1. Introduction
In setting the foundation for any discussion of data analysis, it is important to recognize that most studies are conducted with the goal of providing inferences about some population. If it were possible to assess every element in a population, inference would be unnecessary. Since it is rarely feasible to evaluate the entire population, measurements are made on a sample of the population and those measurements are used to make inference about the distribution of the variable of interest (e.g., body weight, treatment outcome, drug pharmacokinetics, food intake) in the entire population. Imbedded within the concept of using finite samples to represent the larger population is the requirement that the observations be derived from a randomly sampled subset of the population. The larger the sample size, the better will be the approximation of the population distribution.
An evaluation of the sample data frequently includes calculation of sample mean and variance. The sample mean is a measure of location. The standard deviation (stdev), i.e., the square root of the variance, provides a measure of the dispersion of the values about the mean [
1]. In addition to their use in interpreting individual study outcomes, these values are often compared across studies.
Once a sample mean and variance (or stdev) are calculated, researchers often use these estimates to generate inferences about the population parameters, the true mean (which is the expected value of the population), and the variance. For example, the area under the concentration versus time curve (AUC) is one variable used as an indicator of rate and extent of drug absorption. In a crossover bioequivalence (BE) trial, an AUC is computed for each study subject following the administration of a test product and a reference product and the ratio test AUC/reference AUC is of interest. The natural logarithm of the ratio of test AUC/reference AUC (i.e., the difference in natural log (Ln)-transformed AUC values) is subsequently calculated for each study subject. The mean and residual error (variance) of the within subject test/reference product ratios are determined. On the basis of these statistics, we can generate conclusions as to whether or not two products will be bioequivalent when administered to the population of potential patients.
While the concept of “mean” may appear straightforward, the “mean” needs to be appreciated from the perspective of the distribution of the underlying data that determined the method by which that mean was estimated. In this regard, depending upon their characteristics (i.e., what they represent), a set of numbers can be described by different mean values. For this reason, it is important to understand the reason for selecting one type of “mean” over another. Similarly, distributional assumptions influence the calculation of the corresponding error (variance) estimates. Data transformations change the distributional assumptions that apply. Nevertheless, there are instances where investigators use transformations when estimating the means but revert back to arithmetic assumptions in the calculation of the variance. Such method for calculating summary statistics is flawed, rending the sample and population inferences derived from that data analysis likewise flawed.
This leads to the question of the consequence of using (or not using) data transformations in the calculation of means and variances. When the data are derived from a normal (symmetric bell curve) distribution, we can infer that about 68% of the population values will be within one stdev of the mean, about 95% of the population values will be within two stdevs of the mean, and 99.7% of the values will be within three stdevs of the mean (the three-sigma rule [
1]). We do not have this property to rely upon when using the arithmetic mean and the associated stdev to describe data from any other type of distribution. Appropriately chosen data transformations can result in a distribution that is more nearly normal, that is, closer to a symmetric bell shape, than the distribution of the original data and will permit the use of the three-sigma rule and other benefits that apply to normal data. In other words, when applying the 3-sigma rule, it needs to be applied under the conditions of the transformation that made the data distribution closer to a symmetric bell shaped curve.
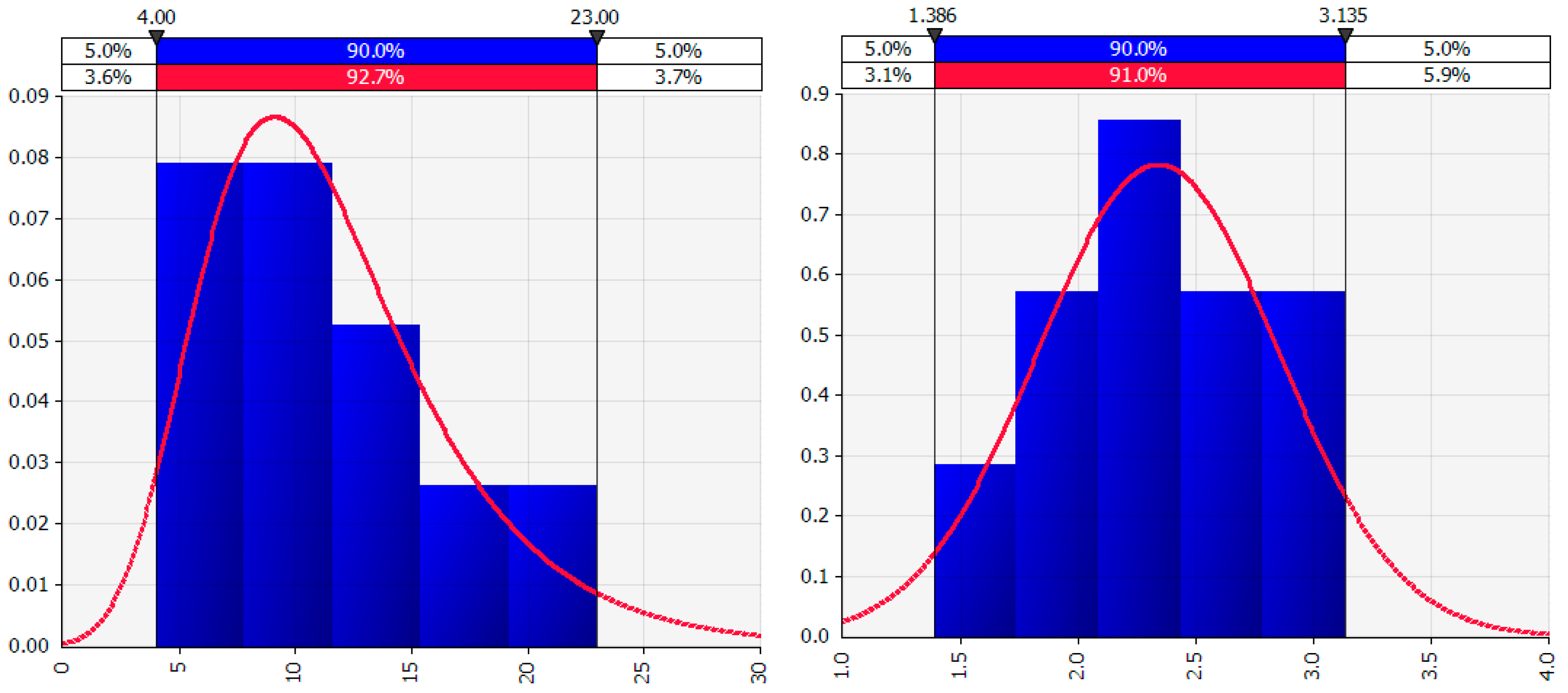
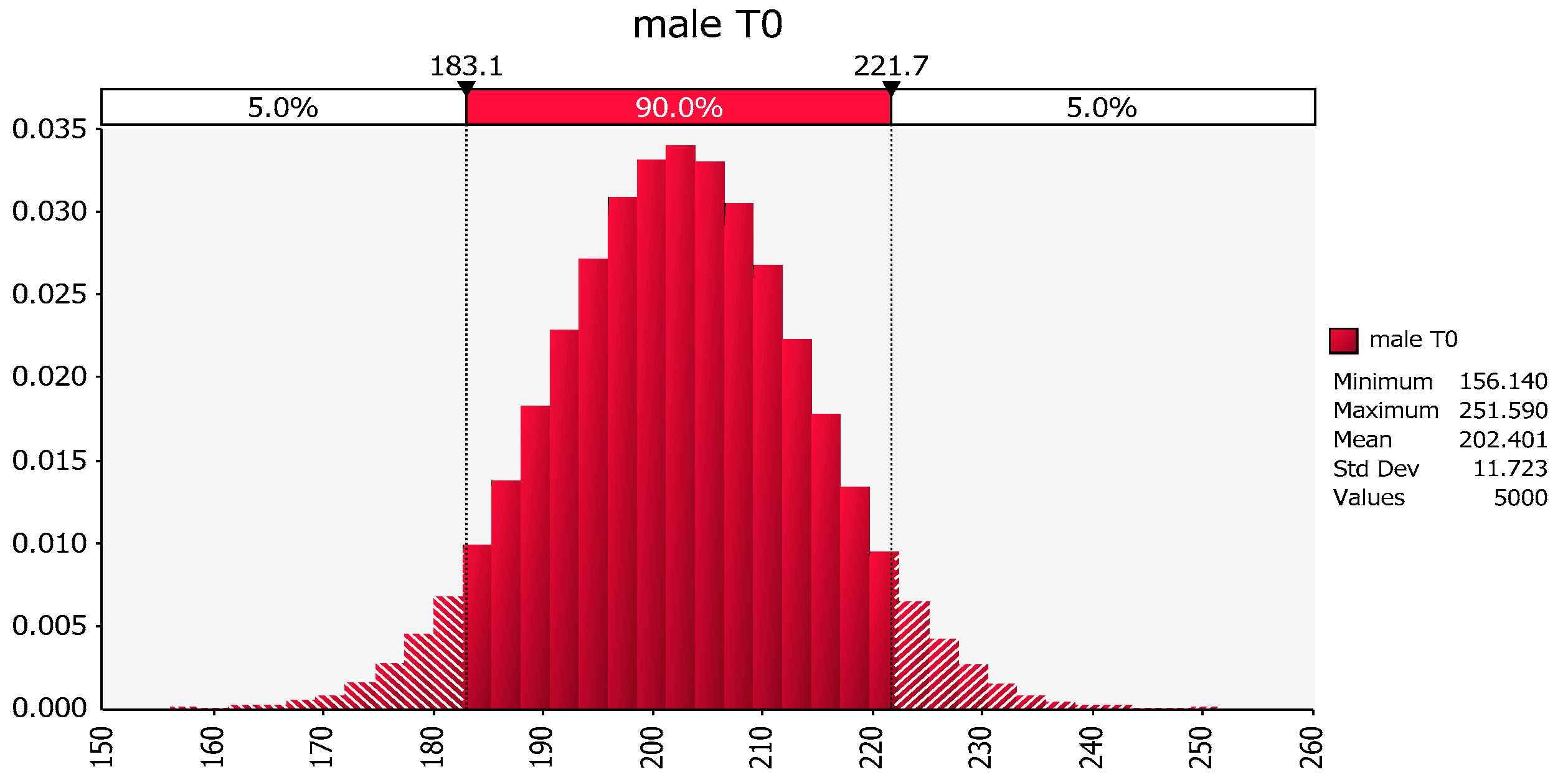
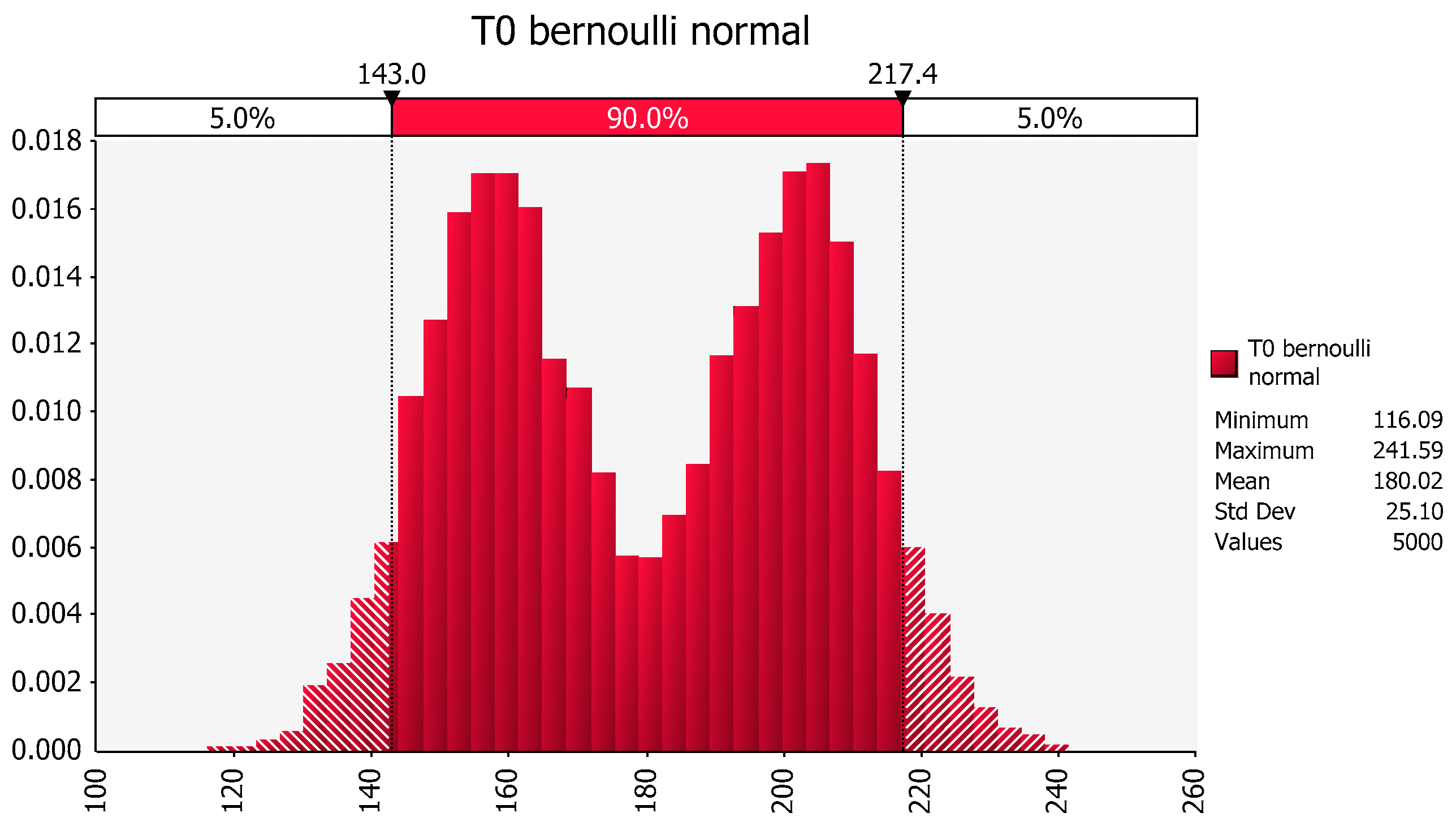
As an example of how the natural logarithm transformation can correct right-skewed data distributions (a larger proportion of low values) and result in a distribution that is more nearly normal (i.e., closer to a symmetric bell shaped curve),
Figure 1 shows the best fit distribution to right-skewed “Number” values in the left graph and the best fit distribution, a normal distribution, to the “Ln number” values in the right graph. The natural logarithm transformation can only be calculated for original values that are non-negative.
Similar results may be shown for the use of the reciprocal transformation (1/”Number”) which applies only to positive values. While there are many data transformations in use, this paper focuses on the natural logarithm transformation and the reciprocal transformation, which are transformations commonly applied to the analysis of right-skewed positive-valued biomedical data.
Taking this example further, we compute the arithmetic mean and the stdevs for both the original “Number” values and the natural logarithm transformed values “Ln number”. The original values are recorded in the units in which they were measured and are familiar to the researcher. However, the “Ln number” values are in units that may be less familiar. As a result, the mean and the mean ± 1, 2 or 3 × stdevs of the Ln-transformed values are transformed back into the original units by exponentiation. When the back-transformed values are compared to those calculated from the original values, we find that the location of the exponentiated mean of the Ln-transformed assessment (i.e., the geometric mean) is shifted to the left of the arithmetic mean. In addition, the distribution of the exponentiated Ln-transformed values is again right-skewed, with larger differences between the mean + stdev than between mean − stdev. While the mean minus some multiple of the stdev may be calculated as a negative number for the untransformed values, the lower limit of the exponentiated Ln-transformed values is constrained to be non-negative. See
Table 1.
Clearly, in the absence of an appropriate data representation (i.e., if and when a transformation of the original observations is appropriate), we will have flawed assessments that will bias our interpretation of the study results and the associated population inferences derived from our analysis. In other words, in the presence of inappropriate data transformations (or in the absence of necessary transformations), the analysis of the data will be biased. It should also be noted that the greater the skewing of the data being evaluated, the greater the magnitude of the difference between the two sets of predictions.
Given the vast differences in inference that might be made depending on the sample statistics used to describe a study’s results, it is evident that authors should specify the nature of the mean being calculated and reported, and that the corresponding stdev needs to be calculated in a manner consistent with the distributional assumptions associated with the calculated mean value.
It is with these points in mind that this educational article provides a review of the different kinds of means, examples of when each may be appropriately applied, and statistically sound methods for estimating the corresponding variances and stdevs. The types of means and their associated stdevs discussed in this article include arithmetic, geometric, harmonic and least squares (see
Appendix A for further discussion of these means). We also discuss how to determine the arithmetic mean and variance when data are pooled across published investigations when only summary statistics are available.
Given the density of information covered in this manuscript, we divided the information into the following sections:
2.1. Illustrating the problems: here we provide a summary of the kinds of data or situations where the different methods of estimating the summary statistics may be appropriate. We also provide a table of values to illustrate the differences in the values of the means and stdevs that are estimated (based upon a single set of initial values) based upon the assumption made about the distribution of that data, and we describe how the types of means and stdevs are matched to the data distribution and to the type of question being addressed.
2.2. Within study estimation: ungrouped data: This section applies to the evaluation of means and stdevs for a single set of observations (e.g., the average elimination half-life (T1/2) for a given drug product). The study design is not intended for a comparison across effects (e.g., no inter-treatment comparison).
2.2.1. Arithmetic mean and stdev.
2.2.2. Harmonic mean and stdev.
2.2.3. Geometric mean and stdev.
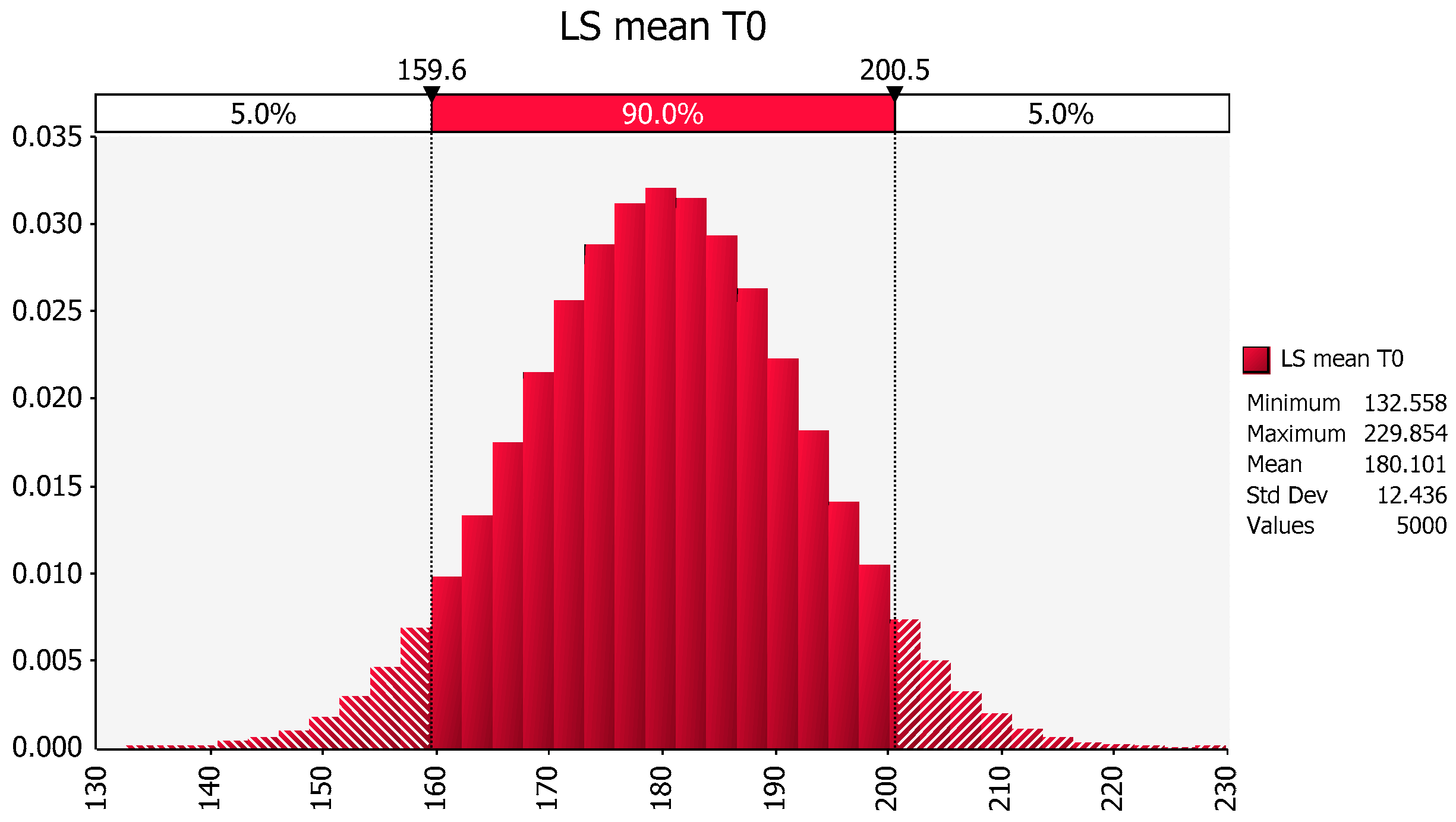
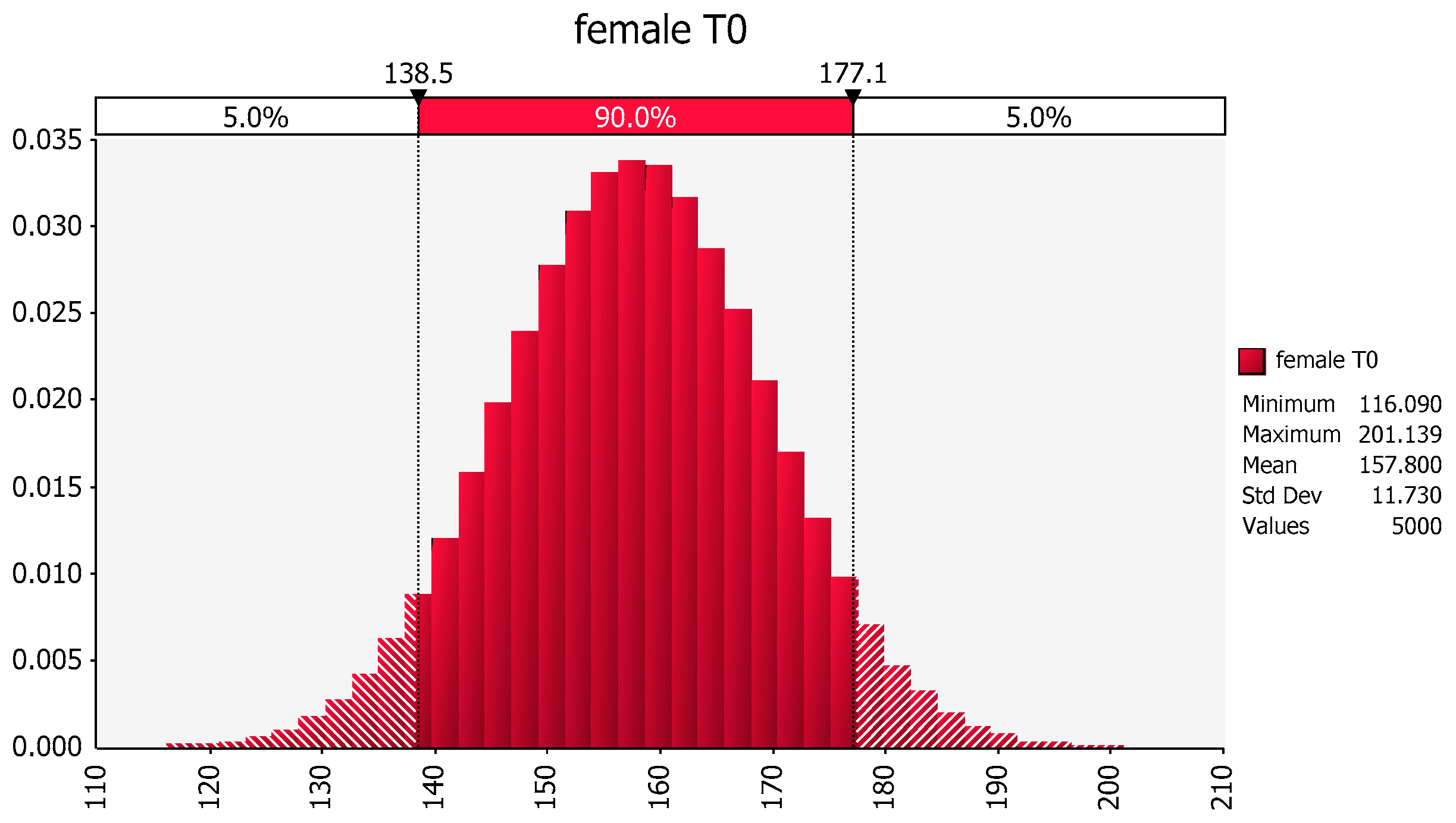
2.3. Within study estimation: grouped data: Here we provide an example to showcase the importance of adjusting for unequal number of observations associated with the factors being compared. An example of a method for estimating the mean and stdev in the presence of study imbalance is provided for a simple situation of a parallel study design where the data are assumed to be normally distributed [
1,
2].
2.4. Between-study comparison: There are occasions when reported means and stdevs are combined to obtain a pooled estimate of the mean and stdev of a variable (e.g., AUC). This kind of analysis is frequently used by the generic drug working group within the Clinical and Laboratory Standards Institute (CLSI) Veterinary Antimicrobial Susceptibility Testing Subcommittee (VAST), VET01 document (Performance Standards for Antimicrobial Disk and Dilution Susceptibility Tests for Bacteria Isolated from Animals; Approved Standard) which can be found at the CLSI website, CLSI.org. When generating a cross-study pooling of data, it is important to consider the differences in the number of observations included in each of the pooled study reports. Using a hypothetical example (intentionally different from situations encountered by the CLSI), we provide a method for generating an unbiased estimate of means and stdevs in the presence of study imbalance. Of course, the statistical considerations (as described earlier in this review) need to be evaluated prior to the inclusion of any dataset within a pooled analysis.
It is important to recognize that there are many experimental and statistical considerations to be considered during study protocol development, data analysis, and study interpretation. Among these are estimator bias, independence of observations, distribution of the residuals, and homogeneity of variances. This information is discussed in great detail in basic statistics textbooks [
1,
2] and therefore will not be covered in this review.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





