Novel Cross-View Human Action Model Recognition Based on the Powerful View-Invariant Features Technique




Abstract
:1. Introduction
2. Research Problem Definition
3. Related Research
4. Sharp Study of View-Invariant Features
4.1. Sample-Affinity Matrix (SAM)
4.2. Preliminary on Autoencoders
4.3. Single-Layer Feature Learning
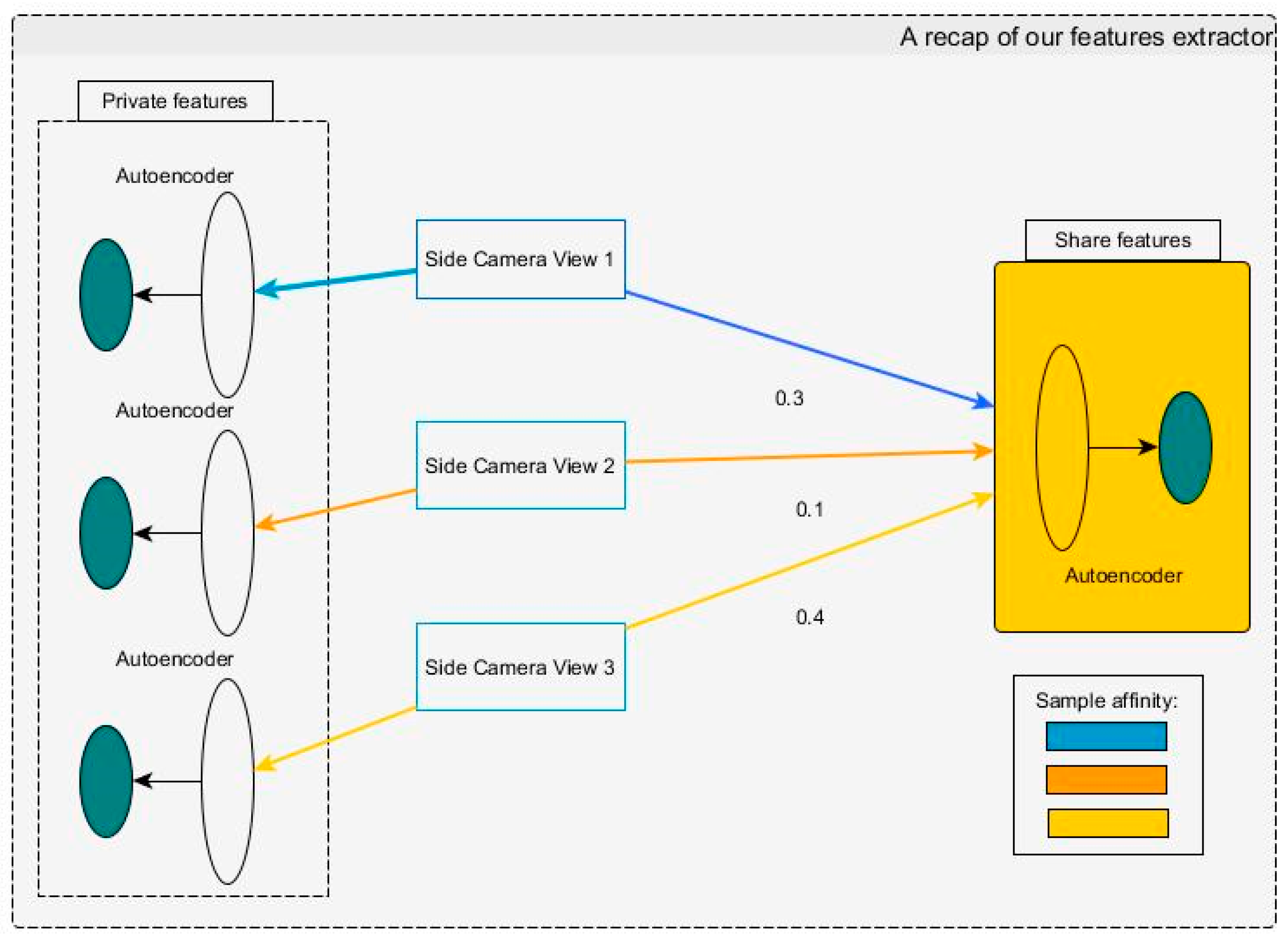
4.3.1. Shared Features
4.3.2. Private Features
4.3.3. Label Information
4.4. Learning Process
5. The Design of the Proposed Approach—Deep Architecture
5.1. Flow Chart of our Project
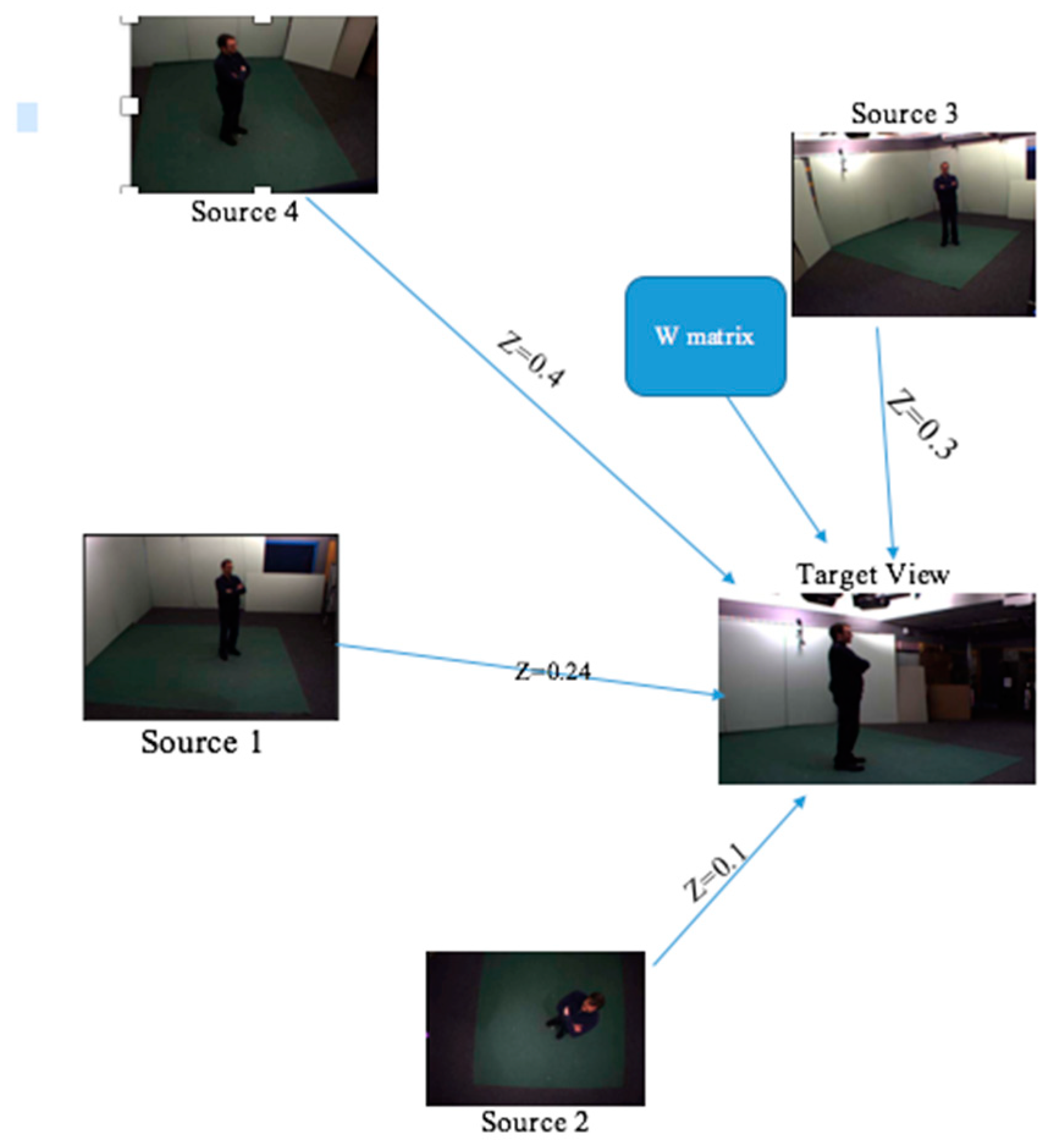
- Take three videos from different perspectives at the same time: Here, we try to capture images of a person from varying angles.
- We then obtain key features from the captured pictures by utilizing Equations (5)–(7): The pictures obviously have various features in common because they belong to one subject and they were taken at the same time. These features are called shared features, while the unique features that every picture has are called private features. We submit these two types of features to the next component as input.
- Applying a novel invariant feature algorithm: This step is a learning point pertinent for the process.
- Create the target views: In this step, we solve the sample-affinity matrix Z for every arrow. We also solve the W mapping matrix and create the target view having all the relevant features that will help in understanding the action.
- Allocate a label and an explanation of the action taking place.
5.2. Novel View-Invariant Features Algorithm
| Input: |
| Output: , |
| i 0 |
| While Layer i ≤ k do |
| Input for learning Wk. |
| Input for learning |
| Do |
| Update Wk applying (9); |
| Update applying (10); |
| While converge |
| Compute . |
| Compute by: . |
| i |
| end while |
6. Experiment
6.1. Using the IXMAS Dataset
6.1.1. Many-to-One Cross-View Action Recognition
6.1.2. One-to-One View Action Recognition
6.2. Use of NUMA 3D Dataset
6.2.1. Many-to-One Cross-View Action Recognition
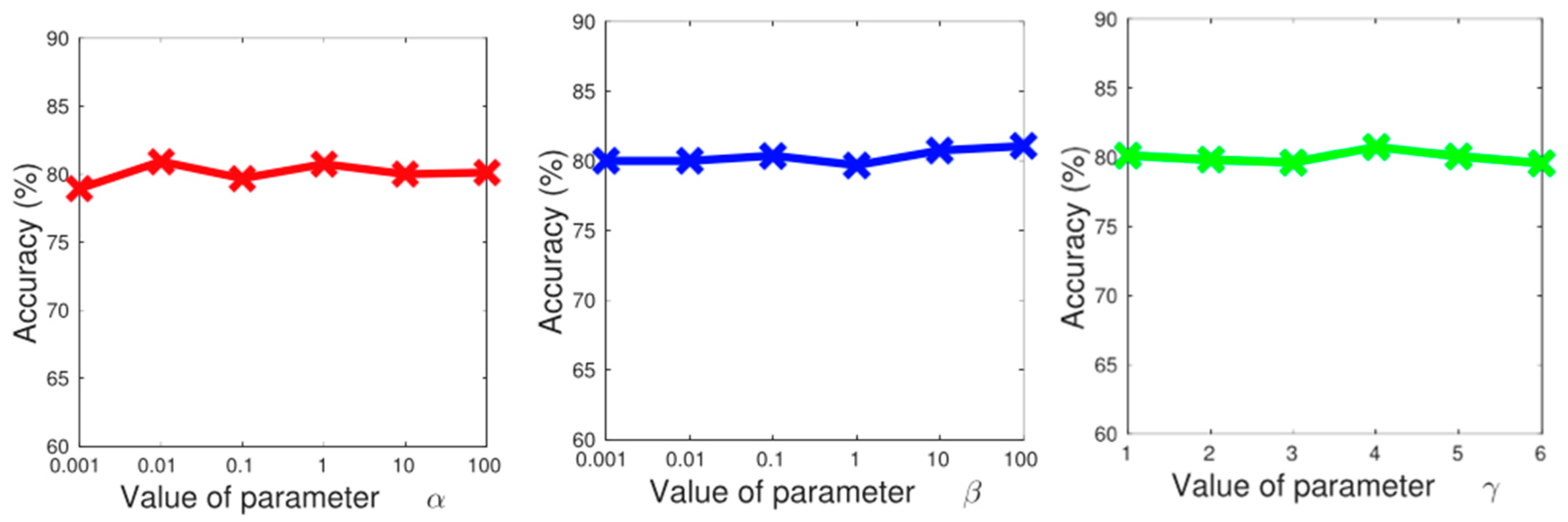
6.2.2. Parameter Analysis
7. Conclusions
Funding
Conflicts of Interest
References
- Kong, Y.; Fu, Y. Bilinear heterogeneous information machine for RGB-D action recognition. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1054–1062. [Google Scholar]
- Kong, Y.; Fu, Y. Max-margin action prediction machine. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1844–1858. [Google Scholar] [CrossRef] [PubMed]
- Altun, K.; Barshan, B.; Tunçel, O. Comparative study on classifying human activities with miniature inertial and magnetic sensors. Pattern Recognit. 2010, 43, 3605–3620. [Google Scholar] [CrossRef] [Green Version]
- Grabocka, J.; Nanopoulos, A.; Schmidt-Thieme, L. Categorization of sparse time series via supervised matrix factorization. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; pp. 928–934. [Google Scholar]
- Junejo, I.N.; Dexter, E.; Laptev, I.; Pérez, P. Crossview action recognition from temporal self-similarities. In Proceedings of the 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 293–306. [Google Scholar]
- Yang, W.; Gao, Y.; Shi, Y.; Cao, L. MRM-lasso: A sparse multiview feature selection method via low-rank analysis. IEEE Trans. Neural Netw. 2015, 26, 2801–2815. [Google Scholar] [CrossRef] [PubMed]
- Yan, Y.; Ricci, E.; Subramanian, S.; Liu, G.; Sebe, N. Multitask linear discriminant analysis for view invariant action recognition. IEEE Trans. Image Process. 2014, 23, 5599–5611. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Z.; Zheng, J.; Phillips, J.; Chellappa, R. Cross-view action recognition via a transferable dictionary pair. In Proceedings of the British Machine Vision Conference, Surrey, UK, 10–12 September 2012; pp. 125.1–125.11. [Google Scholar]
- Ding, G.; Guo, Y.; Zhou, J. Collective matrix factorization hashing for multimodal data. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2075–2082. [Google Scholar]
- Singh, A.P.; Gordon, G.J. Relational learning via collective matrix factorization. In Proceedings of the 14th ACM International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 650–658. [Google Scholar]
- Liu, J.; Wang, C.; Gao, J.; Han, J. Multi-view clustering via joint nonnegative matrix factorization. In Proceedings of the SIAM International Conference on Data Mining, Austin, TX, USA, 2–4 May 2013; pp. 252–260. [Google Scholar]
- Liu, L.; Shao, L. Learning discriminative representations from RGB-D video data. In Proceedings of the 23rd International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 1493–1500. [Google Scholar]
- Argyriou, A.; Evgeniou, T.; Pontil, M. Convex multi-task feature learning. Mach. Learn. 2008, 73, 243–272. [Google Scholar] [CrossRef] [Green Version]
- Ding, Z.; Fu, Y. Low-rank common subspace for multi-view learning. In Proceedings of the IEEE International Conference on Data Mining, Shenzhen, China, 14–17 December 2014; pp. 110–119. [Google Scholar]
- Yu, Q.; Liang, J.; Xiao, J.; Lu, H.; Zheng, Z. A Novel perspective invariant feature transform for RGB-D images. Comput. Vis. Image Understand. 2018, 167, 109–120. [Google Scholar] [CrossRef]
- Zhang, J.; Shum, H.P.H.; Han, J.; Shao, L. Action Recognition from Arbitrary Views Using Transferable Dictionary Learning. IEEE Trans. Image Process. 2018, 27, 4709–4723. [Google Scholar] [CrossRef] [PubMed]
- Kerola, T.; Inoue, N.; Shinoda, K. Cross-view human action recognition from depth maps using spectral graph sequences. Comput. Vis. Image Understand. 2017, 154, 108–126. [Google Scholar] [CrossRef]
- Rahmani, H.; Mahmood, A.; Huynh, D.; Mian, A. Histogram of Oriented Principal Components for Cross-View Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2430–2443. [Google Scholar] [CrossRef] [PubMed]
- Hsu, Y.P.; Liu, C.; Chen, T.Y.; Fu, L.C. Online view-invariant human action recognition using rgb-d spatio-temporal matrix. Pattern Recognit. 2016, 60, 215–226. [Google Scholar] [CrossRef]
- Kumar, A.; Daumé, H. A co-training approach for multi-view spectral clustering. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 393–400. [Google Scholar]
- Zhang, W.; Zhang, K.; Gu, P.; Xue, X. Multi-view embedding learning for incompletely labeled data. In Proceedings of the 23rd International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 1910–1916. [Google Scholar]
- Wang, K.; He, R.; Wang, W.; Wang, L.; Tan, T. Learning coupled feature spaces for cross-modal matching. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2088–2095. [Google Scholar]
- Xu, C.; Tao, D.; Xu, C. Multi-view learning with incomplete views. IEEE Trans. Image Process. 2015, 24, 5812–5825. [Google Scholar] [CrossRef] [PubMed]
- Sharma, A.; Kumar, A.; Daume, H.; Jacobs, D.W. Generalized multiview analysis: A discriminative latent space. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2160–2167. [Google Scholar]
- Weinland, D.; Özuysal, M.; Fua, P. Making action recognition robust to occlusions and viewpoint changes. In Proceedings of the European Conference on Computer Vision, Grete, Greece, 5–11 September 2010; pp. 635–648. [Google Scholar]
- Junejo, I.; Dexter, E.; Laptev, I.; Perez, P. View-independent action recognition from temporal self-similarities. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 172–185. [Google Scholar] [CrossRef] [PubMed]
- Rahmani, H.; Mian, A. Learning a non-linear knowledge transfer model for crossview action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2458–2466. [Google Scholar]
- Liu, J.; Shah, M.; Kuipers, B.; Savarese, S. Crossview Action Recognition via View Knowledge Transfer. Available online: https://web.eecs.umich.edu/~kuipers/papers/Liu-cvpr-11_cross_view_action.pdf (accessed on 12 September 2018).
- Jiang, Z.; Zheng, J. Learning view invariant sparse representations for crossview action recognition. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3176–3183. [Google Scholar]
- Kan, M.; Shan, S.; Zhang, H.; Lao, S.; Chen, X. Multi-view discriminant analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 188–194. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Camps, O.I.; Sznaier, M. Crossview activity recognition using Hankelets. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1362–1369. [Google Scholar]
- Zhang, Z.; Wang, C.; Xiao, B.; Zhou, W.; Liu, S.; Shi, C. Cross-view action recognition via a continuous virtual path. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2690–2697. [Google Scholar]
- Chen, M.; Xu, Z.; Weinberger, K.; Sha, F. Marginalized denoising autoencoders for domain adaptation. In Proceedings of the 29th International Conference on Machine Learning, Edinburgh, UK, 26 June–1 July 2012; pp. 1627–1634. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Zhang, T.; Luo, W.; Yang, J.; Yuan, X.; Zhang, J. Sparseness analysis in the pretraining of deep neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 1425–1438. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Weinberger, K.; Sha, F.; Bengio, Y. Marginalized denoising auto-encoders for nonlinear representations. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1476–1484. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Polytechique, E.A. Computer Vision Laboratory CVLAB. Available online: https://cvlab.epfl.ch/data/pose (accessed on 12 September 2018).
- Weinland, D.; Ronfard, R.; Boyer, E. Free viewpoint action recognition using motion history volumes. Comput. Vis. Image Understand. 2006, 104, 249–257. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Nie, X.; Xia, Y.; Wu, Y.; Zhu, S.C. Crossview action modeling, learning and recognition. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2649–2656. [Google Scholar]
- Farhadi, A.; Tabrizi, M.K.; Endres, I.; Forsyth, D.A. A latent model of discriminative aspect. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 948–955. [Google Scholar]
- Zhang, C.; Zheng, H.; Lai, J. Cross-View Action Recognition Based on Hierarchical View-Shared Dictionary Learning. IEEE Access 2018, 6, 16855–16868. [Google Scholar] [CrossRef]
- Gupta, A.; Martinez, J.; Little, J.J.; Woodham, R.J. 3D pose from motion for crossview action recognition via non-linear circulant temporal encoding. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2601–2608. [Google Scholar]
- Liu, J.; Shah, M. Learning human actions via information maxi-mization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Sadanand, S.; Corso, J.J. Action bank: A high-level representation of activity in video. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1234–1241. [Google Scholar]
- Maji, S.; Bourdev, L.; Malik, J. Action recognition from a distributed representation of pose and appearance. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3177–3184. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Zickle, T. Discriminative virtual views for crossview action recognition. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2855–2862. [Google Scholar]
- Sobeslav, V.; Maresova, P.; Krejcar, O.; Franca, T.C.C.; Kuca, K. Use of cloud computing in biomedicine. J. Biomol. Struct. Dyn. 2016, 34, 2688–2697. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Advantages | Disadvantages |
|---|---|---|
| Multi-view learning approach [9,10,11,12,13,14] | Focuses on expressive and discriminative features | Does not focus much on private features |
| Cotraining method [20] | Trains various learning algorithms for every view and finds explicit correlation of two pairs of information among various views | Cannot handle more than two views simultaneously |
| [21,22] | Maintains common distance between views, and utilizes the two projection matrices on a common feature space in order to map multimodal information | Has little interest in private features |
| [25] method | It achieves a structured categorization of the 3D histogram of oriented gradients (HOG). | It does not keep enough layers of learners. |
| [30] method | Calculates between-class as well as within-class Laplacian matrices | Does not measure the space between two views of the same sample. |
| Our approach | It can keep several layers of learners so as to study view-invariant features in a more effective manner | Because of the large amount of computation involved, the approach can process fewer views |
| It equipoises the sharing of information among views, as per sample similarities | Requires the use of various computer resources. | |
| Measures the distance between two views using SAM Z |
| TEST VIEW 0 | TEST VIEW 1 | TEST VIEW 2 | TEST VIEW 3 | TEST VIEW 4 | |
|---|---|---|---|---|---|
| TRAINING VIEW 0 | (71, 99.4, 99.1, 100, 97.6) | (82, 96.4, 99.3, 100, 86.8) | NA | (76, 97.3, 100, 100, 94.2) | (72, 90.0, 96.4, 100, 88.1) |
| TRAINING VIEW 1 | (80, 85.8, 99.7, 100, 94.3) | (77, T81.5, 98.3, 100, 88.2) | (73, 93.3, 97.0, 100, 92.1) | (72, 83.9, 98.9, 100, 96.3) | NA |
| TRAINING VIEW 2 | (75, 98.2, 90.0, 100, 94.8) | (75, 97.6, 99.7, 100, 91.3) | (73, 99.7, 98.2, 99.4, 98.1) | NA | (76, 90.0, 96.4, 100, 89.5) |
| TRAINING VIEW 3 | (72, 98.8, 100, 100, 94.2) | NA | (74, 99.7, 97.0, 99.7, 96.3) | (70, 92.7, 89.7, 100, 87.9) | (66, 90.6, 100, 99.7, 89.7) |
| TRAINING VIEW 4 | NA | (79, 98.8, 98.5, 100, 93.2) | (79, 99.1, 99.7, 99.7, 93.5) | (68, 99.4, 99.7, 100, 97.2) | (76, 92.7, 99.7, 100, 84.9) |
| Average | (74, 95.5, 97.2, 100, 95.2) | (77, 93.6, 98.3, 100, 89.4) | (76, 98.0, 98.7, 99.7, 95) | (73, 93.3, 97.0, 100, 93.9) | (72, 92.4, 98.9, 99.9, 88) |
| Test View 0 | Test View 1 | Test View 2 | Test View 3 | Test View 4 | |
|---|---|---|---|---|---|
| Training view 0 | (79.6, 92.1, 99.4, 82.4, 72.1, 100) | (76.6, 89.7, 97.6, 79.4, 86.1, 99.7) | NA | (79.8, 94.9, 91.2, 85.8, 77.3, 100) | (72.8, 89.1, 100, 71.5, 62.7, 99.7) |
| Training view 1 | (82.0, 83.0, 87.3, 57.1, 48.8, 99.7) | (68.3, 70.6, 87.8, 48.5, 40.9, 100) | (74.0, 89.7, 92.1, 78.8, 70.3, 100) | (71.1, 83.7, 90.0, 51.2, 49.4, 100) | NA |
| Training view 2 | (73.0, 97.0, 87.6, 82.4, 82.4, 100) | (74.1, 94.2, 98.2, 80.9, 79.7, 100) | (74.0, 96.7, 99.4, 82.7, 70.9, 100) | NA | (66.9, 83.9, 95.4, 44.2, 37.9, 100) |
| Training view 3 | (81.2, 97.3, 97.8, 95.5, 90.6, 100) | NA | (75.8, 96.4, 91.2, 77.6, 79.7, 99.7) | (78.0, 89.7, 78.4, 86.1, 79.1, 99.4) | (70.4, 81.2, 88.4, 40.9, 30.6, 99.7) |
| Training view 4 | NA | (79.9, 96.7, 99.1, 92.7, 94.8, 99.7) | (76.8, 97.9, 90.9, 84.2, 69.1, 99.7) | (76.8, 97.6, 88.7, 83.9, 98.9) | (74.8, 84.9, 95.5, 44.2, 39.1, 99.4) |
| Average | (79.0, 94.4, 93.0, 79.4, 74.5, 99.9) | (74.7, 87.8, 95.6, 75.4, 75.4, 99.9) | (75.2, 95.1, 93.4, 80.8, 72.5, 99.9) | (76.4, 91.2, 87.1, 76.8, 72.4, 99.9) | (71.2, 84.8, 95.1, 50.2, 42.6, 99.7) |
| Methods | Test View 1 | Test View 2 | Test View 3 | Test View 4 | Test View 5 |
|---|---|---|---|---|---|
| Yan et al. [7] | 91.2 | 87.7 | 82.1 | 81.5 | 79.1 |
| Liu et al. [28] | 86.1 | 81.1 | 80.1 | 83.6 | 82.8 |
| Zheng and Jiang [29] | 97.0 | 99.7 | 97.2 | 98.0 | 97.3 |
| Zheng and Jiang [29]-2 | 99.7 | 99.7 | 98.8 | 99.4 | 99.1 |
| Zheng et al. [8] | 98.5 | 99.1 | 99.1 | 100 | 90.3 |
| Liu and Shah [44] | 76.7 | 73.3 | 72.0 | 73.0 | N/A |
| Weinland et al. [25] | 86.7 | 89.9 | 86.4 | 87.6 | 66.4 |
| Our supervised method | 100 | 99.7 | 99.5 | 100 | 100 |
| Methods | Cross-Subject | Crossview | Cross-Environ |
|---|---|---|---|
| Sadanad and Corso [45] | 24.6 | 17.6 | N/A |
| Li et al. [31] | 54.2 | 45.2 | 28.6 |
| Li and Zickler [38] | 50.7 | 47.8 | 27.4 |
| Felzenszwalb et al. [47] | 74.8 | 46.1 | 68.8 |
| Wan et al., LowR + [40] | 81.6 | 73.3 | 79.3 |
| Wang et al. [40] | 78.9 | 65.3 | 71.9 |
| Maji et al. [46] | 54.9 | 24.5 | 48.5 |
| Our supervised method | 83.2 | 77.3 | 89.8 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mambou, S.; Krejcar, O.; Kuca, K.; Selamat, A. Novel Cross-View Human Action Model Recognition Based on the Powerful View-Invariant Features Technique. Future Internet 2018, 10, 89. https://doi.org/10.3390/fi10090089
Mambou S, Krejcar O, Kuca K, Selamat A. Novel Cross-View Human Action Model Recognition Based on the Powerful View-Invariant Features Technique. Future Internet. 2018; 10(9):89. https://doi.org/10.3390/fi10090089
Chicago/Turabian StyleMambou, Sebastien, Ondrej Krejcar, Kamil Kuca, and Ali Selamat. 2018. "Novel Cross-View Human Action Model Recognition Based on the Powerful View-Invariant Features Technique" Future Internet 10, no. 9: 89. https://doi.org/10.3390/fi10090089
APA StyleMambou, S., Krejcar, O., Kuca, K., & Selamat, A. (2018). Novel Cross-View Human Action Model Recognition Based on the Powerful View-Invariant Features Technique. Future Internet, 10(9), 89. https://doi.org/10.3390/fi10090089