Appendix A. Accuracy Assessment of Classified LULCC—Rule-Based Rationality Evaluation
Validating classified LULCC results from a long series of images is always a problem because simultaneous reference data are frequently not available. The rule-based rationality evaluation, suggested by Liu et al. [
35,
39], can be used as an alternative accuracy assessment technique. The advantage of this method is that it employs only a set of rules and no reference map is needed.
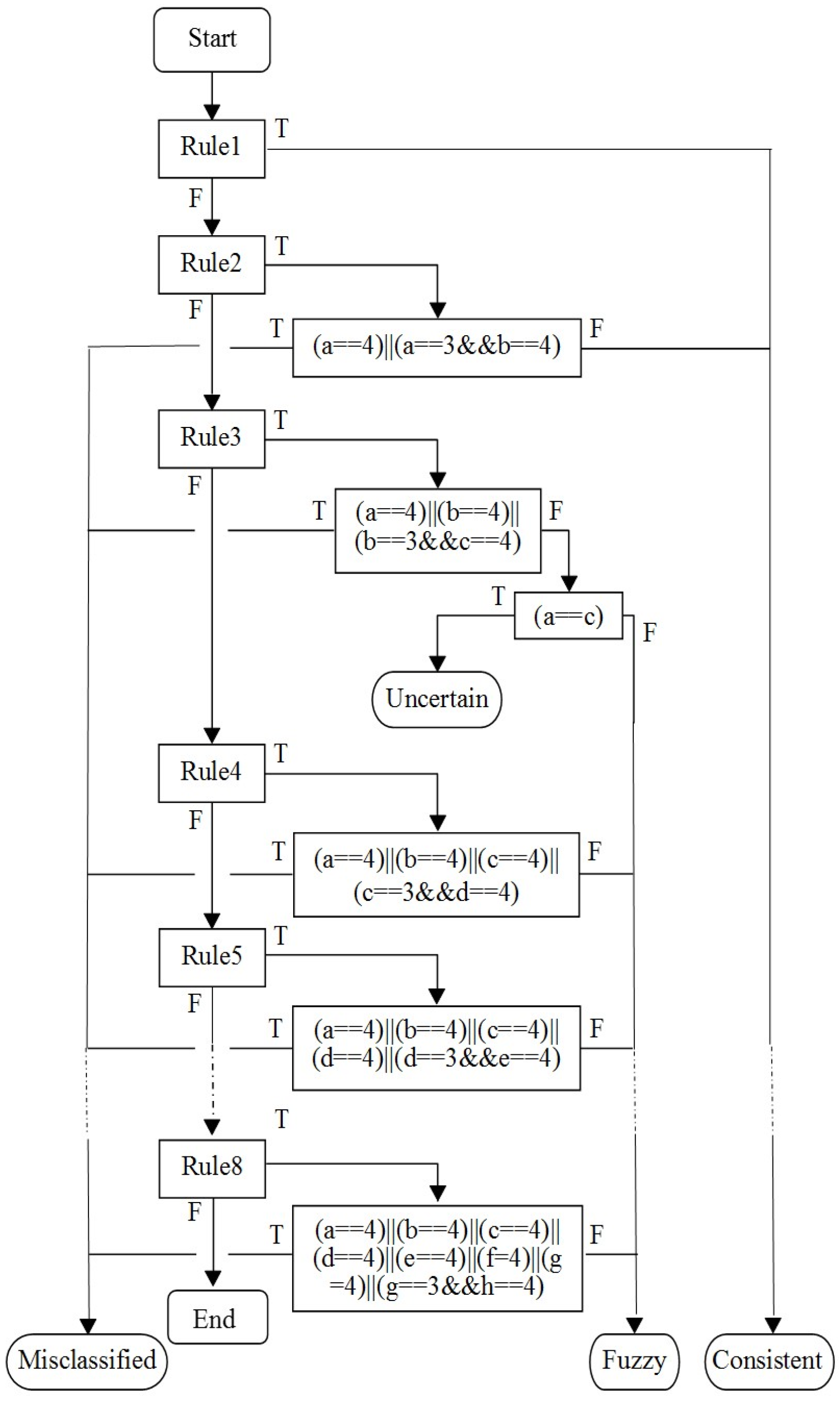
Given that the classified images cover eight points of time (1977, 1984, 1993, 2000, 2004, 2007, 2010, and 2013), the maximum chance for land use change is seven. If t denotes the number of potential changes over the whole period, then . If t equals 0, it means that the pixel under analysis did not change at all during the whole time under study; if t equals 7, the pixel under investigation changed classes in each period. Each pixel in each of the eight points of time was grouped into one of four different assessment outcomes: “Consistent”—the pixel is correctly classified, “Fuzzy”—the pixel is in a fuzzy state, “Uncertain”—the pixel was fuzzy, misclassified, or a real change remains uncertain, or “Misclassified”—the pixel is not correctly classified.
Recall that the images are classified into four groups: C
1 = “Farmland”, C
2 = “Forestland”, C
3 = “Other”, and C
4 = “Built-up”. If a change was detected between two neighboring points of time, it is denoted as T(C
a, C
b). So, T(C
2, C
4) indicates a pixel that changed from forestland to built-up. As shown in
Figure A1, eight rules are employed to assess the rationality of each pixel change. The rules are examined in sequential order.
Figure A1.
Rationality evaluation rules.
Figure A1.
Rationality evaluation rules.
The eight rules are defined and explained as follows:
- Rule 1
If t = 0, then accept “Consistent”.
- Rule 2
If t = 1, i.e., T(Ca, Cb), AND if (a==4)||(a==3&&b==4), THEN accept “Misclassified”; otherwise, “Consistent”.
- Rule 3
If t = 2, i.e., T(Ca, Cb, Cc), AND if (a==4)||(b==4)||(b==3&&c==4), THEN accept “Misclassified”. Otherwise, check if (a==c). If so, “Uncertain”; otherwise, “Fuzzy”.
- Rule 4
If t = 3, i.e., T(Ca, Cb, Cc, Cd), AND if (a==4)||(b==4)||(b==3&&c==4), THEN accept “Misclassified”; otherwise, “Fuzzy”.
- Rule 5
If t = 4, i.e., T(Ca, Cb, Cc, Cd, Ce), AND if (a==4)||(b==4)||(c==4)||(d==4)||(d==3&&e==4), THEN accept “Misclassified”; otherwise, “Fuzzy”.
- Rule 6
If t = 5, i.e., T(Ca, Cb, Cc, Cd, Ce, Cf), AND if (a==4)||(b==4)||(c==4)||(d==4)||(e==4)||(e==3&&f==4), THEN accept “Misclassified”; otherwise, “Fuzzy”.
- Rule 7
If t = 6, i.e., T(Ca, Cb, Cc, Cd, Ce, Cf, Cg), AND if (a==4)||(b==4)||(c==4)||(d==4)||(e==4)||(f=4)||(f==3&&g==4), THEN accept “Misclassified”; otherwise, “Fuzzy”.
- Rule 8
If t = 7, i.e., T(Ca, Cb, Cc, Cd, Ce, Cf, Cg, Ch), AND if (a==4)||(b==4)||(c==4)||(d==4)||(e==4)||(f=4)||(g=4)||(g==3&&h==4), THEN accept “Misclassified”; otherwise, “Fuzzy”.
There are two important assumptions behind these eight rules. First, the change to built-up from other land-use classes is irreversible, so that any pixel that is classified as built-up in a previous point of time and later placed into any other land use class would be regarded as a misclassification. Second, it is also uncommon to build on wetland; therefore, conversions from wetland to built-up are all treated as misclassifications.
Rule 1 is straightforward; if a pixel is classified in the same land-use class for all six periods, then the pixel is regarded as “consistent”. Rule 2 concerns the situation when a once-only change is detected for a pixel. If the land conversion direction is true (T) with the two misclassification statements, then the change is labeled “misclassified”. In other cases, we take it as a possible change and thus regard it as correctly classified (“consistent”). Similar to Rule 2, Rule 3 first defines that if the reverse process (i.e., change from built-up area to another land-use type) or the unlikely process (i.e. change from built-up to other) were detected, the change is taken as misclassified. This rule deals with a one-time error of multi-temporal remote sensing image classification. If a pixel is found to have changed from one class (Ca) to another (Cb) and back to its original status (Ca), it could be taken as a one-time classification error (i.e., Cb is the incorrect class), or it could be that the pixel itself is fuzzy and thus could be classified as Ca or Cb. This one-time inconsistent situation does not affect the final result of cover detection, but it is hard to tell whether it is a classification error or not, so the pixel is regarded as “Uncertain”. Finally, Rule 3 specifies the treatment of a case where the land-use type changed twice to two different classes during the whole study period. In this case, we consider the pixel “Fuzzy” with a composite land use type.
Rules 4, 5, 6, 7, and 8 consider pixels that change frequently between cover types. This is most likely a consequence of mis-registration in geometric image rectification (Townshend et al. 1992, Stow 1999). Obviously, the reverse process and the unlikely process would be both improbable according to Rule 2. For other similar pixels, this can be considered as a “Fuzzy” case with frequent cover classes.
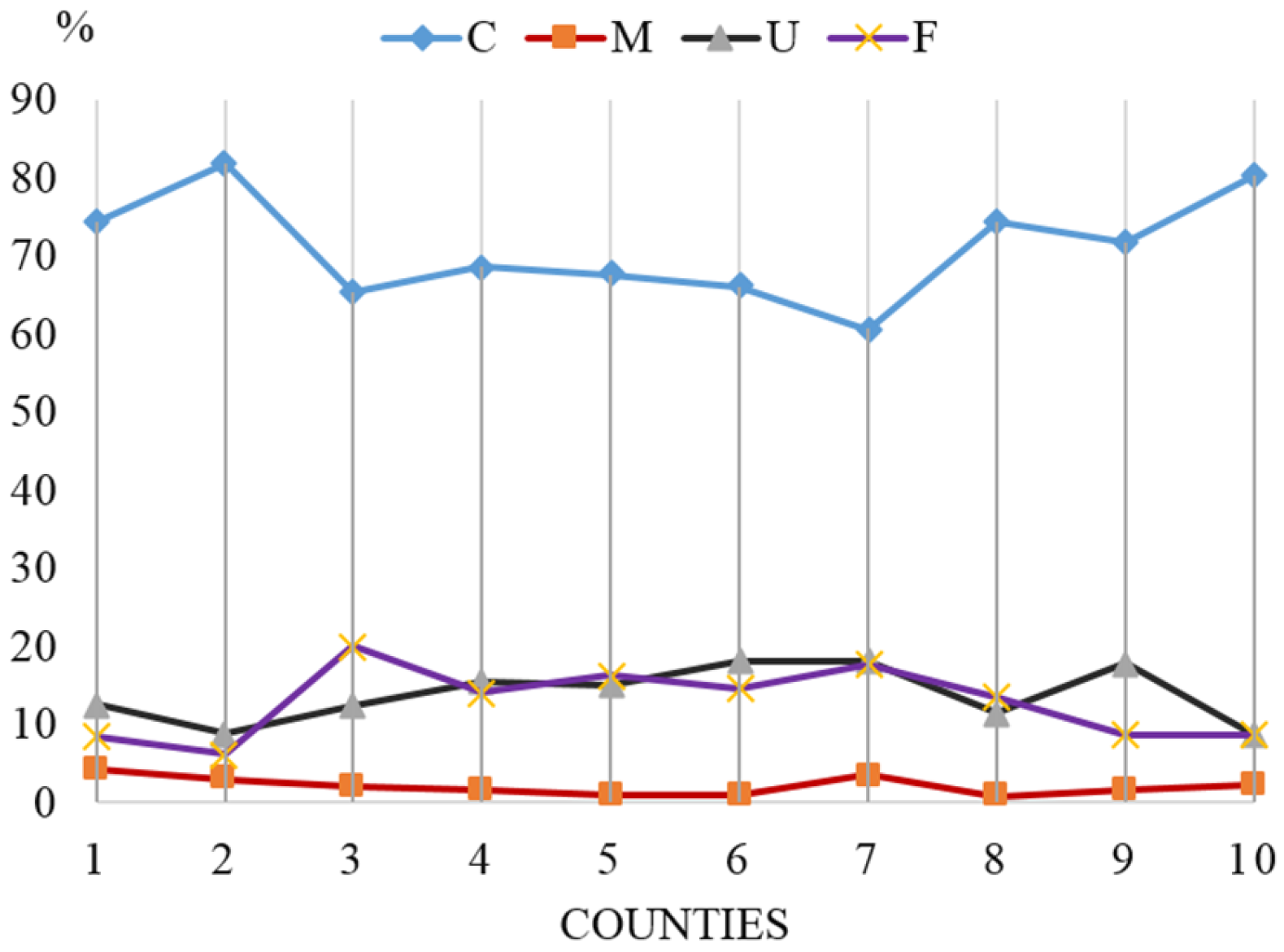
Since, in this study, a county is the basic socioeconomic unit of observation and analysis, the pixel-based results of LULCC detection are represented at the county level in
Figure A2 below. Overall, the rationality evaluation accuracy in aggregate are generally acceptable when the “Misclassified” rate is low—less than 5% for all the 10 counties. On average, it is only 1.84% for the whole study area. The pixels classified as “Consistent” account for 70.94% of the total, and “Uncertain” and “Fuzzy” rates are around 14.42% and 12.80%, respectively.
Figure A2.
Rule-based rationality evaluation results. C, M, U, F stand for “Consistent”, “Misclassified”, “Uncertain”, and “Fuzzy”, respectively. The ten counties are: Huachuan = 1, Jixian = 2, Shuangyashan City = 3, Huanan = 4, Yilan = 5, Boli = 6, Qitaihe City = 7, Fangzheng = 8, Suibin = 9, and Youyi = 10.
Figure A2.
Rule-based rationality evaluation results. C, M, U, F stand for “Consistent”, “Misclassified”, “Uncertain”, and “Fuzzy”, respectively. The ten counties are: Huachuan = 1, Jixian = 2, Shuangyashan City = 3, Huanan = 4, Yilan = 5, Boli = 6, Qitaihe City = 7, Fangzheng = 8, Suibin = 9, and Youyi = 10.
From
Figure A2, it is not hard to infer that the “Uncertain” and “Fuzzy” classes are among the most active pixels where land conversion tends to take place. One possible explanation for these high rates is: as most counties in the study region are located alongside the Songhua River, and summer is usually the rainy season, large tracks of farmland on the riverside are flooded, thus the possibility of classifying these pixels as “Uncertain” and “Fuzzy” is larger than other area. Since some of the once-only land use changes determined by Rule 2 are also regarded as “Consistent”, thus, the unchanged land is smaller than the total amount denoted as “consistent”, and the potential LULCC change is possibly larger than that reflected in the proportion of “Uncertain” and “Fuzzy”.
The rule-based rationality evaluation is not only logically sound, but also good at identifying spatially specific areas that are changed and unchanged, especially at recognizing the misclassification, which is helpful for further classification correction. However, there are also deficiencies in this method. The most important one is the difficulty in matching the programming language and semantic meaning used to differentiate different accuracy evaluation scenarios. For example, the “misclassified rate” is defined based on the two most important and logically identifiable cases, but it is not the common misclassification rate as we usually refer to. Also, it is hard to clearly differentiate once-only changes from fuzzy pixels using Rule 3; thus, the “Uncertain” and “Fuzzy” rates are subject to dispute. However, it is not easy to choose the words that exactly match the logic of programming.
Another caveat of interpreting the accuracy evaluation results lies in the image geometric rectification. The multi-temporal image-to-image registration for 1977 and 1984 was controlled in an allowable range with average root mean square error smaller than 0.5; however, potential registration errors still exist in the entire image and could possibly affect the accuracy assessment of those pixels that lie on the frontiers of land conversion (like on the forestland and wetland boundaries).
Appendix B. Accuracy Assessment of Classified LULCC—The Traditional Approach
Due to limitations of the rule-based rational evaluation method, the commonly adopted accuracy assessment scheme is also employed. To validate the accuracy of the classified LULCC results under this method, the simple equation used to estimate sample size is adopted:
[
40]. The overall accuracy
P for each class of land use is usually assumed to be 80%.
is the half width of the confidence interval; a value of 0.05 is often taken. Following the conventional practice,
is set at 1.96. The calculated results suggest that sample size for each category should be at least 246. Given the four landscape classes, about 1000 points are thus needed to be drawn from the map of the whole study region.
To this end, the spatially balanced sampling method, which draws sample points proportional to the presence of the area [
36], was used to generate 1200 points in the study area. Google Earth was used as the reference data for 2000, 2004, and 2007, respectively (images before 2010 were classified in 2009, whereas images of 2010 and 2013 were classified in 2016). After the layer of randomly sampled points was created, it was converted into a KML file readable by Google Earth and the categories of those points on Google Earth were marked. Next, the extracted Google Earth map information was compared to the classification results [
41,
42]. Based on the two datasets for the same points, the Kappa indices and conversion matrixes can be derived. During this process, an error in ArcMap 10 occurred, which provided wrong numbers in the attributes table. This led to the density of sampling points being incorrectly estimated, with less than 40 points for the minor LULCC categories (built-up and other). To get a larger sample to alleviate this problem, another 400 randomly generated sample points were added to the two minor categories. In the end, the total sample size reached 1550 points.
For the land-use maps before 2000 (1977, 1984, and 1990), it is not feasible to directly take a reference map from Google Earth, because most images in Google Earth are from after 2000. Because no other kinds of maps were available, it was hard to get a reliable reference for those earlier years. Therefore, we took the following two steps to address the problem. First, note that the four classes of land use are not easily re-convertible. For example, it is highly less likely for forestland to be converted to farmland and then reconverted back to forestland. Thus, the first step was to select those consistent points from a land-use classification map from an earlier period and the Google Earth data from 2004 in the whole sample and take those points as unchanged. The second step was to extract the inconsistent points and compare them with the original images. As the geo-corrected and atmospheric-adjusted images are the best available reference data, the inconsistent points were manually recorded to distinguish points of real change from misclassifications. One thing to be noted here is that due to the lower resolution of MSS data in 1977 and 1984, some confusion occurred in farmland and built-up area, so a compromise is to merge these two classes and assess accuracy of them together as one class.
When the images of 2010 and 2013 were classified in 2016, the first step of selecting consistent points was the same as that of the pre-2000 image accuracy assessment. The second step was altered by taking the newly updated Google Earth images as the reference data. In doing so, time efficiency was gained in step one while the accuracy was improved in the second step.
Based on the above steps, the accuracy assessment results are summarized in
Table B1. The overall accuracy rates for the eight points of time are around or above 85%. For 1977 and 1984, as the MSS data have coarser spatial resolution than TM and ETM+ images, we merged farmland and built-up land into one category, called F&B. The overall accuracy based on three classes for 1977 and 1984 is 91.6% and 90.5%, respectively; and the overall Kappa indexes are 86.1% and 84.2%. The classifications of the maps for the other six points of time include four LULCC categories: farmland, forestland, built-up land, and other. The overall accuracy rates for these six periods are around 85%, and the Kappa indexes are about 80%. Given the large sample size, the standard deviations and coefficients of variation for both overall accuracy and Kappa indexes are very small.
Table B1.
Overall accuracy assessment of the LULCC classification results.
Table B1.
Overall accuracy assessment of the LULCC classification results.
| Year | OA 1 (%) | Std 2 (10−2) | CV 3 (%) | Kappa (%) | Std (10−2) | CV (%) |
|---|
| 1977 4 | 91.61 | 0.70 | 0.76 | 86.14 | 1.16 | 0.74 |
| 1984 5 | 90.52 | 0.74 | 0.82 | 84.17 | 1.24 | 0.68 |
| 1993 | 87.81 | 0.83 | 0.95 | 82.21 | 1.21 | 0.68 |
| 2000 | 84.24 | 0.93 | 1.10 | 77.15 | 1.35 | 0.57 |
| 2004 | 86.24 | 0.88 | 1.02 | 80.09 | 1.28 | 0.63 |
| 2007 | 89.08 | 0.79 | 0.89 | 84.44 | 1.13 | 0.75 |
| 2010 | 88.63 | 0.81 | 0.90 | 83.66 | 1.16 | 1.40 |
| 2013 | 86.43 | 0.87 | 1.00 | 80.38 | 1.26 | 1.60 |
The class-specific land use accuracy results are summarized in
Table B2 and
Table B3, respectively. In both tables, the left block is the common confusion matrix [
43]; the middle block contains the calculated indices of user’s accuracy (UA); and the right block contains the indices of producer’s accuracy (PA). To be thorough, the tables also include the Kappa index reflecting the difference between the classification agreement and the agreement expected by chance [
44]. Some authors argue that this index tends to underestimate the accuracy [
45]. The calculated values are generally lower than those from the UA and PA statistics.
Table B2.
LULCC category-based accuracy assessment for 1977 and 1984.
Table B2.
LULCC category-based accuracy assessment for 1977 and 1984.
| | | F&B | Ft | Other | UA | Kappa | Std | PR | Kappa | Std |
|---|
| | F&B | 705 | 16 | 18 | 0.95 | 0.91 | 0.02 | 0.89 | 0.78 | 0.02 |
| 1977 | Ft | 63 | 513 | 4 | 0.88 | 0.82 | 0.02 | 0.97 | 0.95 | 0.01 |
| | Other | 28 | 1 | 201 | 0.87 | 0.85 | 0.03 | 0.90 | 0.88 | 0.02 |
| | F&B | 741 | 12 | 29 | 0.95 | 0.89 | 0.02 | 0.88 | 0.76 | 0.02 |
| 1984 | Ft | 61 | 459 | 7 | 0.87 | 0.81 | 0.02 | 0.97 | 0.96 | 0.01 |
| | Other | 38 | 0 | 203 | 0.84 | 0.81 | 0.03 | 0.85 | 0.82 | 0.03 |
Table B3.
LULCC category-based accuracy assessment for later years.
Table B3.
LULCC category-based accuracy assessment for later years.
| | | Fm | Ft | Other | Bltup | UA | Kappa | Std | PR | Kappa | Std |
|---|
| 1993 | Fm | 585 | 15 | 65 | 19 | 0.86 | 0.75 | 0.02 | 0.89 | 0.8 | 0.02 |
| Ft | 33 | 443 | 5 | 3 | 0.92 | 0.88 | 0.02 | 0.96 | 0.95 | 0.01 |
| Other | 28 | 1 | 170 | 1 | 0.85 | 0.82 | 0.03 | 0.69 | 0.65 | 0.03 |
| Bltup | 12 | 1 | 6 | 163 | 0.9 | 0.88 | 0.03 | 0.88 | 0.86 | 0.03 |
| 2000 | Fm | 559 | 38 | 36 | 12 | 0.87 | 0.76 | 0.02 | 0.81 | 0.67 | 0.02 |
| Ft | 64 | 393 | 2 | 5 | 0.85 | 0.79 | 0.02 | 0.89 | 0.84 | 0.02 |
| Other | 56 | 9 | 186 | 3 | 0.73 | 0.69 | 0.03 | 0.81 | 0.78 | 0.03 |
| Bltup | 13 | 1 | 5 | 166 | 0.9 | 0.88 | 0.03 | 0.89 | 0.88 | 0.03 |
| 2004 | Fm | 564 | 30 | 30 | 7 | 0.89 | 0.81 | 0.02 | 0.82 | 0.69 | 0.02 |
| Ft | 63 | 406 | 2 | 7 | 0.85 | 0.79 | 0.02 | 0.92 | 0.89 | 0.02 |
| Other | 50 | 4 | 195 | 2 | 0.78 | 0.74 | 0.03 | 0.85 | 0.82 | 0.03 |
| Bltup | 15 | 1 | 2 | 170 | 0.9 | 0.89 | 0.02 | 0.91 | 0.9 | 0.02 |
| 2007 | Fm | 561 | 13 | 6 | 3 | 0.96 | 0.93 | 0.01 | 0.81 | 0.7 | 0.02 |
| Ft | 43 | 422 | 3 | 0 | 0.9 | 0.86 | 0.02 | 0.96 | 0.94 | 0.01 |
| Other | 71 | 4 | 216 | 5 | 0.73 | 0.68 | 0.03 | 0.95 | 0.94 | 0.02 |
| Bltup | 17 | 2 | 2 | 180 | 0.9 | 0.88 | 0.02 | 0.96 | 0.95 | 0.02 |
| 2010 | Fm | 569 | 12 | 33 | 17 | 0.90 | 0.83 | 0.02 | 0.87 | 0.78 | 0.02 |
| Ft | 39 | 429 | 9 | 1 | 0.90 | 0.85 | 0.02 | 0.94 | 0.91 | 0.02 |
| Other | 37 | 14 | 198 | 2 | 0.79 | 0.75 | 0.03 | 0.83 | 0.79 | 0.03 |
| Bltup | 11 | 1 | 0 | 176 | 0.94 | 0.93 | 0.02 | 0.90 | 0.88 | 0.02 |
| 2013 | Fm | 566 | 17 | 33 | 15 | 0.90 | 0.81 | 0.02 | 0.82 | 0.69 | 0.02 |
| Ft | 56 | 415 | 5 | 2 | 0.87 | 0.82 | 0.02 | 0.94 | 0.91 | 0.02 |
| Other | 54 | 7 | 188 | 2 | 0.75 | 0.71 | 0.03 | 0.83 | 0.79 | 0.03 |
| Bltup | 16 | 2 | 1 | 169 | 0.90 | 0.89 | 0.02 | 0.90 | 0.89 | 0.02 |
It can be seen from
Table B3 that the classification of farmland and forestland—the focal classes of land use—is reasonably good, with most having an accuracy rate higher than 85%. The accuracy for built-up land is also reasonable after the 1990s, with all the accuracy rates above 90%. The minor category of other land, mainly wetland, has a relatively lower accuracy rate. One explanation is related to the seasonal change: because the dates of the images acquired deviate from those of the reference Google maps, some farmland and wetland along the Songhua River could have different boundaries. Meanwhile, in a 30-by-30-m pixel, some sub-pixel areas may include more than one land use classes. Lastly, small positional deviations between Landsat images and images in Google Earth could also be a potential source for lower accuracy [
46,
47].







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



