1. Introduction
Connected and autonomous vehicle (CAV) technology involves the application of the Internet of Things (IoT) technology in intelligent transportation. CAV has become a vital component of the intelligent transportation system with the rapid deployment of 5G networks [
1]. In the future, vehicle-to-everything (V2X) communications will become a reality [
2], which consists of vehicle-to-vehicle (V2V), vehicle-to-infrastructure (V2I), vehicle-to-pedestrian (V2P), and vehicle-to-network (V2N). Through V2X, we can break through the technical bottlenecks of vehicle non-line-of-sight perception and information sharing. As a result, various CAV applications have also been spawned, such as platooning, advanced driving, and remote driving. However, the delay response, computing speed, and bandwidth of these application services have a high demand for service requirements. For example, the allowable delay for remote driving is 5–10 ms [
3], undoubtedly increasing the communication burden. In this study, we try to propose a resource scheduling strategy to improve the utilization, which aims to meet the V2X service demand.
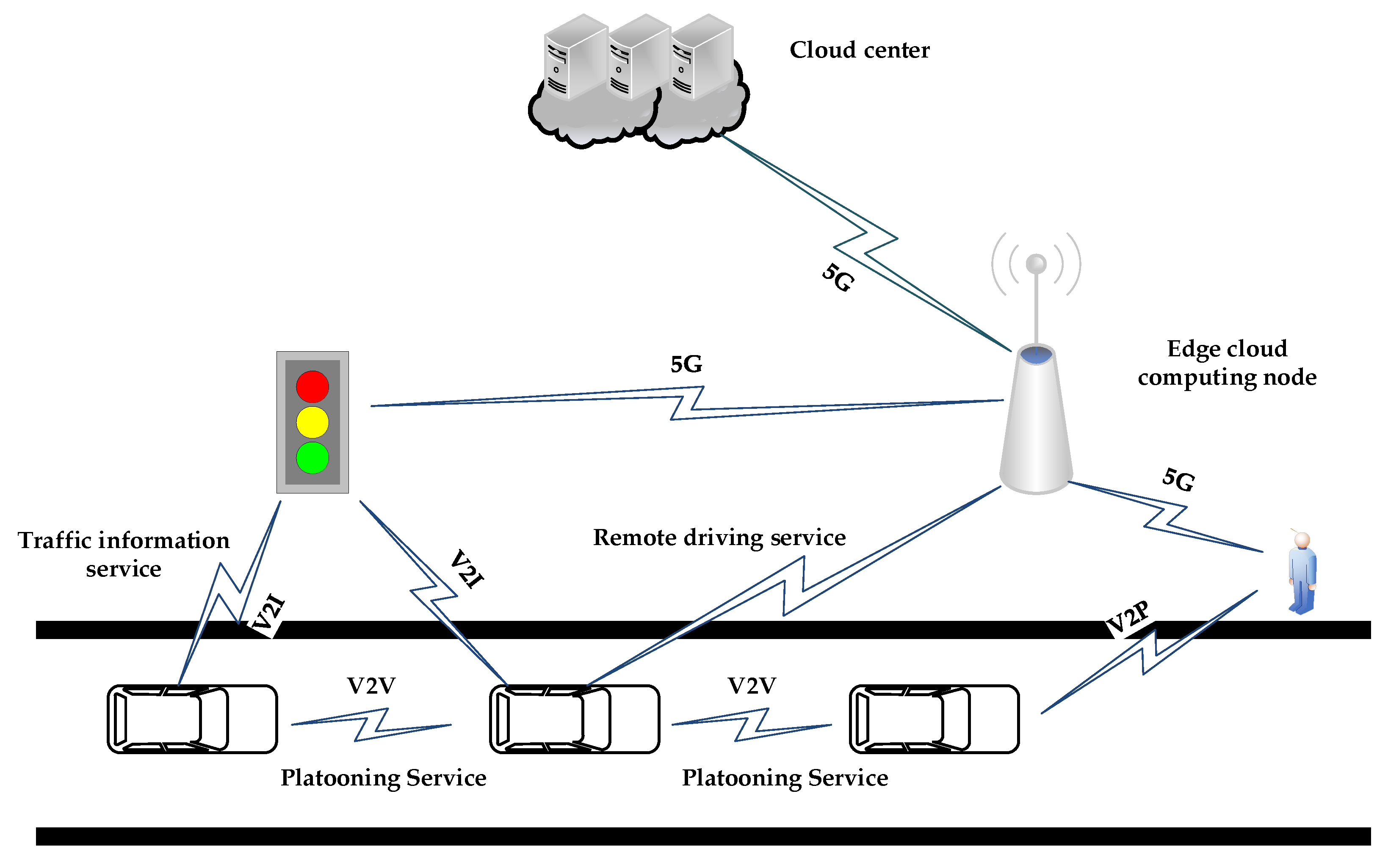
The combination of edge cloud computing and V2X technology has become a new solution to satisfy the above demand, as shown in
Figure 1. The edge cloud is a comprehensive elastic cloud platform with computing, storage, network, and security capabilities [
4]. Edge cloud computing has six advantages: low latency, self-organization, definable, schedulable, high security, and open standards. The most significant benefits are the unified coordination and service capabilities, which will effectively reduce response time, reduce bandwidth, and improve service quality when deploying the V2X applications on the edge cloud. However, the resource capacity of edge computing servers is less than the traditional cloud computing servers [
5]. Thus, it is crucial to make full use of the edge cloud hardware resources within the limit of resource conditions to ensure the high reliability, flexibility, and high performance of the V2X applications.
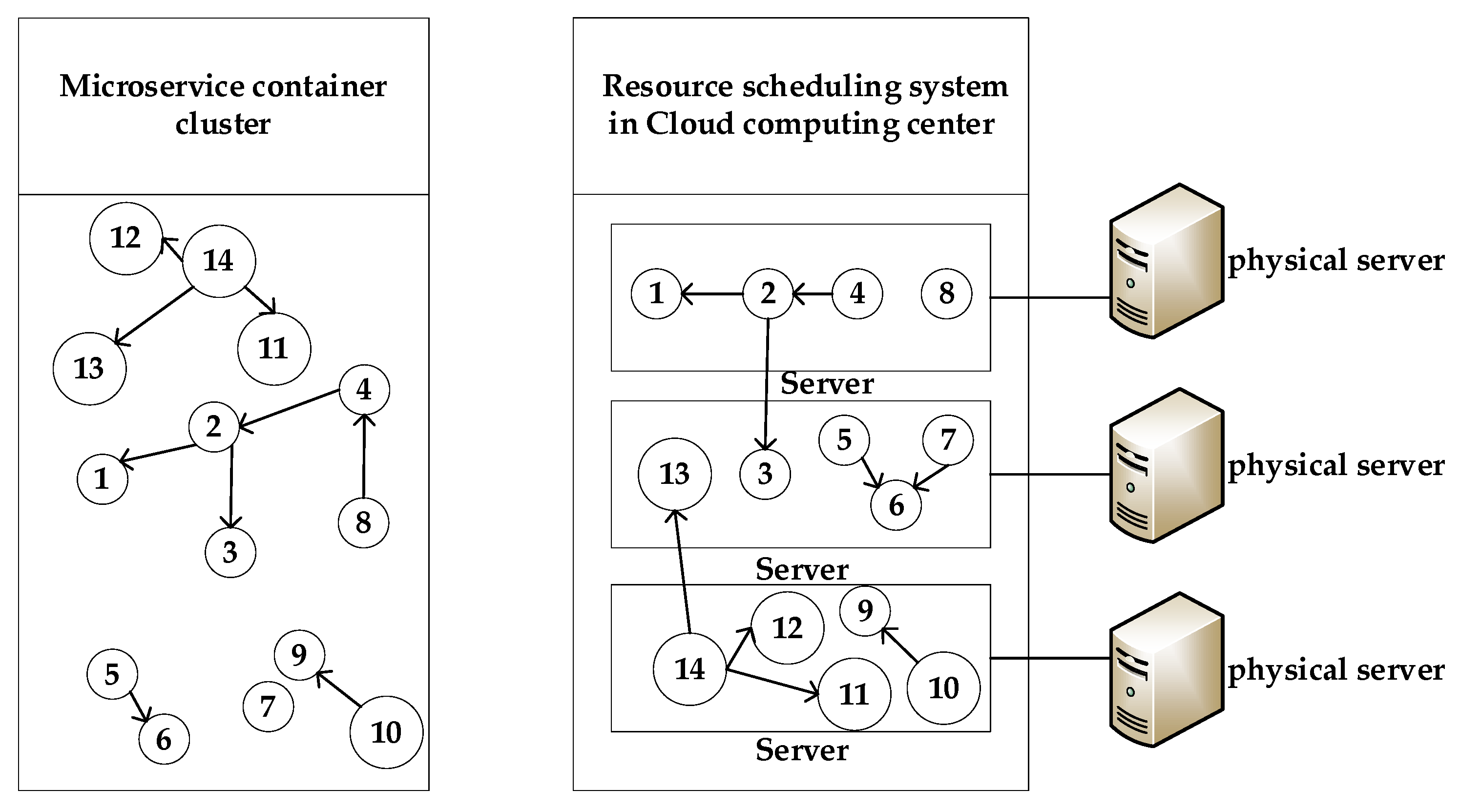
Microservice consists of a series of software components with interdependence and specific functions, which is significant for the full use of resources [
6]. Based on microservice, each application can be independently deployed, extended, and updated, which will reduce the development cycle and increase flexibility. However, microservices were deployed directly on bare metal before the advent of container technology, which was challenging to operate and maintain [
7]. Moreover, the container is a lightweight virtualization technology [
8], whose engine layer provides resource scheduling and component isolation for microservices, as shown in
Figure 2. Containers directly use hardware resources in the physical host, which can meet different platforms’ requirements regarding development, test, and production environments [
9]. However, the granularity of containers is smaller, and the number of physical machines that can be operated is higher, which means that resource management for containers is more complicated. In this study, we will develop a resource scheduling strategy to improve the performance of the container-based microservice.
At present, standard container orchestration tools such as Kubernetes and Docker SwarmKit can only provide simple resource scheduling strategies [
10] that cannot utilize physical machine resources. Thus, some studies proposed strategies for better resource utilization. For example, Liu [
11] proposed an edge computing architecture that utilized container-based microservice to ensure the flexible deployment of applications in 2016. Xu et al. [
12] proposed a cloud center infrastructure which was based on the container virtualization technology. They also put forward a resource scheduling method of container virtual cloud environments to reduce customer operation time and improve supplier resource utilization. Filip et al. [
13] proposed a new microservice scheduling model in a heterogeneous cloud edge environment, whose novelty was the microservices-oriented method. Kaewkasi et al. [
14] proposed a container scheduling strategy based on the ant colony algorithm to solve the shortcomings of the Docker SwarmKit orchestration engine’s scheduling strategy. The above strategy can improve the utilization to a certain extent, but it lacks the consideration of the multi-objective in the scheduling process.
There were some studies considering the multi-objective problem. For example, Kaur et al. [
15] designed a multi-objective function using a game theory model to reduce energy consumption and maximum task completion time by considering different constraints such as memory, CPU, and user budget. Meanwhile, they used lightweight containers instead of traditional virtual machines to reduce the fog device’s overhead, response time and overall energy consumption. Liu et al. [
16] proposed a fuzzy service offload decision mechanism (FSODM) algorithm based on the characteristics of limited resources under edge computing and based on the micro-scale deployment architecture to achieve rapid deployment and dynamic expansion of microservice containers. Hani Sami and Azzam Mourad [
17] proposed an evolutionary memetic algorithm to solve the multi-objective container optimization problem in a dynamic fog environment, whose goals were Quality of Service (QoS) maximization, survivability factor maximization, and active host minimization. Lin et al. [
18] established a multi-objective optimization model for container-based microservice scheduling, which took computing, the storage resources of the physical nodes, the number of microservice requests, and the failure rate of the physical nodes into consideration. The current proposed multi-objective studies lacked the consideration of microservices’ independence, which made the improvement of resource utilization and other goals limited.
Some studies considering mobile agents have been proposed. For example, Shi et al. [
19] used a tail matching subsequence (TMSS) based mobile access prediction method which exploited the inherent user mobility patterns to solve the intermittent connectivity. Meanwhile, the authors developed an integer encoding-based adaptive genetic algorithm (GA) to make offloading decisions, which considered the cloudlet reliability, computation requirements, and mobile device energy consumption. Avgeris et al. [
20] established the vertical and horizontal scaling mechanism to satisfy the QoS requirements. The vertical scaling mechanism used the linear switching system and state feedback controller to develop a dynamic resource allocation and admission control mechanism. The horizontal scaling mechanism was in charge of each edge server’s activation/deactivation, the placement of the applications’ instances, and the distribution of the incoming offloaded requests.
In this study, we try to address several challenges in resource scheduling for V2X microservice deployment. Previous studies did not consider the microservice dependencies, which led to wasted resources. In our study, we try to use the calling distance to quantify the dependence. Then, we model a multi-objective model considering resource utilization, resource balancing, and calling distance. We propose a multiple fitness genetic algorithm to balance the above factors, where a container dynamic migration strategy is introduced in the crossover and mutation operation.
The rest of this study is organized as follows. The resource scheduling model in containerized microservice is discussed in
Section 2. The resource scheduling algorithm is proposed in
Section 3. The simulation experiments will be discussed in
Section 4. Finally, we conclude this study in
Section 5.
2. The Resource Scheduling Model in Containerized Microservice
We establish a multi-objective resource scheduling model based on the edge container cloud architecture for V2X microservices in this article. This model aims to achieve a balance between cross-server calls, server resource utilization, and load balancing. Simultaneously, our model considers the dependencies and hardware constraints between containers, thereby ensuring the response speed, which improves the cloud center’s overall performance.
The existing M microservice containers need to be mapped to N physical hosts. Because small cloud computing centers such as the edge cloud have specific service scenarios, the physical server types they deploy are generally uniform, which means that their resource types and capabilities are set to the same. Therefore, the resource scheduling model can be further described as follows: M containers are divided into H groups, and each group of containers corresponds to a physical host. If H is not equal to N, activate or deactivate the physical host. The goal is to minimize the number of calls between containers across physical hosts, to reduce the number of physical hosts occupied by microservice containers, and to ensure load balancing of activated physical clusters as much as possible. Ultimately, we achieve the best overall performance of microservice deployment.
2.1. Microservice Resource Constraints
In the beginning, we use
as the set of physical hosts, where
,
, …,
}.
n is the number of physical hosts.
= {0, 1} is a binary variable. When it is 1, it indicates that the physical host
is activated. Otherwise, it shows that the physical host
is in the sleep state. When deploying microservices, we firstly consider that each container can only be deployed on one physical host, as shown in Equations (1) and (2). The binary parameter,
, indicates that the container
will be deployed on the host
, where the amount of containers is
.
At the same time, there is also a comprehensive resource constraint, which means that the sum of the resources required by all microservice containers on the same host
i cannot exceed the physical host’s resources, as shown in Equation (3).
In Equation (3), the set of all resources requested by the container is , where the represents the type resource requested by the container . In this article, we use to indicate the set of the type resources that the physical host can provide. In this article, we only consider four types of resources, namely CPU, memory, disk, and bandwidth, so the maximum of is 4.
2.2. Microservice Container Dependencies
The microservice architecture’s characteristic is to differentiate an extensive service project into individual modules for a single service. There exists a calling relationship between these modules, which creates a dependency relationship between the deployed containers. Therefore, the dependency relationship between containers is a factor that must be considered in the resource scheduling process for containers. This means that containers with call dependencies are allocated to the same physical host as much as possible, which can reduce the time for containers to call across physical hosts, minimize the waste of network resources, and improve the QoS.
In this article, the calling distance,
, is used to quantify the dependence between the container
and
, as shown in Equation (4).
Through
, we can calculate the sum of the dependency relationship between the container
in the host
and other used containers, as shown in Equation (5). When the
container in the physical host
has a stronger dependence on different containers, this may indicate that the
container is more suitable for deployment on the physical host
.
Finally, we can calculate the dependency correlation between all containers in the physical machine
, as shown in Equation (6). When the value of
increases, the total dependency of all containers in the same physical host t will be higher. At the same time, this also means that the number of network calls across physical hosts generated in the system is less, and the response time of client requests is shorter.
2.3. Critical Factors in Resource Scheduling
We propose three goals for this model: the shortest calling distance, the highest physical cluster resource utilization rate, and the highest load balancing after analyzing the resource constraints and microservices’ dependencies. In the following chapters, we will quantify the three goals and give the quantification equation.
2.3.1. Microservice Calling Distance
When a user sends a service request, a call chain will be formed on the server. All microservices in the call chain will work together to meet the user needs. Therefore, it is necessary to call the containers deployed in each host. The time taken by container calls in the same physical host will be significantly shorter than those across physical hosts. Therefore, in the process of container deployment and resource scheduling, the cross-physical host calls of the container should be as few as possible. In this way, it is possible to reduce the time for containers to transfer network calls between physical hosts and reduce network resource waste. We define Equation (7) to calculate the calling distance between containers to quantify the calls between containers.
can quantify the calling relationship between containers i and j. In Equation (7), we can use to calculate the sum of the calling distances of all containers starting from a particular container. Then, we use to calculate the sum of the calling distances between all containers that have a dependency on container i. Finally, we can obtain the sum of the calling distance of all containers through D. The smaller the value of D, the faster the microservice response month, and the higher the network resource utilization.
2.3.2. Resource Utilization
Because the computing resources in the edge cloud are relatively small compared to traditional data centers, the energy consumption of the physical host when it is not loaded accounts for around 70% of the energy consumption when it is fully charged. Therefore, it is of considerable significance to the edge cloud data center to effectively use the computing resources and reduce the energy consumption in the data center. When resource scheduling is performed, one of the optimization goals is to occupy the lowest number of physical hosts under the premise of meeting their needs, so that the resources of the physical hosts are effectively used.
We define the parameter Z to represent the total number of physical hosts occupied by deploying containers with microservices, as shown in Equation (8). In the entire edge cloud, the overall resource utilization rate of the physical host group activated for the deployment of microservices is represented by the parameter U, as shown in Equation (9).
In the edge cloud computing center, microservices have different requirements for different types of resources, so it is easy to cause a load of various types of resources in the physical host to be unbalanced, thereby causing a waste of server resources. To effectively use various resources, an optimization goal is to make the physical server achieve a better resource balance as much as possible. This study defines the quantitative calculation method of resource utilization, as shown in Equation (10), where
represents the utilization of type
resources on host
. The parameter
represents the average utilization rate of all resources on the physical host
.
2.3.3. Resource Utilization Imbalance of Server
At the same time, we can also calculate the resource utilization imbalance of server
, according to Ni, as shown in Equation (11). Finally, we can use N to calculate the resource utilization imbalance of the entire edge cloud. The smaller the values of Ni and N, the more balanced the corresponding load.
2.4. Target in Resource Scheduling
After the above quantitative calculations and analysis of the constraints, we can obtain the scheduling model of the edge cloud microservice container. Based on this model, we propose the research goals of this study: the minimum calling distance of microservice containers across physical machines, high resource utilization of edge cloud physical machine clusters, and load balancing. The multi-objective function used in this article is shown in Equation (12).
In this formula,
,
,
,
have the same meaning as described above. In this article, we have defined the physical machine load evaluation function
as shown in Equation (13) to calculate the load performance of each physical host. We quantify the physical host’s load performance with three parameters: the physical host’s resource utilization, load balancing, and the degree of dependence of the microservice container deployed on it.
3. The Resource Scheduling Algorithm
To solve the above model, we design a gene evaluation function based on the classic genetic algorithm, introducing the container dynamic migration strategy into the crossover and mutation processes. Finally, we propose a new multi-fitness genetic algorithm (MFGA) that combines resource utilization, load balancing, and microservice dependencies to solve the resource scheduling problem.
3.1. Chromosome Coding
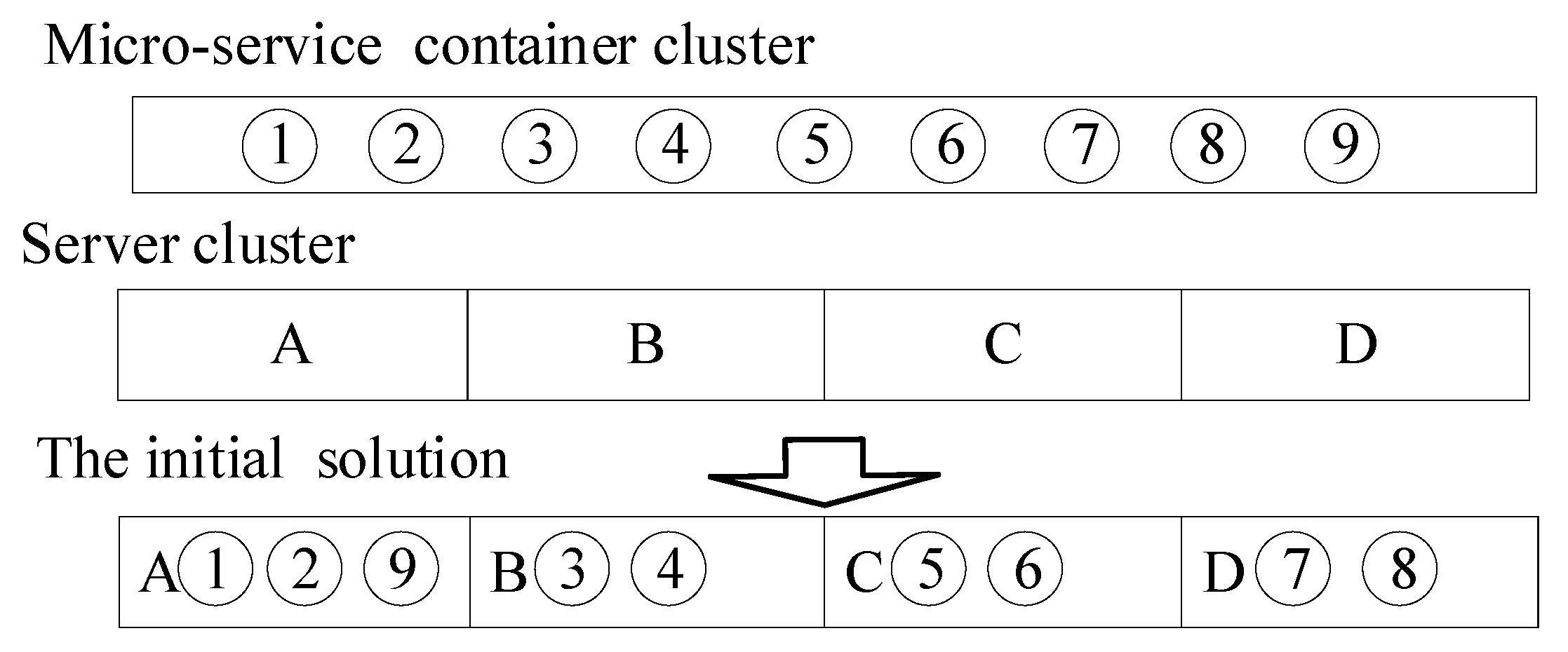
Similarly to evolution in nature, chromosome coding is a vital part of ensuring individual performance. According to the problem analysis, the real number coding method is more suitable to solving this problem [
21]. Therefore, according to this method, we code and assign the initial solution according to the process shown in
Figure 3.
As shown in
Figure 3, the numbers represent the microservice container cluster to be allocated. The letters represent the cloud computing center’s physical hosts cluster. The correspondence between the numbers and the letters represents the deployment of different microservice containers to the designated physical host. First, the system randomly generates an array of integers from 1 to M that does not repeat. According to the resource constraints defined by Equations (1) and (3), the first adaptation algorithm is used to divide the containers into H groups, each group corresponding to a physical host. After the above steps, an individual chromosome code can be formed, which means an initial feasible solution to the problem model.
3.2. Fitness Function
In the genetic algorithm, the fitness function is used to evaluate the quality of the individuals in the population. A small fitness value indicates that the solution to the problem is weak, and vice versa. According to the previous chapter’s model, we propose fitness function combined with the goals, as Equation (14) shows.
In Equation (14), α, β, and λ are weight parameters whose value ranges are (0, 1), representing the proportion of container called distance, resource utilization, and load balancing in the function. The larger the parameter value, the higher the impact of the corresponding goal on the algorithm objective function value. The administrator determines the initial cost according to the actual situation.
3.3. Gene Evaluation Function
By introducing the gene evaluation function
, the fitness value of each gene in an individual can be evaluated. According to the problem model established in the previous chapter, each gene represents the load status of a physical host. Therefore, based on the main parameters that affect the load performance of the physical machine, we establish a gene evaluation function, as shown in Equation (15). This equation can improve each machine’s performance and accelerate the algorithm’s convergence when solving the multi-objective optimization model of microservice resource scheduling.
The parameters in Equation (15), α, β, and λ, are the same as those in Equation (14). The higher the resource utilization on the physical host, the more balanced the load and the more influential the dependency of the microservice containers deployed. Equation (15) can be used to evaluate the fitness value of genes and accelerate the convergence of the algorithm.
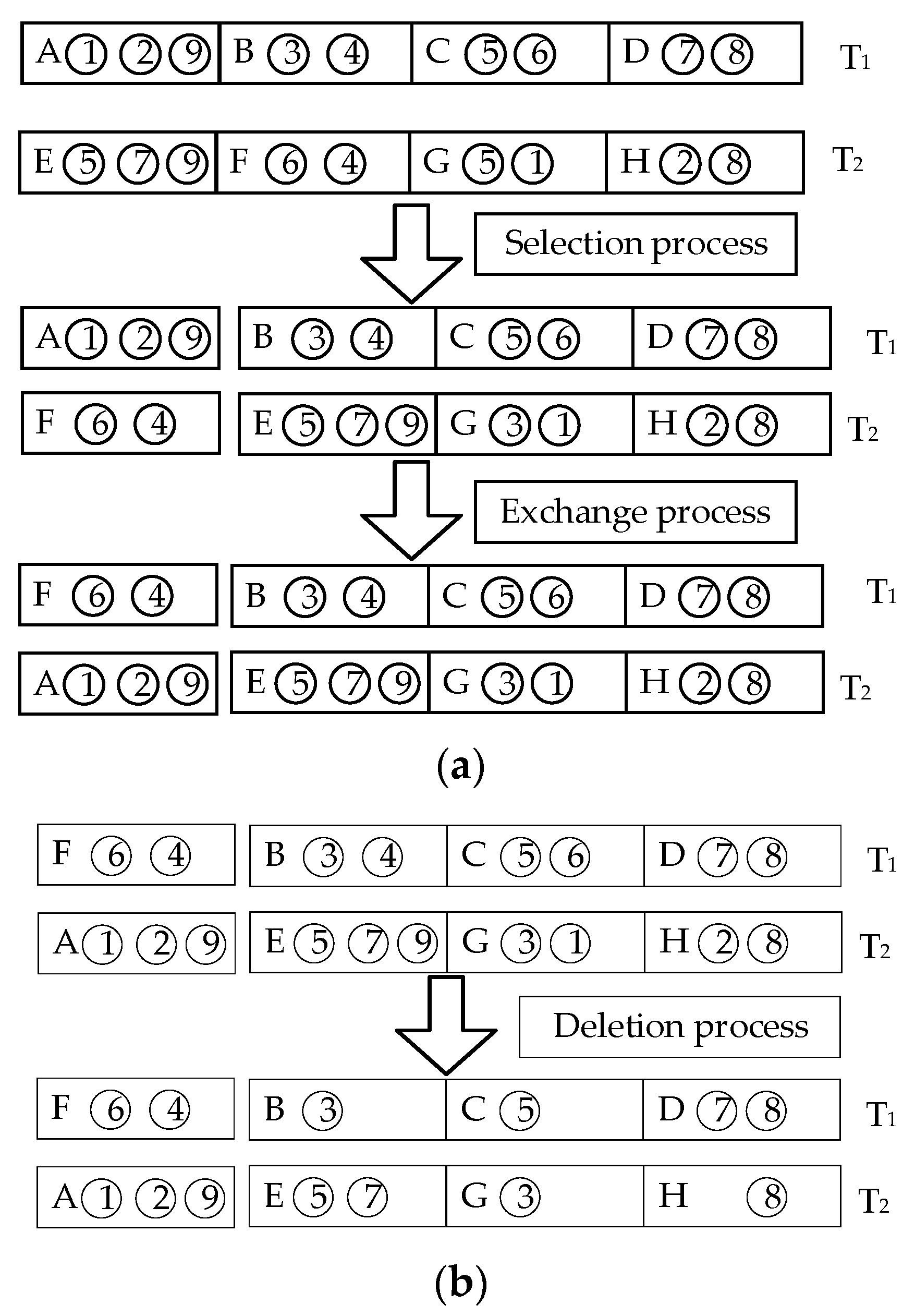
3.4. Crossover Operation
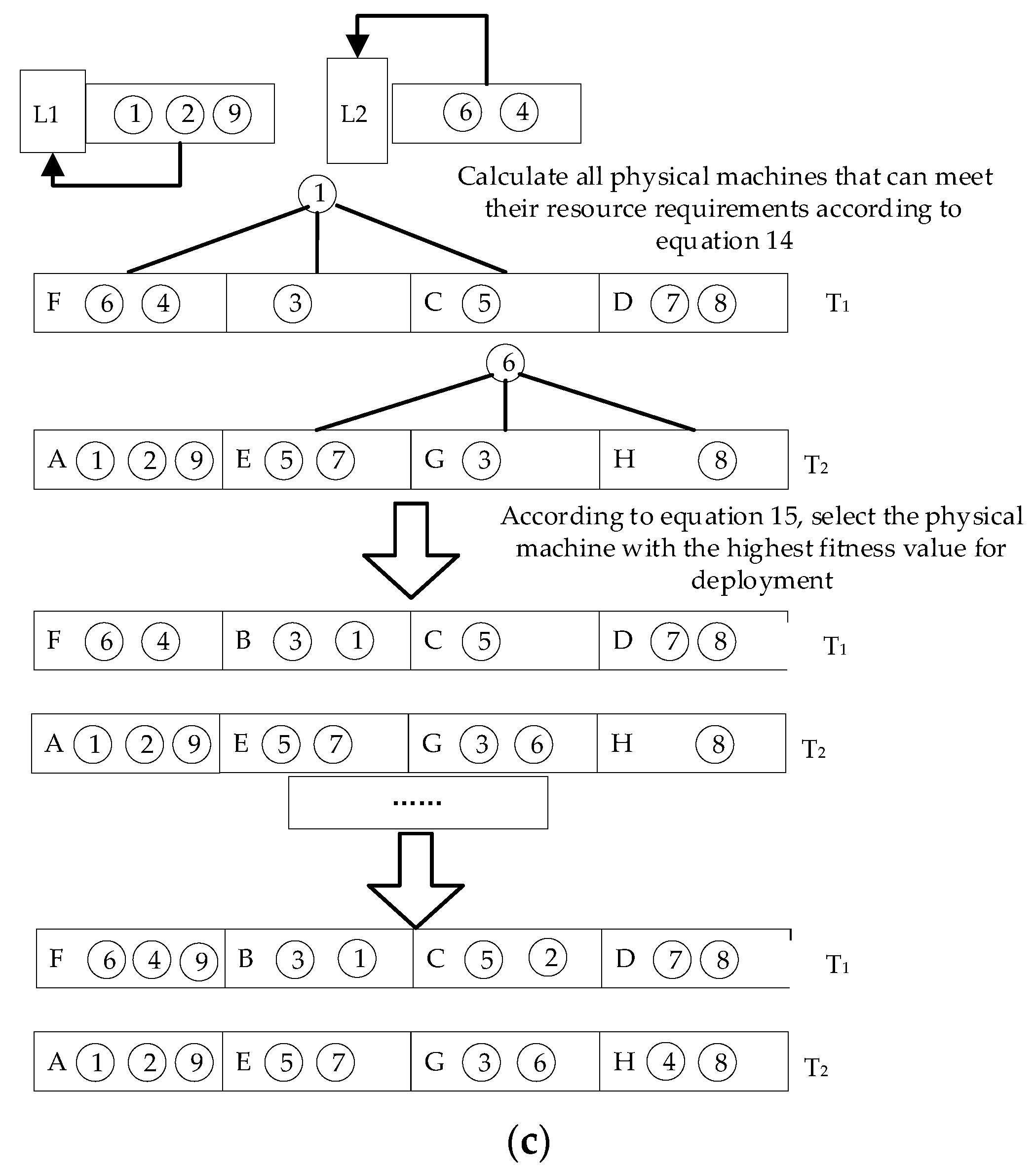
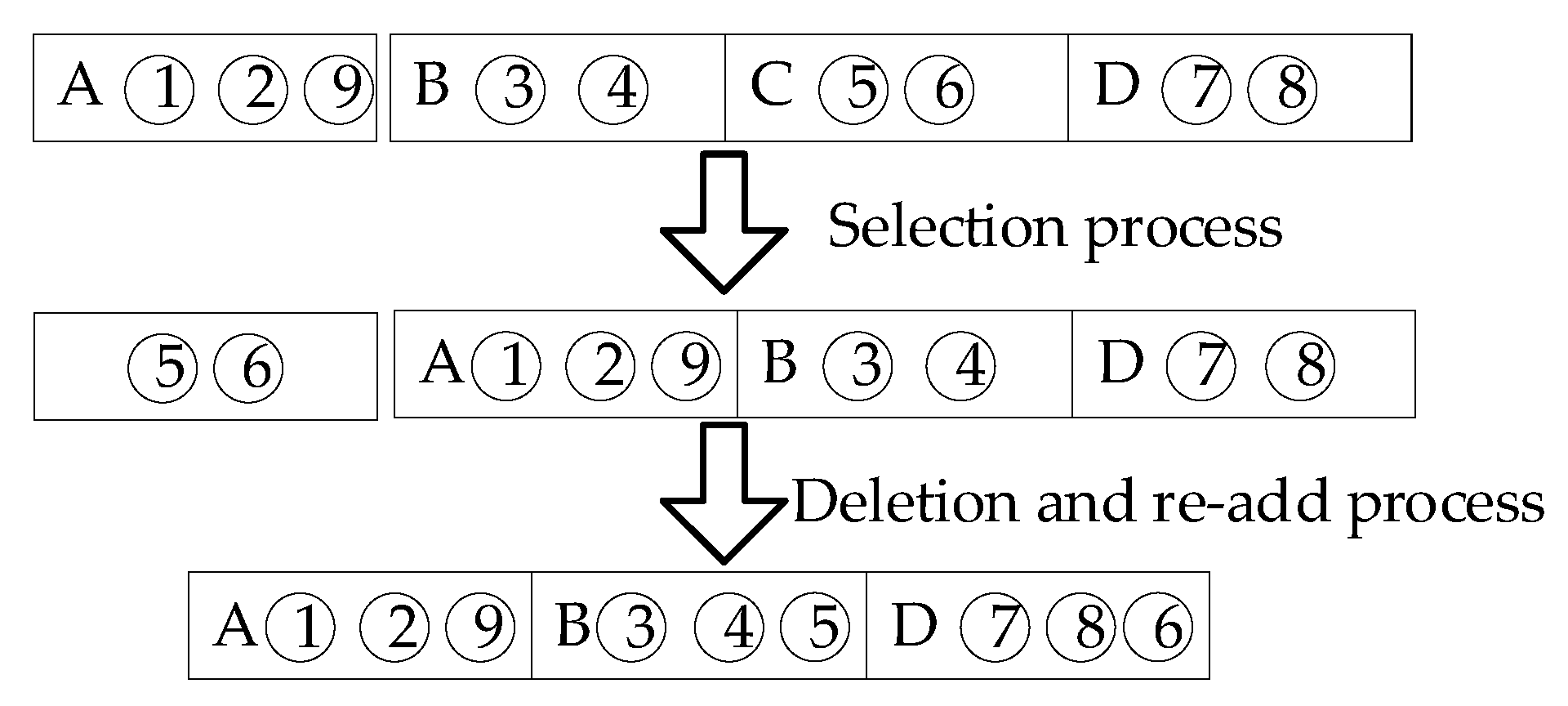
In this section, the crossover operator is redesigned. The gene evaluation function is used to achieve the crossover effectiveness of each task set in the offspring while ensuring a feasible solution, thereby speeding up the convergence of the algorithm. When performing crossover, first select the initial solutions T1 and T2 of the initial population and randomly generate a random number between 0 and 1. If the random number is less than the crossover probability pc, the crossover operation is performed. If it is higher than the crossover probability pc, the two parents enter into the next iteration. Then, it completes the procedure according to the selection of three processes: swap, delete, and re-add. The selection exchange process mainly completes the exchange of the most adaptable genes, as shown in
Figure 4a. The function of the deletion process is to delete the same microservice container in the obtained new chromosome, as shown in
Figure 4b. Finally, in the addition process, containers that are missing due to gene exchange are sorted according to the order in which they were initially placed in the physical host to obtain the crossed offspring, as shown in
Figure 4c.
3.5. Mutation Operation
The mutation process is for local fine-tuning so that individuals cover the optimal global solution [
22]. Therefore, the mutation operator used in the algorithm calculates each gene’s fitness value according to Formula (14) and finds the gene with the smallest fitness value as the mutation object. The physical host corresponding to the gene with the lowest fitness value is canceled. The containers on it are redistributed according to the first adaptation algorithm, as shown in
Figure 5. Finally, the container migration is completed.
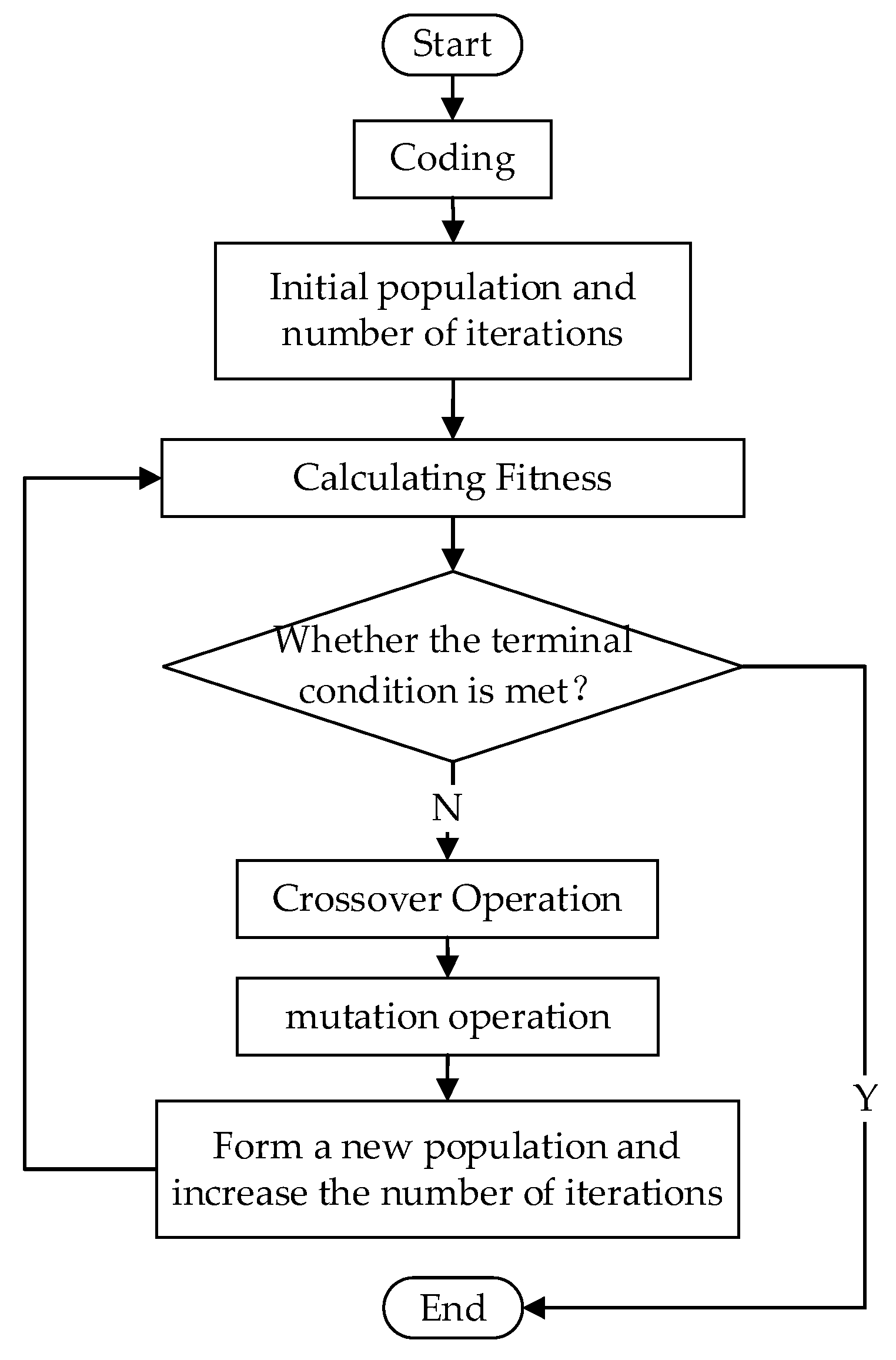
3.6. Algorithm Flow
Steps of microservice resource scheduling based on the MFGA are shown in
Figure 6.
(1) Coding: Coding the problem based on the above model.
(2) Population initialization: Initialize the population using the first adaptation algorithm to obtain the initial feasible solution.
(3) Finding the fitness value: Calculate all individuals’ fitness values according to the resource scheduling model and fitness function.
(4) Crossover operation: Based on the crossover probability of the algorithm, select crossover individuals and perform crossover operations based on the gene evaluation function to complete the update of the individual structure.
(5) Mutation operation: Select mutation individuals based on the mutation probability of the algorithm and perform mutation operations based on the gene evaluation function to obtain the mutated population.
(6) Selection process: Through the selection operator designed by the algorithm in this study, individuals who enter the next generation are selected to obtain a new population. The fitness value of individuals in the new community is calculated.
(7) If the number of iterations reaches the set value (350), the program will be terminated; otherwise, return to Step (4) and continue the cycle.
4. Simulation Experiments and Analyses
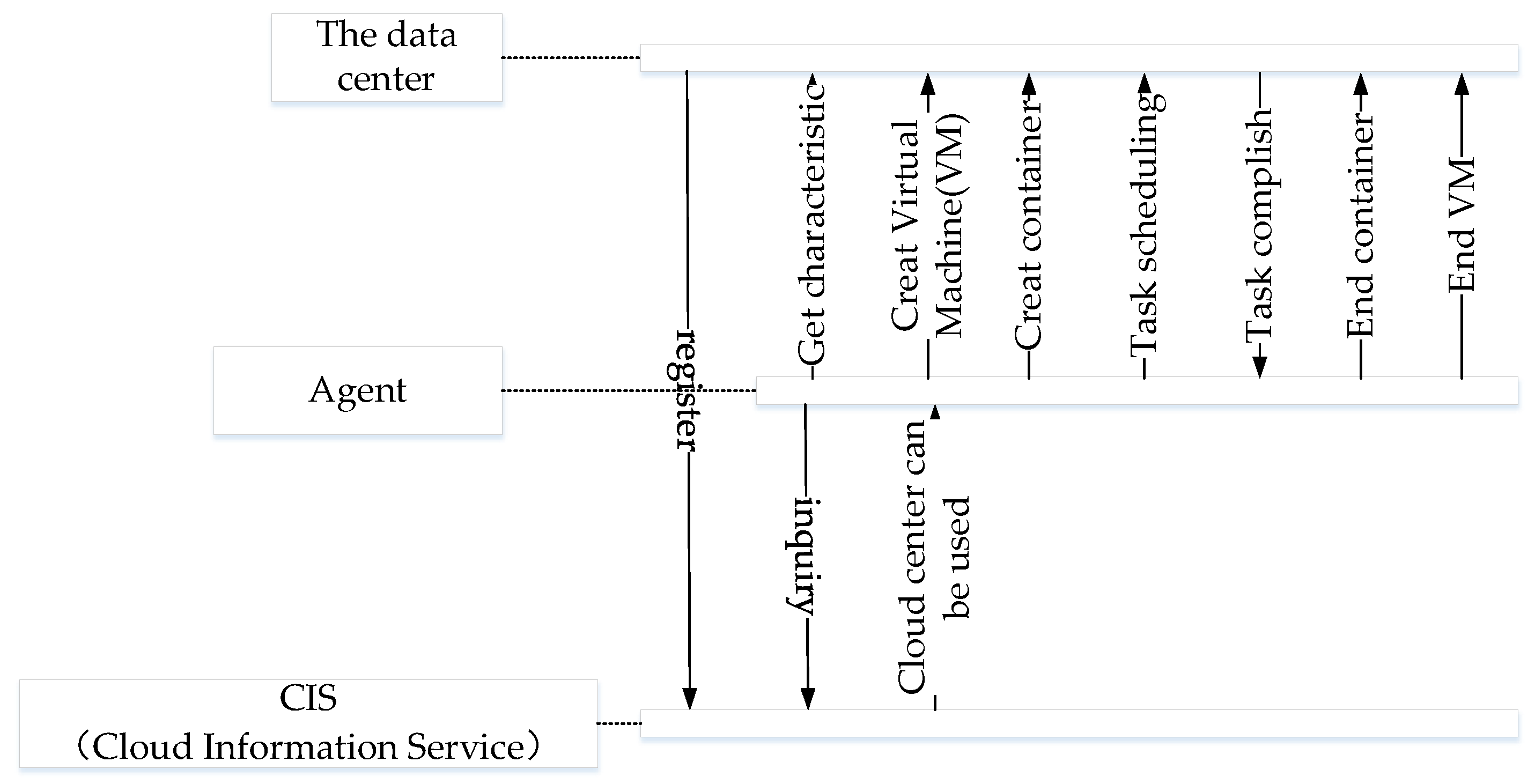
We use Container-CloudSim, whose simulation flows are shown in
Figure 7, which is the container cloud evaluation environment in CloudSim [
13], to simulate the designed microservice resource scheduling optimization model and algorithm. In order to compare the effectiveness of the algorithm, we select the round-robin algorithm (RR) [
23], the most-utilization first algorithm (MF) [
24], and the first come first serve (FCFS) algorithm in ContainerCloudSim-4.0 for comparison.
The experiments were run on Intel
® Core™ i5-4200U
[email protected] GHz and 8G RAM computer. To simulate servers’ situation in edge computing, we set all servers with the same performance, as shown in
Table 1. As stated in the previous chapter, we mainly consider four types of resource utilization: CPU, memory, disk, and bandwidth.
We set the microservice container’s size to be tenth order, hundredth order, and thousandth order to better simulate the deployment scenario of the V2X application deployment, as shown in
Table 2. The characteristics and calling dependencies of containers are created by random functions. These three orders of magnitude can correspond to small-scale, medium-scale, and large-scale deployment scenarios of V2X applications.
We found that when α = 0.3, β = 0.2, and λ = 0.5, the simulation could achieve the best results through multiple sets of experiments. Compared with the other three algorithms, MFGA consumed the fewest physical hosts when the amount of microservice containers reached 280 or more in
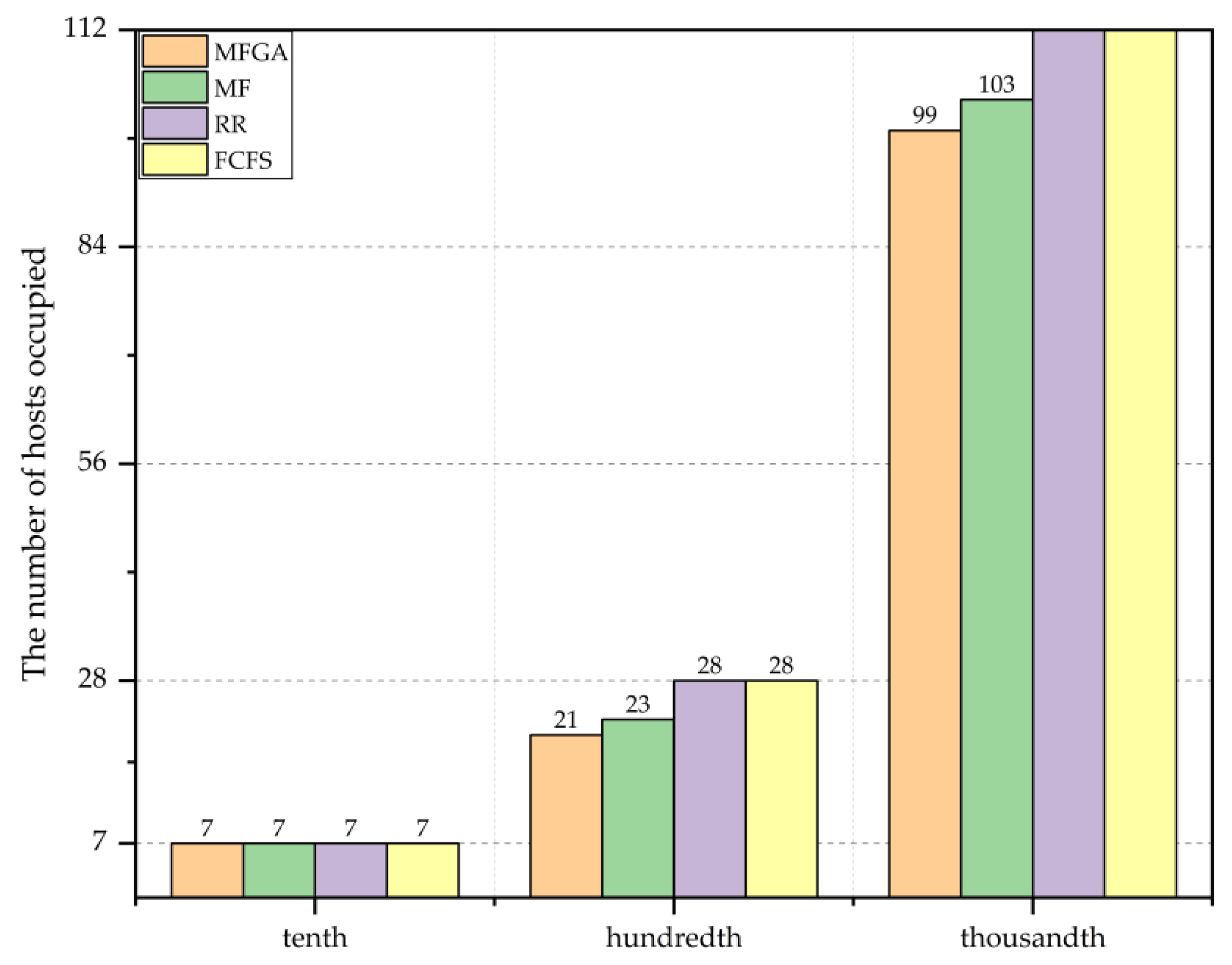
Figure 8. Significantly, the multiple fitness genetic algorithm (MAGA) used 20% fewer hosts than the FCFS and RR algorithms, when the size of containers reached the thousandth order.
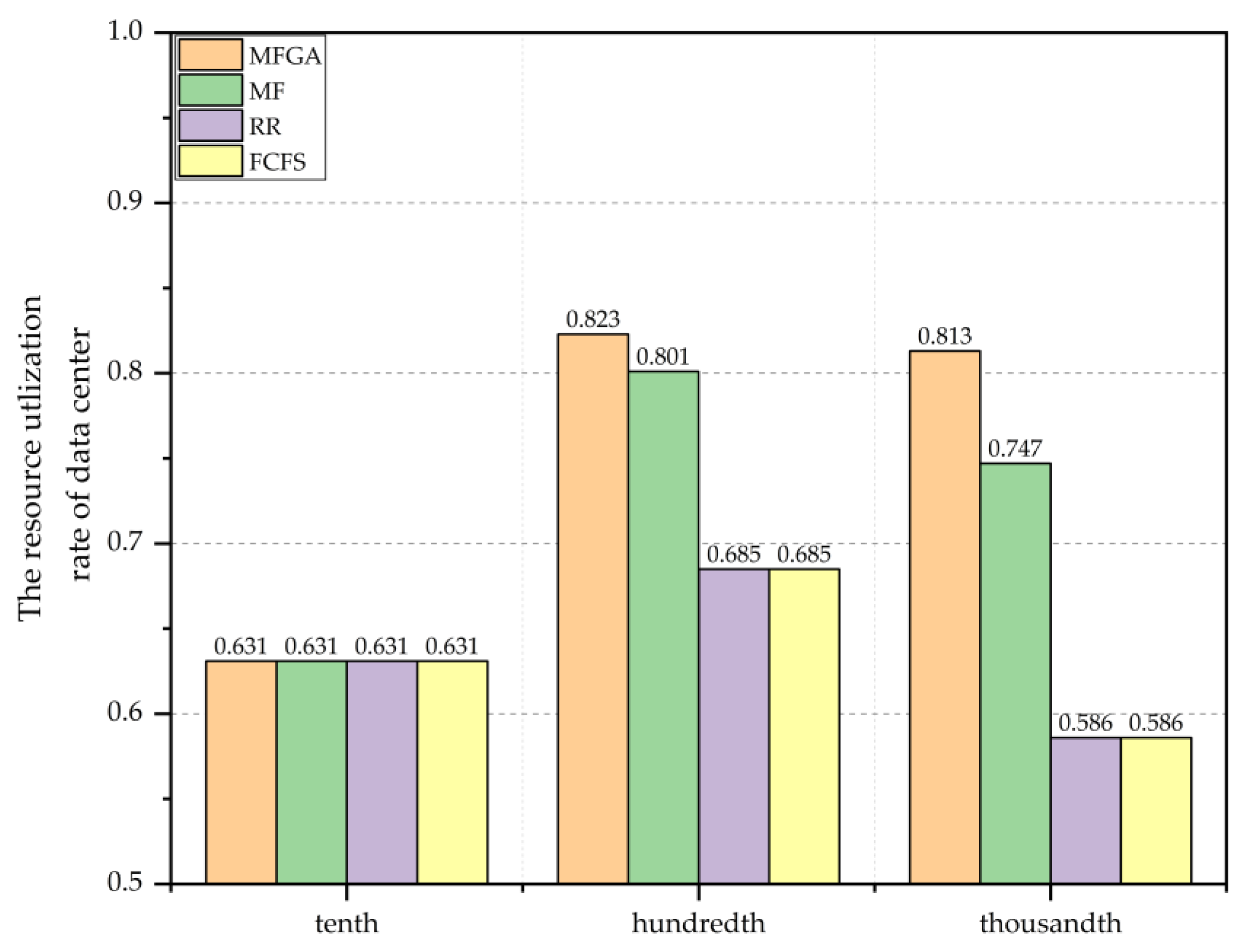
Figure 9 shows the simulation result of the resource utilization rate of the data center. Similarly, the advantages of MFGA become more and more significant in resource utilization with the increase in the microservice containers. The MFGA algorithm keeps the resource utilization of 0.8 in the hundredth or thousandth order scenario, which is superior to all the other algorithms.
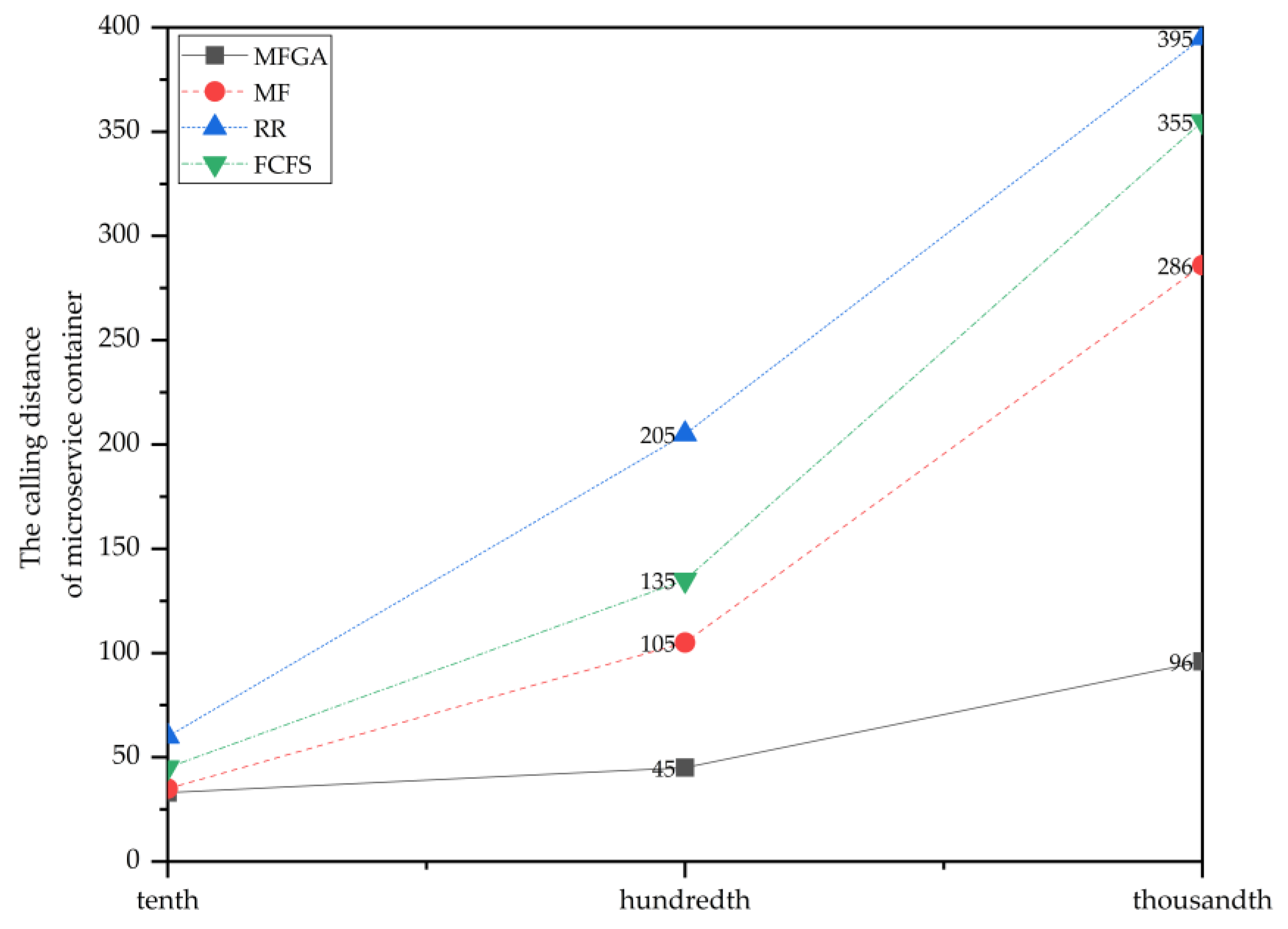
Figure 10 shows the simulation results of four algorithms in terms of calling distance. The MFGA has a smaller calling distance, which means that MFGA needs less cross-server scheduling when deploying containers. Although the number of containers changed drastically, the growth curve of the MFGA was not noticeable compared to the other three algorithms. In other words, the MFGA could perform better in the scenario of a large number of containers due to the consideration of the container’s dependencies, which was an important reason that MFGA performed better in the resource utilization.
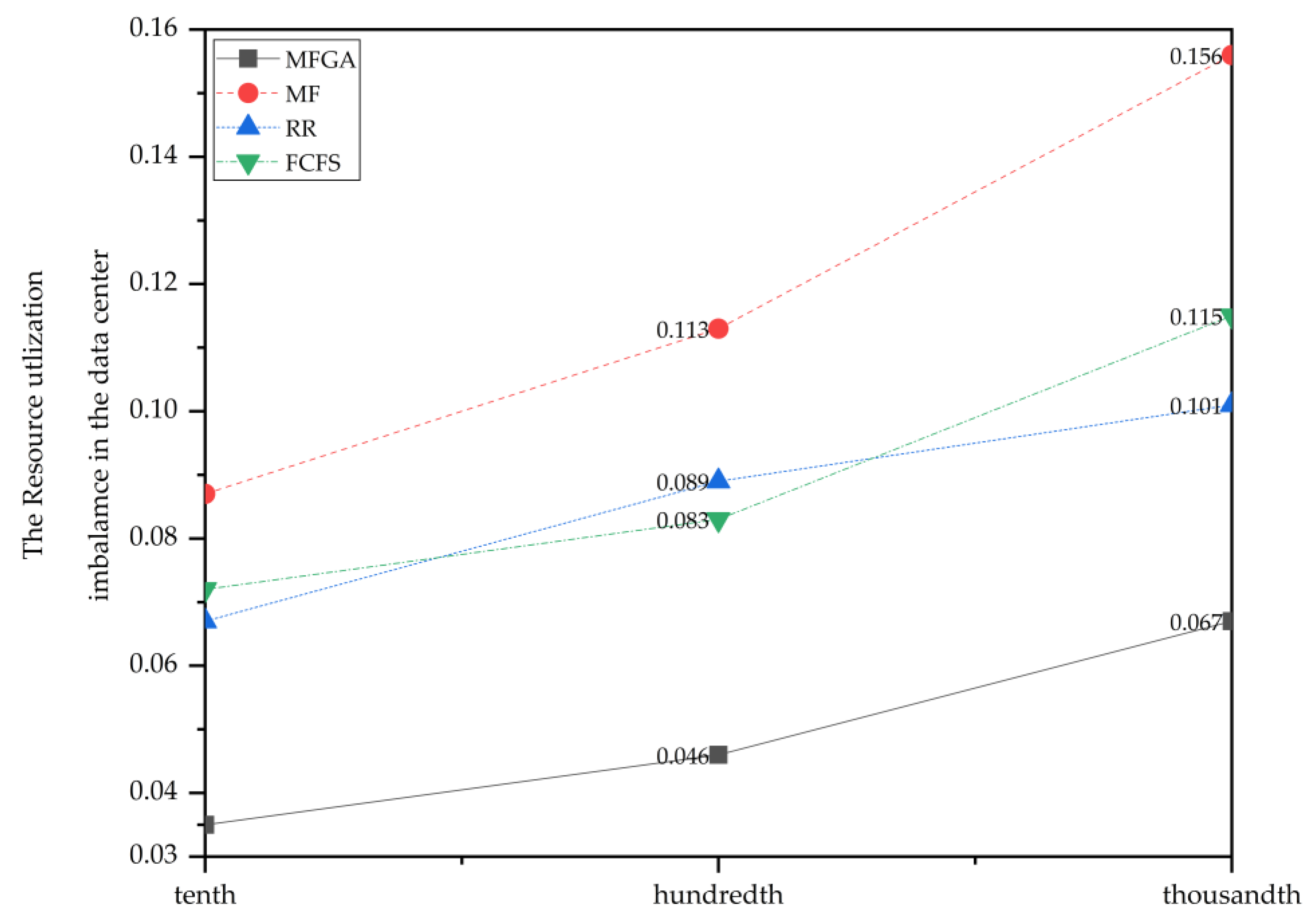
Figure 11 shows the comparison of four algorithms in terms of the resource utilization imbalance. The resource utilization imbalance increased as the number of containers grew. The MFGA maintained a relatively low level in resource utilization imbalance compared to other algorithms, which allowed it to achieve an ideal resource balance effect.
In all, we have achieved our optimization goals: fewest hosts occupied, most resource utilization, lowest calling distance, and resource utilization imbalance. In particular, the MFGA performed well in the thousandth order scenario, which is similar to the real situation of deploying V2X containers. Thus, MGFA is an efficient choice to solve resource scheduling problems.
5. Discussion
In this article, we study the resource scheduling in containerized microservice deployment. To model this problem, we analyze its architecture and quantify the key factors in the scheduling process. After obtaining a multi-objective model, we develop the multiple fitness genetic algorithm, which introduces a container dynamic migration strategy into the process.
To evaluate the efficiency of our model and MGFA, we use Container-CloudSim to simulate the different scenarios in V2X microservice deployment. During the simulation experiments, we find that MGFA performs better than the RR algorithm, the MF algorithm, and the FCFS algorithm, especially when we compare results in terms of the number of hosts occupied, the utilization rate of the data center, resource utilization imbalance, and calling distance.
The method above improves the calculation efficiency of MGFA and makes it more suitable for solving microservice resource scheduling problems. However, we did not consider the situation of deploying the vehicle network application of collaboration with the central cloud. At the same time, the weights in our algorithm are decided by the administrator, which may cause faults in the scheduling process. Last but not least, we only simulate some scenarios in Container-CloudSim, and we do not evaluate our algorithm in an actual situation.
We will develop a weight adaptive adjustment system to change weights based on the different characteristics in edge computing architecture in future work. Moreover, we will design a cloud-side collaborative microservice scheduling strategy to better suit the actual situation. Finally, we will deploy our developed system in a real V2X network to test its performance.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}