Architecture for Enabling Edge Inference via Model Transfer from Cloud Domain in a Kubernetes Environment


Abstract
:1. Introduction
2. Related Work
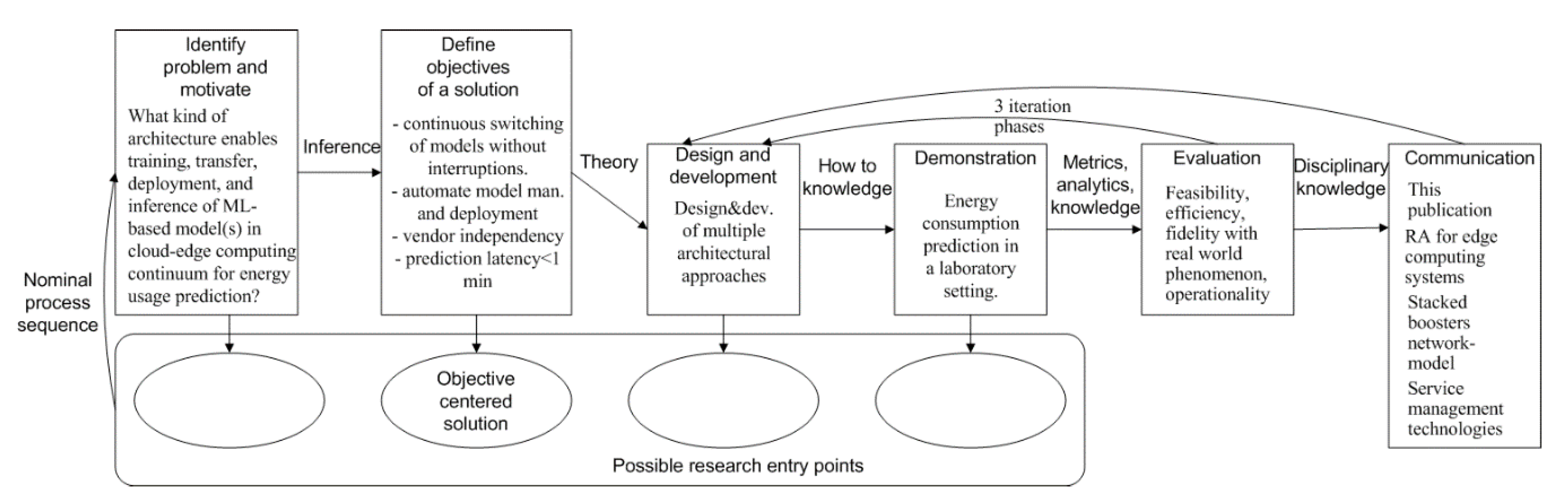
3. Research Method and Process
- What kind of architecture enables training, transfer, deployment, and inference of ML-based model(s) in cloud-edge computing continuum for energy usage prediction?
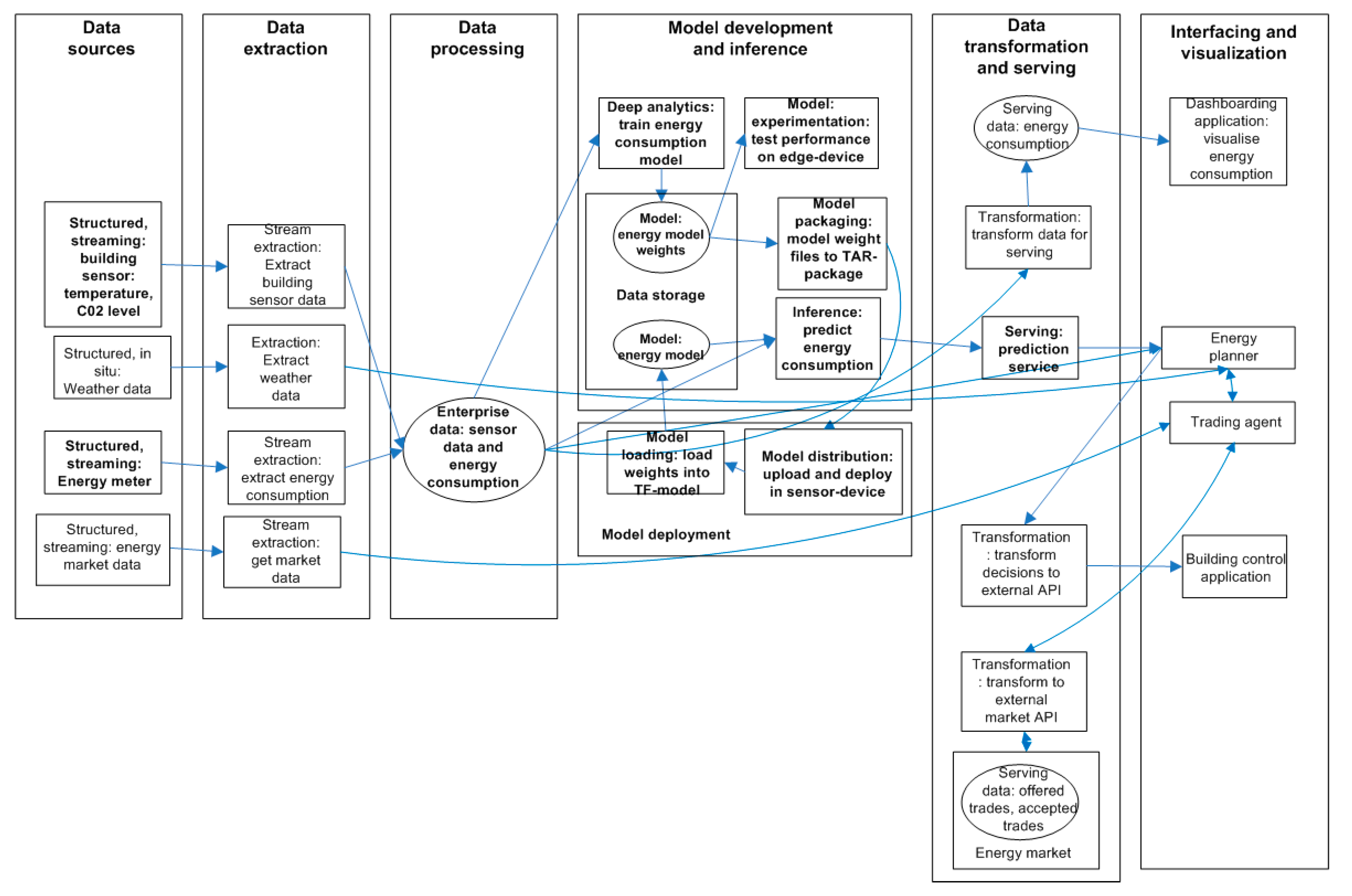
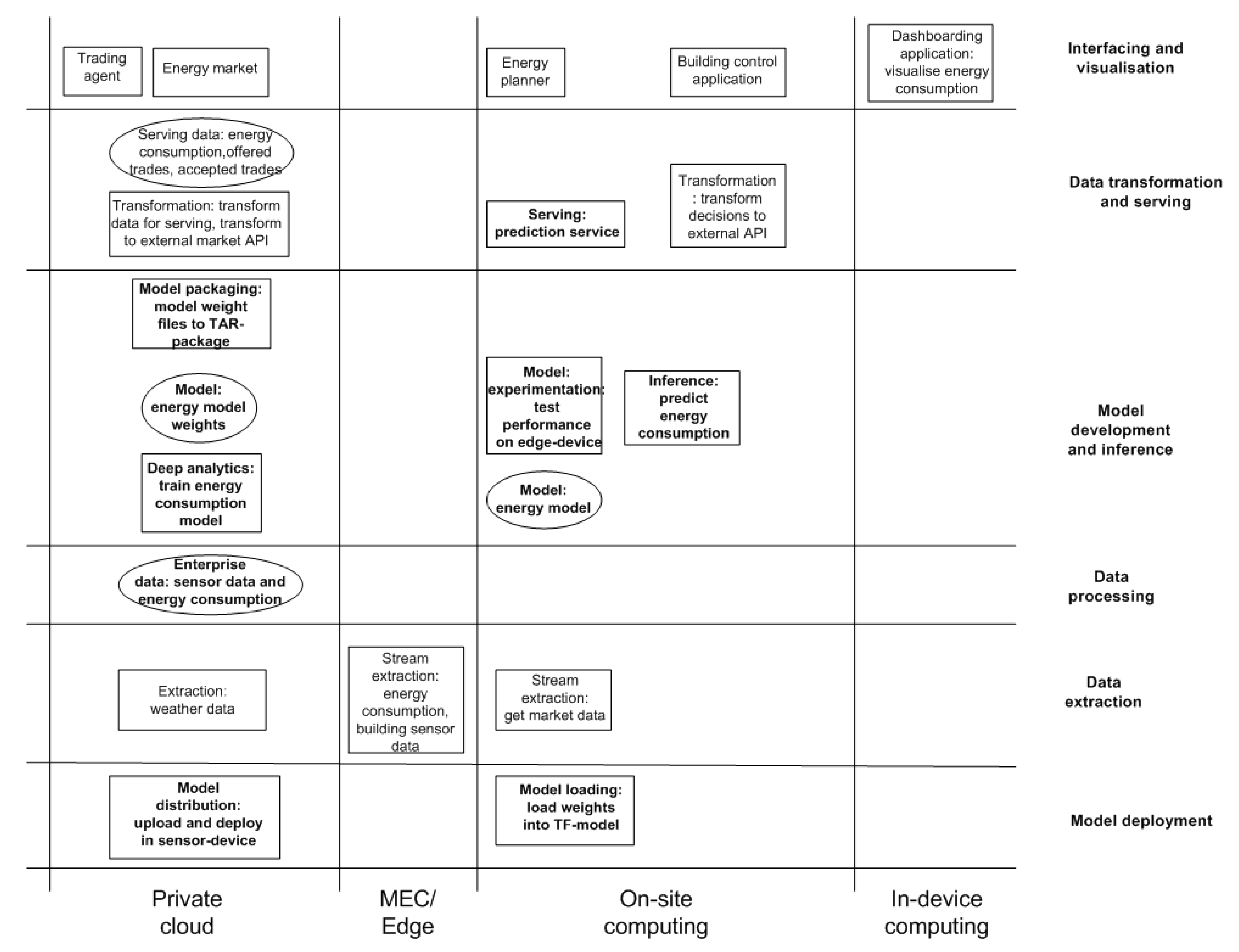
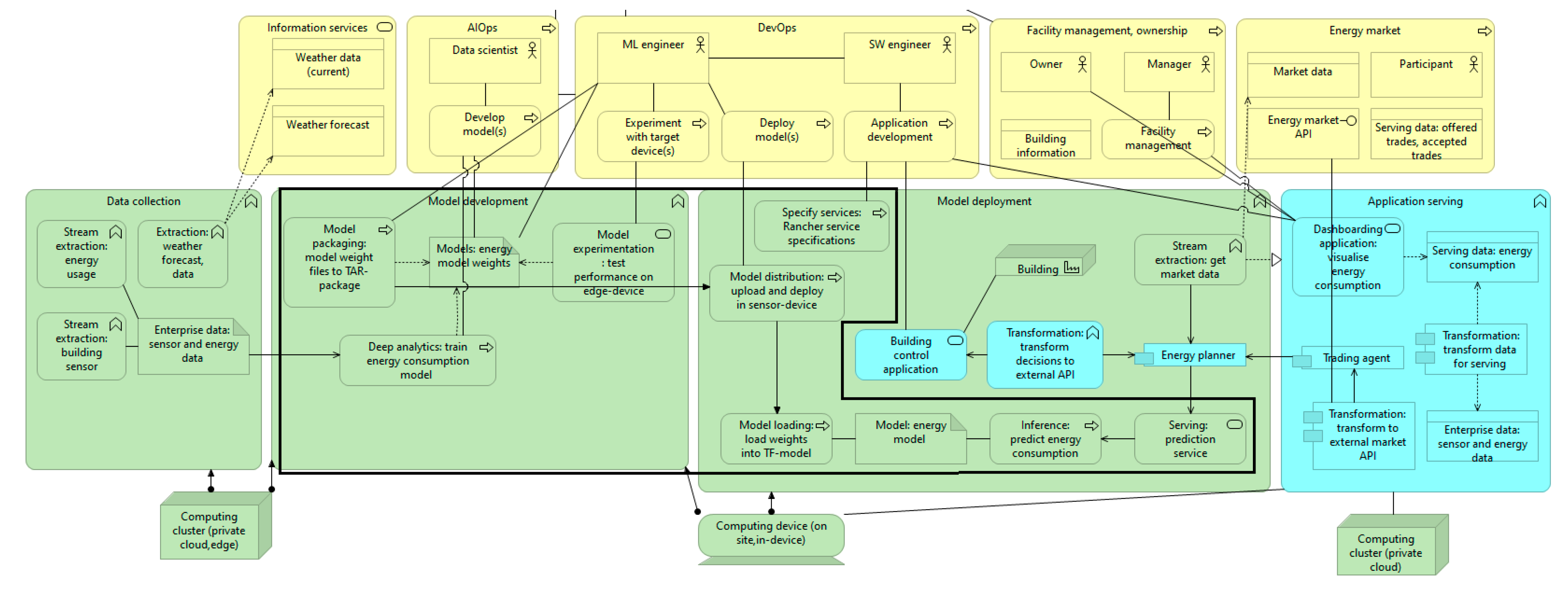
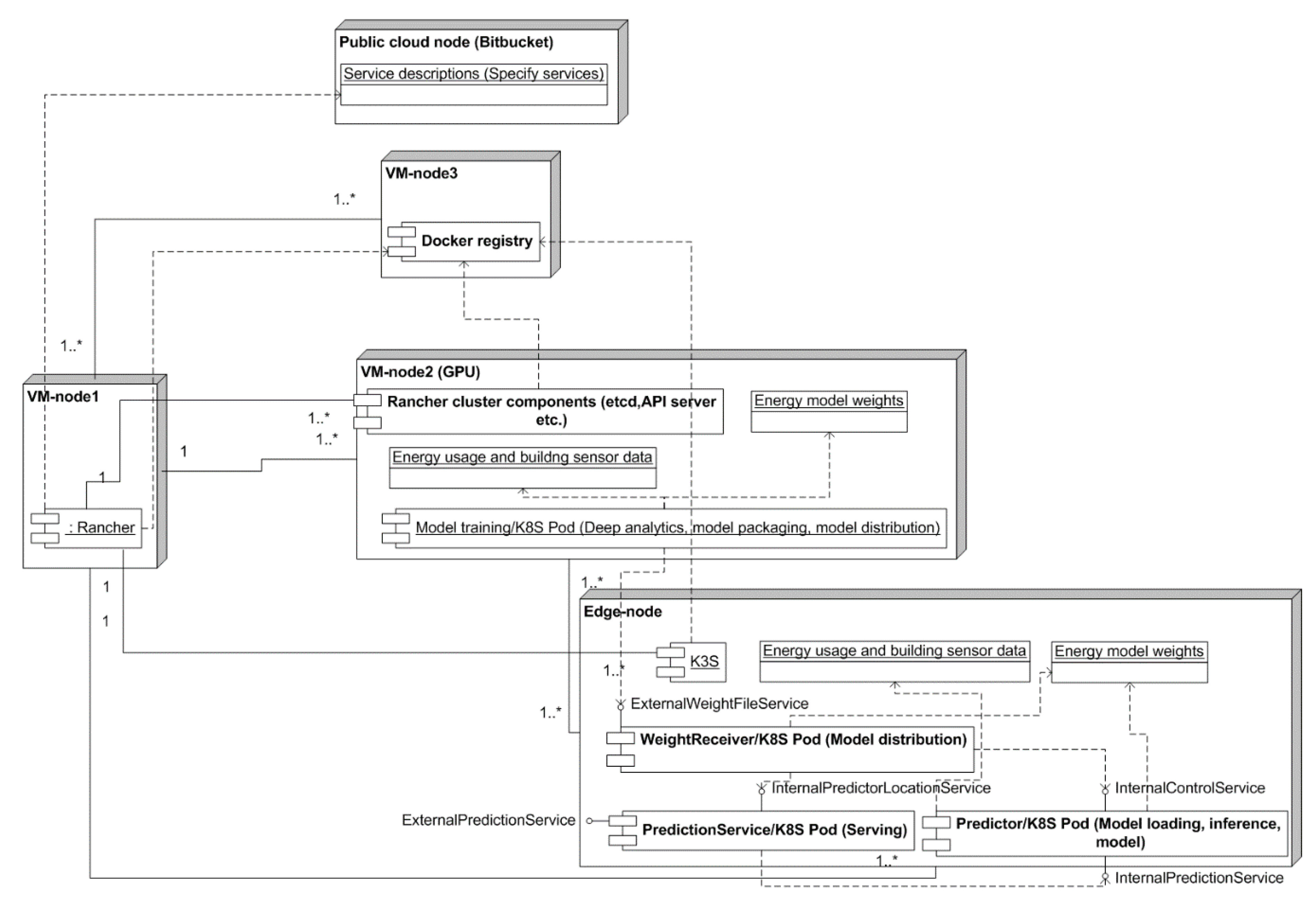
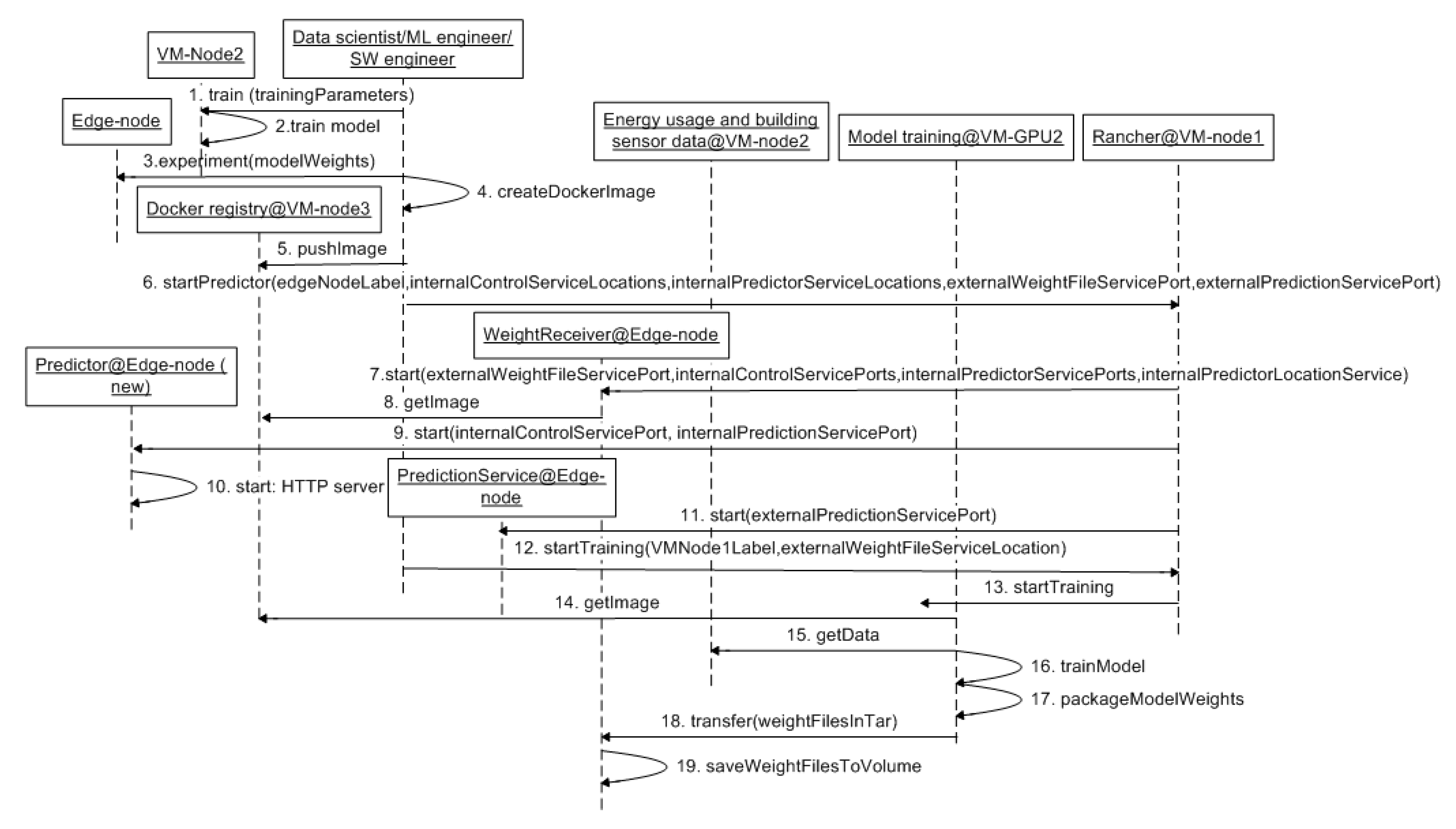
4. Design and Development of the Final Architecture Design
Phase 4: Final Architecture Design
5. Evaluation
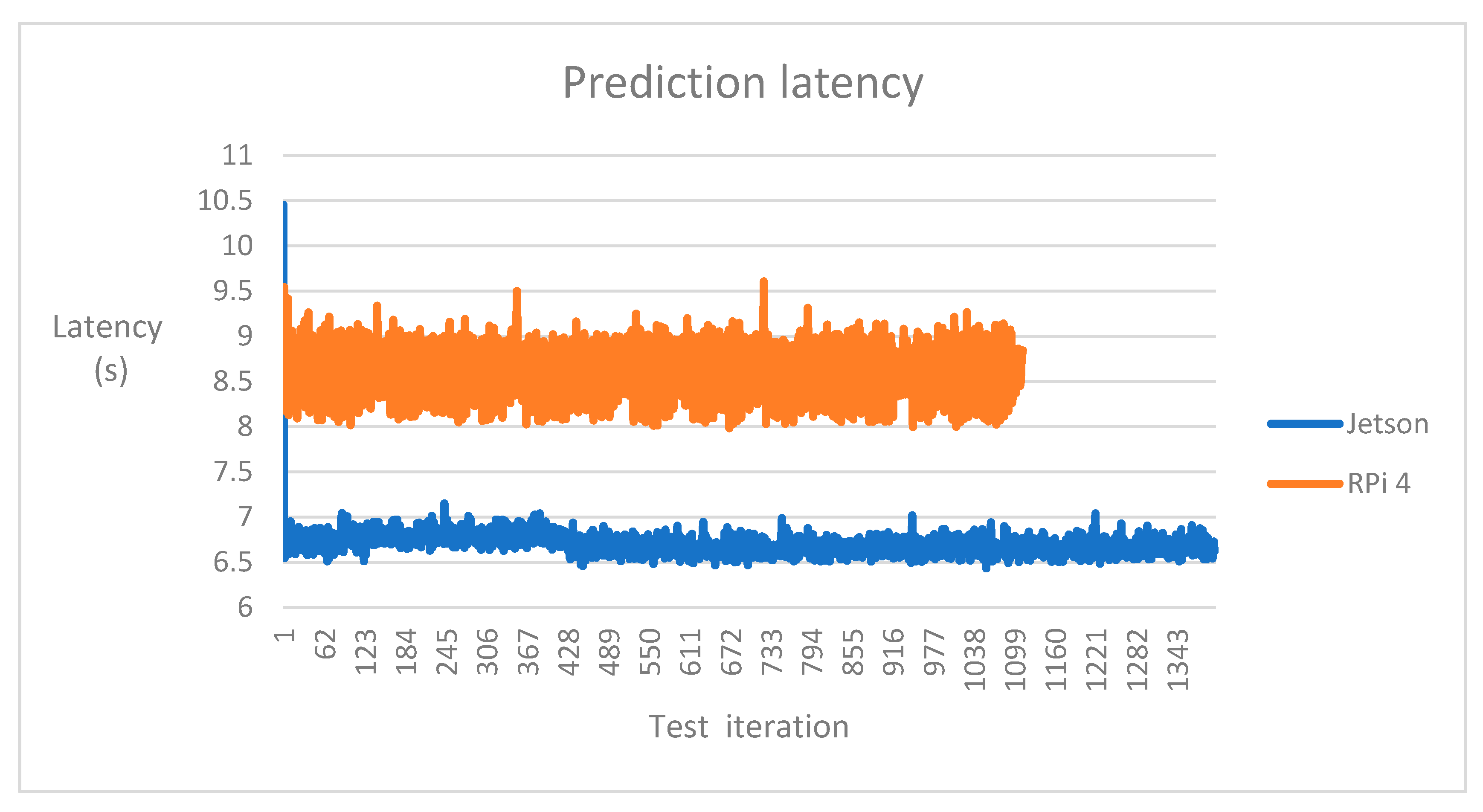
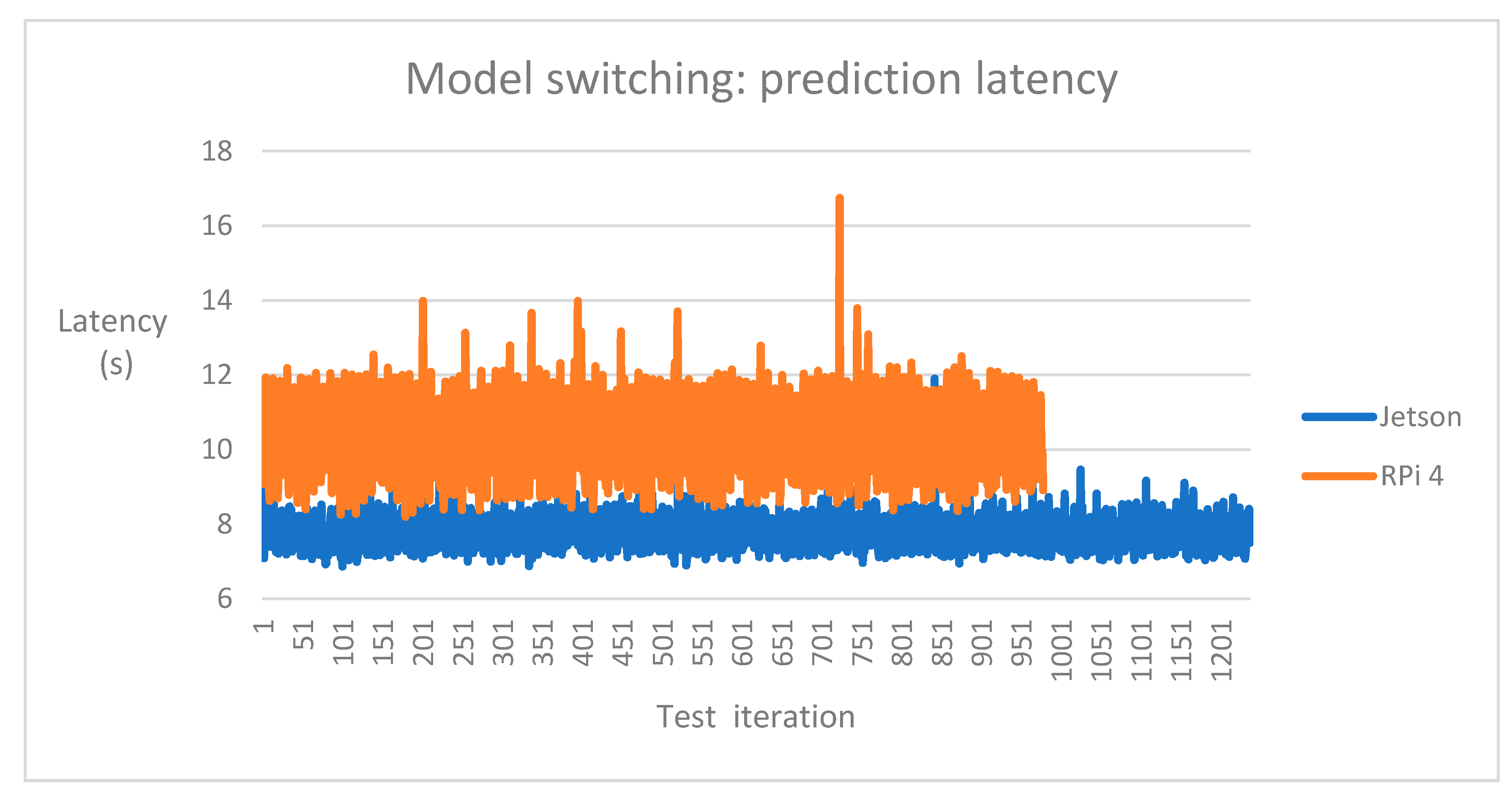
5.1. Results of Performance Tests
5.2. Feasiblity Evaluation of the Initial (Phases 1–3) Architectural Approaches
- A model created based on NN weights provided feasible predictions in the edge nodes (with a negligible rounding error).
- Rancher pipelines [18] was not feasible due to an unresolved error in the Docker image building phase (error was related to updating of pip).
- 64-bit OS version (Ubuntu 20.04 in RPi4) in the edge nodes was compatible with k3s.
- Predictors have to be placed into separate K8S pods in order to achieve uninterrupted operation of prediction services, when a ML-based model is updated in the edge node.
5.3. Evaluation of the Final Architecture Design
5.3.1. Feasibility
- NFS server was tested for storing of model weight files. The integration between Rancher and NFS server was performed successfully with K8S Persistent Volume Claims [48]. However, k3s didn’t provide support for a NFS client. Thus, the received weight files were stored locally to the edge-node, and Rancher’s Local Path Provisioner [18] was utilised for accessing of the files.
- Initially, Docker images for ARM-devices (Jetson Nano, RPi 4) were built with a laptop, which contained Ubuntu VM in a VirtualBox. Docker images were compiled with Docker’s buildx-tool [49], which is an experimental feature in Docker. However, it was discovered that building of the images was too slow as images couldn’t be built within a working day. Thus, Docker images for ARM-devices had to be built with Jetson Nano.
- Nvidia has published base images including Tensorflow libraries to be used for building of Docker images for ARM-devices based on Nvidia’s libraries [50]. The Docker image for Jetson Nano was built based on Nvidia’s base image (l4t-tensorflow:r32.4.3-tf1.15-py3), which contained Tensorflow v1.15. However, RPi 4 does not support Nvidia’s libraries. The authors could not find official Docker images, which would contain Tensorflow libraries for RPi. Thus, an unofficial Tensorflow image [51] was used as a base image for RPi 4.
- In order to get access to GPU-resources, Docker’s default runtime had to be changed to ‘nvidia’ in Jetson Nano. Additionally, k3s uses contained as the default container runtime, which had to be changed to Docker in order to get access to GPU resources via Nvidia’s libraries.
5.3.2. Efficiency
5.3.3. Fidelity with Real World Phenomenon
5.3.4. Operationality
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
Appendix B
- The edge-node was booted.
- A Docker image was built in the edge node, and a weight file was included into the image.
- A Docker container was started based on the Docker image. A model was created based on the weight file.
- A wget() loop was used for getting predictions (predictions for ~2.6 days; 62 hourly predictions). Each request consisted of 600 data points (~3 weeks of input data). The loop slept 1 s after completion of a request.
- Latencies were extracted into a file based on the terminal output.
- The Edge-node was booted.
- Predictor components (Figure 5) were deployed to the edge-node from Rancher’s service catalogue.
- A loop was started, which transferred a new weight file to the edge-node once per minute (by utilising ExternalWeightFileService in Figure 5).
- Another loop was started for requesting predictions (similar loop as step 4 in the prediction inference tests).
- Latencies of both loops were extracted into a text file based on the terminal output.
Appendix C

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Node | Memory (GB) | CPU (cores) | GPU (CUDA Cores) |
|---|---|---|---|
| VM-node1 (Rancher) | 40 | 3 | x |
| VM-node2 (GPU) | 197 | 12 | 3584 |
| Jetson Nano | 4 | 4 | 128 |
| RPi 4 | 4 | 4 | x |
| SW Component | Version | Node |
|---|---|---|
| Rancher | 2.4.7 | VM-node1 |
| Kubernetes-k3s | 1.18.8 | Jetson Nano, RPi 4 |
| Kubernetes-VM | 1.18.6 | VM-node1, VM-node2 |
| Tensorflow | 1.14–1.15 | VM-node2, Jetson Nano, RPi4 |
| Keras | 2.2.0 | VM-node2, Jetson Nano, RPi4 |
Appendix D
Appendix D.1. Phase 1: Feasibility of Predictions in Edge-Nodes
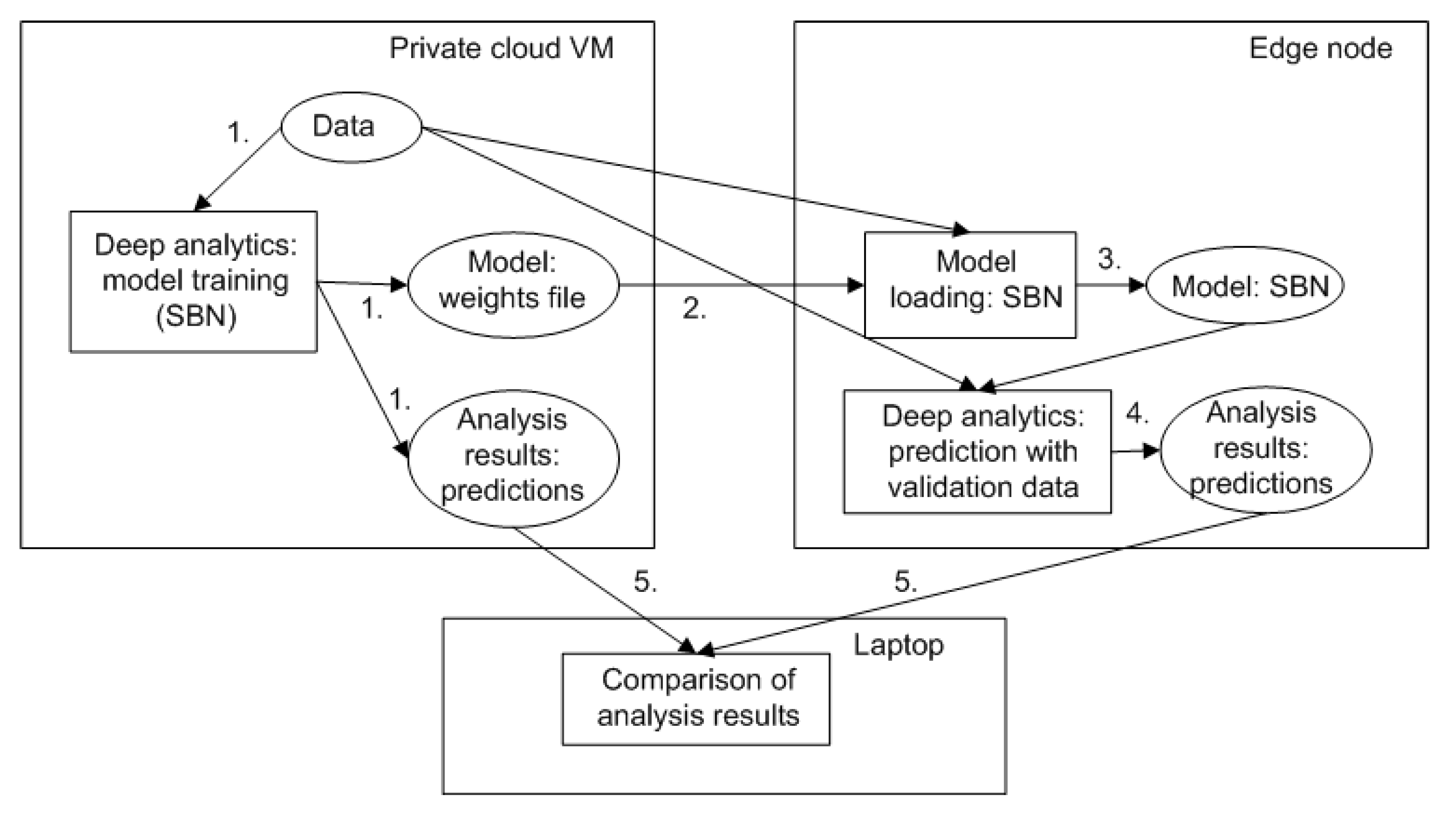
- SBN model(s) were trained in the private cloud based on several existing datasets [23]. After each training phase, weights of the trained model were saved into a file. Additionally, predictions were produced based on validation data (energy consumption prediction for 3 weeks) and saved.
- The weight files were transferred to the edge-node.
- A prediction model was created based on the loaded weight file(s) in the edge-node. Additionally, training data was needed in the edge-node to perform similar scaling of features, which was performed during the training phase.
- Predictions were performed in the edge node (based on validation data) and saved.
- The predictions after training (step 1) and after reloading of the model in the edge-node (step 4) were compared to ensure feasibility of the approach.

- In most cases, the loaded model in edge node produced the same predictions as the original model in the private cloud. However, in ~2.7% of the predictions, there was a rounding error (10−5) which is negligible. Thus, the chosen architectural approach for model training, transfer, and model loading was feasible for further design of the architecture.
Appendix D.2. Phase 2: Automation of ML-Based Model Management and Deployment with Rancher Pipelines
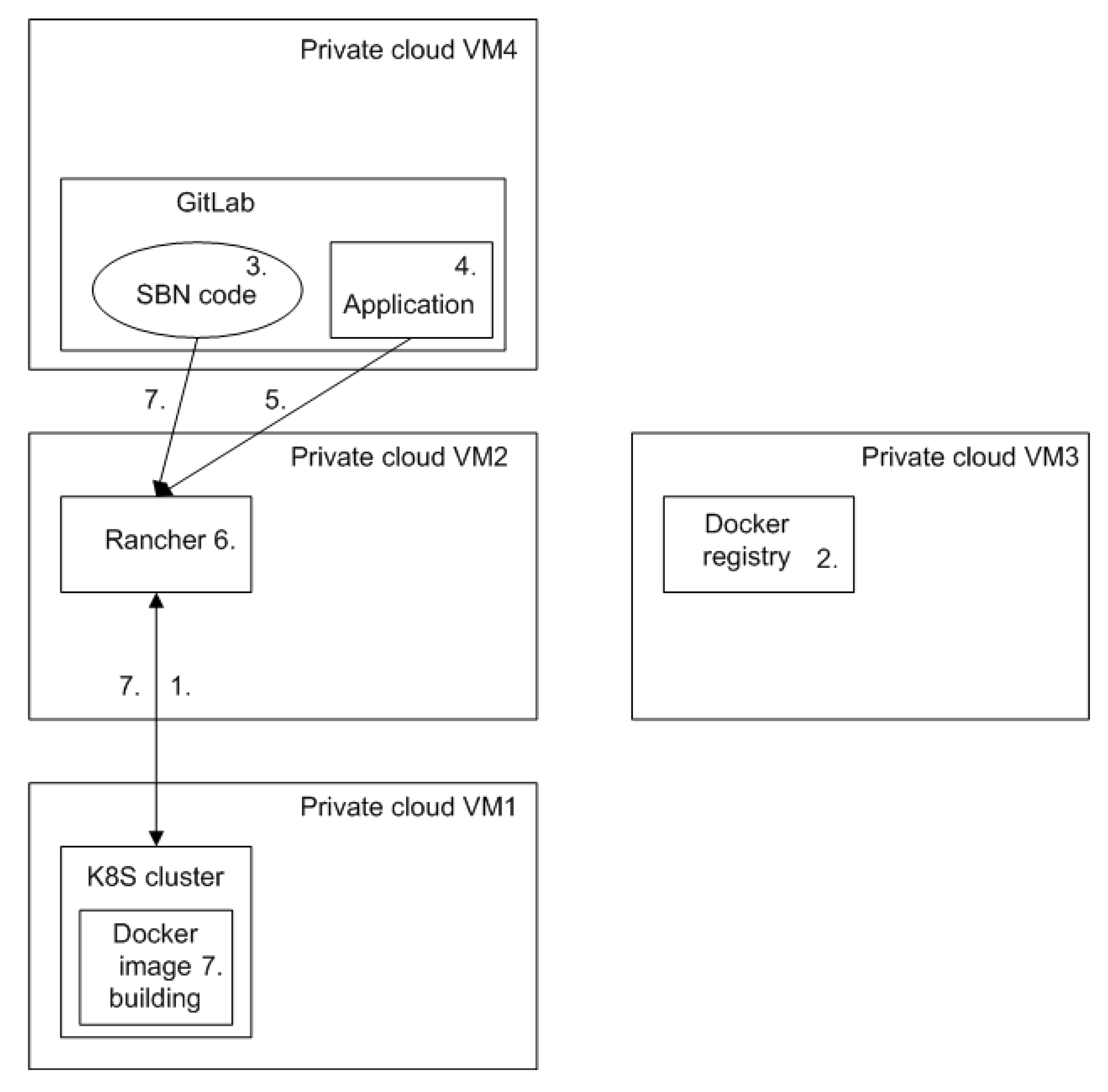
- A K8S cluster was created to a Virtual Machine (VM) (VM1) in the private cloud. The cluster was registered into Rancher (VM2).
- Docker registry [56] was initialised to another VM (VM3) in the private cloud for storing of Docker images.
- Code of the existing SBN-implementation was published in GitLab (VM4). A Dockerfile was added to the code base for building a Docker image based on the code.
- An application was added to GitLab for integration with Rancher.
- The GitLab-application was authenticated with Rancher (Tools/Pipeline).
- A pipeline was added into the K8S-cluster with Rancher. Location of the Dockerfile and Docker registry were provided.
- Building of the Docker image was triggered from Rancher UI, or based on a Git commit to GitLab. The SBN-implementation was downloaded from GitLab, and placed into the K8S-cluster for building.

- Building of the Docker image based on the SBN-implementation (at GitLab) was triggered successfully based on the Git commit. However, the Docker image could not be built due to an error encountered in building. Particularly, the latest version of pip could not be installed, and Docker image creation stopped.
- It was concluded that Rancher pipelines may be utilised for CI/CD of code, but the feature was not applicable for our purpose. Thus, we decided to proceed without Rancher pipelines for further development.
Appendix D.3. Phase 3: Continuous Training and Switching/Updating (CI/CD) of ML-Based Model(s)/Uninterrupted Operation of Prediction Services: Multi-Threaded Predictors in a K8S Pod
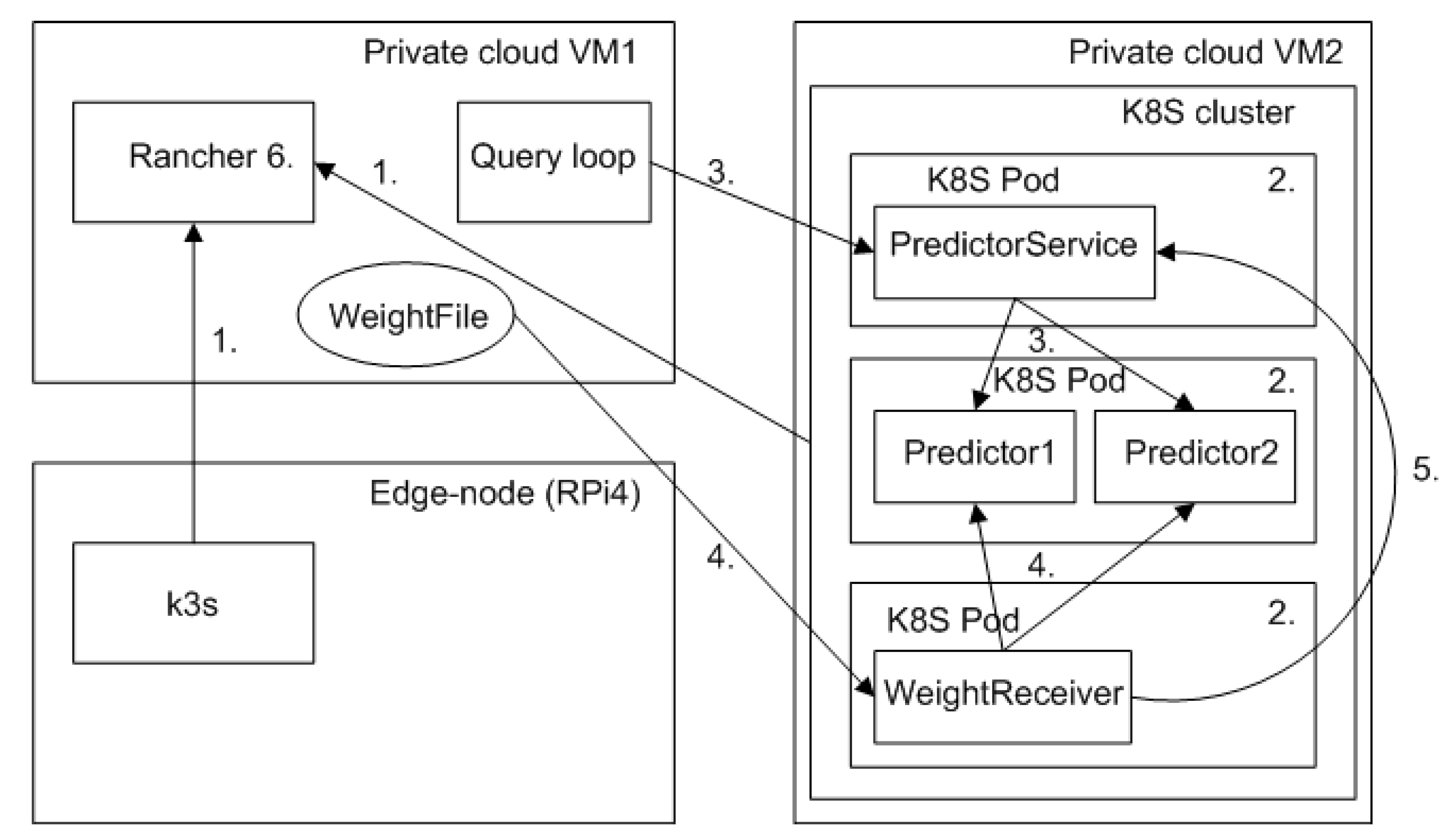
- Two K8S clusters were created and registered to Rancher (VM1). One cluster was running in the private cloud (VM2). The other k3s cluster was executed in the edge node (RPi 4).
- The architecture consisting of multi-threaded predictors, a weight receiver, and a prediction service was placed to the K8S cluster of the private cloud (VM2).
- The predictor was queried for energy consumption prediction from the predictor service, which forwarded queries to the active predictor.
- Model switching was experimented by transferring new weight files to a weight receiver, which managed switching of the predictors. Each time a new weight file was received, the inactive predictor was loaded with a new weight file, and the old predictor was deactivated.
- Location of the active predictor was updated to the prediction service.

- First, a 64-bit OS (Ubuntu 20.04; aarch64) had to be installed to RPi 4 in order to be compatible with k3s (32-bit Raspbian installation wasn’t compatible with k3s; See the issue in k3s GitHub [57]). After the installation of Ubuntu 20.04 in RPi 4, the k3s cluster was registered successfully to Rancher.
- It was discovered that a Keras/Tensorflow-session of the old predictor had to be closed, before the new predictor could be initialised successfully. Thus, predictions couldn’t be provided to end users from the old predictor during the switching operation. This caused an additional delay to the provisioning of predictions. Based on the discovery, it was decided to place predictors to separate K8S Pods in further design of the architecture.
References
- Annual Energy Outlook Early Release. Energy Information Administration (EIA). Available online: https://www.eia.gov/outlooks/aeo/ (accessed on 18 November 2020).
- Rousselot, M. ODYSSEE-MURE Policy Brief: Energy Efficiency Trends in Buildings. Available online: https://www.odyssee-mure.eu/publications/policy-brief/buildings-energy-efficiency-trends.html (accessed on 18 November 2020).
- Heating Cooling. Available online: https://ec.europa.eu/energy/topics/energy-efficiency/heating-and-cooling_en (accessed on 18 November 2020).
- Ruelens, F.; Iacovella, S.; Claessens, B.J.; Belmans, R. Learning agent for a heat-pump thermostat with a set-back strategy using model-free reinforcement learning. Energies 2015, 8, 8300–8318. [Google Scholar] [CrossRef] [Green Version]
- Barrett, E.; Linder, S. Autonomous hvac control, a reinforcement learning approach. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Porto, Portugal, 7–11 September 2015. [Google Scholar]
- Jia, R.; Jin, M.; Sun, K.; Hong, T.; Spanos, C. Advanced building control via deep reinforcement learning. Energy Procedia 2019, 158, 6158–6163. [Google Scholar] [CrossRef]
- Zhang, Z.; Chong, A.; Pan, Y.; Zhang, C.; Lu, S.; Lan, K.P. A Deep Reinforcement Learning Approach to Using Whole Building Energy Model for HVAC Optimal Control. In Proceedings of the Building Performance Modeling Conference and SIMBuild, Chicago, IL, USA, 26–28 September 2018. [Google Scholar]
- Afram, A.; Janabi-Sharifi, F.; Fung, A.S.; Raahemifar, K. Artificial neural network (ANN) based model predictive control (MPC) and optimization of HVAC systems: A state of the art review and case study of a residential HVAC system. Energy Build. 2017, 141, 96–113. [Google Scholar] [CrossRef]
- Jain, A.; Smarra, F.; Reticcioli, E.; D’Innocenzo, A.; Morari, M. NeurOpt: Neural network based optimization for building energy management and climate control. In Proceedings of the 2nd Annual Conference on Learning for Dynamics and Control, Berkeley, CA, USA, 11–12 June 2020; pp. 445–454. [Google Scholar]
- Zhou, B.; Li, W.; Chan, K.W.; Cao, Y.; Kuang, Y.; Liu, X.; Wang, X. Smart home energy management systems: Concept, configurations, and scheduling strategies. Renew. Sustain. Energy Rev. 2016; 61, pp. 30–40. [Google Scholar]
- Hadidi, R.; Cao, J.; Xie, Y.; Asgari, B.; Krishna, T.; Kim, H. Characterizing the Deployment of Deep Neural Networks on Commercial Edge Devices. In Proceedings of the IEEE International Symposium on Workload Characterization (IISWC), Orlando, FL, USA, 3–5 November 2019. [Google Scholar]
- Chen, J.; Ran, X. Deep learning with edge computing: A review. Proc. IEEE 2019, 107, 1655–1674. [Google Scholar] [CrossRef]
- Pakkala, D.; Spohrer, J. Digital Service: Technological Agency in Service Systems. In Proceedings of the Hawaii International Conference on System Sciences, Honolulu, HI, USA, 8–11 January 2019. [Google Scholar]
- Wiedemann, A.; Forsgren, N.; Wiesche, M.; Gewald, H.; Krcmar, H. Research for practice: The DevOps phenomenon. Comm. ACM 2019, 62, 44–49. [Google Scholar] [CrossRef] [Green Version]
- Hummer, W.; Muthusamy, V.; Rausch, T.; Dube, P.; El Maghraoui, K.; Murthi, A.; Oum, P. ModelOps: Cloud-based lifecycle management for reliable and trusted AI. In Proceedings of the IEEE International Conference on Cloud Engineering (IC2E), Prague, Czech Republic, 24–27 June 2019. [Google Scholar]
- Sittón-Candanedo, I.; Alonso, R.S.; Corchado, J.M.; Rodríguez-González, S.; Casado-Vara, R. A review of edge computing reference architectures and a new global edge proposal. Future Gener. Comput. Syst. 2019, 99, 278–294. [Google Scholar] [CrossRef]
- Pääkkönen, P.; Pakkala, D. Extending reference architecture of big data systems towards machine learning in edge computing environments. J. Big Data 2020, 25, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Rancher. Available online: https://rancher.com/ (accessed on 18 November 2020).
- k3s-Lightweight Kubernetes. Available online: https://rancher.com/docs/k3s/latest/en/ (accessed on 18 November 2020).
- Luo, H.; Cai, H.; Yu, H.; Sun, Y.; Bi, Z.; Jiang, L. A short-term energy prediction system based on edge computing for smart city. Future Gener. Comput. Syst. 2019, 101, 444–457. [Google Scholar] [CrossRef]
- Li, K.; Gui, N. CMS: A Continuous Machine-Learning and Serving Platform for Industrial Big Data. Future Internet 2020, 12, 102. [Google Scholar] [CrossRef]
- Peffers, K.; Tuunanen, T.; Rothenberger, M.A.; Shatterjee, S. A Design Science Research Methodology for Information Systems Research. J. Manag. Inf. Syst. 2007, 24, 45–77. [Google Scholar] [CrossRef]
- Salmi, T.; Kiljander, J.; Pakkala, D. Stacked Boosters Network Architecture for Short-Term Load Forecasting in Buildings. Energies 2020, 13, 2370. [Google Scholar] [CrossRef]
- ISO/IEC JTC1/SC 42 Committee. Available online: https://www.iso.org/committee/6794475.html (accessed on 18 November 2020).
- Big Data Value Association. BVA SRIA—European Big Data Value Strategic Research and Innovation Agenda. Available online: http://bdva.eu/sites/default/files/BDVA_SRIA_v4_Ed1.1.pdf (accessed on 18 November 2020).
- Chang, W.L.; Boyd, D.; Levin, O. NIST Big Data Interoperability Framework: Volume 6, Reference Architecure. NIST Big Data Program. Available online: https://www.nist.gov/publications/nist-big-data-interoperability-framework-volume-6-reference-architecture (accessed on 18 November 2020).
- Lin, S.; Simmon, E. The Industrial Internet of Things Volume G1: Reference Architecture; Industrial Internet Consortium: Needham, MA, USA, 2019. [Google Scholar]
- ArchiMate 3.1 Specification. The Open Group. Available online: https://pubs.opengroup.org/architecture/archimate3-doc/ (accessed on 18 November 2020).
- Dang, Y.; Lin, Q.; Huang, P. AIOps: Real-World challenges and research innovations. In Proceedings of the IEEE/ACM 41st International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), Montreal, QC, Canada, 25–31 May 2019. [Google Scholar]
- Galster, M.; Avgeriou, P. Empirically-grounded reference architectures: A proposal. In Proceedings of the Joint ACM SIGSOFT Conference on Quality of Software Architectures and ACM SIGSOFT Conference on Quality of Software Architectures and ACM SIGSOFT Symposium on Architecting Critical Systems, Boulder, CO, USA, 20–24 June 2011. [Google Scholar]
- Hardy, C.; Merrer, E.L.; Sericola, B. Distributed deep learning on edge-devices: Feasibility via adaptive compression. In Proceedings of the IEEE 16th International Symposium on Network Computing and Applications (NCA), Cambridge, MA, USA, 30 October–1 November 2017. [Google Scholar]
- Jeong, H.; Jeong, I.; Lee, H.; Moon, S. Computation offloading for machine learning web apps in the edge server environment. In Proceedings of the IEEE 38th International Conference on Distributed Computing Systems, Vienna, Austria, 2–5 July 2019; pp. 1492–1499. [Google Scholar]
- Zhou, L.; Wen, H.; Teodorescu, R.; Du, D.H.C. Distributing deep neural networks with containerized partitions at the edge. In Proceedings of the 2nd Usenix Workshop on Hot Topics in Edge Computing, Renton, WA, USA, 9 July 2019. [Google Scholar]
- Mehta, R.; Shorey, R. DeepSplit: Dynamic Splitting of Collaborative Edge-Cloud Convolutional Neural Networks. In Proceedings of the 12th International Conference on Communication Systems Networks (COMSNETS), Bengaluru, India, 7–11 January 2020. [Google Scholar]
- Hadidi, R.; Asgari, B.; Cao, J.; Bae, Y.; Kim, H.; Ryoo, M.S.; Kim, H. Edge-Tailored Perception: Fast Inferencing in-the-Edge with Efficient Model Distribution. Available online: https://deepai.org/publication/edge-tailored-perception-fast-inferencing-in-the-edge-with-efficient-model-distribution (accessed on 18 November 2020).
- Hadidi, R.; Cao, J.; Ryoo, M.S.; Kim, H. Toward Collaborative Inferencing of Deep Neural Networks on Internet-of-Things Devices. IEEE Internet Things 2020, 7, 4950–4960. [Google Scholar] [CrossRef]
- Ran, X.; Chen, H.; Chu, X.; Liu, Z.; Chen, J. DeepDecision: A Mobile deep learning framework for edge video analytics. In Proceedings of the IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 1421–1429. [Google Scholar]
- Merkel, D. Docker: Lightweight Linux Containers for Consistent Development and Deployment. Linux J. 2014, 239, 1–5. [Google Scholar]
- Burns, B.; Grant, B.; Oppenheimer, D.; Brewer, E.; Wilkes, J. Borg, Omega, and Kubernetes. Commun. ACM 2016, 59, 50–57. [Google Scholar] [CrossRef]
- Helm. The Package Manager for Kubernetes. Available online: https://helm.sh/ (accessed on 18 November 2020).
- Fathoni, H.; Yang, C.; Chang, C.; Huang, C. Performance Comparison of Lightweight Kubernetes in Edge Devices. In Proceedings of the I-SPAN: International Symposium on Pervasive Systems, Algorithms and Networks, Naples, Italy, 16–20 September 2019. [Google Scholar]
- Goethals, T.; De Turck, F.; Volckaert, B. FLEDGE: Kubernetes Compatible Container Orchestration on Low-Resource Edge Devices. In Proceedings of the IOV: International Conference on Internet of Vehicles, Kaohsiung, Taiwan, 18–21 November 2019. [Google Scholar]
- Le Minh, K.; Le, K.; Le-Trung, Q. DLASE: A light-weight framework supporting Deep Learning for Edge Devices. In Proceedings of the 4th International Conference on Recent Advances in Signal Processing, Telecommunications Computing (SigTelCom), Hanoi, Vietnam, 28–29 August 2020. [Google Scholar]
- Lee, S.H.; Lee, T.; Kim, S.; Park, S. Energy Consumption Prediction System Based on Deep Learning with Edge Computing. In Proceedings of the 2nd International Conference on Electronics Technology, Chengdu, China, 10–13 May 2019. [Google Scholar]
- Sonnenberg, C.; vom Brocke, J. Evaluations in the Science of the Artificial–Reconsidering the Build-Evaluate Pattern in Design Science Research. In Proceedings of the International Conference on Design Science Research in Information Systems and Technology, Las Vegas, NV, USA, 14–15 May 2012. [Google Scholar]
- Wang, Y.; Chen, Q.; Kang, C. Review of Smart Meter Data Analytics: Applications, Methodologies, and Challenges. IEEE Trans. Smart Grid 2019, 10, 3125–3148. [Google Scholar] [CrossRef] [Green Version]
- Nvidia Tesla P100. Available online: https://www.nvidia.com/en-us/data-center/tesla-p100/ (accessed on 18 November 2020).
- Persistent Volumes. Available online: https://kubernetes.io/docs/concepts/storage/persistent-volumes/ (accessed on 18 November 2020).
- Docker Buildx. Available online: https://docs.docker.com/buildx/working-with-buildx/ (accessed on 18 November 2020).
- NVIDIA L4T TensorFlow. Available online: https://ngc.nvidia.com/catalog/containers/nvidia:l4t-tensorflow (accessed on 18 November 2020).
- hellozcb/tensorflow-arm64 at Docker Hub. Available online: https://hub.docker.com/r/hellozcb/tensorflow-arm64 (accessed on 18 November 2020).
- Pääkkönen, P.; Pakkala, D. Reference Architecture and Classification of Technologies, Products and Services for Big Data Systems. Big Data Res. 2015, 2, 166–186. [Google Scholar] [CrossRef] [Green Version]
- Lipcak, P.; Macak, M.; Rossi, B. Big Data Platform for Smart Grids Power Consumption Anomaly Detection. In Proceedings of the Federated Conference on Computer Science and Information Systems, Leipzig, Germany, 1–4 September 2019. [Google Scholar]
- Martínez-Fernández, S.; Ayala, C.P.; Franch, X.; Marques, H.M. Benefits and drawbacks of software reference architectures: A case study. Inf. Softw. Technol. 2017, 88, 37–52. [Google Scholar] [CrossRef] [Green Version]
- TensorFlow Lite. Available online: https://www.tensorflow.org/lite (accessed on 18 November 2020).
- Docker Registry. Available online: https://docs.docker.com/registry/ (accessed on 18 November 2020).
- k3s issue (#1278) in GitHub. Available online: https://github.com/rancher/k3s/issues/1278 (accessed on 18 November 2020).










| Cloud | Edge | |
|---|---|---|
| Communication | Predictions have to be constantly transferred to the edge-nodes. | Model updates are transferred periodically to edge nodes. |
| Privacy concerns | Communicated predictions on building’s energy consumption | Communicated updates to the prediction model. |
| Independency of operation | The solution is dependent on the predictions provided from the cloud domain. | The latest model may be used for predicting energy consumption in the edge node, when network connection is down. |
| Energy consumption concern in edge nodes | Increased energy consumption caused by transfer of predictions. | Transfer of model updates to the edge nodes. Execution of prediction model. |
| Processing performance | High performance CPU/GPU (thousands of CUDA cores) | Low performance CPU/GPU (up to hundreds CUDA cores) |
| Memory | High (up to hundreds GBs) | Low (few GBs) |
| Inference | Model Switching | |||
|---|---|---|---|---|
| Jetson | RPi4 | Jetson | RPi4 | |
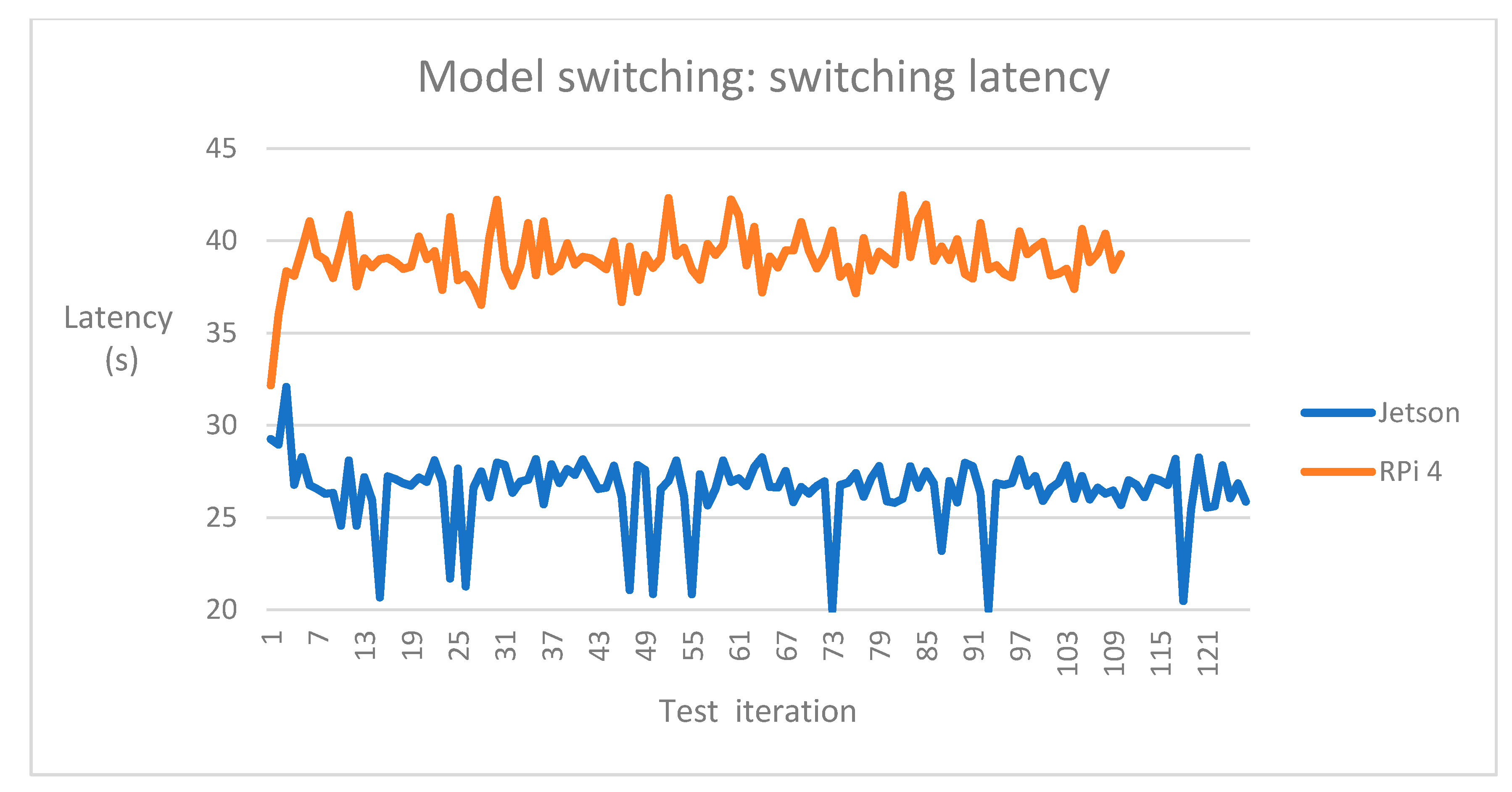
| Avg. latency (s) | 7.72 | 10.03 | 26.49 | 39.09 |
| 99th perc. latency (s) | 9.05 | 12.85 | 29.17 | 42.29 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pääkkönen, P.; Pakkala, D.; Kiljander, J.; Sarala, R. Architecture for Enabling Edge Inference via Model Transfer from Cloud Domain in a Kubernetes Environment. Future Internet 2021, 13, 5. https://doi.org/10.3390/fi13010005
Pääkkönen P, Pakkala D, Kiljander J, Sarala R. Architecture for Enabling Edge Inference via Model Transfer from Cloud Domain in a Kubernetes Environment. Future Internet. 2021; 13(1):5. https://doi.org/10.3390/fi13010005
Chicago/Turabian StylePääkkönen, Pekka, Daniel Pakkala, Jussi Kiljander, and Roope Sarala. 2021. "Architecture for Enabling Edge Inference via Model Transfer from Cloud Domain in a Kubernetes Environment" Future Internet 13, no. 1: 5. https://doi.org/10.3390/fi13010005
APA StylePääkkönen, P., Pakkala, D., Kiljander, J., & Sarala, R. (2021). Architecture for Enabling Edge Inference via Model Transfer from Cloud Domain in a Kubernetes Environment. Future Internet, 13(1), 5. https://doi.org/10.3390/fi13010005