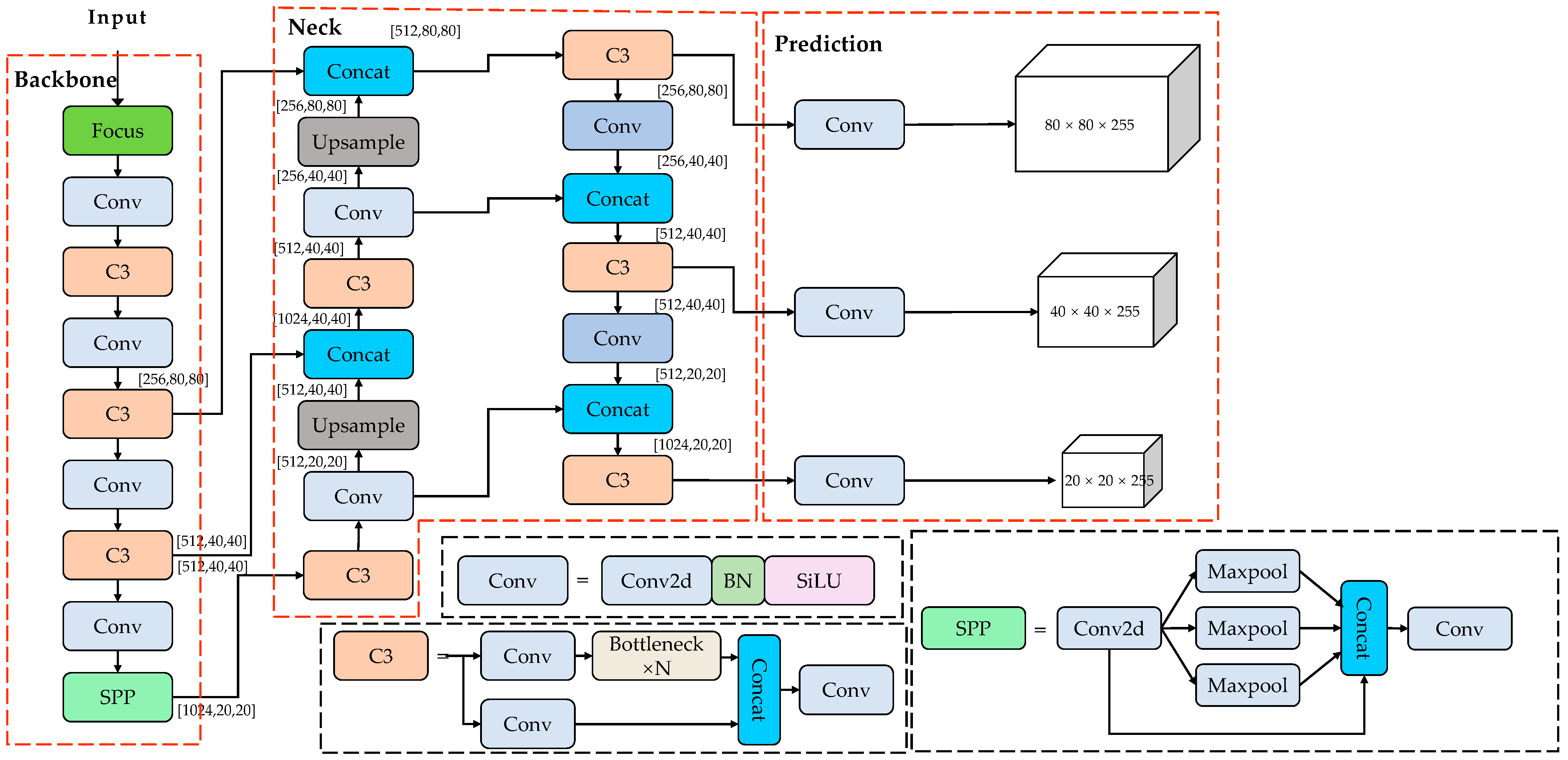
2.1. YOLOv5
2.2. Coordinate Attention (CA)
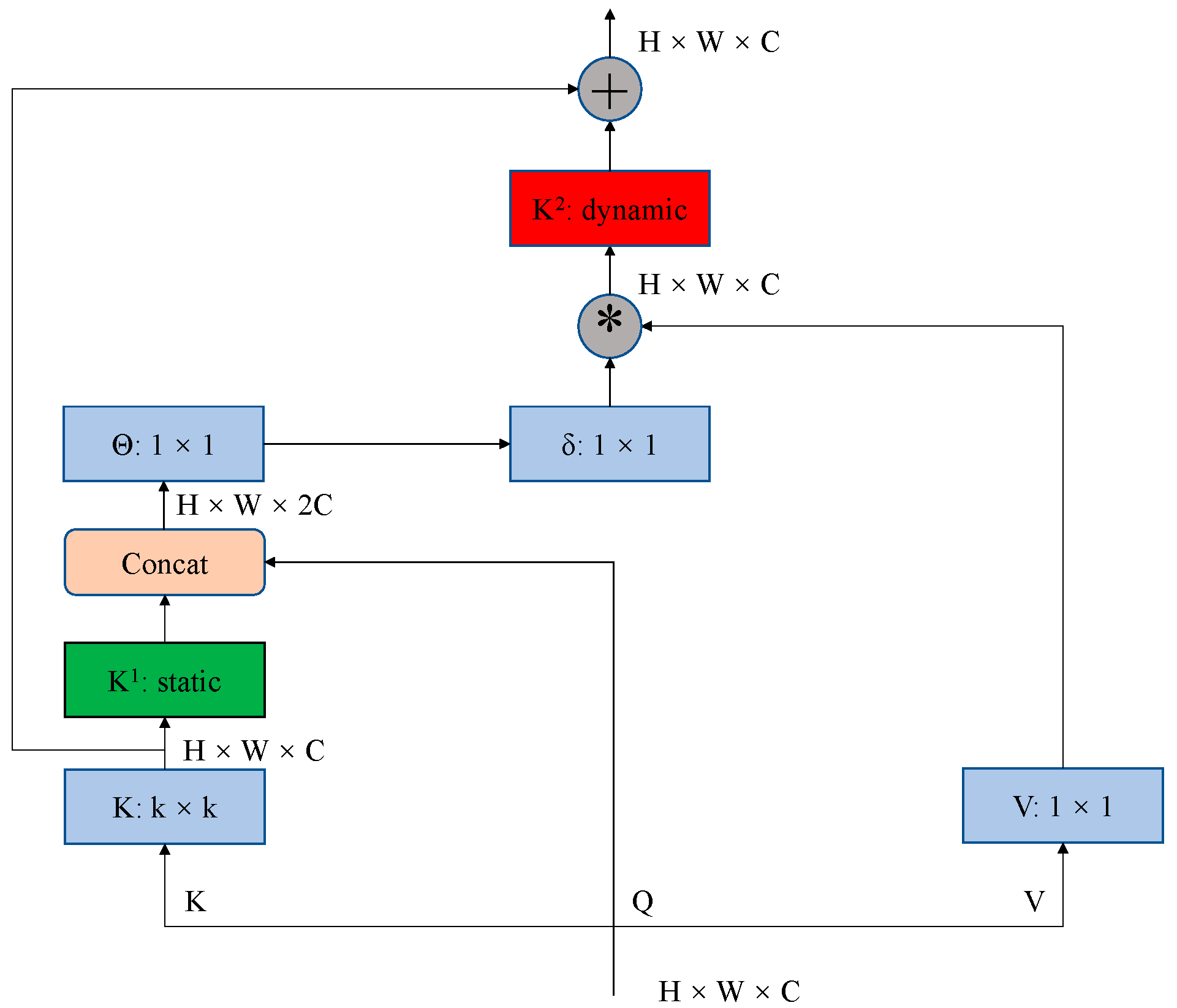
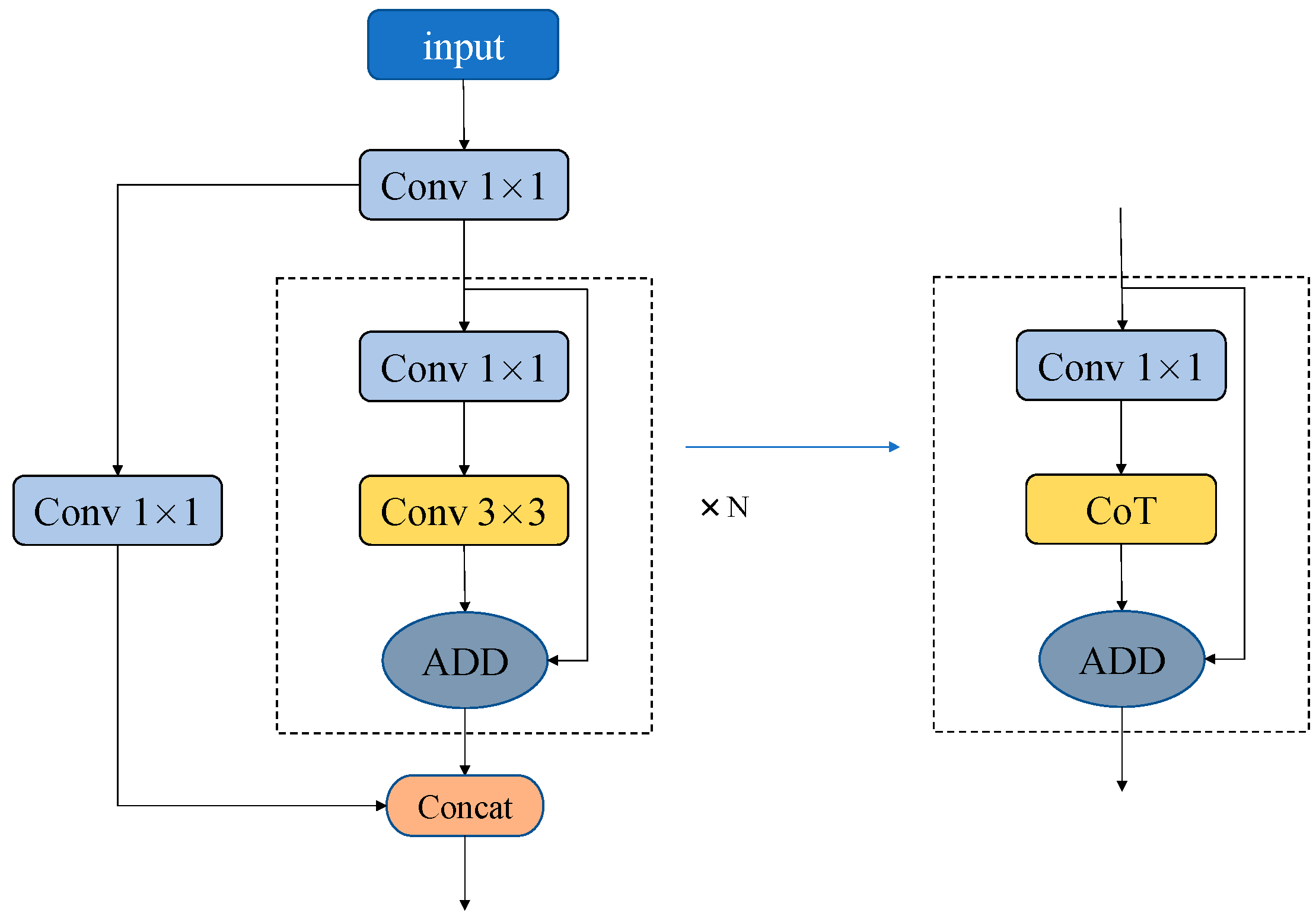
2.3. Contextual Transformer (CoT3)
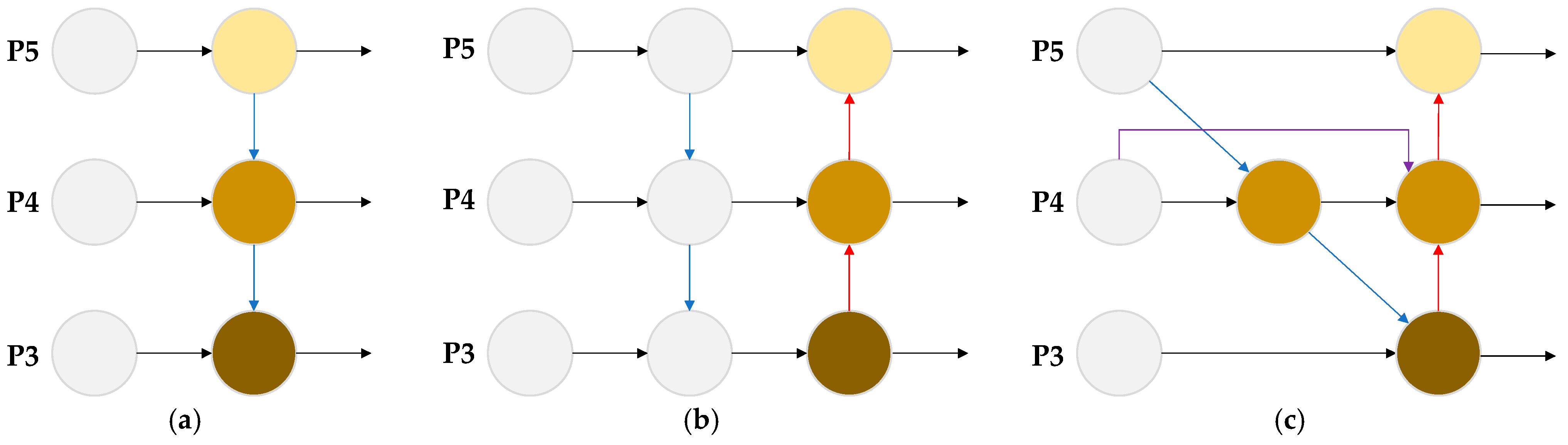
2.4. Bi-Directional Feature Pyramid Network (BiFPN)
2.5. Complete-Intersection-Over-Union (CIoU)
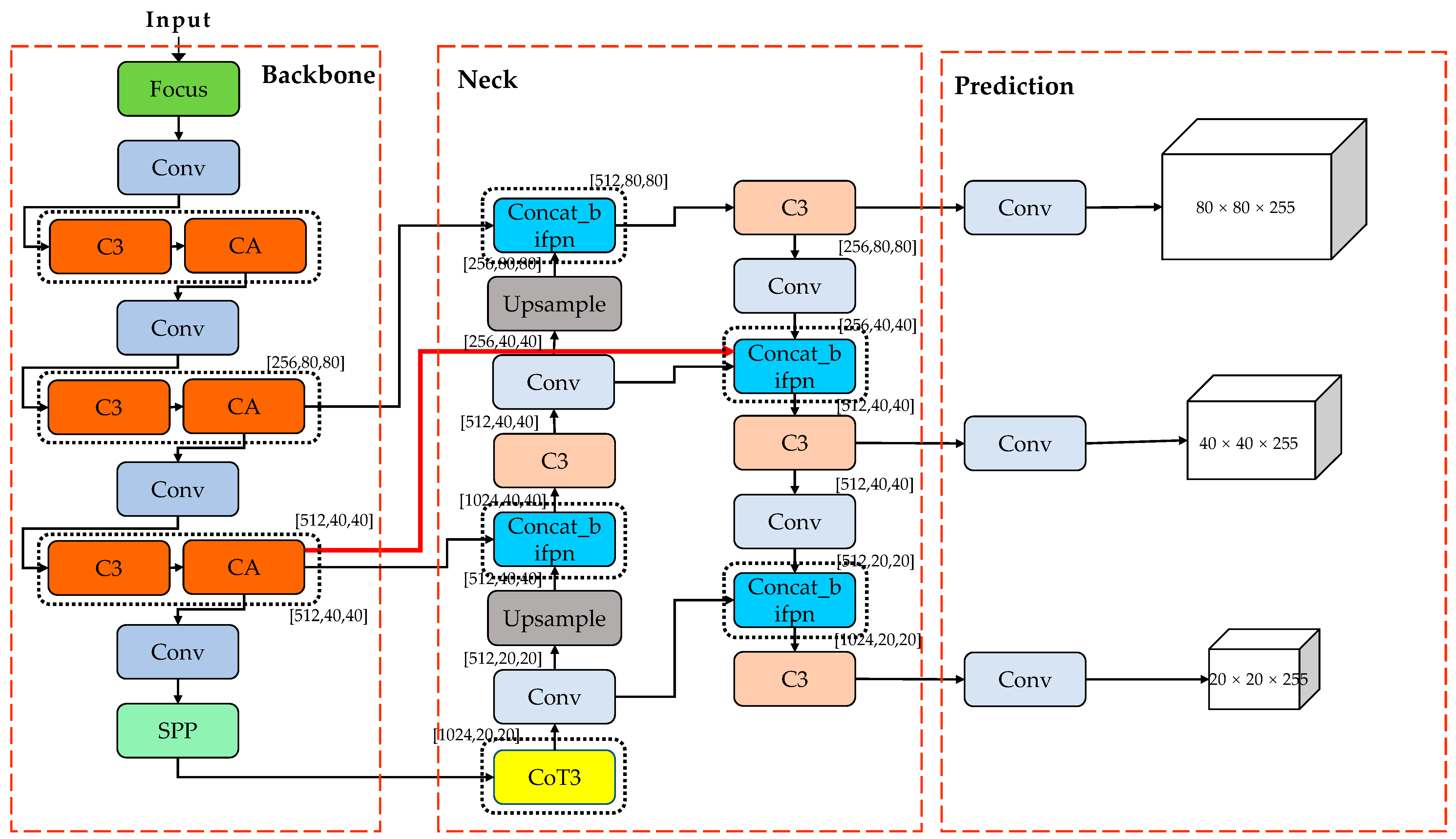
2.6. Improved YOLOv5s-CCAB Structure
3. Evaluation Methodology
3.1. Datasets
3.2. Model Evaluation
4. Results
4.1. Training
4.2. Ablation Experiments
4.3. Comparison
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Y.; Mei, B.; Linhares-Juvenal, T. The economic contribution of the world’s forest sector. Forest Policy Econ. 2019, 100, 236–253. [Google Scholar] [CrossRef]
- Sahoo, G.; Wani, A.; Rout, S.; Sharma, A.; Prusty, A.K. Impact and Contribution of Forest in Mitigating Global Climate Change. Des. Eng. 2021, 4, 667–682. [Google Scholar]
- Ying, L.; Han, J.; Du, Y.; Shen, Z. Forest fire characteristics in China: Spatial patterns and determinants with thresholds. Forest Ecol. Manag. 2018, 424, 345–354. [Google Scholar] [CrossRef]
- Tadic, M. GIS-Based Forest Fire Susceptibility Zonation with IoT Sensor Network Support, Case Study—Nature Park Golija, Serbia. Sensors 2021, 21, 6520. [Google Scholar]
- Varela, N.; Díaz-Martinez, J.L.; Ospino, A.; Zelaya, N. Wireless sensor network for forest fire detection. Procedia Comput. Sci. 2020, 175, 435–440. [Google Scholar] [CrossRef]
- Kizilkaya, B.; Ever, E.; Yekta, Y.H.; Yazici, A. An Effective Forest Fire Detection Framework Using Heterogeneous Wireless Multimedia Sensor Networks. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2022, 18, 1–21. [Google Scholar] [CrossRef]
- Mae, A.; Uco, B.; Nyn, C. Identification and modelling of forest fire severity and risk zones in the Cross—Niger transition forest with remotely sensed satellite data. Egypt. J. Remote Sens. Space Sci. 2021, 24, 879–887. [Google Scholar]
- Tian, Y.; Wu, Z.; Li, M.; Wang, B.; Zhang, X. Forest Fire Spread Monitoring and Vegetation Dynamics Detection Based on Multi-Source Remote Sensing Images. Remote Sens. 2022, 14, 4431. [Google Scholar] [CrossRef]
- Abid, F. A Survey of Machine Learning Algorithms Based Forest Fires Prediction and Detection Systems. Fire Technol. 2020, 57, 559–590. [Google Scholar] [CrossRef]
- Cruz, H.; Eckert, M.; Meneses, J.; Martínez, J. Efficient forest fire detection index for application in unmanned aerial systems (UASs). Sensors 2016, 16, 893. [Google Scholar] [CrossRef]
- Vicente, J.; Guillemant, P. An image processing technique for automatically detecting forest fire. Int. J. Therm. Sci. 2002, 41, 1113–1120. [Google Scholar] [CrossRef]
- Celik, T.; Demirel, H. Fire detection in video sequences using a generic color model. Fire Safety J. 2009, 44, 147–158. [Google Scholar] [CrossRef]
- Huang, J.; Zhao, J.; Gao, W.; Long, C.; Xiong, L.; Yuan, Z.; Han, S. Local Binary Pattern Based Texture Analysis for Visual Fire Recognition. In Proceedings of the 2010 3rd International Congress on Image and Signal Processing, Yantai, China, 16–18 October 2010; pp. 1887–1891. [Google Scholar]
- Xue, X.; Jin, S.; An, F.; Zhang, H.; Fan, J.; Eichhorn, M.P.; Jin, C.; Chen, B.; Jiang, L.; Yun, T. Shortwave radiation calculation for forest plots using airborne LiDAR data and computer graphics. Plant Phenomics 2022, 2022. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 23–28 June 2013. [Google Scholar]
- Girshick, R. Fast R-CNN. Computer Science. In Proceedings of the Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. Ssd: Single Shot Multibox Detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Hawaii, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Muhammad, K.; Ahmad, J.; Mehmood, I.; Rho, S.; Baik, S.W. Convolutional Neural Networks based Fire Detection in Surveillance Videos. IEEE Access 2018, 6, 18174–18183. [Google Scholar] [CrossRef]
- Gagliardi, A.; Villella, M.; Picciolini, L.; Saponara, S. Analysis and Design of a Yolo like DNN for Smoke/Fire Detection for Low-cost Embedded Systems. In Applications in Electronics Pervading Industry, Environment and Society: APPLEPIES; Springer: Cham, Switzerland, 2021; pp. 12–22. [Google Scholar]
- Shen, D.; Chen, X.; Nguyen, M.; Yan, W.Q. Flame detection using deep learning. In Proceedings of the 2018 4th International Conference on Control, Automation and Robotics (ICCAR), Auckland, New Zealand, 20–23 April 2018; pp. 416–420. [Google Scholar]
- Li, P.; Zhao, W. Image fire detection algorithms based on convolutional neural networks. Case Stud. Therm. Eng. 2020, 19, 100625. [Google Scholar] [CrossRef]
- Wang, C.; Liao, H.M.; Wu, Y.; Chen, P.; Hsieh, J.; Yeh, I. CSPNet: A New Backbone that Can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; Springer: Cham, Switzerland; pp. 390–391. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. IEEE Comput. Soc. 2017, 2980–2988. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, A.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual Transformer Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1489–1500. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. IEEE Trans. Cybern. 2022, 52, 8574–8586. [Google Scholar] [CrossRef]
- He, J.; Erfani, S.; Ma, X.; Bailey, J.; Chi, Y.; Hua, X. α-IoU: A Family of Power Intersection over Union Losses for Bounding Box Regression. Adv. Neural Inf. Process. Syst. 2021, 34, 20230–20242. [Google Scholar]
- Chino, D.Y.; Avalhais, L.P.; Rodrigues, J.F.; Traina, A.J. Bowfire: Detection of fire in still images by integrating pixel color and texture analysis. In Proceedings of the 2015 28th SIBGRAPI Conference on Graphics, Patterns and Images, Salvador, Brazil, 26–29 August 2015; pp. 95–102. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft Coco: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Nagle, F.; Johnston, A. Recognising the dynamic form of fire. Sci. Rep. 2021, 11, 10566. [Google Scholar] [CrossRef]
- Sun, C.; Huang, C.; Zhang, H.; Chen, B.; An, F.; Wang, L.; Yun, T. Individual tree crown segmentation and crown width extraction from a heightmap derived from aerial laser scanning data using a deep learning framework. Front. Plant Sci. 2022, 13, 914974. [Google Scholar] [CrossRef]
- Zhao, H.; Ji, Z.; Li, N.; Gu, J.; Li, Y. Target detection over the diurnal cycle using a multispectral infrared sensor. Sensors 2016, 17, 56. [Google Scholar] [CrossRef]
- Shi, B.; Gu, W.; Sun, X. XDMOM: A Real-Time Moving Object Detection System Based on a Dual-Spectrum Camera. Sensors 2022, 22, 3905. [Google Scholar] [CrossRef]
- Cao, X.; Xu, J.; Zhang, R. Mobile edge computing for cellular-connected UAV: Computation offloading and trajectory optimization. In Proceedings of the 2018 IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Kalamata, Greece, 25–28 June 2018; pp. 1–5. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train | Validation | Test | Summary |
|---|---|---|---|---|
| Number | 2380 | 298 | 298 | 2976 |
| Experimental Environment | Details |
|---|---|
| Programming language | Python 3.8 |
| Operating system | Windows 10 |
| Deep learning framework | Pytorch 1.9.0 |
| GPU | NVIDIA GeForce GTX 3080 |
| GPU acceleration tool | CUDA:11.0 |
| Training Parameters | Details |
|---|---|
| Epochs | 300 |
| Batch-size | 16 |
| Img-size (pixels) | 640 × 640 |
| Initial learning rate | 0.01 |
| Optimization algorithm | SGD |
| Pre-training weights file | None |
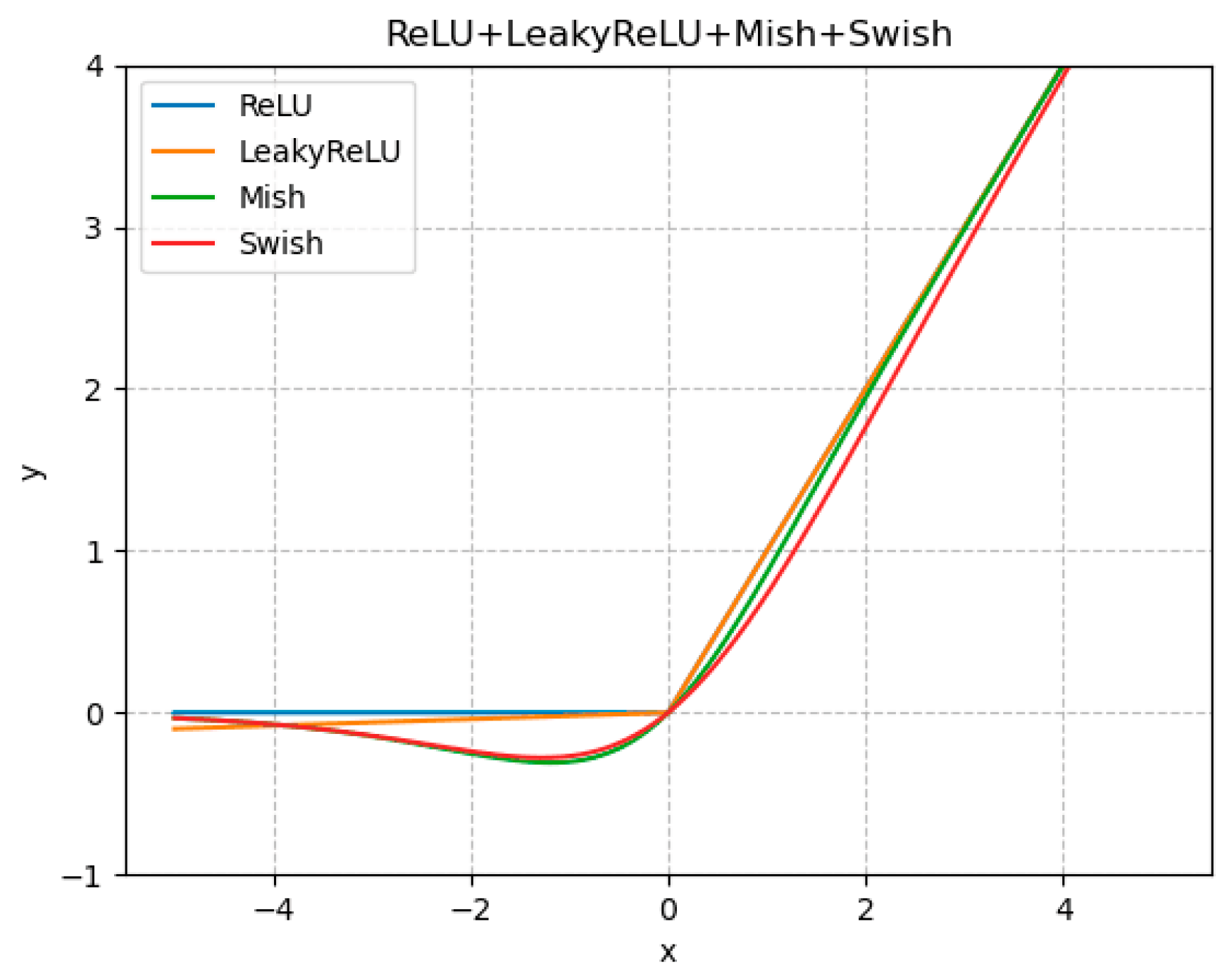
| Activation Function | AP/% |
|---|---|
| Relu | 84.8 |
| LeakyRelu | 86.7 |
| Mish | 82.5 |
| Swish | 84.6 |
| MODEL | [email protected]/% | GFLOPs | FPS | Time/ms |
|---|---|---|---|---|
| YOLOv5s | 81.5 | 16.3 | 43.8 | 22.8 |
| YOLOv5s-CA | 85.4 | 16.3 | 41.6 | 24 |
| YOLOv5s-CoT3 | 85.2 | 16.2 | 42.5 | 23.5 |
| YOLOv5s-a-CIoU | 83.4 | 16.3 | 42 | 23.8 |
| YOLOv5s-BiFPN | 83.7 | 17.6 | 44 | 22.7 |
| YOLOv5s-CA-CoT3 | 86.3 | 16.4 | 33.5 | 29.8 |
| YOLOv5s-CA-CoT3 -a-CIoU | 86.5 | 16.5 | 34.9 | 28.6 |
| YOLOv5s-CCAB | 87.7 | 17.7 | 36.6 | 27.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, G.; Zhou, H.; Li, Z.; Gao, Y.; Bai, D.; Xu, R.; Lin, H. Multi-Scale Forest Fire Recognition Model Based on Improved YOLOv5s. Forests 2023, 14, 315. https://doi.org/10.3390/f14020315
Chen G, Zhou H, Li Z, Gao Y, Bai D, Xu R, Lin H. Multi-Scale Forest Fire Recognition Model Based on Improved YOLOv5s. Forests. 2023; 14(2):315. https://doi.org/10.3390/f14020315
Chicago/Turabian StyleChen, Gong, Hang Zhou, Zhongyuan Li, Yucheng Gao, Di Bai, Renjie Xu, and Haifeng Lin. 2023. "Multi-Scale Forest Fire Recognition Model Based on Improved YOLOv5s" Forests 14, no. 2: 315. https://doi.org/10.3390/f14020315
APA StyleChen, G., Zhou, H., Li, Z., Gao, Y., Bai, D., Xu, R., & Lin, H. (2023). Multi-Scale Forest Fire Recognition Model Based on Improved YOLOv5s. Forests, 14(2), 315. https://doi.org/10.3390/f14020315