

Deep Learning Methods Applied to Drug Concentration Prediction of Olanzapine

Abstract
:1. Introduction
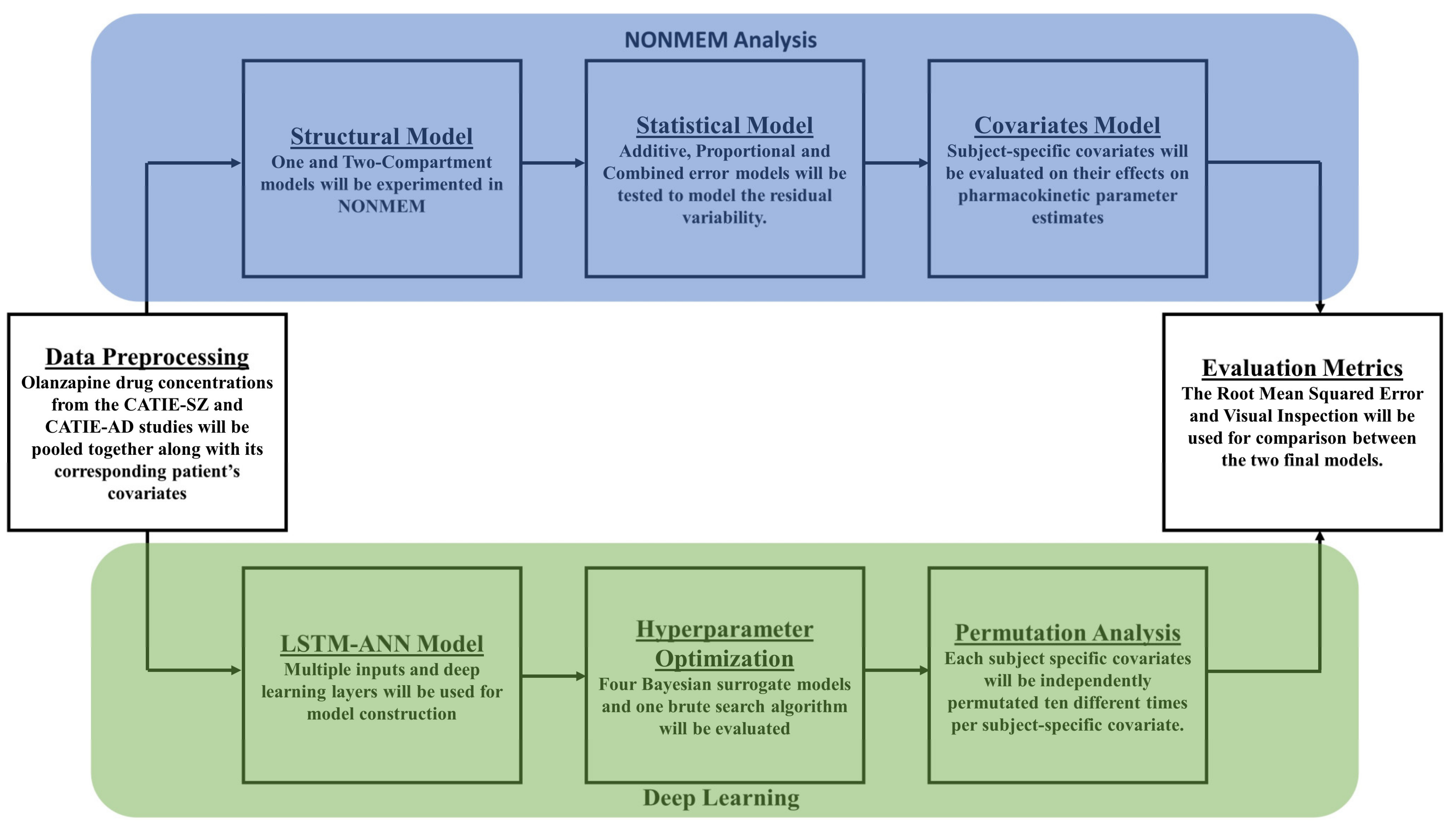
2. Materials and Methods
2.1. Study Population
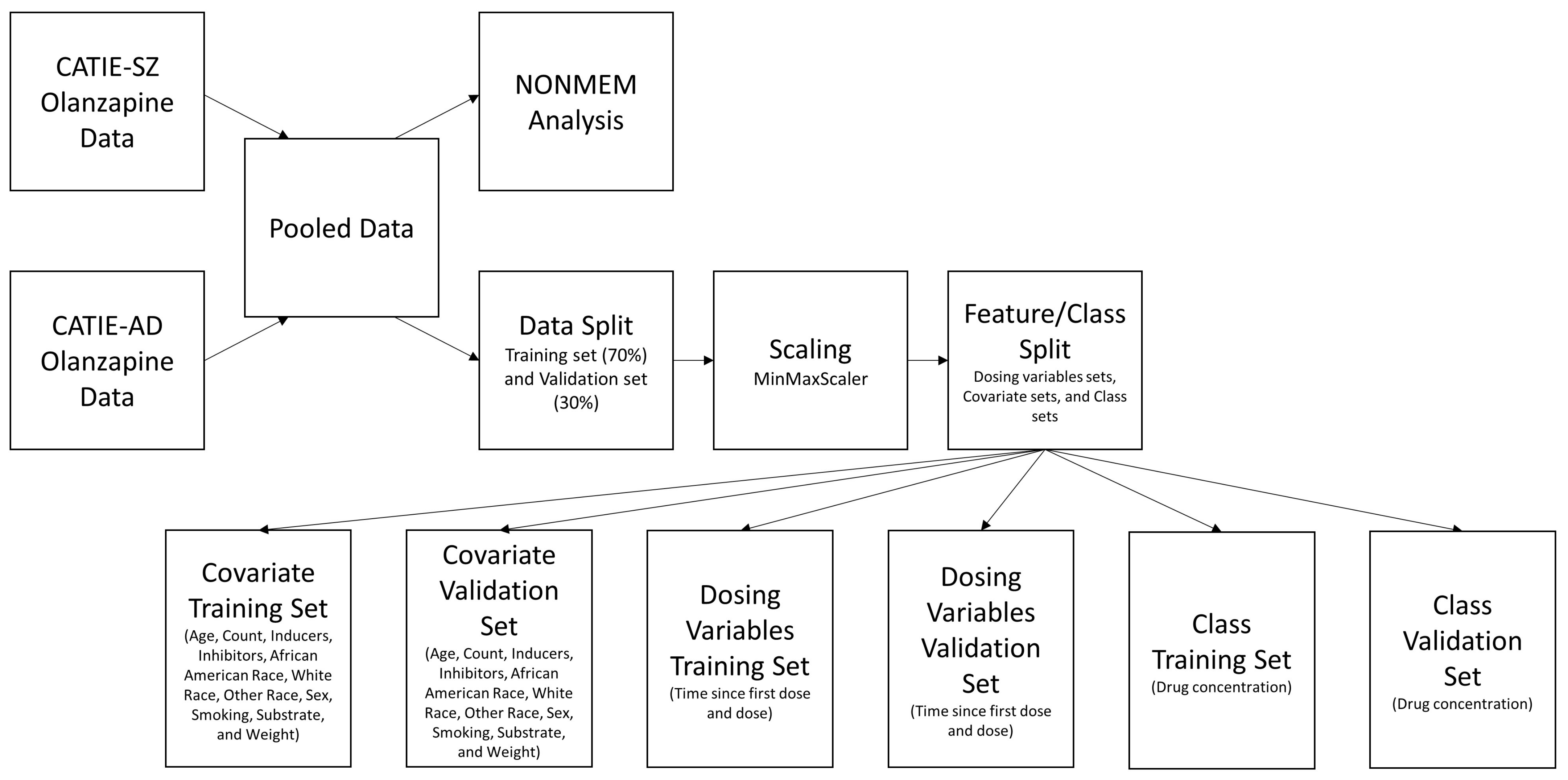
2.2. Preprocessing of Data
2.3. Population Pharmacokinetics
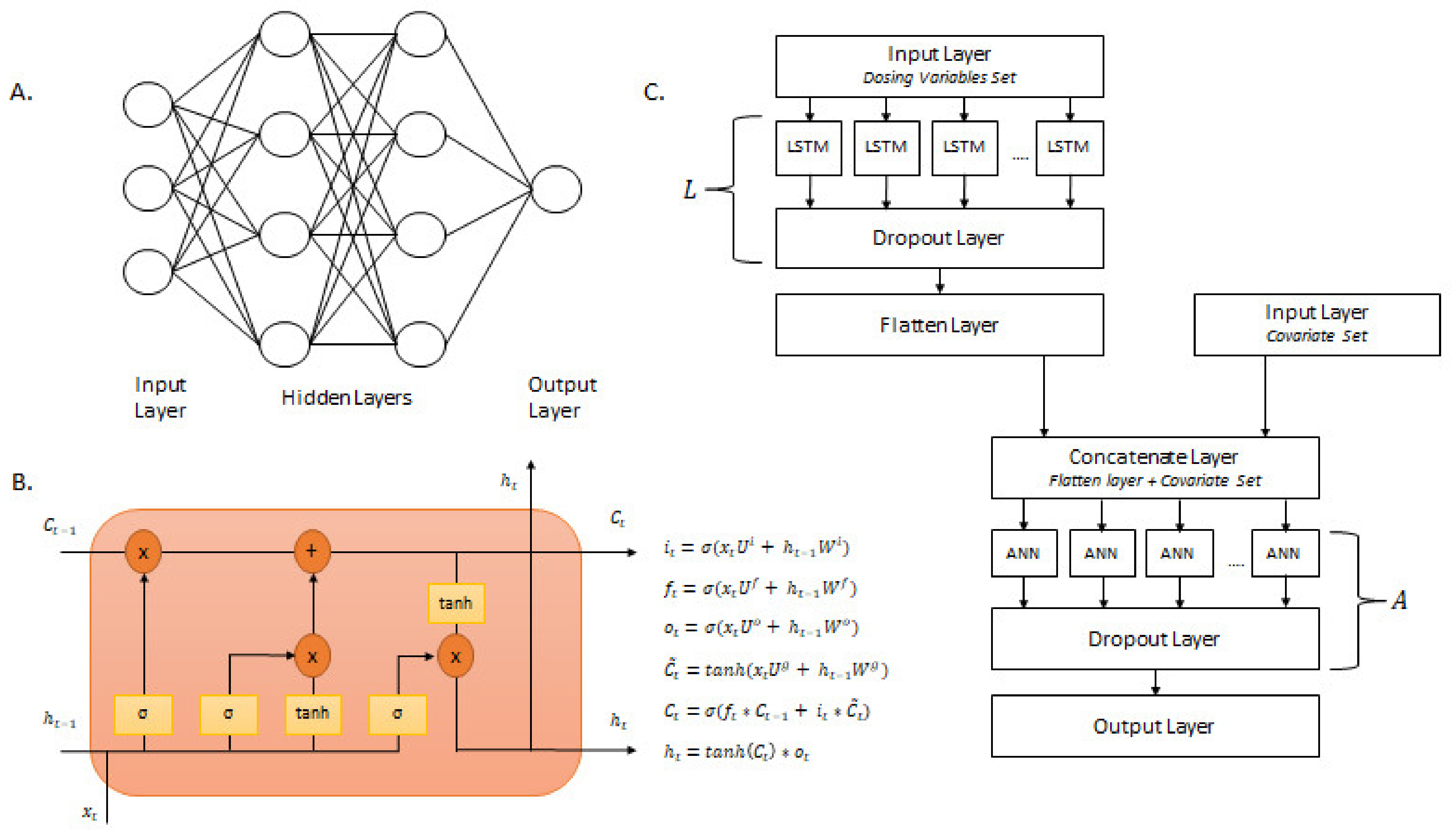
2.4. Neural Networks
2.5. Bayesian Hyperparameter Optimization
2.6. Permutation Analysis
3. Results
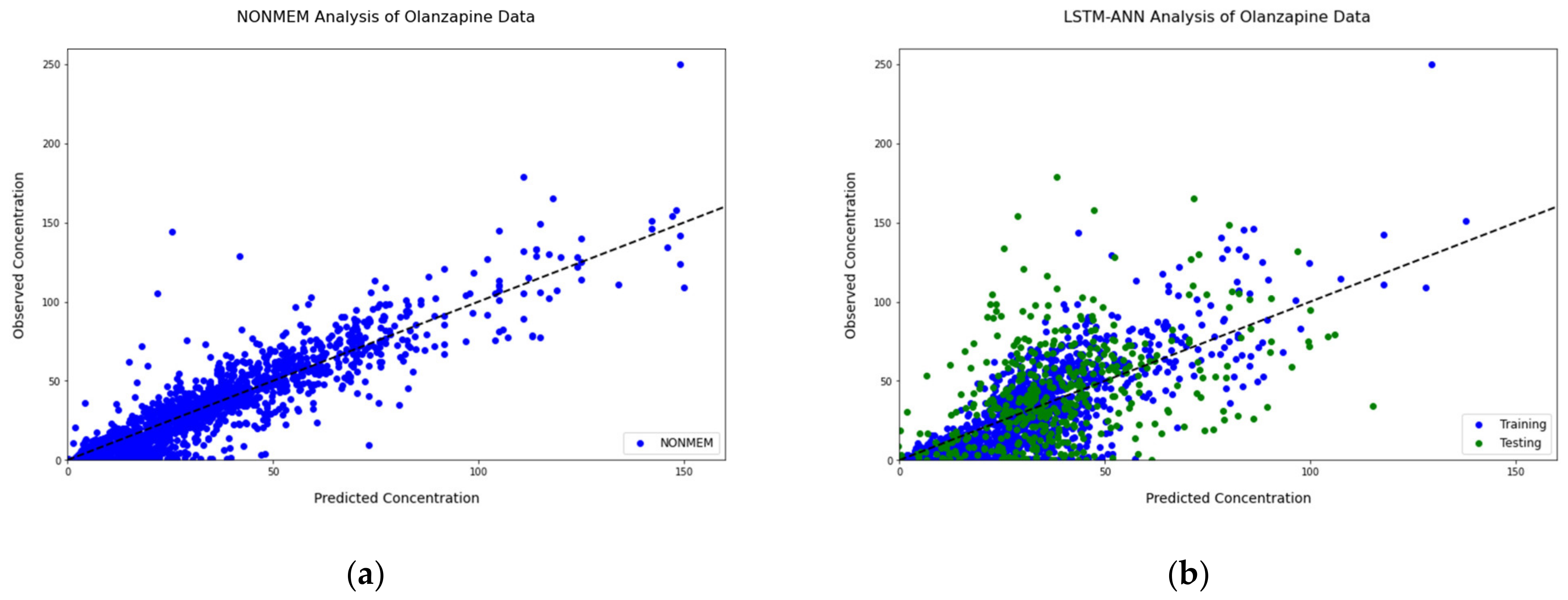
3.1. Population Pharmacokinetics
3.2. Neural Networks: Bayesian Hyperparameter Optimization
3.3. Permutation Analysis
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Krishnaswami, S.; Austin, D.; Della Pasqua, O.; Gastonguay, M.R.; Gobburu, J.; van der Graaf, P.H.; Ouellet, D.; Tannenbaum, S.; Visser, S.A.G. MID3: Mission Impossible or Model-Informed Drug Discovery and Development? Point-Counterpoint Discussions on Key Challenges. Clin. Pharmacol. Ther. 2020, 107, 762–772. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Workgroup, E.M.; Marshall, S.F.; Burghaus, R.; Cosson, V.; Cheung, S.Y.; Chenel, M.; DellaPasqua, O.; Frey, N.; Hamren, B.; Harnisch, L.; et al. Good Practices in Model-Informed Drug Discovery and Development: Practice, Application, and Documentation. CPT Pharmacomet. Syst. Pharmacol. 2016, 5, 93–122. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Janssen, A.; Bennis, F.C.; Mathot, R.A.A. Adoption of Machine Learning in Pharmacometrics: An Overview of Recent Implementations and Their Considerations. Pharmaceutics 2022, 14, 1814. [Google Scholar] [CrossRef] [PubMed]
- McComb, M.; Bies, R.; Ramanathan, M. Machine learning in pharmacometrics: Opportunities and challenges. Br. J. Clin. Pharmacol. 2022, 88, 1482–1499. [Google Scholar] [CrossRef]
- Poynton, M.R.; Choi, B.M.; Kim, Y.M.; Park, I.S.; Noh, G.J.; Hong, S.O.; Boo, Y.K.; Kang, S.H. Machine learning methods applied to pharmacokinetic modelling of remifentanil in healthy volunteers: A multi-method comparison. J. Int. Med. Res. 2009, 37, 1680–1691. [Google Scholar] [CrossRef]
- Keutzer, L.; You, H.; Farnoud, A.; Nyberg, J.; Wicha, S.G.; Maher-Edwards, G.; Vlasakakis, G.; Moghaddam, G.K.; Svensson, E.M.; Menden, M.P.; et al. Machine Learning and Pharmacometrics for Prediction of Pharmacokinetic Data: Differences, Similarities and Challenges Illustrated with Rifampicin. Pharmaceutics 2022, 14, 1530. [Google Scholar] [CrossRef]
- Tolle, K.M.; Chen, H.; Chow, H.-H. Estimating drug/plasma concentration levels by applying neural networks to pharmacokinetic data sets. Decis. Support Syst. 2000, 30, 139–151. [Google Scholar] [CrossRef] [Green Version]
- Lu, J.; Deng, K.; Zhang, X.; Liu, G.; Guan, Y. Neural-ODE for pharmacokinetics modeling and its advantage to alternative machine learning models in predicting new dosing regimens. iScience 2021, 24, 102804. [Google Scholar] [CrossRef]
- Rifaioglu, A.S.; Atas, H.; Martin, M.J.; Cetin-Atalay, R.; Atalay, V.; Dogan, T. Recent applications of deep learning and machine intelligence on in silico drug discovery: Methods, tools and databases. Brief. Bioinform. 2019, 20, 1878–1912. [Google Scholar] [CrossRef] [Green Version]
- Kimber, T.B.; Chen, Y.; Volkamer, A. Deep Learning in Virtual Screening: Recent Applications and Developments. Int. J. Mol. Sci. 2021, 22, 4435. [Google Scholar] [CrossRef]
- Kim, J.; Park, S.; Min, D.; Kim, W. Comprehensive Survey of Recent Drug Discovery Using Deep Learning. Int. J. Mol. Sci. 2021, 22, 9983. [Google Scholar] [CrossRef]
- Patel, V.; Shah, M. Artificial intelligence and machine learning in drug discovery and development. Intell. Med. 2022, 2, 134–140. [Google Scholar] [CrossRef]
- Koch, G.; Pfister, M.; Daunhawer, I.; Wilbaux, M.; Wellmann, S.; Vogt, J.E. Pharmacometrics and Machine Learning Partner to Advance Clinical Data Analysis. Clin. Pharmacol. Ther. 2020, 107, 926–933. [Google Scholar] [CrossRef] [Green Version]
- Ota, R.; Yamashita, F. Application of machine learning techniques to the analysis and prediction of drug pharmacokinetics. J. Control. Release 2022, 352, 961–969. [Google Scholar] [CrossRef]
- Lipinski, C.F.; Maltarollo, V.G.; Oliveira, P.R.; da Silva, A.B.F.; Honorio, K.M. Advances and Perspectives in Applying Deep Learning for Drug Design and Discovery. Front. Robot. AI 2019, 6, 108. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Lou, H.; Chen, J.; Jiang, B.; Yang, D.; Hu, Y.; Ruan, Z. Application of a Backpropagation Artificial Neural Network in Predicting Plasma Concentration and Pharmacokinetic Parameters of Oral Single-Dose Rosuvastatin in Healthy Subjects. Clin. Pharmacol. Drug Dev. 2020, 9, 867–875. [Google Scholar] [CrossRef]
- Tang, J.; Liu, R.; Zhang, Y.L.; Liu, M.Z.; Hu, Y.F.; Shao, M.J.; Zhu, L.J.; Xin, H.W.; Feng, G.W.; Shang, W.J.; et al. Application of Machine-Learning Models to Predict Tacrolimus Stable Dose in Renal Transplant Recipients. Sci. Rep. 2017, 7, 42192. [Google Scholar] [CrossRef] [Green Version]
- Soeorg, H.; Sverrisdottir, E.; Andersen, M.; Lund, T.M.; Sessa, M. Artificial Neural Network vs. Pharmacometric Model for Population Prediction of Plasma Concentration in Real-World Data: A Case Study on Valproic Acid. Clin. Pharmacol. Ther. 2022, 111, 1278–1285. [Google Scholar] [CrossRef]
- Ingrande, J.; Gabriel, R.A.; McAuley, J.; Krasinska, K.; Chien, A.; Lemmens, H.J.M. The Performance of an Artificial Neural Network Model in Predicting the Early Distribution Kinetics of Propofol in Morbidly Obese and Lean Subjects. Anesth. Analg. 2020, 131, 1500–1509. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Frazier, P.I. A tutorial on Bayesian optimization. arXiv 2018, arXiv:1807.02811. [Google Scholar]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; De Freitas, N. Taking the human out of the loop: A review of Bayesian optimization. Proc. IEEE 2015, 104, 148–175. [Google Scholar] [CrossRef] [Green Version]
- Mekruksavanich, S.; Jitpattanakul, A. LSTM Networks Using Smartphone Data for Sensor-Based Human Activity Recognition in Smart Homes. Sensors 2021, 21, 1636. [Google Scholar] [CrossRef] [PubMed]
- Sethi, M.; Ahuja, S.; Rani, S.; Bawa, P.; Zaguia, A. Classification of Alzheimer’s Disease Using Gaussian-Based Bayesian Parameter Optimization for Deep Convolutional LSTM Network. Comput. Math. Methods Med. 2021, 2021, 4186666. [Google Scholar] [CrossRef] [PubMed]
- Jiang, B.; Gong, H.; Qin, H.; Zhu, M. Attention-LSTM architecture combined with Bayesian hyperparameter optimization for indoor temperature prediction. Build. Environ. 2022, 224, 109536. [Google Scholar] [CrossRef]
- He, Y.; Tsang, K.F. Universities power energy management: A novel hybrid model based on iCEEMDAN and Bayesian optimized LSTM. Energy Rep. 2021, 7, 6473–6488. [Google Scholar] [CrossRef]
- Hansen, L.D.; Stokholm-Bjerregaard, M.; Durdevic, P. Modeling phosphorous dynamics in a wastewater treatment process using Bayesian optimized LSTM. Comput. Chem. Eng. 2022, 160, 107738. [Google Scholar] [CrossRef]
- Chakraborty, S.; Tomsett, R.; Raghavendra, R.; Harborne, D.; Alzantot, M.; Cerutti, F.; Srivastava, M.; Preece, A.; Julier, S.; Rao, R.M. Interpretability of deep learning models: A survey of results. In Proceedings of the 2017 IEEE Smartworld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computed, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (Smartworld/SCALCOM/UIC/ATC/CBDcom/IOP/SCI), San Francisco, CA, USA, 4–8 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Ogami, C.; Tsuji, Y.; Seki, H.; Kawano, H.; To, H.; Matsumoto, Y.; Hosono, H. An artificial neural network-pharmacokinetic model and its interpretation using Shapley additive explanations. CPT Pharmacomet. Syst. Pharmacol. 2021, 10, 760–768. [Google Scholar] [CrossRef]
- Li, X.; Xiong, H.; Li, X.; Wu, X.; Zhang, X.; Liu, J.; Bian, J.; Dou, D. Interpretable deep learning: Interpretation, interpretability, trustworthiness, and beyond. Knowl. Inf. Syst. 2022, 64, 3197–3234. [Google Scholar] [CrossRef]
- Altmann, A.; Tolosi, L.; Sander, O.; Lengauer, T. Permutation importance: A corrected feature importance measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef] [Green Version]
- Swartz, M.S.; Perkins, D.O.; Stroup, T.S.; McEvoy, J.P.; Nieri, J.M.; Haak, D.C. Assessing clinical and functional outcomes in the Clinical Antipsychotic Trials of Intervention Effectiveness (CATIE) schizophrenia trial. Schizophr. Bull. 2003, 29, 33–43. [Google Scholar] [CrossRef] [Green Version]
- Schneider, L.S.; Tariot, P.N.; Dagerman, K.S.; Davis, S.M.; Hsiao, J.K.; Ismail, M.S.; Lebowitz, B.D.; Lyketsos, C.G.; Ryan, J.M.; Stroup, T.S. Effectiveness of atypical antipsychotic drugs in patients with Alzheimer’s disease. N. Engl. J. Med. 2006, 355, 1525–1538. [Google Scholar] [CrossRef] [Green Version]
- Stroup, T.S.; McEvoy, J.P.; Swartz, M.S.; Byerly, M.J.; Glick, I.D.; Canive, J.M.; McGee, M.F.; Simpson, G.M.; Stevens, M.C.; Lieberman, J.A. The National Institute of Mental Health Clinical Antipsychotic Trials of Intervention Effectiveness (CATIE) project: Schizophrenia trial design and protocol development. Schizophr. Bull. 2003, 29, 15. [Google Scholar] [CrossRef] [Green Version]
- Lieberman, J.A.; Stroup, T.S.; McEvoy, J.P.; Swartz, M.S.; Rosenheck, R.A.; Perkins, D.O.; Keefe, R.S.; Davis, S.M.; Davis, C.E.; Lebowitz, B.D. Effectiveness of antipsychotic drugs in patients with chronic schizophrenia. N. Engl. J. Med. 2005, 353, 1209–1223. [Google Scholar] [CrossRef] [Green Version]
- Aravagiri, M.; Ames, D.; Wirshing, W.C.; Marder, S.R. Plasma level monitoring of olanzapine in patients with schizophrenia: Determination by high-performance liquid chromatography with electrochemical detection. Ther. Drug Monit. 1997, 19, 307–313. [Google Scholar] [CrossRef]
- Zhou, Z.; Li, X.; Li, K.; Xie, Z.; Cheng, Z.; Peng, W.; Wang, F.; Zhu, R.; Li, H. Simultaneous determination of clozapine, olanzapine, risperidone and quetiapine in plasma by high-performance liquid chromatography–electrospray ionization mass spectrometry. J. Chromatogr. B 2004, 802, 257–262. [Google Scholar] [CrossRef]
- Géron, A. Hands-on machine learning with scikit-learn and tensorflow: Concepts. In Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Sebastopol, CA, USA, 2017. [Google Scholar]
- Varsamopoulos, S.; Bertels, K.; Almudever, C. Designing Neural Network based Decoders for Surface Codes Accelerated BWA-MEM View project hartes View Project Designing Neural Network based Decoders for Surface Codes. arXiv 2018, arXiv:1811.12456. [Google Scholar]
- Callaghan, J.T.; Bergstrom, R.F.; Ptak, L.R.; Beasley, C.M. Olanzapine. Pharmacokinetic and pharmacodynamic profile. Clin. Pharmacokinet. 1999, 37, 177–193. [Google Scholar] [CrossRef]
- Bigos, K.L.; Pollock, B.G.; Coley, K.C.; Miller, D.D.; Marder, S.R.; Aravagiri, M.; Kirshner, M.A.; Schneider, L.S.; Bies, R.R. Sex, race, and smoking impact olanzapine exposure. J. Clin. Pharmacol. 2008, 48, 157–165. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Garbin, C.; Zhu, X.; Marques, O. Dropout vs. batch normalization: An empirical study of their impact to deep learning. Multimed. Tools Appl. 2020, 79, 12777–12815. [Google Scholar] [CrossRef]
- Li, Z.; Gong, B.; Yang, T. Improved dropout for shallow and deep learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Berabi, B. What Is This Flatten Layer Doing in My LSTM? 2021. Available online: https://stackoverflow.com/questions/66952606/what-is-this-flatten-layer-doing-in-my-lstm (accessed on 22 September 2022).
- Tayo, B. Simplicity vs. Complexity in Machine Learning—Finding the Right Balance; Medium: San Francisco, CA, USA, 2019; Available online: https://towardsdatascience.com/simplicity-vs-complexity-in-machine-learning-finding-the-right-balance-c9000d1726fb (accessed on 23 September 2022).
- Weiss, U.; Marksteiner, J.; Kemmler, G.; Saria, A.; Aichhorn, W. Effects of age and sex on olanzapine plasma concentrations. J. Clin. Psychopharmacol. 2005, 25, 570–574. [Google Scholar] [CrossRef] [PubMed]
- Aichhorn, W.; Marksteiner, J.; Walch, T.; Zernig, G.; Hinterhuber, H.; Stuppaeck, C.; Kemmler, G. Age and gender effects on olanzapine and risperidone plasma concentrations in children and adolescents. J. Child Adolesc. Psychopharmacol. 2007, 17, 665–674. [Google Scholar] [CrossRef] [PubMed]
- Chiu, C.C.; Lu, M.L.; Huang, M.C.; Chen, K.P. Heavy smoking, reduced olanzapine levels, and treatment effects: A case report. Ther. Drug Monit. 2004, 26, 579–581. [Google Scholar] [CrossRef] [PubMed]
- Tsuda, Y.; Saruwatari, J.; Yasui-Furukori, N. Meta-analysis: The effects of smoking on the disposition of two commonly used antipsychotic agents, olanzapine and clozapine. BMJ Open 2014, 4, e004216. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Liu, C.; Huang, R.; Zhu, H.; Liu, Q.; Mitra, S.; Wang, Y. Long short-term memory recurrent neural network for pharmacokinetic-pharmacodynamic modeling. Int. J. Clin. Pharmacol. Ther. 2021, 59, 138–146. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| All Patients (n = 523) | CATIE-SZ (Schizophrenia Study) (n = 406) | CATIE-AD (Alzheimer’s Disease Study) (n = 117) | |
|---|---|---|---|
| Observations | 1527 | 1327 | 200 |
| Age, median years ± SD (range) | 45 ± 18 (18–103) | 42 ± 10.9 (18–65) | 78 ± 8.5 (45–103) |
| Race, (n) White Black/African American Asian American Indian Two or more races | |||
| 346 | 253 | 93 | |
| 149 | 131 | 18 | |
| 19 | 14 | 5 | |
| 5 | 4 | 1 | |
| 4 | 4 | 0 | |
| Sex, (n) | |||
| Male | 332 | 289 | 43 |
| Female | 191 | 117 | 74 |
| Smoking, (n) | |||
| Active Smoker | 274 | 267 | 7 |
| Nonsmoker | 249 | 139 | 110 |
| Weight, mean weight (kg) ± SD | 84.43 ± 22.1 | 89.34 ± 21.4 | 67.42 ± 15.07 |
| Hyperparameters of the LSTM-ANN Model | |
|---|---|
| Hyperparameters to Be Tuned | Range to Be Tested |
| Number of L (LSTM + Dropout) | 1–3 layers |
| Number of LSTM nodes | 8–256 nodes |
| Number of A (Dense + Dropout) | 1–3 layers |
| Number of ANN nodes | 8–256 nodes |
| Learning Rate | 0.001–0.0001 |
| Number of Epochs | 40–120 epochs |
| Hyperparameters to stay constant | Fixed Option/Value |
| Activation function for LSTM nodes | ReLU |
| Activation function for ANN nodes | ReLU |
| Optimizer function | ADAM |
| Batch Size | 1 |
| Time Steps | 2 |
| Model | Objective Function | Decrease in Objective Function | |
|---|---|---|---|
| From Base Model | From Previous Model | ||
| Base Model (Structural and Statistical Model) | 10,419.333 | N/A | N/A |
| Base Model + Smoking Status | 10,374.054 | 45.279 | 45.279 |
| Base Model + Smoking Status + Sex | 10,361.536 | 57.794 | 12.518 |
| Base Model + Smoking Status + Sex + Black/African American Race | 10,352.008 | 67.325 | 9.528 |
| Optimized Final Model Structure | |
|---|---|
| Hyperparameters | Option/Value |
| Time Steps | 2 |
| Number of L (LSTM + Dropout) | 1 layer |
| Number of LSTM nodes | 8 nodes |
| Activation function for LSTM nodes | ReLU |
| Number of A (Dense + Dropout) | 2 layers |
| Number of ANN nodes in Layer 1 | 88 nodes |
| Number of ANN nodes in Layer 2 | 184 nodes |
| Activation function for ANN nodes | ReLU |
| Optimizer function | ADAM |
| Learning rate | 0.000125 |
| Number of Epochs | 69 epochs |
| Batch Size | 1 batch |
| Permutation Analysis toward Covariate Importance | |
|---|---|
| Covariates | Weight (Average ± SD) |
| Age | 4.733 ± 0.461 |
| Sex | 3.403 ± 0.683 |
| Smoking | 2.283 ± 0.399 |
| White Race | 1.936 ± 0.484 |
| Weight | 1.427 ± 0.374 |
| Substrate | 1.338 ± 0.415 |
| Black/African American Race | 1.204 ± 0.474 |
| Count | 0.844 ± 0.436 |
| Inducers | 0.730 ± 0.285 |
| Inhibitors | 0.158 ± 0.316 |
| Other Race | 0.147 ± 0.177 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khusial, R.; Bies, R.R.; Akil, A. Deep Learning Methods Applied to Drug Concentration Prediction of Olanzapine. Pharmaceutics 2023, 15, 1139. https://doi.org/10.3390/pharmaceutics15041139
Khusial R, Bies RR, Akil A. Deep Learning Methods Applied to Drug Concentration Prediction of Olanzapine. Pharmaceutics. 2023; 15(4):1139. https://doi.org/10.3390/pharmaceutics15041139
Chicago/Turabian StyleKhusial, Richard, Robert R. Bies, and Ayman Akil. 2023. "Deep Learning Methods Applied to Drug Concentration Prediction of Olanzapine" Pharmaceutics 15, no. 4: 1139. https://doi.org/10.3390/pharmaceutics15041139
APA StyleKhusial, R., Bies, R. R., & Akil, A. (2023). Deep Learning Methods Applied to Drug Concentration Prediction of Olanzapine. Pharmaceutics, 15(4), 1139. https://doi.org/10.3390/pharmaceutics15041139