A Comparative Analysis of Machine Learning Techniques for Cyberbullying Detection on Twitter



Abstract
:1. Introduction
- We conducted an extensive review of quality papers to determine the machine learning (ML) methods widely used in the detection of cyberbullying in social media (SM) platforms.
- We evaluated the classifiers investigated in this work, and test their usability and accuracy on a sizeable generic dataset.
- We developed an automated detection model by incorporating feature extraction in the classifiers to enhance the classifiers’ efficiency on the sizeable generic dataset.
- We compared the performance of seven ML classifiers that are commonly used in the detection of cyberbullying. We also used the Frequency-Inverse Document Frequency (TF-IDF) and Word2Vec models for feature extraction. This comparison analysis helped to understand the limitations and advantages of ML in text classification models.
- What types of existing machine learning techniques/methods are being used extensively to detect cyberbullying in social media platforms?
- How can an automatic cyberbullying detection model be developed with high accuracy and less processing time?
- How can feature extraction be used to enhance the detection process?
2. Background and Related Work
2.1. Natural Language Processing (NLP) in Cyberbullying Detection
- Phonology level (knowledge of linguistic sounds)
- Morphology level (knowledge of the meaningful components of words)
- Lexical level (deals with the lexical meaning of words and parts of speech analyses)
- Syntactic level (knowledge of the structural relationships between words)
- Semantic level (knowledge of meaning)
- Discourse level (knowledge about linguistic units more extensive than a single utterance)
- Pragmatic level (knowledge of the relationship of meaning to the goals and intentions of the speaker)
2.2. Machine Learning in Cyberbullying Detection
2.2.1. Logistic Regression
- if hθ (x) ≥ 0.5, y = 1 (Positive class)
- and if hθ (x) ≤ 0.5, y = 0 (Negative class)
2.2.2. Logistic Light Gradient Boosting Machine
2.2.3. Stochastic Gradient Descent
2.2.4. Random Forest
- In the training data, N is the number of examples (cases), and M is the number of attributes in the classifier.
- Selecting random attributes produces a set of arbitrary decision tresses. For each tree, a training set is selected by selecting n times out of all existing N instances. The remaining instances in the training set are used by predicting their classes to estimate the tree’s error.
- M random variables are chosen for the nodes of each tree to base the decision at that node. In the training package, the most exceptional split is determined using specific m attributes. Each tree is built entirely and not pruned, as can be done in the development of a regular tree classifier.
- This architecture produces a large number of trees. For the most common class, those decision trees vote. Such processes are denominated RFs. RF builds a model consisting of a group of tree-structured classifiers, where each tree votes for the most popular class [93]. The one selected as the output is the most highly voted class.
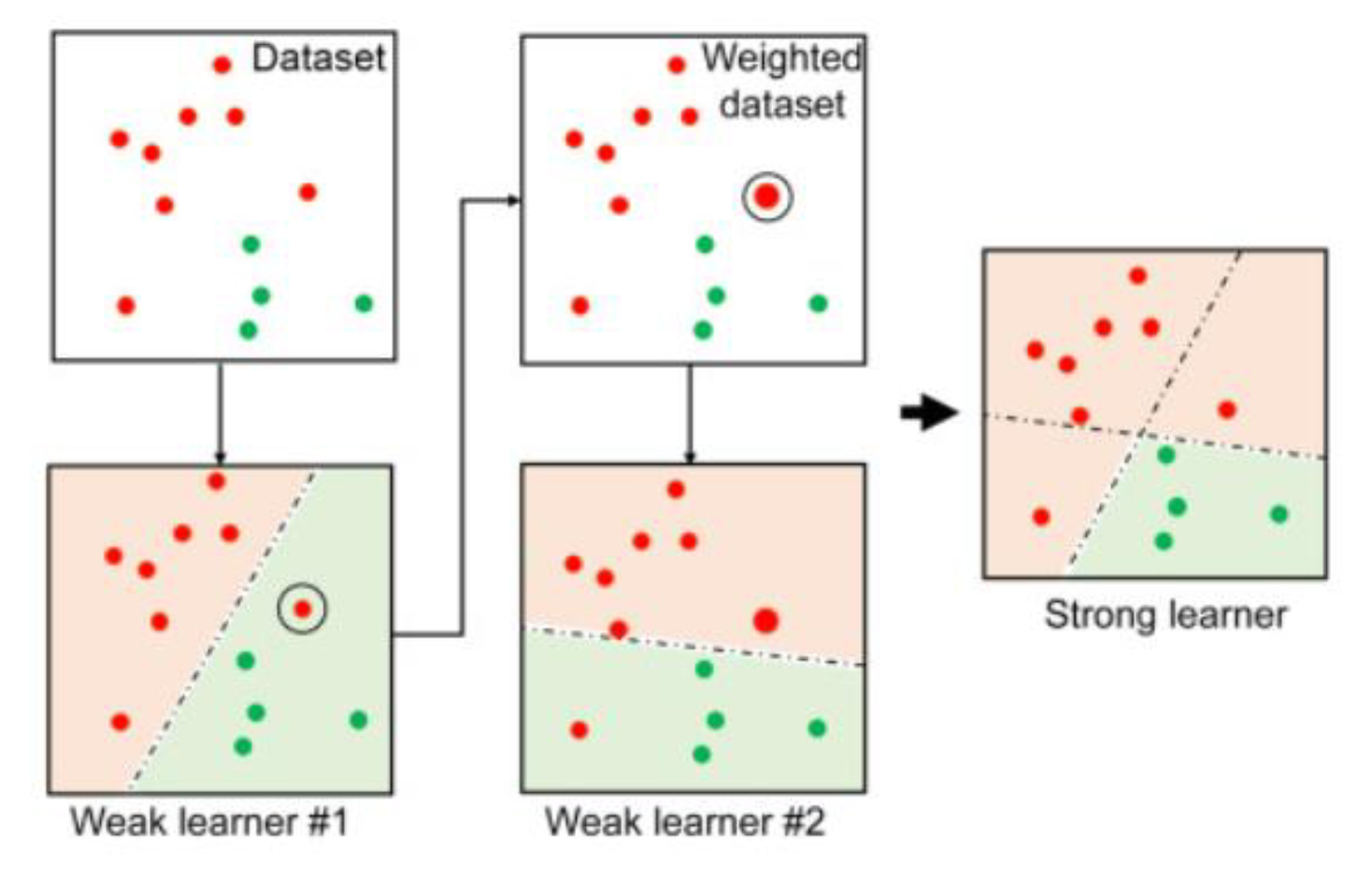
2.2.5. AdaBoost
2.2.6. Multinomial Naive Bayes
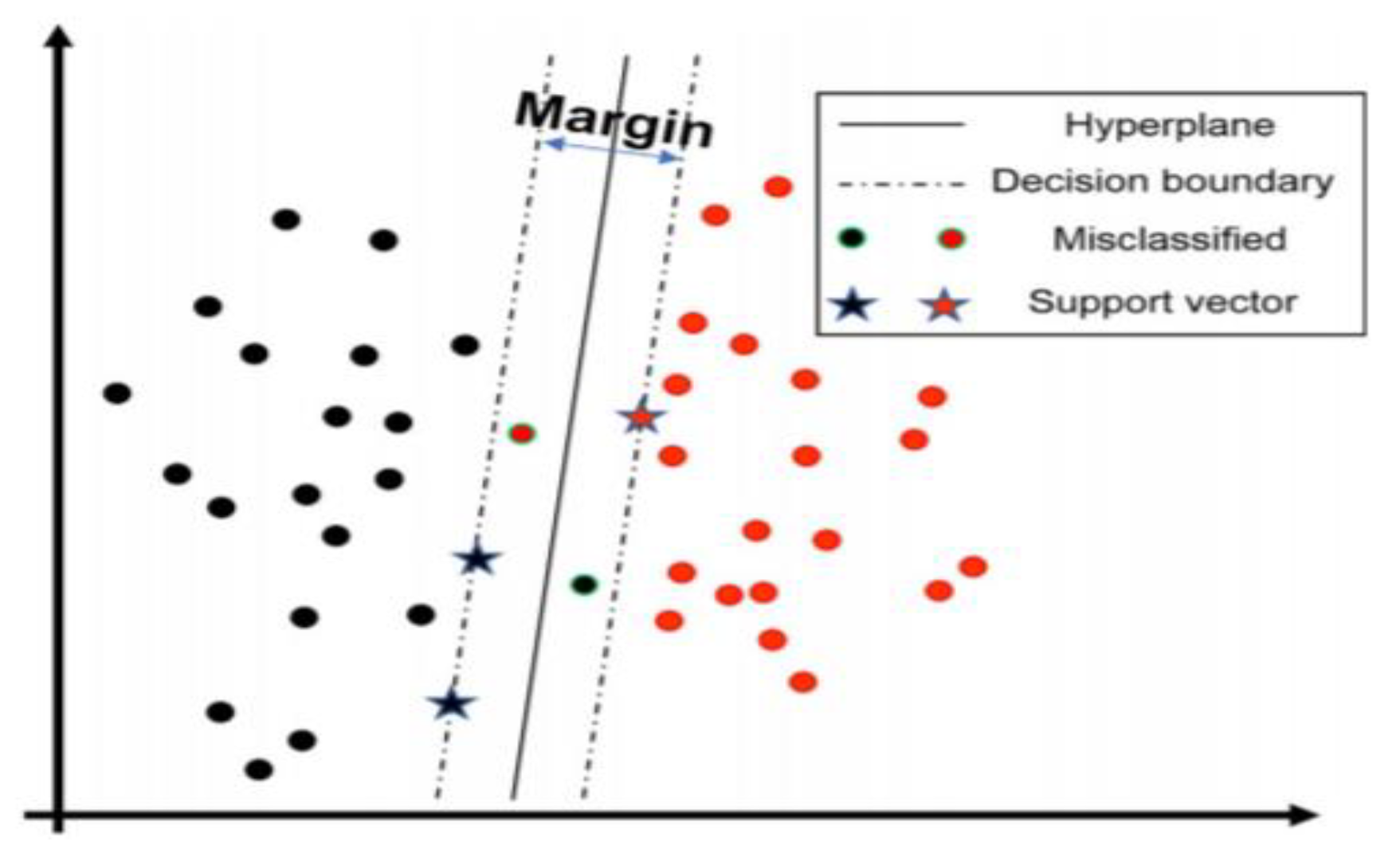
2.2.7. Support Vector Machine Classifier
3. Materials and Methods
3.1. Dataset
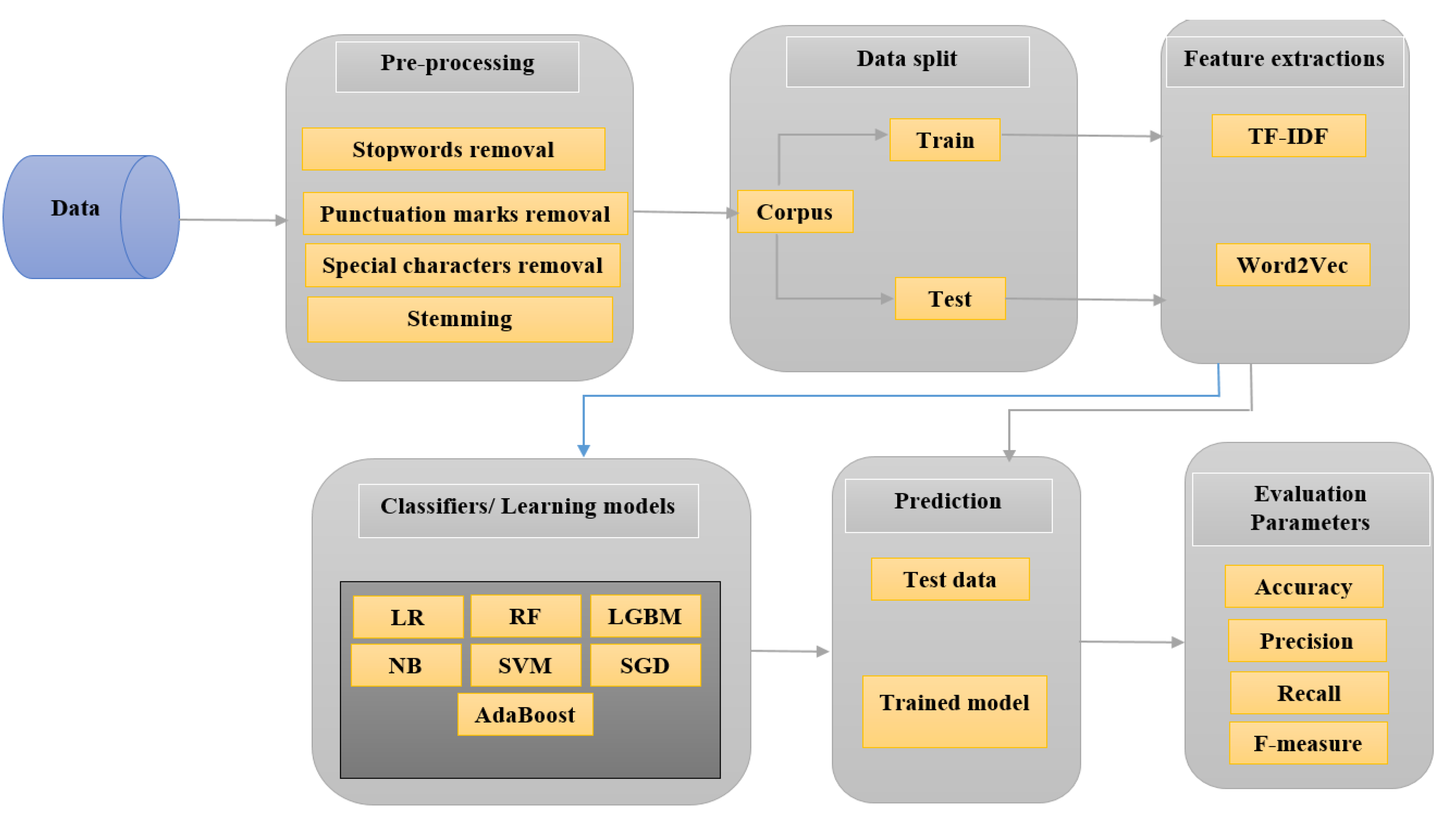
3.2. Model Overview
3.2.1. Pre-processing
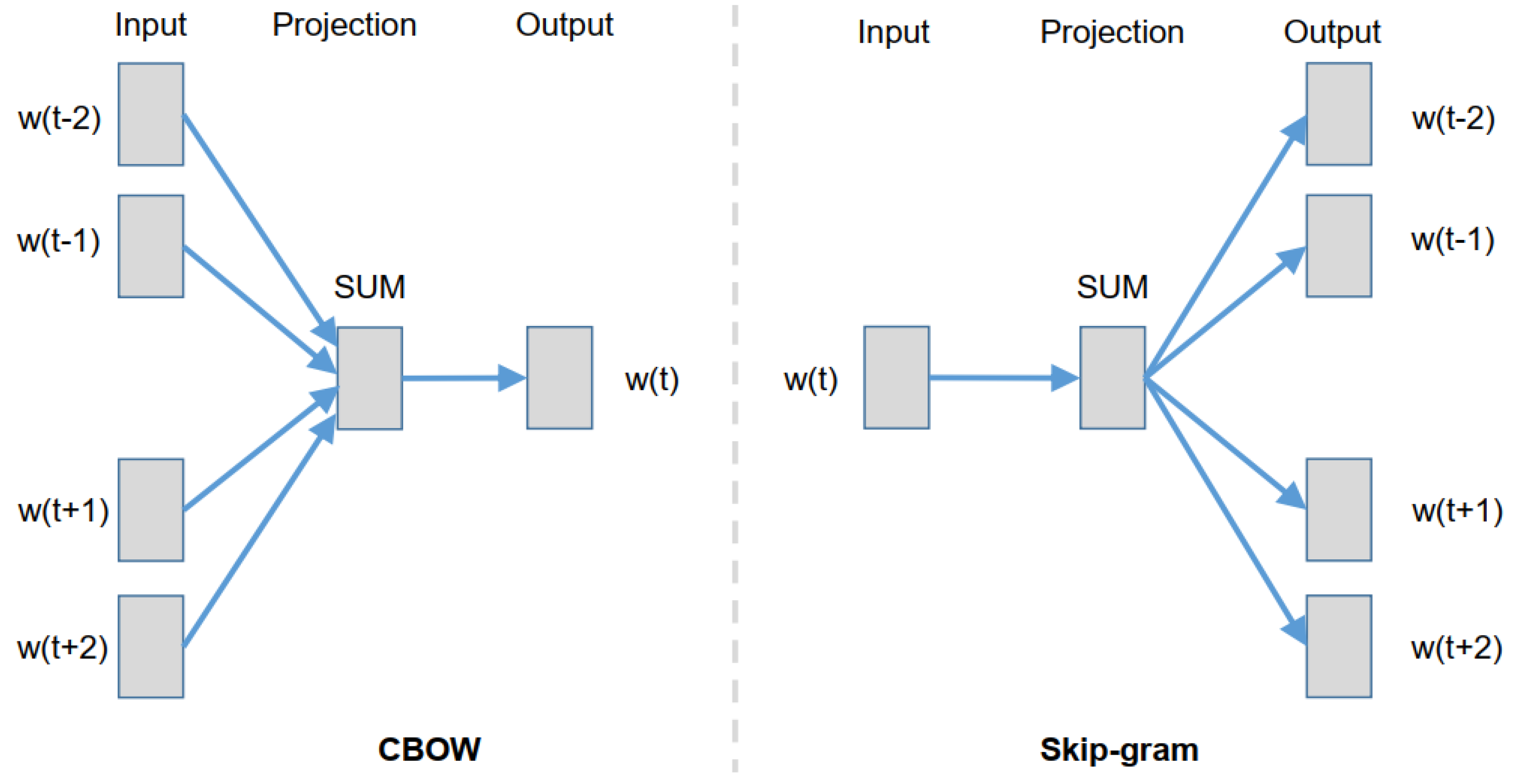
3.2.2. Feature Extraction
3.2.3. Classification Techniques
4. Results and Discussion
4.1. Evaluation Metrics
Accuracy
- Precision calculates the proportion of relevant tweets among true positive (tp) and false positive (fp) tweets belonging to a specific group.
- Recall calculates the ratio of retrieved relevant tweets over the total number of relevant tweets.
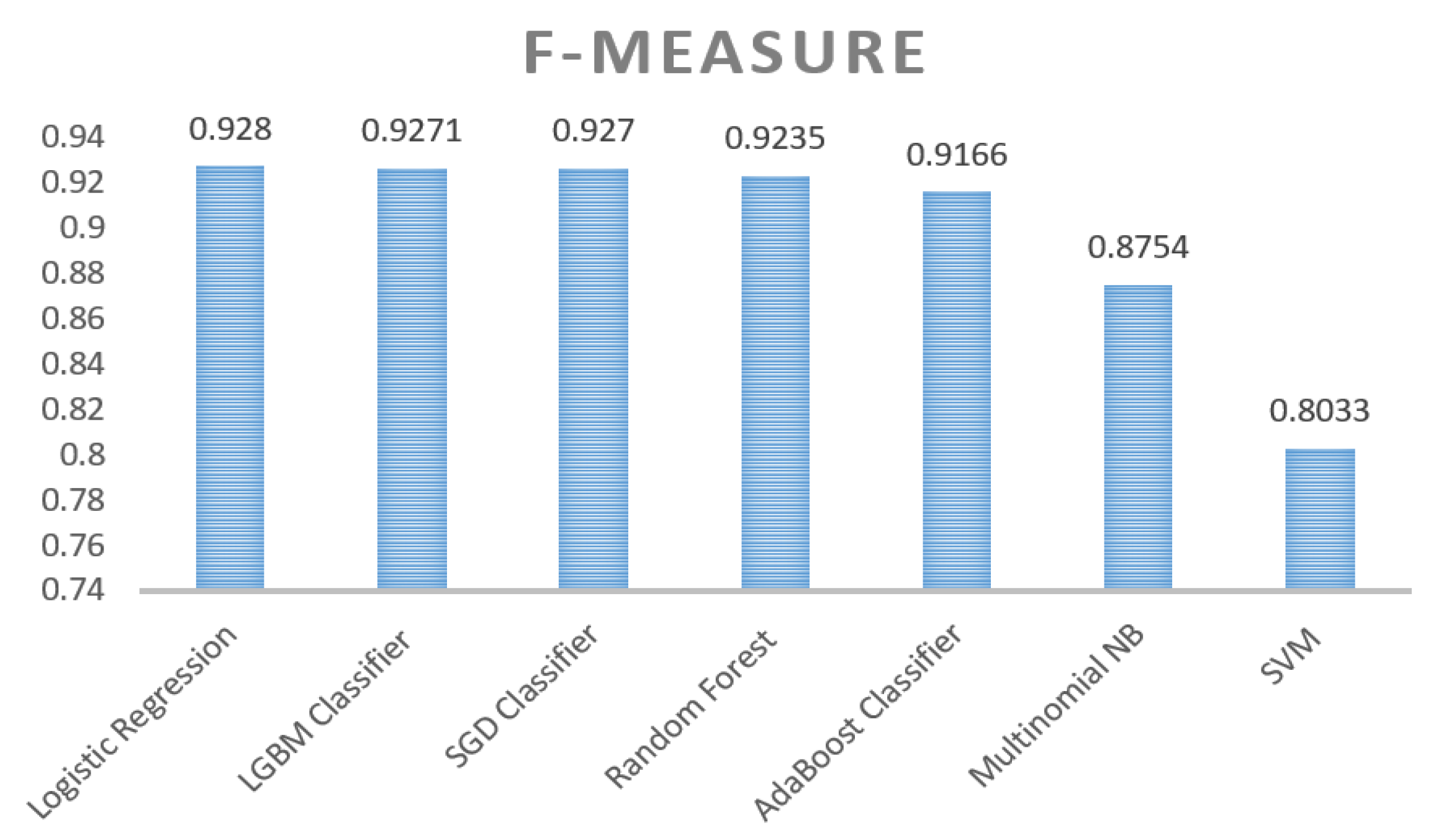
- F-Measure provides a way to combine precision and recall into a single measure that captures both properties.
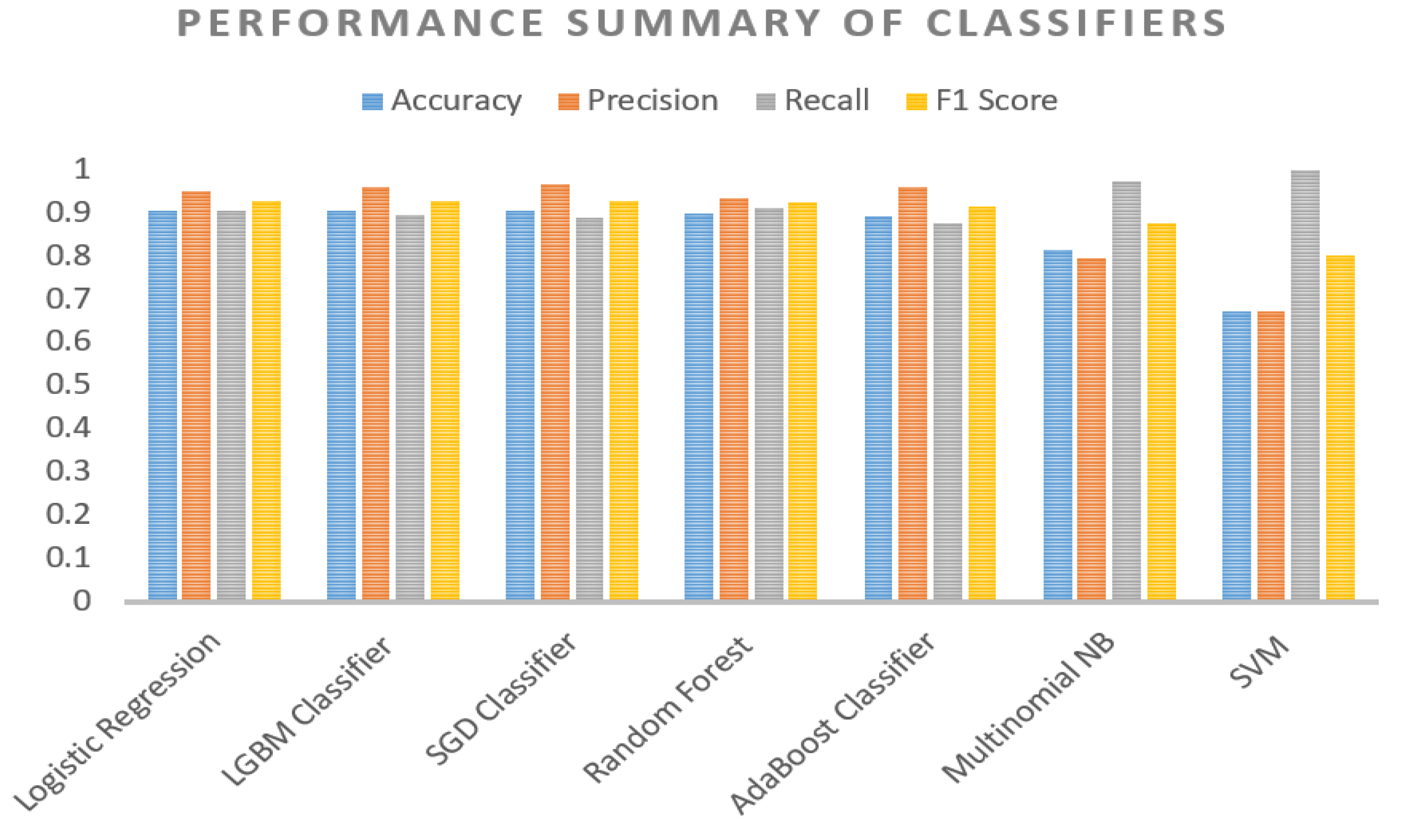
4.2. Performance Result of Classifiers
4.3. Time Complexity of Algorithms
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Edosomwan, S.; Prakasan, S.K.; Kouame, D.; Watson, J.; Seymour, T. The history of social media and its impact on business. J. Appl. Manag. Entrep. 2011, 16, 79–91. [Google Scholar]
- Bauman, S. Cyberbullying: What Counselors Need to Know; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Pereira-Kohatsu, J.C.; Quijano-Sánchez, L.; Liberatore, F.; Camacho-Collados, M. Detecting and Monitoring Hate Speech in Twitter. Sensors 2019, 19, 4654. [Google Scholar] [CrossRef] [Green Version]
- Miller, K. Cyberbullying and its consequences: How cyberbullying is contorting the minds of victims and bullies alike, and the law’s limited available redress. S. Cal. Interdisc. Law J. 2016, 26, 379. [Google Scholar]
- Price, M.; Dalgleish, J. Cyberbullying: Experiences, impacts and coping strategies as described by australian young people. Youth Stud. Aust. 2010, 29, 51. [Google Scholar]
- Smith, P.K. Cyberbullying and Cyber Aggression. In Handbook of School Violence and School Safety; Informa UK Limited: Colchester, UK, 2015. [Google Scholar]
- Sampasa-Kanyinga, H.; Roumeliotis, P.; Xu, H. Associations between Cyberbullying and School Bullying Victimization and Suicidal Ideation, Plans and Attempts among Canadian Schoolchildren. PLoS ONE 2014, 9, e102145. [Google Scholar] [CrossRef]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated Hate Speech Detection and the Problem of Offensive Language. arXiv 2017, arXiv:1703.04009. [Google Scholar]
- Mc Guckin, C.; Corcoran, L. (Eds.) Cyberbullying: Where Are We Now? A Cross-National Understanding; MDPI: Wuhan, China, 2017. [Google Scholar]
- Vaillancourt, T.; Faris, R.; Mishna, F. Cyberbullying in Children and Youth: Implications for Health and Clinical Practice. Can. J. Psychiatry 2016, 62, 368–373. [Google Scholar] [CrossRef]
- Görzig, A.; Ólafsson, K. What Makes a Bully a Cyberbully? Unravelling the Characteristics of Cyberbullies across Twenty-Five European Countries. J. Child. Media 2013, 7, 9–27. [Google Scholar] [CrossRef] [Green Version]
- Salton, G.; Buckley, C. Term-wsevening approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar]
- Liu, Q.; Wang, J.; Zhang, D.; Yang, Y.; Wang, N. Text Features Extraction based on TF-IDF Associating Semantic. In Proceedings of the 2018 IEEE 4th International Conference on Computer and Communications (ICCC), Chengdu, China, 7–10 December 2018; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2018; pp. 2338–2343. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Goldberg, Y.; Levy, O. word2vec Explained: Deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv 2014, arXiv:1402.3722. [Google Scholar]
- Li, J.; Huang, G.; Fan, C.; Sun, Z.; Zhu, H. Key word extraction for short text via word2vec, doc2vec, and textrank. Turk. J. Electr. Eng. Comput. Sci. 2019, 27, 1794–1805. [Google Scholar] [CrossRef]
- Jiang, C.; Zhang, H.; Ren, Y.; Han, Z.; Chen, K.-C.; Hanzo, L. Machine Learning Paradigms for Next-Generation Wireless Networks. IEEE Wirel. Commun. 2016, 24, 98–105. [Google Scholar] [CrossRef] [Green Version]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef] [Green Version]
- Al-Garadi, M.A.; Hussain, M.R.; Khan, N.; Murtaza, G.; Nweke, H.F.; Ali, I.; Mujtaba, G.; Chiroma, H.; Khattak, H.A.; Gani, A. Predicting Cyberbullying on Social Media in the Big Data Era Using Machine Learning Algorithms: Review of Literature and Open Challenges. IEEE Access 2019, 7, 70701–70718. [Google Scholar] [CrossRef]
- Maalouf, M. Logistic regression in data analysis: An overview. Int. J. Data Anal. Tech. Strat. 2011, 3, 281–299. [Google Scholar] [CrossRef]
- Hosmer, D.W.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; Wiley: Hoboken, NJ, USA, 2013; Volume 398. [Google Scholar]
- Chavan, V.S.; Shylaja, S.S. Machine learning approach for detection of cyber-aggressive comments by peers on social media network. In Proceedings of the 2015 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Kochi, India, 10–13 August 2015; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2015; pp. 2354–2358. [Google Scholar]
- Mangaonkar, A.; Hayrapetian, A.; Raje, R. Collaborative detection of cyberbullying behavior in Twitter data. In Proceedings of the 2015 IEEE International Conference on Electro/Information Technology (EIT), Dekalb, IL, USA, 21–23 May 2015; IEEE: New York, NY, USA, 2015; pp. 611–616. [Google Scholar]
- Leon-Paredes, G.A.; Palomeque-Leon, W.F.; Gallegos-Segovia, P.L.; Vintimilla-Tapia, P.E.; Bravo-Torres, J.F.; Barbosa-Santillan, L.I.; Paredes-Pinos, M.M. Presumptive Detection of Cyberbullying on Twitter through Natural Language Processing and Machine Learning in the Spanish Language. In Proceedings of the 2019 IEEE CHILEAN Conference on Electrical, Electronics Engineering, Information and Communication Technologies (CHILECON), Valparaiso, Chile, 13–27 November 2019; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2019; pp. 1–7. [Google Scholar]
- Ho, S.M.; Li, W.; Lai, C.J.; Ankamah, B. Charged Language on Twitter: A Predictive Model of Cyberbullying to Prevent Victimization. In Proceedings of the 2019 AIS SIGSEC Special Interest Group 10th Annual Workshop on Information Security and Privacy (WISP), International Conference on Information Systems (ICIS), AIS, Munich, Germany, 15 December 2019; pp. 1–10. [Google Scholar]
- Ibn Rafiq, R.; Hosseinmardi, H.; Han, R.; Lv, Q.; Mishra, S. Scalable and timely detection of cyberbullying in online social networks. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing—SAC ’18, Pau, France, 9–13 April 2018; pp. 1738–1747. [Google Scholar]
- Cheng, L.; Li, J.; Silva, Y.N.; Hall, D.L.; Liu, H. XBully: Cyberbullying Detection within a Multi-Modal Context. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; ACM: New York, NY, USA, 2019; pp. 339–347. [Google Scholar]
- Nahar, V.; Li, X.; Zhang, H.L.; Pang, C. Detecting cyberbullying in social networks using multi-agent system. Web Intell. Agent Syst. Int. J. 2014, 12, 375–388. [Google Scholar] [CrossRef]
- Mandot, P. What Is Lightgbm, How to Implement It? How to Fine Tune the Parameters? Medium. 2017. Available online: https://medium.com/@pushkarmandot/https-medium-com-pushkarmandot-what-is-lightgbm-how-to-implement-it-how-to-fine-tune-the-parameters-60347819b7fc (accessed on 22 July 2020).
- Rahman, S.; Irfan, M.; Raza, M.; Ghori, K.M.; Yaqoob, S.; Awais, M. Performance Analysis of Boosting Classifiers in Recognizing Activities of Daily Living. Int. J. Environ. Res. Public Health 2020, 17, 1082. [Google Scholar] [CrossRef] [Green Version]
- Brownlee, J. Gradient Boosting With Scikit-Learn, Xgboost, Lightgbm, and Catboost. Machine Learning Mastery. 2020. Available online: https://machinelearningmastery.com/gradient-boosting-with-scikit-learn-xgboost-lightgbm-and-catboost/ (accessed on 22 July 2020).
- Zinovyeva, E.; Härdle, W.K.; Lessmann, S. Antisocial online behavior detection using deep learning. Decis. Support Syst. 2020, 138, 113362. [Google Scholar] [CrossRef]
- Bhattacharya, I.; Lindgreen, E.R. A Semi-Supervised Machine Learning Approach to Detect Anomalies in Big Accounting Data. In Proceedings of the ECIS, Marrakech, Morocco, 15–17 June 2020. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 2017; pp. 3146–3154. [Google Scholar]
- Brownlee, J. Master Machine Learning Algorithms: Discover How They Work and Implement Them from Scratch; Machine Learning Mastery: Vermont, Australia, 2016. [Google Scholar]
- Pawar, R.; Agrawal, Y.; Joshi, A.; Gorrepati, R.; Raje, R.R. Cyberbullying detection system with multiple server configurations. In Proceedings of the 2018 IEEE International Conference on Electro/Information Technology (EIT), Rochester, MI, USA, 3–5 May 2018; IEEE: New York, NY, USA, 2018; pp. 0090–0095. [Google Scholar]
- Aci, C.; Çürük, E.; Eşsiz, E.S. Automatic Detection of Cyberbullying in FORMSPRING.Me, Myspace and Youtube Social Networks. Turk. J. Eng. 2019, 3, 168–178. [Google Scholar] [CrossRef]
- Pawar, R.; Raje, R.R. Multilingual Cyberbullying Detection System. In Proceedings of the 2019 IEEE International Conference on Electro Information Technology (EIT), Brookings, SD, USA, 20–22 May 2019; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2019; pp. 040–044. [Google Scholar]
- Why Logistic Regression over Naïve Bayes. Available online: https://medium.com/@sangha_deb/naive-bayes-vs-logisticregression-a319b07a5d4c (accessed on 22 July 2020).
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar]
- Patel, S. Chapter 5: Random Forest Classifier. 2017. Available online: https://medium.com/machine-learning-101/chapter-5-random-forest-classifier-56dc7425c3e1 (accessed on 22 July 2020).
- Louppe, G. Understanding random forests: From theory to practice. arXiv 2014, arXiv:1407.7502. [Google Scholar]
- Novalita, N.; Herdiani, A.; Lukmana, I.; Puspandari, D. Cyberbullying identification on twitter using random forest classifier. J. Physics Conf. Ser. 2019, 1192, 012029. [Google Scholar] [CrossRef]
- García-Recuero, Á. Discouraging Abusive Behavior in Privacy-Preserving Online Social Networking Applications. In Proceedings of the 25th International Conference Companion on World Wide Web—WWW ’16 Companion, Montreal, QC, Canada, 11–15 April 2016; Association for Computing Machinery (ACM): New York, NY, USA, 2016; pp. 305–309. [Google Scholar]
- Waseem, Z.; Hovy, D. Hateful Symbols or Hateful People? Predictive Features for Hate Speech Detection on Twitter. In Proceedings of the NAACL Student Research Workshop, San Diego, CA, USA, 16–17 June 2016; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2016; pp. 88–93. [Google Scholar]
- Chengsheng, T.; Huacheng, L.; Bing, X. AdaBoost typical Algorithm and its application research. In MATEC Web of Conferences; EDP Sciences: Ulis, France, 2017; Volume 139, p. 00222. [Google Scholar]
- Chatterjee, R.; Datta, A.; Sanyal, D.K. Ensemble Learning Approach to Motor Imagery EEG Signal Classification. In Machine Learning in Bio-Signal Analysis and Diagnostic Imaging; Elsevier BV: Amsterdam, The Netherlands, 2019; pp. 183–208. [Google Scholar]
- Misra, S.; Li, H. Noninvasive fracture characterization based on the classification of sonic wave travel times. In Machine Learning for Subsurface Characterization; Elsevier BV: Amsterdam, The Netherlands, 2020; pp. 243–287. [Google Scholar]
- Ibn Rafiq, R.; Hosseinmardi, H.; Han, R.; Lv, Q.; Mishra, S.; Mattson, S.A. Careful What You Share in Six Seconds.ss2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2015—ASONAM ’15; Association for Computing Machinery (ACM): New York, NY, USA, 2015; pp. 617–622. [Google Scholar]
- Tarwani, S.; Jethanandani, M.; Kant, V. Cyberbullying Detection in Hindi-English Code-Mixed Language Using Sentiment Classification. In Communications in Computer and Information Science; Springer Science and Business Media LLC: Singapore, 2019; pp. 543–551. [Google Scholar]
- Raza, M.O.; Memon, M.; Bhatti, S.; Bux, R. Detecting Cyberbullying in Social Commentary Using Supervised Machine Learning. In Advances in Intelligent Systems and Computing; Springer Science and Business Media LLC: Singapore, 2020; pp. 621–630. [Google Scholar]
- Galán-García, P.; De La Puerta, J.G.; Gómez, C.L.; Santos, I.; Bringas, P.G. Supervised machine learning for the detection of troll profiles in twitter social network: Application to a real case of cyberbullying. Log. J. IGPL 2015, 24, jzv048. [Google Scholar] [CrossRef] [Green Version]
- Akhter, A.; Uzzal, K.A.; Polash, M.A. Cyber Bullying Detection and Classification using Multinomial Naïve Bayes and Fuzzy Logic. Int. J. Math. Sci. Comput. 2019, 5, 1–12. [Google Scholar] [CrossRef]
- Nandakumar, V. Cyberbullying revelation in twitter data using naïve bayes classifier algorithm. Int. J. Adv. Res. Comput. Sci. 2018, 9, 510–513. [Google Scholar] [CrossRef]
- Dinakar, K.; Reichart, R.; Lieberman, H. Modeling the detection of textual cyberbullying. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- Chen, Y.; Zhou, Y.; Zhu, S.; Xu, H. Detecting Offensive Language in Social Media to Protect Adolescent Online Safety. In Proceedings of the 2012 International Conference on Privacy, Security, Risk and Trust and 2012 International Confernece on Social Computing, Amsterdam, The Netherlands, 3–5 September 2012; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2012; pp. 71–80. [Google Scholar]
- Sintaha, M.; Satter, S.B.; Zawad, N.; Swarnaker, C.; Hassan, A. Cyberbullying Detection Using Sentiment Analysis in Social Media. Ph.D. Thesis, BRAC University, Dhaka, Bangladesh, 2016. [Google Scholar]
- McCallum, A.; Nigam, K. A comparison of event models for naive bayes text classification. In AAAI-98 Workshop on Learning for Text Categorization; Amer Assn for Artificial Intelligence: Cambridge, MA, USA, 1998; Volume 752, pp. 41–48. [Google Scholar]
- Buczak, A.L.; Guven, E. A Survey of Data Mining and Machine Learning Methods for Cyber Security Intrusion Detection. IEEE Commun. Surv. Tutor. 2015, 18, 1153–1176. [Google Scholar] [CrossRef]
- Zhang, H. Exploring conditions for the optimality of naïve bayes. Int. J. Pattern Recognit. Artif. Intell. 2005, 19, 183–198. [Google Scholar] [CrossRef]
- Joachims, T. Text categorization with Support Vector Machines: Learning with many relevant features. In the Computer Vision—ECCV 2018; Springer Science and Business Media LLC: Berlin, Germany, 1998; pp. 137–142. [Google Scholar]
- Ptaszynski, M.; Eronen, J.K.K.; Masui, F. Learning Deep on Cyberbullying is Always Better than Brute Force. In Proceedings of the LaCATODA@ IJCAI, Melbourne, Australia, 21 August 2017; pp. 3–10. [Google Scholar]
- Chatzakou, D.; Leontiadis, I.; Blackburn, J.; De Cristofaro, E.; Stringhini, G.; Vakali, A.; Kourtellis, N. Detecting Cyberbullying and Cyberaggression in Social Media. ACM Trans. Web 2019, 13, 1–51. [Google Scholar] [CrossRef]
- Irena, B.; Setiawan, E.B. Fake News (Hoax) Identification on Social Media Twitter using Decision Tree C4.5 Method. J. RESTI (Rekayasa Sist. dan Teknol. Informasi) 2020, 4, 711–716. [Google Scholar] [CrossRef]
- Hosseinmardi, H.; Mattson, S.A.; Ibn Rafiq, R.; Han, R.; Lv, Q.; Mishra, S. Detection of Cyberbullying Incidents on the Instagram Social Network. arXiv 2015, arXiv:1503.03909. [Google Scholar]
- Ptaszynski, M.; Dybala, P.; Matsuba, T.; Masui, F.; Rzepka, R.; Araki, K. Machine learning and affect analysis against cyber-bullying. In Proceedings of the the 36th AISB, Leicester, UK, 29 March–1 April 2010; pp. 7–16. [Google Scholar]
- Dadvar, M.; Jong, F.D.; Ordelman, R.; Trieschnigg, D. Improved cyberbullying detection using gender information. In Proceedings of the Twelfth Dutch-Belgian Information Retrieval Workshop (DIR 2012), University of Ghent, Gent, Belgium, 23–24 February 2012. [Google Scholar]
- Van Hee, C.; Lefever, E.; Verhoeven, B.; Mennes, J.; Desmet, B.; De Pauw, G.; Daelemans, W.; Hoste, V. Detection and fine-grained classification of cyberbullying events. In International Conference Recent Advances in Natural Language Processing (RANLP); INCOMA Ltd.: Shoumen, Bulgaria, 2015; pp. 672–680. [Google Scholar]
- Kowsari, K.; Meimandi, K.J.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text Classification Algorithms: A Survey. Information 2019, 10, 150. [Google Scholar] [CrossRef] [Green Version]
- Sahlgren, M.; Isbister, T.; Olsson, F. Learning Representations for Detecting Abusive Language. In Proceedings of the 2nd Workshop on Abusive Language Online (ALW2), Brussels, Belgium, 31 October–1 November 2018; pp. 115–123. [Google Scholar]
- Salminen, J.; Almerekhi, H.; Milenković, M.; Jung, S.G.; An, J.; Kwak, H.; Jansen, B.J. Anatomy of online hate: Developing a taxonomy and machine learning models for identifying and classifying hate in online news media. In Twelfth International AAAI Conference on Web and Social Media; AAAI Press: Palo Alto, CA, USA, 2018. [Google Scholar]
- Ottesen, C. Comparison between Naïve Bayes and Logistic Regression. DataEspresso. 2017. Available online: https://dataespresso.com/en/2017/10/24/comparison-between-naive-bayes-and-logistic-regression/#:~:text=Na%C3%AFve%20Bayes%20has%20a%20naive,belonging%20to%20a%20certain%20class (accessed on 24 July 2020).
- Deb, S. Naive Bayes vs. Logistic Regression. Medium. 2016. Available online: https://medium.com/@sangha_deb/naive-bayes-vs-logistic-regression-a319b07a5d4c (accessed on 24 July 2020).
- Snakenborg, J.; Van Acker, R.; Gable, R.A. Cyberbullying: Prevention and Intervention to Protect Our Children and Youth. Prev. Sch. Fail. Altern. Educ. Child. Youth 2011, 55, 88–95. [Google Scholar] [CrossRef]
- Patchin, J.W.; Hinduja, S. Traditional and Nontraditional Bullying Among Youth: A Test of General Strain Theory. Youth Soc. 2011, 43, 727–751. [Google Scholar] [CrossRef]
- Tenenbaum, L.S.; Varjas, K.; Meyers, J.; Parris, L. Coping strategies and perceived effectiveness in fourth through eighth grade victims of bullying. Sch. Psychol. Int. 2011, 32, 263–287. [Google Scholar] [CrossRef]
- Olweus, D. Invited expert discussion paper Cyberbullying: An overrated phenomenon? Eur. J. Dev. Psychol. 2012, 9, 1–19. [Google Scholar] [CrossRef]
- Hinduja, S.; Patchin, J.W. Cyberbullying: An Exploratory Analysis of Factors Related to Offending and Victimization. Deviant Behav. 2008, 29, 129–156. [Google Scholar] [CrossRef]
- Hemphill, S.A.; Kotevski, A.; Tollit, M.; Smith, R.; Herrenkohl, T.I.; Toumbourou, J.W.; Catalano, R.F. Longitudinal Predictors of Cyber and Traditional Bullying Perpetration in Australian Secondary School Students. J. Adolesc. Health 2012, 51, 59–65. [Google Scholar] [CrossRef] [Green Version]
- Casas, J.A.; Del Rey, R.; Ortega-Ruiz, R. Bullying and cyberbullying: Convergent and divergent predictor variables. Comput. Hum. Behav. 2013, 29, 580–587. [Google Scholar] [CrossRef]
- Ang, R.P.; Goh, D.H. Cyberbullying among Adolescents: The Role of Affective and Cognitive Empathy, and Gender. Child Psychiatry Hum. Dev. 2010, 41, 387–397. [Google Scholar] [CrossRef]
- Barlińska, J.; Szuster, A.; Winiewski, M. Cyberbullying among Adolescent Bystanders: Role of the Communication Medium, Form of Violence, and Empathy. J. Community Appl. Soc. Psychol. 2012, 23, 37–51. [Google Scholar] [CrossRef]
- Ybarra, M.L.; Mitchell, K.J.; Wolak, J.; Finkelhor, D. Examining Characteristics and Associated Distress Related to Internet Harassment: Findings from the Second Youth Internet Safety Survey. Pediatrics 2006, 118, e1169–e1177. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Smith, P.K.; Mahdavi, J.; Carvalho, M.; Fisher, S.; Russell, S.; Tippett, N. Cyberbullying: Its nature and impact in secondary school pupils. J. Child Psychol. Psychiatry 2008, 49, 376–385. [Google Scholar] [CrossRef]
- Raisi, E.; Huang, B. Cyberbullying Identification Using Participant-Vocabulary Consistency. arXiv 2016, arXiv:1606.08084. [Google Scholar]
- Van Der Zwaan, J.M.; Dignum, V.; Jonker, C.M. A Conversation Model Enabling Intelligent Agents to Give Emotional Support. In Uncertainty Theory; Springer Science and Business Media LLC: Berlin, Germany, 2012; Volume 431, pp. 47–52. [Google Scholar]
- Bosse, T.; Stam, S. A Normative Agent System to Prevent Cyberbullying. In Proceedings of the 2011 IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology, Lyon, France, 22–27 August 2011; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2011; Volume 2, pp. 425–430. [Google Scholar]
- Reynolds, K.; Kontostathis, A.; Edwards, L. Using Machine Learning to Detect Cyberbullying. In Proceedings of the 2011 10th International Conference on Machine Learning and Applications and Workshops, Honolulu, HI, USA, 18–21 December 2011; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2011; Volume 2, pp. 241–244. [Google Scholar]
- Rybnicek, M.; Poisel, R.; Tjoa, S. Facebook Watchdog: A Research Agenda for Detecting Online Grooming and Bullying Activities. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2013; pp. 2854–2859. [Google Scholar]
- Yin, D.; Xue, Z.; Hong, L.; Davison, B.D.; Kontostathis, A.; Edwards, L. Detection of harassment on web 2.0. In Proceedings of the Content Analysis in the WEB, Madrid, Spain, 21 April 2009; Volume 2, pp. 1–7. [Google Scholar]
- Bayzick, J.; Kontostathis, A.; Edwards, L. Detecting the Presence of Cyberbullying Using Computer Software. 2011. Available online: https://april-edwards.me/BayzickHonors.pdf (accessed on 29 October 2020).
- Al-garadi, M.A.; Varathan, K.D.; Ravana, S.D. Cybercrime detection in online communications: The experimental case of cyberbullying detection in the Twitter network. Comput. Hum. Behav. 2016, 63, 433–443. [Google Scholar] [CrossRef]
- Salminen, J.; Hopf, M.; Chowdhury, S.A.; Jung, S.-G.; Almerekhi, H.; Jansen, B.J. Developing an online hate classifier for multiple social media platforms. Hum. Cent. Comput. Inf. Sci. 2020, 10, 1–34. [Google Scholar] [CrossRef]
- Dinakar, K.; Jones, B.; Havasi, C.; Lieberman, H.; Picard, R. Common Sense Reasoning for Detection, Prevention, and Mitigation of Cyberbullying. ACM Trans. Interact. Intell. Syst. 2012, 2, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Dadvar, M.; Trieschnigg, R.B.; Ordelman, R.J.; De Jong, F.M. Improving Cyberbullying Detection with User Context. In European Conference on Information Retrieval; Springer Science and Business Media LLC: Berlin, Gemany, 2013; pp. 693–696. [Google Scholar]
- Van Hee, C.; Jacobs, G.; Emmery, C.; Desmet, B.; Lefever, E.; Verhoeven, B.; De Pauw, G.; Daelemans, W.; Hoste, V. Automatic detection of cyberbullying in social media text. PLoS ONE 2018, 13, e0203794. [Google Scholar] [CrossRef]
- Zhao, R.; Zhou, A.; Mao, K. Automatic detection of cyberbullying on social networks based on bullying features. In Proceedings of the 17th International Conference on Distributed Computing and Networking—ICDCN ’16, Singapore, 4–7 January 2016; Association for Computing Machinery (ACM): New York, NY, USA, 2016; p. 43. [Google Scholar]
- Ahlfors Many Sources. One Theme: Analysis of Cyberbullying Prevention and Intervention Websites. J. Soc. Sci. 2010, 6, 515–522. [Google Scholar] [CrossRef] [Green Version]
- Lenhart, A.; Purcell, K.; Smith, A.; Zickuhr, K. Social Media & Mobile Internet Use among Teens and Young Adults. Available online: http://samaritanbehavioralhealth.net/files/social-media-young-adults.pdf(accessed on 28 October 2020).
- Webb, M.; Burns, J.; Collin, P. Providing online support for young people with mental health difficulties: Challenges and opportunities explored. Early Interv. Psychiatry 2008, 2, 108–113. [Google Scholar] [CrossRef] [PubMed]
- Havas, J.; De Nooijer, J.; Crutzen, R.; Feron, F.J.M. Adolescents’ views about an internet platform for adolescents with mental health problems. Health Educ. 2011, 111, 164–176. [Google Scholar] [CrossRef]
- Jacobs, N.C.; Völlink, T.; Dehue, F.; Lechner, L. Online Pestkoppenstoppen: Systematic and theory-based development of a web-based tailored intervention for adolescent cyberbully victims to combat and prevent cyberbullying. BMC Public Health 2014, 14, 396. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- KiVa Program. Kiva Is an Anti-Bullying Programme|Kiva Antibullying Program|Just Another Kiva Koulu Site. 2020. Available online: http://www.kivaprogram.net (accessed on 17 August 2020).
- Nonauharcelement.Education.gouv.fr. Non Au Harcèlement—Appelez Le 3020. 2020. Available online: https://www.nonauharcelement.education.gouv.fr/ (accessed on 18 August 2020).
- Veiligonline.be. Cyberpesten|Veilig Online. 2020. Available online: https://www.veiligonline.be/cyberpesten (accessed on 18 August 2020).
- Stauffer, S.; Heath, M.A.; Coyne, S.M.; Ferrin, S. High school teachers’ perceptions of cyberbullying prevention and intervention strategies. Psychol. Sch. 2012, 49, 352–367. [Google Scholar] [CrossRef] [Green Version]
- Notar, C.E.; Padgett, S.; Roden, J. Cyberbullying: Resources for Intervention and Prevention. Univers. J. Educ. Res. 2013, 1, 133–145. [Google Scholar]
- Fanti, K.A.; Demetriou, A.G.; Hawa, V.V. A longitudinal study of cyberbullying: Examining riskand protective factors. Eur. J. Dev. Psychol. 2012, 9, 168–181. [Google Scholar] [CrossRef]
- Ybarra, M.L.; Mitchell, K.J. Prevalence and Frequency of Internet Harassment Instigation: Implications for Adolescent Health. J. Adolesc. Health 2007, 41, 189–195. [Google Scholar] [CrossRef]
- Aricak, T.; Siyahhan, S.; Uzunhasanoglu, A.; Saribeyoglu, S.; Ciplak, S.; Yilmaz, N.; Memmedov, C. Cyberbullying among Turkish Adolescents. CyberPsychology Behav. 2008, 11, 253–261. [Google Scholar] [CrossRef] [Green Version]
- Kontostathis, A.; Reynolds, K.; Garron, A.; Edwards, L. Detecting cyberbullying: Query terms and techniques. In Proceedings of the 5th Annual ACM Web Science Conference, New York, NY, USA, 23–26 June 2013; pp. 195–204. [Google Scholar]
- Xu, J.M.; Jun, K.S.; Zhu, X.; Bellmore, A. Learning from bullying traces in social media. In Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Montréal, QC, Canada, 3–8 June 2012; pp. 656–666. [Google Scholar]
- Chowdhary, K.R. Natural language processing for word sense disambiguation and information extraction. arXiv 2020, arXiv:2004.02256. [Google Scholar]
- Liddy, E.D. Natural language processing. In Encyclopedia of Library and Information Science; Springer: New Delhi, India, 2001. [Google Scholar]
- Ali, F.; El-Sappagh, S.; Islam, S.R.; Ali, A.; Attique, M.; Imran, M.; Kwak, K.-S. An intelligent healthcare monitoring framework using wearable sensors and social networking data. Futur. Gener. Comput. Syst. 2020, 114, 23–43. [Google Scholar] [CrossRef]
- Ali, F.; Kwak, D.; Khan, P.; El-Sappagh, S.; Ali, A.; Ullah, S.; Kim, K.H.; Kwak, K.-S. Transportation sentiment analysis using word embedding and ontology-based topic modeling. Knowl. Based Syst. 2019, 174, 27–42. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Year | Feature | Classifier | Accuracy | Dataset used |
|---|---|---|---|---|---|
| Raisi and Huang [57] | 2016 | N/A | N/A | They did not evaluate their proposed model | Twitter and Ask.fm datasets |
| Reynolds, Kontostathis and Edwards [48] | 2011 | Bag of Words (BoW) | Sequential Minimal Optimization (SMO), IBK, JRip, J48 | The model was capable of recognizing 78.5% posts in Formspring dataset | Formspring Link: www.Formspring.me |
| Nahar et al. [66] | 2014 | TF-IDF unigrams | Ensemble | NA | MySpace, Slashdot, Kongregate, Twitter |
| Yin et al. [47] | 2009 | TF-IDF | SVM | Kongregate (0.289) Slashdot (0.273) MySpace (0.351) | MySpace, Slashdot, Kongregate |
| Bayzick et al. [110] | 2011 | Second p Insult word erson pronouns, Swear word, | NA | Correctly identify 85.3% as cyberbully ing posts and 51.91% as innocent posts of MySpace dataset | MySpace |
| Rafiq et al. [26] | 2018 | Negative comments, Total negative words, Unigrams | AdaBoost, LR | NA | Datasets of Vine |
| Galán-García et al. [64] | 2016 | TF–IDF, N-gram | NB, KNN, RF, J48, SMO | - SMO (68.47%) - J48 (65.81) - RF (66.48%) - NB (33.91%) - KNN (59.79%) | |
| Al-garadi et al. [60] | 2015 | Unigram 3-g | SVM, NB | - Naïve Bayes (71%) - SVM (78%) | Twitter |
| Salminen et al. [67] | 2020 | TI-IDF | LR, NB, SVM, XGBoost | -LR (76.8%) - NB (60.6%) -SVM (64.8%) - XGBoost (77.4%) | A total of 197,566 comments from four platforms: YouTube, Reddit, Wikipedia, and Twitter, |
| Dinakar et al. [44] | 2012 | Profanity, BoW, TF-IDF, Weighted unigrams | J48, SVM, NB -based learner, Rule-based Jrip | -NB (63%) - J48 (61%) -SVM (72%) - Rule-based Jrp (70.39%) | Formspring, Youtube |
| Dadvar et al. [68] | 2013 | Emoticons, Message length, N-gram, Bully keywords, Pronouns | SVM | NA | YouTube |
| Van Hee et al. [69] | 2018 | Character n-gram BoW, Word n-gram BoW | LSVM | F1 score of 64% and 61% for English and Dutch respectively | Posts of ASKfm in Dutch and English |
| Cheng et al. [111] | 2019 | NA | LR, LSVM, RF | NA | Vine, Instagram |
| Authors in this study | 2020 | TF-IDF and Word2Vec | LR, LGBM, SGD, RF, AdaBoost, NB, and SVM | - LR (90.57%) - LGBM (90.55%) - SGD (90.6%) - RF (89.84%) - AdaBoost (89.30%) - NB (81.39%) - SVM (67.13%) |
| No. | Algorithm | Accuracy | Precision | Recall | F1 Score | Prediction Time |
|---|---|---|---|---|---|---|
| 1 | Logistic Regression | 90.57% | 0.9518 | 0.9053 | 0.9280 | 0.0015 |
| 2 | LGBM Classifier | 90.55% | 0.9614 | 0.8951 | 0.9271 | 0.0515 |
| 3 | SGD Classifier | 90.6% | 0.9683 | 0.8890 | 0.9270 | 0.0016 |
| 4 | Random Forest | 89.84% | 0.9338 | 0.9134 | 0.9235 | 2.5287 |
| 5 | AdaBoost Classifier | 89.30% | 0.9616 | 0.8756 | 0.9166 | 0.1497 |
| 6 | Multinomial NB | 81.39% | 0.7952 | 0.9736 | 0.8754 | 0.0034 |
| 7 | SVM | 67.13% | 0.6713 | 1.0000 | 0.8033 | 39.9592 |
| No. | Parameters | Algorithm | Training/Prediction Time (s) |
|---|---|---|---|
| 1 | Best Training Time | Multinomial NB | 0.014 |
| 2 | Worst Prediction Time | RF | 2.5287 |
| 3 | Best Prediction Time | LR | 0.0015 |
| 4 | Worst Prediction Time | SVM | 39.96 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muneer, A.; Fati, S.M. A Comparative Analysis of Machine Learning Techniques for Cyberbullying Detection on Twitter. Future Internet 2020, 12, 187. https://doi.org/10.3390/fi12110187
Muneer A, Fati SM. A Comparative Analysis of Machine Learning Techniques for Cyberbullying Detection on Twitter. Future Internet. 2020; 12(11):187. https://doi.org/10.3390/fi12110187
Chicago/Turabian StyleMuneer, Amgad, and Suliman Mohamed Fati. 2020. "A Comparative Analysis of Machine Learning Techniques for Cyberbullying Detection on Twitter" Future Internet 12, no. 11: 187. https://doi.org/10.3390/fi12110187
APA StyleMuneer, A., & Fati, S. M. (2020). A Comparative Analysis of Machine Learning Techniques for Cyberbullying Detection on Twitter. Future Internet, 12(11), 187. https://doi.org/10.3390/fi12110187