1. Introduction
The evolution of Internet of Things systems and multi-sensor devices contributed to the development of systems for human activity monitoring. One set of applications of these technologies is improving the independent living and rehabilitation of older adults and people with special needs [
1]. Likewise, there are approaches for fall detection and risk assessment [
2,
3]. Usually, the human activity monitoring systems transmit the collected data to the cloud for real-time processing and further analysis [
4]. In light of that, the network conditions become an important factor in facilitating data transfer [
5]. Therefore, the development of optimized online systems and test pilots are important. Moreover, these systems should be prepared for older adults, which raises other sets of challenges related to usability and ergonomics; therefore, the resilience of these is essential [
6,
7].
Different types of activities may be detected with the inertial sensors available in the mobile devices, including running, walking, walking upstairs, walking downstairs, and standing [
8,
9]. For the detection of human activities, one of the possibilities is the use of artificial intelligence methods combined with the capabilities of the mobile devices for the development of monitoring tools anywhere at any time [
10]. Still, the data acquisition may have problems related to low memory, power processing, and battery capacity [
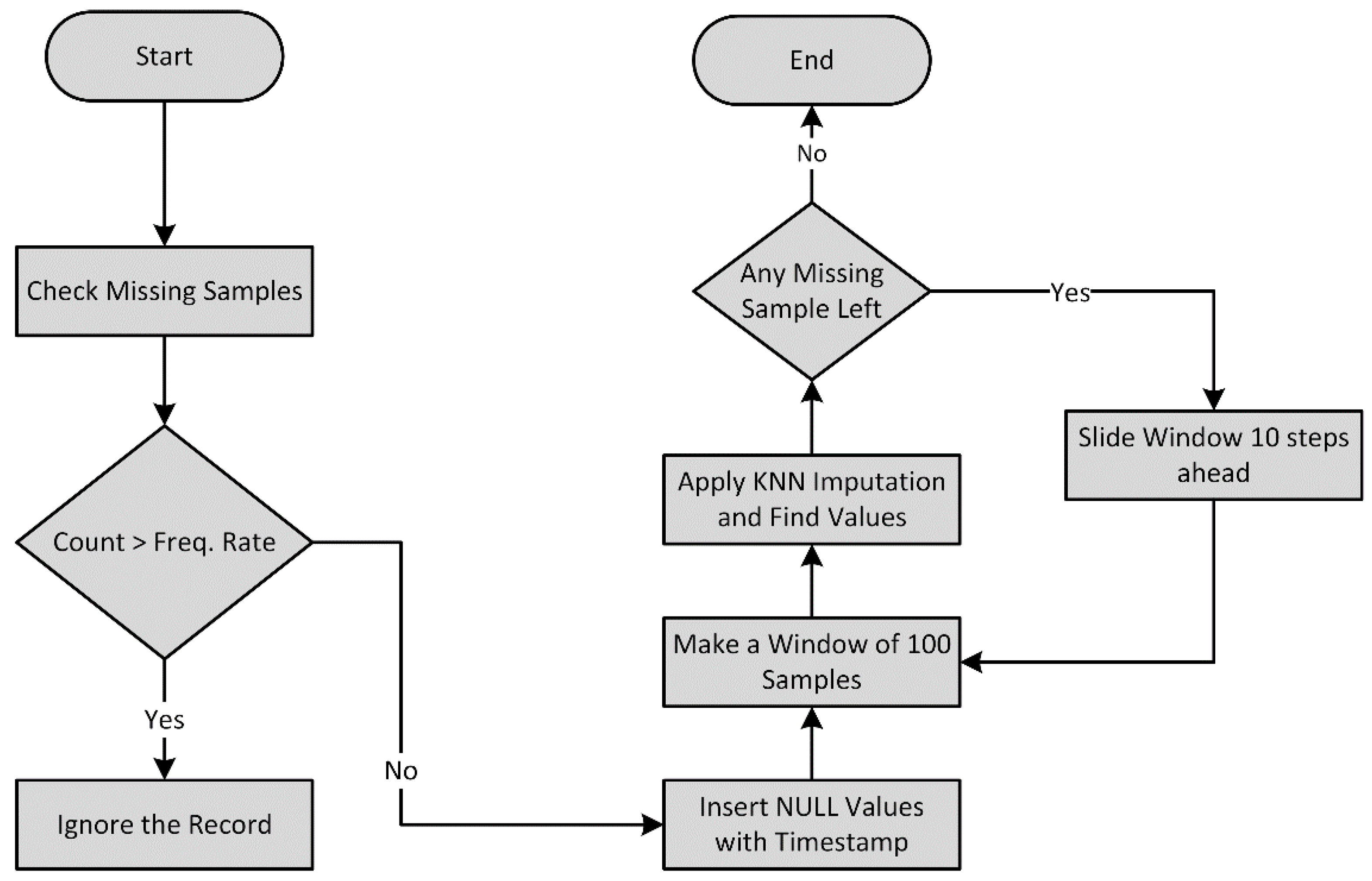
6], causing missing or incorrect samples in the acquired data, and consequent incorrections in the recognition of the activities. Likewise, in the case of wearables, frequently, the devices can be misplaced, causing inaccurate, invalid, or missing data. It is one of the main problems related to the development of intelligent systems for the monitoring of different people. To reduce such faulty data and improve the reliability of these systems, data imputation techniques might be applied. The data imputation methods used in the different systems depend on the timing of missing data, which it can be missing completely at random (MCAR), missing at random (MAR), or missing not at random (MNAR) [
11,
12]. Generally, the data imputation relies on tree-based approaches [
13,
14], multi-matrices factorization model (MMF) [
15], clustering techniques, e.g., K-means [
16] and K-Nearest Neighbor (KNN) [
17], multiple imputation [
18], hot/cold imputation, maximum likelihood, Bayesian estimation, and expectation maximization [
13,
14,
15,
16]. In this study, we considered the case of not using imputation as a competitor for the data imputation with KNN, as it was commonly used in other data imputation problems in different industries [
19,
20].
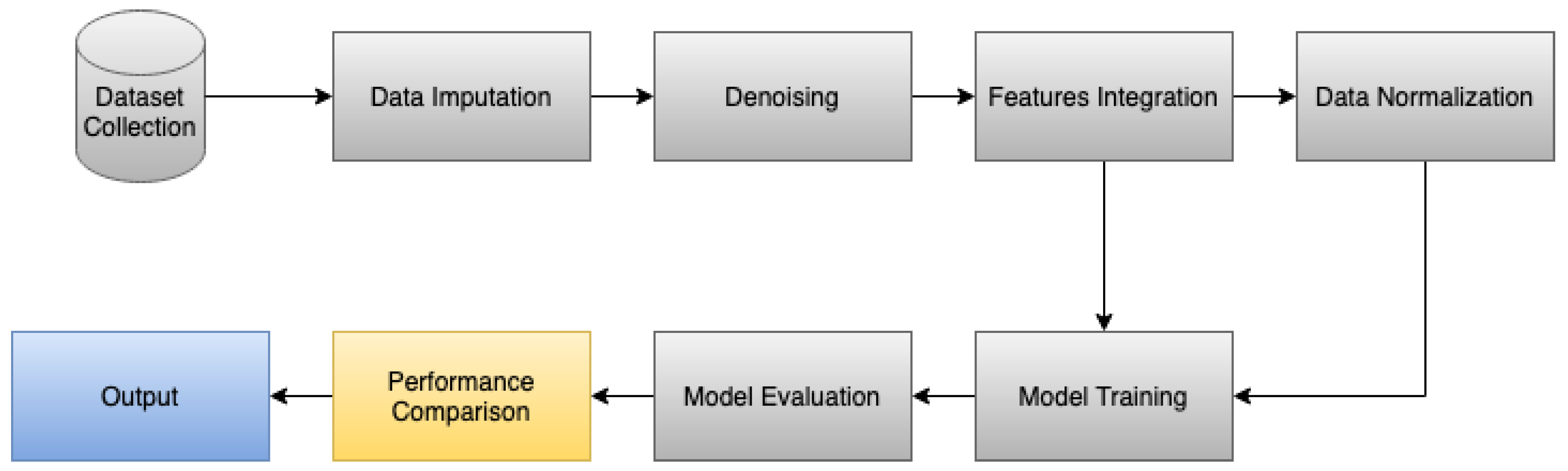
The motivation of this paper is to improve the results on the human activity recognition (considering five activities, i.e., walking, running, standing, walking upstairs, and walking downstairs) by integrating the data imputation algorithm in the data processing pipeline. After this, the whole pipeline consists of data acquisition, data cleaning, identification of the number of missing samples, data segmentation, data imputation, and data. For the data acquisition and cleaning, the previously implemented techniques were used [
8,
9]. After the identification of missing samples and data segmentation, the data imputation was implemented with the KNN imputation algorithm [
17] for the estimation of the values of the different datasets to fulfill the number of outputs correctly. The values of each axis separately in the raw sensory measurements were imputed separately.
The proposed method in this paper uses three inertial sensors, i.e., accelerometer, magnetometer, and gyroscope, with the same frequency of acquisition. After performing the data imputation, the feature extraction process should be performed, which commonly includes a variety of time and frequency domain features, such as the mean, energy, correlation, entropy, frequency of maximum values, standard deviation, maximum, minimum, median, variance, 75th percentile, inter-quartile range, average absolute difference, binned distribution, energy, Signal Magnitude Area (SMA), zero-crossing rate, number of peaks, absolute value of short-time Fourier transform, power of short-time Fourier transform, skewness, kurtosis, and power spectral centroid [
9,
21]. After the extraction and selection of different features, different machine learning methods may be included in the pipeline, such as Random Forest, Artificial Neural Networks (ANN), Support Vector Machine (SVM), Naïve Bayes, Logistic regression, decision tree, K-Nearest Neighbor (KNN), among others.
The rest of the paper is organized as follows:
Section 2 presents the methodology implemented in this study. The consequent results are presented in
Section 3 and are discussed in
Section 4. This study is finalized with the conclusions in
Section 5.
4. Discussion
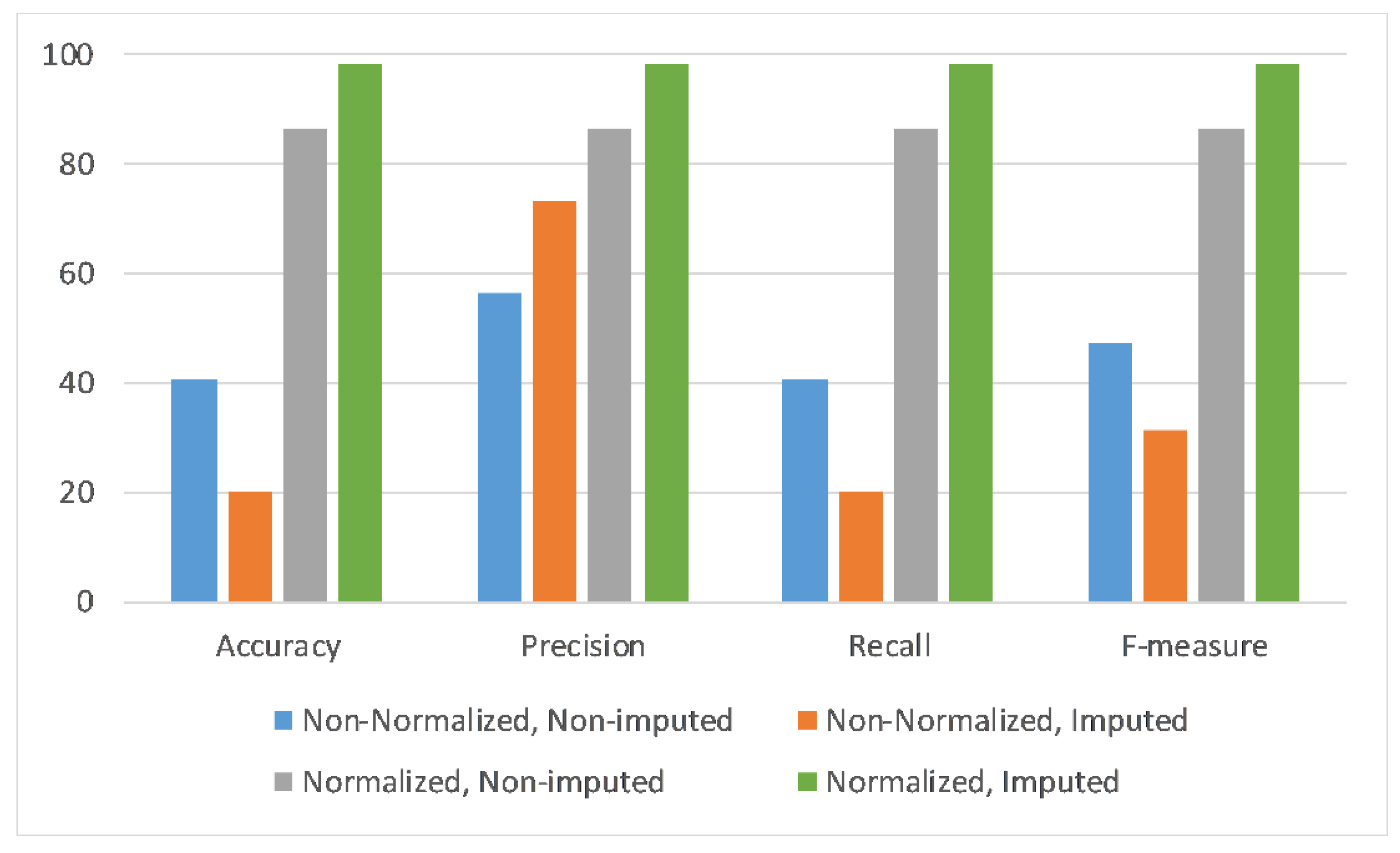
Table 18 summarizes the results obtained after all previously discussed experiments. Thus, 12 different experiments with respect to the different combinations of sensors and tests were used to analyze the effect of data imputation and data normalization, along with different combinations of sensors, as illustrated in
Table 18. These results are presented in
Figure 5,
Figure 6 and
Figure 7, based on the sensors combinations, i.e., accelerometer (Ac) only, accelerometer and magnetometer (Ac + Mg), and accelerometer, magnetometer and gyroscope (Ac + Mg + Gy).
In
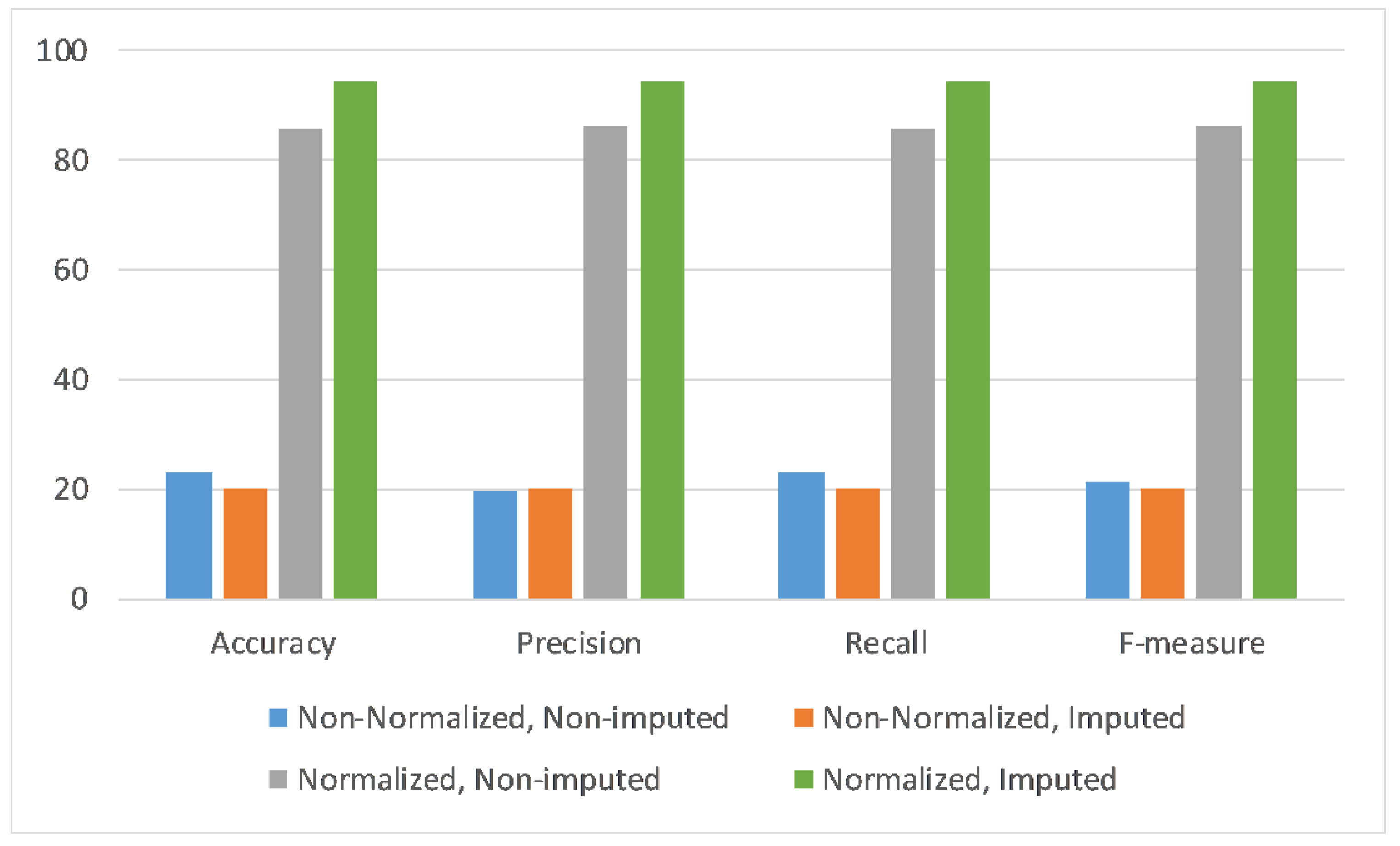
Figure 5, only accelerometer sensor data are utilized to perform the experiments with respect to four scenarios of data normalization and data imputation combinations. Each scenario is evaluated across four performance metrics, i.e., accuracy, precision, recall, and F-measure. It can be observed that the deep learning model performance across all metrics is highest with the application of normalization and imputation on the given dataset.
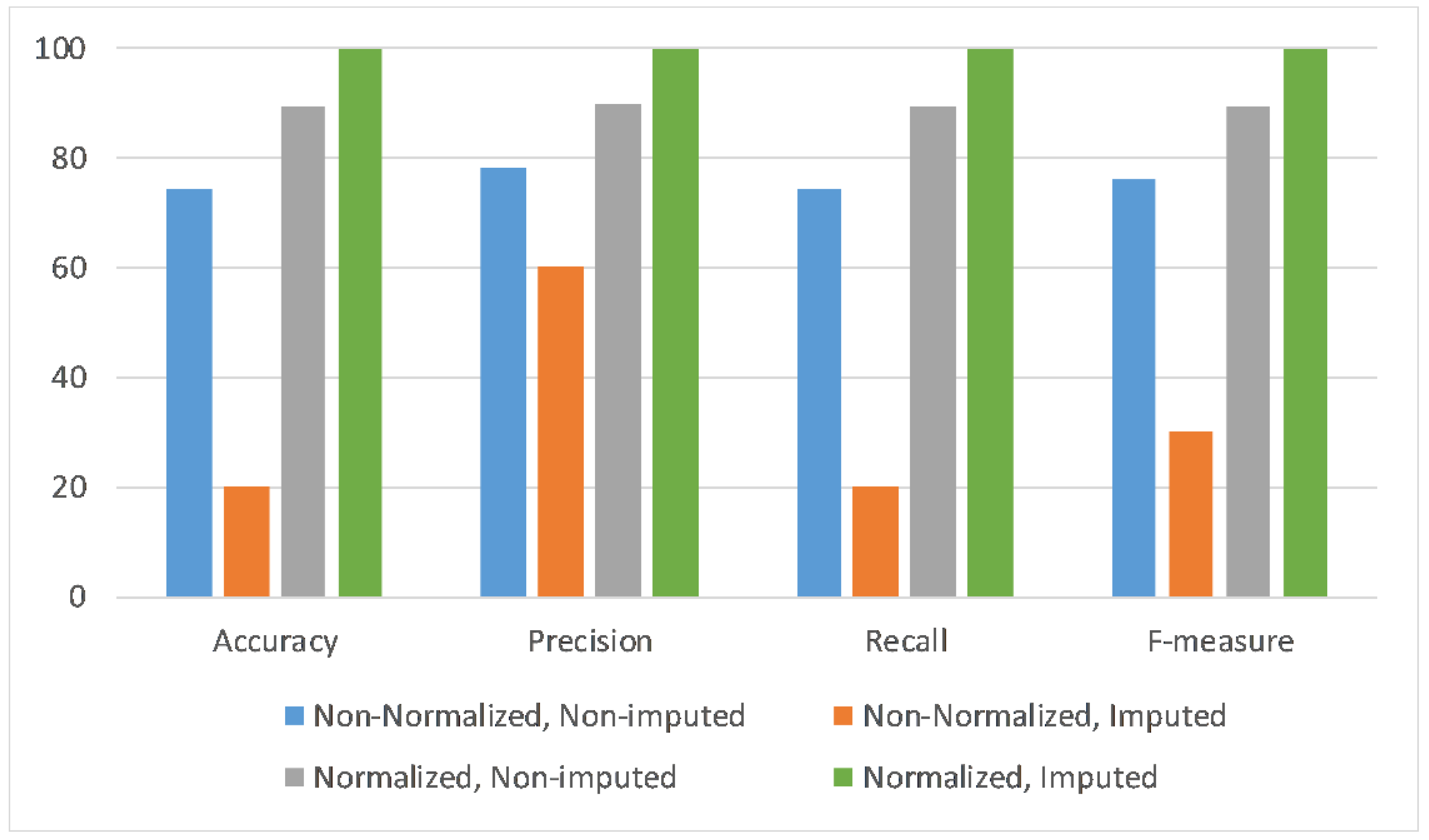
Similarly,
Figure 6 shows the results when utilizing the accelerometer and magnetometer (Ac + Mg) sensors values to test the trained deep learning model with respect to four scenarios of data normalization and data imputation combinations. Each scenario is evaluated across four performance metrics, i.e., accuracy, precision, recall, and F-measure. It can be noticed that the deep learning model performance across all metrics is highest with the application of normalization and imputation on the given dataset.
Likewise,
Figure 7 displays the results when utilizing all three sensors data—i.e., accelerometer, magnetometer, and gyroscope—to test the trained deep learning model with respect to four scenarios of data normalization and data imputation combinations. Each scenario is evaluated across four performance metrics, i.e., accuracy, precision, recall, and F-measure. It can be observed that the deep learning model performance across all metrics is highest with the application of normalization and imputation on the given dataset.
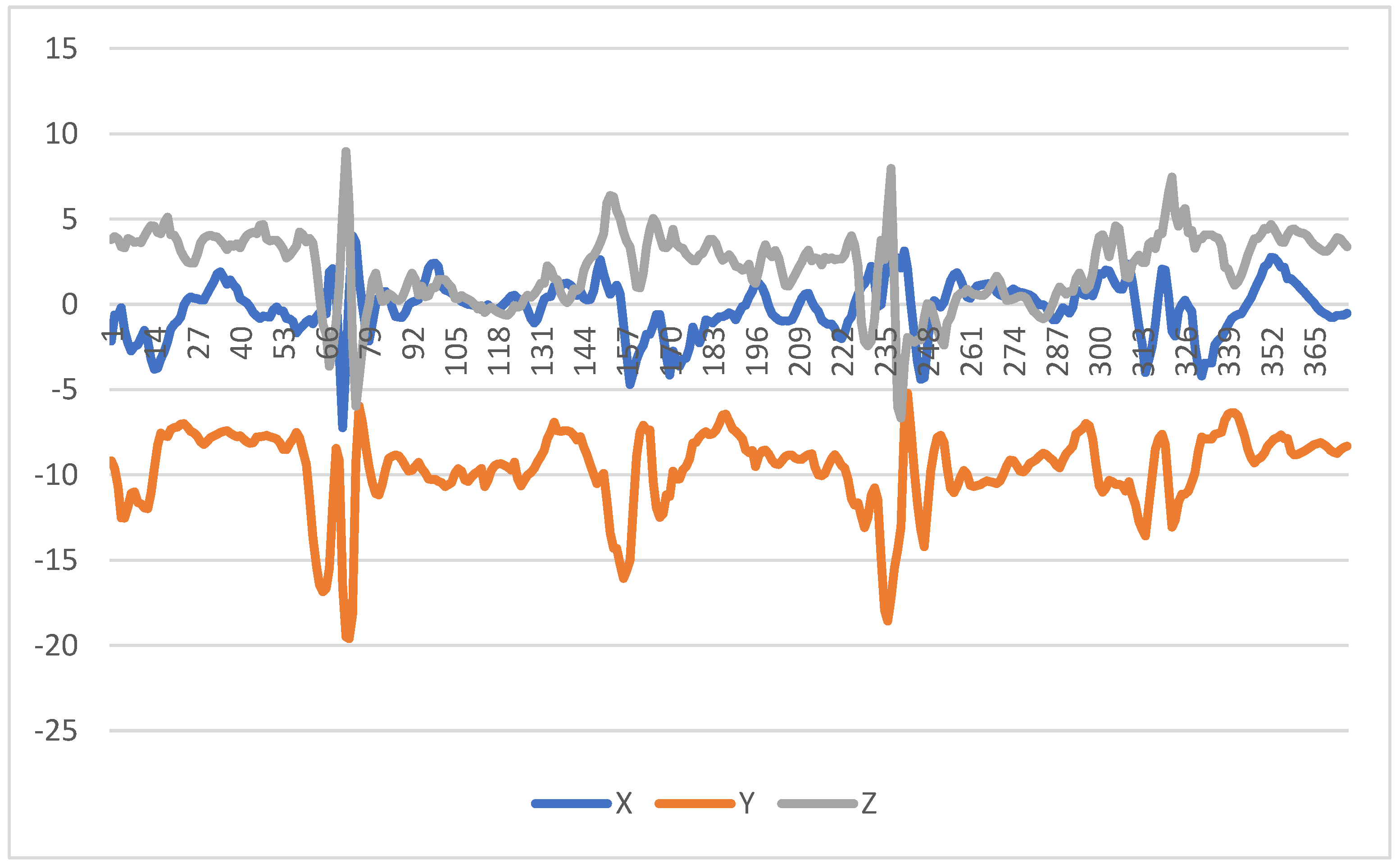
As results of this study, it was verified that the pattern of the imputed data is similar to the original data. However, its frequency and amplitude are higher than in the original data. Regarding the data classification, depending on the number of sensors, the accuracy was between 22.9% and 74.46% for non-normalized data, and between 85.89% and 89.51% for normalized data. After the data imputation process, depending on the number of sensors, the accuracy changed to between 20.00% and 20.19% for non-normalized data, and between 94.56% and 99.82% for normalized data.
In summary, all the experimental results depict that the deep learning model better distinguishes daily living activities when both data normalization and data imputation techniques were applied. Moreover, the deep learning model gives the best results when imputed and normalized data from the combination of all three sensors are used, i.e., the accelerometer, magnetometer, and gyroscope. Furthermore, the use of data imputation reported an improvement of 25.36% in accuracy, 21.58% in precision, 25.36% in recall, and 23.52% in F-measure values over the normalized and imputed dataset across all three sensors, as compared to the non-normalized and non-imputed dataset across all three sensors. Therefore, from the above experimental results, it is verified that the performance of the deep learning model significantly increased when normalization and imputation techniques were applied to the dataset across all three sensors.
As we are using a proprietary dataset, the results are not comparable with others. However, several limitations were found that are related to the acquisition and positioning of the mobile device, the power processing of the methods implemented, and other involuntary limitations of the study [
6,
24].
The results obtained are affected by the reduced sample size. Initially, the data normalization was performed, and the maximum accuracy was around 89.51% [
34,
35] with the recognition of the same activities and with the use of the same sensors of this study. The implementation of imputation techniques increased the results with a maximum accuracy of 100%. Thus, we can conclude that the data imputation techniques increased the different results.
5. Conclusions
The missing samples in the dataset affect the performance of deep learning models. Therefore, in this paper, a methodology was proposed to extrapolate the missing samples of human activity recognition dataset captures to make deep models better classify the human daily living activities. The proposed methodology utilizes the K-Nearest Neighbors (KNN) imputation technique to extrapolate the missing samples in dataset captures. Thus, 12 experiments were performed to analyze the effect of data imputation and data normalization, along with different combinations of sensors.
The proposed methodology, when compared to a non-normalized and non-imputed dataset across all three sensors, reported an improvement of 25.36% in accuracy, 21.58% in precision, 25.36% in recall, and 23.52% in F-measure values over the normalized and imputed dataset across all three sensors. The experimental results revealed that the performance of the implemented model increased with the implementation of the data imputation method.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}