
A Hierarchical Cache Size Allocation Scheme Based on Content Dissemination in Information-Centric Networks


Abstract
:1. Introduction
- We implement a hierarchy partitioning method based on content dissemination to simplify the network topology with the arbitrary graph structure, while the content transmission process is clarified.
- We quantify the importance of nodes from the content transmission process and network topology by formulating a set of calculation methods for weights at each level, which resolves the mismatch between content dissemination and topology location.
- We use real-world network topology to evaluate the performance of the cache size allocation scheme proposed. The results show that our scheme performs better in different aspects.
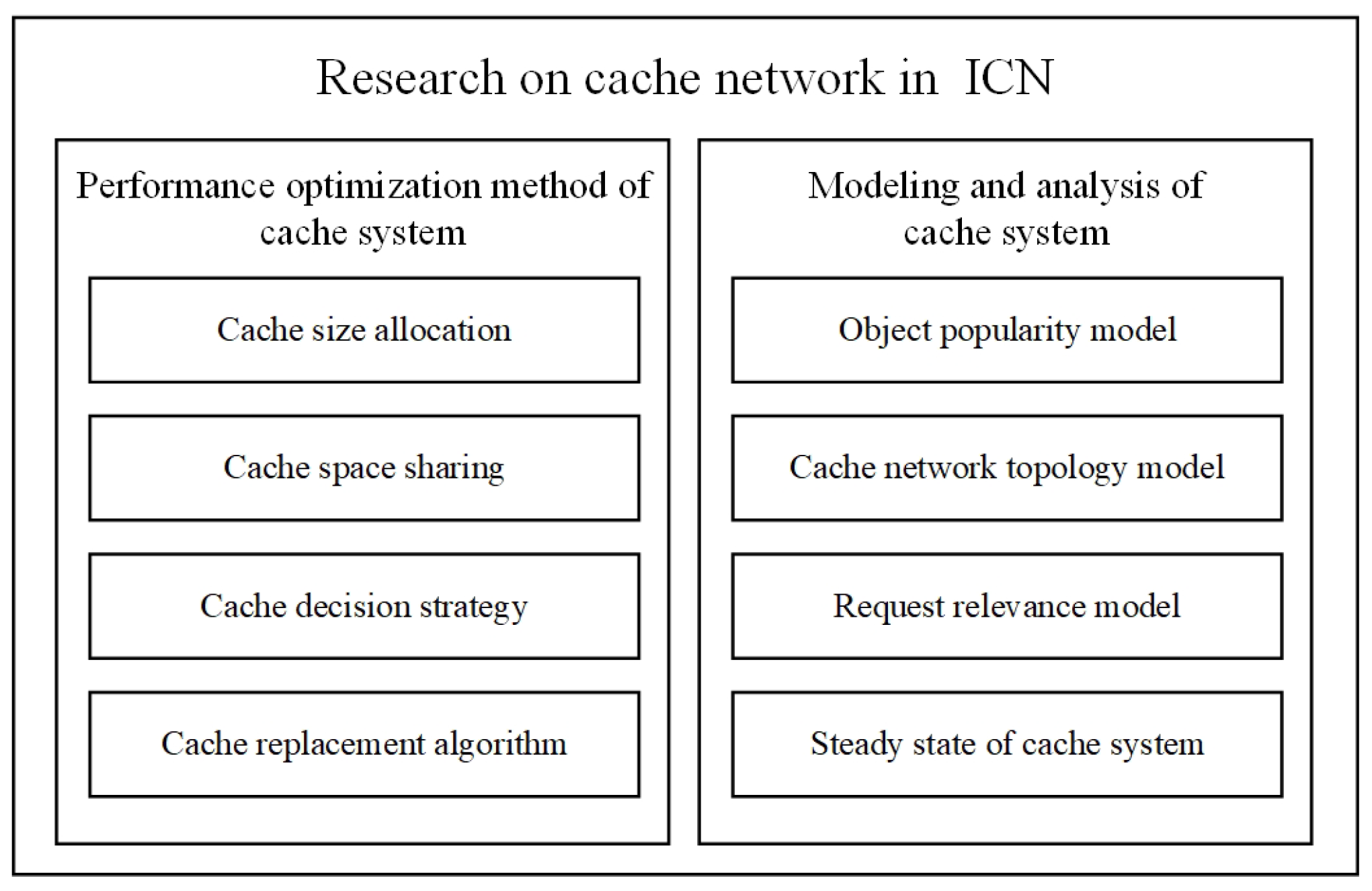
2. Background and Related Work
2.1. New Features and Challenges
2.2. Researches in Caching Field
2.2.1. Present Research Situation
2.2.2. Cache Size Allocation Scheme
3. Problem Statement
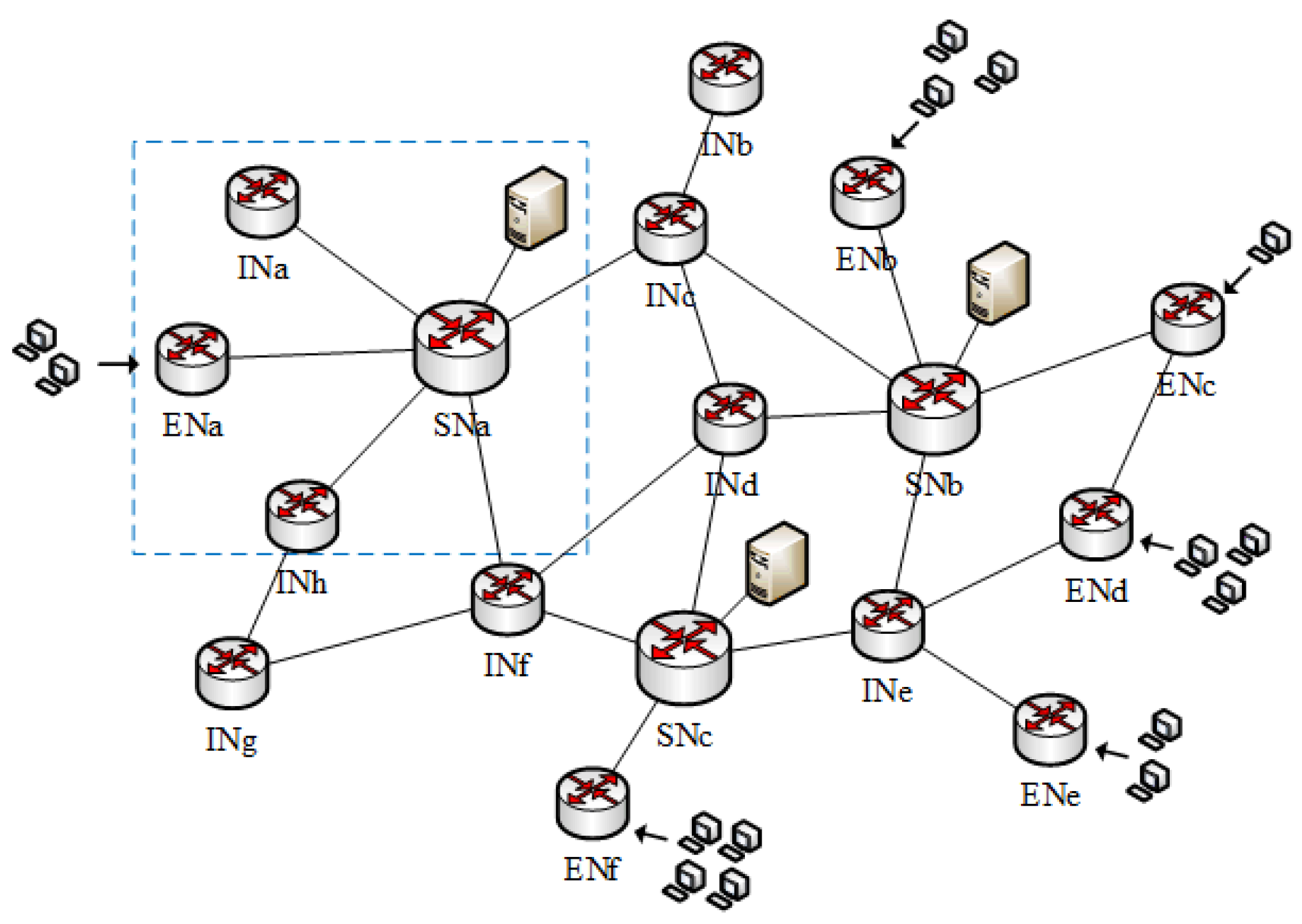
3.1. System Model
3.2. Problem Analysis
4. Level Division
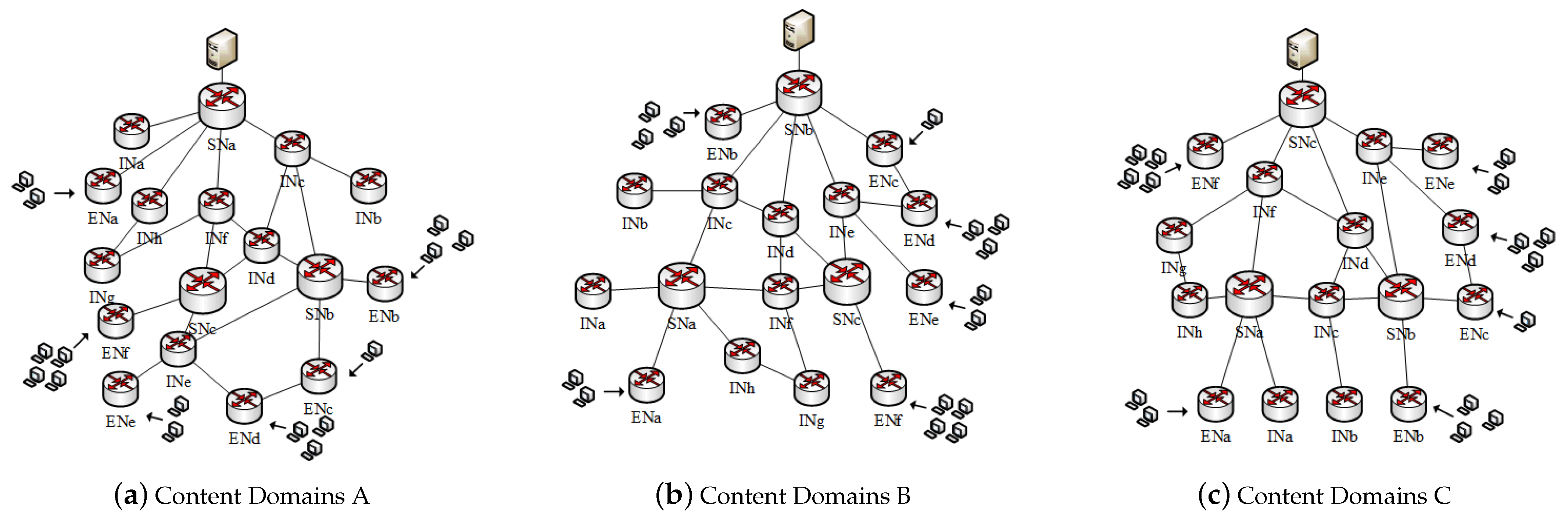
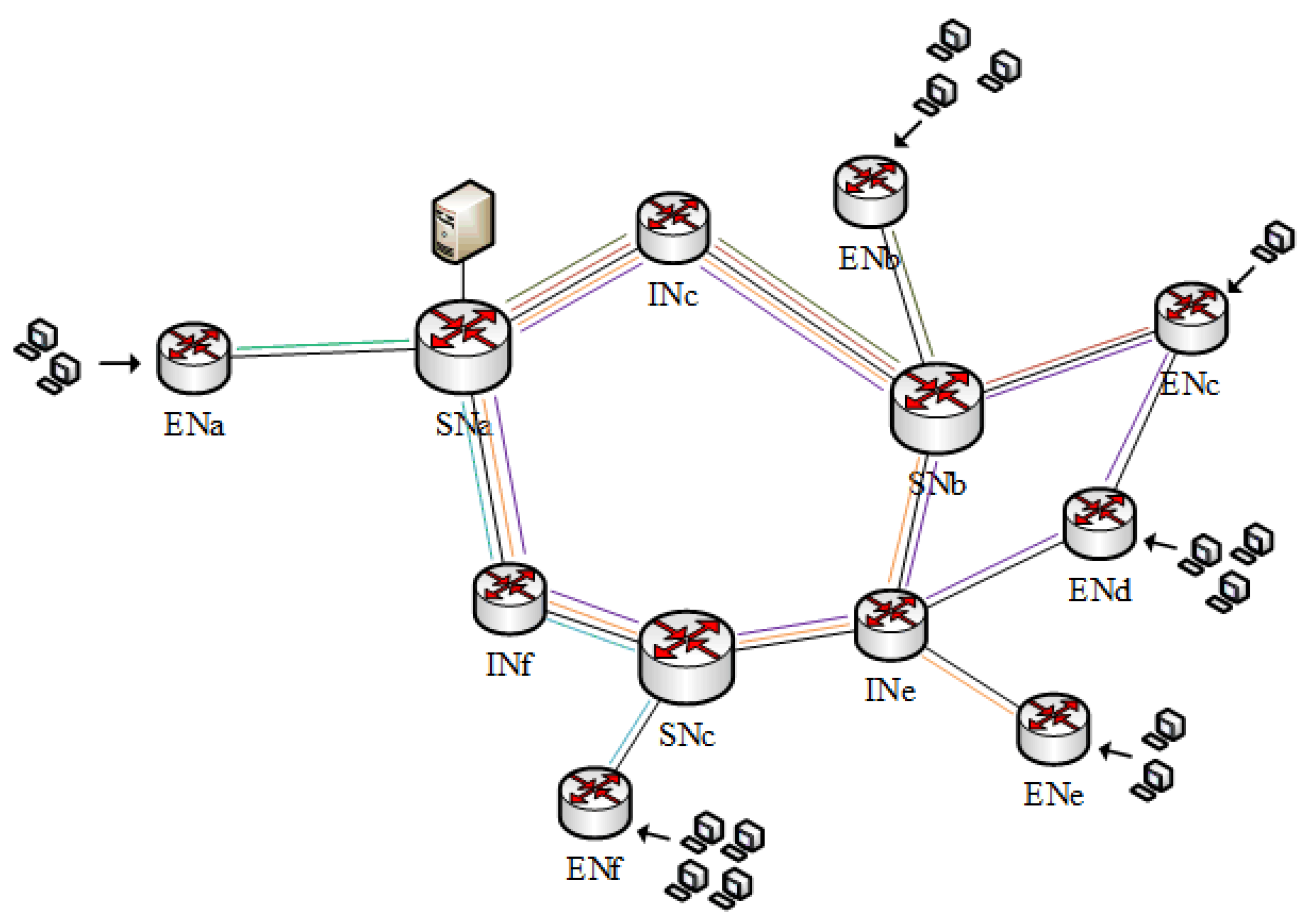
4.1. Content Domain
4.2. Data Path
4.3. Node
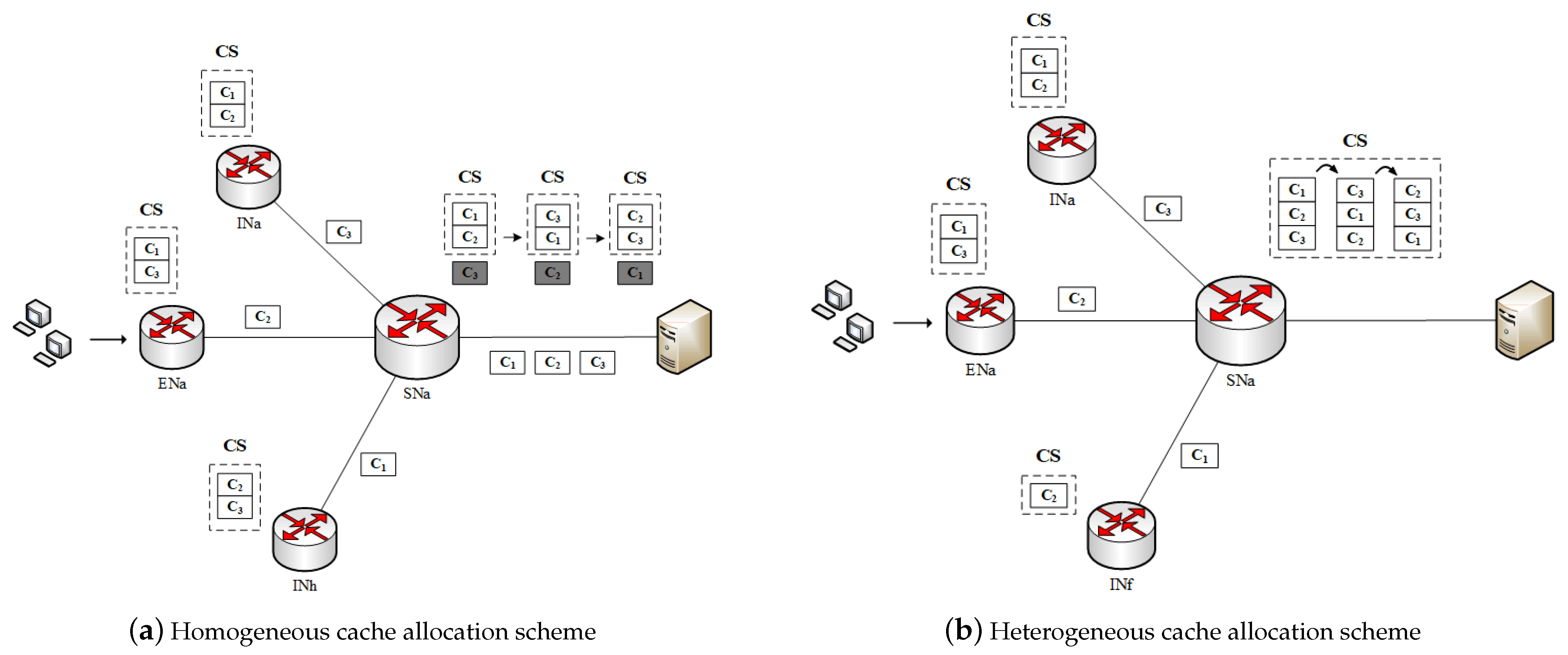
5. Cache Allocation
5.1. Content Domain Weight
5.2. Data Path Weight
5.3. Node Weight
5.4. Global Weight
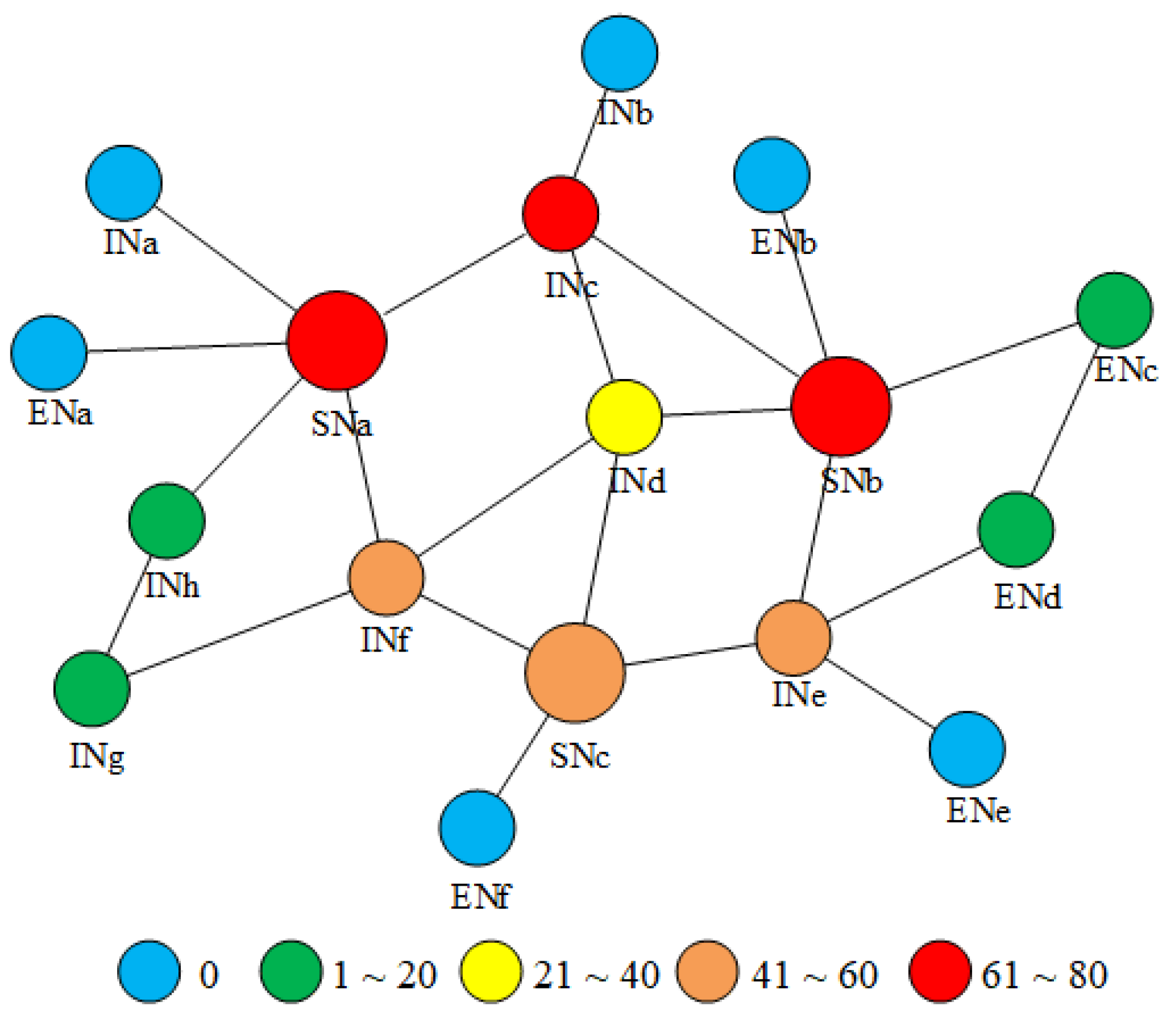
6. Results
6.1. Experimental Setup
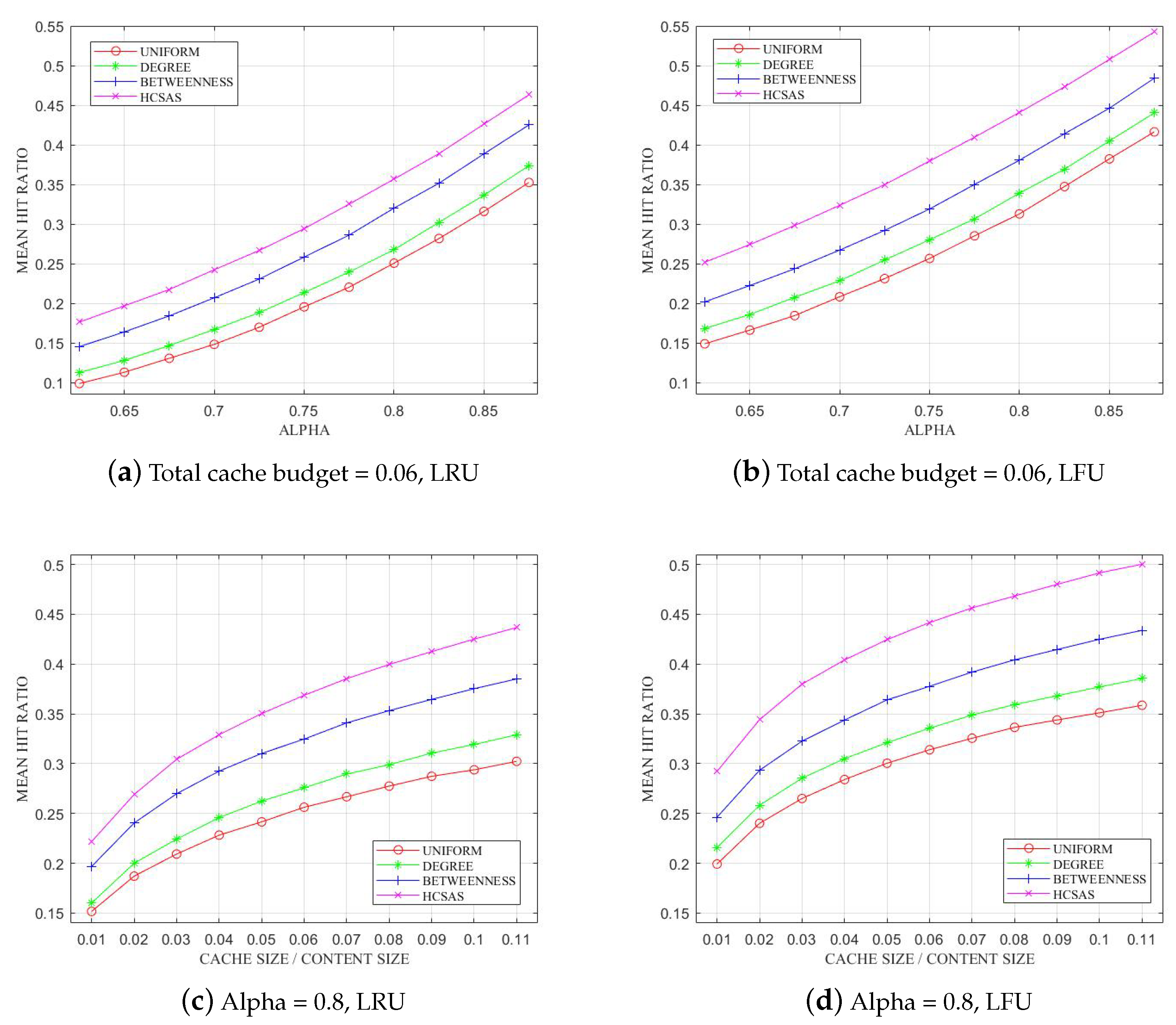
6.2. Cache Hit Ratio
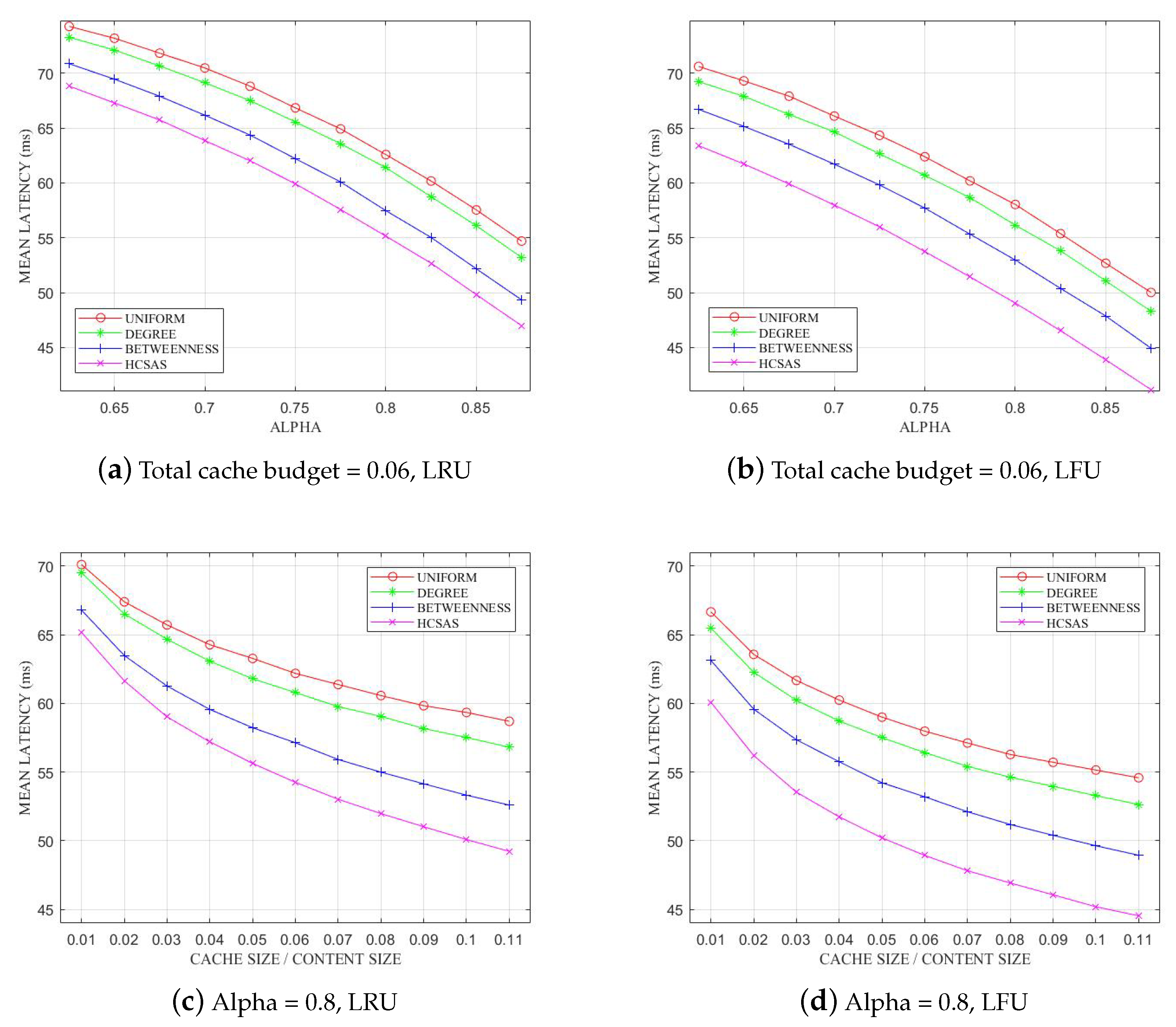
6.3. Request Latency
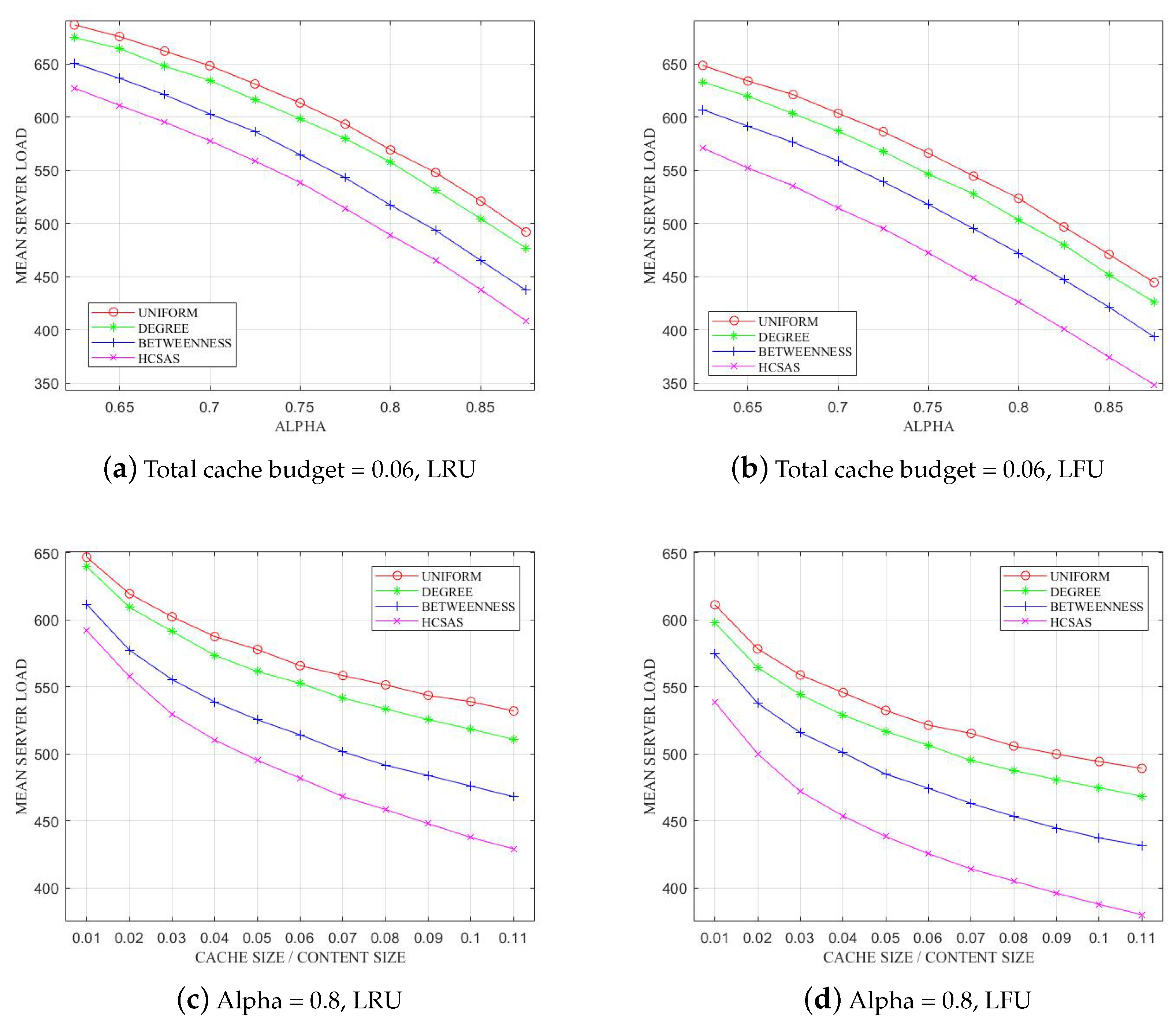
6.4. Content Server Load
7. Discussion
7.1. Content Dissemination
7.2. Cache Size Validity
7.3. Future Research
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Saxena, D.; Raychoudhury, V.; Suri, N.; Becker, C.; Cao, J. Named Data Networking: A Survey. Comput. Sci. Rev. 2016, 19, 15–55. [Google Scholar] [CrossRef] [Green Version]
- Carofiglio, G.; Gehlen, V.; Perino, D. Experimental Evaluation of Memory Management in Content-Centric Networking. In Proceedings of the 2011 IEEE International Conference on Communications (ICC), Kyoto, Japan, 5–9 June 2011; pp. 1–6. [Google Scholar]
- Ahlgren, B.; D’Ambrosio, M.; Marchisio, M.; Marsh, I.; Dannewitz, C.; Ohlman, B.; Pentikousis, K.; Strandberg, O.; Rembarz, R.; Vercellone, V. Design Considerations for a Network of Information. In Proceedings of the 2008 ACM CoNEXT Conference, Madrid, Spain, 9–12 December 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 1–6. [Google Scholar]
- Koponen, T.; Chawla, M.; Chun, B.G.; Ermolinskiy, A.; Kim, K.H.; Shenker, S.; Stoica, I. A Data-Oriented (and beyond) Network Architecture. In Proceedings of the 2007 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Kyoto, Japan, 27–31 August 2007; Association for Computing Machinery: New York, NY, USA, 2007; pp. 181–192. [Google Scholar]
- Lagutin, D.; Visala, K.; Tarkoma, S. Publish/Subscribe for Internet: PSIRP Perspective. Future Internet Assem. 2010, 84, 75–84. [Google Scholar]
- Dannewitz, C.; Kutscher, D.; Ohlman, B.; Farrell, S.; Ahlgren, B.; Karl, H. Network of Information (Netinf)—An Information-Centric Networking Architecture. Comput. Commun. 2013, 36, 721–735. [Google Scholar] [CrossRef]
- Sharma, A.; Tie, X.; Uppal, H.; Venkataramani, A.; Westbrook, D.; Yadav, A. A Global Name Service for a Highly Mobile Internetwork. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 247–258. [Google Scholar] [CrossRef]
- Venkataramani, A.; Kurose, J.F.; Raychaudhuri, D.; Nagaraja, K.; Mao, M.; Banerjee, S. Mobilityfirst: A Mobility-Centric and Trustworthy Internet Architecture. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 74–80. [Google Scholar] [CrossRef]
- Jacobson, V.; Smetters, D.K.; Thornton, J.D.; Plass, M.F.; Briggs, N.H.; Braynard, R.L. Networking Named Content. In Proceedings of the 5th International Conference on Emerging Networking Experiments and Technologies, Rome, Italy, 1–4 December 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 1–12. [Google Scholar]
- Zhang, L.; Afanasyev, A.; Burke, J.; Jacobson, V.; Claffy, K.; Crowley, P.; Papadopoulos, C.; Wang, L.; Zhang, B. Named Data Networking. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 66–73. [Google Scholar] [CrossRef]
- Wang, J.; Cheng, G.; You, J.; Sun, P. SEANet: Architecture and Technologies of an On-site, Elastic, Autonomous Network. J. Netw. New Media 2020, 6, 1–8. [Google Scholar]
- Afanasyev, A.; Burke, J.; Refaei, T.; Wang, L.; Zhang, B.; Zhang, L. A Brief Introduction to Named Data Networking. In Proceedings of the MILCOM 2018—2018 IEEE Military Communications Conference (MILCOM), Los Angeles, CA, USA, 29–31 October 2018; pp. 1–6. [Google Scholar]
- Agyapong, P.K.; Sirbu, M. Economic Incentives in Information-Centric Networking: Implications for Protocol Design and Public Policy. IEEE Commun. Mag. 2012, 50, 18–26. [Google Scholar] [CrossRef]
- Passarella, A. A Survey on Content-Centric Technologies for the Current Internet: CDN and P2P Solutions. Comput. Commun. 2012, 35, 1–32. [Google Scholar] [CrossRef]
- Zhang, G.; Tang, M.; Cheng, S.; Zhang, G.; Song, H.; Cao, J.; Yang, J. P2P Traffic Optimization. Sci. China Inf. Sci. 2012, 55, 1475–1492. [Google Scholar] [CrossRef]
- Wierzbicki, A.; Leibowitz, N.; Ripeanu, M.; Wozniak, R. Cache Replacement Policies Revisited: The Case of P2P Traffic. In Proceedings of the IEEE International Symposium on Cluster Computing and the Grid, 2004 (CCGrid 2004), Chicago, IL, USA, 19–22 April 2004; pp. 182–189. [Google Scholar]
- Hefeeda, M.; Saleh, O. Traffic Modeling and Proportional Partial Caching for Peer-to-Peer Systems. IEEE/ACM Trans. Netw. 2008, 16, 1447–1460. [Google Scholar] [CrossRef] [Green Version]
- Arianfar, S.; Nikander, P.; Ott, J. Packet-Level Caching for Information-Centric Networking. In Proceedings of the Re-Architecting the Internet Workshop, Philadelphia, PA, USA, 30–31 November 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 1–16. [Google Scholar]
- Arianfar, S.; Nikander, P.; Ott, J. On Content-Centric Router Design and Implications. In Proceedings of the Re-Architecting the Internet Workshop, Philadelphia, PA, USA, 30–31 November 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 1–6. [Google Scholar]
- Fang, C.; Yu, F.; Huang, T.; Liu, J.; Liu, Y. A survey of energy-efficient caching in information-centric networking. IEEE Commun. Mag. 2014, 52, 122–129. [Google Scholar] [CrossRef]
- Muscariello, L.; Carofiglio, G.; Gallo, M. Bandwidth and Storage Sharing Performance in Information Centric Networking. In Proceedings of the ACM SIGCOMM Workshop on Information-Centric Networking, Toronto, ON, Canada, 15–19 August 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 26–31. [Google Scholar]
- Zhang, M.; Luo, H.; Zhang, H. A Survey of Caching Mechanisms in Information-Centric Networking. IEEE Commun. Surv. Tutor. 2015, 17, 1473–1499. [Google Scholar] [CrossRef]
- Kim, Y.; Yeom, I. Performance Analysis of In-Network Caching for Content-Centric Networking. Comput. Netw. 2013, 57, 2465–2482. [Google Scholar] [CrossRef]
- Rossini, G.; Rossi, D. A Dive into the Caching Performance of Content Centric Networking. In Proceedings of the 2012 IEEE 17th International Workshop on Computer Aided Modeling and Design of Communication Links and Networks (CAMAD), Barcelona, Spain, 17–19 September 2012; pp. 105–109. [Google Scholar]
- Rossi, D.; Rossini, G. On Sizing CCN Content Stores by Exploiting Topological Information. In Proceedings of the 2012 IEEE INFOCOM Workshops, Orlando, FL, USA, 25–30 March 2012; pp. 280–285. [Google Scholar]
- Xu, Y.; Li, Y.; Lin, T.; Wang, Z.; Niu, W.; Tang, H.; Ci, S. A Novel Cache Size Optimization Scheme Based on Manifold Learning in Content Centric Networking. J. Netw. Comput. Appl. 2014, 37, 273–281. [Google Scholar] [CrossRef]
- Cui, X.; Liu, J.; Huang, T.; Chen, J.; Liu, Y. A Novel Metric for Cache Size Allocation Scheme in Content Centric Networking. In Proceedings of the National Doctoral Academic Forum on Information and Communications Technology 2013, Beijing, China, 21–23 August 2013. [Google Scholar]
- Wang, Y.; Li, Z.; Tyson, G.; Uhlig, S.; Xie, G. Optimal Cache Allocation for Content-Centric Networking. In Proceedings of the 2013 21st IEEE International Conference on Network Protocols (ICNP), Goettingen, Germany, 7–10 October 2013; pp. 1–10. [Google Scholar]
- Krishnan, P.; Raz, D.; Shavitt, Y. The Cache Location Problem. IEEE/ACM Trans. Netw. 2000, 8, 568–582. [Google Scholar] [CrossRef]
- Chauhan, S.; Girvan, M.; Ott, E. Spectral Properties of Networks with Community Structure. Phys. Rev. E 2009, 80, 056114. [Google Scholar] [CrossRef]
- Mangili, M.; Martignon, F.; Capone, A. Optimal Design of Information Centric Networks. Comput. Netw. 2015, 91, 638–653. [Google Scholar] [CrossRef]
- Azimdoost, B.; Farhadi, G.; Abani, N.; Ito, A. Optimal In-Network Cache Allocation and Content Placement. In Proceedings of the 2015 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Hong Kong, China, 26 April–1 May 2015; pp. 263–268. [Google Scholar]
- Wang, Y.; Li, Z.; Tyson, G.; Uhlig, S.; Xie, G. Design and evaluation of the optimal cache allocation for content-centric networking. IEEE Trans. Comput. 2015, 65, 95–107. [Google Scholar] [CrossRef]
- Li, Y.; Wang, J.; Han, R. An On-Path Caching Scheme Based on the Expected Number of Copies in Information-Centric Networks. Electronics 2020, 9, 1705. [Google Scholar] [CrossRef]
- Jin, D.; Lv, J. Optimal Heterogeneous Cache Allocation Mechanism In Information-Centric Networking. Int. J. Innov. Comput. Inf. Control 2021, 17, 193–203. [Google Scholar]
- Lu, Y.; Abdelzaher, T.F.; Saxena, A. Design, implementation, and evaluation of differentiated caching services. IEEE Trans. Parallel Distrib. Syst. 2004, 15, 440–452. [Google Scholar]
- Fricker, C.; Robert, P.; Roberts, J.; Sbihi, N. Impact of traffic mix on caching performance in a content-centric network. In Proceedings of the IEEE INFOCOM Workshops, Orlando, FL, USA, 25–30 March 2012; pp. 310–315. [Google Scholar]
- Breslau, L.; Cao, P.; Fan, L.; Phillips, G.; Shenker, S. Web caching and Zipf-like distributions: Evidence and implications. In Proceedings of the Eighteenth Annual Joint Conference of the IEEE Computer and Communications Societies, New York, NY, USA, 21–25 March 1999; pp. 126–134. [Google Scholar]
- Chesire, M.; Wolman, A.; Voelker, G.M.; Levy, H.M. Measurement and analysis of a streaming media workload. In Proceedings of the 3rd USENIX Symposium on Internet Technologies and Systems, San Francisco, CA, USA, 26–28 March 2001; pp. 1–12. [Google Scholar]
- Laoutaris, N.; Che, H.; Stavrakakis, I. The LCD interconnection of LRU caches and its analysis. Perform. Eval. 2006, 63, 609–634. [Google Scholar] [CrossRef]
- Laoutaris, N.; Syntila, S.; Stavrakakis, I. Meta algorithms for hierarchical web caches. In Proceedings of the IEEE International Conference on Performance, Computing, and Communications, Phoenix, AZ, USA, 15–17 April 2004; pp. 445–452. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Content storage on nodes | |
| Content i in the network or request for content i | |
| Weight of content domain i | |
| Weight of data path i | |
| Weight of node i | |
| Global weight of node n | |
| Collection of content domains in a network | |
| Collection of data paths in a content domain | |
| N | Collection of nodes in a data path |
| Parameters | Value |
|---|---|
| Topology structure | GARR |
| Content placement | LCD |
| Replacement policy | LRU and LFU |
| Total number of network nodes | 104 |
| Content space size | |
| Requests number for system warm-up | |
| Requests number for system data collection | |
| Requests per second | 12 |
| Range of total cache space | 0.01–0.11 |
| Range of Zipf parameter | 0.6–0.9 |
| Experiment run time for each scenario | 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Han, R. A Hierarchical Cache Size Allocation Scheme Based on Content Dissemination in Information-Centric Networks. Future Internet 2021, 13, 131. https://doi.org/10.3390/fi13050131
Liu H, Han R. A Hierarchical Cache Size Allocation Scheme Based on Content Dissemination in Information-Centric Networks. Future Internet. 2021; 13(5):131. https://doi.org/10.3390/fi13050131
Chicago/Turabian StyleLiu, Hongyu, and Rui Han. 2021. "A Hierarchical Cache Size Allocation Scheme Based on Content Dissemination in Information-Centric Networks" Future Internet 13, no. 5: 131. https://doi.org/10.3390/fi13050131
APA StyleLiu, H., & Han, R. (2021). A Hierarchical Cache Size Allocation Scheme Based on Content Dissemination in Information-Centric Networks. Future Internet, 13(5), 131. https://doi.org/10.3390/fi13050131