1. Introduction
Understanding where carbon is stored in forest structures is essential for accurately estimated forest carbon stocks. Accurate estimates of carbon stocks can inform climate change mitigation efforts at global scales [
1] and are critical to understanding nutrient cycling as plant tissues release carbon over different lengths of time [
2,
3]. Improved carbon mass estimates would also assist land management activities aimed at sequestering carbon. Because silvicultural treatments target specific stand components (e.g., thinning from below removes small trees), understanding how carbon varies between stand components is necessary in order to accurately estimate stand-level carbon impacts from a given silvicultural treatment. In order to understand how carbon mass is allocated within a stand, we need to first know how carbon mass is allocated within individual trees and if that allocation varies predictably from tree to tree, and within tree tissues.
Forest carbon stock estimates typically utilize some version of the following approach. A species average tissue density (D) is used to convert tree bole volume into bole biomass [
4,
5]. Tissue density is typically calculated by dividing a sample’s oven-dry wood mass by that sample’s green wood volume. Tree bole biomass is then converted into total tree biomass using conversion factors based on ratios of tree component biomass [
5]. Alternatively, allometric biomass models may be created from relationships between whole tree biomass and diameter at breast height (DBH), or total tree height (HT) and DBH [
6,
7]. Regardless of how tree biomasses are calculated, stand-, forest-, or ecosystem-level biomass can be obtained by summing tree biomass across the scale of interest. Total biomass values are then converted into carbon mass estimates using a carbon fraction of 0.5. This “standard” approach to estimating carbon mass is widely used in forest carbon research throughout the world [
1,
5,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19].
The “standard” approach to carbon mass estimation implies the following: (1) intraspecific variation in wood density is insignificant; (2) intraspecific variation in carbon fraction is nonexistent or negligible; (3) interspecific variation in carbon fraction is nonexistent or negligible; and (4) variation in carbon fraction within a tissue type is nonexistent or negligible. Using a species-level average wood density implies that a unit of wood volume from a given species has the same biomass regardless of the size, age, or location of the tree it came from. This assumption does not account for variation in wood density related to tree height and diameter [
15,
20,
21], regional intraspecific variation in wood density [
22], or variation related to radial position in the bole [
23,
24]. Biomass estimates that assume no variation in density will be biased where regional variation in wood density is significant or where wood density varies significantly with tree size or other measurable features.
The second assumption of this standard approach—average carbon fractions are the same for all species—is not supported by the literature, which shows significant interspecific variation in carbon fractions [
25,
26,
27,
28,
29]. Significant differences between angiosperms and gymnosperms were found in a literature review of available carbon fraction data by Thomas and Martin [
30], with gymnosperms demonstrating higher carbon fractions as a group. Within the angiosperm and gymnosperm groups, significant differences in carbon fractions also exist, with a coefficient of variation greater than 20% between species within the same provenance [
30]. Significant differences in carbon fraction estimates were also found across biomes de Aza et al. [
30,
31]. Accurate carbon mass estimates therefore require carbon fractions to be measured for each species of interest. Failure to do so risks over- or under-estimating the mass of carbon contained within forests.
In evaluating the third assumption, Jones and O’Hara [
27] found significant differences in carbon fractions between heartwood and sapwood within individual coast redwood (
Sequoia sempervirens (Lamb. ex Don D) Endl.) trees. Their results are similar to those found by Lamlom and Savidge [
26] in giant sequoia (
Sequoiadendron giganteum (Lindl.) J. Buchholz), and Bert and Danjon [
32] and de Aza et al. [
31] in maritime pine (
Pinus pinaster Ait.). In all four cases, heartwood contained significantly higher carbon fractions than sapwood. This finding was reversed for sugar maple (
Acer saccharum Marshall) [
26], where carbon fraction increased with distance from pith. Gao et al. [
33] found significant differences between carbon fractions of bark and stemwood in boreal trees. There is currently insufficient data to determine if these findings hold true for other tree species; therefore, more research into intraspecific variation in carbon is necessary in order to determine if carbon fraction varies predictably between wood types within trees. Differences between carbon fractions in heartwood and sapwood could also lead to significant differences in carbon mass estimates across tree sizes, as the heartwood to sapwood proportion is not constant across tree sizes [
34].
Few studies have looked at variations in carbon within tree tissues, so little is known about the potential problems behind assumption four. Lamlom and Savidge [
25] found that the carbon content of early wood was higher than that of late wood in all species studied, suggesting that variation within wood tissue exists and may be predicted on a whole tree basis by factors controlling early/latewood ratios. One study [
35] showed a general increase in carbon fraction with increasing relative tree height in sessile oak. Another study found different trends in carbon fractions along the height of trees depending on tissue type and tree species [
31]. In their synthesis of carbon variation, Thomas and Martin [
29] do not mention variation within tissue types, and mention that only six studies at the time examined variation between tissue types. A more recent synthesis of global carbon variation in carbon fractions [
36] found some relationships between tree tissue carbon and large-scale geographic and environmental metrics, but reported no research on variation within tissue types. Martin et al. [
37] found size-dependent differences in carbon fraction values between sapwood tissue samples from saplings and larger trees. Though there is little research into the topic of carbon variation in tree tissues, the research that does exist suggests that carbon fraction variations within tissues could be explained with additional covariates.
Depending on tree species and growth history, wood density can be higher or lower in heartwood than sapwood [
24]. When present, differences in tissue densities can lead to higher or lower carbon densities, or mass carbon/green wood volume (CD), in heartwood compared to sapwood. For example, Jones and O’Hara [
27] showed that in multiaged coast redwood stands, higher tissue densities in heartwood, combined with higher carbon fractions, resulted in higher stand carbon densities as stand-level heartwood proportions increased over time. Despite demonstrated differences in wood types, most studies of stemwood density only report stemwood average densities rather than tissue-specific values.
Density and carbon fraction of tree bark are not well-studied, although bark can be a significant portion of total tree biomass and can have a higher carbon fraction than stemwood [
31,
38]. This difference in carbon fraction between bark and stemwood suggests that bark carbon fraction should be measured directly and not assumed to be the same as the stemwood. Bark has been shown to be strongly correlated with wood characteristics, such as wood density [
39], suggesting that tree species with similar bark characteristics may have similar tissue properties. Like all matter, the physical characteristics of bark, such as density, color, and texture, are derived from its chemical constituents. It would, therefore, be logical to surmise that similarities in observable bark properties could be related to underlying tree properties such as carbon fraction, wood density, and carbon density. As bark descriptions are widely available for many species, grouping species with similar bark characteristics could be a useful method of categorizing species for carbon mass estimation. In tropical regions where measuring the carbon fraction and wood density of all tree species is too difficult because of the number of species, the potential to improve carbon mass modeling by grouping species using easily identified bark characteristics could be beneficial. It is also important to compare the improvement in carbon estimation when grouping by bark characteristics to grouping at the species and tissue type levels to determine the relative benefit in measuring carbon at each of those levels.
While tissue density has been studied across many species, the majority of carbon fraction studies have looked at angiosperms, with data for only 37 conifer species reported in Thomas and Martin [
30]. Given the importance of conifers in some forest ecosystems, more information on the determinants of variation in carbon fraction between conifer species, and between tissue types within conifers, is needed. Studying more conifer species and analyzing individual tissue-type properties within those conifers would be an important step in improving the overall understanding of carbon dynamics in forest stands. In addition, determining what, if any, variation exists within tissue types may help in developing predictive carbon models in the future. Quantifying improvements in carbon mass estimation from accounting for carbon fraction variation at increasingly smaller scales is important in understanding the relative value of studying carbon fractions at any scale.
Using data from nine conifer species across a range of sizes, bark characteristics, elevations, and latitudes, we approached these issues with the following objectives:
Determine if significant relationships exist between observable tree characteristics and carbon fraction (CF), density (D), and carbon density (CD) of tree tissues;
Determine if there is significant improvement in model performance across increasing levels of model complexity for CF, D, and CD models; and
Quantify differences in tree bole carbon mass estimates between measured tissue carbon fractions and a carbon fraction of 0.5.
2. Materials and Methods
2.1. Plot Locations and Sampled Species
Nine economically and ecologically important conifer species across a wide range of ecosystems were sampled: coast Douglas-fir (
Pseudotsuga menziesii (Mirb.) Franco var.
menziesii), coast redwood, giant sequoia, incense-cedar (
Calocedrus decurrens (Torr.) Florin), Jeffrey pine (
Pinus jeffreyi Balf.), ponderosa pine (
P. ponderosa Lawson & C. Lawson), red fir (
Abies magnifica A. Murray), sugar pine (
P. lambertiana Dougl.), and white fir (
A. concolor (Gord. & Glend.) Lindl. ex Hildebr.). Study plots were located in the following locations: (1) Jackson Demonstration State Forest (39.364 N, 123.708 W), (2) Baker Forest (39.916 N, 121.063 W), (3) Blodgett Forest Research Station (38.910 N, 120.662 W), (4) Whitaker’s Forest (36.699 N, 118.939 W), (5) Teakettle Experimental Area (36.968 N, 119.036 W), (6) outside of Loyalton, CA (39.675 N, 120.165 W), and near (7) Shaver Lake, CA (37.046 N, 119.211 W).
Table 1 shows summary statistics and sample sizes for trees sampled for the study. Carbon density sample size was limited to density samples with paired carbon fraction values. The nine species were placed into three tree groups, based on visible bark characteristics, to determine if there was any significant improvement in model prediction of the three tree properties (CF, D, and CD) attributed to tree group alone. The tree groups were: trees with furrowed bark (Douglas-fir, white fir, and red fir); trees with fibrous bark (coast redwood, giant sequoia, and incense-cedar); and trees with scaly bark (ponderosa pine, sugar pine, and Jeffrey pine).
2.2. Core Extraction and Handling
Tree cores were extracted from sample trees at breast height (1.37 m), midway between breast height and base of live crown, and every 4 m within the live crown. Trees were randomly sampled within study sites, with each sample tree becoming the plot center of a 10-m circular plot. A 40.6 cm long increment borer with an aperture of 5.15 mm was used to extract all cores from sample trees. After extraction, cores were placed in plastic straws, sealed using adhesive tape, and placed in a white plastic tube to reduce exposure to sunlight. To prevent contamination, the increment borer was cleaned between each sample tree with a silicon-based lubricant and clean paper tissues. The sapwood component of each core was determined either by color, or if color differences were minimal then sapwood boundaries were determined by holding the core up to the sun and marking the region where noticeable transitions in translucence were observed. Cores were then placed in a cooler with ice for transportation back to a lab freezer. Paired cores were taken from the same heights with one core used for density analysis and the other core used for carbon fraction analysis. As density is more variable than carbon fraction, only a subset of carbon cores were taken, leading to a total of 42 cores used for carbon analysis and a total of 370 cores used for density analysis.
2.3. Core Processing
In the lab, frozen cores were cut into segments that included four or eight tree rings, depending on the ring widths. It was necessary to use a variable number of ring widths per segment to ensure that enough mass was present in the core segment sample for analysis. Core segments were taken from within the bark, sapwood, and heartwood sections of the selected tree cores. For carbon fraction analysis, the outermost portion of all core segments was removed using a razor blade in order to eliminate oxidized tissue and other possible contaminants from the exterior of the core. These cores were further processed by cutting the core into small pieces of approximately 1 mg or less in mass using a clean razor. This material was separated into two to four vials that were randomly assigned to one of the following sample preparation methods: vacuum desiccation, freeze-drying, oven-drying, or left undried as described in Jones and O’Hara [
28]. Sample weights were recorded by taring a scale (precision ± 0.00005 g) with an empty sample vial on it and recording the weight displayed on the scale after sample material was added. All vials were sealed and placed back into the freezer after weighing. For density analysis, the core segments were used whole as described below.
2.4. Carbon Fraction Analysis
Carbon fraction analysis followed the methods described in Jones and O’Hara [
28]. For carbon fraction determination, weighed subsamples of 3–5 mg from each prepared vial were placed into tin capsules and then into a CE Instruments Flash 2000 CHNS/O analyzer (Rodano, Milano, Italy) for sample carbon fraction (CF
R) determination using combustion and mass chromatography. The CN analyzer was calibrated between sample runs using acetanilide as a standard to develop a calibration curve. The calibration curve had a R
2 of 0.999 or higher for all sample runs. After removing the subsample, the weight of the remaining sample material in each vial was recorded as M
R. The remaining material was then placed in an individual tin labeled with sample ID and dried at 105 °C until stable mass was achieved. This stable oven-dry mass was recorded as M
OD. The final carbon fractions (CF
C) were calculated using this equation:
This calculation was performed so that all carbon fractions used the same oven-dry baseline tissue moisture content and could therefore be compared in a sensible way. A more complete description of the carbon fraction data and analysis can be found in Jones and O’Hara [
28].
2.5. Tissue Density and Carbon Density Analysis
Paired tissue density and carbon fraction core segments were used to match carbon fraction with tissue density measurements from the same tree heights and ring ages within a given tree. The tissue density of each core segment was determined by dividing the green volume (cm3) of the core segment by the oven-dry mass (g) of the core segment. The green volume of the segment was determined by multiplying the segment length (cm) by the internal area of the increment borer aperture (0.265 cm2). Carbon density was determined by multiplying corresponding tissue density and carbon fraction measurements.
2.6. Differences in Carbon Mass Estimates between 0.5 Value and Measured Carbon Fractions for Species-Tissue Types
The average carbon fraction values for each species tissue-type were used to make comparisons of carbon mass for each of the nine tree species, assuming a total bole biomass of 1000 kg for ease of comparison. These 1000 kg trees are referred to as “example trees”, as they serve as an example of variation that can occur outside of variations in total biomass. To eliminate variation due to model selection error [
40], the BIOPAK equations [
41] were used to derive bark and bole masses for all nine species, as this set of equations is one of the few to have validated bole and bark biomass equations for all species in the present study. The total biomass of each example tree was held at 1000 kg to demonstrate the impact of measuring carbon fractions versus using the 0.5 value, assuming no other sources of variation. To derive carbon mass estimates using the standard approach, the biomass for each tree tissue component was multiplied by 0.5.
To calculate bark carbon mass using measured carbon fractions, the estimated bark mass was multiplied by the corresponding bark carbon fraction. For carbon mass of sapwood and heartwood, a representative sample tree for each species was selected from the field data that most closely matched the DBH and height of the relevant 1000 kg example tree for each species. Cores from the representative sample tree were analyzed to determine heartwood and sapwood cross-sectional bole areas for the height from which the cores were taken. These cross-sectional areas were multiplied by the corresponding average species-tissue type densities and summed across all cores from the representative sample tree, thereby yielding a total area weighted core mass for those tissue types. The ratio of the area weighted sums of core heartwood and sapwood masses were then used to determine the tree bole ratios of heartwood to sapwood mass. The bole mass for each tissue type was then multiplied by the respective species tissue type carbon fraction to estimate the total carbon mass of sapwood and heartwood.
2.7. Statistical Analysis
Linear mixed effects (LME) analysis was used to account for the nested structure of the data and to account for random effects related to sampling procedures. For carbon fraction and carbon density analyses, the nested data structure was organized as sample ID nested within core, nested within tree, nested within plot. Within the model, these levels were labeled m, n, o, and p, respectively. For tissue density analysis, the nested data structure was organized as core (p), nested within tree (o), nested within plot (n). Random effects (
ϕ) were assigned to each level of the data structures mentioned above. A compound symmetric correlation matrix was used to model relationships between observations. The equations for the most complex levels of analysis for each property were:
In Equations (2)–(4), fixed effects were assigned to the mean values for the combination of species (i), tissue type (j), and preparation method (k), resulting in the notation CFijk, for carbon fraction analysis, Dijk for tissue density analysis, and CDijk for carbon density analysis. In the case of Dijk, only one preparation method, oven-drying, was used, but for consistency with the other two properties the notation was kept. Models with species level averages (CFik, Dik, CDik) and species level with additional fixed effects added related to other tree characteristics in the form of a covariate matrix (CFik + BlXl, Dik + BlXl, CDik + BlXl) were tested against each other to determine if the covariate matrix improved the overall model fit. Models with tree group level (t) averages (CFtk, Dtk, CDtk) and no covariate matrix were tested against method level models (CFk, Dk, CDk) to determine if grouping by bark characteristics significantly improved the model fit compared to an average model. The models with no additional covariates had the same random effects structure as the models in Equations (2)–(4).
This statistical approach effectively centers the data on the average of a given grouping level. For Equations (2)–(4), that means that the covariate matrix is effectively modeling the variation within a given species tissue type. Accounting for grouping level averages allows for modeling deviations from the respective means as a function of measurable tree characteristics, or location of samples within trees. This approach reduces the influence any one grouping level (species, tissue type, bark group, method) has on the modeled relationships—a necessary step when species level values can vary significantly. Parameters (
Bl) were estimated for several potential covariates and their interactions (
Xl) using LME modeling. LME models for all three tree properties were limited to a maximum of five potential covariates and/or their interactions selected from a larger pool of covariates using the glmulti package v. 1.07 [
42] in the R programing language [
43]. The glmulti package was used to fit the best combination of covariates and their interactions to the data using multiple linear regression. LME modeling was performed using the NLME package v. 3.1–118 [
44] in the R statistical platform. To avoid multicollinearity in the final model, variance inflation factor analysis was performed and any covariate with an inflation factor of 3 or higher was rejected [
45], and the next best candidate model tested.
For the three properties of interest (CF, D, CD), the significance of accounting for grouping level (tree group, species, tissue type) and additional covariates was determined by performing an ANOVA on nested LME models of increasing complexity: (1) models with means for the given method used (CF
k, D
k, and CD
k), (2) models fit to means for the three tree groups (t) and method (CF
tk, D
tk, and CD
tk), (3) models for species level averages (CF
ik, D
ik, and CD
ik); (4) models with species level averages and additional covariates (CF
ik + BlXl, D
ik + BlXl, and CD
ik + BlXl); (5) models with average values for species-tissue types (CF
ijk, D
ijk, and CD
ijk); and (6) models of the forms found in Equations (2)–(4). Maximum log-likelihood (ML) was used during model covariate selection so that models with different fixed effects could be compared. Maximum log-likelihood ratios were also used to determine if nested models were significantly different from each other. The final reported LME models for a given tree property were fit using reduced maximum log-likelihood (REML) methods, as this approach produces less biased parameter estimates [
46]. This means that Akaike information criterion (AIC) [
47] would be different between the final LME models and the models used to determine the importance of tissue type and additional covariates. Marginal r-squared (R
m2) and conditional r-squared (R
c2) values were calculated for the final LME model fits by tree group. These two values are most easily interpreted as the proportion of variation explained by the fixed effects alone (R
m2) and the proportion of variation explained by fixed and random effects (R
c2) [
48].
Carbon fraction data was summarized by species tissue type, along with the relative standard deviation (CV50) of a given measurement from the widely used 0.5 value. These relative deviations were calculated as percentages of the mean value of 0.5 or CV50.
To look at vertical variation in tissue density properties between tree groups, B-splines were fit to each tree group with relative height as the predictor variable and percent mean deviation from the mean method-species-tissue type tissue property as the response. Using percent mean deviations from the method-species-tissue type centers the data and models the variations from these mean values to detect any vertical patterns in the data. The parameters of these B-spline models were compared using a Welch’s t-test and Bonferroni correction to determine if significant differences existed between parameters of the tree groups.
3. Results
Carbon fraction data is shown in
Table 2. Measured mean tree tissue carbon fractions (CF
ij) and standard deviations, shown in parenthesis, ranged from 0.507 (0.009) for white fir sapwood to 0.588 (0.009) for Douglas-fir bark. Corresponding CV
50 values were 0.014 (0.018) to 0.176 (0.018). A comparison of carbon mass estimates for each species tissue type within 1000 kg example trees is shown in
Figure S1. Bark (C
bm), sapwood (C
sm), and heartwood (C
hm) carbon masses were calculated using a carbon fraction of 0.5 for the standard approach example trees and using the CF
ij values from
Table 2.
The mass of the example trees was set at 1000 kg, including bark, so that the only difference in carbon mass estimates within a species was due to the influence of using measured carbon fractions of the species-tissue types versus using the standard value of 0.5. Total carbon masses for the trees estimated with a 0.5 fraction were 500 kg. For the trees estimated using the CF
ij values from
Table 2, the total carbon masses for each species are shown in
Table 3, along with corresponding CV
50 estimates at the tree level. Tree carbon masses ranged from 518 kg for white fir to 553 kg for incense-cedar. CV
50 values ranged from 3.6% for white fir to 10.6% for incense-cedar (
Table 3).
Symbols, descriptions, and units for covariates used in the final LME models are shown in
Table 4.
Table 4 indicates that the most common types of covariate to be included in the final models were those related to height of sample in tree, crown length, or metrics related to height and crown length. Radial distance from pith and wood density also significantly improved final model fits, although they were not as consistent as covariates related to vertical position within the tree.
ANOVA results for comparisons of the nested models show that carbon fraction models were significantly improved with each increase in model complexity (
Table 5). Accounting for tree group or tissue type alone did not significantly improve model performance for either density or carbon density. For density and carbon density models, significant improvements began at the species level with additional covariates added (
Table 5). Models with tissue type and additional covariates (model #6, #12, and #18) performed significantly better than all other model forms for all three tree properties.
The final models for each tree property included covariates representing location of samples within trees (RH, R, HAR), and tree crown metrics (LCR, FHLC, HLC). Covariates related to tree size, such as diameter at breast height or tree height, were tested and not found to improve model fit (
Table 6). The carbon fraction model was significantly improved with the addition of an interaction term for tissue density and fraction of height to live crown (p:FHLC), while the density and carbon density models were both significantly improved with the addition of a term for the interaction between relative distance from bark and relative distance from center (RD
b:RR).
The potential influence of each term on the mean model estimate (CF
ijk, D
ijk, or CD
ijk) was demonstrated by the fraction of variation (FV) values in the FV-upper and FV-lower columns (
Table 6). The upper fraction of variation was calculated by multiplying the given parameter estimate by the mean value of the term plus one standard deviation. The FV-lower values were determined by multiplying the parameter estimates by the mean value minus one standard deviation, then dividing both the FV-upper and FV-lower values by the mean model estimated value. The FV values were displayed as percentages of their respective mean tissue property values (CF
ijk, D
ijk, or CD
ijk). The FV values ranged from −12.24% to 11.44%, with the largest FV values found in the density and carbon density models.
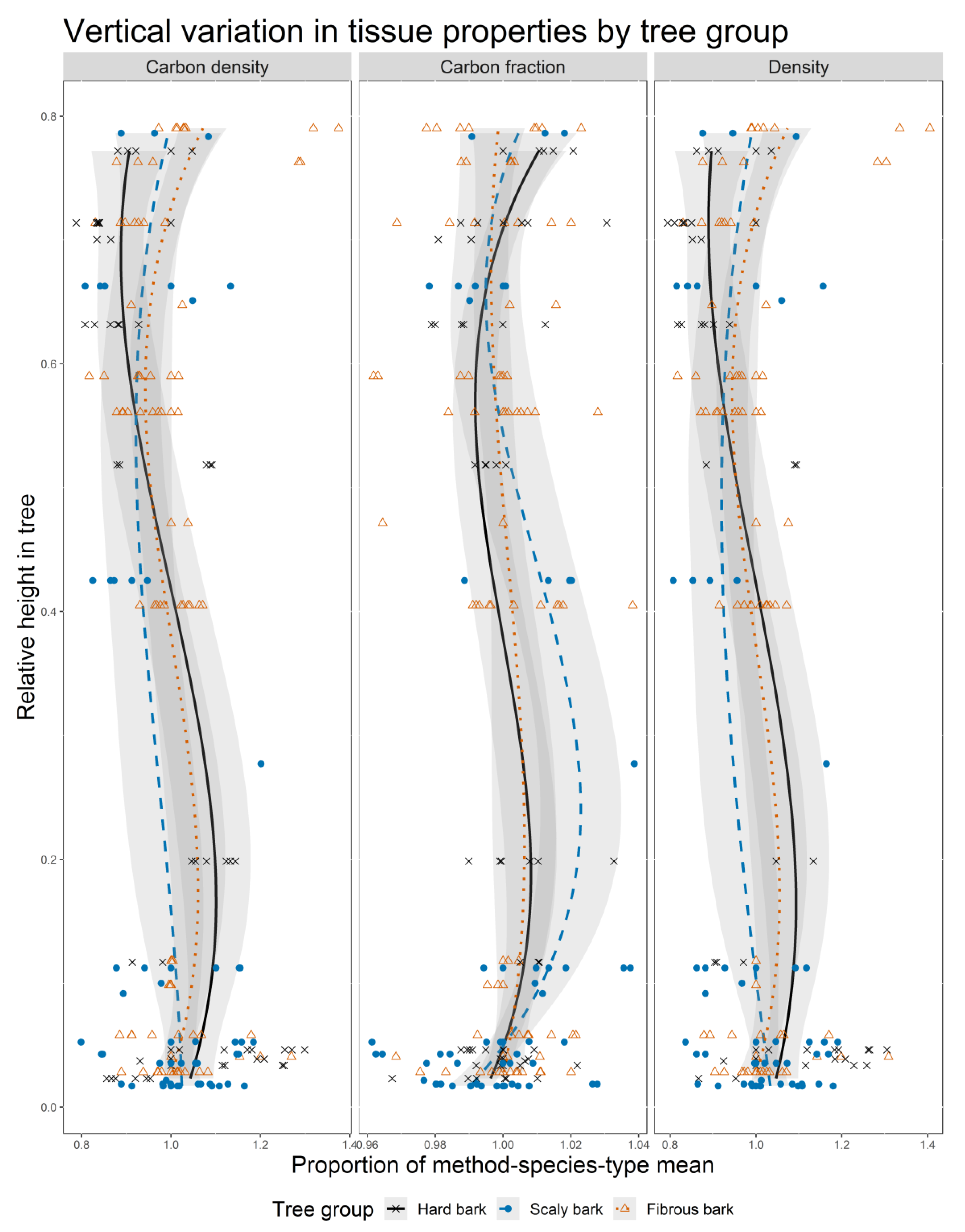
B-spline fits showed vertical trends in each tree property (CF, D, CD) by tree bark group (
Figure 1). There were significant differences between B-spline parameters for the three tree groups for each tree tissue property, thus indicating significant differences in the vertical trends between tree groups (
Table A1). The values on the
x-axis are expressed as percentages of species-tissue type values to center the data. This allowed for a more meaningful comparison of deviations from the average for each tree group. Density and carbon density showed the greatest range in deviations from the species-tissue type means, ranging from approximately 0.8 to 1.4, while carbon fractions stayed relatively close to their respective means, ranging from 0.96 to 1.04. Density and carbon fraction showed negative correlations in their trends with significant variation between tree groups. The fibrous bark group displayed the greatest range in deviations from the mean, followed by the furrowed bark group, with the scaly bark group displaying less variation.
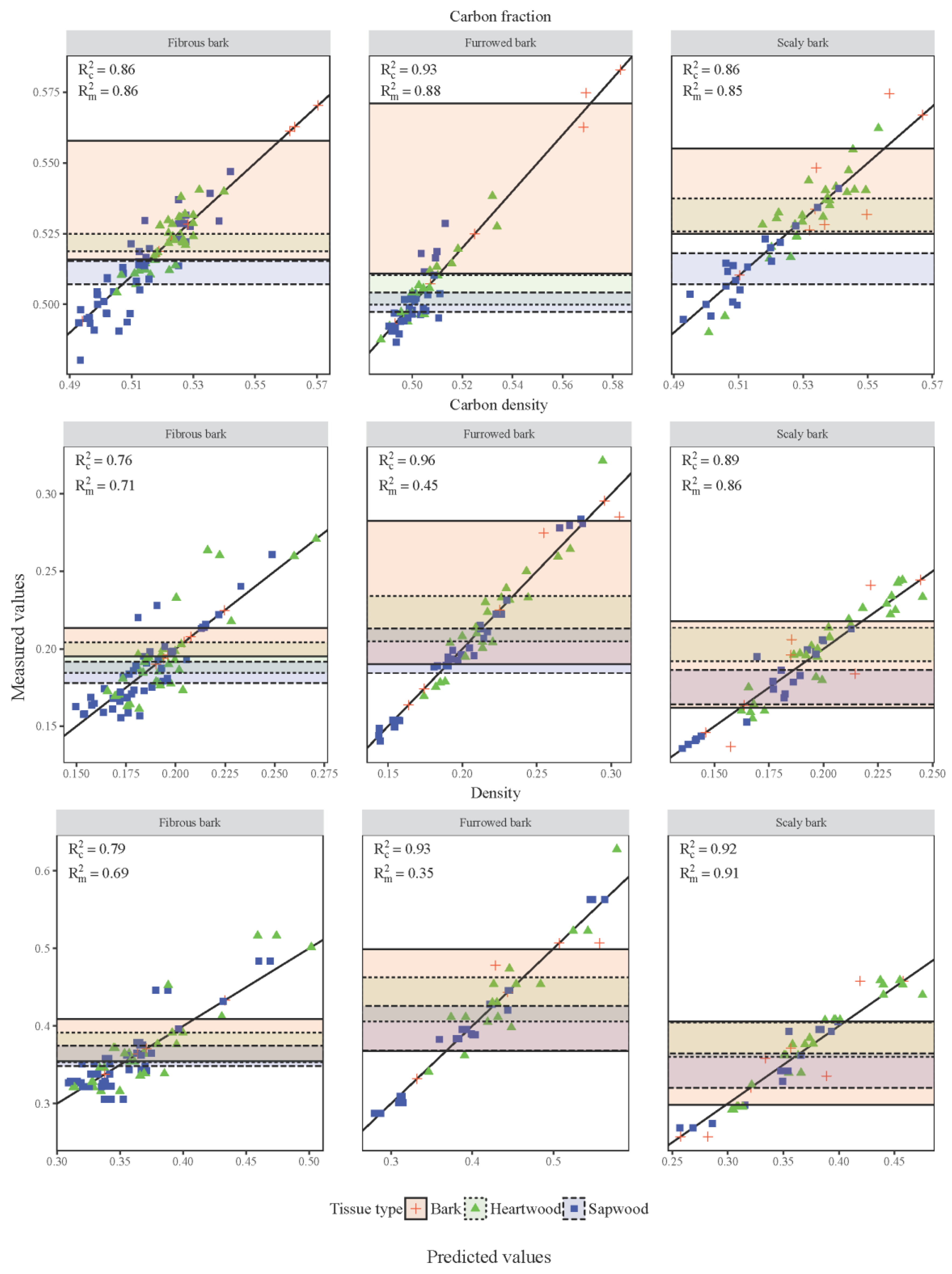
The shaded regions in the graph of the predictions from the LME model versus observed data (
Figure 2) represent the 95% confidence intervals for each tissue type within a given bark group tissue property. The lack of overlapping confidence intervals between the heartwood samples of the three tree groups, along with the lack of overlapping confidence intervals for the sapwood portion of the furrowed bark group and the other two groups, indicated significant differences between those means across the tree groups. The wide confidence intervals for the bark portions of the graphs were related to the high variation found in the bark samples. The R
c2 values for the model fits ranged from 0.64 to 0.95, while the R
m2 values ranged from 0.34 to 0.91. The difference in these two values indicated the variation in the model that is explained by the random effects related to individual trees, and individual cores taken from those trees. Differences between the R
m2 and R
c2 were most pronounced in the density properties of the furrowed bark trees, with smaller differences displayed by carbon density compared to the wood density.
4. Discussion
4.1. Measured Carbon Fractions versus the 0.5 Value
The differences between carbon mass estimates derived from measured CF
ij values versus the values derived from assuming a carbon fraction of 0.5 (
Figure S1) demonstrate the importance of accurately accounting for variation in carbon fractions within trees and between tree species. The increase in estimated carbon mass related to using CF
ij values ranged from 3.6% to 10.6%, which represents the error associated with assuming that all wood biomass has a carbon fraction of 0.5. Given that average carbon fractions for angiosperms are lower than 0.5 [
29], conifers almost certainly play a more important role in global carbon cycles than global estimates based on the 0.5 value currently suggest.
The difference in carbon mass estimates of tissue types are equally important, as different tissues store carbon for variable amounts of time [
49]. Different tissue decay rates mean different rates of carbon dioxide release from the separate tissue carbon pools. Correctly estimating these pools is an important first step in improving the overall understanding of carbon decay dynamics in forests. Accounting for these differences is also important to accurately track carbon mass in forest products.
4.2. Comparisons between Model Complexity Levels
The improvement in AIC and the significant difference determined through log-likelihood ratios shown between model 1 and model 2 (
Table 5) demonstrates the potential to partially explain the variation in carbon fraction values with easily observed bark characteristics. One measure of the improvement in carbon fraction estimation by grouping trees by bark characteristics is the improvement in R
m2 from 0.18 to 0.35, nearly doubling the explained variation due to tree grouping. There is no improvement in model performance for either density or carbon density at the tree group level. This is partially due to the high variation found in these two properties between individuals within a species and within individual trees, as shown by the difference in R
c2 and R
m2 values in
Figure 2.
The higher AIC for the species average carbon density model (CD
ik) compared to the species-tissue type model (CD
ijk) (
Table 5) provides interesting insights into the importance of estimating tissue-level carbon fractions and densities in different species. Tissue types from the same species can have different average carbon fractions [
27,
28,
32] and different average densities [
50]: accounting for these known differences in any carbon density model should improve the predictive power of the model. Interestingly, the species average level model (CD
ik) does not appear to improve model performance above the CD
k model, suggesting that studies into carbon density should focus on a level of complexity at least as complex as the tissue level in order to achieve meaningful improvements in carbon density estimates.
4.3. Carbon Fraction Modeling
Carbon mass estimates using a value of 0.5 often include no error term for the estimate, implying that the term itself has no error. Measured CV
50 values as high as 17.6% (
Table 2) indicate this assumption is incorrect for both whole tree carbon mass and tree tissue carbon mass. There is a strong indication that conifer carbon fractions are generally higher than 0.5 and that angiosperms are generally lower than 0.5 [
29,
36]. Our data support this finding, as all conifer tissues measured in our study had carbon fractions higher than 0.5. This suggests caution should be taken when estimating representative conifer and hardwood carbon fractions for regional carbon estimates.
Though we did not study angiosperms, our findings of significant differences between tissue types within species are consistent with the findings of studies that have specifically looked at carbon fractions in different angiosperm tissue types [
26,
35,
51]. The majority of studies on carbon fraction, however, have not studied different tissue types within a species as potential sources of variation. This is especially true for angiosperm species where sapwood has been the primary tissue type studied [
29]. Given the potential for significantly different carbon fractions between wood types, it is advisable to study both heartwood and sapwood in developing representative tree stem carbon fraction values. This could have important consequences for global carbon storage estimates. It is important to note that whole tree cores are not representative of the entire tree stem at the point of extraction, as the tissue masses in the cores are not proportional to their biomass balance in the stem. Therefore, we suggest that cores be used to estimate the separate tree tissues for carbon fractions and those results be applied to biomass component models that accurately estimate the separate biomasses of the tree components.
The improvement in carbon fraction model fit with increasing model complexity shown in
Table 5 demonstrates that accounting only for species average values does not accurately estimate the carbon fractions found within trees, though species-level averages are clearly superior to using a value of 0.5. This finding is consistent with other studies that have documented significant variation between sapwood, heartwood, and bark within conifers [
27,
28,
31,
38]. In a review of existing carbon fraction studies, Thomas and Martin [
29] found only six studies that measured carbon fractions for different bole tree tissues and none of those studies looked at carbon fractions as measured by all of the common methodologies. By including all of the common carbon fraction analysis methods represented by the Thomas and Martin data [
30], our results are more broadly applicable to carbon fraction research as a whole without being overly influenced by any one method.
The significant improvement in model performance with the addition of the parameter covariate matrix BlXl (model #4 and #6) indicates considerable potential to more accurately predict carbon fractions by utilizing measurable tree characteristics. Our best-fit carbon fraction model (model #6), which included the BlXl matrix, demonstrates that in addition to tissue type, including covariates related to crown length and relative position within the tree result in more accurate carbon fraction estimates. Model #4 did not outperform the more complex models, which suggests that significant physiological differences between tissue types are driving the relationship.
The significant negative relationship between CF
ijk and the p:FHLC interaction term (
Table 6) has not been identified in previous studies. This term has the potential to shift the mean model estimate by up to −1.59% and indicates important differences in carbon fractions between the top and bottom of the tree crown. Bert and Danjon [
32] found a quadratic relationship between carbon fraction and relative tree height but did not report such a relationship for relative position within the crown, as found in this study. The negative relationship found in our study suggests a reduction in carbon fraction within tissue types with increasing relative position in the tree crown. This negative relationship with relative crown position is increased for denser tissue samples (higher p average) within a given species-tissue type. Wood density can be lower in wood found above the base of the live crown [
21] for some species, which would lead to a decrease in the negative impact from the p:FHLC term for those species. The negative correlation between carbon fraction and tissue density is most easily seen in the fibrous and furrowed bark tree groups in
Figure 1, as the carbon and density curves for those groups are nearly mirror images of each other. It is possible that, in isolation, the effect of the p:FHLC term would be very similar to the quadratic relationship found by Bert and Danjon [
32], depending on where peak density occurs in a tree crown. The significant improvement in carbon fraction estimation between model #1 and #2, and the lack of overlap in confidence intervals between mean tissue type values in
Figure 2, indicates that grouping these trees by bark characteristic could be a reasonable first step in improving carbon fraction estimates. The improvement in carbon fraction estimation by accounting for bark features (
Table 5) could be beneficial for carbon estimation in tropical forests, where measuring carbon fractions for every species can be impractical. In these cases, improving carbon fraction estimates by grouping species using easily observed bark characteristics could be beneficial by allowing for improved carbon estimation without the costly process of measuring every species present for carbon fractions.
The positive parameter estimate for the HLC:FHLC term indicates an increased carbon fraction for tissues in trees with high HLC values. This term has the potential to shift the mean model estimate up to 1.47%, depending on the size of the tree and the position relative to the live crown. This increase in carbon fraction is greater for tree tissues located above the live crown. Given this relationship, tall trees with high height to live crowns would be expected to have higher overall average carbon fraction values than short trees with small height to live crowns. This relationship could indicate the potential for canopy class to influence carbon fractions, as all else being equal dominant trees will have longer live crowns than suppressed trees, thus leading to higher FHLC values for dominant trees and therefore a larger positive effect of the HLC:FHLC term.
The negative parameter estimate for the HAR:HLC term indicates a reduction of carbon fraction at the top of the tree, with a rapid weakening of this relationship with increasing distance from the tree top. This term has the smallest potential impact, ranging between −0.47% to 0%. This is because the HAR term decreases at a faster rate than does distance from the tree top. A rapidly decreasing HAR term and a constant HLC term results in a stronger negative relationship near the top of trees than exists further down, though with an overall strengthening of the relationship with increasing HLC values. This negative trend toward the top of trees is primarily displayed by the fibrous bark group from an RH value of 0.4 to 1.0, and may act to bring predicted carbon values back toward the mean species-tissue type value (
Figure 1).
The mean species-tissue type carbon fraction parameter estimate (CFijk) of 1.002 (0.002), suggests that observed carbon fractions are evenly distributed around the mean species-tissue type carbon fraction values. If the parameter estimate was not equal to one, it could indicate that the variance might be better explained by additional covariates or that the variance was not equally distributed around the mean value.
The modeled relationships showed little improvement with the addition of random effects, as shown by the small differences between R
c2 and R
m2 values in
Figure 2. This indicates that the fixed effect portions of the models, specifically the species-specific tissue type averages and the covariate matrix, are accounting for the majority of the variation in the data. This is a critical point in understanding carbon fractions because it indicates that most of the variation in carbon fraction in conifers can be accounted for by calculating species-tissue type averages. This approach may be infeasible in areas with high species diversity, however, in those cases grouping trees by bark characteristics could lead to some improvements in carbon fraction estimation similar to the improvement found between models #1 and #2.
4.4. Tissue Density
Wood density has been studied for varying purposes for over a century [
15,
52]. Appropriate application of this historical data to carbon mass estimation requires an understanding of the underlying relationships between carbon fraction and tissue density. The lack of improvement in AIC in comparing model #7 with models #8 and #9 (
Table 5) indicates that partitioning tree density in tree group and species-level categories alone does not significantly improve model estimates. The best tissue density model utilized tissue type averages and additional covariates (model #12). This means that accounting for changes in tissue density related to observable tree characteristics in addition to tissue type averages not only results in a significant difference in log-likelihood ratios but also improves overall model AIC relative to any of the means only models (D
k, D
ik, D
ijk).
In this study, the final density model (
Table 6) estimates a negative parameter associated with RH, a phenomenon that is common among conifers [
21]. This interaction between RH and D
ijk is likely driven by the tree species in the furrowed bark group, which show the largest reduction in density with increasing RH values (
Figure 1). The potential for this term to influence the mean model estimate is large, ranging from between 12.24% to −0.42%. This indicates the potential improvement in model fit that could be obtained by accounting for the relative position of tissues within the tree.
The reduction in predicted density is partially balanced by the positive parameter estimate for the RDb:Sa interaction term. The impact from this term ranges from −1.50% to 11.44%, nearly equal to the negative range of values from the RH term. The RDb:Sa term indicates that older tissues closer to the pith have higher density values on average. This may be due to increasing lignification that occurs in older tissues, and the accumulation in extractive materials in some tissues over time.
The negative parameter estimate for the RDb:RR term is best interpreted as creating a maximum response at the center of a core with decreasing values away from that core center. Overall, the potential impact on the mean model estimate ranges from this term is −10.07% to −0.03%, which is a large amount of potential variation related to one term.
As with the carbon fraction model, the term representing the species-tissue type average values (D
ijk) had a parameter estimate statistically indistinguishable from 1 (
Table 6). This indicates that the data were fairly evenly distributed around the mean values. The overall fit of the model to the data was significantly improved with the inclusion of random effects related to individual trees and cores (
Figure 2). This is a result of the large inter- and intra-tree variability in wood density. Although the addition of the parameter matrix improved the fit of the model to the data, significant improvement in the model fit was due to the inclusion of random effects, indicating that the fixed effects are not describing as much of the variability as they are in the case of carbon fractions (
Table 5). This could be remedied by adding variables that account for ring width, proportion of earlywood to latewood, and other tree ring-specific variables, as those have been shown to be closely correlated with wood density [
53]. However, these ring-specific variables are not easily measured, and therefore not very useful in estimating overall tree biomass or carbon mass without time consuming sampling procedures.
4.5. Carbon Density
This study used paired density and carbon fraction samples in order to directly analyze the relationship between these two tree properties. The product of these values is carbon density, and, as can be seen in
Figure 1, density dominates the resulting relationship. The trend lines in the carbon density graph are somewhat less extreme versions of the corresponding density curves, with each carbon density curve remaining closer to the mean species-tissue type value at a given RH value than either the carbon fraction or tissue density curves. This reduced spread around the mean values is due to the negative relationships between carbon fraction and tissue density. The trend in carbon density has the same shape as the density curves due to the much larger variation within density samples compared to the carbon fraction samples. Given the complexity of the relationship between carbon fraction and tissue density, it would be advisable to study these two tree characteristics with paired samples rather than trying to study them as independent variables and then later multiply the resulting values together.
The negative parameter for the FHLC:R term indicates a reduction in carbon density closer to the pith and higher in the crown. This reduction is more significant for large diameter trees and would be applicable to each species-tissue type. This effect could partially be driven by the presence of large old-growth trees in the study, such as giant sequoia and some individual pines. It seems that it is this trend in density that is driving the trend in carbon density, as the carbon fraction model suggests no significant effect related to distance from pith, while the density model has negative relationships for relative height and relative distance from the bark.
The negative parameter estimate for the RDb:RR term suggests low carbon density values near pith and values that increase radially from the pith. This is likely driven by the same relationship in the density model, as no comparable term was found for the carbon fraction model.
The LCR:RH term suggests decreasing carbon density for trees with greater live crown proportions, with a decreasing trend up the tree. This term reflects crown relationships that are prevalent in the carbon fraction model, as well as relative height relationships in the density model. It may also indicate that trees with greater live crown ratios will have larger proportions of crown wood, which can be lower in density than wood formed below the crown. This is consistent with our understanding of juvenile and mature wood formation in conifers [
54].
The even distribution of the values around the mean is indicated by the mean estimate parameter value of 1.007 (
Table 6). This suggests that the variables in the model are reflecting the trends in both density and carbon fraction in a balanced way.
The best-fit models for carbon density are less influenced by the addition of random effects (smaller range in R
c2 and R
m2 values for most tree groups) than the tissue density models but more than the carbon fraction models (
Figure 2). As carbon density is a combination of tissue density and carbon fraction, it is logical that the high variability displayed by the density samples would be somewhat reduced by the lower residual variance found in the carbon fraction values. It is also likely that the negative correlation between carbon fraction and tissue density are partially responsible for reducing the residual error allocated to the random effects. This finding is promising, as the high variability in tissue density creates high variability in any final biomass or carbon mass estimate; however, if that variability can be partially offset by correctly accounting for carbon fraction values then the overall carbon mass estimate would display reduced error relative to biomass estimates.




{kind=link}
{kind=link}

