Ex Machina: Analytical platforms, Law and the Challenges of Computational Legal Science






Abstract
:1. Introduction
2. The Computational and Data Driven Turn of Science
3. From Digital Tools to Analytical Platforms: The Advent of Augmented Science
- Literature Analysis. A first group of tools is designed to help researchers in exploring the ever growing amount of papers today available online. Literature analysis systems provide users with both ad hoc search engines helping scientists to quickly find articles they are interested in and visualisation features helping the navigation within the materials and, sometimes, social bookmarking and publication-sharing system. To this category belong tools such as Bibsonomy [42], CiteUlike [43], Google Scholar [44], Mendeley [45], ReadCube [46] , Biohunter [47] (biology) or PubChase [48] (life sciences).
- Data and Code Sharing. A second category of tools supports the management of large sets of data and programming code allowing researchers to efficiently store, share, cite and reuse materials. Github [49] and CodeOcean [50] are two examples of platforms for software sharing and development. The latter, in particular, is focused on facilitating code reuse creating connections between coders, researchers and students. Other sharing platforms are more focused on data: Socialsci [51], for instance, helps researchers collect data for their surveys and social experiments. GenBank [52] makes available online a gene sequence database while tools such as DelveHealth [53] orBioLINCC [54] are specialised in the sharing of clinical data.
- Collaboration. A heterogeneous set of instruments is conceived to facilitate researchers in developing collaborations. Platforms such as Academia [55], ResearchGate [56] and Loop aim to help scientists in reaching out to other researchers and find expertise for scientific cooperations. Tools such as Kudos [57] and AcaWiki [58] help the communication of research activities and results to the general public. Other environments, instead, gather tools helping researchers to directly involve the general public in the research efforts, by sharing CPU time or, for example, classifying pictures. Variously referred to as “crowd science” or “citizen science” [59], these tools attract a growing attention from the scientific community. They are able to draw on the effort and knowledge inputs provided by a large and diverse base of contributors, potentially expanding the range of scientific problems that can be addressed at relatively low cost, while also increasing the speed at which they can be solved.
- Experiments and Everyday Research Tasks. Research is a tough task particularly when involving experiments: researchers have to deal with equipment and data management, with the scheduling of activities, with research protocols, coding and data analysis. A huge collection of tools has been developed to help researchers in these everyday research tasks. Tools such as Asana, LabGuru [60] and Quartzy [61] support daily activities from vision to execution often offering web-based laboratory inventory management systems. Some tools (Tetrascience [62] and Transcriptic [63]) are used to outsource experiments, while others (Dexy [64] and GitLab [65]) are conceived to ease coding activity, and still others (Wolfram Alpha [66], Sweave [67], VisTrails [68], and Tableau [69]) allow generating and analysing data and visualising results.
- Writing. In recent years, several tools have been developed to support paper drafting keeping in mind specific needs of researchers. Some tools such as Endnote [70], Zotero [71], and Citavi [72] allow storing, managing and sharing with colleagues bibliographies, citations and references. Others such as Authorea [73] and ShareLaTex [74] workspace are collaborative writing tools helping researchers to write papers with other people while keeping track of the activities and modification made by authors on the document.
- Publish. A series of platform has been designed to ease the publication and the discussion of scientific papers aiming at the same time, at accelerating scientific communication and discovery. Platforms such as eLife [75], GigaScience [76], and Cureus [77] offer an alternative publishing model, allowing anyone to access published works for free according to the open access principles. Paper repositories such as ArXiv [78], allow authors to increase the exposure of their work (even if in progress) offering, at the same time, new opportunities of scientific interaction. Other tools such as Exec&Share [79] and RunMyCode [80] allow authors to connect papers with additional functionalities such as executable code.
- Research Evaluation. An entire category of platforms, finally, deals with research evaluation both in terms of paper review and analysis of the impact of scientific publication. Tools such as PubPeer [81], Publons [82], and Academic Karma [83] are conceived to change the peer-review system by means of an open and anonymous review process bypassing journals and editors. Platforms such as Altmetric [84], PLOS Article-Level Metrics [85] and ImpactStory [86] offer a set of new tools that analyse the impact of scientific paper by other means than impact factor and citations counts.
4. Law, Computation and the Machines
4.1. Professional Platforms
4.2. Platforms for Legal Research
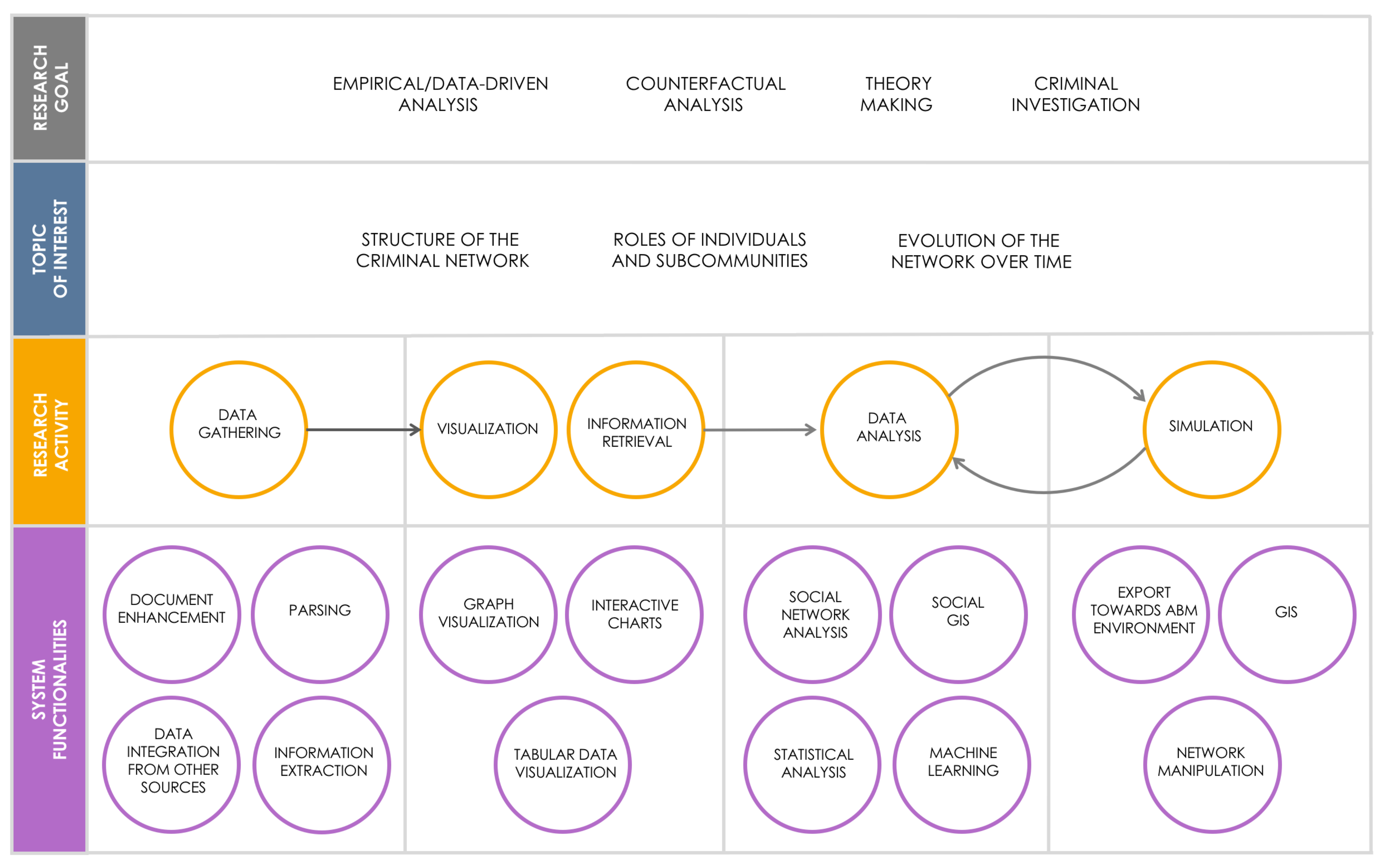
5. An Analytical Platform for Computational Crime Analysis
- A machine learning module for the assessment of criminal dangerousness of individuals belonging to the network under investigation;
- Bipartite and tripartite graphs to enable new network-based inferences; and
- New graph analysis metrics.
- Extracting from processual data all the information needed to build graphs;
- Applying different metrics on graphs;
- Conceiving visualisations, georeferenced too (Social GIS), of the criminal organisation social structure;
- Applying machine learning techniques to support domain experts in the identification of most dangerous individuals; and
- Exporting criminal organisation data (with geographical information (GIS)) towards agent-based modeling environment (ABM) to perform in social simulations.
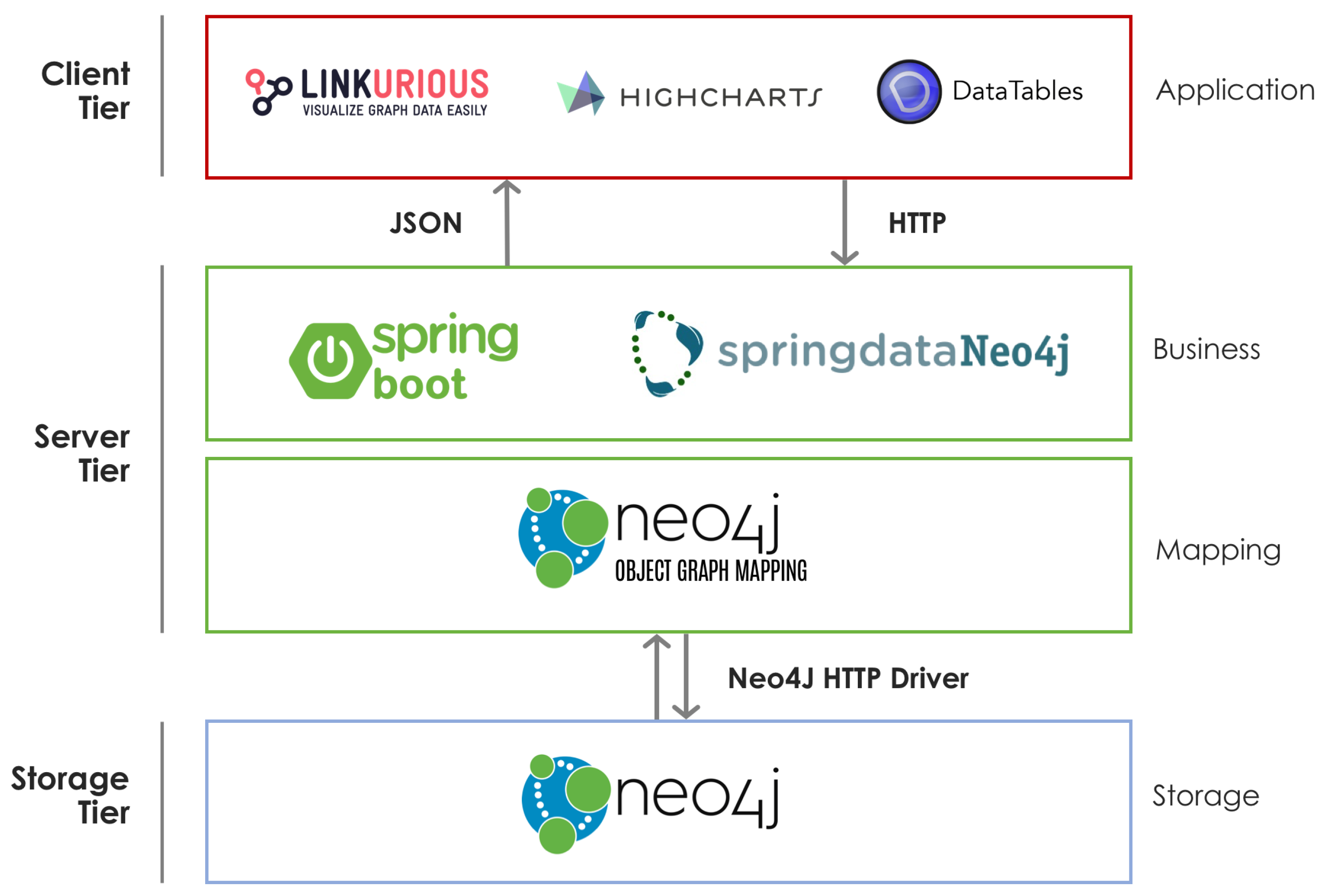
5.1. Architecture and Workflow: Overview
- Storage: This layer stores all the data (including graphs) under examination. Managing data in this layer requires the communication between Neo4j and Spring Data Neo4j. This is accomplished by a Neo4j HTTP Driver (system integrated thanks to a Maven dependency). Data stored include personal details of investigated people, tapping records (wiretapping and environmental tappings) and, finally, the document created by the user by means of CrimeMiner.
- Mapping: This layer is responsible of the mapping of Neo4j relations and entities in Java classes.
- Business: This layer processes data mapped in the Mapping layer and provides developed services to the top layer (thanks to a REST service returning JSON data). In this layer, all SNA metrics are also defined.
- Presentation: This layer includes user interface allowing users to interact with CrimeMiner features. Processed data, exploiting JavaScript libraries, are shown to the user through graph-visualisations (Linkurious [146] , 2D and 3D graphics (Highcharts [147]) and finally, tables with rich functionalities (Datatables [148]).
5.2. Research Goals/System Features
5.2.1. Document Enhancement
5.2.2. Criminal Network Exploration (CNE)
- Individual-telephone tapping: A multigraph G<V,E> where and called .
- Individual-environmental tapping: Bipartite graph G(U,V,E) where , and was involved in .
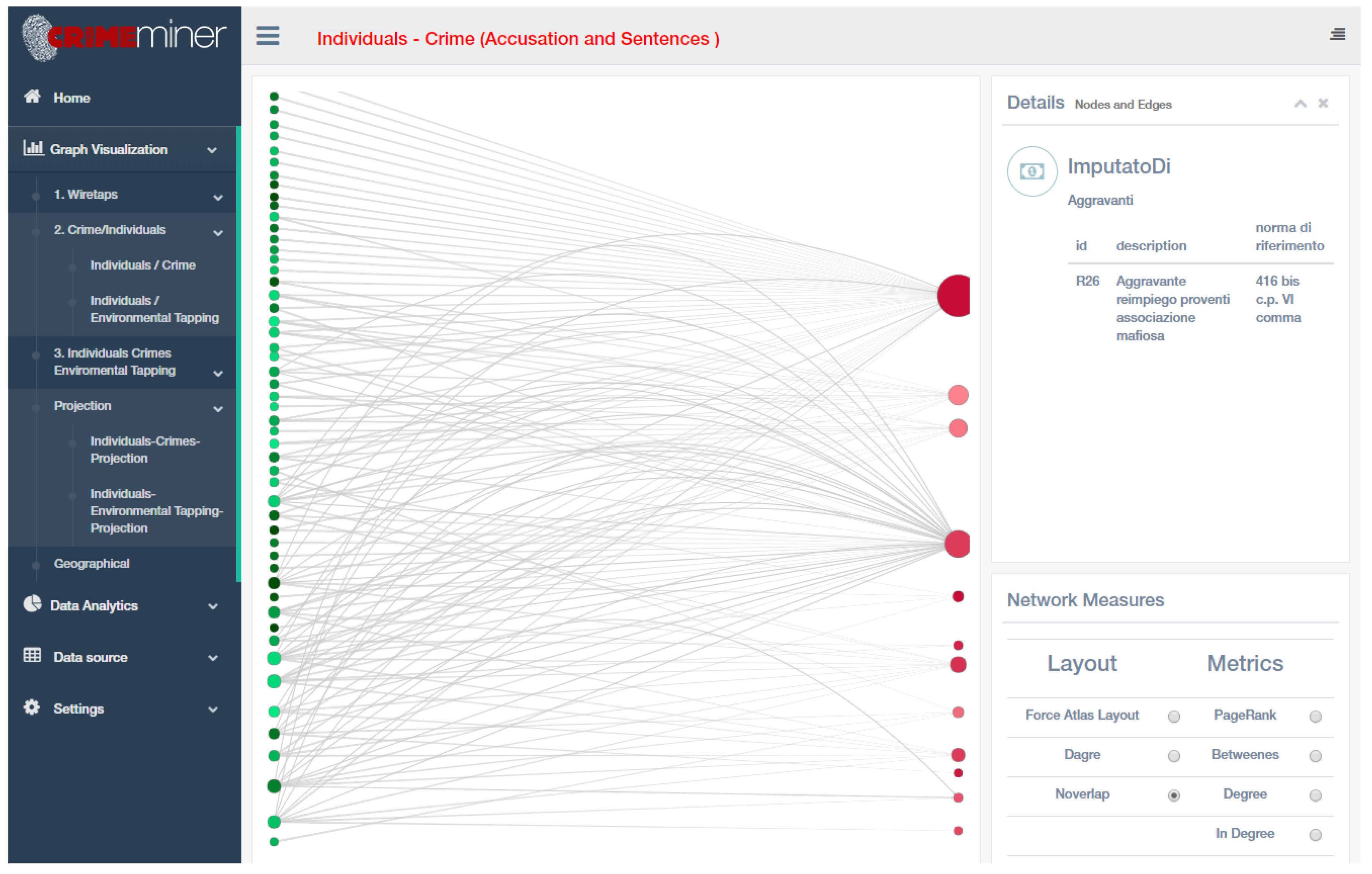
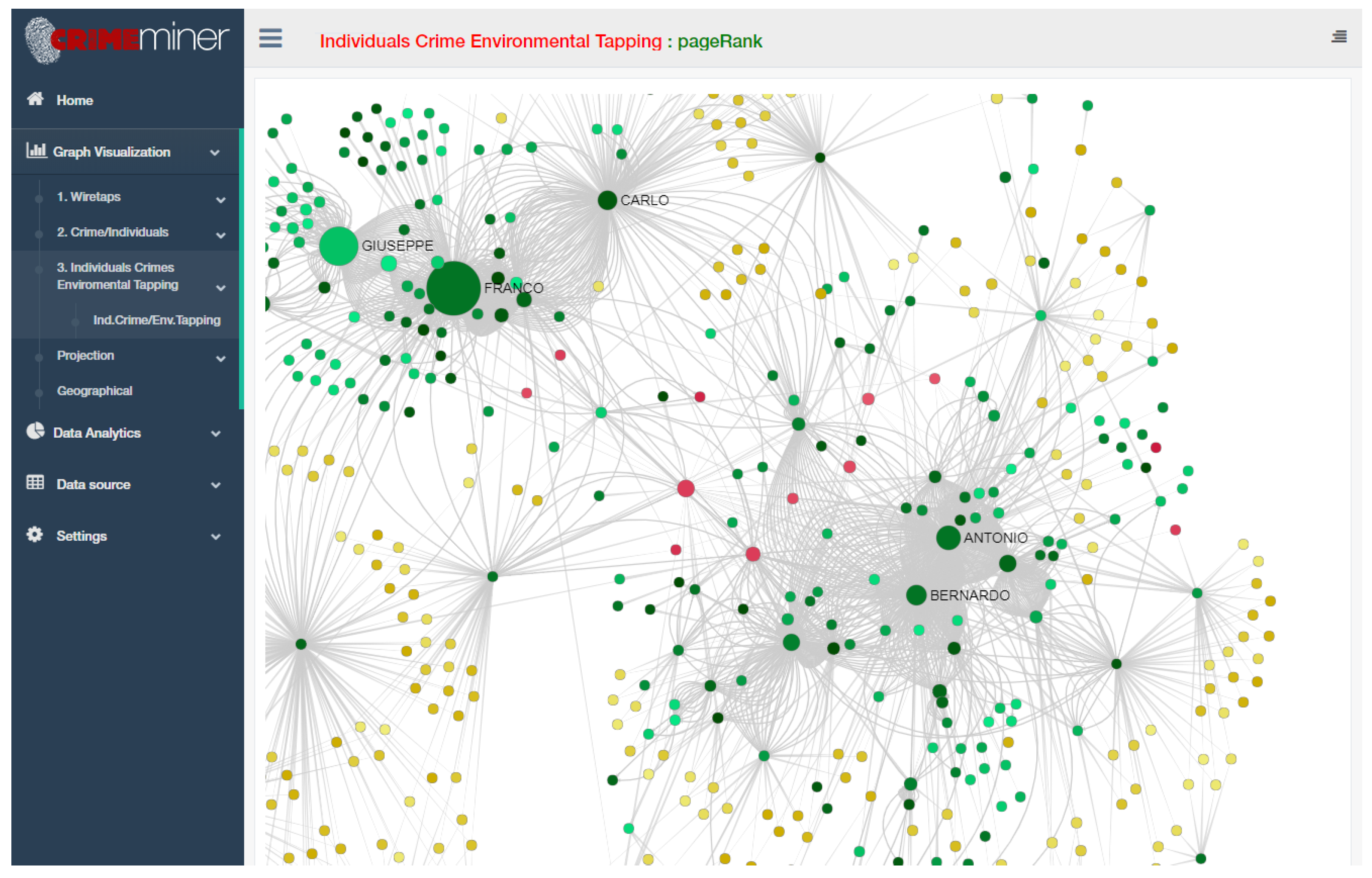
- Individual-crime: Bipartite graph G(U,V,E) where , and committed a crime . Edges are enriched with information about aggravators and mitigators. An example of application is shown in Figure 4.
- Individual-crime projection: A graph built on a individuals-crime bipartite network projection, so G<V,E> where and and share a common crime.
- Individual-Environmental tapping projection: A simple graph representing a network projection using individual-environmental tapping data: G<V,E> where and and were involved in the same environmental tapping.
- Global graph: A graph summarising all data, i.e., individuals, their crimes, the wiretaps, the environmental tappings and all the relationships among them.
5.2.3. Network Analysis (NA)
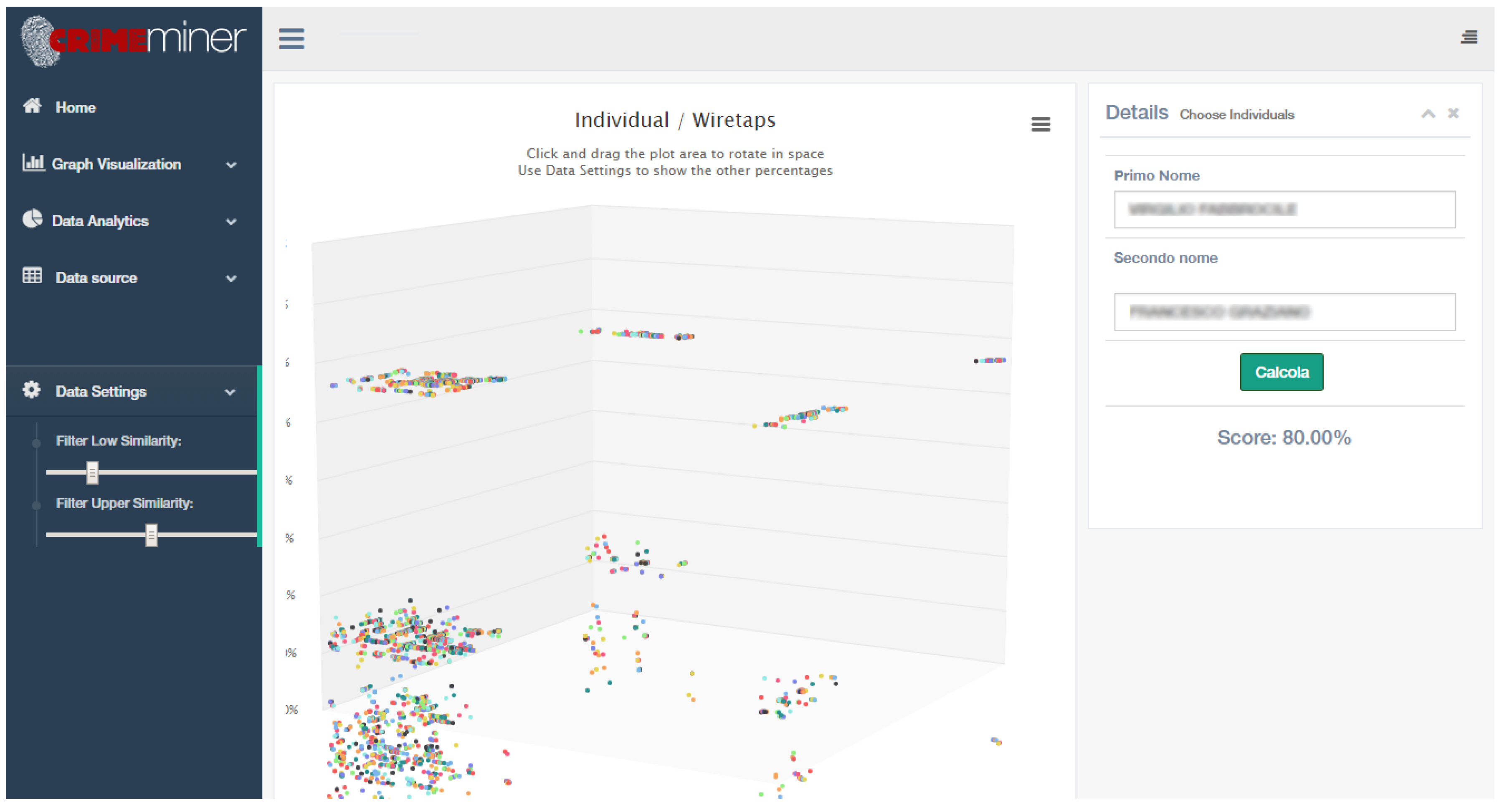
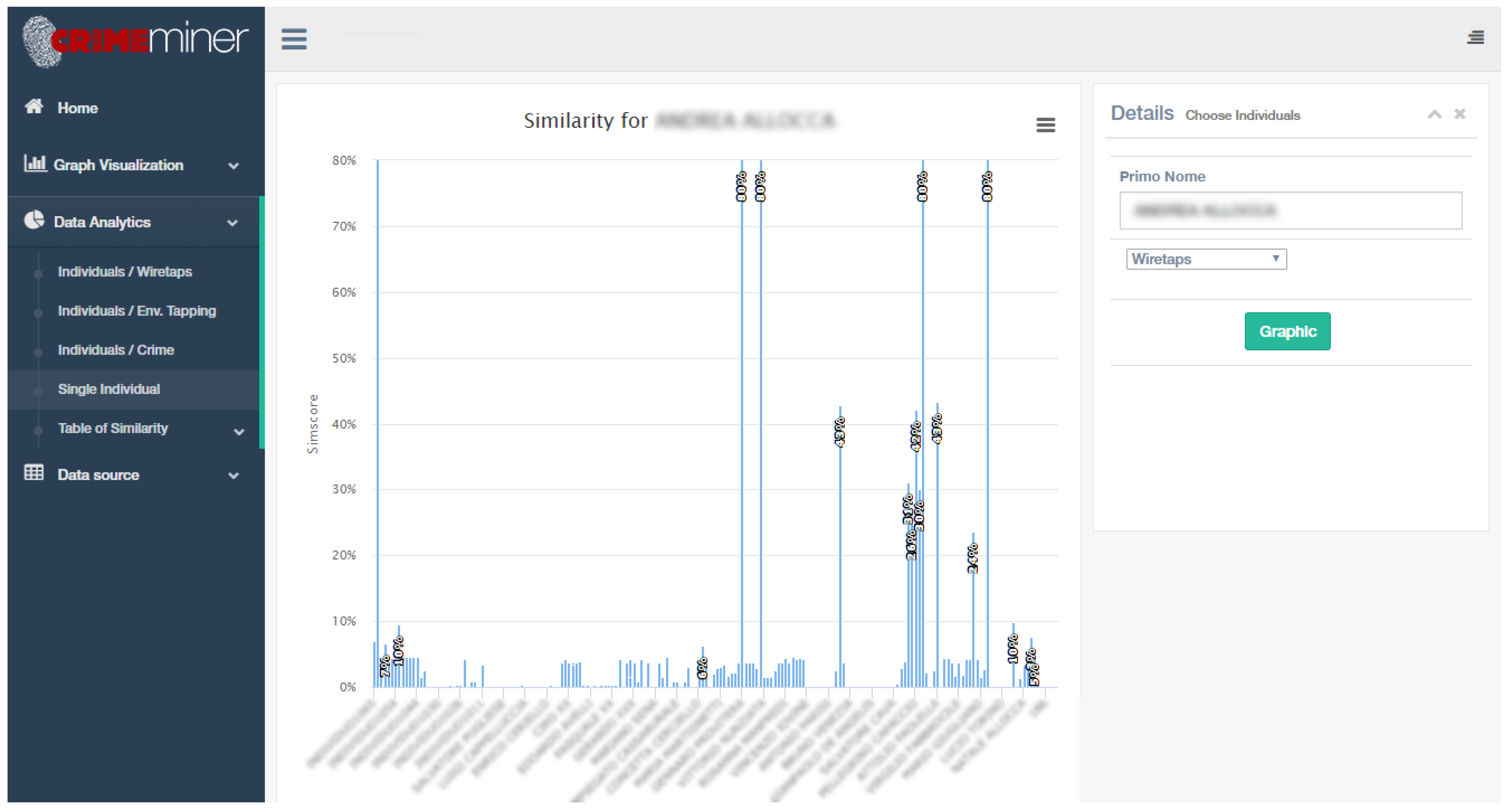
5.2.4. Similarity Measures
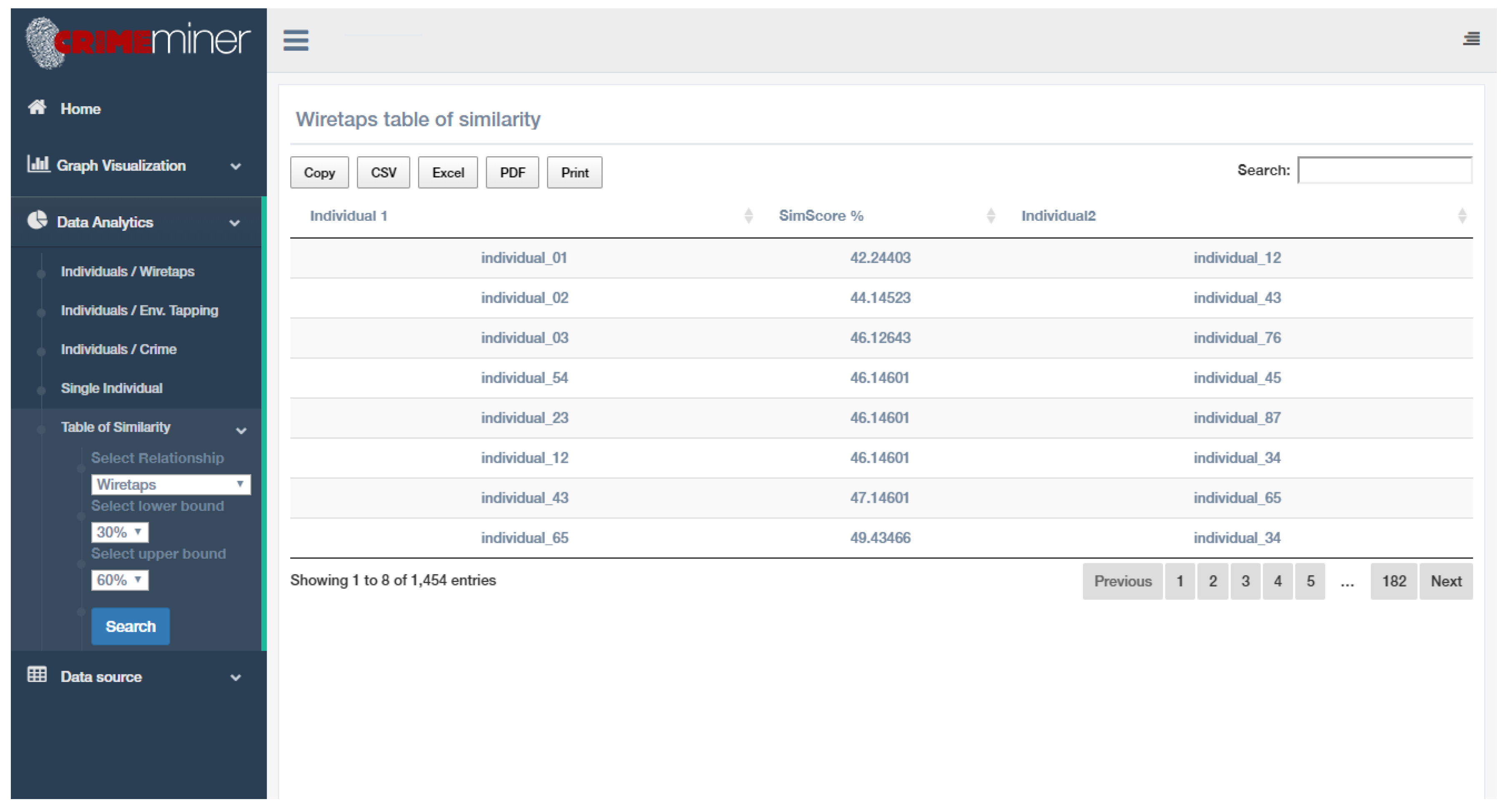
5.2.5. Tabular Data
5.2.6. Simulation
5.2.7. Machine Learning
5.3. Preliminary Results and Future Developments
5.4. Network-Based Inference
5.5. Machine Learning
5.6. Collaboration and Advanced Visualisation
6. Closing Remarks: Issues and Challenges of Computational Legal Science
6.1. Legal Computational Empiricism
6.2. Legal Science as an Instrument-Enabled Science
6.3. Methodological Eclecticism in Legal Science
6.4. A (Less) Disciplinary Approach to Legal Research and Practice
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Ho, D.E.; Kramer, L. The empirical revolution in law. Stan. Law Rev. 2013, 65, 1195. [Google Scholar]
- Cane, P.; Kritzer, H.M. The Oxford Handbook of Empirical Legal Research; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Smits, J.M. The Mind and Method of the Legal Academic; Edward Elgar Publishing: Cheltenham, UK, 2012. [Google Scholar]
- Leeuw, F.L.; Schmeets, H. Empirical Legal Research: A Guidance Book for Lawyers, Legislators and Regulators; Edward Elgar Publishing: Cheltenham, UK, 2016. [Google Scholar]
- Faro, S.; Lettieri, N. Law and Computational Social Science; Edizioni Scientifiche Italiane: Napoli, Italy, 2013. [Google Scholar]
- Ruhl, J.; Katz, D.M.; Bommarito, M.J. Harnessing legal complexity. Science 2017, 355, 1377–1378. [Google Scholar] [CrossRef] [PubMed]
- Leeuw, F.L. Empirical Legal Research The Gap between Facts and Values and Legal Academic Training. Utrecht Law Rev. 2015, 11, 19. [Google Scholar] [CrossRef]
- Katz, D.M.; Bommarito, I.; Michael, J.; Blackman, J. Predicting the behavior of the supreme court of the united states: A general approach. arXiv, 2014; arXiv:1407.6333. [Google Scholar]
- Russell, H.; Susskind, R. Tomorrow’s lawyers: An Introduction to Your Future (2013) Oxford: Oxford University Press. Legal Inf. Manag. 2013, 13, 287–288. [Google Scholar]
- Engel, C. Behavioral law and economics: Empirical methods. MPI Collect. Goods Prepr. 2013. [Google Scholar] [CrossRef]
- Chilton, A.; Tingley, D. Why the study of international law needs experiments. Colum. J. Trans. L. 2013, 52, 173. [Google Scholar]
- Miles, T.J.; Sunstein, C.R. The new legal realism. Univ. Chic. Law Rev. 2008, 75, 831–851. [Google Scholar]
- Lettieri, N.; Malandrino, D.; Vicidomini, L. By investigation, I mean computation. Trends Org. Crime 2017, 20, 31–54. [Google Scholar] [CrossRef]
- Lettieri, N.; Altamura, A.; Faggiano, A.; Malandrino, D. A computational approach for the experimental study of EU case law: Analysis and implementation. Soc. Netw. Anal. Min. 2016, 6, 56. [Google Scholar] [CrossRef]
- De Prisco, R.; Esposito, A.; Lettieri, N.; Malandrino, D.; Pirozzi, D.; Zaccagnino, G.; Zaccagnino, R. Music Plagiarism at a Glance: Metrics of Similarity and Visualizations. In Proceedings of the 21st International Conference Information Visualisation (IV), London, UK, 11–14 July 2017. [Google Scholar]
- De Prisco, R.; Lettieri, N.; Malandrino, D.; Pirozzi, D.; Zaccagnino, G.; Zaccagnino, R. Visualization of Music Plagiarism: Analysis and Evaluation. In Proceedings of the 20th International Conference Information Visualisation (IV), Lisbon, Portugal, 19–22 July 2016; pp. 177–182. [Google Scholar]
- Lettieri, N.; Altamura, A.; Malandrino, D.; Punzo, V. Agents Shaping Networks Shaping Agents: Integrating Social Network Analysis and Agent-Based Modeling in Computational Crime Research. In Portuguese Conference on Artificial Intelligence; Springer: Cham, Switzerland, 2017; pp. 15–27. [Google Scholar]
- Thagard, P. Computational Philosophy of Science; MIT Press: Cambridge, MA, USA, 1993. [Google Scholar]
- Humphreys, P. Extending Ourselves: Computational Science, Empiricism, and Scientific Method; Oxford University Press: Oxford, UK, 2004. [Google Scholar]
- Segura, J.V. Computational epistemology and e-science: A new way of thinking. Minds Mach. 2009, 19, 557. [Google Scholar] [CrossRef]
- Rohrlich, F. Computer Simulation in the Physical Sciences. Available online: https://www.journals.uchicago.edu/doi/10.1086/psaprocbienmeetp.1990.2.193094 (accessed on 20 April 2018).
- Casti, J. Would-be Worlds; Wiley: New York, NY, USA, 1997. [Google Scholar]
- Birdsall, C.K.; Langdon, A.B. Plasma Physics via Computer Simulation; CRC Press: Boca Raton, FL, USA, 2004. [Google Scholar]
- Cangelosi, A.; Parisi, D. Simulating the Evolution of Language; Springer Science & Business Media: London, UK, 2012. [Google Scholar]
- Sun, R. Cognition and Multi-agent Interaction: From Cognitive Modeling to Social Simulation; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Epstein, J.M. Generative Social Science: Studies in Agent-Based Computational Modeling; Princeton University Press: Princeton, NJ, USA, 2006. [Google Scholar]
- Di Ventura, B.; Lemerle, C.; Michalodimitrakis, K.; Serrano, L. From in vivo to in silico biology and back. Nature 2006, 443, 527. [Google Scholar] [CrossRef] [PubMed]
- Humphreys, P. The philosophical novelty of computer simulation methods. Synthese 2009, 169, 615–626. [Google Scholar] [CrossRef]
- Winsberg, E. Science in the Age of Computer Simulation; University of Chicago Press: Chicago, IL, USA, 2010. [Google Scholar]
- Hey, T.; Tansley, S.; Tolle, K.M. The Fourth Paradigm: Data-Intensive Scientific Discovery; Microsoft Research: Redmond, WA, USA, 2009; Volume 1. [Google Scholar]
- Kitchin, R. Big Data, new epistemologies and paradigm shifts. Big Data Soc. 2014, 1, 2053951714528481. [Google Scholar] [CrossRef]
- Venkatraman, V. When All Science Becomes Data Science. Science 2013. [Google Scholar] [CrossRef]
- Boulton, G.; Campbell, P.; Collins, B.; Elias, P.; Hall, W.; Laurie, G.; O’Neill, O.; Rawlins, M.; Thornton, J.; Vallance, P.; et al. Science As an Open Enterprise. 2012. Available online: https://openaccess.sdum.uminho.pt/wp-content/uploads/2013/02/1GeoffreyBoultonOpenAIREworkshopUMinho.pdf (accessed on 20 April 2018).
- Anderson, C. The End of Theory: The Data Deluge Makes the Scientific Method Obsolete. Wired Magazine. 2008. Available online: http://archive.wired.com/science/discoveries/magazine/16-07/pbtheory (accessed on 20 April 2018).
- Bollier, D.; Firestone, C.M. The Promise and Peril of Big Data; Aspen Institute, Communications and Society Program: Washington, DC, USA, 2010. [Google Scholar]
- Cukier, K.; Mayer-Schoenberger, V. The rise of big data: How it’s changing the way we think about the world. Foreign Aff. 2013, 92, 28–40. [Google Scholar]
- Reed, D.A.; Bajcsy, D.P.; Fernandez, M.A.; Griffiths, J.M.; Mott, R.D.; Dongarra, J.; Johnson, C.R.; Inouye, A.S.; Miner, W.; Matzke, M.K.; et al. Computational Science: Ensuring America’s Competitiveness; Technical Report; President’s Information Technology Advisory Committee: Arlington, VA, USA, 2005. [Google Scholar]
- Lazer, D.; Pentland, A.S.; Adamic, L.; Aral, S.; Barabasi, A.L.; Brewer, D.; Christakis, N.; Contractor, N.; Fowler, J.; Gutmann, M.; et al. Life in the network: The coming age of computational social science. Science 2009, 323, 721–723. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cioffi-Revilla, C. Introduction to Computational Social Science; Springer: London, UK; Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Conte, R.; Gilbert, N.; Bonelli, G.; Cioffi-Revilla, C.; Deffuant, G.; Kertesz, J.; Loreto, V.; Moat, S.; Nadal, J.P.; Sanchez, A.; et al. Manifesto of computational social science. Eur. Phys. J. Spec. Top. 2012, 214, 325–346. [Google Scholar] [CrossRef]
- Online Tools for Researchers. Available online: http://connectedresearchers.com/online-tools-for-researchers/ (accessed on 9 March 2018).
- Bibsonomy. Available online: http://www.bibsonomy.org (accessed on 9 March 2018).
- CiteUlike. Available online: http://www.citeulike.org/ (accessed on 9 March 2018).
- Google Scholar. Available online: http://scholar.google.com/ (accessed on 9 March 2018).
- Mendeley. Available online: http://www.mendeley.com/ (accessed on 9 March 2018).
- ReadCube. Available online: https://www.readcube.com (accessed on 9 March 2018).
- Biohunter. Available online: http://www.biohunter.in/ (accessed on 9 March 2018).
- PubChase. Available online: https://www.pubchase.com/ (accessed on 9 March 2018).
- Github. Available online: https://github.com/ (accessed on 9 March 2018).
- Code Ocean. Available online: https://codeocean.com/ (accessed on 9 March 2018).
- Socialsci. Available online: https://www.socialsci.com/ (accessed on 9 March 2018).
- GenBank. Available online: http://www.ncbi.nlm.nih.gov/genbank (accessed on 9 March 2018).
- Delvehealth. Available online: http://www.delvehealth.com/ (accessed on 9 March 2018).
- Biolincc. Available online: https://biolincc.nhlbi.nih.gov/home/ (accessed on 9 March 2018).
- Academia. Available online: http://www.academia.edu/ (accessed on 9 March 2018).
- www.researchgate. Available online: https://www.researchgate.net/ (accessed on 9 March 2018).
- Kudos. Available online: https://www.growkudos.com/ (accessed on 9 March 2018).
- AcaWiki. Available online: http://acawiki.org/ (accessed on 9 March 2018).
- Nielsen, M. Reinventing Discovery: The New Era of Networked Science; Princeton University Press: Princeton, NJ, USA, 2011. [Google Scholar]
- LabGuru. Available online: http://www.labguru.com/ (accessed on 9 March 2018).
- Quartzy. Available online: https://www.quartzy.com/ (accessed on 9 March 2018).
- Tetrascience. Available online: http://www.tetrascience.com/ (accessed on 9 March 2018).
- Transcriptic. Available online: https://www.transcriptic.com/ (accessed on 9 March 2018).
- Dexy. Available online: http://dexy.it/ (accessed on 9 March 2018).
- GitLab. Available online: https://about.gitlab.com/ (accessed on 9 March 2018).
- Wolfram Alpha. Available online: http://www.wolframalpha.com/ (accessed on 9 March 2018).
- Sweave. Available online: http://www.stat.uni-muenchen.de/~leisch/Sweave/ (accessed on 9 March 2018).
- VisTrails. Available online: http://www.vistrails.org/index.php/Main_Page (accessed on 9 March 2018).
- Tableaus. Available online: http://www.tableausoftware.com/products/trial (accessed on 9 March 2018).
- Endnote. Available online: http://endnote.com/ (accessed on 9 March 2018).
- Zotero. Available online: https://www.zotero.org/ (accessed on 9 March 2018).
- Citavi. Available online: http://www.citavi.com/ (accessed on 9 March 2018).
- Authorea. Available online: https://www.authorea.com/ (accessed on 9 March 2018).
- ShareLatex. Available online: https://www.sharelatex.com/ (accessed on 9 March 2018).
- eLife. Available online: http://elifesciences.org/ (accessed on 9 March 2018).
- GigaScience. Available online: http://www.gigasciencejournal.com/ (accessed on 9 March 2018).
- Cureus. Available online: http://www.cureus.com/ (accessed on 9 March 2018).
- ArXiv. Available online: http://arxiv.org/ (accessed on 9 March 2018).
- Exec&Share. Available online: http://www.execandshare.org/ (accessed on 9 March 2018).
- RunMyCode. Available online: http://www.runmycode.org/ (accessed on 9 March 2018).
- PubPeer. Available online: https://pubpeer.com/ (accessed on 9 March 2018).
- Publons. Available online: https://publons.com/ (accessed on 9 March 2018).
- Academic Karma. Available online: http://academickarma.org/ (accessed on 9 March 2018).
- Altmetric. Available online: http://www.altmetric.com/ (accessed on 9 March 2018).
- Article Level Metrics PLOS. Available online: http://article-level-metrics.plos.org/ (accessed on 9 March 2018).
- ImpactStory. Available online: https://impactstory.org/ (accessed on 9 March 2018).
- Popović, Z.; Baker, D.; Khatib, F.; Cooper, S.; Meiler, J. Foldit, Solve Puzzles for Science. Available online: https://fold.it/ (accessed on 2 February 2018).
- Lintott, C. GalaxyZoo, online citizen science project. Available online: https://www.galaxyzoo.org/ (accessed on 2 February 2018).
- Salesses, P.; Schechtner, K.; Hidalgo, C.A. The Collaborative Image of The City: Mapping the Inequality of Urban Perception. PLoS ONE 2013, 8, 1–12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- SETI Project. Available online: https://www.seti.org/ (accessed on 2 February 2018).
- BIONIC. Available online: https://boinc.berkeley.edu/ (accessed on 9 March 2018).
- Cytoscape. Available online: http://cytoscape.org/ (accessed on 9 March 2018).
- Knime. Available online: http://knime.com/ (accessed on 9 March 2018).
- Hacking, I. The Emergence of Probability: A Philosophical Study of Early Ideas About Probability, Induction and Statistical Inference; Cambridge University Press: Cambridge, UK, 2006; pp. 85–91. [Google Scholar]
- Holmes, O.W. The Path of the Law. Harv. Law Rev. 1997, 110, 991–1009. [Google Scholar] [CrossRef]
- Cardozo, B.N. The Paradoxes of Legal Sciences; Columbia University Press: New York, NY, USA, 1928. [Google Scholar]
- Loevinger, L. Jurimetrics–The Next Step Forward. Minn. Law Rev. 1948, 33, 455. [Google Scholar]
- Loevinger, L. Jurimetrics: The methodology of legal inquiry. Law Contemp. Probl. 1963, 28, 5–35. [Google Scholar] [CrossRef]
- Loevinger, L. Jurimetrics: Science and Prediction in the Field of Law. Minn. Law Rev. 1961, 46, 255. [Google Scholar]
- Baade, H.W. Jurimetrics; Basic Books: New York, NY, USA, 1963; Volume 28. [Google Scholar]
- Hoffman, P.S. Lawtomation in legal research: Some indexing problems. Modern Uses Logic Law 1963, 16–27. [Google Scholar]
- Wiener, N. The Human Use of Human Beings: Cybernetics and Society; Number 320; Perseus Books Group: New York, NY, USA, 1988. [Google Scholar]
- Losano, M.G. Giuscibernetica: Macchine e Modelli Cibernetici nel Diritto; Einaudi: Bologna, Italy, 1969. [Google Scholar]
- Black, D. Toward a General Theory of Social Control: Fundamentals; Academic Press: Orlando, FL, USA, 2014; Volume 1. [Google Scholar]
- Bing, J.; Harvold, T. Legal Decisions and Information Systems; Universitetsforlaget: Oslo, Norway, 1977. [Google Scholar]
- Paliwala, A. A History of Legal Informatics; Universidad de Zaragoza Press: Zaragoza, Spain, 2010; Volume 9. [Google Scholar]
- Susskind, R. Legal informatics—A personal appraisal of context and progress. In The End of Lawyers? Paliwala, A., Ed.; Oxford University Press: Oxford, UK, 2008. [Google Scholar]
- Love, N.; Genesereth, M. Computational Law. In Proceedings of the 10th International Conference on Artificial Intelligence and Law. ACM, New York, NY, USA, 6–11 June 2005; pp. 205–209. [Google Scholar]
- Guadamuz, A. Networks, Complexity and Internet Regulation: Scale-Free Law; Edward Elgar: Cheltenham, UK, 2011. [Google Scholar]
- Katz, D.M.; Bommarito, M.J. Measuring the complexity of the law: The United States Code. Artif. Intell. Law 2014, 22, 337–374. [Google Scholar] [CrossRef]
- Mukherjee, S.; Whalen, R. Priority Queuing on the Docket: Universality of Judicial Dispute Resolution Timing. Front. Phys. 2018, 6. [Google Scholar] [CrossRef]
- MIT. Computational Law Research and Development. Available online: http://law.mit.edu (accessed on 9 February 2018).
- Martin, K.D. What is Computational Legal Studies? Available online: https://www.slideshare.net/Danielkatz/what-is-computational-legal-studies-presentation-university-of-houston-workshop-on-law-computation (accessed on 9 February 2018).
- Lawlor, R.C. What Computers Can Do: Analysis and Prediction of Judicial Decisions. Am. Bar Assoc. J. 1963, 49, 337–344. [Google Scholar]
- Haar, C.M.; Sawyer, J.P.; Cumming, S.J. Computer Power and Legal Reasoning: A Case Study of Judicial Decision Prediction in Zoning Amendment Cases. Am. Bar Found. Res. J. 1977, 2, 651–768. [Google Scholar] [CrossRef]
- Katz, D.M. Quantitative legal prediction-or-how i learned to stop worrying and start preparing for the data-driven future of the legal services industry. Emory Law J. 2012, 62, 909. [Google Scholar]
- Perry, W.L. Predictive Policing: The Role of Crime Forecasting in Law Enforcement Operations; Rand Corporation: Santa Monica, MA, USA, 2013. [Google Scholar]
- McShane, B.B.; Watson, O.P.; Baker, T.; Griffith, S.J. Predicting securities fraud settlements and amounts: A hierarchical Bayesian model of federal securities class action lawsuits. J. Empir. Legal Stud. 2012, 9, 482–510. [Google Scholar] [CrossRef]
- Krent, H.J. Post-Trial Plea Bargaining and Predictive Analytics in Public Law. Wash. Lee Law Rev. Online 2016, 73, 595. [Google Scholar]
- Kerr, I.; Earle, J. Prediction, preemption, presumption: How big data threatens big picture privacy. Stan. Law Rev. Online 2013, 66, 65. [Google Scholar]
- Lettieri, N.; Faro, S. Computational social science and its potential impact upon law. Eur. J. Law Technol. 2012, 3, 3. [Google Scholar]
- Whalen, R. Legal networks: The promises and challenges of legal network analysis. Mich. St. Law Rev. 2016, 2016, 539. [Google Scholar]
- Morris, C. How Lawyers Think; Harvard University Press: Cambridge, MA, USA, 1937. [Google Scholar]
- O’Connell, V. Big Law’s $1,000-Plus an Hour Club. 2011. Available online: http://www.reactionsearch.com/wordpress/?p=1126 (accessed on 20 April 2018).
- EvolveandLaw. Available online: http://evolvelawnow.com/ (accessed on 9 March 2018).
- Premonition. Available online: https://premonition.ai/ (accessed on 9 March 2018).
- Stevenson, D.; Wagoner, N.J. Bargaining in the shadow of big data. Fla. Law Rev. 2015, 67, 1337. [Google Scholar]
- Bock, J.W. An Empirical Study of Certain Settlement-Related Motions for Vacatur in Patent Cases. Ind. Law J. 2013, 88, 919. [Google Scholar] [CrossRef]
- Pacer. Available online: https://www.pacer.gov/ (accessed on 2 February 2018).
- Harbertl, T. Supercharging Patent Lawyers with AI. 2013. Available online: https://spectrum.ieee.org/geek-life/profiles/supercharging-patent-lawyers-with-ai (accessed on 20 April 2018).
- Hanke, J.; Thiesse, F. Leveraging text mining for the design of a legal knowledge management system. In Proceedings of the 25th European Conference on Information Systems (ECIS), Guimarães, Portugal, 5–10 June 2017. [Google Scholar]
- AlchemyAPI. Available online: https://www.ibm.com/watson/alchemy-api.html (accessed on 9 March 2018).
- Jeh, G.; Widom, J. SimRank: A Measure of Structural-context Similarity. In Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–25 July 2002. [Google Scholar]
- Ravel Law. Available online: http://ravellaw.com/ (accessed on 9 March 2018).
- Dahbur, K.; Muscarello, T. Classification system for serial criminal patterns. Artif. Intell. Law 2003, 11, 251–269. [Google Scholar] [CrossRef]
- PredPol. Available online: https://www.predpol.com (accessed on 9 March 2018).
- Bond, B.J.; Nehmens, A.J. CompStat. In The Encyclopedia of Crime and Punishment; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Lettieri, N.; Altamura, A.; Malandrino, D. The legal macroscope: Experimenting with visual legal analytics. Inf. Vis. 2017, 16, 332–345. [Google Scholar] [CrossRef]
- D’Orsogna, M.R.; Perc, M. Statistical physics of crime: A review. Phys. Life Rev. 2015, 12, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Short, M.B.; Brantingham, P.J.; Bertozzi, A.L.; Tita, G.E. Dissipation and displacement of hotspots in reaction-diffusion models of crime. Proc. Nat. Acad. Sci. USA 2010, 107, 3961–3965. [Google Scholar] [CrossRef] [PubMed]
- Short, M.B.; Bertozzi, A.L.; Brantingham, P.J. Nonlinear patterns in urban crime: Hotspots, bifurcations, and suppression. SIAM J. Appl. Dyn. Syst. 2010, 9, 462–483. [Google Scholar] [CrossRef]
- Liu, L. Artificial Crime Analysis Systems: Using Computer Simulations and Geographic Information Systems, 1st ed.; Information Science Reference-Imprint of: IGI Publishing: Hershey, PA, USA, 2008. [Google Scholar]
- Malleson, N.; Heppenstall, A.; See, L. Crime reduction through simulation: An agent-based model of burglary. Comput. Environ. Urban Syst. 2010, 34, 236–250. [Google Scholar] [CrossRef]
- Short, M.; Brantingham, P.; D’orsogna, M. Cooperation and punishment in an adversarial game: How defectors pave the way to a peaceful society. Phys. Rev. E 2010, 82, 066114. [Google Scholar] [CrossRef] [PubMed]
- Morselli, C. Inside Criminal Networks; Springer: New York, NY, USA, 2009; Volume 8. [Google Scholar]
- Linkurious. Available online: https://linkurio.us/ (accessed on 9 March 2018).
- HighCharts. Available online: https://www.highcharts.com/ (accessed on 9 March 2018).
- DataTables. Available online: https://datatables.net/ (accessed on 9 March 2018).
- Xu, J.J.; Chen, H. CrimeNet explorer: A framework for criminal network knowledge discovery. ACM Trans. Inf. Syst. (TOIS) 2005, 23, 201–226. [Google Scholar] [CrossRef]
- Alaimo, S.; Giugno, R.; Pulvirenti, A. ncPred: ncRNA-disease association prediction through tripartite network-based inference. Front. Bioeng. Biotechnol. 2014, 2, 71. [Google Scholar] [CrossRef] [PubMed]
- Freeman, L.C. Centrality in social networks conceptual clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef]
- NetLogo. Available online: https://ccl.northwestern.edu/netlogo/ (accessed on 9 March 2018).
- De Prisco, R.; Eletto, A.; Torre, A.; Zaccagnino, R. A Neural Network for Bass Functional Harmonization. In Proceedings of the Part II Applications of Evolutionary Computation, EvoApplications 2010: EvoCOMNET, EvoENVIRONMENT, EvoFIN, EvoMUSART, and EvoTRANSLOG, Istanbul, Turkey, 7–9 April 2010; pp. 351–360. [Google Scholar]
- De Prisco, R.; Malandrino, D.; Zaccagnino, G.; Zaccagnino, R.; Zizza, R. A Kind of Bio-inspired Learning of mUsic stylE. In Proceedings of the 6th International Conference on Computational Intelligence in Music, Sound, Art and Design, EvoMUSART, Amsterdam, The Netherlands, 19–21 April 2017; pp. 97–113. [Google Scholar]
- Dyson, F. The Case for Blunders. Available online: http://www.nybooks.com/articles/2014/03/06/darwin-einstein-case-for-blunders/ (accessed on 20 April 2018).
- O’Neil, C. Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy; Broadway Books: New York, NY, USA, 2017. [Google Scholar]
- Feldman, R. Techniques and applications for sentiment analysis. Commun. ACM 2013, 56, 82–89. [Google Scholar] [CrossRef]
- Pak, A.; Paroubek, P. Twitter as a Corpus for Sentiment Analysis and Opinion Mining. Available online: http://crowdsourcing-class.org/assignments/downloads/pak-paroubek.pdf (accessed on 20 April 2018).
- Lane, N.D.; Xu, Y.; Lu, H.; Campbell, A.T.; Choudhury, T.; Eisenman, S.B. Exploiting social networks for large-scale human behavior modeling. IEEE Perv. Comput. 2011, 10, 45–53. [Google Scholar] [CrossRef]
- Plantin, J.C.; Lagoze, C.; Edwards, P.N. Re-integrating scholarly infrastructure: The ambiguous role of data sharing platforms. Big Data Soc. 2018, 5, 2053951718756683. [Google Scholar] [CrossRef]
- Humphreys, P. Computational empiricism. In Topics in the Foundation of Statistics; Springer: Dordrecht, The Netherlands, 1997; pp. 119–130. [Google Scholar]
- Ruppert, E. Rethinking empirical social sciences. Dialog. Hum. Geogr. 2013, 3, 268–273. [Google Scholar] [CrossRef]
- Eckstein, H. Unfinished business: Reflections on the scope of comparative politics. Comp. Polit. Stud. 1998, 31, 505–534. [Google Scholar] [CrossRef]
- Della Porta, D.; Keating, M. Approaches and Methodologies in the Social Sciences: A Pluralist Perspective; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Sil, R.; Katzenstein, P.J. Beyond Paradigms: Analytic Eclecticism in the Study of World Politics; Palgrave Macmillan: Hampshire, UK, 2010. [Google Scholar]
- Sil, R. The foundations of eclecticism: The epistemological status of agency, culture, and structure in social theory. J. Theor. Polit. 2000, 12, 353–387. [Google Scholar] [CrossRef]
- Teddlie, C.; Tashakkori, A. Foundations of Mixed Methods Research: Integrating Quantitative and Qualitative Approaches in the Social and Behavioral Sciences; Sage: Thousand Oaks, CA, USA, 2009. [Google Scholar]
- Frodeman, R.; Klein, J.T.; Pacheco, R.C.D.S. The Oxford Handbook of Interdisciplinarity; Oxford University Press: Oxford, UK, 2017. [Google Scholar]
- Nature. Mind Meld: Interdisciplinary Science Must Break Down Barriers Between Fields To Build Common Ground. Available online: https://www.nature.com/news/mind-meld-1.18353 (accessed on 20 April 2018).
- Parisi, D. Future Robots: Towards a Robotic Science of Human Beings; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2014; Volume 7. [Google Scholar]
- Benioff, M.R.; Lazowska, E.D. Computational Science: Ensuring America’s Competitiveness; Technical Report; President’s Information Technology Advisory Committee: Washington, DC, USA, 2005. [Google Scholar]
- Posner, R.A. The decline of law as an autonomous discipline: 1962–1987. Harv. Law Rev. 1986, 100, 761. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paradigm | Nature | Form |
|---|---|---|
| First | Experimental science | Empiricism; describing natural phenomena |
| Second | Theoretical science | Modelling and generalisation |
| Third | Computational science | Simulation of complex phenomena |
| Fourth | Exploratory science | Data-intensive; statistical exploration and data mining |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lettieri, N.; Altamura, A.; Giugno, R.; Guarino, A.; Malandrino, D.; Pulvirenti, A.; Vicidomini, F.; Zaccagnino, R. Ex Machina: Analytical platforms, Law and the Challenges of Computational Legal Science. Future Internet 2018, 10, 37. https://doi.org/10.3390/fi10050037
Lettieri N, Altamura A, Giugno R, Guarino A, Malandrino D, Pulvirenti A, Vicidomini F, Zaccagnino R. Ex Machina: Analytical platforms, Law and the Challenges of Computational Legal Science. Future Internet. 2018; 10(5):37. https://doi.org/10.3390/fi10050037
Chicago/Turabian StyleLettieri, Nicola, Antonio Altamura, Rosalba Giugno, Alfonso Guarino, Delfina Malandrino, Alfredo Pulvirenti, Francesco Vicidomini, and Rocco Zaccagnino. 2018. "Ex Machina: Analytical platforms, Law and the Challenges of Computational Legal Science" Future Internet 10, no. 5: 37. https://doi.org/10.3390/fi10050037
APA StyleLettieri, N., Altamura, A., Giugno, R., Guarino, A., Malandrino, D., Pulvirenti, A., Vicidomini, F., & Zaccagnino, R. (2018). Ex Machina: Analytical platforms, Law and the Challenges of Computational Legal Science. Future Internet, 10(5), 37. https://doi.org/10.3390/fi10050037