
Rumor Detection Based on Attention CNN and Time Series of Context Information



Abstract
:1. Introduction
- (1)
- We verify that sentiment polarity features in different time series can effectively identify rumors.
- (2)
- We verify that adding an attention mechanism can effectively adjust the weight of rumor features in different time series, focus on more important features and reduce the number of iterations for model training greatly.
- (3)
- We realized the convolutional neural network model with the attention mechanism added by combining sentiment polarity features and time series information. Additionally, we verified that the improved model can greatly reduce the number of iterations of model training through experimentation.
2. Related Works
2.1. Method Based on Traditional Machine Learning
2.2. Method Based on Deep Learning
3. Problem Statement and Proposed Solution
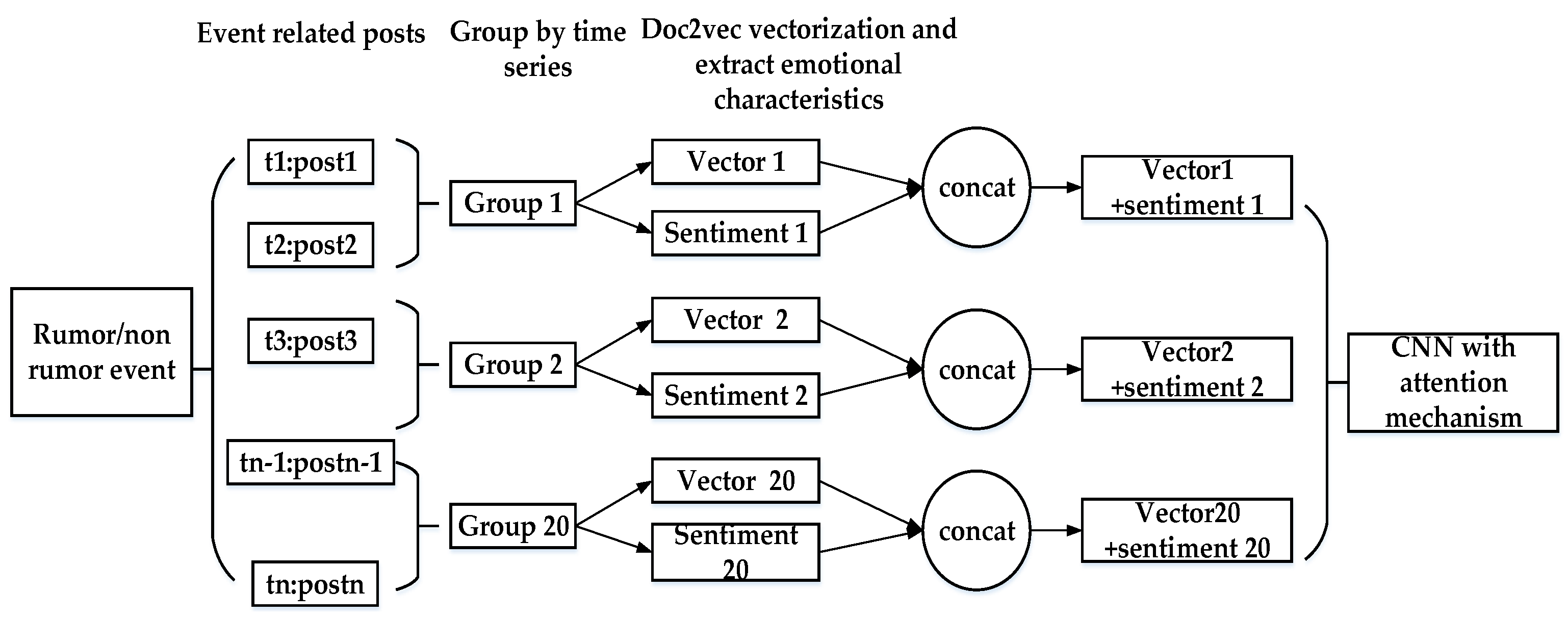
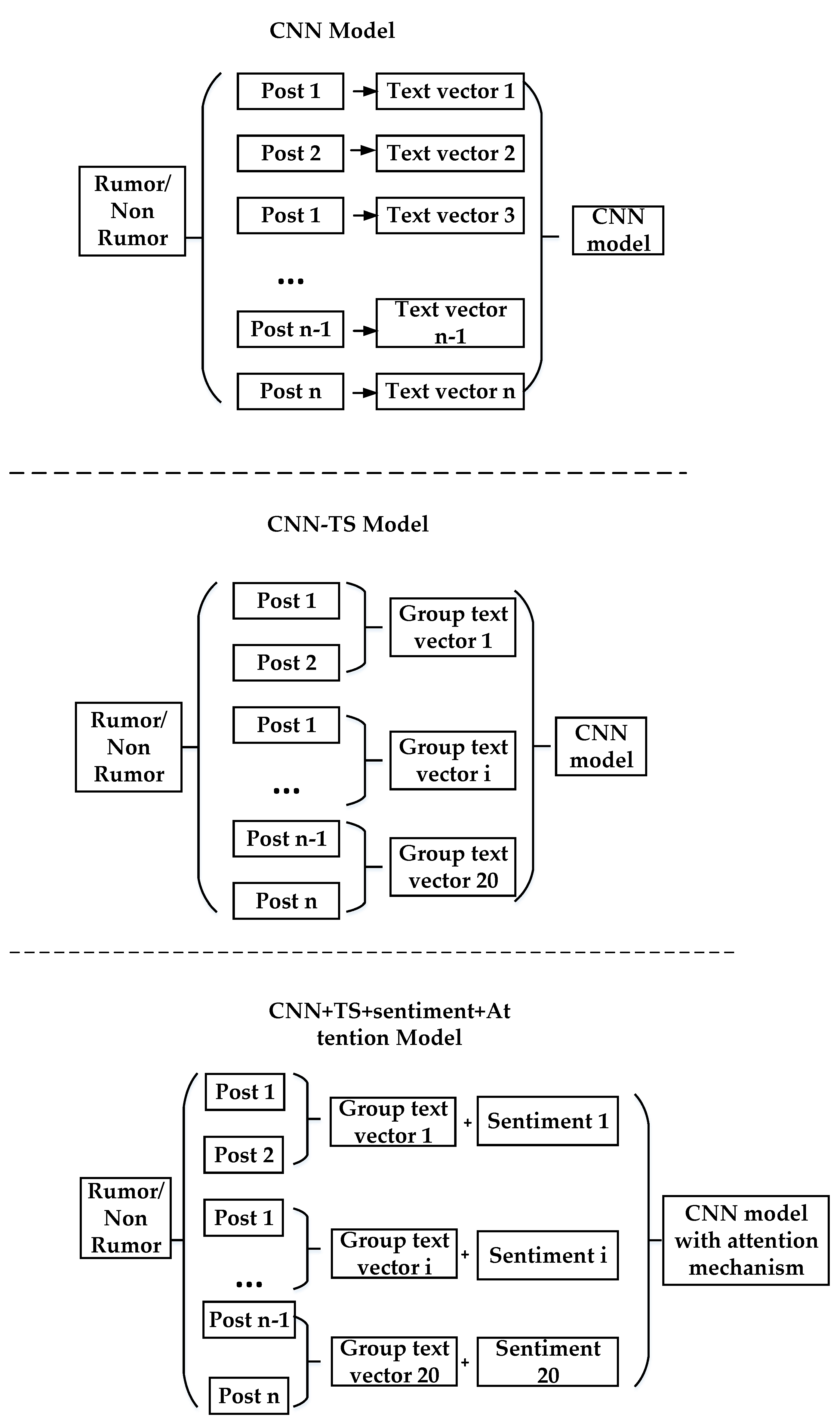
3.1. Problem Statement and Model Framework
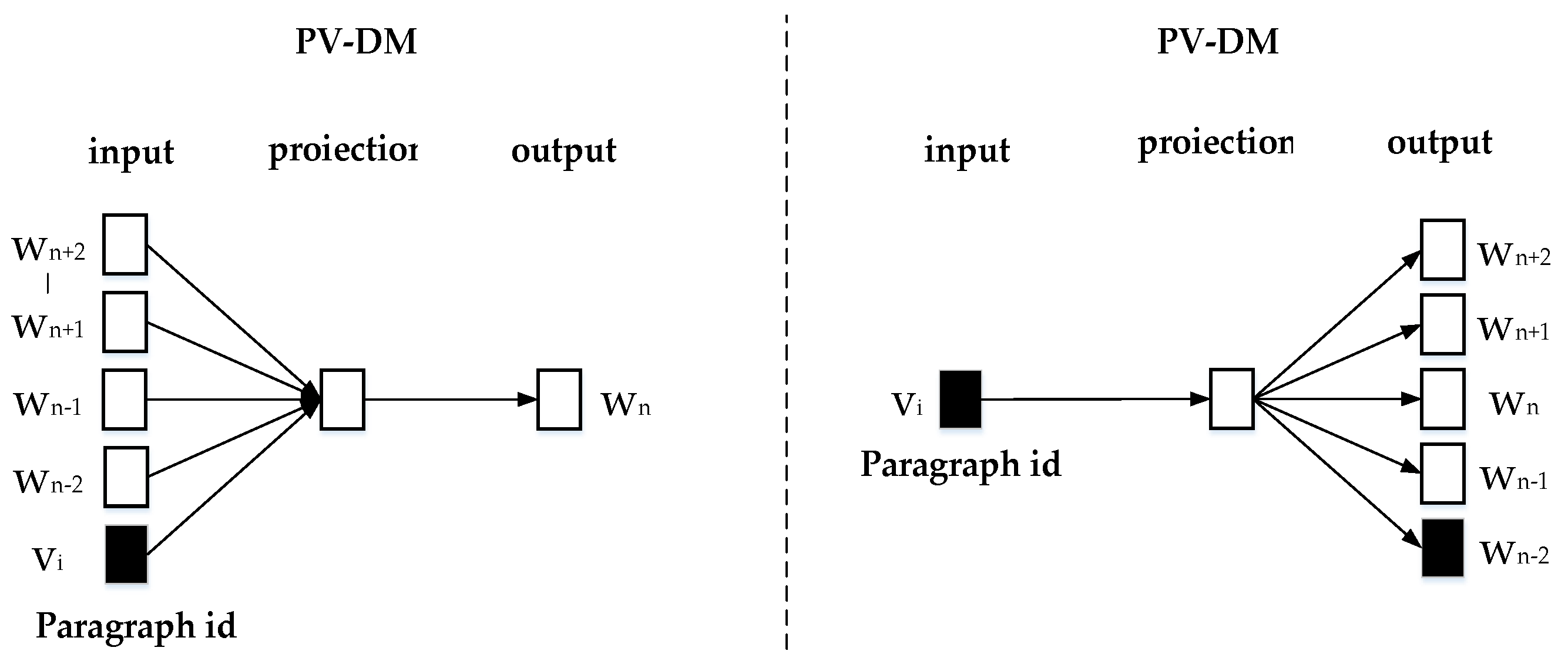
3.2. Construction of Text Vectors
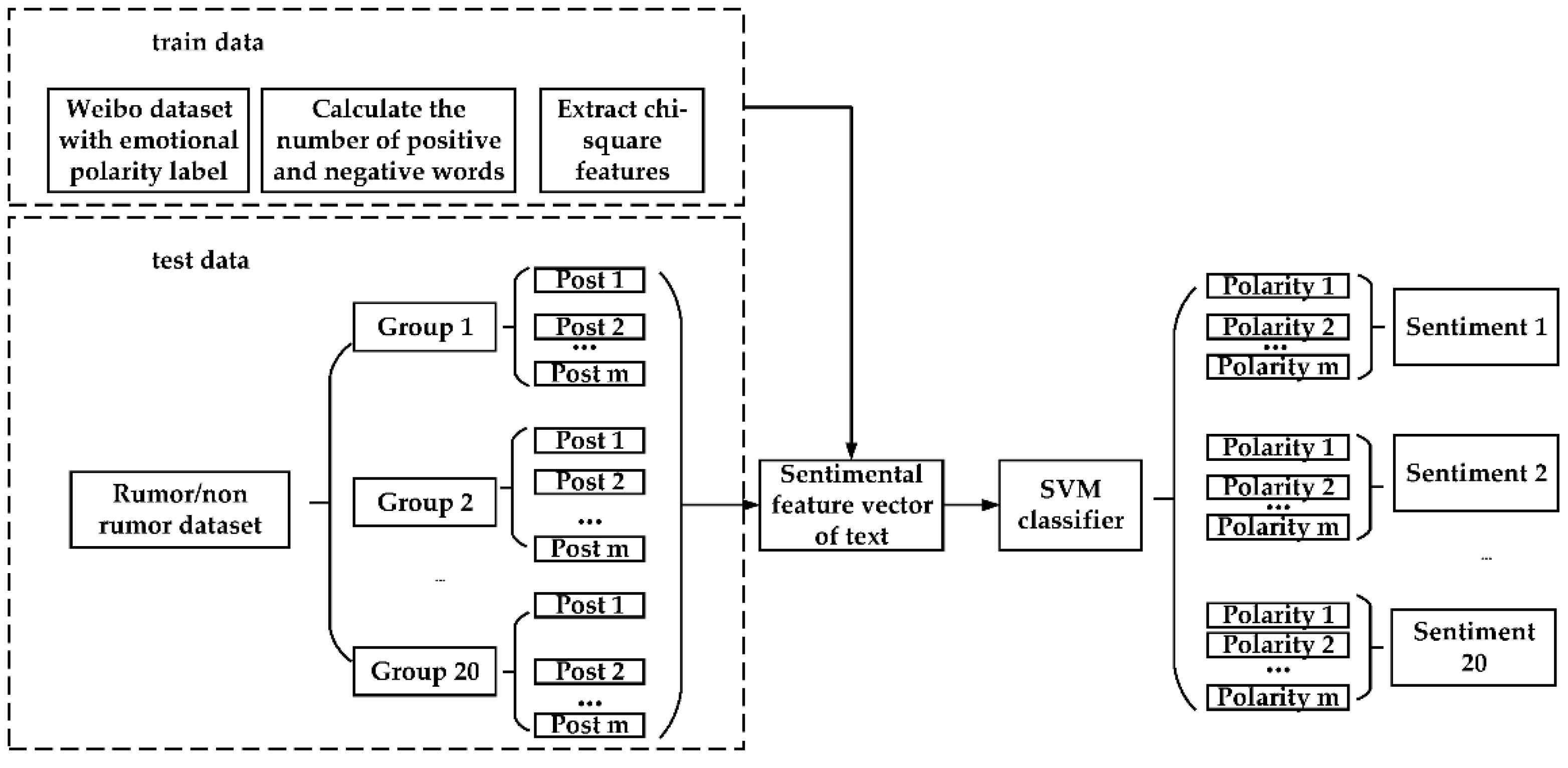
3.3. Time Series Grouping and Extraction of Sentimental Characterisitics
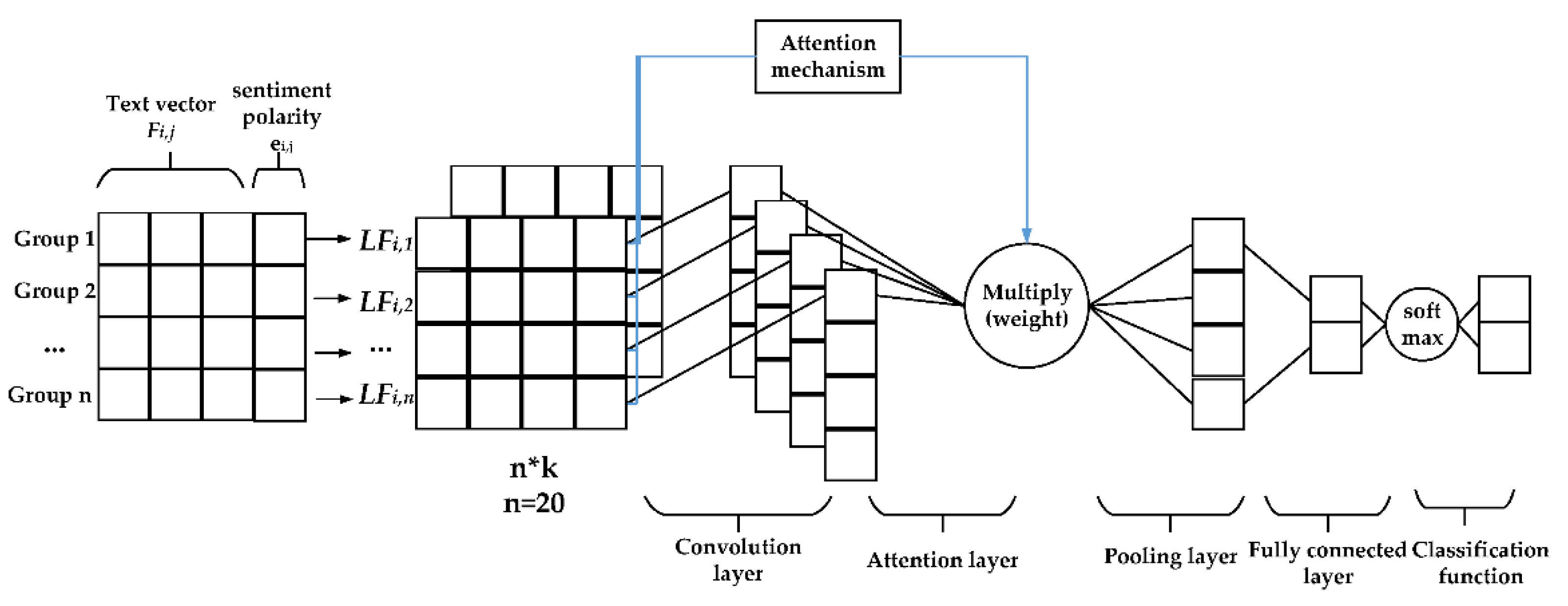
3.4. The CNN Model with the Attention Mechanism That Combines Sentimental Characterisitics and Time Series
4. Experiment, Analysis and Discussion
4.1. Experimental Setup
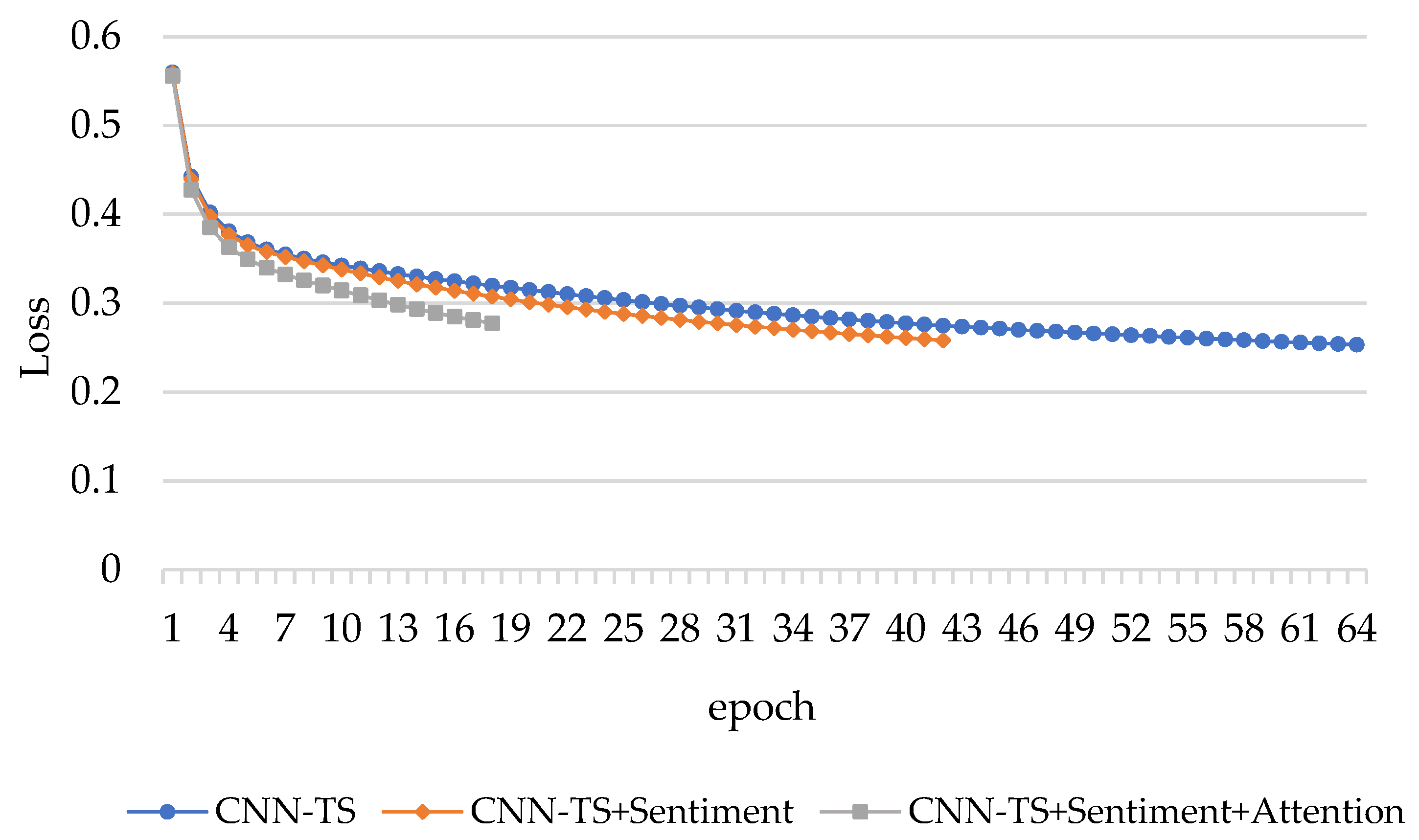
4.2. Experimental Results and Discussion
5. Final Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tan, X.; Zhuang, M.; Lu, X.; Mao, T. An Analysis of the sentiment Evolution of Large-Scale Internet Public Opinion Events Based on the BERT-LDA Hybrid Model. IEEE Access 2021, 9, 15860–15871. [Google Scholar] [CrossRef]
- He, G.; Lu, X.; Li, Z. Automatic Rumor Identification on Microblog. Libr. Inf. Serv. 2021, 57, 114–120. [Google Scholar]
- Yang, F.; Liu, Y.; Yu, X. Automatic detection of rumor on sina weibo. In Proceedings of the 2012 the ACM SIGKDD Workshop on Mining Data Semantic, Beijing, China, 12–16 August 2012. [Google Scholar]
- Sicilia, R.; Giudice, S.; Pei, Y. Twitter rumour detection in the health domain. Expert Syst. Appl. 2021, 110, 33–40. [Google Scholar] [CrossRef]
- Qazvinian, V.; Rosengren, E.; Radev, D.R. Rumor has it: Identifying misinformation in microblogs. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing (EMNLP), Edinburgh, UK, 27–31 July 2011. [Google Scholar]
- Gan, W.; Zhang, H.; Cheng, R. A Study on Online Detection of micro-blog Rumors Based on Naive Bayes Algorithm. In Proceedings of the 2020 Asia-Pacific Conference on Image Processing, Electronics and Computers (IPEC), Dalian, China, 14–16 April 2020. [Google Scholar]
- Mao, E.; Chen, G.; Liu, X.; Wang, B. Research on detecting microblog rumors based on deep features and ensemble classififier. Appl. Res. Comput. 2016, 33, 3369–3373. [Google Scholar]
- Wang, Z.; Guo, Y.; Wang, J. Rumor Events Detection from Chinese Microblogs via Sentiments Enhancement. IEEE Access 2019, 7, 103000–103018. [Google Scholar] [CrossRef]
- Ma, J.; Gao, W.; Mitra, P.; Kwon, S.; Jansen, B.J.; Wong, K.F.; Cha, M. Detecting rumors from microblogs with recurrent neural networks. In Proceedings of the 25th International Joint Conference on Artificial Intelligence (IJCAI’ 16), New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Wang, J.; Peng, Y.; Yu, C. Network Rumor Detection Combining Time Series and Convolutional Neural Network. J. Chin. Comput. Syst. 2020. Available online: http://kns.cnki.net/kcms/detail/21.1106.TP.20210420.1121.025.html (accessed on 20 April 2021).
- Takahashi, T.; Igata, N. Rumor detection on twitter. In Proceedings of the 6th International Conference on Soft Computing and Intelligent Systems and 13th International Symposium on Advanced Intelligence Systems (SCIS-ISIS), Kobe, Japan, 23–27 April 2012. [Google Scholar]
- Kumar, K.K.; Geethakumari, G. Detecting misinformation in online social networks using cognitive psychology. Hum. Cent. Comput. Inf. Sci. 2014, 9, 4–14. [Google Scholar] [CrossRef] [Green Version]
- Yao, X.; Liang, G.; Gu, C. Rumors clarification with minimum credibility in social networks. Comput. Netw. 2021, 193, 108123. [Google Scholar] [CrossRef]
- Bingol, H.; Alatas, B. Rumor Detection in Social Media using machine learning methods. In Proceedings of the 2019 1st International Informatics and Software Engineering Conference (UBMYK), Ankara, Turkey, 1–5 November 2019. [Google Scholar]
- Luo, S.; Wang, J.; Li, B. Study on Rumor Discrimination Based on Improved Combinatorial Optimization Decision Tree. Comput. Simul. 2018, 35, 219–223. [Google Scholar]
- Cai, G.; Bi, M.; Liu, J. A novel rumor detection method based on features of labeled cascade propagation tree. Comput. Sci. Eng. 2018, 40, 1488–1495. [Google Scholar]
- Zeng, Z.; Wang, J. Research on Microblog Rumor Identification Based on LDA and Random Forest. J. China Soc. Sci. Tech. Inf. 2019, 38, 89–96. [Google Scholar]
- Ma, J.; Gao, W.; Wei, Z.; Lu, Y.; Wong, K.F. Detect rumors using time series of social context information on microblogging websites. In Proceedings of the 24th ACM International Conference on Information and Knowledge Management (CIKM), Melbourne, SA, Australia, 19–23 October 2015. [Google Scholar]
- Wang, Z.-H.; Guo, Y. Automatic rumor events detection on Chinese microblogs. J. Chin. Inf. Process. 2019, 33, 132–140. [Google Scholar]
- Xu, Y.; Wang, C.; Dan, Z. Deep Recurrent Neural Network and Data Filtering for Rumor Detection on Sina Weibo. Symmetry 2019, 11, 1408. [Google Scholar] [CrossRef] [Green Version]
- Ruchansky, N.; Seo, S.; Liu, Y. Csi: A hybrid deep model for fake news detection. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management (CIKM’17), Singapore, 6–10 November 2017. [Google Scholar]
- Wu, Z.; Pi, D.; Chen, J. Rumor detection based on propagation graph neural network with attention mechanism. Expert Syst. Appl. 2020, 158, 113595. [Google Scholar] [CrossRef] [PubMed]
- Yin, P.; Pan, W.; Peng, C. Research on Early Detection of Weibo Rumors Based on User Characteristics Analysis. J. Intell. 2020, 39, 81–86. [Google Scholar]
- Tarnpradab, S.; Hua, K.A. Attention Based Neural Architecture for Rumor Detection with Author Context Awareness. In Proceedings of the 2018 13th International Conference on Digital Information Management (ICDIM), Berlin, Germany, 8–11 August 2018. [Google Scholar]
- Li, J.; Ni, S.; Kao, H.Y. Birds of a Feather Rumor Together? Exploring Homogeneity and Conversation Structure in Social Media for Rumor Detection. IEEE Access 2020, 8, 212865–212875. [Google Scholar] [CrossRef]
- Bian, T.; Xiao, X.; Xu, T.; Zhao, P.; Huang, W. Rumor detection on social media with bi-directional graph convolutional networks. In Proceedings of the 2020 34th Association for the Advance of Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Ma, J.; Gao, W.; Wong, K.F. Rumor detection on twitter with tree-structured recursive neural networks. In Proceedings of the 2018 56th Annual Meeting of the Association for Computational Linguistics (ACL), Melbourne, Australia, 26–28 March 2018. [Google Scholar]
- Kumar, S.; Carley, K. Tree LSTMs with Convolution Units to Predict Stance and Rumor Veracity in Social Media Conversations. In Proceedings of the 2019 57th Annual Meeting of the Association for Computational Linguistics (ACL), Florence, Italy, 27 July–2 August 2019. [Google Scholar]
- Liu, Z.; Wei, Z.H.; Zhang, R.X. Rumor detection based on convolutional neural network. J. Comput. Appl. 2017, 37, 3053–3056. [Google Scholar]
- Santhoshkumar, S.; Badu, L. Earlier detection of rumors in online social networks using certainty-factor-based convolutional neural networks. Soc. Netw. Anal. Min. 2020, 10, 10–20. [Google Scholar] [CrossRef]
- Mi, Y.; Tang, H. Rumor Identification Research Based on Graph Convolutional Network. Comput. Eng. Appl. 2020, 57, 161–167. [Google Scholar]
- Yu, K.; Jiang, H.; Li, T.; Han, S.; Wu, X. Data Fusion Oriented Graph Convolution Network Model for Rumor Detection. IEEE Trans. Netw. Serv. Manag. 2020, 17, 2171–2181. [Google Scholar] [CrossRef]
- Bai, N.; Meng, F.; Rui, X.; Wang, Z. Rumour Detection Based on Graph Convolutional Neural Net. IEEE Access 2021, 9, 21686–21693. [Google Scholar] [CrossRef]
- Quoc, L.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the 31st International Conference on International Conference on Machine Learning (ICML’14), Beijing, China, 21–26 June 2014. [Google Scholar]
- Bharti, M.; Jindal, H. Automatic Rumour Detection Model on Social Media. In Proceedings of the 2020 Sixth International Conference on Parallel, Distributed and Grid Computing (PDGC), Waknaghat, India, 6–8 November 2020; pp. 367–371. [Google Scholar]
- Zu, K.; Zhao, M.; Guo, K. Research on the detection of rumor on Sina Weibo. J. Chin. Inf. Process. 2017, 31, 198–204. [Google Scholar]
- Wang, Z.; Guo, Y. Empower rumor events detection from Chinese microblogs with multi-type individual information. Knowl. Inf. Syst. 2020, 62, 3585–3614. [Google Scholar] [CrossRef]
- Wang, Z.; Guo, Y. Rumor events detection enhanced by encoding sentimental information into time series division and word representations. Neurocomputing 2020, 397, 224–243. [Google Scholar] [CrossRef]
- Lu, Y.J.; Li, C.T. GCAN Graph-aware co-attention networks for explainable fake news detection on social media. In Proceedings of the 2020 the 58th Annual Meeting of the Association for Computational Linguistics (ACL), Washington, DC, USA, 5–10 July 2020. [Google Scholar]
- Luo, Y.; Ma, J.; Yeo, C. BCMM:a novel post-based augmentation representation for early rumour detection on social media. Pattern Recognit. 2021, 113, 107818. [Google Scholar] [CrossRef]
- Adel, H.; Schutze, H. Exploring diferent dimensions of attention for uncertainty detection. In Proceedings of the 15th conference of the European chapter of the association for computational linguistics (EACL), Valencia, Spain, 3–7 April 2017. [Google Scholar]
- Yuan, Y.; Wang, Y.; Liu, K. Perceiving more truth: A dilated-block-based convolutional network for rumor identification. Inf. Sci. 2021, 569, 746–765. [Google Scholar] [CrossRef]
- Zhang, H.; Qian, S.; Fang, Q.; Xu, C. Multi-modal Meta Multi-Task Learning for Social Media Rumor Detection. IEEE Trans. Multimed. 2021, 99, 1. [Google Scholar]
- Li, Q.Z.; Zhang, Q.; Si, L. Rumor Detection by exploiting user credibility information, attention and multi-task learning. In Proceedings of the 2019 57th Annual Meeting of the Association for Computational Linguistics (ACL), Florence, Italy, 27 July–2 August 2019. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Zhao, Z.; Resnick, P.; Mei, Q. Enquiring minds: Early detection of rumors in social media from enquiry posts. In Proceedings of the 24th International World Wide Web Conferences Steering Committee, Florence, Italy, 18–22 May 2015. [Google Scholar]
- Sampson, J.; Morstatter, F.; Liu, H.; Wu, L. Leveraging the implicit structure within social media for emergent rumor detection. In Proceedings of the 25th ACM International Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016. [Google Scholar]
- Chen, T.; Li, X.; Yin, H.; Wang, Y. Call Attention to Rumors: Deep Attention Based Recurrent Neural Networks for Early Rumor Detection; Springer: Berlin/Heidelberg, Germany, 2018; pp. 40–52. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Statistical Type | Statistical Value |
|---|---|---|
| Dataset1 | Total Comments | 119,988 |
| Total Positive Comments | 59,993 | |
| Total Negative Comments | 59,995 | |
| Dataset2 | Involved Users | 2,746,818 |
| Total Posts | 3,805,656 | |
| Total Events | 4664 | |
| Total Rumor Events | 2313 | |
| Total Non-Rumor Events | 2351 | |
| Average Posts per Event | 816 | |
| Minimum Posts per Event | 10 | |
| Maximum Posts per Event | 59,138 | |
| Average Time Length per Event | 2460.7 h |
| Positive | Negative | |
|---|---|---|
| True | True Positive (TP) | True Negative (TN) |
| False | False Positive (FP) | False Negative (FN) |
| Layer | Setup |
|---|---|
| Convolution Layer | One layer; Conv2d(1, 3, (3, 51)) |
| Attention Layer | One layer; Conv2d(2, 3, (3, 51), padding = 0, bias = Flase); Sigmoid() |
| Pooling Layer | One layer; MaxPool2d((2, 1), 1) |
| Fully Connected Layer | Linear(51, 4) |
| Classify Function | Softmax |
| Method | Accuracy | Precision | Recall | F1 | |
|---|---|---|---|---|---|
| Traditional ML-based | DT-Rank(2015) | 0.648 | 0.649 | 0.649 | 0.648 |
| LK-RBF(2016) | 0.681 | 0.686 | 0.689 | 0.626 | |
| SVM-TS(2015) | 0.796 | 0.797 | 0.796 | 0.796 | |
| SVMcomDTS(2018) | 0.832 | 0.834 | 0.833 | 0.833 | |
| SVMallDTS(2018) | 0.849 | 0.850 | 0.849 | 0.849 | |
| DNN-based | GRU-2(2016) | 0.833 | 0.833 | 0.834 | 0.833 |
| CNN(2017) | 0.844 | 0.847 | 0.844 | 0.844 | |
| CallAtRumors(2018) | 0.866 | 0.867 | 0.866 | 0.867 | |
| CNN-TS(2021) | 0.851 | 0.839 | 0.866 | 0.852 | |
| CNN-TSSVM(2021) | 0.866 | 0.868 | 0.860 | 0.863 | |
| CNN-TS + Sentiment(ours) | 0.862 | 0.834 | 0.903 | 0.867 | |
| CNN-TS + Sentiment + Attention(ours) | 0.867 | 0.833 | 0.916 | 0.872 | |
| CNN-TSSVM + Sentiment + Attention(ours) | 0.882 | 0.869 | 0.894 | 0.882 | |
| Model | Parameter |
|---|---|
| CNN | 59,138 × 50 |
| CNN-TS | 20 × 50 |
| CNN-TS + Sentiment | 20 × 51 |
| CNN-TS + Sentiment + Attention | 20 ×51 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, Y.; Wang, J. Rumor Detection Based on Attention CNN and Time Series of Context Information. Future Internet 2021, 13, 267. https://doi.org/10.3390/fi13110267
Peng Y, Wang J. Rumor Detection Based on Attention CNN and Time Series of Context Information. Future Internet. 2021; 13(11):267. https://doi.org/10.3390/fi13110267
Chicago/Turabian StylePeng, Yun, and Jianmei Wang. 2021. "Rumor Detection Based on Attention CNN and Time Series of Context Information" Future Internet 13, no. 11: 267. https://doi.org/10.3390/fi13110267
APA StylePeng, Y., & Wang, J. (2021). Rumor Detection Based on Attention CNN and Time Series of Context Information. Future Internet, 13(11), 267. https://doi.org/10.3390/fi13110267