3. Related Work
Query running time prediction is a challenging task widely used in database management systems [
1,
2,
3,
4,
5,
6,
7]. In the context of Web search engines, query running time prediction deals with additional challenges such as dynamic pruning techniques. Dynamic pruning techniques such as the WAND or the BM-WAND can improve the efficiency of queries, but they can take different amounts of time for different queries. That is because their cost is not directly related to the posting list lengths of the query terms as many documents can be skipped. In this context and under different incoming user query rates, query running time prediction algorithms based on machine learning techniques can be useful to determine in advance which resources can be allocated to a given query.
The work in [
20] presented a query running time prediction algorithm that aggregates the terms features into statistics related to the query. The results of the aggregations are used as input to a learned regression model. This work showed promising initial results for disk-based indices. Later, the work in [
21] applied the prediction algorithm presented in [
20] for evenly distributing the query workload across processors acting as replicas for each partition of the document collection. The work in [
22] presented an algorithm which is based on the relative entropy between a query language and the corresponding collection language model.
The work in [
10] specifically presented a query running time predictor for the WAND technique. The proposed predictor is designed for distributed search engines. The authors propose to use a vector with 42 descriptors to represent different features of the queries and the respective posting lists. To estimate the query running time, the proposed algorithm uses a linear regression method which has been trained from the statistics obtained by the aggregations of the terms features. The work in [
23] improves the accuracy of [
10] by including additional data on the query terms for the prediction of the running time. More recently, the authors in [
24] proposed to use index synopses which are stochastic samples of the full index for attaining accurate timing predictions.
The work in [
25] proposed to model the complexity of query features by using a personalization method. This approach outperformed existing predictors in terms of accuracy and memory consumption. The query running time predictor was used to decide on whether to process a single query with multiple threads (the ones with predicted large running times) or a single thread (the ones with predicted small running times). The work in [
26] determined the most relevant parameters used in [
10] and based on that finding proposed to optimize memory usage on heterogeneous hardware. The authors proposed a predictor named Delayed, Dynamic, and Selective (DDS). First, queries are executed for a short period of time
D so short-running queries can be completed without prediction overhead. Then, the algorithm collects 10 features of the query after running it during the first step. In the final step, the algorithm classifies the queries as long or medium using a threshold value. This work was extended in [
27] by presenting more comprehensive experimental evaluation.
The work in [
28] aimed to achieve a minimum query response time when query traffic is high. The algorithm is configured to prune more or less aggressively, depending on the expected duration of the query. The value of
k is also estimated in [
29]. Nevertheless, in [
29] the effectiveness of the search engine is not compromised as it ensures the retrieval of the actual top-k document results. The work in [
30] presented a scheduler to process queries concurrently by using multi-threading. It also allows to execute updates in the posting lists. Queries are decomposed into work units that are assigned to different threads. The authors use the number of query terms and the sum of lengths of the respective posting lists for performing the classification required to set the number of threads to be assigned to each co-occurring query.
The work in [
31] proposed a prediction algorithm for multi-stage retrieval systems where an initial document candidate generation stage is followed by one or more re-rankers. The work in [
32] proposed an analytical performance modeling framework for user queries. The overhead introduced by the proposed analytical model varies between 5% and 6% depending of the particular test. More recently, the work in [
33] proposed a reinforcement learning based approach for search engines. During query evaluation, the query is classified using pre-defined categories, and consequently a match plan is selected. The authors proposed a method to predict which match plan to employ for each incoming query.
The Discrete Fourier Transform (DFT) technique has been previously used in contexts such as patterns recognition in data mining [
34,
35], and to predict the popularity of videos by analyzing videos view count traces in the frequency domain [
36]. In the Web search engine application domain, it has been used for determining (i) document relevance [
37], (ii) document semantic representation [
38] and (iii) document classification [
39]. In this paper, we show that the DFT technique can also be useful for predicting the running time of query processing algorithms.
4. A DFT-Based Query Running Time Prediction Algorithm
Query running time prediction has practical applications in the efficient assignment of resources. In particular, in this paper, we show its benefits for an efficient assignment of threads to incoming queries. The DFT-based algorithm can be used by a scheduler to decide for each query at runtime, whether to assign to it a single thread or more than one thread to process it depending on the estimated time. Furthermore, the scheduler can determine the number of threads to allocate to each query using the predictions provided by our algorithm. An efficient allocation of threads allows to obtain a better utilization of the resources and reduces the latencies of query execution times [
10].
The algorithm proposed in this work uses a new approach to describe user queries with low-dimensional vectors. Our approach allows us to drastically reduce the computational cost without compromising the accuracy of the top-k document results. The cost of predicting a query running time is directly proportional to the number of inputs to the prediction algorithm, regardless of the particular document ranking algorithm being used. Any regression model with several independent variables with an output dependent variable y, must process the entire input vector of p descriptors. In particular, a basic regression model of several variables can be defined as , which corresponds to a multiple linear regression model where is the correlation coefficient to be obtained, is the slope of the regression line and is the error.
To predict the query running time, we propose to use the Discrete Fourier Transform (DFT). The DFT is an approximation of the Fourier Transform and is used to find the content in the frequency of signals that are periodic and discrete, which implies that in the domain of frequency they will also be periodic and discrete. The DFT includes in its descriptor signal data such as the variance, the arithmetic means, and factors associated with the continuity of the signal and its density. The signal obtained with the DFT satisfies the symmetry property [
40]. Therefore, it allows us to use only half the components of the vector.
These properties allow us to obtain a good characterization of the posting, since it includes in its signal (output of the DFT) descriptive information of an input signal. Thus, using the DFT allows to reduce the number of descriptors used to represent the information while remaining representative for each posting list.
In particular, we use the DFT to:
Describe the distribution of scores of each document in the posting list of the terms and to determine how is the distribution of the scores of the documents with higher probability of being part of the top-k document results. In this way, we describe the search space of each posting list.
Describe the variation of the running time of different queries as we retrieve a larger number of top-k document results.
In this work, the distribution of the weights
of the posting lists are treated as signals of the DFT, where these signals are the function of independent variables given by the random distribution of
and determined by the order of the documents identifiers (docIDs). Low DFT frequencies are used to describe how the high values of
are distributed (because they appear less frequently in the posting list according to the Zipf law [
8]) and high DFT frequencies are used to describe the distribution of low values of
(because they appear more frequently in the posting lists).
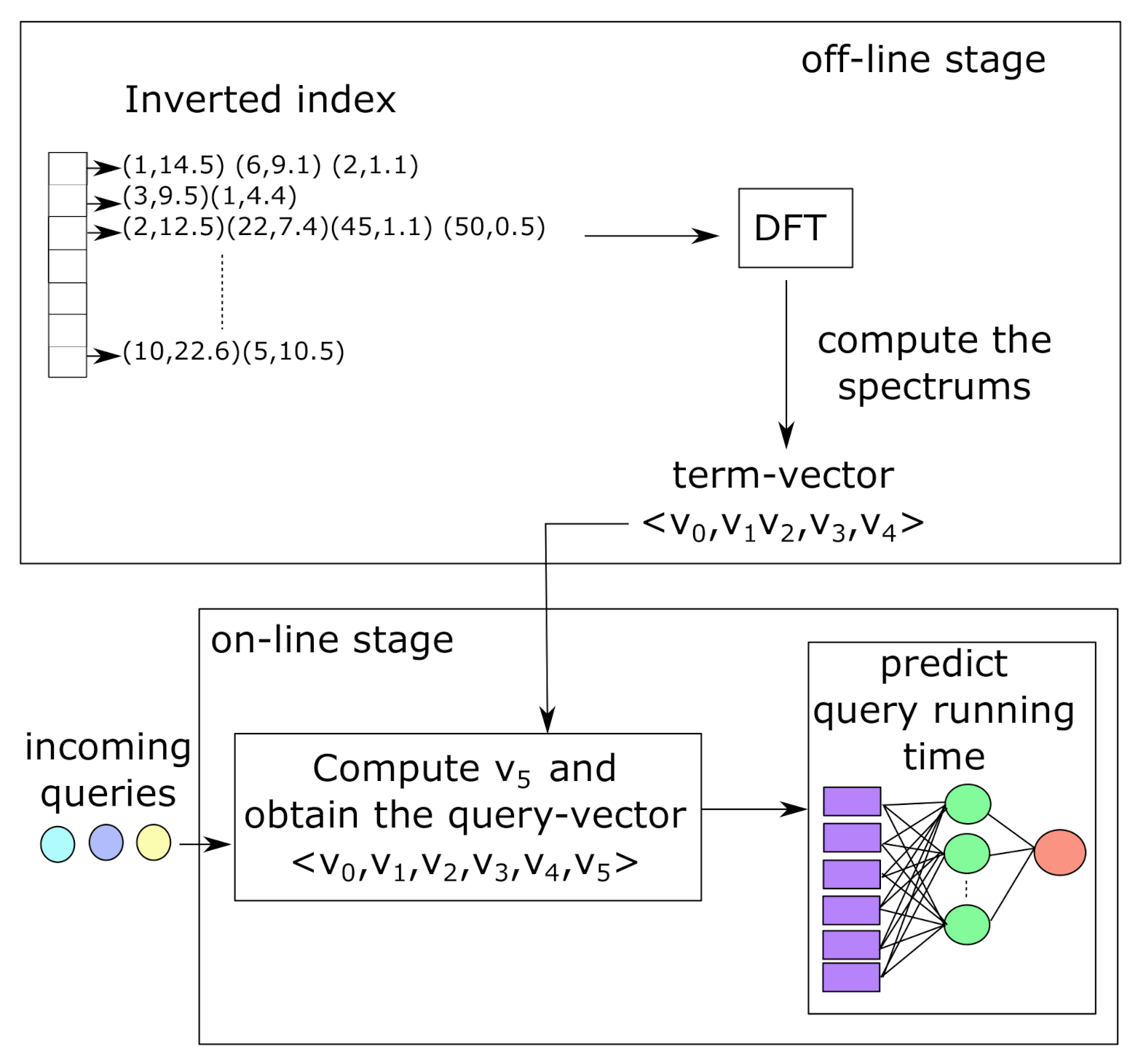
Our DFT-based algorithm builds a query-vector in two stages as illustrated in
Figure 4. During the off-line stage (
Figure 4 on top), our proposal builds a five-dimensional term-vector to represent the posting lists of the terms stored in the inverted index. Three descriptors of the term-vector are obtained with the DFT which calculates the spectrum of the posting lists. The two remaining descriptors of the term-vector correspond to the characterization of the threshold for a given value of top-
k (e.g., top-10) and the posting list size. The term-vectors are used later during the on-line stage, as illustrated in
Figure 4 at bottom, to build a six-dimensional vector representing the incoming user queries. The query-vector feeds a feed-forward neural network with back-propagation which estimates the query running time. In the following, we present the technical details.
4.1. Term Coefficients
Given a query q containing the terms with , where each term has a posting list containing pairs where d is the document identifier and is the score of the term in the document (e.g., the frequency of occurrence of the term t in the document d), our DFT-based algorithm works as follows. We use information regarding the frequency spectrum of density functions obtained from the posting lists of the terms , and the information related to the spectrum of frequency of the processing time for each term required to retrieve the top-k document results. The spectrum of frequencies is obtained with the discrete Fourier transform (DFT). In addition, we use: (a) the size of each posting list (i.e., the number of documents where the term appears), (b) the processing time for , , and for T (t, 10,000), and (c) the threshold value for the top-k document. Then, we describe each term with a five dimension vector .
The density function of the posting lists of the term , describes the search space of the posting list . The of the processing time functions describes the differences of the times required to process the posting list of a term t with different k values. In practice, the values of are the u-th coefficients of Fourier and express the frequency content of a function or a signal. In this analysis, the DFT of can be considered as a characterization of the distribution of the values and, therefore, it can be seen as a function of bulk density in the frequency domain.
We use the spectral power density of
over
, because it represents the cost of processing the signal in the frequency domain. It shows how the power is scattered as a function of the frequency
, which is the minimum frequency (or fundamental frequency) of the DFT. The fundamental frequency
describes the density of posting lists by using the convolution of the broader sinusoidal signal. Thus, it allows us to describe well the posting lists that have a higher density. We also use the magnitude of the spectrum of the fundamental frequency
of the
for the posting lists and for the processing times obtained for each term
, which describes the difference between the processing times as the value of
k increases in a quadratic way.
Table 2 summarizes the descriptors used in the proposed prediction algorithm.
PSD of at a frequency : is the Power Spectral Density (PSD) of the DFT of
in the fundamental frequency
. The calculation is
.
(Equation (
1)) is a vector containing the cumulative sums of
(Equation (
2)) of scores
of each document
inside the intervals
. Each j-th interval
I is equi-spaced at the rate of
items. If there are empty intervals, the cumulative sum is zero in those positions. Each value of
is obtained with Equation (
3).
We set the number of intervals because a greater number of intervals implies a distribution of the average power of the signal in a greater number of frequencies of the DFT. In other words, by increasing the number of intervals the percentage of documents that quantify the density of decreases inside each interval. On the other hand, if the number of intervals is decreased, the power spectral density values tend to increase close to the average value of the signal power and the characterization of the density distribution in the frequency domain is decreased. Then, for the purposes of characterizing how the accumulated sum is distributed (density of values of in each interval) and specifically to describe the posting lists that have higher density and, therefore, a higher cost of processing, it is not necessary to use a large number of intervals. Therefore, we define to keep an accumulated density of scores of 10% of the documents (for posting lists of 10 or more documents), which is a representative percentage to characterize the density of in different parts of the posting lists. Additionally, we have experimentally found to be a value that produces accurate results.
DFT magnitude of Rank-Score of frequency 1/4: is the magnitude of the frequency spectrum of the DFT in the fundamental frequency of the distribution of cumulative density of the documents scores from to . We set to quantify the accumulated density distribution of the high values of of the documents that are more likely to match the query terms.
#Postings: is the number of documents where the term appears.
DFT magnitude of processing times: is the magnitude of the frequency spectrum of the DFT obtained for the vector containing the processing times of a term t at frequency . The elements of the vector are <>. is the running time required to retrieve the top-k documents results for the term t.
Threshold: score value (threshold) for the k-th document (top-k). If the list has less than k documents, then .
4.2. Query Coefficients
To predict the query running time, we compute the query descriptor as a six-dimensional vector <> as follows. For each term , we add the corresponding descriptors and of each term in q, so we obtain an initial query vector with dimension four. Then, we include two additional descriptors computed as the and for each . All vectors are calculated off-line, while is obtained at query run time.
For a given query q, the descriptors <> represent the sum of integrals obtained with the DFT and the descriptor represents the sum of all documents where the query terms appears, which gives an approximation to the search space of q. We do not compute the sum of for each term of the query because it is a lower bound of the score of the top-k and if there are several term lists with high scores, the sum of those scores will increase the value of and it will lose its characteristic of lower bound. We also use the maximum values of and that are minimum bounds.
All of the DFT descriptors are based on the use the fundamental frequency F which depends on the period P of the input signal. That is, the distributions of with period of , the distributions of the cumulative density with period of , and the distributions of processing time with period of where the fundamental frequency is . As we explained above, we use the fundamental frequency to quantify how is the distribution of the high values of the input signal. In our case, high values of the magnitudes of the DFT represent a higher list processing cost.
5. Experimental Evaluation
5.1. Data Collection and Methodology
The research was conducted using a query log and two document collections of different sizes. We build an inverted index for each one of these collections by using the Terrier IR platform (
http://terrier.org/, accessed on 19 June 2021). We pruned the index to keep only the data related to the terms of the query log. Once the indexes were built, we processed the query log using these indexes to retrieve the most relevant document results for each query. In this section, we will further describe the query log, the document collection, the hardware, deployment details and the baseline algorithm used to compare the results obtained by our DFT-based query time prediction algorithm.
In the following sections, we first evaluate the accuracy of the prediction algorithm with different machine learning methods. We show that the best accuracy is obtained with a feed-forward neural network with back-propagation using five neurons in the hidden layer. Then, we present the accuracy and the performance evaluation for our proposal and the baseline algorithm. Finally, we show the benefits of our proposal to facilitate the assignment of threads to incoming queries.
Query log: We use a query log containing 20,000 queries in English selected from the TrecMillion Query Track (
https://trec.nist.gov/data/million.query09.html, accessed on 19 June 2021). The query log is a list of text query like “used car parts”, “poker tournaments” and “lake links”. From this dataset we selected unique queries with two or more terms and removed the stopwords (e.g., this, that, these, etc.). The resulting query log has 15,000 queries.
ClueWeb09 Dataset: We use a 50.2 million document collection from the TREC ClueWeb09 dataset (category B) (
http://www.lemurproject.org/clueweb09.php/, accessed on 19 June 2021). This collection has a total of 428,136,613 unique documents. The resulting index size for this collection is 60.2 GB with 10,230 different terms.
Gov2 Dataset: We use a second collection named TREC Gov2 with 25.2 million documents crawled from .gov sites (
http://ir.dcs.gla.ac.uk/test_collections/gov2-summary.htm, accessed on 19 June 2021). It includes html and text, plus the extracted text of pdf, word and postscript. The resulting index size is 13.7 GB with 12,062 different terms.
Hardware and Deployment Details: The running time of each query includes the pre-processing of uppers bounds plus the time required by the WAND or the BM-WAND iterators to process the query. The running times for the actual execution of the query processing strategies were obtained on an Intel Processor Core i7-3820 with 4 Cores (8 threads) and 32 GB RAM. All the experiments were performed with the whole inverted index loaded into main memory. In the case of the ClueWeb09, due to the index size is larger than the size of the main memory of the hardware, we performed the experiments with batches of 500 queries each. Only the posting lists associated with the terms present in each batch are loaded into the main memory using on average 22 GB of memory space. The average execution time of each query is measured independently one by one. The code of the algorithms presented in this paper are available at
https://github.com/neurovisionhub/dft-running-time-prediction, accessed on 19 June 2021.
Baseline Algorithm: In the experimentation, we evaluate the performance of our DFT-based algorithm for query running time prediction by using the WAND and the BM-WAND dynamic pruning techniques executed under the BM25 and the TF-IDF document scoring methods. We compare the proposed prediction algorithm against the approach proposed in [
10]. We selected this algorithm as our baseline for comparison purposes since it is suitable for predicting the running time of queries solved with the WAND and BM-WAND algorithms for either conjunctive or disjunctive queries.
Evaluation Metrics: The main performance metrics used in our experiments are (i) the Pearson correlation among the predicted query running times and the actual running times obtained from the real execution of each query solution strategy; (ii) the root-mean-square error (RMSE) , where n is the number of queries considered in each run; (iii) the variation coefficient relative to the mean value calculated as VC ; (iv) the average absolute error (AAE) defined as ; and (v) the maximum absolute error observed from the differences between the actual and predicted values ().
5.2. Learning Methods
In this section, we evaluate the accuracy of the prediction algorithm for query solution running time when implemented with different machine learning methods. We tested several methods such as the linear regression, the multivariate linear regression (MV), the extreme machine learning (EML-5) with five neurons in the hidden layer, the feed-forward neural network with back-propagation (BP-5) using five neurons in the hidden layer, the Random Forest (RF) and the support vector machine (SVM). In the following, we present the accuracy achieved with each learning method under the BM-WAND dynamic pruning algorithm. Similar results were obtained with the WAND strategy. We use the BM25 and TF-IDF scoring algorithms on both Web collections, namely the ClueWeb09 and the Gov2.
The BP-5 has six input neurons, one for each descriptor of the six-dimensional characteristic vector and one output. For the purpose of this section, we show results with five neurons in the hidden layer. However, we conducted experiments with 1, 5, 10, 25 and 50 neurons in the hidden layer and the best results were obtained with 5 neurons as we show in the next section. We used the log-Sigmoid transfer function in the hidden layer and a linear transfer function in the output layer.
We evaluated the accuracy of the learning methods by applying a swap c-fold cross validation with c = {2, 3, 5, 10}. In other words, we inverted the size of the c-folds. For c = 2, both training and test folds have the same size (50–50%). For c = 3, the training fold has 33.3% of the data and the test fold has 66.3% of the data, and so on.
Table 3 shows the results reported by the query running time prediction algorithm when executing the learning methods listed above. We show the RMSE, the coefficient of variation (VC) and the Pearson correlation (PrC) obtained with different Web collections and the BM-WAND technique. The results show that VC tends to be small in all cases, meaning that the values are well represented by the mean. The linear and multivariate methods show low accuracy (high RMSE values) because the distribution of the running times of queries is not linear neither a combination of variables. The distribution of the actual query running times tends to be like an inverse of the Zipf’s law. The BP-5 and the Random Forest methods achieve the best results in almost all cases as they achieve low RMSE and high PrC values. However, the Random Forest method tends to create many branches and long paths when the curve representing the execution time for different queries has many inflections.
The EML-5 method presents lower accuracy than the BP-5. That is, the EML-5 presents higher RMSE and lower PrC values than the respective values of the BP-5 method. We conducted additional experiments which showed that the EML-5 requires a larger number of neurons in the hidden layer between 20 and 25, to achieve similar results than the ones achieved by the BP-5 method. Finally, the SVM method tends to be over-fitting to the training set. In our application case (fast Web query solution using inverted indexes) most query running time are very low, thus the SVM is not capable of estimating long query running times. Therefore, in the following sections, we use the BP-5 learning method for the query running time prediction algorithms. We experimentally tested that similar conclusion holds for the baseline prediction algorithm as it only differs from our DFT-based algorithm in the specific attribute vectors used to train the learning method.
5.3. Accuracy Evaluation
In this section, we evaluate the accuracy of the query running time prediction algorithms. We train the respective neural network with 60% of the queries and we use 40% of the remaining queries for the experiments. We evaluate accuracy with and 50 neurons in the hidden layer where we use the log-Sigmoid transfer function in the hidden layer and the linear transfer function in the output layer.
Table 4 shows the accuracy achieved by the query running time prediction algorithms. Numbers in bold font denote the best accuracy results in each case. Our DFT-based algorithm achieves the lowest RSME values and the highest Pearson correlation (PrC) values in most cases. The baseline approach outperforms our proposal only for the BM-WAND with TF-IDF and using the Gov2 Web collection. However, the difference is very small.
Table 4 also shows that the best results are obtained with 5 and 10 neurons in the hidden layer. With more than five neurons, results show no improvement and with more than 10 neurons both approaches tend to lose accuracy.
In
Table 5, we show results obtained with (1) the real execution of the query processing strategies for different datasets, (2) the proposed query running time prediction algorithm, and (3) the baseline query running time prediction algorithm, both operating with five neurons in the hidden layer. In the columns, QRT is the average query running time and
is the maximum query running time observed in the set of processed queries. AAE is the average absolute error and
is the maximum error observed in the predicted running times for the set of processed queries.
In general, the results in
Table 5 show that both approaches are able to make excellent prediction of the QRT values. The proposed algorithm presents smaller error values than the baseline algorithm (numbers in bold font in the table). For the AAE metric, the reduction is in the range between 5% and 15%, whereas for
the reduction is in the range between 49% and 74% for WAND and between 1.6% and 52% for BM-WAND. The
value indicates the single query that demands the maximum running time. For this case, both approaches outperform each other depending on the dataset and query processing strategy. For WAND, the baseline algorithm achieves better overall predictions where it underestimates the exact value by 4% on average whereas the proposed algorithm underestimates the exact value by 14% on average. In this case the baseline algorithm is able to predict the exact values for two maximum queries. Furthermore, the computations associated with the TF-IDF method are much lighter than the BM25 ones which increases the linear effect. For BM-WAND, this underestimation is similar in both approaches with 19% for the baseline algorithm and 18% for the proposed algorithm.
To evaluate the effect of the index size on our DFT-based method,
Table 5 shows that the
reported with the ClueWeb09 tends to be 10% higher when executing the WAND and 15% higher when executing the BM-WAND. This is mainly because as we increase the number of documents some posting lists tend to be significantly larger, which tends to increase the maximum error in of the prediction algorithm. However, the AAE increases only 0.0035 s for the WAND and 0.0055 s for the MB-WAND. Notice that when using the BM-WAND and the TF-IDF, there is no difference between the AAE reported with both datasets. In other words, with a larger dataset, the maximum errors increase by 15% at most, but the average of the absolute error reported by our DFT-based algorithm are very similar.
5.4. Performance Evaluation
In this section, we evaluate the execution time and the memory consumption of the query running time prediction algorithms. At run time, for each incoming query,
Table 6 shows (i) the average execution time required to compute the vectors for queries with two and five terms and (ii) the average execution time required by the neural network that predicts the running time of queries. We present results for a neuronal network with 5, 10, 25 and 50 neurons in the hidden layer. The results show that the proposed algorithm reduces the on-line query vector construction time in a significant manner (90–92%) as it handles a smaller number of attributes than the baseline algorithm (6 vs. 42 attributes, respectively). Furthermore, the proposed algorithm is able to reduce in at least 32% the execution time of the neuronal network that uses the small query vector to predict each query running time. In total, considering the query vector construction time and its use in the neural network for predicting the respective query running time, the improvement in execution time of the proposed algorithm over the baseline algorithm is in the range 77–82%.
Table 7 shows the memory consumption in bytes required to store (1) the descriptors of the term-vector and (2) the descriptor of the query-vector for each query being solved in the processor. As expected, the proposed algorithm also reduces the memory consumption requirements of each incoming query in a significant manner in about 70%.
5.5. An Application Case for Query Running Time Prediction
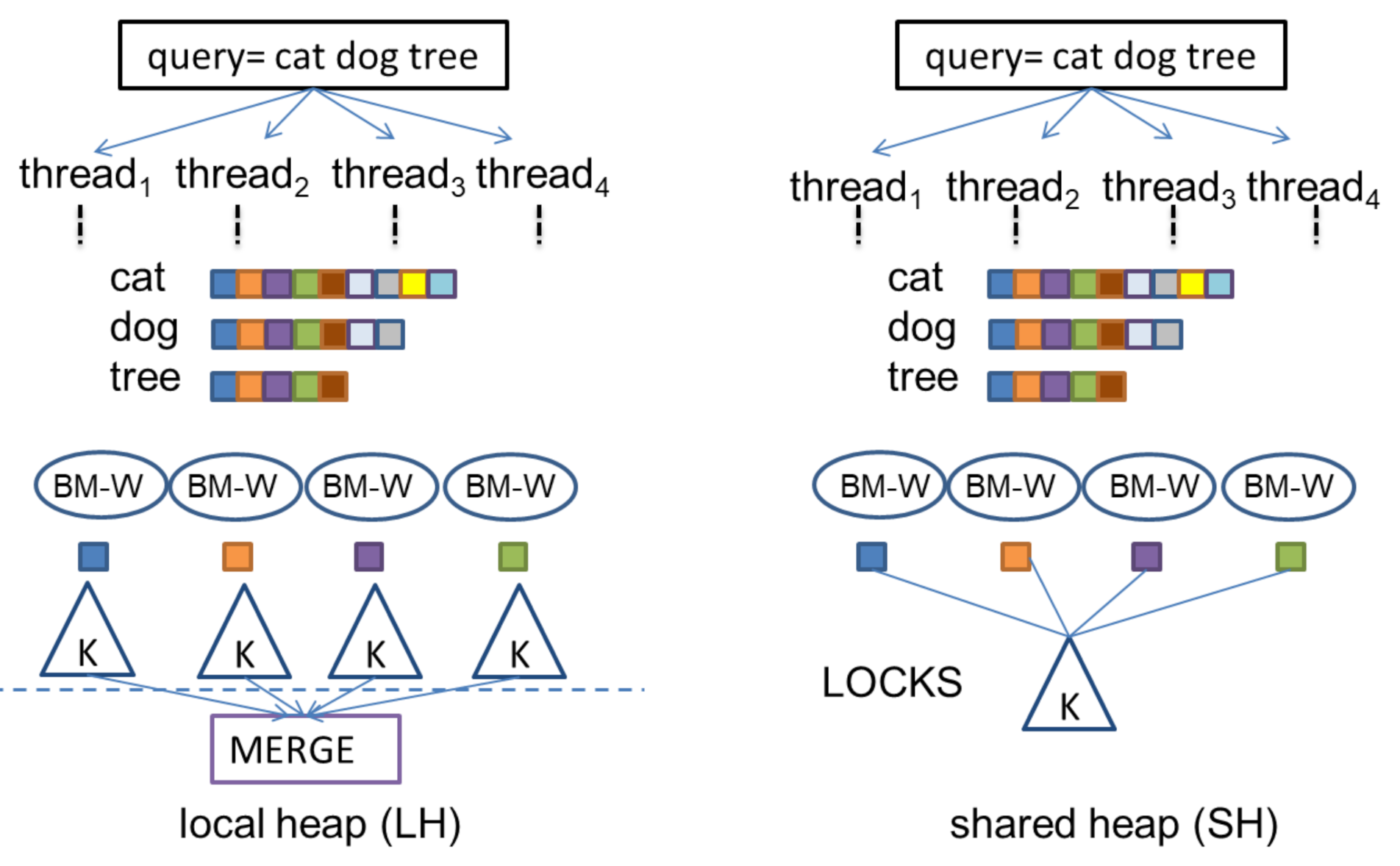
In this section, we describe two multi-threaded query processing strategies [
29] as an application case for the query running time prediction algorithm presented in the paper. In the first strategy, called Local BM-WAND (LBM-WAND), each thread keeps a local heap to hold the top-
k documents calculated by the thread. The posting lists of the documents index are distributed among a total of
T threads using the rule
. This posting list partition rule ensures that any given document is always assigned to the same thread. Then, each thread processes the query using its own local inverted index. At the end of the query processing process, we merge the local heaps of each thread to select the top-
k document results. To this end, a synchronization barrier is executed before the merge operation. The second strategy, called Shared BM-WAND(SBM-WAND), uses the same index partition scheme as the LBM-WAND but all threads update a single global heap of size
k holding the top-
k results. Therefore, the SBM-WAND strategy does not perform a merge of partial document results at the end of the process as it already contains the top-
k results. A lock operation is executed to guarantee exclusive access to the shared heap during updates to prevent from read-write conflicts.
Figure 5 describes these two parallel strategies for query processing.
Experimentally, we have found [
29] that the LBM-WAND strategy performs better than the SBM-WAND strategy when the sequential query running time is below a given
value. The SBM-WAND strategy outperforms the LBM-WAND strategy for queries demanding running times larger than
. In practice, the value of
can be calculated as a part of the training process for the DFT algorithm. Thus, for each incoming query, a scheduler uses the proposed DFT-based algorithm to decide on which strategy to apply at run time.
The number of threads T required for solving single queries is determined as the minimum necessary to ensure that no query is solved beyond an upper bound for the response time in the index service. In this way, the total number of threads available for query processing can be grouped into a set of T-threads units capable of using either LBM-WAND or SBM-WAND for solving single queries in parallel. In practice, for our Web collections and test processor, with threads is sufficient for achieving query response times below 50 ms which is a standard upper bound for search engines.
5.5.1. Accuracy Evaluation of the DFT-Based Algorithm under Multi-Threaded Query Processing
We evaluate the predictive ability of the algorithm to determine the query running time for a given number of threads. This prediction is challenging since the running time does not decrease linearly with the number of threads.
Table 8 shows the Pearson correlation (PrC) and the error RMSE obtained by both prediction algorithms for different number of neurons in the hidden layer and different number of threads (1, 2, 4 and 8). The correlation and error are evaluated against the actual execution of each multi-threading strategy (LBM-WAND and SBM-WAND). As we increase the number of threads, both prediction algorithms achieve a more accurate prediction of the query running time. This is mainly because the differences between the maximum and minimum query running times tend to be smaller with thread increase. The baseline prediction algorithm presents better prediction accuracy than our DFT-based algorithm for the case of a single neuron in the hidden layer. The results show that the proposed algorithm achieves more accurate predictions than the baseline algorithm with five and more neurons in the hidden layer. The SBM-WAND strategy presents relatively larger error values (RMSE) because in this case it is more difficult for the algorithm to predict the number of locks executed to control the accesses to the shared heap.
Table 9 shows the query running times for 1, 2, 4 and 8 threads obtained with (i) the actual execution of the LBM-WAND (L) and SBM-WAND (S) strategies, (ii) the respective query running times predicted by the proposed algorithm and (iii) the respective query running times predicted by the baseline algorithm, both using 5 neurons in the hidden layer. The results show that the proposed algorithm reduces the absolute error (AAE) by 7% on average whereas the maximum absolute error (
) is reduced by 26% on average. For the single query demanding the maximum running time (
) the baseline algorithm underestimates its value by 16% on average, whereas the proposed algorithm is less effective in this case as it underestimates its value by 28% on average.
Notice that the results in
Table 9 show that the LBM-WAND strategy is 29% less efficient than the SBM-WAND strategy on average. This is true for the average values taken by considering the whole set of queries used in the experiments. However, for the same test dataset, LBM-WAND is on average 10% more efficient than SBM-WAND for a small subset of queries (5%). In practice, the size of this subset depends on the specific query contents and how frequently they occur in the dynamic incoming stream of user queries.
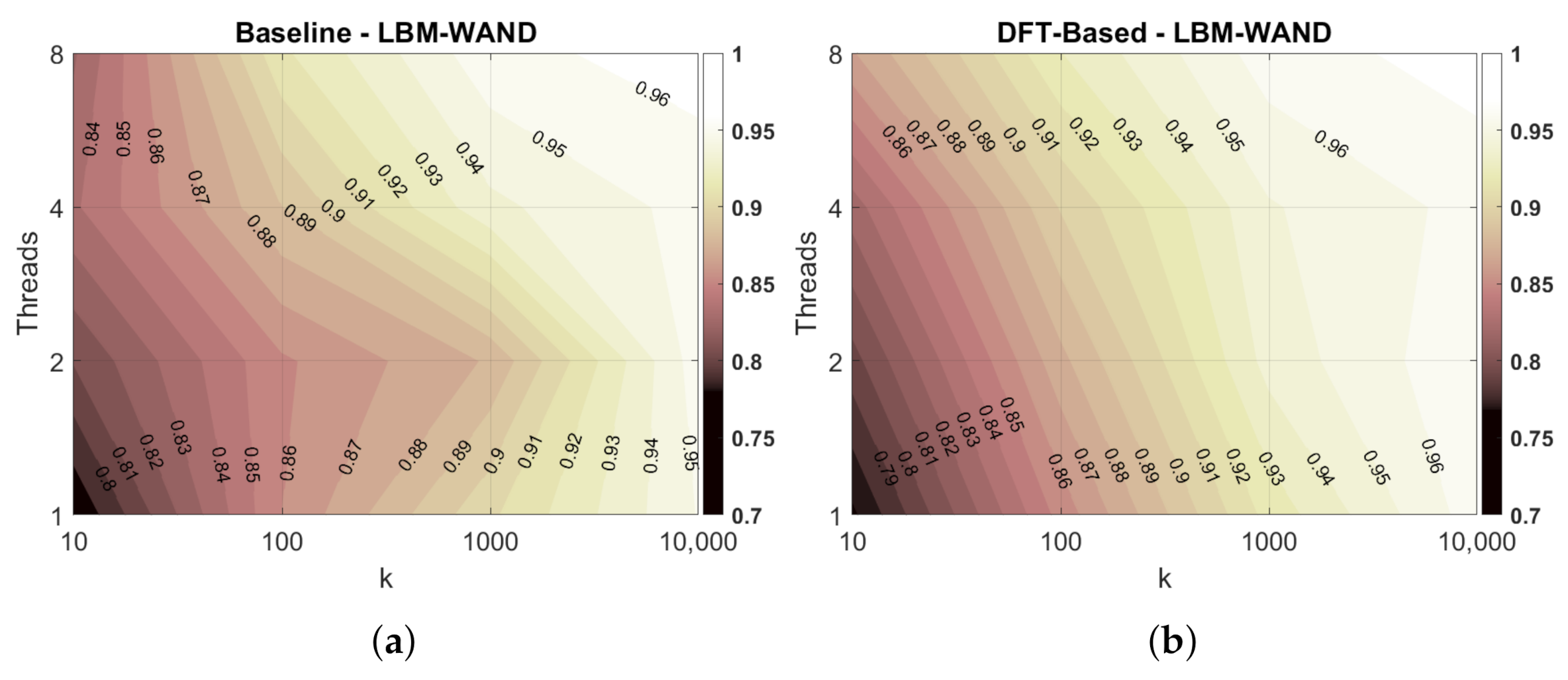
Finally, we show in
Figure 6 the Pearson correlation reported by the baseline and the DFT-based algorithm with different values for top-
k document results and different number of threads. The
y-axis (left) shows the number of threads ranging from 1 to 8. The
y-axis (right) shows the Pearson correlation from 80% to 100%. The
x-axis shows the
k values from 10 to 10,000. We show results obtained with the LMB-WAND strategy. Similar results were obtained for the SBM-WAND strategy. For
, both prediction algorithms report similar results. With a larger
k value, the DFT-based algorithm reports better results. On the other hand, as we increase the number of threads the Pearson correlation reported by both algorithms is slightly reduced. However, the lost in the correlation is very small, less than 5%.
5.5.2. Performance Evaluation of the DFT-Based Algorithm under Multi-Threaded Query Processing
In this section, we present the efficiency reported by the LBM-WAND, the LBM-WAND multi-thread strategies and a DFT-based scheduler as described in previous section. The Scheduler uses the DFT-based algorithm to estimate the query running time to decide whether to use the LBM-WAND or the SBM-WAND strategy. We show results for different number of threads ranging from 1 to 8, for the BM-WAND pruning algorithm and the ClueWeb09 dataset.
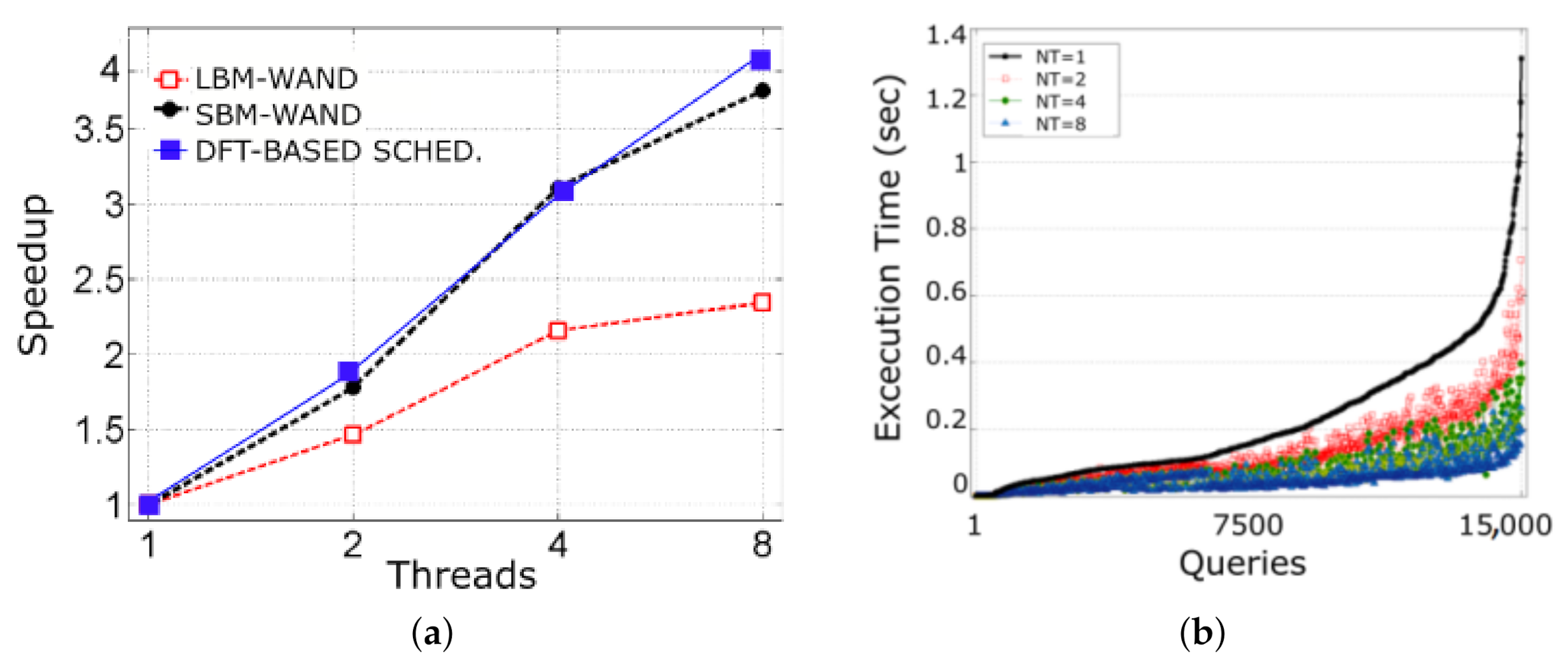
Figure 7a shows that the speedup reported by the SBM-WAND drastically improves the speedup reported by the LBM-WAND strategy. For eight threads, the SBM-WAND almost doubles the speed-up reported by the LSB-WAND. Additionally, the DFT-based Scheduler algorithm reports speedups slightly higher than the SBM-WAND.
Finally, in
Figure 7b, we present the execution times in seconds with different number of threads. The
x-axis shows the queries identifiers ordered according to their execution time from lowest (left) to highest (right). Results show that query execution times tends to decrease with a larger number of threads.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}