
DNS Firewall Based on Machine Learning


Abstract
:1. Introduction
- Due to the non-existence of a DNS dataset, a list of malicious and non-malicious domains needs to be selected;
- From the list of domains, other features that can add value to the analysis should be derived. This process consists of data enrichment and involves the use of OSINT sources;
- The resulting dataset must be analyzed and prepared before it is submitted to ML algorithms. This step includes an exploratory data analysis to ascertain the existence of missing data and extreme values. It also involves the processing of data in order to obtain a dataset that can be analyzed using ML algorithms;
- The ML algorithms should be selected according the type of analysis to be done (e.g., supervised versus unsupervised learning);
- The features importance should be accessed to maximize the accuracy while reducing the time to classify the domain names;
- Different experimental analysis should be conducted to determine which algorithm(s) is most suitable for further use;
- Conclusions should be drawn on the effectiveness of the solution and on its possible use in in-band or out-band mode to detect and mitigate problems related to communication with malicious domains.
2. State of the Art
3. Proposal and Methodology
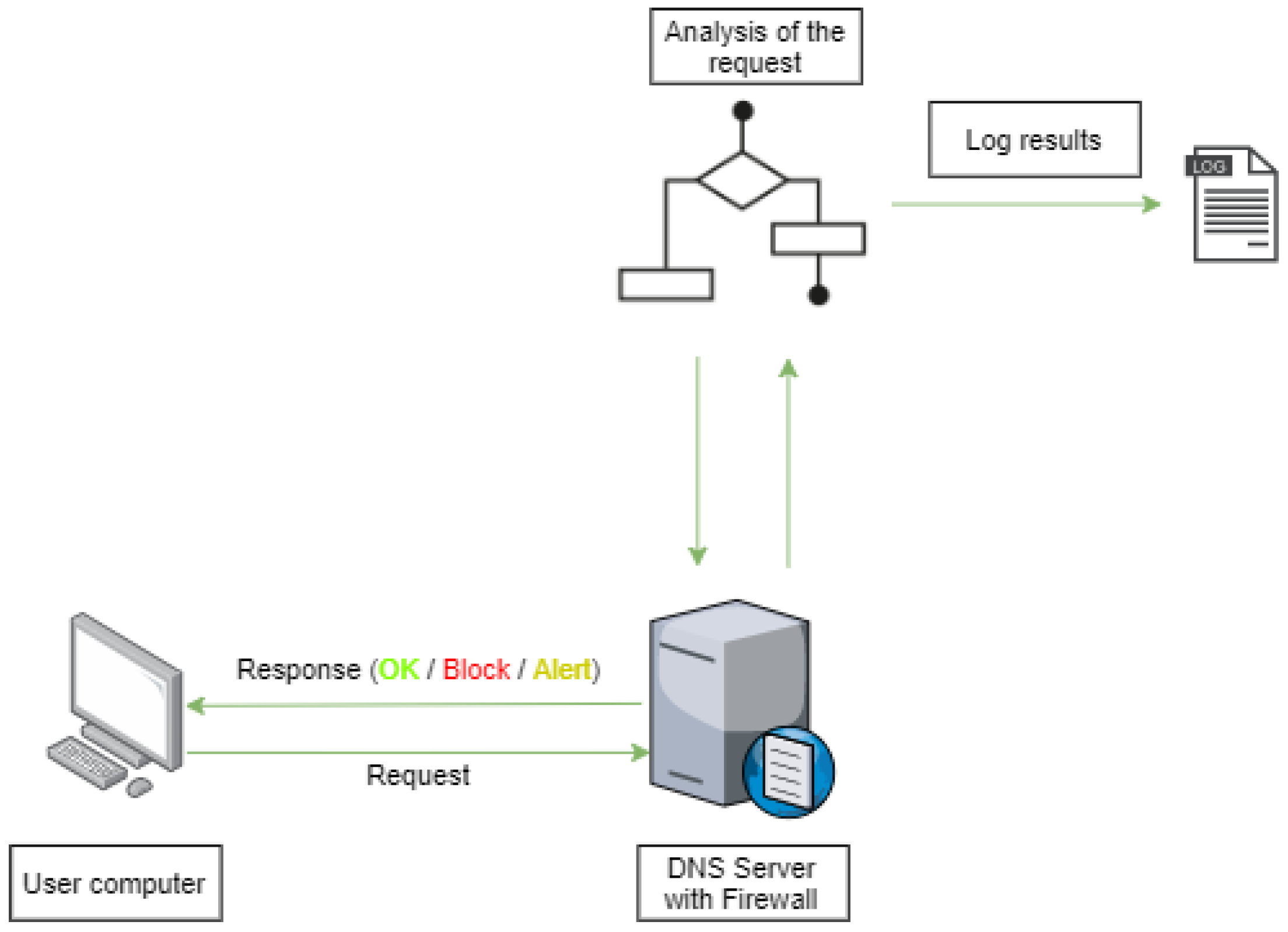
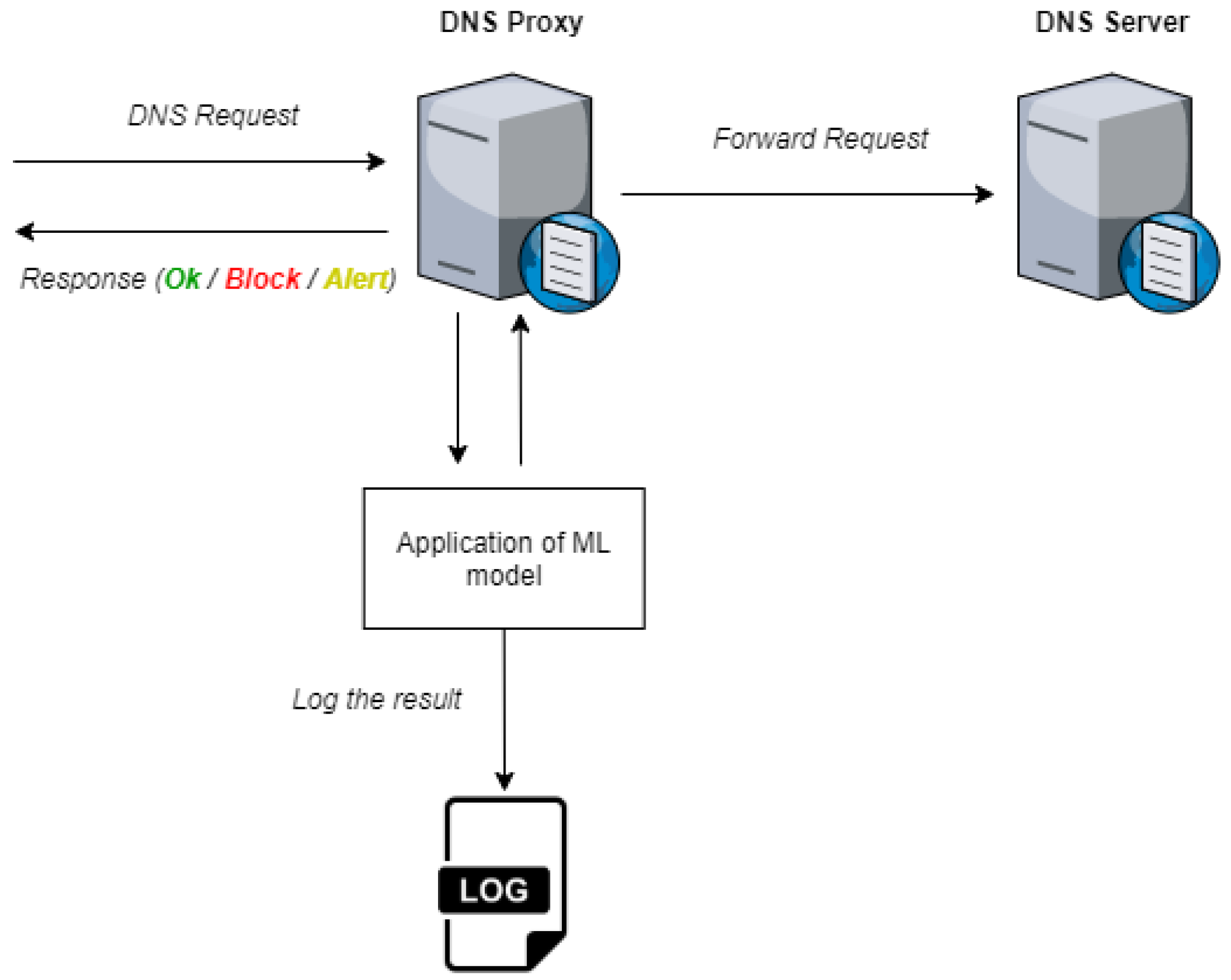
- In-band: As illustrated in Figure 1, for the in-band mode, the DNS resolution requests are analyzed in real time. This allows the determination of whether the requested domain is malicious or not and blocks or alerts as soon as possible to the fact. The overhead introduced by the DNS firewall is important and will be addressed in the analysis considering different DNS request workloads.
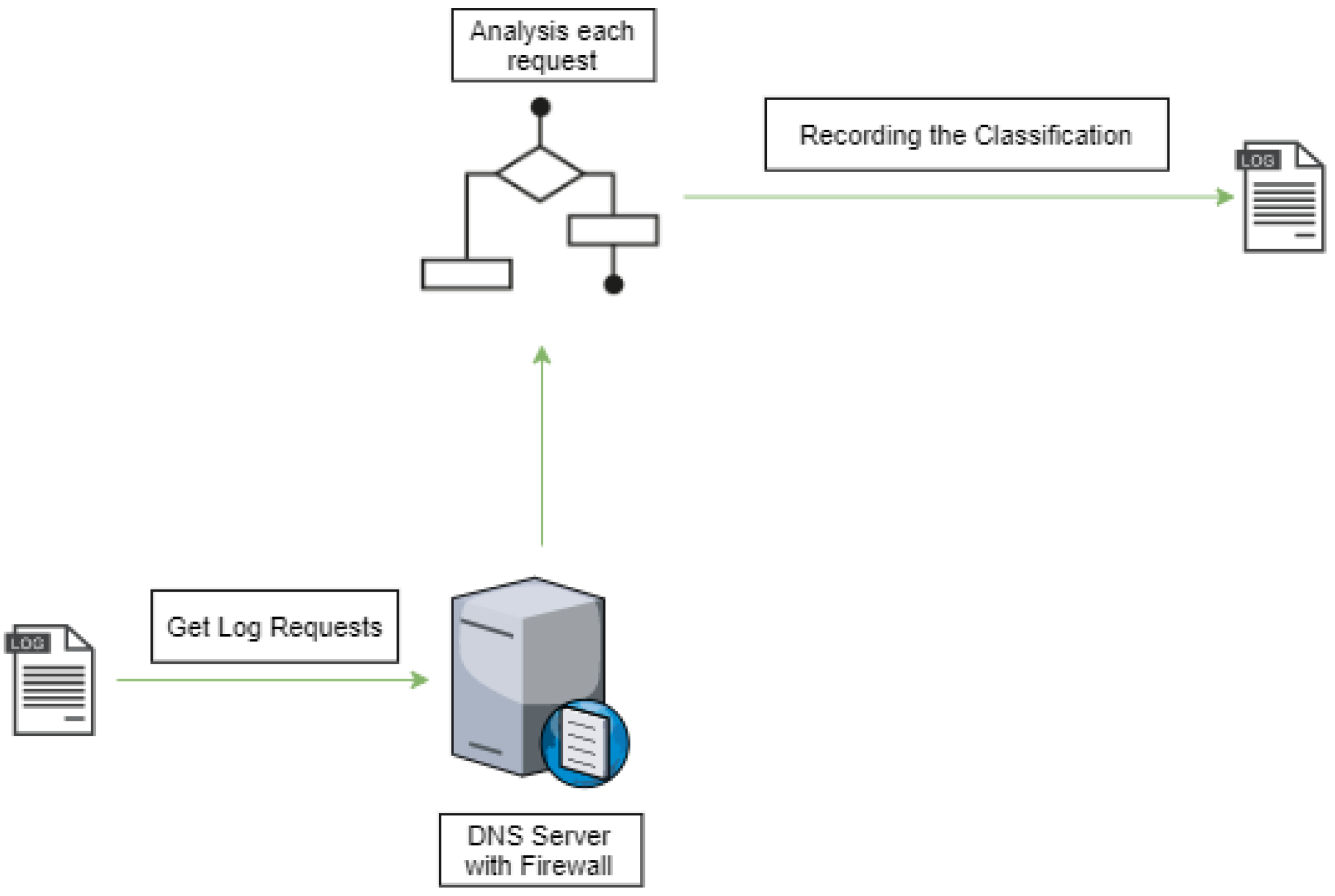
- Out-band: As illustrated in Figure 2, in the out-band mode the DNS firewall will only periodically analyze the DNS log. This way it will only be able to provide a posterior analysis. Thus, it is useful to identify devices within the network that are involved in malicious communications. This operation mode does not introduce overhead to the normal processing of DNS requests.
4. DNS Dataset
- Domain–Baseline DNS used to enrich data, e.g., derive features;
- DNSRecordType–DNS record type queried;
- MXDnsResponse–The response from a DNS request for the record type MX;
- TXTDnsResponse–The response from a DNS request for the record type TXT;
- HasSPFInfo–If the DNS response has Sender Policy Framework attribute;
- HasDkimInfo–If the DNS response has Domain Keys Identified Email attribute;
- HasDmarcInfo–If the DNS response has Domain-Based Message Authentication;
- IP–The IP address for the domain;
- DomainInAlexaDB–If the domain is registered in the Alexa DB;
- CommonPorts–If the domain is available on common ports (21, 22, 23, 25, 53, 80, 110, 143, 161, 443, 445, 465, 587, 993, 995, 3306, 3389, 7547, 8080, 8888);
- CountryCode–The country code associated with the IP of the domain;
- RegisteredCountryCode–The country code defined in the domain registration process (WHOIS);
- CreationDate–The creation date of the domain (WHOIS);
- LastUpdateDate–The last update date of the domain (WHOIS);
- ASN–The Autonomous System Number for the domain;
- HttpResponseCode–The HTTP/HTTPS response status code for the domain;
- RegisteredOrg–The organization name associated with the domain (WHOIS);
- SubdomainNumber–The number of subdomains for the domain;
- Entropy–The Shannon Entropy of the domain name;
- EntropyOfSubDomains–The mean value of the entropy for the subdomains;
- StrangeCharacters–The number of characters different from [a-zA-Z] and considering the existence maximum of two numeric integer values;
- TLD–The Top Level Domain for the domain;
- IpReputation–The result of the blocklisted search for the IP;
- DomainReputation–The result of the blocklisted search for the domain;
- ConsoantRatio–The ratio of consonant characters in the domain;
- NumericRatio–The ratio of numeric characters in the domain ();
- SpecialCharRatio–The ratio of special characters in the domain;
- VowelRatio–The ratio of vowel characters in the domain;
- ConsoantSequence–The maximum number of consecutive consonants in the domain;
- VowelSequence–The maximum number of consecutive vowels in the domain;
- NumericSequence–The maximum number of consecutive numbers in the domain;
- SpecialCharSequence–The maximum number of consecutive special characters in the domain;
- DomainLength–The length of the domain;
- Class–The class of the domain (malicious = 0 and non-malicious = 1);
5. Data Analysis
5.1. Data Preparation
5.2. Machine Learning: Classification
- Feature importance: This method uses the Extra Trees Classifier algorithm to fit and return the importance of the features;
- Univariate selection: Using a mathematical approach based on statistics this method works by picking up the best features on univariate statistical tests;
- RFE: According to [31], this method fits a model and deletes the feature (or features) with the lowest importance until the specified number of features is reached.
- Code Snippet 1: Feature Importance function
- import pandas as pd
- from sklearn.ensemble import Extra Trees Classifier
- #
- # @Parameters:
- # X−Independent variables
- # y−Dependent variable
- # feature_number−predefined number of features to be selected
- #
- def feature_importance(X, y, feature_number):model = Extra Trees Classifier ()model.fit(X, y)feat_importances = pd.Series(model.feature_importances_,index=X.columns)
- return feat_importances.nlargest(feature_number). axes [0].values
- Code Snippet 2: Univarate Selection function
- import pandas as pd
- from sklearn.feature_selection import Select K Best
- #
- # @Parameters:
- # X−Independent variables
- # y−Dependent variable
- # feature_number−predefined number of features to be selected
- #
- def univariate_selection (X, y, feature_number ):bestfeatures = SelectKBest (score_func=chi2, k=feature_number)fit = bestfeatures.fit (X, y)dfscores = pd.DataFrame (fit.score_)dfcolumns = pd.DataFrame (X. columns)featureScores = pd.concat ([dfcolumns, dfscores], axis = 1)featureScores.columns = [’Features’, ’Score’]return featureScores.nlargest (feature_number, ’Score’). Features. values
- Code Snippet 3: RFE function
- import pandas as pd
- from sklearn.tree import Decision Tree Regressor
- from sklearn.model_selection import Stratified K Fold
- from sklearn.feature_selection import RFECV
- #
- # @Parameters:
- # X−Independent variables
- # y−Dependent variable
- # feature_number−predefined number of features to be selected
- #
- def rfe_cross_validation (X, y, feature_number):rfecv = RFECV (estimator = Decision Tree Regressor (), step = 1,cv = Stratified K Fold (1 0), verbose = 1,min_features_to_select = feature_number,;n_jobs = 4)rfecv.fit (X, y)rfecv.transform (X)dset = pd.DataFrame ()dset [’attr’] = X.columnsdset [’importance’] = rfecv.estimator_.feature_impor tances_dset = dset.sort_values (by = ’importance’, ascending = False)return dset.attr.head (feature_number).values
- SVM: According to [35], the SVM “accomplishes the classification task by constructing, in a higher dimensional space, the hyperplane that optimally separates the data into two categories”. The SVM algorithm can solve both linear and non-linear problems by using a parameter named a kernel, which allows the researcher to set the more relevant mathematical function regarding the problem. According to the SkLearn documentation [36], there are four distinct kernel functions: linear, polynomial, RBF and sigmoid. According to the study [37], where an identical dataset was used and comparisons were made between the four kernel types, the precision achieved was higher when linear kernel functions were used. Therefore in this evaluation we also used the linear kernel function;
- LR: The LR algorithm is a statistical regression method based on supervised learning used for predictive analysis. It makes use of linear relationships between the independent features and the target label. According to [38], this algorithm has advantages such as simple implementation and excellent performance over linear datasets. Considering that one of the goals of this research is to have a solution capable of predicting malicious domains as close to real-time as possible, performance is a major factor for choosing the algorithm;
- LDA: According to [39] the LDA is a commonly used method to classify data based on a dimensionality reduction. The main goal of a dimensionality reduction is to delete the redundant features in a dataset while retaining the majority of the data. Although it is used for predictive analysis in classification problems, there are vast use cases for this algorithm, such as face recognition [40] and medical research [41,42];
- KNN: As mentioned by DeepAI [43] “the k-nearest neighbors algorithm, or kNN, is one of the simplest machine learning algorithms. Usually, k is a small, odd number - sometimes only 1. The larger k is, the more accurate the classification will be, but the longer it takes to perform the classification”. According to [44], the optimal value of k-nearest neighbors is different for distinct data samples. For this research, the number of the k-nearest neighbors parameter was kept as 5 (the default value adopted in the SkLearn framework) [45];
- CART: The CART term refers to Decision Tree algorithms that can be used on predictive problems to do classification and regression. For this research, the Decision Tree Classifier was used, in which, according to the SkLearn documentation [46], the main goal is “to create a model that predicts the value of a target variable by learning simple decision rules inferred from the data features”. One of the main advantages of this algorithm is the simplicity of understanding and interpretation, along with the excellent performance demonstrated in previous analyses already mentioned in the state of art;
- NB: The NB algorithms are used on supervised ML algorithms by applying Bayes Theorem. According to SkLearn documentation [47], there are three major models based on NB: Gaussian, Multinomial, and Bernoulli. The Gaussian is commonly used for classification problems. The Multinomial is more used in text classification problems and implements the NB algorithm for multinomial data. The Bernoulli method implements the NB algorithm according to multivariate data distribution mainly used for text classification. Therefore we selected the Gaussian NB model in order to classify and predict the dataset in a timely manner.
- Accuracy: The accuracy is the ratio between the correctly predicted observations versus the total number of observations;
- Precision: The precision is the ratio between the correctly predicted positive observations and the total predicted positive observations;
- Recall: The recall is the ratio between the correctly predicted positive observations and all observations in the actual class (0 or 1);
- F1 score: The F1 score is the average of precision and recall and takes into account the false positives and false negatives;
- Score time: Corresponds to the time for the test of the estimator on each cross-validation iteration.
6. Results
- Processor: Intel Core i7-8565U @ 1.80 Ghz;
- Memory: SDRAM DDR4-2400 16 GB (16 GB × 1);
- Graphics Processor: Intel UHD Graphics 620;
- Storage: 512 GB PCIe Gen 3 × 4;
- -
- Read up to 3100 MB/s;
- -
- Write up to 2800 MB/s.
7. Discussion and Recommendations
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AutoML | Automated Machine Learning |
| CART | Decision Tree |
| CSV | Comma-separated Values |
| DDOS | Distributed Denial of Service |
| DGA | Domain generation algorithm |
| DNS | Domain Name Service |
| DNSSEC | DNS Security Extensions |
| GDPR | General Data Protection Regulation |
| IP | Internet Protocol |
| KNN | K-Nearest Neighbors |
| LDA | Linear Discriminant Analysis |
| LR | Logistic Regression |
| ML | Machine Learning |
| NB | Naive Bayes |
| OSINT | Open Source Intelligence |
| RBF | Radial basis function |
| RFC | Request For Comments |
| RFE | Recursive Feature Elimination |
| SANS | SANS Internet Storm Center |
| SVM | Support-Vector Machine |
| TLD | Top Level Domain |
| TTL | Time To Live |
References
- Verisign. The Domain Name Industry Brief. Available online: https://www.verisign.com/en_US/domain-names/dnib/index.xhtml (accessed on 28 November 2021).
- Scmagazine. Vast Majority of Newly Registered Domains Are Malicious. Available online: https://www.scmagazine.com/home/security-news/malware/vast-majority-of-newly-registered-domains-are-malicious (accessed on 9 February 2020).
- Weimer, F. Passive DNS Replication. Available online: https://static.enyo.de/fw/volatile/pdr-draft-11.pdf (accessed on 28 November 2021).
- Perdisci, R.; Corona, I.; Dagon, D.; Lee, W. Detecting malicious flux service networks through passive analysis of recursive DNS traces. In Proceedings of the Annual Computer Security Applications Conference, ACSAC, Honolulu, HI, USA, 7–11 December 2009; pp. 311–320. [Google Scholar]
- Bilge, L.; Kirda, E.; Kruegel, C.; Balduzzi, M. EXPOSURE: Finding Malicious Domains Using Passive DNS Analysis. Available online: https://sites.cs.ucsb.edu/~chris/research/docndss11_exposure.pdf (accessed on 28 November 2021).
- Palaniappan, G.; Sangeetha, S.; Rajendran, B.; Sanjay; Goyal, S.; Bindhumadhava, B.S. Malicious Domain Detection Using Machine Learning on Domain Name Features, Host-Based Features and Web-Based Features. Procedia Comput. Sci. 2020, 171, 654–661. [Google Scholar] [CrossRef]
- Segawa, S.; Masuda, H.; Mori, M. Proposal and Prototype of DNS Server Firewall with Flexible Response Control Mechanism. In Proceedings of the 20th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing, SNPD 2019, Piscataway, NJ, USA, 8–10 July 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019; pp. 466–471. [Google Scholar]
- IDC 2020 Global DNS Threat Report|DNS Attacks Defense|EfficientIP. 2020. Available online: https://www.efficientip.com/resources/idc-dns-threat-report-2020/ (accessed on 11 July 2021).
- IDC 2021 Global DNS Threat Report|Network Security. 2021. Available online: https://www.efficientip.com/resources/idc-dns-threat-report-2021/ (accessed on 22 August 2021).
- Domain Name System (DNS) Security: Attacks Identification and Protection Methods. 2018. Available online: https://csce.ucmss.com/cr/books/2018/LFS/CSREA2018/SAM4137.pdf (accessed on 22 August 2021).
- Ariyapperuma, S.; Mitchell, C.J. Security vulnerabilities in DNS and DNSSEC. In Proceedings of the Second International Conference on Availability, Reliability and Security, ARES, Vienna, Austria, 10–13 April 2007; pp. 335–342. [Google Scholar] [CrossRef]
- Anderson, C.; Conwell, J.T.; Saleh, T. Investigating cyber attacks using domain and DNS data. Netw. Secur. 2021, 2021, 6–8. Available online: https://www.sciencedirect.com/science/article/abs/pii/S1353485821000283 (accessed on 28 November 2021). [CrossRef]
- Arends, R.; Austein, R.; Larson, M.; Massey, D.; Rose, S.W. rfc4033. 2005. Available online: https://www.nist.gov/publications/dns-security-introduction-and-requirements-rfc-4033?pub_id=150135 (accessed on 22 August 2021).
- ICANN Research–TLD DNSSEC Report. Available online: http://stats.research.icann.org/dns/tld_report/ (accessed on 23 July 2021).
- Chung, T.; van Rijswijk-Deij, R.; Chandrasekaran, B.; Choffnes, D.; Levin, D.; Maggs, B.M.; Wilson, C. An End-to-End View of DNSSEC Ecosystem Management. Available online: https://www.usenix.org/system/files/login/articles/login_winter17_03_chung.pdf (accessed on 28 November 2021).
- Van Adrichem, N.L.M.; Blenn, N.; Lúa, A.R.; Wang, X.; Wasif, M.; Fatturrahman, F.; Kuipers, F.A. A measurement study of DNSSEC misconfigurations. Secur. Inf. 2015, 4, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Antić, D.; Veinović, M. Implementation of DNSSEC-secured name servers for ni.rs zone and best practices. Serb. J. Electr. Eng. 2016, 13, 369–380. [Google Scholar] [CrossRef]
- Van Adrichem, N.L.; Lua, A.R.; Wang, X.; Wasif, M.; Fatturrahman, F.; Kuipers, F.A. DNSSEC misconfigurations: How incorrectly configured security leads to unreachability. In Proceedings of the 2014 IEEE Joint Intelligence and Security Informatics Conference, JISIC, NW, Washington, DC, USA, 24–26 September 2014; pp. 9–16. [Google Scholar] [CrossRef] [Green Version]
- Plohmann, D.; Yakdan, K.; Klatt, M.; Bader, J.; Gerhards-Padilla, E. A Comprehensive Measurement Study of Domain Generating Malware. In Proceedings of the 25th USENIX Conference on Security Symposium, Berkeley, CA, USA, 10–12 August 2016; USENIX Association: Berkeley, CA, USA, 2016; Volume 16, pp. 263–278. [Google Scholar]
- Ren, F.; Jiang, Z.; Wang, X.; Liu, J. A DGA domain names detection modeling method based on integrating an attention mechanism and deep neural network. Cybersecurity 2020, 3, 1–13. [Google Scholar] [CrossRef]
- Zago, M.; Gil Pérez, M.; Martínez Pérez, G. UMUDGA: A dataset for profiling algorithmically generated domain names in botnet detection. Data Brief 2020, 30, 105400. [Google Scholar] [CrossRef] [PubMed]
- Singh, A. Malicious and Benign Webpages Dataset. Data Brief 2020, 32, 106304. [Google Scholar] [CrossRef] [PubMed]
- Rapid7 Labs. Available online: https://opendata.rapid7.com/sonar.fdns_v2 (accessed on 28 November 2021).
- SANS Internet Storm Center. Available online: https://isc.sans.edu/ (accessed on 22 November 2020).
- Marques, C.; Malta, S.; Magalhães, J.P. DNS dataset for malicious domains detection. Data Brief 2021, 38, 107342. [Google Scholar] [CrossRef] [PubMed]
- Brownlee, J. Data Preparation for Machine Learning: Data Cleaning, Feature Selection, and Data Transforms in Python. Available online: https://bd.zlibcdn2.com/book/16370100/0383c0 (accessed on 28 November 2021).
- Scikit Learn. Available online: https://scikit-learn.org/stable/ (accessed on 15 September 2020).
- Srikanth Yadav, M.; Kalpana, R. Data preprocessing for intrusion detection system using encoding and normalization approaches. In Proceedings of the 11th International Conference on Advanced Computing, ICoAC 2019, Chennai, India, 18–28 December 2019; Institute of Electrical and Electronics Engineers Inc.: Chennai, India, 2019; pp. 265–269. [Google Scholar] [CrossRef]
- Sathya Durga, V.; Jeyaprakash, T. An Effective Data Normalization Strategy for Academic Datasets using Log Values. In Proceedings of the 4th International Conference on Communication and Electronics Systems, ICCES 2019, Coimbatore, India, 17–19 July 2019; Institute of Electrical and Electronics Engineers Inc.: Coimbatore, India, 2019; pp. 610–612. [Google Scholar] [CrossRef]
- Akanbi, O.A.; Amiri, I.S.; Fazeldehkordi, E. A Machine-Learning Approach to Phishing Detection and Defense. Available online: https://www.sciencedirect.com/book/9780128029275/a-machine-learning-approach-to-phishing-detection-and-defense?via=ihub= (accessed on 28 November 2021). [CrossRef]
- Recursive Feature Elimination—Yellowbrick v1.3.post1 Documentation. Available online: https://www.scikit-yb.org/en/latest/api/model_selection/rfecv.html (accessed on 2 July 2021).
- Dougherty, E.R.; Hua, J.; Sima, C. Performance of Feature Selection Methods. Curr. Genom. 2009, 10, 365. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sumaiya Thaseen, I.; Aswani Kumar, C. Intrusion detection model using fusion of chi-square feature selection and multi class SVM. J. King Saud Univ. Comput. Inf. Sci. 2017, 29, 462–472. [Google Scholar] [CrossRef] [Green Version]
- Sklearn.feature_selection.SelectKBest—Scikit-Learn 0.24.2 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.SelectKBest.html (accessed on 6 May 2021).
- Adankon, M.M.; Cheriet, M. Support Vector Machine. Available online: https://link.springer.com/referenceworkentry/10.1007%2F978-1-4899-7488-4_299 (accessed on 28 November 2021).
- 1.4. Support Vector Machines—Scikit-Learn 0.24.2 Documentation. Available online: https://scikit-learn.org/stable/modules/svm.html (accessed on 7 May 2021).
- Intan, P.K. Comparison of Kernel Function on Support Vector Machine in Classification of Childbirth. J. Mat. MANTIK 2019, 5, 90–99. [Google Scholar] [CrossRef] [Green Version]
- Advantages and Disadvantages of Linear Regression. Available online: https://iq.opengenus.org/advantages-and-disadvantages-of-linear-regression/ (accessed on 5 August 2021).
- Balakrishnama, S.; Ganapathiraju, A. Linear Discriminant Analysis—A Brief Tutorial. Available online: http://datajobstest.com/data-science-repo/LDA-Primer-[Balakrishnama-and-Ganapathiraju].pdf (accessed on 28 November 2021).
- Lu, J.; Plataniotis, K.N.; Venetsanopoulos, A.N. Face Recognition Using LDA-Based Algorithms. IEEE Trans. Neural Netw. 2003, 14, 195–200. [Google Scholar] [PubMed] [Green Version]
- Fu, R.; Tian, Y.; Shi, P.; Bao, T. Automatic Detection of Epileptic Seizures in EEG Using Sparse CSP and Fisher Linear Discrimination Analysis Algorithm. J. Med. Syst. 2020, 44, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Elnasir, S.; Mariyam Shamsuddin, S. Palm Vein Recognition Based on 2D-Discrete Wavelet Transform and Linear Discrimination Analysis Big Data Review View Project Knowledge Management for Adaptive Hypermedia Learning System View Project. Available online: http://home.ijasca.com/data/documents/3_Selma.pdf (accessed on 28 November 2021).
- kNN Definition|DeepAI. Available online: https://deepai.org/machine-learning-glossary-and-terms/kNN (accessed on 22 August 2021).
- Hassanat, A.B.; Abbadi, M.A.; Altarawneh, G.A.; Alhasanat, A.A. Solving the Problem of the K Parameter in the KNN Classifier Using an Ensemble Learning Approach. Available online: https://arxiv.org/abs/1409.0919 (accessed on 28 November 2021).
- Sklearn.neighbors.KNeighborsClassifier—Scikit-Learn 0.24.2 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html (accessed on 27 May 2021).
- 1.10. Decision Trees—Scikit-Learn 0.24.2 Documentation. Available online: https://scikit-learn.org/stable/modules/tree.html (accessed on 15 August 2021).
- 1.9. Naive Bayes—Scikit-Learn 0.24.2 Documentation. Available online: https://scikit-learn.org/stable/modules/naive_bayes.html (accessed on 12 July 2021).
- Sklearn.Model_Selection.Cross_Validate—Scikit-Learn 0.24.2 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_validate.html (accessed on 22 August 2021).
- Claudioti/Machine-Learning. Available online: https://github.com/claudioti/machine-learning (accessed on 20 August 2021).
- TPOT. Available online: http://epistasislab.github.io/tpot/ (accessed on 5 July 2021).
- Marques, C. Dataset Creator. Available online: https://github.com/claudioti/dataset-creator (accessed on 15 September 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Accuracy | Precision | Recall | F1 Score | Time (sec) |
|---|---|---|---|---|---|
| SVM | 0.912 | 0.949 | 0.872 | 0.898 | 3.087 |
| LR | 0.916 | 0.949 | 0.878 | 0.905 | 0.014 |
| LDA | 0.908 | 0.950 | 0.861 | 0.894 | 0.012 |
| KNN | 0.951 | 0.965 | 0.936 | 0.946 | 1.793 |
| CART | 0.947 | 0.967 | 0.926 | 0.939 | 0.011 |
| NB | 0.903 | 0.947 | 0.851 | 0.887 | 0.012 |
| Algorithm | Accuracy | Precision | Recall | F1 Score | Time (sec) |
|---|---|---|---|---|---|
| SVM | 0.919 | 0.940 | 0.895 | 0.909 | 3.375 |
| LR | 0.916 | 0.949 | 0.878 | 0.904 | 0.014 |
| LDA | 0.906 | 0.957 | 0.848 | 0.889 | 0.013 |
| KNN | 0.947 | 0.966 | 0.926 | 0.940 | 3.237 |
| CART | 0.956 | 0.969 | 0.941 | 0.952 | 0.013 |
| NB | 0.908 | 0.955 | 0.854 | 0.891 | 0.013 |
| Algorithm | Accuracy | Precision | Recall | F1 Score | Time (sec) |
|---|---|---|---|---|---|
| SVM | 0.910 | 0.937 | 0.878 | 0.899 | 3.250 |
| LR | 0.913 | 0.939 | 0.883 | 0.903 | 0.013 |
| LDA | 0.907 | 0.938 | 0.869 | 0.895 | 0.014 |
| KNN | 0.957 | 0.970 | 0.943 | 0.953 | 1.369 |
| CART | 0.961 | 0.976 | 0.945 | 0.958 | 0.013 |
| NB | 0.897 | 0.936 | 0.851 | 0.884 | 0.012 |
| Algorithm | Accuracy | Precision | Recall | F1 Score | Time (sec) |
|---|---|---|---|---|---|
| CART (AutoML) | 0.962 | 0.973 | 0.952 | 0.959 | 0.025 |
| Feature Importance | Univariate Selection | RFE | AutoML | |
|---|---|---|---|---|
| ASN | X | X | ||
| ConsoantRatio | X | X | X | X |
| CountryCode | X | X | ||
| CreationDate | X | X | ||
| DomainLength | X | X | X | |
| HasSPFInfo | X | X | ||
| HttpResponseCode | X | |||
| Ip | X | X | ||
| LastUpdateDate | X | |||
| MXDnsResponse | X | |||
| NumericRatio | X | X | X | |
| NumericSequence | X | X | X | |
| StrangeCharacters | X | X | X | X |
| SubdomainNumber | X | |||
| TLD | X | X | ||
| TXTDnsResponse | X | X | ||
| VowelRatio | X |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marques, C.; Malta, S.; Magalhães, J. DNS Firewall Based on Machine Learning. Future Internet 2021, 13, 309. https://doi.org/10.3390/fi13120309
Marques C, Malta S, Magalhães J. DNS Firewall Based on Machine Learning. Future Internet. 2021; 13(12):309. https://doi.org/10.3390/fi13120309
Chicago/Turabian StyleMarques, Claudio, Silvestre Malta, and João Magalhães. 2021. "DNS Firewall Based on Machine Learning" Future Internet 13, no. 12: 309. https://doi.org/10.3390/fi13120309
APA StyleMarques, C., Malta, S., & Magalhães, J. (2021). DNS Firewall Based on Machine Learning. Future Internet, 13(12), 309. https://doi.org/10.3390/fi13120309