
Context-Induced Activity Monitoring for On-Demand Things-of-Interest Recommendation in an Ambient Intelligent Environment


Abstract
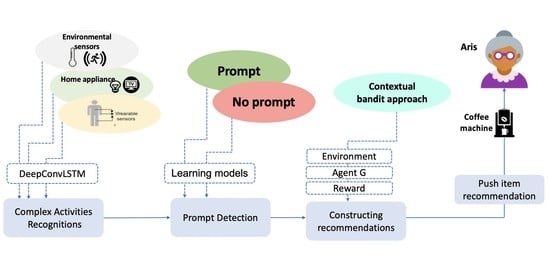
:
1. Introduction
- Proposition of a recommender system based on the contextual bandit approach by fusing the context information from the past and current activities to recommend the correct item.
- Formulation of a reward function for automatic updates without requiring feedback from users to improve the recommendations.
- Provision of minor and major updates to help tackle the dynamicity in human activities while improving the quality of recommendations.
- Evaluation of the developed model using three public datasets.
2. Related work
3. Contextual-Bandit-Based Reminder Care System
3.1. Complex Activity Detection
- Elementary activity recognition: In this approach, the common configuration of DeepConvLSTM was used as the classifier to detect elementary activities. The DeepConvLSTM was configured to four convolutional layers with feature maps and two LSTM layers with 128 cells. This stage was tested on two public datasets PAMAP2 dataset [33] and PUCK dataset [34]. The result shows that DeepConvLSTM achieved a promising accuracy of 77.2%.
- Ontology for complex activity recognition: After achieving the detection of elementary activities, we built an OWL (OntologyWeb Language3) model, which includes the artefacts, locations, environment, and activities required to define things involved in the interaction. From the Aris scenario, preparing a cup of tea could involve changes in the motion sensor (local environmental sensor), status of the kettle in triggering the usages, and time period for this activity, which would rarely be in the early morning before sunrise. From the example, we can extract numbers of context: First, from the motion sensor referring to Aris’ place (the kitchen); Secondly, the item context where the kettle has been used; and finally, the time context of when this activity took place.
- Rule-based orchestration: This step utilizes the output from the two previous steps for the detection of complex activities. A set of rules produced based on the previous ontological models are implemented. Following the Aris tea preparation illustration, we can create an ontological rule in a descriptive language as:
3.2. Prompt Detection
3.3. Conducting Recommendations
3.3.1. Problem Definition
3.3.2. Method
- Past activities context (PAC): Note that each activity is desired to have a different pattern; thus, for each activity, the system extracts the path/sequences of items used from the past records (recorded in the log file) as a type of context. The observed paths of each activity are then stored in a memory based on which the agent can decide an item to be recommended at a specific situation.
- Current activity Context (CAC): The contexts on the current states are extracted from the received data obtained from the previous two stages. For example, when the system receives that the user needs a prompt for preparing coffee, the context of the current activity (locations, previous items, user position and time) will be extracted.
- Item context (IC): This essentially concerns information about items, such as determining to which activity an item belongs, how long such an item can be in use, and how many times such items are needed by the user for the current activity. For example, a coffee machine as an item can be used for the activity of ‘preparing coffee’, where it can be used for around 2 min each time.
| Algorithm 1 Our procedure to recommended a correct item for user’s activity. It takes context x as input, and returns a recommended item as output a. |
|
- Randomized (AdaptiveGreedy), which focuses on taking the action that has the highest reward.
- Active choices (AdaptiveGreedy), which is the same for AdaptiveGreedy but with active parameter None, which means actions will not be taken randomly.
- Upper confidence bound (LinUCB), which stores a square matrix, which has dimension equal to total numbers of features for the fitted model. Details about the parameters for each policy of two streaming models: Linear regression and stochastic gradient distance will be detailed in Section 5.
4. Dataset
4.1. PUCK Dataset
Features Engineering
- 1.
- Combining the environmental data sensors (motion, items, power meter, burner, water usage, door etc.) with the wearable sensors for each participant by matching the time step among them.
- 2.
- Labelling complex activities for the whole dataset.
- 3.
- Extracting the start and the end of each activity as a session to define when the user needs a prompt.
- 4.
- Selecting only the common sensors among all participants where the total measurement counts and participants each greater than 25th percentiles.
- 5.
- Dividing the sensors into four groups to be processed: movement sensors, motion sensors, count sensors and continuous values sensors and process each group as follows:
- (a)
- In movement sensors group, each measurement includes six values (X, Y, Z, Yaw, Roll and Pitch). We extracted the following features: Mean (X, Y, Z, YY, RR and PP), STD (X, Y, Z, YY, RR and PP) Correlations (X//Y//Z) and (Yaw//Roll//Pitch), which leads to 36 features in total.
- (b)
- For motions sensors group, if at least one trigger in a group is counted as trigger for the group, count and then compute the fraction counts across the groups. Based on the PUCK dataset, we have 11 groups (features) altogether.
- (c)
- Count sensors, which have on, off measurements, such as (door, item, shake and medicine container sensor), we count and compute the fraction counts of each session (20 features).
- (d)
- For the last group, we calculate the average for continuous value sensors, such as electricity and temperature (three features).
- 6.
- After extracting the all features (70 features), we apply the previous groups process for all the participant sessions.
4.2. ARAS Dataset
Features Engineering
4.3. ADL Normal Dataset
Features Engineering
5. Evaluation
6. Scope of Improvements Directions for RCS
- The RCS with real life. As mentioned, our system was only tested on public datasets. Dealing with real time data, our system should be capable of synchronization among the three stages starting from the complex activity detection until the user receives an item recommendation. We need to build our model for prompt detection that can exactly define when the user needs a recommendation. Failure in this task makes the system construct not beneficial recommendations that could affect the quality of the system.
- RSC testbed. Building a testbed helped to evaluate our system in the real life. The main issue with public datasets is missing required features. For example, the time period of each activity as some activities rarely happen at night time, such as Aris preparing a cup of coffee at midnight. Thus, if the system was feeding with the time period of each activity, it will be expected to recommend going back to bed for Aris and to mention the time to remind her.
- Trust-aware of the recommendations. Our system deals with sensitive and critical data about the patient, a lack of integrity could harm the user’s life by suggesting incorrect items, such a recommending a medicine when the user has already taken it. To ensure the safety of the recommendations, the data that feeds our system needs to be protected.The blockchain is planned as a potential step forward to address the integrity challenge. Our previous work [41] introduced a conceptual framework for data integrity protection.
- Unexpected action. In some statuses, our system could face an issue when the user uses two items at the same time, and there is only a short time period between them. This case could make the agent receive wrong feedback about the recommended item, which could affect the system update. For example, if the agent recommends turning the coffee machine on, whereas the user brings the milk at the same moment and then accepts the recommendation. After calculating the reward, it seems that is the milk is the correct item not the coffee machine.
- Easy to handle. As we mentioned before, we targeted Alzheimer’s patient in the mild stage; therefore, our system should consider that elderly people cannot hold a phone to receive the recommendations. Consequently, designing a system that acts as caregiver for the patients is important to meet the user’s expectations.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alzheimer’s Society. Available online: https://www.alzheimers.org.uk/ (accessed on 25 November 2021).
- Brookmeyer, R.; Abdalla, N.; Kawas, C.H.; Corrada, M.M. Forecasting the prevalence of preclinical and clinical Alzheimer’s disease in the United States. Alzheimer’s Dement. 2018, 14, 121–129. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alzheimer’s Association. 2018 Alzheimer’s disease facts and figures. Alzheimer’s Dement. 2018, 14, 367–429. [Google Scholar] [CrossRef]
- Alzheimer’s Association. 2019 Alzheimer’s disease facts and figures. Alzheimer’s Dement. 2019, 15, 321–387. [Google Scholar] [CrossRef]
- Yao, L.; Wang, X.; Sheng, Q.Z.; Dustdar, S.; Zhang, S. Recommendations on the internet of things: Requirements, challenges, and directions. IEEE Internet Comput. 2019, 23, 46–54. [Google Scholar] [CrossRef]
- Oyeleke, R.; Yu, C.; Chang, C. Situ-centric reinforcement learning for recommendation of tasks in activities of daily living in smart homes. In Proceedings of the 42nd Annual Computer Software and Applications Conference, Tokyo, Japan, 23–27 July 2018; Volume 2, pp. 317–322. [Google Scholar]
- Ahmed, Q.A.; Al-Neami, A.Q. A Smart Biomedical Assisted System for Alzheimer Patients. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2020; p. 012110. [Google Scholar]
- Armstrong, N.; Nugent, C.; Moore, G.; Finlay, D. Developing smartphone applications for people with Alzheimer’s disease. In Proceedings of the 10th International Conference on Information Technology and Applications in Biomedicine, Corfu, Greece, 3–5 November 2010; pp. 1–5. [Google Scholar]
- Choon, L. Helper System for Managing Alzheimer’s People Using Mobile Application. Univ. Malays. Pahang. 2015. Available online: https://www.semanticscholar.org/paper/Helper-system-for-managing-Alzheimer%27s-people-using-Lim/151088501b1b2fec480b1168cf38d38aff808b31 (accessed on 25 November 2021).
- Alharbi, S.; Altamimi, A.; Al-Qahtani, F.; Aljofi, B.; Alsmadi, M.; Alshabanah, M.; Alrajhi, D.; Almarashdeh, I. Analyzing and Implementing a Mobile Reminder System for Alzheimer’s Patients. Int. Res. J. Eng. Technol. 2019, 6, 444–454. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3422933 (accessed on 25 November 2021).
- Aljehani, S.; Alhazmi, R.; Aloufi, S.; Aljehani, B.; Abdulrahman, R. iCare: Applying IoT Technology for Monitoring Alzheimer’s Patients. In Proceedings of the 1st International Conference on Computer Applications & Information Security, Riyadh, Saudi Arabia, 4–6 April 2018. [Google Scholar]
- Altulyan, M.S.; Huang, C.; Yao, L.; Wang, X.; Kanhere, S.; Cao, Y. Reminder Care System: An Activity-Aware Cross-Device Recommendation System. In International Conference on Advanced Data Mining and Applications; Springer: Berlin, Germany, 2019. [Google Scholar]
- Altulayan, M.S.; Huang, C.; Yao, L.; Wang, X.; Kanhere, S. Contextual Bandit Learning for Activity-Aware Things-of-Interest Recommendation in an Assisted Living Environment. In Australasian Database Conference; Springer: Berlin, Germany, 2021; pp. 37–49. [Google Scholar]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Yao, L.; Sheng, Q.Z.; Ngu, A.H.; Ashman, H.; Li, X. Exploring recommendations in internet of things. In Proceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval, Gold Coast Queensland, Australia, 6–11 July 2014; pp. 855–858. Available online: https://dl.acm.org/doi/10.1145/2600428.2609458 (accessed on 25 November 2021).
- Asiri, S.; Miri, A. An IoT trust and reputation model based on recommender systems. In Proceedings of the 2016 14th Annual Conference on Privacy, Security and Trust (PST), Auckland, New Zealand, 12–14 December 2016; pp. 561–568. [Google Scholar]
- Chakraverty, S.; Mithal, A. Iot based weather and location aware recommender system. In Proceedings of the 2018 8th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 11–12 January 2018; pp. 636–643. [Google Scholar]
- Gao, K.; Yang, X.; Wu, C.; Qiao, T.; Chen, X.; Yang, M.; Chen, L. Exploiting location-based context for poi recommendation when traveling to a new region. IEEE Access 2020, 8, 52404–52412. [Google Scholar] [CrossRef]
- Lee, J.S.; Ko, I.Y. Service recommendation for user groups in internet of things environments using member organization-based group similarity measures. In Proceedings of the 2016 IEEE International Conference on Web Services (ICWS), San Francisco, CA, USA, 27 June–2 July 2016; pp. 276–283. [Google Scholar]
- Pazzani, M.J.; Billsus, D. Content-Based Recommendation Systems. In The Adaptive Web; Springer: Berlin, Germany, 2007; pp. 325–341. [Google Scholar]
- Erdeniz, S.; Maglogiannis, I.; Menychtas, A.; Felfernig, A.; Tran, T.N. Recommender systems for iot enabled m-health applications. In IFIP International Conference on Artificial Intelligence Applications and Innovations; Springer: Berlin, Germany, 2018; pp. 227–237. [Google Scholar]
- De Campos, L.; Fernández-Luna, J.; Huete, J.; Rueda-Morales, M.A. Combining content-based and collaborative recommendations: A hybrid approach based on Bayesian networks. Int. J. Approx. Reason. 2010, 51, 785–799. [Google Scholar] [CrossRef] [Green Version]
- HamlAbadi, K.; Saghiri, A.; Vahdati, M.; Takht Fooladi, M.; Meybodi, D.M.R. A framework for cognitive recommender systems in the Internet of Things. In Proceedings of the 4th International Conference on Knowledge-Based Engineering and Innovation, Tehran, Iran, 22 December 2017; pp. 0971–0976. [Google Scholar]
- Saghiri, A.M.; Vahdati, M.; Gholizadeh, K.; Meybodi, M.R.; Dehghan, M.; Rashidi, H. A framework for cognitive Internet of Things based on blockchain. In Proceedings of the 4th International Conference on Web Research, Tehran, Iran, 25–26 April 2018; pp. 138–143. [Google Scholar]
- Gladence, L.M.; Anu, V.M.; Rathna, R.; Brumancia, E. Recommender System for Home Automation Using IoT and Artificial Intelligence. J. Ambient. Intell. Humaniz. Comput. 2020. Available online: https://link.springer.com/article/10.1007/s12652-020-01968-2 (accessed on 25 November 2021).
- Han, Y.; Han, Z.; Wu, J.; Yu, Y.; Gao, S.; Hua, D.; Yang, A. Artificial intelligence recommendation system of cancer rehabilitation scheme based on iot technology. IEEE Access 2020, 8, 44924–44935. [Google Scholar] [CrossRef]
- Massimo, D. User preference modeling and exploitation in IoT scenarios. In Proceedings of the 23rd International Conference on Intelligent User Interfaces, Tokyo, Japan, 7–11 March 2018; pp. 675–676. [Google Scholar]
- Massimo, D.; Elahi, M.; Ricci, F. Learning user preferences by observing user-items interactions in an IoT augmented space. In Proceedings of the Adjunct Publication of the 25th Conference on User Modeling, Adaptation and Personalization, Bratislava, Slovakia, 9–12 July 2017. [Google Scholar]
- Steenwinckel, B.; De Backere, F.; Nelis, J.; Ongenae, F.; De Turck, F. Self-learning algorithms for the personalised interaction with people with dementia. In Proceedings of the Workshops of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 153–158. [Google Scholar]
- Li, L.; Chu, W.; Langford, J.; Schapire, R. A contextual-bandit approach to personalized news article recommendation. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 661–670. [Google Scholar]
- Intayoad, W.; Kamyod, C.; Temdee, P. Reinforcement Learning Based on Contextual Bandits for Personalized Online Learning Recommendation Systems. Wirel. Pers. Commun. 2020, pp. 1–16. Available online: https://link.springer.com/article/10.1007/s11277-020-07199-0 (accessed on 25 November 2021).
- Zhang, C.; Wang, H.; Yang, S.; Gao, Y. A contextual bandit approach to personalized online recommendation via sparse interactions. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin, Germany, 2019; pp. 394–406. [Google Scholar]
- Reiss, A.; Stricker, D. Creating and benchmarking a new dataset for physical activity monitoring. In Proceedings of the 5th International Conference on PErvasive Technologies Related to Assistive Environments, Heraklion, Greece, 6–8 June 2012; pp. 1–8. [Google Scholar]
- Das, B.; Cook, D.; Schmitter-Edgecombe, M.; Seelye, A. PUCK: An automated prompting system for smart environments: Toward achieving automated prompting—Challenges involved. Pers. Ubiquitous Comput. 2012, 16, 859–873. [Google Scholar] [CrossRef] [PubMed]
- Boser, B.; Guyon, I.; Vapnik, V. A training algorithm for optimal margin classifiers. In Proceedings of the 5th Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Quinlan, J. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.; Hastie, T.; Tibshirani, R. Additive logistic regression: A statistical view of boosting (with discussion and a rejoinder by the authors). Ann. Stat. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Alemdar, H.; Ertan, H.; Incel, O.D.; Ersoy, C. ARAS human activity datasets in multiple homes with multiple residents. In Proceedings of the 2013 7th International Conference on Pervasive Computing Technologies for Healthcare and Workshops, Venice, Italy, 5–8 May 2013; pp. 232–235. [Google Scholar]
- Cook, D.J.; Schmitter-Edgecombe, M. Assessing the quality of activities in a smart environment. Methods Inf. Med. 2009, 48, 480. [Google Scholar] [PubMed] [Green Version]
- Cortes, D. Adapting multi-armed bandits policies to contextual bandits scenarios. arXiv 2018, arXiv:1811.04383. [Google Scholar]
- Altulyan, M.; Yao, L.; Kanhere, S.S.; Wang, X.; Huang, C. A unified framework for data integrity protection in people-centric smart cities. Multimed. Tools Appl. 2020, 79, 4989–5002. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Explanation | |
|---|---|---|
| G | Agent | |
| Context, set of context | ||
| a | Action(item) | |
| r | Reward | |
| A | Set of items | |
| M | Memory | |
| S | State | |
| Minor update | ||
| Major update | ||
| Reward Delay Period | ||
| ∏ | Policies | |
| State value of each sensor |
| Policy | Note | Hyberparameters | ||||||
|---|---|---|---|---|---|---|---|---|
| Beta_PRIOR | Alpha | Smoothing | Decay | Refit_BUFFER | Active_CHOICE | Decay_TYPE | ||
| LinUCB [30] | LinUCB policy stores a square matrix, which has dimension equal to total numbers of features for the fitted model. | None | 0.1 | - | - | - | - | - |
| AdaptiveGreedy [40] | It focuses on taking the action that has the highest reward. | None | - | (1,2) | 0.9997 | - | - | percentile |
| AdaptiveGreedy(Active) | It is the same for AdaptiveGreedy but with different hyberparameters | ((3./nchoices, 4), 2) | None | 0.9997 | - | weighted | percentile | |
| SoftmaxExplorer [40] | It depends on softmax function to select the action | None | - | (1,2) | - | 50 | - | - |
| ActiveExplorer [40] | It depends on an active learning heuristic for taking the action | ((3./nchoices, 4), 2) | - | None | - | 50 | - | - |
| Dataset | Policies | ||||
|---|---|---|---|---|---|
| LinUCB (OSL) | Adaptive Active Greedy (OLS) | Adaptive Greedy (OSL) | Softmax Explorer (SGD) | Active Explorer (SGD) | |
| PUCK | 0.68 | 0.64 | 0.63 | 0.79 | 0.65 |
| ARAS House (A) | 0.80 | 0.81 | 0.77 | 0.85 | 0.69 |
| ARAS House (B) | 0.92 | 0.91 | 0.91 | 0.90 | 0.75 |
| ADL | 0.99 | 0.99 | 0.99 | 0.97 | 0.83 |
| Dataset | The Reward Delay Period | Policies | ||||
|---|---|---|---|---|---|---|
| LinUCB (OSL) | Adaptive Active Greedy (OLS) | Adaptive Greedy (OSL) | Softmax Explorer (SGD) | Active Explorer (SGD) | ||
| PUCK | 5 s | 0.68 | 0.64 | 0.63 | 0.79 | 0.65 |
| 10 s | 0.74 | 0.55 | 0.65 | 0.75 | 0.60 | |
| 15 s | 0.62 | 0.52 | 0.48 | 0.70 | 0.58 | |
| ARA s Hou se (A) | 5 s | 0.80 | 0.81 | 0.77 | 0.85 | 0.69 |
| 10 s | 0.68 | 0.65 | 0.58 | 0.72 | 0.56 | |
| 15 s | 0.68 | 0.72 | 0.68 | 0.60 | 0.49 | |
| ARA s Hou se (B) | 5 s | 0.92 | 0.91 | 0.91 | 0.90 | 0.75 |
| 10 s | 0.76 | 0.76 | 0.78 | 0.79 | 0.66 | |
| 15 s | 0.71 | 0.65 | 0.76 | 0.74 | 0.61 | |
| ADL | 5 s | 0.99 | 0.99 | 0.99 | 0.97 | 0.83 |
| 10 s | 0.99 | 0.99 | 0.99 | 0.98 | 0.83 | |
| 15 s | 0.95 | 0.95 | 0.95 | 0.90 | 0.78 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Altulyan, M.; Yao, L.; Huang, C.; Wang, X.; Kanhere, S.S. Context-Induced Activity Monitoring for On-Demand Things-of-Interest Recommendation in an Ambient Intelligent Environment. Future Internet 2021, 13, 305. https://doi.org/10.3390/fi13120305
Altulyan M, Yao L, Huang C, Wang X, Kanhere SS. Context-Induced Activity Monitoring for On-Demand Things-of-Interest Recommendation in an Ambient Intelligent Environment. Future Internet. 2021; 13(12):305. https://doi.org/10.3390/fi13120305
Chicago/Turabian StyleAltulyan, May, Lina Yao, Chaoran Huang, Xianzhi Wang, and Salil S. Kanhere. 2021. "Context-Induced Activity Monitoring for On-Demand Things-of-Interest Recommendation in an Ambient Intelligent Environment" Future Internet 13, no. 12: 305. https://doi.org/10.3390/fi13120305
APA StyleAltulyan, M., Yao, L., Huang, C., Wang, X., & Kanhere, S. S. (2021). Context-Induced Activity Monitoring for On-Demand Things-of-Interest Recommendation in an Ambient Intelligent Environment. Future Internet, 13(12), 305. https://doi.org/10.3390/fi13120305