An Improved Approach for Text Sentiment Classification Based on a Deep Neural Network via a Sentiment Attention Mechanism


Abstract
:1. Introduction
- We leverage traditional sentiment lexicon and a current popular attention mechanism to design a novel sentiment attention mechanism. The sentiment attention mechanism shows strong capability of interactively learning sentiment and context words to highlight the important sentiment features for text sentiment analysis.
- Both text sequential correlation information generated by recurrent neural network and context local features captured by the convolutional neural network are essential in the text sentiment classification task, so we designed a deep neural network to effectively combine a GRU-based recurrent neural network and a convolutional neural network to enrich textual structure information.
- Extensive experiments have been conducted on two real-world datasets with a binary-sentiment-label and a multi-sentiment-label to evaluate the effectiveness of the SDNN model for text sentiment classification. The experimental results demonstrate that the proposed SDNN model achieves substantial improvements over the compared methods.
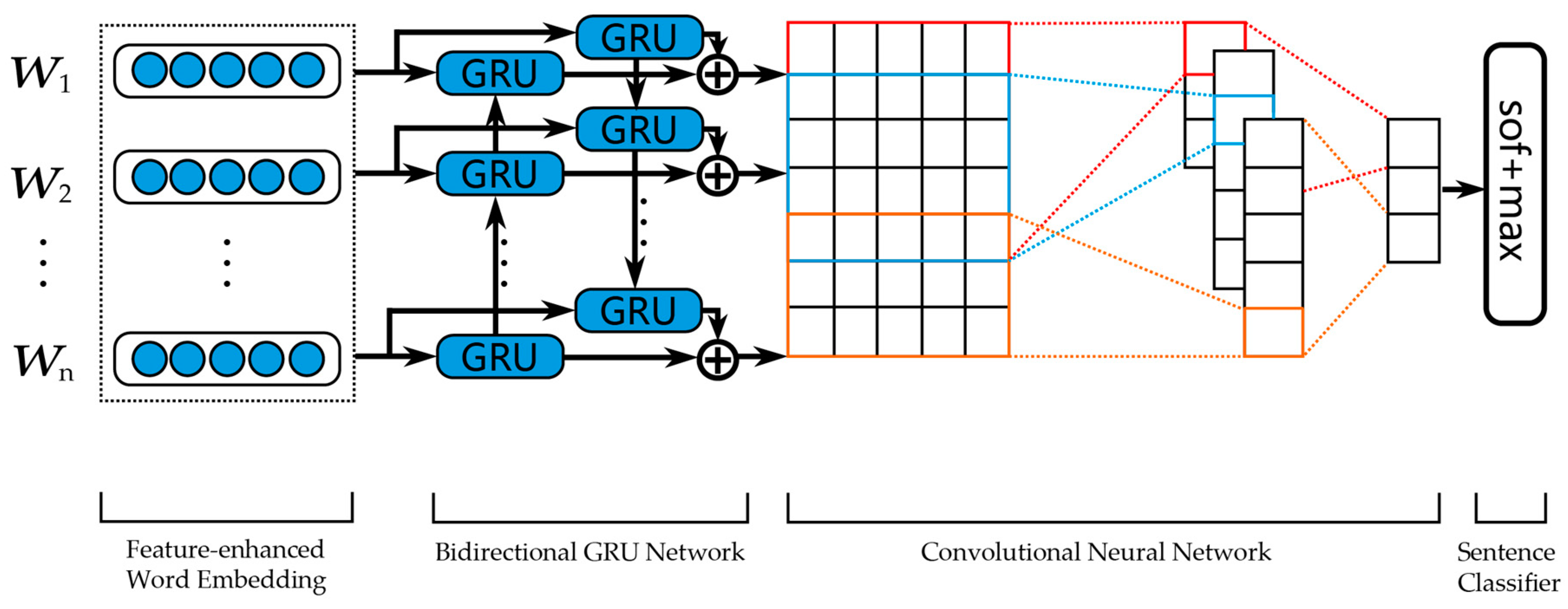
2. Model
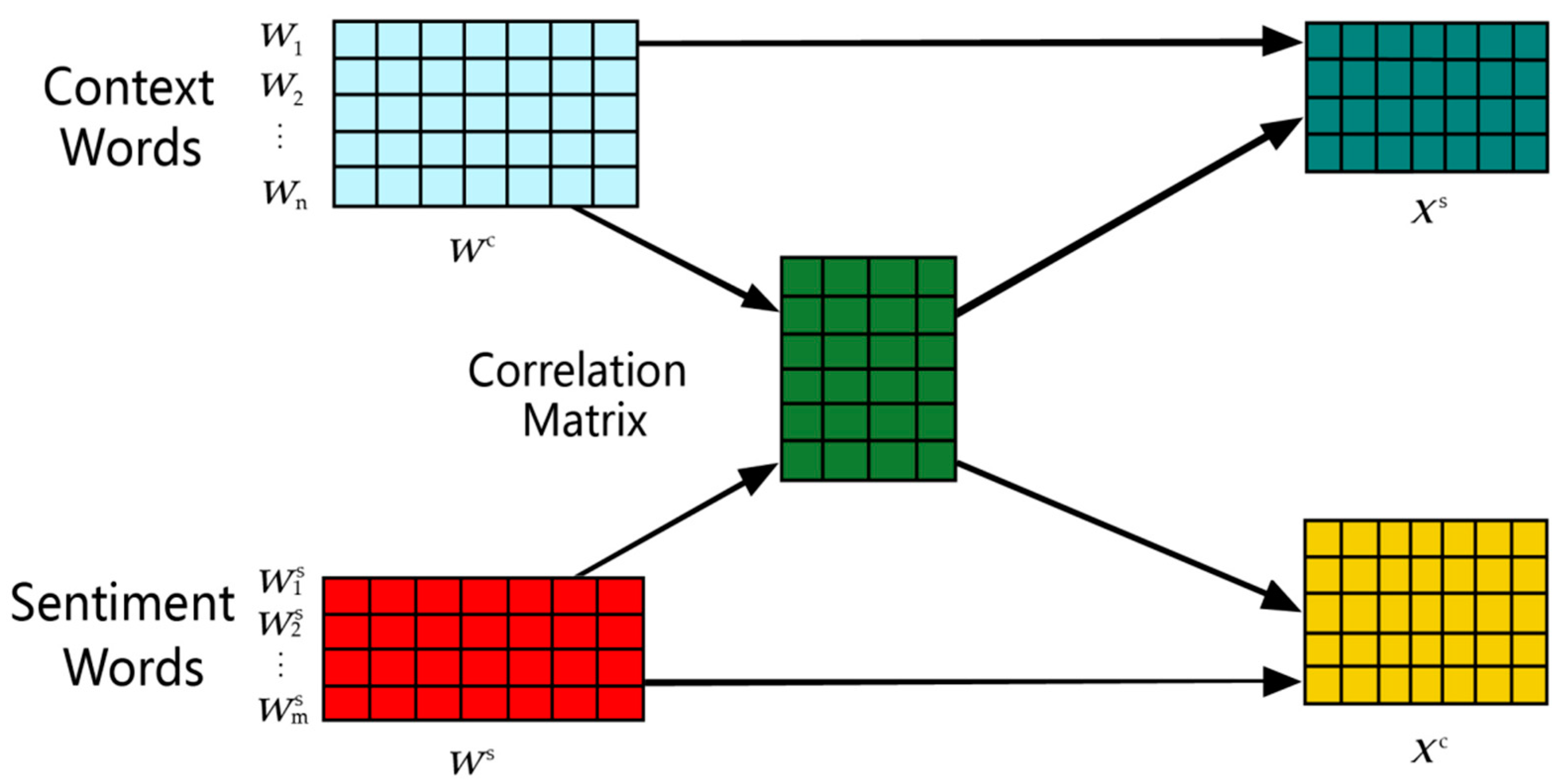
2.1. Feature-Enhanced Word Embedding Module
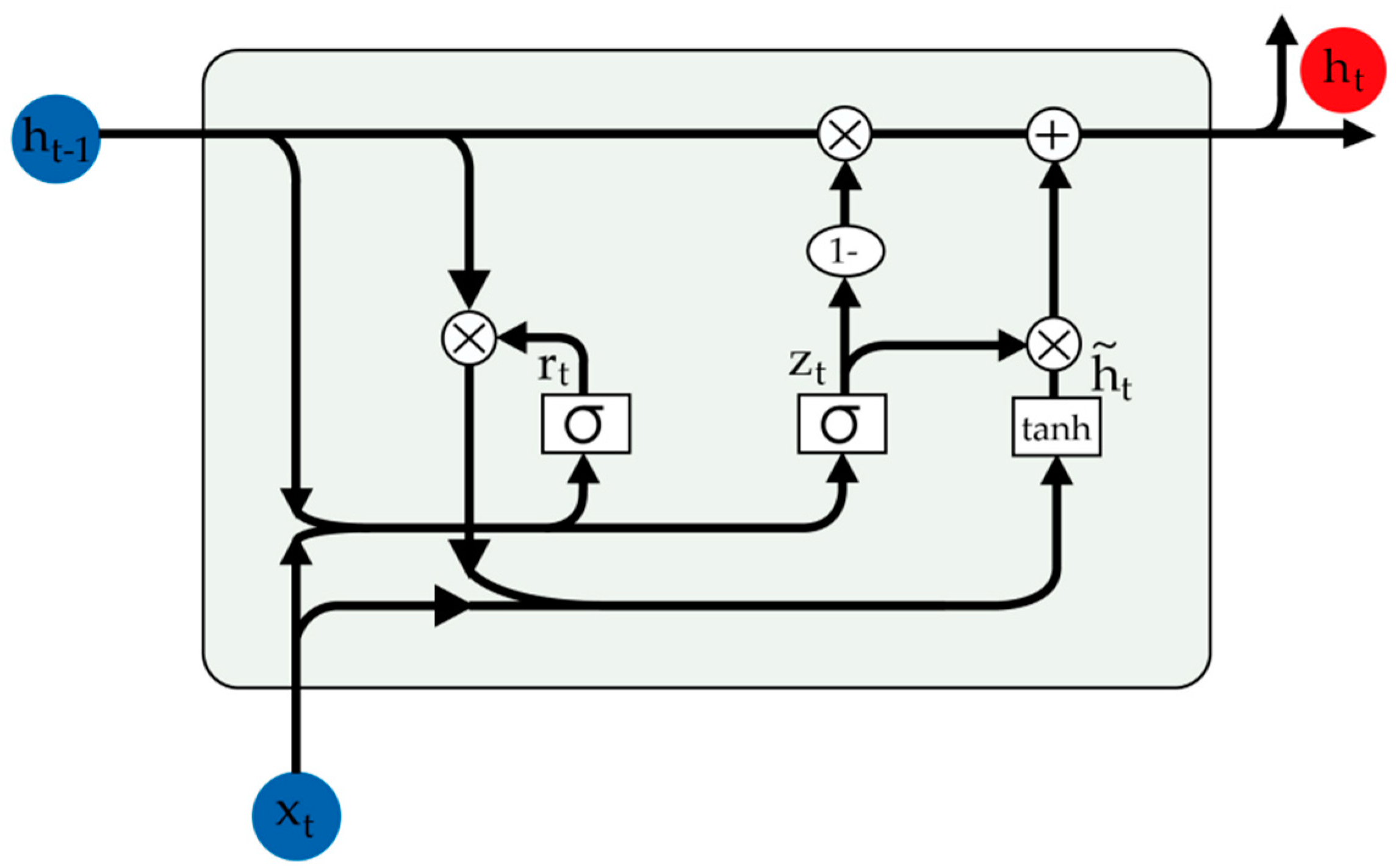
2.2. Deep Neural Network Module
2.3. Sentence Classifier Module
3. Experiments
3.1. Datasets
3.2. Implementation Details
3.3. Baseline Methods
3.4. Experimental Results
3.4.1. Overall Performance
3.4.2. Effects of Different Combinations of Bi-GRU and CNN
3.4.3. Effects of the Dimension of Sentiment Resource Words
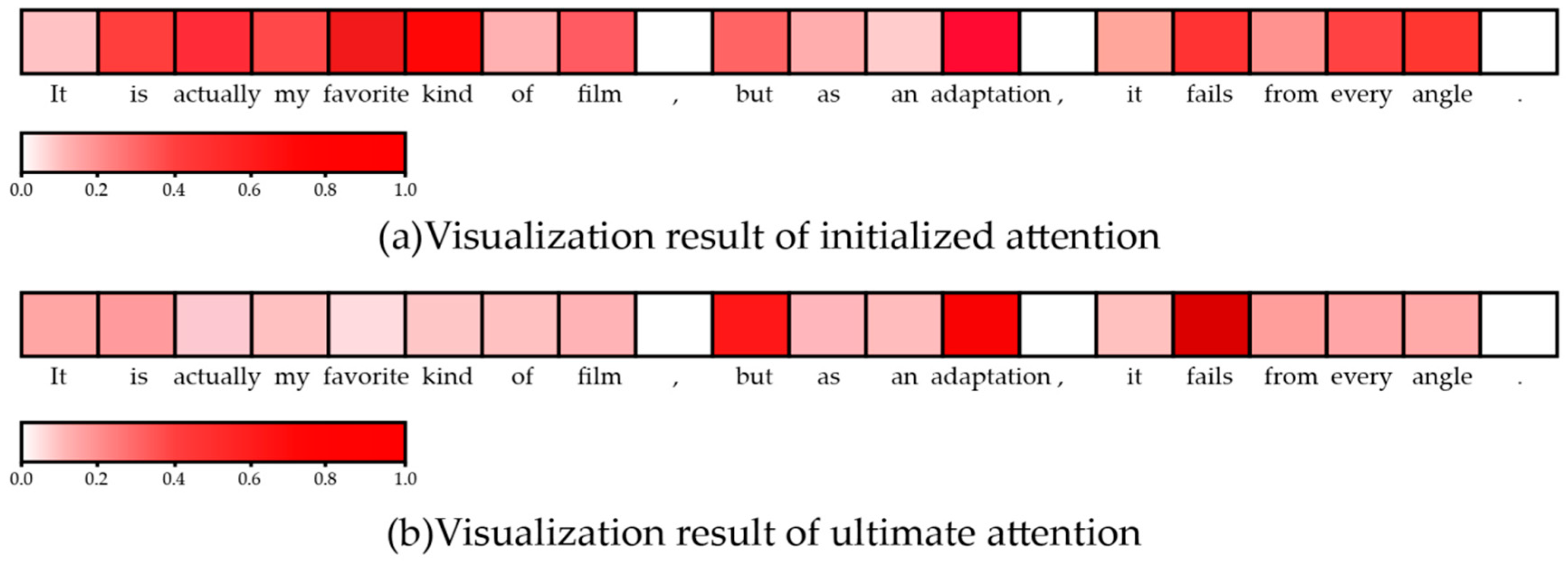
3.5. Visualization of Attention Mechanism
4. Conclusions and Future Work
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Bing, L. Sentiment Analysis and Opinion Mining. In Encyclopedia of Machine Learning and Data Mining; Springer: Boston, MA, USA, 2012; Volume 30, p. 167. [Google Scholar]
- Wang, S.; Manning, C.D. Baselines and bigrams: Simple, good sentiment and topic classification. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, Jeju Island, Korea, 8–14 July 2012; Volume 2, pp. 90–94. [Google Scholar]
- Jiang, Q.W.; Wang, W.; Han, X. Deep feature weighting in naive Bayes for Chinese text classification. In Proceedings of the 2016 Fourth International Conference on Cloud Computing and Intelligence Systems, Beijing, China, 17–19 August 2016; pp. 160–164. [Google Scholar]
- Yin, C.; Xi, J. Maximum entropy model for mobile text classification in cloud computing using improved information gain algorithm. Multimed. Tools Appl. 2016, 76, 1–17. [Google Scholar] [CrossRef]
- Joachims, T. Transductive inference for text classification using support vector machines. In Proceedings of the Sixteenth International Conference on Machine Learning, Bled, Slovenia, 27–30 June 1999; pp. 200–209. [Google Scholar]
- Kiritchenko, S.; Zhu, X.; Cherry, C.; Saif, M. Detecting aspects and sentiment in customer reviews. In Proceedings of the 8th International Workshop on Semantic Evaluation, Dublin, Ireland, 23–24 August 2014; pp. 437–442. [Google Scholar]
- Gatt, A.; Krahmer, E. Survey of the state of the art in natural language generation: core tasks, applications and evaluation. Vestn. Oftalmol. 2017, 45, 1–16. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S. Recent Trends in Deep Learning Based Natural Language Processing. IEEE Comput. Intell. Mag. 2017, 13, 55–75. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Volume 2, pp. 3111–3119. [Google Scholar]
- Nal, K.; Edward, G.; Phil, B. A convolutional neural network for modelling sentences. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 23–25 June 2014; pp. 655–665. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved semantic representations from tree-structured long short-term memory networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 30–31 July 2015; pp. 1556–1566. [Google Scholar]
- Cho, K.; Merrienboer, B.V.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using rnn encoder-decoder for statistical machine translation. In Proceedings of the Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1724–1735. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Zhou, X.J.; Wan, X.J.; Xiao, J.G. Attention-based lstm network for cross-lingual sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 247–256. [Google Scholar]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; p. 207. [Google Scholar]
- Du, J.; Gui, L.; Xu, R.; He, Y. A convolutional attention model for text classification. In Proceedings of the National CCF Conference on Natural Language Processing and Chinese Computing, Dalian, China, 8–12 November 2017; pp. 183–195. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Hu, M.Q.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. [Google Scholar]
- Qian, Q.; Huang, M.; Lei, J. Linguistically Regularized LSTMs for Sentiment Classification. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1679–1689. [Google Scholar]
- Pang, B.; Lee, L. A Sentimental Education: Sentiment Analysis Using Subjectivity, Summarization Based on Minimum Cuts. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; pp. 271–278. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.Y.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; Volume 1631, p. 1642. [Google Scholar]
- Zhang, R.; Lee, H.; Radev, D. Dependency Sensitive Convolutional Neural Networks for Modeling Sentences and Documents. In Proceedings of the 15th Annual Conference of the North American Chapter of the Association for Computational, San Diego, CA, USA, 12–17 June 2016; pp. 1512–1521. [Google Scholar]
- Andrychowicz, M.; Denil, M.; Gomez, S.; Hoffman, M.W.; Pfau, D.; Schaul, T.; Shillingford, B.; Freitas, N.D. Learning to learn by gradient descent by gradient descent. arXiv 2016, arXiv:1606.04474. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Li, Y.; Wang, X.; Xu, P. Chinese Text Classification Model Based on Deep Learning. Future Internet 2018, 10, 113. [Google Scholar] [CrossRef]
- Gui, L.; Zhou, Y.; Xu, R.; He, Y.; Lu, Q. Learning representations from heterogeneous network for sentiment classification of product re-views. Knowl. Based Syst. 2017, 124, 34–45. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | c | l | m | train | dev | test | |V| | |Vpre| |
|---|---|---|---|---|---|---|---|---|
| Movie review (MR) | 2 | 21 | 59 | 10,662 | - | CV | 20,191 | 16,746 |
| Stanford Sentiment Treebank (SST) | 5 | 18 | 51 | 8544 | 1101 | 2210 | 17,836 | 12,745 |
| Models | MR | SST | ||
|---|---|---|---|---|
| Accuracy | F1 | Accuracy | F1 | |
| SVM | 76.4 | 78.8 | 40.7 # | 42.4 |
| Feature-SVM | 77.3 | 79.4 | 41.5 | 43.3 |
| LSTM | 77.4 # | 79.6 | 46.4 # | 47.6 |
| Bi-LSTM | 79.3 # | 81.0 | 49.1 # | 50.5 |
| CNN | 81.5 # | 82.7 | 48.0 # | 49.3 |
| BLSTM-C | 82.4 | 83.8 | 50.2 # | 52.0 |
| Tree-LSTM | 80.7 # | 82.1 | 50.1 # | 51.8 |
| LR-Bi-LSTM | 82.1 # | 83.6 | 50.6 # | 52.3 |
| Self-Attention | 81.7 | 82.9 | 48.9 | 50.1 |
| SDNN | 83.7 | 84.9 | 51.2 | 52.9 |
| SDNN w/o sentiment attention | 82.5 | 84.1 | 50.0 | 51.5 |
| Models | MR | SST |
|---|---|---|
| Bi-GRU+CNN | 83.7 | 51.2 |
| CNN+Bi-GRU | 77.0 | 46.1 |
| CNN-Bi-GRU | 81.9 | 48.5 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Liu, P.; Zhang, Q.; Liu, W. An Improved Approach for Text Sentiment Classification Based on a Deep Neural Network via a Sentiment Attention Mechanism. Future Internet 2019, 11, 96. https://doi.org/10.3390/fi11040096
Li W, Liu P, Zhang Q, Liu W. An Improved Approach for Text Sentiment Classification Based on a Deep Neural Network via a Sentiment Attention Mechanism. Future Internet. 2019; 11(4):96. https://doi.org/10.3390/fi11040096
Chicago/Turabian StyleLi, Wenkuan, Peiyu Liu, Qiuyue Zhang, and Wenfeng Liu. 2019. "An Improved Approach for Text Sentiment Classification Based on a Deep Neural Network via a Sentiment Attention Mechanism" Future Internet 11, no. 4: 96. https://doi.org/10.3390/fi11040096
APA StyleLi, W., Liu, P., Zhang, Q., & Liu, W. (2019). An Improved Approach for Text Sentiment Classification Based on a Deep Neural Network via a Sentiment Attention Mechanism. Future Internet, 11(4), 96. https://doi.org/10.3390/fi11040096