For the results reported in this article, we used the execution time and energy consumption values as the input for simulations that calculate the fog and cloud computing costs according to our model, but we intend to implement a system that uses our model to choose between processing values in the fog or the cloud as future work.
4.1. Choosing an Approach to Estimate f
When following the steps presented in
Section 3.2 to estimate the probability that a value passes the filter (
f), we come across the question of whether it would be more profitable to make a decision at the beginning of the stream and then process the values accordingly or to make several decisions along the stream with the intent of accounting for possible changes in data patterns.
In order to evaluate the possibility of making several decisions along the stream, we implemented two different estimation procedures, which we call Local and Cumulative. In both approaches, we first divide our stream into a certain number of blocks (b). As the number of values we are allowed to test (v) is still the same, we can now check values in the first blocks and values in the last block. The total number of elements in each block depends on the stream size (z) and can be calculated as for the first blocks and for the last one.
In the Local approach, we leverage the information obtained by testing local values in order to try to better estimate
f for each block. To that end, we test the values at the beginning of each block and count how many of them passed the filter, then divide this number by the number of tested values. Continuing the example from
Section 3.2, for
, we would be able to check
data point in each of the first three blocks and
data points in the last one. If the number of values that passed the filter (
n) was one in each of the first and second blocks, none passed the filter in the third, and one passed it in the fourth, we would have
,
,
, and
for each block, respectively.
In the Cumulative approach, we attempt to use the results from all previously-tested blocks in order to make a more informed estimate using a larger number of data points. In this case, we also test the values at the beginning of each block and count how many passed the filter, but we then accumulate the number of both tested and passed values with the count from previous blocks. In our example, that would lead to for the first block, for the second block, for the third, and for last block.
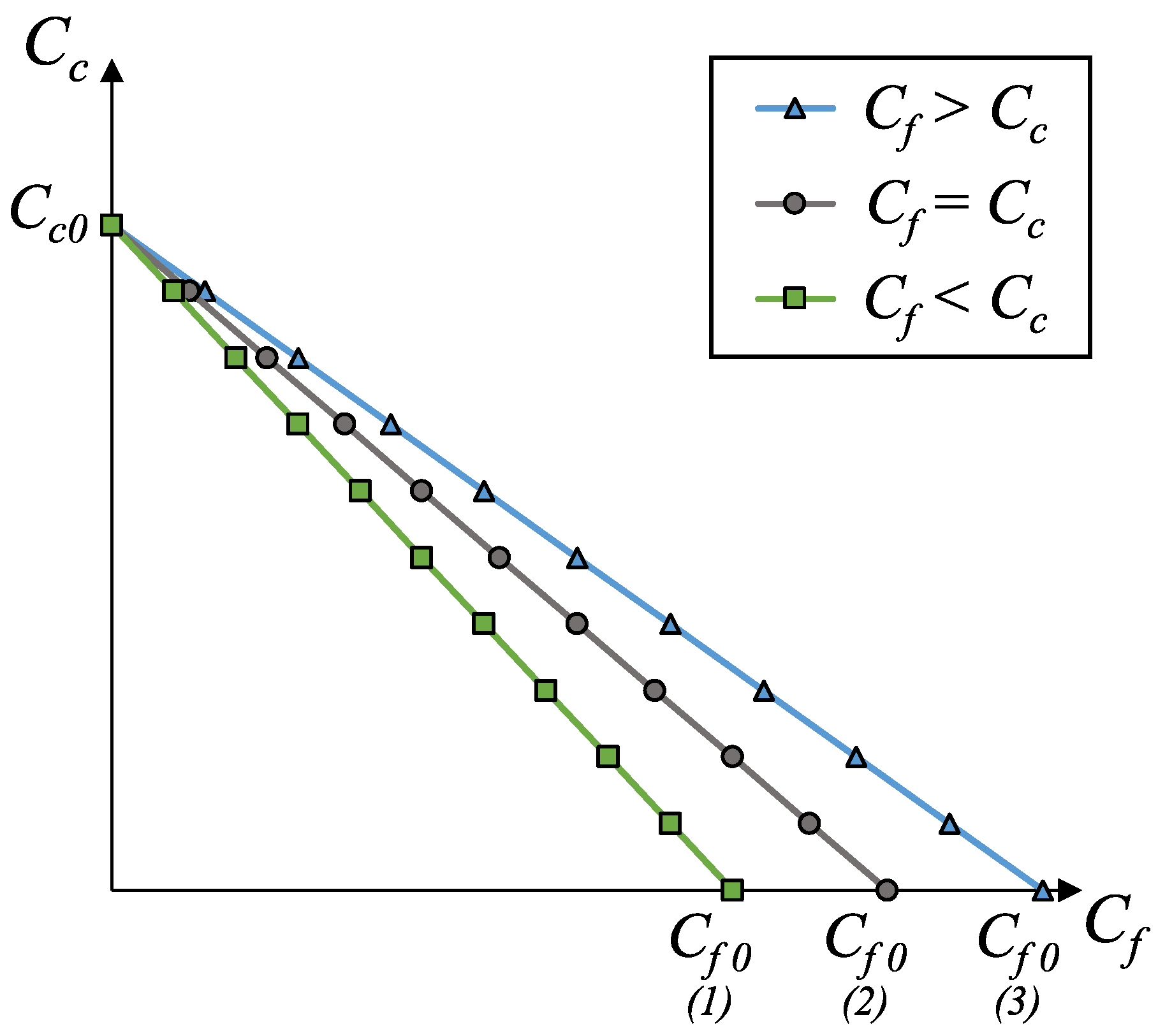
Using these two approaches to estimate
f, we calculated the costs in terms of execution time for all benchmarks and datasets using the simplified versions of Equations (
1) and (
2) obtained in
Section 3.2 (i.e.,
and
). The figures in this subsection present a summary of these results. For the sake of simplicity, we did not include all possible combinations between datasets and applications, as some of the graphs are very similar to the ones shown. All figures employ the same values for stream size (
z = 65,536) and custom execution code cost (
t, shown in
Table A2 and
Table A3 in
Appendix B), but
Figure 2,
Figure 3,
Figure 4 and
Figure 5 use the measured time of
[
24] as the cost of sending data to the cloud (
s), while
Figure 6,
Figure 7,
Figure 8 and
Figure 9 show what the costs would be like if
s was ten times smaller (
). In the first case, the results are fog-prone, that is, the fog is more likely to be profitable, as
s is about one order of magnitude larger than
t. On the other hand, the results in the second case are cloud-prone, as the cloud is more likely to be profitable when we have close values for
s and
t.
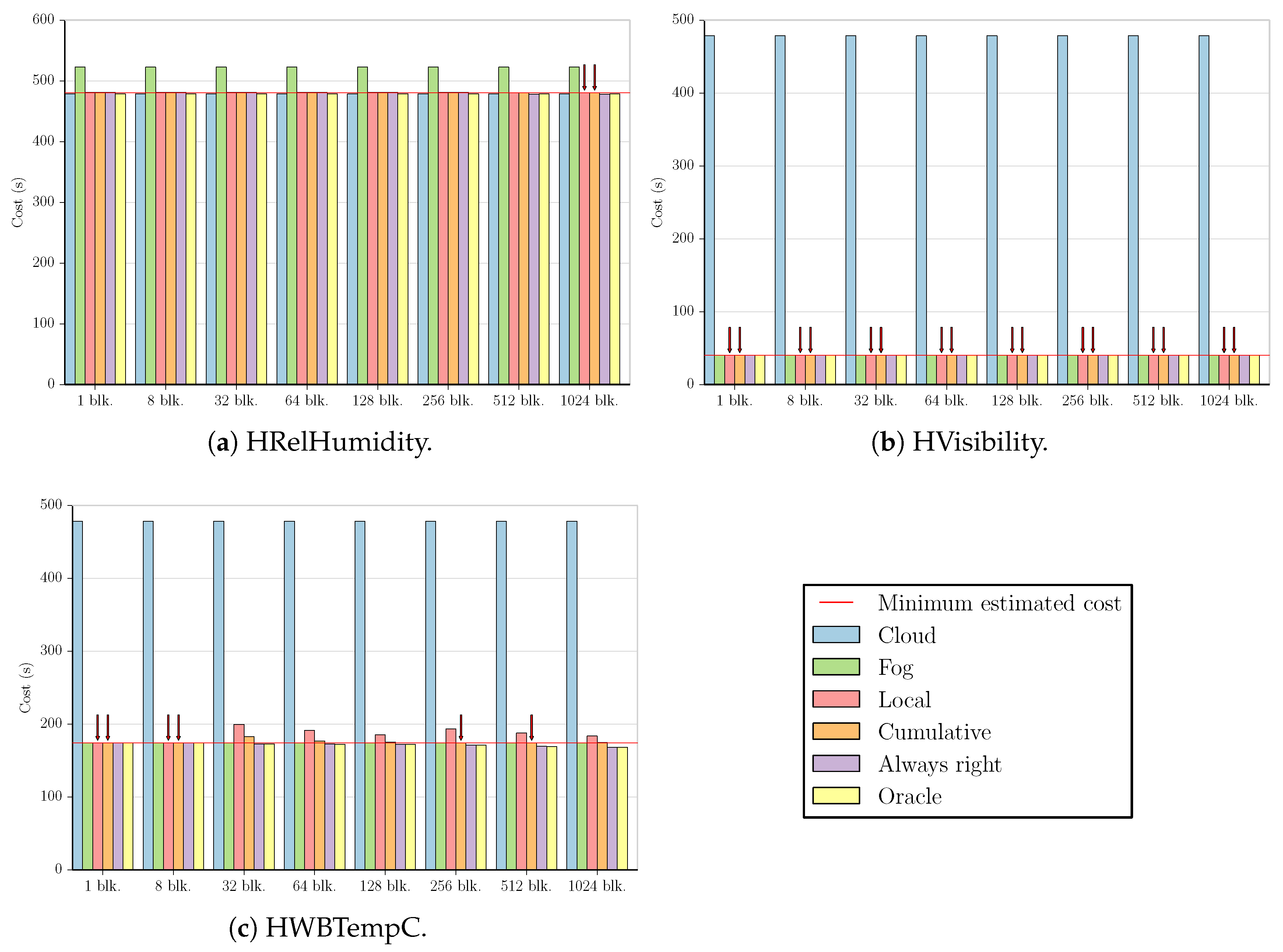
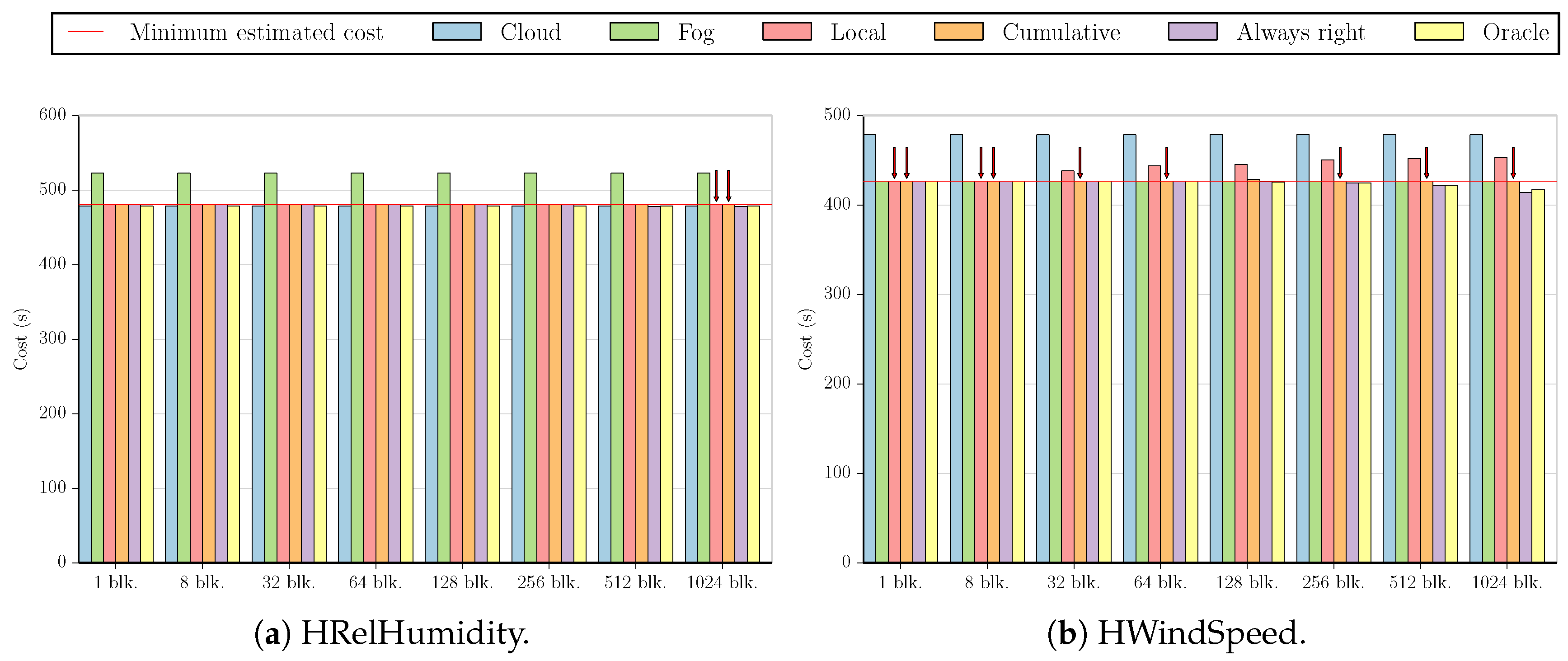
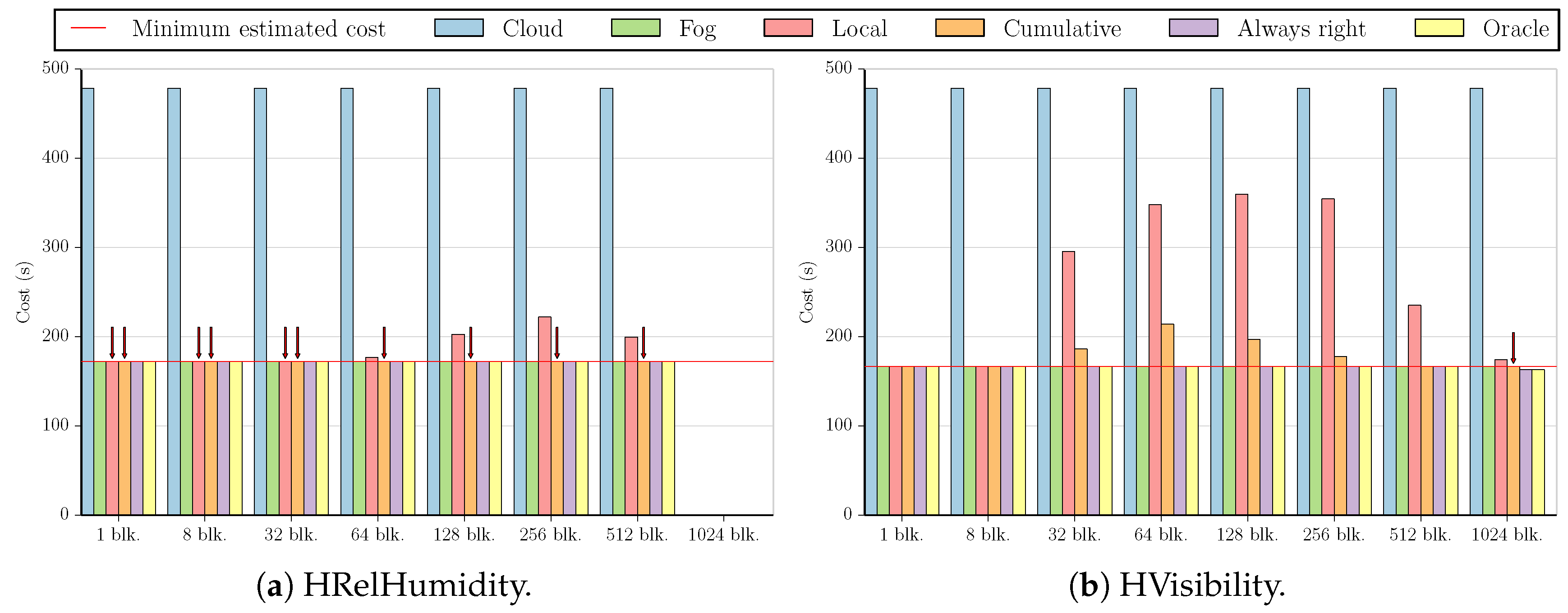
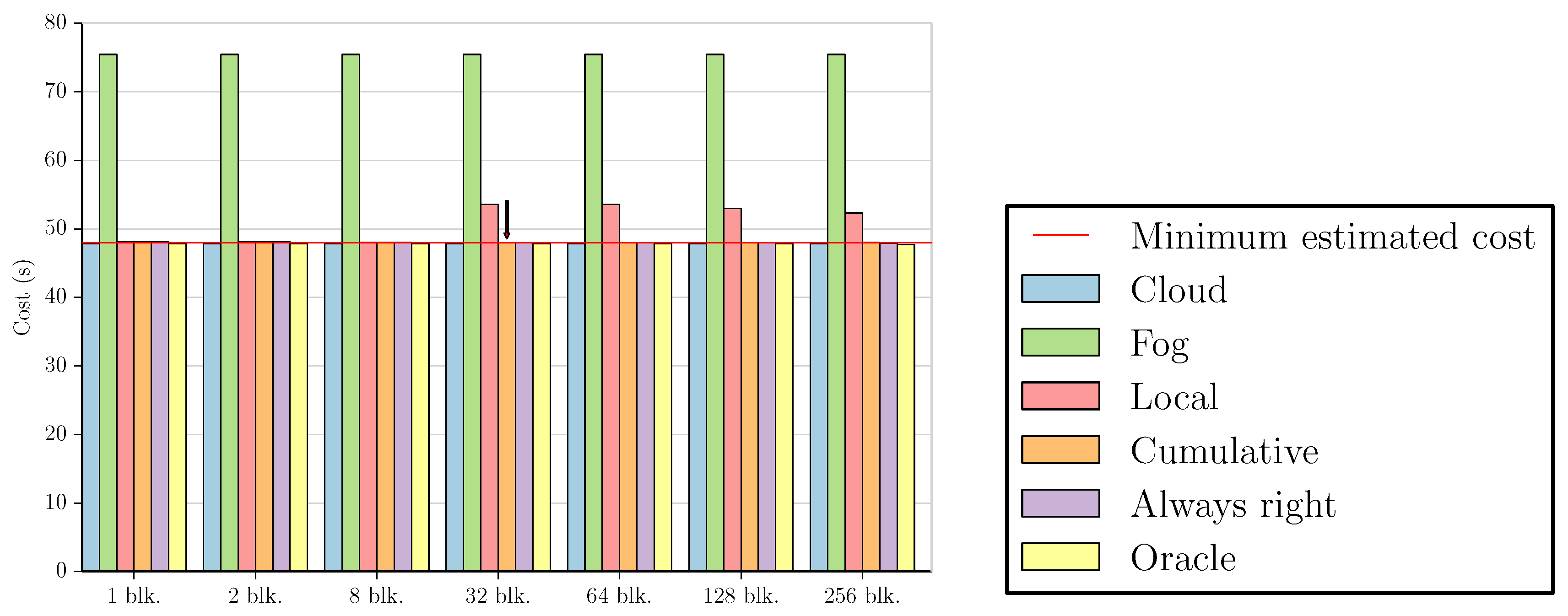
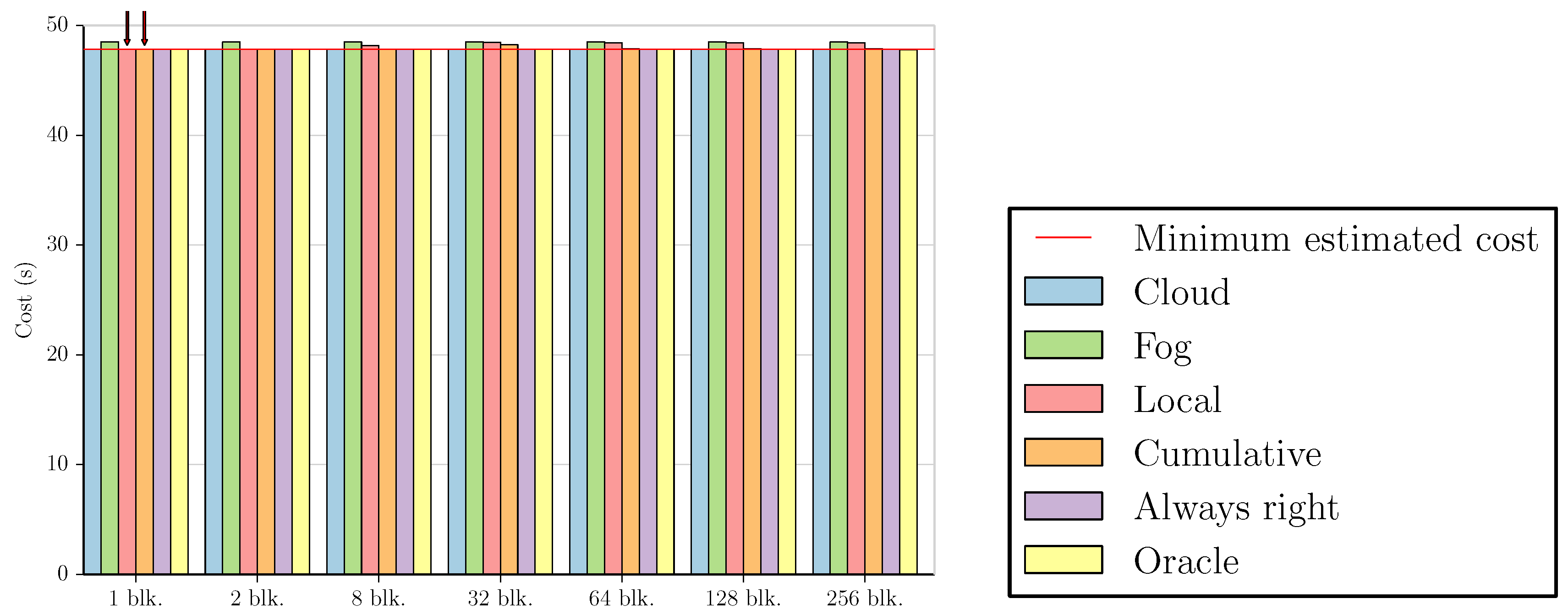
These figures compare the cost of processing all data in the cloud (Cloud); processing all data in the fog (Fog); the cost of using the Local and Cumulative approaches to estimate f and then decide where the data should be processed in each block (Local and Cumulative, respectively); what the cost would be if there was a procedure that always chose correctly between the fog and the cloud after testing the values at the beginning of each block (Always right); and what the cost would be if we knew where to process the data in each block without any testing (Oracle). The red line in each graph shows the minimum estimated cost among all the tested numbers of blocks for a certain combination of dataset and benchmark, considering only Local and Cumulative estimates. The red arrows point to all Local and Cumulative bars that have the same value as the minimum cost.
We start by analyzing the fog-prone results. The graphs for the MinMax
benchmark present three different sets of characteristics. The first can be seen in
Figure 2a. Despite being fog-prone, the most profitable choice in this case is the cloud. The division into 1024 blocks gives us the best estimate, increasing the cost by
in comparison to sending all values to the cloud. However, we note that the estimate obtained by using one block increases the cost by only
.
The second case is the one shown in
Figure 2b, which is similar to the results for the HWindSpeed and Synthetic datasets (the difference being that the cost values are around 100
and 300
for these two datasets, respectively). Here, all the divisions result in the same estimate for both the Local and Cumulative approaches. For HWindSpeed and Synthetic datasets, the Cumulative approach results in the same estimate for all values, with Local starting to have increasingly worse estimates with 256 blocks and 512 blocks, respectively.
The third case is the one depicted in
Figure 2c. Although the Cumulative approach shows good estimates for a higher number of blocks, we see that both Local and Cumulative obtain the minimum cost value for one and eight blocks, as well.
The graphs for MinMax
show two sets of characteristics.
Figure 3a illustrates the first one, which is a similar result to that of
Figure 2a, and
Figure 3b depicts the second, which is akin to the graphs for the HVisibility, HWBTempC, and Synthetic benchmarks. In this case, dividing the stream into only one block results in the minimum cost value for all benchmarks except HWBTempC, for which the Cumulative approach reduces the cloud cost by
when dividing by 128 blocks, compared to
for just one block.
All graphs for the Outlier 16 benchmark are similar to
Figure 4, with every estimate resulting in the minimum cost apart from the Local approach using 1024 blocks (for the Synthetic benchmark, even this case results in the minimum cost).
For Outlier 256, most graphs look like
Figure 5a, where dividing by up to 32 blocks in both approaches results in the minimum cost. Unlike the other datasets, HVisibility allows us to test the division by 1024 blocks, as seen in
Figure 5b, given that the number of values we can test in this case is larger than 1024, and therefore there is at least one value per block.
Analyzing these results, we observe that in most cases, changing the number of blocks or the estimation procedure only affects the costs by a slight margin, with the difference between the fog and cloud computing costs being much more prominent.
We now look at the cloud-prone results.
Figure 6a has the results for the MinMax
benchmark running on the HRelHumidity dataset. All estimates result in the minimum cost, which is an increase of
over the cost of processing all data in the cloud.
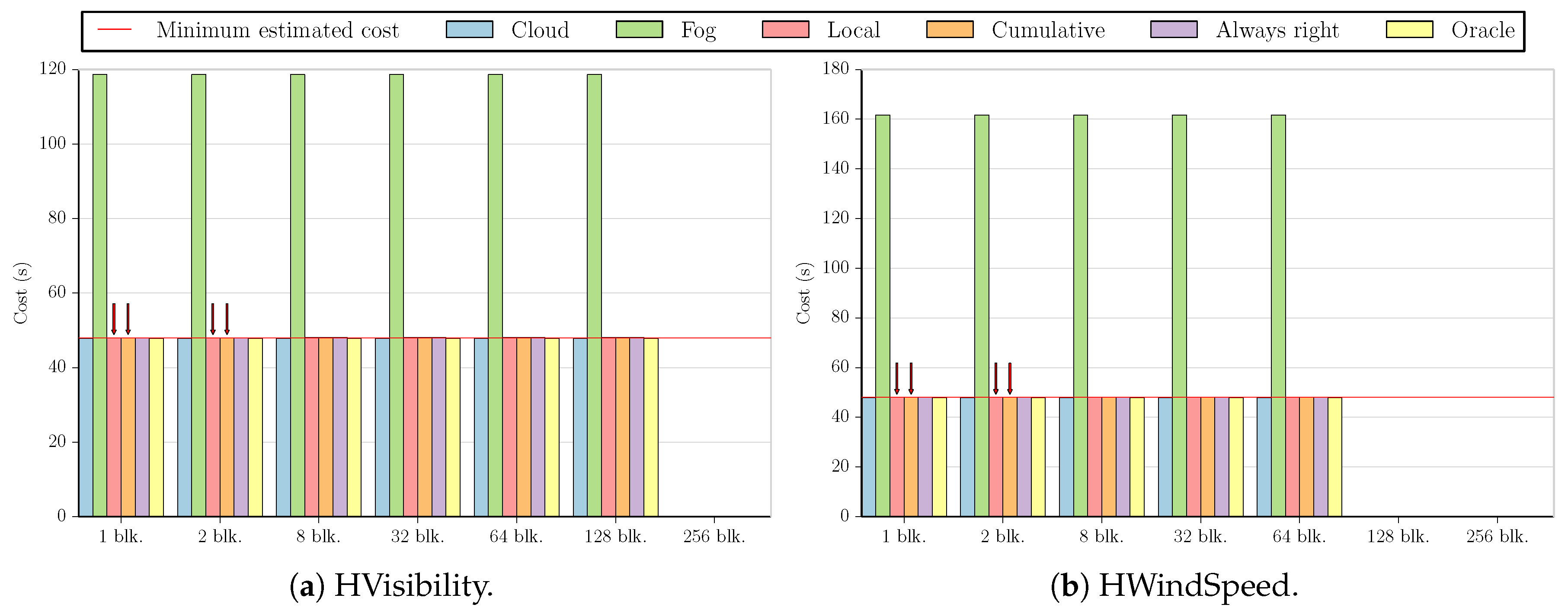
While the results shown in
Figure 6b are cloud-prone, we see that in fact, the fog is more profitable when executing the MinMax
benchmark on the HVisibility dataset, with all estimates having approximately the same cost as processing all values in the fog (less than a
difference).
Figure 6c also shows one of the datasets for the MinMax
benchmark, HWBTempC. This result is somewhat similar to that of the Synthetic dataset in the sense that the cloud is more profitable in both cases; the Local approach presents a few estimates with high cost (with two and eight blocks for HWBTempC and with 128 and 256 blocks for Synthetic), and only one estimate has the lowest cost value (Local with 256 blocks for HWBTempC and Cumulative with 64 blocks for Synthetic).
Figure 6d displays the final dataset for the MinMax
benchmark. Similar to
Figure 6b, this test also presents a lower cost for processing all data in the fog. However, the difference between cloud and fog costs is much smaller in this case, and the best estimate (Local with 64 blocks) reduces the cost of processing all data in the fog by
.
Figure 7 illustrates the results for MinMax
, which are similar for all datasets. In this benchmark, processing all the data in the cloud costs much less than doing so in the fog, and the Local approach usually yields higher estimates for several block numbers (with the exception of HRelHumidity, where all estimates are the same in both approaches). Using only one block results in the minimum cost for the HRelHumidity and HWindSpeed datasets, but the difference in cost of using only one block when compared to the minimum cost in the other datasets is only
,
, and
for HVisibility, HWBTempC, and Synthetic, respectively.
As we can see in
Figure 8, the values for the cost of processing all data in the cloud and in the fog are very similar for Outlier 16. This is the case for all datasets in this benchmark, but the minimum value is achieved by different numbers of blocks in distinct datasets. For HRelHumidity and HWBTempC, the minimum is obtained by using one block; for HWindSpeed, two; for Synthetic, eight; and for HVisibility, 256. Both Local and Cumulative approaches present the same results for the minimum cost case in all datasets except HVisibility, where the Local approach presents a lower cost.
Similarly to
Figure 5a,b, most of the graphs for the Outlier 256 benchmark apart from the dataset HVisibility (
Figure 9a) look like the one in
Figure 9b. Again, this is due to the fact that only the HVisibility dataset allows us to test at least one value per block, in this case for 128 blocks. In all cases, dividing by one or two blocks results in the minimum cost for both the Local and Cumulative approaches. For HWBTempC, dividing by eight blocks also yields this result.
Again, we can see that in most cases, changing the number of blocks or the estimation procedure does not have a large impact on the cost, and simply choosing correctly between the fog and the cloud will lead to most of the performance gains.
Therefore, this evaluation allows us to conclude that using the straightforward solution of looking at the first values of the stream (that is, when there is only one block) leads to good results in terms of cost for several test cases. Furthermore, in the instances where this is not the best approach, the increase in cost is very small, not justifying the use of more complex division methods. Considering this, in the following subsections, we will look at the values at the beginning of the stream to estimate f.
4.2. Deciding between Fog and Cloud Considering Execution Time
As seen in
Section 3, we only depend on the variables
s,
t, and
f for our calculations, so we start by finding these values.
Table A2 and
Table A3 in
Appendix B show the values for
t in milliseconds measured for each benchmark and dataset, and we use the measurement of
[
24] in all fog-prone test cases and
for the cloud-prone ones. Having these values, we can now calculate
and
for the worst-case scenario from the fog point of view, that is, when
.
We are considering that
z = 65,536, so we can use Equation (
5) to determine the penalty for processing a value in the fog when it would cost less to do so in the cloud (
p). Given our large stream size, the penalty for each value is very small in fog-prone cases (less than
) and still relatively small in cloud-prone ones (less than
), as can be seen in
Table A2 and
Table A3 in
Appendix B. This difference is due to the fact that values for
s and
t are closer to each other in our cloud-prone cases.
Therefore, we can look at a reasonable number of values and still have a very low increase in cost. We decided that we are willing to have a maximum increase in cost of
, so that enables us to test over 3000 values for Outlier 16 and both MinMax cases, over 900 values for Outlier 256 for fog-prone cases, and ten times fewer values for cloud-prone cases (the exact numbers are also displayed in the aforementioned table). By examining the output of the benchmarks, we are able to count the values that passed the filter (
n), which leads us to the
f estimates, as well as the real
f values for comparison. Again, all of these results are reported in
Table A2 and
Table A3.
Finally, we use the calculated
f values to plot a graph similar to the one in
Figure 1 for each benchmark. Like
Section 4.1, here, we also used the simplified versions of Equations (
1) and (
2) (i.e.,
and
). The result is illustrated in
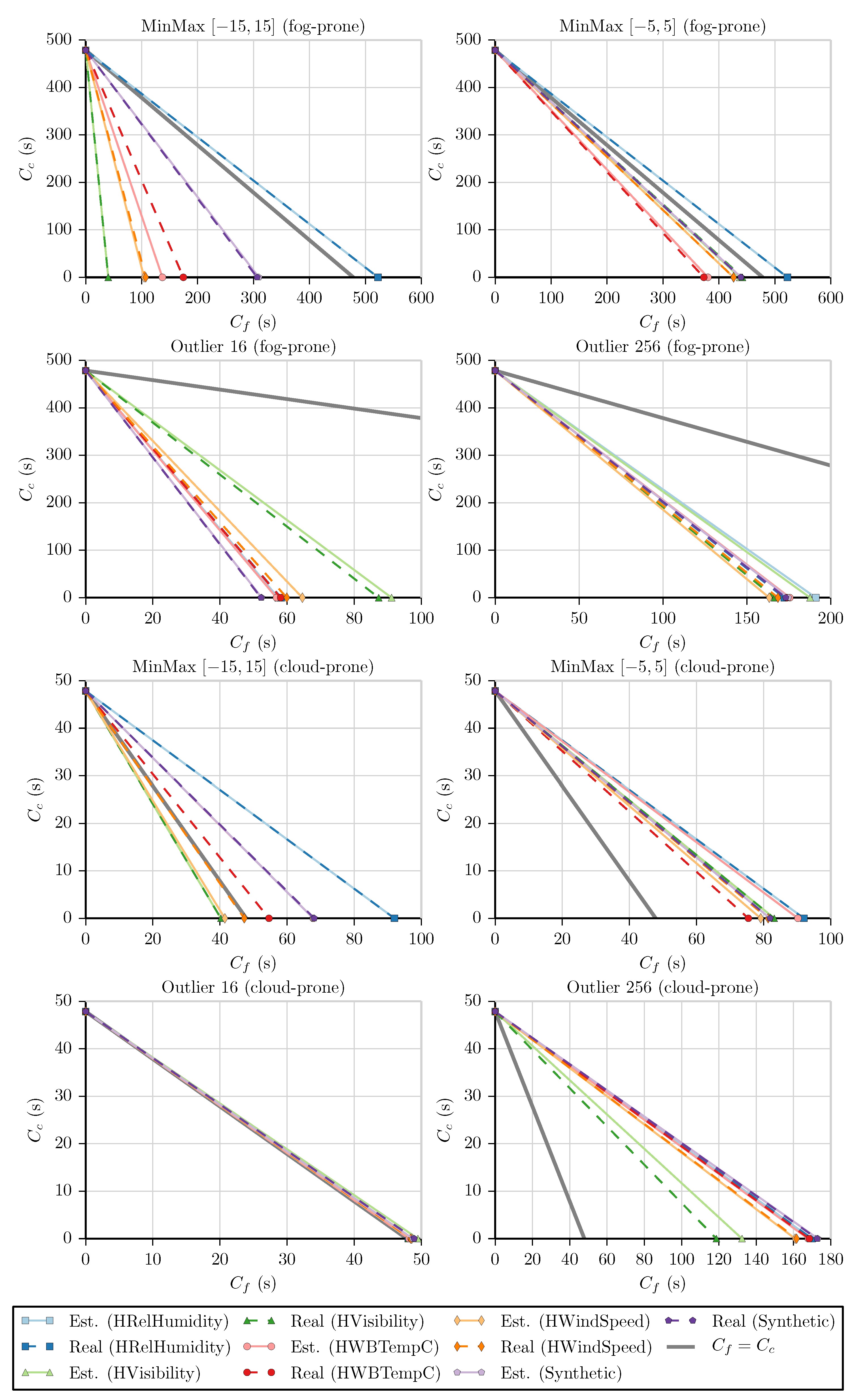
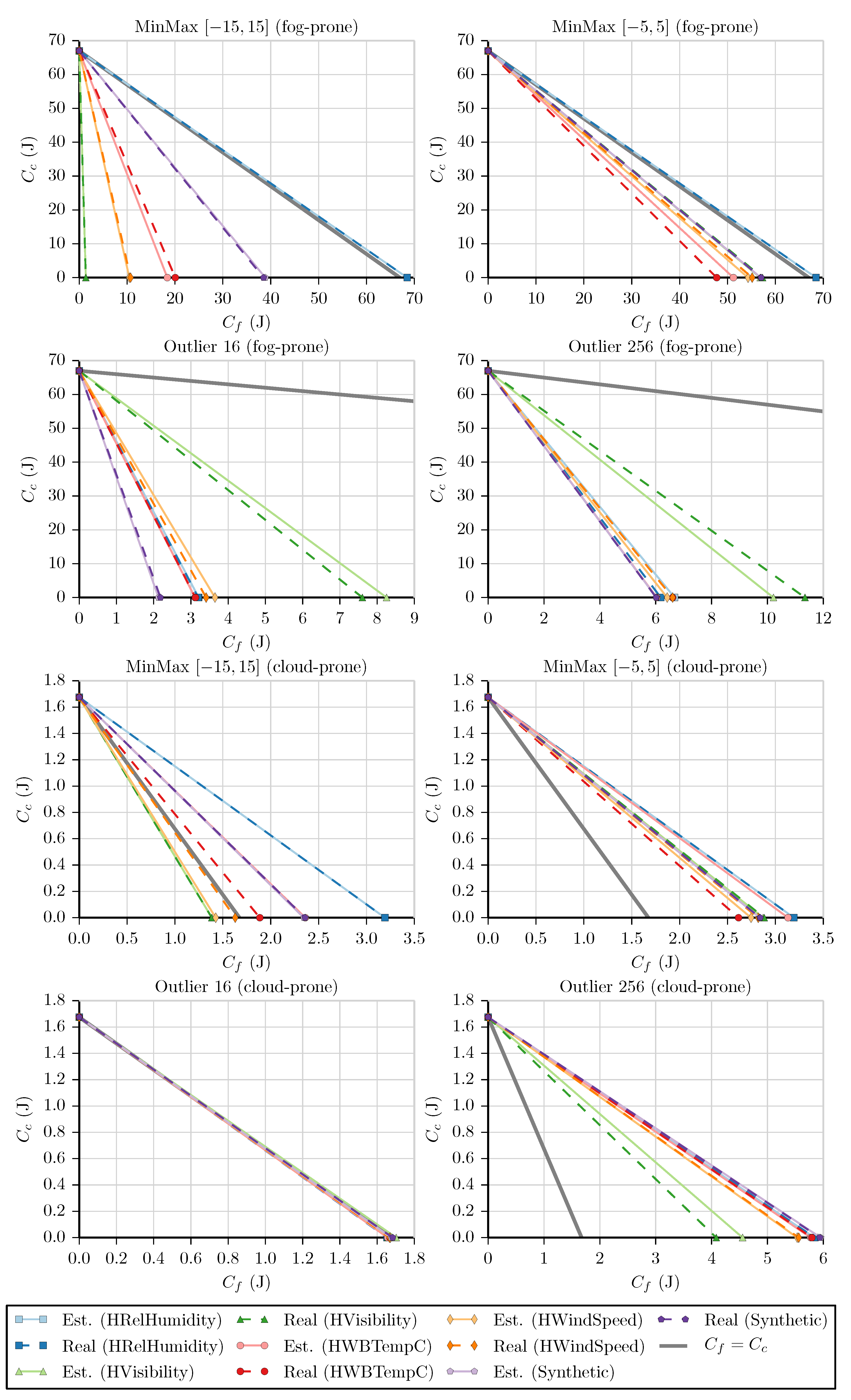
Figure 10. The continuous lines represent the tests that use the estimated values of
f (Est.), and the dashed lines represent the tests that use the real values of
f (Real). The continuous thick gray line represents the case where
, that is, a line with a slope of
. By observing the graphs, we can determine that most of the lines are below the
threshold for fog-prone cases and above it for cloud-prone cases, as expected. As discussed in
Section 3, the lines below the threshold mean that it is more profitable in terms of execution time to run these filters in the device that is collecting the data instead of sending the values to be processed in the cloud. On the other hand, lines above the threshold mean that, from the point of view of the device, it is more profitable to process these data on the cloud.
A few notable exceptions are the MinMax benchmarks being executed on the HRelHumidity dataset in the fog-prone scenario and the MinMax benchmark being executed on the HVisibility and HWindSpeed datasets on the cloud-prone scenario. In the first case, we see that although it was more likely that the fog would be more profitable, the lines are above the threshold, indicating that in fact the cloud is the correct choice. This can be explained by looking at the values of f for the MinMax benchmarks on the HRelHumidity dataset, which are equal to one, meaning that all values passed the filter. We can see that the cloud is more profitable every time this happens, as is always larger than . In the second case, the lines are below the threshold, indicating that the fog is more profitable instead of the cloud. This can again be explained by looking at the values of f. MinMax has for HVisibility and for HWindSpeed. Using the values of s and t in each case, we can calculate what f would be when . For HVisibility, , leading to . For HWindSpeed, and . The f value for both test cases is below the f value for the threshold, indicating that the fog is indeed the correct choice for them.
We can also calculate the values of the slopes in order to verify the accuracy of our
f estimation. We do so by determining the slope of each of the lines using both the estimated and real
f values. The slopes obtained, as well as the error of the estimated values in comparison to the real ones, are shown in
Table A2 and
Table A3 in
Appendix B. In 16 out of the 20 fog-prone cases and in 16 out of the 20 cloud-prone cases, the error is less than
in our predictions, which we consider a good result, as we are able to get a close estimate of
f while only risking an increase of
in the processing cost. Furthermore, it is worth noting that while the eight remaining test cases present larger errors, the choice between fog and cloud is the correct one in all of them.
4.3. Deciding between Fog and Cloud Considering Energy Consumption
Similarly to what we did in the previous subsection, we start by obtaining values for s, t, and f. However, we will now use energy consumption as our cost type and evaluate our test cases on two different devices, namely a NodeMCU platform and a Raspberry Pi 3 board.
For the NodeMCU, we calculate
t by taking the execution time for each test case (displayed in
Table A2 and
Table A3 in
Appendix B) and multiplying it by the voltage of the device (2
) and the electric current for when no data are being transmitted (
) [
27], resulting in the values reported in
Table A4 and
Table A5 in
Appendix B. We use the same method to calculate the values of
s, multiplying the time it takes to send the data to the cloud (
for fog-prone cases and
for cloud-prone cases) by the voltage and by the electric current for when data are being transmitted (70
) [
27], producing
for fog-prone cases and
for cloud-prone ones. The next step is to calculate
and
for
, the worst-case scenario from the fog point of view.
Given
z = 65,536, we use Equation (
5) to determine the penalty for processing a value in the fog when it would cost less to do so in the cloud (
p).
Table A4 and
Table A5 have all the values for
p, which are less than 0.0002 for fog-prone scenarios and less than 0.006 for cloud-prone scenarios. We again use
as the limit for the increase in cost that we are willing to pay to estimate the value of
f, which allows us to test over 13,000 values for most fog-prone cases (with the exception of Outlier 256, where
v ranges between 3600 and 5700, as this benchmark executes a more costly procedure in comparison to the others) and over 320 values for most cloud-prone ones (here, the values of
v range between 90 and 150 for Outlier 256), as can been seen in
Table A4 and
Table A5.
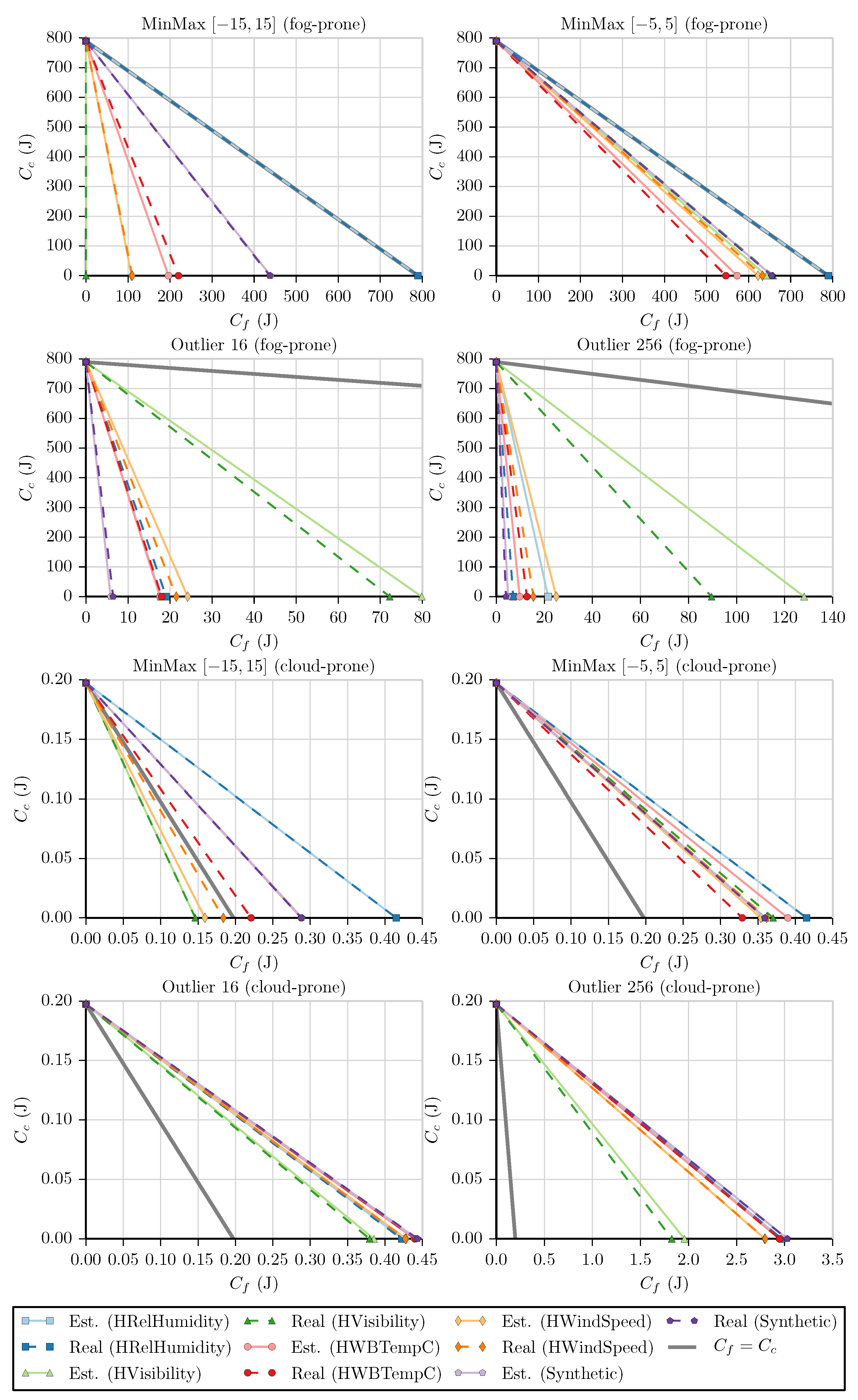
The last step is to estimate
f and plot the resulting linear equations using the simplified versions of Equations (
1) and (
2) (i.e.,
and
), as illustrated by
Figure 11. From
Table A4 and
Table A5, we see that the slope estimate error is less than
in 13 out of the 20 fog-prone cases and in 16 out of the 20 cloud-prone ones, which again is a good result for only
maximum risk in the processing cost. Moreover, from the 11 remaining test cases, 10 correctly choose the more profitable approach (the case that does not choose correctly is discussed below). We see that these results are analogous to the ones obtained in
Section 4.2, with the expected choice being made on most fog- and cloud-prone cases and the same four test cases appearing as exceptions (fog-prone MinMax
and MinMax
executed on HRelHumidity and cloud-prone MinMax
on HVisibility and HWindSpeed).
Nonetheless, we can see one interesting difference in the cloud-prone Outlier 16 cases, as all lines are very close to
. In this type of situation, it is necessary to check the slope values to get a more accurate view of the decisions being made. From
Table A5, we have the following slope estimates (and real values): for HRelHumidity, −1.0070 (−1.0128); for HVisibility, −0.9836 (−1.0105); for HWBTempC, −1.0106 (−1.0032); for HWindSpeed, −1.0019 (−1.0048); and for Synthetic, −0.9990 (−0.9945). From that, we have that fog is chosen for HRelHumidity, HWBTempC, and HWindSpeed, with the cloud being chosen for the other two datasets. However, in the case of HVisibility, the real slope value tells us that the best choice would have been processing the values on the fog. Even so, considering how close the fog cost (
) is to the cloud cost (
) in this case, choosing the less profitable option will not greatly affect the performance of the system.
Instead of also executing our test cases on a Raspberry Pi 3 device, we employ a different approach to calculate the value of
t. First, we use our infrastructure [
23] to count the number of instructions for each test case (displayed in
Table A6 and
Table A7 in
Appendix B). As our infrastructure is a virtual machine, we then multiply this number by the number of host per guest instructions (60 for MinMax and 66 for Outlier [
23]) and by the average number of cycles per instruction (which we estimate to be one). This gives us an estimate of the number of cycles that each test case would take to process the whole data stream on the Raspberry Pi 3. We then divide this result by the clock rate (
[
28]) to find out the time each test case takes to process all stream values and by the stream size (
z = 56,536) to finally obtain the execution time of each test case. We then proceed with the same method that we used for NodeMCU to obtain the
t values reported in
Table A6 and
Table A7. In this device, the voltage is
, and the electric current for when no data are being transmitted is 330
.
We determine the value of
s in the same way as we did for NodeMCU, that is, by multiplying the time it takes to send the data to the cloud (
for fog-prone cases and
for cloud-prone cases) by the voltage and by the electric current for when data are being transmitted (500
) [
28], which gives us
for fog-prone cases and
for cloud-prone ones.
After that, we calculate
and
for
and use Equation (
5) to determine the penalty for processing a value in the fog when it would cost less to do so in the cloud (
p, which can be found in
Table A6 and
Table A7). In the fog-prone cases,
p is less than 0.00001, and in the cloud-prone cases, it is less than 0.03. This time, we use
as the limit for the increase in cost that we are willing to pay to estimate the value of
f in the fog-prone cases and
as the limit in cloud-prone cases. This is done due to the fact that we have very small values for
p in the former and larger values for
p in the latter. With these limits, we can test over 11,000 values for most fog-prone cases (with the exception of Outlier 256, where
v ranges between 1700 and 2900) and over 290 values for most cloud-prone ones (here, the values of
v range between 40 and 80 for Outlier 256), as indicated in
Table A6 and
Table A7.
Finally, we estimate
f using the simplified versions of Equations (
1) and (
2) to plot the graphs in
Figure 12.
Table A6 and
Table A7 show us that 10 out of the 20 fog-prone cases and 16 out of the 20 cloud-prone ones have a slope estimate error of less than
. Although there are four fog-prone scenarios where the error is higher than
and three cloud-prone scenarios where it is higher than
, the most profitable option between cloud and fog is chosen in all cases.
Like the previous cases, most fog-prone and cloud-prone tests result in the expected choice, with the exception of fog-prone MinMax and MinMax executed on HRelHumidity and cloud-prone MinMax on HVisibility and HWindSpeed.
4.4. Simulating Other Scenarios
As we have seen with our study of fog-prone and cloud-prone scenarios in the previous subsections, another application for our model is simulating the decision process for different ranges of values. This is useful to help us visualize how changes in technology may affect the decision to filter values in the device instead of sending them to be processed in the cloud. It also allows us to analyze how far we can change s and t and still keep the same decisions.
The value of s is related to factors such as the network protocol being used (e.g., TCP, UDP); the implementation of network processes (e.g., routing); and the communication technology employed by the device (e.g., Wi-Fi, Bluetooth, Bluetooth Low Energy, LTE, Zigbee, WiMax). Moreover, it may include costs related to information security like authentication and data confidentiality. Therefore, improving the performance of any of these elements would decrease the value of s and lead us to change the decision from processing values in the fog to sending them to be processed in the cloud.
At the same time, t is related to factors such as the quality of the filtering procedure’s code and the technology of the processing unity used by the device. While we do not expect the performance of these elements to decrease with time, it is possible that t may increase as progressively more limited devices are employed or more robust features are added to the procedures being executed, which would also lead to processing data in the cloud being more profitable than doing so in the fog.
In our simulations, we use the estimated
f values for the fog-prone cases of the Synthetic dataset. The upper values for
t are approximations of the result of Equation (
6), and the
s values are numbers close to the
, when the cost type is execution time, and
, when the cost type is energy consumption. We calculate the slope of the lines obtained with these coefficients to observe how changing them affects our results.
In all figures in this subsection, the dashed area represents the space where the values used in
Section 4.2 and
Section 4.3 are located. The green cells (below the continuous line) are the ones where the slope is less than or equal to
, that is, the cases where fog computing is more profitable. The blue cells (above the continuous line) are the cases where cloud computing has the lower cost.
Figure 13a depicts the simulation results for MinMax
. In this case, we need to either increase
t or decrease
s by
to reach a situation where fog computing no longer has the lowest cost.
Figure 13b shows the simulation results for MinMax
, for which we need to increase
t or decrease
s by only
to change our decision. This is due to this case having a higher
f than the previous one, which brings its initial slope already close to
.
Figure 13c illustrates the simulation results for Outlier 16, and an increase in
t or decrease in
s of
is necessary in this instance to make cloud computing the more profitable choice, as the initial slope is far from
due to a very low value of
f.
Figure 13d has the simulation results for Outlier 256. In this test, we need to increase
t or decrease
s by
to change our decision. Although this case also presents a very low
f value, this is compensated by a
t value that is much closer to
s than the other cases, explaining why its initial slope is much closer to
than Outlier 16.
The energy consumption values used in this analysis are the ones obtained for the NodeMCU device.
Figure 14a has the MinMax
simulation results, for which there is a need to either increase
t or decrease
s by
for cloud computing to become the most profitable choice. Similarly to the results in
Figure 13b, the MinMax
values displayed in
Figure 14b also needs to be adjusted by a much smaller factor than what is required by MinMax
in order to change the decision between fog and cloud, that is, we need to increase
t or decrease
s by only
. Again, this can be explained by this case having a higher
f than that of MinMax
, which brings its initial slope already close to
.
Figure 14c shows the simulation results for Outlier 16, which require a very large adjustment of
to change our decision. Again, this can be explained by the initial slope being far from
due to a very low value of
f.
Figure 14d presents the simulation results for Outlier 256, and here, we need to increase
t or decrease
s by
to change our decision. As in the case of
Figure 13d, the low
f value of this instance is compensated by a larger
t value, which brings its slope to
when compared to Outlier 16.
Lastly, it is relevant to point out that we also simulated all of these cases employing the real f values. Although that leads us to slightly different slopes, the decision between fog and cloud stays the same in all scenarios. If we had used a smaller value for the maximum increase in cost allowed, we would have seen some marginal discrepancies in borderline cases (i.e., cases where the slope is very close to ), as f would have been less precise due to being estimated using fewer data points. Divergences can also occur due to rounding differences in borderline cases. We do not consider this an issue, as borderline cases have similar fog and cloud costs.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













