
The Important Role of Global State for Multi-Agent Reinforcement Learning



Abstract
:1. Introduction
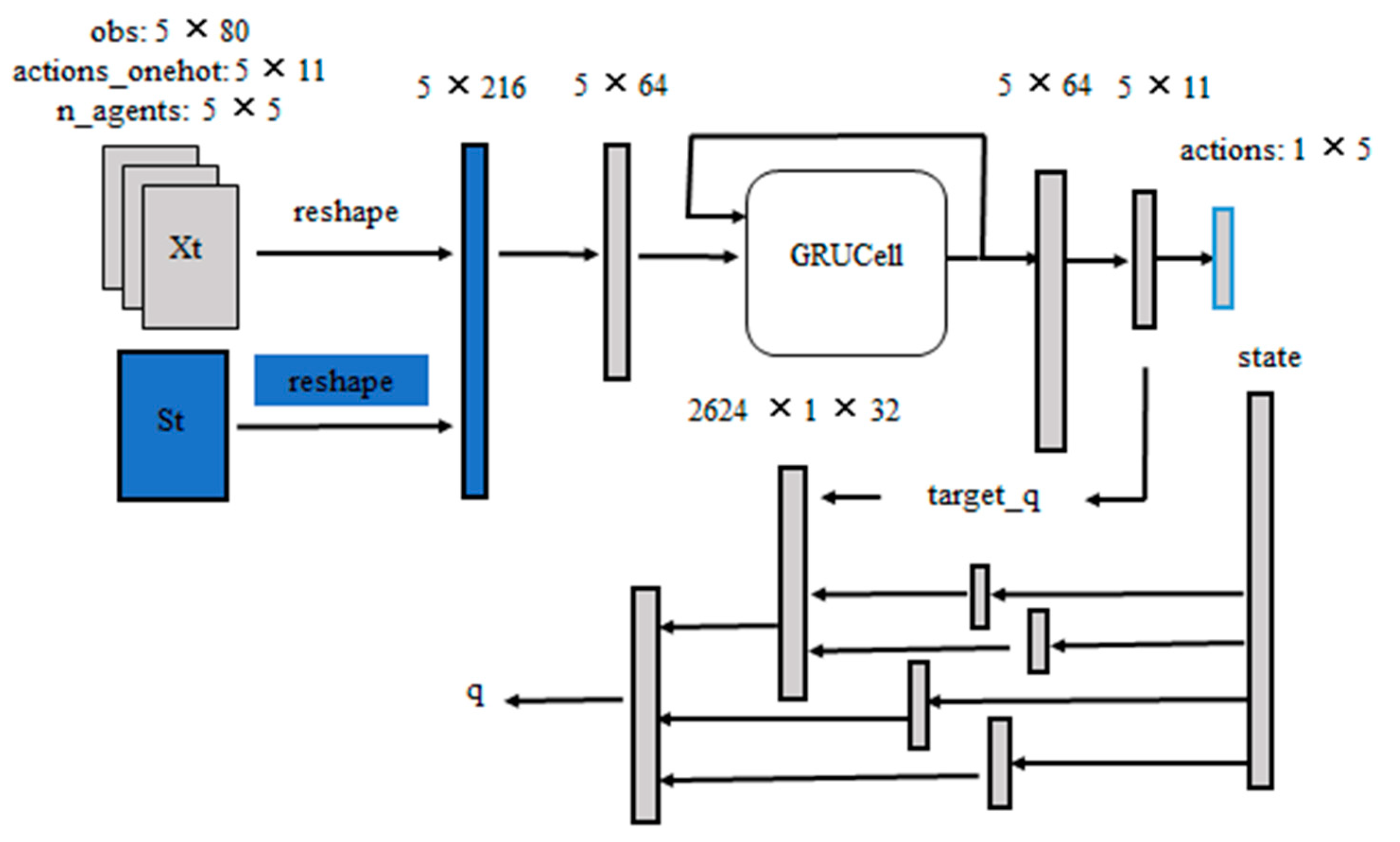
2. Materials and Methods
- A.
- Multi-Agent Reinforcement Learning Methods
- B.
- Environmental importance in MARL.
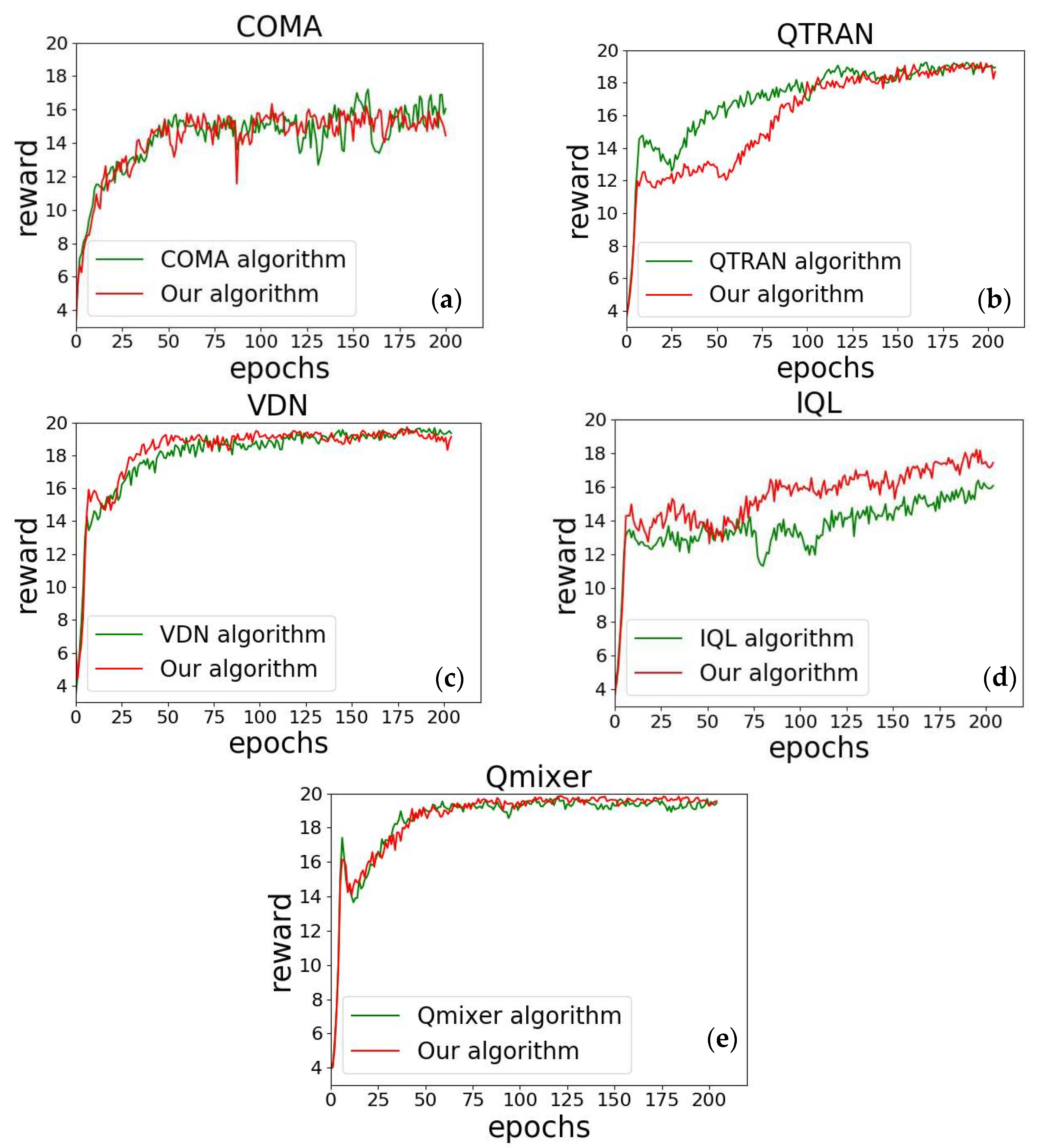
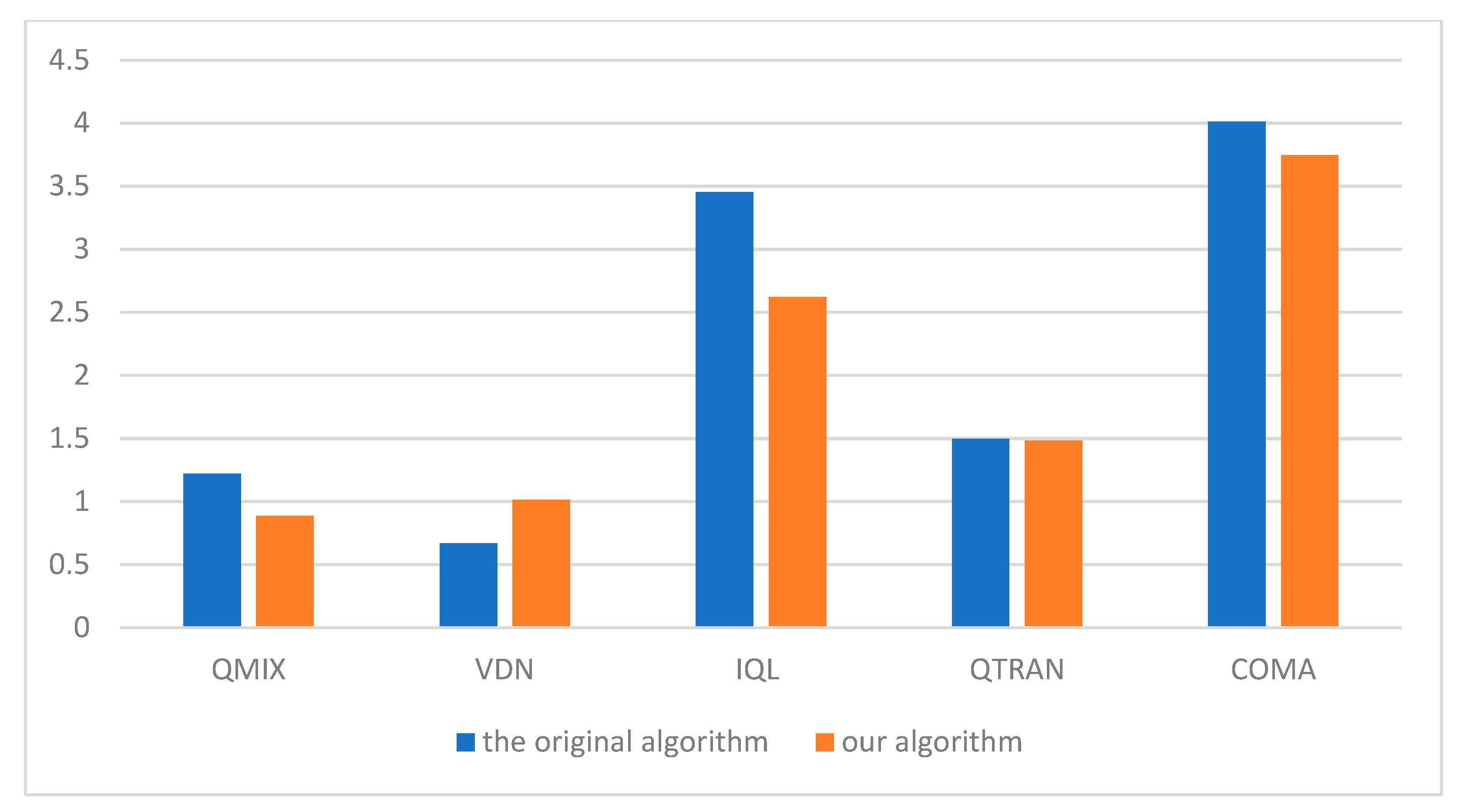
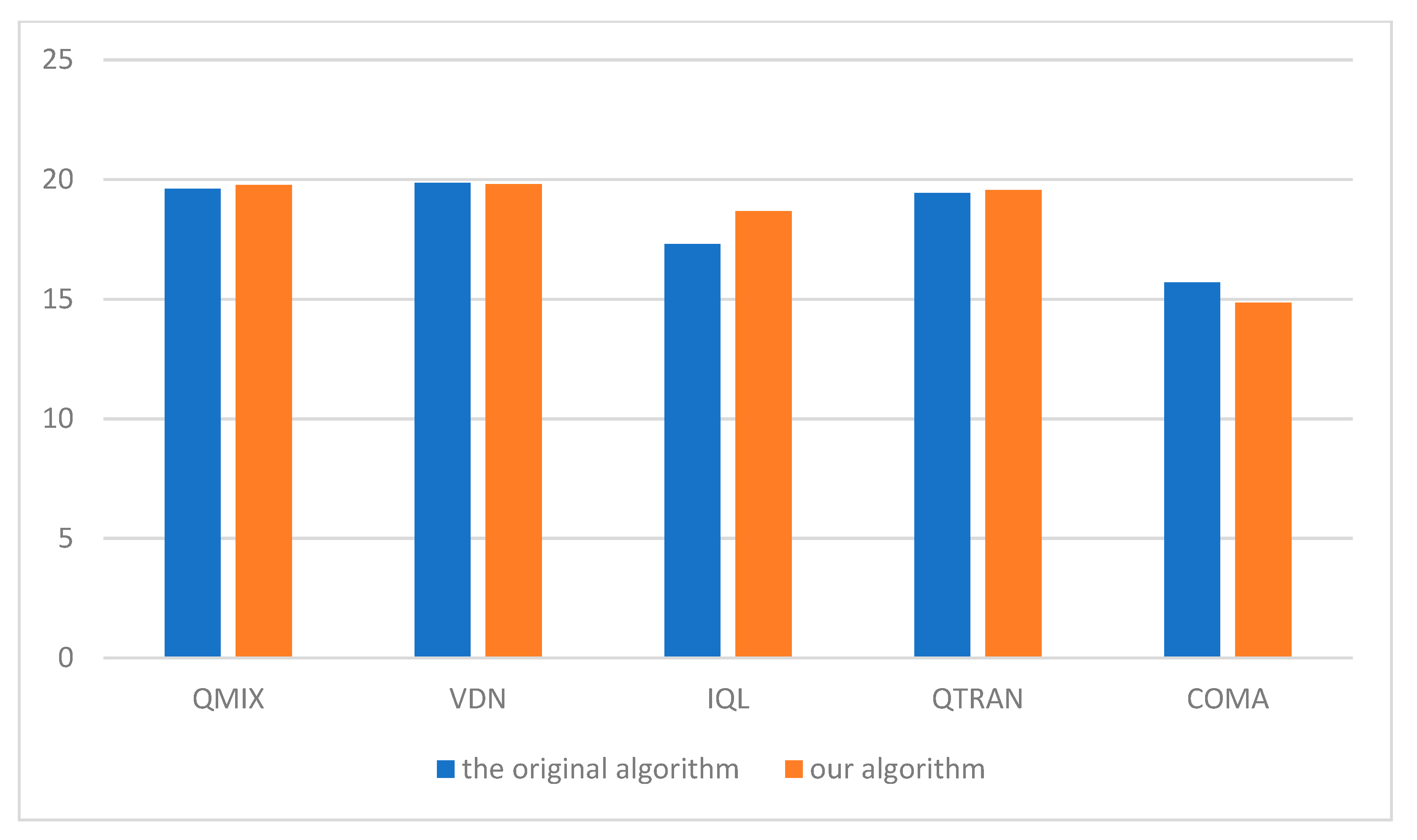
3. Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sun, R. Optimization for deep learning: Theory and algorithms. arXiv 2019, arXiv:1912.08957. [Google Scholar]
- Whitman, J.; Bhirangi, R.; Travers, M.; Choset, H. Modular robot design synthesis with deep reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10418–10425. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Abdel-Nasser, M.; Mahmoud, K. Accurate photovoltaic power forecasting models using deep LSTM-RNN. Neural Comput. Appl. 2019, 31, 2727–2740. [Google Scholar] [CrossRef]
- Zhou, Q.; Li, H.; Wang, J. Deep model-based reinforcement learning via estimated uncertainty and conservative policy optimization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 6941–6948. [Google Scholar]
- Huang, W.; Pham, V.H.; Haskell, W.B. Model and reinforcement learning for markov games with risk preferences. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 2022–2029. [Google Scholar]
- Kosugi, S.; Yamasaki, T. Unpaired image enhancement featuring reinforcement-learning-controlled image editing software. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11296–11303. [Google Scholar]
- Jain, V.; Fedus, W.; Larochelle, H.; Precup, D.; Bellemare, M.G. Algorithmic improvements for deep reinforcement learning applied to interactive fiction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 4328–4336. [Google Scholar]
- Gärtner, E.; Pirinen, A.; Sminchisescu, C. Deep Reinforcement Learning for Active Human Pose Estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10835–10844. [Google Scholar]
- Liu, Y.; Liu, Q.; Zhao, H.; Pan, Z.; Liu, C. Adaptive quantitative trading: An imitative deep reinforcement learning approach. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 2128–2135. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Hernandez-Leal, P.; Kartal, B.; Taylor, M.E. A survey and critique of multiagent deep reinforcement learning. Auton. Agents Multi-Agent Syst. 2019, 33, 750–797. [Google Scholar] [CrossRef] [Green Version]
- Stone, P.; Veloso, M. Multiagent systems: A survey from a machine learning perspective. Auton. Robot. 2000, 8, 345–383. [Google Scholar] [CrossRef]
- Shoham, Y.; Powers, R.; Grenager, T. If multi-agent learning is the answer, what is the question? Artif. Intell. 2007, 171, 365–377. [Google Scholar] [CrossRef] [Green Version]
- Alonso, E.; d’Inverno, M.; Kudenko, D.; Luck, M.; Noble, J. Learning in multi-agent systems. Knowl. Eng. Rev. 2001, 16, 277–284. [Google Scholar] [CrossRef] [Green Version]
- Tuyls, K.; Weiss, G. Multiagent learning: Basics, challenges, and prospects. AI Mag. 2012, 33, 41. [Google Scholar] [CrossRef] [Green Version]
- Busoniu, L.; Babuska, R.; De Schutter, B. A comprehensive survey of multiagent reinforcement learning. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2008, 38, 156–172. [Google Scholar] [CrossRef] [Green Version]
- Nowé, A.; Vrancx, P.; De Hauwere, Y.M. Game theory and multi-agent reinforcement learning. In Reinforcement Learning; Springer: Berlin/Heidelberg, Germany, 2012; pp. 441–470. [Google Scholar]
- Rashid, T.; Samvelyan, M.; Schroeder, C.; Farquhar, G.; Foerster, J.; Whiteson, S. Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; PMLR: London, UK, 2018; pp. 4295–4304. [Google Scholar]
- Russell, S.J.; Zimdars, A. Q-decomposition for reinforcement learning agents. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 656–663. [Google Scholar]
- Tan, M. Multi-agent reinforcement learning: Independent vs. cooperative agents. In Proceedings of the Tenth International Conference on Machine Learning, Amherst, MA, USA, 27–29 June 1993; pp. 330–337. [Google Scholar]
- Foerster, J.; Farquhar, G.; Afouras, T.; Nardelli, N.; Whiteson, S. Counterfactual multi-agent policy gradients. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Sunehag, P.; Lever, G.; Gruslys, A.; Czarnecki, W.M.; Zambaldi, V.; Jaderberg, M.; Lanctot, M.; Sonnerat, N.; Leibo, J.Z.; Tuyls, K.; et al. Value-decomposition networks for cooperative multi-agent learning. arXiv 2017, arXiv:1706.05296. [Google Scholar]
- Hausknecht, M.; Stone, P. Deep recurrent q-learning for partially observable mdps. In Proceedings of the 2015 AAAI Fall Symposium Series, Arlington, VA, USA, 12–14 November 2015. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Schaul, T.; Quan, J.; Antonoglou, I. Prioritized experience replay [C/OL]. In Proceedings of the 4th Inter national Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Bellemare, M.G.; Ostrovski, G.; Guez, A.; Thomas, P.; Munos, R. Increasing the action gap: New operators for reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Osband, I.; Blundell, C.; Pritzel, A.; Van Roy, B. Deep exploration via bootstrapped DQN. Adv. Neural Inf. Processing Syst. 2016, 29, 4026–4034. [Google Scholar]
- Synnaeve, G.; Nardelli, N.; Auvolat, A.; Chintala, S.; Lacroix, T.; Lin, Z.; Richoux, F.; Usunier, N. Torchcraft: A library for machine learning research on real-time strategy games. arXiv 2016, arXiv:1611.00625. [Google Scholar]
- Vinyals, O.; Ewalds, T.; Bartunov, S.; Georgiev, P.; Vezhnevets, A.S.; Yeo, M.; Makhzani, A.; Küttler, H.; Agapiou, J.; Schrittwieser, J.; et al. Starcraft ii: A new challenge for reinforcement learning. arXiv 2017, arXiv:1708.04782. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | QMIX | QTRAN | IQL | VDN | COMA |
|---|---|---|---|---|---|
| Action_selector | Epsilon_greedy | Epsilon_greedy | Epsilon_greedy | Epsilon_greedy | Epsilon_greedy |
| agent | rnn | rnn | rnn | rnn | rnn |
| agent_output_type | q | q | q | q | q |
| Batch_size | 32 | 32 | 32 | 32 | 32 |
| Batch_size_run | 1 | 1 | 1 | 1 | 1 |
| Buffer_cpu_only | true | true | true | true | true |
| Buffer_size | 5000 | 5000 | 5000 | 5000 | 5000 |
| Critic_lr | 0.0005 | 0.0005 | 0.0005 | 0.0005 | 0.0005 |
| env | Sc2 | Sc2 | Sc2 | Sc2 | Sc2 |
| Epsilon_finish | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 |
| Epsilon_start | 1 | 1 | 1 | 1 | 1 |
| gamma | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| Grad_norm_clip | 10 | 10 | 10 | 10 | 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Zhang, W.; Leng, Y.; Wang, X. The Important Role of Global State for Multi-Agent Reinforcement Learning. Future Internet 2022, 14, 17. https://doi.org/10.3390/fi14010017
Li S, Zhang W, Leng Y, Wang X. The Important Role of Global State for Multi-Agent Reinforcement Learning. Future Internet. 2022; 14(1):17. https://doi.org/10.3390/fi14010017
Chicago/Turabian StyleLi, Shuailong, Wei Zhang, Yuquan Leng, and Xiaohui Wang. 2022. "The Important Role of Global State for Multi-Agent Reinforcement Learning" Future Internet 14, no. 1: 17. https://doi.org/10.3390/fi14010017
APA StyleLi, S., Zhang, W., Leng, Y., & Wang, X. (2022). The Important Role of Global State for Multi-Agent Reinforcement Learning. Future Internet, 14(1), 17. https://doi.org/10.3390/fi14010017