1. Introduction
Narrative text in electronic health records (EHRs) is a rich resource to advance medical and machine learning research. To make this unstructured information suitable for clinical applications, there is a large demand for natural language processing (NLP) solutions that extract clinically relevant information from the raw text [
1]. A major hurdle in the development of NLP models for healthcare is the lack of large, annotated training data. There are two reasons for this. First, privacy concerns prevent sharing of clinical data with other researchers. Second, annotating data is a cumbersome and costly process which is impractical for many organizations, especially at the scale demanded by modern NLP models.
Synthetic data has been proposed as a promising alternative to real data. It addresses the privacy concern simply by not describing real persons [
2]. Furthermore, if task-relevant properties of the real data are maintained in the synthetic data, it is also of comparable utility [
2]. We envision that researchers use synthetic data to work on shared tasks where real data cannot be shared because of privacy concerns. In addition, even within the bounds of a research institute, real data may have certain access restrictions. Using synthetic data as a surrogate for the real data can help organizations to comply with privacy regulations. Besides addressing the privacy concerns, synthetic data is an effective way to increase the amount of available data without additional costs because of its additive nature [
3,
4]. Prior work showed exciting results when generating both structured [
5] and unstructured medical data [
2]. In particular, recent advances in neural language modeling show promising results in generating high-quality and realistic text [
6].
However, the generation of synthetic text alone does not make it useful for training of NLP models because of the lack of annotations. In this paper, we propose the use of language models to jointly generate synthetic text and training annotations for named-entity recognition (NER) methods. Our idea is to add in-text annotations to the language model training data in form of special tokens to delimit start/end boundaries of named entities (
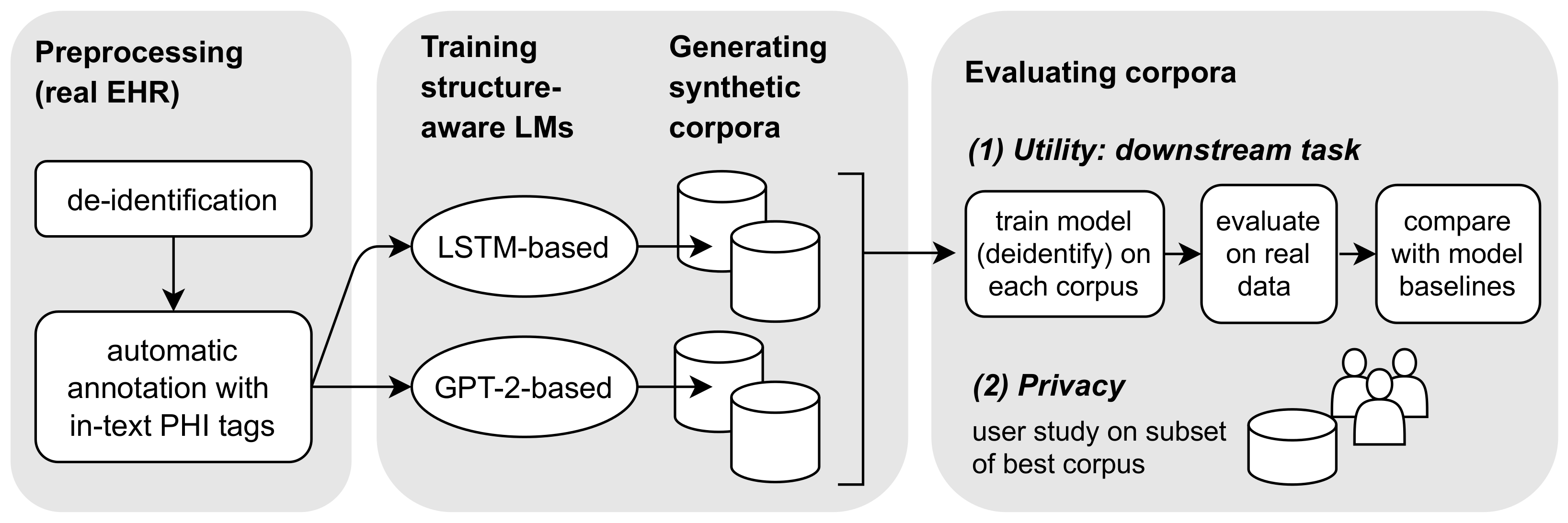
Figure 1). The source of those in-text annotations can be a (potentially noisy) pre-trained model or manual annotation. By adding the special tokens to the training data, they explicitly become part of the language modeling objective. In that way, language models learn to produce text that is automatically annotated for downstream NER tasks—we refer to them as “structure-aware language models.” Below, we will briefly outline our research pipeline; see
Figure 2 for an overview.
We compare two state-of-the-art language modeling approaches for the generation of synthetic EHR notes: a Long Short-Term Memory (LSTM) network [
7] and a transformer-based network (GPT-2) [
8]. To train these language models, we use a large and heterogeneous corpus of one million Dutch EHR notes. This dataset is unique in that it entails records of multiple institutions and care domains in the Netherlands.
We evaluate our approach by considering both utility and privacy of synthetic text. For utility, we choose the challenging NLP downstream task of de-identification. The objective of de-identification is to detect instances of protected health information (PHI) in text, such as names, dates, addresses and professions [
9]. After detection, the PHI is masked or removed for privacy protection. De-identification as a downstream task is particularly interesting, because it requires sensitive data which would not be shared otherwise. We consider utility of synthetic data under two use-cases: (1) as a replacement for real data (e.g., in data sharing), and (2) as a data augmentation method to extend a (possibly small) set of real documents. To add in-text annotations for the de-identification downstream task, we obtain heuristic PHI annotations on the language model training data through a pre-trained de-identification method called “deidentify” [
10]. Note that this setup is not limited to de-identification. In principle, any other information extraction method (or manual annotation) could act as a source for initial training annotations.
To evaluate privacy of synthetic records, we design a user study where participants are presented with the synthetic documents that entail the highest risks of privacy disclosure. As we have no 1-to-1 correspondence between real and synthetic documents, we devise a method to collect high-risk candidates for evaluation. We posit that synthetic documents with a high similarity to real documents have a higher risk of disclosing privacy sensitive information. We use ROUGE n-gram overlap [
11] and retrieval-based BM25 scoring [
12] to collect the set of candidate documents. Participants were asked to make judgments on the existence and replication of sensitive data in those examples with the goal to (1) evaluate the privacy of our synthetic data, and (2) to inform and motivate future research and privacy policies on the privacy risk assessment of free text that looks beyond PHI.
This paper makes the following contributions:
We show that neural language models can be used successfully to generate artificial text with in-line annotations. Despite varying syntactic and stylistic properties, as well as topical incoherence, they are of sufficient utility to be used for training downstream machine learning models.
Our user study provides insights into potential privacy threats associated with generative language models for synthetic EHR notes. These directly inform research on the development of automatic privacy evaluations for natural language.
3. Materials and Methods
This section describes our experimental setup including the dataset, procedure for training the language models and evaluation of utility and privacy.
3.1. Corpus for Language Modeling
To construct a large and heterogeneous dataset for language model training, we sample documents from the EHRs of 39 healthcare organizations in the Netherlands. Three domains of healthcare are represented within this sample: elderly care, mental care and disabled care. All text was written by trained care professionals such as nurses and general practitioners, and the language of reporting is Dutch. A wide variety of document types is present in this sample. This includes intake forms, progress notes, communications between care givers, and medical measurements. While some documents follow domain-specific conventions, the length, writing style and structure differs substantially across reports. The sample consists of 1.06 million reports with approximately 52 million tokens and a vocabulary size of 335 thousand. For language model training, we randomly split the dataset into training, validation, and testing sets with a 80/10/10 ratio. We received approval for the collection and use of the dataset from the privacy board of Nedap Healthcare.
3.2. Pre-Processing and Automatically Annotating the Language Modeling Data
Before using the collected real data for developing the language model, we pseudonymize it as follows. First, we detect PHI using a pre-trained de-identification tool for Dutch healthcare records called “deidentify” [
10]. The “deidentify” model is a BiLSTM-CRF trained on Dutch healthcare records in the domains of elderly care, mental care and disabled care. The data is highly similar to the data used in this study and we expect comparable effectiveness to the results reported in the original paper (entity-level F1 of 0.893 [
10]). After de-identfication, we replace the PHI with random, but realistic surrogates [
27]. The surrogate PHI will serve as “ground-truth” annotations in the downstream NLP task (
Section 3.4).
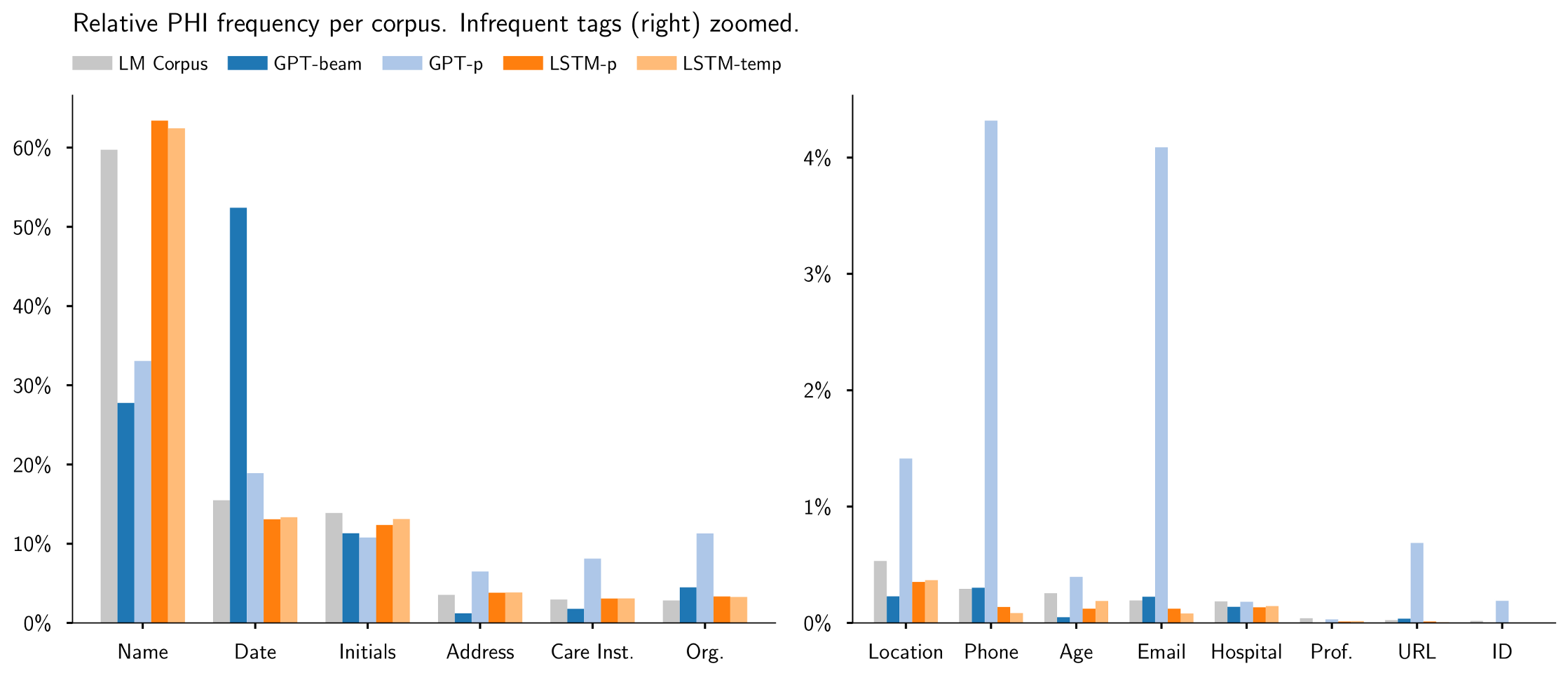
Table 1 shows the distribution of PHI in the language modeling corpus. To make annotations explicitly part of the language modeling objective, we add in-text annotations from the PHI offsets (as shown in
Figure 1). Each annotation is delimited by a special
<xSTART> and
<xEND> token where
x stands for the entity type. We acknowledge that the automatically annotated PHI will be noisy. However, we assume that quality is sufficient for an initial exploration of the viability of our synthetic data generation approach. Unless otherwise stated, we use the spaCy (
https://github.com/explosion/spaCy, accessed on 19 May 2021) tokenizer and replace newlines with a
<PAR> token.
We would like to highlight the motivation for annotating the real documents (i.e., before language modeling) and not the synthetic documents (i.e., after language generation). In theory, because we have a pre-trained NER model available, both options are possible. However, there are two reasons why we propose to make the annotations part of the language modeling. First, the language models may learn to generate novel entities that a pre-trained model would not detect (we provide tentative evidence for this in
Section 4.2.2). Second, because we could generate synthetic datasets many orders of magnitude larger than the source data, it is more efficient to annotate the language modeling data. The second argument especially holds if no pre-trained annotation model is available and records have to be manually annotated.
3.3. Generative Language Models
We compare two language modeling approaches for the generation of synthetic corpora: LSTM-based [
20] and transformer-based (GPT-2) [
6]. Below, we outline the model architectures as well as the decoding methods to generate four synthetic corpora. For a summary, see
Table 2 and
Table 3.
3.3.1. LSTM-Based Model
Because of their success in generating English EHR, we re-implement the method including hyperparameters by Melamud and Shivade [
7]. The model is a 2-layer LSTM with 650 hidden-units, an embedding layer of size 650 and a softmax output layer. Input and output weights are tied. The model is trained for 50 epochs using vanilla gradient descent, a batch size of 20 and a sequence length of 35. We also use learning rate back-off from [
7]. The initial learning rate is set to 20 and reduced by a factor of 4 after every epoch where the validation loss did not decrease. The minimum learning rate is set to 0.1. For efficiency reasons, we replace tokens that occur fewer than 10 times in the training data with
<unk> [
7].
3.3.2. Transformer-Based Model (GPT-2)
From the family of transformer models, we use GPT-2 [
6]. Prior work showed promising results using GPT-2 for the generation of English EHR [
8]. To the best of our knowledge, there is no Dutch GPT-2 model for the clinical domain which we could re-use. However, prior work showed that pre-trained English models can be adapted to the Dutch language with smaller computational demand than training from scratch [
28]. The intuition is, that the Dutch and English language share similar language rules and even (sub-)words. Below, we provide a summary of this fine-tuning process.
Adapting the vocabulary: We train a byte-pair-encoding (BPE) tokenizer on our Dutch EHR corpus. All sub-word embeddings are randomly initialized. To benefit from the pre-trained English GPT-2 model (small variant) [
6], we copy embeddings that are shared between the English and Dutch tokenizer. To account for the in-text annotations, we add a tokenization rule to not split PHI tags into sub-words.
Fine-tuning the model: The layers of the pre-trained GPT-2 model represent text at different abstraction levels. For transfer learning, the key is to take advantage of the previously learned information that is relevant for the current task, but adjust representations such that they are suitable for the new language and domain-specific terminology. To do so, layers are split into groups and we use gradual unfreezing with differential learning rates, such that the last layer group (with corpus-specific information) is changed more than the first ones, where learned representations can be re-used. To train layer groups on our data, we used the one-cycle-policy [
29], where learning rates are scheduled with cosine annealing. Our GPT-2 model was split into four layer groups which were trained in 5 epochs. We provide additional details on model and fine-tuning steps in
Table 2 and
Appendix A.
3.3.3. Decoding Methods for Generation of Synthetic Corpora
Using the LSTM, GPT-2 and different decoding methods, we generated four synthetic corpora of approximately 1 million tokens each (
Table 3). As initial context for each report, we selected random prompts of length 3. These were sampled from held-out EHRs to minimize the possibility of reconstructing real documents during generation. Generation of a text was terminated either when a maximum token count was reached, or when the model produced an end-of-document token. For all corpora, we impose a subjective minimum document length of 50 tokens.
Following Holtzman et al. [
24], we generate two corpora with nucleus sampling (
, LSTM-p and GPT-p). Additionally, we implement the decoding methods of the papers that proposed the LSTM [
7] and GPT-2 [
8] for the generation of EHRs. For the LSTM, we generate a corpus with temperature sampling (
, LSTM-temp). For the GPT-2 we use beam search (
, GPT-beam) and exclude texts without PHI tags, as the corpus already had a lower overall number of tags which are essential for the utility in the downstream task. For both GPT-2 corpora, we set the generator to not repeat n-grams longer than 2 words within one text to increase variability. In rare cases, the language models produced annotations with trailing start/end tags. These malformed annotations were removed in an automatic post-processing step. We quantify how many annotations were removed in
Section 4.1.1.
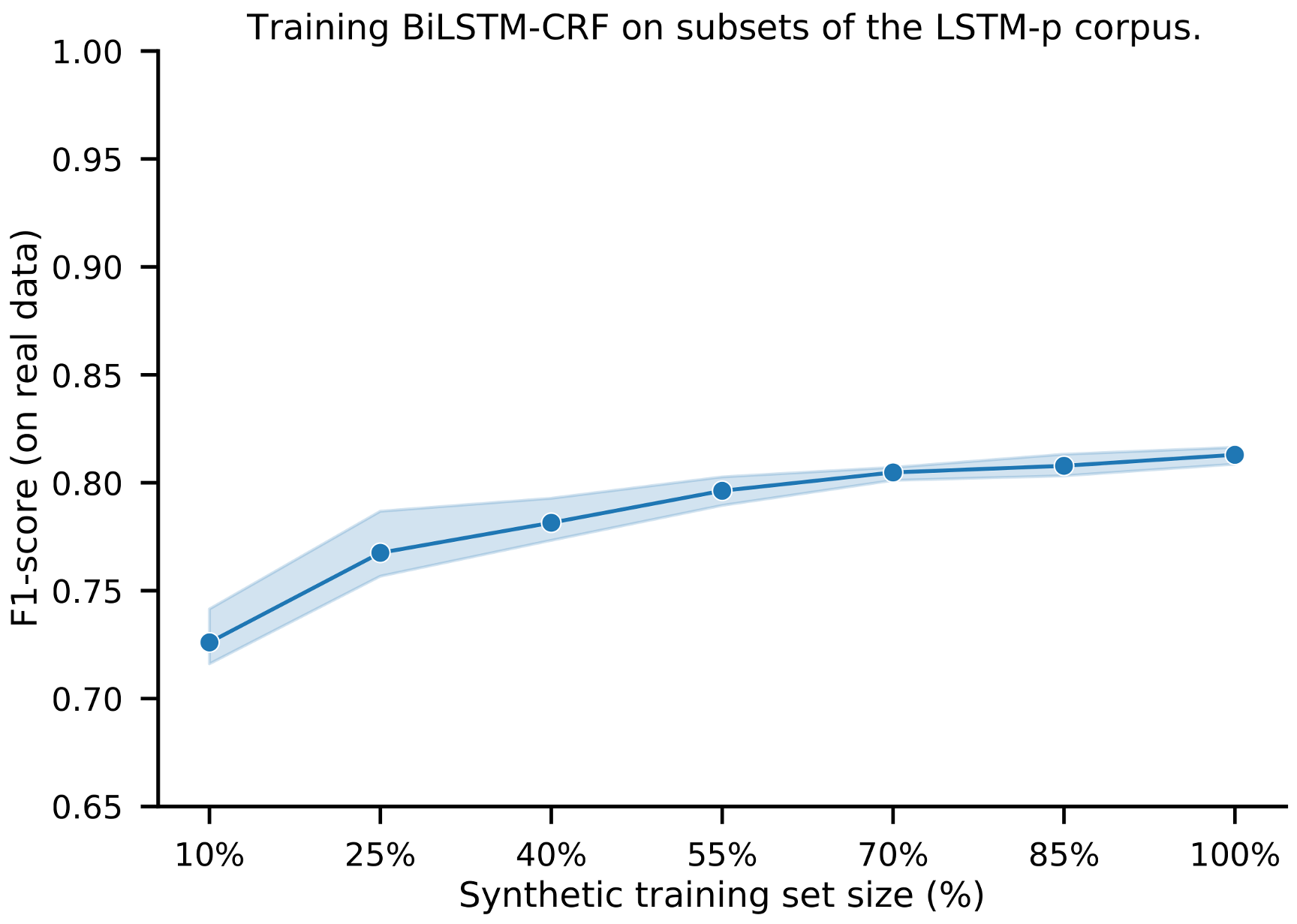
3.4. Extrinsic Evaluation on NLP Downstream Task
To understand if the synthetic data and annotations have sufficient utility to be used for training of NLP models, we measure effectiveness in a de-identification downstream task. The objective of de-identification is to detect instances of PHI in text, such as names, dates, addresses and professions [
9]. Ideally, a de-identification model trained on synthetic data performs as good or better than a model trained on real data. To evaluate this, we train a BiLSTM-CRF de-identification model in three settings: (1) using real data, (2) extending real with synthetic data, and (3) using only synthetic data (
Figure 3). As implementation for the BiLSTM-CRF, we use “deidentify” (
https://github.com/nedap/deidentify, accessed on 19 May 2021) with the same architecture and hyperparameters as reported in the original paper [
10]. As real data, we use the NUT corpus of that study with the same test split such that results are comparable. NUT consists of 1260 records with gold-standard PHI annotations.
The effectiveness of the de-identification models is measured by entity-level precision, recall and F1. The BiLSTM-CRF trained on real data is considered as the upper baseline for this problem. We also report scores of a rule-based system (DEDUCE [
30]) which gives a performance estimate in the absence of any real or synthetic training data.
3.5. Privacy Evaluation
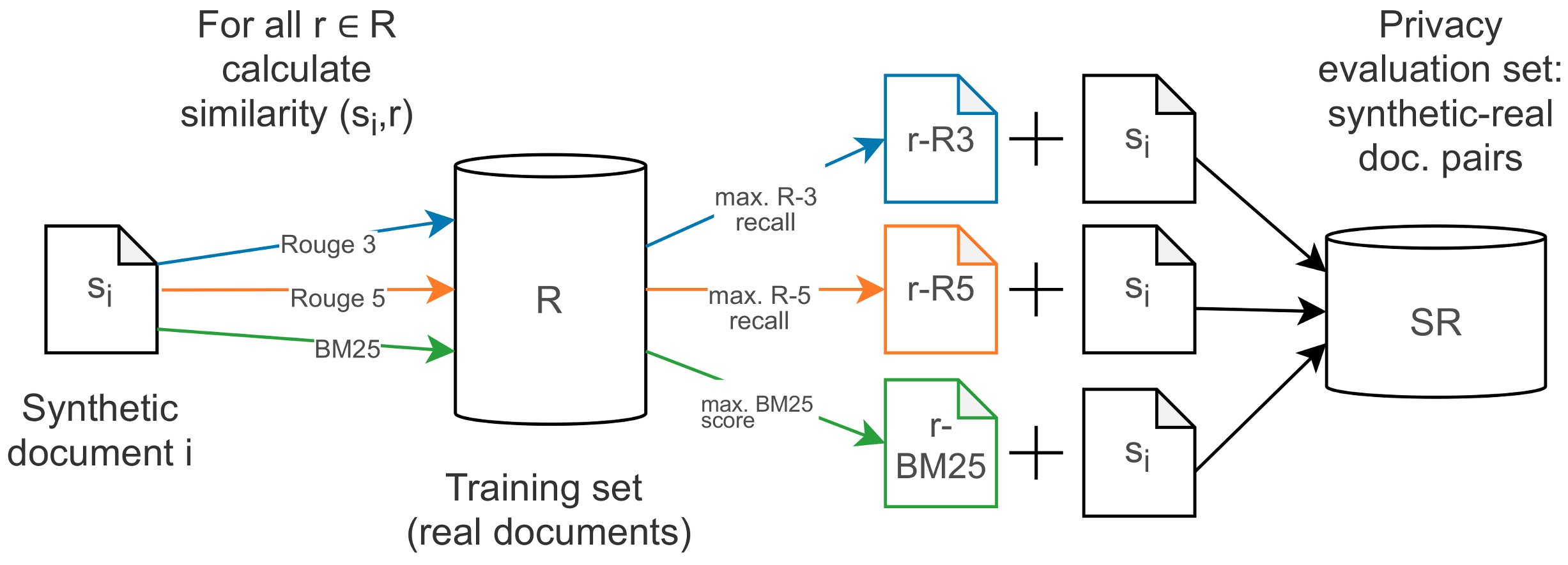
To gain insights into the privacy of synthetic data, we conducted a user study for a subset of synthetic documents from the corpus with highest utility in the downstream task. Our goal was to check whether any information “leaked” from the real data into the synthetic data, and whether this information could be used to re-identify an individual.
Finding potential worst cases for privacy. The assumption is that a privacy leak may have occurred when certain information of a real document reappears in a synthetic document. Similarly to the study by Choi et al. [
31], we have no 1-to-1 correspondence between real and synthetic records. Let
be a synthetic document and
be a real document. Assuming that the likelihood of a privacy leak is higher when the proximity between
s and
r is high, we get a set of document pairs (
) where for each
s the most similar document
r is retrieved as candidate source document (cf.
Figure 4). We use three measures to obtain the most similar documents to a synthetic document: ROUGE-N recall [
11], with
and with
, and retrieval-based BM25 scoring [
12]. We use standard BM25 parameters
and
[
12].
Instead of randomly sampling synthetic documents for manual inspection, we used several filtering steps to maximize the probability of showing pairs with high similarity and readability during evaluation: We first sorted the documents by highest ROUGE scores. Afterwards, we removed duplicates, documents longer than 1000 characters (to control the reading effort of participants), and documents that received high similarity scores mostly based on structural elements (e.g.,
<PAR> tokens). We took the top 122 documents with highest ROUGE score for the user study. Full details of the filtering procedure are provided in
Appendix D.
Participants were asked to answer the following questions for each pair of real/synthetic documents:
- Q1:
“Do you think the real doc provides enough information to identify a person?”
- Q2:
“Do you think the synthetic doc contains person identifying information?”
- Q3:
“Do you think that there is a link between the synthetic and real doc in the sense that it may identify someone in the real doc?”
- Q4:
“Please motivate your answer for Q3.”
Questions 1–3 are on a 5-point Likert scale (Yes, Probably yes, Not sure, Probably not, No), and Q4 is an open text answer. Participants received a short introduction about the task and privacy. We supplied two trial documents for participants to get used to the task. These documents were excluded from analysis. The full questionnaire and participation instructions are given in
Appendix D.
As the privacy sensitive data could not be shared with external parties, we recruited 12 participants from our institution (Nedap Healthcare). Due to the participant pool, there is a potential bias for technical and care related experts. We consider the impact for a privacy evaluation low, and indeed, because of their domain knowledge, participants have provided some helpful domain-related qualitative feedback. All participants were native Dutch speakers and each document pair was independently examined by two participants. We computed inter-participant agreement for each question with Cohen’s Kappa. As the Likert scales produce ordinal data and there is a natural and relevant rank-order, we also calculated the Spearman’s Rank-Order Correlation, to better capture the difference in participants disagreeing by, for example, answering “Yes” and “Probably” versus “Yes” and “No.” This is especially relevant for the questions in this evaluation, which are hard to answer and likely to result in participants showing different levels of confidence due to personal differences. Both Kappa score and Spearman correlation were calculated per question, micro-averaged over all document pairs.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










